
16
Database Management Systems
1. Differentiate among data, information, and knowledge.
Ans.:
Data
They can be defined as a set of isolated and unrelated raw facts, represented by values, which have little or no meaning, simply because they lack a context for evaluation. Usually, the values are represented in the forms of characters, numbers, or any symbol such as ‘Monica’, ‘35’, and ‘chef’. Note that although these words and numbers have certain meaning, it is difficult to figure out exactly what these values signify.
Information
When the data are processed and converted into a meaningful and useful form, they are known as information. Hence, it can be defined as a set of organized and validated collection of data. For example, ‘Monica is 35 years old and she is a chef’.
Knowledge
It is the act of understanding the context in which the information is used. It can be based on learning through information, experience, and/or intuition. Based on the knowledge, the information can be used in a particular context, for example, if an hotelier uses the information about Monica (she is a chef) to hire her, he is using his knowledge. Hence, knowledge can also be referred to as a person's capability and wisdom and how much that person knows about a particular subject. Consequently, it can be said that data constitute information, and information constitutes knowledge.
Figure 16.1 shows the relationship among data, information, and knowledge.

Figure 16.1 Data, Information, and Knowledge
2. Define the term ‘database’.
Ans.: A database can be defined as a collection of related data from which users can efficiently retrieve the desired information. It can be anything from a simple collection of roll numbers, names, addresses, and phone numbers of students to a complex collection of sound, images, and even video or film clippings. Though they are generally computerized, instances of non-computerized databases from everyday life can be cited in abundance. A dictionary, a phone book, a collection of recipes, and a TV guide are examples of non-computerized databases. The examples of computerized databases include customer files, employee rosters, books catalog, equipment inventories, and sales transactions.
3. Define the following database terms:
(a) Field
(b) Record
(c) Table
(d) Data type
Ans.: (a) Field: It is also referred to as a column. It represents one related part of a table and is the smallest logical structure of storage in a database. It holds one piece of information about an item or subject. For example, in a database maintaining information about an employee, the fields can be Code, Dept, Name, Address, City, and Phone (Figure 16.2).
(b) Record: It is also referred to as a row. It is a collection of multiple related fields that can be treated as a unit. For example, fields Code, Dept, Name, Address, City, and Phone for a particular employee form a record. Figure 16.2 contains 8 records (from 0101 to 0108) and each record has 6 fields.

Figure 16.2 Table
(c) Table: It is a named collection of logically related multiple records. For example, a collection of all the employee records of a company form employee table. Note that every record in a table has the same set of fields. Depending on the database software, it can also be referred to as a file. The collection of multiple related files (tables) forms the database.
(d) Data Type: It determines the type of data that can be stored in a column. Although many data types are available, the most commonly used data types are as follows:
![]() Character: It is used to store characters, numbers, special characters, or combinations of any of these. Note that if a numeric value is stored in an alphanumeric field, the value is treated as character, not a number.
Character: It is used to store characters, numbers, special characters, or combinations of any of these. Note that if a numeric value is stored in an alphanumeric field, the value is treated as character, not a number.
![]() Numeric: It is used to store only numeric values.
Numeric: It is used to store only numeric values.
![]() Date and time: It is used to store date and time values. The values for this data type vary widely depending on the database software being used.
Date and time: It is used to store date and time values. The values for this data type vary widely depending on the database software being used.
4. What is an E-R model? What are its basic constructs?
Ans.: An entity-relationship (E-R) model is the most popular conceptual model used for designing a database. It was originally proposed by Dr. Peter Chen in 1976 as a way to unify the network and relational database views. It views the real world as a set of basic objects (known as entities), their characteristics (known as attributes), and associations among these objects (known as relationships). The entities, attributes, and relationships are the basic constructs of an E-R model.
Entity
It is an object that has an independent existence in the real world. It includes all those ‘things’ about which data are collected. It may be a tangible object such as a student, a place, or a part. It may also be non-tangible such as an event, a job title, or a customer account. Diagrammatically, it is represented in rectangle. For example, the entities CUSTOMER and ITEMS can be represented as shown in Figure 16.3.

Figure 16.3 Entities
Attribute
It is the property of an entity that characterizes and describes it. In a database, entities are represented by tables and attributes by columns. For example, a CUSTOMER entity might have numerous attributes such as Code, Name, and Address. Similarly, the ITEMS entity may have attributes like Item_Id and Price. They are drawn in elliptical shapes along with the entity rectangles (Figure 16.4).
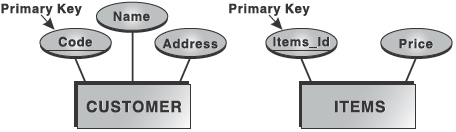
Figure 16.4 Attributes
Relationship
It is an association, dependency, or link between two or more entities and is represented by a diamond symbol. It describes how two or more entities are related to each other. For example, the relationship Buys associates with CUSTOMER and ITEMS entities (Figure 16.5).
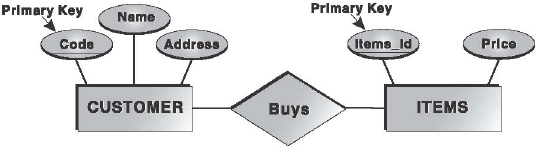
Figure 16.5 Entities, Attributes, and Relationship
Even though a relationship may involve more than two entities, the most commonly encountered relationships are binary, involving exactly two entities. Generally, such binary relationships are of three types:
- One-to-one relationship (1:1): In this relationship, one record in a table is related to only one record in another table. For example, a department cannot be headed by more than one department head and a department head can be the head of only one department.
- One-to-many relationship (1:M): In this relationship, one record in a table (parent table) can be related to many records in another table (child table). For example, a father may have more than one child but the child has only one father.
- Many-to-many relationship (M:M): In this relationship, one record in a table can be related to one or more records in second table, and one or more records in the second table can be related to one or more records in the first table. For example, a customer can buy many items and same item can be bought by many customers.
5. Discuss the various ways to organize files? Also discuss their advantages and disadvantages.
Ans.: A file may be defined as a systematized self-containing collection of related records. Usually, they are organized in three fashions: sequential, direct, and indexed sequential.
Sequential Files
In sequential files, the data are stored and/or retrieved in a logical order, that is, in a sequence. The records are stored one after another in an ascending or descending order, based on the key field (which is unique for each record) of the records. Generally, these files are stored on sequential storage devices like magnetic tapes. In such files, to retrieve a record, all the records must be traversed sequentially before reaching to the desired record. An analogy to sequential files may be taken as an audiocassette. If the listener is at the first song and wants to listen to the fourth song, the second and third songs needs to be traversed through, respectively.
Some advantages of sequential files are as follows:
| They are easy to organize and maintain. | |
| The hardware, associated with sequential organization, is also relatively cheaper, compared to the other file organizations. |
Some disadvantages of sequential files are as follows:
| Sequential search takes a very long time. If there are N records in the file, on an average, the user will have to go through N/2 records before finding the right one. | |
| Making changes (such as adding, deleting, and updating records) to a sequential file is also a difficult operation. For example, to add a record in the middle of a sequential file, the entire file has to be sorted, rewritten, and stored on the storage device again. |
Direct Files
They facilitate accessing any record directly or randomly without having to traverse the sequence of the records. These files are also known as random or relative files. Even though only one item can be accessed at a time, but that item may be stored anywhere in the file. For example, in case of CDs (compact discs), any song can be played randomly. Generally, these files are stored on direct access storage devices (DASDs) such as hard disks and CDs.
When the records are stored, the program itself generates the address for the record by applying certain techniques to its key field. These addresses are stored in a master index, which is loaded into the main memory before any database manipulation takes place. It defines the relationship between the primary key and the corresponding disk addresses (a piece of information that tells the disk R/W head where to look for data).
