
5
Context Free Grammar
5.1 CONTEXT FREE GRAMMAR: DEFINITION AND EXAMPLES
Q. Define context free grammar. Why is it called context free?
Ans. According to Chomsky Hierarchy, Context Free Grammar (CFG) is Type 2 Grammar.
In mathematical description we can describe it as
Where all the production are in the form α → β, where α ![]() VN, i.e. set of non-terminals and /α/ = 1, i.e. there will be only one non-terminal at the left-hand-side and β
VN, i.e. set of non-terminals and /α/ = 1, i.e. there will be only one non-terminal at the left-hand-side and β ![]() VN U Σ, i.e. β is a combination of non-terminals and terminals.
VN U Σ, i.e. β is a combination of non-terminals and terminals.
Before describing why this type of grammar is called context free, we have to know the definition of context. Non-terminals symbols are the producing symbols because they produce some extra symbols. So the production rules are in the format of
{A string consists of at least one non-terminal} → {A string of terminals and/or non-terminals}. If any symbol is present with the producing non-terminal at the left-hand-side of the production rule then that extra symbol is called context. Context can be of two types (a) left context; (b) right context.
In context free grammar, at the left-hand-side of each production rules there is only one nonterminal. (No context is added with it). For this reason this type of grammar is called context free grammar.
Q. Construct a CFG for the language L = { WCWR | W![]() (a,b)*}.
(a,b)*}.
Ans. W is a string of any combination of a and b. Hence, WR is also a string of any combination of a and b, but it is a string which is the reverse of W. The C is a terminal symbol like a, b. Hence if we take C as a mirror we will be able to see the reflection of W in the WR part.
Like C, abCba, abbaCabba like this. It means there is some generating symbol in the middle by replacing which it adds same terminal symbol before and after C. As W![]() (a,b)* so null symbol are also accepted in the place of a,b. That means only C is accepted by this language set.
(a,b)* so null symbol are also accepted in the place of a,b. That means only C is accepted by this language set.
From the above discussion the production rules will be:
S → aSb/bSb/C.
The Grammar will be G = {VN, Σ, P, S}, where
VN: {S},
Σ: {a, b, C},
P: S → aSb/bSb/C,
S: {S}.
Q. Construct a CFG for the Regular Expression (0 + 1)* 0 1*.
Ans. If we describe the regular expression in English language it will be any combination of 0 and 1 followed by single 0 and ends with any number of 1.
In this regular expression a single 0 is in between (0 + 1)* and 1*. That is, in the language set only 0 can exist. For constructing the grammar for this regular expression keep the single 0 as fixed. Then before and after of this 0 consider two non-terminals A and B, which can be replaced multiple times.
Hence, the production rule (P) of the Grammar for constructing this regular expression will be
S → A0B,
A → 0A/ 1A/![]() ,
,
B → 1B/![]() ,
,
The Grammar will be G = {VN, Σ, P, S}, where
VN: {S, A, B},
Σ: {0,1,![]() }
}
S: {S}.
Q. Construct a CFG for the RE (011 + 1)* (01)*
sol.
The regular expression consists of two parts (011 + 1)* and (01)*. Hence from the start symbol we are taking two non-terminals each of them is producing one part. (011 + 1) can be written as 011/ 1. As it is any combination of (represented by *) so null string is also included in the language set.
From the above discussion the production rules (P) of the grammar will be
S → BC,
B → AB/![]() ,
,
A —> 011/1,
C → DC/![]() ,
,
D →01.
The grammar will be G = {VN, Σ, P, S}, where
VN: {S, A, B, C, D},
Σ: {0,1,![]() },
},
S: {S}.
Q. Construct a CFG for a string in which there will be equal number of binary digits.
Ans. Binary digits means 0 and 1. We have to construct a Grammar for a string where there will be equal number of 0 and 1. These numbers may come in any order, but in the string the number of 0 and 1 will be equal. Hence the string may start with 0, may start with 1. 0 can come after 0 or 1 can come after 0. 1 can come after 1 or 0 can come after 1.
The production rules (P) for this Grammar will be
S → 0S0/1S1/0S1/1S0/ ![]()
The Grammar will be G = {VN, Σ, P, S}, where
VN: {S}
Σ: {0,1, ![]() },
},
S: {S}.
Q. Construct a CFG for the string [abba(baa)naab(aaba)n | n≥ 0].
Ans. In English language the description for the string will be abba followed by any number of (baa) followed by aab followed by any number of aaba, in which number of baa and number of aaba are same. Value of n may be 0. Hence the string abbaaab is also accepted by the language set. One thing to be noticed in the string that, number of (baa) and number of (aaba) are same in the string.
The production rule (P) for the grammar of this language set will be
S → abbaA
A → (baa)A(aaba)
A → aab
The grammar will be G = {VN, Σ, P, S}, where
VN: {S, A},
Σ: {a, b},
S: {S}.
Q. Construct a CFG for {anbncmdm | n, m≥ 1}
Ans. The string can be described like this: A string of equal number of a and b followed by equal number of c and d.
In this string, number of a and number of b will be same, and number of c and number of d will be same. Break the string into two parts A and B. Both are non-terminals. A will generate the string anbn and B will generate the string cmdm.
Now the Production rules (P) for the Grammar of the language will be
S → AB,
A → aAb/ab,
B → cBd/cd.
The Grammar will be G = {VN, Σ, P, S}, where
VN: {S, A, B},
Σ: {a, b, c, d},
S: {S}.
Q. Construct a grammar for the language {anbmcmdn | m, n≥ 1}
Ans. In this string number of a and number of d are same, and number of b and number of c are same. Here a comes first followed by b, c, and d. But the problem of breaking the string into two parts is that here b and c come in the middle of a and d. In this case, if we take a non-terminal for generating bmcm
Now the production rules (P) for the grammar of the language will be
S → aSd/aAd,
A → bAc/bc.
The grammar will be G = {VN, Σ, P, S}, where
VN: {S, A},
Σ: {a,b,c,d},
S: {S}.
5.2 DERIVATION AND PARSE TREE
Q. Define left-most derivation and right-most derivation.
Ans. In the process of generating a language from a given production rules of a grammar, the non-terminals are replaced by the corresponding strings of the right-hand-side of the production. But if there are more than one non-terminal then it must be determined which one will be replaced. Depending on this selection derivation are divided into two parts (a) left most derivation; (b) right-most derivation.
(a) A derivation is called a left most derivation if we replace only the left most non-terminal by some production rule at each step of the generating process of the language from the grammar.
(b) A derivation is called a right most derivation if we replace only the right most non-terminal by some production rule at each step of the generating process of the language from the grammar.
Q. Construct the string 0100110 from the Grammar given below by using
(a) left most derivation
(b) right most derivation
S → 0S/1AA
A → 0/1A/0B
B → 1/0BB
Ans.
Left most derivation
S → 0S→01AA → 010BA → 0100BBA → 01001BA → 010011A → 0100110
(The replaced non-terminals are underlined.)
Right most derivation
S → 0S → 01AA. → 01A0 → 010B0 → 0100BB0 → 0100B10 → 0100110
(The replaced non-terminals are underlined.)
Q. Construct the string abbbb from the Grammar given below by using
(a)Left most derivation
(b)Right most derivation
S → aAB
A → bBb
B → A/![]()
Ans.
Left most derivation
S→ aAB → abBbB → abAbB → abbBbbB → abbbbB → abbbb
Right most derivation
S → aAB → aA → abBb → abAb → abbBbb → abbbb
Q. What is parsing? Define parse tree. What are the conditions for constructing a parse tree from a CFG? Why parse tree construction is only possible for CFG?
Ans.
Parsing a string is finding a derivation for that string from a given grammar.
Parse tree is the tree representation of deriving a context free language (CFL) from a given Context free Grammar. These types of trees are some times called derivation trees.
“A parse tree is an ordered tree in which left-hand-side of a production represents a parent node and children nodes are represented by the production's right-hand-side.”
Conditions for constructing a parse tree from a CFG
(i) Each vertex of the tree must have a label. The label is a non-terminal or terminal or null (Λ).
(ii) The root of the tree is the start symbol, i.e. S.
(iii) The label of the internal vertices are non-terminal symbols ![]() VN
VN
(iv) If there is a production A → X1X2……XK. Then for a vertex, label A, the children of that node will be X1X2......XK.
(v) A vertex n is called a leaf of the parse tree if its label is a terminal symbol ![]() Σ or null (Λ).
Σ or null (Λ).
Parse Tree construction is only possible for CFG. This is because the properties of a tree match with the properties of CFG.
Here we are describing the similar properties of a Tree and a CFG.
(a) For a tree there must have some root. For every CFG there is a single start symbol.
(b) Each node of a tree has single label. For every CFG at the left-hand-side there is a single nonterminal.
(c) A child node is derived from a single parent. For constructing a CFL from a given CFG a nonterminal is replaced by a suitable string at the right-hand-side (If for a non-terminal there are multiple productions). Each of the characters of the string is generating a node. That is for each single node there is a single parent.
For these similarities a parse tree can only be generated for a CFG.
(NB: Parse tree is not possible context sensitive grammar because there are production like bB→aa or AA→ B that means at the left-hand-side there may be more than one symbols.)
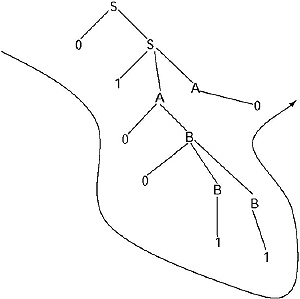
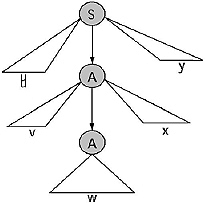
Q. Find the parse tree for generating the string 0100110 from the grammar given below.
S → 0S/1AA
A → 0/1A/0B
B → 1/0BB
Ans.
For generating the string 0100110 from the above given CFG the Left Most derivation will be
S → 0S → 01AA → 010BA → 0100BBA → 01001BA → 010011A → 0100110
The parse tree for this derivation:
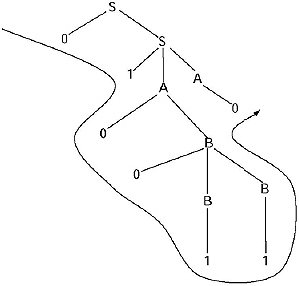
For generating the string 0100110 from the above given CFG the right most derivation will be
S → 0S → 01AA. → 01A0 → 010B0 → 0100BB0 → 0100B10 → 0100110
The parse tree for this derivation:
(NB: When you will be told to generate a parse tree you can generate that by left most derivation or right most derivation.)
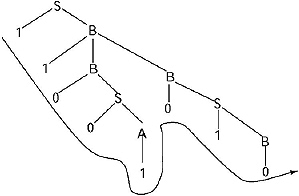
Q. Find the parse tree for generating the string 11001010 from the given grammar.
S → 1B/0A
A → 1/1S/0AA
B → 0/0S/1BB
Ans.
For Generating the string 11001010 from the above given CFG the left most derivation will be.
S →1B →11BB → 110SB → 1100AB → 11001B →110010S → 1100101B →11001010.
The parse tree for this derivation:
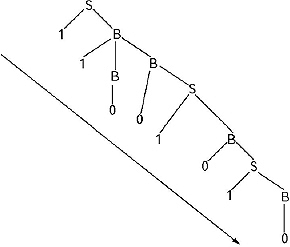
The left most derivation for Generating the string 11001010 from the above given CFG:
S→1B →11BB →11B0S →11B01B → 11B010S → 11B0101B → 11B01010 →11001010
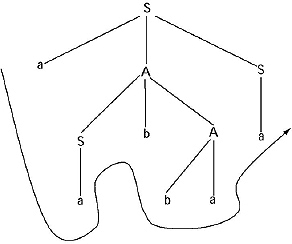
Q. Construct a parse tree for the string aabbaa from the grammar given below.
S → a/aAS
A →SS/ SbA/ ba
Ans.
The derivation for generating the string from the above grammar.
