
11.2. Conversations with Hibernate
You've been introduced to the concept of conversations several times throughout the previous chapters. The first time, we said that conversations are units of work that span user think-time. We then explored the basic building blocks you have to put together to create conversational applications: detached objects, reattachment, merging, and the alternative strategy with an extended persistence context.
It's now time to see all these options in action. We build on the previous example, the closing and completion of an auction, and turn it into a conversation.
11.2.1. Providing conversational guarantees
You already implemented a conversation—it just wasn't long. You implemented the shortest possible conversation: a conversation that spanned a single request from the application user: The user (let's assume we're talking about a human operator) clicks the Complete Auction button in the CaveatEmptor administration interface. This requested event is then processed, and a response showing that the action was successful is presented to the operator.
In practice, short conversations are common. Almost all applications have more complex conversations—more sophisticated sequences of actions that have to be grouped together as one unit. For example, the human operator who clicks the Complete Auction button does so because they're convinced this auction should be completed. They make this decision by looking at the data presented on the screen—how did the information get there? An earlier request was sent to the application and triggered the loading of an auction for display. From the application user's point of view, this loading of data is part of the same unit of work. It seems reasonable that the application also should know that both events—the loading of an auction item for display and the completion of an auction—are supposed to be in the same unit of work. We're expanding our concept of a unit of work and adopting the point of view of the application user. You group both events into the same conversation.
The application user expects some guarantees while going through this conversation with the application:
The auction the user is about to close and end isn't modified while they look at it. Completion of the auction requires that the data on which this decision is based is still unchanged when the completion occurs. Otherwise, the operator is working with stale data and probably will make a wrong decision.
The conversation is atomic: At any time the user can abort the conversation, and all changes they made are rolled back. This isn't a big issue in our current scenario, because only the last event would make any permanent changes; the first request only loads data for display. However, more complex conversations are possible and common.
You as the application developer wish to implement these guarantees with as little work as possible.
We now show you how to implement long conversations with Hibernate, with and without EJBs. The first decision you'll have to make, in any environment, is between a strategy that utilizes detached objects and a strategy that extends the persistence context.
11.2.2. Conversations with detached objects
Let's create the conversation with native Hibernate interfaces and a detached object strategy. The conversation has two steps: The first step loads an object, and the second step makes changes to the loaded object persistent. The two steps are shown in figure 11.2.
Figure 11-2. A two-step conversation implemented with detached objects

The first step requires a Hibernate Session to retrieve an instance by its identifier (assume this is a given parameter). You'll write another ManageAuction controller that can handle this event:
public class ManageAuction {
public Item getAuction(Long itemId) {
Session s = sf.getCurrentSession();
s.beginTransaction();
Item item = (Item) s.get(Item.class, itemId);
s.getTransaction().commit();
return item;
}
...
}
We simplified the code a little to avoid cluttering the example—you know exception handling isn't really optional. Note that this is a much simpler version than the one we showed previously; we want to show you the minimum code needed to understand conversations. You can also write this controller with DAOs, if you like.
A new Session, persistence context, and database transaction begin when the getAuction() method is called. An object is loaded from the databases, the transaction commits, and the persistence context is closed. The item object is now in a detached state and is returned to the client that called this method. The client works with the detached object, displays it, and possibly even allows the user to modify it.
The second step in the conversation is the completion of the auction. That is the purpose of another method on the ManageAuction controller. Compared to previous examples, you again simplify the endAuction() method to avoid any unnecessary complication:
public class ManageAuction {
public Item getAuction(Long itemId) ...
...
public void endAuction(Item item) {
Session s = sf.getCurrentSession();
s.beginTransaction();
// Reattach item
s.update(item);
// Set winning bid
// Charge seller
// Notify seller and winner
...
s.getTransaction().commit();
}
}
The client calls the endAuction() method and passes back the detached item instance—this is the same instance returned in the first step. The update() operation on the Session reattaches the detached object to the persistence context and schedules an SQL UDPATE. Hibernate must assume that the client modified the object while it was detached. (Otherwise, if you're certain that it hasn't been modified, a lock() would be sufficient.) The persistence context is flushed automatically when the second transaction in the conversation commits, and any modifications to the once detached and now persistent object are synchronized with the database.
The saveOrUpdate() method is in practice more useful than upate(), save(), or lock(): In complex conversations, you don't know if the item is in detached state or if it's new and transient and must be saved. The automatic state-detection provided by saveOrUpdate() becomes even more useful when you not only work with single instances, but also want to reattach or persist a network of connected objects and apply cascading options. Also reread the definition of the merge() operation and when to use merging instead of reattachment: "Merging the state of a detached object" in Chapter 9, section 9.3.2.
