
Chapter 7. Flexible Iterator Interfaces
Iterating over a set of elements is a common operation in any program. Some programming languages provide native constructs to iterate over elements, and object-oriented programming languages have guidance in the form of design patterns on how to implement generic iteration functionality. However, there is very little guidance of this kind for procedural programming languages like C.
The verb “iterate” means to do the same thing multiple times. In programming, it usually means to run the same program code on multiple data elements. Such an operation is often required, which is why it is natively supported in C for arrays, as shown in the following code:
for(i=0;i<MAX_ARRAY_SIZE;i++){doSomethingWith(my_array[i]);}
If you want to iterate over a different data structure, like a red-black tree, for example, then you have to implement your own iteration function. You might equip this function with data structure–specific iteration options, like whether to traverse the tree depth-first or breadth-first. There is literature available on how to implement such specific data structures and how the iteration interfaces for these data structures look. If you use such a data structure-specific interface for iteration and your underlying data structure changes, you’d have to adapt your iteration function and all your code that calls this function. In some cases this is just fine, and even required, because you want to perform some special kind of iteration specific to the underlying data structure—perhaps to optimize the performance of your code.
In other cases, if you have to provide an iteration interface across component boundaries, having such an abstraction that leaks implementation details isn’t an option because it might require interface changes in the future. For example, if you sell your customers a component providing iteration functions, and your customers write code using these functions, then they likely expect their code to work without any modification if you provide them with a newer version of your component that maybe uses a different data structure. In that case, you’d even put some extra effort into your implementation to make sure that the interface to the customers stays compatible so that they do not have to change (or maybe not even recompile) their code.
That is where we start in this chapter. I’ll show you three patterns on how you, the iterator implementer, can provide stable iterator interfaces to the user (the customer). The patterns do not describe the specific kinds of iterators for specific kinds of data structures. Instead, the patterns assume that within your implementation you already have functions to retrieve the elements from your underlying data structure. The patterns show the options you have to abstract these functions in order to provide a stable iteration interface.
Figure 7-1 shows an overview of the patterns covered in this chapter and their relationships, and Table 7-1 provides a summary of the patterns.

Figure 7-1. Overview of patterns for iterator interfaces
Running Example
You implemented an access control component for your application with an underlying data structure in which you have a function to randomly access any of the elements. More specifically, in the following code you have a struct array that holds account information like login names and passwords:
structACCOUNT{charloginname[MAX_NAME_LENGTH];charpassword[MAX_PWD_LENGTH];};structACCOUNTaccountData[MAX_USERS];
The next code shows how users can access this struct to read specific information like the login names:
voidaccessData(){char*loginname;loginname=accountData[0].loginname;/* do something with loginname */loginname=accountData[1].loginname;/* do something with loginname */}
Of course, you could simply not worry about abstracting access to your data structure and let other programmers directly retrieve a pointer to this struct to loop over the struct elements and access any information in the struct. But that would be a bad idea because there might be information in your data structure that you do not want to provide to the client. If you have to keep your interface to the client stable over time, you won’t be able to remove information you once revealed to the client, because your client might use that information and you don’t want to break the
client’s code.
To avoid this problem, a much better idea is to let the user only access the required information. A simple solution is to provide Index Access.
Index Access
Problem
You want to make it possible for the user to iterate elements in your data structure in a convenient way, and it should be possible to change internals of the data structure without resulting in changes to the user’s code.
The user might be somebody who writes code that is not versioned and released with your codebase, so you have to make sure that future versions of your implementation also work with the user code written against the current version of your code. Thus, the user should not be able to access any internal implementation details, such as the underlying data structure you use to hold your elements, because you might want to change that at a later point.
Solution
Provide a function that takes an index to address the element in your underlying data structure and return the content of this element. The user calls this function in a loop to iterate over all elements as shown in Figure 7-2.