S → aAS → aSbAS → aabAS → aabbaS_→ aabbaa.
The derivation tree:
5.3 AMBIGUITY
Q. What do you mean by ambiguous language or ambiguous grammar? Explain with an example.
Ans. For generating a string from a given grammar we have to derive the string step by step from the production rules of the given grammar. For this derivation we know two types of derivations (i) left most derivation and (ii) right most derivation. Except these two there is also one approach called mixed approach. Here particularly left most or right most is not maintained in each step, whereas any of the non-terminals present in the deriving string is replaced by suitable production rule.
By this processes different types of derivation can be generated for deriving a particular string from a given grammar. For each of the derivations a parse tree is generated.
Different parse trees generated from the different derivations may be same or may be different.
A grammar of a language is called ambiguous If any of the cases for generating a particular string; more than one left most derivation or more than one right most derivation or more than one parse tree can be generated
Lets assume there is a grammar
S →aS/AS/A,
A → AS/a.
Generate the string aaa from the given grammar.
Sol. The string can be generated in many ways. Here we are giving two ways.
(i) S→ aS → aAS → aaS → aaA → aaa
(ii) S→A → AS → ASS → aAS → aaS → aaA → aaa
The parse tree for derivation (i) The parse tree derivation (ii)
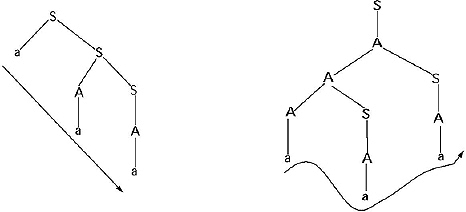
Here for the same string derived from the same grammar we are getting more than one parse tree. Hence according to the definition, the grammar is an ambiguous grammar.
Q. Prove that the following grammar is ambiguous.
VN:{S},
Σ: {id, + ,*},
P: S → S + S/S * S/id,
S: {S}.
Ans. Let take a string id + id*id.
The string can be generated in the following ways
(a) S → S + S → S + S * S → id + S*S → id + id*S → id + id* id,
(b) S → S * S → S + S *S → id + S*S → id + id*S → id + id*id.
The parse tree for (a): The parse tree for (b)
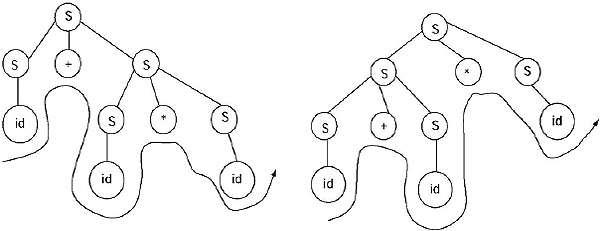
As we are getting two parse tree for generating a string from the given grammar, so the Grammar is ambiguous.
Q. Prove that the following grammar is ambiguous.
S → a/abSb/aAb A → bS/aAAb
Ans. Take a string abababb. The string can be generated in the following ways
(a) S → abSb → abaAbb → ababSbb → abababb
(b) S → aAb → abSb → abaAbb → ababSbb → abababb
Parse trees for (a) and (b) will be
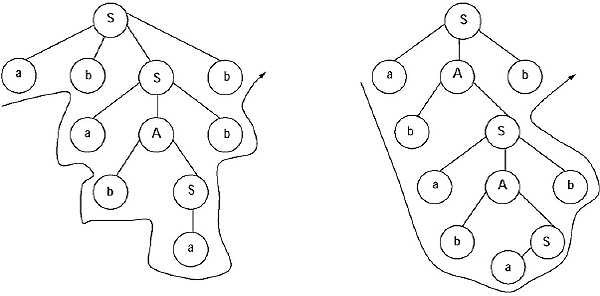
As we are getting two parse tree for generating a string from the given grammar, so the grammar is ambiguous.
Q. Prove that the following grammar is ambiguous.
S → 0Y/01
X → 0XY /0
Y → XY1 /1
Ans. Take a string 000111. The string can be derived in the following ways.
(a) S → 0Y→ 0XY1 → 00XYY1 → 000YY1 → 0001Y1 → 000111
(b) S → 0Y → 0XY1 → 0XXY11 → 00XY11 → 000Y11 → 000111
Parse trees for (a) and (b) will be
As we are getting two parse tree for generating a string from the given grammar, so the grammar is ambiguous.
Q. Define ambiguous CFG, inherently ambiguous CFL, and unambiguous CFL.
Ans.
(a) A CFG G is said to be ambiguous if there exists some w ![]() L(G) that has at least two distinct parse trees.
L(G) that has at least two distinct parse trees.
(b) A CFL L is said to be inherently ambiguous if all its grammars are ambiguous.
(c) If L is a CFL for which there exists an unambiguous grammar, then L is said to be unambiguous. (Even one grammar for L is unambiguous, and then L is an unambiguous language.)
Q. Does ambiguous grammar create problem? Explain with a suitable example.
Ans. Yes, ambiguous grammar create problem.
Lets take an example For a grammar G, the production rule is E → E + E′ E*E/a.
From here we have to construct a + a* a.
The string can be generated in two different ways
(a) E → E + E → E + E*E → a + E*E → a + a*E → a + a*a
(b) E →E*E → E + E*E → a + E*E → a + a*E → a + a*a
So for these two cases two parse trees are
So the grammar is ambiguous.
In the place of 'a put ‘2'. Hence the derivations will be
(a) E → E + E → E + E*E → 2 + E*E → 2 + 2*E → 2 + 2*2,
(b) E →E*E → E + E*E → 2 + E*E → 2 + 2*E → 2 + 2*2.
Upto this step both of them seem same. But the real problem is in the parse tree.
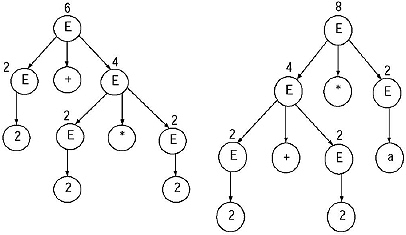
The correct result is 2 + 2*2 = 2 + 4 = 6 (according to the rules of mathematics * has higher precedence over + ).
From here we can decide that ambiguity is bad for programming language.
Q. How can we remove ambiguity from a grammar?
Ans. There is no particular rule to remove ambiguity from a context free grammar. Some times ambiguity can be removed by hand. In the previous case, ambiguity can be removed by setting priority to the operators ‘ + ’ and ‘*'. If ‘*' is set as higher priority than ‘ + ‘ then ambiguity can be removed. More bad news is that some CFL have only ambiguous Grammar. That means in no way the ambiguity can be removed. This type of ambiguity is called inherent ambiguity.
5.4 LEFT RECURSION AND LEFT FACTORING
Q. What is left recursion? Describe with an example.
Ans. A context-free grammar is called left recursive if a non-terminal ‘A' as a left most symbol appears alternatively at the time of derivation either immediately (called direct left-recursive) or through some other non-terminal definitions (called indirect/hidden left-recursive).
In other words a grammar is left recursive if it has a non-terminal ‘A' such that there is a derivation.
![]() for some string α
for some string α
Example:
Direct Left Recursion:
Let the grammar is A → Aα/β, where α and β consists of terminal and/or non-terminals but β does not start with A.
At the time of derivation if we start from A and replace A by the production A → Aα, then for all the time A will be the left most non-terminal symbol.
Indirect Left Recursion:
Take a grammar in the form
A → Bα/γ,
B → Aβ/γ,
where α, β, γ, and δ consist of terminal and/or non-terminal.
At the time of derivation if we start from A replace the A by the production A → Ba and after that the B is replaced by the production B → Aβ, then A will appear again as a left most non-terminal symbol.
This is called indirect left recursion.
In general a grammar in the form
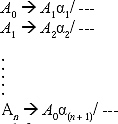
is indirect left recursive grammar.
(NB: Left recursive grammar is to be converted into a non-left recursive grammar because top down parsing technique cannot handle left recursion. top down parsing is a part of compiler design).
Q. How to convert a left recursive grammar into a non-left recursive grammar?
Ans. Immediate left recursion can be removed by the following process. This is called Moore's proposal. For a grammar in the form
A → A α | β, where β does not start with A.
The equivalent grammar after removing left recursion becomes
A → β A',
A′ → αA′|ε .
In general for a grammar in the form A → Aα1 |…| A αm | β1 |…| βn, where β1…βn do not start with A, the equivalent grammar after removing left recursion is
A → β1 A′ |…| βn A′
A′ → α1 A′ |…| αm; A′ | ε
For indirect left recursion removal there is an algorithm
Arrange non-terminals in some order: A1…An

Q. Remove left recursion from the following grammar.
E→ E + T |T
T→ T*F| F
F→ id | (E)
Ans. In the grammar there are two immediate left recursions E E + T and T → T * F
By using Moore's proposal the left recursion E → E + Tis removed as
E→ TE and E′ → + TE / ![]() .
.
The left recursion T → T*F is removed as
T → F T
T → *FT | ![]()
The context free grammar after removing left recursion becomes
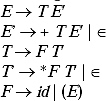
Q. Remove left recursion from the following grammar.
S → Aa | b
A → Sc | d.
Ans. The grammar has indirect left recursion. Rename S as A1 and A as A2. The grammar is
A1 → A2a/ b,
A2 → A1c/d
For i = 1, j = 1, there is no production in the form A1 → A1a.
For i = 2, j = 1, there is a production in the form A2 → A1a. The production is A2 → A1c. According to the algorithm for removal of indirect left recursion the production becomes
A2 → A2ac/ bc.
This left recursion for the production A2 → A2ac/ bc/ d is removed and the production rules are
![]()
The actual non-left recursive grammar is
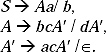
Q. Remove left recursion from the following grammar.
S → Aa | b
A → Ac | Sd | f
Ans. The grammar has indirect left recursion. Rename S as A1 and A as A2. The grammar is
![]()
For i = 1, j = 1, there is no production in the form A1 → A1α.
For i = 2, j = 1, there is a production in the form A2 → A1α. The production is A2 → A1d.
According to the algorithm for removal of indirect left recursion the production becomes
A2 → A2ad/ bd.
The A2 production is A2 → A2c/A2ad/bd/f.
This left recursion for the production A2 → A2c/A2ad/bd/f. is removed and the production rules are
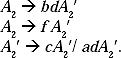
The actual non-left recursive grammar is
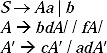
Q. What is left factoring? Describe with an example.
Ans. Let in a grammar there is a production rule in the form A → αβ1/ αβ2/…/ αβn. The parser generated from this kind of grammar is not efficient as it requires backtracking. To avoid this problem we need to left factor the grammar.
Let the string that we need to construct is αβ2. The parser is a computer program. It will check only one symbol at a time. Therefore, first it will take ‘α'. For getting ‘α', there are n number of productions. But which production is to be chosen? Let it has chosen A → αβ1. After traversing ‘a', it will take the next symbol ‘β2' in the string. But from the current situation it is not possible to get ‘β2'. So, the parser needs to traverse back again. This is called backtracking. Left Factor solves this problem of backtracking.
To left factor a grammar, we collect all productions that have the same left-hand-side Non-Terminal and begin with the same terminal symbols on the right-hand-side. We combine the common strings into a single production and then append a new non-terminal symbol to the end of this new production. Finally, we create a new set of productions using this new non-terminal for each of the suffixes to the common production.
After left factoring the above grammar is transformed into:
A → αA1
A1 → β1/β1/…/βn
Q. Left Factor the following grammar.
A → abB | aB | cdg | cdeB | cdfB
Ans. In the previous grammar, the right-hand-side productions abB and aB both starts with ‘a'. So they can be left factored. Same way cdg, cdeB and cdfB all starts with ‘ cd. So they can also be left factored.
The left factored grammar is
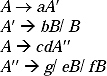
5.5 SIMPLIFICATION OF CFG
Q. Why do we need to simplify a CFG?
Ans. Context free grammar may contain different types of useless symbols, unit productions, and null productions. These types of symbols and productions increase number of steps in generating a language from a CFG. Reduced grammar contains less number of non-terminals and productions, so the time complexity for language generating process becomes less from reduced grammar.
