
![]()
Requirements
Oh, you can’t always get what you want
But if you try sometimes you just might find
You get what you need
—The Rolling Stones
Chapter 1 was about projects in general, whether iPhone apps, avionics for a jet airplane, a medical records system, or the e-filing system for the Internal Revenue Service. But now it’s time to focus on the subject of this book and stick to the much simpler world of PHP/MySQL apps. While the job of gathering requirements in general might be hard or, in some cases, even impossible, for PHP/MySQL apps it’s pretty simple. This is in large part because applications that have huge performance demands or are so complicated as to require dozens or even hundreds of developers very rarely, if ever, are programmed in PHP or use MySQL instead of a database like Oracle, SQL Server, or DB2.
So, we’ll leave those large, complicated, multiyear projects to others and just worry about the much smaller, simpler projects that characterize the PHP/MySQL world.
Usually, most authors who write about requirements discuss the process of producing them, but they don’t give you the requirements themselves. Obviously, I can’t do that either, because I don’t know what you’re trying to build. But, I can come closer than most. I’ll tell you what sections a requirements document has to have and explain what you need to put in each section. In some cases, I’ll give you the exact words you can use. (Remember, I’m only dealing with PHP/MySQL applications.) Rather than discuss all the possible approaches, I’ll just tell you what to do. Of course, it’s just friendly advice, not a legal requirement, but I figure that since developers hate writing requirements so much, they’ll appreciate a paint-by-numbers kit instead of a four-year Bachelor of Fine Arts degree. Ten years ago I would have been accused of oversimplifying a critical part of the software engineering process, but nowadays, given the popularity of Agile methods, which dispense with up-front requirements altogether, I sound like an old-fashioned, stick-in-the-mud, traditionalist. I thank the Agile movement for making my once-radical ideas seem like conservative ones.
Outline of the Requirements Document
Yeah, it really needs to be a document. Written down. Not scribbled on a white board with a DO NOT ERASE notation for the cleaning staff, or a pile of Post-it notes, or an archive of e-mails. If you don’t want to write text, use diagrams or cartoons. As long as it’s written down in the form of a self-contained document, spreadsheet, or database.
While you can certainly write the requirements with Microsoft Word, Apple Pages, or any other word processor, there’s a real benefit to keeping them as a text file, as I’ll explain in the section “When the Requirements Change.”
To my way of thinking, requirements for a PHP/MySQL application go into 17 sections, all of which have to be present:
- Database: The main entities (explained in Chapter 4). No need for attributes, as they should go into the database design document.
- CRUD: PHP pages for Creating, Retrieving, Updating, and Deleting data.
- Processing: Anything more elaborate than CRUD or reports, such as scheduling supermarket employees, assigning meetings to rooms, and recommending books.
- Reports: Output from the database (on-screen, PDF, CSV, XML, RTF, etc.).
- External interfaces: Connections to other computer systems.
- Internationalization: Making the application localizable—and localization itself—adapting it for a specific language and culture, such as Spanish or German. (Internationalization is often abbreviated I18N, for the I, the N, and the 18 letters in between. Localization is L10N).
- Accessibility: For disabled users.
- User administration: Managing user logins and access restrictions.
- Billing: Charging users.
- Browsers and platform: Supported browsers and the operating systems on which they run (the client). Also, the platform on which the application runs (the server).
- Installation: Support for installing the application.
- Capacity: Number of simultaneous users, amount of data in the database, size of reports, response time, etc.
- Documentation: Internal and external documentation provided to users, administrators, and developers.
- Training: For users, administrators, and developers.
- Support and maintenance: Ongoing support (bugs, feature requests, usage questions) and updates.
- Conversion: From the previous system or other records (electronic or paper) to the new system.
- Use cases: Detailed descriptions of interactions between an actor (person or some other system) and the application, resulting in some outcome of value to the actor.
Always include all 17 sections, even if there’s nothing to be done (e.g., billing or conversion), in which case the requirement will be phrased negatively (“There will be no support for billing.”). That prevents the customer from assuming erroneously that something will be included. (“I know that we didn’t specify training explicitly, you bozo, but all systems come with training!”) What’s more, if it turns out you’re not the only one competing for the job, it will help ensure that you’re playing on a level field.
Rough First Draft: Scope Without Detail
Customers don’t know what all their requirements are at the start. They have to see the system first. They’ll see some things they definitely don’t like, and that will help them articulate what they do want. This has always been true, and it’s a cornerstone of the Agile approach.
But, at some high level, customers do know what they want, and that’s what you need to capture in the rough first draft of the requirements. Don’t know what the reports should look like? Then the reports section can say: “There will be reports.” Not planning on any documentation? Then say: “There will be no documentation.” That will probably cause the customer to say: “What do you mean no documentation? We need documentation!” See, customers really do know what they want—just not the details. The first draft corresponds to what they know they want, and it’s vague about what they’re vague about. You write this first draft at the start of the project, before any development begins. These aren’t just-in-time requirements; they’re up-front requirements.
For many of the sections, I just don’t believe that waiting until halfway through development and being able to try out a half-dozen interim releases are going to help the customer know the answers. I could come up with a weird scenario in which the customer can’t know whether a German localization will be needed until there’s been a chance to try out the system, but, really, nothing is going to happen down the road to help with this. It’s about marketing, and it has nothing to do with using the system hands-on. The same goes for external interfaces, billing, installation, documentation, conversion, and a few other sections. Those decisions can be made at the start and should be, because they have a huge effect on design and development.
On the other hand, anything related to user-interface design, reports, and processing should be specified only in the most general way at the start. For these matters, the requirements should evolve as the developers and the customer work together with a live, if incomplete, system as a laboratory.
