
All life is an experiment. The more experiments you make the better.
—Ralph Waldo Emerson
After an overview of the most famous front-end architectures and their implementations, it’s time to dig into the main topic of this book: Reactive Programming with JavaScript.
I watched many videos and read many articles and books on the argument, and I have to admit that often I had the impression that something was missing, like we were just scratching the surface instead of going in depth inside the Reactive ecosystem.
The main aim of this chapter is to provide all the tools needed for understanding Reactive Programming more than focusing on a single library, embracing the concepts behind this programming paradigm. This should allow us to embrace any reactive library without the need to invest too much time for switching our mindset.
I often saw developers embracing a specific library or framework and being real ninjas with them, but once moved away, they struggled with approaching different implementations – mainly because they didn’t understand what there was behind the implementation.
Understanding the core principles of the reactive paradigm will allow you to master any library or framework independently from the different implementations without treating just as a “black box .”
There are many reactive libraries available in the open source ecosystem and, we are going to discuss the most famous like Rx.JS and XStream. After that we are going to understand the key principles of Reactive programming such as what is a stream, the difference between hot and cold observables, and back pressure.
Unfortunately, reactive programming has a high learning curve mainly due to the concepts it is leveraging, but once you get used to them, you will start reasoning in a reactive way for everything without any issue.
Reactive Programming 101
First and foremost, implementing reactive programming means working mainly with events streams , but in order to understand what an event stream is, we should start with a simple diagram for better understanding how a stream works.

Marble diagram representation example
It’s very important to understand how it works because often in the documentation you can understand how the APIs work by just looking at the diagram without the need to read the full explanation.
Also, marble diagrams are useful during the testing phase because when we need to simulate an event stream, we will use them against our event stream implementation. But let’s see what they are so we can understand better the concept of event stream.
In a marble diagram, we can spot a horizontal line representing the time (our stream), and the value inside the colorful circles are events that are happening at a certain point in time in our application (events).
The vertical line, instead, represents the end of our stream, after that point the stream is completed.
After the application started, a stream emits the value 4.
After a certain amount of time, the stream emits the value 1 and right after 3.
After all these events, the stream was completed.

Marble diagram with error
The last bit to mention is when we apply transformation to the values inside a stream via operators.
An operator is a method that allows us to manipulate the data in a stream or the stream itself.

Marble diagram with map operator applied to an initial stream that returns a new stream with data manipulated
Until now, we understood that an event stream is a sequence of values (events) passed in a certain period (stream).
We can then assume that everything inside an application could be a stream, and in a certain way it’s exactly what the reactive paradigm is leveraging: we can transform listeners with callbacks in event streams, we can wrap an http request in a stream and handle the response by manipulating the data before updating a view, and we can use streams as communication channels for passing data between two or more objects, and many other use cases.
In the reactive panorama we need to introduce a particular type of stream: the observable.
An Observable is a lazily evaluated computation that can synchronously or asynchronously return zero to (potentially) infinite values from the time it’s invoked onwards. ( http://bit.ly/2sWVEAf )
In order to consume data emitted by an observable, we need to create an observer (consumer); this subscribes to the observable and reacts every time a value is emitted by the observable (producer).
If we want to summarize in technical words what an observable is, we could say that an observable is an object that wrap some data consumed by an observer (an object with a specific contract) and once instantiated provides a cancellation function.
The observer is an object that allows us to retrieve the value emitted by an observable and has a specific contract exposing three methods: next, error, and complete functions.
When you deal with observables and observers bear in mind two well-known design patterns for fully understand their mechanisms: the observer and the iterator patterns.
Observer Pattern
The Observer Pattern is a behavioral pattern where an object called Subject maintains a list of other objects (observers) that want to be notified when a change happens inside the program.
The observers are usually subscribing to a change and then every time they receive a notification, they verify internally if they need to handle the notification or not.
Usually, in typed languages, the Observer Pattern is composed by a subject and one or multiple observers.

Observer Pattern UML
Iterator Pattern
The Iterator Pattern is a behavioral pattern used for traversing a data container like an array or an object, for instance.
As JavaScript developers, we should be familiar with this pattern, considering it was added in ECMAScript 2015.
This pattern allows an object to be traversed calling a method (next) for retrieving a subsequent value from the current one if it exists. The iterator pattern usually exposes the next method and the hasNext method that returns a Boolean used for checking if the object traversed contains more values or not.

