
Chapter 6. State and the concurrent world
- The problems with mutable state
- Clojure’s approach to state
- Refs, agents, atoms, and vars
- Futures and promises
State—you’re doing it wrong.
Rich Hickey
The above quote is from a presentation by Rich Hickey in which he mentions Clojure’s approach to concurrency and state. He means that most languages use an approach to modeling state that doesn’t work. To be precise, it used to work when computers were less powerful and ran programs in a single-threaded fashion. In today’s world of increasingly multicore and multi-CPU computers, the model has broken down.
This is evidenced by the difficulty of writing bug-free multithreaded code in typical object-oriented languages like Java and C++. Still, programmers continue to make the attempt. You can see why this is so: the demands on today’s software require that it take advantage of all available CPU cores. As software needs grow in complexity, parallelism is becoming an implicit requirement. This chapter is about concurrent programs and the problems they face in dealing with state. We’ll first examine what these problems are and then look at the traditional solutions to these problems. We’ll then look at Clojure’s approach to dealing with these issues and show that when trying to solve difficult problems, it’s sometimes worth starting with a fresh slate.
6.1. The problem with state
State is the current set of values associated with things in a program. For example, a payroll program might deal with employee objects. Each employee object represents the state of the employee, and every program usually has a lot of such state. There’s no problem with state, per se, or even with mutating state. The real world is full of perceived changes: people change, plans change, the weather changes, and the balance in bank accounts changes. The problem occurs when concurrent (multithreaded) programs share this sort of state among different threads and then attempt to make updates to it. When the illusion of single-threaded execution breaks down, the code encounters all manner of inconsistent data. In this section, we’ll look at a solution to this problem. But before we do, let’s recap the issues faced by concurrent programs operating on shared data.
6.1.1. Common problems with shared state
Most problems with multithreaded programs happen because changes to shared data aren’t correctly protected. The book Java Concurrency in Practice, by Brian Goetz, does an incredible job of throwing light on these issues. The book uses Java to illustrate examples, so it isn’t directly useful, but it’s still highly recommended. For purposes of this chapter, we’ll summarize the issues as follows.
Lost or buried updates
Lost updates occur when two threads update the same data one after the other. The update made by the first thread is lost because it’s overwritten by the second one. A classic example is two threads incrementing a counter whose current value is 10. Because execution of threads is interleaved, both threads can do a read on the counter and think the value is 10, and then both increment it to 11. The problem is that the final value should have been 12, and the update done by one of the threads was lost.
Dirty and unrepeatable reads
A dirty read happens when a thread reads data that another thread is in the process of updating. When the updating thread is done, the data that was read by the other thread is inconsistent (dirty). Similarly, an unrepeatable read happens when a thread reads a particular set of data, but because other threads are updating it, the thread can never do another read that results in it seeing the same data again.
Phantom reads
A phantom read happens when a thread reads data that’s been deleted (or more data is added). The reading thread is said to have performed a phantom read because it has summarily read data that no longer exist.
6.1.2. The traditional solution
The most obvious solution to these problems is to impose a level of control on those parts of the code that mutate shared data. This is done using locks, which are constructs that control the execution of sections of code, ensuring that only a single thread runs a lock-protected section of code at a time. When using locks, a thread can execute a destructive method (one that mutates data) that’s protected with a lock only if it’s able to first obtain the lock. If a thread tries to execute such code while some other thread holds the lock, it blocks until the lock becomes available again. The blocking thread is allowed to resume execution only after it obtains the lock at a later time.
This approach might seem reasonable, but it gets complicated the moment more than one piece of mutable data needs a coordinated change. When this happens, each thread that needs to make those changes must obtain multiple locks, leading to more contention and resulting in concurrency problems. It’s difficult to ensure correctness of multithreaded programs that have to deal with multiple mutating data structures. Further, finding and fixing bugs in such programs is difficult thanks to the inherent nondeterministic nature of multithreaded programs.
Still, programs of significant complexity have been written using locks. It takes a lot more time and money to ensure things work as expected and a larger maintenance budget to ensure things continue to work properly while changes are being made to the program. It makes you wonder if there isn’t a better approach to solving this problem.
This chapter is about such an approach. Before we get into the meat of the solution, we’ll examine a couple of things. First, we’ll look at the general disadvantages of using locks in multithreaded programs. Then, we’ll take a quick overview of the new issues that arise from the presence of locking.
Disadvantages of locking
The most obvious disadvantage of locking is that code is less multithreaded than it was before the introduction of locks. When one thread obtains and holds a lock, no other thread can execute that code, causing other threads to wait. This can be wasteful, and it reduces throughput of multithreaded applications.
Further, locks are an excessive solution. Consider the case where a thread only wants to read some piece of mutable data. To ensure that no other thread makes changes while it’s doing its work, the reader thread must lock all concerned mutable data. This causes not only writers to block but other readers too. This is unnecessarily wasteful.
Lastly, another disadvantage of locking is that, well, the programmer must remember to lock! If someone introduces a bug that involves a forgotten lock, it can be difficult to track down and fix. There are no automatic mechanisms to flag this situation and no compile-time or runtime warnings associated with such situations, other than the fact that the program behaves in an unexpected manner! The knowledge of what to lock and in what order to lock things (so that the locks can be released in the reverse order) can’t be expressed within program code—typically, it’s recorded in technical documentation. Everyone in the software industry knows how well documentation works.
Unfortunately, these aren’t the only disadvantages with using locks; it causes new problems too. We’ll examine some of them now.
The new problems with locking
When a single thread needs to change more than one piece of mutable data, it needs to obtain locks for all of them. This is the only way for a lock-based solution to offer coordinated changes to multiple items. The fact that threads need to obtain locks to do their work causes contention for these locks. This contention results in a few issues that are typically categorized as shown in table 6.1.
