
8.1. Integrating legacy databases
In this section, we hope to cover all the things you may encounter when you have to deal with an existing legacy database or (and this is often synonymous) a weird or broken schema. If your development process is top-down, however, you may want to skip this section. Furthermore, we recommend that you first read all chapters about class, collection, and association mappings before you attempt to reverse-engineer a complex legacy schema.
We have to warn you: When your application inherits an existing legacy database schema, you should usually make as few changes to the existing schema as possible. Every change that you make to the schema could break other existing applications that access the database. Possibly expensive migration of existing data is also something you need to evaluate. In general, it isn't possible to build a new application and make no changes to the existing data model—a new application usually means additional business requirements that naturally require evolution of the database schema.
We'll therefore consider two types of problems: problems that relate to the changing business requirements (which generally can't be solved without schema changes) and problems that relate only to how you wish to represent the same business problem in your new application (these can usually, but not always, be solved without database schema changes). It should be clear that the first kind of problem is usually visible by looking at just the logical data model. The second more often relates to the implementation of the logical data model as a physical database schema.
If you accept this observation, you'll see that the kinds of problems that require schema changes are those that necessitate addition of new entities, refactoring of existing entities, addition of new attributes to existing entities, and modification to the associations between entities. The problems that can be solved without schema changes usually involve inconvenient table or column definitions for a particular entity. In this section, we'll concentrate on these kinds of problems.
We assume that you've tried to reverse-engineer your existing schema with the Hibernate toolset, as described in chapter 2, section 2.3, "Reverse engineering a legacy database." The concepts and solutions discussed in the following sections assume that you have basic object/relational mapping in place and that you need to make additional changes to get it working. Alternatively, you can try to write the mapping completely by hand without the reverse-engineering tools.
Let's start with the most obvious problem: legacy primary keys.
8.1.1. Handling primary keys
We've already mentioned that we think natural primary keys can be a bad idea. Natural keys often make it difficult to refactor the data model when business requirements change. They may even, in extreme cases, impact performance. Unfortunately, many legacy schemas use (natural) composite keys heavily and, for the reason we discourage the use of composite keys, it may be difficult to change the legacy schema to use noncomposite natural or surrogate keys.
Therefore, Hibernate supports the use of natural keys. If the natural key is a composite key, support is via the <composite-id> mapping. Let's map both a composite and a noncomposite natural primary key.
Mapping a natural key
If you encountered a USERS table in a legacy schema, it's likely that USERNAME is the actual primary key. In this case, you have no surrogate identifier that is automatically generated. Instead, you enable the assigned identifier generator strategy to indicate to Hibernate that the identifier is a natural key assigned by the application before the object is saved:
<class name="User" table="USERS">
<id name="username" column="USERNAME" length="16">
<generator class="assigned"/>
</id>
...
</class>
The code to save a new User is as follows:
User user = new User();
user.setUsername("johndoe"); // Assign a primary key value
user.setFirstname("John");
user.setLastname("Doe");
session.saveOrUpdate(user); // Will result in an INSERT
// System.out.println( session.getIdentifier(user) );
session.flush();
How does Hibernate know that saveOrUpdate() requires an INSERT and not an UPDATE? It doesn't, so a trick is needed: Hibernate queries the USERS table for the given username, and if it's found, Hibernate updates the row. If it isn't found, insertion of a new row is required and done. This is certainly not the best solution, because it triggers an additional hit on the database.
Several strategies avoid the SELECT:
Add a <version> or a <timestamp> mapping, and a property, to your entity. Hibernate manages both values internally for optimistic concurrency control (discussed later in the book). As a side effect, an empty timestamp or a 0 or NULL version indicates that an instance is new and has to be inserted, not updated.
Implement a Hibernate Interceptor, and hook it into your Session. This extension interface allows you to implement the method isTransient() with any custom procedure you may need to distinguish old and new objects.
On the other hand, if you're happy to use save() and update() explicitly instead of saveOrUpdate(), Hibernate doesn't have to distinguish between transient and detached instances—you do this by selecting the right method to call. (This issue is, in practice, the only reason to not use saveOrUpdate() all the time, by the way.)
Mapping natural primary keys with JPA annotations is straightforward:
@Id private String username;
If no identifier generator is declared, Hibernate assumes that it has to apply the regular select-to-determine-state-unless-versioned strategy and expects the application to take care of the primary key value assignment. You can again avoid the SELECT by extending your application with an interceptor or by adding a version-control property (version number or timestamp).
Composite natural keys extend on the same ideas.
Mapping a composite natural key
Suppose that the primary key of the USERS table consists of a USERNAME and DEPARTMENT_NR. You can add a property named departmentNr to the User class and create the following mapping:
<class name="User" table="USERS">
<composite-id>
<key-property name="username"
column="USERNAME"/>
<key-property name="departmentNr"
column="DEPARTMENT_NR"/>
</composite-id>
...
