
Chapter 8. Database access
- JDBC and the Groovy Sql class
- Simplifying Hibernate and JPA using GORM
- Working with the NoSQL database
Virtually every significant application uses persistent data in one form or another. The vast majority of them save the data in relational databases. To make it easy to switch from one database to another, Java provides the JDBC[1] API. While JDBC does handle the required tasks, its low-level nature leads to many lines of code to handle even the simplest tasks.
1 You would think that JDBC stands for Java Database Connectivity. Everyone would agree with you, except for the people at Sun (now Oracle) who created the API. They claim that JDBC is a trademarked acronym that doesn’t stand for anything. Clearly lawyers were involved somewhere in the process. I’m not going to be bound by such silliness, and if I get sued as a result, I’ll be sure to blog about it.
Because the software is object-oriented and the database is relational, there’s a mismatch at the boundary. The open source Hibernate project attempts to bridge that gap at a higher level of abstraction. Java includes the Java Persistence API (JPA) as a uniform interface to Hibernate and other object-relational mapping (ORM) tools.
Groovy, as usual, provides some simplifications to the Java APIs. For raw SQL, the Groovy standard library includes the groovy.sql.Sql class. For ORM tools like Hibernate, the Grails project created a domain-specific language (DSL) called GORM. Finally, many of the so-called “No SQL” databases that have become popular recently also provide Groovy APIs to simplify their use. Figure 8.1 shows the technologies covered in this chapter.
Figure 8.1. Java uses JDBC and JPA, with Hibernate being the most common JPA provider. Most NoSQL databases have a Java API that can be wrapped by Groovy; in this chapter GMongo is used to access MongoDB. GORM is a Groovy DSL on top of Spring and Hibernate. Finally, the groovy.sql.Sql class makes it easy to use raw SQL with a relational database.

With relational databases everything ultimately comes down to SQL, so I’ll start there.
8.1. The Java approach, part 1: JDBC
JDBC is a set of classes and interfaces that provide a thin layer over raw SQL. That’s a significant engineering achievement, actually. Providing a unified API across virtually every relational database is no trivial task, especially when each vendor implements significantly different variations in SQL itself.
Still, if you already have the SQL worked out, the JDBC API has classes and methods to pass it to the database and process the results.
The following listing shows a simple example, based on a single persistent class called Product.
Listing 8.1. The Product class, a POJO mapped to a database table
package mjg;
public class Product {
private int id;
private String name;
private double price;
public Product() {}
public Product(int id, String name, double price) {
this.id = id;
this.name = name;
this.price = price;
}
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public double getPrice() { return price; }
public void setPrice(double price) { this.price = price; }
}
The Product class has only three attributes, one of which (id) will represent the primary key in the database. The rest of the class is simply constructors, getters and setters, and (not shown) the normal toString, equals, and hashCode overrides. The complete version is available in the book source code.
The next listing shows the ProductDAO interface.
Listing 8.2. A DAO interface for the Product class
import java.util.List;
public interface ProductDAO {
List<Product> getAllProducts();
Product findProductById(int id);
void insertProduct(Product p);
void deleteProduct(int id);
}
To implement the interface I need to know the table structure. Again, to keep things simple, assume I only have a single table, called product. For the purposes of this example the table will be created in the DAO implementation class, using the H2 database.
The implementation class is JDBCProductDAO. A couple of excerpts are shown ahead. Java developers will find both the code and the attendant painful verbosity quite familiar.
The following listing shows the beginnings of the implementation, including constants to represent the URL and driver class.
Listing 8.3. A JDBC implementation of the DAO interface
public class JDBCProductDAO implements ProductDAO {
private static final String URL = "jdbc:h2:build/test";
private static final String DRIVER = "org.h2.Driver";
public JDBCProductDAO() {
try {
Class.forName(DRIVER);
} catch (ClassNotFoundException e) {
e.printStackTrace();
return;
}
createAndPopulateTable();
}
// ... More to come ...
}
The import statements have been mercifully omitted. The private method to create and populate the table is shown in the next listing.
Listing 8.4. Adding creation and population of the Product table to the DAO
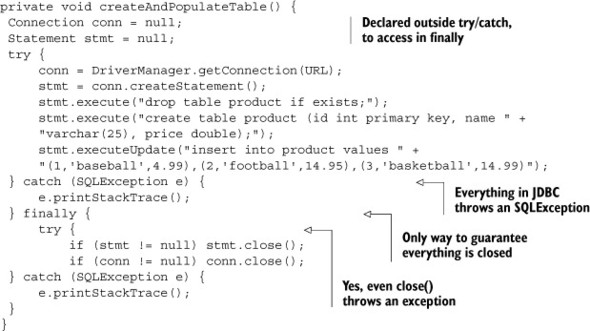
A phrase often used when describing Java is that the essence is buried in ceremony. JDBC code is probably the worst offender in the whole API. The “essence” here is to create the table and add a few rows. The “ceremony” is all the boilerplate surrounding it. As the listing shows, try/catch blocks are needed because virtually everything in JDBC throws a checked SQLException. In addition, because it’s absolutely necessary to close the database connection whether an exception is thrown or not, the connection must be closed in a finally block. To make matters even uglier, the close method itself also throws an SQLException, so it, too, must be wrapped in a try/catch block, and of course the only way to avoid a potential NullPointerException is to verify that the connection and statement references are not null when they’re closed.
This boilerplate is repeated in every method in the DAO. For example, the following listing shows the implementation of the findProductById method.