So far, you've solved only one of the conversation implementation problems: little code was required to implement the conversation. However, the application user still expects that the unit of work is not only isolated from concurrent modifications, but also atomic.
You isolate concurrent conversations with optimistic locking. As a rule, you shouldn't apply a pessimistic concurrency-control strategy that spans a long-running conversation—this implies expensive and nonscalable locking. In other words, you don't prevent two operators from seeing the same auction item. You hope that this happens rarely: You're optimistic. But if it happens, you have a conflict resolution strategy in place. You need to enable Hibernate's automatic versioning for the Item persistent class, as you did in "Enabling versioning in Hibernate" in Chapter 10, section 10.2.2. Then, every SQL UPDATE or DELETE at any time during the conversation will include a version check against the state present in the database. You get a StaleObjectStateException if this check fails and then have to take appropriate action. In this case, you present an error message to the user ("Sorry, somebody modified the same auction!") and force a restart of the conversation from step one.
How can you make the conversation atomic? The conversation spans several persistence contexts and several database transactions. But this isn't the scope of a unit of work from the point of view of the application user; she considers the conversation to be an atomic group of operations that either all fail or all succeed. In the current conversation this isn't a problem, because you modify and persist data only in the last (second) step. Any conversation that only reads data and delays all reattachment of modified objects until the last step is automatically atomic and can be aborted at any time. If a conversation reattaches and commits modifications to the database in an intermediate step, it's no longer atomic.
One solution is to not flush the persistence contexts on commit—that is, to set a FlushMode.MANUAL on a Session that isn't supposed to persist modifications (of course, not for the last step of the conversation). Another option is to use compensation actions that undo any step that made permanent changes, and to call the appropriate compensation actions when the user aborts the conversation. We won't have much to say about writing compensation actions; they depend on the conversation you're implementing.
Next, you implement the same conversation with a different strategy, eliminating the detached object state. You extend the persistence context to span the whole conversation.
11.2.3. Extending a Session for a conversation
The Hibernate Session has an internal persistence context. You can implement a conversation that doesn't involve detached objects by extending the persistence context to span the whole conversation. This is known as the session-per-conversation strategy, as shown in figure 11.3.
A new Session and persistence context are opened at the beginning of a conversation. The first step, loading of the Item object, is implemented in a first database transaction. The Session is automatically disconnected from the underlying JDBC Connection as soon as you commit the database transaction. You can now hold on to this disconnected Session and its internal persistence context during user think-time. As soon as the user continues in the conversation and executes the next step, you reconnect the Session to a fresh JDBC Connection by beginning a second database transaction. Any object that has been loaded in this conversation is in persistent state: It's never detached. Hence, all modifications you made to any persistent object are flushed to the database as soon as you call flush() on the Session. You have to disable automatic flushing of the Session by setting a FlushMode.MANUAL—you should do this when the conversation begins and the Session is opened.
Figure 11-3. A disconnected persistence context extended to span a conversation
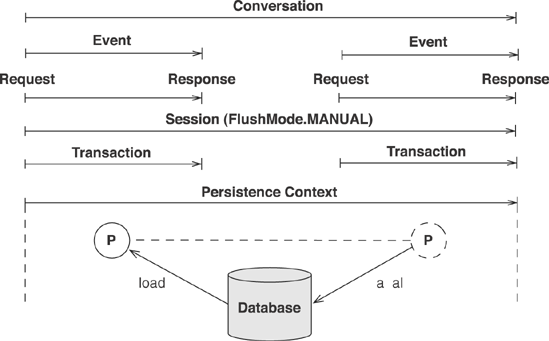
Modifications made in concurrent conversations are isolated, thanks to optimistic locking and Hibernate's automatic version-checking during flushing. Atomicity of the conversation is guaranteed if you don't flush the Session until the last step, the end of the conversation—if you close the unflushed Session, you effectively abort the conversation.
We need to elaborate on one exception to this behavior: the time of insertion of new entity instances. Note that this isn't a problem in this example, but it's something you'll have to deal with in more complex conversations.
Delaying insertion until flush-time
To understand the problem, think about the way objects are saved and how their identifier value is assigned. Because you don't save any new objects in the Complete Auction conversation, you haven't seen this issue. But any conversation in which you save objects in an intermediate step may not be atomic.
The save() method on the Session requires that the new database identifier of the saved instance must be returned. So, the identifier value has to be generated when the save() method is called. This is no problem with most identifier generator strategies; for example, Hibernate can call a sequence, do the in-memory increment, or ask the hilo generator for a new value. Hibernate doesn't have to execute an SQL INSERT to return the identifier value on save() and assign it to the now-persistent instance.