Figure 7-2. Index-accessed iteration
The equivalent to this approach would be that in an array, the user would simply use an index to retrieve the value of one array element or to iterate over all elements. But when you have a function that takes such an index, more complex underlying data structures are also possible to iterate without requiring the user’s knowledge.
In order to achieve this, provide the users only the data they are interested in and do not reveal all elements of your underlying data structure. For example, do not return a pointer to the whole struct element, return a pointer only to the struct member the user is interested in:
Caller’s code
void*element;element=getElement(1);/* operate on element 1 */element=getElement(2);/* operate on element 2 */
Iterator API
#define MAX_ELEMENTS 42/* Retrieve one single element identified by the provided 'index' */void*getElement(intindex);
Consequences
Users can retrieve the elements by using the index to conveniently loop over the elements in their code. They do not have to deal with the internal data structure from which this data was gathered. If something in the implementation changes (for example, the retrieved struct member is renamed), users need not recompile their code.
Other changes to the underlying data structure might turn out to be more difficult. If, for example, the underlying data structure changes from an array (randomly accessible) to a linked list (sequentially accessible), then you’d have to iterate the list each time until you get to the requested index. That would not be efficient at all, and to make sure to also allow such changes in the underlying data structure, it would be better to use a Cursor Iterator or Callback Iterator instead.
If the user retrieves only basic data types that can be returned as Return Value of a C function, then the user implicitly retrieves a copy of this element. If the corresponding element in the underlying data structure changes in the meantime, then this would not affect the user. But if the user retrieves a more complex data type (like a string), then compared to simply providing direct access to the underlying data structure, you have with Index Access the advantage that you can copy the current data element in a thread-safe way and provide it to the user, for example with a Caller-Owned Buffer. If you are not operating in a multithreaded environment, you could simply return a pointer for complex data types.
When accessing a set of elements, the user often wants to iterate over all elements. If somebody else adds or removes an element in the underlying data in the meantime, then the user’s understanding of the index to access the elements might become invalid, and they might unintentionally retrieve an element twice during the iteration. A straightforward solution to this would be to simply copy all elements the user is interested in into an array and provide this exclusive array to the user, who can then conveniently loop over this array. The user would have Dedicated Ownership of that copy and could even modify the elements. But if that is not explicitly required, copying all the elements might not be worth it. A much more convenient solution, where the user does not have to worry about changes to the underlying data order during iteration, is to provide a Callback Iterator instead.
Known Uses
The following examples show applications of this pattern:
-
James Noble describes the External Iterator pattern in his article “Iterators and Encapsulation”. This is an object-oriented version of the concept described in this pattern.
-
The book Data Structures and Problem Solving Using Java by Mark Allen Weiss (Addison-Wesley, 2006) describes this approach and calls it access with an array-like interface.
-
The function
service_response_time_get_column_nameof the Wireshark code returns the name of columns for a statistics table. The name to be returned is addressed with an index parameter provided by the user. The column names cannot change at runtime, and therefore even in multithreaded environments this way of accessing the data or iterating over column names is safe. -
The Subversion project contains code that is used to build up a table of strings. These strings can be accessed with the function
svn_fs_x__string_table_get. This function takes an index as parameter that is used to address the string to be retrieved. The retrieved string is copied into a provided buffer. -
The OpenSSL function
TXT_DB_get_by_indexretrieves a string selected with an index from a text database and stores it in a provided buffer.
Applied to Running Example
Now you have a clean abstraction for reading the login names, and you don’t reveal internal implementation details to the user:
char*getLoginName(intindex){returnaccountData[index].loginname;}
Users do not have to deal with accessing the underlying struct array. This has the advantage that access to the required data is easier for them and that they cannot use any information that is not intended for them. For example, they cannot access sub-elements of your struct that you might want to change in the future and that can only be changed if nobody accesses this data because you do not want to break the users’ code.
