
Chapter 1
TOWARD A COMPARATE DATA RESOURCE
Only a comparate data resource fully supports the business.
The discussion of data resource integration must begin with an explanation of the existing disparate data resource in an organization and what’s needed to develop a comparate data resource. Chapter 1 briefly summarizes Chapters 1, and 2 from Data Resource Simplexity. Chapter 1 is a review only, and if more detail is needed, the reader should consult Data Resource Simplexity. Some additional material has been added based on comments received, and additional terms have been defined. A common approach to resolving disparity is presented, which includes a Common Data Architecture and a Common Data Culture.
RAMPANT DATA DISPARITY
The data resource in most public and private sector organizations is in a state of complete disarray. The data resource does not conform to any consistent organization-wide data architecture. It is seldom maintained by any formal set of concepts, principles, and techniques. It is seldom managed with the same intensity as other critical organization resources.
The Business Information Demand
An organization represents any administrative and functional structure for conducting some form of business, such as a public sector organization, quasi-public sector organization, private sector organization, association, society, foundation, and so on, however large or small, whether for profit or not for profit, and for however long it has been operating. The term organization will be used throughout the book. The term enterprise will not be used because of its private sector and profit centric meaning.
Every organization has a dynamic demand for information to support the business. The business information demand is an organization’s continuously increasing, constantly changing, need for current, accurate, integrated information, often on short notice or very short notice, to support its business activities. It is a very dynamic demand for information to support a business that constantly changes.
I’ve received several questions about what is meant by business. What about science, or recreation, or other areas that are not viewed as a true business? The business is in the eyes of the beholder, and is not necessarily just a for-profit business in the private sector. The business is what an organization is accomplishing, regardless of the organizational objectives.
The problem in most public and private sector organizations today is that the business information demand is not being supported by the data resource, or is not being fully supported to the organization’s satisfaction.
What seems to have happened is that people forgot the basic principles of data resource management and are forging ahead without a solid foundation. The basic theories relevant to data resource management are set theory, graph theory, normalization theory, relational theory, dependency theory, communication theory, semiotic theory, and so on. Specific concepts and principles for data resource management are based on these theories. The specific concepts and principles would have led to development of a data resource that fully supported an organization’s business information demand had they been followed.
Data processing as we know it today began back in the mid-20th Century. It evolved from hand-kept records, to punch cards, to magnetic tape, to larger and more powerful computers, to the information technology that we have today. While considerable discussion abounds about whether that evolution has been beneficial and cost effective to the business, that evolution has occurred and organizations are living with the results.
Prominent people, such as Claude Shannon, Edgar F. ‘Ted’ Codd, Peter Chen, John Zachman, and others, have contributed substantially to the basic principles for properly managing data as a critical resource of the organization. James Martin and others promoted canonical synthesis in the 1960’s and 1970’s. If organizations had followed the canons of data management, the resulting individual data models would readily connect to form a seamless data architecture for the organization. However, the canons were not complete and, even if enhanced by an organization, were seldom followed. The result is a major contribution to the creation of disparate data.
Several years ago I gave a seminar to a class of university students completing their Master’s program in information management. They were astounded to hear many of the topics I presented. I asked for a show of hands from the students that were well versed in the basic theories, concepts, and principles I presented. No hands went up—and they are at the end of a Master’s program! The students immediately turned on the professor wanting to know why these basic theories, concepts, and principles were not being taught.
The Y2K panic of the late 1990s should have been an alert to the pending problems with data resource management. However, the panic ended, very few problems occurred, and organizations moved on to their traditional data resource management feeling they successfully averted a major crisis, confirming that their data resource management practices were acceptable.
The millennium date problem is not the end. What about other monetary units, such as the European monetary unit? What if phone numbers added digits to become a 3-4-4 or a 4-4-4 number, or became alpha-numeric? What if the metric conversion were enforced? What if the Social Security Number added a digit? Can any of these situations be successfully handled?
Lexical Challenge
Information technology in general, and data resource management in particular, have a major lexical challenge. Words and terms are created, often used interchangeably, misused, abused, corrupted, and discarded without regard for the real meaning or any impact on the business. Words and terms often have no definitions, minimal definitions, poor definitions, conflicting definitions, unclear definitions, or multiple definitions. Many words and terms have been defined and redefined to the point they are meaningless. Many synonyms and homonyms have been created, adding to the problem. As a result, the data management profession today is lexically weak.
I recently heard an interesting statement when I was at an event. The promoter of a business was extolling the features of their business. In his pitch he said that their business operated 24–7–365. I thought about that for a minute and wondered if he really meant their business would be around for seven years. I’m sure he meant either 24–365 or 24–7–52. I was going to question him, but he was so into pumping words that I decided not to interrupt.
The lexical challenge is not unique to data management. I do considerable outside reading and watch numerous documentary programs. I heard one program discuss the geology of the Moon and another program discuss the geology of Mars. I thought that interesting because geology comes from geo logos, meaning Earth study. In other words, geology is a study of the Earth. Therefore, the term geology of the Moon would literally mean study of the Earth of the Moon, which doesn’t make much sense. The true words would be lunology for study of the Moon and aerology for the study of Mars.
To help resolve the lexical challenge and promote a lexically rich data management profession, proper words and terms are presented, comprehensively defined to provide a denotative meaning, and used consistently throughout the book.
Data
Data are the individual facts that are out of context, have no meaning, and are difficult to understand. They are often referred to as raw data, such as 123.45. Data have historically been defined as plural.
Data in context are individual facts that have meaning and can be readily understood. They are the raw facts wrapped with meaning, such as 123.45 is the checking account balance at a point in time. However, data in context are not yet information.
A resource is a source of supply or support; an available means; a natural source of wealth or revenue; a source of information or expertise; something to which one has recourse in difficulty; a possibility of relief or recovery; or an ability to meet and handle a situation.
A data resource is a collection of data (facts), within a specific scope, that are of importance to the organization. It is one of the four critical resources in an organization, equivalent to the financial resource, the human resource, and real property. The term is singular, such as the organization data resource, the student data resource, or the environmental data resource. The data resource must be managed equivalent to the other three critical resources.
Data resource management is the formal management of the entire data resource at an organization’s disposal, as a critical resource of the organization, equivalent to the human resource, financial resource, and real property, based on established concepts, principles, and techniques, leading to a comparate data resource that supports the current and future business information demand.
Information
Information is a set of data in context, with relevance to one or more people at a point in time or for a period of time. Information is more than data in context—it must have relevance and a time frame. Information has historically been defined as singular.
Information management is coordinating the need for information across the organization to ensure adequate support for the current and future business information demand. It should not be confused with data resource management.
Knowledge
Knowledge is cognizance, cognition, the fact or condition of knowing something with familiarity gained through experience or association. It’s the acquaintance with or the understanding of something, the fact or condition of being aware of something, or apprehending truth or fact. Knowledge is information that has been retained with an understanding about the significance of that information. Knowledge includes something gained by experience, study, familiarity, association, awareness, and/or comprehension.
Tacit knowledge, also known as implicit knowledge, is the knowledge that a person retains in their mind. It’s relatively hard to transfer to others and to disseminate widely. Explicit knowledge, also known as formal knowledge, is knowledge that has been codified and stored in various media, such as books, magazines, tapes, presentations, and so on, and is held for mankind, such as in a reference library or on the web. It is readily transferable to other media and capable of being disseminated.
Organizational knowledge is information that is of significance to the organization, is combined with experience and understanding, and is retained by the organization. It’s information in context with respect to understanding what is relevant and significant to a business issue or business topic—what is meaningful to the business. It’s analysis, reflection, and synthesis about what information means to the business and how it can be used. It’s a rational interpretation of information that leads to business intelligence.
Knowledge management is the management of an environment where people generate tacit knowledge, render it into explicit knowledge, and feed it back to the organization. The cycle forms a base for more tacit knowledge, which keeps the cycle going in an intelligent learning organization. It’s an emerging set of policies, organizational structures, procedures, applications, and technology aimed toward increased innovation and improved decisions. It’s an integrated approach to identifying, sharing, and evaluating an organization’s information. It’s a culture for learning where people are encouraged to share information and best practices to solve business problems.
