
Chapter 7. The Spring framework
- Using Groovy classes in Spring applications
- Refreshable beans
- Inline scripted beans
- The Grails BeanBuilder class
- Spring AOP with Groovy classes
As Java frameworks go, Spring is one of the most successful. Spring brought the ideas of dependency injection, complex object lifecycle management, and declarative services for POJOs to the forefront of Java development. It’s a rare project that doesn’t at least consider taking advantage of all Spring has to offer, including the vast array of Spring “beans” included in its library. Spring touches almost every facet of enterprise Java development, in most cases simplifying them dramatically.
In this chapter I’ll look at how Groovy interacts with the Spring framework. As it turns out, Groovy and Spring are old friends. Spring manages Groovy beans as easily as it handles Java. Spring includes special capabilities for working with code from dynamic languages, however, which I’ll review here.
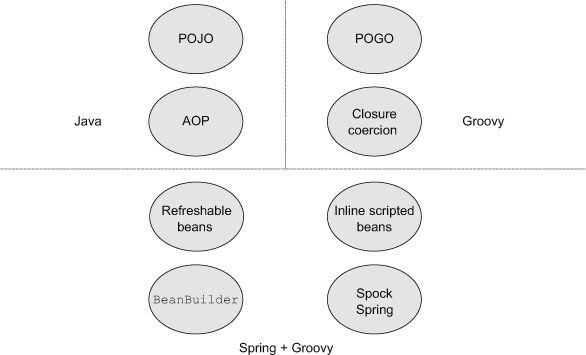
Groovy can be used to implement beans or to configure them. In this chapter I’ll try to review all the ways Groovy can help Spring. Figure 7.1 contains a guide to the technologies discussed in this chapter.
Figure 7.1. Guide to the Spring technologies with Groovy. Spring manages POGOs as easily as POJOs, so the examples include Groovy implementations of both normal beans and aspects. Closure coercion is used to implement the RowMapper interface in a JdbcTemplate. Refreshable beans are Groovy source files that can be modified at runtime. Inline scripted beans are included inside XML configuration files. Grails provides a BeanBuilder class for configuring beans. Finally, Spock has a library that allows it to be used with Spring’s test context feature.
To show how Groovy helps Spring, I need to review what Spring is all about and how it’s used and configured. I’ll start with a simple, but non-trivial, sample application. Rather than show all the pieces (which are in the source code repository for the book), I’ll highlight the overall architecture and the Groovy parts.
7.1. A Spring application
For all its benefits, Spring is a hard framework to demonstrate to developers unfamiliar with it. The “Hello, World” application in Spring makes you question why you’d ever want it, because it replaces a couple of lines of simple, easy-to-understand, strongly typed Java with several additional lines of code, plus about 20 lines of XML. That’s not exactly a ringing endorsement.
To see the real value of Spring you have to see a real application, even if it’s simplified in various ways. The following application models the service and persistence layers of an account management application. The presentation layer is arbitrary, so the following code could be used in either a client-side or a server-side application. In this case, I’ll demonstrate the functionality through both unit and integration tests.
Java and Groovy Spring Beans
Rather than build the entire application in Java and then convert it to Groovy as in other chapters, to save space this application mixes both languages. The point is that Spring managed beans can be implemented in either Java or Groovy, whichever is most convenient.
Consider an application that manages bank accounts. I’ll have a single entity class representing an account, with only an id and a balance, along with deposit and withdraw methods.
The next listing shows the Account class in Groovy, which has a serious advantage over its Java counterpart: it makes it easy to work with a java.math.BigDecimal.
Listing 7.1. An Account POGO in Groovy that uses BigDecimal

Financial calculations are one of the reasons we need java.math.BigDecimal and java.math.BigInteger. Using BigDecimal keeps round-off errors from being sent into an account where it can accumulate over time.[1] It’s easy to show how quickly round-off errors can become a problem. Consider the following two lines:
1 If you haven’t seen Office Space yet (http://mng.bz/c6o8), you have a real treat ahead of you.
println 2.0d – 1.1d println 2.0 – 1.1
The first line uses doubles, while the second line uses java.math.BigDecimal. The first evaluates to 0.8999999999999999, while the second evaluates to 0.9. In the double case I’ve only done a single calculation and already I have enough error to show up.
When coding in Java working with BigDecimal is awkward because it’s a class rather than a primitive. That means you can’t use your normal +, *, - operators and have to use the class’s API instead.
Because Groovy has operator overloading, however, none of that is necessary. I can simply declare the balance to be a BigDecimal, and everything else just works, even if I use the Account class from Java.
One additional comment about the Account: at the moment no constraints are being applied to ensure that the balance stays positive. This is as simple as I can make it, just for exposition purposes.
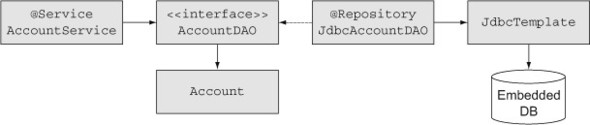
The overall design for using the Account class is shown in figure 7.2. This is a very simple form of a layered architecture, with transactional support in the service layer and a persistence layer that consists of an interface and a DAO class, discussed shortly.
Figure 7.2. A simple account management application. Transactions are demarcated in the service layer. The persistence layer consists of a single DAO class that implements an interface and uses the Spring JdbcTemplate to access an embedded database.
The persistence layer follows the normal Data Access Object design pattern. The next listing shows a Java interface, called AccountDAO, written in Java.
Listing 7.2. The AccountDAO interface, in Java
package mjg.spring.dao;
import java.util.List;
import mjg.spring.entities.Account;
public interface AccountDAO {
int createAccount(double initialBalance);
Account findAccountById(int id);
List<Account> findAllAccounts();
void updateAccount(Account account);
void deleteAccount(int id);
}
The interface contains typical methods for transferring Account objects to the database and back. There’s a method to create new accounts, update an account, and delete an account; a method to find an account by id; and one to return all the accounts.
The implementation of the interface, using a Groovy class called JdbcAccountDAO, works with the JdbcTemplate from Spring. Rather than show the whole class (which is available in the book source code), let me present just the structure and then emphasize the Groovy aspect afterward. An outline of the class is shown in the following listing.
