
Chapter 6. Example Application
Let’s finish with a look at an example application, IoT telemetry ingestion and anomaly detection for home automation systems. Figure 6-1 labels how the parts of the fast data architecture are used. I’ve grayed out less-important details from Figure 2-1, but left them in place for continuity.
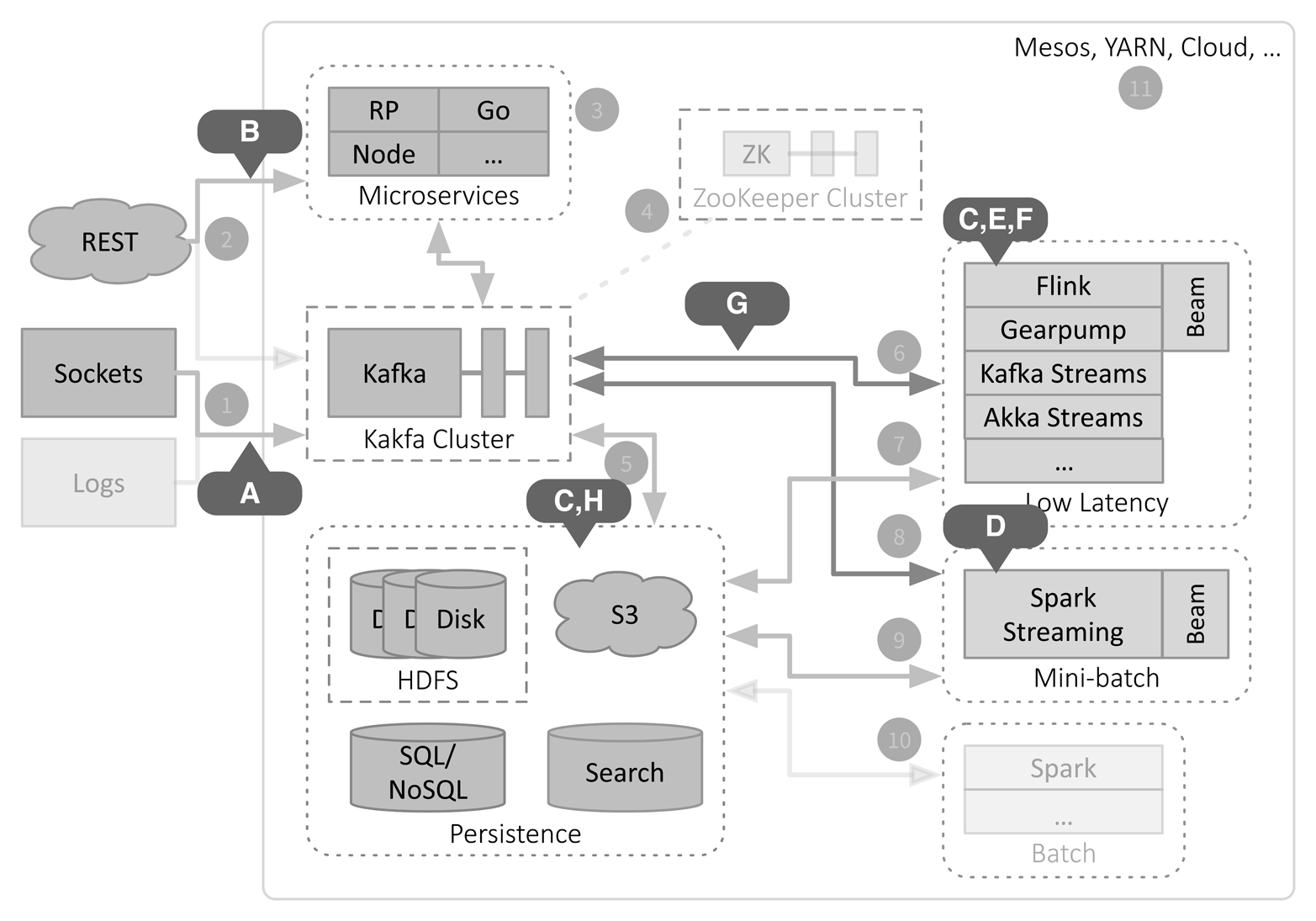
Figure 6-1. IoT example
Let’s look at the details of this figure:
-
Stream telemetry data from devices into Kafka. This includes low-level machine and operating system metrics, such as temperatures of components like hard drive controllers and CPUs, CPU and memory utilization, etc. Application-specific metrics are also included, such as service requests, user interactions, state transitions, and so on. Various logs from remote devices and microservices will also be ingested, but they are grayed out here to highlight what’s unique about this example.