Q. What are processes of simplification of a CFG?
Ans. Context free grammar can be simplified in the following three processes.
(i) Removal of useless symbols
(a) Removal of non-generating symbols
(b) Removal of non-reachable symbols
(ii) Removal of unit productions
(iii) Removal of null productions.
Q. Define non-generating symbol and non-reachable symbol.
Ans. Non-generating symbols are those symbols, which do not produce any terminal string. Non-reachable symbols are those symbols, which cannot be reached at any time starting from the start symbol.
Q. How useless symbols can be removed from a given context free grammar?
Ans. Useless symbols are of two types (a) non-generating, and (b) non-reachable. These two types of useless symbols can be removed according to the following process
(a) Find the non-generating symbols, i.e. the symbols which do not generate any terminal string. If start symbol is found non-generating leave that symbol. Because start symbol cannot be removed, as the language generating process start from that symbol.
(b) For removing non-generating symbols remove those productions whose right-side and/or left-side contain those symbols.
(c) Now find the non-reachable symbols, i.e. the symbols which cannot be reached, starting from the start symbol.
(d) Remove the non-reachable symbols like rule (b)
[There is no hard and first rule for which symbol (non-generating or non-reachable) will be removed first, but most of the cases non-generating symbol is removed first, then non-reachable symbol is removed. However, depending upon the situation this can be changed.]
Q. Remove Useless symbols from the given Context Free Grammar.
S → AC
S → BA
C → CB
C → AC
A → a
B → aC/b
Ans. There are two types of useless symbols, non-generating symbol and non-reachable symbol. First we are finding non-generating symbols.
Those symbols which do not produce any terminal string are non-generating symbol. Here S and C are non-generating symbol as they do not produce any terminal string. But S is the start symbol, so it cannot be removed.
So we have to remove the symbol C. To remove C, all the productions containing C as a symbol (left-hand-side or right-hand-side) must be removed. By removing the productions the minimized grammar will be
S →BA,
A→a,
B→b.
Now we have to find non-reachable symbols, the symbols which cannot be reached at any time starting from the start symbol. There is no non-reachable symbol in the grammar. So the minimized form of the grammar by removing useless symbols is
S →BA,
A→a,
B→b.
Q. Remove useless symbols from the given CFG.
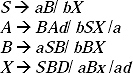
Sol. First we are going to find non-generating symbols, the non-terminals which do not produce any terminal string.
Here S and B are not producing any terminal string, so they are non-generating symbol. But S cannot be removed as it is start symbol. To remove B from the production rules of the given grammar, all the productions containing B as a symbol will be removed. By removing B from the grammar the modified production rules will be

Now we have to find non-reachable symbols, the symbols which cannot be reached starting from the start symbol.
Here in (a) the symbol A cannot be reached by any path at any time starting from the start symbol S. So A is a non-reachable symbol. To remove A, all the productions containing A as a symbol will be removed. By removing A from the production rules of the grammar the minimized grammar will be.
S → bX,
X → ad.
Q. Remove useless symbol from the given grammar.
S → aAa
A → bBB
B → ab
C → aB
Sol. First we are going to remove Non-generating symbols, the non-terminals which do not produce any terminal string. Here S, A and C are non-generating symbols. However, as S is the start symbol it cannot be removed. However, A and C will be removed. The production rules containing A and/or C as a symbol will be removed. By removing A and C the production becomes
B → ab. However there is no meaning of the grammar containing this single production rule and no start symbol. Therefore, we have to first remove the non-reachable symbols then non-generating symbols.
Here non-reachable symbols are B and C, But B is a generating symbol, so B cannot be removed. By removing C the production rules of the grammar becomes.
S → aAa
A → bBB
B → ab.
Here non-generating symbols are S and A. However, any one of them cannot be removed. If we remove there will be no existence of the grammar or the language generating power of the grammar will be hampered.
Q. Reduce the following CFG by removing useless symbols from the grammar.
S →aC/ SB
A → bSCa / ad
B → aSB/ bBC
C → aBC/ ad
Sol. First we are going to remove the non-generating symbols from the production rules. Here S and B are not producing any terminal string, so they are non-generating symbols. But S is the start symbol so it cannot be removed. So, only B will be removed. By removing B the grammar becomes
S → aC
A → bSCa/ ad
C → ad
Now we have to find the non-reachable symbols, the non-terminals which cannot be reached starting from the start symbol. Here symbol A cannot be reached by any path starting from the start symbol. Therefore, A will be removed. By removing A the production becomes
S →aC
C → ad
This is the reduced format of the grammar by removing useless symbols.
Q. What is unit production? What the problems unit production create in CFG? What is the procedure to remove unit production from a given context free grammar?
Ans. Production in the form non-terminal → Single non-terminal is called unit production. Unit production increases the number of steps as well as complexity at the time of generating language from the grammar. This will be clear if we take an example.
Lets assume there is a grammar S → AB, A → E, B→ C, C → D, D →b, E→ a. From here when we are going to generate a language then it will be generated by the following way
S → AB → EB →aB → aC → aD → ab, Number of steps are 6.
The grammar by removing unit production and as well as minimizing will be
S →AB, A→a, B → b.
From the language will be generated by the following way S → AB → aB → ab, Number of steps is 3.
Procedure to remove unit production:
There is an algorithm to remove unit production from a given CFG.
While (there exist a unit production NT → NT)
{
select a unit production A →B
for(every non-unit production B →α)
{
add production A →α to the grammar.
eliminate A →B from grammar.
}
}
Q. Remove unit production from the following grammar.
S → AB, A → E, B→C, C →D, D →b, E→a
Ans. In this grammar unit productions are A →E, B→ C and C →D. if we want to remove the unit production A → E from the grammar first we have to find a non-unit production in the form E → {Some string of terminal or non-terminal or both}. There is a production E → a. Hence the production A → a will be added to the production rule. And the modified production rule will be
S → AB, A → a, B → C, C →D, D →b, E →a.
For removing another unit production B →C we have to find a non-unit production
C →{Some string of terminal or non-terminal or both}. However, there is no such production found.
For removing a unit production C →D we have found a non-unit production D →b .So the production C →b will be added to the production rule set and C→ D will be removed. The modified production rule will be
S → AB, A → a, B → C, C →b, D →b, E →a.
Now the unit production B →C will be removed by B →b as there is a non-unit production C →b. The modified production rule will be
S → AB, A → a, B → b, C →b, D →b, E →a.
[This is the grammar without unit production, but it is not minimized. There are useless symbols (non-reachable symbol) C, D, and E. Therefore, if we want to minimize the grammar these symbols will be removed. By removing the useless symbols the grammar will be
S → AB, A →a, B →b]
Q. Remove unit production from the following grammar.
S → AB, A →a, B → C, C → D, D →b.
Ans. The unit productions in the grammar are B →C, C →D.
To remove unit production B→C we have to search for a non-unit production
C → {Some string of terminal or non-terminal or both}. There is no such production rule found. So, we are trying to remove the unit production C →D.
There is a non-unit production D →b. So, the unit production C →D will be removed by including a production C →b.
The modified production rules will be
S →AB, A →a, B→C, C→b, D→b
There is a unit production B →C exists. This unit production can be removed by including a production B →b to the grammar.
The modified production rules will be
S → AB, A →a, B →b, C →b, D →b
In this grammar no unit production exists.
(This grammar is unit production free, but not minimized. There are useless symbols in the form of non-reachable symbols. Here non-reachable symbols are C and D, which cannot be reached starting from the start symbol S. By removing the useless symbols the grammar will become S → AB, A → a, B →b.)
Q. Remove Unit production from the following grammar.
S → aX/ Yb/ Y
X →S
Y →Yb/ b
Ans. The unit productions in the grammar are S → Y and X → S. To remove unit production S → Y, we have to find a non-unit production where Y → {Some string of terminal or non-terminal or both}. There is a non-unit production Y →Yb/ b. The unit production S →Y will be removed by including production S → Yb/ b in the production.
The modified production rules will be
S → aX/ Yb/b
X →S
Y →Yb/ b
In the previous production rules there is a unit production X →S. This production can be removed by including the productionX → aX/Yb/b to the production rules.
The modified production rules will be.
S →aX/Yb/b,
X → aX/Yb/b,
Y →Yb/b.
(This is also minimized grammar.)
Q. Remove Unit production from the following grammar.
S → AA
A → B/BB
B → abB/b/bb
Ans. In the previous grammar there is a unit production A → B. To remove the unit production we have to find a non-unit production B → {Some string of Terminal or Non-terminal or both}. There is a non-unit production B → abB/b/bb. So the unit production A → B can be removed by including the production A → abB/b/bb to the production rule.
The modified production rule will be
S → AA
A → BB/abB/b/bb
B → abB/b/bb.
(This is also minimized grammar.)
Q. What do you mean by null production? When null production cannot be removed? What is the procedure to remove null production?
Ans. A production in the form NT → Є is called null production.
If ![]() (null string) is in the language set generated from the grammar, then that null production cannot be removed.
(null string) is in the language set generated from the grammar, then that null production cannot be removed.
That is if we get ![]() then that null production cannot be removed from the production rules.
then that null production cannot be removed from the production rules.
Procedure to remove null production:
Step I: If A → Є is a production to be eliminated then we look for all productions, whose right side contain A.
Step II: Replace each occurrence of A in each of these productions to obtain the non-Є production.
Step III: These non-null productions must be added to the grammar to keep the language generating power same.
Q. Remove e production from the following grammar.
S → aA,
A → b/Є.
Sol. In the previous production rules there is a null production A → Є. The grammar does not produce null string as a language so this null production can be removed.
According to step I we have to look for all productions whose right side contain A. There is one S → aA.
According to second step we have to replace each occurrence of 'A' in each of the productions. There is only one occurrence of 'A' in S → aA. So after replacing it will become S → a.
According to step three, these productions will be added to the grammar.
Hence the grammar will be
S → aA/a,
A →b.
Now in the new production rules there is no null production.
Q. Remove e production from the following grammar.
S →aX/ bX
X → a/b/Є.
Sol. In the previous grammar there is a null production X → Є. In the language set produced by the grammar there is no null string, so this null production can be removed.
For removing this null production we have to look for all the productions whose right side contains X. There are two such productions in the grammar S → aX and S → bX.
We have to replace each occurrence of 'X' in each of the productions to obtain non-null production. In both the productions X has occurred only once. Therefore, after replacing the productions will become S → a and S → b, respectively.
These productions must be added to the grammar to keep the language generating power same. So, after adding these, productions the grammar will be
S → aX/ bX/ a/ b,
X → a/ b.
Q. Remove e production from the following grammar.
S → ABaC,
A → BC,
B →b/ Є,
C →D/ Є,
D → d.
Sol. In the previous grammar there are two null productions B → Є and C → Є. The grammar does not produce any null string. So these null productions can be removed to obtain a non-null production.
To remove the null production B → Є we have to find the productions whose right side contain B. There are two productions in the grammar S → ABaC and A →BC.
We have to replace each occurrence of B in each of the productions by null to obtain non-null production. In the previous two cases B has occurred only once. After replacing B by null the productions will become S → AaC and A →C These productions will be added to the grammar to keep the language generating power same.
To remove the null production C → Є we have to find those productions whose right side contain C. There are two productions S → ABaC and A →BC.
We have to replace each occurrence of C in each of the productions by null to obtain non-null production. In the previous two cases C has occurred only once. After replacing C by null the productions will become S → ABa and A→B. These productions will be added to the grammar to keep the language generating power same.
In the previous two productions S → ABaC and A →BC, B and C both are there. But we have replaced B and C in two steps. If simultaneously B and C are replaced by null, the productions will become S → Aa and A → Є, respectively. These productions will also be added to keep the language generating power same.
So, after removing the two null productions B → Є and C → Є, the modified grammar will become
S → ABaC / AaC/ ABa/ Aa,
A → BC/ C/ B/ Є,
B →b
C →D,
D →d.