Disparate Data
Disparate means fundamentally distinct or different in kind; entirely dissimilar. Disparate data are data that are essentially not alike, or are distinctly different in kind, quality, or character. They are unequal and cannot be readily integrated to meet the business information demand. They are low quality, defective, discordant, ambiguous, heterogeneous data. Massively disparate data is the existence of large quantities of disparate data within a large organization, or across many organizations involved in similar business activities.
A disparate data resource is a data resource that is substantially composed of disparate data that are dis-integrated and not subject- oriented. It is in a state of disarray, where the low quality does not, and cannot, adequately support an organization’s business information demand.
I’ve encountered some naysayers since Data Resource Simplexity was published. One complained that comparate was not a recognized word, and by creating it, I was adding to the lexical challenge. Well, I did find comparate in one of those large dictionaries sitting on a pedestal in a library, so it is a recognized word. Also, comparate helps resolve the lexical challenge because it doesn’t carry any connotative meanings. I define it and use it consistently to help resolve the lexical challenge.
Another naysayer said that simplexity was not a real word and added to the lexical challenge. Again, Simplexity is the title of an excellent book by Jeffrey Kluger. The concept he presented was so powerful that I decided to adopt that concept and apply it to data resource management. Like comparate, simplexity carries no connotative meanings. I define it and use it consistently to help resolve the lexical challenge.
Structured Data
Structured means something arranged in a definite pattern of organization; manner of construction; the arrangement of particles or parts in a substrate or body, arrangement or interrelation of parts as dominated by the general character of the whole; the aggregate of elements of an entity in their relationships to each other; the composition of conscious experience with its elements and their composition.
Structured data are data that are structured according to traditional database management systems with tables, rows, and columns that are readily accessible with a structured query language. Structured data are considered tabular data.
Unstructured means not structured, having few formal requirements, or not having a patterned organization; without structure, having no structure, or structureless. Unstructured data are data that are not structured, have few formal requirements, or do not have a patterned organization. Use of the term unstructured data is most inappropriate, and will not be used.
In Data Resource Simplexity I established the term super-structured data to replace unstructured data, and justified the change. The comments I received were very positive, because people realized that unstructured data was the wrong term and another more accurate term was needed. However, the comments were negative because the term super-structured was easily confused with the term superstructure. Superstructure means a vertical extension of something above a base, such as the superstructure of a battleship, and has no meaning with respect to the data resource.
After looking at a variety of terms that represent an intricate interweaving of multiple structures, I’ve settled on a better term. Complex means composed of two or more parts; having a bound form; hard to separate, analyze, or solve; a whole made up of complicated or interrelated parts; a composite made up of distinct parts; intricate as having many complexly interrelating parts or elements.
Complex structured data are any data that are composed of two or more intricate, complicated, and interrelated parts that cannot be easily interpreted by structured query languages and tools. The complex structure needs to be broken down into the individual component structures to be more easily analyzed. Complex structured data include text, voice, video, images, spatial data, and so on. Therefore, I now use the sequence unstructured data, structured data, highly structured data, and complex structured data.
I’ve recently run across the terms poly-structured data and multi-structured data. However, those terms are used in reference to database management systems. They are not used in reference to an organization’s entire data resource, including data within and without a database management system.
The terms represent complex structured data that have been broken down into simpler structures that can be handled in database management system. Hence, the complex structure of the data is managed as various sub-structures that comprise that complex structure. However, used in that context, the terms do not adequately represent the very intricate structure that can be found in an organization’s data resource, both within and without database management systems.
People ask me what is perpetuating the lexical challenge in data resource management. People are simply pumping the words without realizing what they are saying, or what the words really mean. Data management professionals need to stop pumping words and terms without understanding their true meaning. They need to start using words and terms that are well defined and are used consistently. That’s the only way to resolve the lexical challenge.
More on Information
Information was defined above. However, some people have different perceptions of information. One perception is that information is the same as data in context. Whenever raw data are wrapped with meaning, those data become information.
However, if information is considered to be data in context, then what is the term for information that is relevant and timely? That might lead to relevant information and non-relevant information. Now two hierarchies exist, as shown below.
Data – Data in context – Information – Knowledge
Data – Relevant information / Non-relevant information – Knowledge
The problem with the second hierarchy is that non-relevant information does not contribute to knowledge. The result is that the lexical challenge is not resolved. Therefore, the first hierarchy is the proper definition, and the one that will be used throughout the book.
Another perception is that information is any summary data or derived data. The perception is not valid because whether data are primitive or derived, they are still data. They have not yet become relevant or timely and are not yet information. The distinction will become clear as a disparate data resource is understood and resolved.
If data in context are not relevant or timely, then they are not information. However, the data may not be relevant to a specific individual at the current time, but could be relevant to someone at some time. Tide tables are a good example. If you are going sailing in Puget Sound and someone gives you tide tables for Nantucket, you would say that’s not information because it’s not relevant. However, those tide tables could be relevant to someone going sailing on the East Coast.
Therefore, the definition of information can be expanded. Specific information is a set of data in context that is relevant to a person at a point in time or for a period of time. General information is a set of data in context that could be relevant to one or more people at a point in time or for a period of time.
Information overload is a misused term and is part of the lexical challenge. The term will not be used in the current book. Several terms can be used to replace information overload.
Information assimilation overload occurs when information is coming too fast for a person to take in and understand. A certain amount of time is needed for information to be assimilated, and the delivery needs to match that assimilation.
Disparate information is any information that is disparate with respect to the recipient. It could result from information acquired from different sources that are organized differently, or it could result from information created from disparate data that provide conflicting information. In other words, disparate information could be disorganized information or it could be conflicting information.
Sorting through disparate information to organize that information or find the correct information is not information assimilation overload. It’s a processing overload to organize the disparate information into a form appropriate to the recipient.
Information paranoia is the fear of not knowing everything that is relevant or could be relevant at some point in time. It’s a situation where a person is obsessed with gaining information for information’s sake.
Non-information is a set of data in context that is not relevant or timely to the recipient. It is neither specific information nor general information.
Information sharing is the sharing of information between people and organizations according to the definition of information. For example, several jurisdictions may create a task force for a major criminal activity. The task force meets and shares the information each jurisdiction has about the criminal activity. The material shared is timely and relevant, and qualifies as information sharing.
Data overload is a deluge of data or data in context coming at a recipient, but it is not relevant and timely. It’s a deluge of non-information that is not wanted by the recipient. It’s not information assimilation overload.
Data Are Plural
I made a strong case in Data Resource Simplexity that the term data is plural. Since then, I’ve received many comments about whether data should be singular or plural. Traditionally, data has been plural equivalent to facts, and datum has been singular equivalent to a fact. However, current usage seems to accept data as singular, although I’ve seen no good, denotative definition of data in the singular form.
The most common comment I hear is ‘data are’ just doesn’t sound right. That’s a poor excuse for considering data as singular. Saying a data is easy to manage is like saying people is easy to manage. Other phrases using data in the singular are equally confusing.
One approach to resolving the problem is to consider data an irregular noun like deer or sheep where the meaning is in the context. In other words, data can be used in either the singular or plural form depending on the context. In the singular form, data represents an individual fact similar to the traditional datum. In the plural form, data represents a collection of facts and datum is the singular form. However, the data management profession has enough confusion without treating data as an irregular noun.
I often ask people to provide a comprehensive, denotative definition of data in the singular by completing the phrase Data is … I have very few responses, and the responses I do receive are really definitions of the data resource rather than data. Therefore, data will be used as plural throughout the book to emphasize that the data resource contains many data (facts) about the business that are important to the operation and evaluation of the business. Datum will be used as the singular of data.
Data Are a Resource
I made a strong case in Data Resource Simplexity that data are managed as a resource of the organization, and not as an asset of the organization. I’ve had a number of discussions with data management professionals who claim, some rather adamantly, that data are an asset. The reason seems to be that if data are considered an asset, then somehow, almost automatically, they will be managed properly. That reason alone implies, or is even an admission, that data are not properly managed, and will only be properly managed if they are considered an asset.