Table 6.1. Issues that arise from the use of locks
|
Issue |
Description |
|---|---|
| Deadlock | This is the case where two or more threads wait for the other to release locks that they need. This cyclic dependency results in all concerned threads being unable to proceed. |
| Starvation | This happens when a thread is not allocated enough resources to do its job, causing it to starve and never complete. |
| Livelock | This is a special case of starvation, and it happens when two threads continue executing (changing their states) but make no progress toward their final goal. A typical example used to visualize this is of two people meeting in a hallway and each trying to pass the other. If they both wait for the other to move, it results in a deadlock. If they both keep moving for the other, they end up still blocking each other from passing. This situation results in a livelock, because they’re both doing work and changing states but are still unable to proceed. |
| Race condition | This is a general situation where the interleaving of execution of threads causes an undesired computational result. Such bugs are difficult to debug because race conditions happen in relatively rare scenarios. |
With all these disadvantages and issues that accompany the use of locks, you must wonder if there isn’t a better solution to the problem of concurrency and state. We’ll explore this in the next section, beginning with a fresh look at modeling state itself.
6.2. Identities and values
Now that we’ve explored the landscape of some of the common problems of concurrent programs and shared state, including the popular solution to them, we’re ready to examine an alternative point of view. Let’s begin by reexamining a construct offered by most popular programming languages to deal with state—that of objects. Object-oriented languages like Java, C++, Ruby, and Python offer the notion of classes that contain state and related operations. The idea is to provide the means to encapsulate things in order to separate responsibility among various abstractions, allowing for cleaner design. This is a noble goal and is probably even achieved once in a while. But most languages have a flaw in this philosophy that causes problems when these same programs need to run as multithreaded applications. And most programs eventually do need multithreading, either because requirements change or to take advantage of multicore CPUs.
The flaw is that these languages conflate the idea of what Rich Hickey calls identity with that of state. Consider a person’s favorite set of movies. As a child, this person’s set might contain films made by Disney and Pixar. As a grown-up, the person’s set might contain other movies such as ones directed by Tim Burton or Robert Zemeckis. The entity represented by “favorite movies” changes over time. Or does it?
In reality, there are two different sets of movies; at one point (earlier) favorite-movies referred to the set containing children’s movies. At another point (later), it referred to a different set that contained other movies. What changes over time, therefore, is not the set itself but which set the entity “favorite movies” refers to. Further, at any given point, a set of movies itself doesn’t change. The time line demands different sets containing different movies over time, even if some movies appear in more than one set.
To summarize, it’s important to realize that we’re talking about two distinct concepts. The first is that of an identity—someone’s favorite movies. It’s the subject of all the action in the associated program. The second is the sequence of values that this identity assumes over the course of the program. These two ideas give us an interesting definition of state—the value of an identity at a particular point time.
This idea of state is different from what traditional implementations of object-oriented languages provide out of the box. For example, in a language like Java or Ruby, the minute a class is defined with stateful fields and destructive methods (those that change a part of the object), concurrency issues begin to creep into the world and can lead to many of the problems discussed earlier. This approach to state might have worked a few years ago when everything was single threaded; it doesn’t work anymore.
Now that you understand some of the terms involved, let’s further examine the idea of using a series of immutable values to model the state of an identity.
6.2.1. Immutable values
An immutable object is one that can’t change once it has been created. In order to simulate change, you’d have to create a whole new object and replace the old one. In the light of our discussion so far, this means that when the identity of “favorite movies” is being modeled, it should be defined as a reference to an immutable object (a set, in this case). Over time, the reference would point to different (also immutable) sets. This ought to apply to objects of any kind, not only sets. Several programming languages already offer this mechanism in some of their data types, for instance, numbers and strings. As an example, consider the following assignment:
x = 101
Most languages treat the number 101 as an immutable value. Languages provide no constructs to do the following, for instance:
x.setUnitsDigit(3) x.setTensDigit(2)
No one expects this to work, and no one expects this to be a way to transform 101 into 123. Instead, you might do the following:
x = 101 + 22
At this point, x points to the value 123, which is a completely new value and is also immutable. Some languages extend this behavior to other data types. For instance, Java strings are also immutable. In programs, the identity represented by x refers to different (immutable) numbers over time. This is similar to the concept of favorite-movies referring to different immutable sets over time.
6.2.2. Objects and time
As you’ve seen, objects (such as x or favorite-movies) don’t have to physically change in order for programs to handle the fact that something has happened to them. As discussed previously, they can be modeled as references that point to different objects over time. This is the flaw that most OO languages suffer from: they conflate identities (x or favorite-movies) and their values. Most such languages make no distinction between an identity such as favorite-movies and the memory location where the data relating to that identity is stored. A variable kyle, for example, might directly point to the memory location containing the data for an instance of the Person class.
In typical OO languages, when a destructive method (or procedure) executes, it directly alters the contents of the memory where the instance is stored. Note that this doesn’t happen when the same language deals with primitives, such as numbers or strings. The reason no one seems to notice this difference in behavior is that most languages have conditioned programmers to think that composite objects are different from primitives such as strings and numbers. But this is not how things should be, and there’s another way.
Instead of letting programs have direct access to memory locations via pointers such as favorite-movies and allowing them to change the content of that memory location, programs should have only a special reference to immutable objects. The only thing they should be allowed to change is this special reference itself, by making it point to a completely different, suitably constructed object that’s also immutable. This concept is illustrated in figure 6.1.
Figure 6.1. A reference that points to completely different immutable values over time
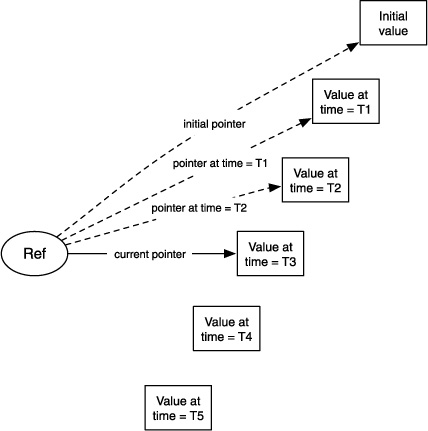
This should be the default behavior of all data types, not only select ones like numbers or strings. Custom classes defined by a programmer should also work this way.
