
9.2. Object identity and equality
A basic Hibernate client/server application may be designed with server-side units of work that span a single client request. When a request from the application user requires data access, a new unit of work is started. The unit of work ends when processing is complete and the response for the user is ready. This is also called the session-per-request strategy (you can replace the word session with persistence context whenever you read something like this, but it doesn't roll off the tongue as well).
We already mentioned that Hibernate can support an implementation of a possibly long-running unit of work, called a conversation. We introduce the concept of conversations in the following sections as well as the fundamentals of object identity and when objects are considered equal—which can impact how you think about and design conversations.
Why is the concept of a conversation useful?
9.2.1. Introducing conversations
For example, in web applications, you don't usually maintain a database transaction across a user interaction. Users take a long time to think about modifications, but, for scalability reasons, you must keep database transactions short and release database resources as soon as possible. You'll likely face this issue whenever you need to guide the user through several screens to complete a unit of work (from the user's perspective)—for example, to fill an online form. In this common scenario, it's extremely useful to have the support of the persistence service, so you can implement such a conversation with a minimum of coding and best scalability.
Two strategies are available to implement a conversation in a Hibernate or Java Persistence application: with detached objects or by extending a persistence context. Both have strength and weaknesses.
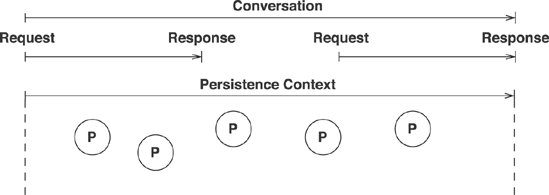
Figure 9-2. Conversation implementation with detached object state

The detached object state and the already mentioned features of reattachment or merging are ways to implement a conversation. Objects are held in detached state during user think-time, and any modification of these objects is made persistent manually through reattachment or merging. This strategy is also called session-per-request-with-detached-objects. You can see a graphical illustration of this conversation pattern in figure 9.2.
A persistence context only spans the processing of a particular request, and the application manually reattaches and merges (and sometimes detaches) entity instances during the conversation.
The alternative approach doesn't require manual reattachment or merging: With the session-per-conversation pattern, you extend a persistence context to span the whole unit of work (see figure 9.3).
First we have a closer look at detached objects and the problem of identity you'll face when you implement a conversation with this strategy.
Figure 9-3. Conversation implementation with an extended persistence context
9.2.2. The scope of object identity
As application developers, we identify an object using Java object identity (a==b). If an object changes state, is the Java identity guaranteed to be the same in the new state? In a layered application, that may not be the case.
In order to explore this, it's extremely important to understand the relationship between Java identity, a==b, and database identity, x.getId().equals( y.getId() ). Sometimes they're equivalent; sometimes they aren't. We refer to the conditions under which Java identity is equivalent to database identity as the scope of object identity.
For this scope, there are three common choices:
A primitive persistence layer with no identity scope makes no guarantees that if a row is accessed twice the same Java object instance will be returned to the application. This becomes problematic if the application modifies two different instances that both represent the same row in a single unit of work. (How should we decide which state should be propagated to the database?)
A persistence layer using persistence context-scoped identity guarantees that, in the scope of a single persistence context, only one object instance represents a particular database row. This avoids the previous problem and also allows for some caching at the context level.
Process-scoped identity goes one step further and guarantees that only one object instance represents the row in the whole process (JVM).
For a typical web or enterprise application, persistence context-scoped identity is preferred. Process-scoped identity does offer some potential advantages in terms of cache utilization and the programming model for reuse of instances across multiple units of work. However, in a pervasively multithreaded application, the cost of always synchronizing shared access to persistent objects in the global identity map is too high a price to pay. It's simpler, and more scalable, to have each thread work with a distinct set of persistent instances in each persistence context.
We would say that Hibernate implements persistence context-scoped identity. So, by nature, Hibernate is best suited for highly concurrent data access in multiuser applications. However, we already mentioned some issues you'll face when objects aren't associated with a persistence context. Let's discuss this with an example.