Any item or resource is only considered an asset or a durable asset when it appears on the General Ledger or Chart of Accounts for an organization. CFOs place things on the General Ledger or Chart of Accounts when they consider those things to be an asset of the organization. The determination is made by a CFO, not by data management professionals.
When a data management professional declares or demands that data are an asset, then one should ask the organization’s CFO if data are listed on the General Ledger or Chart of Accounts. In the vast majority of organizations, data are not listed. Hence, data are not viewed by the CFO as an asset of the organization. Many executives and managers actually consider the data resource to be a liability rather than an asset because of the disparity.
The attitude that if they (CFOs) consider the data as an asset, then we (data management professionals) will properly manage those data just has to cease. Data management professionals have a very long way to go to stop the burgeoning data disparity and resolve the existing data disparity before the data resource can be considered properly managed. Data management professionals have to earn the right for data to be considered an asset of the organization.
The best approach in most organizations, and the approach I use, is to consider data as a critical resource of the organization. Then properly manage that critical data resource so well that it fully supports the current and future business information demand and is considered to be a real asset to the organization by the CFO.
Information and Knowledge Storage
When specific or general information is stored, it becomes part of the data resource, it is treated as data, and is managed like any other data. Those data will only become information again when they become relevant and timely. The same is true for knowledge. Stored knowledge becomes data and is managed like any other data. Those data will only become knowledge again when they are extracted as information, combined with experience, and retained.
A book on a shelf, a document on a server, raw data, a stored form or document, a stored report, and so on, are all considered data and managed as part of the organization’s data resource. The documentation of information or knowledge is still data to other people, and may become information or knowledge to those people.
Looking at the situation the other way around, all information and knowledge were data at one time. By becoming relevant and timely, those data became information. By being combined with business experience and retained, that information became knowledge. Therefore, no information resource or knowledge resource exists with respect to stored information and knowledge.
The data-information-knowledge cycle is the cycle from data, to data in context, to specific or general information, to knowledge, and back to data when stored, as shown in Figure 1.1.
I don’t want to belabor the issue, but when information and knowledge are stored, they become part of the organization’s data resource and are managed according to formal data resource management concepts, principles, and techniques. Whether those data were once raw data, specific or general information, or knowledge makes no difference. Everything stored is part of the data resource, is considered data, and is formally managed as data.
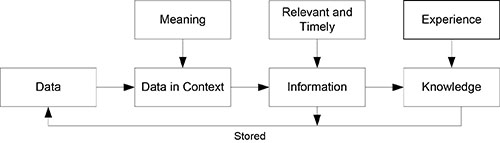
Figure 1.1. The data–information–knowledge cycle.
As the process of data resource integration is unfolded, the reason for considering stored information and knowledge as data in the organization’s data resource will become clear.
Basic Problems
A disparate data resource exists for many specific reasons. A whole book could be written about the specific reasons for disparate data. I never cease to be amazed at how ingenious people can be at screwing up a data resource. Just when I think I’ve seen it all, I run across yet another way that people have used to create disparate data.
The multitude of reasons for the creation of disparate data can be grouped into four basic problems. These are the basic problems that need to be prevented to stop further creation of disparate data, and resolved to integrate existing disparate data into a comparate data resource.
Lack of Awareness
The first basic problem is that the organization at large is not aware of all the data, within or without the organization, that are at their disposal. Organizations seldom have a complete inventory of all data within the organization, and are less likely to have an inventory of data available from outside the organization. Individuals within the organization often know the data that are available for their business activities, but are not aware of all the data available to the organization.
The lack of a formal data inventory leads to a huge hidden data resource that could be available to the organization. That hidden data resource contains dormant data that could be used by the organization. Not being able to use those dormant data leads to hidden information about the business, which leads to hidden knowledge. The result is a failure to fully support the business information demand.
Lack of Understanding
The second basic problem is that organizations have a general lack of thorough understanding about the data available in their data resource. Even if a complete, current, detailed inventory of all data available to the organization were maintained, the organization at large still lacks a thorough understanding of those data. A few individuals may thoroughly understand a small subset of the data they routinely use, but the organization lacks a widespread, common understanding of all the data in their data resource.
Some people claim that it’s not necessary for everyone in the organization to understand all of the data. But, that’s not the point. The point is that people need to understand the existing data well enough to not create additional disparate data. All data need to be documented to the extent that anyone in the organization can readily understand those data when the need arises.
High Data Redundancy
The third basic problem is that data in the existing data resource are highly redundant. The same business fact has been independently captured and stored in multiple locations in the organization’s data resource. Data redundancy is the unknown and unmanaged duplication of business facts in a disparate data resource. The data redundancy factor is the number of sources for a single business fact in an organization’s data resource.
Data redundancy should not be confused with data replication. Data replication is the consistent copying of data from one primary data site to one or more secondary data sites. The copied data are kept in synch with the primary data on a regular basis.
High Data Variability
The fourth basic problem is a high variability in the format and content of disparate data. The format can vary across databases, reports, screens, documents, and forms. The format and content may change from one data file to another and from one data record to another within the same data file.
Data variability is the variation in format and content of a redundant fact stored in a disparate data resource. The data variability factor is the number of variations in format or content for a single business fact.
Disparate Data Trends
Several prominent trends contribute to development of a disparate data resource, including the disparate data cycle, the natural data resource drift of the data resource toward disparity, the data resource spiral, data deluge, Malthusian Principle, the data dilemma that organizations face, and disparate data shock. Each of these trends is summarized below. A more detailed description can be found in Data Resource Simplexity.
Disparate Data Cycle
The disparate data cycle is a self-perpetuating cycle where disparate data continue to be produced at an ever-increasing rate because people do not know about existing data or do not want to use existing data. People come to the data resource, but can’t find the data they need, don’t trust the data, or can’t access the data. These people create their own data, which perpetuates the disparate data cycle. The next people that come to the data resource find the same situation, and the cycle keeps going.
Data Resource Drift
Data resource drift is the natural, steady drift of a data resource towards disparity if its development is not properly managed and controlled. The natural drift is toward a disparate, low quality, complex data resource. The longer the drift is allowed to continue, the more difficult it will be to achieve a comparate data resource. The natural drift is continuing unchecked in most public and private sector organizations today, and will continue until organizations consciously alter that natural drift.
Disparate Data Spiral
The evolution of data disparity from traditional operational data into new technologies, such as spatial data, data analytics, complex structured data, and so on, creates a situation where the disparate data cycle is spiraling out of control with no foreseeable end in sight. The evolution is increasing by orders of magnitude and is creating disparate data faster than ever before.
The disparate data spiral is the spiraling increase in data disparity from existing technologies into new technologies. Both the volume of disparate data and the complexity of those disparate data are increasing. The spiraling disparity severely impacts the business activities of the organization.
Data Deluge
The data deluge is the situation where massive quantities of data are being captured and stored at an alarming rate. These data are being captured by traditional means, by scanning, by imaging, by remote sensing, by machine generation, and by derivation. Those data are being stored on personal computers, networks, departmental computers, and mainframe computers. The quantity of data in many organizations is increasing exponentially. If the data proliferation continues, the data deluge of the 1990s and early 2000s will appear trivial.
Malthusian Principle
The Malthusian principle deals with the power of populations to overwhelm their means of subsistence, causing misery, suffering, and eventually leading to extinction of that population if no corrective action is taken. Populations tend to grow geometrically, while their means of subsistence tend to grow arithmetically. At some point in time, the population growth exceeds the means of subsistence.
In Data Resource Simplexity I (loosely) applied the Malthusian Principle to an organization’s data resource. The volume of disparate data is growing geometrically, while the organization’s ability to understand and manage those data is only growing arithmetically. At some point in time the volume of disparate data will overwhelm an organization and could result in that organization failing to be fully successful.