</class>
The code to save a new User looks like this:
User user = new User();
// Assign a primary key value
user.setUsername("johndoe");
user.setDepartmentNr(42);
// Set property values
user.setFirstname("John");
user.setLastname("Doe");
session.saveOrUpdate(user);
session.flush();
Again, keep in mind that Hibernate executes a SELECT to determine what saveOrUpdate() should do—unless you enable versioning control or a custom Interceptor. But what object can/should you use as the identifier when you call load() or get()? Well, it's possible to use an instance of the User class, for example:
User user = new User();
// Assign a primary key value
user.setUsername("johndoe");
user.setDepartmentNr(42);
// Load the persistent state into user
session.load(User.class, user);
In this code snippet, User acts as its own identifier class. It's more elegant to define a separate composite identifier class that declares just the key properties. Call this class UserId:
public class UserId implements Serializable {
private String username;
private Integer departmentNr;
public UserId(String username, Integer departmentNr) {
this.username = username;
this.departmentNr = departmentNr;
}
// Getters...
public int hashCode() {
int result;
result = username.hashCode();
result = 29 * result + departmentNr.hashCode();
return result;
}
public boolean equals(Object other) {
if (other==null) return false;
if ( !(other instanceof UserId) ) return false;
UserId that = (UserId) other;
return this.username.equals(that.username) &&
this.departmentNr.equals(that.departmentNr);
}
}
It's critical that you implement equals() and hashCode() correctly, because Hibernate relies on these methods for cache lookups. Identifier classes are also expected to implement Serializable.
You now remove the username and departmentNr properties from User and add a userId property. Create the following mapping:
<class name="User" table="USERS">
<composite-id name="userId" class="UserId">
<key-property name="username"
column="USERNAME"/>
<key-property name="departmentNr"
column="DEPARTMENT_NR"/>
</composite-id>
...
</class>
Save a new instance of User with this code:
UserId id = new UserId("johndoe", 42);
User user = new User();
// Assign a primary key value
user.setUserId(id);
// Set property values
user.setFirstname("John");
user.setLastname("Doe");
session.saveOrUpdate(user);
session.flush();
Again, a SELECT is needed for saveOrUpdate() to work. The following code shows how to load an instance:
UserId id = new UserId("johndoe", 42);
User user = (User) session.load(User.class, id);
Now, suppose that the DEPARTMENT_NR is a foreign key referencing the DEPARTMENT table, and that you wish to represent this association in the Java domain model as a many-to-one association.
Foreign keys in composite primary keys
We recommend that you map a foreign key column that is also part of a composite primary key with a regular <many-to-one> element, and disable any Hibernate inserts or updates of this column with insert="false" update="false", as follows:
<class name="User" table="USER">
<composite-id name="userId" class="UserId">
<key-property name="username"
column="USERNAME"/>
<key-property name="departmentId"
column="DEPARTMENT_ID"/>
</composite-id>
<many-to-one name="department"
class="Department"
column="DEPARTMENT_ID"
insert="false" update="false"/>
...
</class>
Hibernate now ignores the department property when updating or inserting a User, but you can of course read it with johndoe.getDepartment(). The relationship between a User and Department is now managed through the departmentId property of the UserId composite key class:
UserId id = new UserId("johndoe", department.getId() );
User user = new User();
// Assign a primary key value
user.setUserId(id);
// Set property values
user.setFirstname("John");
user.setLastname("Doe");
user.setDepartment(department);
session.saveOrUpdate(user);
session.flush();
Only the identifier value of the department has any effect on the persistent state; the setDepartment(department) call is done for consistency: Otherwise, you'd have to refresh the object from the database to get the department set after the flush. (In practice you can move all these details into the constructor of your composite identifier class.)
An alternative approach is a <key-many-to-one>:
<class name="User" table="USER">
<composite-id name="userId" class="UserId">
<key-property name="username"
column="USERNAME"/>
<key-many-to-one name="department"
class="Department"
column="DEPARTMENT_ID"/>
</composite-id>
...
</class>
However, it's usually inconvenient to have an association in a composite identifier class, so this approach isn't recommended except in special circumstances. The <key-many-to-one> construct also has limitations in queries: You can't restrict a query result in HQL or Criteria across a <key-many-to-one> join (although it's possible these features will be implemented in a later Hibernate version).
Foreign keys to composite primary keys
Because USERS has a composite primary key, any referencing foreign key is also composite. For example, the association from Item to User (the seller) is now mapped with a composite foreign key.
Hibernate can hide this detail from the Java code with the following association mapping from Item to User:
<many-to-one name="seller" class="User">
<column name="USERNAME"/>
<column name="DEPARTMENT_ID"/>
</many-to-one>
Any collection owned by the User class also has a composite foreign key—for example, the inverse association, items, sold by this user:
<set name="itemsForAuction" inverse="true">
<key>
<column name="USERNAME"/>
<column name="DEPARTMENT_ID"/>
</key>
<one-to-many class="Item"/>
</set>
Note that the order in which columns are listed is important and should match the order in which they appear in the <composite-id> element of the primary key mapping of User.
This completes our discussion of the basic composite key mapping technique in Hibernate. Mapping composite keys with annotations is almost the same, but as always, small differences are important.