Listing 8.5. The findProductById method with all the required ceremony

As with so many things in Java, the best thing you can say about this code is that eventually you get used to it. All that’s being done here is to execute a select statement with a where clause including the necessary product ID and converting the returned database row into a Product object. Everything else is ceremony.
I could go on to show the remaining implementation methods, but suffice it to say that the details are equally buried. See the book source code for details.
1. JDBC is a very verbose, low-level set of classes for SQL access to relational databases.
2. The Spring JdbcTemplate class (covered in chapter 7) is a good choice if Groovy is not available.
Years ago this was the only realistic option for Java. Now other options exist, like Spring’s JdbcTemplate (discussed in chapter 7 on Spring) and object-relational mapping tools like Hibernate (discussed later in this chapter). Still, if you already know SQL and you want to implement a DAO interface, Groovy provides a very easy alternative: the groovy.sql.Sql class.
8.2. The Groovy approach, part 1: groovy.sql.Sql
The groovy.sql.Sql class is a simple façade over JDBC. The class takes care of resource management for you, as well as creating and configuring statements and logging errors. It’s so much easier to use than regular JDBC that there’s never any reason to go back.
The next listing shows the part of the class that sets up the connection to the database and initializes it.
Listing 8.6. A ProductDAO implementation using the groovy.sql.Sql class
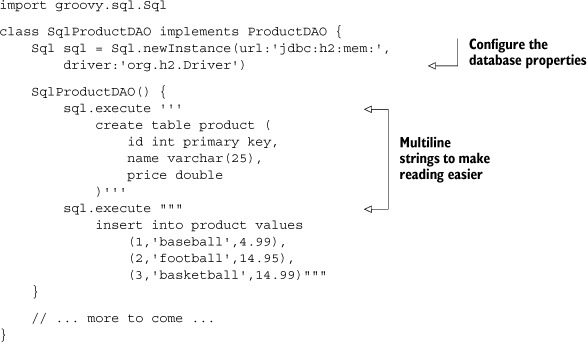
The groovy.sql.Sql class contains a static factory method called newInstance that returns a new instance of the class. The method is overloaded for a variety of parameters; see the GroovyDocs for details.
The execute method takes an SQL string and, naturally enough, executes it. Here I’m using a multiline string to make the create table and insert into statements easier to read. The Sql class takes care of opening a connection and closing it when finished.
The Sql class
The groovy.sql.Sql class does everything raw JDBC does, and handles resource management as well.
The same execute method can be used to delete products:
void deleteProduct(int id) {
sql.execute 'delete from product where id=?', id
}
The execute method not only creates the prepared statement, it also inserts the provided ID into it and executes it. It’s hard to get much simpler than that.
Inserting products can use the same method, but with a list of parameters:
void insertProduct(Product p) {
def params = [p.id, p.name, p.price]
sql.execute
'insert into product(id,name,price) values(?,?,?)', params
}
The class has another method called executeInsert, which is used if any of the columns are auto-generated by the database. That method returns a list containing the generated values. In this example the id values are supplied in the program. Auto-generated values will be considered in section 8.3 on Hibernate and JPA.
Retrieving products involves a minor complication. There are several useful methods for querying. Among them are firstRow, eachRow, and rows. The firstRow method is used when a single row is required. Either eachRow or rows can be used if there are multiple rows in the result set. In that case, eachRow returns a map of column names to column values, and the rows method returns a list of maps, one for each row.
The complication is that the returned column names are in all capitals. For example, the query
sql.firstRow 'select * from product where id=?', id
returns
[ID:1, NAME:baseball, PRICE:4.99]
for an id of 1. Normally I’d like to use that map as the argument to the Product constructor, but because the Product attributes are all lowercase that won’t work.
One possible solution is to transform the map into a new one with lowercase keys. That’s what the collectEntries method in the Map class is for. The resulting implementation of the findProductById method is therefore
Product findProductById(int id) {
def row = sql.firstRow('select * from product where id=?', id)
new Product( row.collectEntries { k,v -> [k.toLowerCase(), v] } );
}
It would be easy enough to generalize this to the getAllProducts method by using eachRow and transforming them one at a time. A somewhat more elegant solution is to use the rows method and transform the resulting list of maps directly:
List<Product> getAllProducts() {
sql.rows('select * from product').collect { row ->
new Product(
row.collectEntries { k,v -> [k.toLowerCase(), v] }
)
}
}
This solution is either incredibly elegant or too clever by half, depending on your point of view. Collecting[2] everything together (except for the initialization shown in the constructor already), the result is shown in the following listing.
2 No pun intended.
Listing 8.7. The complete SqlProductDAO class, except for the parts already shown
class SqlProductDAO implements ProductDAO {
Sql sql = Sql.newInstance(url:'jdbc:h2:mem:',driver:'org.h2.Driver')
List<Product> getAllProducts() {
sql.rows('select * from product').collect { row ->
new Product(
row.collectEntries { k,v -> [k.toLowerCase(), v] }
)
}
}
Product findProductById(int id) {
def row = sql.firstRow('select * from product where id=?', id)
new Product(
row.collectEntries { k,v -> [k.toLowerCase(), v] } );
}
void insertProduct(Product p) {
def params = [p.id, p.name, p.price]
sql.execute
'insert into product(id,name,price) values(?,?,?)', params
}
void deleteProduct(int id) {
sql.execute 'delete from product where id=?', id
}
}
By the way, there’s one other option available,[3] but only if the Person class is implemented in Groovy. If so, I can add a constructor to the Person class that handles the case conversion there:
3 Thanks to Dinko Srkoc on the Groovy Users email list for this helpful suggestion.
class Product {
int id
String name
double price
Person(Map args) {
args.each { k,v ->
setProperty( k.toLowerCase(), v)
}
}
}
With this constructor, the getAllProducts method reduces to
List<Product> getAllProducts() {
sql.rows('select * from product').collect { new Product(it) }
}
It’s hard to beat that for elegance.