Again in this grammar there is a null production A → Є. By removing the null production according to the previous way the modified grammar will become
S → ABaC / AaC/ ABa/ Aa/ BaC / aC/ Ba/ a,
A → BC/ C/ B,
B →b,
C →D,
D → d.
The grammar is not in minimized format because there are three unit productions A → C, A →B and C →D. By removing the unit productions from the grammar, the minimized grammar will become
S → ABaC / AaC/ ABa/ Aa/ BaC / aC/ Ba/ a,
A → BC/ d/ b,
B →b,
C →d,
D →d.
Again in the grammar there is a non-reachable symbol D. By removing the non-reachable symbol the minimized grammar will be
S → ABaC / AaC/ ABa/ Aa/ BaC / aC/ Ba/ a,
A → BC/ d/ b,
B →b,
C →d,
Q. Remove e production from the following grammar.
S → ABAC,
A → aA/ Є,
B → bB/ Є,
C → Є.
Sol. In the grammar there are two null productions. A → Є and B → Є. The grammar does not produce any null string. So these null productions can be removed to obtain a non-null production.
To remove the null production A → Є we have to find all the productions whose right-hand-side contain A. There are two productions S → ABAC and A →aA. Among them in the production S → ABAC there are two A and one B. We have to replace each occurrence of A in each of the productions by null to obtain non-null production. By replacing we get S → ABC, S → BAC,S → BC (First right most, then left most then both) and A → a (For A →aA).
To remove null production B → Є we have to find all the productions whose right side contains B. There are two productions S → ABAC and B →bB, each of them have single occurrence of B. For obtaining non-null productions we have to replace each occurrence of B in each of the productions by null. By replacing we get S → AAC and B →b.
In the production S → ABAC, there are both A and B. But we have replaced A and B in two separate steps. If simultaneously A and B are replaced by null, the productions will become
S → AC, S→C.
So, after removing the two null productions A → Є and B → Є the modified grammar will become
S → ABAC/ ABC/ AAC/ BAC/ BC/ AC/ C,
A → aA/ a,
B → bB/ b,
C → c.
There is no null production in the grammar.
Q. Remove e production from the following grammar.
S → aS/ A,
A → aA/ Є
Sol. In the previous grammar there is a null production A → Є But in the language set generated by the grammar there is a null string, which can be generated by the following way S → A → Є As null string is in the language set so the null production cannot be removed from the grammar.
5.6 NORMAL FORM
Q. What is called normal form of a grammar? What is the utility of normal form?
For a grammar the right-hand-side (RHS) of a production can be any string of variables and terminals, i.e. (VN U ∑)*. A grammar is said to be in normal form when every production of the grammar has some specific form. That means except allowing any member of (VN U ∑) on the RHS of the productions, we permit only specific members on the RHS of the production. But these restrictions should not hamper the language generating power of the grammar.
Utility of Normal Form:
When a grammar is made in normal form, every production of the grammar is converted in some specific form. These help us to design some algorithm to answer certain questions. Similarly if a CFG is converted into CNF, one can easily answer whether the language generated by the grammar, i.e. L(G) is finite or not. For a CFG converted into CNF the parse tree generated from the CNF is always a Binary tree. Same like if a CFG is converted in GNF then a PDA accepting the language generated by the grammar can easily be designed.
Q. Define Chomsky normal form. What is the process of converting a CFG into CNF?
A CFG is called in CNF if all the productions of the grammar are in the following form
non-terminal → String of exactly two non-terminals
non-terminal → Single Terminal
Process:
Step I:
(a) Eliminate all Є - production.
(b) Eliminate all unit production.
(c) Eliminate all useless symbols.
Step II:
If (all the productions are in the form NT → string of exactly two NTs or NT→ Single Terminal) Declare the CFG is in CNF. And stop
Else
follow step III and/or IV and/or V.
Step III: (Elimination of terminals on the R.H.S. of length two or more)
Consider any production of the form
NT → T1T2….Tn, where n ≥ 2 (T means Terminal and NT means non-terminal).
For a terminal Ti introduce a new variable (non-terminal) say NT1 and a corresponding production NTi → Ti. Repeat this for every terminal on the RHS so that every productions of the grammar has either a single terminal or two or more variables.
Step IV: (Restriction of number of variables on the RHS to two).
Consider any production of the form
NT S NT,NT,…NT , where n ≥3.
The production NT → NT1NT2…NTn is replaced by new productions
NT → NT1A1
A1 → NT2A2
A2 → NT3A3
-------
-------
An-2 NTn-1 TNn
Here Ai s are new variables.
Step V: (Conversion of string containing terminals and non-terminals, to string of non-terminal on the RHS)
Consider any production of the form
NT → T1T2….Tn NT1….NTn, where n ≥1.
For the part T1T2….Tn, follow Step III
Check the resultant string by Step II. If not in CNF follow StepIV
By this process the generated new grammar is in CNF.
Q. Convert the following grammar into CNF.
S → bA/ aB
A → bAA/ aS/ a
B → aBB/ bS/ a
Sol. The productions S →bA, S →aB, A →bAA, A →aS, B → aBB, B →bS are not in CNF. So we have to convert these into CNF. Let replace terminal 'a' by non-terminal Ca and terminal 'b' by non-terminal Cb. Hence two new productions will be added to the grammar
Ca → a and Cb → b.
By replacing a and b by new non-terminals and including the two productions the modified grammar will be
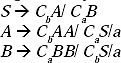
In the modified grammar all the productions are not in CNF. The productions A → CbAA and B → CaBB are not in CNF, because they contain more than two non-terminals at the right-hand-side. Let replace AA by a new non-terminal D and BB by another new non-terminal E. Hence two new productions will be added to the grammar D → AA and E → BB. Therefore, the new modified grammar will be
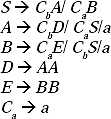
Cb → b
Q. Convert the following grammar into CNF.
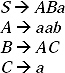
Ans. Except B AC, all the productions in the grammar are not in CNF. We have to convert them into CNF keeping the language generating power same.
Lets replace 'a' by Da and ' b' by Db. Hence two new productions Da → a and Db → b will be added to the grammar. By replacing 'a' by Da and ' b' by Db and adding two productions the modified grammar:
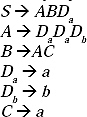
S → ABDa and A → DaDaDbare not in CNF. Take two non-terminals E and F. Replace AB by E and DD by F. Therefore, two new productions E → AB and F → DD will be added to the grammar. By replacement and adding the productions the modified grammar will be
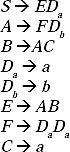
In the previous grammar all the productions are in the form of non-terminal → String of exactly two non-terminals or non-terminal → Single Terminal. Hence the grammar is in CNF.
Q. Convert the following grammar into CNF.
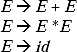
where ∑ = {+,*,id”}
Ans. Except E → id all the other productions of the grammar are not in CNF. In the grammar E →E + E and E →E * E there are two terminals + and *. Take two non-terminals C and D for replacing ‘ + ‘ and ‘*', respectively. Two new productions will be added to the grammar. By replacing ‘ + ‘ and ‘*' the modified production rules will be
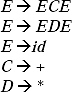
In the production rules E → ECE and E → EDE there are three non-terminals. Replace EC by another non-terminal F and ED by G. Therefore, two new productions F → EC and G → ED will be added to the grammar. By replacing and adding the new productions the modified grammar will be
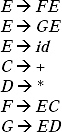
In the previous grammar all the productions are in the form of non-terminal → String of exactly two non-terminals or non-terminal → Single Terminal. Hence the grammar is in CNF.
Q. Convert the following grammar into CNF
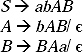
Ans. In the grammar there are two null productions A → Є and B→ Є First these productions must be removed, after that the grammar can be converted into CNF. After removing the null production A → Є the modified grammar will be
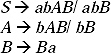
After removing the null production B → Є the modified grammar will be
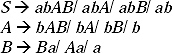
Now this grammar can be converted into CNF. In the grammar except A → b and B → a all the productions are not in CNF. Let take two non-terminals Ca and Cb which will replace a and b, respectively. Therefore, two new productions Ca → a and Cb → b will be added to the grammar. After replacing and adding new productions the modified grammar will be
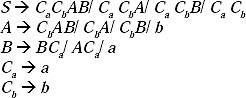
In this modified grammar ![]() are not in CNF. Let take two another non-terminals D and E, which will be replaced in the place of CaCb and AB, respectively. Hence, two new productions D → CaCb and E → AB will be added to the grammar. By replacing and adding two new productions the modified grammar will be
are not in CNF. Let take two another non-terminals D and E, which will be replaced in the place of CaCb and AB, respectively. Hence, two new productions D → CaCb and E → AB will be added to the grammar. By replacing and adding two new productions the modified grammar will be
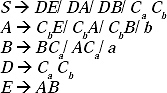
![]()
In the previous grammar all the productions are in the form of non-terminal → String of exactly two non-terminals or non-terminal → Single Terminal. Hence the grammar is in CNF.
Q. Define Greibach normal form (GNF). What is the application of GNF?
Ans. A grammar is said to be in GNF if every productions of the grammar is of the form
non-terminal → (Single Terminal)(String of non-terminals)
non-terminal → Single Terminal
In one line it can be said that all the productions will be in the form
non-terminal → (Single Terminal)(non-terminal)*
(* means any combination of NT s including null)
Application:
If a CFG can be converted into GNF, then from that GNF, the Pushdown Automata (Machine Format of a CFG) accepting the CFL can easily be designed.
Q. What is the process of converting a given CFG into GNF?
Ans. Before going into detail about the process of converting a CFG into GNF we have to know two lemmas which are useful for the conversion process.
Lemma I: If ![]() belongs to the Productions rules(P) of G. Then a new grammar
belongs to the Productions rules(P) of G. Then a new grammar ![]() can be constructed by replacing A → β 1,
can be constructed by replacing A → β 1,![]() , which will produce
, which will produce
![]() This production belongs to P in G'
This production belongs to P in G'
It can be proved that L(G) = L(G' )
Lemma II:![]() be a CFG and the set of A productions belongs to P be A → α1
be a CFG and the set of A productions belongs to P be A → α1 ![]()
Introduce a new non-terminal X. Let ![]() and P can be formed by replacing the A-productions by
and P can be formed by replacing the A-productions by
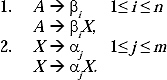
It can be proved that L (G) = L (G).
[The main production was ![]() If we replace
If we replace ![]() in the production
in the production ![]() the production will become
the production will become ![]() Then replace A by βi The production will become
Then replace A by βi The production will become ![]()
If we replace A → βj in the production ![]() , the production will become A → βiαj.
, the production will become A → βiαj.
Take another non-terminal X, which will be replaced in the place of the string after αj in both the productions ![]() So the A productions will be
So the A productions will be ![]() productions will be
productions will be ![]() Hence the lemma II is correct.]
Hence the lemma II is correct.]
Process for Conversion a CFG into GNF
Step I: Eliminate null productions and unit productions from the Grammar and convert the Grammar into CNF.
Step II: Rename the non-terminals of ![]() with start symbolA1
with start symbolA1
Step III: Using Lemma I modify the productions. Such that left-hand-side variable subscript is less than or equal to right-hand-side starting variable subscript, that is in mathematical notation it can be said all the productions will be in the form Ai → AjV where i ≤j.
Step IV: By repeating applications of Lemma I and Lemma II, all the productions of the modified grammar will come into GNF.
Q. Convert the following grammar into GNF.
![]()
Ans.
Step I: There is no unit productions and no null production in the grammar. The given grammar is in CNF.
