
Chapter 2. An Array of Sequences
As you may have noticed, several of the operations mentioned work equally for texts, lists and tables. Texts, lists and tables together are called trains. […] The
FORcommand also works generically on trains.1Geurts, Meertens, and Pemberton, ABC Programmer’s Handbook
Before creating Python, Guido was a contributor to the ABC language—a 10-year research project to design a programming environment for beginners. ABC introduced many ideas we now consider “Pythonic”: generic operations on different types of sequences, built-in tuple and mapping types, structure by indentation, strong typing without variable declarations, and more. It’s no accident that Python is so user-friendly.
Python inherited from ABC the uniform handling of sequences. Strings, lists, byte sequences, arrays, XML elements, and database results share a rich set of common operations including iteration, slicing, sorting, and concatenation.
Understanding the variety of sequences available in Python saves us from reinventing the wheel, and their common interface inspires us to create APIs that properly support and leverage existing and future sequence types.
Most of the discussion in this chapter applies to sequences in general,
from the familiar list to the str and bytes types that are new in Python 3.
Specific topics on lists, tuples, arrays, and queues are also covered here,
but the specifics of Unicode strings and byte sequences appear in Chapter 4.
Also, the idea here is to cover sequence types that are ready to use.
Creating your own sequence types is the subject of Chapter 12.
What’s new in this chapter
The sequence types are a very stable part of Python, therefore most the changes here are not updates but improvements over the 1st edition of Fluent Python. The most significant are:
-
New diagram and description of the internals of sequences, contrasting containers and flat sequences.
-
Brief comparison of the performance and storage characteristics of
listversustuple. -
Caveats of tuples with mutable elements, and how to detect them if needed.
-
Coverage of named tuples moved to “Classic Named Tuples” in Chapter 5, where they are compared to the new data classes.
Overview of Built-In Sequences
The standard library offers a rich selection of sequence types implemented in C:
- Container sequences
-
list,tuple, andcollections.dequecan hold items of different types, including nested containers. - Flat sequences
-
str,bytes,bytearray,memoryview, andarray.arrayhold items of one simple type.
A container sequence holds references to the objects it contains, which may be of any type, while a flat sequence stores the value of its contents in its own memory space, and not as distinct objects. See Figure 2-1.
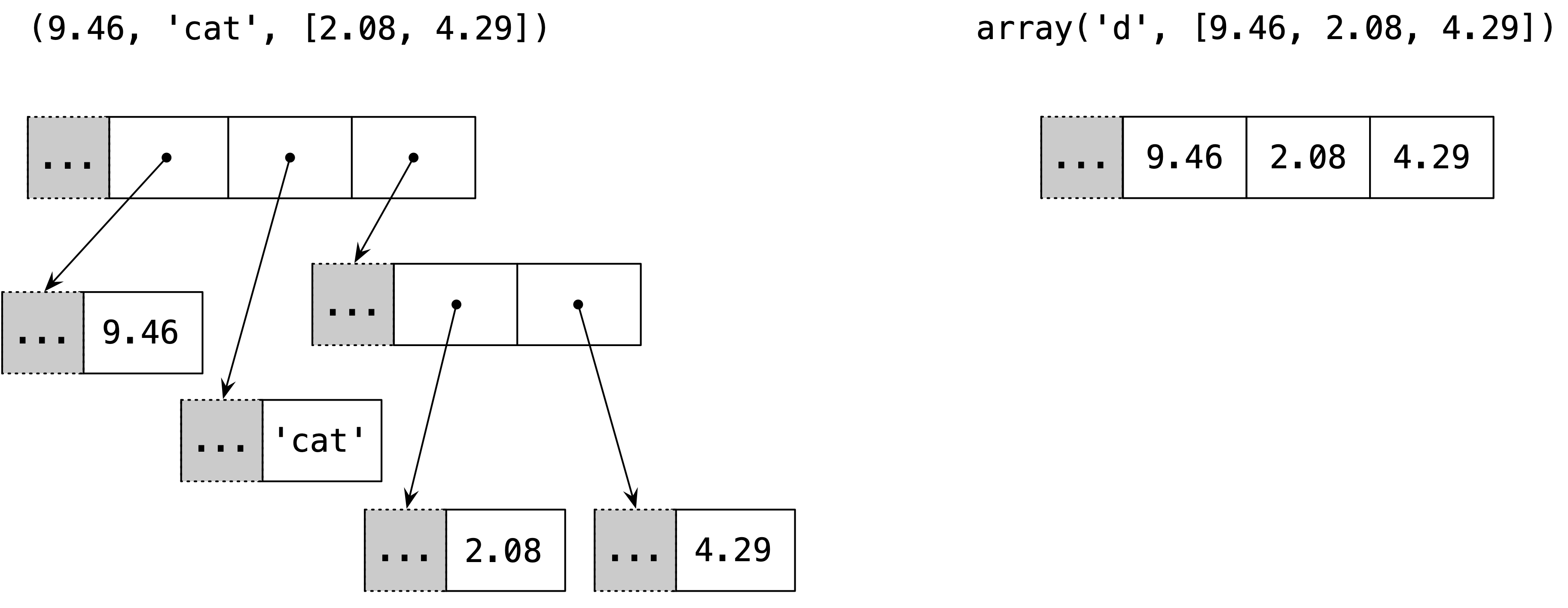
Figure 2-1. Simplified memory diagram of a tuple and an array, each holding 3 items. Gray cells represent the in-memory header of each Python object—not drawn to proportion. The tuple has an array of references to its contents. Each item is a separate Python object, possibly holding references to other Python objects, like that 2-item list. In contrast, the Python array is a single object, holding a C language array of 3 doubles.
Thus, flat sequences are more compact, but they are limited to holding primitive machine values like bytes, integers, and floats.
Note
Every Python object in memory has a header with metadata. The simplest Python object, a float, has two metadata fields.
On a 64-bit Python build, the struct representing a float has these 64-bit fields:
* ob_refcnt: the object’s reference count;
* *ob_type: a pointer to the object’s type;
* ob_fval: a C double holding the value of the float.
That’s why an array with of floats is much more compact than a tuple of floats:
the array is a single object holding the raw values of the floats,
while the tuple is several objects—the tuple itself and each float object contained in it.
Another way of grouping sequence types is by mutability:
- Mutable sequences
-
list,bytearray,array.array,collections.deque, andmemoryview - Immutable sequences
-
tuple,str, andbytes
Figure 2-2 helps visualize how mutable sequences inherit all methods from immutable sequences,
and implement several additional methods.
The built-in concrete sequence types do not actually subclass the Sequence and MutableSequence abstract base classes (ABCs),
but they are virtual subclasses registered with those ABCs—as we’ll see in in [Link to Come]. Being virtual subclasses, tuple and list pass these tests:
>>>fromcollectionsimportabc>>>issubclass(tuple,abc.Sequence)True>>>issubclass(list,abc.MutableSequence)True
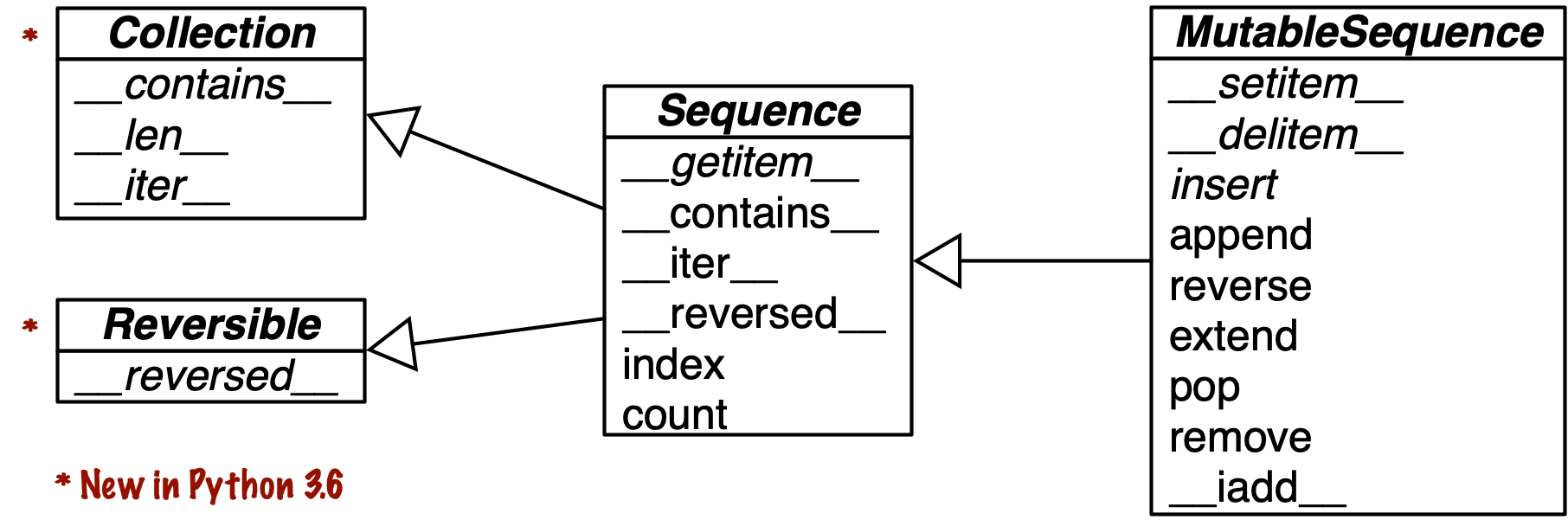
Figure 2-2. Simplified UML class diagram for some classes from collections.abc (superclasses are on the left; inheritance arrows point from subclasses to superclasses; names in italic are abstract classes and abstract methods)
Keep in mind these common traits: mutable versus immutable; container versus flat. They are helpful to extrapolate what you know about one sequence type to others.
The most fundamental sequence type is the list: a mutable container.
I expect you are very familiar with them, so we’ll jump right into list comprehensions,
a powerful way of building lists that is sometimes underused because the syntax may look unusual at first.
Mastering list comprehensions opens the door to generator expressions,
which—among other uses—can produce elements to fill up sequences of any type.
Both are the subject of the next section.
List Comprehensions and Generator Expressions
A quick way to build a sequence is using a list comprehension (if the target is a list) or a generator expression (for all other kinds of sequences).
