
Chapter 5. Data Lifetime and Ownership
If we have a look at procedural programming languages like C, there are no native object-oriented mechanisms. This makes life harder to some extent, because most design guidance is tailored for object-oriented software (like the Gang of Four design patterns).
This chapter discusses patterns for how to structure your C program with object-like elements. For these object-like elements, the patterns put special focus on who is responsible for creating and destroying them—in other words, they put special focus on lifetime and ownership. This topic is especially important for C because C has no automatic destructor and no garbage collection mechanism, and thus special attention has to be paid to cleanup of resources.
However, what is an “object-like element” and what is the meaning of it for C? The term object is well defined for object-oriented programming languages, but for non-object-oriented programming languages it is not clear what the term object means. For C, a simple definition for object is the following:
“An object is a named region of storage.”
Kernighan and Ritchie
Usually such an object describes a related set of data that has an identity and properties and that is used to store representations of things found in the real world. In object-oriented programming, an object additionally has the capability of polymorphism and inheritance. The object-like elements described throughout this book do not address polymorphism or inheritance, and therefore we’ll not use the term object anymore. Instead, we’ll consider such an object-like element simply as an instance of a data structure and will furthermore call it instance.
Such instances do not stand by themselves, but instead they usually come with related pieces of code that make it possible to operate on the instances. This code is usually put together into a set of header files for its interface and a set of implementation files for its implementation. Throughout this chapter, the sum of all this related code that, similar to object-oriented classes, often defines the operations that can be performed on an instance, will be called software-module.
When programming C, the described instances of data are usually implemented as abstract data types (for example, by having an instance of a struct with functions accessing the struct members). An example of such an instance is the C stdlib FILE struct that stores information like the file pointer or the position in the file. The corresponding software-module is the stdio.h API and its implementation of functions like fopen and fclose, which provide access to the FILE instances.
Figure 5-1 shows an overview of the patterns discussed in this chapter and their relationships, and Table 5-1 provides a summary of the patterns.

Figure 5-1. Overview of patterns for lifetime and ownership
As a running example, in this chapter you want to implement a device driver for your Ethernet network interface card. The Ethernet network interface card is installed on the operating system your software runs on, so you can use the POSIX socket functions to send and receive network data. You want to build some abstraction for your user because you want to provide an easier way to send and receive data compared to socket functions, and because you want to add some additional features to your Ethernet driver. Thus you want to implement something that encapsulates all the socket details. To achieve this, start with a simple Stateless Software-Module.
Stateless Software-Module
Problem
You want to provide logically related functionality to your caller and make that functionality as easy as possible for the caller to use.
You want to make it simple for the caller to access your functionality. The caller should not have to deal with initialization and cleanup aspects of the provided functions, and the caller should not be confronted with implementation details.
You don’t necessarily need the functions to be very flexible regarding future changes while maintaining backwards compatibility—instead the functions should provide an easy-to-use abstraction for accessing the implemented functionality.
You have many options for organizing the header and implementation files, and going through and evaluating each of these options becomes a lot of effort if you have to do it for each and every functionality that you implement.
Solution
Keep your functions simple and don’t build up state information in your implementation. Put all related functions into one header file and provide the caller this interface to your software-module.
No communication or sharing of internal or external state information takes place between the functions, and state information is not stored between function calls. This means the functions calculate a result or perform an action that does not depend on other function calls in the API (the header file) or previous function calls. The only communication that takes place is between the caller and the called function (for example, in the form of Return Values).
If a function requires any resources, such as heap memory, then the resources have to be handled transparently for the caller. They have to be acquired, implicitly initialized before they are used, and released within the function call. This makes it possible to call the functions completely independent from one another.
Still, the functions are related and because of this they are put together into one API. Being related means that the functions are usually applied together by a caller (interface segregation principle) and that if they change, they change for the same reason (common closure principle). These principles are described in the book Clean Architecture by Robert C. Martin (Prentice Hall, 2018).
Put the declarations of the related functions into one Header File, and put the implementations of the functions into one or more implementation files, but into the same Software-Module Directory. The functions are related because they logically belong together, but they do not share a common state or influence one another’s state, so there is no need to share information between the functions via global variables or to encapsulate this information by passing instances between the functions. That’s why each single function implementation could be put into a separate implementation file.