Step II: In the grammar there are two non-terminals S and A. Rename the non-terminals as A1 and A2, respectively. The modified grammar will be
![]()
Step III: In the grammar A2 → A1A1 is not in the format Ai → AjVwhere i≤j. Replace the leftmostA1 at the right-hand-side of the production A2 → A1A1 After replacing the modified A2 production will be
![]()
The production A2 → aA1/ b is in the format A → βi, and the production A2→ A2A2A1 is in the format of A → Aαj Therefore, we can introduce a new non-terminal B2 and the modified A2 production will be (According to Lemma II )
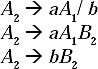
And B2 productions will be
![]()
Step IV: All A2 productions are in the format of GNF. In the production A1 → A2A2/ a, A → a is in the prescribed format. But the production A1 → A2A2 is not in the format of GNF. Replace the left most A2, at the right-hand-side of the production by the previous A2 productions. The modified A1 productions will be
Aj → aAjA2/ bA2/ aA1B1A1/ bB1A1
The B2 productions are not in GNF. Replace left most A2 at the right-hand-side of the two productions by the A2 productions. The modified B2 productions will be
![]()
For the given CFG the GNF will be.
![]()
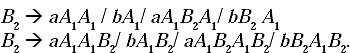
Q. Convert the following CFG into GNF.
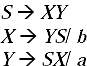
Ans.
Step I: In the grammar there is no null production and no unit production. The grammar also is in CNF.
Step II: In the grammar there are three non-terminals S, X, Y. Rename the non-terminals as A1, A2, A3, respectively. After renaming the modified grammar will be
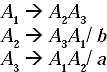
Step III: In the grammar the production A3 → A1A2 is not in the format Ai→ AjVwhere i ≤ j.
Replace the leftmost A1 at the right-hand-side of the production A3 → A1A2 by the production A1 → A2A3. The production will become A3 → A2A3A2, which is not again in the format of Ai → AjVwhere i ≤ j. Replace the leftmost A2 at the right-hand-side of the production A3 → A2A3A2, by the production A2 S A3A1/ b. The modified A3 production will be
A3 → A3A1A3A2/ bA3A2/ a.
The production A3 → bA3A2/ a is in the format of A → β,and the production A3 → A3A1A3A2 is in the format of A → Aa So, we can introduce a new non-terminal B and the modified A3 production will be (According to Lemma II)
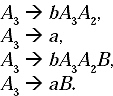
And B productions will be
![]()
Step IV: All the A3 productions are in the specified format of GNF.
The A2 production is not in the specified format of GNF. Replacing A3 productions in A2 productions, the modified A2 production we get
A2 → bA3A2A1/ aA1/ bA3A2BA1/ aBA1 / b
Now all the A2 productions are in the prescribed format of GNF.
The A1 production is not in the prescribed format of GNF. Replacing A2 productions in A1 the modified A1 productions will be
A1 → bA3A2A1A3 / aA1A3/ bA3A2BA1A3/ aBA1A3/ bA3
All the A1 productions are in the prescribed format of GNF.
But the B productions are till not in the prescribed format of GNF. By replacing the left most A1 at the right-hand-side of the B productions by A1 productions, the modified B productions will be
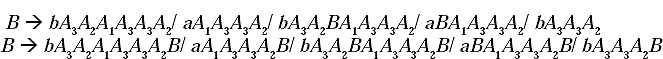
Now all the B productions of the grammar are in the prescribed format of GNF.
So for the given CFG the GNF will be.
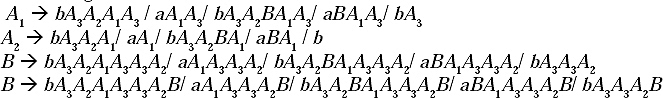
Q. Convert the following CFG into GNF.
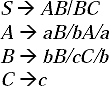
Ans.
Step I: In the previous grammar there is no unit production and no null production. However, all productions are not in CNF. Let take two non-terminals Da and Db which will be placed in the place of 'a' and ‘b', respectively. Therefore, two new productions Da → a and Db →b will be added to the grammar.
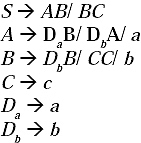
Now all the productions are in CNF.
Step II: There are six non-terminals in the grammar. Rename the non-terminals as A1, A2…, A6. After replacing the modified productions will be
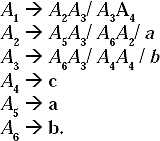
The productions for A1, A2, A3 are all in the format Ai → AjV, where i ≤ j. Replace A6 and A4 in the productions A3 → A6A3 and A3 → A4A4 by A6 → b and A4 → c, respectively. The modified A3 productions will be
A3 → bA3 cA4 / b All the productions are now in the format of GNF.
Replace A5 and A6 in the productions A2 → A5A3 and A2 → A6A2 by A5 →a and A6 → b, respectively. The modified A2 productions will be
A2 → aA3 bA2/a All the productions are now in the format of GNF.
The A1 productions A1 → A2A3/A3A4 are not in the format of GNF. Replace A2 at the right-hand-side of the production A1 → A2A3. The modified production will be
A1 →aA3A3/bA2Al3/aA3.
Replace A3 at the right-hand-side of the production A1→A3A4. The modified production will be
![]()
Therefore for the given CFG the GNF will be.
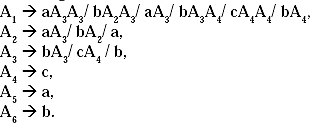
5.7 CONSTRUCTING FA FROM REGULAR GRAMMAR
Q. What is the process of constructing finite automata directly from a regular grammar?
Ans.
Step I:
(a) If the grammar does not produce any null string then, number of states of the finite automata will be equal to the number of non-terminals of the Regular Grammar + 1. Each state of the finite automata represents each non-terminal and the extra state is the final state of the FA. If it produce null string then number of states is same as number of non-terminals.
(b) The initial state of the finite automata is the start symbol of the Regular Grammar.
(c) If the Language generated by the Regular Grammar contains null string then the initial state will also be the final state of the constructing finite automata.
Step II:
(a) For a production in the form A → aB, make a δ function δ (A, a) → B. There will be an arc from state A to state B with label a.
![]()
(b) For a production in the form A → a, make a δ function δ(A, a) → Final state.
![]()
(c) For a production A → ![]() , make a δ function δ(A,
, make a δ function δ(A, ![]() )→ A, and A will be final state.
)→ A, and A will be final state.
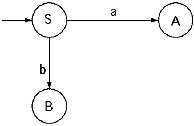
Q. Convert the following Regular grammar into finite automata.
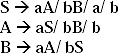
Ans. In the grammar there are three non-terminals S, A, and B. Therefore, number of states of the finite automata will be four. Let name the final state as C.
(i) For the production S → aA/ bB the transitional diagram will be
(ii) For the production S → a/b the transitional diagram including the previous will be
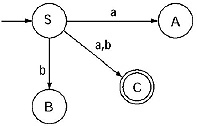
(iii) For the production A → aS/bB/b the transitional diagram including the previous will be
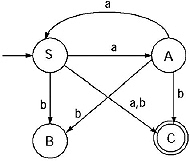
For the production B → aA/bS transitional diagram including the previous will be
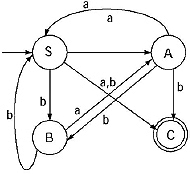
This is the finite automata for the given Regular Grammar.
Q. Convert the following Regular grammar into finite automata.
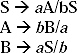
Ans. In the grammar there are three non-terminals S, A and B. So, number of states of the finite automata will be four. Let name the final state as C.
(i) For the production S → aA/bS, the transitional diagram will be
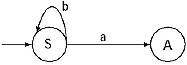
(ii) For the production A → bB/a, the transitional diagram including the previous one will be.
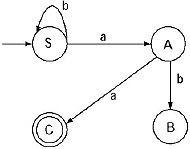
(iii) For the production B → aS/b, the transitional diagram including the previous one will be
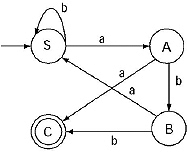
This is the finite automata for the given Regular Grammar.
5.8 CLOSURE PROPERTIES OF CFL
Q. Prove that CFLs are closed under union, concatenation and star-closure.
Ans. Union:
Let L1 is a CFL for the CFG G1 = (VN1, Σ1, P1, S1) and L2 is a CFL for the CFG G2 = ( VN2, Σ2, P2, S2). We have to prove that L = L1 U L2 is also in CFL.
Let us construct a CFG G = (VN, Σ, P, S) using the two grammars G1 and G2 as follows:
VN = VM U VN2 U {s}
Σ = Σ1 U Σ2
P = P1 U P2 U {S → S1/ S2}.
From the above discussion it is clear that the language set generated from the grammar G contains all the strings that are derived from S1 as well as S2. Hence it is proved that L = L1 U L2.
Concatenation:
Let L1 is a CFL for the CFG G1 = (VN1, Σ1, P1, S1) and L2 is a CFL for the CFG G2 = (VN2, Σ2, P2, S2). We have to prove that L = L1L1 is also in CFL.
Let us construct a Grammar G = (V, Σ, P, S) using the two grammars G1 and G2 as follows.
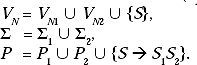
From the above discussion it is clear that the language set generated from the grammar G contains all the strings that are derived from S1 as well as S2. Hence it is proved that L= L1L1.
Star Closure:
Let L is a CFL for the CFG G1 = (VN1, Σ1, P1, S1). We have to prove that L* is also in CFL.
Let us construct a Grammar G = (VN, Σ, P, S) using the grammar G1 as follows
![]()
Obviously, G is a CFG. It is easy to see that L(G) = L*
Q. Prove that CFL are not closed under intersection and complementation.
Ans.
Intersection:
Consider two languages
![]()
We can easily show that the two languages L1 and L2 are context free. (By constructing grammar)
Consider ![]()
Hence ![]()
The anbncn is a Context sensitive language not a Context free. From here we can conclude that CFLs are not closed under intersection.
Complementation:
From set theory we can prove ![]() (D' Morgan's Law.)
(D' Morgan's Law.)
If the union of the complements of L1 and L2 are closed, i.e. also context free, then the LHS will also be context free. But we have proved that ![]() is not context free. We are getting contradiction here. Hence CFLs are not closed under complementation.
is not context free. We are getting contradiction here. Hence CFLs are not closed under complementation.
Q. Prove that every regular language is a CFL.
Ans. From recursive definition of Regular set we know Ø and ![]() are regular expression. If R is regular expression, then R + R (Union), R.R (Concatenation) and R* (Kleene Star) are also regular expressions. A regular expression R is a string of terminal symbols. The Ø and
are regular expression. If R is regular expression, then R + R (Union), R.R (Concatenation) and R* (Kleene Star) are also regular expressions. A regular expression R is a string of terminal symbols. The Ø and ![]() are also CFL, and we know CFL are closed under Union, concatenation and Kleene star. Therefore, every regular language is a CFL.
are also CFL, and we know CFL are closed under Union, concatenation and Kleene star. Therefore, every regular language is a CFL.
5.9 PUMPING LEMMA FOR CFL
Q. What is the application of Pumping Lemma for CFL?
Ans. Pumping lemma for CFL is used to prove that certain sets are not context free. Every CFL fulfils some general properties. But if a set of language fulfils all the properties of Pumping Lemma for CFL, it cannot be said that the language is context free. But the reverse, i.e. if a language breaks the properties it can be said confirm that the language is not context free.
Q. Prove the following lemma.
“If G be a CFG in CNF and T be a derivation tree belongs to G. If the length of the longest path in T is less than or equal to k, then the yield of T is of length less than or equal to 2K-1”
Ans. We will prove this by method of induction on k. The k is the longest path for all trees with root label A. (Called A-Tree). When the length of the longest path of an A-tree is of length 1, the root has only one son and that is terminal symbol. When the root has two sons, the labels are variable (The CFG is in CNF). So the yield of T is of length 1. We have got a base for induction.
Let K > 1, let T be an A-tree with the longest path of length less than or equal to k. The grammar is in CNF, so the root of T that is A has exactly two sons with labels A1 and A2. The length of the longest path of the two sub trees with the two sons as root, is less than or equal to k-1.