If you are not using these syntactic forms on a daily basis, I bet you are missing opportunities to write code that is more readable and often faster at the same time.
If you doubt my claim that these constructs are “more readable,” read on. I’ll try to convince you.
Tip
For brevity, many Python programmers refer to list comprehensions as listcomps, and generator expressions as genexps. I will use these words as well.
List Comprehensions and Readability
Here is a test: which do you find easier to read, Example 2-1 or Example 2-2?
Example 2-1. Build a list of Unicode codepoints from a string
>>>symbols='$¢£¥€¤'>>>codes=[]>>>forsymbolinsymbols:...codes.append(ord(symbol))...>>>codes[36, 162, 163, 165, 8364, 164]
Example 2-2. Build a list of Unicode codepoints from a string, take two
>>>symbols='$¢£¥€¤'>>>codes=[ord(symbol)forsymbolinsymbols]>>>codes[36, 162, 163, 165, 8364, 164]
Anybody who knows a little bit of Python can read Example 2-1. However, after learning about listcomps, I find Example 2-2 more readable because its intent is explicit.
A for loop may be used to do lots of different things: scanning a sequence to count or pick items,
computing aggregates (sums, averages), or any number of other processing tasks.
The code in Example 2-1 is building up a list.
In contrast, a listcomp is more explicit. Its goal is to build a new list.
Of course, it is possible to abuse list comprehensions to write truly incomprehensible code.
I’ve seen Python code with listcomps used just to repeat a block of code for its side effects.
If you are not doing something with the produced list, you should not use that syntax.
Also, try to keep it short.
If the list comprehension spans more than two lines, it is probably best to break it apart or rewrite as a plain old for loop.
Use your best judgment: for Python as for English, there are no hard-and-fast rules for clear writing.
Syntax Tip
In Python code, line breaks are ignored inside pairs of [], {}, or ().
So you can build multiline lists, listcomps, tuples, dictionaries etc. without using the line continuation escape which doesn’t work if you accidentaly type a space after it.
Also, when those delimiters are used to define a literal with a comma-separated series of items, a trailing comma will be ignored.
So, for example, when coding a multi-line list literal, it is thoughtful to put a comma after the last item,
making it a little easier for the next coder do add one more item to that list, and reducing noise when reading diffs.
List comprehensions build lists from sequences or any other iterable type by filtering and transforming items.
The filter and map built-ins can be composed to do the same, but readability suffers, as we will see next.
Listcomps Versus map and filter
Listcomps do everything the map and filter functions do, without the contortions of the functionally challenged Python lambda.
Consider Example 2-3.
Example 2-3. The same list built by a listcomp and a map/filter composition
>>>symbols='$¢£¥€¤'>>>beyond_ascii=[ord(s)forsinsymbolsiford(s)>127]>>>beyond_ascii[162, 163, 165, 8364, 164]>>>beyond_ascii=list(filter(lambdac:c>127,map(ord,symbols)))>>>beyond_ascii[162, 163, 165, 8364, 164]
I used to believe that map and filter were faster than the equivalent listcomps,
but Alex Martelli pointed out that’s not the case—at least not in the preceding examples.
The 02-array-seq/listcomp_speed.py script in the Fluent Python code repository is a simple speed test comparing listcomp with filter/map.
I’ll have more to say about map and filter in Chapter 7.
Now we turn to the use of listcomps to compute Cartesian products: a list containing tuples built from all items from two or more lists.
Cartesian Products
Listcomps can build lists from the Cartesian product of two or more iterables. The items that make up the cartesian product are tuples made from items from every input iterable. The resulting list has a length equal to the lengths of the input iterables multiplied. See Figure 2-3.
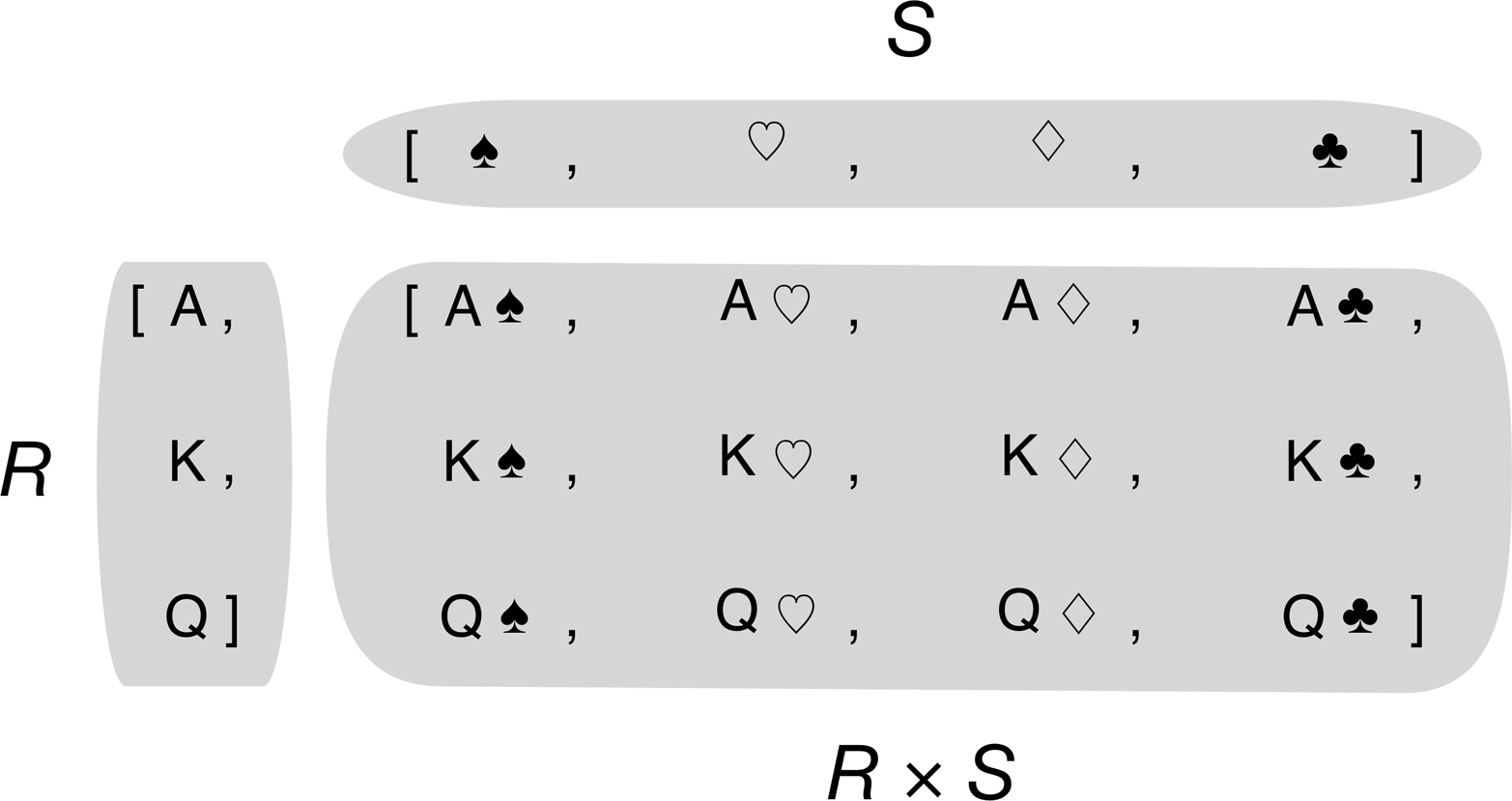
Figure 2-3. The Cartesian product of three card ranks and four suits is a sequence of twelve pairings
For example, imagine you need to produce a list of T-shirts available in two colors and three sizes. Example 2-4 shows how to produce that list using a listcomp. The result has six items.
Example 2-4. Cartesian product using a list comprehension
>>>colors=['black','white']>>>sizes=['S','M','L']>>>tshirts=[(color,size)forcolorincolorsforsizeinsizes]>>>tshirts[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'),('white', 'M'), ('white', 'L')]>>>forcolorincolors:...forsizeinsizes:...((color,size))...('black', 'S')('black', 'M')('black', 'L')('white', 'S')('white', 'M')('white', 'L')>>>tshirts=[(color,size)forsizeinsizes...forcolorincolors]>>>tshirts[('black', 'S'), ('white', 'S'), ('black', 'M'), ('white', 'M'),('black', 'L'), ('white', 'L')]
This generates a list of tuples arranged by color, then size.
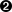
Note how the resulting list is arranged as if the
forloops were nested in the same order as they appear in the listcomp.
To get items arranged by size, then color, just rearrange the
forclauses; adding a line break to the listcomp makes it easy to see how the result will be ordered.
In Example 1-1 (Chapter 1), the following expression was used to initialize a card deck with a list made of 52 cards from all 13 ranks of each of the 4 suits, sorted by suit then rank:
self._cards=[Card(rank,suit)forsuitinself.suitsforrankinself.ranks]
Listcomps are a one-trick pony: they build lists. To generate data for other sequence types, a genexp is the way to go. The next section is a brief look at genexps in the context of building nonlist sequences.
Generator Expressions
To initialize tuples, arrays, and other types of sequences, you could also start from a listcomp, but a genexp saves memory because it yields items one by one using the iterator protocol instead of building a whole list just to feed another constructor.
Genexps use the same syntax as listcomps, but are enclosed in parentheses rather than brackets.
Example 2-5 shows basic usage of genexps to build a tuple and an array.
Example 2-5. Initializing a tuple and an array from a generator expression
>>>symbols='$¢£¥€¤'>>>tuple(ord(symbol)forsymbolinsymbols)(36, 162, 163, 165, 8364, 164)>>>importarray>>>array.array('I',(ord(symbol)forsymbolinsymbols))array('I', [36, 162, 163, 165, 8364, 164])
If the generator expression is the single argument in a function call, there is no need to duplicate the enclosing parentheses.
The
arrayconstructor takes two arguments, so the parentheses around the generator expression are mandatory. The first argument of thearrayconstructor defines the storage type used for the numbers in the array, as we’ll see in “Arrays”.
Example 2-6 uses a genexp with a Cartesian product to print out a roster of T-shirts of two colors in three sizes.