The Hibernate identity scope is the scope of a persistence context. Let's see how this works in code with Hibernate APIs—the Java Persistence code is the equivalent with EntityManager instead of Session. Even though we haven't shown you much about these interfaces, the following examples are simple, and you should have no problems understanding the methods we call on the Session.
If you request two objects using the same database identifier value in the same Session, the result is two references to the same in-memory instance. Listing 9.1 demonstrates this with several get() operations in two Sessions.
Listing 9-1. The guaranteed scope of object identity in Hibernate
Session session1 = sessionFactory.openSession(); Transaction tx1 = session1.beginTransaction(); // Load Item with identifier value "1234" Object a = session1.get(Item.class, new Long(1234) ); Object b = session1.get(Item.class, new Long(1234) ); ( a==b ) // True, persistent a and b are identical tx1.commit(); session1.close(); // References a and b are now to an object in detached state Session session2 = sessionFactory.openSession(); Transaction tx2 = session2.beginTransaction(); Object c = session2.get(Item.class, new Long(1234) ); ( a==c ) // False, detached a and persistent c are not identical tx2.commit(); session2.close(); |
Object references a and b have not only the same database identity, but also the same Java identity, because they're obtained in the same Session. They reference the same persistent instance known to the persistence context for that unit of work. Once you're outside this boundary, however, Hibernate doesn't guarantee Java identity, so a and c aren't identical. Of course, a test for database identity, a.getId().equals( c.getId() ), will still return true.
If you work with objects in detached state, you're dealing with objects that are living outside of a guaranteed scope of object identity.
9.2.3. The identity of detached objects
If an object reference leaves the scope of guaranteed identity, we call it a reference to a detached object. In listing 9.1, all three object references, a, b, and c, are equal if we only consider database identity—their primary key value. However, they aren't identical in-memory object instances. This can lead to problems if you treat them as equal in detached state. For example, consider the following extension of the code, after session2 has ended:
... session2.close(); Set allObjects = new HashSet(); allObjects.add(a); allObjects.add(b); allObjects.add(c);
All three references have been added to a Set. All are references to detached objects. Now, if you check the size of the collection, the number of elements, what result do you expect?
First you have to realize the contract of a Java Set: No duplicate elements are allowed in such a collection. Duplicates are detected by the Set; whenever you add an object, its equals() method is called automatically. The added object is checked against all other elements already in the collection. If equals() returns true for any object already in the collection, the addition doesn't occur.
If you know the implementation of equals() for the objects, you can find out the number of elements you can expect in the Set. By default, all Java classes inherit the equals() method of java.lang.Object. This implementation uses a double-equals (==) comparison; it checks whether two references refer to the same in-memory instance on the Java heap.
You may guess that the number of elements in the collection is two. After all, a and b are references to the same in-memory instance; they have been loaded in the same persistence context. Reference c is obtained in a second Session; it refers to a different instance on the heap. You have three references to two instances. However, you know this only because you've seen the code that loaded the objects. In a real application, you may not know that a and b are loaded in the same Session and c in another.
Furthermore, you obviously expect that the collection has exactly one element, because a, b, and c represent the same database row.
Whenever you work with objects in detached state, and especially if you test them for equality (usually in hash-based collections), you need to supply your own implementation of the equals() and hashCode() methods for your persistent classes.
Understanding equals() and hashCode()
Before we show you how to implement your own equality routine. we have to bring two important points to your attention. First, in our experience, many Java developers never had to override the equals() and hashCode() methods before using Hibernate (or Java Persistence). Traditionally, Java developers seem to be unaware of the intricate details of such an implementation. The longest discussion threads on the public Hibernate forum are about this equality problem, and the "blame" is often put on Hibernate. You should be aware of the fundamental issue: Every object-oriented programming language with hash-based collections requires a custom equality routine if the default contract doesn't offer the desired semantics. The detached object state in a Hibernate application exposes you to this problem, maybe for the first time.