Someone using this interface, such as someone who wants to write a function that checks if there is any login name starting with the letter “X,” writes the following code:
boolanyoneWithX(){inti;for(i=0;i<MAX_USERS;i++){char*loginName=getLoginName(i);if(loginName[0]=='X'){returntrue;}}returnfalse;}
You are happy with your implementation until the data structure that you use to store the login names changes, because you need a more convenient way to insert and delete account data, which is quite difficult when storing the data in a plain array. Now the login names are no longer stored in a single plain array but in an underlying data structure that offers you an operation to get from one element to the next without offering an operation to randomly access elements. More specifically, you have a linked list that can be accessed, as shown in the following code:
structACCOUNT_NODE{charloginname[MAX_NAME_LENGTH];charpassword[MAX_PWD_LENGTH];structACCOUNT_NODE*next;};structACCOUNT_NODE*accountList;structACCOUNT_NODE*getFirst(){returnaccountList;}structACCOUNT_NODE*getNext(structACCOUNT_NODE*current){returncurrent->next;}voidaccessData(){structACCOUNT_NODE*account=getFirst();char*loginname=account->loginname;account=getNext(account);loginname=account->loginname;...}
That makes the situation difficult with your current interface, which provides one randomly index-accessed login name at a time. To further support this, you’d have to emulate the index by calling the getNext function and counting until you reach the indexed element. That is quite inefficient. All that hassle is only necessary because you designed the interface in a way that turned out to be not flexible enough.
To make things easier, provide a Cursor Iterator to access the login names.
Cursor Iterator
Problem
You want to provide an iteration interface to your user that is robust in case the elements change during the iteration and that enables you to change the underlying data structure at a later point without requiring any changes to the user’s code.
The user might be somebody who writes code that is not versioned and released with your codebase, so you have to make sure that future versions of your implementation also work with the user code written against the current version of your code. Thus, the user should not be able to access any internal implementation details, such as the underlying data structure you use to hold your elements, because you might want to change that at a later point.
Aside from that, when operating in multithreaded environments, you want to provide the user a robust and clearly defined behavior if the element’s content changes while the user iterates over it. Even for complex data like strings, the user should not have to worry about other threads changing that data while the user wants to read it.
You don’t care if you have to make an extra implementation effort to achieve all this, because many users will use your code, and if you can take implementation effort away from the user by implementing it in your code, then the overall effort will be decreased.
Solution
Create an iterator instance that points to an element in the underlying data structure. An iteration function takes this iterator instance as argument, retrieves the element the iterator currently points to, and modifies the iteration instance to point to the next element. The user then iteratively calls this function to retrieve one element at a time as shown in Figure 7-3.