The following code shows an example for a simple Stateless Software-Module:
Caller’s code
intresult=sum(10,20);
API (header file)
/* Returns the sum of the two parameters */intsum(intsummand1,intsummand2);
Implementation
intsum(intsummand1,intsummand2){/* calculate result only depending on parameters andnot requiring any state information */returnsummand1+summand2;}
The caller calls sum and retrieves a copy of the function result. If you call the function twice with the same input parameters, the function would deliver the exact same result because no state information is maintained in the Stateless Software-Module. As in this special case, no other function that holds state information is called either.
Figure 5-2 shows an overview of the Stateless Software-Module.

Figure 5-2. Stateless Software-Module
Consequences
You have a very simple interface, and the caller does not have to cope with initializing or cleaning up anything for your software-module. The caller can simply call one of the functions independently of previous function calls and other parts of the program, for example, other threads that concurrently access the software-module. Having no state information makes it much easier to understand what a function does.
The caller does not have to cope with questions about ownership because there is nothing to own—the functions have no state. The resources required by the function are allocated and cleaned up within the function call and are thus transparent to the caller.
But not all functionality can be provided with such a simple interface. If the functions within an API share state information or data (for example, one has to allocate resources required by another), then a different approach, like a Software-Module with Global State or a Caller-Owned Instance, has to be taken in order to share this information.
Known Uses
These types of related functions gathered into one API are found each time that the function within the API does not require shared information or state information. The following examples show applications of this pattern:
-
The
sinandcosfunctions from math.h are provided in the same header file and calculate their results solely based on the function input. They do not maintain state information, and each call with the same input produces the same output. -
The string.h functions
strcpyorstrcatdo not depend on each other. They don’t share information, but they belong together and are thus part of a single API. -
The Windows header file VersionHelpers.h provides information about which Microsoft Windows version is currently running. Functions like
IsWindows7OrGreaterorIsWindowsServerprovide related information, but the functions still don’t share information and are independent from one another. -
The Linux header file parser.h comes with functions like
match_intormatch_hex. These functions try to parse an integer or a hexadecimal value from a substring. The functions are independent from one another, but they still belong together in the same API. -
The source code of the NetHack game also has many applications of this pattern. For example, the vision.h header file includes functions to calculate if the player is able to see specific items on the game map. The functions
couldsee(x,y)andcansee(x,y)calculate if the player has a clear line of sight to the item and if the player also faces that item. Both functions are independent from each other and don’t share state information. -
The pattern Header Files present a variant of this pattern with more focus on API flexibility.
-
The pattern called Per-Request Instance from the book Remoting Patterns by Markus Voelter et al. (Wiley, 2007) explains that a server in a distributed object middleware should activate a new servant for each invocation, and that it should, after the servant handles the request, return the result and deactivate the servant. Such a call to a server maintains no state information and is similar to calls in Stateless Software-Modules, but with the difference that Stateless Software-Modules don’t deal with remote entities.
Applied to Running Example
Your first device driver has the following code:
API (header file)
voidsendByte(chardata,char*destination_ip);charreceiveByte();
Implementation
voidsendByte(chardata,char*destination_ip){/* open socket to destination_ip, send data via this socket and closethe socket */}charreceiveByte(){/* open socket for receiving data, wait some time and returnthe received data */}
The user of your Ethernet driver does not have to cope with implementation details like how to access sockets and can simply use the provided API. Both of the functions in this API can be called at any time independently from each other and the caller can obtain data provided by the functions without having to cope with ownership and freeing resources. Using this API is simple but also very limited.
Next, you want to provide additional functionality for your driver. You want to make it possible for the user to see whether the Ethernet communication works, and thus you want to provide statistics showing the number of sent or received bytes. With a simple Stateless Software-Module, you cannot achieve this, because you have no retained memory for storing state information from one function call to another.
To achieve this, you need a Software-Module with Global State.
Software-Module with Global State
Context
You want to provide functions with related functionality to a caller. The functions operate on common data shared between them, and they might require preparation of resources like memory that has to be initialized prior to using your functionality, but the functions do not require any caller-dependent state information.
Problem
You want to structure your logically related code that requires common state information and make that functionality as easy as possible to use for the caller.
You want to make it simple for the caller to access your functionality. The caller should not have to deal with initialization and cleanup aspects of the functions, and the caller should not be confronted with implementation details. The caller should not necessarily realize that the functions access common data.
You don’t necessarily need the functions to be very flexible regarding future changes while maintaining backwards compatibility—instead the functions should provide an easy-to-use abstraction for accessing the implemented functionality.
Solution
Have one global instance to let your related function implementations share common resources. Put all functions that operate on this instance into one header file and provide the caller this interface to your software-module.
