
Chapter 6. Example Application
Let’s finish with a look at an example application, similar to systems that several Lightbend customers have implemented.1 Here, telemetry for IoT (Internet of Things) devices is ingested into a central data center. Machine learning models are trained and served to detect anomalies, indicating that a hardware or software problem may be developing. If any are found, preemptive action is taken to avoid loss of service from the device.
Vendors of networking, storage, and medical devices often provide this service, for example.
Figure 6-1 sketches a fast data architecture implementing this system, adapted from Figure 2-1, with a few simplifications for clarity. As before, the numbers identify the diagram areas for the discussion that follows. The bidirectional arrows have two numbers, to discuss each direction separately.
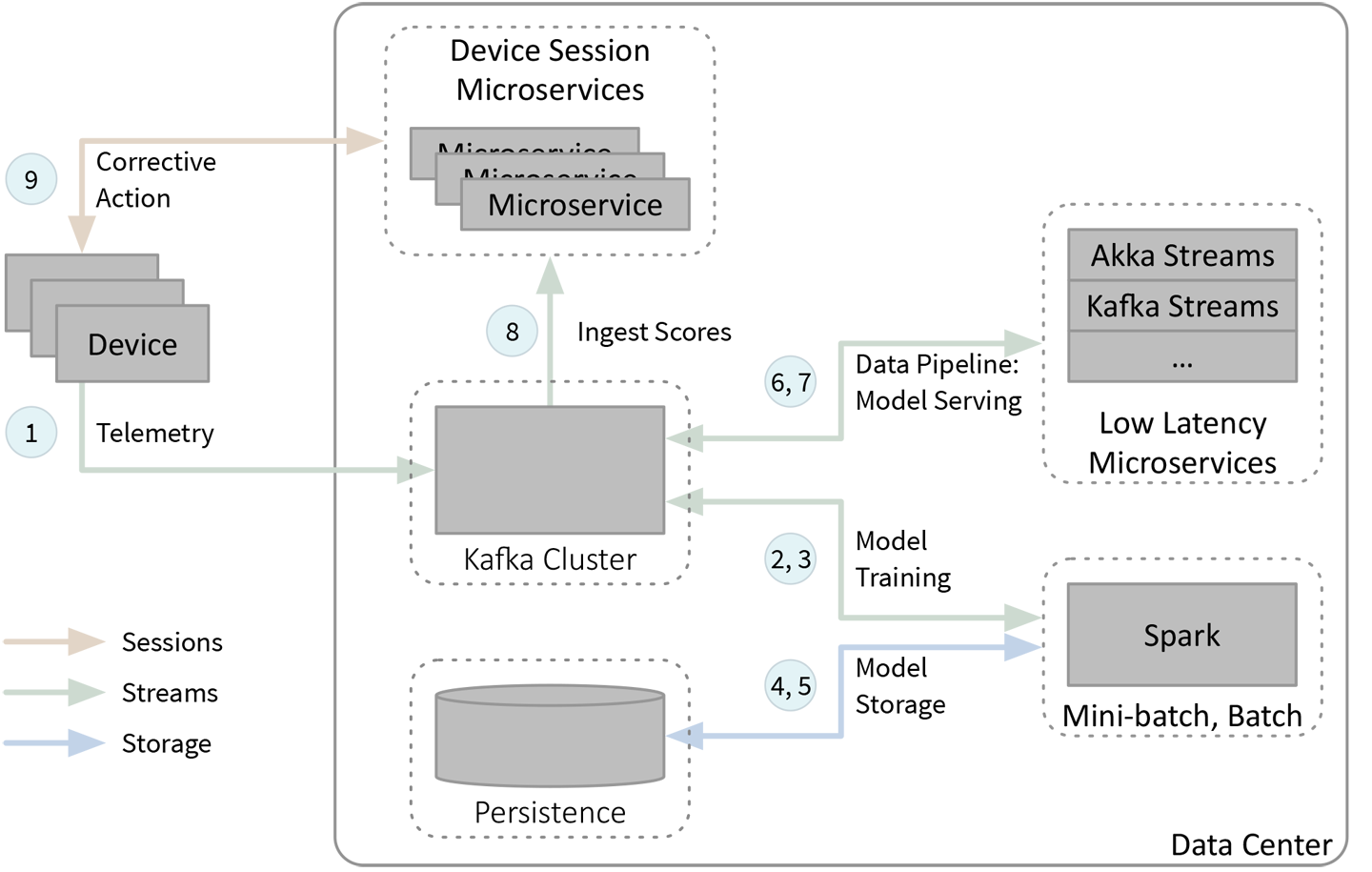
Figure 6-1. IoT anomaly detection example
There are three main segments of this diagram. After the telemetry is ingested (label 1), the first segment is for model training with periodic updates (labels 2 and 3), with access to persistent stores for saving models and reading historical data (labels 4 and 5). The second segment is for model serving—that is, scoring the telemetry with the latest model to detect potential anomalies (labels 6 and 7)—and the last segment is for handling detected anomalies (labels 8 and 9).