Iterator Pattern UML
Putting the Code into Practice
Let’s create an example by walking through the code for a better understanding of how an observable/observer relation works in practice:
As you can see from this first example in the first line we have created an observable that contains a range of values from 1 to 10; that means we have these values ready to be emitted to an observer when the observer will subscribe to it.
On the second line we subscribe to the observable; the subscribe method in many libraries has three parameters that correspond to callbacks called once the observable is emitting a value, an error, or a complete signal.
In the rest of the code we are just reacting to the information emitted by the observable printing to the console an output that could be either an event from the stream or an error or the complete signal.
When an observable receives events can also allow us to manipulate the data for providing a different output from them like we have seen previously in the marble diagram where we were mapping each single value emitted, increasing by 1 each of them.
Different Reactive libraries are providing different sets of utilities, but the most complete one when the book was written is without any doubt Rx.js. This library provides a set of operators for manipulating not only the events emitted by the observable but also with other observables; it is not unusual to transform observable of observables in flat observables: think about them as an array of arrays. These operators will allow us to flat the object nesting accessing directly to the values in the observables without the iteration complexity.
We are going to see the possibilities offered by operators in the next section when we explore the different Reactive libraries so we can understand in practice how to use it and what we can do with them. Obviously, we will review only the most used ones because there are literally hundreds and our focus is on understanding the mechanism behind them more than exploring the entire library.
Stream Implementations
Now that we understood what streams are, it’s time to get a better understanding of what is available in the front-end reactive ecosystem. The first library we are going to take into consideration is Rx.JS 5.
Rx.JS
Rx.JS is the most famous and used reactive library at the moment; it’s used almost everywhere, from Angular 2 where the library is integrated inside the framework to many other smaller or larger frameworks that are embracing this library and leveraging its power.
It’s one of the most complete reactive libraries with many operators and a great documentation, Rx.JS is part of Reactive Extensions ( http://reactivex.io ). Learning it will mean being able to switch from one language to another using the same paradigm and often the same APIs.
Rx.JS can be used on front-end applications as well on back-end ones with Node.js ; obviously its asynchronous nature will help out on both sides of an application’s development.
There are two main versions available. Version 4 is the first JavaScript porting of the Reactive Extension, and then recently another implementation started to rise up that is version 5. The two libraries have several differences in our examples and so we will use version 5.
In this section, we won’t be able to play with all the operators available on Rx.JS because this library is broad enough for having its own book (in fact, there are many books available that I strongly suggest you give a go). Our main aim is to grasp a few key concepts, considering we are going to use it in many other examples in this and the next chapters.
When we need to reduce our data for retrieving a final value.
When we retrieve data from an HTTP endpoint.
When we need to communicate with multiple objects via observables.
Considering how large Rx.JS is, we introduce another important concept such as the difference between hot and cold observables, to help to understand better how the other libraries work.
Let’s start with a simple example on reducing an array of data and retrieve the sum of values filtering the duplicates present in the initial array .
As you can see in the example above, we are converting an array of numbers to an observable (Rx.Observable.from(data)), then we start to transform the values inside the array step by step, applying multiple transformations.
In fact, first we are filtering the values creating a new array containing only the even numbers, then we remove all the duplicates inside the array with the distinct operator provided by Rx.JS; and finally we sum the values inside the array with the reduce operator.

Final result returned by the previous snippet with Rx.JS
Every time we are applying a transformation via an operator, we are creating a new observable that is returned at the end of the operation.
This means we can concatenate multiple operators by applying several transformations to the same data source.
In order to output the final result of our observable, we are subscribing to the observable with the subscribe method, and this method accepts three functions. The first one is triggered every time the observable emits data, the second one if the observable emits an error, and the last one is triggered once the observable receives a complete signal from the producer (in our case, the end of the array).
Remember that these callbacks are not all mandatory; we can potentially skip to declare the error and complete callbacks if we don’t need to react to these events.
Imagine for a moment how you would implement the same logic in imperative programming… done it?
Ok, now you probably understood how functional and reactive paradigms can help to express complex operations in few lines of code, having a clear idea of what’s happening, without storing temporary values anywhere, and without generating any side effects. Everything is contained inside the observables and cannot be modified from external operations.
The next example, instead, aims to retrieve the response from an API on the Web and then propagate the result to a hypothetical view.