The “elegant” solution in the chapter breaks down if the class attributes use camel case, which is normal. The corresponding database table entries would then use underscores to separate the words.
As shown by Tim Yates on the Groovy Users email list,[4] you can use Groovy metaprogramming to add a toCamelCase method to the String class to do the conversion. The relevant code is
4 See http://groovy.329449.n5.nabble.com/Change-uppercase-Sql-column-names-to-lowercase-td5712088.html for the complete discussion.
String.metaClass.toCamelCase = {->
delegate.toLowerCase().split('_')*.capitalize().join('').with {
take( 1 ).toLowerCase() + drop( 1 )
}
}
Every Groovy class has a metaclass retrieved by the getMetaClass method. New methods can be added to the metaclass by assigning closures to them, as is done here. A no-arg closure is used, which implies that the new method will take zero arguments.
Inside the closure the delegate property refers to the object on which it was invoked. In this case it’s the string being converted. The database table columns are in uppercase separated by underscores, so the delegate is converted to lowercase and then split at the underscores, resulting in a list of strings.
Then the spread-dot operator is used on the list to invoke the capitalize method on each one, which capitalizes only the first letter. The join method then reassembles the string.
Then comes the fun part. The with method takes a closure, and inside that closure any method without a reference is invoked on the delegate. The take and drop methods are used on lists (or, in this case, a character sequence). The take method retrieves the number of elements specified by its argument. Here that value is 1, so it returns the first letter, which is made lowercase. The drop method returns the rest of the elements after the number in the argument is removed, which in this case means the rest of the string.
The result is that you can call the method on a string and convert it. 'FIRST_NAME' .toLowerCase() becomes 'firstName', and so on.
Welcome to the wonderful world of Groovy metaprogramming.
The advantages of groovy.sql.Sql over raw JDBC are obvious. If I have SQL code already written, I always use it.
1. The groovy.sql.Sql class makes working with raw SQL better in every way: resource management, multiline strings, closure support, and mapping of result sets to maps.
2. Related examples in this book can be found in chapter 7 on Spring and chapter 9 on REST.
5 Worst SQL Joke Ever Told: SQL query walks into a bar, selects two tables and says, “Mind if I join you?” (rimshot). (Warning: NoSQL version later in this chapter.)
Rather than write all that SQL, you can instead use one of the object-relational mapping (ORM) tools available, the most prevalent of which is still Hibernate. The Java Persistence API (JPA) specification acts as a front-end on ORM tools and is the subject of the next section.
8.3. The Java approach, part 2: Hibernate and JPA
One approach to simplifying JDBC is to automate as much of it as possible. The early years of Java saw attempts to add ORM tools directly to the specification, with varying degrees of success. First came Java Data Objects, which worked directly with compiled bytecodes and are largely forgotten today. Then came Enterprise JavaBeans (EJB) entity beans, which were viewed by the community as a mess in the first couple of versions.
As frequently happens when there’s a need and only an unpopular specification available, the open source community developed a practical alternative. In this case the project that emerged was called Hibernate, which still aims to be the ORM tool of choice in the Java world when dealing with relational databases.
In regular JDBC a ResultSet is connected to the data source as long as the connection is open, and goes away when the connection is closed. In the EJB world, therefore, you needed two classes to represent an entity: one that was always connected, and one that was never connected. The former was called something analogous to ProductEJB, and the latter was a ProductTO, or transfer object.[6] When getting a product from the database the ProductEJB held the data for a single row, and its data was transferred to a ProductTO for display. The transfer object wasn’t connected, so it could get stale, but at least it didn’t use up a database connection, which is a scarce commodity. Transferring the data from the EJB to the TO was done by a session EJB, where the transaction boundaries occurred. The session EJBs formed the service layer, which also held business logic. The whole process was much like that shown in figure 8.2.
6 Older terms included Data Transfer Object (DTO) and Value Object (VO).
Figure 8.2. Controllers contact transactional session EJBs, which acquire database data through entity EJBs. The data is copied to transfer objects and returned to the controller.
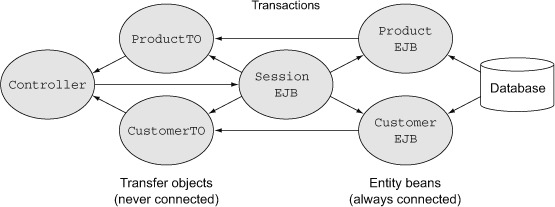
The result is that the ProductEJB class and the ProductTO class were essentially identical, in that they both contained the same method signatures, even though the implementations were different. Martin Fowler (author of Patterns of Enterprise Application Architecture [Addison-Wesley, 2002], Refactoring [Addision-Wesley, 1999], and several other books) calls that an anti-pattern and says that it’s a symptom of a flawed design.
One of the key differences between Hibernate and EJBs is the concept of a Hibernate session. The innovation was that, rather than one class of objects that were always connected and another class of objects that were never connected, what was needed was a set of objects that were sometimes connected and sometimes not. In Hibernate, when objects are part of a Hibernate session, the framework promises to keep them in sync with the database. When the session closes, the object is disconnected, thereby becoming its own transfer object. Any time an object is retrieved through Hibernate, it becomes part of a Hibernate session.