On the other hand, you may not have to override equals() and hashCode(). The identity scope guarantee provided by Hibernate is sufficient if you never compare detached instances—that is, if you never put detached instances into the same Set. You may decide to design an application that doesn't use detached objects. You can apply an extended persistence context strategy for your conversation implementation and eliminate the detached state from your application completely. This strategy also extends the scope of guaranteed object identity to span the whole conversation. (Note that you still need the discipline to not compare detached instances obtained in two conversations!)
Let's assume that you want to use detached objects and that you have to test them for equality with your own routine. You can implement equals() and hashCode() several ways. Keep in mind that when you override equals(), you always need to also override hashCode() so the two methods are consistent. If two objects are equal, they must have the same hashcode.
A clever approach is to implement equals() to compare just the database identifier property (often a surrogate primary key) value:
public class User {
...
public boolean equals(Object other) {
if (this==other) return true;
if (id==null) return false;
if ( !(other instanceof User) ) return false;
final User that = (User) other;
return this.id.equals( that.getId() );
}
public int hashCode() {
return id==null ?
System.identityHashCode(this) :
id.hashCode();
}
}
Notice how this equals() method falls back to Java identity for transient instances (if id==null) that don't have a database identifier value assigned yet. This is reasonable, because they can't possibly be equal to a detached instance, which has an identifier value.
Unfortunately, this solution has one huge problem: Identifier values aren't assigned by Hibernate until an object becomes persistent. If a transient object is added to a Set before being saved, its hash value may change while it's contained by the Set, contrary to the contract of java.util.Set. In particular, this problem makes cascade save (discussed later in the book) useless for sets. We strongly discourage this solution (database identifier equality).
A better way is to include all persistent properties of the persistent class, apart from any database identifier property, in the equals() comparison. This is how most people perceive the meaning of equals(); we call it by value equality.
When we say all properties, we don't mean to include collections. Collection state is associated with a different table, so it seems wrong to include it. More important, you don't want to force the entire object graph to be retrieved just to perform equals(). In the case of User, this means you shouldn't include the boughtItems collection in the comparison. This is the implementation you can write:
public class User {
...
public boolean equals(Object other) {
if (this==other) return true;
if ( !(other instanceof User) ) return false;
final User that = (User) other;
if ( !this.getUsername().equals( that.getUsername() ) )
return false;
if ( !this.getPassword().equals( that.getPassword() ) )
return false;
return true;
}
public int hashCode() {
int result = 14;
result = 29 * result + getUsername().hashCode();
result = 29 * result + getPassword().hashCode();
return result;
}
}
However, there are again two problems with this approach. First, instances from different Sessions are no longer equal if one is modified (for example, if the user changes the password). Second, instances with different database identity (instances that represent different rows of the database table) can be considered equal unless some combination of properties is guaranteed to be unique (the database columns have a unique constraint). In the case of user, there is a unique property: username.
This leads us to the preferred (and semantically correct) implementation of an equality check. You need a business key.
Implementing equality with a business key
To get to the solution that we recommend, you need to understand the notion of a business key. A business key is a property, or some combination of properties, that is unique for each instance with the same database identity. Essentially, it's the natural key that you would use if you weren't using a surrogate primary key instead. Unlike a natural primary key, it isn't an absolute requirement that the business key never changes—as long as it changes rarely, that's enough.
We argue that essentially every entity class should have some business key, even if it includes all properties of the class (this would be appropriate for some immutable classes). The business key is what the user thinks of as uniquely identifying a particular record, whereas the surrogate key is what the application and database use.
Business key equality means that the equals() method compares only the properties that form the business key. This is a perfect solution that avoids all the problems described earlier. The only downside is that it requires extra thought to identify the correct business key in the first place. This effort is required anyway; it's important to identify any unique keys if your database must ensure data integrity via constraint checking.
