
We are going to explore features which are new to C# in the 5.0 release. Notably, most of them are related to built-in asynchrony features added to the language, which allow you to easily use the hardware running your software to its full potential. We will also discuss Task Parallel Library (TPL), which introduces primitives for asynchronous programming, C# 5.0 language support for easy asynchrony, TPL DataFlow, higher-level abstractions for agent-based asynchronous programming, and framework improvements that take advantage of the new asynchrony features, such as improvements to the I/O APIs.
All things considered, the latest release of the .NET Framework is enormous, and the concepts introduced in this chapter will serve as reference for the material covered in the rest of the book.
When we talk about C# 5.0, the primary topic of conversation is the new asynchronous programming features. What does asynchrony mean? Well, it can mean a few different things, but in our context, it is simply the opposite of synchronous. When you break up the execution of a program into asynchronous blocks, you gain the ability to execute them side-by-side, in parallel.
Pit of Success: in stark contrast to a summit, a peak, or a journey across a desert to find victory through many trials and surprises, we want our customers to simply fall into winning practices by using our platform and frameworks. To the extent that we make it easy to get into trouble we fail. –Rico Mariani
Unfortunately, building asynchronous software has not always been easy, but with C# 5.0 you will see how easy it can be. As you can see in the following diagram, executing multiple actions concurrently can bring various positive qualities to your programs:
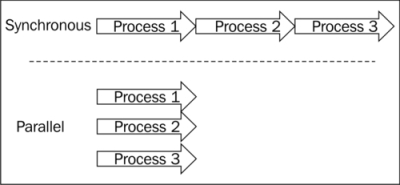
Parallel execution can bring performance improvements to the execution of a program. The best way to put this into context is by way of an example, an example that has been experienced all too often in the world of desktop software.
Let's say you have an application that you are developing, and this software should fulfill the following requirements:
- When the user clicks on a button, initiate a call to a web service.
- Upon completion of the web service call, store the results into a database.
- Finally, bind the results and display them to the user.
There are a number of problems with the naïve way of implementing this solution. The first is that many developers write code in such a way that the user interface will be completely unresponsive while we are waiting to receive the results of these web service calls. Then, once the results finally arrive, we continue to make the user wait while we store the results in a database, an operation that the user does not care about in this case.
The primary vehicle for mitigating these kinds of problems in the past has been writing multithreaded code. This is of course nothing new, as multi-threaded hardware has been around for many years, along with software capabilities to take advantage of this hardware. Most of the programming languages did not provide a very good abstraction layer on top of this hardware, often letting (or requiring) you program directly against the hardware threads.
Thankfully, Microsoft introduced a new library to simplify the task of writing highly concurrent programs, which is explained in the next section.
The Task Parallel Library (TPL) was introduced in .NET 4.0 (along with C# 4.0). We did not cover it in Chapter 2, Evolution of C#, for several reasons. Firstly, it is a huge topic and could not have been examined properly in such a small space. Secondly, it is highly relevant to the new asynchrony features in C# 5.0, so much so that they are the literal foundation upon which the new features are built. So, in this section, we will cover the basics of the TPL, along with some of the background information about how and why it works.
TPL introduces a new type, the Task type, which abstracts away the concept of something that must be done into an object. At first glance, you might think that this abstraction already exists in the form of the Thread class. While there are some similarities between Task and Thread, the implementations have quite different implications.
With a Thread class, you can program directly against the lowest level of parallelism supported by the operating system, as shown in the following code:
Thread thread = new Thread(new ThreadStart(() =>
{
Thread.Sleep(1000);
Console.WriteLine("Hello, from the Thread");
}));
thread.Start();
Console.WriteLine("Hello, from the main thread");
thread.Join();In the previous example, we create a new Thread class, which when started will sleep for a second and then write out the text Hello, from the Thread. After we call thread.Start(), the code on the main thread immediately continues and writes Hello, from the main thread. After a second, we see the text from the background thread printed to the screen.
In one sense, this example of using the Thread class shows how easy it is to branch off the execution to a background thread, while allowing execution of the main thread to continue, unimpeded. However, the problem with using the Thread class as your "concurrency primitive" is that the class itself is an indication of the implementation, which is to say, an operating system thread will be created. As far as abstractions go, it is not really an abstraction at all; your code must both manage the lifecycle of the thread, while at the same time dealing with the task the thread is executing.
