

OBJECTIVES
199
CHAPTER
10
Testing and Quality
Assurance
n
Understand the basic techniques for software verification and validation
and when to apply them.
n
Analyze the basics of software testing along with a variety of software
testing techniques.
n
Discuss the basics of software inspections and how to perform them.
91998_CH10_Tsui.indd 199 1/10/13 10:59:27 AM

10.1 Introduction to Testing and Quality Assurance
One of the main goals of software development is to produce high-quality software,
with quality usually defined as meeting the specifications and fit to use. To achieve that
goal, there is a need for testing—maintaining a set of techniques for detecting and cor-
recting errors in a software product.
Notice that the best way to obtain quality in a product is to put it there in the first
place. If a well-defined process that is appropriate to the company and the project is fol-
lowed, and all team members take pride in their work and use appropriate techniques,
chances are that the final product will probably be of high quality. If a process is inap-
propriate or craftsmanship is careless, then the product will most likely be of low quality.
Unfortunately, it is not often that all the ideal processes, people, tools, methodologies,
and conditions are met. Thus testing of the artifacts, both along the way and at the end,
becomes an ongoing process.
Quality assurance refers to all activities designed to measure and improve quality in
a product, including the whole process, training, and preparation of the team. Quality
control usually refers to activities designed to verify the quality of the product, detect
faults or defects, and ensure that the defects are fixed prior to release.
Every software program has a static structure—the structure of the source code—and
a dynamic behavior. Intermediate software products such as requirements, analysis, and
design documents have only a static structure. There are several techniques for detect-
ing errors in programs and in intermediate documentation:
n
Testing, which is the process of designing test cases, executing the program in a con-
trolled environment, and verifying that the output is correct. Testing is usually one of
the most important activities in quality control. Section 10.2 provides more informa-
tion on testing.
n
Inspections and reviews, which can be applied to a program or to intermediate software
artifacts. Inspections and reviews require the involvement of more than one person
in addition to the original creator of the product. They are typically labor intensive
but have been shown to be an extremely effective way of finding errors. Reviews and
inspections have been found to be most cost effective when applied to requirements
specifications. Section 10.5 provides more details on these techniques.
n
Formal methods, which are mathematical techniques used to “prove” that a program
is correct. These are rarely applied in business and commercial industries. Section 10.6
provides more information on these.
n
Static analysis, which is the process of analyzing the static structure of a program or
intermediate software product. This analysis is usually automated and can detect
errors or error-prone conditions. Section 10.7 provides more information on static
analysis.
All quality control activities need a definition of quality. What is a good program or
a good design document or a good user interface? The quality of any product can be
defined in two slightly different ways:
n
It conforms to specifications.
n
It serves its purpose.
200 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 200 1/10/13 10:59:27 AM

Notice that these definitions are not equivalent, although they define similar notions.
A product may conform perfectly to its specifications but serve no useful purpose what-
soever. In a less extreme case, a program may conform to its specification but not be as
useful as planned because the environment changed. It is also possible that the specifi-
cation did not contemplate all aspects.
Some of the pioneers in quality also wrestled with the definition of quality. Juran
and Godfrey (1999) defined quality as fitness to use. Crosby (1979) posed quality as con-
formance to requirements and pushed the concept of prevention of error and of zero
defects.
Corresponding to these two notions of quality, we have the following two activities:
n
Verification, which is the act of checking that a software product conforms to its
requirements and specifications. The requirements for a software product are traced
through the development phases, and the transformation of software from one phase
to another is “verified.”
n
Validation, which is the act of checking that a finished software product meets users’
requirements and specifications. This can usually be done only at the end of a project,
with a complete software system.
The three definitions of fault, failure, and error presented here will delineate the differ-
ences of a problem found by users from the source of the problem. We usually identify a
fault as the cause of a failure, but it is not always possible to identify
one specific fault as the cause of a failure. Oftentimes, faults may exist
without being detected or observed in the form of failures. During
testing, failures that reveal the presence of faults are observed.
Note that this distinction is important for all software docu-
ments, not just running programs. For example, a requirement
that is hard to understand is a fault. It becomes a failure only if
it leads to the misunderstanding of a requirement, which in turn
causes an error in design and code that manifests itself in the
form of software failure. A human error creates a fault, and fault
may cause a failure. Not all defects turn into failures, especially
those that stay dormant because the specific code logic was never executed.
When deciding how a program should behave, you need to be aware of all the
explicit and implicit requirements and specifications. An explicit requirement needs to
be mentioned in the requirement documents, and an explicit specification is recognized
as authoritative by the software team. Notice that specifications are not always produced
for all projects, but they can be generic and included by reference. For example, there
may be a requirement such as “conforms to the Human Interface Guidelines of its plat-
form,” which makes those guidelines an explicit specification.
In many cases, there are also implicit specifications. These are not authoritative, but
they are good references and should be followed whenever possible. When inspecting
or reviewing a software product or planning test cases, these implicit specifications need
to be made explicit, even if only as guidelines.
You must also distinguish between the severity of a fault, which is a measure of the
impact or consequences it may have to the users or the organization, and the priority,
Fault/defect A condition that may cause a
failure in a system. It is caused by an error
made by the software engineer. A fault is
also called a bug.
Failure/problem The inability of a system
to perform a function according to its speci-
fications. It is a result of the defect in the
system.
Error A mistake made by a software engi-
neer or programmer.
10.1 Introduction to Testing and Quality Assurance
201
91998_CH10_Tsui.indd 201 1/10/13 10:59:27 AM

which is a measure of its importance in the eyes of the developing organization. Software
failures could have high severity and low priority and vice versa. For example, a bug caus-
ing a program crash under rare conditions will usually be given a lower priority than less
severe bugs that occur under most common conditions. However, for the most part, high
severity failures are also given a high priority.
10.2 Testing
In the Guide to Software Engineering Body of Knowledge (2004), testing is defined as fol-
lows:
Testing is an activity performed for evaluating product quality, and for
improving it, by identifying defects and problems.
Software testing consists of the dynamic verification of the behavior of a program
based on a finite set of test cases, suitably selected from the usually infinite executions
domain, against the expected behavior.
All testing requires the definition of test criteria, which are used to determine what a
suitable set of test cases should be. Once the selected set of test cases is executed, the
testing may be stopped. Thus, test criteria may also be viewed as a means to determine
when testing may be stopped by observing that software product failures are not occur-
ring when all the selected test cases are run. Additional information on test-stopping
criteria can be found in Section 10.4.
Testing is a complex activity that involves many activities and thus must be planned.
The goal of testing or the quality goal for the specific project must be determined, the
test methodology and techniques that need to be utilized to achieve the goal have to
be set, resources must be assigned, tools must be brought in, and a schedule must be
agreed upon. A test plan that spells out all these details has to be developed. For large,
complex software, establishing the test plan itself is a nontrivial endeavor.
10.2.1 The Purposes of Testing
Testing usually has two main purposes:
n
To find defects in the software so that they can be corrected or mitigated.
n
To provide general assessment of quality, which includes providing some assurance
that the product works for many considered cases, and an estimate of possible remain-
ing faults.
Myers (1979) established his position as a strong proponent of the first view. That is, the
main purpose of testing is to find faults, the more the better, before the software product is
released to the users. This view is a bit negative, and it often made testers uncomfortable. It
stands in contrast with the more positive view of testing, which is to show that the software
product works. It took a long cultural change for the testers themselves to feel that it is
fine to report defects. The testers’ contribution to software quality is the discovery of these
defects and their help in having them corrected prior to product release.
It is important to realize that, outside of very simple programs, testing cannot prove
that a product works. It can only find defects, and show that the product works for the
cases that were tested, without guaranteeing anything for other cases that were not
202 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 202 1/10/13 10:59:27 AM