I also (loosely) applied the Malthusian Principle to the organization’s growing volume of comparate data. The volume of comparate data is growing geometrically, according to Moore’s Law. The ability of an organization to thoroughly understand and use those comparate data to support the business information demand is only growing arithmetically. At some point in time the sheer volume of comparate data will overwhelm the organization.
Since I wrote Data Resource Simplexity, several people have pointed out that the Malthusian Principle is wrong. Technology comes along just in time to save a population from starving. As a population steadily grows, technology takes incremental jumps to keep up with the demand for food. Several people claim that my application of the Malthusian Principle to the data resource is wrong because technology steadily improves to manage larger volumes of data, provide faster processing, and provide faster transfer rates.
However, that’s only one aspect of the Malthusian Principle as applied to the data resource. The other aspect is the progressive loss of understanding with the increased volume of disparate data. Eventually the loss of understanding of the growing volume of data will limit an organization’s ability to effectively and efficiently use the data, unless some means are taken to capture and retain that understanding. Technology can help retain the understanding, but technology cannot understand the data.
Data resource integration lowers data disparity and helps organizations better manage the data through better understanding of the less disparate data. That may be technology coming to the aid of data resource management, but it’s a different type of technology than the technology of speed storage capacity and data transfer. It’s an understanding technology that is sorely lacking today.
Data Dilemma
The data dilemma is the situation where the ability to meet the business information demand is being compromised by the continued development of large quantities of disparate data. The dilemma exists in most organizations facing a growing disparate data resource. It arises from the conflict between building and maintaining a high-quality data resource, within a formal data architecture, for long term stability, to meet the high demand for integrated data to support the business; and the need to strive for early deliverables, inexpensive implementations, and quick fixes to current problems.
Disparate Data Shock
Disparate data shock is the sudden realization that a data dilemma exists in an organization and that it is severely impacting an organization’s ability to be responsive to changes in the business environment. It’s the panic that an organization has about the poor state of its data resource. It’s the realization that disparate data are not adequately supporting the current and future business information demand. It’s the panic that sets in about the low quality of the data resource, that the quality is deteriorating, and very little is being done to improve the situation.
Data Disparity Factors
The creation of disparate data is more than the natural drift of the data resource, the natural occurrence of events, or a few things not being done correctly. Specific factors contributing to the burgeoning data disparity are constant change, hype-cycles, and attitudes. Each of these factors is summarized below.
Constant Change
Data resource management is facing two major types of change. First, is the constant change in the business environment, which requires constant change in the management of data to support the business environment. Second, is the constant change in the technology of data resource management. Managing these two changes is often overwhelming.
The rate and magnitude of change has been increasing, and continues to increase. Change is relentless and persistent. Nothing stays constant for very long with today’s business and technology. The only thing constant today is the increasing rate and magnitude of change. Organizations must learn to move at the speed of change, or move at the speed of the business.
The business in most public and private sector organizations is very dynamic. Technology is evolving rapidly, employee turnover is higher, skills are in high demand, resources are down in a tight economy, the demand for integrated data is up, lead times are shorter, and quicker turnaround for critical situations is needed. Organizations cannot properly handle constant change with massive quantities of disparate data.
Hype-Cycles
A hype-cycle is a major initiative that is promoted in an attempt to properly manage an organization’s data resource, but often ends up making that data resource more disparate and impacting the business. A hype-cycle runs its course when the income from conferences, books, consulting, training, and software declines. Then a new hype-cycle begins and the process starts all over. Several major hype-cycles are prominent in data resource management today.
Data Governance. The first is data governance. It’s the latest in a string of hype-cycles from database management, through data administration, to data governance. The previous hype-cycles failed, and data governance is failing. The basic problem with data governance is that you can’t govern the data, any more than you could administer data.
I explained in Data Resource Simplexity that you can’t govern data or any other object; you can only govern people. I made the case that any management of the data as a resource to an organization is really data resource management—managing the data resource; not administering or governing the data resource.
Data governance includes a whole shopping list of topics and individual techniques. Some are unique to data resource management and some apply to all disciplines and professions. I have yet to see a basic set of concepts, principles, and techniques for data governance. What I see is a collection of topics without a foundation.
I recently ran across a new theme for data governance—business driven data governance. My first thought was if that is a new theme, then what was the former theme? Was the former theme non-business driven data governance? If so, why would any initiative regarding something as important as managing a critical data resource not be driven by the business?
I also saw two other new themes—data governance for meta-data and data governance for master data. Again, if those themes are really new, then traditional data governance did not include meta-data or master data, both of which are components of an organization’s data resource. Why were they initially excluded?
The answer to these questions, I believe, is that data governance is a hype-cycle and these new themes are needed just to keep the hype-cycle going. New themes will continue to be added until a hype-cycle eventually dies, just like database management and data administration died.
I recently saw an article on extending governance to information—information governance. I wondered what that term really meant, because you can’t govern information any more than you can govern data. How would you govern the relevance and timeliness of something that a person needs? How could you even govern what information a person needs? Like data, you might have information management that coordinates the need for information within an organization, but I fail to see how you could have information governance.
The article provided nothing to clarify what information governance really meant. It was the same old hype as data governance, but with a new title for information governance. Actually, the article confused, yet again, the difference between data and information. The hype-cycles continue.
Master Data Management . The second is master data management. It has become so broad and undefined (or multi-defined) that one does not know the real meaning of master data management. Does it mean there are slave data? Does it mean data reference sets? Does it mean core business data? Does it mean business critical data? Does it mean the highest in a series of skill levels? Does it mean the record of reference? Does it mean the same as data governance? Master data management is failing because it is ill-defined and is not supported by a sound set of concepts, principles, and techniques.
If master data management is about the management of reference data, then the term should be reference data management. If it is about core business data or data critical to the business, then the terms should be core business data and business critical data. I recently heard a new theme that master data management was really about meta-data. If that’s true, then the term should be meta-data management. Other perceptions of master data management should have specific terms within data resource management.
I see articles about how master data management and data governance are maturing. I went through exactly the same cycle with database management and data administration from when they started, through their maturity, to their decline and replacement by data governance and master data management. Wouldn’t it be nice to establish formal data resource management and make it persistent?
Other Hype-Cycles. A multitude of other hype-cycles have come and some have gone, such as service oriented architecture, canonical synthesis, the object-oriented paradigm, XML, cloud computing, federated databases, client-server, RPG, enterprise architecture, NoSQL, ERPs, and so on. I can remember when client-server first came along and would solve all of the existing data disparity problems. I heard the same for federated databases and with a variety of design tools. Yet, the data disparity got worse.
I recently saw online discussions stating data modeling is dead and relational technology is dead. The general theme over time has been Oh, now that (fill in the blank) is here, (fill in the blank) is no longer needed. That theme is simply an attempt to put the final coup-de-grace on an old hype-cycle and promote a new hype-cycle.
Comments About Hype-Cycles. I’ve received many comments about data governance and master data management being hype-cycles. People claim they are substantive, they are real, they are not hype, and so on. So, the question becomes what are master data management, data governance, and similar terms?
Data governance, master data management, and other hype-cycles are not formal data resource management. At best, they are initiatives or campaigns within an organization to manage the data resource. Most likely, they are hype-cycles, driven by personal or financial incentives, that will eventually run their course and be replaced by other hype-cycles. The name may change, but the hype-cycles live on.
Hype-cycles usually lead to increased disparate data, either directly or indirectly. Usually, the intention is to resolve data disparity and formalize data resource management. However, the end result is often an increase in data disparity. A good rhetorical question is Who’s at fault—the perpetuators or the adopters of hype-cycles?
Knowledge Areas. Data resource management contains knowledge areas that are persistent and transcend initiatives. Initiatives are often labeled with catchy terms that catch people’s eyes according to the mood of the time. Initiatives come and go while the basic knowledge areas remain persistent.
What if terms were created for documenting disparate data, mapping all public works, organizing health care data, and so on? Do these terms become knowledge areas within data resource management, or do they simply become initiatives that use appropriate knowledge areas. Data resource management will never stabilize, and a data management profession will never be created, if every hype-cycle and initiative that is established becomes a data resource management knowledge area.