What’s important at the start, and at all times throughout the project, is that the scope be delineated, so it’s clear how much of the problem the application is supposed to address and, just as important, what it won’t address. How it solves the problem it’s supposed to solve—the detail—should be specified later, either because not enough is known about it until later or because the developers don’t need the details until later, or both. If the developers don’t need the details until later, such as exactly what reports are needed and what they look like, it’s better to wait. Any guess at the details might change anyway, and it’s better to work things out collaboratively between the customer and the developers when both are highly motivated to work on that part of the system. Neither party is inclined to work on such details at the start, when there’s so much else to think about.
Following was my rough first-draft requirements document for the Conference on World Affairs (CWA) system:
- Database: Entities are Persons, Panels, Topics, Venues, Donations, Houses, Trips.
- CRUD: A web page for each entity consisting of a form with a field for each column.
- Processing: None. (The application pretty much just pushes data from place to place, not actually doing much of anything with it).
- Reports: Panelists, Alpha List, Stable List, Betty Sheet, Trips, Housing. More will be specified later. Samples have been supplied. (Alpha List, Stable List, and Betty Sheet are CWA terms; it’s not important what they mean).
- External Interfaces: None. Totally standalone. There might be a report to get data to populate the online schedule on the CWA website, but that will just be a CSV file.
- I18N and L10N: None; English only. (Although data itself can be Unicode).
- Accessibility: None other than what the OS offers (e.g., bigger cursor).
- User Administration: Administrator and user logins. No finer-grained restrictions.
- Billing: None.
- Browsers and Platform: Safari and Chrome on MacOS, Internet Explorer and Chrome on Windows. Latest browsers only; no effort will be expended to support very old browsers. Nothing special for mobile. If it works on an iPhone, fine; if not, tough luck.
- Installation: None, other than the single production system run by the University of Colorado Managed Services department.
- Capacity: Five-to-ten simultaneous users. Database must hold 80 years of data (CWA started in 1948), with 100 panelists and 200 panels per year. Up to ten thousand donors.
- Documentation: None.
- Training: No formal training, but developer will meet with users occasionally.
- Support and Maintenance: Support via email. An occasional phone call is OK, too. System will be updated and enhanced in future years as needed.
- Conversion: From existing Excel spreadsheets and FileMaker database. CWA office will extract data and email it to developer.
- Use Cases: TBD (to be determined). (Missing in the first draft, although I had a pretty clear idea of how the system was supposed to be used and had lots of screenshots, reports, and notes from the system I was replacing).
Bingo! The requirements! Only took about a half-hour to write, and they’re complete in scope, with nothing left out. Well, except for the details: what the CRUD pages look like and what the reports are.
Actually what I said to the CWA people at the start was even less detailed than the 17-section requirements document: “The system will handle panels, panelists and other persons, and donations, and it will generate all the reports you’re used to having.” That was exactly what they wanted to hear.
With the requirements in hand, I jumped into development. I started with the database design, which is where you should always start. (Reminder: This chapter and the rest of the book are only about PHP/MySQL applications.) Then, to check out the database, I did the conversion. With some real data in the database, I started in on the reports, using samples from previous conferences as my guide. At that point I was pretty sure the database design was basically OK. It would have to be modified as development proceeded, which is always the case, but it was fundamentally sound.
I didn’t show any of the reports to the CWA office staff because they were identical to the samples the staff had supplied me. I wasn’t ready yet to learn about new reports staff members might need. With a database-centric design, reports can be added without affecting the rest of the system, so I wasn’t worried.
At this point I was ready for the CRUD pages. I took a guess about what might work. Every time I showed what I had to the users, they had suggestions for how to make it better. This was the most time-consuming part of development, and the part where the users had the most input. Eventually we came up with a set of CRUD pages that they were happy with, and we went with those, with some additional tweaking as they used the system.
The same thing for reports. As I said, I copied the reports from past years (produced mostly from Excel) exactly, and we added a half-dozen additional reports as the CWA staff came up with ideas. I had also put in a generalized SQL-based query facility, originally for my own use, but the assistant CWA coordinator liked it so much that she taught herself SQL and started using it. She developed a set of about a dozen canned queries that might have been handled by reports developed by me at her request, but there was no need for me to do anything. Maybe this level of initiative is unique to assistant coordinators at universities, but you should check. Your users might be more capable than you think.
Toward the end of the this chapter, I’ll call my approach, which I’ve been using since the late 1960s, Planned Agile. It’s agile enough (lower-case “a”), but with a planning/design phase before any development starts.
A Closer Look at the Requirements Sections
Here are some additional comments on the 17 requirements sections.
This is the subject of Chapter 4.
For every PHP application I’ve developed, all of the CRUD pages follow a pattern: there’s a short query form, sometimes with only one field (e.g., last name), and a Search (or Find) button. Clicking that button queries the database and shows a list of rows (records), each summarized by a minimal amount of data, such as last name and first name and having an associated Detail button, one per row. Clicking Detail shows all the data for the row, at which point the user can read the data (the R in CRUD) or update it (U). There’s also a button to delete the row (D) next to the Detail button. A button at the top displays an empty form, for creating (C) new rows.
It’s a good idea at the start to show your customer a mock-up of one of your CRUD pages, maybe with some sample data inside the PHP file, as the database probably isn’t ready. Every page has a common layout, with things like a logo, a help button, and links to key parts of the application, and you can show a mock-up of those, too. For example, Figure 2-1 shows what the CWA Topics CRUD page looks like.

Figure 2-1. Topics CRUD page
Topics (what panelists talk about) can be retrieved by code or year. Figure 2-2 shows part of what you see when you click Search:
Figure 2-2. Retrieved topics
If customers can see an example of what the CRUD interaction will be like, they can visualize where the development is going to be headed. Some of them, used to desktop applications, may never have used a web database application, so it’s important that they get acclimated to what PHP/MySQL applications are like. Actually, they have used such applications if they’ve ever bought anything from Amazon or accessed Facebook, but maybe they never realized it.