tested. If testing is done correctly, it can provide some reassurance that the software will
work for situations similar to the test cases, but it is usually impossible to prove that the
software will work for all cases.
For the most part, testers will concentrate on finding defects when testing; however,
the testers need to keep in mind that they are also providing a quality assessment and
contributing to the success and quality of the product. The test results are analyzed by
the testers to determine if the specified quality and testing goals have been achieved.
Based on the analysis and depending on the results of the analysis, more testing may be
recommended.
10.3 Testing Techniques
There is a wide variety of testing techniques, applicable to different circumstances. In
fact, there are so many techniques, and they are presented in so many ways, that any
attempt to classify all of them will necessarily be incomplete.
The following questions will clarify thinking about testing activities. They can be used
to classify different testing concepts, test case design techniques, test execution tech-
niques, and testing organizations.
n
Who does the testing? Basically, we have three options here:
n
Programmers: Programmers usually create test cases and run them as they write
the code to convince themselves that the program works. This programmer activity
related to testing is usually considered to be unit testing.
n
Testers: A tester is a technical person whose role for the particular item being
tested is just to write test cases and ensure their execution. Although programming
knowledge is extremely useful for testers, testing is a different activity with differ-
ent intellectual requirements. Not all good programmers will be good testers. Some
professional testers also statistically analyze the results from testing and assess the
quality level of the product. They are often called to assist in making product release
decisions.
n
Users: It is a good idea to involve users in testing, in order to detect usability prob-
lems and to expose the software to a broad range of inputs in real-world scenarios.
Users are sometimes involved in software product acceptance decisions. The orga-
nization will usually ask some users to perform normal noncritical activities with the
new software. Traditionally, if the users belong to the developing organization, we
call this Alpha testing, and if the users are not from the organization we call it Beta
testing. Many organizations publicly state that they will use preliminary versions of
their own product as part of their normal operations. This is usually known by color-
ful names such as “eat your own dog food.”
n
What is tested? There are three main levels:
n
Unit testing: This involves testing the individual units of functionality—for example,
a single procedure or method, or a single class.
n
Functional testing: This involves determining if the individual units, when put
together, will work as a functional unit.
n
Integration and system testing: This involves testing the integrated functionality of
the complete system. When dealing with very large software systems, functions
10.3 Testing Techniques
203
91998_CH10_Tsui.indd 203 1/10/13 10:59:27 AM

may be integrated into a component. Many components are then brought together
to form a system. In that case, there is one more level, called component testing.
Notice that, although these distinctions are important and useful in practice, we
cannot always make a precise rule to distinguish among these levels. For example,
when testing a unit that depends on many other modules, we are mixing unit and
integration testing, and when we are developing components for use by others, the
whole system may correspond to a traditional unit.
n
Why are we testing? Which specific kinds of defects are we trying to detect or which
risks are we trying to mitigate. There are different types of testing conducted for dif-
ferent purposes:
n
Acceptance testing: This is the explicit and formal testing conducted by the custom-
ers prior to officially accepting the software product and paying for it. The accep-
tance test criterion is usually set early at requirements time. The criteria for customer
acceptance may include some specific test cases and the number of test cases that
must pass.
n
Conformance testing: This involves the testing of the software product against a set
of standards or policies. Test cases are usually generated from the standards and
policies that the product must conform to.
n
Configuration testing: Some software products may allow several different configura-
tions. For example, a software product may run with several databases or different
networks. Each of these different combinations (or configurations) of databases and
networks must be tested. The complexities and problems related to configuration
management will be further discussed in Chapter 11.
n
Performance testing: This involves verification that the program behaves according
to its performance specifications, such as some number of transactions per second
or some number of simultaneous users.
n
Stress testing: This ensures that the program behaves correctly and degrades grace-
fully under stress conditions, such as a high load or low availability of resources.
Stress testing will extend the testing of software beyond the performance specifica-
tion to see where the breaking points are.
n
User-interface testing: This is testing that focuses only on the user interface.
n
How do we generate and choose test cases? We can choose test cases based on the fol-
lowing:
n
Intuition: Here we do not provide any guidance as to how to generate cases, relying
solely on intuition. Most of the time, alpha and beta testing relies solely on the user’s
intuition. Some of the intuitions are really based on past experiences that have left
an indelible impression. Very experienced users and long-time product support
personnel are often called to generate test cases from these intuitions.
n
Specification: Testing based solely on specifications, without looking at the code is
commonly called black-box testing. The most common specification-based tech-
niques are equivalence-class partitioning. The input for the soft-
ware system is divided into several equivalence classes for which
we believe the software should behave similarly, generating one
test case for each class. Also, boundary-value analysis, which is an
extension to equivalence class technique and where test cases are
Black-box testing A testing methodology
where the test cases are mostly derived from
the requirements statements without consid-
eration of the actual code content.
204 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 204 1/10/13 10:59:27 AM

generated at the boundaries of the equivalence classes, is used. Both of these tech-
niques are discussed further in the following sections.
n
Code: Techniques based on knowledge of the actual code are
commonly called white-box testing. These techniques are
based on defining some measure of coverage for the code
and then designing test cases to achieve that coverage. Path
analysis is an example of a white-box testing technique, and it is discussed in Section
10.3.3.
n
Existing test case: This refers to a technique called regression testing, which executes
some (or all) test cases available for a previous version of the system on a new ver-
sion. Any discrepancy in the test results indicates a problem with the new system or
with the test case. The specific situation needs to be evaluated by the tester.
n
Faults: There are two main techniques that create test cases based on faults. The first is
error guessing, in which test cases are designed in an attempt to figure out the most
plausible faults, usually based on the history of faults discovered on similar projects.
The second technique is error-prone analysis, which identifies through reviews and
inspections those areas of requirements and design that seem to continuously contain
defects. These error-prone areas will often be the source of programming errors.
Another perspective to consider during testing is to examine the flow and amount of
testing activities. For small projects, the amount of testing usually includes unit testing and
functional testing. The large effort associated with system testing is usually not needed.
However, in most large systems, the progression of testing can include four levels. The indi-
vidual module is usually tested by its author, the programmer. Several modules may contrib-
ute to a specific function, and all the required modules need to be complete and available
for the functional test. The functional test cases are often derived from the requirements
specification. This type of testing is sometimes referred to as black-box testing. Unit testing,
as mentioned before, is often performed with white-box techniques.
As the different functions of the software system complete the functional tests, the
modules associated with those functions are gathered and locked in a repository in prep-
aration for a component test. The components that have passed component testing are
then gathered and locked into a repository. Finally, all the components must complete
a system/regression test. Any changes to the software after the system test will require
a retest of all components to ensure that the system did not regress. The progression of
these test phases is illustrated in Figure 10.1.
Let’s consider a payroll system as an example. We will test the check printing module
in unit testing. Check printing is part of a function called check computation, deposit,
and print. The check computation, deposit, and print function is tested during the
functional testing phase. This functional area is part of a larger component that gener-
ates monthly payroll for full-time employees. The monthly full-time employee payroll is
tested during the component test. Finally, all the components are merged into a system
and the complete payroll system is tested during the system test phase.
10.3.1 Equivalence Class Partitioning
Equivalence class partitioning is a specification-based, black-box technique. It is based
on dividing the input into several classes that are deemed equivalent for the purposes
of finding errors. That is, if a program fails for one member of the class, then we expect
White-box testing A testing methodology
where the test cases are mostly derived from
examining the code and the detailed design.
10.3 Testing Techniques
205
91998_CH10_Tsui.indd 205 1/10/13 10:59:27 AM