Composite keys with annotations
The JPA specification covers strategies for handling composite keys. You have three options:
Encapsulate the identifier properties in a separate class and mark it @Embeddable, like a regular component. Include a property of this component type in your entity class, and map it with @Id for an application-assigned strategy.
Encapsulate the identifier properties in a separate class without any annotations on it. Include a property of this type in your entity class, and map it with @EmbeddedId.
Encapsulate the identifier properties in a separate class. Now—and this is different that what you usually do in native Hibernate—duplicate all the identifier properties in the entity class. Then, annotate the entity class with @IdClass and specify the name of your encapsulated identifier class.
The first option is straightforward. You need to make the UserId class from the previous section embeddable:
@Embeddable
public class UserId implements Serializable {
private String username;
private String departmentNr;
...
}
As for all component mappings, you can define extra mapping attributes on the fields (or getter methods) of this class. To map the composite key of User, set the generation strategy to application assigned by omitting the @GeneratedValue annotation:
@Id
@AttributeOverrides({
@AttributeOverride(name = "username",
column = @Column(name="USERNAME") ),
@AttributeOverride(name = "departmentNr",
column = @Column(name="DEP_NR") )
})
private UserId userId;
Just as you did with regular component mappings earlier in the book, you can override particular attribute mappings of the component class, if you like.
The second composite-key mapping strategy doesn't require that you mark up the UserId primary key class. Hence, no @Embeddable and no other annotation on that class is needed. In the owning entity, you map the composite identifier property with @EmbeddedId, again, with optional overrides:
@EmbeddedId
@AttributeOverrides({
@AttributeOverride(name = "username",
column = @Column(name="USERNAME") ),
@AttributeOverride(name = "departmentNr",
column = @Column(name="DEP_NR") )
})
private UserId userId;
In a JPA XML descriptor, this mapping looks as follows:
<embeddable class="auction.model.UserId" access ="PROPERTY">
<attributes>
<basic name="username">
<column name="UNAME"/>
</basic>
<basic name="departmentNr">
<column name="DEPARTMENT_NR"/>
</basic>
</attributes>
</embeddable>
<entity class="auction.model.User" access="FIELD">
<attributes>
<embedded-id name="userId">
<attribute-override name="username">
<column name="USERNAME"/>
</attribute-override>
<attribute-override name="departmentNr">
<column name="DEP_NR"/>
</attribute-override>
</embedded-id>
...
</attributes>
</entity>
The third composite-key mapping strategy is a bit more difficult to understand, especially for experienced Hibernate users. First, you encapsulate all identifier attributes in a separate class—as in the previous strategy, no extra annotations on that class are needed. Now you duplicate all the identifier properties in the entity class:
@Entity
@Table(name = "USERS")
@IdClass(UserId.class)
public class User {
@Id
private String username;
@Id
private String departmentNr;
// Accessor methods, etc.
...
}
Hibernate inspects the @IdClass and singles out all the duplicate properties (by comparing name and type) as identifier properties and as part of the primary key. All primary key properties are annotated with @Id, and depending on the position of these elements (field or getter method), the entity defaults to field or property access.
Note that this last strategy is also available in Hibernate XML mappings; however, it's somewhat obscure:
<composite-id class="UserId" mapped="true">
<key-property name="username"
column="USERNAME"/>
<key-property name="departmentNr"
column="DEP_NR"/>
</composite-id>
You omit the identifier property name of the entity (because there is none), so Hibernate handles the identifier internally. With mapped="true", you enable the last JPA mapping strategy, so all key properties are now expected to be present in both the User and the UserId classes.
This composite identifier mapping strategy looks as follows if you use JPA XML descriptors:
<entity class="auction.model.User" access="FIELD">
<id-class class="auction.model.UserId"/>
<attributes>
<id name="username"/>
<id name="departmentNr"/>
</attributes>
</entity>
Because we didn't find a compelling case for this last strategy defined in Java Persistence, we have to assume that it was added to the specification to support some legacy behavior (EJB 2.x entity beans).
Composite foreign keys are also possible with annotations. Let's first map the association from Item to User:
@ManyToOne
@JoinColumns({
@JoinColumn(name="USERNAME", referencedColumnName = "USERNAME"),
@JoinColumn(name="DEP_NR", referencedColumnName = "DEP_NR")
})
private User seller;
The primary difference between a regular @ManyToOne and this mapping is the number of columns involved—again, the order is important and should be the same as the order of the primary key columns. However, if you declare the referencedColumnName for each column, order isn't important, and both the source and target tables of the foreign key constraint can have different column names.
The inverse mapping from User to Item with a collection is even more straightforward:
@OneToMany(mappedBy = "seller") private Set<Item> itemsForAuction = new HashSet<Item>();
This inverse side needs the mappedBy attribute, as usual for bidirectional associations. Because this is the inverse side, it doesn't need any column declarations.
In legacy schemas, a foreign key often doesn't reference a primary key.