If you have multiple tasks to execute, spawning multiple threads can be disastrous, because the operating system can only spawn a finite number of them. For performance intensive applications, a thread should be considered a heavyweight resource, which means you should avoid using too many of them, and keep them alive for as long as possible. As you might imagine, the designers of the .NET Framework did not simply leave you to program against this without any help. The early versions of the frameworks had a mechanism to deal with this in the form of the ThreadPool, which lets you queue up a unit of work, and have the thread pool manage the lifecycle of a pool of threads. When a thread becomes available, your work item is then executed. The following is a simple example of using the thread pool:
int[] numbers = { 1, 2, 3, 4 };
foreach (var number in numbers)
{
ThreadPool.QueueUserWorkItem(new WaitCallback(o =>
{
Thread.Sleep(500);
string tabs = new String(' ', (int)o);
Console.WriteLine("{0}processing #{1}", tabs, o);
}), number);
}This sample simulates multiple tasks, which should be executed in parallel. We start with an array of numbers, and for each number we want to queue a work item that will sleep for half a second, and then write to the console. This works much better than trying to manage multiple threads yourself because the pool will take care of spawning more threads if there is more work. When the configured limit of concurrent threads is reached, it will hold work items until a thread becomes available to process it. This is all work that you would have done yourself if you were using threads directly.
However, the thread pool is not without its complications. First, it offers no way of synchronizing on completion of the work item. If you want to be notified when a job is completed, you have to code the notification yourself, whether by raising an event, or using a thread synchronization primitive, such as ManualResetEvent
. You also have to be careful not to queue too many work items, or you may run into system limitations with the size of the thread pool.
With the TPL, we now have a concurrency primitive called Task. Consider the following code:
Task task = Task.Factory.StartNew(() =>
{
Thread.Sleep(1000);
Console.WriteLine("Hello, from the Task");
});
Console.WriteLine("Hello, from the main thread");
task.Wait();Upon first glance, the code looks very similar to the sample using Thread, but they are very different. One big difference is that with Task, you are not committing to an implementation. The TPL uses some very interesting algorithms behind the scenes to manage the workload and system resources, and in fact, allows you customize those algorithms through the use of custom schedulers and synchronization contexts. This allows you to control the parallel execution of your programs with a high degree of control.
Dealing with multiple tasks, as we did with the thread pool, is also easier because each task has synchronization features built-in. To demonstrate how simple it is to quickly parallelize an arbitrary number of tasks, we start with the same array of integers, as shown in the previous thread pool example:
int[] numbers = { 1, 2, 3, 4 };Because Task can be thought of as a primitive type that represents an asynchronous task, we can think of it as data. This means that we can use things such as Linq to project the numbers array to a list of tasks as follows:
var tasks = numbers.Select(number =>
Task.Factory.StartNew(() =>
{
Thread.Sleep(500);
string tabs = new String(' ', number);
Console.WriteLine("{0}processing #{1}", tabs, number);
}));And finally, if we wanted to wait until all of the tasks were done before continuing on, we could easily do that by calling the following method:
Task.WaitAll(tasks.ToArray());
Once the code reaches this method, it will wait until every task in the array completes before continuing on. This level of control is very convenient, especially when you consider that, in the past, you would have had to depend on a number of different synchronization techniques to achieve the very same result that was accomplished in just a few lines of TPL code.
With the usage patterns that we have discussed so far, there is still a big disconnect between the process that spawns a task, and the child process. It is very easy to pass values into a background task, but the tricky part comes when you want to retrieve a value and then do something with it. Consider the following requirements:
- Make a network call to retrieve some data.
- Query the database for some configuration data.
- Process the results of the network data, along with the configuration data.
The following diagram shows the logic:
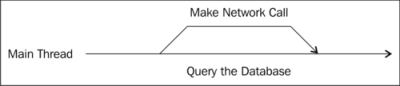
Both the network call and query to the database can be done in parallel. With what we have learned so far about tasks, this is not a problem. However, acting on the results of those tasks would be slightly more complex, if it were not for the fact that the TPL provides support for exactly that scenario.
There is an additional kind of Task, which is especially useful in cases like this called Task<T>. This generic version of a task expects the running task to ultimately return a value, whenever it is finished. Clients of the task can access the value through the .Result property of the task. When you call that property, it will return immediately if the task is completed and the result is available. If the task is not done, however, it will block execution in the current thread until it is.