Put the function declaration in one Header File, and put all the implementations for your software-module into one implementation file in a Software-Module Directory.
In this implementation file, have a global instance (a file-global static struct or several file-global static variables—see Eternal Memory) that holds the common shared resources that should be available for your function implementations. Your function implementations can then access these shared resources similar to how private variables work in object-oriented programming languages.
The initialization and lifetime of the resources are transparently managed in the software-module and are independent from the lifetime of its callers. If the resources have to be initialized, then you can initialize them at startup time, or you can use lazy acquisition to initialize the resources right before they are needed.
The caller does not realize from the function call syntax that the functions operate on common resources, so you should document this for the caller. Within your software-module, the access to these file-global resources might have to be protected by synchronization primitives such as a Mutex to make it possible to have multiple callers from different threads. Make this synchronization within your function implementation, so that the caller does not have to deal with synchronization aspects.
The following code shows an example of a simple Software-Module with Global State:
Caller’s code
intresult;result=addNext(10);result=addNext(20);
API (header file)
/* Adds the parameter 'value' to the values accumulatedwith previous calls of this function. */intaddNext(intvalue);
Implementation
staticintsum=0;intaddNext(intvalue){/* calculation of the result depending on the parameterand on state information from previous function calls */sum=sum+value;returnsum;}
The caller calls addNext and retrieves a copy of the result. When calling the function twice with same the input parameters, the function might deliver different results because the function maintains state information.
Figure 5-3 shows an overview of the Software-Module with Global State.

Figure 5-3. Software-Module with Global State
Consequences
Now your functions can share information or resources, even though the caller is not required to pass parameters containing this shared information, and the caller is not responsible for allocating and cleaning up resources. To achieve this sharing of information in your software-module, you implemented the C version of a Singleton. Beware of the Singleton—many have commented on the disadvantages of this pattern, and often it is instead called an antipattern.
Still, in C such Software-Modules with Global State are widespread, because it is quite easy to write the keyword static before a variable, and as soon as you do that, you have your Singleton. In some cases that is OK. If your implementation files are short, having file-global variables is quite similar to having private variables in object-oriented programming. If your functions do not require state information or do not operate in multithreaded environments, then you might be just fine. However if multithreading and state information become an issue and your implementation file becomes longer and longer, then you are in trouble and the Software-Module with Global State is not a good solution anymore.
If your Software-Module with Global State requires initialization, then you either have to initialize it during an initialization phase like at system startup, or you have to use lazy acquisition to initialize short before the first use of resources. However, this has the drawback that the duration for your function calls varies, because additional initialization code is implicitly called at the very first call. In any case, the resource acquisition is performed transparently to the caller. The resources are owned by your software-module, and thus the caller is not burdened with ownership of resources and does not have to explicitly acquire or release the resources.
However, not all functionality can be provided with such a simple interface. If the functions within an API share caller-specific state information, then a different approach, like a Caller-Owned Instance, has to be taken.
Known Uses
The following examples show applications of this pattern:
-
The string.h function
strtoksplits a string into tokens. Each time the function is called, the next token for the string is delivered. In order to have the state information about which token to deliver next, the function uses static variables. -
With a Trusted Platform Module (TPM) one can accumulate hash values of loaded software. The corresponding function in the TPM-Emulator v0.7 code uses static variables to store this accumulated hash value.
-
The
mathlibrary uses a state for its random number generation. Each call ofrandcalculates a new pseudorandom number based on the number calculated with the previousrandcall.srandhas to be called first in order to set the seed (the initial static information) for the pseudorandom number generator called withrand. -
An Immutable Instance can be seen as part of a Software-Module with Global State with the special case that the instance is not modified at runtime.
-
The source code of the NetHack game stores information about items (swords, shields) in a static list defined at compile time and provides functions to access this shared information.
-
The pattern called Static Instance from the book Remoting Patterns by Markus Voelter et al. (Wiley, 2007) suggests providing remote objects with lifetime decoupled from the lifetime of the caller. The remote objects can, for example, be initialized at startup time and then be provided to a caller when requested. Software-Module with Global State presents the same idea of having static data, but it is not meant to have multiple instances for different callers.