Foreign key referencing nonprimary keys
Usually, a foreign key constraint references a primary key. A foreign key constraint is an integrity rule that guarantees that the referenced table has one row with a key value that matches the key value in the referencing table and given row. Note that a foreign key constraint can be self-referencing; in other words, a column with a foreign key constraint can reference the primary key column of the same table. (The PARENT_CATEGORY_ID in the CaveatEmptor CATEGORY table is one example.)
Legacy schemas sometimes have foreign key constraints that don't follow the simple "FK references PK" rule. Sometimes a foreign key references a nonprimary key: a simple unique column, a natural nonprimary key. Let's assume that in CaveatEmptor, you need to handle a legacy natural key column called CUSTOMER_NR on the USERS table:
<class name="User" table="USERS">
<id name="id" column="USER_ID">...</id>
<property name="customerNr"
column="CUSTOMER_NR"
not-null="true"
unique="true"/>
</class>
The only thing that is probably new to you in this mapping is the unique attribute. This is one of the SQL customization options in Hibernate; it's not used at runtime (Hibernate doesn't do any uniqueness validation) but to export the database schema with hbm2ddl. If you have an existing schema with a natural key, you assume that it's unique. For completeness, you can and should repeat such important constraints in your mapping metadata—maybe you'll use it one day to export a fresh schema.
Equivalent to the XML mapping, you can declare a column as unique in JPA annotations:
@Column(name = "CUSTOMER_NR", nullable = false, unique=true) private int customerNr;
The next issue you may discover in the legacy schema is that the ITEM table has a foreign key column, SELLER_NR. In an ideal world, you would expect this foreign key to reference the primary key, USER_ID, of the USERS table. However, in a legacy schema, it may reference the natural unique key, CUSTOMER_NR. You need to map it with a property reference:
<class name="Item" table="ITEM">
<id name="id" column="ITEM_ID">...</id>
<many-to-one name="seller" column="SELLER_NR"
property-ref="customerNr"/>
</class>
You'll encounter the property-ref attribute in more exotic Hibernate mappings. It's used to tell Hibernate that "this is a mirror of the named property." In the previous example, Hibernate now knows the target of the foreign key reference. One further thing to note is that property-ref requires the target property to be unique, so unique="true", as shown earlier, is needed for this mapping.
If you try to map this association with JPA annotations, you may look for an equivalent to the property-ref attribute. You map the association with an explicit reference to the natural key column, CUSTOMER_NR:
@ManyToOne @JoinColumn(name="SELLER_NR", referencedColumnName = "CUSTOMER_NR") private User seller;
Hibernate now knows that the referenced target column is a natural key and manages the foreign key relationship accordingly.
To complete this example, you make this association mapping between the two classes bidirectional, with a mapping of an itemsForAuction collection on the User class. First, here it is in XML:
<class name="User" table="USERS">
<id name="id" column="USER_ID">...</id>
<property name="customerNr" column="CUSTOMER_NR" unique="true"/>
<set name="itemsForAuction" inverse="true">
<key column="SELLER_NR" property-ref="customerNr"/>
<one-to-many class="Item"/>
</set>
</class>
Again the foreign key column in ITEM is mapped with a property reference to customerNr. In annotations, this is a lot easier to map as an inverse side:
@OneToMany(mappedBy = "seller") private Set<Item> itemsForAuction = new HashSet<Item>();
Composite foreign key referencing nonprimary keys
Some legacy schemas are even more complicated than the one discussed before: A foreign key might be a composite key and, by design, reference a composite natural nonprimary key!
Let's assume that USERS has a natural composite key that includes the FIRSTNAME, LASTNAME, and BIRTHDAY columns. A foreign key may reference this natural key, as shown in figure 8.1.
To map this, you need to group several properties under the same name—otherwise you can't name the composite in a property-ref. Apply the <properties> element to group the mappings:
Figure 8-1. A composite foreign key references a composite primary key.

<class name="User" table="USERS">
<id name="id" column="USER_ID">...</id>
<properties name="nameAndBirthday" unique="true" update="false">
<property name="firstname" column="FIRSTNAME"/>
<property name="lastname" column="LASTNAME"/>
<property name="birthday" column="BIRTHDAY" type="date"/>
</properties>
<set name="itemsForAuction" inverse="true">
<key property-ref="nameAndBirthday">
<column name="SELLER_FIRSTNAME"/>
<column name="SELLER_LASTNAME"/>
<column name="SELLER_BIRTHDAY"/>
</key>
<one-to-many class="Item"/>
</set>
</class>
As you can see, the <properties> element is useful not only to give several properties a name, but also to define a multicolumn unique constraint or to make several properties immutable. For the association mappings, the order of columns is again important:
<class name="Item" table="ITEM">
<id name="id" column="ITEM_ID">...</id>
<many-to-one name="seller" property-ref="nameAndBirthday">
<column name="SELLER_FIRSTNAME"/>
<column name="SELLER_LASTNAME"/>
<column name="SELLER_BIRTHDAY"/>
</many-to-one>
</class>
Fortunately, it's often straightforward to clean up such a schema by refactoring foreign keys to reference primary keys—if you can make changes to the database that don't disturb other applications sharing the data.