-
Mediate two-way sessions between devices in the field and microservices over REST. These sessions process user requests to adjust room temperatures, control lighting and door locks, program timers and time-of-day transitions (like raising the room temperature in the morning), and invoke services (like processing voice commands). Sessions can also perform administration functions like downloading software patches and even shutting down a device if problems are detected. Using one Akka Actor per device is an ideal way to mirror a device’s state within the microservice and use the network of Akka Actors to mirror the real topology. Because Akka Actors are so lightweight (you can run millions of them concurrently on a single laptop, for example), they scale very well for a large device network.
-
Clean, filter, and transform telemetry data and session data to convenient formats using Kafka Streams, and write it to storage using Kafka Connect. Most data is written to HDFS or S3, where it can be subsequently scanned for analysis, such as for machine learning, aggregations over time windows, dashboards, etc. The data may be written to databases and/or search engines if more focused queries are needed.
-
Train machine learning models “online”, as data arrives, using Spark Streaming (see the next section for more details). Spark Streaming can also be used for very large-scale streaming aggregations where longer latencies are tolerable.
-
Apply the latest machine learning models to “score” the data in real time and trigger appropriate responses using Flink, Gearpump, Akka Streams, or Kafka Streams. Use the same streaming engine to serve operational dashboards via Kafka (see G). Compute other running analytics. If sophisticated Beam-style stream processing is required, choose Flink or Gearpump.
-
Use Akka Streams for complex event processing, such as alarming.
-
Write stream processing results to special topics in Kafka for low-latency, downstream consumption. Examples include the following:
-
Updates to machine learning model parameters
-
Alerts for anomalous behavior, which will be consumed by microservices for triggering corrective actions on the device, notifying administrators or customers, etc.
-
Data feeds for dashboards
-
State changes in the stream for durable retention, in case it’s necessary to restart a processor and recover the last state of the stream
-
Buffering of analytics results for subsequent storage in the persistence tier (see H)
-
-
Store results of stream processing.
Other fast data deployments will have broadly similar characteristics.
Machine Learning Considerations
Machine learning has emerged as a product or service differentiator. Here are some applications of it for our IoT scenario:
- Anomaly detection
-
Look for outliers and other indications of anomalies in the telemetry data. For example, hardware telemetry can be analyzed to predict potential hardware failures so that services can be performed proactively and to detect atypical activity that might indicate hardware tampering, software hacking, or even a burglary in progress.
- Voice interface
-
Respond to voice commands for service.
- Image classification
-
Alert the customer when people or animals are detected in the environment using images from system cameras.
- Recommendations
-
Recommend service features to customers that reflect their usage patterns and interests.
- Automatic tuning of the IoT environment
-
In a very large network of devices and services, usage patterns can change dramatically during the day, and during certain times of year. Usage spikes are common. Hence, being able to automatically tune how services are distributed and allocated to devices, how and when devices interact with services, etc. makes the overall system more robust.
There are nontrivial aspects of deploying machine learning. Like stream processing in general, incremental training of machine learning models has become important. For example, if you are detecting spam, ideally you want your model to reflect the latest kinds of spam, not a snapshot from some earlier time. The term “online” is used for machine learning algorithms where training is incremental, often per-datum. Online algorithms were invented for training with very large data sets, where “all at once” training is impractical. However, they have proven useful for streaming applications, too.
Many algorithms are compute-intensive enough that they take too long for low-latency situations. In this case, Spark Streaming’s mini-batch model is ideal for striking a balance, trading off longer latencies for the ability to use more sophisticated algorithms.
When you’re training a model with Spark Streaming mini-batches, you can apply the model to the mini-batch data at the same time. This is the simplest approach, but sometimes you need to separate training from scoring. For robustness reasons, you might prefer “separation of concerns,” where a Spark Streaming job focuses only on training and other jobs handle scoring. Then, if the Spark Streaming job crashes, you can continue to score data with a separate process. You also might require low-latency scoring, for which Spark Streaming is currently ill suited.
This raises the problem of how models can be shared between these processes, which may be implemented in very different tools. There are a few ways to share models:
-
Implement the underlying model (e.g., logistic regression) in both places, but share parameters. Duplicate implementations won’t be an easy option for sophisticated machine learning models, unless the implementation is in a library that can be shared. If this isn’t an issue, then the parameters can be shared in one of two ways:
-
The trainer streams updates to individual model parameters to a Kafka topic. The scorer consumes the stream and applies the updates.
-
The trainer writes changed parameters to a database, perhaps all at once, from which the scorer periodically reads them.
-
-
Use a third-party machine learning service, either hosted or on-premise,1 to provide both training and scoring in one place that is accessible from different streaming jobs.
Note that moving model parameters between jobs means there will be a small delay where the scoring engine has slightly obsolete parameters. Usually this isn’t a significant concern.
1 E.g., Deeplearning4J.