Using this kind of task, which promises you a result, you can write your programs such that you can plan for and initiate the parallelism that is required, and handle the response in a very logical manner. Look at the following code:
varwebTask = Task.Factory.StartNew(() =>
{
WebClient client = new WebClient();
return client.DownloadString("http://bing.com");
});
vardbTask = Task.Factory.StartNew(() =>
{
// do a lengthy database query
return new
{
WriteToConsole=true
};
});
if (dbTask.Result.WriteToConsole)
{
Console.WriteLine(webTask.Result);
}
else
{
ProcessWebResult(webTask.Result);
}In the previous example, we have two tasks, the webTask, and dbTask, which will execute at the same time. The webTask
is simply downloading the HTML from http://bing.com. Accessing things over the Internet can be notoriously flaky due to the dynamic nature of accessing the network so you never know how long that is going to take. With the dbTask task, we are simulating accessing a database to return some stored settings. Although in this simple example we are just returning a static anonymous type, database access will usually access a different server over the network; again, this is an I/O bound task just like downloading something over the Internet.
Rather than waiting for both of them to execute like we did with Task.WaitAll, we can simply access the .Result property of the task. If the task is done, the result will be returned and execution can continue, and if not, the program will simply wait until it is.
This ability to write your code without having to manually deal with task synchronization is great because the fewer concepts a programmer has to keep in his/her head, the more resources he/she can devote to the program.
Tip
If you are curious about where this concept of a task that returns a value comes from, you can look for resources pertaining to "Futures", and "Promises" at:
http://en.wikipedia.org/wiki/Promise_%28programming%29
At the simplest level, this is a construct that "promises" to give you a result in the "future", which is exactly what Task<T> does.
Having a proper abstraction for asynchronous tasks makes it easier to coordinate multiple asynchronous activities. Once the first task has been initiated, the TPL allows you to compose a number of tasks together into a cohesive whole using what are called continuations . Look at the following code:
Task<string> task = Task.Factory.StartNew(() =>
{
WebClient client = new WebClient();
return client.DownloadString("http://bing.com");
});
task.ContinueWith(webTask =>
{
Console.WriteLine(webTask.Result);
});Every task object has the .ContinueWith method, which lets you chain another task to it. This continuation task will begin execution once the first task is done. Unlike the previous example, where we relied on the .Result method to wait until the task was done—thus potentially holding up the main thread while it completed—the continuation will run asynchronously. This is a better approach for composing tasks because you can write tasks that will not block the UI thread, which results in very responsive applications.
Task composability does not stop at providing continuations though, the TPL also provides considerations for scenarios, where a task must launch a number of subtasks. You have the ability to control how completion of those child tasks affects the parent task. In the following example, we will start a task, which will in turn launch a number of subtasks:
int[] numbers = { 1, 2, 3, 4, 5, 6 };
varmainTask = Task.Factory.StartNew(() =>
{
// create a new child task
foreach (intnum in numbers)
{
int n = num;
Task.Factory.StartNew(() =>
{
Thread.SpinWait(1000);
int multiplied = n * 2;
Console.WriteLine("Child Task #{0}, result {1}", n, multiplied);
});
}
});
mainTask.Wait();
Console.WriteLine("done");Each child task will write to the console, so that you can see how the child tasks behave along with the parent task. When you execute the previous program, it results in the following output:
Child Task #1, result 2 Child Task #2, result 4 done Child Task #3, result 6 Child Task #6, result 12 Child Task #5, result 10 Child Task #4, result 8
Notice how even though you have called the .Wait() method on the outer task before writing done, the execution of the child task continues a bit longer after the task is concluded. This is because, by default, child tasks are detached, which means their execution is not tied to the task that launched it.
Tip
An unrelated, but important bit in the previous example code, is you will notice that we assigned the loop variable to an intermediary variable before using it in the task.
int n = num;
Task.Factory.StartNew(() =>
{
int multiplied = n * 2;If you remember our discussion on continuations in Chapter 2, Evolution of C#, your intuition would suggest that you should be able to use num directly in the lambda expression. This is actually related to the way closures work, and is a common misconception when trying to "pass in" values in a loop. Because the closure actually creates a reference to the value, rather than copying the value in, using the loop value will end up changing every time the loop iterates, and you will not get the behavior you expect.
As you can see, an easy way to mitigate this is to set the value to a local variable before passing it into the lambda expression. That way, it will not be a reference to an integer that changes before it is used.
You do however have the option to mark a child task as Attached, as follows:
Task.Factory.StartNew(
() =>DoSomething(),
TaskCreationOptions.AttachedToParent);The TaskCreationOptions
enumeration has a number of different options. Specifically in this case, the ability to attach a task to its parent task means that the parent task will not complete until all child tasks are complete.