This completes our exploration of natural, composite, and foreign key-related problems you may have to deal with when you try to map a legacy schema. Let's move on to other interesting special mapping strategies.
Sometimes you can't make any changes to a legacy database—not even creating tables or views. Hibernate can map classes, properties, and even parts of associations to a simple SQL statement or expression. We call these kinds of mappings formula mappings.
8.1.2. Arbitrary join conditions with formulas
Mapping a Java artifact to an SQL expression is useful for more than integrating a legacy schema. You created two formula mappings already: The first, "Using derived properties," in chapter 4, section 4.4.1, was a simple derived read-only property mapping. The second formula calculated the discriminator in an inheritance mapping; see chapter 5, section 5.1.3, "Table per class hierarchy."
You'll now apply formulas for a more exotic purposes. Keep in mind that some of the mappings you'll see now are complex, and you may be better prepared to understand them after reading all the chapters in part 2 of this book.
Understanding the use case
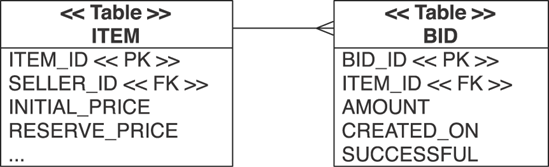
You now map a literal join condition between two entities. This sounds more complex than it is in practice. Look at the two classes shown in figure 8.2.
A particular Item may have several Bids—this is a one-to-many association. But it isn't the only association between the two classes; the other, a unidirectional one-to-one, is needed to single out one particular Bid instance as the winning bid. You map the first association because you'd like to be able to get all the bids for an auctioned item by calling anItem.getBids(). The second association allows you to call anItem.getSuccessfulBid(). Logically, one of the elements in the collection is also the successful bid object referenced by getSuccessfulBid().
Figure 8-2. A single-association that references an instance in a many-association

The first association is clearly a bidirectional one-to-many/many-to-one association, with a foreign key ITEM_ID in the BID table. (If you haven't mapped this before, look at chapter 6, section 6.4, "Mapping a parent/children relationship.")
The one-to-one association is more difficult; you can map it several ways. The most natural is a uniquely constrained foreign key in the ITEM table referencing a row in the BID table—the winning row, for example a SUCCESSFUL_BID_ID column.
Legacy schemas often need a mapping that isn't a simple foreign key relationship.
Mapping a formula join condition
Imagine that each row in the BID table has a flag column to mark the winning bid, as shown in figure 8.3. One BID row has the flag set to true, and all other rows for this auction item are naturally false. Chances are good that you won't find a constraint or an integrity rule for this relationship in a legacy schema, but we ignore this for now and focus on the mapping to Java classes.
To make this mapping even more interesting, assume that the legacy schema didn't use the SQL BOOLEAN datatype but a CHAR(1) field and the values T (for true) and F (for false) to simulate the boolean switch. Your goal is to map this flag column to a successfulBid property of the Item class. To map this as an object reference, you need a literal join condition, because there is no foreign key Hibernate can use for a join. In other words, for each ITEM row, you need to join a row from the BID table that has the SUCCESSFUL flag set to T. If there is no such row, the anItem.getSuccessfulBid() call returns null.
Let's first map the Bid class and a successful boolean property to the SUCCESSFUL database column:
Figure 8-3. The winning bid is marked with the SUCCESSFUL column flag.
<class name="Bid" table="BID">
<id name="id" column="BID_ID"...
<property name="amount"
...
<properties name="successfulReference">
<property name="successful"
column="SUCCESSFUL"
type="true_false"/>
...
<many-to-one name="item"
class="Item"
column="ITEM_ID"/>
...
</properties>
<many-to-one name="bidder"
class="User"
column="BIDDER_ID"/>
...
</class>
The type="true_false" attribute creates a mapping between a Java boolean primitive (or its wrapper) property and a simple CHAR(1) column with T/F literal values—it's a built-in Hibernate mapping type. You again group several properties with <properties> under a name that you can reference in other mappings. What is new here is that you can group a <many-to-one>, not only basic properties.
The real trick is happening on the other side, for the mapping of the successfulBid property of the Item class:
<class name="Item" table="ITEM">
<id name="id" column="ITEM_ID"...
<property name="initialPrice"
...
<one-to-one name="successfulBid"
property-ref="successfulReference">
<formula>'T'</formula>
<formula>ITEM_ID</formula>
</one-to-one>
<set name="bids" inverse="true">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
</class>
Ignore the <set> association mapping in this example; this is the regular one-to-many association between Item and Bid, bidirectional, on the ITEM_ID foreign key column in BID.
Note:
Isn't <one-to-one> used for primary key associations? Usually, a <one-to-one> mapping is a primary key relationship between two entities, when rows in both entity tables share the same primary key value. However, by using a formula with a property-ref, you can apply it to a foreign key relationship. In the example shown in this section, you could replace the <one-to-one> element with <many-to-one>, and it would still work.
The interesting part is the <one-to-one> mapping and how it relies on a property-ref and literal formula values as a join condition when you work with the association.