My CWA application was going to have a user interface a lot less fancy than that of Amazon or Facebook, and I wanted my customer to know that, too. For most simple PHP/MySQL applications you’re going to build, a lot of complex JavaScript to make the page highly interactive just isn’t called for. You’re unlikely to want to hire (or have the money to hire) a world-class graphics designer, either. I do my own designs; they’re clunky, but workable, and they’re what my customers can afford. It’s about setting expectations.
If there’s anything in this section, you’ll want to schedule its development first thing, as complex processing takes an unknown amount of development time and needs an unknown amount of acceptance testing. It may even be a research project.
Or, maybe not. When we started building the SuperSked supermarket-scheduling application for Windows, we already had the scheduling module from the character-based UNIX system, and all we had to do was translate it from Fortran to C. That took time, but no research or experimentation was involved, and the unit tests were already built.
A surprising number of applications don’t do any processing. They’re just CRUD and reports, which is all the CWA system is. Some of the reports involve fancy SQL and PHP computation to arrange the data, but I wouldn’t classify any of that as complicated enough to warrant being in the processing section.
I discuss this topic in Chapter 7.
Here you talk about any other systems that feed data into the application, or any other systems the application has to feed. Online feeds tend to be difficult to implement. Importing or exporting data files is easier, because you only have to deal with the data format, not with data transmission complications.
The customer probably knows what these are at the start of the project. Nothing is going to happen with development in the next three or six months to shed any light on what the external interfaces are.
Perhaps all you can do at the start is enumerate the interfaces. Gathering the technical documentation and assembling the third-party components (e.g., Open Database Connectivity (ODBC) drivers and data-format libraries) might take time, but at least you know what will be needed.
Consider anything related to external interfaces as high risk, because you never know how well those third-party components are going to work and how reliable the other systems are. High risk suggests you do the development work early in the schedule, so you can get all the bad news as early as possible.
Sometimes the only external interface is to feed data to another system in an easy-to-deal-with format like CSV or XML. In this case the work is not much more complicated than a report, but I’d still list it in this section and do it early, since you never know what the downstream system is going to do with your data until you give it a try. Also, while XML is well defined, CSV isn’t. Systems handle commas and quotes in all sorts of ways, or sometimes not at all.
I18N and L10N
Internationalization, or I18N, means designing the application so it can be localized to a language and culture. Generally, strings are the biggest problem, but dates, times, numbers, and monetary units may also be involved.
Supplying whatever the I18N mechanism needs to adapt the system for a specific language and culture is called localization (L10N). You can localize any application, even if it wasn’t designed for I18N, by making a copy of the source code and changing it. But that’s a horrible way to do it. If localization is in the cards, you need I18N.
I18N is pretty easy if you design for it at the start, and a real mess to add in after the application is finished. Generally, you handle strings by taking anything that appears at the user interface from a table, and each localization has its own table. There are two complications, however.
- Almost every language is more verbose than English, so the localized strings will mess up your page layouts.
- Right-to-left languages may require special handling.
PHP has library functions to localize dates and times, and numbers and monetary units are straightforward to deal with.
Once the application is designed for I18N, a localization has to be supplied for each required locality. This job is generally done by outside contractors, who have a staff of people who can do the work. It’s probably a bad idea to try to do it yourself on the cheap by using Google Translate or relying on your high school language courses.
This section should contain any requirements for making the application usable by people with disabilities. It’s not that hard to build such web applications, since the real work is done by the browser and the operating system (OS) on which it runs. The real issue is whether you’ll have the budget and the time to do testing with users with disabilities, which is the only way to tell if your design has succeeded.
For more information, Google “Web Content Accessibility Guidelines.”
User Administration
You’ll definitely want to implement a login mechanism, and I’ll give you all the code you’ll need in Chapter 6. The complicated part is if you need different classes of users. For example, some of the CWA data are entered by students, especially donations, which come in regularly. But we don’t want those students to have access to panelists’ data, much of which is confidential.
We decided different classes of users were too complicated for the first version of the CWA system, and the requirements said as much. (In Chapter 7 I explain how you’d do it if you had to.)
Billing
Usage might be billed by the month or year, by the session, by what information is accessed (e.g., so much per credit report), or in other ways. If you have a requirement to do any of that, you’ll have to implement the necessary bookkeeping. Maybe you have to do the billing as well. This can get very complicated, so make sure you explicitly state any requirements.
Browsers and Platform
You usually don’t care about the user’s computer or OS, only his or her browser. HTML, CSS, and JavaScript standards have evolved substantially over the last several years, so supporting any browser older than the newest version means extra work, both implementation and testing. Even with that testing, if users have a browser different from that of the development team, problems are going to arise.
If at all possible, allow a very small number of browsers, and only the latest versions of them. This is practical if the customers are within a single organization and have the freedom to upgrade their computers, but impractical if the web site is open to the world at large. In that case you have a lot of implementation hassles and testing ahead of you. So you’d better make sure you state any requirements to support old browsers.
On the server side, where your application mostly runs, you care about the PHP and MySQL versions. The web server, which is almost certainly going to be Apache or IIS, matters much less, as does the OS, which will be some form of UNIX (probably Linux or BSD) or Windows. OS X Server or anything else is pretty rare.
To make things easy, see if you can write the requirement to specify LAMP on the server side: Linux, Apache, MySQL, and PHP. Using BSD instead of Linux won’t matter, but anything else different makes for complications that can usually be avoided, and should be.
Installation
It’s hard to make systems installable, but the beauty of web applications is that they usually don’t have to be installed more than once. Specify that if you can. In Chapter 3 I discuss setting up the platforms you’ll need. That’s all the installation you want. If the system does have to be an installable product, make sure that’s in the requirements so you can schedule the extra development and testing required.