In contrast with Example 2-4, here the six-item list of T-shirts is never built in memory: the generator expression feeds the for loop producing one item at a time.
If the two lists used in the Cartesian product had 1,000 items each,
using a generator expression would save the cost of building a list with a million items just to feed the for loop.
Example 2-6. Cartesian product in a generator expression
>>>colors=['black','white']>>>sizes=['S','M','L']>>>fortshirtin('%s%s'%(c,s)forcincolorsforsinsizes):...(tshirt)...black Sblack Mblack Lwhite Swhite Mwhite L
The generator expression yields items one by one; a list with all six T-shirt variations is never produced in this example.
[Link to Come] is devoted to explaining how generators work in detail. Here the idea was just to show the use of generator expressions to initialize sequences other than lists, or to produce output that you don’t need to keep in memory.
Now we move on to the other fundamental sequence type in Python: the tuple.
Tuples Are Not Just Immutable Lists
Some introductory texts about Python present tuples as “immutable lists,” but that is short selling them. Tuples do double duty: they can be used as immutable lists and also as records with no field names. This use is sometimes overlooked, so we will start with that.
Tuples as Records
Tuples hold records: each item in the tuple holds the data for one field and the position of the item gives its meaning.
If you think of a tuple just as an immutable list, the quantity and the order of the items may or may not be important, depending on the context. But when using a tuple as a collection of fields, the number of items is usually fixed and their order is always important.
Example 2-7 shows tuples used as records. Note that in every expression, sorting the tuple would destroy the information because the meaning of each data item is given by its position in the tuple.
Example 2-7. Tuples used as records
>>>lax_coordinates=(33.9425,-118.408056)>>>city,year,pop,chg,area=('Tokyo',2003,32_450,0.66,8014)>>>traveler_ids=[('USA','31195855'),('BRA','CE342567'),...('ESP','XDA205856')]>>>forpassportinsorted(traveler_ids):...('%s/%s'%passport)...BRA/CE342567ESP/XDA205856USA/31195855>>>forcountry,_intraveler_ids:...(country)...USABRAESP
Latitude and longitude of the Los Angeles International Airport.
Data about Tokyo: name, year, population (thousands), population change (%), area (km²).
A list of tuples of the form
(country_code, passport_number).
As we iterate over the list,
passportis bound to each tuple.
The
%formatting operator understands tuples and treats each item as a separate field.
The
forloop knows how to retrieve the items of a tuple separately—this is called “unpacking.” Here we are not interested in the second item, so it’s assigned to_, a dummy variable.
Tuples work well as records because of the unpacking mechanism—our next subject.
Unpacking
In Example 2-7, we assigned ('Tokyo', 2003, 32_450, 0.66, 8014) to city, year, pop, chg, area in a single statement.
Then, in the last line, the % operator assigned each item in the passport tuple to one slot in the format string in the print argument.
Those are two examples of tuple unpacking.
Tip
Tuple unpacking works with any iterable object.
The only requirement is that the iterable yields exactly one item per variable in the receiving tuple, unless you use a star (*) to capture excess items as explained in “Using * to grab excess items”.
The term tuple unpacking is widely used by Pythonistas, but iterable unpacking is gaining traction, as in the title of PEP 3132 — Extended Iterable Unpacking.
The most visible form of unpacking is parallel assignment; that is, assigning items from an iterable to a tuple of variables, as you can see in this example:
>>>lax_coordinates=(33.9425,-118.408056)>>>latitude,longitude=lax_coordinates# unpacking>>>latitude33.9425>>>longitude-118.408056
An elegant application of tuple unpacking is swapping the values of variables without using a temporary variable:
>>>b,a=a,b
Another example of unpacking is prefixing an argument with a star when calling a function:
>>>divmod(20,8)(2, 4)>>>t=(20,8)>>>divmod(*t)(2, 4)>>>quotient,remainder=divmod(*t)>>>quotient,remainder(2, 4)
The preceding code also shows a further use of tuple unpacking: enabling functions to return multiple values in a way that is convenient to the caller.
As another example, the os.path.split() function builds a tuple (path, last_part) from a filesystem path:
>>>importos>>>_,filename=os.path.split('/home/luciano/.ssh/id_rsa.pub')>>>filename'id_rsa.pub'
Sometimes when we only care about certain parts of a tuple when unpacking,
a dummy variable like _ is used as placeholder, as in the preceding example.
Warning
If you write internationalized software, _ is not a good dummy variable because it is traditionally used as an alias to the gettext.gettext function, as recommended in the gettext module documentation.
Otherwise, it’s a conventional name for a placeholder variable to be ignored.
Another way of using just some of the items when unpacking is to use the * syntax, as we’ll see right away.
Using * to grab excess items
Defining function parameters with *args to grab arbitrary excess arguments is a classic Python feature.
In Python 3, this idea was extended to apply to parallel assignment as well:
>>>a,b,*rest=range(5)>>>a,b,rest(0, 1, [2, 3, 4])>>>a,b,*rest=range(3)>>>a,b,rest(0, 1, [2])>>>a,b,*rest=range(2)>>>a,b,rest(0, 1, [])
In the context of parallel assignment, the * prefix can be applied to exactly one variable,
but it can appear in any position:
>>>a,*body,c,d=range(5)>>>a,body,c,d(0, [1, 2], 3, 4)>>>*head,b,c,d=range(5)>>>head,b,c,d([0, 1], 2, 3, 4)
Finally, a powerful feature of tuple unpacking is that it works with nested structures.
Nested Tuple Unpacking
The tuple to receive an expression to unpack can have nested tuples, like (a, b, (c, d)),
and Python will do the right thing if the expression matches the nesting structure. Example 2-8 shows nested tuple unpacking in action.
Example 2-8. Unpacking nested tuples to access the longitude
metro_areas=[('Tokyo','JP',36.933,(35.689722,139.691667)),('Delhi NCR','IN',21.935,(28.613889,77.208889)),('Mexico City','MX',20.142,(19.433333,-99.133333)),('New York-Newark','US',20.104,(40.808611,-74.020386)),('Sao Paulo','BR',19.649,(-23.547778,-46.635833)),]('{:15}|{:^9}|{:^9}'.format('','lat.','long.'))fmt='{:15}|{:9.4f}|{:9.4f}'forname,cc,pop,(latitude,longitude)inmetro_areas:iflongitude<=0:(fmt.format(name,latitude,longitude))
Each tuple holds a record with four fields, the last of which is a coordinate pair.
By assigning the last field to a nested tuple, we unpack the coordinates.
if longitude <= 0:limits the output to metropolitan areas in the Western hemisphere.
The output of Example 2-8 is:
| lat. | long. Mexico City | 19.4333 | -99.1333 New York-Newark | 40.8086 | -74.0204 Sao Paulo | -23.5478 | -46.6358
Warning
Before Python 3, it was possible to define functions with nested tuples in the formal parameters (e.g., def fn(a, (b, c), d):).
This is no longer supported in Python 3 function definitions,
for practical reasons explained in PEP 3113 — Removal of Tuple Parameter Unpacking.
To be clear: nothing changed from the perspective of users calling a function.
The restriction applies only to the definition of functions.
Python 3.5 introduced more flexible syntax for iterable unpacking, summarized in What’s New In Python 3.5.
As designed, tuples are very handy.
But when using them as records, sometimes it is desirable to name the fields.
The solution is the namedtuple factory we will cover in Chapter 5.
Now let’s consider the tuple class as an immutable variant of the list class.
Tuples as Immutable Lists
The Python interpreter and standard library make extensive use of tuples as immutable lists, and so should you. This brings two key benefits:
-
Clarity: when you see a
tuplein code, you know its length will never change. -
Performance: a
tupleuses less memory than alistof the same length, and they allow Python to do some optimizations.
However, be aware that the immutability of a tuple only applies to the references contained in it.
References in a tuple cannot be deleted or replaced.
But if one of those references points to a mutable object, and that object is changed, then the value of the tuple changes.
The next snippet demonstrates this point by creating two tuples—a and b—which are initialy equal. When the last item in b is changed, they become different:
>>>a=(10,'alpha',[1,2])>>>b=(10,'alpha',[1,2])>>>a==bTrue>>>b[-1].append(99)>>>a==bFalse>>>b(10, 'alpha', [1, 2, 99])
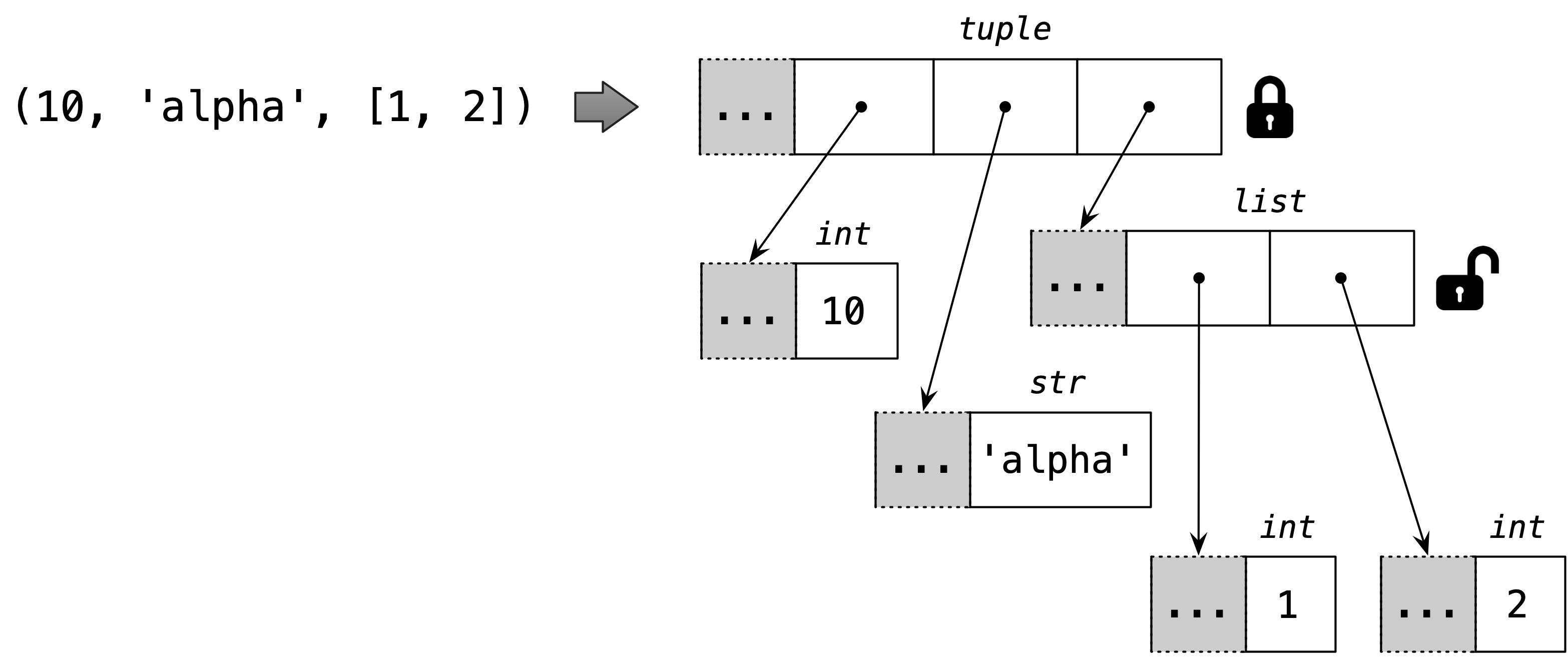
Figure 2-4. The content of the tuple itself is immutable, but that only means the references held by the tuple will always point to the same objects. However, if one of the referenced objects is a list, its content may change.