Listing 7.3. Implementing the AccountDAO using JdbcTemplate, in Groovy

The various query methods take an argument of type RowMapper<T>, whose definition is
public interface RowMapper<T> {
T mapRow(ResultSet rs, int rowNum) throws SQLException
}
When you execute one of the query methods in JdbcTemplate, Spring takes the ResultSet and feeds each row through an implementation of the RowMapper interface. The job of the mapRow method is then to convert that row into an instance of the domain class. The normal Java implementation would be to create an inner class called, say, AccountMapper, whose mapRow method would extract the data from the ResultSet row and convert it into an Account instance. Providing an instance of the AccountMapper class to the queryForObject method would then return a single Account. The same instance can be supplied to the query method, which then returns a collection of Accounts.
This is exactly the type of closure coercion demonstrated in chapter 6. A variable called accountMapper is defined and assigned to a closure with the same arguments as the required mapRow method. The variable is then used in both the findAccountById and findAllAccounts methods.
There are two uses for Groovy here:
1. A Groovy class implemented a Java interface, which makes integration easy and simplifies the code.
2. Closure coercion eliminated the expected inner class.
In the example in the book source code I also included the service class referenced in figure 7.2. It uses Spring’s @Transactional annotation to ensure that each method operates in a required transaction. There is nothing inherently Groovy about it, so again I’ll just show an outline of the implementation in the next listing.
Listing 7.4. A portion of the AccountService class in Java
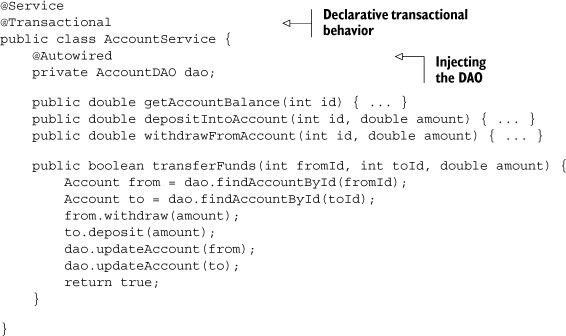
The @Autowired annotation is used by Spring to plug in (inject) an instance of a class implementing the AccountDAO interface into the service class. See the Spring documentation [2] for more details on autowiring.
The service implementation is in Java mostly because there’s no great advantage to implementing it in Groovy, though I could easily have done so.
The last piece of the puzzle is the Spring bean configuration file. The configuration in the book source code uses a combination of XML and a component scan for the repository and service classes. Again, nothing in it uses Groovy, so I won’t present it here. For the record, the sample uses Spring’s <embedded-database> tag to set up a sample H2 database in memory that is reinitialized on each run. The rest is as described.
Returning now to Groovy, I want to show the Gradle build file in the next listing.
Listing 7.5. The Gradle build file for the account application
apply plugin:'groovy'
apply plugin:'eclipse'
repositories {
mavenCentral()
}
def springVersion = '3.2.2.RELEASE'
def spockVersion = '0.7-groovy-2.0'
dependencies {
compile "org.codehaus.groovy:groovy-all:2.1.5"
compile "org.springframework:spring-context:$springVersion"
compile "org.springframework:spring-jdbc:$springVersion"
runtime "com.h2database:h2:1.3.172"
runtime "cglib:cglib:2.2"
testCompile "org.springframework:spring-test:$springVersion"
testCompile "org.spockframework:spock-core:$spockVersion"
testCompile "org.spockframework:spock-spring:$spockVersion"
}
The build file is typical of projects presented in this book so far. It declares both the Groovy and Eclipse plugins. It uses Maven central for the repository. The dependencies include Groovy and Spock, as usual. Spring is added by declaring the spring-context and spring-jdbc dependencies. Those dependencies wind up adding several other Spring-related JARs. The h2database dependency is used for the H2 driver needed by the embedded database.
One interesting addition is the spock-spring dependency. Spring includes a powerful testing framework of its own, which is based on JUnit and automatically caches the Spring application context. The spock-spring dependency lets Spock tests work with the Spring testing context.
The first test class is a Spock test for the JdbcAccountDAO. The following listing shows some of the tests from the complete set.
Listing 7.6. Spock tests for the JdbcAccountDAO implementation
import spock.lang.Specification;
@ContextConfiguration("classpath:applicationContext.xml")
@Transactional
class JdbcAccountDAOSpec extends Specification {
@Autowired
JdbcAccountDAO dao
def "dao is injected properly"() {
expect: dao
}
def "find 3 accounts in sample db"() {
expect: dao.findAllAccounts().size() == 3
}
def "find account 0 by id"() {
when:
Account account = dao.findAccountById(0)
then:
account.id == 0
account.balance == 100.0
}
// tests for other methods as well
}
The @ContextConfiguration annotation tells the test runner how to find the Spring bean configuration file. Adding @Transactional means that each test runs in a required transaction that (and this is the cool part) rolls back automatically at the end of each test, implying that the database is reinitialized at the beginning of each test. The DAO is autowired into the test class. The individual tests check that all the methods in the DAO work as expected.
The next listing shows the tests for the service class, which includes using the old method from Spock described in chapter 6 on testing.
Listing 7.7. Spock tests for the service class
import spock.lang.Specification
@ContextConfiguration("classpath:applicationContext.xml")
@Transactional
class AccountServiceSpec extends Specification {
@Autowired
AccountService service
def "balance of test account is 100"() {
expect: service.getAccountBalance(0) == 100.0
}
// ... other tests as necessary ...
def "transfer funds works"() {
when:
service.transferFunds(0,1,25.0)
then:
service.getAccountBalance(0) ==
old(service.getAccountBalance(0)) - 25.0
service.getAccountBalance(1) ==
old(service.getAccountBalance(1)) + 25.0
}
}
As before, the annotations let the Spock test work with Spring’s test framework, which caches the application context. I used the old operation from Spock to check changes in the account balance after a deposit or withdrawal. No other additions are needed to use Spock with the Spring test context.
This application, though simple, illustrates a lot of Spring’s capabilities, from declarative transaction management to autowiring to simplified JDBC coding to effective testing. From Spring’s point of view, Groovy beans are just bytecodes by another name. As long as the groovy-all JAR file is in the classpath, Spring is quite happy to use beans written in Groovy.
Spring manages beans from Groovy as easily as it manages beans from Java. There are special capabilities that Spring offers beans from dynamic languages, though. I’ll illustrate them in the next sections, beginning with beans that can be modified in a running system.
7.2. Refreshable beans
Since version 2.0, Spring has provided special capabilities for beans from dynamic languages like Groovy. One particularly interesting, if potentially dangerous, option is to deploy what are known as refreshable beans.