it to fail for all other members; conversely, if it is correct for one member of the class, we
expect it to be correct for all members.
The equivalence classes are determined by looking at the requirements specification
and by the tester’s intuition, without looking at the implementation. The equivalence
classes will cover the complete input domain. At no point does any class overlap with
any other class.
For example, consider a marketing application that processes records for people. One
important factor is age; the requirements call for dividing people into four groups based
on age: children (0–12), teenagers (13–19), young adults (20–35), and adults (>35). Any
age less than 0 or greater than 120 is considered an error.
It is a reasonable assumption, just by looking at the requirement, to partition our valid
data into four equivalence classes, in this case corresponding to the four intervals that
would produce output; we would then choose one test case for each equivalence class.
We would also have two kinds of invalid data, negative numbers and really large num-
bers. These two additional groups provide a total of six equivalence classes. Table 10.1
shows a possible choice of test cases for each of the six equivalence classes.
Note that the equivalence class partitioning technique does not specify which ele-
ment to choose as representative for the class. It just asks that we choose one from the
Figure 10.1 Progression of testing.
Unit test
Unit test
Unit test
Functional test
Functional test
Component test
Component test
System/regression
test
. . .
. .
.
Table 10.1 Equivalence Class Example
Class Representative
Low
25
0–12 6
13–19 15
20–35 30
36–120 60
High 160
206 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 206 1/10/13 10:59:28 AM

class. Typical choices will be the one in the middle, if there is an interval, or just one of
the common cases.
Also, it will not always be clear what to choose as the equivalence classes, and there
may be differences of opinion. The bulk of the class analysis will be similar, but there may
be small variations in the actual details.
For example, consider a function called
largest, that takes two integers as param-
eters and returns the largest of them. We could define three equivalence classes as
shown in Table 10.2. The third class in the table may be considered as the boundary
between the first two classes, and it may be utilized only when doing boundary value
analysis. It may also be folded into either of the other two classes, resulting in a class
such as
First >= Second.
Equivalence class partitioning is most useful when the requirements are expressed as
a series of conditions. It is less useful when the requirements seem to call for loops. For
example, if we are testing a function that sums all the elements in an array or vector, it
would be hard to decide what the equivalence classes are, and there will be much differ-
ence of opinion; however, the basic idea would still be useful.
10.3.2 Boundary Value Analysis
Although equivalence class partitioning makes sense and is a useful technique, experi-
ence has shown that many errors are actually made at the boundaries rather than under
normal conditions. If there is an error on age 6 in Table 10.1, it will probably mean the
programmer forgot the whole range of ages, or the code is completely wrong. A more
probable error is to have some confusion about the ranges where, for example, using
<
is confused with the boundary condition of
<=.
Boundary value analysis uses the same classes as equivalence partitioning, testing at
the boundaries rather than just an element from the class. A complete boundary value
analysis calls for testing the boundary, the immediate case inside the boundary, and the
immediate case outside of the boundary. Because the equivalence classes usually form
a progression of intervals, there will be overlap in the test cases. We usually consider the
test case as coming from the interval to which it belongs.
This technique may generate a high number of test cases. You can usually reduce test
cases by considering the boundary as falling in between numbers and just test for above
and below the boundaries. Table 10.3 shows a boundary value analysis for the age-
classification problem presented earlier. The equivalence classes are shown in the first
column. The boundary value analysis is divided into three categories: (1) all cases (which
include the boundary, one below the boundary, and one above the boundary) that the
class generates, (2) the cases that would be considered belonging to the class, and (3) the
reduced cases, considering the boundary as falling between numbers.
Table 10.2 Equivalence Classes for Largest Function
Method
First > Second
Second > First
First = Second
10.3 Testing Techniques
207
91998_CH10_Tsui.indd 207 1/10/13 10:59:28 AM

Note that this technique produces a large number of test cases, even if only the
reduced ones are considered. In many cases you might need to reduce them even further
by considering which cases are most important. However, do not let the number of test
cases become an excuse for not conducting a thorough test.
Also note that this technique is applicable only to ordinal variables—that is, those
that can be sorted and organized in intervals. Without this organization there are no
special values that can be recognized as boundaries. Fortunately, many programs deal
mostly with this kind of data.
10.3.3 Path Analysis
Path analysis provides a test design technique that is reproducible, traceable, and count-
able. It is often used as a white-box testing technique, which means that you are looking
at the actual code or the detailed design when developing the test cases. Two tasks are
involved in path analysis:
n
Analyze the number of paths that exist in the system or program.
n
Determine how many paths should be included in the test.
First consider the example shown in Figure 10.2, where the rectangles and diamonds
represent processing and decision functions, the arrows show the control flows, and the
circles with numbers indicate the path segments. There are two independent paths,
Path1
and
Path2, shown in the figure. In order to cover all the statements indicated here, both
Table 10.3 Boundary Values and Reduced Test Cases
Class All Cases Belonging Cases Reduced Cases
Low
21, 0 21 21
0–12
21, 0, 1, 11, 12, 13
0, 1 11, 12 0 12
13–19 12, 13, 14 18, 19, 20 13, 14 18, 19 13 19
20–35 19, 20, 21 34, 35, 36 20, 21 34, 35 20 35
36–120 35, 36, 37 119, 120, 121 36, 37 119, 120 36 120
High 120, 121 121 121
Figure 10.2 A simple logical structure.
S1
C1
S2
S3
1
2
3
4
Path1: S1 – C1 – S3
Path2: S1 – C1 – S2 – S3
OR
Path1: Segments (1, 4)
Path2: Segments (1, 2, 3)
208 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 208 1/10/13 10:59:28 AM
paths are needed. Thus test cases must be generated to traverse through both Path1 and
Path2. There is one binary decision processing in the figure. In order to cover both branches,
again, both
Path1 and Path2 must be traversed. In this case, two independent paths are
needed to accomplish total statement coverage or to accomplish all branch coverage. We
will show that this is not always the situation. Consider Figure 10.3, where the logic is similar
to a CASE structure.
The rectangles and the diamonds, again, represent the statements and the decision
processing, the arrows show the control flow, and the circles with numbers indicate the
path segments. Note that there are four independent paths. However, we do not need to
traverse all four paths to have all the statements covered. If
Path1, Path2, and Path3 are
executed, then all the statements (
C1, C2, C3, S1, S2, S3, S4, and S5) are executed. Thus for
full statement coverage we need only to have test cases to run
Path1, Path2, and Path3.
We can ignore
Path4.
Now, let us consider branch coverage. In Figure 10.3, there are three decision condi-
tionals,
C1, C2, and C3. They each generate two branches as follows:
1. C1:
n
B1 composed of C1-S2.
n
B2 composed of C1-C2.
2. C2:
n
B3 composed of C2-S3.
n
B4 composed of C2-C3.
3. C3:
n
B5 composed of C3-S4.
n
B6 composed of C3-S5.
Figure 10.3 A CASE structure.
S1
S5
C1
C2
C3
S4
S3
S2
1
2
8
3
5
6
7
9
4
10
The 4 independent paths cover
Path1: includes S1-C1-S2-S5
Path2: includes S1-C1-C2-S3-S5
Path3: includes S1-C1-C2-C3-S4-S5
Path4: includes S1-C1-C2-C3-S5
10.3 Testing Techniques
209
91998_CH10_Tsui.indd 209 1/10/13 10:59:28 AM