The exceptions are identifier-generation strategies that are triggered after the INSERT occurs. One of them is identity, the other is select; both require that a row is inserted first. If you map a persistent class with these identifier generators, an immediate INSERT is executed when you call save()! Because you're committing database transactions during the conversation, this insertion may have permanent effects.
Look at the following slightly different conversation code that demonstrates this effect:
Session session = getSessionFactory().openSession(); session.setFlushMode(FlushMode.MANUAL); // First step in the conversation session.beginTransaction(); Item item = (Item) session.get(Item.class, new Long(123) ); session.getTransaction().commit(); // Second step in the conversation session.beginTransaction(); Item newItem = new Item(); Long newId = (Long) session.save(newItem); // Triggers INSERT! session.getTransaction().commit(); // Roll back the conversation! session.close();
You may expect that the whole conversation, the two steps, can be rolled back by closing the unflushed persistence context. The insertion of the newItem is supposed to be delayed until you call flush() on the Session, which never happens in this code. This is the case only if you don't pick identity or select as your identifier generator. With these generators, an INSERT must be executed in the second step of the conversation, and the INSERT is committed to the database.
One solution uses compensation actions that you execute to undo any possible insertions made during a conversation that is aborted, in addition to closing the unflushed persistence context. You'd have to manually delete the row that was inserted. Another solution is a different identifier generator, such as a sequence, that supports generation of new identifier values without insertion.
The persist() operation exposes you to the same problem. However, it also provides an alternative (and better) solution. It can delay insertions, even with post-insert identifier generation, if you call it outside of a transaction:
Session session = getSessionFactory().openSession(); session.setFlushMode(FlushMode.MANUAL); // First step in the conversation session.beginTransaction(); Item item = (Item) session.get(Item.class, new Long(1)); session.getTransaction().commit(); // Second step in the conversation Item newItem = new Item(); session.persist(newItem); // Roll back the conversation! session.close();
The persist() method can delay inserts because it doesn't have to return an identifier value. Note that the newItem entity is in persistent state after you call persist(), but it has no identifier value assigned if you map the persistent class with an identity or select generator strategy. The identifier value is assigned to the instance when the INSERT occurs, at flush-time. No SQL statement is executed when you call persist() outside of a transaction. The newItem object has only been queued for insertion.
Keep in mind that the problem we've discussed depends on the selected identifier generator strategy—you may not run into it, or you may be able to avoid it. The nontransactional behavior of persist() will be important again later in this chapter, when you write conversations with JPA and not Hibernate interfaces.
Let's first complete the implementation of a conversation with an extended Session. With a session-per-conversation strategy, you no longer have to detach and reattach (or merge) objects manually in your code. You must implement infrastructure code that can reuse the same Session for a whole conversation.
Managing the current Session
The current Session support we discussed earlier is a switchable mechanism. You've already seen two possible internal strategies: One was thread-bound, and the other bound the current Session to the JTA transaction. Both, however, closed the Session at the end of the transaction. You need a different scope of the Session for the session-per-conversation pattern, but you still want to be able to access the current Session in your application code.
A third built-in option does exactly what you want for the session-per-conversation strategy. You have to enable it by setting the hibernate.current_session_context_class configuration option to managed. The other built-in options we've discussed are thread and jta, the latter being enabled implicitly if you configure Hibernate for JTA deployment. Note that all these built-in options are implementations of the org.hibernate.context.CurrentSessionContext interface; you could write your own implementation and name the class in the configuration. This usually isn't necessary, because the built-in options cover most cases.
The Hibernate built-in implementation you just enabled is called managed because it delegates the responsibility for managing the scope, the start and end of the current Session, to you. You manage the scope of the Session with three static methods:
public class ManagedSessionContext implements CurrentSessionContext {
public static Session bind(Session session) { ... }
public static Session unbind(SessionFactory factory) { ... }
public static boolean hasBind(SessionFactory factory) { ... }
}
You can probably already guess what the implementation of a session-per-conversation strategy has to do:
When a conversation starts, a new Session must be opened and bound with ManagedSessionContext.bind() to serve the first request in the conversation. You also have to set FlushMode.MANUAL on that new Session, because you don't want any persistence context synchronization to occur behind your back.
All data-access code that now calls sessionFactory.getCurrentSession() receives the Session you bound.
When a request in the conversation completes, you need to call ManagedSessionContext.unbind() and store the now disconnected Session somewhere until the next request in the conversation is made. Or, if this was the last request in the conversation, you need to flush and close the Session.
All these steps can be implemented in an interceptor.