Capacity
Capacity might be inconsequential, as it was for the CWA application, or important but reasonable, as it was with Rgrade (the report card application), or extremely challenging, as it might be for Facebook (which really is implemented in PHP and MySQL). In any event, you have to know so you can plan accordingly. Adding application servers is no problem, since each login is independent. But once the database gets too big for a single instance things get very complicated, driving up the development costs considerably.
Documentation
Documentation consists of any informative materials delivered with the application for users, including help files, online manuals, printed books, and quick-reference cards, as well as any internal documentation (other than code comments) provided for future maintenance.
Internal documentation is pretty rare these days, and I haven’t seen any in years. Sometimes systems such as Doygen automatically generate documentation, but that doesn’t count, because it’s automatic. Sometimes specially formatted comments are added just above each function; if you do that, make sure they’re updated as the code changes.
Writing a proper user’s manual, which I’ve done quite a bit of, is a huge job, so, if you’ve committed to writing one, make sure it’s staffed, scheduled, and paid for. Help files are easier because they’re shorter and more succinct, but they still take time to do right.
Training
For an in-house application, users expect to get trained, but it might not be by the development staff. Most often you’ll be asked to train some key people in the users’ organization, and they’ll do the actual training. The training you do can be informal—no need for hundreds of PowerPoints.
Unless your application is pretty expensive, commercial users won’t expect any training. At most, some will want to see a few training videos shot with a screen-capturing utility and some narration.
Whatever you plan to do, make sure it’s in the requirements.
Support and Maintenance
There will always be support and maintenance, for which you’ll normally charge at the same hourly rate you billed for development, unless you’re an employee. That much can be stated just that way in the requirements. What you need to make special note of is whether there’s any expectation of 24/7 or weekend availability, any telephone support, or anything else that ought not to be left to the customer’s imagination.
Conversion
There is lots to say about conversion, all in Chapter 8.
Note that it’s “when,” not “if.” Requirements always change during and even after development, because the world changes and as the system gets implemented a better understanding of what it needs to do emerges. Since requirements start out with so much missing detail, they’d better change, or developers won’t know what to do. You can delay nailing down the requirements, but you can’t postpone them forever.
Writing the initial requirements, prior to or concurrent with scheduling and staffing, results in a baseline requirements document. This can be called requirements development. What happens subsequently to change the baseline is requirements management. There are two essential activities that you have to perform when a requirement changes: logging the change and modifying the requirements document.
Log every request for a requirements change in the issue tracking system I described in Chapter 1, the same system used to log bugs and other support matters. This procedure serves three purposes, at least.
- Ensuring that the proposed change isn’t misplaced or ignored.
- Putting it on the agenda for a status or planning meeting. (I organize all such meetings from the issues tracker).
- Documenting the change in case anyone in the future wants to know why the schedule slipped.
I like to keep things very simple, as you already know. Just record the text the way it came to you (e.g., text of an e-mail or copied from a memo), a brief title (five to ten words), a unique ID (e.g., 1234, REQ-0123, or let the tracker generate one), the date, who it came from, its category (“requirement”), and its status (“proposed”). Then, if it gets approved, change its status to “approved” and write fresh text, if needed, to document exactly what was approved. Keep the original text intact. HESK, the issue tracker I use, doesn’t allow me to customize statuses, so I give new requirements a status of “in progress” and then change them to “resolved” if and when they get approved.
When and if the requirement ever gets scheduled for a particular version, fill in a version number field. Then the issue log becomes the definitive list of what’s in the release. Fixed bugs get the same treatment.
A big mistake is to define so many fields in the issue tracker that it becomes a burden to log everything. Don’t forget that your job is to implement the application, not to win an award for documenting how you did it.
Modifying the Requirements Document
Here, too, keep the bookkeeping down to a level where it’s easy to do it, to increase the chance that you’ll actually do it. (That’s the way I am, anyway.) I like to make it very easy to keep the requirements document up to date.
An important principle in database design, as I explain in Chapter 4, is that the same data should never appear twice, because it’s too easy for the copies to get out of synch. That applies here, too: you don’t want to have a copy of the issue in the requirements document when it’s already in the issue tracker. So, until you’re ready to revise the requirements document, just reference a new requirement by its ID. (This is like using a foreign key in a database.) When you do revise the document, the issue tracker’s copy is no longer the primary reference, and should be marked that way so you’ll know. I’ll go through all of this step by step in the remainder of this section.
To make it reasonably easy to read requirements that refer to issues by ID, it’s convenient to generate a report of approved requirements from the issue tracking system to accompany the requirements document. That still means a lot of going back and forth for readers. Much better would be a script that automatically inserts the text of the issue from the tracker into the requirements document. It’s probably possible to do this with a Visual Basic script running in Microsoft Word, although I haven’t tried that. It’s much more straightforward to do if you write the requirements document as plain text, as I’ll demonstrate.
Note that this doesn’t violate the one-copy rule, since the source document only has a reference to the issue. The combined document, with the issue text automatically inserted is for viewing only, not for reediting. It’s just a report.
For an example, consider the baseline requirement shown in Listing 2-1, shown as it might be typed into a text editor.
Listing 2-1. Housing Report baseline requirement
Housing Report
One row for each participant or other person to be housed.
Columns: Name, Companion, Housing Committee Contact, Housers Names, Houser Street/ZIP, Houser Phone, Arrival Trip Details, Departure Trip Details, Days Here, Smoking OK, Pets OK, Participant Notes
See sample from last year for format and other details.
Suppose a requirement change is approved. It’s in the HESK issue tracker as Issue 1553, as shown in Figure 2-3.