Some advantages of direct files are as follows:
| Since direct search is done in the computer's main memory, it takes less amount of time. Based on the address found in the master index, R/W head immediately goes to the correct disk position and retrieves the desired record. | |
| Updation, addition, and deletion of records are much faster as compared to sequential files. |
Some disadvantages of direct files are as follows:
| This method is expensive than sequential, because usually the direct files are stored on direct access devices, which are expensive as compared to sequential storage devices. | |
| Direct access devices are less storage efficient because they tend to generate wide gaps in between any two records. In addition, address generation overhead is also involved for accessing records due to addressing functions. |
Indexed Sequential Files
An indexed file includes an index table (also known as reference table) that relates key field values to storage locations of the corresponding records. Hence, indexing can be defined as a technique of ordering the records in a table without making any modification in the table.
Essentially, indexed sequential technique is a hybrid of sequential and direct file organization. It provides a combination of access types that are supported by a sequential file and a direct file. The indexed file organization uses a separate index file, which contains the key values and the location of the corresponding record. The records are organized in an orderly sequence and the index table is used to access the records without searching through the entire file. The records may be in random sequence but the index table is stored in sorted sequence on the key values. Since the index table is in sorted sequence, the file management system simply accesses the records in the order of the index values. To access a particular record, a search is made in the index table to determine the address of the first record of the segment in which the data are placed. Then a direct access is made to that address. After that, a sequential search is invoked until the desired record is located.
Some advantages of indexed sequential files are as follows:
| They require considerably less space than the data files as they require only two fields—the key field and the address of the record's location, even if the record may have numerous fields. | |
| Indexes do not affect the file organization of records physically, that is, various indexes can use the same file without rearranging its records. |
Some disadvantages of indexed sequential files are as follows:
| The use of an extra file (index file) causes an overhead as other file organizations do not use any extra file. | |
| Though indexing speeds up the data retrieval, it may slow down the update process because indexes also need to be maintained along with the data file while adding and deleting. | |
| Since the index sequential files require direct access storage devices, they are an expensive means of file organization. |
6. Write a short note on file-oriented approach. What are the disadvantages of file-processing system that led to the development of database system?
Ans.: In file-oriented approach, the data are stored in the form of files and a number of application programs are written by programmers to add, modify, delete, and retrieve data to and from appropriate files. New application programs are written as and when needed by the organization. For example, consider a bookstore that uses a file-processing system to keep track of all the available books. The system maintains a file named BOOK to store the information related to books. This information include book title, ISBN, price, year of publishing, copyright date, category, number of pages, name of the author, and name and address of the publisher.
In addition, it has many application programs that allow users to manipulate the information stored in BOOK file. For example, it may contain programs to add information about a new book, modify any existing book information, print the details of books according to their categories, etc. If a need arises to keep additional information about the publishers of the books that include phone number and e-mail id, the system creates a new file, say PUBLISHER, that includes name, address, phone number, and e-mail id of the publishers. New application programs are written and added to the system to manipulate the information in the PUBLISHER file. In this way, as the time goes by, more files and application programs are added to the system.
The file-processing system has a number of disadvantages that led to the development of database systems:
| Same information may be duplicated in several files. For example, the name and the address of the publisher are stored in BOOK file as well as in PUBLISHER file. This duplication of data is known as data redundancy, which leads to wastage of storage space. The other problem with this system is that the data may not be updated consistently. Suppose a publisher requests for a change in his address. Since the address of the publisher is stored in the BOOK as well as PUBLISHER file, both the files must be updated. If the address of the publisher is not modified in any of the two files, then the same publisher will have different address in two different files. This is known as data inconsistency. | |
| In any application, there are certain data integrity rules that need to be maintained. These rules could be in the form of certain conditions or constraints. In a file-processing system, all these rules need to be explicitly programmed in all application programs which are using that particular data item. For example, the integrity rule that each book should have a book title has to be implemented in all the application programs separately that are using the BOOK file. In addition, when new constraints are to be enforced, all the application programs should be changed accordingly. | |
| It lacks the insulation between program and data. This is because the file structure is embedded in the application program itself, thus, it is difficult to change the structure of a file as it requires changing all the application programs accessing it. For example, an application program in C++ defines the file structure using the keyword struct or class. Suppose the data type of the field ISBN is changed from string to number, changes have to be made in all the application programs that are accessing the BOOK file. | |
| Handling new queries is difficult, since it requires change in the existing application programs or requires a new application program. For example, suppose a need arises to print the details of all the textbooks published by a particular publisher. One way to handle this request is to use the existing application program that prints the details of the books according to their categories, and then manually generate the list of textbooks published by a particular publisher. Obviously, it is unacceptable. Alternatively, the programmer is requested to write a new application program. Suppose such a new application program is written. Now suppose after some time, a request arises to filter the list of textbooks with price greater than $50. Then again we have to write a new application program. | |
| Since many users are involved in creating files and writing application programs, the various files in the system may have different file structures. Moreover, the programmers may choose different programming languages to write application programs. | |
| Since application programs are added in an unplanned manner, due to which the details of each file is easily available to every user. Thus, this system lacks security feature. |
7. What is a database management system (DBMS)? What are its advantages over the file-processing system?
Ans.: A database management system (DBMS) can be defined as a collection of interrelated data and a set of programs to access those data. The primary goal of DBMS is to provide an environment that is both congenial and efficient to retrieve and store information. It allows a user to store, update, and retrieve data in abstract terms. It eases the maintenance and retrieval of information from a database. It also relieves the user from having to know about the exact physical representations of data and from specifying detailed algorithms for storing, updating, and retrieving the data.
The centralized nature of DBMS provides several advantages, which overcome the limitations of the conventional file-processing system:
| Reduction in data redundancy: Data redundancy refers to the duplication of data. In non-database systems, each application has its own separate files. This can often lead to redundancy in stored data, which results in wastage of space. A DBMS does not maintain separate copies of the same data. | |
| Reduction in inconsistency: When data are represented by two distinct entity and database is not aware of this, then there will be some occasions on which one of the two entries has been updated. At such times, the database is said to be inconsistent. DBMS ensures that the database is always consistent by ensuring that any change made to either of the two entries is automatically applied to the other one also. This process is known as propagating update. | |
| Sharing of data: It allows the existing applications to use the data in the database simultaneously. It also helps in developing new applications, which will use the same stored data. Due to shared data, it is possible to satisfy the data requirement of new applications without having to create any additional stored data or with marginal modification. | |
| Enforcement of standards: Since access to the database must be through the DBMS, standards are easier to enforce. Standards may relate to the naming of the data, the format of the data, the structure of the data, etc. | |
| Improvement in data security: Usually, different systems of an organization would access different components of the operational data. In such an environment, enforcing security can be quite difficult. Setting up of a DBMS makes it easier to enforce security restrictions since the data are stored centrally. DBMS can ensure that the only means of access to the database is through the authorized channel. | |
| Maintenance of data integrity: Data integrity refers to ensuring that the data in the database are accurate. Since, in DBMS, the data are centralized and are used by a number of users at a time, it is essential to enforce integrity controls. Integrity may be compromised in many ways. | |
| Better interaction with users: As compared to traditional database systems, a DBMS often provides better service to the users. DBMS improves the availability of up-to-date information since the data can now be shared. Centralizing the data in a database also means that users can obtain new and combined information that would have been impossible to obtain otherwise. | |
| Efficient system: It is very common to change the contents of stored data. These changes can easily be made in a DBMS than in a conventional system as these changes do not need to have any impact on application programs. The cost of developing and maintaining systems is also lower. |