In this case we won’t use any specific architecture but we are going to work well with the single responsibility principle and good encapsulation .
After creating the constant with the URL to consume, we are creating a method (simplifyUserData) for filtering the data we want to use in our application, by just returning a subset of the information instead of the entire record retrieved from that URL.
The endpoint used is a public endpoint usually used for mocking data, but in our case we are going to receive an array of objects that looks like this:
We want to consume this endpoint every second but only twice during the application life cycle.
In order to do that we create an observable with an interval of a second (Rx.Observable.interval), specifying how many times we want to perform this operation (take operator) and then we want to fetch the data from a URL (first mergeMap) and then return the data fetched as JSON, splitting the object retrieved (mergeAll operator, we could have use other operators like concatAll, for instance, obtaining the same result) in order to emit a value per time instead of the entire array in one go. Finally we simplify the data with the method we created at the beginning of the script (map operator).
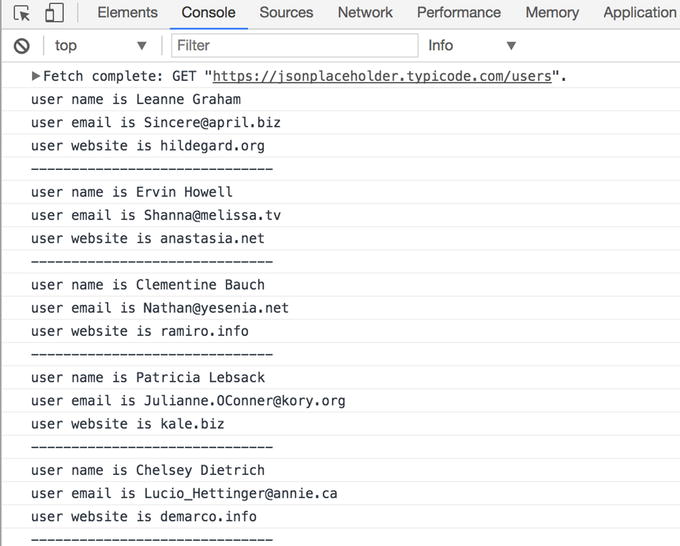
Output of previous example with Rx.JS
Now we need to understand in depth why we have done all these operations for manipulating the data to get the result displayed in the screenshot above.
This is because fetch is a Promise A+ and these promises are recognized by Rx.JS, so without the need of using the fromPromise operators like the standard promises, we can use them straightaway inside our Observable created by the mergeMap operator.
MergeMap is an operator that is doing two things. The first one is merging two streams in a unique one and then iterating with the values emitted inside the streams: in this case it’s flatting the promise in order to return just a stream with the service response.
The second mergeMap operator is used with another promise and we are specifying the return value emitted in that stream should be the JSON representation of the data fetched from the endpoint.
This second promise is due to the fetch API contract as you can see in the MDN specifications : http://bit.ly/2sWVEAf .
The last operator is the mergeAll one, which usually should be used for merging all the observables inside an observable of observables, but in this case, it is flatting the last promise containing the array with the data retrieved and emitting each single value of the array in an iterative way instead of emitting the entire array as a unique value, allowing us to use the final operator (map) for simplifying the data emitted.
It’s easy to understand how versatile and powerful Rx.JS could be in a situation like this one. Obviously at this stage we know that there is some work to do to get familiar with all the different operators offered by Rx.JS, but don’t be too sad because it’s a step we all have done before mastering the reactive paradigm.
Before reviewing another chunk of code, we need to explain another key concept of the observables: what it means when an observable is hot or cold.
Hot and Cold Observables
We can have two different types of observables: hot and cold.
A cold observable is lazy and unicast by nature; it starts to emit values only when someone subscribes to it.
Instead, the hot observables could emit events also before someone is listening without the need to wait for a trigger for starting its actions; also they are multicast by design.
Another important characteristic that we should understand for recognizing hot and cold observables is to understand how the producer is handled in both scenarios.
In cold observables, the producer lives inside the observable itself; therefore every time we subscribe to a cold observable, the producer is created again and again.
Instead, in the hot observable the producer is unique and shared across multiple observers; therefore we will receive fresh values every time we are subscribing to it without receiving all of them since the first value emitted. Obviously, there are ways in hot observables to create a buffer of values to emit every time an observer is subscribing to it, but we are not going to evaluate each single scenario right now.