The mutable value of tuples with mutable items can be a source of bugs. If you want to make sure a tuple will stay unchanged, you can compute its hash. As we’ll see in “What Is Hashable?”, an object is only hashable if its value cannot ever change. Therefore, here is a way to check that a tuple (or any object) has a fixed value:
>>>deffixed(o):...try:...hash(o)...exceptTypeError:...returnFalse...returnTrue...>>>tf=(10,'alpha',(1,2))>>>tm=(10,'alpha',[1,2])>>>fixed(tf)True>>>fixed(tm)False
We explore this issue further in “The Relative Immutability of Tuples”.
Despite this caveat, tuples are widely used as immutable lists. They offer some performance advantages explained by Python core developer Raymond Hettinger in a StackOverflow answer to the question Are tuples more efficient than lists in Python? To summarize, Hettinger wrote:
-
To evaluate a tuple literal, the Python compiler generates bytecode for a tuple constant in one operation, but for a list literal, the generated bytecode pushes each element as a separate constant to the data stack, and then builds the list.
-
Given a hashable tuple
t, thetuple(t)constructor just returns a reference to the samet. There’s no need to copy, because iftis hashable, its value is fixed. In contrast, given a listl, thelist(l)constructor must create a whole new copy ofl. -
Because of its fixed length, a
tupleinstance is allocated the exact memory space in needs. Instances oflist, on the other hand, are allocated with room to spare, to ammortize the cost of future appends. -
The references to the items in a tuple are stored in an array within the tuple struct itself, while a list holds a pointer to an array of references stored elsewhere. The added indirection makes CPU caches less effective, with potential impact on performance. But the indirection is necessary because when a list grows beyond the space currently allocated, the array of references needs to be relocated to make room.
Tuple versus list methods
When using a tuple as an immutable variation of list, it is good to know how similar are their APIs.
As you can see in Table 2-1,
tuple supports all list methods that do not involve adding or removing items,
with one exception—tuple lacks the __reversed__ method.
However, that is just for optimization; reversed(my_tuple) works without it.
| list | tuple | ||
|---|---|---|---|
|
● |
● |
|
|
● |
|
|
|
● |
Append one element after last |
|
|
● |
Delete all items |
|
|
● |
● |
|
|
● |
Shallow copy of the list |
|
|
● |
● |
Count occurrences of an element |
|
● |
Remove item at position |
|
|
● |
Append items from iterable |
|
|
● |
● |
|
|
● |
Support for optimized serialization with |
|
|
● |
● |
Find position of first occurrence of |
|
● |
Insert element |
|
|
● |
● |
Get iterator |
|
● |
● |
|
|
● |
● |
|
|
● |
|
|
|
● |
● |
|
|
● |
Remove and return last item or item at optional position |
|
|
● |
Remove first occurrence of element |
|
|
● |
Reverse the order of the items in place |
|
|
● |
Get iterator to scan items from last to first |
|
|
● |
|
|
|
● |
Sort items in place with optional keyword arguments |
|
a Reversed operators are explained in [Link to Come]. | |||
Every Python programmer knows that sequences can be sliced using the s[a:b] syntax.
We now turn to some less well-known facts about slicing.
Slicing
A common feature of list, tuple, str, and all sequence types in Python is the support of slicing operations, which are more powerful than most people realize.
In this section, we describe the use of these advanced forms of slicing. Their implementation in a user-defined class will be covered in Chapter 12, in keeping with our philosophy of covering ready-to-use classes in this part of the book, and creating new classes in Part IV.
Why Slices and Range Exclude the Last Item
The Pythonic convention of excluding the last item in slices and ranges works well with the zero-based indexing used in Python, C, and many other languages. Some convenient features of the convention are:
-
It’s easy to see the length of a slice or range when only the stop position is given:
range(3)andmy_list[:3]both produce three items. -
It’s easy to compute the length of a slice or range when start and stop are given: just subtract
stop - start. -
It’s easy to split a sequence in two parts at any index
x, without overlapping: simply getmy_list[:x]andmy_list[x:]. For example:
>>>l=[10,20,30,40,50,60]>>>l[:2]# split at 2[10, 20]>>>l[2:][30, 40, 50, 60]>>>l[:3]# split at 3[10, 20, 30]>>>l[3:][40, 50, 60]
But the best arguments for this convention were written by the Dutch computer scientist Edsger W. Dijkstra (see the last reference in “Further Reading”).
Now let’s take a close look at how Python interprets slice notation.
Slice Objects
This is no secret, but worth repeating just in case: s[a:b:c] can be used to specify a stride or step c, causing the resulting slice to skip items.
The stride can also be negative, returning items in reverse.
Three examples make this clear:
>>>s='bicycle'>>>s[::3]'bye'>>>s[::-1]'elcycib'>>>s[::-2]'eccb'
Another example was shown in Chapter 1 when we used deck[12::13] to get all the aces in the unshuffled deck:
>>>deck[12::13][Card(rank='A', suit='spades'), Card(rank='A', suit='diamonds'),Card(rank='A', suit='clubs'), Card(rank='A', suit='hearts')]
The notation a:b:c is only valid within [] when used as the indexing or subscript operator,
and it produces a slice object: slice(a, b, c).
As we will see in “How Slicing Works”, to evaluate the expression seq[start:stop:step],
Python calls seq.__getitem__(slice(start, stop, step)).
Even if you are not implementing your own sequence types, knowing about slice objects is useful because it lets you assign names to slices, just like spreadsheets allow naming of cell ranges.
Suppose you need to parse flat-file data like the invoice shown in Example 2-9.
Instead of filling your code with hardcoded slices, you can name them.
See how readable this makes the for loop at the end of the example.
Example 2-9. Line items from a flat-file invoice
>>>invoice="""...0.....6.................................40........52...55...........1909 Pimoroni PiBrella $17.50 3 $52.50...1489 6mm Tactile Switch x20 $4.95 2 $9.90...1510 Panavise Jr. - PV-201 $28.00 1 $28.00...1601 PiTFT Mini Kit 320x240 $34.95 1 $34.95...""">>>SKU=slice(0,6)>>>DESCRIPTION=slice(6,40)>>>UNIT_PRICE=slice(40,52)>>>QUANTITY=slice(52,55)>>>ITEM_TOTAL=slice(55,None)>>>line_items=invoice.split('')[2:]>>>foriteminline_items:...(item[UNIT_PRICE],item[DESCRIPTION])...$17.50 Pimoroni PiBrella$4.95 6mm Tactile Switch x20$28.00 Panavise Jr. - PV-201$34.95 PiTFT Mini Kit 320x240
We’ll come back to slice objects when we discuss creating your own collections in “Vector Take #2: A Sliceable Sequence”.
Meanwhile, from a user perspective, slicing includes additional features such as multidimensional slices and ellipsis (...) notation.
Read on.
Multidimensional Slicing and Ellipsis
The [] operator can also take multiple indexes or slices separated by commas.
The __getitem__ and __setitem__ special methods that handle the [] operator simply receive the indices in a[i, j] as a tuple.
In other words, to evaluate a[i, j], Python calls a.__getitem__((i, j)).
This is used, for instance, in the external NumPy package, where items of a two-dimensional numpy.ndarray can be fetched using the syntax a[i, j] and a two-dimensional slice obtained with an expression like a[m:n, k:l]. Example 2-22 later in this chapter shows the use of this notation.
Except for memoryview, the built-in sequence types in Python are one-dimensional, so they support only one index or slice, and not a tuple of them.2
The ellipsis—written with three full stops (...) and not … (Unicode U+2026)—is recognized as a token by the Python parser.
It is an alias to the Ellipsis object, the single instance of the ellipsis class.3 As such, it can be passed as an argument to functions and as part of a slice specification, as in f(a, ..., z) or a[i:...].
NumPy uses ... as a shortcut when slicing arrays of many dimensions; for example,
if x is a four-dimensional array, x[i, ...] is a shortcut for x[i, :, :, :,].
See the Tentative NumPy Tutorial to learn more about this.
At the time of this writing, I am unaware of uses of Ellipsis or multidimensional indexes and slices in the Python standard library.
If you spot one, let me know.
These syntactic features exist to support user-defined types and extensions such as NumPy.
Slices are not just useful to extract information from sequences; they can also be used to change mutable sequences in place—that is, without rebuilding them from scratch.
Assigning to Slices
Mutable sequences can be grafted, excised, and otherwise modified in place using slice notation on the left side of an assignment statement or as the target of a del statement.
The next few examples give an idea of the power of this notation:
>>>l=list(range(10))>>>l[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>>l[2:5]=[20,30]>>>l[0, 1, 20, 30, 5, 6, 7, 8, 9]>>>dell[5:7]>>>l[0, 1, 20, 30, 5, 8, 9]>>>l[3::2]=[11,22]>>>l[0, 1, 20, 11, 5, 22, 9]>>>l[2:5]=100Traceback (most recent call last):File"<stdin>", line1, in<module>TypeError:can only assign an iterable>>>l[2:5]=[100]>>>l[0, 1, 100, 22, 9]
When the target of the assignment is a slice, the right side must be an iterable object, even if it has just one item.