For refreshable beans, rather than compile classes as usual, you deploy the actual source code and tell Spring where to find it and how often to check to see if it has changed. Spring checks the source code at the end of each refresh interval, and if the file has been modified it reloads the bean. This gives you the opportunity to change deployed classes even while the system is still running.[3]
3 Yes, that’s a scary notion to me, too. The Spider-Man corollary applies: With Great Power Comes Great Responsibility.
I’ll demonstrate a somewhat contrived but hopefully amusing example. In the previous section I presented an application for managing accounts. Let me now assume that the account manager, presumably some kind of bank, decides to get into the mortgage business. I now need a class representing a mortgage application, which a client would submit for approval. I’m also going to need a mortgage evaluator, which I’ll implement both in Java and in Groovy. The overall system is shown in figure 7.3.
Figure 7.3. The GroovyEvaluator is a refreshable bean. The source code is deployed, and Spring checks it for changes after each refresh interval. If it has changed, Spring reloads the bean.

To keep this example simple, the mortgage application class only has fields representing the loan amount, the interest rate, and the number of years desired, as shown in the next listing.
Listing 7.8. A trivial mortgage application class in Groovy
class MortgageApplication {
BigDecimal amount
BigDecimal rate
int years
}
As before, Groovy is used just to reduce the amount of code and to make it easier to work with BigDecimal instances. An instance of this class is submitted to the bank, which runs it through a mortgage evaluator to decide whether or not to approve it. The following listing shows a Java interface representing the evaluator, which will be implemented in both Java and Groovy.
Listing 7.9. The Evaluator interface in Java
public interface Evaluator {
boolean approve(MortgageApplication application);
}
The interface contains only one method, approve, which takes a mortgage application as an argument and returns true if the application is approved and false otherwise.
Pretend now that it is currently the summer of 2008. The general public is blissfully unaware of terms like credit default swaps, and banks are eager to loan as much money as possible to as many people as possible. In other words, here’s a Java implementation of the Evaluator interface.
Listing 7.10. A Java evaluator, with a rather lenient loan policy
public class JavaEvaluator implements Evaluator {
public boolean approve(MortgageApplication application) {
return true;
}
}
That’s a very forgiving loan policy, but if everyone else is doing it, what could go wrong?
What went wrong, of course, is that in the late summer and early fall of 2008, Bear Stearns collapsed, Lehman Brothers went bankrupt, and the U.S. economy nearly collapsed. The bank needs to stop the bleeding as soon as possible. If the evaluator in place is the Java evaluator just shown, then the system has to be taken out of service in order to modify it. The fear is that if the system is taken offline, then customers might worry that it will never come back again.[4]
4 That’s an It’s a Wonderful Life reference: “George, if you close those doors, you’ll never open them again!”
There’s another possibility, however. Consider the Groovy version of the mortgage evaluator, whose behavior is equivalent to the Java version, as shown in the following listing.
Listing 7.11. A Groovy mortgage evaluator deployed as source code
class GroovyEvaluator implements Evaluator {
boolean approve(MortgageApplication application) { true }
}
Again, it simply returns true, just as the Java version did. Rather than compiling this class and deploying it as usual, however, this time I want to create a refreshable bean. To do so, I need to work with the lang namespace in the Spring configuration file (assuming I’m using XML; alternatives exist for Java configuration files). I also need to deploy the source code itself, rather than the compiled version of this file.
Deploying source
Note that for refreshable beans you deploy the source, not the compiled bean.
The next listing shows the bean configuration file with both evaluators. Note the addition of the lang namespace and the Groovy bean.
Listing 7.12. The bean configuration file with the refreshable Groovy evaluator bean

Groovy provides a namespace for beans from dynamic languages, including Groovy, BeanShell, and JRuby. One of the elements declared in that namespace is <lang: groovy>, whose script-source attribute is used to point to the source code of a Groovy class. Note that unlike the Java evaluator bean in the same file, this attribute points to the actual source file, rather than the compiled bean. The other important attribute for the element is refresh-check-delay, which indicates the time period, in milliseconds, after which Spring will check to see if the source file has changed. Here the delay has been set to one second.
Now comes the fun part.[5] The next listing shows a demo application that loads the Groovy evaluator bean and calls the approve method 10 times, sleeping for one second between each call.
5 Seriously. This is a fun demo to do in front of a live audience. Try it and see.
Listing 7.13. A demo application that loads the Groovy bean and calls approve 10 times

The idea is to start the demo running and then, while the iteration is going, edit the source code to change the return value of the approve method from true to false.[6] The output of the program resembles
6 Did you notice that the approve method was invoked with a null argument, acknowledging that the mortgage application doesn’t matter at all? That’s part of the gag, so be sure to chuckle when you do it.
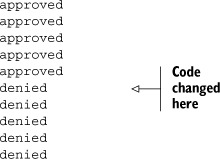
The source code is changed halfway through the loop to stop the bleeding. If Congress should then spring[7] into action and award a massive government bailout, it can be changed back.[8]
7 Ouch. Yes, a bad pun, but an irresistible one.
8 Or not.
The ability to change the implementation of a bean inside a running system is powerful, but obviously risky. Spring only makes it available to beans from dynamic languages like Groovy.
As much fun as the banking application illustrated in this section is, few companies will allow you to deploy source code into production and then edit it while the system is running. So when would you actually use this capability?
Some problems only occur when a system is under load. Think of a refreshable bean as an adaptable probe that can be inserted into a Spring-based system by a server-side developer in a controlled fashion. You have the freedom to do more than just change a log level or some other property (which you could in principle do with JMX, the Java Management Extensions). You can change what the probe is doing in real time and diagnose what’s actually going on.
Dierk Koenig, lead author of Groovy in Action (Manning, 2007), calls this pattern “keyhole surgery.” It’s used as a minimally invasive procedure when you don’t know what you’re going to find when you go in.[9]
9 Check out Dierk’s presentation “Seven Groovy Usage Patterns for Java Developers” on www.slideshare.net for more details.
Before discussing the other Spring capability restricted to beans from dynamic languages, namely inline scripted beans, let me introduce another idea. One of the great features of Spring is that it provides a convenient infrastructure for aspect-oriented programming. I want to discuss what that means and how to use Groovy to implement an aspect.
7.3. Spring AOP with Groovy beans
Many of Spring’s capabilities are implemented using aspect-oriented programming (AOP). Spring provides the infrastructure for developing aspects. The interesting part is that aspects can be written as easily in Groovy as in Java.
AOP is a big subject, but I can summarize a few of the key features here.[10] Aspects are designed to handle crosscutting concerns, which are features that apply to many different locations. Examples of crosscutting concerns include logging, security, and transactions. Each of them needs to be applied at multiple locations in a system, which results in considerable duplication, as well as tangling of different kinds of functionality in the same feature.