Let’s see a hot and a cold observable in action for having a better understanding of how to use these two types of objects using Rx.JS.
Cold Observables
The best way to understand a cold observable is seeing it in action:

Output of cold observable with Rx.JS
In this example we are creating an observable that is emitting a sequential value every 2 seconds: it will start from 0 until infinite because we didn’t specify how many values we want to emit before the event streams is completed.
We use the startWith operator when we want to show an initial value in our user interface or to start a sequence of events without waiting for the values passed asynchronously.
In a cold observable we have the producer, in this case the observable emitting sequential numbers, which is instantiated three times – basically any time a consumer is subscribing to it. In the image above you can clearly see the sequence of numbers is starting every time a consumer is subscribing to the producer.
We can conclude that the cold observable re-instantiates the producer any time a consumer is subscribing and it is unicast so the values produced are listened by a consumer per time; also we can have multiple consumers subscribing to the same producer.
By default all the observables we create in Rx.JS are cold but we have different ways for transforming them into hot observables.
Hot Observables
Let’s see what a hot observable looks like:
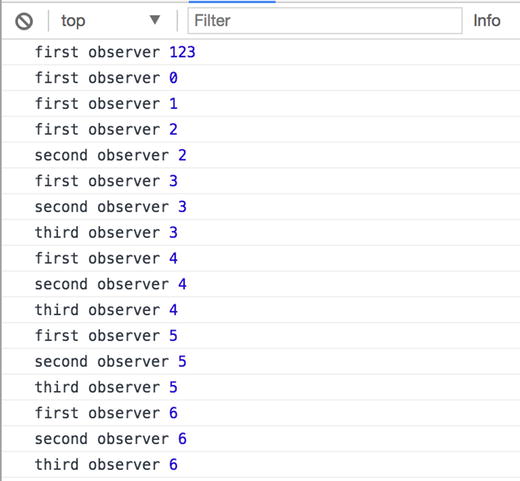
Output of hot observable with Rx.JS
Publish operator is useful to transform our cold observables to hot observables because it returns a ConnectableObservable instead and observable object.
A ConnectableObservable starts emitting values only when a connect method is called or, like in our example, when we use refCount operator.
RefCount operator is used when we don’t need to control the start and stop of the ConnectableObservable but instead we automate this process; when a consumer subscribes to a ConnectableObservable, it is the logic provided by refCount that will trigger the connect method for emitting the values to the subscribers.
Also the refCount logic will unsubscribe once there are any subscribers ready for receiving new values.
When we have a hot observable the producer becomes multicast and the values emitted are shared across all the subscribers but at the same time we need to remember that by default, it’s not waiting for any consumer to subscribe. Instead it is emitting values immediately after the connect method is called.
There are operators that will allow you to control when a hot observable starts to emit values like multicast and connect instead of refCount, which is automating these steps. Just keep this in mind when you work with Rx.JS because there are many opportunities available with this great library so keep an eye on the documentation and the implementation will become very smooth.
Understanding what we are subscribing to and what are the characteristics and benefits of a hot or a cold observable could save a lot of debugging time and many headaches once our code hits the production stage.
I think it is clear that Rx.JS is not just that – it’s way more than that but with these simple examples we are trying to memorize a few useful key concepts that will facilitate the integration of this library in our existing or new applications.
Now it’s time to see another reactive library flavor with XStream. It’s important to understand that the concepts showed in the Rx.JS sections are very similar in other libraries; therefore owning them will allow you to pick the right library for the a project.
XStream
XStream is one of the most recent reactive libraries created by André Staltz for providing a simple way to approach reactive programming tailored specifically for Cycle.js.
XStream leverages a few concepts that we have already seen in action with Rx.JS like the observables but by simplifying the core concepts behind streams. All the streams are hot observables and there isn’t a way to create cold observables with this library.
I personally think the author took into consideration the reactive programming learning curve when he worked on this library, and he tried smoothing out the entry level in order to be more approachable by newbies and experts as well.
On top, XStream is very fast, second only to Most.js (another reactive library), and very light too, around 30kb; and with less than 30 operators available, it represents a super basic library for dealing with observables, perfect for any prototype or project that requires the use of observables but without all the “commodities ” offered by other libraries with plenty of operators.