Now that we’ve talked about this new approach to objects and mutation over time, let’s see why this might be useful and what might be special about such references to immutable objects.
6.2.3. Immutability and concurrency
It’s worth remembering that the troubles with concurrency happen only when multiple threads attempt to update the same shared data. In the first part of this chapter, we reviewed the common problems that arise when shared data is mutated incorrectly in a multithreaded scenario. The problems with mutation can be classified into two general types: losing updates (or updating inconsistent data) and reading inconsistent data.
If all data is immutable, then we eliminate the second issue. If a thread reads something, it’s guaranteed to never change while it’s being used. The concerned thread can go about its business, doing whatever it needs to with the data—calculating things, displaying information, or using it as input to other things. In the context of our example concerning favorite movies, a thread might read someone’s favorite set of movies at a given point and use it in a report about popular movies. Meanwhile, a second thread might update a person’s favorites. In this scenario, because the sets are immutable, the second thread would create a new set of movies, leaving the first thread with valid and consistent (and merely stale) data.
We’ve glossed over some of the technicalities involved in ensuring that this works, and we’ll explore Clojure’s approach in much greater depth in the following sections. In particular, threads should be able to perform repeated reads correctly, even if another thread updated some or all of the data. Assuming things do work this way, the read problem in a multithreaded situation can be considered solved. It leaves only the issue of when two or more threads try to update the same data at the same time.
Solving this second problem requires some form of supervision by the language runtime and is where the special nature of references comes into play. Because no identity has direct access to the contents of various memory locations (that in turn contain the data objects), the language runtime has a chance of doing something to help supervise writes. Specifically, because identities are modeled using special references, as mentioned previously, the language can provide constructs that allow supervised changes to these indirect references. These constructs can have concurrency semantics, thereby making it possible for multiple threads to update shared data correctly. The semantics can ensure more than safe writes; they can signal errors when writes fail or enforce certain other constraints when a write is to be made.
This isn’t possible in most other popular languages today, because they allow direct access to (and mutation of) memory locations. A language that satisfies two requirements can hope to solve the concurrency problem: the first is that identities not point directly to memory locations but do so indirectly via managed references, and the second is that data objects themselves be immutable. This separation of identity and state is the key. You’ll see Clojure’s flavor of this approach over the next few sections.
6.3. The Clojure way
As you saw in the previous section, there’s an alternative when it comes to modeling identities and their state. Instead of letting an identity be a simple reference (direct access to a memory location and its contents), it can be a managed reference that points to an immutable value. Over the course of the program, this reference can be made to point to other immutable values as required by the program logic. If state is modeled this way, then the programming language facilities that allow a managed reference to point to different things can support concurrency semantics—it can check for modified data, can enforce validity, can enforce that other programming constructs be used (such as transactions), and so forth. This is exactly the Clojure way.
Clojure provides managed references to state, as described previously. It provides four different kinds of managed references, each suitable in different situations. It also provides language-level constructs that help in changing what these references point to. Further, to coordinate changes to more than one reference, Clojure exposes an interesting take on a software transactional memory (STM) system. We’ll examine each of these in detail now.
Before we do so, it’s useful to talk about one more thing. In order for any language to work this way (managed references, immutable objects), an important requirement must be met—that of performance. Working with this model of state and mutation needs to be as fast as the old way of in-place mutation. Traditional solutions to this issue have been unsatisfactory, but Clojure solves it in an elegant way.
6.3.1. Requirements for immutability
Let’s again consider our example concerning movies and multiple threads. Imagine that the first thread is dealing with Rob’s set of favorite movies when he was a child. If a second thread were to update his favorites to a new set, the data seen by the first thread should still be valid. One way to achieve this is to make a copy of the object being updated so that readers still have valid (if old) data while the writer updates it to the new object.
The problem with this approach is that naively copying something over in this manner is extremely inefficient. Often, the speed of such a copy operation grows linearly with the size of the objects being copied. If every write involved such an expensive operation, it would be impossible to use in a production environment. Therefore, given that an approach that involves blind copying of data is not viable, the alternative must involve sharing the data structures in question. Specifically, the new and updated objects must in some way point to the old values, while making additional changes required to perform updates.
To make the performance requirements clearer, such an implementation must have approximately the same performance characteristics as the old mutable implementation. For example, a hash table must behave in a constant time (or near enough) manner. This performance guarantee must be satisfied, in addition to satisfying the previous constraint that the older version still be usable. This would allow other threads that had read the data prior to the update to continue with their job. In summary, the requirements are that the immutable structures do the following:
- Leave the old version of itself in a usable state when it mutates
- Satisfy the same performance characteristics as the mutable versions of themselves
You’ll now see how Clojure satisfies these requirements.
Persistent data structures
The common usage of the word persistence in computer science refers to persisting data into a nonvolatile storage system, such as a database. But there’s another way that term is used, one that’s quite common in the functional programming space. A persistent data structure is one that preserves the previous version of itself when it’s modified. Older versions of such data structures persist after updates. Such data structures are inherently immutable, because update operations yield new values every time.
All of the core data structures offered by Clojure are persistent. These include maps, vectors, lists, and sets. These persistent data structures also perform extremely well because instead of using copying, they share structure when an update needs to be done. Specifically, they maintain nearly all the performance guarantees that are made by such data structures, and their performance is on par with or extremely close to that of similar data structures that are provided by the Java language.
With this implementation, Clojure has the means to provide the managed reference model for mutating state. We’ll examine this in the next section.
6.3.2. Managed references
Given Clojure’s efficient implementation of persistent data structures, the approach of modeling state through managed references becomes viable. Clojure has four distinct offerings in this area, each useful in certain scenarios. Table 6.2 gives an overview of the options available.
Table 6.2. Clojure provides four different types of managed references.
|
Managed reference type |
Useful for |
|---|---|
| ref | Shared changes, synchronous, coordinated changes |
| agent | Shared changes, asynchronous, independent changes |
| atom | Shared changes, synchronous, independent changes |
| var | Isolated changes |
Clojure provides a managed reference for the different situations that arise when writing programs that use multiple threads. This ranges from the case that needs to isolate any change to within the thread making it to the case when threads need to coordinate changes that involve multiple shared data structures. In the next few sections, we’ll examine each one in turn.