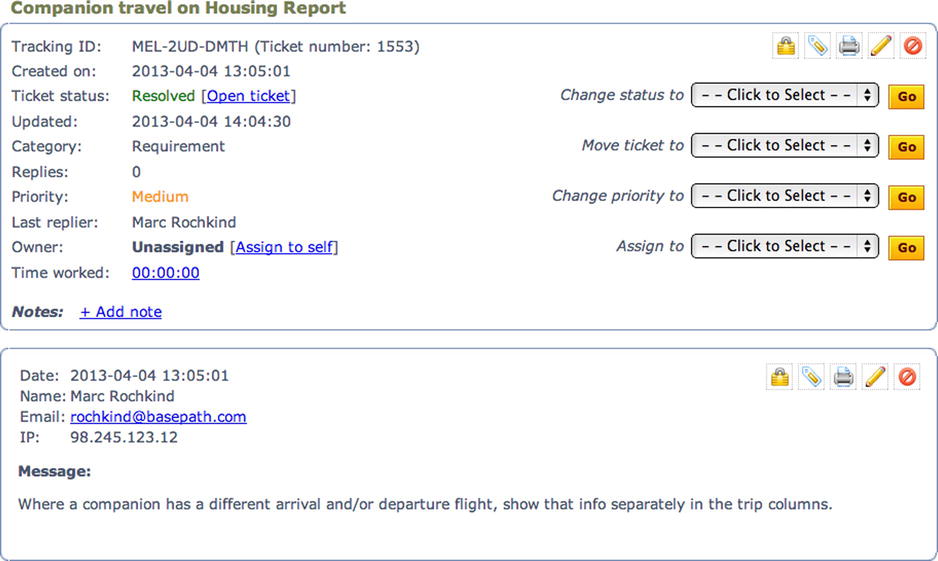
Figure 2-3. Change to Housing Report requirement
When this change is approved, the requirement is edited to reference the issue by its ID, as shown in Listing 2-2.
Listing 2-2. Housing Report baseline requirement with reference to Issue 1553
Housing Report
One row for each participant or other person to be housed.
Columns: Name, Companion, Housing Committee Contact, Housers Names, Houser Street/ZIP, Houser Phone, Arrival Trip Details, Departure Trip Details, Days Here, Smoking OK, Pets OK, Participant Notes
See sample from last year for format and other details.
{Issue 1553}
Now for the best part: since all the issues are in a MySQL database (one reason I chose HESK) and the requirements document is a text file, it’s easy to write a PHP program that combines the two, as shown in Listing 2-3.
Listing 2-3. Inserting Issues into Requirements Document
define(DB_USER, "rochkind_hesk");
define(DB_PASSWORD, "...");
$pdo = new PDO('mysql:host=localhost;dbname=rochkind_hesk',
DB_USER, DB_PASSWORD);
$pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$s = file_get_contents("CWA-requirements.txt");
$s = str_replace(" ", "<br>", $s);
while (preg_match('/^(.*){(w+) (d+)}(.*)$/s', $s, $m))
$s = $m[1] . issue($m[2], $m[3]) . $m[4];
echo $s;
function issue($cmd, $n) {
global $pdo;
$stmt = $pdo->prepare("select id, subject, message from
hesk_tickets where id = :id");
$stmt->execute(array('id' => $n));
if ($row = $stmt->fetch()) {
if ($cmd == "Issue")
return "
<table border=1 cellspacing=0 cellpadding=10>
<tr><td>
<p><b>Issue {$row['id']}: {$row['subject']}</b>
<p>{$row['message']}
</table>
";
else
return "<br>Issue {$row['id']}: {$row['subject']}";
}
else
return "<b>[Can't locate Issue $n]</b>";
}
The PHP program replaced “{Issue 1553}” with the data from the database, and the output is shown in Figure 2-4, which is much easier to read.

Figure 2-4. Combined requirements
As an advanced PHP programmer, you should be able to see what this program is doing, but here’s a very brief run-through anyway: the lines that assign to or reference the variable $pdo open a PDO connection to the HESK database and, inside the function issue, fetch the ID, subject, and message for that issue. (I talk much more about PDO in Chapter 5.)
The call to file_get_contents reads the entire text from the requirements document itself, and the next line puts in HTML brk tags to maintain the paragraphing. Next comes a preg_match loop to replace issue references (e.g., “{Issue 1553}”) with HTML that incorporates the issue details, supplied by the call to the function issue. Then it outputs the processed text.
The function queries the database for the issue data and formats the data as a table, if the full issue is wanted, or just the ID and subject otherwise. (I’ll explain the latter shortly.)
If plain text is too plain for you, which it is for me, you can use Markdown to add some formatting by augmenting the text with markers for headings, emboldening, and a few other embellishments. (See daringfireball.net/projects/markdown for the details.) Listing 2-4 shows the requirement with some Markdown added (### and **). Note that the document is still perfectly readable even with interspersed Markdown annotations.
Listing 2-4. Housing Report requirement with Markdown added
### Housing Report
One row for each participant or other person to be housed.
**Columns:** Name, Companion, Housing Committee Contact, Housers Names, Houser Street/ZIP, Houser Phone, Arrival Trip Details, Departure Trip Details, Days Here, Smoking OK, Pets OK, Participant Notes
See sample from last year for format and other details.
{Full 1553}
There’s a free PHP implementation of Markdown you can use at michelf.ca/projects/php-markdown. (It’s also included in the downloadable source for this book at www.apress.com.) The changes to the PHP program to handle Markdown are trivial. The file has to be included at the top
require_once 'markdown.php';
and the two lines
$s = file_get_contents("CWA-requirements.txt");
$s = str_replace(" ", "<br>", $s);
are changed to the single line
$s = Markdown(file_get_contents("CWA-requirements.txt"));
because Markdown automatically starts a new paragraph when a blank line appears. Figure 2-5 shows the new output, now decently formatted.