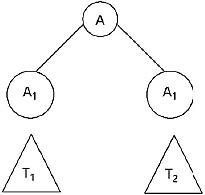
If w1 and w2 are the yields of T1 and T2, respectively, by induction
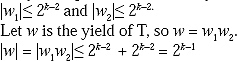
The yield of T is of length less than or equal to 2K-1. (Proved)
Q. State and prove Pumping Lemma for CFL.
Ans. Statement: Let L be a CFL. Then we can find a natural number n such that
(a) Every z ![]() L with z ≥ n can be written as w = uvwxy, for some strings u,v,w,x,y.
L with z ≥ n can be written as w = uvwxy, for some strings u,v,w,x,y.
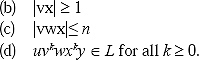
Proof: We can prove it that if G is a context free grammar,then we can find a context free grammar G1 having no null productions such that ![]()
If null string (![]() ) belongs to the language set L, we will consider L – {
) belongs to the language set L, we will consider L – {![]() } and will construct CNF of the grammar G generating L – {
} and will construct CNF of the grammar G generating L – {![]() } [If null string does not belong to L, we will construct CNF of G generating L].
} [If null string does not belong to L, we will construct CNF of G generating L].
Let number of non-terminals (VN) of the grammar is m. |VN| = m and n = 2m. To prove that n is the required number, we start with a string z where ![]() Construct a derivation tree or parse treeT of the string z. If the length of the longest path in T is almost m, then we can write the length of the yield of T, i.e.
Construct a derivation tree or parse treeT of the string z. If the length of the longest path in T is almost m, then we can write the length of the yield of T, i.e. ![]() So T has a path, say
So T has a path, say ![]() of length greater than or equal to m + 1. Path length of greater than or equal to m + 1 needs atleast m + 2 vertices, where the last vertex is the leaf. Thus in
of length greater than or equal to m + 1. Path length of greater than or equal to m + 1 needs atleast m + 2 vertices, where the last vertex is the leaf. Thus in ![]() all the labels except the last one are variables. As |N| = m, in m + 1 labels of the parse tree T, some labels are repeated.
all the labels except the last one are variables. As |N| = m, in m + 1 labels of the parse tree T, some labels are repeated.
Choose the repeated label as follows. We start with the leaf of ![]() and travel upwards. We stop when we get some label repeated (Let we have got label A as repeated, first).
and travel upwards. We stop when we get some label repeated (Let we have got label A as repeated, first).
Let v1 and v2 be the vertices with repeated label (Let A) obtained at the time of upward traversal from leaf of ![]() . Between v1 and v2 let v1 is nearer to root. In
. Between v1 and v2 let v1 is nearer to root. In ![]() , the portion of the path from v1 to leaf has only one label repeated (Let A), so its length is almost m + 1.
, the portion of the path from v1 to leaf has only one label repeated (Let A), so its length is almost m + 1.
Let T1 and T2 are two subtrees taking root as v1 and v1, respectively. Let z1 and w are the yields of T1 and T2, respectively. As ![]() is the longest path in T, v1 to leaf is the longest path of T1 and its length is almost m + 1. So the length of z1 (yield of T1), i.e. |z1|≤ 2m
is the longest path in T, v1 to leaf is the longest path of T1 and its length is almost m + 1. So the length of z1 (yield of T1), i.e. |z1|≤ 2m
As z is the yield of T and T1 is a proper subtree of T. Yield of T1 is z1. So yield of T, i.e. z can be written as z = uz1y.
As z1 is the yield of T1 and T2 is a proper subtree of T1. Yield of T2 is w. So yield of T1, i.e. z1 can be written as z1 = vwx. T2 is a proper subtree of T1 so |vwx|> |w|. So |vx|≥1. Thus we can write z = uvwxy with |vwx|≤n and |vx|≥1. This proves from (i) to (iii) of the pumping lemma theorem.
As T is tree with root S (S tree) and T1, T2 are tree with root B (B tree), we can write ![]() and,
and, ![]()
As ![]() By this the theorem is proved.
By this the theorem is proved.
Q. How pumping lemma can be applied to prove that certain sets are not regular?
Ans. We use pumping lemma for CFL to show that certain sets L are not context free. We assume that the set is context free. By applying pumping lemma we get a contradiction. This prove can be done in the following ways
Step I: Assume L is context free. Find a natural number such that ![]()
Step II: So we can write z = uvwxy for some strings u,v,w,x,y.
Step III: Find a suitable k such that ![]() This is a contradiction, so L is not context free.
This is a contradiction, so L is not context free.
Q. Show that L = {a“b”c”, where n 1} is not context free.
Ans.
Step I: Assume that the language set L is CFL. Let n be a natural number obtained by using pumping lemma.
Step II: Let ![]() According to pumping lemma for CFL we can write z = uvwxy, where |vx| ≥ 1.
According to pumping lemma for CFL we can write z = uvwxy, where |vx| ≥ 1.
Step III: uvwxy = anbncn. As 1 ![]() v or x cannot contain all the three symbols a, b and c. So v or x will be in any of the following forms.
v or x cannot contain all the three symbols a, b and c. So v or x will be in any of the following forms.
(i) Contain only a and b, i.e. in the form aibj.
(ii) Or Contain only b and c i.e. in the form bicj
(iii) Or contain only the repetition of any of the symbols among a,b,c.
Let take the value of k as 2. v2 or x2 will be in the form aibiaibi (As v is a string here aba is not equal to a2b or ba2) or bicj bicj. So uv2wx2y cannot be in the form ambmcm. So uv2wx2y ![]() L.
L.
If v or x contain repetition of any of the symbols among a, b, c, then v or x will be any of the form of ai, bi or ci. Let take the value of k as 0. uv°wx°y = uwy. In the string, the number of occurrences of one of the other two symbols in uvy is less than n. So uv2wx2y ![]() L.
L.
2
Q. Prove that the language ![]() is not context free.
is not context free.
Ans.
Step I: Assume that the language set L is CFL. Let n be a natural number obtained by using pumping lemma.
Step II: Let z = ![]() According to pumping lemma for CFL we can write z = uvwxy, where |vx| ≥ 1 and |vwx| n and |vwx| ≤ n.
According to pumping lemma for CFL we can write z = uvwxy, where |vx| ≥ 1 and |vwx| n and |vwx| ≤ n.
Step III: The string z contains only ‘a’, so v and x will be also a string of only ‘a’. Let v = ap and x = aq., where (p + q) ≥ 1. Since n ≥ 0, and uvwxy = 2i, so ![]() (n–1). As uvnwxny
(n–1). As uvnwxny ![]() L, |uvnwxny| is also a power of 2, say 2j
L, |uvnwxny| is also a power of 2, say 2j
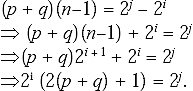
Here, (p + q) may be even or odd, but 2(p + q) is always even. Whereas 2(p + q) + 1 is odd, which cannot be a power of 2. Thus L is not context free.
Q. Prove that L = {0p/where p is prime} is not a CFL.
Ans.
Step I: Suppose L = L(G) is context free. Let n be a natural number obtained from the pumping lemma for CFL.
Step II: Let p is a number > n, z = 0p ![]() L. By using Pumping Lemma for CFL we can write z = uvwxy, where |vx ≥ 1 and |vwx| ≤ n.
L. By using Pumping Lemma for CFL we can write z = uvwxy, where |vx ≥ 1 and |vwx| ≤ n.
Step III: Let k = 0. From the pumping lemma for CFL we can write uv0wx0y, i.e. uwy ![]() L. As uvy is in the form 0p, where p is prime; so |uwy| is also a prime number. Let take it as q. Let
L. As uvy is in the form 0p, where p is prime; so |uwy| is also a prime number. Let take it as q. Let
|vx| = r. Then |uvqwxqy| = q + qr = q(1 + r). This is not prime as it has factors q, (1 + r) including 1 and q(1 + r). So uvqwxqy ![]() L. This is a contradiction. Therefore L is not context free.
L. This is a contradiction. Therefore L is not context free.
5.10 OGDEN'S LEMMA FOR CFL
Q. State Ogden's lemma for CFL. What is its superiority over pumping lemma?
Ans. Ogden's lemma states that if a language L is context-free, then there exists some number p > 0 (where p may or may not be a pumping length) such that for any string w of length at least p in L and every way of “marking” p or more of the positions in w, w can be written as
w = uvxyz,
with strings u, v, x, y, and z, such that
1. x has at least one marked position,
2. either u and v both have marked positions or y and z both have marked positions,
3. vxy has at mostp marked positions, and
4. uvixyiz is in L for every i ≥ 0.
Ogden's lemma can be used to show that certain languages are not context-free, in cases where the pumping lemma for CFLs is not sufficient. An example is the language {aibjckdl: i = 0 or j = k = l}. It is also useful to prove the inherent ambiguity of some languages.
5.11 DECISION ALGORITHMS
Q. What are the decision algorithms for CFLs?
Ans. From a CFL we can decide either it is empty, finite or infinite by using decision algorithms for CFL.
Emptiness: In a CFG {VN, Σ, P, S} if S is nothing but only start symbol then it is non-empty, otherwise the language is empty.
(We have already learnt the process of removing useless symbols from a given CFG. There we did not remove the start symbol if it is found Non-generating. According to decision algorithm if S is found to be useless, L(G) is empty, if not- L(G) contain atleast one element, i.e. L(G) is non-empty.)
Finiteness: A language L generated from a given CFG is finite if there are no cycles in the directed graph generated from the production rules of the given CFG. The longest string generated by the grammar is 2 (length of the longest path in the directed graph).
(Number of vertices of the directed graph is same as number of non-terminals in the grammar. If there is a production rule S →AB the directed graph will be in the form.)
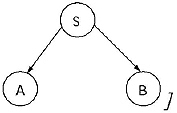
Infiniteness: A language L generated from a given CFG is infinite if there is atleast one cycle in the directed graph generated from the production rules of the given CFG.
Q. Verify the following grammars are empty or not.
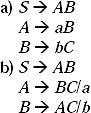
Ans. (a) In the grammar S is not generating any terminal symbol. In the language set generated by the grammar there exist only null. So the CFG is empty.
(b)
In the grammar S is generating terminal symbols. Hence the CFG is not empty.
Q. Verify the languages generated by the following grammars are finite or not. If finite find the longest string generated by the grammar.

Ans.
(a) The directed graph for the first one is
The graph does not contain any loop. So the language generated by the CFG is finite. The length of the longest path is 3 ![]() So the longest string generated by the grammar is 23 = 8.
So the longest string generated by the grammar is 23 = 8.
(b) The directed graph for the second one is
The graph contains two loops. Hence the language generated by the CFG is infinite.
Q. What are the applications of CFL?
Ans. (a) Designing syntax analysis part of a compiler of a language
(b) Development of extensive markup language (XML)
WHAT WE HAVE LEARNED SO FAR
1. According to Chomsky Hierarchy context free grammar (CFG) is Type 2 grammar.
2. In every production of a CFG at the left-hand-side there is a single non-terminal.
3. A derivation is called a Left Most Derivation if only the leftmost non-terminal is replaced by some production rule at each step of the generating process of the language from the grammar.
4. A derivation is called a right most derivation if only the rightmost non-terminal is replaced by some production rule at each step of the generating process of the language from the grammar.
5. Parsing a string is finding a derivation for that string from a given grammar.
6. A parse tree is an ordered tree in which left-hand-side of a production represents a parent node and children nodes are represented by the production's right-hand-side.
7. A grammar of a language is called ambiguous, if any of the cases for generating a particular string; more than one parse tree can be generated.
8. Ambiguity in grammar creates problem at the time of generating languages from the grammar.
9. There is no hard and fast rule for removing ambiguity from a CFG. Some ambiguity can be removed by hand. Some CFG are always ambiguous. Those are called inherently ambiguous.
10. CFG may contain different types of useless symbols, unit productions, and null productions. These types of symbols and productions increase number of steps in generating a language from a CFG.
11. Reduced grammar contains less number of non-terminals and productions, so the time complexity for language generating process becomes less from reduced grammar.