You retrieve a Hibernate session via a session factory. The session factory reads all the mapping metadata, configures the framework, and performs any necessary preprocessing. It’s supposed to be instantiated only once, acting as a singleton.
Those readers who are familiar with the Spring framework (as discussed in chapter 7) should suddenly become interested, because managing singletons is one of the things that Spring is all about. Another of its capabilities is declarative transaction management, which fits in nicely too. The result is that designs in the EJB 2.x world were replaced by a combination of Spring for the declarative transactions and the session factory and Hibernate for the entity beans.
In version 3 of EJB the architecture was redesigned again to fit more closely with that used by Spring and Hibernate. The entity beans part led to the creation of the Java Persistence API. The JPA world uses the same concepts but labels them differently.[7] The Hibernate Session becomes an EntityManager. The SessionFactory is an EntityManagerFactory. Objects that are managed (that is, in the Hibernate session) compose a persistence context.
7 Of course it does. Using the same terms would be too easy.
Finally, in the original Hibernate, mapping from entity classes to database tables was done through XML files. Over time XML has become less popular and has been replaced by annotations. Hibernate and JPA share many annotations, which is fortunate.
It’s time for an example, which will bring Spring, Hibernate, and JPA together. Chapter 7 on the Spring framework discusses Spring in some detail. Here I’ll just highlight the parts needed for the example.
To start I’ll need a database. For that I’ll use H2, a pure Java file- or memory-based database. Spring provides an embedded database bean to make it easy to work with H2. The relevant bean from the Spring configuration file is
<jdbc:embedded-database id="dataSource" type="H2">
<jdbc:script location="classpath:schema.sql"/>
<jdbc:script location="classpath:test-data.sql"/>
</jdbc:embedded-database>
The schema and test-data SQL files define a single table, called PRODUCT, with three rows:
create table PRODUCT (
id bigint generated by default as identity (start with 1),
name varchar(255), price double, primary key (id)
)
insert into PRODUCT(name, price) values('baseball', 5.99)
insert into PRODUCT(name, price) values('basketball', 10.99)
insert into PRODUCT(name, price) values('football', 7.99)
Spring provides a bean to represent the EntityManagerFactory, which has a handful of properties to set:
<bean id="entityManagerFactory" class=
"org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="persistenceUnitName" value="jpaDemo" />
<property name="packagesToScan">
<list>
<value>mjg</value>
</list>
</property>
<property name="jpaVendorAdapter">
<bean class=
"org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="database" value="H2" />
</bean>
</property>
</bean>
The LocalContainerEntityManagerFactoryBean[8] class uses the data source bean defined previously, scans the given packages for entities, and uses Hibernate as its implementation.
8 Extremely long class names are a Spring staple. My favorite is AbstractTransactional-Data-Source-Spring-ContextTests, which has 49 characters and is even deprecated. What’s yours?
The entity itself is the Product class, this time with a sprinkling of JPA (or Hibernate) annotations:
@Entity
public class Product {
@Id
private int id;
private String name;
private double price;
// ... constructors ...
// ... getters and setters ...
// ... toString, equals, hashCode ...
}
The @Entity and @Id annotations declare Product to be a class mapped to a database table and identify the primary key, respectively. Because, by an amazing coincidence,[9] the Product attribute names and the database column names happen to match, I don’t need the additional physical annotations like @Table and @Column.
9 Not really.
The ProductDAO interface is the same as that shown in section 8.1 on JDBC, except that now the insertProduct method returns the new database-generated primary key. The JpaProductDAO implementation class is where the action happens, and it’s shown in the next listing.
Listing 8.8. The JpaProductDAO class, which uses JPA classes to implement the DAO

The JPA implementation is wonderfully spare, but that’s because it assumes the transaction management is handled elsewhere and that Spring will handle allocating and closing the necessary database resources.
I would never be comfortable writing that much code without a decent test case. Spring’s test context framework manages the application context, allows the test fixture to be injected, and, if a transaction manager is supplied, automatically rolls back transactions at the end of each test.
To handle the transactions I used another Spring bean, JpaTransactionManager, which uses the entity manager factory previously specified:
<bean id="transactionManager"
class="org.springframework.orm.jpa.JpaTransactionManager"
p:entityManagerFactory-ref="entityManagerFactory" />
The resulting test case is shown in the following listing.
Listing 8.9. A Spring test case for the JPA DAO implementation
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations="classpath:applicationContext.xml")
@Transactional
public class JpaProductDAOTest {
@Autowired
private ProductDAO dao;
@Test
public void testFindById() {
Product p = dao.findProductById(1);
assertEquals("baseball", p.getName());
}
@Test
public void testGetAllProducts() {
List<Product> products = dao.getAllProducts();
assertEquals(3, products.size());
}
@Test
public void testInsert() {
Product p = new Product(99, "racketball", 7.99);
int id = dao.insertProduct(p);
Product p1 = dao.findProductById(id);
assertEquals("racketball", p1.getName());
}
@Test
public void testDelete() {
List<Product> products = dao.getAllProducts();
for (Product p : products) {
dao.deleteProduct(p.getId());
}
assertEquals(0, dao.getAllProducts().size());
}
}
The tests check each of the DAO methods. My favorite is testDelete, which deletes every row in the table, verifies that they’re gone, and doesn’t add them back in, which has the side effect of giving any DBAs heart palpitations. Fortunately, Spring rolls back all the changes when the test is finished, so nothing is lost, but a good time is had by all.