Figure 2-5. Output formatted with Markdown
Even with the issues expanded inline within the requirements, the document can still turn into an unreadable patchwork if there are a lot of changes, as there surely will be. You’ll want to take time out at some point and produce another version that incorporates all the changes directly in the text. It’s still a good idea to reference the issues, however. A good way to do that is to use “Title” in the issue reference instead of “Issue” (emboldened), as in Listing 2-5, with the output shown in Figure 2-6.
Listing 2-5. Updated Housing Report requirement.
### Housing Report
One row for each participant or other person to be housed.
**Columns:** Name, Companion, Housing Committee Contact, Housers Names, Houser Street/ZIP, Houser Phone, Arrival Trip Details, Departure Trip Details, Days Here, Smoking OK, Pets OK, Participant Notes
Where a companion has a different arrival and/or departure flight, show that info separately in the trip columns.
See sample from last year for format and other details.
*This requirement incorporates the following issues:*
{Title 1553}

Figure 2-6. Updated Housing Report requirement
As I said, once an issue is incorporated into a revision of the requirements document, its text in the issue tracker is for historical purposes only; the document is the authority. If the requirement has to be revised, a new issue has to be created. I added a custom field to HESK called “InDoc” to note issues that have been incorporated into the document and are therefore no longer the prime reference.
The small PHP utility shown here is a good example of how just a little bit of code can make a huge productivity difference. Imagine having to refer to the issue tracker, or even a report generated from it, for every issue reference. It’s not bad with only a few issues referenced from the requirements document, but in the real world, there are going to be more like a thousand. That would be intolerable.
What made it feasible for me to write this little program were two decisions about how I represented the requirements.
- The requirements document as a plain text file, augmented with Markdown.
- Requirements changes stored in a MySQL database, easily accessed from PHP.
All done with completely free software, and very little mechanism. As the architect Mies van der Rohe said, “Less is more.” Toss out Microsoft Word, free yourself from that expensive issue tracker with a proprietary database, and you’ve really got something.
Here’s another way to put it: all engineering documentation, including the requirements document, should also be able to be treated as data, and any databases should allow access from PHP (or some other scripting language). No proprietary formats allowed.
Use Cases
A PHP/MySQL application doesn’t just sit there. It’s supposed to be used, usually by humans, but sometimes by other systems, too. A detailed description of an interaction between a human or system (the actor) and the application that results in something of value is called a use case. Collect enough of these and you have a complete picture of how the system is supposed to be used.
For example, here’s a use case for Rgrade (the report card system) for a teacher recording a grade.
- Preconditions: Rgrade installed, teacher set up to use it, student in system, teacher has decided what grade to give.
- Log in to Rgrade.
- Navigate to the student list and find the student by last name, and first name if necessary.
- Navigate to the student’s report card.
- Locate the category and grading period.
- Enter or change the grade.
- Save the form, unless that’s automatic.
- Verify that the proper grade has been entered.
- Postconditions: Student’s grade is recorded.
Note that the actual steps performed by the teacher are preceded by preconditions, which are assumed to be true before the interaction takes place, and followed by postconditions, which are true after the interaction. In fact, achieving the postconditions is the entire purpose of the interaction.
What I have isn’t exactly how these steps would appear on a help page or in a training manual, because the terminology isn’t quite right (“category,” “grading period,” “form,” etc.). But it does capture the most important of the interactions between a teacher and the Rgrade application.
Other Rgrade use cases covered interactions like the following:
- Getting a student added who isn’t on the list.
- Deleting a student.
- Changing a student’s name.
- Entering teacher’s comments.
- Generating draft report cards.
- Printing final report cards.
The Universal Modeling Language (UML), an international standard that you can read at uml.org, provides a notation for use cases, which you can use if you know UML. But it’s more important to get the use cases down than it is to use a particular form for writing them, and I have never used UML myself, for anything. Numbered steps will work fine for your use cases. (Don’t allow a feeling that you have to do everything the absolutely right way to intimidate you into not doing things at all!)
Aside from having enough use cases to cover the important interactions, it’s equally important to make sure all the steps are there, leaving nothing to be assumed. Notice in the preceding example that I had steps for logging in, locating the category and grading period, and verifying the results, all of which might have been assumed. This is not the time to be succinct.
The use cases themselves go into section 17 of the requirements document, as requirements in their own right. Additionally, they’re used to check the other requirements. What you should do, alone or with a group, is go through every step of every use case slowly, ensuring that one or more requirements cover all the system functions necessary to carry out each step. Then add requirements as needed. For example, step 6, “enter or change the grade,” means that there must be a requirement to provide some means of editing that data. A requirement like “all grades on the report card shall be editable” does the trick. This example is perhaps too obvious, but others that occur in practice are more subtle and cause problems later if you overlook requirements.
A completely separate activity involving use cases is to ensure that there are entities and attributes (tables and columns) in the database design to support every step of every use case. Even this simple example calls for entities like teacher, student, and report card. Categories and grading periods might be entities, or perhaps attributes. Grades are needed, too, of course. Since user login happens in the use case, there needs to be something in the database for that.
Employing the use cases to check the other requirements won’t completely capture all the meaning in the use cases, which is why they go into the requirements separately.
Another great thing about use cases, unique among the other kinds of requirements, is that they’re little stories, with characters and plot. So they’re much more understandable by the people for whom the application is being built. You can talk about the CRUD requirements for two hours and get hardly any comments, but when you start going through a use case, you’ll be stopped in the first five minutes with a comment like the following: “What if two students have the same name?” or “We sometimes have to grade new students before the office gets them completely registered and in the system.” Far, far better to expose these messy realities while you’re still crystalizing the requirements than after the teachers start trying out the system and decide it must have been implemented by some guy from outside Texas who never even taught in an elementary school. (Oh, wait, it was!)