10 A complete discussion of AOP can be found in AspectJ in Action, 2nd edition (Manning, 2009), by Ramnivas Laddad, www.mannin10g.com/laddad2/.
Crosscutting concerns are written as methods, known as advice. The next issue is where to apply the advice. The generic term for all available locations where advice can be applied is joinpoints. The set of selected joinpoints for a given aspect is known as a pointcut. The combination of an advice and a pointcut is what defines an aspect.
The sample application for this section and the next is shown in figure 7.4.
Figure 7.4. Spring AOP in action. ChangeLogger is a Java aspect that logs a message before each set method. UpdateReporter does the same in Groovy but reports on existing values. The GroovyAspect is an inline scripted bean defined inside the configuration file.
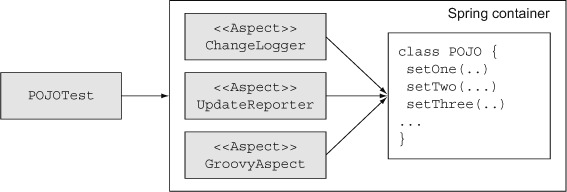
The following listing shows an example of an aspect, using Spring annotations, written in Java. This aspect is applied whenever a set method is about to be called, and it logs which method is being invoked and what the new value will be.
Listing 7.14. A Java aspect that logs changes to properties
package mjg.aspects;
import java.util.logging.Logger;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
@Aspect
public class ChangeLogger {
private Logger log = Logger.getLogger(
ChangeLogger.class.getName());
@Before("execution(void set*(*))")
public void trackChange(JoinPoint jp) {
String method = jp.getSignature().getName();
Object newValue = jp.getArgs()[0];
log.info(method + " about to change to " +
newValue + " on " + jp.getTarget());
}
}
The @Aspect annotation tells Spring this is an aspect. The @Before annotation defines the pointcut using AspectJ pointcut language. [11] This particular pointcut applies at all methods that begin with the letters set that take a single argument and return void. The trackChange method is the advice. The JoinPoint argument is supplied by Spring when the aspect is called. It provides context for the execution. In this case, the JoinPoint has methods to retrieve the signature of the method being advised, as well as the arguments supplied to the method and the target object.
11 The documentation for AspectJ is hosted with Eclipse, of all places. See http://www.eclipse.org/aspectj/ for details.
To demonstrate this aspect in action, I need to configure Spring to apply the aspect, and I need an object to advise. The latter is easy enough. The next listing shows a simple class with three properties.
Listing 7.15. A simple POJO with three set methods
package mjg;
public class POJO {
private String one;
private int two;
private double three;
public String getOne() { return one; }
public void setOne(String one) { this.one = one; }
public int getTwo() { return two; }
public void setTwo(int two) { this.two = two; }
public double getThree() { return three; }
public void setThree(double three) { this.three = three; }
@Override
public String toString() {
return "POJO [one=" + one + ", two=" + two +
", three=" + three + "]";
}
}
The class is called POJO, and it has three properties, called one, two, and three. Each has a getter and a setter. The aspect will run before each of the set methods.
Spring’s AOP infrastructure has some restrictions compared to full AOP solutions. Spring restricts pointcuts to only public method boundaries on Spring-managed beans. I therefore need to add the POJO bean to Spring’s configuration file. I also need to tell Spring to recognize the @Aspect annotation and to generate the needed proxy. The resulting bean configuration file is presented in the following listing.
Listing 7.16. The Spring bean configuration file for AOP
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
... namespace declarations elided ... >
<aop:aspectj-autoproxy />
<bean id="tracker" class="mjg.aspects.ChangeLogger" />
<bean id="pojo" class="mjg.POJO" p:one="1" p:two="2" p:three="3"/>
</beans>
The aop namespace provides the <aspect-autoproxy> element, which tells Spring to generate proxies for all classes annotated with @Aspect. The tracker bean is the Java aspect shown previously. The pojo bean is the POJO class just discussed.
Now I need to call the set methods in order to see the aspect in action. The next listing shows a test case based on JUnit 4 that uses Spring’s JUnit 4 test runner, which caches the application context in between tests.
Listing 7.17. A JUnit 4 test case to exercise the POJO
package mjg;
import static org.junit.Assert.*;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@ContextConfiguration("classpath:applicationContext.xml")
@RunWith(SpringJUnit4ClassRunner.class)
public class POJOTest {
@Autowired
private POJO pojo;
@Test
public void callSetters() {
pojo.setOne("one");
pojo.setTwo(22);
pojo.setThree(333.0);
assertEquals("one", pojo.getOne());
assertEquals(22, pojo.getTwo());
assertEquals(333.0, pojo.getThree(),0.0001);
}
}
Spring injects an instance of the POJO into the test and executes the test, which simply calls the three setters and checks that they work properly. The interesting part is in the console output, which shows the aspect in play:
INFO: setOne about to change to one on POJO [one=1, two=2, three=3.0] INFO: setTwo about to change to 22 on POJO [one=one, two=2, three=3.0] INFO: setThree about to change to 333.0 on POJO [one=one, two=22, three=3.0]
The aspect reports the name of each set method and its argument when it’s called. Everything works as advertised.
There’s one issue, though. What if you want to know the current value of each property before the setter changes it? There’s no obvious way to find out. The joinpoint gives access to the target, and I know that a set method is being called, but while I know conceptually that for every setter there’s a getter, figuring out how to invoke it isn’t trivial. Determining the proper get method could probably be done with a combination of reflection and string manipulation, but there’s work involved.
At least, there’s work involved unless I appeal to Groovy. I can do everything I just described in a handful of lines of Groovy, as the next listing demonstrates.
Listing 7.18. A Groovy aspect for printing property values before they are changed
package mjg.aspects
import java.util.logging.Logger
import org.aspectj.lang.JoinPoint
import org.aspectj.lang.annotation.Aspect
import org.aspectj.lang.annotation.Before
@Aspect
class UpdateReporter {
Logger log = Logger.getLogger(UpdateReporter.class.name)
@Before("execution(void set*(*))")
void reportOnSet(JoinPoint jp) {
String method = jp.signature.name
String base = method – 'set'
String property = base[0].toLowerCase() + base[1..-1]
def current = jp.target."$property"
log.info "About to change $property from $current to ${jp.args[0]}"
}
}
The UpdateReporter class is written in Groovy. It has the @Aspect and @Before annotations exactly as the Java aspect did. The method being invoked is computed the same way the Java aspect did, with the only minor difference being that Groovy accesses the signature and name properties rather than explicitly invoking the associated getSignature and getName methods. That’s a case of foreshadowing, actually, because it means that all I really need to do is to figure out the name of the property.