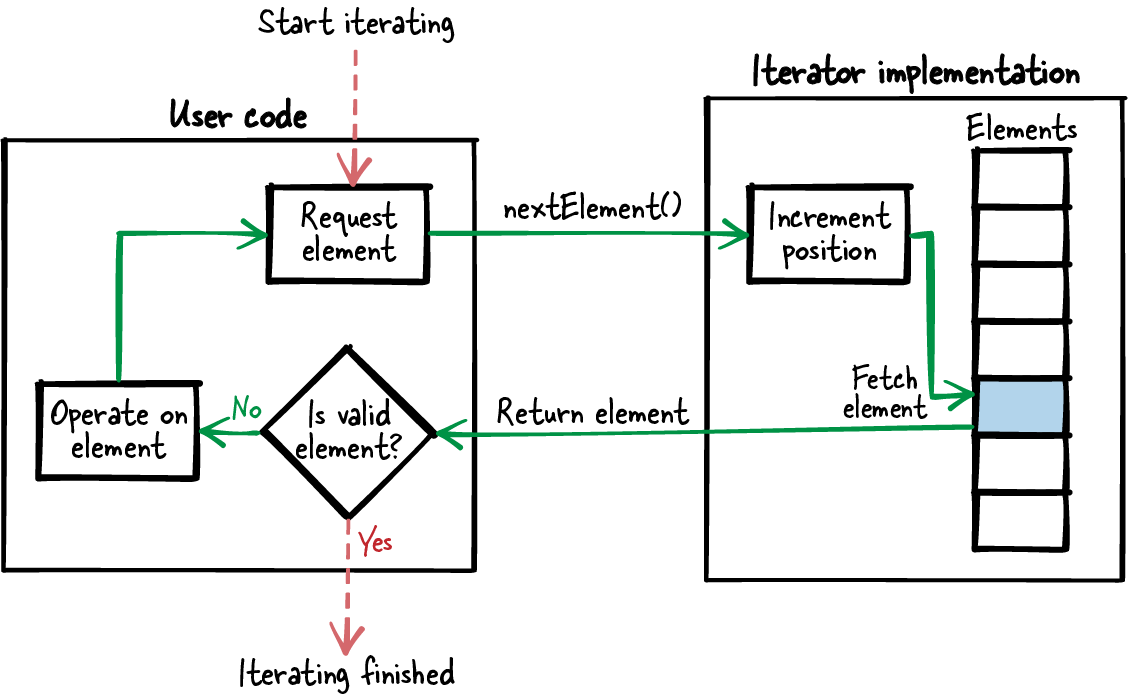
Figure 7-3. Iteration with a Cursor Iterator
The iterator interface requires two functions to create and destroy the iterator instance and one function to perform the actual iteration and to retrieve the current element. Having explicit create/destroy functions makes it possible to have an instance in which you store your internal iteration data (position, data of the current element). The user then has to pass this instance to all your iteration function calls as shown in the following code:
Caller’s code
void*element;ITERATOR*it=createIterator();while(element=getNext(it)){/* operate on element */}destroyIterator(it);
Iterator API
/* Creates an iterator and moves it to the first element */ITERATOR*createIterator();/* Returns the element currently pointed to and sets the iterator to thenext element. Returns NULL if the element does not exist. */void*getNext(ITERATOR*iterator);/* Cleans up an iterator created with the function createIterator() */voiddestroyIterator(ITERATOR*iterator),
If you do not want the user to be able to access this internal data, then you can hide it and provide the user with a Handle instead. That makes it possible that even changes to this internal data of the iteration instance do not affect the user.
When retrieving the current element, basic data types can be provided direcetly as the Return Value. Complex data types can either be returned as a reference or copied into the iterator instance. Copying them into the iterator instance gives you the advantage that the data is consistent, even if the data in the underlying data structure changes in the meantime (for example, because it is being modified by someone else in a multithreaded environment).
Consequences
The user can iterate the data simply by calling the getNext method as long as valid elements are retrieved. They do not have to deal with the internal data structure from which this data was gathered, nor do they have to worry about an element index or about the maximum number of elements. But not being able to index the elements also means that the user cannot randomly access the elements (which could be done with Index Access).
Even if the underlying data structure changes, for example, from a linked list to a randomly accessible data structure like an array, then that change can be hidden in the iterator implementation and the user need not change or recompile code.
No matter which kind of data the user retrieves—simple or complex data types—they need not be afraid that the retrieved element will become invalid if the underlying element is changed or removed in the meantime. To make this possible, the user now has to explicitly call functions to create and destroy the iterator instance. Compared to Index Access, more function calls are necessary.
When accessing a set of elements, the user often wants to iterate over all elements. If somebody else adds an element to the underlying data in the meantime, then the user might miss this element during the iteration. If this is a problem for you and you want to make sure that the elements do not change at all during the iteration, then it is easier to use a Callback Iterator.
Known Uses
The following examples show applications of this pattern:
-
James Noble describes an object-oriented version of this iterator as the Magic Cookie pattern in his article “Iterators and Encapsulation.”
-
The article “Interruptible Iterators” by Jed Liu et al. describes the presented concept as cursor object.