The last piece of the puzzle is the Maven build file. You can see it, as usual, in the book source code.
That’s a fair amount of code and configuration, and I’ve only got one class and one database table. Frankly, if I can’t make that work, I might as well give it up. It’s when you add relationships that life gets complicated.[10]
10 On many levels; sometimes the jokes just write themselves.
1. The Java Persistence API manages object-relational mapping providers that convert objects to table rows and back again.
2. Hibernate is the most common JPA provider in the industry.
3. ORM tools provide transitive persistence, persistence contexts, SQL code generation, and more.
4. Like all Java libraries, they’re still pretty verbose.
Groovy can help this situation in a couple of ways, which will be discussed in the next section.
8.4. The Groovy approach, part 2: Groovy and GORM
Before getting into the Grails Object-Relational Mapping (GORM) part of Grails, let me identify a couple of places where Groovy can simplify the example application from the previous section.
8.4.1. Groovy simplifications
The entity class Product could be written as a POGO. That wouldn’t change the behavior, but it would cut the size of the class by about two-thirds. That and the other Spring-related parts of the application could be converted to Groovy, which is shown in more detail in chapter 7 on Spring.
A Gradle build file is contained in the book source code. It looks like most of the build files shown in earlier chapters, but it’s considerably shorter and easier to read than the corresponding Maven build.
8.4.2. Grails Object-Relational Mapping (GORM)
The Grails framework consists of a set of Groovy DSLs on top of Spring and Hibernate. Because the combination of Spring and Hibernate is a very common architecture in the Java world, Grails is a natural evolution that simplifies the coding and integration issues.
Grails is discussed in more detail in chapter 10 on web applications, but the Hibernate integration part is relevant here. Grails combines Groovy domain-specific languages (DSLs) to make configuring the domain classes easy.
Domain Classes
In Grails the term domain is like entity in JPA. Domain classes map to database tables.
Consider a small but nontrivial domain model based on the same Product class used earlier in this chapter. The next listing shows the Product class, now in Groovy.
Listing 8.10. The Product class, this time as a POGO in a Grails application
class Product {
String name
double price
String toString() { name }
static constraints = {
name blank:false
price min:0.0d
}
}
In Grails each domain class implicitly has a primary key called id of some integer type, which isn’t shown here but exists nevertheless. The constraints block here is part of GORM.[11] Each line in the constraints block is actually a method call, where the name of the method is the attribute name. The blank constraint implies, naturally enough, that the name of the product can’t be an empty string. The price constraint sets a minimum value of 0, and the d makes it a double, because the constraint type must match the attribute data type.
11 The lizard creature that Captain Kirk fought in the Star Trek original series episode “Arena” was a Gorn, not a GORM. I mean, who ever heard of Grails Object-Relational Napping, anyway? (Though there’s probably a “lazy loading” joke in there somewhere.)
This application will have three more domain classes, representing customers, orders, and lines on the orders. Next up is the Customer class, shown in the next listing.
Listing 8.11. The Customer class. Customers have many orders (hopefully).

Customers have a name attribute and a Set representing their orders.
Grails hasmany
In Grails the hasMany property implies a one-to-many relationship. By default, the contained objects form a set.
The name cannot be blank. The Order class is shown in the following listing.
Listing 8.12. The Order class, which has many orders and belongs to a customer

There’s a lot going on here. First, an order contains a Set of order lines. Orders also belong to a specific customer. The customer reference implies that you can navigate from an order to its associated customer. By assigning it to the belongsTo property in this way, a cascade-delete relationship exists between the two classes. If a customer is deleted from the system, all of its orders are deleted as well.
Grails belongsto
In Grails, the word belongsTo implies a cascade-delete relationship.
The getPrice method computes the price of the order by summing up the prices on each order line. It too is a derived quantity and is therefore not saved in the database.
The dateCreated and lastUpdated properties are automatically maintained by Hibernate. When an order is first saved, its dateCreated value is set; and every time it’s modified, lastUpdated is saved as well.
Finally, the mapping block is used to customize how the class is mapped to a database table. By default, Grails will generate a table whose name matches the class name. Because the word order is an SQL keyword, the resulting DDL statement would have problems. In the mapping block the generated table name is specified to be orders, rather than order, to avoid that problem. Also, Hibernate treats all associations as lazy. In this case, that means that if an order is loaded, a separate SQL query will be required to load the order lines as well. In the mapping block, the fetch join relationship means that all the associated order lines will be loaded at the same time as the order, via an inner join.
The OrderLine class contains the product being ordered and the quantity, as shown in the following listing.
Listing 8.13. The OrderLine POGO, which is assembled to build an Order
class OrderLine {
Product product
int quantity
double getPrice() { quantity * product?.price }
static constraints = {
quantity min:0
}
}
The getPrice method multiplies the quantity times the price of the product to get the price of the order line. This, in turn, is summed in order to get the total price, as you saw earlier.
Note also that the OrderLine class does not have a reference to the Order it belongs to. This is a unidirectional cascade-delete relationship. If the order is deleted, all the order lines go, but you cannot navigate from an order line to its associated order.
When you declare a hasMany relationship, Grails then provides methods for adding the contained objects to their containers. To illustrate one of those methods, here’s the file BootStrap.groovy, which is a configuration file used in a Grails application for initialization code. The next listing shows code that instantiates a customer, two products, an order, and some order lines and saves them all to the database.