Applied to Running Example
Now you have the following code for your Ethernet driver:
API (header file)
voidsendByte(chardata,char*destination_ip);charreceiveByte();intgetNumberOfSentBytes();intgetNumberOfReceivedBytes();
Implementation
staticintnumber_of_sent_bytes=0;staticintnumber_of_received_bytes=0;voidsendByte(chardata,char*destination_ip){number_of_sent_bytes++;/* socket stuff */}charreceiveByte(){number_of_received_bytes++;/* socket stuff */}intgetNumberOfSentBytes(){returnnumber_of_sent_bytes;}intgetNumberOfReceivedBytes(){returnnumber_of_received_bytes;}
The API looks very similar to an API of a Stateless Software-Module, but behind this API now lies functionality to retain information between the function calls, which is needed for the counters for sent and received bytes. As long as there is only one user (one thread) who uses this API, everything is just fine. However, if there are multiple threads, then with static variables you always run into the problem that race conditions occur if you don’t implement mutual exclusion for the access to the static variables.
All right—now you want the Ethernet driver to be more efficient, and you want to send more data. You could simply call your sendByte function frequently to do this, but in your Ethernet driver implementation that means that for each sendByte call, you establish a socket connection, send the data, and close the socket connection again. Establishing and closing the socket connection takes most of the communication time.
This is quite inefficient and you’d prefer to open your socket connection once, then send all the data by calling your sendByte function several times, and then close the socket connection. But now your sendByte function requires a preparation and a teardown phase. This state cannot be stored in a Software-Module with Global State because as soon as you have more than one caller (that is, more than one thread), you’d run into the problem or multiple callers wanting to simultaneously send data—maybe even to different destinations.
To achieve that, provide each of these callers with a Caller-Owned Instance.
Caller-Owned Instance
Context
You want to provide functions with related functionality to a caller. The functions operate on common data shared between them, they might require preparation of resources like memory that has to be initialized prior to using your functionality, and they share caller-specific state information among one another.
Problem
You want to provide multiple callers or threads access to functionality with functions that depend on one another, and the interaction of the caller with your functions builds up state information.
Maybe one function has to be called before another because it influences a state stored in your software-module that is then needed by the other function. This can be achieved with a Software-Module with Global State, but it only works as long as there is only one caller. In a multithreaded environment with multiple callers, you cannot have one central software-module holding all caller-dependent state information.
Still, you want to hide implementation details from the caller, and you want to make it as simple as possible for the caller to access your functionality. It has to be clearly defined if the caller is responsible for allocating and cleaning up resources.
Solution
Require the caller to pass an instance, which is used to store resource and state information, along to your functions. Provide explicit functions to create and destroy these instances, so that the caller can determine their lifetime.
To implement such an instance that can be accessed from multiple functions, pass a struct pointer along with all functions that require sharing resources or state information. The functions can now use the struct members, which are similar to private variables in object-oriented languages, to store and read resource and state
information.
The struct can be declared in the API to let the caller conveniently access its members directly. Alternatively, the struct can be declared in the implementation, and only a pointer to the struct can be declared in the API (as suggested by Handle). The caller does not know the struct members (they are like private variables) and can only operate with functions on the struct.
Because the instance has to be manipulated by multiple functions and you do not know when the caller finished calling functions, the lifetime of the instance has to be determined by the caller. Therefore, Dedicate Ownership to the caller and provide explicit functions for creating and destroying the instance. The caller has an aggregate relationship to the instance.
Aggregation Versus Association
If an instance is semantically related to another instance, then those instances are associated. A stronger type of association is an aggregation, in which one instance has ownership of the other.
The following code shows an example of a simple Caller-Owned Instance:
Caller’s code
structINSTANCE*inst;inst=createInstance();operateOnInstance(inst);/* access inst->x or inst->y */destroyInstance(inst);
API (header file)
structINSTANCE{intx;inty;};/* Creates an instance which is required for workingwith the function 'operateOnInstance' */structINSTANCE*createInstance();/* Operates on the data stored in the instance */voidoperateOnInstance(structINSTANCE*inst);/* Cleans up an instance created with 'createInstance' */voiddestroyInstance(structINSTANCE*inst);
Implementation
structINSTANCE*createInstance(){structINSTANCE*inst;inst=malloc(sizeof(structINSTANCE));returninst;}voidoperateOnInstance(structINSTANCE*inst){/* work with inst->x and inst->y */}voiddestroyInstance(structINSTANCE*inst){free(inst);}
The function operateOnInstance works on resources created with the previous function call createInstance. The resource or state information between the two function calls is transported by the caller, who has to provide the INSTANCE for each function call and who also has to clean up all the resources by calling destroyInstance.
Figure 5-4 shows an overview of the Caller-Owned Instance.