Other options in TaskCreationOptions let you give hints and instructions to the task scheduler. From the documentation, the following are the descriptions of all these options:
None: This specifies that the default behavior should be used.PreferFairness: This is a hint to aTaskSchedulerclass to schedule a task in as fair a manner as possible, meaning that tasks scheduled sooner will be more likely to be run sooner, and tasks scheduled later will be more likely to be run later.LongRunning: This specifies that a task will be a long-running, coarse-grained operation. It provides a hint to theTaskSchedulerclass that oversubscription may be warranted.AttachedToParent: This specifies that a task is attached to a parent in the task hierarchy.DenyChildAttach: This specifies that an exception of the typeInvalidOperationExceptionwill be thrown if an attempt is made to attach a child task to the created task.HideScheduler: This prevents the ambient scheduler from being seen as the current scheduler in the created task. This means that operations such asStartNeworContinueWiththat are performed in the created task, will seeDefaultas the current scheduler.
The best part about these options, and the way the TPL works, is that most of them are merely hints. So you can suggest that a task you are starting is long running, or that you would prefer tasks scheduled sooner to run first, but that does not guarantee this will be the case. The framework will take the responsibility of completing the tasks in the most efficient manner, so if you prefer fairness, but a task is taking too long, it will start executing other tasks to make sure it keeps using the available resources optimally.
Error handling in the world of tasks needs special consideration. In summary, when an exception is thrown, the CLR will unwind the stack frames looking for an appropriate try/catch handler that wants to handle the error. If the exception reaches the top of the stack, the application crashes.
With asynchronous programs, though, there is not a single linear stack of execution. So when your code launches a task, it is not immediately obvious what will happen to an exception that is thrown inside of the task. For example, look at the following code:
Task t = Task.Factory.StartNew(() =>
{
throw new Exception("fail");
});This exception will not bubble up as an unhandled exception, and your application will not crash if you leave it unhandled in your code. It was in fact handled, but by the task machinery. However, if you call the .Wait() method, the exception will bubble up to the calling thread at that point. This is shown in the following example:
try
{
t.Wait();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}When you execute that, it will print out the somewhat unhelpful message One or more errors occurred, rather than the fail message that is the actual message contained in the exception. This is because unhandled exceptions that occur in tasks will be wrapped in an AggregateException exception, which you can handle specifically when dealing with task exceptions. Look at the following code:
catch (AggregateException ex)
{
foreach (var inner in ex.InnerExceptions)
{
Console.WriteLine(inner.Message);
}
}If you think about it, this makes sense, because of the way that tasks are composable with continuations and child tasks, this is a great way to represent all of the errors raised by this task. If you would rather handle exceptions on a more granular level, you can also pass a special TaskContinuationOptions parameter as follows:
Task.Factory.StartNew(() =>
{
throw new Exception("Fail");
}).ContinueWith(t =>
{
// log the exception
Console.WriteLine(t.Exception.ToString());
}, TaskContinuationOptions.OnlyOnFaulted);This continuation task will only run if the task that it was attached to is faulted (for example, if there was an unhandled exception). Error handling is, of course, something that is often overlooked when developers write code, so it is important to be familiar with the various methods of handling exceptions in an asynchronous world.
Now that the foundation for asynchrony has been set, we are ready to finally start talking about C# 5.0. The first feature we are going to discuss is quite possibly the largest impact to the way we develop applications—asynchronous programming using a new language feature that introduces the async and await
keywords.
Before we go too far, let's do a quick review of the versioning situation. Although it seemed like it was going to improve when the CLR, C#, and the .NET Framework all were incremented to 4.0, it has regressed into confusing territory. The following diagram shows the comparison between the versions:
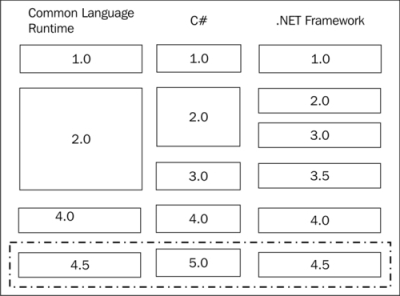
C# 5.0 comes with .NET 4.5, which also includes a new version of the Common Language Runtime. So when you develop C# 5.0 applications, you will generally be targeting the 4.5 version of the Framework.