Every coder knows that concatenation is a common operation with sequences.
Introductory Python tutorials explain the use of + and * for that purpose,
but there are some subtle details on how they work, which we cover next.
Using + and * with Sequences
Python programmers expect that sequences support + and *.
Usually both operands of + must be of the same sequence type,
and neither of them is modified but a new sequence of that same type is created as result of the concatenation.
To concatenate multiple copies of the same sequence, multiply it by an integer. Again, a new sequence is created:
>>>l=[1,2,3]>>>l*5[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]>>>5*'abcd''abcdabcdabcdabcdabcd'
Both + and * always create a new object, and never change their operands.
Warning
Beware of expressions like a * n when a is a sequence containing mutable items because the result may surprise you.
For example, trying to initialize a list of lists as my_list = [[]] * 3 will result in a list with three references to the same inner list, which is probably not what you want.
The next section covers the pitfalls of trying to use * to initialize a list of lists.
Building Lists of Lists
Sometimes we need to initialize a list with a certain number of nested lists—for example, to distribute students in a list of teams or to represent squares on a game board. The best way of doing so is with a list comprehension, as in Example 2-10.
Example 2-10. A list with three lists of length 3 can represent a tic-tac-toe board
>>>board=[['_']*3foriinrange(3)]>>>board[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]>>>board[1][2]='X'>>>board[['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
Create a list of three lists of three items each. Inspect the structure.
Place a mark in row 1, column 2, and check the result.
A tempting but wrong shortcut is doing it like Example 2-11.
Example 2-11. A list with three references to the same list is useless
>>>weird_board=[['_']*3]*3>>>weird_board[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]>>>weird_board[1][2]='O'>>>weird_board[['_', '_', 'O'], ['_', '_', 'O'], ['_', '_', 'O']]
The outer list is made of three references to the same inner list. While it is unchanged, all seems right.
Placing a mark in row 1, column 2, reveals that all rows are aliases referring to the same object.
The problem with Example 2-11 is that, in essence, it behaves like this code:
row=['_']*3board=[]foriinrange(3):board.append(row)
The same
rowis appended three times toboard.
On the other hand, the list comprehension from Example 2-10 is equivalent to this code:
>>>board=[]>>>foriinrange(3):...row=['_']*3...board.append(row)...>>>board[['_','_','_'],['_','_','_'],['_','_','_']]>>>board[2][0]='X'>>>board[['_','_','_'],['_','_','_'],['X','_','_']]
Each iteration builds a new
rowand appends it toboard.Only row 2 is changed, as expected.
Tip
If either the problem or the solution in this section are not clear to you, relax. Chapter 6 was written to clarify the mechanics and pitfalls of references and mutable objects.
So far we have discussed the use of the plain + and * operators with sequences,
but there are also the += and *= operators, which produce very different results depending on the mutability of the target sequence.
The following section explains how that works.
Augmented Assignment with Sequences
The augmented assignment operators += and *= behave quite differently depending on the first operand.
To simplify the discussion, we will focus on augmented addition first (+=),
but the concepts also apply to *= and to other augmented assignment operators.
The special method that makes += work is __iadd__ (for “in-place addition”).
However, if __iadd__ is not implemented, Python falls back to calling __add__.
Consider this simple expression:
>>>a+=b
If a implements __iadd__, that will be called.
In the case of mutable sequences (e.g., list, bytearray, array.array), a will be changed in place (i.e., the effect will be similar to a.extend(b)).
However, when a does not implement __iadd__, the expression a += b has the same effect as a = a + b: the expression a + b is evaluated first, producing a new object, which is then bound to a.
In other words, the identity of the object bound to a may or may not change,
depending on the availability of __iadd__.
In general, for mutable sequences, it is a good bet that __iadd__ is implemented and that += happens in place.
For immutable sequences, clearly there is no way for that to happen.
What I just wrote about += also applies to *=, which is implemented via __imul__.
The __iadd__ and __imul__ special methods are discussed in [Link to Come].
Here is a demonstration of *= with a mutable sequence and then an immutable one:
>>>l=[1,2,3]>>>id(l)4311953800>>>l*=2>>>l[1, 2, 3, 1, 2, 3]>>>id(l)4311953800>>>t=(1,2,3)>>>id(t)4312681568>>>t*=2>>>id(t)4301348296
ID of the initial list
After multiplication, the list is the same object, with new items appended
ID of the initial tuple
After multiplication, a new tuple was created
Repeated concatenation of immutable sequences is inefficient, because instead of just appending new items, the interpreter has to copy the whole target sequence to create a new one with the new items concatenated.4
We’ve seen common use cases for +=.
The next section shows an intriguing corner case that highlights what “immutable” really means in the context of tuples.
A += Assignment Puzzler
Try to answer without using the console: what is the result of evaluating the two expressions in Example 2-12?5
Example 2-12. A riddle
>>>t=(1,2,[30,40])>>>t[2]+=[50,60]
What happens next? Choose the best answer:
*A.* `t` becomes `(1, 2, [30, 40, 50, 60])`. *B.* `TypeError` is raised with the message `'tuple' object does not support item assignment`. *C.* Neither. *D.* Both *A* and *B*.
When I saw this, I was pretty sure the answer was B, but it’s actually D, “Both A and B.”! Example 2-13 is the actual output from a Python 3.8 console.6
Example 2-13. The unexpected result: item t2 is changed and an exception is raised
>>>t=(1,2,[30,40])>>>t[2]+=[50,60]Traceback (most recent call last):File"<stdin>", line1, in<module>TypeError:'tuple' object does not support item assignment>>>t(1, 2, [30, 40, 50, 60])
Online Python Tutor is an awesome online tool to visualize how Python works in detail. Figure 2-5 is a composite of two screenshots showing the initial and final states of the tuple t from Example 2-13.
Figure 2-5. Initial and final state of the tuple assignment puzzler (diagram generated by Online Python Tutor)
If you look at the bytecode Python generates for the expression s[a] += b (Example 2-14), it becomes clear how that happens.
Example 2-14. Bytecode for the expression s[a] += b
>>>dis.dis('s[a] += b')1 0 LOAD_NAME 0 (s)3 LOAD_NAME 1 (a)6 DUP_TOP_TWO7 BINARY_SUBSCR8 LOAD_NAME 2 (b)11 INPLACE_ADD12 ROT_THREE13 STORE_SUBSCR14 LOAD_CONST 0 (None)17 RETURN_VALUE
Put the value of
s[a]onTOS(Top Of Stack).Perform
TOS += b. This succeeds ifTOSrefers to a mutable object (it’s a list, in Example 2-13).Assign
s[a] = TOS. This fails ifsis immutable (thettuple in Example 2-13).
This example is quite a corner case—in 20 years using Python, I have never seen this strange behavior actually bite somebody.
I take three lessons from this:
-
Avoid putting mutable items in tuples.
-
Augmented assignment is not an atomic operation—we just saw it throwing an exception after doing part of its job.
-
Inspecting Python bytecode is not too difficult, and can be helpful to see what is going on under the hood.
After witnessing the subtleties of using + and * for concatenation,
we can change the subject to another essential operation with sequences: sorting.
list.sort and the sorted Built-In Function
The list.sort method sorts a list in-place—that is, without making a copy.
It returns None to remind us that it changes the receiver7 and does not create a new list.
This is an important Python API convention: functions or methods that change an object in-place should return None to make it clear to the caller that the receiver was changed, and no new object was created.
Similar behavior can be seen, for example, in the random.shuffle(s) function,
which shuffles the mutable sequence s in-place, and returns None.
Note
The convention of returning None to signal in-place changes has a drawback: we cannot cascade calls to those methods.
In contrast, methods that return new objects (e.g., all str methods) can be cascaded in the fluent interface style.
See Wikipedia’s “Fluent interface” entry for further description of this topic.
In contrast, the built-in function sorted creates a new list and returns it.
In fact, it accepts any iterable object as an argument, including immutable sequences and generators (see [Link to Come]).
Regardless of the type of iterable given to sorted, it always returns a newly created list.
Both list.sort and sorted take two optional, keyword-only arguments:
reverse-
If
True, the items are returned in descending order (i.e., by reversing the comparison of the items). The default isFalse. key-
A one-argument function that will be applied to each item to produce its sorting key. For example, when sorting a list of strings,
key=str.lowercan be used to perform a case-insensitive sort, andkey=lenwill sort the strings by character length. The default is the identity function (i.e., the items themselves are compared).
Tip
The key optional keyword parameter can also be used with the min() and max() built-ins and with other functions from the standard library (e.g., itertools.groupby() and heapq.nlargest()).
Here are a few examples to clarify the use of these functions and keyword arguments. The examples also demonstrate that Timsort—the sorting algorithm used in Python—is stable (i.e., it preserves the relative ordering of items that compare equal)8:
>>>fruits=['grape','raspberry','apple','banana']>>>sorted(fruits)['apple', 'banana', 'grape', 'raspberry']>>>fruits['grape', 'raspberry', 'apple', 'banana']>>>sorted(fruits,reverse=True)['raspberry', 'grape', 'banana', 'apple']>>>sorted(fruits,key=len)['grape', 'apple', 'banana', 'raspberry']>>>sorted(fruits,key=len,reverse=True)['raspberry', 'banana', 'grape', 'apple']>>>fruits['grape', 'raspberry', 'apple', 'banana']>>>fruits.sort()>>>fruits['apple', 'banana', 'grape', 'raspberry']
This produces a new list of strings sorted alphabetically9.
Inspecting the original list, we see it is unchanged.
This is the previous “alphabetical” ordering, reversed.
A new list of strings, now sorted by length. Because the sorting algorithm is stable, “grape” and “apple,” both of length 5, are in the original order.
These are the strings sorted in descending order of length. It is not the reverse of the previous result because the sorting is stable, so again “grape” appears before “apple.”
So far, the ordering of the original
fruitslist has not changed.
This sorts the list in place, and returns
None(which the console omits).
Now
fruitsis sorted.