12. Useless symbols are of two types, Non-generating symbol and non-reachable symbol.
13. Non-generating symbols are those symbols, which do not produce any terminal string.
14. Non-reachable symbols are those symbols, which cannot be reached at any time starting from the start symbol.
15. Production in the form non-terminal → Single non-terminal is called unit production. Unit production increases the number of steps as well as complexity at the time of generating language from the grammar.
16. A production in the form ![]() is called null production. If (null string) is in the language set generated from the grammar, then that null production cannot be removed.
is called null production. If (null string) is in the language set generated from the grammar, then that null production cannot be removed.
17. When a grammar is made in normal form, every production of the grammar is converted in some specific form. These help us to design some algorithm to answer certain questions.
18. A context free grammar is called in CNF if all the productions of the grammar are in the following form
non-terminal → String of exactly two non-terminals,
non-terminal → Single terminal.
19. A grammar is said to be in Greibach Normal Form (GNF) if every productions of the grammar is of the form
non-terminal → (single terminal)(String of non-terminals)
non-terminal → single terminal
20. CFLs are closed under union, concatenation and star-closure.
21. CFLs are not closed under intersection and complementation.
22. Pumping lemma and Ogden's lemma for CFL is used to prove that certain sets are not context free.
23. A language L generated from a given CFG is finite if there are no cycles in the directed graph generated from the production rules of the given CFG.
24. A language L generated from a given CFG is infinite if there is atleast one cycle in the directed graph generated from the production rules of the given CFG.
SOLVED PROBLEMS
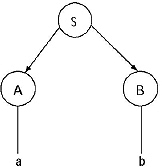
1. Construct CFG for the following
(a) Set of string of 0 and 1 where consecutive 0 can occur but no consecutive 1 can occur.
(b) Set of all (positive and negative) odd integers.
(c) Set of all (positive and negative) even integers.
Ans.
(a) There will be two non-terminals - S and A. S will produce production S → 0S. As two consecutive 0 can appear, so there will be a production S → 0. In the language set 01 can appear. Hence there will be production S → 1.
The string can start with 1, so there may be a production S → 1S. But consecutive 1 will not appear, so the production will be S → 1A. ‘A’ can produce 0 but not 1. So there will be production A → 0.
If the string start with 1, then the production rule S → 1A is applied. As in the language set there will be no consecutive 1, so A may produce A 0A. But if this is the production then there will be no chance of occurring 1 in the string except at last. Hence the production will be A → 0S.
Hence the grammar is
S → 0S, S → 1A, S→ 0, S→ 1, A → 0S, A → 0.
(b) An integer is odd if its rightmost entry contains any one of ‘1’, ‘3’, ‘5’, ‘7’ or ‘9’. If the integer is positive then its leftmost entry contains ‘ + ’ sign, if negative then its leftmost entry contains ‘-’ sign. The production rules are
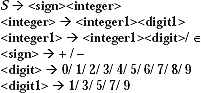
Set of non-terminals VN are {S, <sign>, <integer>, <integer1>, <digit>, <digit1>}
(c) An integer is odd if its rightmost entry contains any one of ‘2’, ‘4’, ‘6’, ‘8’ or ‘0’. If the integer is positive then its left most entry contains ‘ + ’ sign, if negative then its left most entry contains ‘-’ sign. The production rules are
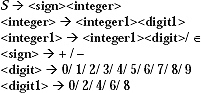
Set of non-terminals VN are {S, <sign>, <integer>, <integer1>, <digit>, <digit1>}
2.
(a) Construct the string aaabbabbba from the Grammar
S →aB/ bA
A → a/ aS/ bAA
B → b/ bS/ aBB by using
(i) Left Most Derivation
(ii) Right Most Derivation
Ans.
Left Most Derivation:

Right Most Derivation:

3. Check whether the following grammar is ambiguous or not.
S → a/ Sa/ bSS/ SSb/ SbS
Ans. Lets take a string baababaa. Lets try to generate the string by deriving from the given CFG.
Derivation 1:
The string is derived by left most derivation, i.e. only the leftmost non-terminal is replaced by suitable non-terminal.
![]()
Derivation 2:
The string is derived by right most derivation, i.e. only the rightmost non-terminal is replaced by suitable non-terminal.
![]()
The parse tree for the first derivation:
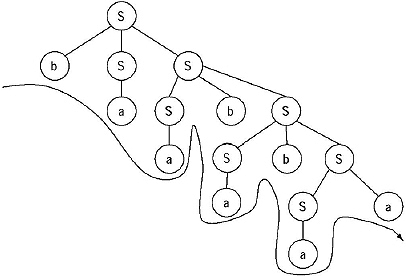
The parse tree for the second derivation
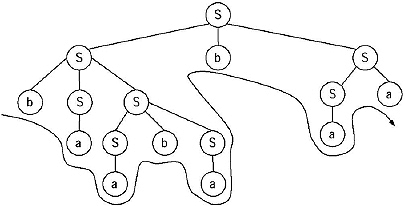
For the string baababaa two different parse trees are constructed. Therefore, the given context free grammar is ambiguous.
4. Check whether the following grammar is ambiguous or not.
S → SS/a/b
Ans. Let take a string abba. Lets try to generate the string by deriving from the given CFG.
Derivation 1:
The string is derived by left most derivation, i.e. only the leftmost non-terminal is replaced by suitable non-terminal.
![]()
Derivation 2:
The string is derived by left most derivation, i.e. only the leftmost non-terminal is replaced by suitable non-terminal.
![]()
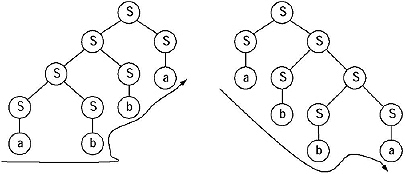
For the string abba two different parse trees are constructed. So, the given context free grammar is ambiguous.
5. Simplify the following CFG.
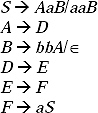
Ans. Simplifying a CFG means
(a) Removing Useless Symbol.
(b) Removing unit production.
(c) Removing null production.
Simplify the context free grammar by the following steps.
Remove null production:
In the grammar there is a null production ![]() . The grammar does not produce any null string. Therefore the null production can be removed. To remove the null productions find all the productions whose right side contains non-terminal B. There are two productions S → AbB and S → aaB. To remove the null production replace each occurrence of B by
. The grammar does not produce any null string. Therefore the null production can be removed. To remove the null productions find all the productions whose right side contains non-terminal B. There are two productions S → AbB and S → aaB. To remove the null production replace each occurrence of B by ![]() and add that new production to the grammar to keep the language generating power same.
and add that new production to the grammar to keep the language generating power same.
The grammar after removing the null production become
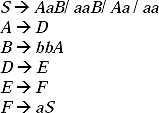
Remove unit production:
In the grammar, there are three unit productions: A → D, D → E and E → F. To remove the unit production E → F, we have to find a non-unit production F → {Some string of terminal or nonterminal or both}. There is such a production F → aS. Remove E → by that non-unit production F → aS
After removing the unit production E → F, the grammar become
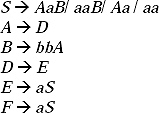
By the same process after removing all the unit productions the grammar become.

Remove useless symbol:
In a grammar there are two types of useless symbols.
(a) Non-generating symbol and (b) non-reachable symbol
In the grammar all are generating symbols, so we have to find non-reachable symbol.
In the grammar D, E, and F are non-reachable symbol because they are not reached any way starting from the start symbol. After removing useless symbols the grammar become
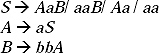
6. Convert the following grammar into CNF.
![]()
Ans.
A Context free grammar is called in CNF if all the productions of the grammar are in the following form
non-terminal → String of exactly two non-terminals
non-terminal → Single Terminal
The previous grammar does not contain any useless symbol, unit production or null production. So, the grammar can be directly converted to CNF.
In the previous grammar S → bA,S → aB, B → bAA, B → aS, A → aBB, B→ bS are not in CNF. So, these productions are needed to be converted into CNF. But the productions A → b and B → a are in CNF.
Consider two extra non-terminals Ca and Cb and two production rules Ca → a and Cb → b. Replace ‘a’ by Ca and ‘b’ by Cb in the above productions. The modified production rule become
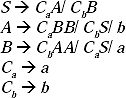
In the grammar A → CaBB and B → CbAA are not in CNF as they contain string of three non-terminals at the right-hand-side of the production. Introduce two production rules X → BB and Y → AA and replace BB by X and AA by Y. The modified production rule becomes.
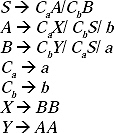
Here all the productions are in the specified format of CNF. The CFG is converted to CNF.
7. Convert the following grammar into CNF.
Ans. The context free grammar is not simplified as it contains useless symbols and unit productions. First we have to simplify the CFG then it can be converted into CNF.
In the grammar E is the useless symbol (non-generating symbol) as it does not produce any terminal symbol. So the production A → E is removed. The modified grammar becomes
There are two unit productions in the grammar. After removing the unit productions the grammar become
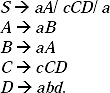
In the grammar except S → a, all other productions are not in CNF.
Consider four extra non-terminals Ca, Cb, Cc, Cd and two production rules Ca → a and Cb → b, Cc → c and Cd d. Replace 'a' by Ca and 'b' by Cb, c by Cc and dby Cd in the above productions. The modified production rule become
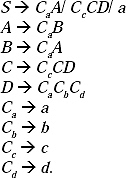
Here S → CcCD, C → CcCD and D → CaCbCd are not in CNF. Introduce two production rules X → CD and Y → CbCd and replace CD by X and CbCd by Y. The modified production rule becomes.
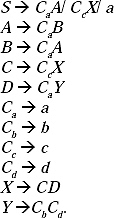
Here all the productions are in the specified format of CNF. The CFG is converted to CNF.
8. Convert the following grammar into CNF.
![]()
Ans. The grammar contains two non-terminal symbols E and T and four terminal symbols + , (, ), a. The grammar contains a unit production E → T. First the unit production has to be removed. After removing the unit production E → T the modified grammar becomes
![]()
In the above grammar except E → a and T → a all the other productions are not in CNF.
Introduce three non-terminals A, B, C and three production rules A → + , B → ( and C → ) and appropriate terminal by appropriate non-terminals. The modified production rules become.
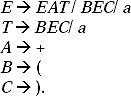
In the above grammar, E → EAT, E → BEC and T → BEC are not in CNF. Consider two non-terminals X and Y and two production rules X → AT and Y → EC. The modified production rules become.
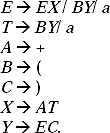
Here all the productions are in the specified format of CNF. The CFG is converted to CNF.
9. Convert the following grammar into CNF.
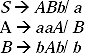
Ans. The grammar contains unit production A →S B. After removing the unit production the grammar is
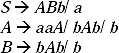
Except S → a and B → b the productions of the grammar are not in CNF.
Consider two non-terminals Ca and Cb and two production rules Ca → a and Cb → b and replace ‘a’ by Ca and ‘ b’ by Cb in appropriate production. The modified production rules become
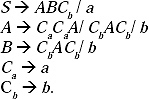
Consider three non-terminals X, Y, and Z. and three production rules X → BCb, Y → ACb, Z → CaA. Replace appropriate group of non-terminals in the production by appropriate new non-terminal. The production rule become
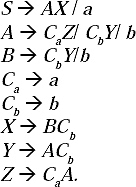
10. Convert the following grammar into GNF.
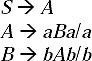
Ans. The grammar is not in CNF. So it has to be converted into CNF. Introduce two non-terminals Ca , Cb and two production rule Ca → a, Cb → b.
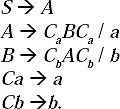
Introduce two non-terminals X and Y and two production rules X → BCa and Y → ACb
The production rule become
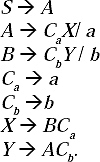
Step I: In the grammar there is no null production and no unit production. The grammar also is in CNF.