Also beneficial is a comment like “the system doesn’t have to do that. We do that ourselves.” If that’s the official word, you’ve just saved a bunch of development time.
In summary: The use cases are probably the most important part of the requirements.
Requirements War Stories
Here are two true stories about requirements, one sad and one happy. Ironically, in the sad one the requirements were complete, clear, and well articulated. In the happy one, the requirements were shaky at best. The sad one goes first. I’ve changed the names of the people involved.
The Runaway Developer
Back in my days running XVT Software, a user-interface tool company I started in 1987, we needed a small subsystem that various modules could call to get parameter values. It’s the kind of thing that might be handled these days with XML, but, as was common back then, we invented our own simple property-value language for representing parameters (e.g., like Windows INI files or Mac OS plist files). With several highly educated computer scientists on board, we specified the language formally, leaving no wiggle room at all. Those were the complete, clear, and well-articulated requirements.
The developer assigned to the task of writing the code to read in and access the parameters went at it, but he was still working on his assignment after a couple of weeks. I figured a programmer with his talents should be able to write a little parser in at most two days, stick the parameters in a hash table or something like that, and be done with it. We were a small company and this was a very small part of the overall system. I myself have written code for similar tasks in less than a day.
So I called him in for a chat. He was very proud of his work, but he wasn’t quite done with it. I asked him to tell me how he had gone about it. It turned out that what he was doing wasn’t compiling our dumbed-down parameter language at all. He had defined a metalanguage for describing input specifications and was writing a compiler for that, along with an interpreter for the intermediate language he’d invented. Then, with this completed, all he had to do was write the specification for our language in his metalanguage, and, PRESTO!, he’d be done.
I’m embarrassed to say I lost my temper. I shouldn’t have, because it was my fault. He was only being himself.
The moral of this story? It’s quite enough to implement the requirements. A smart programmer might go a little beyond, to do some obvious generalization, such as allowing for five phone numbers if the requirement is for two. But inventing and implementing a new programming language when there was no requirement for any such thing, is going much too far. Enough of that kind of runaway development can kill a project.
(In the Agile world this is called YAGNI, for “you ain’t gonna need it,” but, when practiced literally, that’s going too far the other way. Sometimes several requirements can be absorbed into the same generalized facility.)
The Arzano Ranch
Mike, an acquaintance of mine, came to me and Ellen, a mutual friend, and asked us if we’d like to join him on a little programming project for an airline consultant named Ed Arzano. Ed had developed a new way of pricing seats on airplanes to maximize revenue based on some theoretical work done by an applied mathematician who was Mike’s brother. Very cozy.
I agreed and told Mike my hourly rate. He told me to charge a lot more, so I did. We all did.
The first meeting with Ed went swimmingly. He sketched out what he needed, and we all got on it right away. Mike worked on the algorithm, being mathematically trained, Ellen worked on a simple user interface, and I worked on the back-end data management. In a couple of weeks we had it done. We showed it to Ed, and he loved it. He took it off to show to an operations specialist at an airline, which I think was Frontier, based in Denver. They liked it, too.
Ed was so thrilled that when we next met with him he sketched out more ideas. We went off and revised the system. Same thing: We finished on time, Ed loved it, and off he went to demo his invention.
Next meeting with Ed, a rerun. More changes, more development, more demonstrations.
And on, and on, and on, for months. Ed was always happy, but never satisfied. Not because we were letting him down but because our system was inspiring him to come up with new ideas.
You’d think that months of never being done and having the requirements change every two weeks would be a bad thing, but it wasn’t. We enjoyed the work, and Ed was making real progress. He was a great guy, too. We were sorry to see the project end. (Years later I heard that he had started his own airline).
We made so much money on this gig that we bought a ski condo in Breckenridge, Colorado. The whole thing—not a timeshare. Of course, we named it the Arzano Ranch.
Moral: This all took place in the mid-1980s; if I’d thought of calling it Agile Development, I could have been somebody.
OK, a more serious moral: If the requirements are changing because reality is changing, and not because you didn’t bother documenting them, then go with the flow. Recall from Chapter 1 that satisfying the customer is what makes your project successful.
With physical-world projects, like building a bridge, the cost of a change gets much higher the later the phase, becoming prohibitive once construction has begun. So, the key phases—requirements, design, construction, verification—have to be done strictly in that order, and each phase has to be 100% complete and as perfect as possible before you begin the next phase.
In the early days of software development, the same approach was followed, with the addition of an integration phase between construction and verification, since software is normally developed in modules (as bridges are too, sometimes). This is the so-called waterfall model, named because progress flows from one phase to another like water falling over rocks.
Personally, in my 45 years developing software, I’ve never been on a project that followed the waterfall model exactly, although I’ve been on many projects that saved integration and verification (testing) until the end, which, as you would expect, was always a disaster.
Another problem with the waterfall approach, or anything roughly similar to it, is that it’s a struggle to deal with requirements. As I’ve shown in this chapter, it’s impossible to know all the requirements at the start, and, for areas like the user interface, it’s harmful to pretend that you do. You do know a lot, however, and what you know should definitely be documented at the start. But there has to be a way to incorporate evolution of the requirements, or perhaps outright changes, during development.
About a dozen years ago a group of developers formalized Agile Software Development, in direct opposition to the waterfall approach, primarily to deal with the two problems I mentioned: evolutionary requirements and integration/testing at the end. While there’s a lot to the various Agile methods, the most important ones are
- Dividing the project into very short (like a week) fixed-length increments with a deliverable system at the end of each increment.
- Establishing requirements only for each increment, thus allowing arbitrary changes throughout the project.
- Continual communication with a representative of the customer who, ideally, is on the development team.
- Daily communication among members of the development team.
- Continuous unit testing and integration.