Tip
If you have an absolute need to target Version 4.0 of the framework, you can download the Async Targeting Pack for Visual Studio 2012, which will give you the ability to compile and deploy your C# 5.0 applications to .NET 4.0. However, keep in mind that this is only for the C# 5.0 language features, such as async/await. The other framework updates in .NET 4.5 will not be available.
You may be asking yourself what exactly is new, considering the Task Parallel Library was introduced in the previous version of the framework. The difference is that the language itself now takes an active part in the asynchronous operation of your program. Let's start with a simple example showing the feature in action:
public async void DoSomethingAsync() { Console.WriteLine("Async: method starting"); awaitTask.Delay(1000); Console.WriteLine("Async: method completed"); }
This is a very simple method from the programmer's logical perspective. It writes to the console to say Async: method starting, then it waits one second, and finally writes Async: method completed. Make special note of the two keywords in that method: async and await.
In another part of the program, we call that method writing to the console before and after we call the method as follows:
Console.WriteLine("Parent: Starting async method");
DoSomethingAsync();
Console.WriteLine("Parent: Finished calling async method");Aside from the two new keywords, this code looks entirely sequential. Without knowing how async works, you might assume that the messages written to the console would come in this pattern: parent, async, async, parent. Although this is the order in which the statements are written, this is not the order in which they are executed. You can see the following example:
Parent: Starting async method Child: Async method starting Parent: Finished calling async method Child: Async method completed
The statements are out of order because the method, or part of it, was executed asynchronously. What is happening here is that the compiler is analyzing the method, and literally breaking it up in such a way that everything that happens after the await keyword occurs asynchronously. Execution of the calling thread returns immediately and continues, and everything after the await call is executed in continuation.
The first reaction from most developers when they first encounter this is, "What!?"
Although it will seem hard to understand at first, once you understand how the compiler handles this, you can start to build a mental model that will help you. If we were to write that same asynchronous method using the TPL, it would look something like the following:
public void DoSomethingAsyncWithTasks()
{
Console.WriteLine("Child: Async method starting");
var context = TaskScheduler.FromCurrentSynchronizationContext();
Task.Delay(1000)
.ContinueWith(t =>
{
Console.WriteLine("Child: Async method completed");
}, context);
}In this method, we have highlighted the lines of code present in the original method. The Task.Delay method, which returns Task, is called to kick off the task (in this sample case, just waiting for one second). The next line of code is then put into a continuation, which will execute as soon as the calling task is done.
Another interesting, and perhaps more important, feature of this rewritten code is that the continuation will run on the same synchronization context as the code before the asynchronous task. So it will actually run on the same thread as the code prior to the await keyword. This becomes particularly important when you are dealing with UI code, because you cannot set property values or call UI control methods from a thread other than the main UI thread without having an exception thrown.
Tip
To be clear, this is not exactly what the compiler generates. Behind the scenes it will create a state machine that represents each stage of execution of the rewritten code. This can get very complex, when you start having loops that call and await asynchronous methods.
Despite that, the previous example is identical, logically speaking, to what the compiler generates in this case. So rather than spending a lot of time trying to explain what the compiler is doing, it is better to create a logical mental model of the behavior that you can work with.
So far you will notice that every example we have given has had the asynchronous work done in a method, and is then called by another method that awaits the value. The method, or function, is a central piece of the asynchronous puzzle. Just as you can with tasks, you can return values from asynchronous methods.
In this example, we have an asynchronous method with Task<string> set as the return type:
public asyncTask<string>GetStringAsynchronously() { await Task.Delay(1000); return "This string was delayed"; }
Because the method was decorated with the async keyword, you can return an actual string, without having to wrap it in a task. When the caller awaits the result, it will be a string, so you can treat it as a simple return type as follows:
public async void CallAsynchronousStringMethod ()
{
string value = await GetStringAsynchronously();
Console.WriteLine(value);
}Again we see that you are able to deal with asynchronous operations, without having to worry about the infrastructure to execute them. As we showed earlier, when we rewrite the previous method to use tasks, it becomes obvious how the compiler handles the return values. Look at the following code:
var context = TaskScheduler.FromCurrentSynchronizationContext();
GetStringAsynchronously()
.ContinueWith(task =>
{
string value = task.Result;
Console.WriteLine(value);
}, context);Another reason that it is helpful to think of the way the compiler rewrites async methods with tasks and continuations, is because it keeps the fact that the TPL is in use to the fore. This means that you can use the new keywords in tandem with all of the existing features of the tasks in order to parallelize your application to match your requirements. This is important to remember, because you may be missing opportunities for parallelism, if you use the await keyword every time.