In order to cover all branches, we will need to traverse Path1 to cover B1, Path2 to
cover
B2 and B3, Path3 to cover B4 and B5, and Path4 to cover B6. In this case, all four
paths need to be executed to achieve total branch coverage. This example thus demon-
strates that we would need more paths to cover all branches than to cover all statements.
One may view all branches coverage testing to be a stronger test than all statements
coverage testing.
Now, let us review the situation with a loop construct shown in Figure 10.4. All the
symbols used are the same as before. The loop structure here depends on the condition
C1. There are two independent paths. Path1 covers segments 1 and 4 through three
statements (
S1, C1, and S3). Path2 covers segments 1, 2, 3, 4 through all four statements
(
S1, C1, S2, S3). For this simple loop construct, only one path is needed to cover all the
statements. Thus
Path2, which includes all the statements, is the one path that we need
to design the test case for all statement coverage. For
Path2, we do have to design the
test case such that
S2 modifies the state so that the second encounter with C1 will direct
the traversal to
S3. While it is true that the statements C1 and S2 inside loop may be tra-
versed multiple times, we do not need to design a test case for each potential iteration.
For this simple loop structure
Path2 provides all statement coverage. In terms of branch
coverage, there are two branches that need to be considered:
n
B1 composed of C1-S2
n
B2 composed of C1-S3
Path2 covers both B1 and B2. For this simple loop, only one path, Path2, is needed to
cover all statements and to achieve total branch coverage.
We casually used the term independent paths earlier. It was somewhat intuitive in the
figures. Let us define this idea more precisely here.
A set of paths is said to be a linearly independent set if every path may be constructed
as a “linear combination” of paths from this set.
Figure 10.4 A simple loop structure.
1
2
4
3
Linearly independent paths are
Path1: S1-C1-S3 (segments 1, 4)
Path2: S1-C1-S2-C1-S3 (segments 1, 2, 3, 4)
S3
S1
C1
S2
210 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 210 1/10/13 10:59:28 AM

We will demonstrate this very powerful set with the simple example shown in Figure
10.5. There are two conditionals,
C1 and C2, and two sets of statements, S1 and S2, and
the path segments are represented with numbered circles. There are a total of four pos-
sible paths that are represented in a matrix form. For example,
Path1 is shown as row 1
with path segments
1, 5, and 6 marked with a 1. The unmarked cells may be interpreted
as zeroes. Thus
Path1 may be represented with a vector (1, 0, 0, 0, 1, 1). Looking at the
matrix in this figure, we can see that with
Path1, Path2, and Path3, all the path segments
are covered. In fact,
Path4 can be constructed with a linear combination of Path1, Path2,
and
Path3 as follows:
Path4 = Path3 + Path1 – Path2
Path4 = (0,1,1,1,0,0) + (1,0,0,0,1,1) – (1,0,0,1,0,0)
Path4 = (1,1,1,1,1,1) – (1,0,0,1,0,0)
Path4 = (0,1,1,0,1,1)
Row 4 in the matrix shows that Path4 indeed traverses through path segments 2, 3, 5 and
6. Path1, Path2, and Path3 form a linearly independent set of paths.
There is a simple way to determine the number of paths that make up the linearly inde-
pendent set. The McCabe cyclomatic complexity number introduced in Chapter 8 can be
used as the number of paths in the linearly independent set. As indicated in Figure 10.5, we
can compute the cyclomatic number as follows:
Number of binary decisions + 1 = 2 + 1 = 3
Thus for Figure 10.5, the cyclomatic number 3 states that there are three linearly inde-
pendent paths for the construct in this figure.
One more example is provided in Figure 10.6 to demonstrate path analysis in terms
of the relative amount of test coverage provided. In this figure, there are three binary
decision constructs placed in sequence. For each of the binary decisions, there are two
separate logical paths. Because the binary decision constructs are in sequence, we
Figure 10.5 A linearly independent set of paths.
1
111
11
11
111
11
1 2 3 4 5 6
5
4
6
2
Consider
Path1, Path2, and Path3 as
the Linearly Independent Set
S1
C1
C2
3
S2
Path1
Path2
Path3
Path4
10.3 Testing Techniques
211
91998_CH10_Tsui.indd 211 1/10/13 10:59:29 AM

have 2 3 2 3 2 = 8 total number of logical paths. Using the cyclomatic number, 3 + 1 =
4, the number of linearly independent paths is four. One such set of four linearly inde-
pendent paths is shown in Figure 10.6. A close examination shows that all the state-
ments in the logic diagram are covered if
Path1 and Path4 are executed. Path1 covers
S1, C1, S2, C2, C3, and S4. Only S3 and S5 need to be covered. Either Path4 or Path8 will
cover
S3 and S5. Thus Path1 and Path4 provide full test coverage of the statements.
Now, let us examine the branches in Figure 10.6. Because there are three binary deci-
sions, there are a total of six branches, two for each of the binary decisions. The branches
are
C1-S2, C1-C2, C2-C3, C2-S3, C3-S4, and C3-S5. Path1 traverses through C1-S2, C2-C3,
and
C3-S4. Path8 traverses though C1-C2, C2-S3, and C3-S5. Thus with Path1 and Path8,
all of the branches are covered. Only two paths are needed, again.
Figure 10.6 provides us with a feel for the relative number of paths required to cover
different types of testing:
n
Eight total logical paths
n
Four total linearly independent paths
n
Two total paths to provide total branch coverage
n
Two total paths to provide total statement coverage
Figure 10.6 Total number of paths and linearly independent paths.
1
4
2
Because for each binary decision, there are 2 paths and
there are 3 in sequence, there are 2
3
= 8 total “logical” paths
How many linearly independent paths are there?
Using cyclomatic number = 3 decisions + 1 = 4
One set would be:
Path1: includes segments (1, 2, 4, 6, 9)
Path2: includes segments (1, 2, 4, 6, 8)
Path3: includes segments (1, 2, 4, 5, 7, 9)
Path5: includes segments (1, 3, 6, 9)
Path1: S1-C1-S2-C2-C3-S4
Path2: S1-C1-S2-C2-C3-S5
Path3: S1-C1-S2-C2-S3-C3-S4
Path4: S1-C1-S2-C2-S3-C3-S5
Path5: S1-C1-C2-C3-S4
Path6: S1-C1-C2-C3-S5
Path7: S1-C1-C2-S3-C3-S4
Path8: S1-C1-C2-S3-C3-S5
C1
S1
3
S2
5
6
7
C2
S3
8 9
C3
S5 S4
212 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 212 1/10/13 10:59:29 AM

Because every statement is “part” of some branch, total branch coverage would pro-
vide total statement coverage. The reverse, however, is not necessarily true. Now, imag-
ine someone proudly proclaiming good quality because he or she performs 100% state-
ment coverage testing! It turns out to be the lowest level of the test coverage hierarchy.
10.3.4 Combinations of Conditions
In many cases when we need to combine several variables, we get a very large number
of combinations. Sometimes there is a need to reduce those combinations while trying
to maximize coverage. A common technique is to generate only enough combinations
to cover all pairs of values.
For example, consider a marketing module that classifies people depending on their
age, income, and region of residency. Assume that we have the equivalence classes for
the variables shown in Table 10.4.
Table 10.4 Equivalence Classes for Variable
Variable Classes
Age Young
Adult
Old
Income High
Medium
Low
Region North
South
If all combinations are considered, then there will be 18 different classes (3 3 3 3 2),
which is not a small number of test cases. Using boundary value analysis, we may gener-
ate 12 cases for the age variable, 12 for the income variable, and 9 for the region variable.
This would generate combinations of 12 3 12 3 9, or 1296, cases, which is definitely a
large number of test cases. Having more variables or more equivalence classes per variable
complicates the problem even more. It is clear that, for integration and system testing, the
number of test cases can easily reach thousands or tens of thousands of test cases.
In some situations, the variables are not independent, which means that reducing the
number of combinations that need to be tested would be very difficult. In most cases,
testing all possible conditions is not practical, so we need to reduce the number of cases
tested. This, of course, increases the risk of a defect being undetected. Techniques for
reducing the number of cases while keeping risks manageable include coverage analysis,
such as producing just enough test cases to achieve statement or path coverage rather
than full condition coverage, assessment of the important cases, and producing combina-
tions in order to test all possible pairs of values but not all combinations.
10.3.5 Automated Unit Testing and Test-Driven Development
Unit testing refers to testing the most basic units of functionality, like individual methods
or classes. Most programmers will need to do unit testing while programming to gain
confidence that their code works. After the whole component is completed, then the
code will go to the testers, who will independently do unit testing again.
10.3 Testing Techniques
213
91998_CH10_Tsui.indd 213 1/10/13 10:59:29 AM