The property is found by taking the name of the set method, subtracting out the letters set, and converting the result to standard property syntax. Now that I have the name of the property, I just need to access it from the target, which is done on the next line. I used a Groovy string to make sure that the property is evaluated. The result is that in three lines of Groovy I now know what the original value of the property is. All that remains is to log it to standard output.
To run this aspect I just added a corresponding bean to the configuration file:
<bean id="updater" class="mjg.aspects.UpdateReporter" />
Now if I run the same test case the output is as shown here:
INFO: About to change one from 1 to one INFO: setOne about to change to one on POJO [one=1, two=2, three=3.0] INFO: About to change two from 2 to 22 INFO: setTwo about to change to 22 on POJO [one=one, two=2, three=3.0] INFO: About to change three from 3.0 to 333.0 INFO: setThree about to change to 333.0 on POJO [one=one, two=22, three=3.0]
Both the Groovy aspect and the Java aspect are executing on the set methods of the POJO. The advantage of the Groovy aspect is that it’s easily able to determine the existing value of the property before changing it.
Life isn’t quite as simple as I’m describing it. The string manipulation that processed the set method determined a property name. If the property doesn’t actually exist (or, rather, the get method doesn’t exist), accessing it isn’t going to work. Still, asking that each setter has a corresponding getter doesn’t seem to be too much to expect, especially because Groovy POGOs do that automatically.
To finish this section, listing 7.19 shows an aspect added to the banking example from the beginning of this chapter, tracing methods in the Account class. Because Account is a POGO, I don’t have explicit setter methods. I don’t necessarily want to track all the getters, either, because one of them is getMetaClass, and that’s not a business method.
One way around that is to use a Java interface implemented by the POGO. Instead, here I’m going to use explicit pointcuts and put them together.
Here’s the complete AccountAspect listing with the pointcuts and advice.
Listing 7.19. An aspect tracking methods in the Account POGO
import java.util.logging.Logger
import org.aspectj.lang.JoinPoint
import org.aspectj.lang.annotation.Aspect
import org.aspectj.lang.annotation.Before
import org.aspectj.lang.annotation.Pointcut
@Aspect
class AccountAspect {
Logger log = Logger.getLogger(AccountAspect.class.name)
@Pointcut("execution(* mjg..Account.deposit(*))")
void deposits() {}
@Pointcut("execution(* mjg..Account.withdraw(*))")
void withdrawals() {}
@Pointcut("execution(* mjg..Account.getBalance())")
void balances() {}
@Before("balances() || deposits() || withdrawals()")
void audit(JoinPoint jp) {
String method = jp.signature.name
og.info("$method called with ${jp.args} on ${jp.target}")
}
}
The @Pointcut annotation is how you create a named pointcut. The name is set by the name of the method on which it’s applied. The three pointcuts here match the deposit, withdraw, and getBalance methods in the Account class. The @Before advice combines them using an or expression and logs the method calls. When running the AccountSpec tests, the (truncated) output is similar to this:
Jun 28, 2013 12:03:29 PM INFO: getBalance called with [] on mjg.spring.entities.Account(id:4, balance:100.0) Jun 28, 2013 12:03:29 PM INFO: deposit called with [100] on mjg.spring.entities.Account(id:8, balance:100.0) INFO: withdraw called with [100] on mjg.spring.entities.Account(id:9, balance:100.0) Jun 28, 2013 12:03:29 PM INFO: getBalance called with [] on mjg.spring.entities.Account(id:9, balance:0.0)
The JoinPoint can be used to get more information, but those are AOP details rather than Groovy.
In both of these examples the aspect was provided in its own class. Spring provides an alternative, however, in the form of beans defined right in the bean definition file.
7.4. Inline scripted beans
Another capability Spring provides to beans from dynamic languages is that they can be coded right inside the XML configuration.[12]
12 I have to admit that in several years of using Spring and Groovy I’ve never found a compelling use case for inline scripted beans that couldn’t have been handled with regular classes. If you have one, please let me know.
Here’s an example. The following sections can be used in a bean configuration file, as shown in the next listing.
Listing 7.20. Additions to bean configuration file for an inline scripted aspect
<lang:groovy id="aspectScript">
<lang:inline-script>
<![CDATA[
import org.aspectj.lang.JoinPoint
import java.util.logging.Logger
class GroovyAspect {
Logger log = Logger.getLogger(GroovyAspect.getClass().getName())
def audit(JoinPoint jp) {
log.info "${jp.signature.name} on ${jp.target.class.name}"
}
}
]]>
</lang:inline-script>
</lang:groovy>
<aop:config>
<aop:aspect ref="aspectScript">
<aop:before method="audit" pointcut="execution(* *.*(*))"/>
</aop:aspect>
</aop:config>
The <inline-script> tag wraps the source code for the Groovy bean. I took the added step of wrapping the code in a CDATA section, so the XML parser will leave the Groovy source alone when validating the XML.
Rather than use annotations, this time the code is written as though it was any other bean. As a result I had to add the <config> element as well. As usual, an aspect is a combination of a pointcut and an advice. In this case the pointcut is contained in the <before> element, but this time it applies to every one-argument method in the system. The advice is the audit method in the aspectScript bean, which just prints the name of the method being invoked and the name of the object containing it.
The resulting output adds more lines to the console:
INFO: setOne on mjg.POJO INFO: setTwo on mjg.POJO INFO: setThree on mjg.POJO
The original motivation for inline scripted beans was that you could do as much processing as you liked in the script before releasing the bean. [13] Now that Spring has moved to version 3.x, however, there are additional options for configuring beans.
13 As I say, it’s a reach. The Spring docs suggest that this is a good opportunity for scripted validators, but I don’t see it.
7.5. Groovy with JavaConfig
Spring introduced a third way to configure beans in version 3.0. Originally all beans were configured using XML. Then version 2.0 introduced annotations (assuming JDK 1.5 is available) like @Component, @Service, and @Repository and component scans that picked them up.
In version 3.0 Spring introduced a Java configuration option. Instead of defining all your beans in a central location in XML, or spreading annotations throughout the code base in Java, now you can define the beans in a Java class annotated with @Configuration. Inside the configuration file, individual beans are annotated with @Bean.
One of the advantages of this approach is that the configuration information is strongly typed, because it’s all written in Java. Another advantage, though, is that you’re now free to write whatever code you want, as long as you ultimately return the proper object.