In the following example, we are calling an asynchronous method twice. The method returns Task<string>, so instead of calling await, which would (logically) hold execution of the second task until the first one was completed, we put the return values into variables, and use the
Task.WhenAll method to wait until they both complete as follows:
private async void Sample_04()
{
Task<string>firstTask = GetAsyncString("first task");
Task<string>secondTask = GetAsyncString("second task");
await Task.WhenAll(firstTask, secondTask);
Console.WriteLine("done with both tasks");
}
public async Task<string>GetAsyncString(string value)
{
Console.WriteLine("Starting task for '{0}'", value);
await Task.Delay(1000);
return value;
}This allows both tasks to execute at the same time, and still gives you the ability to compose your program using the await keyword.
Error handling with asynchronous methods is very straightforward. Because the C# compiler is already rewriting the method entirely to await the completion of the task at hand before continuing, it lets you use the same exception based error handling methods that you have been using since C# 1.0.
The following is an example of an async method that throws an exception from Task:
private async Task ThisWillThrowAnException()
{
Console.WriteLine("About to start an async task that throws an exception");
await Task.Factory.StartNew(() =>
{
throw new Exception("fail");
});
}As we discussed in the Error handling with tasks section, if you were interacting with the return value of this method as a regular task, then the exception would not be directly raised in the same context as the calling code. Either it will be raised when you call the .Wait method on the task, or you can handle it in a special continuation. But if you use await with the method, then you can wrap the code in a try/catch block as follows:
try
{
await ThisWillThrowAnException();
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}Execution of this code will seamlessly transition to the catch block when the unhandled exception is raised from the async method. This means that you don't really have to think about how you are going to handle exceptions if they are thrown from an asynchronous context, you simply catch them as you would if it was regular synchronous code.
Up to this point, we have just been discussing the mechanics of the asynchronous programming features that have been released in .Net 4.0 and C# 5.0. However, the significance of making parallel software applications easy to program deserves to be highlighted once again. There are several factors that highlight the importance of these new developments.
The First is Moore's law, which famously states that the number of transistors in CPUs is likely to double every year. While this law held true for many years, over the last decade some practical limits in cost and heat have been reached, with what is commercially possible on a single CPU. As a result, manufacturers began making computers with multiple CPUs. These new designs still manage to keep up with the prediction of Moore's law, but programs have to be specifically written to take advantage of the hardware.
Another huge factor in the impact of async is the rise of distributed computing. These days it is becoming more and more popular to architect programs as individual programs running on multiple computers. These peer-to-peer or client-server architectures are rarely CPU-bound, because of the latency in communicating between one computer and another over the network (or Internet). When faced with this kind of architecture, it becomes very very important to be able to parallelize the computation so that the user interface is not left waiting for a network call to complete.
Moving forward, software applications that take advantage of opportunities to use parallelism will be the ones that are superior in performance and usability. Many of the largest Internet companies, such as Google, are already taking advantage of massive parallelization, to tackle very large problems that simply would not be computationally possible on a single computer. The async keyword makes it so that you almost do not have to think about how and when you take advantage of it (almost).
In addition to all of the C# 5.0 language improvements, the .NET Framework 4.5 also brings some improvements to the table. These improvements, of course, are available to all .NET languages (that is, VB.NET), but as they become available along with C# 5.0, they warrant mention.
One interesting newcomer to the framework is the TPL DataFlow library, which aims to improve the architecture of your applications. The NuGet description for the library describes the library:
TPL Dataflow is a .NET Framework library for building concurrent applications. It promotes actor/agent-oriented designs through primitives for in-process message passing, dataflow, and pipelining. TDF builds upon the APIs and scheduling infrastructure provided by the Task Parallel Library (TPL), and integrates with the language support for asynchrony provided by C#.
It can be installed via NuGet by searching for TPL DataFlow, or visiting the NuGet site at https://nuget.org/packages/Microsoft.Tpl.Dataflow.
As stated in the description, data flow builds on top of the Task Parallel Library, a trend that I trust you are starting to see in this release, where the TPL, and by extension async/await of C# 5, help you parallelize your programs; it does so without any prescription of how to structure your application at a higher level. In contrast, the TPL DataFlow library provides various building blocks for communication between disparate parts of an application.