In the first section of this chapter, we examined the problems faced by multithreaded programs when shared data is involved. These problems are typically handled using locks, and we also examined the problems associated with locks.
Managed references and language-level support for concurrency semantics offer an alternative to locks. In the next section, we’ll examine the first of Clojure’s managed references—the ref—and show how the language provides lock-free concurrency support.
6.4. Refs
Clojure provides a special construct in ref (short for reference) to create a managed reference that allows for synchronous and coordinated changes to mutable data. A ref holds a value that can be changed in a synchronous and coordinated manner. As an example, let’s consider our expense-tracking domain. You’ll create a ref to hold all the users of our imaginary system. The following is an example of this, and we’ve initialized the ref with an empty map:
(def all-users (ref {}))
At this point, all-users is a ref, which points to our initial value of an empty map. You can check this by dereferencing it using the deref function:
(deref all-users)
{}
Clojure also provides a convenient reader macro to dereference such a managed reference: the @ character. The following works the same way as calling deref:
@all-users
{}
Now that you know how to create and read back a ref, you’re ready to see how you can go about changing what it points to.
6.4.1. Mutating refs
Now, you’ll write a function that adds a new user to our existing set. Clojure’s refs can be changed using the ref-set, alter, or commute functions. ref-set is the most basic of these; it accepts a ref and a new value and replaces the old value with the new. Try the following to see it in action:
(ref-set all-users {})
;; No transaction running
;; [Thrown class java.lang.IllegalStateException]
Because refs are meant for situations where multiple threads need to coordinate their changes, the Clojure runtime demands that mutating a ref be done inside an STM transaction. STM stands for software transactional memory, and an STM transaction is analogous to a database transaction but for changes to in-memory objects. You’ll learn more about Clojure’s STM system in the following section; for now, you’ll start an STM transaction using a built-in macro called dosync. You can check that this works by trying your previous call to ref-set but this time inside the scope of a dosync:
(dosync
(ref-set all-users {}))
{}
That worked as expected, and you can use ref-set like this to reset your list of users. dosync is required for any function that mutates a ref, including the other two we mentioned earlier, alter and commute.
Alter
Typically, a ref is mutated by using its current value, applying a function to it, and storing the new value back into it. This read-process-write operation is a common scenario, and Clojure provides the alter function that can do this as an atomic operation. The general form of this function is
(alter ref function & args)
The first and second arguments to alter are the ref that’s to be mutated and the function that will be applied to get the new value of the ref. When the function is called, the first argument will be the current value of the ref, and the remaining arguments will be the ones specified in the call to alter (args).
Before examining the commute function, let’s get back to our intention of writing a function to add a new user to our list of existing users. First, here’s a function to create a new user:
(defn new-user [id login monthly-budget]
{:id id
:login login
:monthly-budget monthly-budget
:total-expenses 0})
This uses a Clojure map to represent a user—a common pattern used where traditional objects are needed. We’ve deliberately kept the representation simple; in real life your users would probably be a lot more, well, real. Next, here’s the add-user function:
(defn add-new-user [login budget-amount]
(dosync
(let [current-number (count @all-users)
user (new-user (inc current-number) login budget-amount)]
(alter all-users assoc login user))))
Note the use of dosync. As mentioned previously, it starts an STM transaction, which allows us to use alter. In the previous code snippet, alter is passed the all-users ref, which is the one being mutated. The function you pass it is assoc, which takes a map, a key, and a value as parameters. It returns a new map with that value associated with the supplied key. In our case, our newly created user gets associated with the login name. Note that the first argument to assoc is the current value of the ref allusers (the map that contains the existing set of users).
Further note that we chose to include the entire let form inside the transaction started by dosync. The alternative would have been to call only alter inside the dosync. Clojure wouldn’t have complained because dereferencing a ref (@all-users) doesn’t need to happen inside a transaction. The reason you do it this way, is to ensure that you see a consistent set of users. You want to avoid the buried update problem where two threads read the count, and one thread commits a new user (increasing the real count), causing the other thread to commit a new user with a duplicate id.
One final note: in the previous example, it doesn’t matter in what order you add users. If two threads were both trying to add a user to our system, you wouldn’t care in what order they’re added. Such an operation is said to be commutative, and Clojure has optimized support for commutes.
Commute
When two threads try to mutate a ref using either ref-set or alter, and one of them succeeds (causing the other to fail), the second transaction starts over with the latest value of the ref in question. This ensures that a transaction doesn’t commit with inconsistent values. The cost of this mechanism is that a transaction may be tried multiple times.
For those situations where it doesn’t matter what the most recent value of a ref is (only that it’s consistent and recent), Clojure provides the commute function. The name derives from the commutative property of functions, and you might remember this from math class. A function is commutative if it doesn’t matter in which order the arguments are applied. For example, addition is commutative, whereas subtraction is not:
a + b = b + a a – b != b - a
The commute function is useful where the order of the function application isn’t important. For instance, imagine that a number was being incremented inside a transaction. If two threads were to go at it in parallel, at the end of the two transactions, it wouldn’t matter which thread had committed first. The result would be that the number was incremented twice.
When the alter function is applied, it checks to see if the value of the ref has changed because of another committed transaction. This causes the current transaction to fail and for it to be retried. The commute function doesn’t behave this way; instead, execution proceeds forward and all calls to commute are handled at the end of the transaction. The general form of commute is similar to alter:
(commute ref function & args)
As explained earlier, the function passed to commute should be commutative. Similar to alter, the commute function also performs the read-apply-write operation on one atomic swoop.
You’ve now seen the three ways in which a ref can be mutated. In showing these, we’ve mentioned STM transactions quite a bit. In the next section, you’ll learn a little more about Clojure’s implementation of the STM system.
6.4.2. Software transactional memory
A common solution to the problems of shared data and multithreading is the (careful) use of locks. But this approach suffers from several problems, and we examined common ones in section 6.1.2. These issues make using locks messy and error prone while also making code based on locks infamously difficult to debug.