Warning
By default, Python sorts strings lexicographically by character code. That means ASCII uppercase letters will come before lowercase letters, and non-ASCII characters are unlikely to be sorted in a sensible way. “Sorting Unicode Text” covers proper ways of sorting text as humans would expect.
Once your sequences are sorted, they can be very efficiently searched.
Fortunately, the standard binary search algorithm is already provided in the bisect module of the Python standard library.
We discuss its essential features next, including the convenient bisect.insort function,
which you can use to make sure that your sorted sequences stay sorted.
Managing Ordered Sequences with bisect
The bisect module offers two main functions—bisect and insort—that use the binary search algorithm to quickly find and insert items in any sorted sequence.
Searching with bisect
bisect(haystack, needle) does a binary search for needle in haystack—which must be a sorted sequence—to locate the position where needle can be inserted while maintaining haystack in ascending order.
In other words, all items appearing up to that position are less than or equal to needle.
You could use the result of bisect(haystack, needle) as the index argument to haystack.insert(index, needle)—however, using insort does both steps, and is faster.
Tip
Raymond Hettinger wrote a SortedCollection recipe that leverages the bisect module and is easier to use than these standalone functions.
Example 2-15 uses a carefully chosen set of “needles” to demonstrate the insert positions returned by bisect.
Its output is in Figure 2-6.
Example 2-15. bisect finds insertion points for items in a sorted sequence
importbisectimportsysHAYSTACK=[1,4,5,6,8,12,15,20,21,23,23,26,29,30]NEEDLES=[0,1,2,5,8,10,22,23,29,30,31]ROW_FMT='{0:2d} @ {1:2d} {2}{0:<2d}'defdemo(bisect_fn):forneedleinreversed(NEEDLES):position=bisect_fn(HAYSTACK,needle)offset=position*'|'(ROW_FMT.format(needle,position,offset))if__name__=='__main__':ifsys.argv[-1]=='left':bisect_fn=bisect.bisect_leftelse:bisect_fn=bisect.bisect('DEMO:',bisect_fn.__name__)('haystack ->',''.join('%2d'%nforninHAYSTACK))demo(bisect_fn)
Use the chosen
bisectfunction to get the insertion point.Build a pattern of vertical bars proportional to the
offset.Print formatted row showing needle and insertion point.
Choose the
bisectfunction to use according to the last command-line argument.Print header with name of function selected.

Figure 2-6. Output of Example 2-15 with bisect in use—each row starts with the notation needle @ position and the needle value appears again below its insertion point in the haystack
The behavior of bisect can be fine-tuned in two ways.
First, a pair of optional arguments, lo and hi, allow narrowing the region in the sequence to be searched when inserting. lo defaults to 0 and hi to the len() of the sequence.
Second, bisect is actually an alias for bisect_right, and there is a sister function called bisect_left.
Their difference is apparent only when the needle compares equal to an item in the list: bisect_right returns an insertion point after the existing item, and bisect_left returns the position of the existing item, so insertion would occur before it.
With simple types like int, inserting before or after makes no difference,
but if the sequence contains objects that are distinct yet compare equal, then it may be relevant.
For example, 1 and 1.0 are distinct, but 1 == 1.0 is True. Figure 2-7 shows the result of using bisect_left.

Figure 2-7. Output of Example 2-15 with bisect_left in use (compare with Figure 2-6 and note the insertion points for the values 1, 8, 23, 29, and 30 to the left of the same numbers in the haystack).
An interesting application of bisect is to perform table lookups by numeric values—for example,
to convert test scores to letter grades, as in Example 2-16.
Example 2-16. Given a test score, grade returns the corresponding letter grade
>>>breakpoints=[60,70,80,90]>>>grades='FDCBA'>>>defgrade(score):...i=bisect.bisect(breakpoints,score)...returngrades[i]...>>>[grade(score)forscorein[55,60,65,70,75,80,85,90,95]]['F', 'D', 'D', 'C', 'C', 'B', 'B', 'A', 'A']
The code in Example 2-16 is from the bisect module documentation, which also lists functions to use bisect as a faster replacement for the index method when searching through long ordered sequences of numbers.
When used for table lookups, bisect_left produces very different results10.
Note the letter grade results in Example 2-17.
Example 2-17. bisect_left maps a score of 60 to grade F, not D as in Example 2-16.
>>>breakpoints=[60,70,80,90]>>>grades='FDCBA'>>>defgrade(score):...i=bisect.bisect_left(breakpoints,score)...returngrades[i]...>>>[grade(score)forscorein[55,60,65,70,75,80,85,90,95]]['F', 'F', 'D', 'D', 'C', 'C', 'B', 'B', 'A']
These functions are not only used for searching, but also for inserting items in sorted sequences, as the following section shows.
Inserting with bisect.insort
Sorting is expensive, so once you have a sorted sequence, it’s good to keep it that way.
That is why bisect.insort was created.
insort(seq, item) inserts item into seq so as to keep seq in ascending order.
See Example 2-18 and its output in Figure 2-8.
Example 2-18. Insort keeps a sorted sequence always sorted
importbisectimportrandomSIZE=7random.seed(1729)my_list=[]foriinrange(SIZE):new_item=random.randrange(SIZE*2)bisect.insort(my_list,new_item)(f'{new_item:2d}->{my_list}')

Figure 2-8. Output of Example 2-18
Like bisect, insort takes optional lo, hi arguments to limit the search to a sub-sequence.
There is also an insort_left variation that uses bisect_left to find insertion points.
Much of what we have seen so far in this chapter applies to sequences in general,
not just lists or tuples.
Python programmers sometimes overuse the list type because it is so handy—I know I’ve done it.
If you are handling lists of numbers, arrays are the way to go.
The remainder of the chapter is devoted alternatives to lists and tuples.
When a List Is Not the Answer
The list type is flexible and easy to use, but depending on specific requirements,
there are better options.
For example, an array saves a lot of memory when you need to store millions of floating-point values.
On the other hand, if you are constantly adding and removing items from opposite ends of a list,
it’s good to know that a deque (double-ended queue) is a more efficient FIFO data structure.
Tip
If your code frequently checks whether an item is present in a collection (e.g., item in my_collection),
consider using a set for my_collection, especially if it holds a large number of items.
Sets are optimized for fast membership checking.
But they are not sequences (their content is unordered).
We cover them in Chapter 3.
For the remainder of this chapter, we discuss mutable sequence types that can replace lists in many cases, starting with arrays.
Arrays
If a list will only contain numbers, an array.array is more efficient: it supports all mutable sequence operations (including .pop, .insert, and .extend), and additional methods for fast loading and saving such as .frombytes and .tofile.
A Python array is as lean as a C array.
As shown in Figure 2-1, an array of float values does not hold full-fledged float instances,
but only the packed bytes representing their machine values—similar to an array of double in the C language.
When creating an array, you provide a typecode, a letter to determine the underlying C type used to store each item in the array.
For example, b is the typecode for signed char.
If you create an array('b'), then each item will be stored in a single byte and interpreted as an integer from –128 to 127.
For large sequences of numbers, this saves a lot of memory.
And Python will not let you put any number that does not match the type for the array.
Example 2-19 shows creating, saving, and loading an array of 10 million floating-point random numbers.
Example 2-19. Creating, saving, and loading a large array of floats
>>>fromarrayimportarray>>>fromrandomimportrandom>>>floats=array('d',(random()foriinrange(10**7)))>>>floats[-1]0.07802343889111107>>>fp=open('floats.bin','wb')>>>floats.tofile(fp)>>>fp.close()>>>floats2=array('d')>>>fp=open('floats.bin','rb')>>>floats2.fromfile(fp,10**7)>>>fp.close()>>>floats2[-1]0.07802343889111107>>>floats2==floatsTrue
Import the
arraytype.Create an array of double-precision floats (typecode
'd') from any iterable object—in this case, a generator expression.Inspect the last number in the array.
Save the array to a binary file.
Create an empty array of doubles.
Read 10 million numbers from the binary file.
Inspect the last number in the array.
Verify that the contents of the arrays match.
As you can see, array.tofile and array.fromfile are easy to use.
If you try the example, you’ll notice they are also very fast.
A quick experiment shows that it takes about 0.1s for array.fromfile to load 10 million double-precision floats from a binary file created with array.tofile.
That is nearly 60 times faster than reading the numbers from a text file,
which also involves parsing each line with the float built-in.
Saving with array.tofile is about 7 times faster than writing one float per line in a text file.
In addition, the size of the binary file with 10 million doubles is 80,000,000 bytes (8 bytes per double, zero overhead), while the text file has 181,515,739 bytes, for the same data.
Tip
Another fast—but more flexible—way of saving numeric data is the pickle module for object serialization.
Saving an array of floats with pickle.dump is almost as fast as with array.tofile. However, pickle automatically handles almost all built-in types, including nested containers, and even instances of user-defined classes (if they are not too tricky in their implementation).
For the specific case of numeric arrays representing binary data, such as raster images,
Python has the bytes and bytearray types discussed in Chapter 4.
We wrap up this section on arrays with Table 2-2,
comparing the features of list and array.array.
| list | array | ||
|---|---|---|---|
|
● |
● |
|
|
● |
● |
|
|
● |
● |
Append one element after last |
|
● |
Swap bytes of all items in array for endianess conversion |
|
|
● |
Delete all items |
|
|
● |
● |
|
|
● |
Shallow copy of the list |
|
|
● |
Support for |
|
|
● |
● |
Count occurrences of an element |
|
● |
Optimized support for |
|
|
● |
● |
Remove item at position |
|
● |
● |
Append items from iterable |
|
● |
Append items from byte sequence interpreted as packed machine values |
|
|
● |
Append |
|
|
● |
Append items from list; if one causes |
|
|
● |
● |
|
|
● |
● |
Find position of first occurrence of |
|
● |
● |
Insert element |
|
● |
Length in bytes of each array item |
|
|
● |
● |
Get iterator |
|
● |
● |
|
|
● |
● |
|
|
● |
● |
|
|
● |
● |
|
|
● |
● |
Remove and return item at position |
|
● |
● |
Remove first occurrence of element |
|
● |
● |
Reverse the order of the items in place |
|
● |
Get iterator to scan items from last to first |
|
|
● |
● |
|
|
● |
Sort items in place with optional keyword arguments |
|
|
● |
Return items as packed machine values in a |
|
|
● |
Save items as packed machine values to binary file |
|
|
● |
Return items as numeric objects in a |
|
|
● |
One-character string identifying the C type of the items |
|
a Reversed operators are explained in [Link to Come]. | |||
Tip
As of Python 3.8, the array type does not have an in-place sort method like list.sort().