Attitude
Attitude includes the attitudes of business professionals, data management professionals, consultants and trainers, conference providers, software vendors, and so on. It includes ego, arrogance, a need for control, a lack of teamwork, limited cooperation, limited scope, individual independence, personal agendas, conflicts of interest, atypical behavior, the not-invented-here syndrome, change for change sake, my model versus your model, my tool versus your tools, my perception versus your perception, and so on. All of these attitudes lead to a disparate data resource.
The prominent attitudes are lack of a business perspective, being private sector centric, paralysis-by-analysis, a brute-force-physical approach, and concentrating on the T of IT. Each of these is summarized below.
Lack of Business Perspective. Many data professionals lack a real business perspective. They are fixated on how things should be according to their perception and experience with databases, rather than how the business perceives the world in which they operate. The data resource must represent how the organization perceives the business world from their perspective, based on the way they operate in that business world.
Private Sector Centric. Many data management professionals are private sector centric. They think primarily of the private sector with respect to data resource management and largely ignore the public sector. Data resource management is extremely important in the public sector with their broad range of business activities, broad time frame, monumental projects requiring sustained efforts, relatively permanent lines of business, different funding structure with legislative mandates, a relatively fixed citizen set, short terms for executives, emotionally charged situations, readily shared data, and so on.
Related to the public sector focus is the term CRM, which usually means customer relationship management. However, in the public sector it means citizen relationship management. Relations with citizens in the public sector are considerably different than relations with customers in the private sector.
Paralysis-By-Analysis. Many projects are paralyzed by ongoing analysis. Paralysis-by-analysis is a process of ongoing analysis and modeling to make sure everything is complete and correct. Data analysts and data modelers are well known for analyzing a situation and working the problem forever before moving ahead. They often want to build more into the data resource than the organization really wants or needs. The worst, and most prevalent, complaint about data resource management is its tendency to paralyze the development process by exacerbating the analysis process. Prolonging analysis delays the project and forces the business to proceed with development, often at the expense of creating disparate data.
Brute Force Physical Approach. The opposite of paralysis-by-analysis is a brute-force-physical approach for developing and maintaining a data resource. The brute-force-physical approach goes directly to the task of developing the physical database. It skips all of the formal analysis and modeling activities, and often skips the involvement of business professionals and domain experts. People taking such an approach consider that developing the physical database is the real task at hand. The result is the creation of more disparate data.
A related situation is cutting the database code without any formal analysis. The primary purpose of most data modeling tools, in spite of how they are advertised and marketed, is to cut the code for the physical database. Physical data models are often developed, maybe reviewed superficially by the business professionals, and the database is developed. The result is usually increased data disparity.
Another related situation is conceptual modeling, which is often used as an excuse to get something in place quickly to keep the business happy, and then forge ahead with developing the physical database. Formal data normalization and even data denormalization are often ignored in the process.
Concentrating on the T of IT. Many people concentrate on the T of Information Technology rather than the I of Information Technology. People have been concerned with what new technology can do, rather than what it can do for the business.
The new technology syndrome is a repeating cycle of events that occurs with new technology. New technology appears as a new way of doing things. People play with the new technology, in a physical sense, to see what it can do or is capable of doing, like a child plays with a new toy. Then people use the new technology in some aspect of the business, or base major segments of the business on the new technology. It’s like a new tool looking for a place to be useful. Disparity begins to creep in because of the physical implementation. When people finally decide to formalize the technology, the disparity already exists.
Other Attitudes. Other attitudes that lead to a disparate data resource are data standards, which are often physical oriented and often conflict; data registries, which create a perception that if the data model is documented in a registry, it becomes official; universal data models and generic data architectures, which are an attempt to get every organization to manage their data the same way; and purchased applications, which often require the organization to warp their business to fit the application.
Result of Disparate Data Factors
The result of the constant change, hype-cycles, and attitudes described above lead to an organization sacrificing its future for the present and the creation of a Borgesian Nightmare.
Sacrificing the Future for the Present. Organizations have been sacrificing the future for the present. They have concentrated on developing applications, building databases, and using technology that will meet the current business information demand, but not the future business information demand. The emphasis is on short term deliverables, rather than long term viability of the data resource.
Most organizations are now in the future and are suffering from emphasis on the present of yesteryear. They are suffering from an orientation toward technology, not toward information. The historical orientation to the present and to technology has finally caught up with them and the disparity is severely hampering the organization’s business activities. Organizations are literally facing the neglects of the past.
Organizations must concentrate on both the short term and the long term use of information technology. They must meet the short term demands while considering the long term demands for good information. They need to concentrate on long term support of the business as well as short term support. To do otherwise simply perpetuates disparity.
Borgesian Nightmare. The increasing data resource disparity results in a Borgesian nightmare. A Borgesian nightmare is a labyrinth that is impossible to navigate, which causes people to have nightmares. The disparate data resource in many organizations is becoming a Borgesian nightmare. Organizations are drowning in a labyrinth of disparate data and people have nightmares about how to effectively and efficiently manage the data resource to fully meet an organization’s current and future business information demand.
No Quick Solutions
Preventing and resolving data resource disparity has no quick fix. Quick fixes are simply another hype that doesn’t provide any solutions. A silver bullet is an attempt to achieve some gain without any pain. The silver bullet syndrome is the on-going syndrome that organizations go through searching for quick fixes to their data problems. A tarnished silver bullet is the result of attempting to find a silver bullet—considerable pain with minimal gain, and maybe considerable loss.
Plausible deniability is the ability of an organization to deny the fact that their data resource is disparate and live with the illusion of high quality data. Most public and private sector organizations have enough plausible deniability about the state of their data resource to last the rest of their organizational lives.
What an organization believes about the quality of their data resource and the real quality of their data resource are often quite different. Most people are aware of the disparate nature of the organization’s data resource, but don’t want to believe (deny) that the data resource quality is low. Many are ashamed or embarrassed to admit that the data resource is disparate.
The result of silver bullets and plausible deniability lead to a self-defeating fallacy. The self-defeating fallacy states that no matter how much you believe that something can happen, if it is not possible, it will not happen. The self-fulfilling prophecy states that if you really believe in something that can happen, and it is possible, it will happen.
A status quo does not work. The natural drift of the data resource toward disparity will continue and the data resource will become more disparate. A status quo simply leads to organizational failure by reason of information deprivation.
Data resource disparity has no quick fixes or magic cures. Tools won’t stop or resolve data disparity, because tools can’t understand the data. Only people can understand data, and tools document that understanding. Scanners are good for an inventory, but can’t understand the data. They often create a false confidence in the data resource by providing a complete inventory.
Standards can’t resolve data disparity, and often don’t help prevent data disparity. Standards themselves are often disparate and actively add to the data disparity. The same situation exists with generic data architectures and universal data models, data registries, data repositories, and so on.
Beware of high-tech solutions that appear to resolve data disparity. Technology won’t solve the disparate data problem. The real solution is hard work—the real hard-thinking kind of work. The real solution comes from people who can understand the disparate data resource and develop a comparate data resource.
Data Risk and Hazard
The constant change, hype-cycles, and attitudes create both a hazard and a risk for the organization. Hazard is a possible source of danger or a circumstance that creates a dangerous situation. Risk is the possibility of suffering harm or loss from some event; a chance that something will happen.
Data resource hazard is the existence of disparate data. A greater volume and a greater degree of disparity make the hazard greater. Data resource risk is the chance that use of the disparate data will adversely impact the business. Both the data resource hazard and data resource risk are large in most public and private sector organizations.
Probability neglect is overestimating the odds of things we most dread happening and underestimating the odds of things we least dread happening. Probability neglect for the data resource is happening in most public and private sector organizations. Data resource probability neglect is overestimating the odds of not meeting the current business information demand and underestimating the odds of not meeting the future business information demand.
The availability heuristic states that the better you can imagine a dangerous event, the likelier you are to be afraid of that event. The reverse is actually true for the data resource in most organizations. Organizations are not imagining the danger of failing to meet the future business information demand and are not afraid of that failure. Looking deeper into a disparate data resource makes the availability heuristic quite obvious. One comment I heard from a client after realizing their data resource was disparate was How did we ever manage to do this to our data resource?
COMPARATE DATA RESOURCE
Comparate is the opposite of disparate and means fundamentally similar in kind. Comparate data are data that are alike in kind, quality, and character, and are without defect. They are concordant, homogeneous, nearly flawless, nearly perfect, high-quality data that are easily understood and readily integrated.
A comparate data resource is a data resource composed of comparate data that adequately support the current and future business information demand. The data are easily identified and understood, readily accessed and shared, and utilized to their fullest potential. A comparate data resource is an integrated, subject oriented, business driven data resource that is the official record of reference for the organization’s business.
The discussion of a comparate data resource includes data resource quality, data resource management concepts, supporting theories and principles, the Data Resource Management Framework, a comparate data resource vision, and how to achieve that vision. Each of these is described below.
Data Resource Quality
The second law of thermo dynamics can be applied to the data resource. Entropy is the state or degree of disorderliness. It is a loss of order, which is increasing disorderliness. Entropy increases over time, meaning that things become more disorderly over time, as shown by the natural drift of the data resource toward disorder. Disorderliness means low quality, which is a disparate data resource.
The data resource is an open system and follows the laws of increasing entropy, virtually without limit. However, the entropy can be reversed to restore orderliness, but only with the input of energy. Work must be done to restore orderliness. Orderliness means high quality, which is a comparate data resource.
Quality is a peculiar and essential character, the degree of excellence, being superior in kind. Quality is defined through four virtues—clarity, elegance, simplicity, and value.
Data resource quality is a measure of how well the data resource supports the current and future business information demand. Ideally, the data resource should fully support the current and future business information demand of the organization to be considered a high quality data resource. Data quality is a subset of data resource quality dealing with data values. Ultimate data resource quality is a data resource that is stable across changing business and changing technology, so it continues to support the current and future business information demand.
Proactive data resource quality is the process of establishing the desired quality criteria and ensuring that the data resource meets those criteria from this point forward. It’s oriented toward preventing defects from entering the data resource. Retroactive data resource quality is the process of understanding the existing quality of the data resource and improving the quality to the extent that is reasonably possible. It’s oriented toward correcting the existing low quality data resource by removing defects.
Data Resource Simplexity was oriented toward proactive data resource quality. The current book on Data Resource Integration is oriented toward retroactive data resource quality.
Information quality is how well the business information demand is met. It includes both the data used to produce the information and the information engineering process. The information engineering process includes everything from determining the information need to the method of presenting the information.
Information engineering is the discipline for identifying information needs and developing information systems to meet those needs. It’s a manufacturing process that uses data from the data resource as the raw material to construct and transmit information.
The information engineering objective is to get the right data, to the right people, in the right place, at the right time, in the right form, at the right cost, so they can make the right decisions, and take the right actions. The operative term in the definition is the right data, meaning high quality data. The information quality can be no better than the data used to produce that information.
Data engineering is the discipline that designs, builds, and maintains the organization’s data resource and makes the data available to information engineering. It’s a formal process for developing a comparate data resource. Data engineering is also responsible for maintaining the disparate data resource and for transforming that disparate data resource to a comparate data resource. Data resource management includes data engineering, plus all of the architectural and cultural components of data resource management.
Quality is not free, as some people claim. Quality is less expensive if built in from the beginning, compared to being built in later, but it is not free. The second law of thermodynamics substantiates that quality is not free, and the data resource will not correct itself. The sooner that a comparate data resource is developed, the less costly it will be.
Data Resource Management Concepts
Developing a comparate data resource begins with the description of a few basic concepts about data resource management. These concepts include understanding the data resource, developing an independent data architecture, the Business Intelligence Value Chain, and the comparate data cycle. Each of these topics is summarized below. More detailed descriptions can be found in Data Resource Simplexity.
Uncertainty and Understanding
The disparate data cycle is perpetuated by uncertainty, both uncertainty about the business and uncertainty about the organization’s disparate data resource. Uncertainty about the organization’s data resource is the primary concern for data resource integration. Resolving uncertainty about the data resource helps people face the uncertainty about the business.
Uncertainty is resolved through understanding. The thorough understanding principle states that a thorough understanding of the data with respect to the business resolves uncertainty and puts the brakes on data disparity. It’s the understanding of data with respect to the business that’s important. Thoroughly understanding the organization’s data resource is a major step towards lowering uncertainty and preventing further disparity.
Data de-coherence is an interference in the coherent understanding of the true meaning of data with respect to the business. It is due to the variability in the meaning, structure, and integrity of the data. The variability is large in a disparate data resource leading to a large data de-coherence.
Independent Data Architecture
The data resource is one component of an information technology infrastructure that also contains the platform resource, the business activities, and information system. Disparity exists in all four components of the infrastructure. Resolving disparity in the data resource helps resolve disparity in the other components.
However, the architectures of the four components must be kept separate. The principle of independent architectures states that each primary component of the information technology infrastructure has its own architecture independent of the other architectures. That principle must be kept in mind when developing a comparate data resource.
Business Intelligence Value Chain
Intelligence is the ability to learn or understand or deal with new or trying situations; the skilled use of reason; the ability to apply knowledge to manipulate one’s environment or to think abstractly. Business Intelligence is a set of concepts, methods, and processes to improve business decision making using any information from multiple sources that could affect the business, and applying experiences and assumptions to deliver accurate perspectives of business dynamics.
The Business Intelligence Value Chain is a sequence of events where value is added from the data resource, through each step, to the support of business goals. The data resource is the foundation that supports the development of information. Information supports the knowledge worker in a knowledge environment. The knowledge worker provides business intelligence to an intelligent, learning organization. Business intelligence supports the business strategies, which support the business goals of the organization.
Any level in the Business Intelligence Value Chain has no better quality than its supporting level. Since the data resource is the foundation, the quality of any higher level, such as information, can be no better than the quality of the data resource. Therefore, the degree to which business goals are met can be no better than the quality of the data resource.
Comparate Data Cycle
The comparate data cycle is a self-perpetuating cycle where the use of comparate data is continually reinforced because people understand and trust the data. It is the flip side of the disparate data cycle. When people come to the data resource, they can usually find the data they need, can trust those data, and can readily access those data. The result is a shared data resource. Similarly, people who can’t find the data they need formally add their data to the data resource, and the enhanced data resource is readily available to anyone looking for data to meet their business need.
Supporting Theories and Principles
Several theories and principles from outside data resource management support the resolution of data disparity and the creation of a comparate data resource. Each of these theories and principles is summarized below. More detailed descriptions can be found in Data Resource Simplexity.
Basic Definitions
A theory is a plausible or scientifically acceptable general principle or body of principles offered to explain phenomena; a body of theorems presenting a concise systematic view of a subject.
A concept is something conceived in the mind, a thought, or a notion; an abstract or generic idea generalized from particular instances; a generic or generalized ideal from specific instances. A concept can be basic, applying to data resource management in general, or it can be specific, applying to one aspect of data resource management.
A principle is a comprehensive and fundamental law, doctrine, or assumption; a rule of conduct. A principle can be basic, applying to data resource management in general, or it can be specific, applying to one aspect of data resource management.
A technique is a body of technical methods; a method of accomplishing a desired aim. Technique, as used here, represents how to accomplish a principle; the principle is the what and the technique is the how.
Basic Principles
Several basic principles support development of a comparate data resource, including think globally—act locally, the precautionary principle, the principles of unintended consequences and intended consequences, the data resource comparity principle, the data resource iatrogenesis principle, cognitive dissonance, and the principles of gradual change and delayed change. Each of these principles is summarized below.
People need to stop thinking locally and acting locally with respect to the organization’s data resource. The think globally – act locally principle provides a broad orientation for developing a comparate data resource. People need to think globally about the comparate data resource, but act locally to ensure that data resource contains their data and those data are readily available.