Working with the association
The full SQL query for retrieval of an auction item and its successful bid looks like this:
select
i.ITEM_ID,
i.INITIAL_PRICE,
...
b.BID_ID,
b.AMOUNT,
b.SUCCESSFUL,
b.BIDDER_ID,
...
from
ITEM i
left outer join
BID b
on 'T' = b.SUCCESSFUL
and i.ITEM_ID = b.ITEM_ID
where
i.ITEM_ID = ?
When you load an Item, Hibernate now joins a row from the BID table by applying a join condition that involves the columns of the successfulReference property. Because this is a grouped property, you can declare individual expressions for each of the columns involved, in the right order. The first one, 'T', is a literal, as you can see from the quotes. Hibernate now includes 'T' = SUCCESSFUL in the join condition when it tries to find out whether there is a successful row in the BID table. The second expression isn't a literal but a column name (no quotes). Hence, another join condition is appended: i.ITEM_ID = b.ITEM_ID. You can expand this and add more join conditions if you need additional restrictions.
Note that an outer join is generated because the item in question may not have a successful bid, so NULL is returned for each b.* column. You can now call anItem.getSuccessfulBid() to get a reference to the successful bid (or null if none exists).
Finally, with or without database constraints, you can't just implement an item.setSuccessfulBid() method that only sets the value on a private field in the Item instance. You have to implement a small procedure in this setter method that takes care of this special relationship and the flag property on the bids:
public class Item {
...
private Bid successfulBid;
private Set<Bid> bids = new HashSet<Bid>();
public Bid getSuccessfulBid() {
return successfulBid;
}
public void setSuccessfulBid(Bid successfulBid) {
if (successfulBid != null) {
for (Bid bid : bids)
bid.setSuccessful(false);
successfulBid.setSuccessful(true);
this.successfulBid = successfulBid;
}
}
}
When setSuccessfulBid() is called, you set all bids to not successful. Doing so may trigger the loading of the collection—a price you have to pay with this strategy. Then, the new successful bid is marked and set as an instance variable. Setting the flag updates the SUCCESSFUL column in the BID table when you save the objects. To complete this (and to fix the legacy schema), your database-level constraints need to do the same as this method. (We'll come back to constraints later in this chapter.)
One of the things to remember about this literal join condition mapping is that it can be applied in many other situations, not only for successful or default relationships. Whenever you need some arbitrary join condition appended to your queries, a formula is the right choice. For example, you could use it in a <many-to-many> mapping to create a literal join condition from the association table to the entity table(s).
Unfortunately, at the time of writing, Hibernate Annotations doesn't support arbitrary join conditions expressed with formulas. The grouping of properties under a reference name also wasn't possible. We expect that these features will closely resemble the XML mapping, once they're available.
Another issue you may encounter in a legacy schema is that it doesn't integrate nicely with your class granularity. Our usual recommendation to have more classes than tables may not work, and you may have to do the opposite and join arbitrary tables into one class.
8.1.3. Joining arbitrary tables
We've already shown the <join> mapping element in an inheritance mapping in chapter 5; see section 5.1.5, "Mixing inheritance strategies." It helped to break out properties of a particular subclass into a separate table, out of the primary inheritance hierarchy table. This generic functionality has more uses—however, we have to warn you that <join> can also be a bad idea. Any properly designed system should have more classes than tables. Splitting a single class into separate tables is something you should do only when you need to merge several tables in a legacy schema into a single class.
Moving properties into a secondary table
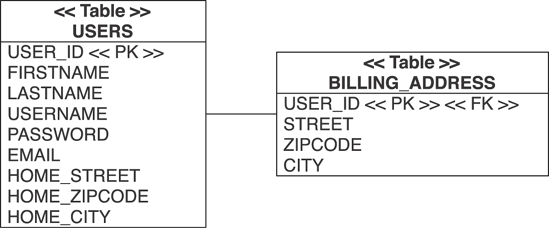
Suppose that in CaveatEmptor, you aren't keeping a user's address information with the user's main information in the USERS table, mapped as a component, but in a separate table. This is shown in figure 8.4. Note that each BILLING_ADDRESS has a foreign key USER_ID, which is in turn the primary key of the BILLING_ADDRESS table.
To map this in XML, you need to group the properties of the Address in a <join> element:
Figure 8-4. Breaking out the billing address data into a secondary table
<class name="User" table="USERS">
<id>...
<join table="BILLING_ADDRESS" optional="true">
<key column="USER_ID"/>
<component name="billingAddress" class="Address">
<property name="street"
type="string"
column="STREET"
length="255"/>
<property name="zipcode"
type="string"
column="ZIPCODE"
length="16"/>
<property name="city"
type="string"
column="CITY"
length="255"/>
</component>
</join>
</class>
You don't have to join a component; you can as well join individual properties or even a <many-to-one> (we did this in the previous chapter for optional entity associations). By setting optional="true", you indicate that the component property may also be null for a User with no billingAddress, and that no row should then be inserted into the secondary table. Hibernate also executes an outer join instead of an inner join to retrieve the row from the secondary table. If you declared fetch="select" on the <join> mapping, a secondary select would be used for that purpose.