Figure 5-4. Caller-Owned Instance
Consequences
The functions in your API are more powerful now because they can share state information and operate on shared data while still being available for multiple callers (that is, multiple threads). Each created Caller-Owned Instance has its own private variables, and even if more than one such Caller-Owned Instance is created (for example, by multiple callers in a multithreaded environment), it is not a problem.
However, to achieve this, your API becomes more complicated. You have to make explicit create() and destroy() calls for managing the instance’s lifetime, because C does not support constructors and destructors. This makes handling with instances much more difficult because the caller obtains ownership and is responsible for cleaning up the instance. As this has to be done manually with the destroy() call, and not via an automatic destructor like in object-oriented programing languages, this is a common pitfall for memory leaks. This issue is addressed by Object-Based Error Handling, which suggests that the caller should also have a dedicated cleanup function to make this task more explicit.
Also, compared to a Stateless Software-Module, calling each of the functions becomes a bit more complicated. Each function takes an additional parameter referencing the instance, and the functions cannot be called in arbitrary order—the caller has to know which one has to be called first. This is made explicit through the function signatures.
Known Uses
The following examples show applications of this pattern:
-
An example of the use of a Caller-Owned Instance is the doubly linked list provided with the
glibclibrary. The caller creates a list withg_list_allocand can then insert items into this list withg_list_insert. When finished working with the list, the caller is responsible for cleaning it up withg_list_free. -
This pattern is described by Robert Strandh in the article “Modular C”. It describes how to write modular C programs. The article states the importance of identifying abstract data types—which can be manipulated or accessed with functions—in the application.
-
The Windows API to create menus in the menu bar has a function to create a menu instance (
CreateMenu), functions to operate on menus (likeInsertMenuItem), and a function to destroy the menu instance (DestroyMenu). All these functions have one parameter to pass the Handle to the menu instance. -
Apache’s software-module to handle HTTP requests provides functions to create all required request information (
ap_sub_req_lookup_uri), to process it (ap_run_sub_req), and to destroy it (ap_destroy_sub_req). These functions take astructpointer to the request instance in order to share request information. -
The source code of the NetHack game uses a
structinstance to represent monsters and provides functions to create and destroy a monster. The NetHack code also provides functions to obtian information from monsters (is_starting_pet,is_vampshifter). -
The pattern called Client-Dependent Instance, from the book Remoting Patterns by Markus Voelter et al. (Wiley, 2007), suggests for distributed object middlewares, providing remote objects whose lifetime is controlled by the clients. The server creates new instances for clients and the client can then work with these instances, pass them along, or destroy them.
Applied to Running Example
Now you have the following code for your Ethernet driver:
API (header file)
structSender{chardestination_ip[16];intsocket;};structSender*createSender(char*destination_ip);voidsendByte(structSender*s,chardata);voiddestroySender(structSender*s);
Implementation
structSender*createSender(char*destination_ip){structSender*s=malloc(sizeof(structSender));/* create socket to destination_ip and store it in Sender s*/returns;}voidsendByte(structSender*s,chardata){number_of_sent_bytes++;/* send data via socket stored in Sender s */}voiddestroySender(structSender*s){/* close socket stored in Sender s */free(s);}
A caller can first create a sender, then send all the data, and then destroy the sender. Thus, the caller can make sure that the socket connection does not have to be established again for each sendByte() call. The caller has ownership of the created sender, has full control over how long the sender lives, and is responsible for cleaning it up:
Caller’s code
structSender*s=createSender("192.168.0.1");char*dataToSend="Hello World!";char*pointer=dataToSend;while(*pointer!='�'){sendByte(s,*pointer);pointer++;}destroySender(s);
Next, let’s assume that you are not the only user of this API. There might be multiple threads using your API. As long as one thread creates a sender for sending to IP address X and another thread creates a sender for sending to Y, we are just fine, and the Ethernet driver creates independent sockets for both threads.
However, let’s say the two threads want to send data to the same recipient. Now the Ethernet driver is in trouble because on one specific port, it can only open one socket per destination IP. A solution to this problem would be to not allow two different threads to send to the same destination—the second thread creating the sender could simply receive an error. But it is also possible to allow both threads to send data using the same sender.
To achieve this, simply construct a Shared Instance.
Shared Instance
Context
You want to provide functions with related functionality to a caller. The functions operate on shared common data, and they might require preparation of resources like memory that has to be initialized prior to using your functionality. There are multiple contexts in which the functionality can be called, and these contexts are shared between the callers.
Problem
You want to provide multiple callers or threads access to functionality with functions that depend on one another, and the interaction of the caller with your functions builds up state information, which your callers want to share.
Storing the state information in a Software-Module with Global State is not an option because there are multiple callers who want to build up different state information. Storing the state information per caller in a Caller-Owned Instance is not an option because either some of your callers want to access and operate on the same instance, or because you don’t want to create new instances for every caller in order to keep resource costs low.
Still, you want to hide implementation details from the caller, and you want to make it as simple as possible for the caller to access your functionality. It has to be clearly defined if the caller is responsible for allocating and cleaning up resources.
Solution
Require the caller to pass an instance, which is used to store resource and state information, along to your functions. Use the same instance for multiple callers and keep the ownership of that instance in your software-module.
Just like with the Caller-Owned Instance, provide a struct pointer or a Handle that the caller then passes along the function calls. When creating the instance, the caller now also has to provide an identifier (for example, a unique name) to specify the kind of instance to create. With this identifier you can know if such an instance already exists. If it exists, you don’t create a new instance, but instead return the struct pointer or Handle to the instance that you already created and returned to other
callers.
To know if an instance already exists, you have to hold a list of already created instances in your software-module. This can be done by implementing a Software-Module with Global State to hold the list. In addition to whether an instance was already created or not, you can store the information of who currently accesses which instances or at least how many callers currently access an instance. This additional information is required because when everybody is finished accessing an instance, it is your duty to clean it up because you are the one who has Dedicated Ownership of it.
You also have to check whether your functions can be called simultaneously by different callers on the same instance. In some easier cases, there might be no data whose access has to be mutually excluded by different callers because it is only read. In such cases an Immutable Instance, which does not allow the caller to change the instance, could be implemented. But in other cases, you have to implement mutual exclusion in your functions for resources shared through the instance.
The following code shows an example of a simple Shared Instance:
Caller1’s code
structINSTANCE*inst=openInstance(INSTANCE_TYPE_B);/* operate on the same instance as caller2 */operateOnInstance(inst);closeInstance(inst);
Caller2’s code
structINSTANCE*inst=openInstance(INSTANCE_TYPE_B);/* operate on the same instance as caller1 */operateOnInstance(inst);closeInstance(inst);
API (header file)
structINSTANCE{intx;inty;};/* to be used as IDs for the function openInstance */#define INSTANCE_TYPE_A 1#define INSTANCE_TYPE_B 2#define INSTANCE_TYPE_C 3/* Retrieve an instance identified by the parameter 'id'. That instance iscreated if no instance of that 'id' was yet retrieved from anyother caller. */structINSTANCE*openInstance(intid);/* Operates on the data stored in the instance. */voidoperateOnInstance(structINSTANCE*inst);/* Releases an instance which was retrieved with 'openInstance'.If all callers release an instance, it gets destroyed. */voidcloseInstance(structINSTANCE*inst);
Implementation
#define MAX_INSTANCES 4structINSTANCELIST{structINSTANCE*inst;intcount;};staticstructINSTANCELISTlist[MAX_INSTANCES];structINSTANCE*openInstance(intid){if(list[id].count==0){list[id].inst=malloc(sizeof(structINSTANCE));}list[id].count++;returnlist[id].inst;}voidoperateOnInstance(structINSTANCE*inst){/* work with inst->x and inst->y */}staticintgetInstanceId(structINSTANCE*inst){inti;for(i=0;i<MAX_INSTANCES;i++){if(inst==list[i].inst){break;}}returni;}voidcloseInstance(structINSTANCE*inst){intid=getInstanceId(inst);list[id].count--;if(list[id].count==0){free(inst);}}
The caller retrieves an INSTANCE by calling openInstance. The INSTANCE might be created by this function call, or it might have already been created by a previous function call and might also be used by another caller.
The caller can then pass the INSTANCE along to the operateOnInstance function calls, to provide this function with the required resource or state information from the INSTANCE. When finished, the caller has to call closeInstance so that the resources can be cleaned up, if no other caller operates on the INSTANCE anymore.
Figure 5-5 shows an overview of the Shared Instance.
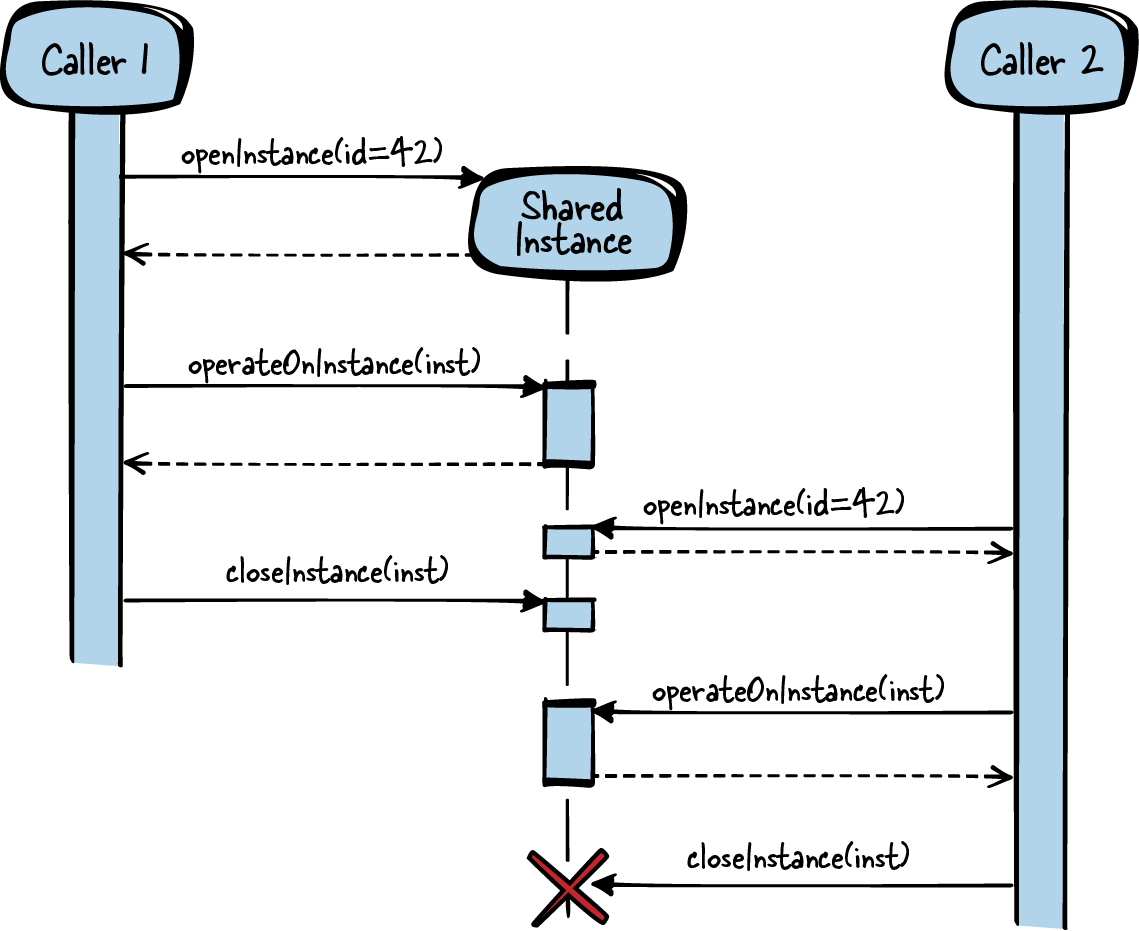
Figure 5-5. Shared Instance
Consequences
Multiple callers now have simultaneous access to a single instance. This quite often implies that you have to cope with mutual exclusion within your implementation in order not to burden the user with such issues. This implies that the duration for a function call varies because the caller never knows if another caller currently uses the same resources and blocks them.
Your software-module, not the caller, has ownership of the instance, and your software-module is responsible for cleaning up resources. The caller is still responsible for releasing the resources so that your software-module knows when to clean everything up—as with the Caller-Owned Instance, this is a pitfall for memory leaks.
Because the software-module has ownership of the instances, it can also clean up the instances without requiring the callers to initiate cleanup. For example, if the software-module receives a shutdown signal from the operating system, it can clean up all instances because it has ownership of them.
Known Uses
The following examples show applications of this pattern:
-
An example of the use of a Shared Instance is the stdio.h file-functions. A file can be opened by multiple callers via the function
fopen. The caller retrieves a Handle to the file and can read from or write to the file (fread,fprintf). The file is a shared resource. For example, there is one global cursor position in the file for all callers. When a caller finishes operating on the file, it has to be closed withfclose. -
This pattern and its implementation details for object-oriented programming languages are presented as Counting Handle in the article “C++ Patterns: Reference Accounting” by Kevlin Henney. It describes how a shared object on the heap can be accessed and how its lifetime can be handled transparently.