8. List some disadvantages of DBMS.
Ans.: DBMS has many advantages, however, before implementing it over the traditional file-processing system, the cost and risk factors of implementing it should also be considered. The various disadvantages of DBMS are as follows:
| High cost: Installing new database system may require investment in hardware and software. It requires more main memory and disk storage. Moreover, it is quite expensive. Therefore, a company needs to consider the overhead cost of implementing a new database system. | |
| Training new personnel: When an organization plans to adopt a database system, it may need to recruit or hire a specialized data administration group, which can coordinate with different user groups for designing views, establishing recovery procedures, and fine-tuning the data structures to meet the requirements of the organization. Hiring such professionals is expensive. | |
| Explicit back-up and recovery: A shared corporate database must be accurate and available at all times. Therefore, a system using online updating requires explicit back-up and recovery procedures. | |
| System failure: When a computer system containing the database fails, all users have to wait until the system is functional again. Moreover, if DBMS or application program fails, a permanent damage may occur to the database. |
9. Describe the different components of DBMS.
Ans.: DBMS involves data, the hardware that physically stores that data, and the software that utilizes the hardware's file system in order to store the data and provide a standardized method for retrieving or changing the data, and finally, the users who turn the data into information. The various components of DBMS are explained as follows:
| Data: Data stored in a database include numerical data including whole numbers, floating-point numbers, and non-numerical data such as characters, date, or logical values (true or false). More advanced systems may include more complicated data entities such as pictures and images as data types. | |
| Hardware: It can range from a PC to a network of computers. It also includes various storage devices (like hard disks) and input and output devices (like monitor, printer, etc.). | |
| Software: It includes the DBMS, operating system, network software (if necessary), and the application programs. | |
| Users: In DBMS, generally three broad classes of users are considered. These are application programmers, end-users, and database administrator (DBA). The application programmers develop the application programs. These programs can manipulate the database in all the possible ways. The end-users access the database from a terminal using a query language provided by the DBMS or through application programs developed by application programmers. The DBA is the person who is responsible for the design, construction, and maintenance of a database. |
10. Who is a DBA? What are the various responsibilities of DBA?
Ans.: A DBA is a person who has central control over both data and application programs. He/she has many different responsibilities, but the overall goal of a DBA is to maintain the DBMS and to provide users with access to the required information when they need it. He/she makes sure that the database is protected and that any chance of data loss is minimized. Typical responsibilities of the DBA are listed below:
| Granting different types of authorization to regulate which parts of the database various users can access. | |
| Ensuring regular back-ups of a database, and in case of failure (or disaster like fire or flood), using suitable recovery procedures to restore the database services with as little down time as possible. | |
| Ensuring regular and accurate update of database. | |
| Collaborating in the design and development of databases to meet new user needs and respond to anticipate technological innovations. | |
| Communicating regularly with internal technical applications and operational staff to ensure the database integrity and security. | |
| Identifying and resolving user's problems. | |
| Facilitating sharing of common data by overseeing proper key management. | |
| Procuring and maintaining database software and related documents and tools. |
11. List the different database languages.
Ans.: A DBMS mainly provides two database languages to implement the databases.
- Data definition language (DDL): It is used to create and delete database and its objects. These commands are primarily used by the DBA during the building and removal phases of a database project.
- Data manipulation language (DML): It is used to retrieve, insert, modify, and delete database information. These commands will be used by all database users during the routine operation of the database.
12. Define the role of data dictionary?
Ans.: Apart from the data, the database also stores metadata, which describes the tables, columns, indexes, constraints, and other items that are used for making the database. In simple words, metadata is data about data. This metadata is stored in an area called the data dictionary. Hence, a data dictionary defines the basic organization of a database. It contains the list of all files in the database, the number of records in each file, and the names and types of each field. It does not contain any actual data from the database, but only the information for managing it.
13. Define the following terms:
(a) View
(b) Database schema
Ans.: (a) View: A database can be accessed by many users and each of them may have a different perspective or view of the data. A database system provides a facility to define different views of the data for different users. A view is a subset of the database that contains virtual data derived from the database files but it does not exist in physical form. That is, no physical file is created for storing the data values of the view, rather only the definition of the view is stored.
(b) Database schema: It refers to the overall structure of the database, that is, all the information that is going to be represented in the database like name of the tables in the database, data types of the each data item of each table, constraints, relationship between the tables, etc. Note that once the schema of the database is created, usually it is not changed. If in case it needs to be modified, only the DBA, who has access to manipulate the structure of any object in the schema, can modify it.
14. Explain the DBMS architecture.
Ans.: The DBMS architecture describes how data in the database are viewed by the users. It is not concerned with how the data are handled and processed by the DBMS. According to the ANSI/SPARC DBMS Report (1977), a DBMS can be envisioned as a three-layered system [Figure 16.6 (a)]:
- Internal level: It is the lowest level of data abstraction that deals with the physical representation of the database on the computer and thus, is also known as physical level. It describes how the data are physically stored and organized on the storage medium.
- Conceptual level: This level of abstraction deals with the logical structure of the entire database and thus, is also known as logical level. It describes what data are stored in the database, the relationships among the data, and the complete view of the user's requirements without any concern for the physical implementation. That is, it hides the complexity of physical storage structures. The conceptual view is the overall view of the database and it includes all the information that is going to be represented in the database.
- External level: It is the highest level of abstraction that deals with the user's view of the database and thus, is also known as view level. It permits users to access data in a way that is customized according to their needs, so that the same data can be seen by different users in different ways, at the same time. In this way, it provides a powerful and flexible security mechanism by hiding the parts of the database from certain users as the user is not aware of the existence of any attributes that are missing from the view.
Figure 16.6 (b) shows the three-level architecture for EMPLOYEE_INFO database containing details like employee code, employee name, salary, etc.
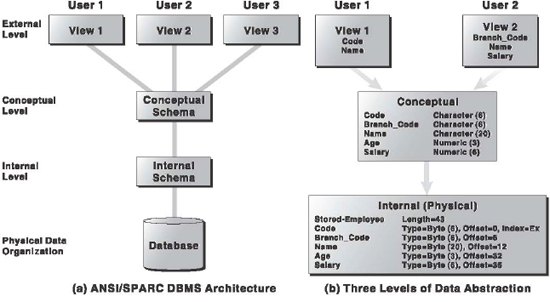
Figure 16.6 DBMS Architecture
Figure 16.6 (b) can be interpreted as follows:
| At the conceptual level, the database contains information regarding EMPLOYEE having fields like Code (6 characters), Branch_Code (6 characters), Name (20 characters), Age (3 digits), and Salary (6 digits). This is the conceptual schema of the database. | |
| At the physical level, STORED-EMPLOYEE represents the total record length (43 bytes). This structure contains all the five fields along with their byte representation and the pointer to the next record. Note that the records are indexed on Code field by an index called ‘Ex’. This is the internal schema of the database. | |
| External view is for two different users. The first user's external view incorporates only two fields: Code and Name. The second user's external view incorporates three fields: Branch_Code, Name, and Salary. This is the external schema of the database. |
The main advantage of the three-level database architecture is that it allows a clear separation of the conceptual view from the external data representation and from the physical data structure layout. This clear separation between different views results in data independence.
15. Write a short note on data independence.
Ans.: Data independence is the ability to change the schema at one level of the database system without having to change the schema at the other levels. It is of two types:
- Logical data independence: The separation of the external views from the conceptual view, which enables the users to change the conceptual view without affecting the external views or application programs, is called logical data independence. Examples of logical schema change can be the addition/removal of entities in the database.
- Physical data independence: The separation of the conceptual view from the internal view enables us to provide a logical description of the database without the need to specify physical structures. This is often called physical data independence. Modification at the physical level is occasionally necessary in order to improve performance. Examples of physical schema change can be the reorganization of files, adding a new access path, etc.
16. Define database model. Explain different database models.
Ans.: A database model or simply a data model is an abstract model that describes how the data are represented and used. It consists of a set of data structures and conceptual tools that is used to describe the structure of a database. Every database and DBMS is based on a particular database model. There are three basic types of database models: hierarchical, relational, and network.