Creating a conversation interceptor
You need an interceptor that is triggered automatically for each request event in a conversation. If you use EJBs, as you'll do soon, you get much of this infrastructure code for free. If you write a non- Java EE application, you have to write your own interceptor. There are many ways how to do this; we show you an abstract interceptor that only demonstrates the concept. You can find working and tested interceptor implementations for web applications in the CaveatEmptor download in the org.hibernate.ce.auction.web.filter package.
Let's assume that the interceptor runs whenever an event in a conversation has to be processed. We also assume that each event must go through a front door controller and its execute() action method—the easiest scenario. You can now wrap an interceptor around this method; that is, you write an interceptor that is called before and after this method executes. This is shown in figure 11.4; read the numbered items from left to right.
Figure 11-4. Interception of events to manage the lifecycle of a Session

When the first request in a conversation hits the server, the interceptor runs and opens a new Session ❶ automatic flushing of this Session is immediately disabled. This Session is then bound into Hibernate's ManagedSessionContext. A transaction is started ❷ before the interceptor lets the controller handle the event. All code that runs inside this controller (or any DAO called by the controller) can now call sessionFactory.getCurrentSession() and work with the Session. When the controller finishes its work, the interceptor runs again and unbinds the current Session ❸. After the transaction is committed ❹, the Session is disconnected automatically and can be stored during user think-time.
Now the server waits for the second request in the conversation.
As soon as the second request hits the server, the interceptor runs, detects that there is a disconnected stored Session, and binds it into the ManagedSessionContext ❺. The controller handles the event after a transaction was started by the interceptor ❻. When the controller finishes its work, the interceptor runs again and unbinds the current Session from Hibernate. However, instead of disconnecting and storing it, the interceptor now detects that this is the end of the conversation and that the Session needs to be flushed ❼, before the transaction is committed ❽. Finally, the conversation is complete and the interceptor closes the Session ❾.
This sounds more complex than it is in code. Listing 11.5 is a pseudoimplementation of such an interceptor:
Listing 11-5. An interceptor implements the session-per-conversation strategy
public class ConversationInterceptor {
public Object invoke(Method method) {
// Which Session to use?
Session currentSession = null;
if (disconnectedSession == null) {
// Start of a new conversation
currentSession = sessionFactory.openSession();
currentSession.setFlushMode(FlushMode.MANUAL);
} else {
// In the middle of a conversation
currentSession = disconnectedSession;
}
// Bind before processing event
ManagedSessionContext.bind(currentSession);
// Begin a database transaction, reconnects Session
currentSession.beginTransaction();
// Process the event by invoking the wrapped execute()
Object returnValue = method.invoke();
// Unbind after processing the event
currentSession =
ManagedSessionContext.unbind(sessionFactory);
// Decide if this was the last event in the conversation
if ( returnValue.containsEndOfConversationToken() ) {
// The event was the last event: flush, commit, close
currentSession.flush();
currentSession.getTransaction().commit();
currentSession.close();
disconnectedSession = null; // Clean up
} else {
// Event was not the last event, continue conversation
currentSession.getTransaction().commit(); // Disconnects
disconnectedSession = currentSession;
}
return returnValue;
}
}
|
The invoke(Method) interceptor wraps around the execute() operation of the controller. This interception code runs every time a request from the application user has to be processed. When it returns, you check whether the return value contains a special token or marker. This token signals that this was the last event that has to be processed in a particular conversation. You now flush the Session, commit all changes, and close the Session. If this wasn't the last event of the conversation, you commit the database transaction, store the disconnected Session, and continue to wait for the next event in the conversation.
This interceptor is transparent for any client code that calls execute(). It's also transparent to any code that runs inside execute (): Any data access operation uses the current Session; concerns are separated properly. We don't even have to show you the data-access code, because it's free from any database transaction demarcation or Session handling. Just load and store objects with getCurrentSession().
The following questions are probably on your mind:
Where is the disconnectedSession stored while the application waits for the user to send the next request in a conversation? It can be stored in the HttpSession or even in a stateful EJB. If you don't use EJBs, this responsibility is delegated to your application code. If you use EJB 3.0 and JPA, you can bind the scope of the persistence context, the equivalent of a Session, to a stateful EJB—another advantage of the simplified programming model.
Where does the special token that marks the end of the conversation come from? In our abstract example, this token is present in the return value of the execute() method. There are many ways to implement such a special signal to the interceptor, as long as you find a way to transport it there. Putting it in the result of the event processing is a pragmatic solution.
This completes our discussion of persistence-context propagation and conversation implementation with Hibernate. We shortened and simplified quite a few examples in the past sections to make it easier for you to understand the concepts. If you want to go ahead and implement more sophisticated units of work with Hibernate, we suggest that you first also read Chapter 16.
On the other hand, if you aren't using Hibernate APIs but want to work with Java Persistence and EJB 3.0 components, read on.