-
The Windows registry can be accessed simultaneously by multiple threads with the function
RegCreateKey(which opens the key, if it already exists). The function delivers a Handle that can be used by other functions to operate on the registry key. When the registry operations are finished, theRegCloseKeyfunction has to be called by everybody who opened the key. -
The Windows functionality to access Mutex (
CreateMutex) can be used to access a shared resource (the Mutex) from multiple threads. With the Mutex, interprocess synchronization can be implemented. When finished working with the Mutex, each caller has to close it by using the functionCloseHandle. -
The B&R Automation Runtime operating system allows multiple callers to access device drivers simultaneously. A caller uses the function
DmDeviceOpento select one of the available devices. The device driver framework checks if the selected driver is available and then provides a Handle to the caller. If multiple callers operate on the same driver, they share the Handle. The callers can then simultaneously interact with the driver (send or read data, interact via IO-controls, etc.), and after this interaction they tell the device driver framework that they are finished by callingDmDeviceClose.
Applied to Running Example
The driver now additionally implements the following functions:
API (header file)
structSender*openSender(char*destination_ip);voidsendByte(structSender*s,chardata);voidcloseSender(structSender*s);
Implementation
structSender*openSender(char*destination_ip){structSender*s;if(isInSenderList(destination_ip)){s=getSenderFromList(destination_ip);}else{s=createSender(destination_ip);}increaseNumberOfCallers(s);returns;}voidsendByte(structSender*s,chardata){number_of_sent_bytes++;/* send data via socket stored in Sender s */}voidcloseSender(structSender*s){decreaseNumberOfCallers(s);if(numberOfCallers(s)==0){/* close socket stored in Sender s */free(s);}}
The API of the running example did not change a lot—instead of having create/destroy functions, your driver now provides open/close functions. By calling such a function, the caller retrieves the Handle for the sender and indicates to the driver that this caller is now operating a sender, but the driver does not necessarily create this sender at that point in time. That might have already been done by an earlier call to the driver (maybe performed by a different thread). Also, a close call might not actually destroy the sender. The ownership of this sender remains in the driver implementation, which can decide when to destroy the senders (for example, when all callers close the sender, or if some termination signal is received).
The fact that you now have a Shared Instance instead of a Caller-Owned Instance is mostly transparent to the caller. But the driver implementation changed—it has to remember if a specific sender was already created and provide this shared instance instead of creating a new one. When opening a sender, the caller does not know whether this sender will be newly created or whether an existing sender is retrieved. Depending on this, the duration of the function call might vary.
The presented running driver example showed different kinds of ownership and data lifetime in a single example. We saw how a simple Ethernet driver evolved by adding functionality. First, a Stateless Software-Module was sufficient because the driver did not require any state information. Next, such state information was required, and it was realized by having a Software-Module with Global State in the driver. Then, the need for more performant send functions and for multiple callers for these send functions came up and was first implemented by the Caller-Owned Instance and in a next step by the Shared Instance.
Summary
The patterns in this chapter showed different ways of structuring your C programs and how long different instances in your program live. Table 5-2 gives an overview of the patterns and compares their consequences.
| Stateless Software-Module | Software-Module with Global State | Caller-Owned Instance | Shared Instance | |
|---|---|---|---|---|
Resource sharing between functions | Not possible | Single set of resources | Set of resources per instance ( = per caller) | Set of resources per instance (shared by multiple callers) |
Resource ownership | Nothing to own | The software-module owns the static data | The caller owns the instance | The software-module owns instances and provides references |
Resource lifetime | No resources live longer than a function call | Static data lives forever in the software-module | Instances live until callers destroy them | Instances live until the software-module destroys them |
Resource initialization | Nothing to initialize | At compile time or at startup | By the caller when creating an instance | By the software-module when the first caller opens an instance |
With these patterns, a C programmer has some basic guidance about the design options for organizing programs into software-modules and the design options regarding ownership and lifetime when constructing instances.
Further Reading
The patterns in this chapter cover how to provide access to instances and who has ownership of these instances. A very similar topic is covered by a subset of the patterns from the book Remoting Patterns by Markus Voelter et al. (Wiley, 2007). The book presents patterns for building distributed object middleware, and three of these patterns focus on lifetime and ownership of objects created by remote servers. Compared to that, the patterns presented in this chapter focus on a different context. They are not patterns for remote systems, but for local procedural programs. They focus on C programming, but can also be used for other procedural programming languages. Still, some of the underlying ideas in the patterns are very similar to those in Remoting Patterns.
Outlook
The next chapter presents different kinds of interfaces for software-modules with a special focus on how to make the interface flexible. The patterns elaboarate on the trade-off between simplicity and flexibility.