Hierarchical Database Model
This model is the oldest type of data model, developed by IBM in 1968. It organizes the data in a tree-like structure in which each child node (also known as dependents) can have only one parent node. In other words, it is a collection of records connected to one another through links. The top of the tree structure consists of a single node that does not have any parent and is called the root node. The root may have any number of dependents; each of these dependents may have any number of lower level dependents.
For example, consider an EMPLOYEE_INFO database that includes the record types (collection of similar type of records) EMPLOYEE, PROJECT, and DURATION. The EMPLOYEE record type includes the fields Employee_Code, Employee_Name, and Salary of an employee. The PROJECT record type includes Project_Code and Project_Description. The DURATION record type includes No_of_hrs spent by the employee on a project. Every employee is assigned some projects.
The hierarchical model for the EMPLOYEE_INFO database is shown in Figure 16.7. One complete record of each record type represents a node. The node for an EMPLOYEE record is linked to all those nodes of the PROJECT record type that represent the projects on which that employee is working. In addition, each node of the PROJECT record type is linked to a specific node of DURATION record type.
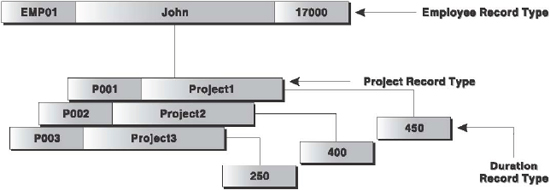
Figure 16.7 Hierarchical Database Model
The main advantage of the hierarchical data model is that the data access is quite predictable in structure, and therefore, both retrieval and updates can be highly optimized by a DBMS. However, the main drawback of this model is that the links are ‘hard-coded’ into the data structure, that is, the links are permanently established and cannot be modified. The hard coding makes the hierarchical model rigid. In addition, the physical links make it difficult to expand or modify the database and the changes require substantial redesigning efforts.
Network Database Model
The first specification of network data model was presented by Conference on Data Systems Languages (CODASYL) in 1969, followed by the second specification in 1971. It is powerful but complicated. In this model, the data is represented by a collection of records and the relationships among data are represented by links. A link is an association between precisely two records.
The network model of the EMPLOYEE_INFO database is shown in Figure 16.8. In this figure, each record of all the record types represents a node. All the nodes are linked to each other without any hierarchy. For instance, each No_of_hrs spent on a particular project by an employee is linked to that node of the PROJECT record type. All the nodes of the DURATION record type containing the No_of_hrs spent by the employee are linked to the EMPLOYEE record type.
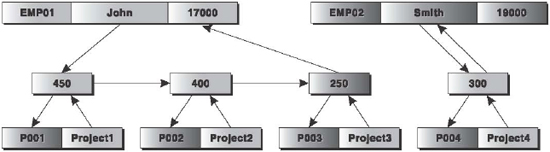
Figure 16.8 Network Database Model
The main limitation of the network data model is that it can be quite complicating to maintain all the links and a single broken link can lead to problems in the database. In addition, since there are no restrictions on the number of links, the database design can become overwhelmingly complex.
Relational Database Model
It was developed by E. F. Codd of IBM in 1970. The hierarchical and network models, though more flexible than the traditional file systems, were still not flexible enough. The limitations of these database models led to the development of the relational data model. The key difference between the network and hierarchical database models, and the relational model is in terms of flexibility. It is relatively easy and quick to create a new database structure and amend the existing structures in relational systems as compared to a network and hierarchical database.
This model represents the database as a collection of simple two-dimensional tables called relations. The rows of a relation are referred to as tuples and columns of a relation are referred to as attributes. The relationship between the two relations is implemented through a common attribute in the relations and not by physical links or pointers.
The relational model of the EMPLOYEE_INFO database is shown in Figure 16.9. In this figure, the EMPLOYEE_INFO database includes three relations: EMPLOYEE, PROJECT, and DURATION. The EMPLOYEE relation includes the attributes Employee_Code, Employee_Name, and Salary. The PROJECT relation includes the attributes Project_Code and Project_Description. The DURATION relation includes the attributes Employee_Code, Project_Code, and No_of_hrs. Since an employee is assigned a project, the relations EMPLOYEE and PROJECT are linked with each other with the help of the relation DURATION.
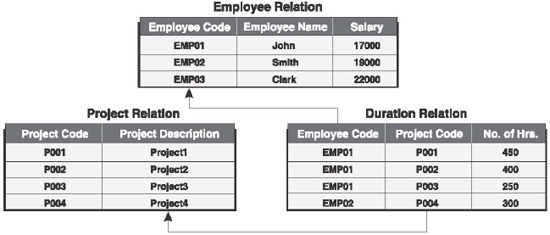
Figure 16.9 Relational Database Model
17. Explain the various keys used in relational database.
Ans.: Key is one of the important concepts of relational database. There are mainly three keys used in the relational database:
| Primary key: An attribute or a set of attributes that uniquely identify each record in a relation is known as a primary key. This implies no two records in the relation can have same value for the primary key. In addition, the attribute chosen as primary key cannot accept null value. For example, in EMPLOYEE relation, the attribute Employee_Code is the primary key because all employee codes are unique. Note that there can be only one primary key in a relation. If the key is composed of more than one attribute, then it is known as composite key, sometimes also known as concatenated key or structured key. | |
| Candidate key: In a relation, there can be more than one attribute that can uniquely identify each record. All such attributes are known as candidate keys. One of these candidate keys is chosen as a primary key; the candidate keys that are not chosen as primary key are known as alternate keys. For example, in EMPLOYEE relation, there are two candidate keys: Employee_Code and Employee_Name (considering no two employees can have the same name). If the attribute Employee_Code is chosen as the primary key, the attribute Employee_Name becomes the alternate key. | |
| Foreign key: An attribute of a relation that references the primary key of another relation is referred to as foreign key. Figure 16.10 illustrates how a foreign key constraint is related to a primary key constraint. Here, the attribute Item_Code in the PURCHASE relation references the attribute Item_Code in the ITEM relation. Thus, the attribute Item_Code in the PURCHASE relation is the foreign key. |
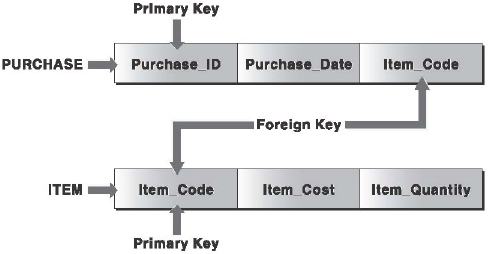
Figure 16.10 Foreign Key
18. What are the various applications of DBMS?
Ans.: Database systems are widely used in different areas because of their numerous advantages. Some of the most common applications of DBMS are as follows:
| Airlines and railways: They are used for online reservation and for displaying the schedule information. | |
| Banking: They are used for customer inquiry, accounts, loans, and other transactions. | |
| Education: They are used for course registration, result, and other information. | |
| Telecommunications: They are used to store information about the communication network, telephone numbers, record of calls, for generating monthly bills, etc. | |
| Credit card transactions: They are used for keeping track of purchases on credit cards in order to generate monthly statements. | |
| E-commerce: The integration of heterogeneous information sources (e.g., catalogs) for business activity such as online shopping, booking of holiday package, consulting a doctor, etc. | |
| Health-care information systems and electronic patient record: They are used for maintaining the patient health-care details. | |
| Digital libraries and digital publishing: They are used for management and delivery of large bodies of textual and multimedia data. | |
| Finance: They are used for storing information such as sales, purchases of stocks and bonds, or data useful for online trading. | |
| Sales: They are used to store product, customer, and transaction details. | |
| Human resources: They are used for storing information about organizations’ employees, salaries, benefits, taxes, and for generating salary checks. |
19. What do you mean by a transaction? Discuss the ACID properties of a transaction in a database.
Ans.: A collection of operations that form a single logical unit of work is called a transaction. The operations that make up a transaction typically consist of requests to access existing data, modify existing data, add new data, or any combination of these requests. For the successful completion of a transaction and database changes to be permanent, the transaction must be completed in its entirety. That is, each step (or operation) in the transaction must succeed for the transaction to be successful. If any part of the transaction fails, then the entire transaction fails.