Listing 8.14. Initialization code in BootStrap.groovy
class BootStrap {
def init = { servletContext ->
if (!Product.findByName('baseball')) {
Product baseball =
new Product(name:'baseball', price:5.99).save()
Product football =
new Product(name:'football', price:12.99).save()
Customer cb = new Customer(name:'Charlie Brown').save()
Order o1 = new Order(number:'1', customer:cb)
.addToOrderLines(product:baseball, quantity:2)
.addToOrderLines(product:football, quantity:1)
.save()
}
}
def destroy = {
}
}
The code in the init closure is executed when the application is started. The addToOrderLines method comes from declaring that an Order has many OrderLine instances. The save method first validates each object against its constraints and then saves it to the database.
Grails uses Hibernate’s ability to generate a database schema. An entity relationship diagram (ERD) for the generated database is shown in figure 8.3.[12]
12 This diagram was generated using MySQL Workbench, which is a free tool available at www.mysql.com/products/workbench/.
Figure 8.3. An entity relationship diagram for the generated database, given the domain classes listed in the text
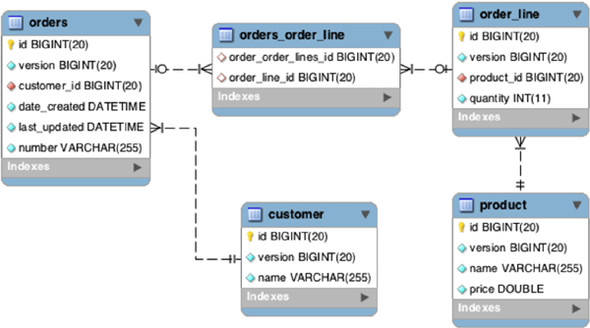
In this case the database is MySQL version 5, so the data type for id is BIGINT. It also converts the camel case properties dateCreated and lastUpdated into underscores in the table. Because the relationship between Order and OrderLine was unidirectional, Hibernate generates a join table between them called orders_order_line.
Grails also adds a column called version to each table. Hibernate uses this for optimistic locking. That means whenever a row of a table is modified and saved, Hibernate will automatically increment the version column by one. That’s an attempt to get locking behavior without actually locking a row and paying the resulting performance penalty. If the application involves many reads but only a few writes, this works well. If there are too many writes, Grails also adds an instance method called lock to each domain class that locks the row. That’s called pessimistic locking and will result in worse performance, so it’s only used when necessary.
Grails does far more than this. For example, Grails uses Groovy to generate dynamic finder methods for each domain class. For the Product class, Grails generates static methods on the domain class that include
- Product.list(), which returns all product instances
- Product.findByName(...), which returns the first product matching the name
- Product.findAllByPriceGreaterThan(...), which returns all the products whose prices are greater than the argument
- Product.findAllByNameIlikeAndPriceGreaterThan(...,...), which returns products whose names satisfy a case-insensitive SQL like clause and which have prices greater than the second argument
There are many more; see the Grails documentation[13] for details. In each case Grails uses the mappings to generate SQL code satisfying the desired conditions.
13 See http://grails.org/doc/latest/ for the Grails documentation. Chapter 6 in those docs discusses GORM in detail.
Grails also uses Groovy to provide a builder for criteria queries. Hibernate has an API for criteria queries that allows you to build up a query programmatically. The Java API works but is still quite verbose. Grails dramatically simplifies it so that you can write expressions like this:
Product.withCriteria {
like('name','%e%')
between('price', 2.50, 10.00)
order('price','desc')
maxResults(10)
}
This generates an SQL statement to find all products whose names include the letter e and whose prices are between $2.50 and $10.00. It returns the first 10 matching products in descending order by price.
One of the fundamental principles in Hibernate is the concept of a Hibernate session. As stated in the previous section, Hibernate ensures that any object inside a Hibernate session (what JPA calls a persistence context) will be kept in sync with the database. In Hibernate, objects can be in one of three states,[14] as shown in figure 8.4.
14 The Hibernate docs defining the states can be found at http://mng.bz/Q9Ry.
Figure 8.4. New and deleted objects are transient. When they are saved they become persistent, and when the session closes they become detached. Knowing the state of an object is key to understanding how it works in Hibernate.
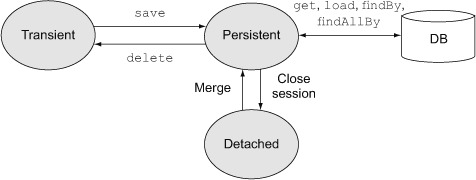
Any object retrieved through Hibernate—for example, by using one of the dynamic finders or criteria queries—is placed in the persistent state and will stay in sync with the database while it remains in that state. Newly created objects that have not yet been saved are transient, and objects that are in memory when the Hibernate session is closed are then detached. Detached objects are no longer connected to the database.
The key question is, when is the Hibernate session created, and when is it closed? Over time a common practice has been established to scope the session to a single HTTP request. This is known in the Hibernate literature as the Open Session in View (OSIV) pattern, and it’s implemented through a request interceptor. The Spring framework comes with a library class to do this automatically, which Grails uses by default.
OSIV Bean
Grails uses an OSIV bean from Spring to scope the Hibernate session to each HTTP request. The bean intercepts incoming requests and creates the session, and then it intercepts the outgoing responses and closes the session.
Finally, transactions are managed using Spring’s declarative transaction capabilities, using the @Transactional annotation. All Grails service methods are transactional by default, but their behavior can be customized using the annotation.
Setting up all this infrastructure—managing the sessions and transactions, mapping domain classes to tables, establishing relationships, handling optimistic locking, generating dynamic finders and criteria queries, and scoping the Hibernate session to each request—requires a lot of work when putting Spring and Hibernate together manually. Grails does all of this for you, and much more besides.