The notion of a secondary table is also included in the Java Persistence specification. First, you have to declare a secondary table (or several) for a particular entity:
@Entity
@Table(name = "USERS")
@SecondaryTable(
name = "BILLING_ADDRESS",
pkJoinColumns = {
@PrimaryKeyJoinColumn(name="USER_ID")
}
)
public class User {
...
}
Each secondary table needs a name and a join condition. In this example, a foreign key column references the primary key column of the USERS table, just like earlier in the XML mapping. (This is the default join condition, so you can only declare the secondary table name, and nothing else). You can probably see that the syntax of annotations is starting to become an issue and code is more difficult to read. The good news is that you won't have to use secondary tables often.
The actual component property, billingAddress, is mapped as a regular @Embedded class, just like a regular component. However, you need to override each component property column and assign it to the secondary table, in the User class:
@Embedded
@AttributeOverrides( {
@AttributeOverride(
name = "street",
column = @Column(name="STREET",
table = "BILLING_ADDRESS")
),
@AttributeOverride(
name = "zipcode",
column = @Column(name="ZIPCODE",
table = "BILLING_ADDRESS")
),
@AttributeOverride(
name = "city",
column = @Column(name="CITY",
table = "BILLING_ADDRESS")
)
})
private Address billingAddress;
This is no longer easily readable, but it's the price you pay for mapping flexibility with declarative metadata in annotations. Or, you can use a JPA XML descriptor:
<entity class="auction.model.User" access="FIELD">
<table name="USERS"/>
<secondary-table name="BILLING_ADDRESS">
<primary-key-join-column
referenced-column-name="USER_ID"/>
</secondary-table>
<attributes>
...
<embedded name="billingAddress">
<attribute-override name="street">
<column name="STREET" table="BILLING_ADDRESS"/>
</attribute-override>
<attribute-override name="zipcode">
<column name="ZIPCODE" table="BILLING_ADDRESS"/>
</attribute-override>
<attribute-override name="city">
<column name="CITY" table="BILLING_ADDRESS"/>
</attribute-override>
</embedded>
</attributes>
</entity>
Another, even more exotic use case for the <join> element is inverse joined properties or components.
Inverse joined properties
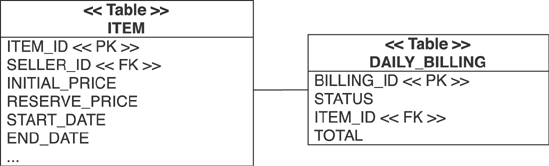
Let's assume that in CaveatEmptor you have a legacy table called DAILY_BILLING. This table contains all the open payments, executed in a nightly batch, for any auctions. The table has a foreign key column to ITEM, as you can see in figure 8.5.
Each payment includes a TOTAL column with the amount of money that will be billed. In CaveatEmptor, it would be convenient if you could access the price of a particular auction by calling anItem.getBillingTotal().
You can map the column from the DAILY_BILLING table into the Item class. However, you never insert or update it from this side; it's read-only. For that reason, you map it inverse—a simple mirror of the (supposed, you don't map it here) other side that takes care of maintaining the column value:
<class name="Item" table="ITEM">
<id>...
<join table="DAILY_BILLING" optional="true" inverse="true">
<key column="ITEM_ID"/>
<property name="billingTotal"
type="big_decimal"
column="TOTAL"/>
</join>
</class>
Figure 8-5. The daily billing summary references an item and contains the total sum.
Note that an alternative solution for this problem is a derived property using a formula expression and a correlated subquery:
<property name="billingTotal"
type="big_decimal"
formula="( select db.TOTAL from DAILY_BILLING db
where db.ITEM_ID = ITEM_ID )"/>
The main difference is the SQL SELECT used to load an ITEM: The first solution defaults to an outer join, with an optional second SELECT if you enable <join fetch="select">. The derived property results in an embedded subselect in the select clause of the original query. At the time of writing, inverse join mappings aren't supported with annotations, but you can use a Hibernate annotation for formulas.
As you can probably guess from the examples, <join> mappings come in handy in many situations. They're even more powerful if combined with formulas, but we hope you won't have to use this combination often.
One further problem that often arises in the context of working with legacy data are database triggers.
8.1.4. Working with triggers
There are some reasons for using triggers even in a brand-new database, so legacy data isn't the only scenerio in which they can cause problems. Triggers and object state management with an ORM software are almost always an issue, because triggers may run at inconvenient times or may modify data that isn't synchronized with the in-memory state.
Suppose the ITEM table has a CREATED column, mapped to a created property of type Date, that is initialized by a trigger that executes automatically on insertion. The following mapping is appropriate:
<property name="created"
type="timestamp"
column="CREATED"
insert="false"
update="false"/>
Notice that you map this property insert="false" update="false" to indicate that it isn't to be included in SQL INSERTs or UPDATEs by Hibernate.