XStream is using instead of observables the streams concepts , which are event emitters with multiple listeners. A listener is an object with a specific contract, and it has three public methods: next, error, and complete; as the name suggests, a listener object is listening to events emitted by a stream.
Comparing streams and listeners to Rx.JS observables and observers, we can say that a stream is acting like a hot observable and the listener like an observer mimicking the same implementation.
Last but not least, in XStream we can use producers for generating events broadcasted via a stream to multiple objects. The producer controls the life cycle of the stream emitting the values at its convenience. A producer has a specific signature, and it exposes two main methods: start and stop. We will see later an example that will introduce the producer concept.
Now it’s time to see XStream in action, porting the examples we have approached previously during the Rx.JS section.
The first example is related to reducing an array of values that extracts just the even numbers, removing the duplicates and calculating their sum:
The data object contains an array of unordered integers with duplicates values and even and odd numbers. Our aim for this exercise is to filter the array retrieving only the even numbers, removing the duplicates after the first transformation, and finally calculating the final sum.
After instantiating the array source, we are defining the transformation we are going to apply; the first one is filtering the even numbers from the initial array with the method filterEven .
In this method we are checking that each value we are going to receive is divisible by 2 or not. If so it means the value is an even number so we want to keep it, otherwise we will skip it (remember that a stream will emit 1 value per time).
The second method is removeDuplicates , but in XStream there isn’t an operator for doing it automatically like for Rx.JS. As we said at the beginning, XStream is meant for learning how to handle streams more than having a complete library with many operators.
Therefore we are going to use the compose operator that returns a stream and expects a new stream as input. OutputStream will be our new stream used by the next operator emitting the array generated inside the removeDuplicates method.
Inside removeDuplicates we create an array for storing the unique values and we push them only if are not present inside the array.
The last transformation for this exercise is calculating the sum of the values filtered in the previous steps. We are going to use the fold operator that requests a function with two arguments : an accumulator and the current value to evaluate for calculating the final result, very similar to the reduce method used when you wanted to calculate the values inside an array.
Finally, we can create the stream using xs.fromArray passing the initial array, and this will produce an initial stream that will emit the array values. After that we apply all the different transformations via XStream operators like filter, compose, and fold. Bear in mind that the second parameter of the fold operator is the accumulator initial value, and in our case we want to start from the value zero and sum all the others.
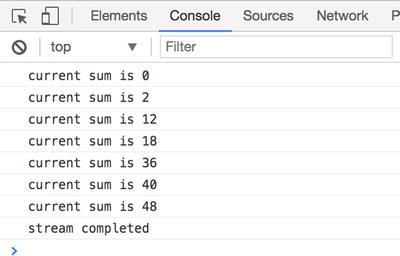
Output of XStream example, slightly different from the Rx.JS example due to the fold operator
As we can see, this example made with XStream resembles the one we did previously with Rx.JS. The key takeaway here is the fact that understanding how the observables work are helping us to switch from a reactive library to another one without investing time on learning new concepts but just applying a few basic concepts with different syntax and operators.
Our second example is based on retrieving some data from a REST endpoint every few seconds.
In this case we can leverage the power of the producer objects available in XStream for fetching the remote data and emitting the result to a stream.
Considering we want to retrieve the data every few seconds for a certain amount of times, we can use an interval stream instead of a set interval like we would do in plain JavaScript.
This is our code example:
As you can see in the example above, we start defining our producer object; remember that a producer is just an object that requires two methods: start and stop . The start method will be called once the first consumer subscribes to the stream.
Keep in mind that a producer can have just one listener per time; therefore, in order to broadcast the results to multiple listeners, we have to create a stream that uses the producer to emit the values.
Our producer contains also another method called emitter that returns a listener object that we are going to use inside the interval stream created in the start method.
The start method uses the xs.periodic operator that accepts as an argument an interval of time when an event is emitted by the stream; so in our case, every 5 seconds a new event will be emitted.
We also used the operator take that is used for retrieving a certain amount of values from that stream, ignoring all the others emitted.
The last thing to do is to subscribe to that stream with a listener and every tick (next method) fetches the data from the endpoint.
The endpoint is the same one as the previous example in Rx.JS, so we need to expect the same JSON object fetched from the endpoint.
The main goal of this example is outputting a simplified version of this data that could be used in a hypothetical view of our application.