TPL DataFlow introduces two interfaces, which like IEnumerable are both simple and quite deep in their implications. The following diagram shows these interfaces:
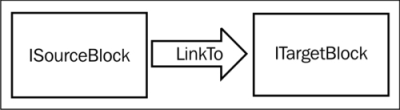
We start with the ITargetBlock<T>
, which is a block of code that will process a number of posted messages. You will primarily interact with it by calling the .Post method to post a message to the block. The other side of the equation is the ISourceBlock<T>, which acts as a source of data. Together, these interfaces, and the concrete implementations that ship with the TPL DataFlow library, help you create applications that are structured into discrete producers, and consumers.
The ActionBlock<T> block is the simplest implementation of the ITargetBlock<T>. It accepts a delegate in the constructor that defines what action will be taken when a message is posted to it. The following is how you define a simple block that accepts a string and writes it to the console:
var block = new ActionBlock<string>(s =>
{
Console.WriteLine(s);
});Once you have defined the block, you can start posting messages to it. The action block executes asynchronously, which is not a requirement, just to show how this implementation handles the posting of messages. Look at the following code:
for (inti = 0; i< 30; i++)
{
block.Post("Processing #" + i.ToString());
}Here we see a very simple loop that iterates 30 times and posts a string to the target action. Once you have defined the target block, you can use a number of different implementations of source blocks that come with the TPL DataFlow library to create very interesting routing scenarios.
One such ISourceBlock<T> that you will find quite useful is the TransformBlock<T, K> block. As the name suggests, the transform block lets you take in one kind of data, and potentially transform it into another. In the following example, we will create two blocks; the TransformBlock will take an integer and convert it to a string. The resulting output will then be routed to ActionBlock, which accepts a string for processing. Look at the following example code:
TransformBlock<int, string> transform = new TransformBlock<int, string>(i => { // take the integer input, and convert to a string return string.Format("squared = {0}", i * i); }); ActionBlock<string> target = new ActionBlock<string>(value => { // now use the string generated by the transform block Console.WriteLine(value); }); transform.LinkTo(target);
Input and output types for the transform block are designated in the form of generic parameters. You add the action block to the end of the data flow chain by using the .LinkTo method, which directs all the output of the source block to the target. This is explained in the following code:
for (inti = 0; i< 30; i++) transform.Post(i);
When you post an integer to the transform block, you will see that the message first flows through the transform block, and is then routed to the action block.
Another kind of source block shown in the following diagram, which can help you process a stream of information, is a batch block:
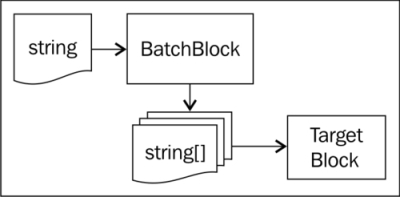
Usually this kind of batch processing can be useful if there are certain costs associated with the processing of each message, such as informational lookups to a database. Many times in cases like this, you can batch up the query values and do a single database lookup for multiple messages at a time and amortize the cost of the lookup as you increase the batch size. Look at the following example:
var batch = new BatchBlock<string>(5); var processor = new ActionBlock<string[]>(values => { Console.WriteLine("Processing {0} items:", values.Length); foreach (var item in values) { Console.WriteLine(" item: {0}", item); } }); batch.LinkTo(processor); for (inti = 0; i< 32; i++) { batch.Post(i.ToString()); }
You can think of the batch block as a specific kind of transform block that takes a single instance of a message in the frontend, waits until a specified number of these messages have arrived, and then delivers that group as an array to the target block. This can be useful when you have a system that has to do some setup, such as looking up reference data for every message that it receives. If you can process many messages in one batch, then the cost of the initialization can be amortized over time. The more messages you process, the lower the cost. The following example shows how this is achieved:
// manually trigger batch.TriggerBatch();
You can also manually trigger a batch if you know that the threshold number of messages has not been reached. In this way, you can process a batch of a smaller size if your system has to process a message within a certain amount of time.