After saving a new Item, Hibernate isn't aware of the value assigned to this column by the trigger, because it occurred after the INSERT of the item row. If you need the generated value in the application, you must explicitly tell Hibernate to reload the object with an SQL SELECT. For example:
Item item = new Item(); ... Session session = getSessionFactory().openSession(); Transaction tx = session.beginTransaction(); session.save(item); session.flush(); // Force the INSERT to occur session.refresh(item); // Reload the object with a SELECT System.out.println( item.getCreated() ); tx.commit(); session.close();
Most problems involving triggers may be solved in this way, using an explicit flush() to force immediate execution of the trigger, perhaps followed by a call to refresh() to retrieve the result of the trigger.
Before you add refresh() calls to your application, we have to tell you that the primary goal of the previous section was to show you when to use refresh(). Many Hibernate beginners don't understand its real purpose and often use it incorrectly. A more formal definition of refresh() is "refresh an in-memory instance in persistent state with the current values present in the database."
For the example shown, a database trigger filling a column value after insertion, a much simpler technique can be used:
<property name="created"
type="timestamp"
column="CREATED"
generated="insert"
insert="false"
update="false"/>
With annotations, use a Hibernate extension:
@Temporal(TemporalType.TIMESTAMP)
@org.hibernate.annotations.Generated(
org.hibernate.annotations.GenerationTime.INSERT
)
@Column(name = "CREATED", insertable = false, updatable = false)
private Date created;
We have already discussed the generated attribute in detail in chapter 4, section 4.4.1.3, "Generated and default property values." With generated="insert", Hibernate automatically executes a SELECT after insertion, to retrieve the updated state.
There is one further problem to be aware of when your database executes triggers: reassociation of a detached object graph and triggers that run on each UPDATE.
Before we discuss the problem of ON UPDATE triggers in combination with reattachment of objects, we need to point out an additional setting for the generated attribute:
<version name="version"
column="OBJ_VERSION"
generated="always"/>
...
<timestamp name="lastModified"
column="LAST_MODIFIED"
generated="always"/>
...
<property name="lastModified"
type="timestamp"
column="LAST_MODIFIED"
generated="always"
insert="false"
update="false"/>
With annotations, the equivalent mappings are as follows:
@Version
@org.hibernate.annotations.Generated(
org.hibernate.annotations.GenerationTime.ALWAYS
)
@Column(name = "OBJ_VERSION")
private int version;
@Version
@org.hibernate.annotations.Generated(
org.hibernate.annotations.GenerationTime.ALWAYS
)
@Column(name = "LAST_MODIFIED")
private Date lastModified;
@Temporal(TemporalType.TIMESTAMP)
@org.hibernate.annotations.Generated(
org.hibernate.annotations.GenerationTime.ALWAYS
)
@Column(name = "LAST_MODIFIED", insertable = false, updatable = false)
private Date lastModified;
With always, you enable Hibernate's automatic refreshing not only for insertion but also for updating of a row. In other words, whenever a version, timestamp, or any property value is generated by a trigger that runs on UPDATE SQL statements, you need to enable this option. Again, refer to our earlier discussion of generated properties in section 4.4.1.
Let's look at the second issue you may run into if you have triggers running on updates. Because no snapshot is available when a detached object is reattached to a new Session (with update() or saveOrUpdate()), Hibernate may execute unnecessary SQL UPDATE statements to ensure that the database state is synchronized with the persistence context state. This may cause an UPDATE trigger to fire inconveniently. You avoid this behavior by enabling select-before-update in the mapping for the class that is persisted to the table with the trigger. If the ITEM table has an update trigger, add the following attribute to your mapping:
<class name="Item"
table="ITEM"
select-before-update="true">
...
</class>
This setting forces Hibernate to retrieve a snapshot of the current database state using an SQL SELECT, enabling the subsequent UPDATE to be avoided if the state of the in-memory Item is the same. You trade the inconvenient UPDATE for an additional SELECT.
A Hibernate annotation enables the same behavior:
@Entity
@org.hibernate.annotations.Entity(selectBeforeUpdate = true)
public class Item { ... }
Before you try to map a legacy scheme, note that the SELECT before an update only retrieves the state of the entity instance in question. No collections or associated instances are eagerly fetched, and no prefetching optimization is active. If you start enabling selectBeforeUpdate for many entities in your system, you'll probably find that the performance issues introduced by the nonoptimized selects are problematic. A better strategy uses merging instead of reattachment. Hibernate can then apply some optimizations (outer joins) when retrieving database snapshots. We'll talk about the differences between reattachment and merging later in the book in more detail.
Let's summarize our discussion of legacy data models: Hibernate offers several strategies to deal with (natural) composite keys and inconvenient columns easily. Before you try to map a legacy schema, our recommendation is to carefully examine whether a schema change is possible. In our experience, many developers immediately dismiss database schema changes as too complex and time-consuming and look for a Hibernate solution. This sometimes isn't justified, and you should consider schema evolution a natural part of your schema's lifecycle. If tables change, then a data export, some transformation, and an import may solve the problem. One day of work may save many days in the long run.
Legacy schemas often also require customization of the SQL generated by Hibernate, be it for data manipulation (DML) or schema definition (DDL).