For the User class, username is a great candidate business key. It's never null, it's unique with a database constraint, and it changes rarely, if ever:
public class User {
...
public boolean equals(Object other) {
if (this==other) return true;
if ( !(other instanceof User) ) return false;
final User that = (User) other;
return this.username.equals( that.getUsername() );
}
public int hashCode() {
return username.hashCode();
}
}
For some other classes, the business key may be more complex, consisting of a combination of properties. Here are some hints that should help you identify a business key in your classes:
Consider what attributes users of your application will refer to when they have to identify an object (in the real world). How do users tell the difference between one object and another if they're displayed on the screen? This is probably the business key you're looking for.
Every attribute that is immutable is probably a good candidate for the business key. Mutable attributes may be good candidates, if they're updated rarely or if you can control the situation when they're updated.
Every attribute that has a UNIQUE database constraint is a good candidate for the business key. Remember that the precision of the business key has to be good enough to avoid overlaps.
Any date or time-based attribute, such as the creation time of the record, is usually a good component of a business key. However, the accuracy of System.currentTimeMillis() depends on the virtual machine and operating system. Our recommended safety buffer is 50 milliseconds, which may not be accurate enough if the time-based property is the single attribute of a business key.
You can use database identifiers as part of the business key. This seems to contradict our previous statements, but we aren't talking about the database identifier of the given class. You may be able to use the database identifier of an associated object. For example, a candidate business key for the Bid class is the identifier of the Item it was made for together with the bid amount. You may even have a unique constraint that represents this composite business key in the database schema. You can use the identifier value of the associated Item because it never changes during the lifecycle of a Bid—setting an already persistent Item is required by the Bid constructor.
If you follow our advice, you shouldn't have much difficulty finding a good business key for all your business classes. If you have a difficult case, try to solve it without considering Hibernate—after all, it's purely an object-oriented problem. Notice that it's almost never correct to override equals() on a subclass and include another property in the comparison. It's a little tricky to satisfy the requirements that equality be both symmetric and transitive in this case; and, more important, the business key may not correspond to any well-defined candidate natural key in the database (subclass properties may be mapped to a different table).
You may have also noticed that the equals() and hashCode() methods always access the properties of the "other" object via the getter methods. This is extremely important, because the object instance passed as other may be a proxy object, not the actual instance that holds the persistent state. To initialize this proxy to get the property value, you need to access it with a getter method. This is one point where Hibernate isn't completely transparent. However, it's a good practice to use getter methods instead of direct instance variable access anyway.
Let's switch perspective now and consider an implementation strategy for conversations that doesn't require detached objects and doesn't expose you to any of the problems of detached object equality. If the identity scope issues you'll possibly be exposed to when you work with detached objects seem too much of a burden, the second conversation-implementation strategy may be what you're looking for. Hibernate and Java Persistence support the implementation of conversations with an extended persistence context: the session-per-conversation strategy.
9.2.4. Extending a persistence context
A particular conversation reuses the same persistence context for all interactions. All request processing during a conversation is managed by the same persistence context. The persistence context isn't closed after a request from the user has been processed. It's disconnected from the database and held in this state during user think-time. When the user continues in the conversation, the persistence context is reconnected to the database, and the next request can be processed. At the end of the conversation, the persistence context is synchronized with the database and closed. The next conversation starts with a fresh persistence context and doesn't reuse any entity instances from the previous conversation; the pattern is repeated.
Note that this eliminates the detached object state! All instances are either transient (not known to a persistence context) or persistent (attached to a particular persistence context). This also eliminates the need for manual reattachment or merging of object state between contexts, which is one of the advantages of this strategy. (You still may have detached objects between conversations, but we consider this a special case that you should try to avoid.)
In Hibernate terms, this strategy uses a single Session for the duration of the conversation. Java Persistence has built-in support for extended persistence contexts and can even automatically store the disconnected context for you (in a stateful EJB session bean) between requests.
We'll get back to conversations later in the book and show you all the details about the two implementation strategies. You don't have to choose one right now, but you should be aware of the consequences these strategies have on object state and object identity, and you should understand the necessary transitions in each case.
We now explore the persistence manager APIs and how you make the theory behind object states work in practice.