Consider the following example. In the account manager example discussed previously, say I want to charge a processing fee once a month.[14] To do so I create a class that processes accounts, called, naturally enough, AccountProcessor. I want the Account Processor to get all the accounts and charge each one a fee of one dollar.[15]
14 Gee, I feel more like a real banker already.
15 It’s not much, but it’s a start.
If I did this in the traditional way, I would inject the AccountDAO into the AccountProcessor. Then, in a processAccounts method, I would use the DAO to retrieve the accounts and charge the fee on each. With the Java configuration option, however, I have an alternative.
The following listing shows the AccountProcessor class, in Java this time.
Listing 7.21. An account processor that debits each account by one dollar
package mjg.spring.services;
import java.util.List;
import mjg.spring.entities.Account;
public class AccountProcessor {
private List<Account> accounts;
public void setAccounts(List<Account> accounts) {
this.accounts = accounts;
}
public List<Account> getAccounts() { return accounts; }
public double processAccounts() {
double total = 0.0;
for (Account account : accounts) {
account.withdraw(1.0);
total += 1.0;
}
return total;
}
}
Instead of injecting the AccountDAO into the processor, I gave it a list of accounts as an attribute. The processAccounts method runs through them, withdrawing a dollar from each and returning the total. Without the dependency on the AccountDAO, this processor could be used on any collection of accounts from any source. This has the extra benefit of always retrieving the complete set of accounts from the DAO. Injecting the account list would initialize it when the application starts but not update it later.
So how does the collection of accounts get into my processor? The next listing shows the Java configuration file.
Listing 7.22. A Java configuration file that declares the AccountProcessor bean
package mjg.spring;
import mjg.spring.dao.AccountDAO;
import mjg.spring.services.AccountProcessor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JavaConfig {
@Autowired
private AccountDAO accountDAO;
@Bean
public AccountProcessor accountProcessor() {
AccountProcessor ap = new AccountProcessor();
ap.setAccounts(accountDAO.findAllAccounts());
return ap;
}
}
The @Configuration annotation indicates that this is a Java configuration file that defines beans for Spring. Each bean is defined with the @Bean annotation. The name of the method is the name of the bean, and the return type is the class for the bean. Inside the method my job is to instantiate the bean, configure it appropriately, and return it.
The implementation of a bean method can be as simple as instantiating the bean and returning it, setting whatever properties are needed along the way. In this case, though, I decided to autowire in the AccountDAO bean (which was picked up in the component scan) and then use the DAO to retrieve all the accounts and put them in the processor.
The next listing shows a Spock test to prove that the system is working. It relies on the embedded database again, which, as you may recall, configures three accounts.
Listing 7.23. A Spock test to check the behavior of the AccountProcessor
package mjg.spring.services
import mjg.spring.dao.AccountDAO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration
import org.springframework.transaction.annotation.Transactional
import spock.lang.Specification
@ContextConfiguration("classpath:applicationContext.xml")
@Transactional
class AccountProcessorSpec extends Specification {
@Autowired
AccountProcessor accountProcessor
@Autowired
AccountDAO dao
def "processing test accounts should yield 3"() {
given: def accounts = dao.findAllAccounts()
when: def result = accountProcessor.processAccounts()
then:
result == 3.0
accounts.every { account ->
account.balance.toString().endsWith "9"
}
}
}
Both the AccountProcessor and the AccountDAO beans are autowired into the test. The DAO is used to retrieve the accounts. Then, when the processor processes the accounts, three dollars are returned.
The other test condition relies on the fact that the initial balance for each account is divisible by 10. Therefore, after subtracting one from each account, the updated balances should all end in the digit 9. It’s kind of kludgy, but it works.
The point of this exercise was to show that with the Java configuration option you can write whatever code you want to configure the bean before releasing it. There’s not much Groovy can add to that, though it’s worth proving that the Java configuration option works on a Groovy class as well.
Normally I wouldn’t use Spring to manage basic entity instances. Spring specializes in managing back-end services, especially those that would normally be designed as singletons. Spring beans are all assumed to be singletons unless otherwise specified. Still, you can tell Spring to provide a new instance each time by making the scope of the bean equal to prototype.
Listing 7.24 shows a Java (actually, a Groovy) configuration file, with a single bean definition of type Account called prototypeAccount. It uses the AccountDAO to generate a new bean each time a prototypeAccount is requested, essentially making Spring a factory for Account beans, all of which start with an initial balance of 100.
Listing 7.24. A Spring configuration file in Groovy as a factory for Accounts
package mjg.spring.config
import mjg.spring.dao.AccountDAO
import mjg.spring.entities.Account
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import org.springframework.context.annotation.Scope
@Configuration
class GroovyConfig {
@Autowired
AccountDAO dao
@Bean @Scope("prototype")
Account prototypeAccount() {
int newId = dao.createAccount(100.0)
new Account(id:newId,balance:100.0)
}
}
The @Configuration and @Bean annotations are the same as their counterparts in the Java configuration file. The AccountDAO is autowired in as before. This time, though, the @Scope annotation is used to indicate that the prototypeAccount is not a singleton. The implementation uses the DAO to create each new account with the given balance and then populates an Account object with the generated ID.
To prove this is working properly, here is another Spock test in the next listing.
Listing 7.25. A Spock test for the prototype Accounts
package mjg.spring.services
import mjg.spring.entities.Account
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.context.ApplicationContext
import org.springframework.test.context.ContextConfiguration
import org.springframework.transaction.annotation.Transactional
import spock.lang.Specification
@ContextConfiguration("classpath:applicationContext.xml")
@Transactional
class AccountSpec extends Specification {
@Autowired
ApplicationContext ctx
def "prototype accounts have consecutive ids and balance 100"() {
when:
Account a1 = (Account) ctx.getBean("prototypeAccount")
Account a2 = (Account) ctx.getBean("prototypeAccount")
Account a3 = (Account) ctx.getBean("prototypeAccount")
then:
a3.id == a2.id + 1
a2.id == a1.id + 1
a1.balance == 100.0
a2.balance == 100.0
a3.balance == 100.0
}
}
This time the application context itself is autowired into the test, because I want to call its getBean method myself multiple times. The test then gets three instances of prototype-Account and verifies first that their account numbers are consecutive and then that all three have the expected balance.
The bottom line is that you can use Groovy to create a Spring configuration file as easily as you can use Java, and in both cases you have the full power of the language to do whatever additional configuration you might want before releasing the beans.
All of the techniques so far have discussed how to use capabilities defined in Spring. There’s one new capability, however, that allows you to define complex beans using a builder notation. This mechanism came from the Grails project but can be used anywhere.