Software transactional memory (STM) is a concurrency control mechanism that works in a fashion similar to database transactions. Instead of controlling access to data stored on disks, inside tables and rows, STMs control access to shared memory. Using an STM system offers many advantages to multithreaded programs, the most obvious being that it’s a lock-free solution. You can think of it as getting all the benefits of using locks but without any of the problems. You also gain increased concurrency because this is an optimistic approach compared with the inherently pessimistic approach of locking.
In this section, you’ll get a high-level overview of what STM is and how it works.
STM Transactions
Lock-based solutions prevent more than one thread from executing a protected part of the code. Only the thread that acquired the right set of locks is allowed to execute code that has been demarcated for use with those locks. All other threads that want to execute that same code, block until the first thread completes and relinquishes those locks.
An STM system takes a nearly opposite approach. First, code that needs to mutate data is put inside a transaction. In the case of Clojure, this means using the dosync macro. Once this is done, the language runtime takes an optimistic approach in letting threads execute the transaction. Any number of threads are allowed to begin the transaction. Changes made to refs within the transaction are isolated, and only the threads that made the changes can see the changed values.
The first thread that completely executes the block of code that’s the transaction is allowed to commit the changed values. Once a thread commits, when any other thread attempts to commit, that transaction is aborted and the changes are rolled back.
The commit performed when a transaction is successful is atomic in nature. This means that even if a transaction makes changes to multiple refs, as far as the outside world is concerned, they all appear to happen at the same instant (when the transaction commits). STM systems can also choose to retry failed transactions, and many do so until the transaction succeeds. Clojure also supports this automatic retrying of failed transactions, up to an internal limit.
Now that you know how transactions work at a high level, let’s recap an important set of properties that the STM system exhibits.
Atomic, consistent, isolated
The Clojure STM system has ACI properties (atomicity, consistency, isolation). It doesn’t support durability because it isn’t a persistent system and is based on volatile, in-memory data. To be specific, if a transaction mutates several refs, the changes become visible to the outside world at one instant. Either all the changes happen, or, if the transaction fails, the changes are rolled back and no change happens. This is how the system supports atomicity.
When refs are mutated inside a transaction, the changed data are called in-transaction values. This is because they’re visible only to the thread that made the changes inside the transaction. In this manner, transactions isolate the changes within themselves (until they commit).
Clojure’s refs (and also agents and atoms) accept validator functions when created. These functions are used to check the consistency of the data when changes are made to them. If the validator function fails, the transaction is rolled back. In this manner, the STM system supports consistency.
Before moving onto the other types of managed references in Clojure, we’ll make one final point about the STM.
MVCC
Clojure’s STM system implements multiversion concurrency control (MVCC). This is the type of concurrency supported by several database systems such as Oracle and PostgreSQL. In an MVCC system, each contender (threads in the case of Clojure) is given a snapshot of the mutable world when it starts its transaction.
Any changes made to the snapshot are invisible to other contenders until the changes are committed at the end of a successful transaction. But thanks to the snapshot model, readers never block writers (or other readers), increasing the inherent concurrency that the system can support. In fact, writers never block readers either, thanks to the same isolation. Contrast this with the old locking model where both readers and writers block while one thread does its job.
Having seen the way the ref managed reference works in Clojure and also how the associated mechanism of the software transactional memory works, you can write multithreaded programs that need to coordinate changes to shared data. In the next section, we’ll examine a method to mutate data in an uncoordinated way.
6.5. Agents
Clojure provides a special construct called an agent that allows for asynchronous and independent changes to shared mutable data. The agent function allows the creation of agents, which hold values that can be changed using special functions. Clojure provides two functions, send and send-off, that result in mutating the value of an agent. Both accept the agent that needs to be updated, along with a function that will be used to compute the new value. The application of the function happens at a later time, on a separate thread. By corollary, an agent is also useful to run a task (function) on a different thread, with the return value of the function becoming the new value of the agent. The functions sent to agents are called actions.
Creating an agent is similar to creating a ref:
(def total-cpu-time (agent 0))
Dereferencing an agent to get at its current value is similar to using a ref:
(deref total-cpu-time) 0
Clojure also supports the @ reader macro to dereference agents, so the following is equivalent to calling deref:
@total-cpu-time 0
Having created an agent, let’s see how you can mutate it.
6.5.1. Mutating agents
As described in the preceding paragraphs, agents are useful when changes to them can be made in an asynchronous fashion. The changes are made by sending an action (a regular Clojure function) to the agent, which runs on a separate thread at a later time. There are two flavors of this, and we’ll examine them both.
Send
The general form of the send function is as follows:
(send the-agent the-function & more-args)
As an example, consider adding a few hundred milliseconds to the total-cpu-time agent you created earlier:
(send total-cpu-time + 700)
The addition operator in Clojure is implemented as a function, no different from regular functions. The action function sent to an agent should accept one or more parameters. When it runs, the first parameter it’s supplied is the current value of the agent, and the remaining parameters are the ones passed via send.
In this example, the + function is sent to the total-cpu-time agent, and it uses the current value of the agent (which is 0) as the first argument and 700 as the second argument. At some point in the future, although it isn’t noticeable in our example because it will happen almost immediately, the addition function will execute and the new value of total-cpu-time will be set as the value of the agent. You can check the current value of the agent by dereferencing it:
(deref total-cpu-time) 700
If the action took a long time, it might be a while before dereferencing the agent shows the new value. Dereferencing the agent before the agent runs will continue to return the old value. The call to send itself is nonblocking, and it returns immediately.
Actions sent to agents using send are executed on a fixed thread pool maintained by Clojure. If you send lots of actions to agents (more than the number of free threads in this pool), they get queued and will run in the order in which they were sent. Only one action runs on a particular agent at a time. This thread pool doesn’t grow in size, no matter how many actions are queued up. This is why you should use send for actions that are CPU intensive and don’t block, because blocking actions will use up the thread pool. But for blocking actions, Clojure does provide another function, and we’ll look at that now.