-
This kind of iteration is used for file access. For example, the
getlineC function iterates over the lines in a file, and the iterator position is stored in theFILEpointer. -
The OpenSSL code provides the functions
ENGINE_get_firstandENGINE_get_nextto iterate a list of encryption engines. Each of these calls takes the pointer to anENGINE structas a parameter. Thisstructstores the current position in the iteration. -
The Wireshark code contains the functions
proto_get_first_protocolandproto_get_next_protocol. These functions make it possible for a user to iterate over a list of network protocols. The functions take avoidpointer as out-parameter to store and pass along state information. -
The code of the Subversion project for generating diffs between files contains the function
datasource_get_next_token. This function is to be called in a loop in order to get the next diff token from a provided datasource object that stores the iteration position.
Applied to Running Example
You now have the following function to retrieve the login names:
structITERATOR{charbuffer[MAX_NAME_LENGTH];structACCOUNT_NODE*element;};structITERATOR*createIterator(){structITERATOR*iterator=malloc(sizeof(structITERATOR));iterator->element=getFirst();returniterator;}char*getNextLoginName(structITERATOR*iterator){if(iterator->element!=NULL){strcpy(iterator->buffer,iterator->element->loginname);iterator->element=getNext(iterator->element);returniterator->buffer;}else{returnNULL;}}voiddestroyIterator(structITERATOR*iterator){free(iterator);}
The following code shows how this interface is used:
boolanyoneWithX(){char*loginName;structITERATOR*iterator=createIterator();while(loginName=getNextLoginName(iterator)){if(loginName[0]=='X'){destroyIterator(iterator);returntrue;}}destroyIterator(iterator);returnfalse;}

The application does not have to deal with the index and the maximum number of elements anymore

In this case, the required cleanup code for destroying the iterator leads to code duplication.
Next, you don’t just want to implement the anyoneWithX function, but you also want to implement an additional function that, for example, tells you how many login names start with the letter “Y.” You could simply copy the code, modify the body of the while loop, and count the occurrences of “Y” but with this approach you’ll end up with duplicated code because both of your functions will contain the same code for creating and destroying the iterator and for performing the loop operation. To avoid this code duplication, you can use a Callback Iterator instead.
Callback Iterator
Problem
You want to provide a robust iteration interface that does not require the user to implement a loop in the code for iterating over all elements and that enables you to change the underlying data structure at a later point without requiring any changes to the user’s code.
The user might be somebody who writes code that is not versioned and released with your codebase, so you have to make sure that future versions of your implementation also work with the user code written against the current version of your code. Thus, the user should not be able to access any internal implementation details, such as the underlying data structure you use to hold your elements, because you might want to change that at a later point.
Aside from that, when operating in multithreaded environments, you want to provide the user a robust and clearly defined behavior if the element’s content changes while the user iterates over it. Even for complex data like strings, the user should not have to worry about other threads changing that data while the user wants to read it. Also, you want to make sure that the user iterates over each element exactly once. That should hold even if other threads try to create new elements or delete existing elements during the iteration.
You don’t care if you have to make an extra implementation effort to achieve all this, because many users will use your code, and if you can take implementation effort away from the user by implementing it in your code, then the overall effort will be decreased.
You want to make access to your elements as easy as possible. In particular, the user shouldn’t have to cope with iteration details like mappings between index and element or the number of available elements. Also, they shouldn’t have to implement loops in their code because that would lead to duplications in the user code, so Index Access or a Cursor Iterator isn’t an option for you.
Solution
Use your existing data structure-specific operations to iterate over all your elements within your implementation, and call some provided user-function on each element during this iteration. This user-function gets the element content as a parameter and can then perform its operations on this element. The user calls just one function to trigger the iteration, and the whole iteration takes place inside your implementation as shown in Figure 7-4.

Figure 7-4. Iteration with a Callback Iterator
To realize this, you have to declare a function pointer in your interface. The declared function takes an element that should be iterated over as parameter. The user implements such a function and passes it to your iteration function. Within your implementation you iterate over all elements, and you’ll call the user’s function for each element with the current element as parameter.