7.6. Building beans with the Grails BeanBuilder
So far in this book I haven’t said much about Grails, the powerful framework that combines Groovy DSLs with Spring MVC and Hibernate. I’ll discuss Grails much more in chapter 10 on Groovy web applications, but part of it is relevant here. Normally innovations in Spring find their way into Grails, usually in the form of a plugin, but every once in a while a Grails innovation goes the other way.
The Grails BeanBuilder is an example. The grails.spring.BeanBuilder class uses Groovy’s builder syntax to create Spring configuration files. Everything you can do in regular configuration files you can do using the Grails BeanBuilder class. The best part, and the part most relevant for discussion here, is that you don’t need to be working on a Grails project to use the BeanBuilder.
Note
Rumor has it that the Grails BeanBuilder class will be added to the core Spring libraries in version 4, which will make using it trivial. Still, the process described here is useful for any general external library.
The version of Spring used for the examples in this chapter is 3.2, which doesn’t include the BeanBuilder. A few versions ago Grails was reformulated to split its dependencies into separate JARs as much as possible, the same way Spring was refactored in version 3. The Grails distribution thus contains a JAR file called grails-spring-2.2.2.jar, corresponding to Grails version 2.2.2.
The Grails-Spring JAR could simply be added to my projects as an external JAR dependency, but because the rest of my project was built with Gradle I prefer to list my additional dependency that way too. The Grails-Spring JAR itself depends on Simple Logging Framework for Java (SLF4J), so its dependencies must be added too.
The following listing shows the complete build file, which assumes the project is using traditional Maven structure.
Listing 7.26. The complete Gradle build file, including Grails-Spring dependencies
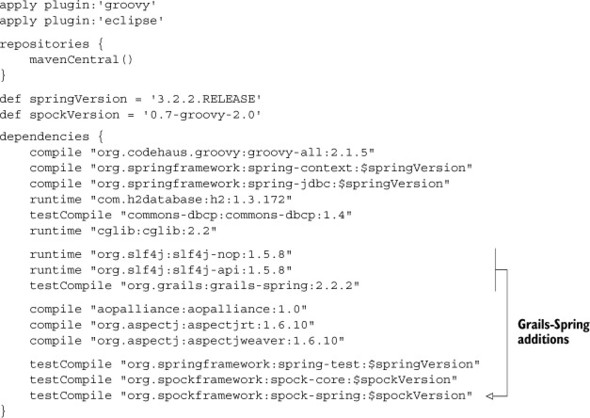
The additions shown in the build file are all that’s necessary to use the Grails BeanBuilder in a regular application. The Grails-Spring dependency (and SLF4J) are listed in the regular way. Any additional required JARs (and there are several) will then be downloaded automatically.
To demonstrate how to use the BeanBuilder, let me take a different approach from the earlier examples. The BeanBuilder is a class provided by an open source project. Open source projects by definition make their source code available. While browsing through the implementation of an open source project is certainly educational, I’d like to point out an oft-overlooked resource. The better open source projects are loaded with test cases. Because nobody is really fond of writing documentation,[16] sometimes it’s hard to figure out exactly how to use a particular capability in a project. If you’re lucky, whoever wrote the feature you want also wrote test cases for it. Then the tests demonstrate in great detail how the feature is intended to be used. Test cases are executable documentation, illustrating the ways the author meant for you to use the feature.
16 Other than in book form, I mean. Writing books is both fun and easy. That’s my story, and I’m sticking to it.
In the case of the Grails BeanBuilder, there’s a test case called grails.spring .BeanBuilderTests, which has a couple of very nice properties:
- It was originally authored by Graeme Rocher, the head of the Grails project and possibly the best developer I’ve ever met.[17]
17 Except for maybe Guillaume Laforge, Dierk Koenig, Paul King, Andres Almiray, or a few others. The Groovy ecosystem is filled with wicked-smart developers.
- The test case has nearly 30 different tests in it, demonstrating everything you might want to do with the class.
In this section I want to review some basic features of the BeanBuilderTests class. In fact, I copied the class into the book source code just to make sure everything worked. I needed to remove a couple of tests that weren’t relevant to running BeanBuilder independently from Grails, but everything else tested successfully.
Before I continue, I should highlight this approach as a good general rule:
Test Cases
Downloading the source code of an open source project is useful even if you never look at the implementation. The test cases alone are often more valuable than the actual documentation.
That advice might be more useful than anything else said in this book.
The next listing shows the first test case in the BeanBuilderTests class.
Listing 7.27. The BeanBuilderTests class with its first test case
class BeanBuilderTests extends GroovyTestCase {
void testImportSpringXml() {
def bb = new BeanBuilder()
bb.beans {
importBeans "classpath:grails/spring/test.xml"
}
def ctx = bb.createApplicationContext()
def foo = ctx.getBean("foo")
assertEquals "hello", foo
}
}
To use BeanBuilder all you have to do is instantiate the class. This is similar to using MarkupBuilder, SwingBuilder, AntBuilder, or any of the wide range of builders written in Groovy. Here the builder is assigned to the variable bb, so using the builder starts with bb.beans, which is like creating a root <beans> element in a Spring configuration file. The curly braces then indicate child elements. Here the child element is an importBeans element, which reads the file test.xml from the classpath. Before proceeding, here’s the text of test.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.0.xsd">
<bean id="foo" class="java.lang.String">
<constructor-arg value="hello" />
</bean>
</beans>
This is a typical beans configuration file containing a single bean definition. The bean is an instance of java.lang.String whose value is hello and whose name is foo.
Returning to the test case, after importing the XML file the createApplicationContext method is invoked, which makes the beans available through the application context. Then the test calls getBean to return the foo bean and checks that its value is hello.
The conclusions to be drawn are that to use the BeanBuilder you must (1) instantiate the class, (2) define the beans using normal builder syntax, (3) create the application context from the builder, and (4) access and use the beans in the normal way.
The next listing contains another test in the test case that illustrates setting a bean’s properties.