The broadcast block shown in the following diagram is an interesting source block:
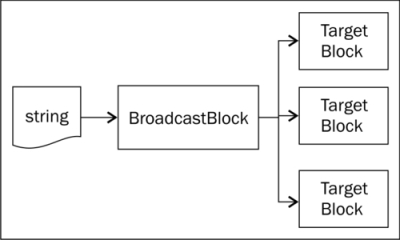
The way it works is that you can link multiple target blocks to the broadcaster. When a message is posted to the broadcaster, it will diligently be delivered to every target. One obvious application of this block is to write a server application that has to service multiple clients at the same time. Each client is then represented by a target block that gets linked to the broadcaster. Whenever you need to notify every client, you can just post a message to the broadcaster. Look at the following example:
var broadcast = new BroadcastBlock<string>(value =>
{
return value;
});
broadcast.LinkTo(new ActionBlock<string>(value =>Console.WriteLine("receiver #1: {0}", value)));
broadcast.LinkTo(new ActionBlock<string>(value =>Console.WriteLine("receiver #2: {0}", value)));
broadcast.LinkTo(new ActionBlock<string>(value =>Console.WriteLine("receiver #3: {0}", value)));
broadcast.LinkTo(new ActionBlock<string>(value =>Console.WriteLine("receiver #4: {0}", value)));
broadcast.Post("value posted");In this example, we link four separate action blocks. When we post value posted, we will see four separate verifications of receipt in the console output. In a way, this is very similar to the existing event system in the C# language.
To take advantage of the new async/await features, some very core features of the .NET Framework have evolved. Namely, the I/O features including streams, network, and file operations. This is huge because, as mentioned previously, I/O bound operations are coming to dominate the execution time of a modern application. So any improvements in the API to deal with those operations can be seen as a good sign.
At the lowest level are additions to the Stream API. Since .NET 1.0, this has been one of my favorite abstractions because it can be used in so many different ways. Reading and writing to a file, or a network socket, or a database, all use the stream API to represent a series of bytes of unknown size. Of course, the limiting factor here has been that, depending on the stream implementation that you are using, the performance and latency can vary greatly. So you should not write code to a network stream in the same way as code that is written to an in-memory stream, because the performance will be vastly different.
With async though, this changes because the Stream class has received new awaitable versions of all of the methods in the class. In the following example, we write an asynchronous method that takes a set of numbers, and writes them to a string as follows:
private static async void WriteNumbersToStream(Stream stream, IEnumerable<int> numbers)
{
StreamWriter writer = new StreamWriter(stream);
foreach (intnum in numbers)
{
await writer.WriteLineAsync(num.ToString());
}
}Although code like this would have been possible to write in a similar fashion before, the addition of methods like .WriteLineAsync lets you write code that is simple without having to worry about the stream holding up execution of the calling thread.
Because of the underlying improvements in the stream API, other areas, such as reading and writing files have improved. Look at the following code:
private static async void WriteContentstoConsoleAsync(string filename)
{
FileStream file = File.OpenRead(filename);
StreamReader reader = new StreamReader(file);
while (!reader.EndOfStream)
{
string line = await reader.ReadLineAsync();
Console.WriteLine(line);
}
}I honestly cannot tell you how many times I have seen variations of this method over the years, of course, written in a non-asynchronous way. Without asynchrony, this method would absolutely choke if you attempted to read a very large file. A perfect example of this is the Notepad application that has come with every version of Windows. If you try to open a very large file, be prepared to wait because the interface will be frozen while the file is streamed from the disk.
But with the asynchronous version here, the interface will not be bogged down, regardless of the size of the file. That is the great feature of async, it accepts the kind of code developers are likely to write, and makes it so that common performance issues, such as buffering, will not affect the performance of the application quite as much. This is a perfect example of the "Pit of Success".
One of the only non-async related improvements are caller attributes. In Java, there is a very common convention, which has made you specify a class level static variable called TAG that would contain some useful string identifier for this class as follows:
private static final String TAG = "NameOfThisClass";
Anytime you want to write information to the system log (logcat), you can just use the TAG variable so that you can easily identify the information in the log output as follows:
Log.e(TAG, "some log message");
So anytime you need to log something, the caller is responsible for self-reporting the metadata about where and why this was logged. Of course, the need to have metadata such as this for logging reaches across languages, so the C# language designers finally added a nice little feature to help you out here.
C# has always had a very powerful reflection system, so it has always been possible to take a look at the stack information in a log method. This simplifies log calls because the caller does not have to do anything special. However, this method was prone to returning unexpected results when an application was compiled in release mode, because of compiler optimizations. Also, some of the relevant classes have been excluded in portable libraries.
You can now add some compiler-optimized parameters to log methods in C# 5. When you call the method, the compiler will insert the appropriate metadata so that the correct values are returned at runtime, as follows:
public void Log([CallerMemberName]string name = null)
{
Console.WriteLine("The caller is named {0}", name);
}The following are two other attributes that you can use: