
2 Robotics, Evolution and Simulation
Preamble: When watching a swarm of autonomous robots perform even the simplest actions such as driving around randomly while avoiding to crash into each other, an impression of a highly complex and unpredictable system arises, and it is hard not to draw an analogy to populations of living organisms. Somehow it seems obvious to try to transfer some of the intriguing mechanisms from nature to such artificial robot populations and to look if an intelligent system can emerge. Trying to do so, it soon gets obvious that there is still a long road to follow until the underlying mechanisms will be understood sufficiently well to be used in a practical way for the automatic generation of intelligent, robust and controllable robot behavior. But no matter how long it takes, the idea never seems to lose its fascination.
Undoubtedly, there has been great progress in the fields of robotics, artificial evolution and simulation in the last decades. Each field individually as well as interdisciplinary fields such as ER and multi-agent systems have evolved and gained new insights to a large extent. This chapter summarizes the current state of research related to this thesis, introduces basic terms, preliminaries and concepts, and gives a general motivation. First, learning and particularly evolutionary techniques are introduced by focussing on the fields of EC, ER and ESR. Particularly, the roles of the controller representation in ER and of the GPM in general are discussed. In the second part of the chapter, current research in the field of simulation is presented. Each of these fields has a huge list of publications, therefore, only the most relevant work can be outlined and referenced here. The numerous significant articles going beyond the scope of this thesis can be found, for example, in several survey papers referred to below. Particularly, the works by Meyer et al. [127], Walker et al. [199], Jin [86] and Nelson et al. [139] summarize the fields of ER and ESR, the work by Floreano et al. [46] deals with neuroevolution (i. e., evolution of ANNs) in ER, and the works by Railsback et al. [157] and Nikolai and Madey [140] give a survey of general-purpose ABS.
2.1 Evolutionary Training of Robot Controllers
ER is a methodology for the automatic creation of robotic controllers. ER approaches usually borrow the basic ideas from classic EC approaches which, in turn, model highly abstract versions of the processes which are believed to be the driving factors of natural evolution. Classic EC methods are meta-heuristics, usually used to solve computationally hard optimization problems [201]. Beyond that, EC has been successfully used to evolve programs for the calculation of specific mathematical functions [111], the shapes of workpieces such as pipes [161] or antennas [81], for the optimization of non-functional properties of programs [205], rather playfully for the generation of specific “magic squares” [161], and for various other purposes. Classically, EC has been composed of sub-fields such as Evolutionary Algorithms, Evolution Strategies, and Genetic Algorithms. Today this differentiation is not considered to be strict anymore by most authors, and it does not affect the results presented here. Therefore, it is not further attended for the remainder of the thesis, and, rather, the term EC is used.
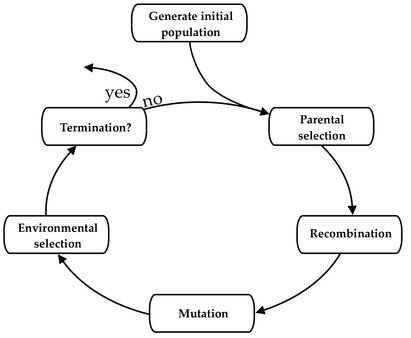
Fig. 2.1. Classic evolutionary cycle as used in many EC approaches. The process starts with a – usually randomly generated – initial population of solution candidates for some (optimization) problem. The candidates are rated using a fitness function which is usually given more or less directly by the problem definition. Based on the rating, a “parental” selection is used to create a sub-population of expectedly superior individuals from which (optionally by using a recombination operation) an offspring population is created. The individuals from this population are subsequently mutated and, optionally, subjected to an additional “environmental” selection. If a termination criterion is reached, the algorithm stops, otherwise the next iteration of the loop is started.
Most EC approaches have in common to use the basic evolutionary cycle, depicted in Fig. 2.1, or a modified version leaving out, for example, one of the two selection operations, the recombination operation (cf., for example, the Evolution Strategies [160]), or even the termination condition in open-ended evolutionary approaches [158].
Similar to the procedure in classic EC, populations of individuals in ER evolve to achieve desired properties by being subject to selection, recombination, and mutation. There, individuals represent robot controllers, more high-level behavioral strategies for swarms or even robot morphologies [132]. This process can be performed with a single robot evaluating each individual of the population successively (encapsulated), or a population of robots, each storing and evaluating one individual (distributed). In contrast to EC, fitness usually has to be measured by observing robot behavior in an environment rather than being calculated directly from the individual. Furthermore, the environment itself provides for part of the selection pressure implicitly which affects evolution apart from the influence of fitness (cf. below and Chap. 6). Overall, the subparts of the course of evolution in ER can take place in an asynchronous way which is why a more parallel view is better suiting for ER than the cycle view of classic EC. Particularly when performing decentralized evolution, the whole evolution process takes place onboard of robots letting mutation, recombination and selection of individual robots occur in parallel. In that case, particularly selection cannot be modeled as a global operator, but has to be performed in a local way through robot to robot communication. Fig. 2.2 depicts the basic evolutionary process taking place onboard of a robot.
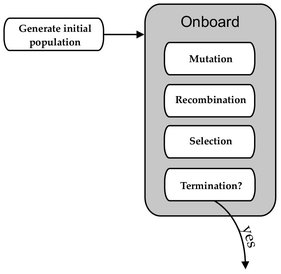
Fig. 2.2. Evolutionary process onboard of a robot. In a decentralized ER scenario, the evolutionary operators mutation, recombination and selection are performed in a local way on every individual robot or using local robot-to-robot communication.
While the general evolutionary process described so far can be used to evolve robot behaviors as well as robot morphologies, the remainder of the thesis focuses on the evolution of robot behaviors. Various types of robot behaviors have been evolved in the past, the most popular of which has been Collision Avoidance (CA)a (or Obstacle Avoidance). CA denotes behaviors including a capability of driving (or walking etc.) around while avoiding to crash into obstacles or other robots [139]. Other behaviors include Wall Following [184], Object Detection and Recognition [121], [207], Shortest Path Discovery [185], Object Transport [59], and others; the references denote exemplary examples out of bigger pools of publications referring to the respective behaviors. Beyond these behaviors which can be performed by a single robot or in parallel by a population of robots, a popular behavior specifically suited for swarms of robots is Group Transport [61] which denotes the collective transport of an object usually too heavy for a single robot to carry or push. Other popular swarm behaviors include Coordinated Motion [37], [167], Bridge Traversal and Gap Crossing [25], and others.
2.1.1 Two Views on Selection in ER and ESR
Evolutionary approaches in the field of ER and its subfield ESR tend to be more closely related to natural evolution than classic EC approaches, as the former include physical individuals that operate in a spatial environment and are confronted with physical constraints as well as inherent benefits such as parallelism. The main differences between the fields are focussed around selection and fitness calculation as these operations usually include a strong interaction with a complex environment in ER, as opposed to most classic EC approaches. In this respect, ER can be looked at from two different perspectives, namely a classic EC perspective and a biological perspective, both of which can yield specific insights.
The classic EC point of view. In classic EC, selection is usually performed by considering the “fitness” of all individuals of a population and favoring the “better” ones [201]. There, fitness is given by one or several numeric value(s) calculated directly from an individual, and it reflects the individual’s relative quality, often with respect to an optimization problem to solve. In contrast, fitness in ER is computed by observing an individual’s performance in an environment. This environmental fitness calculation can be noisy, fuzzy or time-delayed [18], [75], [151] which is why, at some places in this thesis, it will be considered a “measurement” rather than a calculation. Obviously, environmental circumstances can highly affect the success of an individual in terms of its ability to collect fitness points. Additionally, the environment is in many cases responsible for an implicit pre-selection of individuals. In such cases the individuals have to match some environmental requirement to even be considered for fitness-based selection. For example, a common practice in a decentralized swarm scenario is to let robots perform reproduction (including selection) when they meet, i. e., come spatially close to each other. Then, evolution implicitly selects for the ability to find other robots – in addition to selection based on the fitness value [19]. Nolfi and Floreano refer to these two different factors influencing selection as explicit vs. implicit fitness[142], the former denoting a calculated (or “measured”) fitness value, and the letter a robot’s quality in terms of the environment-based part of selection. In the following, these terms are adopted, using the term fitness as an abbreviating alternative when explicit fitness is meant. Overall, a complex environment adds fuzziness, noise and time-dependencies to the calculation of fitness and it introduces an implicit factor to the selection process, compared to a classic EC approach.
The biological point of view. In evolutionary biology, an individual’s reproductive fitness is calculated from its ability to both survive to adulthood and reproduce with an expectation of contributing to the gene pool of future generations [52]. There are several competing approaches on how to exactly calculate reproductive fitness in nature (particularly short-term vs. long-term calculations [175] etc.). In any case, reproductive fitness in nature as well as explicit and implicit fitness in ER reflect the expectation of an individual to produce offspring genetically related to itself. However, reproductive fitness in natural evolution is an observable but (mostly) unchangeable property. Particularly, natural evolution by itself does not have an explicit target which it aims to, but its direction is solely dictated by interactions of individuals with their environment, and by the selection pressure established by these means. In contrast, explicit as well as (to a lesser extent) implicit fitness in ER can be designed to guide evolution in a certain direction. There, explicit fitness is often rather straight-forward to design (although possibly complicated to adjust) as, by the basic idea of ER, it captures properties that can be more easily encoded on a high level than programmed on a behavioral level. For example, when evolving CA, driving can yield positive fitness points while being close to a wall or colliding can be punished. Implicit fitness, on the other hand, is more difficult to influence as the entire environment has to be designed accordingly. Furthermore, implicit fitness can include complex long-term properties such as, e. g., a robot promoting its own offspring in producing new offspring. This is due to the fact that offspring behavior contains partially the same genes (i. e., pieces of behavioral descriptions) as the according parental behaviors. Therefore, implicit fitness of the parent robots can increase indirectly when the offspring chance of contributing to the gene pool increases.
As opposed to nature, evolution in ER is supposed to be controlled to move into a certain direction. Therefore, the explicit fitness function and, to some extent, implicit environmental selection properties can be designed according to desired behavioral criteria. To give another example, the following situation can be considered: let a swarm of robots be explicitly selected for the ability to find a shortest path from a nest to a forage place, for example, by giving a fitness bonus reciprocally proportional to the time required for the travel between nest and forage place. As long as the robot density is sufficiently low to allow arbitrarily many robots to simultaneously traverse each path in the environment while keeping the interference of robots with each other low, explicit fitness will be the strongest selective power, hopefully leading eventually to the discovery of the shortest path. If, however, the shortest path is too narrow to fit more than a few individuals at a time, evolution might implicitly select for individuals that use longer, but less crowded paths, or for those that can decide which path to take based on congestion rates. Depending on the exact properties of the different paths, implicit selection might highly affect evolution in this example. In [19], the impact of environmental selection has been experimentally investigated in an even more extreme scenario using mainly implicit selection with a minor explicit part (cf. Sec. 6.4.3 of Chap. 6). There, robots learned to explore the environment by being selected for mating when they came spatially close to each other. In a second experiment, robots learned foraging by being implicitly forced to collect energy or to die otherwise. Overall, it turns out that in complex environments explicit fitness can play a subordinated role with implicit fitness having the major impact on selection. On the other hand, explicit fitness is easier to design in a proper way to drive evolution into a desired direction. Therefore, it is desired to arrange evolutionary settings such that major selection pressure is induced explicitly with implicit factors playing a supportive role.
Table 2.1. Classification of fitness functions in ER. The table lists seven types of fitness functions one of which most ER approaches can be assigned to. The second column shows the a priori knowledge required for the use of the according fitness function type (the less a priori knowledge required the more flexible the learning process).
| Fitness function class | A priori knowledge incorporated |
|---|---|
| Training data fitness functions (to use with training data sets) | Very high |
| Behavioral fitness functions | High |
| Functional incremental fitness functions | Moderate – high |
| Tailored fitness functions | Moderate |
| Environmental incremental fitness functions | Moderate |
| Competitive and co-competitive selection | Very low – moderate |
| Aggregate fitness functions | Very low |
2.1.2 Classification of Fitness Functions in ER
According to Nelson et al. [139], fitness functions in ER (including both explicit and implicit aspects) can be classified along the scheme depicted in Tab. 2.1. The basis for this classification scheme is the degree of a priori knowledge that is reflected in the fitness functions. A priori knowledge is knowledge about the system that is not evolved but hard-coded by humans before the beginning of an evolutionary run. While a priori knowledge can facilitate achieving a desired behavior in a certain environment, it makes the process less generalizable to arbitrary environments. For example, a fitness function with the purpose of rating a maze escaping behavior might involve fitness bonuses for crossing certain check points on the way out. As such check points are specific to the maze to be solved, they do not easily generalize to other mazes making the approach somewhat static.
The reason for choosing this classification scheme is that a priori knowledge reflects the level of truly novel learning that has been accomplished [89]. The more a priori knowledge is put into a learning process, the less true learning has to be accomplished by the system. In fact, from an abstract point of view a regular static behavioral algorithm can be considered a special case of a learning algorithm with so much a priori knowledge that no flexibility is left to the learning process at all. Fitness functions that require little a priori knowledge, on the other hand, can be used to exploit the full richness of a solution space, beneficial aspects of which may not have been evident to the experimenter beforehand [37], [142], [190]. The types of fitness functions listed in the table are outlined in the following according to the definitions given by Nelson et al.
Training data fitness functions. Fitness functions of this type require the most a priori knowledge. They can be used in gradient descent optimization and learning scenarios, for example for training ANNs by using error back propagation. There, fitness is directly connected to the error that is produced when the trained controller is presented a given set of inputs with a known set of optimal associated outputs, fitness being maximized when the output error is minimal. A training data set has to contain sufficient examples in order that the learning system can extrapolate a valid generalizable control law. Thus, an ideal training data set (which is in ER in most cases unavailable and infeasible to create) contains knowledge of all salient features of the control problem in question. Several examples of fitness functions of this type being successfully used in learning scenarios are given by Nelson et al. [139].
Behavioral fitness functions. Fitness functions of this type are typically rather easy to assemble which is why they are widely used in ER. Behavioral fitness functions are task-specific and hand-formulated, and they can measure various aspects of what a robot is doing and how it is doing it. In distinction to more elaborate fitness function types, behavioral fitness functions measure how a robot is behaving, but typically not what it has accomplished with respect to the desired behavior. For example, a behavioral fitness function for CA could observe the wheel motors and proximity sensors of a robot and initiate a bonus when the robot drives forward while punishing it when approaching an obstacle. However, this fitness calculation does not consider the robot’s success on a task level which is given by moving crash-free and preferably quickly through a field of obstacles. Such fitness calculation includes a priori knowledge of how a robot should learn a desired behavior, which introduces the risk of cutting out other possible solutions. For example, in the case of CA, communicating with other robots to get information about crowded places might lead to improved results, but this solution is precluded when using the above fitness function. In contrast, aggregate fitness functions measure aspects of what a robot has accomplished, without regard to how it has been accomplished (see below). There are many examples of behavioral fitness functions in the literature, e. g., [7],[84], [118]. In this thesis, the fitness function for CA is a behavioral fitness function.
Functional incremental fitness functions. This type of fitness functions is used to guide evolution gradually from simple to more complex behaviors. The evolutionary process begins by selecting for a simple ability such as, for example, CA. Once the simple ability has been evolved, the fitness calculation method is replaced by an augmented version which induces selection for a more complex behavior. For example, a task of maze escaping might be activated after a foundation of CA has been evolved. In an evolutionary run, the fitness calculation can be incremented in several stages of increasing complexity. When evolving complex behaviors, this type of fitness functions can help overcoming the bootstrap problem (cf. Sec. 2.1.3). However, it is difficult to define the different stages in such a way that each can build upon the preceding one. Furthermore, it can be hard to decide if one of the temporary behaviors is already evolved properly. As incremental fitness functions involve the hand-coding of intermediate steps of behaviors to be evolved, there is inherently a significant portion of a priori knowledge required. Successful approaches using functional incremental fitness functions can be found in [9], [64], [153].
Tailored fitness functions. These fitness functions contain behavior-based terms as well as aggregate terms, i. e., terms which include observations on a task level, measuring how well a problem has been solved independently of any specific behavioral aspects. For example, when evolving a phototaxis behavior (approaching or avoiding light sources), a possible fitness function might reward controllers that arrive at light sources (or dark places), regardless of their actual actions on a sensoric or actuator level. This would be considered an aggregate term of the fitness function, and the fitness function itself would be considered aggregate if it was the only term. If the calculation additionally involved a behavioral term, such as rewarding robots which face toward (or away from) a light source, the fitness function would be considered tailored. Another example of a tailored fitness function is the evolution of Object Transport where in an aggregate part the fitness function might measure if an object has been transported properly, and additionally reward aspects such as being close to an object or pushing it in the right direction in its behavioral part. Examples from literature include [97], [155], [171]. The “Gate Passing” behavior in this thesis is evolved using a tailored fitness function, cf. Chap. 4.
Environmental incremental fitness functions. Fitness functions of this type are similar to functional incremental fitness functions as they involve increasing the difficulty of gaining fitness during an evolutionary run. However, in contrast to the former, the complexity of the fitness function is not directly increased by adding or complex-ifying terms, but the environment in which the robots operate is made more complex. For example, after a first solution to a phototaxis task has been found, light sources might begin to move, or more obstacles might be added to make it more difficult to approach the light. In terms of explicity of the selection process (cf. Sec. 2.1.1), this type of fitness functions involves a substantial implicit part which has to be designed carefully to make the evolutionary process successful. Further examples can be found in [9], [128], [135], [149].
Competitive and co-competitive selection. This category refers, rather than just to a type of fitness functions, to a specific type of selection including an according set of fitness functions. Competitive and co-competitive selection exploits direct competition between members of an evolving population or several co-evolving populations. In contrast to other ER scenarios which in almost all cases involve controllers competing with each other in the sense that their measured fitness levels are compared to each other during selection, in competitive evolution the success of one robot directly depends on its capability of reducing the success of another robot. An example is a limited-resources scenario where robots fight for food to survive. In co-competitive selection, the population is divided into several subpopulations which have conflicting target behaviors. Designed properly, this can lead to an “arms race” between the competing subpopulations. A popular and particularly well-studied case of co-competitive selection is given in predator-prey scenarios. More examples of competitive and co-competitive selection can be found in [20, [26], [27], [138], [141].
Aggregate fitness functions. Fitness functions of this type rate behaviors based on the success or failure of a robot with respect to the task to complete, not considering any behavioral aspects of how the task has been completed. For example, a (naïve) aggregate fitness function for Gap Crossing might reward robots according to the time they require to cross a gap. This type of fitness calculation, sometimes called all-in-one evaluation, reduces human bias induced by a priori knowledge to a minimum by aggregating the evaluation of all of the robot’s behaviors into a single task-based term. Truly aggregate fitness functions are difficult to design, and such approaches often end up in trivial behavior due to insurmountable success requirements. In the above example of Gap Crossing, a robot population is likely to never achieve the capability of crossing the gap at all which would result in no robot ever gaining superior fitness in comparison to the other robots (cf. bootstrap problem, below). There are few examples of a successful use of aggregate fitness functions in the literature; some can be found in [74], [80], [115].
2.1.3 The Bootstrap Problem
A properly working selection operator relies on the ability of the fitness function to distinguish the qualities of the behaviors in a given population. Otherwise, for example, if all behaviors of a population obtain zero fitness, the evolutionary process is not directed, but purely random. For sophisticated fitness functions, the bootstrap problem denotes the unlikeliness of the occurrence of any behavior which achieves a significantly superior fitness compared to the rest of the population when starting in a population of robots with similar behavioral qualities. As in the beginning of a run all robots are expected to have similar fitness, selection cannot direct evolution in that phase, but the first significant improvement has to be achieved by random mutations only (including mutations which result from recombination). The same is true for local optima, i. e., neutral fitness plateaus where the whole population has evolved a part of the behavioral requirements given by the fitness function, and, therefore, all robots are indistinguishable by fitness. Hence, when all individuals of a population reside on a neutral fitness plateau, selection is not capable of working properly, leaving mutation as the only operator capable of producing improvements. If an improvement demanded by the fitness function is too hard to be achieved by mutation, the population remains stuck on the plateau. For evolution to work, fitness functions should be designed in a way that a behavior with an above-average rating is likely to occur in any phase of evolution. For example, Urzelai et al. report that a phototaxis behavior in a complex arena can be evolved more easily when it is preceded by the evolution of a CA behavior [195]. However, when evolving complex behaviors it may be very challenging to avoid (premature) situations where the occurrence of a significant improvement is highly improbable.
The bootstrap problem is often considered the main impediment to evolving complex behavior, and consequently it is currently one of the main challenges of ER. A possible solution to the bootstrap problem is to use incremental fitness functions (functional or environmental) which reward intermediate steps of mediocre behavior, until finally leading to the desired target behavior. This approach has been successfully used in several studies[10], [56], [64], [99], [128], [133], [135],[136],[137],[149],[150] [153], [194], [195]. However, incremental approaches require a great amount of a priori knowledge regarding the problem to solve or a complex augmenting environment which both, if inaccurately designed, can lead the evolutionary process to a dead end. Moreover, incremental evolution usually requires to precisely order the different sub-tasks, and to determine when to switch from a sub-task to another. For these reasons, incremental approaches are not easily generalizable to more complex or more open tasks.
Another approach to overcome the bootstrap problem is to efficiently explore the neighborhood of the currently evolved candidate behaviors for one with an above-average fitness. Similar ideas have been widely investigated in EC as diversity-preserving mechanisms [55], [169] and life-time learning [71], [147]. Typically they rely on a distance measure between genotypes or phenotypes. Recently, another approach has been followed to directly measure behavioral diversity in ER with the purpose of supporting population diversity [134]; this approach relies on measuring distances between behaviors rather than between genotypes or phenotypes. In Chap. 5 of this thesis, novel genotypic encodings and mutation operators are proposed which allow for evolving the GPM together with the robot behavior. As a side effect, this approach leads to a higher population diversity which, in turn, can reduce the bootstrap problem. As discussed in Chap. 5, this is a possible explanation (although not the most satisfactory one) of the improvements observed in comparison to the approach studied in Chap. 4.
2.1.4 The Reality Gap
Another well-known problem in ER is the transfer of simulated results into real-world applications [83], [85]. It has been shown for many pairs of simulation environments and corresponding real robot hardware that controllers which have been evolved in simulation can have a very different behavior when transferred to real robots [142]. This problem, often referred to as the reality gap, arises from several real-world factors which are inherently hard to simulate; among these are
- – unknown (physical or structural) details of the real environment and the real robots,
- – known properties which are infeasible to simulate due to computational costs,
- – unpredictable motoric and sensory differences between robots,
- – mechanical and software failures.
Furthermore, small variances between simulation and reality can quickly lead to great differences in terms of robot positions and angles. Particularly, this makes behaviors virtually unsimulatable which are relying on exact distance and turning instructions. Let, for example, a robot be instructed to turn for 45 degrees and drive straight ahead thenceforward. Obviously, it can soon reach significantly different positions if the actual turn which is accomplished by its motors is in a range between 40 and 50 degrees (where 5 degrees of variance due to mechanical properties are a rather moderate estimation when working with current mobile robots).
On the other hand, there are obvious advantages in terms of computational and cost efficiency of utilizing simulation when evolving robot controllers. Therefore, there have been different attempts to avoid the reality gap. A common method is to use a sophisticated simulation engine with physics computation and artificially added noise to create unpredicted situations. To deal with the high computational complexity of these simulations, an established method is to use different levels of detail depending on the purpose of the simulation [2], [3], [83]. Another way is to combine evolution in simulation with evolution on real robots [199]. Following this approach, it is possible to use the measured differences between simulation and reality as a feedback in an “anticipation” mechanism to adjust the simulation engine [63]. Another idea is to adjust evolutionary parameters and operators in a rather simple simulation and to actually evolve behaviors onboard of real robots. This approach avoids the reality gap under the reasonable assumption that, although motoric and sensory details might be hard to simulate, the mechanisms of evolution work on real robots basically in the same way as in simulation [199]. The experiments described in this thesis are based on this assumption; Chap. 4 provides further evidence for its validity by transferring simulation results to real robots. However, this approach requires to actually evolve behaviors in an expensive real-world scenario after having tested the basic process in simulation. Chap. 6 proposes and discusses a method for predicting the success of an evolutionary run in a real-world environment based on simulation data.
2.1.5 Decentralized Online Evolution in ESR
Many of the concepts presented in this thesis are in principle applicable to various evolutionary approaches within and outside of ER. For example, the FSM as a formal model has been used to evolve programs for several interesting tasks, such as the prediction of prime numbers, in the field of Evolutionary Programming [50]. Here, however, all concepts are applied to a robot swarm in an embedded evolutionary setting with the purpose to learn behaviors in an online and onboard manner.
As outlined in Sec. 1.2, most approaches in ER and ESR can be categorized into offline or online techniques. In an offline setting a robotic system (i. e., swarm or single robot) learns to solve a desired task in an artificial environment (real or simulated). Subsequently, the evolved behavior is hard-coded into the controllers to solve the task in a real environment. In online settings a robotic system has to learn in an environment which it simultaneously has to solve the task in. This means that during a run, currently evolved behavior is evaluated by observing its performance on the task to solve. In contrast to offline evolution, it is usually not possible (or infeasible) to wait for an eventually evolved behavior of sufficiently high quality, but intermediate behaviors have to be employed and evaluated, too. The requirement of learning behaviors online is given, for example, when robots have to adapt quickly to new and possibly unknown situations or when they have to learn how to deal with novel objectives which occur randomly during a run. Particularly, when robots explore new areas which are at least partially unknown beforehand, objectives may change constantly.
Typically to ESR, a further distinction is made between approaches which utilize observing computers (centralized) and those which do not (decentralized or onboard). In a decentralized system, every robot has to make all decisions based on local observations, only. In most examples from literature, centralized techniques are employed in combination with offline evolution while online evolution accompanies decentralized techniques. Popular examples of centralized offline evolution include, e. g., [1], [4], [53], [59], [60], [61], [178], [179], [192], [198]; popular examples of decentralized on-line evolution include, e. g., [19], [68], [70], [93], [94], [130], [170], [184], [185], [186], [187],[188], [189]. There exist some examples which are best categorized as decentralized offline evolution [69], [182], but, to the knowledge of the author, no work exists so far combining centralized with online evolution.
Evolutionary approaches that are on the decentralized and online side of the classification scheme (such as those proposed in this thesis) are sometimes called Embodied Evolution (EE) [200]. One of the first works in EE has been the “Probabilistic Gene Transfer Algorithm” [200] as well as the work of Simões and Barone [36]. Both approaches use an ANN model as a control mechanism to evolve robotic behavior (cf. discussion in Sec. 2.1.6). Embodied evolution can be implemented in simulation as well as on real robot platforms, and it can be applied to a variety of different scenarios. Due to the decentralization, embodied approaches scale well to large swarms of robots, and due to the online property, the main focus is on finally achieving an adaptation to a real environment, rather than to a simulated environment or an environment in a laboratory experiment. Therefore, simulation and laboratory experiments are used in EE to study evolutionary mechanisms only, but not to evolve behaviors for the purpose of using them as static controllers in real-world environments.
Offline and centralized techniques are known to converge more quickly to good solutions for several problem classes than EE techniques do, but there is a broad range of applications for which they cannot be used. Particularly in swarm robotics, there are innumerable important applications for which EE appears to be a better choice. Whenever swarms of robots are supposed to solve tasks in new and (partially) unknown areas which are not accessible to humans or other global observers, a decentralized approach is required; and whenever such an area contains unknown sub-challenges interfering with the global goal, or when unforeseeable changes to the environment are likely to occur during the robots’ mission, an online approach is necessary.
Real-world applications range from recovering victims in disaster areas or unmanned discovery of the surface of the sea or of other planets, to healing diseases by injecting a swarm of nano-robots into the human body. While such applications seem rather futuristic today, their theoretical feasibility in terms of available robot hardware is steadily increasing. Therefore, ER research has to keep up to prospectively be able to provide the required software for the control of future swarms of robots (or to play an appropriate part in a more general control framework – which is more likely, from today’s perspective).
Beyond the rather uncritical examples listed above (in terms of their intended purposes), there are many imaginable applications which might harm people or the earth’s environment in various ways. Applications related to weapons, military equipment, spy out of people, which is even today technologically feasible in several ways, and many others are not discussed here, although the proposed techniques cannot be prevented from being used in these areas. However, profound ethical considerations are beyond the scope of this thesis and the author’s competence. Nevertheless, thorough analyses of the ethical implications of all planned applications are inevitable and should be ubiquitous for all technologies that have a potential to majorly influence the wellbeing of people. Particularly, mere market analyses cannot be an appropriate replacement for such analyses.
2.1.6 Evolvability, Controller Representation and the Genotype-Phenotype Mapping
According to current biological understanding, in natural evolution there is a rather strict separation between the genotypic world where mutation and recombination take place and many characteristics of an organism are encoded, and the phenotypic world where individuals inhabit a niche in the environment and are subject to selection as part of the “survival of the fittest” (or the “struggle for life”, as Charles Darwin framed it in the “Origin of Species”). In artificial evolution, this separation can be omitted for simplicity reasons by evolving solely in the solution space or phenotypic space. In the case of ER this means that mutation and recombination are directly applied to behavioral programs of robots. Most approaches in ER so far have been performed in this manner due to the limited resources on real robot hardware. However, a well-established approach from EC is to mimic natural evolution by introducing a genotypic representation of an individual, different from the phenotypic representation. As in nature, each genotype then corresponds to a phenotype, i. e., a robot controller, which has to be computed from the genotype by a translation procedure called GPM. Thus, mutation and recombination operations are performed in the genotypic space while evaluation and selection take place in the phenotypic space. This differentiation between genotypes and phenotypes has proven to enhance the performance of evolution for several reasons. Due to the possibility of introducing genotypic representations with less syntactical constraints than the corresponding phenotypes have, a “smoother” search space can be accomplished. For example, in a work by Keller and Banzhaf, bit strings are used to genetically encode C programs, using a repair mechanism as part of the GPM to make every string valid [92]. The authors report a significant improvement in terms of quality of the found solutions compared to an approach with phenotypes only, explaining the improvement by the hard syntactical constraints on mutation and recombination when working solely in the phenotypic space. Similarly, the phenotypic space used in this thesis consists of controllers encoded as FSMs (cf. Sec. 2.1.7) which are accompanied by hard syntactical constraints. The according genotypic space introduced in Chap. 5 consists of sequences of integers which are translated into FSMs by using a script including a repair mechanism. Experiments with this static genotypic representation show an improvement in terms of mean fitness and complexity of evolved behaviors, confirming the results of Keller and Banzhaf.
Beyond that, important properties of natural genotypes can be obtained using a GPM which include expressive power, compactness and evolvability [142]. There, expressive power refers to the capability of a genotypic encoding to capture many different phenotypic characteristics and allow for a variety of potential solutions to be considered by evolution; a compact genotypic encoding is given if the genotypes’ length sub-linearly reflects the complexity of the phenotype; and evolvability is described in [142] as the capability of an evolutionary system to continually produce improvements by repeatedly exerting the evolutionary operators (note, however, the difference in the definition of evolvability introduced in Chap. 5).
Usually, the GPM is a non-bijective mapping, meaning that many different genotypes can be translated into the same phenotype. Furthermore, the GPM is not necessarily static, but it can depend on time and the state of the environment. There are approaches that let the genotype pass a process of development (sometimes called “meiosis”), which yields more and more complex structures by considering the current states of the organism in development and the environment [67]. Another nature-mimicking idea is to make the GPM evolvable, i. e., itself subject to evolution [142]. Inspired by the natural process of gene expression, where the rules for translating base sequences into proteins themselves are encoded in the DNA [52], the GPM can be encoded in a part of the genotype making it implicitly subject to adaptation during evolution. This can result in an adaptation of the GPM to the fitness landscape given by the task to evolve and the environmental properties. As a consequence, the indirect effects of mutation and recombination on the phenotypic level can be adapted to the fitness landscape, actively directing the search process towards better phenotypes by skipping areas of low fitness. A practical benefit of this approach is that the mutation and recombination operators do not have to be adjusted manually before every evolutionary run, but the adaptation is performed automatically, according to the behavior to evolve and the environment it is evolved in. A related approach is followed in the well-known Evolution Strategies [13] where the mutation strength is encoded as part of the genotype, thus being evolvable during evolution.
A more general benefit intended to be achieved by the usage of evolvable GPMs is an increase in evolvability (in the above sense). While in nature the GPM is known to be a flexible part of evolution, to the effect that the rules determining the translation of the DNA into proteins are themselves encoded in the DNA, the effects of this flexibility on evolvability are still discussed [39],[40] [114], [152]. Likewise, it is still an open question if an evolvable GPM can increase evolvability in ER. This thesis provides evidence that an evolvable GPM can significantly increase the expected evolutionary success in ER in terms of behaviors evolved, and that an evolvable GPM can adapt to a given search space structure as proposed above (cf. Chap. 5). Both these results cannot prove an increase in evolvability as they can be explained by different effects, too, but they may serve as building blocks toward a general understanding of evolutionary processes in ER.
An evolvable GPM allows for evolution to learn structural properties of the search space, which depend on the behavior to be evolved, and to use this knowledge for improving evolvability during a run. Fig. 2.3 shows an example of a desirable adaptation of the mutation step size when searching the minimum of a “Schaffer 2” function (a typical benchmark function in EC) in a one-dimensional real-valued search space. Due to the flexibility of the GPM, operators can be adapted indirectly by changing the meaning of a part of the genotype, thus changing the impact of the operator when working on that part. In the example, mutation can change during evolution to skip the gaps in the fitness landscape and move on to better fitness regions.
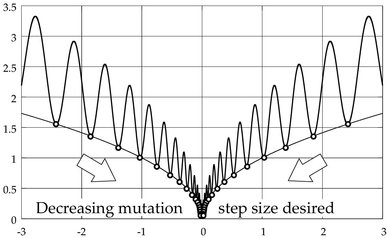
Fig. 2.3. Adaptation of mutation step size in a one-dimensional real-valued search space. The depicted Schaffer 2 function is given by f : ℝ → ℝ : x ↦ |x|0.5 (sin2 (50 · |x|0.2) + 1). When approaching the minimum at x = 0, an individual’s mutation step size should decrease to skip the local maxima and still approach the global minimum rather than oscillating around it.
2.1.7 Controller Representation
The term Controller Representation (or simply Controller) refers to the structure of programs running onboard of robots with the purpose of controlling their behavior. In the past, ANNs have been used most frequently to encode robotic control systems. According to Nelson et al. in 2009, about 40 % of the published results in ER have been achieved using ANNs, while another 30 % used evolvable programming structures, i. e., Genetic Programming [139]. Of the approximately 50 papers reviewed by Nelson et al., only two use FSM-based encodings. The current preference of ANN-based controllers can be attributed to the rather straight-forward implementation of ANNs including a set of well-studied learning operations other than evolution, and simply to the broad success of ANNs in learning various behaviors. However, in most cases these benefits come at the cost of resulting controllers which have a complicated structure and are hard to interpret. In the case of ER, this is due to the randomized changes to the genotype introduced by evolutionary operators such as mutation or recombination which optimize the phenotypic performance without respecting any structural benefits of the genotype. The consequence is that evolved controllers are hard to analyze from a genotypic point of view. While it may seem plausible by observation that a robot has learned a certain behavior, is is usually not possible to prove it. This comes as an additional difficulty to the problem observed by Braitenberg that it is hard to predict robotic behavior solely from knowledge of the controller (cf. Chap. 1, [17]). While this may seem acceptable in some areas, there are many robotic applications for which it is crucial to guarantee that tasks are solved every time with the same precision or in the same manner (e. g., in medical applications where errors can cost lives or on space missions where erroneous behavior can be very expensive).
On the other hand, there are several successful approaches in EC which rely on the rather simple theory of FSMs, e. g., [48], [49], [50], [51], [177]. In ER, there are also a few successful approaches reported using FSMs, e. g., [91], [208], [209]. In [91], the authors call their method Genetic Programming due to the genetic operations performed on the controllers. However, the controllers are built from simple if-then-else blocks triggering atomic actions based on sensoric information, which in essence can be represented by an FSM. (Considering similar cases, there might be a higher number of FSM-based approaches than assumed, as some authors might call their methods differently.) In both publications, the authors report that controllers were generated in simulation and then successfully tested on real robots and in simulation.
The semantics of FSMs is much more comprehensive than the semantics of ANNs leading to controllers that can be analyzed automatically for various non-trivial properties. This is the main reason why in this thesis FSMs have been deployed as controllers, based on a newly proposed controller model called Moore Automaton for Robot Behavior (MARB) [102], [105], [106]. Beyond this thesis, the MARB model has proven successful in a medical application (in a non-ER setting) studied by Jung et al. who have used MARBs to generate controllers for a robotic exoskeleton walking assistant with crutches for paraplegic patients [88].
The price for the analyzability of FSMs is their lower expressive power and, when used in a straight forward way, their lower evolvability compared to ANNs which are both Turing-complete and highly evolvable in many scenarios. However, as reported many times, for example by Braitenberg, complex control structures are not necessarily required to encode complex behaviors. Particularly, the complex behaviors which Braitenberg established by direct connections from sensors to motors (cf. Chap. 1), are performed by even simpler control structures than FSMs. Furthermore, by far the most of all existing controllers learned with ANNs could as well be represented as FSMs meaning that the expressive power of ANNs is generally not exploited in today’s robotic controllers. The second drawback, namely the lower evolvability of FSMs, is a more serious problem, and searching for a solution to it is a main topic of this thesis. It is discussed in Chap. 4 where an approach without a distinction between genotypic and phenotypic representation is presented, and in Chap. 5 where a genotypic representation for FSM-based controllers and a completely evolvable GPM are introduced. In the approach without a genotypic representation, the structural benefits of the MARB model are exploited by a mutation operator which is designed to “harden” those parts of an FSM which are expected to be involved in good behavior. Other parts of the FSM stay loosely connected and can get deleted within few mutations. In this way, the complexity of the automaton gets adapted to the complexity of the task to be learned (similarly to an ANN-based approach by Stanley and Miikkulainen [180]). In the approach with an evolvable GPM, the translation from genotypes to phenotypes is supposed to evolve along with the behavior making mutations and recombinations adaptable to the search space structure, as described above.
2.1.8 Recombination Operators
Recombination is rather rarely used in ER as it tends to hardly improve evolution by being laborious to design and set up [142]. Nevertheless, there are studies that show the successful adoption of recombination operators in ER. For example, Spears et al. evolve FSMs for the solution of resource protection problems by representing a genotype as a matrix assigning to each state/input pair an action and a next state (essentially a Mealy machine) [177]. They observe that evolution is capable of finding the appropriate number of states necessary to learn a behavior of a certain complexity. Furthermore, they report that a recombination operator has a great positive influence on evolution. In Chap. 4, a similar recombination operator is used on controllers represented as MARBs without involving an explicit GPM. The main result, however, is that it has a rather small effect (if any) on evolution. Moreover, the effect is positive in certain specific parameter combinations only, by even being harmful in others.
2.1.9 Success Prediction in ESR
A key problem in ESR is to accurately select controllers for offspring production with respect to performing a desired behavior [142]. This means that “better” controllers in terms of the desired behavioral qualities should have a higher chance of being selected than “worse” ones. However, it is usually not possible to grade arbitrary evolved controllers detached from the environment in which the desired task has to be accomplished. Therefore, all ESR scenarios require the existence of an environment (real, simulated or even further abstracted) where the controllers can be tested in. Using an environment to establish the quality of controllers (i. e., their explicit and implicit fitness) makes ESR more closely related to natural evolution than most classic EC approaches (cf. the two different views on ESR in Sec. 2.1.1).
Requiring a complex environment for fitness evaluation makes it hard to predict the success probability of a given ESR scenario, i. e., the probability that a behavior capable to solve a given task will be evolved in an acceptable time. On the other hand, such a prediction is essential if failures can yield to expensive hardware damage or even harm humans. Due to the reality gap, this is a common case for many desired applications. The need for evolving online or at least in an environment designed as similar to the real environment as possible tends to make experiments expensive.
There has been a lot of theoretical work in the fields of classic EC, spatially structured evolutionary algorithms, evolutionary optimization in uncertain or noisy environments, and ER aiming at the calculation of the expected success of an evolutionary run, and, as a result, on the calculation of the required settings to increase the chance of success [5],[6],[62], [77], [86], [95], [151], [154], [166]. Furthermore, there are well-established models of natural processes from the field of Evolutionary Biology [52], and interdisciplinary concepts such as Genetic Drift [98] and Schema Theory [77]. However, there is, to the knowledge of the author, so far no theoretical model which includes implicit (environmental) selection as well as explicit (fitness based) selection in the calculation of success. The combination of these two types of selection is considered typical to ESR [142], and occurs neither in classic EC nor in Evolutionary Biology separately.
In Chap. 6, the influence of environments on the evolution process in ESR is studied theoretically and experimentally. A hybrid mathematical and data-driven model based on Markov chains is presented that can be used to predict the success of an ESR run. By successively adding more and more data from simulation or laboratory experiments, the prediction can be improved to a desired level of accuracy before performing an expensive real-world run. The model considers implicit selection properties and the selection confidence of a system, i. e., a measure of the probability of selecting the “better” out of two different robots in terms of their desired behavioral properties. The latter is related, but not identical, to explicit fitness. The model calculates the expected success rate of a given ESR scenario based on a series of “fingerprints”, i. e., abstracted selection data typical to a scenario derived from available simulation or real-robot experiments. So far, experiments support the hypothesis that the model can provide accurate success estimations, although more experiments are required to confirm this statement, cf. Sec. 6.4. However, it is important to note that the model as presented in this thesis is still at a basic stage and further work is necessary to make it applicable to real-world problems, cf. discussion in Chap. 6.
2.2 Agent-based Simulation
The field of ABS has experienced a quick growth since the early 1990s. It has been established in many fields of academic research as an indispensable technology to yield insights that neither formal reasoning nor empirical testing are able to achieve [173]. ABS offers intriguing ways to model superordinate effects which emerge from local interactions of individual agent behaviors. Applications range broadly from economic examinations of stock trading policies through traffic planning and social interaction modeling to the development of complex behavior which includes robot evolution in ESR. In the last two decades, various ABS platforms have been developed, some of which have specific properties intended to suit a particular problem area while others serve as general-purpose frameworks. The former include MAML for social sciences, NetLogo, StarLogo and, more recently, ReLogo for education, Jade, NeSSi and OMNET++ for networking, Breve and Repast for artificial intelligence, MatLab, and OpenStarLogo for natural sciences, and Aimsun and OBEUS for urban/traffic simulation. Among the latter, i. e., the general-purpose ABS frameworks, there are programs of different powerfulness and complexity, for example, Anylogic, Ascape, DeX, EcoLab, Madkit, Magsy, Mason, NetLogo, ReLogo, Repast, Swarm, SOAR and many more. These lists intersect, as some simulations have originally been developed for a specific application area and generalized later, and they are by far not limited to the given examples. These simulations mostly run on popular operating systems such as Windows, Linux or Mac OS including a Java Runtime Environment or GNU C/C++ Compiler. Many of these frameworks are publicly available for free, at least for noncommercial usage [140], [157], [172].
Depending on the focus of the users, each of these simulation frameworks has its advantages and drawbacks. Some fit in very special application areas only, such as the microscopic traffic modeling framework Aimsun [8], [22], while others are flexibly adjustable to various types of applications, such as Netlogo [174], Mason [117], Swarm [31], [129], and Repast [29], [144],[145],[148], as well as the merger of Repast and NetLogo, ReLogo [119]. In addition to those, many others have emerged in the last years driven by specific requirements and emphases of the developers. Particularly, great progress has been made in developing more and more practical ABS toolkits. These toolkits enable individual developers to implement considerably more powerful and complex applications using the agent paradigm than before. Simultaneously, there has been a quick increase in the number of such toolkits [140]. There have been efforts in organizing the available ABS frameworks by comparing several of their functional and non-functional properties with each other. However, such efforts, due to the large number of available simulations, either focus on few programs or give rough overviews only. In [23], the eight toolkits Swarm, Mason, Repast, StarLogo, NetLogo, Obeus, AgentSheets, and AnyLogic are described and compared to each other; MASON, Repast, NetLogo and SWARM are analyzed, and compared to each other in [157]; Tobias and Hofmann examine the four toolkits Repast, Swarm, Quicksilver, and VSEit [189]; Serenko et al. examine 20 toolkits with a focus on instructors’ satisfaction when using the software in academic courses [172]; Nikolai and Madey perform a broad examination and categorization of a large list of ABS toolkits [140].
However, it has been pointed out recently that ABS is still at an “infancy stage” and more work in analytical development, optimization, and validation is needed [24]. Other simulation paradigms, such as discrete-event simulation, system dynamics, or finite-element-based simulation are claimed to be different in this respect as they have already developed a rich set of theories and practices. One issue that is particularly important for big research projects, is the development of structured and reusable code. Structured code can be the foundation of an error-free implementation, especially if unskilled programmers are involved. This is, for example, frequently the case in academic research where students are involved within the scope of a thesis or a laboratory course, but also in many other projects which include people without a software engineering background. While there exist popular easy-to-learn ABS toolkits such as MASON or NetLogo, their architectures do not guide unskilled users actively to well-structured code, but leave it to their own competency. This can lead to code that is hard to reuse, and understand, and, in turn, to potentially erroneous implementations. It is still challenging for non-experts to generate suitable simulation models and implement them in a structured and reusable way using most of the current simulation frameworks.
Furthermore, considering the multitude of available simulation programs, it is challenging to select for a given task an appropriate ABS framework to work with. Beyond task-inherent constraints, the existence of convenient features has to be taken into account which range from practical functionalities, such as automatic chart generation or an intuitive user interface, to flexibility, extendability and reusability [24], [120]. Modularity is another key feature, as different programmers should be able to work on one large project without interfering with each other while still being able to reuse each others’ code. Moreover, it should be possible to reconfigure the programmed modules from use case to use case and to reuse modules in simulations different from the one they were originally designed for. Another important requirement is efficiency which concerns time consumption as well as memory usage because long or complex simulations tend to occupy large amounts of memory. A support for automatically outsourcing simulation runs, for example to a cloud service, is therefore desirable, too. Overall, from a non-expert perspective, the seeming benefit of a huge variety of available ABS frameworks turns out to be overwhelming, and the difficulty in generating structured code is a major reason for the break down of software projects involving unskilled users (at least according to the author’s experience which is limited to the area of academic research).
In this thesis a novel architecture for programming agent simulations is introduced, which is called SPI. The SPI is particularly suitable to guide student programmers with little experience to well-structured and reusable simulation components. It introduces an intermediate layer, the Scheduler/Plugin Layer (SPL), between the simulation engine and the simulation model which contains all types of functionality required for a simulation, but logically separable from the simulation model. This includes (but is by far not limited to) visualization, probes, statistics calculations, logging, scheduling, API to other programming languages etc. The SPL offers a uniform way of extracting functionalities from the simulation model which logically do not belong there. Due to the rigorous detachment of the simulation model from the simulation engine, which can be bridged solely by using the SPL, users are forced to implement not only on the model side, but also modules on the SPL side. The extracted modules can be attached and detached flexibly, and used in completely different scenarios, making the code reusable. The modules that can be placed in the SPL are called plugins in general, and schedulers if they are mainly used for scheduling purposes. The SPI architecture can be implemented in a simple way as an extension to most state-of-the-art simulation frameworks. It has been inspired by the Model/View/Controller (MVC) architectural pattern [21] and can be seen as a generalization of that pattern.
For this thesis, the SPI has been implemented as part of the ABS framework EAS [109]. It has been created out of the requirement of a general-purpose simulation framework that could be used in projects where academic research is combined with student work and that supports all the above-mentioned criteria in an active and intuitive way with a focus on modularity and reusability. This means that the desired framework should not only allow implementations to have these properties (which is the case for many of the currently available simulation frameworks), but the programming architecture should guide particularly unskilled users in an intuitive way to a well-structured implementation.
EAS has a slim simulation core which, due to its size and simplicity can be considered virtually error-free. It provides a notion of time and the SPL interface that establishes a connection to simulation models. All additional functionalities are implemented as part of a simulation model or a plugin/scheduler. By removing all unnecessary functionalities from the simulation core, the time and space efficiency is left to the end-user programmers meaning that the simulation core does not constitute a bottleneck of speed or memory.
Another feature of EAS is the direct connection to the job scheduling system JoSchKa [15]. JoSchKa can be used to schedule a magnitude of jobs to work on several local computers in parallel or it can establish a connection to a cloud service to use even greater computing resources over the internet. Using JoSchKa, EAS can run different simulation runs on many computers in parallel or computationally expensive simulations on a single powerful remote computer.
EAS is programmed in Java and can be used as a general-purpose simulation framework. It is a rather new simulation platform being developed in its latest stage for about three years (in 2014). Nevertheless, many common simulation scenarios (including 2D grid and continuous simulations as well as 2D and 3D physics simulations) and a set of important plugins (such as visualization, chart generation, trajectory drawing, logging etc.) are already implemented in EAS. It is an open-source project running under a creative commons license, and it can be downloaded including all sources and documentation from sourceforgeb.
In the next chapter, a detailed description of the SPI and the EAS Framework is given, and the results of a study are presented which compares EAS with the state-of-the-art ABS toolkits MASON and NetLogo.