Inexperienced programmers tend to perform limited unit testing, rather writing big
chunks of code and testing only the high-level pieces; this practice makes it hard to
locate errors when they arise. If the individual pieces are tested as they are being written,
then the chance of catching the errors increases considerably.
Another common mistake is to write the test cases as part of the main function and to
discard them after they run. A much better practice is to use an automated unit testing
tool such as
JUnit for Java. There are equivalent libraries written for many other pro-
gramming languages. This makes it possible to keep the tests and do regression testing
at the program version level as we change the program.
Having the unit tests would allow us to refactor the program. Refactoring changes the
program structure without changing its behavior, as described in Chapter 5. If we refac-
tor constantly we will usually end up with good code. The presence of unit regression
testing at the program unit level helps ensure that no error is introduced while conduct-
ing refactoring.
Another advantage of keeping the tests is that they serve as an executable detailed
specification and they document the assumptions made during the writing of the pro-
gram.
A good practice would then be to write unit tests immediately after writing a piece of
code. The smaller the units that are tested, the better. Some of the techniques described
earlier may be used to create good test cases.
An even better practice may be to write the unit tests before writing the code, and
then using them to make sure the code works. This allows you to first state the require-
ments as a test case, and then implement them. It also helps guide you to write only
small pieces of code without testing. This technique is known as test-driven develop-
ment, which assumes you will proceed in the following fashion:
1. Write a test case.
2. Verify that the test case fails.
3. Modify the code so that the test case succeeds. (The goal is to write the simplest
code you can, without worrying about future tests or requirements.)
4. Run the test case to verify it now works and run the previous test cases to verify
that the code has not regressed with any newly introduced defect.
5. Refactor the code to make it pretty.
In the following section we provide an example of how test-driven development
would proceed for a simple problem.
10.3.6 An Example of Test-Driven Development
Let’s look at the triangle problem, a popular exercise in introductory programming and
software engineering. The problem asks us to decide, given the length of the three sides
of a triangle, if it is isosceles, equilateral, or scalene. We also have to determine whether
the lengths of the sides form a valid triangle.
We have modified the problem to adapt it to object-oriented programming, and simpli-
fied it to just check whether the triangle is valid. The requirements ask that we write Java
214 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 214 1/10/13 10:59:29 AM

code for a class called Triangle that represents a triangle. The class will store information
about the three sides of a triangle and define several methods. For convenience, we will
use
a, b, and c for the three sides rather than side1, side2, and side3 or an array.
The following public methods are to be defined:
1. A constructor, taking three integers, representing the first, second, and third
sides.
2. Method getA, which takes no parameters and returns the length of the first side,
and corresponding
getB, getC methods.
3. A method isValid, which takes no parameters and returns a Boolean true if the
triangle is valid, false otherwise. A valid triangle is one for which all sides have
positive length (strictly, greater than 0) and all satisfy the triangle inequality; for all
sides, the sum of two sides is greater than the third.
Test-driven development (TDD) calls for writing test cases before any code. It also
advocates that the tests be automated so that they can be run as many times as neces-
sary. In the following paragraphs, the TDD example is illustrated in a somewhat personal
and conversational manner.
We first create the
JUnit test class, an easy process; we just need to create a class
extending
junit.framework.TestCase. After that, any public method whose name
starts with
test will be automatically run by JUnit. For convenience, we define a main
method that runs all the tests. The skeleton for the class is as follows:
import junit.framework.TestCase;
public class TestTriangle extends TestCase {
public static void main(String args[]) {
junit.swingui.TestRunner.run(TestTriangle.class);
}
}
We now define the first test case. Note that it is usually hard to test the first few
methods in isolation; you need at least a
get and a set method to be able to verify that
something worked. We decided to create a test case for verifying the constructor and
the three
get methods. Purists of test-driven development could argue that we should
have done just the constructor and one of the
get methods, but we thought the code
was simple enough.
The test case goes as follows:
public void testConstructor() {
Triangle t=new Triangle(3,5,7);
assertTrue(t.getA()==3);
assertTrue(t.getB()==5);
assertTrue(t.getC()==7);
}
10.3 Testing Techniques
215
91998_CH10_Tsui.indd 215 1/10/13 10:59:29 AM

In this case we are testing the following:
n
There is a class and a public constructor, taking three integer parameters.
n
There are three methods, getA, getB, and getC.
n
The value returned by getA is the first parameter passed to the constructor, getB is the
second, and
getC is the third.
We then try to compile, and it does not work, just as we expected. So we create the
code for the following class:
class Triangle {
private int a, b, c;
// constructs a triangle based on parameters
public Triangle(int a, int b, int c)
{
this.a=a;
this.b=b;
this.c=c;
}
public int getA() { return a;}
public int getB() { return a;}
public int getC() { return a;}
}
We run the tests again, and see that the code does not work. We go and check the
code again. Can you see the error? (We cut-and-pasted from
getA to create getB and
getC but forgot to change the value returned.) So we correct the errors and try the test
again. This time, it works.
We now create a test case for the
isValid method. Given that we feel this method is
not that simple, we will do TDD in smaller steps. We will write very simple test cases, and
then very simple code, making the test cases drive the code.
We can write a very simple test case such as the following:
public void testIsValid() {
Triangle t=new Triangle(-5,3,7);
assertFalse(t.isValid());
We run it, and it fails (with a compilation error). Now we try to write the code.
A good practice for complicated code is to write the simplest code you can think of
that will make your test succeed. It does not matter if the code is wrong, as long as your
test case succeeds. This will force you to write more test cases, therefore ensuring you
test better.
In this case, we’ll follow that practice. The test case just calls for a triangle that is not
valid; we can simply write the code like this:
public boolean isValid() {
return false;
}
216 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 216 1/10/13 10:59:29 AM

Now the test case succeeds, and we need to write more test cases. We rewrite our test
case as follows:
public void testIsValid() {
Triangle t=null;
t=new Triangle(-5,3,7);
assertFalse(t.isValid());
t=new Triangle(3,5,7);
assertTrue(t.isValid());
}
We make sure it fails, and then continue to write more code. We could write code just
to see whether
a is less than 0, but we decide to test for all three conditions. The code
looks like this:
public boolean isValid() {
return a>0 && b>0 && c>0;
}
We test the case and it succeeds. Now, because we know our code will get more com-
plicated, we decide to refactor. The
isValid method needs to decide on two different
conditions: (1) whether all sides are positive, and (2) whether the sides satisfy the triangle
inequality. We thus decide to write two tests: (1)
allPositive, to see whether all sides
are positive, and (2)
allSatisfyInequality, to see whether all sides satisfy the inequal-
ity. We change
isValid and write the allPositive method as follows:
boolean allPositive() {
return a>0 && b>0 && c>0;
}
public boolean isValid() {
return allPositive();
}
Note that we are not making allPositive public, because it is not called for in the
specification. We make it a package method rather than a private one so that the test
class can access it and test it.
We now need to test the
allPositive method. We write a few test cases, covering the
three main cases (
a<0, b<0, c<0), one more for one boundary (a=0), and then one more to
verify that the function works for a triangle with sides all positive. We run the tests, and
they pass. We believe this is enough testing for this function. Would you feel comfortable
now? If not, what test cases would you add?
We now go to work on the
allSatisfyInequality method. We create a simple test
case such as the following:
public void testAllSatisfyInequality() {
Triangle t=null;
t=new Triangle(10,5,2);
assertFalse(t.allSatisfyInequality());
t=new Triangle(5,6,3);
assertTrue(t.allSatisfyInequality());
}
10.3 Testing Techniques
217
91998_CH10_Tsui.indd 217 1/10/13 10:59:29 AM