To ensure the integrity of the data, the DBMS must maintain some desirable properties of the transaction. These properties are known as ACID properties, the acronym derived from the first letter of the terms atomicity, consistency, isolation, and durability. The ACID properties of the transaction are as follows:
| Atomicity: It implies that either all of the operations that make up a transaction should execute or none of them should occur. It is the responsibility of the transaction management component of a DBMS to ensure atomicity. | |
| Consistency: It implies that if all the operations of a transaction are executed completely, the database is transformed from one consistent state to another. It is the responsibility of the application programmers who code the transactions to ensure the consistency of the database. | |
| Isolation: It implies that each transaction appears to run in isolation with other concurrently running transactions. That is, the execution of a transaction should not be interfered by any other concurrently running transaction. It is the responsibility of the concurrency control component of the DBMS to allow concurrent execution of transactions without any interference from each other. | |
| Durability: It implies that once a transaction is completed successfully, the changes made by the transaction persist in the database, even if the system fails. The durability property is ensured by the recovery management component of the DBMS. |
20. What do you mean by a data warehouse? Also list its characteristics.
Ans.: A data warehouse is a repository of subjectively selected and suitable operational data, which can successfully answer any ad hoc, complex, statistical, or analytical queries. It is a collection of databases, data tables, and mechanisms to access the data on a single subject. Simply put, it stores an aggregation of an organization's data. This vast database stores information like a data repository but goes a step further, allowing users to access data to perform research-oriented analysis (data mining). In simple terms, it is a collection of data gathered and organized so that it can easily be analyzed, extracted, synthesized, and otherwise used for the purposes of further understanding the data. It may be contrasted with data that are gathered to meet immediate business objectives such as order and payment transactions, although these data would also usually become part of a data warehouse.
According to William Inmon, the father of the modern data warehouse, it is a subject-oriented, integrated, time-variant, non-volatile collection of data in the support of decision-making. Based on this definition, we can envision four basic characteristics of the data warehouse:
- Subject-oriented: A data warehouse is organized around a major subject such as customer, products, and sales. Data are organized according to subject instead of application. For example, an insurance company using a data warehouse would organize its data by customer, premium, and claim instead of by different products (auto sweep policy, joint life policy, etc.).
- Non-volatile: A data warehouse is always a physically separate store of data. Due to this separation, it does not require transaction processing, recovery, concurrency control, etc. The data are not updated if changed in any way once it enters the data warehouse, but is only loaded, refreshed, and accessed for queries.
- Time varying: Data are stored in a data warehouse to provide a historical perspective. Every key structure in the data warehouse contains, implicitly or explicitly, an element of time. It contains a place of sorting data that are 5–10 years old, or older, to be used for comparison, trends, and forecasting.
- Integrated: A data warehouse is usually constructed by integrating multiple, heterogeneous sources such as relational databases and flat files. The database contains data from most or all of an organization's operational applications, and these data are made consistent.
21. Define data warehousing.
Ans.: Data warehousing refers to the process used by organizations to create and maintain data warehouses and then extract meaning and inform decision-making from their informational assets through these data warehouses.
22. Write a short note on data mining.
Ans.: With rapid computerization in the past two decades, almost all the organizations have collected a vast amount of data in their databases. These organizations need to understand their data and also want to discover useful information in terms of patterns or rules from the existing data. The extraction of hidden and predictive information from such large databases is known as data mining. Data mining tools predict future trends and behaviours, which allow organizations to make proactive and knowledge-driven decisions. Identifying the profile of customers with similar buying habits, finding all items that are frequently purchased with some other item, finding all credit card applicants with poor or good credit risks are some of the examples of data mining queries.
Data mining is practiced by using certain software tools, which are geared for the user who typically does not know exactly what to search, but is looking for particular patterns or trends. These applications use pattern recognition technologies as well as statistical and mathematical techniques and can have a key impact on the return on investment (ROI) for technology expenditure upon discovering marketing or customer service data about one's clients. Though data in large operational databases and flat files can be provided as input for the data mining process, data in data warehouses are more suitable for data mining process.
23. Describe some applications of data warehousing and data mining.
Ans.: Data warehousing helps in decision support, trend analysis, financial forecasting, call record analysis, agricultural industries. Some of the significant applications of data warehousing are as follows:
| Decision support system: The systems that aim to extract high-level information stored in databases, and to use that information in making a variety of decisions which are important for the organization are known as decision-support systems (DSS). Data warehousing helps the decision makers in decision-making by providing the correct level of information. | |
| Data mining: The data warehouses are more suitable for data mining rather than data in large operational databases and flat files. This is because the data in data warehouses are integrated, subject-oriented, and are in summarized form. Hence, the data mining process can directly use this data without performing any aggregations. | |
| Web mining: It is similar to data mining in the context as information or data are extracted from a large repository of data. It is something more from the traditional data mining as the concept of World Wide Web (WWW) is also used here. It is used to analyze the behaviour of data and check the effectiveness, which further help to quantify the successively retrieval of information. It also helps to examine the data collected from search engines, web spiders, web transactions, and web browsers. |
Data mining can be used in many areas such as banking, finance, and telecommunications industries. Some of the significant applications of data mining technologies are given as follows:
| Market-basket analysis: Companies can analyze the customer behaviour based on their buying patterns, and may launch products according to the customer needs. The companies can also decide their marketing strategies such as advertising, store location, etc. They can also segment their customers, stores, or products based on the data discovered after data mining. | |
| Investment analysis: Customers can also look at the areas such as stocks, bonds, and mutual funds where they can invest their money to get good returns. | |
| Fraud detection: By finding the association between frauds, new frauds can be detected using data mining. | |
| Manufacturing: Companies can optimize their resources like machines, manpower, and materials by applying data mining technologies. | |
| Credit risk analysis: Given a set of customers and an assessment of their credit worthiness, descriptions for various classes can be developed. These descriptions can be used to classify a new customer into one of the classes. |
Other than these applications, some other applications of data mining include quality control, process control, medical management, store management, student recruitment and retention, pharmaceutical research, electronic commerce, claims processing, etc.
24. Discuss about the recent trends in database.
Ans.: Some of the recent trends in database technology are distributed database system, object-oriented database system, data warehousing, and data mining.
Distributed Database System
It consists of a collection of sites, connected together by the use of some kind of communication network. Each site is a database system site in its own right and the sites have agreed to work together, so that a user at any site can access anywhere in the network as if the data were all stored at the user's local site. In other words, each site has its own local database, its own local users, its own local DBMS and transaction management software, and its own local data communication manager. In particular, a given user can perform operations on the data at the user's own local site as if that site did not participate in the distributed system at all. The distributed database system can thus be regarded as a kind of partnership among the individual local DBMSs at the individual local sites.
Big corporations with widespread operations can benefit from distributed databases. In such organizations, computer processing is also distributed, with processing done locally at each location. A distributed database is fragmented into smaller data sets. Normally, the database is divided into data sets based on usage. If a fragment contains data that are most relevant to one location, that data set is kept at that location. Each fragment of data at every location may be managed with the same type of DBMS. For example, at every location, Oracle DBMS may be used. In such case, the distributed database is referred to as a homogenous database. On the other hand, if the data fragments are managed at different locations with different DBMSs, then the distributed database is referred to as a collection of heterogeneous database systems.