Send-off
The general form of the send-off function is exactly the same as for send:
(send-off the-agent the-function & more-args)
The semantics of what happens when send-off is called are the same as that of send, the only difference being that send-off can handle potential blocking actions. This is because it uses a different thread pool from the one used by send, and this thread pool can grow in size to accommodate more actions sent using send-off. Again, only one action runs on a particular agent at a time.
We’ll now look at a few convenient constructs provided by Clojure that are useful when programming using agents.
6.5.2. Working with agents
This section will examine a few functions that come in rather handy when working with agents. A common scenario when using agents to do work asynchronously is that several actions are sent (using either send or send-off), and then one waits until they all complete. Clojure provides two functions that help in this situation. We’ll also look at ways to test agents for errors.
Another common use case is that a notification is desired when an action sent to an agent completes successfully. This is where watchers come in. Finally, you’ll see how the value of an agent can be kept consistent by validating it with some business rules each time an attempt is made to change it.
Await and await-for
await is a function that’s useful when execution must stop and wait for actions that were previously dispatched to certain agents to be completed. The general form is
(await & the-agents)
As an example, let’s say you had agents named agent-one, agent-two, and agent-three. Let’s also say you sent several actions to these three agents, either from your own thread or from another agent. At some point, you could cause the current thread to block until all actions sent to your three agents completed, by doing the following:
(await agent-one agent-two agent-three)
await blocks indefinitely, so if any of the actions didn’t return successfully, the current thread wouldn’t be able to proceed. In order to avoid this, Clojure also provides the await-for function. The general form looks similar to that of await, but it accepts a maximum timeout in milliseconds:
(await-for timeout-in-millis & the-agents)
Using await-for is safer in the sense that the max wait time can be controlled. If the timeout does occur, await-for returns nil. An example of using it is shown here:
(await-for 1000 agent-one agent-two agent-three)
This will abort the blocking state of the thread if the timer expires before the actions have completed. It’s common to check if the actions succeeded or not by testing the agents for any errors after using await-for.
Agent errors
When an action doesn’t complete successfully (it throws an exception), the agent knows about it. If you try to dereference an agent that’s in such an error state, Clojure will throw another exception. Take a look:
(def bad-agent (agent 10))
This sets up an agent with an initial value of 10. You’ll now send it an action that will cause an exception to be thrown, leaving the agent in an error state.
(send bad-agent / 0)
This is caused by the classic divide-by-zero error. If you now try to dereference bad-agent
(deref bad-agent) Agent has errors [Thrown class java.lang.Exception]Agent has errors
you can discern the error is by using the agent-errors function:
(agent-errors bad-agent) (#<ArithmeticException java.lang.ArithmeticException: Divide by zero>)
agent-errors returns a list of exceptions thrown during the execution of the actions that were sent to the agent. The objects in this list are instances of the particular exception class corresponding to the error that happened, and they can be queried using Java methods, for example:
(use 'clojure.contrib.str-utils)
(let [e (first (agent-errors bad-agent))
st (.getStackTrace e)]
(println (.getMessage e))
(println (str-join "
" st)))
If an agent has errors, you can’t send it any more actions. If you do, Clojure throws the same exception, informing you that the agent has errors. In order to make the agent usable again, Clojure provides the clear-agent-errors function:
(clear-agent-errors bad-agent)
The agent is now ready to accept more actions.
Validations
The complete general form of the agent function that creates new agents is
(agent initial-state & options)
The options allowed are
:meta metadata-map :validator validator-fn
If the :meta option is used, then the map supplied with it will become the metadata of the agent. If the :validator option is used, it should be accompanied by either nil or a function that accepts one argument. The validator-fn is passed the intended new state of the agent, and it can apply any business rules in order to allow or disallow the change to occur. If the validator function returns false or throws an exception, then the state of the agent is not mutated.
You’ve now seen how agents can be used in Clojure. Before moving on to the next kind of managed reference, you’ll see how agents can also be used to cause side effects from inside STM transactions.
6.5.3. Side effects in STM transactions
We said earlier that Clojure’s STM system automatically retries failed transactions. After the first transaction commits, all other transactions that had started concurrently will abort when they, in turn, try to commit. Aborted transactions are then started over. This implies that code inside a dosync block can potentially execute multiple times before succeeding, and for this reason, such code should be without side effects.
As an example, if there was a call to println inside a transaction, and the transaction was tried several times, the println will be executed multiple times. This behavior would probably not be desirable.
There are times when a transaction does need to generate a side effect. It could be logging or anything else such as writing to a database or sending a message on a queue. Agents can be used to facilitate such intended side effects. Consider the following pseudo code:
(dosync
(send agent-one log-message args-one)
(send-off agent-two send-message-on-queue args-two)
(alter a-ref ref-function)
(some-pure-function args-three))
Clojure’s STM transactions hold all actions that need to be sent to agents until they succeed. In the pseudo code shown here, log-message and send-message-on-queue are actions that will be sent only when the transaction succeeds. This ensures that even if the transaction is tried multiple times, the side effect causing actions gets sent only once. This is the recommended way to produce side effects from within a transaction.
This section walked through the various aspects of using agents. To recap, agents allow asynchronous and independent changes to mutable data. The next kind of managed reference is called an atom, and it’s the subject of the next section.
6.6. Atoms
Clojure provides a special construct in atom that allows for synchronous and independent changes to mutable data. The difference between an atom and an agent is that updates to agents happen asynchronously at some point in the future, whereas atoms are updated synchronously (immediately). Atoms differ from refs in that changes to atoms are independent from each other and can’t be coordinated so that they either all happen or none do.
Creating an atom looks similar to creating either refs or agents:
(def total-rows (atom 0))
total-rows is an atom that starts out being initialized to zero. You could use it to hold the number of database rows inserted by a Clojure program as it restores data from a backup, for example. Reading the current value of the atom uses the same dereferencing mechanism used by refs and agents
(deref total-rows) 0
or by using the @ reader macro:
@total-rows 0
Now that you’ve seen how to create atoms and read their values, let’s address mutating them.