Listing 7.28. Setting bean properties in the BeanBuilder, from BeanBuilderTests
void testSimpleBean() {
def bb = new BeanBuilder()
bb.beans {
bean1(Bean1) {
person = "homer"
age = 45
props = [overweight:true, height:"1.8m"]
children = ["bart", "lisa"]
}
}
def ctx = bb.createApplicationContext()
assert ctx.containsBean("bean1")
def bean1 = ctx.getBean("bean1")
assertEquals "homer", bean1.person
assertEquals 45, bean1.age
assertEquals true, bean1.props?.overweight
assertEquals "1.8m", bean1.props?.height
assertEquals(["bart", "lisa"], bean1.children)
}
Inside the builder the syntax uses the bean name followed by the bean class in parentheses. In this case, bean1 is the name or ID of an instance of the Bean1 class. Near the bottom of the file you’ll find the definition of Bean1:
class Bean1 {
String person
int age
Properties props
List children
}
In fact, several beans are defined at the bottom of the class. Unlike Java, Groovy source files can have multiple classes defined in them. The Bean1 class contains attributes of type String, int, Properties, and List. The test case assigns the name to homer and the age to 45, uses the map syntax to assign the overweight and height properties, and sets the list to the names of the children.[18]The tests then assert that the bean is in the application context and that, after retrieving it, all the properties have been set as described.
18 Leaving out Maggie, who sadly always seems to be an afterthought.
You’re not limited to defining a single bean, of course. The next listing shows a test that creates several beans and sets their relationships.
Listing 7.29. Defining several related beans with the BeanBuilder
void testBeanReferences() {
def bb = new BeanBuilder()
bb.beans {
homer(Bean1) {
person = "homer"
age = 45
props = [overweight:true, height:"1.8m"]
children = ["bart", "lisa"]
}
bart(Bean1) {
person = "bart"
age = 11
}
lisa(Bean1) {
person = "lisa"
age = 9
}
marge(Bean2) {
person = "marge"
bean1 = homer
children = [bart, lisa]
}
}
def ctx = bb.createApplicationContext()
def homer = ctx.getBean("homer")
def marge = ctx.getBean("marge")
def bart = ctx.getBean("bart")
def lisa = ctx.getBean("lisa")
assertEquals homer, marge.bean1
assertEquals 2, marge.children.size()
assertTrue marge.children.contains(bart)
assertTrue marge.children.contains(lisa)
}
The beans named homer, bart, and lisa are all instances of the Bean1 class. The marge bean is an instance of Bean2, which adds a reference of type Bean1 called bean1. Here the bean1 reference in marge is assigned to homer. The Bean1 class also has a children attribute of type List, so it’s assigned to a list containing bart and lisa.
I don’t want to go through all the tests here, but there are a couple of features that should be highlighted. For example, you can define beans at different scopes, as shown in the next listing.
Listing 7.30. Defining beans at different scopes
void testScopes() {
def bb = new BeanBuilder()
bb.beans {
myBean(ScopeTest) { bean ->
bean.scope = "prototype"
}
myBean2(ScopeTest)
}
def ctx = bb.createApplicationContext()
def b1 = ctx.myBean
def b2 = ctx.myBean
assert b1 != b2
b1 = ctx.myBean2
b2 = ctx.myBean2
assertEquals b1, b2
}
By setting the scope attribute on myBean to prototype, retrieving the bean twice results in separate instances. The scope of myBean2 is singleton by default, so asking for it twice results in two references to the same object.
You can also use tags from different Spring namespaces. Earlier in this chapter I created an aspect using Groovy. The following listing shows a similar case using the BeanBuilder.
Listing 7.31. Defining an aspect using BeanBuilder
void testSpringAOPSupport() {
def bb = new BeanBuilder()
bb.beans {
xmlns aop:"http://www.springframework.org/schema/aop"
fred(AdvisedPerson) {
name = "Fred"
age = 45
}
birthdayCardSenderAspect(BirthdayCardSender)
aop.config("proxy-target-class":true) {
aspect(id:"sendBirthdayCard",ref:"birthdayCardSenderAspect" ) {
after method:"onBirthday", pointcut:
"execution(void grails.spring.AdvisedPerson.birthday())
and this(person)"
}
}
}
def appCtx = bb.createApplicationContext()
def fred = appCtx.getBean("fred")
assertTrue (fred instanceof SpringProxy )
fred.birthday()
BirthdayCardSender birthDaySender = appCtx.getBean(
"birthdayCardSenderAspect")
assertEquals 1, birthDaySender.peopleSentCards.size()
assertEquals "Fred", birthDaySender.peopleSentCards[0].name
}
The aop namespace is declared using xmlns. In the builder that’s interpreted as a (non-existent) method call, whose interpretation is to make the namespace available under the aop prefix. The fred bean is an instance of AdvisedPerson, whose definition is
@Component(value = "person")
class AdvisedPerson {
int age
String name
void birthday() {
++age
}
}
The birthdayCardSenderAspect is an instance of BirthdayCardSender, which is defined at the bottom of the file:
class BirthdayCardSender {
List peopleSentCards = []
void onBirthday(AdvisedPerson person) {
peopleSentCards << person
}
}
Using the config element from the aop namespace, the builder declares an aspect called sendBirthdayCard that references the aspect. After any execution of the birthday method in an advised person, the aspect’s onBirthday method is executed, which adds the person to the peopleSentCards collection. The test then verifies that the aspect did in fact run.
Other tests illustrate other capabilities in BeanBuilder. For example, if the property you’re trying to set requires a hyphen, you put the property in quotes. Some tests show examples like
aop.'scoped-proxy'()
or
jee.'jndi-lookup'(id:"foo", 'jndi-name':"bar")
See the test file for a wide range of examples. The bottom line is that anything you can do in a regular Spring bean configuration file, you can do with the Grails BeanBuilder.
1. Spring manages POGOs the same way it manages POJOs, so beans can be implemented in Groovy as easily as in Java.
2. Closure coercion eliminates the need for anonymous inner classes.
3. By adding a single JAR file, Spock tests work inside the Spring test context.
4. Refreshable beans allow you to modify the system without restarting it.
5. Inline scripted beans are embedded in configuration files.
6. The Grails BeanBuilder gives yet another way to configure Spring.
7.7. Summary
This chapter demonstrated all the places where Groovy can work productively with the Spring framework. In addition to writing Spring beans in Groovy, which sometimes results in significant code savings, there are features of Spring unique to beans from dynamic languages. I showed both refreshable beans, in which you deploy the source code and can revise it without stopping the system, and inline scripted beans, in which the beans are defined directly in the configuration file. Groovy beans can also be Spring AOP aspects, as shown. Finally, I reviewed tests from the BeanBuilder class from Grails, which can be used to create Spring bean definitions using the normal Groovy builder syntax, even outside of Grails.
In the next chapter, it’s time to look at database development and manipulation. There, in addition to the cool capabilities of the groovy.sql.Sql class, I’ll also use another contribution from the Grails project, the Grails Object Relational Mapping (GORM) capability.