Object-oriented Database System
With the widespread networking of computers and the growth of Internet, the role of computers has expanded from its traditional base of transaction processing into new areas, many of which depend on the computer's multimedia capability. Whilst the relational model is well suited to transaction processing, it cannot manage the complex data structures such as image and sound, which are typical of multimedia applications. In addition, the relational model does not easily support the distribution of one database across a number of servers. Furthermore, there are several disciplines, such as medicine and multimedia, where the relational database is not practical, due to the types of data involved. These fields of work needed more flexibility in data representation and accessibility. Due to these reasons, object-oriented database management system (OODBMS) was developed.
An object-oriented database stores and maintains objects. An object is an item that can contain both data and the procedures that manipulate the data. For example, a student object might contain not only data about a student's name, roll number, and address, but also procedures on some tasks such as printing the student record or calculating the student's tuition fees. Like the other models, the object model assumes that objects can conceptually be collected together into meaningful groups known as classes. An object grouping is meaningful because objects of the same class have common attributes, behaviours, and relationships with other objects. Like the network model, the relationships among objects are specified via a ‘physical’ link (pointer) between objects.
Figure 16.11 shows a simple example of object-oriented database structure. The class Population is the root of a class hierarchy, which includes the Nation class. The Population class is also the root of two subclasses: Men and Women. The Nation class is the root of other subclasses: Country1, Country2, and Country3. Notice that each class has its own set of attributes apart from the root class's attributes.
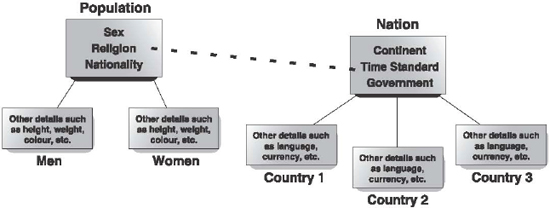
Figure 16.11 Object-Oriented Database Model
Data Warehousing
Refer Question No. 20.
Data Mining
Refer Question No. 22.
25. What is a SQL? Explain the characteristics and standards of SQL.
Ans.: A structured query language (SQL) is a database language that has been developed for defining and manipulating data sets from a database. It is an international standard; both American National Standards Institute (ANSI) and International Standards Organization (ISO) have standardized it. It is a medium of communicating to the DBMS what the user wants it to do. It is sometimes referred to as a non-procedural database language, which implies that the SQL statements describe what data are to be retrieved, rather than specifying how to find the data.
Characteristics of SQL
Some of the characteristics of SQL are described as follows:
| Standard independent language: The universal rules of the SQL have been established by ANSI and ISO. Therefore, it is an open language, implying it is not owned or controlled by any single company. Today, it is offered by all the leading DBMS vendors. It is not just for a particular product; it works with Oracle, Microsoft SQL Server, and Sybase, just to name a few. Each vendor may have their proprietary extensions to SQL, but the basics of SQL are almost identical across all the database vendors. It means, regardless of the DBMS, the result of an SQL query will be the same. This vendor independence has enabled programmers to develop truly independent database applications. | |
| Cross-platform abilities: One of the biggest hardships of using a programming language to access database is that it seldom produces a ‘true’ cross-platform application. It may be relatively new to some of the most popular programming languages like COBOL or C, but it has been in use on different hardware platforms for years. In most cases, the same SQL statement can be used on a desktop, a server, or a mainframe. An SQL-enabled database and the programs that use it can be moved from one DBMS to another vendor's DBMS with minimal (or no) conversion effort. | |
| Easy to learn and use: SQL statements resemble simple English sentences, making it easy to learn and understand. It has been created such that it is intuitive, simple, non-procedural (one need not specify step-by-step instructions to execute certain actions), and maps human's cognitive model. Being non-procedural in nature, the user just has to type a single SQL declaration and hand it to the DBMS. The DBMS then executes internal code (hidden from the user) and returns a set, which is a group of data that are logically defined. | |
| Less programming: It allows extraction, manipulation, and organization of data with less programming as compared to traditional methods. It allows for record sets that are more complex to be created but requires less coding. It also allows tables to be joined together in ways that are not easily accomplished in other programming languages. Since it is a text-based programming language (i.e., no executables are created for SQL-only programs), the SQL statement can also be constructed at run-time to give programs amazing flexibility. Furthermore, it can be used from within most programming languages. Whether you code in C++ or Java, it is the method of choice for accessing data. | |
| Universality: An alternative to using SQL statements is to write code in a procedural language like C++. The problem with this approach is that you are then closely tied to the procedural language, the metadata, and the specific DBMS. If there is a change in the structure of the tables, the code must be changed. If a new DBMS is installed, most of the codes must be revised to mesh with the new DBMS of pointers, record set definitions, etc. However, by using SQL statements, almost all changes are handled by the DBMS, behind the scenes from the programmer. | |
| Scaling: Many applications are developed for desktop environments. As they grow, a number of problems become apparent with these systems. For example, database software designed for the desktop generally fails when numerous people try to use the data at the same time. Therefore, organization has to move from desktop systems to a more robust DBMS. Almost all these heavy duty DBMS rely on SQL as the main form of communication to scale well. | |
| Speed: Over the last 10 years, SQL data engines have been the focus of an intense effort to improve performance. The intense competition among database vendors has resulted in faster, more robust DBMSs that work at lower costs per transaction. Although SQL itself does not alleviate speed problems, the implementation of faster DBMS does, and those faster DBMSs require communications in SQL. | |
| Cost effective: It is more expensive to run a server-centric DBMS (that only speaks SQL) than it is to use a desktop system (which does not necessarily need to use SQL). First, the software is more expensive. Second, in most cases, operating systems that are more expensive are needed to run in order to support the DBMS. Third, the operating system is required to be tuned differently to optimize for a DBMS than for other applications. Last, personnel with more expensive qualifications are engaged. However, the price of hardware and software is frequently the smallest item in an IT budget. As the data centre grows, at some point the reliability, performance, and standardization benefits of a DBMS that uses SQL outweighs the cost. |
SQL Standards
A database language standard specifies the semantics of various components of a DBMS. It defines the structures and operations of a data model implemented by the DBMS, as well as other components that support data definition, data access, security, programming language interface, and data administration. The SQL standard specifies data definition, data manipulation, and other associated facilities of a DBMS that supports the relational data model. Various standard of SQL are listed in Table 16.1.
Table 16.1 SQL Standards
Year |
Name | Description |
1986 |
SQL86 | It was first published by ANSI in 1986 and ratified by ISO in 1987. |
1989 |
SQL89 | It had some minor revision. |
1992 |
SQL92 | Major revisions were made. |
1999 |
SQL99 | It added regular expression matching, recursive queries, triggers, non-scalar types, some object-oriented features. |
2003 |
SQL2003 | It introduced XML-related features, standardized sequences, and columns with auto-generated values. |
2006 |
SQL2006 | It defined ways of importing and storing XML data in an SQL database, manipulating it within the database, and publishing both XML and conventional SQL-data in XML form. |
2008 |
SQL2008 | It added INSTEAD OF triggers and the TRUNCATE statement. |
26. What are the various data types used in SQL?
Ans.: SQL is considered a strongly typed language. This means that any piece of data represented by a table's field has an associated data type, that is, a set of rules describing a specific set of information, including the allowed range and operations and how information is stored. The type of a data value both defines and constrains the kinds of operations, which may be performed on it. SQL has numerous data types, such as Char, Numeric, and Date. Some of the most commonly used SQL data types are listed in Table 16.2.