If you need to sort an array, use the sorted function to rebuild it sorted:
a=array.array(a.typecode,sorted(a))
To keep a sorted array sorted while adding items to it, use the bisect.insort function (as seen in “Inserting with bisect.insort”).
If you do a lot of work with arrays and don’t know about memoryview,
you’re missing out. See the next topic.
Memory Views
The built-in memoryview class is a shared-memory sequence type that lets you handle slices of arrays without copying bytes.
It was inspired by the NumPy library (which we’ll discuss shortly in “NumPy”).
Travis Oliphant, lead author of NumPy, answers When should a memoryview be used? like this:
A memoryview is essentially a generalized NumPy array structure in Python itself (without the math). It allows you to share memory between data-structures (things like PIL images, SQLlite databases, NumPy arrays, etc.) without first copying. This is very important for large data sets.
Using notation similar to the array module, the memoryview.cast method lets you change the way multiple bytes are read or written as units without moving bits around. memoryview.cast returns yet another memoryview object, always sharing the same memory.
Example 2-20 shows how to create alternate views on the same array of 6 bytes, to operate on it as 2×3 matrix or a 3×2 matrix:
Example 2-20. Handling 6 bytes memory of as 1×6, 2×3, and 3×2 views
>>>fromarrayimportarray>>>octets=array('B',range(6))>>>m1=memoryview(octets)>>>m1.tolist()[0, 1, 2, 3, 4, 5]>>>m2=m1.cast('B',[2,3])>>>m2.tolist()[[0, 1, 2], [3, 4, 5]]>>>m3=m1.cast('B',[3,2])>>>m3.tolist()[[0, 1], [2, 3], [4, 5]]>>>m2[1,1]=22>>>m3[1,1]=33>>>octetsarray('B', [0, 1, 2, 33, 22, 5])
Build array of 6 bytes (typecode
'B').Build
memoryviewfrom that array, then export it as list.Build new
memoryviewfrom that previous one, but with 2 rows and 3 columns.Yet another
memoryview, now with 3 rows and 2 columns.Ovewrite byte in
m2at row 1, column 1 with 22.Ovewrite byte in
m3at row 1, column 1 with 33.Display original array, proving that the memory was shared among
octets,m1,m2, andm3.
Indexing a memoryview using a tuple—as in the expression m2[1,1] above—is a feature that was added in Python 3.5.
The awesome power of memoryview can also be used to corrupt.
Example 2-21 shows how to change a single byte of an item in an array of 16-bit integers.
Example 2-21. Changing the value of an 16-bit integer array item by poking one of its bytes
>>>numbers=array.array('h',[-2,-1,0,1,2])>>>memv=memoryview(numbers)>>>len(memv)5>>>memv[0]-2>>>memv_oct=memv.cast('B')>>>memv_oct.tolist()[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]>>>memv_oct[5]=4>>>numbersarray('h', [-2, -1, 1024, 1, 2])
Build
memoryviewfrom array of 5 16-bit signed integers (typecode'h').memvsees the same 5 items in the array.Create
memv_octby casting the elements ofmemvto bytes (typecode'B').Export elements of
memv_octas a list of 10 bytes, for inspection.Assign value 4 to byte offset 5.
Note change to
numbers: a 4 in the most significant byte of a 2-byte unsigned integer is 1024.
We’ll see another short example with memoryview in the context of binary sequence manipulations with struct (Chapter 4, Example 5-25).
Meanwhile, if you are doing advanced numeric processing in arrays, you should be using the NumPy libraries. We’ll take a brief look at them right away.
NumPy
Throughout this book, I make a point of highlighting what is already in the Python standard library so you can make the most of it. But NumPy is so awesome that a detour is warranted.
For advanced array and matrix operations, NumPy is the reason why Python became mainstream in scientific computing applications. NumPy implements multi-dimensional, homogeneous arrays and matrix types that hold not only numbers but also user-defined records, and provides efficient elementwise operations.
SciPy is a library, written on top of NumPy, offering many scientific computing algorithms from linear algebra, numerical calculus, and statistics. SciPy is fast and reliable because it leverages the widely used C and Fortran code base from the Netlib Repository. In other words, SciPy gives scientists the best of both worlds: an interactive prompt and high-level Python APIs, together with industrial-strength number-crunching functions optimized in C and Fortran.
As a very brief NumPy demo, Example 2-22 shows some basic operations with two-dimensional arrays.
Example 2-22. Basic operations with rows and columns in a numpy.ndarray
>>>importnumpyasnp>>>a=np.arange(12)>>>aarray([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])>>>type(a)<class 'numpy.ndarray'>>>>a.shape(12,)>>>a.shape=3,4>>>aarray([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])>>>a[2]array([ 8, 9, 10, 11])>>>a[2,1]9>>>a[:,1]array([1, 5, 9])>>>a.transpose()array([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
Import NumPy, after installing (it’s not in the Python standard library). Conventionally,
numpyis imported asnp.Build and inspect a
numpy.ndarraywith integers 0 to 11.Inspect the dimensions of the array: this is a one-dimensional, 12-element array.
Change the shape of the array, adding one dimension, then inspecting the result.
Get row at index
2.Get element at index
2, 1.Get column at index
1.Create a new array by transposing (swapping columns with rows).
NumPy also supports high-level operations for loading, saving, and operating on all elements of a numpy.ndarray:
>>>importnumpy>>>floats=numpy.loadtxt('floats-10M-lines.txt')>>>floats[-3:]array([ 3016362.69195522, 535281.10514262, 4566560.44373946])>>>floats*=.5>>>floats[-3:]array([ 1508181.34597761, 267640.55257131, 2283280.22186973])>>>fromtimeimportperf_counteraspc>>>t0=pc();floats/=3;pc()-t00.03690556302899495>>>numpy.save('floats-10M',floats)>>>floats2=numpy.load('floats-10M.npy','r+')>>>floats2*=6>>>floats2[-3:]memmap([ 3016362.69195522, 535281.10514262, 4566560.44373946])
Load 10 million floating-point numbers from a text file.
Use sequence slicing notation to inspect the last three numbers.
Multiply every element in the
floatsarray by .5 and inspect the last three elements again.Import the high-resolution performance measurement timer (available since Python 3.3).
Divide every element by 3; the elapsed time for 10 million floats is less than 40 milliseconds.
Save the array in a .npy binary file.
Load the data as a memory-mapped file into another array; this allows efficient processing of slices of the array even if it does not fit entirely in memory.
Inspect the last three elements after multiplying every element by 6.
Tip
Installing NumPy and SciPy from source may be challenging. The Installing the SciPy Stack page on SciPy.org recommends using special scientific Python distributions such as Anaconda, Enthought Canopy, and WinPython, among others. These are large downloads, but come ready to use. Users of popular GNU/Linux distributions can usually find NumPy and SciPy in the standard package repositories. For example, you can use this command to install them on Ubuntu:
$ sudo apt install python3-numpy python3-scipyThis was just an appetizer.
NumPy and SciPy are formidable libraries, and are the foundation of other awesome tools such as the Pandas—which implements efficient array types that can hold nonnumeric data and provides import/export functions for many different formats like .csv, .xls, SQL dumps, HDF5, etc.—and Scikit-learn—currently the most widely used Machine Learning toolset. Most NumPy and SciPy functions are implemented in C or C++, and can leverage all CPU cores because they release Python’s GIL (Global Interpreter Lock). The Dask project supports parallelizing NumPy, Pandas, and Scikit-Learn processing across clusters of machines. These packages deserve entire books about them. This is not one of those books. But no overview of Python sequences would be complete without at least a quick look at NumPy arrays.
Having looked at flat sequences—standard arrays and NumPy arrays—we now turn to a completely different set of replacements for the plain old list: queues.
Deques and Other Queues
The .append and .pop methods make a list usable as a stack or a queue (if you use .append and .pop(0), you get FIFO behavior).
But inserting and removing from the head of a list (the 0-index end) is costly because the entire list must be shifted in memory.
The class collections.deque is a thread-safe double-ended queue designed for fast inserting and removing from both ends.
It is also the way to go if you need to keep a list of “last seen items” or something like that,
because a deque can be bounded—i.e., created with a fixed maximum length—and then, when it is full,
it discards items from the opposite end when you add new ones. Example 2-23 shows some typical operations performed on a deque.
Example 2-23. Working with a deque
>>>fromcollectionsimportdeque>>>dq=deque(range(10),maxlen=10)>>>dqdeque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)>>>dq.rotate(3)>>>dqdeque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)>>>dq.rotate(-4)>>>dqdeque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)>>>dq.appendleft(-1)>>>dqdeque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)>>>dq.extend([11,22,33])>>>dqdeque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)>>>dq.extendleft([10,20,30,40])>>>dqdeque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
The optional
maxlenargument sets the maximum number of items allowed in this instance ofdeque; this sets a read-onlymaxleninstance attribute.Rotating with
n > 0takes items from the right end and prepends them to the left; whenn < 0items are taken from left and appended to the right.Appending to a
dequethat is full (len(d) == d.maxlen) discards items from the other end; note in the next line that the0is dropped.Adding three items to the right pushes out the leftmost
-1,1, and2.Note that
extendleft(iter)works by appending each successive item of theiterargument to the left of the deque, therefore the final position of the items is reversed.
Table 2-3 compares the methods that are specific to list and deque (removing those that also appear in object).
Note that deque implements most of the list methods, and adds a few specific to its design,
like popleft and rotate.
But there is a hidden cost: removing items from the middle of a deque is not as fast.
It is really optimized for appending and popping from the ends.