The precautionary principle states that if an action or policy has a suspected risk of causing harm to the public or the environment, in the absence of scientific consensus that the action is not harmful, the burden of proof that it is not harmful falls on those who advocate taking the action. The data resource precautionary principle states that if an action or policy has a suspected risk of causing harm to the data resource, in the absence of scientific consensus that the action or policy is not harmful, the burden of proof that it is not harmful falls on those who advocate taking the action.
The principle of unintended consequences states that any intervention in a complex system may or may not have the intended result, but will inevitably create unintended and often undesirable outcomes. The principle of intended consequences states that any intervention in a complex system, such as a data resource, should be guaranteed to have the intended result. If that guarantee cannot be made, then the intervention should not be taken.
The anthropic principle is the law of human existence. Our existence in the universe depends on numerous constants and parameters whose values fall within a very narrow range. If a single variable is slightly different we would not exist. The data resource anthropic principle states that if the data resource management rules are followed, a comparate data resource will be developed. The rules create the right conditions for development of a comparate data resource. If the rules are not followed, a disparate data resource will be developed.
Iatrogenesis refers to the inadvertent adverse effects or complications caused by or resulting from medical treatment or advice. The term originated in medicine and is generally referred to as harm caused by the healer. The data resource iatrogenesis principle states that the disparate data resource was caused by or resulted from the actions of the data management professionals and/or business professionals in an effort to create data to meet the business information demand. Unlike medicine, the actions may have been intentional or unintentional.
Cognitive dissonance is the disharmony that is created when an individual’s personal reality does not fit the actual reality of the situation. When a person perceives that the state of the data resource is pretty good and receives information that the actual state of the data resource is bad, a tremendous disharmony is created. That person usually reacts in some way, such as ignoring the situation, denying that the situation exists, laying blame for the situation, or setting about correcting the situation.
The principle of gradual change states that the disparate data resource evolved slowly and almost unnoticed until it was too late to correct. The principle of delayed change states that nothing will change to prevent a situation from getting worse until it’s too late. When the situation is finally discovered, such as a disparate data resource, it becomes a monumental task to resolve the problem.
Supporting Theories
Several theories from outside data resource management support development of a comparate data resource, including communication theory, semiotic theory, set theory, graph theory, and relational theory. Each of these theories is summarized below.
Communication theory states that information is the opposite of entropy, where entropy is disorderliness or noise. A message contains information that must be relevant and timely to the recipient. If the message does not contain relevant and timely information, it is simply noise (non-information). Syntactic information is raw data. It is arranged according to certain rules. Syntactic information alone is meaningless—it’s just raw data. Semantic information has context and meaning. It is relevant and timely. It is also arranged according to certain rules.
Note that syntactic information from communication theory has been defined as data, and semantic information has been split into data in context and information. The distinctions were made to lay a better foundation for understanding and resolving disparate data.
Semiotics is a general theory of signs and symbols and their use in expression and communication. Semiotic theory deals with the relation between signs and symbols, and their interpretation. It consists of syntax, semantics, and pragmatics. Syntax deals with the relation between signs and symbols, and their interpretation. Specifically, it deals with the rules of syntax for using signs and symbols. Semantics deals with the relation between signs and symbols, and what they represent. Specifically, it deals with their meaning. Pragmatics deals with the relation between signs and symbols, and their users. Specifically, it deals with their usefulness.
Set theory is a branch of mathematics or of symbolic logic that deals with the nature and relations of sets. The traditional form has been slightly modified to be useful for managing data.
Graph theory is a branch of discrete mathematics that deals with the study of graphs as mathematical structures used to model relations between objects from a certain collection. A graph consists of a collection of vertices (or nodes), and a collection of edges (or arcs) that connect pairs of vertices. The edges may be directed from one vertex to another, or undirected, meaning no distinction between the two vertices.
Relational theory was developed by Dr. Edgar F. (Ted) Codd to describe how data are designed and managed. The theory represents data and their interrelations through a set of rules for structuring and manipulating data, while maintaining their integrity. It is based on mathematical principles and is the base for design and use of relational database management systems.
Data Resource Management Framework
The Data Resource Management Framework is a framework that represents the discipline for complete management of a comparate data resource. It represents the cooperative management of an organization-wide data resource that supports the current and future business information demand. The segments and components of the Data Resource Management Framework are shown in Figure 1.2.
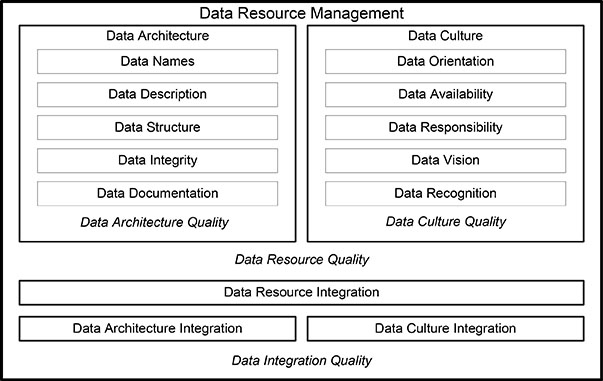
Figure 1.2. The Data Resource Management Framework.
The Data Resource Management Framework contains two main segments, data architecture and data culture, commonly referred to as the data architecture segment and the data culture segment. Each of these two segments has a quality aspect, specifically data architecture quality and data culture quality. Together, these two quality aspects provide the overall data resource quality.
The data architecture segment contains components for data names, data definitions, data structure, data rules, and data documentation. The data culture segment contains components for data orientation, data availability, data responsibility, data vision, and data recognition.
The Data Resource Management Framework has been enhanced to include data resource integration, consisting of data architecture integration and data culture integration. These two topics are described in the next chapter on Data Resource Integration. The details of data architecture integration are described in Chapter 3 on Data Architecture Integration, and the details of data culture integration are described in Chapter 13 on Data Culture Integration.
The Data Resource Management Framework has been formally merged into the Data Column of the Zachman Framework as the complete discipline for managing an organization’s data resource. The initial merger was done in 2005, before the enhancement of the Data Resource Management Framework that included data resource integration. However, the enhancement for data resource integration is included in the merger by extension to provide an enhanced discipline for managing an organization’s data resource.
Data architecture quality is how well the data architecture components contribute to overall data management quality. Data culture quality is how well the data culture components contribute to the overall data management quality.
Data Architecture Segment
Architecture (general) is the art, science, or profession of designing and building structures. It’s the structure or structures as a whole, such as the frame, heating, plumbing, wiring, and so on, in a building. It’s the style of structures and method of design and construction, such as Roman or Colonial architecture. It’s the design or system perceived by people, such as the architecture of the Solar System
Architecture (data) is the art, science, or profession of designing and building a data resource. It’s the structure of the data resource as a whole. It’s the style or type of design and construction of the data resource. It’s a system, conceived by people, that represents the business world.
Data architecture (1) is the method of design and construction of an integrated data resource that is business driven, based on real-world subjects as perceived by the organization, and implemented into appropriate operating environments. It consists of components that provide a consistent foundation across organizational boundaries to provide easily identifiable, readily available, high-quality data to support the current and future business information demand.
Data architecture (2) is the component of the Data Resource Management Framework that contains all of the activities, and the products of those activities, related to the identification, naming, definition, structuring, integrity, accuracy, effectiveness, and documentation of the data resource.
The architectural segment consists of five components, data names, data definitions, data structure, data integrity, and data documentation, that define the architecture of the data resource The first four components deal with understanding the organization’s perception of the business world and the activities they perform in that business world. The fifth component is documentation of that single, robust understanding for all to view.
Data Culture Segment
The cultural segment contains five components, data orientation, data availability, data responsibility, data vision, and data recognition It represents the cultural aspects of building, managing, and using the data resource to support the business information demand. It deals with people’s ability to build, maintain, and use the common single understanding for business success.
Culture is the act of developing the intellectual and moral faculties; expert care and training; enlightenment and excellence of taste acquired by intellectual and aesthetic training; acquaintance with and taste in fine arts, humanities, and broad aspects of science; the integrated pattern of human knowledge, belief, and behavior that depends upon man’s capacity for learning and transmitting knowledge to succeeding generations; the customary beliefs, social forms, and material traits of a racial, religious, or social group.