Table 16.2 Common SQL Data Types
Data Type |
Description |
Char(Size) |
It defines a fixed-size length character string (can contain letters, numbers, and special characters), where Size can be a maximum of 255. |
Varchar(Size) |
It defines a variable length character string (can contain letters, numbers, and special characters) of up to Size characters. |
Integer |
It defines an integer only data type (usually a 32-bit signed integer). |
Numeric(S, D) or Decimal(S, D) |
It holds numbers with fractions. The maximum numbers of digits are specified in S. The maximum number of digits to the right of the decimal is specified in D. |
Date |
This data type is used to store date. By default, the format is YYYY-MM-DD. |
Time |
This data type is used to store time. By default, the format is HH:MM:SS. |
Boolean |
This data type accepts a single value that can be true or false. |
27. Explain DDL commands in SQL with the help of examples.
Ans.: Data definition language (DDL) consists of those commands in SQL that directly create or delete database objects such as tables and indexes, specify links between tables, and impose constraints between database tables. The most important DDL statements in SQL are CREATE TABLE, ALTER TABLE, and DROP TABLE.
CREATE TABLE
This statement is used to define the structure of the table.
Syntax:
CREATE TABLE table-name ( <column1> <data-type>, <column2> <data-type>, . . . <columnN> <data-type> );
Example:
CREATE TABLE EMPLOYEE ( Empid INTEGER, Dept CHAR(10), Empname CHAR(15), Address CHAR(25), Salary DECIMAL(8, 2) );
The above example creates a database table named EMPLOYEE. The table has four columns with each column associated with a specific data type. For example, the Empid column is defined as an INTEGER and Empname is defined as CHAR(15). This means that when data are added to the table, the Empid column will only hold integers and the Empname column will hold character string values up to a maximum of 15 characters.
ALTER TABLE
This statement allows a user to change the structure of an existing table. New columns can be added with the ADD clause. Existing columns can be modified with the MODIFY clause. Columns can be removed from a table by using the DROP clause.
Syntax:
ALTER TABLE table-name <ADD
| MODIFY | DROP column(s)>;
Examples:
ALTER TABLE EMPLOYEE ADD E-mail CHAR(25);
ALTER TABLE EMPLOYEE MODIFY Empname CHAR(25);
ALTER TABLE EMPLOYEE DROP Dept;
The first ALTER statement will add a new column named E-mail having a maximum width of 25 characters in the EMPLOYEE table. The second statement will change the Empname to have a maximum width of 25 characters in the EMPLOYEE table. The last statement will delete the Dept column from the EMPLOYEE table.
DROP TABLE
This statement is used to remove the table definition (along with all the records).
Syntax:
DROP TABLE table-name;
Example:
DROP TABLE EMPLOYEE;
This SQL statement will delete the EMPLOYEE table.
28. Explain DML commands in SQL with the help of examples.
Ans.: Data manipulation language (DML) consists of those commands that operate on the data in the database. These include statements that add data to the table as well as those statements that are used to query the database. The most important DML statements in SQL are INSERT, UPDATE, DELETE, and SELECT:
INSERT
This statement is used to add records in a table.
Syntax:
INSERT INTO table-name (column1, column2, …, scolumnN)
VALUES (value1, value2, …, valueN);
Example:
INSERT INTO EMPLOYEE (Empid, Dept, Empname, Address, Salary)
VALUES (101, ‘RD01’, ‘Prince’, ‘Park Way’, 15000);
This statement will add a new record at the bottom of the EMPLOYEE table (created in Q27) consisting of the values in the parenthesis. Note that for each of the listed columns, a matching value must be specified. If one is inserting values corresponding to all columns of the table, then the column list can be ignored. For example, the above statement can also be rewritten as follows:
INSERT INTO EMPLOYEE VALUES (101, ‘RD01’, ‘Prince’,
‘Park Way’, 15000);
UPDATE
This statement is used to make changes to the data in the database.
Syntax:
UPDATE table-name SET column1 = value1 [, column2 = value2] …
[, columnN = valueN] [WHERE condition];
Examples:
UPDATE EMPLOYEE SET Salary = Salary + 1000; UPDATE EMPLOYEE SET Salary = Salary + 1000
WHERE Dept = ‘RD01’;
The first UPDATE statement will update (in our case, increments) the Salary field with 1000 for all the records. The second UPDATE statement will check the WHERE clause first (WHERE Dept = ‘RD01’) and increase the value of Salary field by 1000 for only those records where department (Dept) is ‘RD01’.
DELETE
This statement is used to delete all or selected records from the specified table.
Syntax:
DELETE FROM table-name [WHERE condition];
Example:
DELETE FROM EMPLOYEE WHERE Salary > 8000;
This statement deletes all the records from the EMPLOYEE table, which satisfy the WHERE condition. That is, records for all the employees whose Salary is more than 8000 will be deleted. Note that, if the WHERE condition is not used then all the records from the specified table will be deleted.
SELECT
This statement actually queries the database and retrieves the requested result set. It allows users to retrieve data from one or more tables with various conditions. It allows the user to specify the desired data to be retrieved, the order to arrange the data, calculations to be performed on the data set, and many such operations. It has a well-structured set of clauses.
Syntax:
SELECT column(s) or computed attribute(s)
[AS new-name] FROM table-name [WHERE condition] [GROUP BY column(s)] [HAVING condition] [ORDER BY column(s) [ASC|DESC]];
Example:
SELECT Empid, Dept, Empname, Address, Salary
FROM EMPLOYEE;
This statement will display all the records of EMPLOYEE table. Note that it is not mandatory to type the entire field list. An asterisk (*) can be used to substitute the field list as shown below:
SELECT * FROM EMPLOYEE;
29. Define aggregate function. List various aggregate functions available in SQL.
Ans.: A function that takes a collection of values as input and returns a single output is referred to as an aggregate function, also known as group function. Various aggregate functions available in SQL are listed in Table 16.3.
Table 16.3 Aggregate Functions in SQL
Function |
Description |
COUNT(column-name) |
It returns the number of rows of a column. |
COUNT(*) |
It returns the number of selected rows. |
AVG(column-name) |
It returns the average or mean value of a column. |
MAX(column-name) |
It returns the highest value of a column. |
MIN(column-name) |
It returns the lowest value of a column. |
SUM(column-name) |
It returns the total sum of a column. |
30. Explain the use of GROUP BY and HAVING clause with the help of an example.
Ans.: In many situations, it is required to apply the aggregate function on a group of tuples from a relation rather on the whole relation. The tuples in the relation can be divided on the basis of the values of one or more attributes. The tuples belonging to a particular group have the same value for the attribute on the basis of which grouping is done. The GROUP BY clause can be used in the SELECT command to divide the relation into groups on the basis of values of one or more attributes. After dividing the relation into groups, the aggregate functions can be applied on the individual group independently. They are performed separately for each group and return the corresponding result value separately.
To understand the use of GROUP BY clause, suppose the user wants to find the average salaries department-wise in the EMPLOYEE table. For this, the user first needs to group the records of EMPLOYEE table based on Dept column and then to calculate the average salary for each group (i.e., department) as shown below:
SELECT AVG(Salary) FROM EMPLOYEE GROUP BY Dept;
Sometimes, we may want to state a condition that applies to only specific groups rather than all. For example, the user may be interested only in those departments in which the average salary of employees is greater than 13000. This can be done by using the HAVING clause with the GROUP BY as shown below:
SELECT Dept, AVG(Salary) FROM EMPLOYEE GROUP BY Dept HAVING AVG(Salary) > 13000;
31. What is the similarity and difference between HAVING and WHERE clause?
Ans.: Adding a HAVING clause to a SELECT statement sets conditions for the GROUP BY clause in a similar way the WHERE statement sets conditions for the SELECT clause. The HAVING search conditions are almost identical to WHERE search conditions. The only difference between the two is that WHERE search conditions cannot include aggregate functions, while HAVING search conditions often include these functions.
32. What are SQL joins? Explain with the help of an example.
Ans.: SQL possesses a very powerful feature join that enables to gather and manipulate data from across several tables. Without this feature, the database creator would have to store all the data elements necessary for each application in one table. Moreover, without common tables, the same data may have to be stored in several tables. However, the join feature enables the database designer to design smaller, more specific tables that are easier to maintain than a single larger table.