I’ve been practicing variations of #1, #3, #4, and #5 for years, without knowing anything about the agile approach. In the mid-1970s a group of us at Bell Labs developed the Programmer’s Workbench, which used the then-new UNIX system as a platform for developer tools for use by mainframe programmers. There was a huge debate at the start between a few developers who had just come off a big military project and wanted to formalize the requirements and a few, including me, who were much looser in how we approached software projects. We won.
So, when I learned about Agile methods, I was like the character in Moliere’s The Bourgeois Gentleman who discovered that he had “been speaking prose all my life, and didn’t even know it!”
The part of Agile I couldn’t ever get comfortable with, and still can’t, is the part that says that you only develop requirements one week at a time. Really? Yes, it’s true. The Agile intelligentsia have nothing but contempt for requirements.
For example, in his book, The Agile Samurai, Jonathan Rasmusson says, “Whatever requirements you do gather are guaranteed to change.” Does he mean that if the CWA office tells me they need a list of topics submitted by participants in exactly the same format they’ve been using for years, the format for the list of topics is guaranteed to change? That the Richardson School District report card specification, approved by the school board, is guaranteed to change? That the supermarket checker shift schedule posted by hundreds of A&P, Kroger, and Safeway stores is guaranteed to change? No, those won’t change, and they should be documented at the start of the project along with everything else that’s known. They should be part of the initial planning, analysis, and design, before any coding begins.
Here’s another: In the seminal book on Agile methods, Extreme Programming Explained: Embrace Change, Kent Beck says, “Out of the thousands of pages used to describe requirements, if you deliver the right 5, 10 or 20 percent, you will likely realize all of the business benefit envisioned for the whole system. So what were the other 80 percent? Not requirements—they weren’t mandatory or obligatory.” I can’t think of a single project in which delivering 20% of the requirements, or even 75%, would have been acceptable. What part of Rgrade could I have skipped? Listing all the students? Teacher logins? Entering grades? Allowing for teacher comments? Printing the report cards? No, I had to implement 100% of the requirements before the school district would deploy the system. SuperSked, being commercial software, maybe could have shipped with 90% of the requirements satisfied. The CWA database project, maybe also 90%, as we had already slimmed it down to the bare minimum for the first year, with the idea that next year we’d do more.
So, when it comes to requirements, I think the Agile writers and consultants are either exaggerating for dramatic effect or they really do believe that this is how software projects ought to be run. If the latter, they’re flat out wrong.
Anyway, enough Agile bashing. I’ll just present my view of how you ought to deal with requirements if you’re using the Agile approach, and leave the job of sorting out the polemics for another time. (As I hope I’ve made clear, when it comes to customer communication, team communication, unit testing, continuous integration, and frequent delivery, the Agile guys are totally on the right track.)
Let’s do it with pictures. First, Figure 2-7 shows a strict waterfall sequence and Figure 2-8 shows Agile iterations.

Figure 2-7. Waterfall project

Figure 2-8. Agile project
There are some projects for which a strict waterfall approach might work, and very small, informal projects, such as the Arzano Ranch, which I described earlier, that are suitable for a strict Agile approach. Generally, though, none are appropriate: waterfall is much too rigid and idealistic, and Agile suffers from no overall plan. Without an overall plan, there’s no way to estimate a completion date or a budget, no way to come up with a coherent database design, and no way to leverage development by handling similar functions with generalized coding, unless the functions show up in the same iteration.
Actually, I don’t believe any project uses a strict Agile approach, despite what the gurus preach. Figure 2-9 shows what projects really do, and what I have always done when I controlled the project. Since everybody likes coming up with pretentious names, I’ll call my approach Planned Agile: You start with a plan/analysis/design period where you work with the high-level requirements, but you do the low-level plan/analysis/design work iteratively.

Figure 2-9. Planned Agile project
To repeat myself, I don’t claim that the Planned Agile approach is original. Just the opposite: nearly all Agile projects are doing it that way but for some reason are reluctant to admit it.
The one-week iterations don’t have to be one week; for many projects and teams that’s too short to be efficient, like a too-short traffic light at an intersection is inefficient, because it takes time to turn over to the next iteration.
What goes on in the initial plan/analysis/design period? Documenting the requirements to the extent possible, enumerating the use cases, running the use cases against the requirements, designing the database, structuring the implementation, and deciding on the platform and tools (Chapter 3). Throughout the project, as the team members focus on their iteration, someone—not necessarily the whole team—has to manage the overall plan. In Agile terminology, the plan for each iteration comes from choosing stories from the backlog. In Planned Agile, there’s some of that, but also awareness that the overall plan should determine the order of attack.
If you don’t believe me that Planned Agile is what Agile projects actually do, or ought to do, check out two authoritative books which, while very long and tedious to read, emphasize that Agile needs an overall plan.
- Dean Leffingwell, Agile Software Requirements: Lean Requirements Practices for Teams, Programs, and the Enterprise (2010).
- Barry Boehm and Richard Turner, Balancing Agility and Discipline: A Guide for the Perplexed (2003).
What about the rest of Agile: pair programming, daily scrum, sprints, burn-down charts, and so on? I haven’t tried most of them, but my guess is that they’re effective ways of working. Whether you do them or something else won’t have much effect on the project compared to the effect of having a strong team, working with the customer to get the requirements right, and continuous integration. Those are the big three.
Chapter Summary
- For PHP/MySQL projects, you can structure your requirements document into 17 sections (see earlier for the details).
- The initial requirements should establish the scope of the project but not necessarily include all the details.
- The use cases are the most important part of the requirements.
- Log all requirement changes in the issues tracker.
- Keep the requirements in a text file that references requirement-change issues.
- Revise the requirements document periodically to incorporate changes, but still reference the associated issues.
- Agile software development is a good approach, but it should be augmented by plan/analysis/design at the start and throughout the project.