Data culture (1) is the function of managing the data resource as a critical resource of the organization equivalent to managing the financial resource, the human resource, and real property. It consists of directing and controlling the development, administering policies and procedures, influencing the actions and conduct of anyone maintaining or using the data resource, and exerting a guiding influence over the data resource to support the current and future business information demand.
Data culture (2) is the component of the Data Resource Management Framework that contains all of the activities, and the products of those activities, related to orientation, availability, responsibility, vision, and recognition of the data resource.
Comparate Data Resource Vision
The comparate data resource vision is the disparate data resource thoroughly understood and integrated into a comparate data resource, supported by a Data Resource Guide, to fully support the current and future business information demand. The comparate data resource vision is shown in Figure 1.3. The existing data and any new data are integrated into a comparate data resource. The comparate data resource is supported by a comprehensive Data Resource Guide that fully documents the data resource. People can go to that Data Resource Guide, find the data they need to perform their business activities, and extract those data to appropriate information systems to meet the business information demand.

Figure 1.3. Comparate data resource vision.
Data engineering has the responsibility to understand the disparate data resource and build the comparate data resource and the Data Resource Guide. That responsibility is driven by the need to support the current and future business information demand. Information engineering has the responsibility to use the comparate data resource to meet the business information demand.
A common data architecture and a common data culture are the two contexts for resolving data disparity and developing a comparate data resource. Together they help the organization move from the complexity of disparate data to the simplexity of a comparate data resource. They help the organization break the disparate data cycle and begin a comparate data cycle. The Common Data Architecture is described in Chapter 3, and the Common Data Culture is described in Chapter 13.
Disparity is a common and persistent problem in all aspects of information technology. Disparity has been happening since data processing first began, and has continued without interruption as data processing evolved into information technology. It is continuing at an ever-increasing rate, with no end in sight. Disparity is impacting the business of both public sector and private sector organizations in ways that are obvious and in ways that are not so obvious.
The only real end to the existing disparity is when an organization goes out of business and ceases to exist. At that point the disparity disappears, unless, of course, another organization inherits the disparity. Although going out of business may be an option for some private sector organizations, it is generally not an option for public sector organizations. Public sector organizations need to keep operating regardless of the level of disparity.
Another option to resolving disparity is to close down the business for six months to a year, resolve the disparity, set a new higher quality foundation, and then restart the business. Such action is not possible for any business that I know about. In today’s business world, closing shop for even a few weeks or months is tantamount to going out of business.
The only option left is to resolve disparity on-the-fly, if an organization is to stay in business and remain successful in that business. However, an organization must first stop the ever-increasing disparity before they can begin resolving the existing disparity. It has been shown over and over that trying to resolve the existing disparity without first stopping the increasing disparity will not produce meaningful results. Disparate data are produced faster than they can be understood and resolved.
Development of a comparate data resource is driven by three basic rules. First, any data that are known to be false, or are not known to be true, will not be promoted. Second, the truth about the quality of the data in a disparate data resource will never be concealed or altered. Third, the organization should have no suspicion about the work, the intentions, or the integrity of the data.
Achieving a Comparate Data Resource
Achieving a comparate data resource requires a change in attitudes and an organizational orientation toward developing a comparate data resource. Each of these topics is described below.
Attitudes
Since I wrote Data Resource Simplexity, I’ve talked with a number of people about the problems with data resource management today. Many agree with what I stated, but felt that too many problems existed to be addressed at one time, or the problems were outside their particular span of control. They asked what I’d recommend as the top three things to address in their organization to reduce the data hazard and data risk.
I explained my choice of the three things I’d address, not necessarily in order of severity. Other things certainly need to be addressed, but these are my top three.
First, is the attitude of database managers and technicians who feel they don’t need no stinking data architect to tell them how to build their databases. Note the attitude toward personalizing the database, which inevitably leads to brute-force-physical development and further data disparity.
Second, is the attitude of some data modelers who don’t listen to the business, have their own perception of the business, or have their own modeling notation. A good data modeler must listen to the business and develop a data model that represents the business as the business professionals describe it, in a manner that those business professionals readily understand.
Third, is the attitude of some vendors who want to warp the business to fit their particular software product. Not all vendors have such an attitude, but beware of those that do. The result will only be detrimental to the business, will likely go over budget and beyond the due date, and will likely not meet the objectives as originally defined. Find a vendor that will work with the organization to provide a solution that represents business the way the organization does business.
Organizational Orientation
I’ve been asked several times what I would do to help an organization get started on the path toward building a comparate data resource. My response has been that organizations need to recognize that disparate data exist and adopt an orientation toward resolving those disparate data and creating a comparate data resource. My emphasis on a new orientation is described below.
Organizations have the opportunity to accept or reject the concepts, principles, and techniques that lead to a comparate data resource. Organizations can choose between a disparate and a comparate data resource, and between success or failure of the data resource to adequately support the current and future business information demand.
Organizations need to recognize and avoid patterns of failure and choose to adopt patterns of success. A pattern of failure is a sequence of events that lead toward a disparate data resource and its failure to support the current and future business information demand. It’s a pattern of thought or behavior that is often profit or attitude driven. A pattern of success is a sequence of events that lead toward a comparate data resource and full support for the current and future business information demand.
Organizations have the opportunity to choose to adjust their attitudes about how the data resource is developed and managed. Attitude, behavior, ego, arrogance, and so on, are patterns of failure that lead to a disparate data resource.
Organizations need to embrace formal data resource management concepts, principles, and techniques, and use them consistently to develop a comparate data resource. The concepts, principles, and techniques are well known, have been around for years, and have been proven successful.
Organizations can, and must, choose to mitigate the risks and hazards of a disparate data resource. They need to put the brakes on the disparate data cycle and the natural drift of the data resource toward disparity. They need to start a comparate data cycle that leads to a comparate data resource. To do otherwise may be hazardous to the organization’s health.
Organizations need to consider establishing a chief data architect, because it’s obvious that the chief information officer is not interested in the data resource. One person who is primarily responsible for development of a comparate data resource needs to be designated.
The orientation almost sounds too simple in principle, but it can and has been achieved. The concepts, principles, and techniques described in the current book are simple, yet they are elegant in resolving disparate data and developing a comparate data resource; detailed, yes, but simple and elegant in their orientation.
SUMMARY
The data resource in most public and private sector organizations today is really bad. Data resource quality in many organizations is at an all-time low, and is getting worse. Some evidence shows that people are actively making the data quality worse, knowingly or unknowingly.
Tackling data resource disparity is not easy, but it is far from impossible. It takes real tough thinking and hard work to understand and resolve disparate data and create a comparate data resource. The tough thinking is understanding the existing disparate data. The hard work is getting people to change their attitudes about developing a comparate data resource. Architectural issues are relatively easy, but the cultural issues are relatively difficult.
Organizations must choose to understand the disparate data resource and develop a comparate data resource. They must accept that theories, concepts, principles, and techniques are available for understanding disparate data and developing a comparate data resource. They must remove the past barriers and allow people to see things in a very elegant and simple way, and use the technology available to develop a comparate data resource that fully supports the current and future business information demand of the organization.
QUESTIONS
The following questions are provided as a review of existing disparate data and development of a comparate data resource, and to stimulate thought about evolving from a disparate data resource to a comparate data resource.
- What are the basic theories that support data resource management?
- What are the components of relational theory, and which of those support development of a comparate data resource within a common data architecture?
- What does the Data Resource Management Framework represent?
- Why does a lexical challenge exist in data resource management?
- What are the basic problems with a disparate data resource?
- Why do hype-cycles lead to a disparate data resource?
- Why do attitudes lead to a disparate data resource?
- Why are there no quick solutions to resolving disparate data and creating a comparate data resource?
- Why are both a common data architecture and a common data culture needed to achieve a comparate data resource?
- Why should data be considered a critical resource of the organization?