The append and popleft operations are atomic, so deque is safe to use as a FIFO queue in multithreaded applications without the need for using locks.
| list | deque | ||
|---|---|---|---|
|
● |
|
|
|
● |
● |
|
|
● |
● |
Append one element to the right (after last) |
|
● |
Append one element to the left (before first) |
|
|
● |
● |
Delete all items |
|
● |
|
|
|
● |
Shallow copy of the list |
|
|
● |
Support for |
|
|
● |
● |
Count occurrences of an element |
|
● |
● |
Remove item at position |
|
● |
● |
Append items from iterable |
|
● |
Append items from iterable |
|
|
● |
● |
|
|
● |
Find position of first occurrence of |
|
|
● |
Insert element |
|
|
● |
● |
Get iterator |
|
● |
● |
|
|
● |
|
|
|
● |
|
|
|
● |
|
|
|
● |
● |
Remove and return last itemb |
|
● |
Remove and return first item |
|
|
● |
● |
Remove first occurrence of element |
|
● |
● |
Reverse the order of the items in place |
|
● |
● |
Get iterator to scan items from last to first |
|
● |
Move |
|
|
● |
● |
|
|
● |
Sort items in place with optional keyword arguments |
|
a Reversed operators are explained in [Link to Come]. b | |||
Besides deque, other Python standard library packages implement queues:
queue-
This provides the synchronized (i.e., thread-safe) classes
SimpleQueue,Queue,LifoQueue, andPriorityQueue. These can be used for safe communication between threads. All exceptSimpleQueuecan be bounded by providing amaxsizeargument greater than 0 to the constructor. However, they don’t discard items to make room asdequedoes. Instead, when the queue is full the insertion of a new item blocks—i.e., it waits until some other thread makes room by taking an item from the queue, which is useful to throttle the number of live threads. multiprocessing-
Implements its own unbounded
SimpleQueueand boundedQueue, very similar to those in thequeuepackage, but designed for interprocess communication. A specializedmultiprocessing.JoinableQueueis also available for easier task management. asyncio-
Provides
Queue,LifoQueue,PriorityQueue, andJoinableQueuewith APIs inspired by the classes in thequeueandmultiprocessingmodules, but adapted for managing tasks in asynchronous programming. heapq-
In contrast to the previous three modules,
heapqdoes not implement a queue class, but provides functions likeheappushandheappopthat let you use a mutable sequence as a heap queue or priority queue.
This ends our overview of alternatives to the list type, and also our exploration of sequence types in general—except for the particulars of str and binary sequences, which have their own chapter (Chapter 4).
Chapter Summary
Mastering the standard library sequence types is a prerequisite for writing concise, effective, and idiomatic Python code.
Python sequences are often categorized as mutable or immutable, but it is also useful to consider a different axis: flat sequences and container sequences. The former are more compact, faster, and easier to use, but are limited to storing atomic data such as numbers, characters, and bytes. Container sequences are more flexible, but may surprise you when they hold mutable objects, so you need to be careful to use them correctly with nested data structures.
Unfortunately, Python has no foolproof immutable container sequence type: even “immutable” tuples can have their values change, when they contain mutable items like lists or user-defined objects.
List comprehensions and generator expressions are powerful notations to build and initialize sequences. If you are not yet comfortable with them, take the time to master their basic usage. It is not hard, and soon you will be hooked.
Tuples in Python play two roles: as records with unnamed fields and as immutable lists.
When a tuple is used as a record, tuple unpacking is the safest,
most readable way of getting at the fields.
The new * syntax makes tuple unpacking even better by making it easier to ignore some fields and to deal with optional fields.
When using a tuple as an immutable list, remember that a tuple value is only garanteed to be fixed if all the items in it are also immutable.
Calling hash(t) on a tuple is a quick way to assert that its value is fixed.
A TypeError will be raised if t contains mutable items.
Sequence slicing is a favorite Python syntax feature, and it is even more powerful than many realize.
Multidimensional slicing and ellipsis (...) notation, as used in NumPy,
may also be supported by user-defined sequences.
Assigning to slices is a very expressive way of editing mutable sequences.
Repeated concatenation as in seq*n is convenient and, with care,
can be used to initialize lists of lists containing immutable items.
Augmented assignment with += and *= behaves differently for mutable and immutable sequences.
In the latter case, these operators necessarily build new sequences.
But if the target sequence is mutable, it is usually changed in place—but not always,
depending on how the sequence is implemented.
The sort method and the sorted built-in function are easy to use and flexible,
thanks to the key optional argument they accept, with a function to calculate the ordering criterion.
By the way, key can also be used with the min and max built-in functions.
To keep a sorted sequence in order, always insert items into it using bisect.insort; to search it efficiently, use bisect.bisect.
Beyond lists and tuples, the Python standard library provides array.array.
Although NumPy and SciPy are not part of the standard library,
if you do any kind of numerical processing on large sets of data,
studying even a small part of these libraries can take you a long way.
We closed by visiting the versatile and thread-safe collections.deque,
comparing its API with that of list in Table 2-3 and mentioning other queue implementations in the standard library.
Further Reading
Chapter 1, “Data Structures” of Python Cookbook, 3rd Edition (O’Reilly) by David Beazley and Brian K. Jones has many recipes focusing on sequences, including “Recipe 1.11. Naming a Slice,” from which I learned the trick of assigning slices to variables to improve readability, illustrated in our Example 2-9.
The second edition of Python Cookbook was written for Python 2.4, but much of its code works with Python 3, and a lot of the recipes in Chapters 5 and 6 deal with sequences. The book was edited by Alex Martelli, Anna Martelli Ravenscroft, and David Ascher, and it includes contributions by dozens of Pythonistas. The third edition was rewritten from scratch, and focuses more on the semantics of the language—particularly what has changed in Python 3—while the older volume emphasizes pragmatics (i.e., how to apply the language to real-world problems). Even though some of the second edition solutions are no longer the best approach, I honestly think it is worthwhile to have both editions of Python Cookbook on hand.
The official Python Sorting HOW TO has several examples of advanced tricks for using sorted and list.sort.
PEP 3132 — Extended Iterable Unpacking is the canonical source to read about the new use of *extra syntax on the left hand of parallel assignments.
If you’d like a glimpse of Python evolving, Missing *-unpacking generalizations is a bug tracker that proposed enhancements to the iterable unpacking notation. PEP 448 — Additional Unpacking Generalizations resulted from the discussions in that issue. The proposed were merged into Python 3.5, after the first edition of this book was printed.
Raymond Hettinger’s response to Are tuples more efficient than lists in Python? on StackOverflow is great, but does not mention that tuple(t) returns t only if it is a hashable tuple. When t is unhashable, tuple(t) returns a shallow copy of t. Also, implementation details may have changed since that answer was posted in 2014. In particular, I found much smaller space savings with sys.getsizeof using the same example tuple and list objects as Hettinger did. Artem Golubin wrote a blog post on the same subject, titled Optimization tricks in Python: lists and tuples, last updated in April, 2018 as I write this.
Eli Bendersky’s blog post “Less Copies in Python with the Buffer Protocol and memoryviews includes a short tutorial on memoryview.
There are numerous books covering NumPy in the market, and many don’t mention “NumPy” in the title. Two examples are the open access Python Data Science Handbook by Jake VanderPlas, and Wes McKinney’s Python for Data Analysis, 2e.
“NumPy is all about vectorization”. That is the opening sentence of Nicolas P. Rougier’s open access book From Python to NumPy. Vectorized operations apply mathematical functions to all elements of an array without an explicit loop written in Python. They can operate in parallel, using special vector instructions in modern CPUs, leveraging multiple cores or delegating to the GPU, depending on the library. The first example in Rougier’s book shows a speedup of 500 times after refactoring a nice Pythonic class using a generator method, into a lean and mean function calling a couple of NumPy vector functions.
Fernando Pérez—a physicist—created IPython, a powerful replacement for the Python console that also provides a GUI, integrated inline graph plotting, literate programming support (interleaving text with code), and rendering to PDF. Interactive, multimedia IPython sessions can be shared over HTTP as Jupyter notebooks. See screenshots and video at The IPython Notebook. IPython was so succesful that the project received millions of dollars in grants from the Sloan Foundation and other research institutions to hire full-time developers to enhance it. That effort resulted in Project Jupyter and the new JupyterLab web-based IDE released in July, 2019. Scientists love the combination of Python’s elegant power, Jupyter’s interactivity, and the strenghts of NumPy/SciPy. That’s what made Python one of the top languages in scientific computing, paving the way for its success in the field of Machine Learning.
To learn how to use deque (and other collections) see the examples and practical recipes in
8.3.
collections — Container datatypes in the Python documentation.
The best defense of the Python convention of excluding the last item in ranges and slices was written by Edsger W.
Dijkstra himself, in a short memo titled “Why Numbering Should Start at Zero”.
The subject of the memo is mathematical notation, but it’s relevant to Python because
Dijkstra explains with rigor and humor why a sequence like 2, 3, …,
12 should always be expressed as 2 ≤ i < 13.
All other reasonable conventions are refuted, as is the idea of letting each user choose a convention.
The title refers to zero-based indexing, but the memo is really about why it is desirable that 'ABCDE'[1:3] means 'BC' and not 'BCD' and why it makes perfect sense to write range(2, 13) to produce 2, 3, 4, …, 12.
By the way, the memo is a handwritten note, but it’s beautiful and totally readable.
Dijkstra handwriting is so clear that someone created a font out of his notes.
1 Leo Geurts, Lambert Meertens, and Steven Pemberton, ABC Programmer’s Handbook, p. 8.
2 In “Memory Views” we show that especially constructed memory views can have more than one dimension.
3 No, I did not get this backwards: the ellipsis class name is really all lowercase and the instance is a built-in named Ellipsis, just like bool is lowercase but its instances are True and False.
4 str is an exception to this description. Because string building with += in loops is so common in the wild, CPython is optimized for this use case. str instances are allocated in memory with room to spare, so that concatenation does not require copying the whole string every time.
5 Thanks to Leonardo Rochael and Cesar Kawakami for sharing this riddle at the 2013 PythonBrasil Conference.
6 A reader suggested that the operation in the example can be done with t[2].extend([50,60]), without errors. I am aware of that, but my intent is to show the strange behavior of the += operator in this case.
7 Receiver is the target of a method call, the object bound to self in the method body.
8 For a bit of Timsort trivia, see the optional sidebar “Soapbox”.
9 The words in this example are sorted alphabetically because they are 100% made of lowercase ASCII characters. See warning after the example.
10 Thanks to reader Gregory Sherman for pointing this out.