The test fails to compile, so we write the following code:
// returns true if all sides satisfy the triangle
// inequality false otherwise
boolean allSatisfyInequality() {
return (a<(b+c)) && (b<(a+c)) && (c<(a+b));
}
Now the test passes. To gain confidence that the code works, we decide to extend the
test case to cover at least each side breaking the inequality and one boundary condition.
So we extend it as follows:
public void testAllSatisfyInequality() {
Triangle t=null;
t=new Triangle(10,5,2);
assertFalse(t.allSatisfyInequality());
t=new Triangle(5,15,2);
assertFalse(t.allSatisfyInequality());
t=new Triangle(3,4,7);
assertFalse(t.allSatisfyInequality());
t=new Triangle(5,6,3);
assertTrue(t.allSatisfyInequality());
}
We run the test case, and it works. As developers, we feel quite confident that the
code is correct. We can now pass it on to later stages in the process, which may include
inspection, formal unit testing by the testing organization, and functional and integra-
tion testing.
A few more observations about test-driven development can be made at this point:
n
Test-driven development is an effective technique that helps programmers quickly
build reliable code; however, it is not a substitute for other quality control activities.
n
Test-driven development should be combined with formal unit and integration test-
ing, code inspections, and other quality control techniques to ensure a high-quality
implementation of the requirements.
n
Test-driven development usually leads to writing more tests, and simpler code. In fact, TDD
usually achieves at least statement coverage.
n
Test cases in TDD are produced based on the developer’s intuitions and experience,
although other techniques may be used.
10.4 When to Stop Testing
A key question often asked by novice testers and students of testing is when one should
stop testing. A simple answer is to stop testing when all the planned test cases are
executed and all the problems found are fixed. In reality, it may not be that simple. We
are often pressured by schedule to release software product. Two techniques will be
discussed here. The first is based on keeping track of the test results and observing the
218 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 218 1/10/13 10:59:29 AM

statistics. If the number of problems discovered stabilizes to near zero, we would usually
consider stopping the testing. Consider Figure 10.7, which illustrates a problem find
rate through time.
The number of problems found per hour will eventually be so small that the value
received from testing starts to diminish. In Figure 10.7, the curve hits a peak on day 2
and starts to decline on day 3. The testers could have set a goal in the plan stating that
testing will stop when the problem find rate reaches some prespecified level, such as
0.01/hour or 1/100 hours. They could also create a graph depicting the accumulative
number of problems found. Such a curve will usually look like a stretched S figure and is
often called an S-curve. They might then specify that when the observed length of time
(for example, 12 hours, 1 day, 1 week) of accumulative problems found achieves some
point of stability, further testing will be terminated.
Another technique is to pepper the existing code with defects and observe how many
of the seeded defects are discovered. This technique requires the seeding of the defects
to be done by some person other than the actual tester. For example, consider seeding a
program with 10 defects. As failures are observed, the defects are then sorted between
seeded defects and real defects. Assume that after executing many of the test cases, 7 of
the seeded defects and 45 nonseeded defects are detected. The following approach can
then be used to estimate the number of remaining unseeded defects:
7/10 = 45/RD, where RD = Real Defects
RD is estimated as approximately 64. You can thus assume that there still are approxi-
mately 19 more unseeded defects remaining in the software product. This is equivalent
to saying that there is a good chance that 19/64, or 30%, of the estimated real defects
still remain in the product. If discovering 70% of the real defects was the target, then
the testers could proclaim victory and stop testing. On the other hand, if the target is to
discover 90% of the estimated real defects, then the testers would need to find 9 of the
10 seeded defects before they stop testing. One caution is that the testers must ensure
Figure 10.7 Decreasing problem find rate.
Day
1
Day
2
Day
3
Day
4
Day
5
Time
Problem
find rate
Number of problems
found per hour
10.4 When to Stop Testing
219
91998_CH10_Tsui.indd 219 1/10/13 10:59:30 AM

that the seeded defects are all pulled out of the software product prior to releasing to
the users.
Note that this technique assumes that defects naturally occurring in the code are simi-
lar to the ones we have seeded. Although this is a reasonable assumption, it is not always
true, which would lead us to produce bad estimates about remaining defects.
If we want to produce quality software, we must strive to stop testing only after
we are convinced that the product is as good as we want it or when testing does not
produce any further improvements in quality. Thus there is always an element of “past
experience” in some of these decisions. Many projects, however, decide to stop testing
prematurely due to schedule pressure or availability of resources. Shipping a product
because you ran out of time or out of money will almost always result in a low-quality
product. The direct effects of low-quality product are the pressure and cost placed on the
postrelease support and maintenance team. Indirectly, the software product’s reputation
and the customers’ sense of satisfaction will also suffer.
10.5 Inspections and Reviews
One of the most cost-effective techniques for detecting errors is to have the code or the
intermediate documents reviewed by a team of software developers. Here, we will use
the term review as a generic term to specify any process involving human testers read-
ing and understanding a document and then analyzing it with the purpose of detecting
errors, and reserve the term inspection for a particular variation that will also be described.
These inspections are sometimes referred to as Fagan inspections in the literature.
Note that reviews for the purposes of finding errors are discussed here. There are
many other techniques involving teams of people analyzing source code or other docu-
ments, including what is sometimes called a walk-through, which involves the author of
a document explaining the material to a team of people for some other purpose such as
knowledge-dissemination or brainstorming and evaluation of design alternatives. We
will reserve the term review for analysis done by a team of people to detect errors.
Software inspections are detailed reviews of work in progress following the process
developed by Michael Fagan at IBM. A small group of three to six people typically study a
work product independently and then meet to analyze the work in more detail. Although
the work product should be basically completed, it is considered as a work in progress
until it has passed the review and any necessary corrections have been made.
The inspection process usually consists of the following steps:
1. Planning: An inspection team and a moderator are designated and materials are
distributed to team members several days prior to the actual inspection meeting.
The moderator makes sure the work product satisfies some entry criteria—for
example, for code inspection, that the source code compiles or that it does not
produce warnings when passed through a static analysis tool.
2. Overview: An overview of the work product and related areas is presented, similar
to a walk-through. This step may be omitted if participants are already familiar
with the project.
220 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 220 1/10/13 10:59:30 AM