You can add an additional void* parameter to your iteration function and to the function pointer declaration. In the implementation of your iteration function, you simply pass that parameter to the user’s function. That makes it possible for the user to pass some context information to the function:
Caller’s code
voidmyCallback(void*element,void*arg){/* operate on element */}voiddoIteration(){iterate(myCallback,NULL);}
Iterator API
/* Callback for the iteration to be implemented by the caller. */typedefvoid(*FP_CALLBACK)(void*element,void*arg);/* Iterates over all elements and calls callback(element, arg)on each element. */voiditerate(FP_CALLBACKcallback,void*arg);
Sometimes the user does not want to iterate over all elements but wants to find one specific element. To make that use case more efficient, you can add a break condition to your iteration function. For example, you can declare the function pointer for the user function that operates on the elements of return type bool, and if the user function returns the Return Value true, you stop the iteration. Then the user can signal as soon as the desired element is found and save the time it would take for iterating all the rest of the elements.
When implementing the iteration function for multithreaded environments, make sure to cover the situation when during the iteration, the current element is changed, new elements are added, or elements are deleted by other threads. In case of such changes, you could Return Status Codes to the user who currently iterates, or you could prevent such changes during an iteration by locking write access to the elements in the meantime.
Because the implementation can ensure that the data is not changed during the iteration, it is not necessary to copy the elements on which the user operates. The user simply retrieves a pointer to this data and works with the original data.
Consequences
The user code for iterating over all elements is now just a single line of code. All the implementation details, like an element index and the maximum number of elements, are hidden inside the iterator implementation. The user does not even have to implement a loop to iterate over the elements. They also do not have to create or destroy an iterator instance, nor do they have to cope with the internal data structure from which the elements are gathered. Even if you change the type of underlying data structure in your implementation, they need not even recompile the code.
If the underlying elements change during an iteration, then the iterator implementation can react accordingly, which ensures that the user iterates over a consistent set of data while not having to cope with locking functionality in the user code. All this is possible because the control flow does not jump between the user code and the iterator-code. The control flow stays inside the iterator implementation, and thus the iterator implementation can detect if elements are changed during the iteration and react accordingly.
The user can iterate over all elements, but the iteration loop is implemented inside the iterator implementation, so the user cannot randomly access elements as with Index Access.
In the callback, your implementation runs user code on each element. To some extent this means that you have to trust that the user’s code does the right thing. For example, if your iterator implementation locks all elements during the iteration, then you expect the user code to quickly do something with the retrieved element and to not perform any time-consuming operations, because during this iteration, all other calls accessing this data will be locked.
Using callbacks implies that you have a platform- and programming language–specific interface, because you call the code implemented by your caller, and you can only do that if that code uses the same calling conventions (i.e., the same way of providing function parameters and returning data). That means, for implementing an iterator in C, you can only use this pattern if the user code is also written in C. You cannot provide a C Callback Iterator, for example, to a user writing code with Java (which could with some effort be done with any of the other iterator patterns).
When reading the code, the program flow with callbacks is more difficult to follow. For example, compared to having a simple while loop directly in the code, it might be more difficult to find out that the program iterates over elements when seeing only one line of user code with a callback parameter. Thus, it is critical to give the iteration function a name that makes it clear that this function performs an iteration.
Known Uses
The following examples show applications of this pattern:
-
James Noble describes an object-oriented version of this iterator as the Internal Iterator pattern in his article “Iterators and Encapsulation”.
-
The function
svn_iter_apr_hashof the Subversion project iterates over all elements in a hash table that is provided to the function as a parameter. For each element of the hash table, a function pointer, which has to be provided by the caller, is called, and if that call returnsSVN_ERR_ITER_BREAK, the iteration is stopped. -
The OpenSSL function
ossl_provider_forall_loadediterates over a set of OpenSSL provider objects. The function takes a function pointer as a parameter, and that function pointer is called for each provider object. Avoid*parameter can be provided to the iteration call, and this parameter is then provided for each call in the iteration so that users can pass their own context. -
The Wireshark function
conversation_table_iterate_tablesiterates through a list of “conversation” objects. Each such object stores information about sniffed network data. The function takes a function pointer and avoid*as parameters. For each conversation object, the function pointer is called with thevoid*as context.