Let’s look at the details of this figure:
-
Telemetry data from the devices in the field are streamed into Kafka, typically over asynchronous socket connections. The telemetry may include low-level machine and operating system metrics, such as component temperatures, CPU and memory utilization, and network and disk I/O performance statistics. Application-specific metrics may also be included, such as metrics for service requests, user interactions, state transitions, and so on. Various logs may be ingested, too. This data is captured into one or more Kafka topics.
-
The data is ingested into Spark for periodic retraining or updating of the anomaly detection model.2 We use Spark because of its ability to work with large data sets (if we need to retrain using a lot of historical data), because of its integration with a variety of machine learning libraries, and because we only need to retrain occasionally, where hours, days, or even weeks is often frequently enough. Hence, this data flow does not have low-latency requirements, but may need to support processing a lot of data at once.
-
Updated model parameters are written to a new Kafka topic for downstream consumption by our separate serving system.
-
Updated model parameters are also written to persistent storage. One reason is to support auditing. Later on, we might need to know which version of the model was used to score a particular record. Explainability is one of the hard problems in neural networks right now; if our neural network rejects a loan application, we need to understand why it made that decision to ensure that bias against disadvantaged groups did not occur, for example.
-
The Spark job might read the last-trained model parameters from storage to make restarts faster after crashes or reboots. Any historical data needed for model training would also be read from storage.
-
There are two streams ingested from Kafka to the microservices used for streaming. The first is the original telemetry data that will be scored and the second is the occasional updates for the model parameters. Low-latency microservices are used for scoring when we have tight latency constraints, which may or may not be true for this anomaly detection scenerio, but would be true for fraud detection scenarios implemented in a similar way. Because we can score one record at a time, we don’t need the same data capacity that model training requires. The extra flexibility of using microservices might also be useful.
-
In this example, it’s not necessary to emit a new scored record for every input telemetry record; we only care about anomalous records. Hopefully, the output of such records will be very infrequent. So, we don’t really need the scalability of Kafka to hold this output, but we’ll still write these records to a Kafka topic to gain the benefits of decoupling from downstream consumers and the uniformity of doing all communications using one technique.
-
For the IoT systems we’re describing, they may already have general microservices that manage sessions with the devices, used for handling requests for features, downloading and installing upgrades, and so on. We leverage these microservices to handle anomalies, too. They monitor the Kafka topic with anomaly records.
-
When a potential anomaly is reported, the microservice supporting the corresponding device will begin the recovery process. Suppose a hard drive appears to be failing. It can move data off the hard drive (if it’s not already replicated), turn off the drive, and notify the customer’s administrator to replace the hard drive when convenient.
The auditing requirement discussed for label 4 suggests that a version marker should be part of the model parameters used in scoring and it should be added to each record along with the score. An alternative might be to track the timestamp ranges for when a particular model version was used, but keep in mind our previous discussion about the difficulties of synchronizing clocks!
Akka Actors are particularly nice for implementing the “session” microservices. Because they are so lightweight, you can create one instance of a session actor per device. It holds the state of the device, mirrors state transitions, services requests, and the like, in parallel with and independent of other session actors. They scale very well for a large device network.
One interesting variation is to move model scoring down to the device itself. This approach is especially useful for very latency-sensitive scoring requirements and to mitigate the risk of having no scoring available when the device is not connected to the internet.
Figure 6-2 shows this variation.

Figure 6-2. IoT anomaly detection scoring on the devices
The first five labels are unchanged.
-
Where previously anomaly records were ingested by the session microservices, now they read model parameter updates.
-
The session microservices push model parameter updates to the devices.
-
The devices score the telemetry locally, invoking corrective action when necessary.
Because training doesn’t require low latency, this approach reduces the “urgency” of ingesting telemetry into the data center. It will reduce network bandwidth if the telemetry needed for training can be consolidated and sent in bursts.
Other Machine Learning Considerations
Besides anomaly detection, other ways we might use machine learning in these examples include the following:
- Voice interface
-
Interpret and respond to voice commands for service.
- Improved user experience
-
Study usage patterns to optimize difficult-to-use features.
- Recommendations
-
Recommend services based on usage patterns and interests.
- Automatic tuning of the runtime environment
-
In a very large network of devices and services, usage patterns can change dramatically over time and other changed circumstances. Usage spikes are common. Hence, being able to automatically tune how services are distributed and used, as well as how and when they interact with remote services, can make the user experience better and the overall system more robust.
Model drift or concept drift refers to how a model may become stale over time as the situation it models changes. For example, new ways of attempting fraud are constantly being invented. For some algorithms or systems, model updates will require retraining from scratch with a large historical data set. Other systems support incremental updates to the model using just the data that has been gathered since the last update. Fortunately, it’s rare for model drift to occur quickly, so frequent retraining is seldom required.
We showed separate systems for model training and scoring, Spark versus Akka Streams. This can be implemented in several ways:
-
For simple models, like logistic regression, use separate implementations, where parameters output by the training implementation are plugged into the serving system.
-
Use the same machine learning library in both training and serving systems. Many libraries are agnostic to the runtime environment and can be linked into a variety of application frameworks.
-
Run the machine learning environment as a separate service and request training and scoring through REST invocations or other means. Be careful about the overhead of REST calls in high-volume, low-latency scenarios.
1 You can find case studies at lightbend.com/customers.
2 A real system might train and use several models for different purposes, but we’ll just assume one model here for simplicity.