6.6.1. Mutating atoms
Clojure provides several ways to update the value of an atom. There’s an important difference between atoms and refs, in that changes to one atom are independent of changes to other atoms. Therefore, there’s no need to use transactions when attempting to update atoms.
Reset!
The general form of the reset! function follows:
(reset! atom new-value)
The reset! function doesn’t use the existing value of the atom and sets the provided value as the new value of the atom. This might remind you of the ref-set function, which also does the same job but for refs.
Swap!
The swap! function has the following general form:
(swap! the-atom the-function & more-args)
You could pass swap! the addition function whenever you finish inserting a batch of rows:
(swap! total-rows + 100)
Here, in a synchronous manner, the + function is applied to the current value of total-rows (which is zero) and 100. The new value of total-rows becomes 100. If you were to use a mutation function that didn’t complete before another thread changed the value of the atom, swap! would then retry the operation until it did succeed. For this reason, mutation functions should be free of side effects.
Clojure also provides a lower-level function called compare-and-set! that can be used to mutate the value of an atom. swap! internally uses compare-and-set!
Compare-and-Set!
Here’s the general form of the compare-and-set! function:
(compare-and-set! the-atom old-value new-value)
This function atomically sets the value of the atom to the new value, if the current value of the atom is equal to the supplied old value. If the operation succeeds, it returns true; else it returns false. A typical workflow of using this function is to dereference the atom in the beginning, do something with the value of the atom, and then use compare-and-set! to change the value to a new one. If another thread had changed the value in the meantime (after it had been dereferenced), then the mutation would fail.
The swap! function does that internally: it dereferences the value of the atom, applies the provided mutation function, and attempts to update the value of the atom using compare-and-set! by using the value that was previously dereferenced. If compare-and-set! returns false (the mutation failed because the atom was updated elsewhere), the swap! function will reapply the mutation function until it succeeds.
Atoms can be used whenever there’s need for some state but not for coordination with any other state. Using refs, agents, and atoms, all situations that demand mutation of shared data can be handled. Our last stop will be to study vars, because they’re useful when state needs to be mutated but not shared.
6.7. Vars
We looked at vars in chapter 3, specifically in section 3.2.1. In this section, we’ll take a quick look at how vars can be used to manage state in an isolated (thread-local) manner.
Vars can be thought of as pointers to mutable storage locations, which can be updated on a per-thread basis. When a var is created, it can be given an initial value, which is referred to its root binding:
(def *hbase-master* "localhost")
In this example, *hbase-master* is a var that has a root binding of "localhost". The starting and ending asterisks are conventions that denote that this var needs to be rebound before use. This can be enforced by not specifying any root binding, causing the Clojure system to throw an exception when an attempt is made to use the var before binding. Here’s an example:
(def *hbase-master* "localhost") (println "Hbase-master is:" *hbase-master*)
This prints "Hbase-master is: localhost" to the console. Now let’s attempt to use a var without a root binding:
(def *rabbitmq-host*) (println "RabbitMQ host is:" *rabbitmq-host*) Var user/*rabbitmq-host* is unbound. [Thrown class java.lang.IllegalStateException]
Whether a var has a root binding or not, when the binding form is used to update the var, that mutation is visible only to that thread. If there was no root binding, other threads would see no root binding; if there was a root binding, other threads would see that value. Let’s look at an example. You’ll create a function that will fetch the number of rows in a users table from different databases: test, development, and staging. Imagine that you define the database host using a var like so:
(def *mysql-host*)
This var has no root binding, so it will need to be bound before use. You’ll do that in a function that’s meant to do a database query, but for the purposes of this example it will return some dummy data such as the length of the hostname. In the real world, you’d run the query against the database using something like a JDBC library:
(defn db-query [db]
(binding [*mysql-host* db]
(count *mysql-host*)))
Next, you’ll create a list of the hosts you want to run your fake function against:
(def mysql-hosts ["test-mysql" "dev-mysql" "staging-mysql"])
Finally, you could run your query function against all the hosts
(pmap db-query mysql-hosts)
which returns (10 9 13).
pmap works like map, but each time the supplied function is called on an element of the list, it’s done so on an available thread from an internally maintained thread pool. The call to binding sets up *mysql-host* to point to a different host, and the query function proceeds appropriately. Each execution of the db-query function sees a different value of *myql-host*, as expected.
Now you’ve seen how vars work, and we’ve covered the four different options that Clojure offers when it comes to concurrency, state, and performing updates. The various options, namely, refs, agents, atoms, and vars, are each useful in different scenarios. You’ll eventually run into a situation where one of these will be a good fit, and you’ll be grateful for Clojure’s language-level support for lock-free concurrency.
6.8. State and its unified access model
This section is a quick recap of the constructs Clojure offers for managing state. We covered each of them over the past few sections, and it’s now possible to make an observation. All of the constructs for managing state enjoy a unified access model that allows the used functions to manage them similarly. This is true whether the managed reference is a ref, an agent, or an atom. Let’s take another quick look at these functions.
Creating
Here are the functions that can create each type of managed reference:
(def a-ref (ref 0)) (def an-agent (agent 0)) (def an-atom (atom 0))
Notice how each accepts an initial value during creation.
Reading
All three kinds of references can be dereferenced the same way:
(deref a-ref) or @a-ref (deref an-agent) or @an-agent (deref an-atom) or @an-atom
This uniformity makes Clojure’s references easier to use, because they work in such a similar manner. Let’s also recap how their values can be changed.
Mutation
Changing a managed reference in Clojure always follows the same model: a function is applied to the current value, and the return value is set as the new value of the reference. Table 6.3 shows the functions that allow such mutation.
Table 6.3. Ways to mutate refs, agents, and atoms
|
Refs |
Agents |
Atoms |
|---|---|---|
| (ref-set ref new-value) (alter ref function & args) (commute ref function & args) |
(send agent function & args) #(send-off agent function & args) |
(reset! atom new-value) (swap! atom function & args) (compare-and-set! atom old-value new-value) |
Transactions
Finally, there’s the question of which references need transactions and which don’t. Because refs support coordinated changes, mutating them needs the protection of STM transactions: all such code needs to be inside the dosync macro. Agents and atoms don’t need STM transactions. Functions used to calculate new values of refs or atoms must be free of side effects, because they could be retried several times.