Step II: In the grammar there are seven non-terminals S, A, B, Ca, Cb, X, Y. Rename the non-terminals as A1 A2, A3 A4, A5, A6, and A7, respectively. After renaming the non-terminals the modified grammar will be
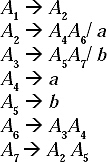
Step III: In the above production A6 → A3A4 and A7 → A2 A5 are not in the form Ai → AjV where i≤j.
Using Lemma 1 replace A3 → A5A7/ b in the production A6 → A3A4. The rule becomes
A6 → A5A7A4 / bA4
Till A6 → A5A7A4 is not in the form Ai → AjVwhere i≤j. Using Lemma I replace A5 → b in the production. The modified production is A6 → bA7A4/ bA4, which is in GNF
Step IV: Using Lemma 1 replace ![]() in the production A7 → A2 A5. The production rule becomes
in the production A7 → A2 A5. The production rule becomes ![]()
Till A7 → A4A6A5 is not in the form Ai → AjV where i≤j. Using Lemma I replace A4 → a in the production.
The modified production is A7 → aA6A5/ aA5, which is in GNF
Lemma II can be applied on the productions A2 → A4A6/ a and A3 → A5A7/ b
Applying Lemma II on A2 →A4A6/ a we get
![]()
X → A6/ A6X are not in GNF. Replacing A6 → bA7A4/ bA4 in the production, the productions
![]() are in GNF.
are in GNF.
Applying Lemma II on A3 → A5A7/ b we get
![]()
Y → A7/ A7 Y are not in GNF. Replacing ![]() in the production, the productions
in the production, the productions
![]() are in GNF
are in GNF
A1 → A2 is not in GNF. Replacing A2 → a/ aX in the production we get Al → a/ aX, which is in GNF.
The grammar converted into GNF is
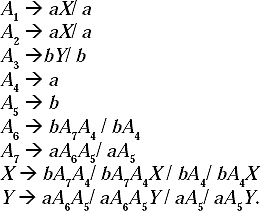
11. Remove left recursion from the given grammar
![]()
Ans. The grammar has indirect left recursion. To remove the left recursion rename A as A1 and B as A2. The modified production rules becomes
![]()
For i = 1, j = 1, there is no production in the form A1 → A1α.
For i = 2, j = 1, there is a production in the form A2 → A1α. The production is A2 → Ald. According to the algorithm for removal of indirect left recursion the production becomes
A2 → A2ad/bd.
Now the A2 production is A2 → A2c/ A2ad/ bd/ e
A2 → A2c has immediate left recursion. After removing the left recursion the production becomes
![]()
![]()
A2 → A2ad has immediate left recursion. After removing the left recursion the production becomes
![]()
![]()
The actual non-left recursive grammar is
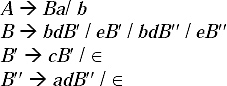
12. Construct equivalent finite automata from the following regular grammar.
![]()
Ans. In the grammar there are two non-terminals S and A. So, in the finite automata there are three states. For the production S → aS the transitional diagram:
For the production S → b the transitional diagram:
![]()
For the production S → bA the transitional diagram:
![]()
For the ‘S’ production the complete transitional diagram
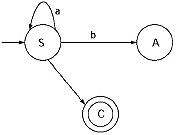
For ‘A’ production the transitional diagram:
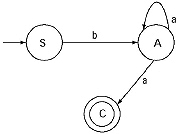
The complete transitional diagram for the above grammar is
13. Construct equivalent finite automata from the following regular grammar.
![]()
Ans. The grammar accepts null string. So A is the final state. For the production rule A → ![]() the transitional diagram is
the transitional diagram is
For the production S→Aa the transitional diagram:
![]()
For the production A → Sb/Ab the transitional diagram:?
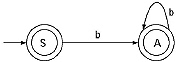
The complete transitional diagram:
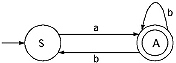
14. Verify the languages generated by the following grammars are finite or not. If finite find the longest string generated by the grammar.
![]()
Ans. (a) In the grammar there are three non-terminals. For this reason in the directed graph for the grammar there are three nodes. The directed arc are for S to A, A to B and B to S.
The graph contains loop. So the language generated by the CFG is infinite.
(b) In the grammar there are five non-terminals. For this reason in the directed graph for the grammar there are three nodes.
The directed graph for the grammar:
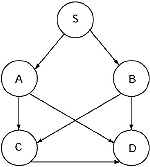
The directed graph does not contain any loop. So the grammar is finite. The length of the longest path is 3. The longest string generated by the grammar is 23 = 8.
MULTIPLE CHOICE QUESTIONS
1. CFL is______language.
(a) Type 0,
(b) Type 1,
(c) Type 2,
(d) Type 3.
2. Parsing a string from a given grammar means.
(a) Finding a derivation.
(b) Finding a Left most derivation.
(c) Finding a Right most derivation.
(d) Finding a derivation tree.
3. A grammar is called ambiguous if
(a) it generates more than one string.
(b) it generates both Left most and Right most derivation for a given string.
(c) it generates more than one parse tree for a given string.
(d) it fulfills both (b) and (c).
4. Which is not true for ambiguous grammar?
(a) Ambiguity creates problem in generating language from a given grammar
(b) All Ambiguity can be removed.
(c) Inherent ambiguity cannot be removed.
(d) Some ambiguity can be removed by hand.
5. Non-generating symbols are those symbols which
(a) does not generate any string of non-terminals
(b) does not generate any null string
(c) does not generate any string of terminal and non-terminals
(d) does not generate any string of terminals.
6. Useless symbols in CFG are
(a) Non generating Symbol and non-reachable symbols
(b) Null alphabets and null string
(c) Non-terminal symbols
(d) All of these.
7. Which of the followings is unit production?
(a) (String of NT) → (String of NT)
(b) (Single NT) → (String of NT)
(c) (Single NT) → (Single NT)
(d) (String of NT) → (Single NT).
8. Which is true for the following CFG?
![]()
(a) Null production can be removed,
(b) Null production cannot be removed,
(c) As A does not produce null so null cannot be removed,
(d) Both (b) and (c).
9. Which of the following production is in CNF? (More Specific)
(a) (NT) → (String of NT),
(b) (NT) → (String of terminal and non-terminal),
(c) (NT) → (String of Terminal),
(d) (NT) → (String of exactly two NT).
10. Which of the following production is in GNF? (More Specific)
(a) (NT) → (Single T)(String of NT)
(b) (NT) → (Single NT)(String of T),
(c) (NT) → (String of terminal and non-terminal),
(d) (NT) → (String of NT).
11. Which of the following common in both CNF and GNF?
(a) (NT) → (Single T)(String of NT),
(b) (NT) → (String of exactly two NT),
(c) (NT) → (String of NT),
(d) (NT) → (Single T).
12. CFL are not closed under
(a) Union
(b) Concatenation
(c) Complementation
(d) Star closure.
13. The intersection of CFL and RE is always
(a) CFL,
(b) RE,
(c) CSL,
(d) CFL or CSL.
14. Which of the following is in GNF?
(a) A → BC,
(b) A → a,
(c) A → Ba,
(d) A → aaB.
Ans. 1.c, 2.a, 3.c, 4.b, 5.d, 6.a, 7.c, 8.b, 9.d, 10.a, 11.d, 12.c, 13.a, 14.b.
EXERCISES
1. Construct CFG for the followings
(a) anam, where n > 0 and m = n + 1
(b) anbam, where m, n > 0
(c) anbncm, where n > 0 and m = n + 1
(d) L = (011 + 1)*(01)*
(e) L = {Set of all integers}.
2.
(a) Construct the string 0110001 from the Grammar
S →AB
A → 0A/1B/0
B → 1A/0B/1 by using
(i) Left most derivation
(ii) Right most derivation
(b) Construct the string baaabbba from the Grammar
S → AaB/ AbB
A → Sa/ b
B → Sb/ a by using
(i) Left most derivation
(ii) Right most derivation
3.
(a) Find the parse tree for generating the string abaabaa from the grammar given below
![]()
(b) Find the parse tree for generating the string aabbaa from the grammar given below
![]()
4. Show that the following grammars are ambiguous.
(a) S → abSb/ aAb/ a
A → bS/ aAAb
(b) E → E + E/ E* E/ id
(c) S → aB/ bA
A → aS/ bAA/ a
B → bS/ aBB/ b
5. Remove useless productions from the following grammars
(a) S → AB/ a
A → b
(b) S → AB/ AC
A → 0A1/ 1A0/ 0
B → 11 A/ 00B/ AB
C → 01 C0/ 0D1
D → 1D 0C
6. Remove unit production from the following grammars

7. Remove null production from the following grammars

8. Simplify the following context free grammar.
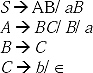
9. Convert the following grammars into CNF.
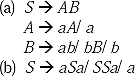
10. Convert the following grammar into GNF.
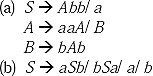
11. Construct DFA equivalent to the Regular Grammar
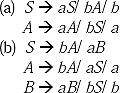
12. Prove that L = anbnc2n is not context free by using Pumping Lemma for CFL.
13. Verify the languages generated by the following grammars are finite or not.
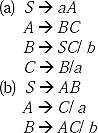
14. Remove left recursion from the following grammar and then perform left factoring.
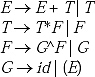
15. Generate the string id + id*id from the grammar
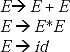
Where precedence of operator is given below
Are you getting any ambiguity in the grammar?
FILL IN THE BLANKS
1. According to Chomsky Hierarchy Context Free Grammar is Type______grammar.
2. The grammar where production rules are in the format of {A string consists of at least one Non-Terminal} → {A string of terminals and/ or non terminals} is______grammar in particular.
3. The grammar S → aSb/bSb/C produces the string______
4. Finding a derivation for a string from a given grammar is called______
5. The Tree representation of deriving a Context free language from a given Context grammar is called______
6. Parse Tree construction is only possible for______Grammar
7. The root of the parse tree of a given context free language is represented by the______of the corresponding Context Free Grammar.
8. A CFG G is said to be______if there exists some w C L(G) that has at least two distinct parse trees.
9. A CFL L is said to be______if all its grammars are ambiguous.
10. The Context Free grammar where a non-terminal ‘A as a left-most symbol appears alternatively at the time of derivation either immediately or through some other non terminal definitions is called______grammar.
11. To avoid the problem of backtracking we need to perform ______
12. In a context free grammar the symbols which do not produce any terminal string is called______
13. In a Context Free Grammar, the symbols which can not be reached at any time starting from the start symbol are called______
14. In a Context Free Grammar Non-Generating Symbol and Non-Reachable Symbol both are called______symbol.
15. In a Context Free Grammar the production in the form Non Terminal → Single Non Terminal is called______
16. In a Context Free Grammar a production in the form NT → 6 is called______
17. Normalizing a Context Free Grammar should not hamper the______power of the grammar.
18. A Context free grammar where all the productions of the grammar are in the form
Non Terminal → String of exactly two Non Terminals
Non Terminal → Single Terminal is called______Normal Form
19. A Context free grammar where all the productions of the grammar are in the form
Non Terminal → (Single Terminal)(String of Non Terminals)
Non Terminal → Single Terminal is called______Normal Form
20. Context Free Languages are not closed under______and______
21. ______is used to prove that certain sets are not Context free
22. anbncn where n > 1 is not______language but______language.
23. If the length of the longest path of the directed graph generated from a Context Free Grammar is n, then the longest string generated by the grammar is______.
24. A language L generated from a given CFG is finite if there are no______in the directed graph generated from the production rules of the given CFG.
ANSWERS
1. Two
2. Context Free
3. WCWR | We (a,b)*
4. Parsing
5. Parse Tree
6. Context Free
7. Start Symbol
8. Ambiguous
9. inherently ambiguous
10. Left Recursive
11. Left Factoring
12. Non-Generating Symbols
13. Non-Reachable Symbols
14. Useless
15. unit production
16. null production
17. language generating
18. Chomsky
19. Greibach
20. Intersection, complementation
21. Pumping lemma for CFL
22. Context Free, Context
23. 2n
24. cycles