Applied to Running Example
You now provide the following function for accessing the login names:
typedefvoid(*FP_CALLBACK)(char*loginName,void*arg);voiditerateLoginNames(FP_CALLBACKcallback,void*arg){structACCOUNT_NODE*account=getFirst(accountList);while(account!=NULL){callback(account->loginname,arg);account=getNext(account);}}
The following code shows how to use this interface:
voidfindX(char*loginName,void*arg){bool*found=(bool*)arg;if(loginName[0]=='X'){*found=true;}}voidcountY(char*loginName,void*arg){int*count=(int*)arg;if(loginName[0]=='Y'){(*count)++;}}boolanyoneWithX(){boolfound=false;iterateLoginNames(findX,&found);returnfound;}intnumberOfUsersWithY(){intcount=0;iterateLoginNames(countY,&count);returncount;}
The application no longer contains an explicit loop statement.
As a possible enhancement, the callback function could have a return value that determines whether the iteration is continued or stopped. With such a return value, the iteration could, for example, be stopped once the findX function iterates over the first user starting with “X.”
Summary
This chapter showed you three different ways to implement interfaces that provide iteration functionality. Table 7-2 gives an overview of the three patterns and compares their consequences.
| Index Access | Cursor Iterator | Callback Iterator | |
|---|---|---|---|
Element access | Allows random access | Only sequential access | Only sequential access |
Data structure changes | Underlying data structure can only easily be changed to another random-access data structure | Underlying data structure can easily be changed | Underlying data structure can easily be changed |
Info leaked through interface | Amount of elements; usage of a random-access data structure | Iterator position (user can stop and continue the iteration at a later point) | - |
Code duplication | Loop in user code; index increment in user code | Loop in user code | - |
Robustness | Difficult to implement robust iteration behavior | Difficult to implement robust iteration behavior | easy to implement robust iteration behavior because control flow stays within the iteration code, and insert/delete/modify operations can simply be locked during the iteration (but would block other iterations during that time) |
Platforms | Interface can be used across different languages and platforms | Interface can be used across different languages and platforms | Can only be used with the same language and platform (with the same calling convention) as the implementation |
Further Reading
If you’re ready for more, here are some resources that can help you further your knowledge of iterator interface design.
-
The most closely related work regarding iterators in C is an online version of university class notes by James Aspnes. The class notes describe different C iterator designs, discuss their advantages and disadvantages, and provide source code examples.
-
There is more guidance on iterators for other programming languages, but many of the concepts can also be applied to C. For example, the article “Iterators and Encapsulation” by James Noble describes eight patterns on how to design object-oriented iterators, the book Data Structures and Problem Solving Using Java by Mark Allen Weiss (Addison-Wesley, 2006) describes different iterator designs for Java, and the book Higher-Order Perl by Mark Jason Dominus (Morgan Kaufmann, 2005) describes different iterator designs for Perl.
-
The article “Loop Patterns” by Owen Astrachan and Eugene Wallingford contains patterns that describe best practices for implementing loops and that include C++ and Java code snippets. Most of the ideas are also relevant for C.
-
The book C Interfaces and Implementations by David R. Hanson (Addison-Wesley, 1996) describes C implementations and their interfaces for several common data structures like linked lists or hash tables. These interfaces of course also contain functions that traverse these data structures.
Outlook
The next chapter focuses on how to organize the code files in large programs. Once you apply the patterns from the previous chapters to define your interfaces and to program their implementations, you end up with many files. Their file organization has to be tackled to implement modular, large scale programs.