While we’re on the topic of mutation, it’s worthwhile to note that Clojure provides a hook, which can be used to run arbitrary code when a reference changes state. This mechanism works for refs, agents, atoms, and vars.
6.9. Watching for mutation
Sometimes it’s useful to add an event listener that gets notified when the value of a stateful construct changes. Clojure provides the add-watch function for this purpose. It allows you to register a regular Clojure function as a “watcher” against any kind of reference. When the value of the reference changes, the watcher function is run.
The watcher must be a function of four arguments: a key to identify the watcher, the reference it’s being registered against, the old value of the reference, and finally, the new value of the reference. Here it is in action:
(def adi (atom 0)) (defn on-change [the-key the-ref old-value new-value] (println "Hey, seeing change from" old-value "to" new-value)) (add-watch adi :adi-watcher on-change)
Now that it’s all set up, you can test it. Let’s check the current value of adi and then update it:
user> @adi 0 user> (swap! adi inc) Hey, seeing change from 0 to 1 1
As mentioned before, this can be used for all of Clojure’s special managed references. It’s also possible to remove a watch if it’s no longer required. Clojure provides the remove-watch function to do this. Using it is simple:
(remove-watch adi :adi-watcher)
So far, we’ve covered several options provided by Clojure to manage the mutation of state. In the next section, we’ll examine another couple of constructs that aid the development of concurrent programs.
6.10. Futures and promises
A future is an object that represents code that will eventually execute on a different thread. A promise is an object that represents a value that will become available at some point in the future. We’ll explore the usage of futures first.
6.10.1. Futures
A future is a simple way to run code on a different thread, and it’s useful for long-running computations or blocking calls that can benefit from multithreading. To understand how to use it, let’s examine this contrived function that takes over five seconds to run:
(defn long-calculation [num1 num2] (Thread/sleep 5000) (* num1 num2))
Now that we have this slow-running function, let’s imagine you needed to run multiple such computations. The code might look like the following:
(defn long-run []
(let [x (long-calculation 11 13)
y (long-calculation 13 17)
z (long-calculation 17 19)]
(* x y z)))
If you run this in the REPL and use time to see how long this takes, you might see something like this:
user=> (time (long-run)) "Elapsed time: 14998.165 msecs" 10207769
Now, you can see the long-run will benefit from being multithreaded. That’s where futures come in. The general form of a future is
(future & body)
It returns an object that will invoke body on a separate thread. The returned object can be queried for the return value of the body. In case the computation hasn’t completed yet, the threading asking for the value will block. The result of the computation is cached, so subsequent queries for the value are immediate. Let’s write a faster version of the long-run function:
(defn fast-run []
(let [x (future (long-calculation 11 13))
y (future (long-calculation 13 17))
z (future (long-calculation 17 19))]
(* @x @y @z)))
Let’s test this using the time function as well:
user> (time (fast-run)) "Elapsed time: 5000.078 msecs" 10207769
As you can see, futures are a painless way to get things to run on a different thread. Here are a few future-related functions Clojure provides:
- future?—Checks to see if the object is a future, returns true if it is.
- future-done?—Returns true if the computation represented by this future object is completed.
- future-cancel—Attempts to cancel this future. If it has already started executing, it doesn’t do anything.
- future-cancelled?—Returns true if the future has been canceled.
You’ve seen the basics of using futures in this section. The next section will talk about promises.
6.10.2. Promises
A promise is an object that represents a commitment that a value will be delivered to it. You create one using the no-argument promise function:
(def p (promise))
In order to ask for the promised value, you can dereference it:
(def value (deref p))
Or, as usual, you can use the reader macro version of dereferencing:
@p
The way the value delivery system works is via the use of the deliver function. The general form of this function is
(deliver promise value)
Typically, this function is called from a different thread, so it’s a great way to communicate between threads. The deref function (or the reader macro version of it) will block the calling thread if no value has been delivered to it yet. The thread automatically unblocks when the value becomes available. The concept of promises finds a lot of use in things such as data-flow programming.
Together, futures and promises are ways to write concurrent programs that need to pass data between threads in a simple way. They are a nice, complementary addition to all the other concurrency options you saw earlier in this chapter.
6.11. Summary
We’ve covered some heavy material in this chapter! We began with a look at the new reality of an increasing number of cores inside CPUs and the need for increasingly multithreaded software. We then looked at the problems that are encountered when programs have more than one thread of execution, specifically when these threads need to make changes to shared data. We looked at the traditional way of solving these problems—using locks—and then briefly looked at the new problems that they introduce.
Finally, we looked at Clojure’s approach to these issues. It has a different approach to state, one that involves immutability. Changes to state are modeled by carefully changing managed references so that they point to different immutable values over time. And because the Clojure runtime itself manages these references, it’s able to offer the programmer a great deal of automated support in their use.
First, data that needs to change must use one of the four options that Clojure offers. This makes it explicit to anyone reading the code in the future. Next, it offers a software transactional memory (STM) system that helps in making coordinated changes to more than one piece of data. This is a huge win, because it’s a lock-free solution to a hairy problem!
Clojure also offers agents and atoms, which allow independent changes to mutable data. These are different in that they’re asynchronous and synchronous, respectively, and each is useful in different situations. Finally, Clojure offers vars that can be used where changes to data need to be isolated within threads. The great thing is that despite offering options that are quite different from each other, they have a uniform way of creating and accessing the data inside them.
Clojure’s approach to state and mutation is an important step forward in terms of the current status quo of dealing with state and multithreaded programming. As we discussed in section 6.2, most popular object-oriented languages confuse identities and state, whereas Clojure keeps them distinct. This allows Clojure to provide language-level semantics that make concurrent software easier to write (and read and maintain!) and more resilient to bugs that afflict lock-based solutions.