3. Preparation: Every inspector is expected to study the work product and related
materials thoroughly in preparation for the actual meeting. Checklists may be
used to help detect common problems.
4. Examination: An actual meeting is arranged where the inspectors review the prod-
uct together. The designated reader presents the work, typically paraphrasing the
text while everyone else focuses on finding defects. The author is not allowed to
serve as the reader. Every defect detected is classified and reported. Typically, the
meeting is dedicated only to finding defects; so no time is spent during the meet-
ing on analyzing why defects occurred or how to solve them. Usually sessions are
limited to one or two hours. As a result of the examination, the product is either
accepted as is, corrected by the author with the moderator verifying the results, or
corrected along with a reinspection.
5. Rework: After the meeting, the author corrects all defects, if any. The author is not
required to consult with any inspector but is usually allowed to do so.
6. Follow-up: The corrections are checked by the moderator, or the corrected work is
inspected again, depending on the result of the inspection.
Inspections are highly focused on finding defects, with all other considerations being
secondary. Discussions about how to correct those defects or any other improvements
are actively discouraged during such inspections in order to detect more defects. The
output of an inspection meeting would be a list of defects that need to be corrected and
an inspection report for management. The report describes what was inspected, lists the
inspection team members and roles, and summarizes the number of and the severity of
defects found. The report also states whether a reinspection is required.
Inspection teams are small groups of coworkers, usually of three to six people, with
the author included. Usually all members of the inspection team are working on related
efforts such as design, coding, testing, support, or training, so they can more easily
understand the product and find errors. Their own work is usually affected by the artifact
that they are inspecting, which means that the inspectors are motivated participants.
Managers generally do not participate in inspections as this usually hinders the process.
The inspectors would have a tough time behaving “naturally” with managers participat-
ing in the inspection meetings. An inspection team, besides the author, has the partici-
pants in the roles of moderator, reader, and scribe. Typically, authors are not allowed to
assume any of these roles.
Inspections have proved to be a cost-effective technique to finding defects. A great
advantage of inspection is that it can be applied to all intermediate artifacts, including
requirements specifications, design documents, test cases, and user guides. This allows
for defects to be detected early in the software process and corrected inexpensively.
Although inspections are work intensive, their cost is usually much less than catching the
errors in testing, where the cost of correcting them is much higher.
Although inspections are focused on finding defects, they do have a positive side
effect in that they help disseminate knowledge about specific parts of the project and also
about the best practices and techniques. Tsui and Priven (1976) describe positive experi-
ences with using inspections to manage software quality at IBM as early as the 1970s.
10.5 Inspections and Reviews
221
91998_CH10_Tsui.indd 221 1/10/13 10:59:30 AM

10.6 Formal Methods
In a strict definition, formal methods are mathematical techniques used to prove with
absolute certainty that a program works. A broader definition would include all discrete
mathematics techniques used in software engineering.
Formal methods are more often used for requirements specifications. The specifica-
tions are written in a formal language, such as Z, VDM, or Larch, and then properties of
the specifications are proved, through model-checking or theorem-proving techniques.
Proving properties of formal specifications is probably the most popular application of
formal methods. Formal methods can also be applied to prove that a particular imple-
mentation conforms to a specification at some level. Formal methods are typically
applied to specifications and utilized to prove that the design conforms to the specifica-
tion.
At the code level, formal methods usually involve specifying the precise semantics
of a program in some programming language. Given this formalization, we can proceed
to prove that given a set of preconditions the output will satisfy certain postconditions.
Most programming languages need to be extended to allow for the specification of pre-
conditions and postconditions. Once these are specified, there are tools that will, in many
cases, produce a proof that the program is correct.
Considering that the other techniques cannot guarantee the absence of errors, the
idea of proving the correctness of a program is very appealing. However, formal methods
have several drawbacks:
n
They require a considerable amount of effort to master the techniques. They require
in-depth knowledge of mathematics and a measure of abstract thinking. Although
most programmers and software engineers could be trained in these techniques, the
fact is that most of them do not have training in this area. Even after training, formal
methods require a substantial effort to be applied to a program. Gerhart and Yelowitz
(1976) describe the difficulties related to using formal methods.
n
They are not applicable to all programs. In fact, a fundamental theorem of theory of
computation says we cannot mathematically prove any interesting property about
programs in general. As a specific example, we cannot show, given an arbitrary pro-
gram, whether it will halt or not. Either we restrict ourselves to a subset of all programs
or there are some programs for which we cannot prove or disprove the property.
Unfortunately, many practical programs would fall into this category.
n
They are useful only for verification, not for validation. That is, using formal methods
we could prove that a program evolved from and conforms to its specification but not
that it is actually useful or that it is what the users really wanted, because that is a value
judgment involving people.
n
They are not usually applicable to all aspects of software development. For example,
they would be very hard to apply to user-interface design.
In spite of their drawbacks, formal methods are useful and have been applied with
success to some special real-world problems in industries such as aerospace or federal
government. Learning formal methods can give much useful insight to a software
engineer, and they can be applied to particular modules that need extremely high reli-
222 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 222 1/10/13 10:59:30 AM

ability. Even if specifications are not completely formal, the mental discipline of formal
methods can be extremely useful. They can be applied selectively, so that critical or
difficult parts of a system are formally specified. Informal reasoning, similar to formal
methods, can be applied to gain more confidence about the correctness of a program.
Preconditions and postconditions can also serve as documentation and help under-
stand the source code.
10.7 Static Analysis
Static analysis involves the examination of the static structures of executable and non-
executable files with the aim of detecting error-prone conditions. This analysis is usually
done automatically and the results are reviewed by a person to eliminate false positives
or errors that are not real.
Static analysis can be applied to the following situations:
n
Intermediate documents, to check for completeness, traceability, and other character-
istics. The particular check applied will depend on the document and how structured
it is. At the most basic level, if you are dealing with unstructured data such as word-
processing documents, you can verify that it follows a certain template, or that certain
words do or do not appear.
n
If the document is in a more structured format, be it XML or a specific format used by
your tools, then more involved checking can be performed. You can automatically
check for traceability (e.g., all design items are related to one or more requirements)
and completeness (e.g., all requirements are addressed by one or more design items).
Many analysis and design documents have an underlying model based on graphs or
trees, which would make checks for connectivity, fan-in, and fan-out possible. Most
integrated CASE tools provide some static analysis of the models created with them.
n
Source code, to check for programming style issues or error-prone programming prac-
tices. At the most basic level, compilers will detect all syntactic errors, and modern
compilers can usually produce many warnings about unsafe or error-prone code.
Deeper static analysis can be done with special tools to detect modules that are exces-
sively complex or too long and to detect practices that are probably an error. The
specific practices that are considered error-prone will vary depending on the program-
ming language, the particular tool, and the coding guidelines of the organization.
Most tools provide an extensive set of checks that can be extended and provide ways
to configure the tool to specify which checks to run. For example, in Java, there are two
equality operations. You can use the
= = operator, which checks for object identity (the
two expressions refer to the exact same object) and the equals method, which checks
whether the member variables of each object are equal. In the majority of the cases the
intended semantics is to call the equals method, which means that the tool could warn
about uses of the
= = operator except for primitive values. Two popular open source
tools to perform static checks on Java source code are PMD and CheckStyle. Both of
them can detect more than 100 potential problems.
n
Executable files, to detect certain conditions, with the understanding that much infor-
mation is usually lost in the translation from source code to executable files. With the
popularity of virtual machines and bytecode rather than traditional executables, an
10.7 Static Analysis
223
91998_CH10_Tsui.indd 223 1/10/13 10:59:30 AM