The Spring framework is one of the most common open source projects in all of Java, and Hibernate is still the most common ORM tool. Any project considering using them together owes it to itself to consider using Grails.
1. Groovy simplifies all database access by using POGOs instead of POJOs, using closures for result set processing, and making building and testing easier.
2. The GORM API makes configuring Hibernate-based applications easy. When combined with Spring (as in Grails), transactions and the Hibernate session become simple, too.
3. It’s not so easy to use GORM outside of Grails, which is tightly tied to Spring. Trying to do so is rare enough in the industry that the process wasn’t covered in this chapter.
Recent versions of Grails can also map to non-relational databases, but you can also use regular Groovy to do that, as the next section shows.
8.5. Groovy and NoSQL databases
One of the most interesting trends in software development in the past few years[15] has been the growth of alternative, non-relational databases. The generic term NoSQL (which the majority of the community interpret as “Not Only SQL”) refers to a range of schema-less databases that are not based on relational approaches.
15 Other than the rise of dynamic languages on the JVM, of course.
The subject of NoSQL databases is already large and rapidly growing, and it’s well beyond the scope of this book. But many of the databases have a Java API, and some of them also have Groovy wrappers that simplify them.
One of the most interesting is MongoDB,[16] whose Java API is rather awkward but is dramatically improved through a Groovy wrapper called GMongo. The GMongo project, whose GitHub repository is located at https://github.com/poiati/gmongo, is the product of Paulo Poiati and is the subject of this section.
16 See www.mongodb.org/ for downloads and documentation.
MongoDB is a document-oriented database that stores its data in binary JSON (BSON) format. This makes it perfect for storing data downloaded from RESTful web services, which often produce JSON data on request.
8.5.1. Populating Groovy vampires
This example came about because I was wandering in a bookstore recently and noticed that while there was only one bookshelf labeled “Computer,” there were three others labeled “Teen Paranormal Romance.” Rather than lament the decline of Western Civilization I chose to take this as evidence that I needed to add Groovy vampires to my book.
Consider the web service provided by the movie review site Rotten Tomatoes, http://developer.rottentomatoes.com. If you register for an API key, you can make HTTP GET requests that search for movies, cast members, and more. The data is returned in JSON form. The base URL for the API is located at http://api.rottentomatoes.com/api/public/v1.0. All requests start with that URL.
For example, searching for information about the movie Blazing Saddles[17] is done by accessing http://api.rottentomatoes.com/api/public/v1.0/movies.json?q=Blazing%20Saddles&apiKey=... (supply the API key in the URL). The result is a JSON object that looks like the following listing.
17 That’s not a vampire movie, obviously, but the urge to save Mongo in MongoDB is irresistible. “Mongo only pawn in game of life” is a brilliant line and arguably the peak of the Alex Karras oeuvre.
Listing 8.15. A portion of the JSON object representing the movie Blazing Saddles
{
"total": 1,
"movies": [
{
"id": "13581",
"title": "Blazing Saddles",
"year": 1974,
"mpaa_rating": "R",
"runtime": 93,
"release_dates": {
"theater": "1974-02-07",
"dvd": "1997-08-27"
},
"ratings": {
"critics_rating": "Certified Fresh",
"critics_score": 89,
"audience_rating": "Upright",
"audience_score": 89
},
"synopsis": "",
...,
"abridged_cast": [
{
"name": "Cleavon Little",
"id": "162693977",
"characters": [
"Bart"
]
},
{
"name": "Gene Wilder",
"id": "162658425",
"characters": [
"Jim the Waco Kid"
]
},
...
],
"alternate_ids": {
"imdb": "0071230"
},
...
}
In addition to the data shown, the JSON object also has links to the complete cast list, reviews, and more. Another reason to use a database like MongoDB for this data is that not every field appears in each movie. For example, some movies contain a critic’s score and some do not. This fits with the whole idea of a schema-less database based on JSON.
First, to populate the MongoDB I’ll use an instance of the com.gmongo.GMongo class. This class wraps the Java API directly. In fact, if you look at the class in GMongo.groovy, you’ll see that it consists of
class GMongo {
@Delegate
Mongo mongo
// ... Constructors and other methods ...
}
There follow various constructors and simple patch methods. The @Delegate annotation from Groovy is an Abstract Syntax Tree (AST) transformation[18] that exposes the methods in the com.mongodb.Mongo class, which comes from the Java API, through GMongo. The AST transformation means you don’t need to write all the delegate methods by hand.
18 Discussed in chapter 4 on integration and in appendix B, “Groovy by feature,” and used in many other places in this book.
Initializing a database is as simple as
GMongo mongo = new GMongo()
def db = mongo.getDB('movies')
db.vampireMovies.drop()
MongoDB uses movies as the name of the database, and collections inside it, like vampireMovies, are properties of the database. The drop method clears the collection.
Searching Rotten Tomatoes consists of building a GET request with the proper parameters. In this case, the following code searches for vampire movies:
String key = new File('mjg/rotten_tomatoes_apiKey.txt').text
String base = "http://api.rottentomatoes.com/api/public/v1.0/movies.json?"
String qs = [apiKey:key, q:'vampire'].collect { it }.join('&')
String url = "$base$qs"
The API key is stored in an external file. Building the query string starts with a map of parameters, which is transformed into a map of strings of the form “key=value” and then joined with an ampersand. The full URL is then the base URL with an appended query string. Getting the movies and saving them into the database is almost trivial:
def vampMovies = new JsonSlurper().parseText(url.toURL().text) db.vampireMovies << vampMovies.movies
The JsonSlurper receives text data in JSON form from the URL and converts it to JSON objects. Saving the results into the database is as simple as appending the whole collection.