The join condition actually puts the concept of foreign key in practical use to link data from two or more tables together into a single query result—from one single SELECT statement. A ‘join’ can be recognized in a SELECT statement if it has more than one table after the FROM keyword. The syntax to use the join condition is as follows:
SELECT list-of-columns FROM table-name1 [AS alias-name], table-name2 [AS alias-name] [WHERE table1_keyfield = table2_foreign_keyfield];
For example, consider the EMPLOYEE and DEPARTMENT tables shown in Figure 16.12.
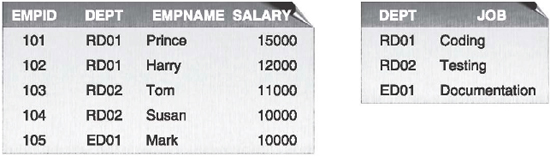
Figure 16.12 EMPLOYEE and DEPARTMENT Tables
One way to join these tables is by using the following statement:
SELECT * FROM EMPLOYEE, DEPARTMENT;
This query produces the following result:
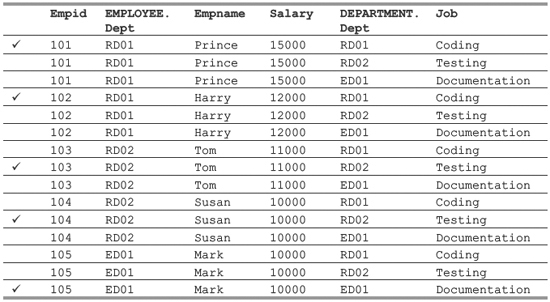
Although the above query is perfectly correct, but obviously, it did not retrieve the desired result. Every single row of the first table has been joined with each row of the second table, not just the rows that we think should correspond (the ![]() marked records). This is called a Cartesian join or cross-join, and can rapidly generate enormous tables. According to this join, if there are two tables, each with a thousand rows, then 1000 × 1000 = 1000000 rows are displayed. Hence, to reduce the number of rows, and to get the desired result, we need to perform equi-join by using the WHERE clause to join the tables on the matching column as shown below:
marked records). This is called a Cartesian join or cross-join, and can rapidly generate enormous tables. According to this join, if there are two tables, each with a thousand rows, then 1000 × 1000 = 1000000 rows are displayed. Hence, to reduce the number of rows, and to get the desired result, we need to perform equi-join by using the WHERE clause to join the tables on the matching column as shown below:
SELECT * FROM EMPLOYEE, DEPARTMENT WHERE EMPLOYEE.Dept = DEPARTMENT.Dept;
Now, this query will produce the following result:
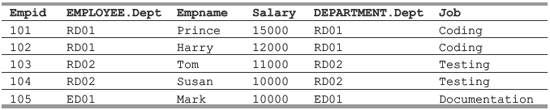
Note that in the above query, the matching columns (Dept) are used along with their table names with a dot operator (.). This is done to clearly mention the table to which the columns belong. In any case, if the table names are not mentioned along with the column, SQL will generate an error. Secondly, an asterisk (*) is used to display all the columns from both joined tables to be listed. However, just like normal SELECT statements, we can use specific column names as well as:
SELECT Empid, EMPLOYEE.Dept, Empname, Job FROM EMPLOYEE, DEPARTMENT WHERE EMPLOYEE.Dept = DEPARTMENT.Dept;
33. What is the purpose of UNION command in SQL? How is it different from join?
Ans.: There are occasions where the user might want to see the results of multiple queries together, combining their output. In such situations, UNION can be used. UNION is somewhat similar to ‘join’ as they both are used to relate information from multiple tables. It adds the result of a second SELECT clause to the table created by the main SELECT command. One restriction of UNION is that all corresponding columns need to be of the same data type (numeric columns must correspond to numeric columns, string columns with string columns). Moreover, when using UNION, only distinct values are selected. For example, to get the list of department IDs, the following query is used:
SELECT Dept FROM EMPLOYEE UNION SELECT Dept FROM Department;
This query produces the following result:

34. What do you mean by subquery? What guidelines should be used while using subqueries?
Ans.: A subquery is a SELECT statement that nests inside the WHERE clause of another SELECT statement. In relational databases, there may be many situations when the user has to perform a query, temporarily store the result(s), and then use this result as part of another query. This nesting of queries is known as subquery. The basic idea behind it is that instead of a ‘static’ condition, the user can insert a query as part of a WHERE clause. The main reason of using subquery is that it breaks down a complex query into a series of logical steps, and as a result, solves a problem with a single statement.
Syntax:
SELECT list-of-columns FROM table-name WHERE attribute conditional operator (SELECT list-of-columns FROM table-name [WHERE condition]);
Example:
SELECT Empname, Salary FROM EMPLOYEE WHERE Salary = (SELECT MIN(Salary) FROM EMPLOYEE);
Output:
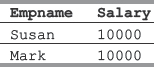
In the above example, the subquery (SELECT MIN(Salary) FROM EMPLOYEE) will return 10000 as the result. This result will then be used by the main query to display the queried output.
While creating a subquery, the following guidelines should be considered:
| The subquery must be on the right side of the conditional operator. | |
| The subquery must be enclosed within parenthesis. | |
| Multiple select subqueries can be combined (using AND, OR) in the same statement, but it is not advisable. | |
| When a subquery is part of a WHERE condition, the SELECT clause in the subquery must have columns that match in number and type to those in the WHERE clause of the outer query. |
Multiple-choice Questions
1. A DBMS provides __________ to retrieve, insert, modify, and delete database information.
(a) DDL
(b) XML
(c) DML
(d) Both (a) and (b)
2. Data integrity refers to __________.
(a) Non-duplication of data
(b) Accuracy of data
(c) Security of data
(d) Centralized data
3. Which is not a component of a relational database?
(a) Entity
(b) Attribute
(c) Table
(d) Hierarchy
4. The __________ of abstraction deals with the logical structure of the entire database.
(a) Physical level
(b) External level
(c) Conceptual level
(d) None of these
5. Father and son share __________ type of relationship.
(a) 1:M
(b) M:M
(c) 1:1
(d) None of these
6. The database model that uses a series of two-dimensional tables to store information is __________.
(a) Object-oriented database model
(b) Hierarchical database model
(c) Relational database model
(d) Network database model
7. A logical collection of information that supports business analysis activities and decision-making tasks is __________.
(a) An object-oriented database
(b) A data warehouse
(c) A database
(d) A data-mining tool
8. You want to run a SELECT command that lists all employees by the ascending order of their names. What clause would you include in the query to do the ordering?
(a) LIST ASC BY Emp_Name
(b) ORDER BY Emp_Name
(c) SORT BY Emp_Name
(d) WHERE Emp_Name ASC
9. SQL is a __________ language.
(a) Low-level
(b) Procedural
(c) High-level
(d) Non-procedural
10. To select all the records from a table named STUDENT, where the First_Name is ‘Mark’ and the Last_Name is ‘Edward’, which of the following SQL statement should be used?
(a) SELECT * FROM STUDENT WHERE First_Name = ‘Mark’ AND Last_Name = ‘Edward’
(b) SELECT First_Name = ‘Mark’ Last_Name = ‘Edward’ FROM STUDENT
(c) SELECT ‘Mark’ ‘Edward’ FROM STUDENT.First_Name, STUDENT.Last_Name
(d) None of these
11. Which of the following is not a valid SQL data type?
(a) Numeric
(b) Varchar
(c) Boolean
(d) Int
12. Which of the following SQL commands is used to modify the structure of a table?
(a) ALTER
(b) UPDATE
(c) INSERT
(d) DELETE
Answers
1. (c)
2. (b)
3. (d)
4. (c)
5. (a)
6. (c)
7. (b)
8. (b)
9. (d)
10. (a)
11. (d)
12. (a)