executable may contain a substantial amount of information, allowing for many mean-
ingful checks. For example,
java.class files contain information about all the defined
classes and all the methods and fields defined by the class. This information allows for
the creation of call and dependency graphs, inheritance hierarchies, and the calcula-
tion of metrics such as cyclomatic or Halstead complexity. Warnings can be issued
whenever the complexity metric or the inheritance depth is above a certain threshold,
which would signal an excessively complex and error-prone module.
n
FindBugs is an open source bytecode checker for the Java language that provides for
more than 100 individual checks, and sample configuration files to verify consistency
with Sun’s Java coding guidelines.
Static analysis tools are extremely useful and are available for most of the popular
programming languages; however we need to realize that these tools typically provide
a very high number of false positives—that is, conditions that are flagged as error-prone
by the tool but are not an actual error. It is not uncommon that 50% or more of the warn-
ings correspond to valid usage. Conversely, there will still be many errors that are not
caught by these tools.
The output of static analysis tools needs to be checked by experienced software
engineers to verify whether the warnings correspond to actual errors or to correct code,
and we should not gain a false sense of security by the fact that a program passes those
checks.
10.8 Summary
The steps to achieving a high-quality product must be taken from the inception of the
project; however, having ways to detect and later correct errors can help you achieve even
higher quality. In this chapter we discussed the basic ideas of verification and validation.
The basic techniques for verification, inspections and reviews, testing, static analysis, and
formal methods were then introduced. Of those techniques, testing and inspections can
be also used for validation. We have also discussed techniques for generating good test
cases through equivalence classes, boundary value analysis, and path analysis as well as
some fundamental concepts for setting criteria about when to stop testing.
Although all of these techniques have their cost, releasing a low-quality product is
even costlier. All software engineers need to apply these techniques to their own work,
and every project needs to apply them to the whole set of artifacts produced.
10.9 Review Questions
1. Consider the diagram shown in Figure 10.8.
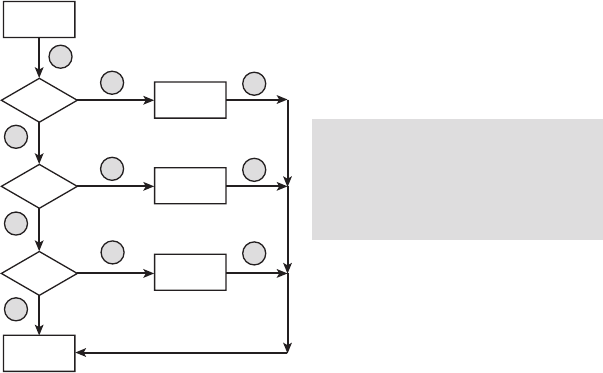
a. How many logical paths are there? List them all.
b. How many paths are required to cover all the statements?
c. How many paths are required to cover all the branches?
2. In code inspection, what would you set as the condition (e.g., how many discov-
ered defects) for reinspection?
3. List the four techniques discussed to perform verification and validation.
224 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 224 1/10/13 10:59:30 AM

4. List two techniques you can use to perform validation—that is, to ensure your
program meets user requirements.
5. Briefly explain the concept of static analysis, and to which software products it can
be applied.
6. Briefly explain two different ways to decide when to stop testing.
7. Consider the simple case of testing 2 variables, X and Y, where X must be a non-
negative number, and Y must be a number between 25 and +15. Utilizing bound-
ary value analysis, list the test cases.
8. Describe the steps involved in a formal inspection process and the role of a mod-
erator in this process.
9. What is the difference between performance testing and stress testing?
10.10 Exercises
1. Consider the seeded defect approach to creating a stop-testing condition and the
example in this chapter.
a. After reaching the 70% level, suppose that more and more (e.g., 20) unseeded
defects are found without discovering a single new seeded defect. Explain
what you think is happening.
b. After reaching the 70% level, suppose that the remaining three seeded de-
fects are found along with only four more real defects. Explain what you think
is happening.
2. For the triangle problem described in Section 10.3.6, do the following exercises:
a. Use test-driven development to define a method called Equilateral that re-
turns true if the triangle is equilateral (and valid). An equilateral triangle is that
for which all sides are of equal length.
Figure 10.8 A logical flow structure
C1
S1
C2
S3
10.10 Exercises
225
91998_CH10_Tsui.indd 225 1/10/13 10:59:30 AM

b. Evaluate the coverage that the test cases you produced achieve. If you did not
achieve full path coverage, create test cases to achieve path coverage.
c. Perform equivalence class partitioning, and create all necessary test cases.
3. Describe your level of comfort for quality if a group of software developers tell you
that they utilized test-driven development. Explain why.
10.11 Suggested Readings
K. Beck, Test Driven Development: By Example (Reading, MA: Addison-Wesley Professional,
2002).
Checkstyle 4.1 tool, http://checkstyle.sourceforge.net, 2006.
E. M. Clarke and J. M. Wing, “Formal Methods: State of The Art and Future Directions,”
ACM Computing Surveys 28, no. 4 (December 1996): 626–643.
D. Coppit et al., “Software Assurance by Bounded Exhaustive Testing,” IEEE Transactions
on Software Engineering 13, no. 4 (April 2005): 328–339.
P. B. Crosby, Quality Is Free (New York: McGraw Hill, 1979).
M. E. Fagan, “Design and Code Inspections to Reduce Errors in Program Development,”
IBM Systems Journal 15, no. 3 (1976): 219–248.
FindBugs, http://findbugs.sourceforge.net, 2006.
S. L. Gerhart and L. Yelowitz, “Observations of Fallability in Applications of Modern Pro-
gramming Methodologies,” IEEE Transactions on Software Engineering 2, no. 3 (September
1976): 195–207.
Guide to the Software Engineering Body of Knowledge (2004 Version), http://www
.swebok.org, 2005.
D. Hamlet, “Foundation of Software Testing: Dependability Theory,” ACM SIGSOFT Soft-
ware Engineering Notes 19, no. 5 (December 1944): 128–139.
P. C. Jorgensen, Software Testing: A Craftsman’s Approach (Boca Raton, FL: CRC Press,
1995).
JUnit.org, http://www.junit.org/index.htm, 2006.
J. M. Juran and A. B. Godfrey, eds., Juran’s Quality Handbook, 5th ed. (New York: McGraw
Hill, 1999).
C. Kaner, J. Bach, and B. Pettichord, Lessons Learned in Software Testing (New York: Wiley,
2002).
A. M. Memon, M. E. Pollack, and M. L. Soffa, “Hierarchical GUI Test Case Generation Using
Automated Planning,” IEEE Transactions on Software Engineering 27, no. 2 (February 2001):
144–158.
G. J. Myers, The Art of Software Testing (New York: Wiley, 1979).
226 Chapter 10 Testing and Quality Assurance
91998_CH10_Tsui.indd 226 1/10/13 10:59:30 AM

T. J. Ostrand, E. J. Weyuker, and R. M. Bell, “Predicting the Location and Numbers of Faults
in Large Software Systems,” IEEE Transactions on Software Engineering 13, no. 4 (April
2005): 340–355.
S. C. Reid, “An Empirical Analysis of Equivalence Partitioning, Boundary Value Analysis
and Random Testing,” 4th IEEE International Software Metrics Symposium (November
1997): 64–73.
J. Rubin, A Handbook of Usability Testing (New York: Wiley, 1994).
F. Tsui and L. Priven, “Implementation of Quality Control in Software Development,” AFIPS
Conference Proceedings, National Computer Conference, vol. 45, (1976): 443–449.
D. A. Wheeler, B. Brykczynski, and R. N. Meeson Jr., eds., Software Inspection: An Industry
Best Practice (Los Alamitos, CA: IEEE Computer Society Press, 1996).
J. A. Whittaker, “What Is Software Testing? And Why Is It So Hard?” IEEE Software (January
/February 2000): 70–79.
10.11 Suggested Readings
227
91998_CH10_Tsui.indd 227 1/10/13 10:59:30 AM

Intentional Blank 228
91998_CH10_Tsui.indd 228 1/10/13 10:59:30 AM
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.