The API has a limit of 30 results per page. The search results include a property called next that points to the next available page, assuming there is one. The script therefore needs to loop that many times to retrieve the available data:
def next = vampMovies?.links?.next
while (next) {
println next
vampMovies = slurper.parseText("$next&apiKey=$key".toURL().text)
db.vampireMovies << vampMovies.movies
next = vampMovies?.links?.next
}
That’s all there is to it. Using a relational database would require mapping the movie structure to relational tables, which would be a bit of a challenge. Because MongoDB uses BSON as its native format, even a collection of JSON objects can be added with no work at all.
There’s an Eclipse plugin, called MonjaDB, which connects to MongoDB databases. Figure 8.5 shows a portion of the vampireMovies database.
Figure 8.5. A portion of the vampire movies database, using the MonjaDB plugin for Eclipse

8.5.2. Querying and mapping MongoDB data
Now that the data is in the database I need to be able to search it and examine the results. This can be done in a trivial fashion, using the find method, or the data can be mapped to Groovy objects for later processing.
The find method on the collection returns all JSON objects satisfying a particular condition. If all I want is to see how many elements are in the collection, the following suffices:
println db.vampireMovies.find().count()
With no arguments, the find method returns the entire collection. The count method then returns the total number.
Mapping JSON to Groovy brings home the difference between a strongly typed language, like Groovy, and a weakly typed language, like JSON. The JSON data shown is a mix of strings, dates, integers, and enumerated values, but the JSON object has no embedded type information. Mapping this to a set of Groovy objects takes some work.
For example, the following listing shows a Movie class that holds the data in the JSON object.
Listing 8.16. Movie.groovy, which wraps the JSON data
@ToString(includeNames=true)
class Movie {
long id
String title
int year
MPAARating mpaaRating
int runtime
String criticsConsensus
Map releaseDates = [:]
Map<String, Rating> ratings = [:]
String synopsis
Map posters = [:]
List<CastMember> abridgedCast = []
Map links = [:]
}
The Movie class has attributes for each contained element, with the data types specified. It contains maps for the release dates, posters, ratings, and additional links, and a list for the abridged cast. A CastMember is just a POGO:
class CastMember {
String name
long id
List<String> characters = []
}
A Rating holds a string and an integer:
class Rating {
String rating
int score
}
Just to keep things interesting, the MPAA rating is a Java enum, though it could just as easily have been implemented in Groovy:
public enum MPAARating {
G, PG, PG_13, R, X, NC_17, Unrated
}
Converting a JSON movie to a Movie instance is done through a static method in the Movie class. A portion of the fromJSON method is shown in the next listing.
Listing 8.17. A portion of the method that converts JSON movies to Movie instances
static Movie fromJSON(data) {
Movie m = new Movie()
m.id = data.id.toLong()
m.title = data.title
m.year = data.year.toInteger()
switch (data.mpaa_rating) {
case 'PG-13' : m.mpaaRating = MPAARating.PG_13; break
case 'NC-17' : m.mpaaRating = MPAARating.NC_17; break
default :
m.mpaaRating = MPAARating.valueOf(data.mpaa_rating)
}
m.runtime = data.runtime
m.criticsConsensus = data.critics_consensus ?: ''
The complete listing can be found in the book source code but isn’t fundamentally different from what’s being shown here.
A test to prove the conversion is working is shown in the following listing.
Listing 8.18. A JUnit test to verify the JSON conversion
1. NoSQL databases like MongoDB, Neo4J, and Redis are becoming quite common for specific use cases.
2. Most NoSQL databases make a Java-based API available, which can be called directly from Groovy.
3. Often a Groovy library will be available that wraps the Java API and simplifies it. Here, GMongo is used as an example.
19 NoSQL version of Worst SQL Joke Ever Told: DBA walks into a NoSQL bar; can’t find a table, so he leaves.
Once the mapping works, finding all vampire movies that have a critic’s consensus is as simple as the following script:
GMongo mongo = new GMongo()
def db = mongo.getDB('movies')
db.vampireMovies.find([critics_consensus : ~/.*/]).each { movie ->
println Movie.fromJSON(movie)
}
It’s hard to be much simpler than that. Working with MongoDB[20] is just as easy as using a traditional relational database.[21]
20 A detailed treatment of MongoDB is contained in the book MongoDB in Action (Manning, 2011) by Kyle Banker: www.manning.com/banker/.
21 For some reason, none of the Twilight movies were returned from the “vampire” query. I thought about fixing that, and ultimately decided it wasn’t a bug, but a feature.
8.6. Summary
Virtually every significant application requires persistent data. The vast majority of those are based on relational databases. In the Java world, relational persistence uses either JDBC or an object-relational mapping tool like Hibernate or JPA. This chapter reviewed both approaches and examined how Groovy can simplify them.
The Groovy Sql class removes most of the clutter that accompanies raw JDBC. Any code that uses JDBC directly can be significantly simplified using the Sql class.
Many modern applications use JPA for persistence, especially with Hibernate as the underlying API and the Spring framework to handle singletons and transactions. Just configuring such an application is a nontrivial task. On the other hand, the Grails framework handles all of it elegantly and with a minimum of effort.
Finally, many so-called NoSQL databases have a Java API. Some, like MongoDB, include a Groovy wrapper that makes working with the underlying databases simple.