When we create simplifyUserData method for extracting only the information we need from the value emitted in the stream; this function is returning a filtered object containing only a few fields instead of the entire collection.
After that, we create our listener object with the typical signature next, error, and complete methods where we are handling the values emitted by the stream.
Finally, we create the glue between the stream and the listener object by creating a stream with xs.create passing as the argument our producer.
Then we iterate through all the values emitted, filtering the user data and in the last line of our script we associate the listener to the stream that will trigger the producer to start emitting the values.
In this case there are some differences compared to Rx.JS example but again the key concepts are still there.
The last example for the XStream library is focused on how we broadcast values to multiple listener objects; in this case XStream is helping us because all the streams are hot, therefore multicast by nature.
We don’t need to perform any action or understand what kind of stream we are dealing with. That’s also why I recommend always starting with a simple library like XStream that contains everything we need for getting our hands dirty with streams and then moving to a more complete toolbox library like Rx.JS or Most.js .
The first thing is to create a stream (periodicStream constant) that emits every second a random number.
Then every time we are adding a new listener to the main stream, each listener receives the value emitted by the periodicStream.
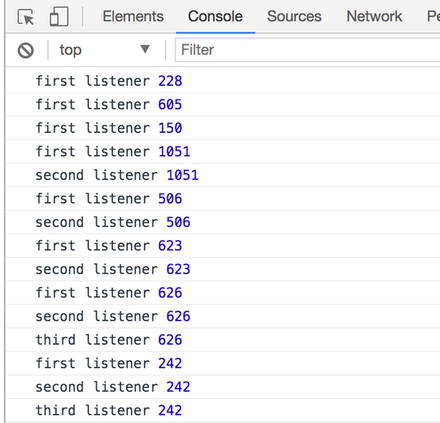
Output XStream example with hot streams
Now we can see we have the expected behavior, when the second and the third listener subscribe to the stream they receive the value emitted without any information of the previous values like we have seen in the cold observable example in Rx.JS.
From this last example it is clear that if you need to manage with a certain granularity the streams type in a project, Rx.JS would be the right choice for that. Otherwise XStream could simplify and speed up your development, considering that it is pretty straightforward.
Back Pressure
Another important Reactive Programming concept is backpressure and how we can use it for improving our reactive applications.
When we work with multiple streams, they could emit a large amount of events in a short period of time. Therefore we need a way for alleviating the amount of data consumed by the observers if we don’t really need all of them or if the process to elaborate them is too computationally intense, and the consumer is not able to keep up.
Usually we have two possibilities to handle back pressure in our application: first, we can queue the value, creating a buffer and elaborate all the values received, so in this case we don’t miss the values emitted. This strategy is called loss-less strategy .
Another strategy could be skipping some events and reacting only after a certain amount of time, filtering what we receive because maybe this information is not critical for what the consumer needs to do; in this case we call this strategy lossy strategy .
Imagine, for example, that we are merging two observables with a zip operator . The first observable is providing some capital case letters every second, and the second observable is emitting lowercase letters every 200 milliseconds.
The zip operator in this case will create a new observable with the values of the two streams coupled together, but because it needs to couple the letters from different streams that are emitting values with different speed, inside the zip operator we have a buffer for storing the values of the second observable until the first one is going to emit the following value.
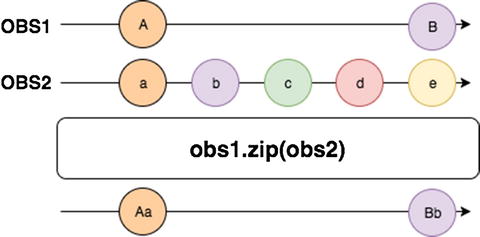
As you can see from the marble diagram above, the second stream is producing 5 times more values than the first one in the same amount of time, so the new observable will need to maintain the data in a buffer to match the values before emitting them to the consumer.
Unfortunately, these kinds of scenarios in Reactive Programming are not rare and in this occasion, back pressure operators come to the rescue.
These operators allow us to alleviate the pressure from the observer by simply stopping a reaction from values emitted by an observable, pausing the reception of values until we define when to resume receiving the values.
Let’s write a concrete example with Rx.JS for understanding better the concept described.

Outcome of our next exercise on back pressure
This small example is composed by two files: the main application and the React component .
The main application will generate the observable that will produce random values in a specific range ready to be displayed inside the component.
What is happening in the main application file is that we are generating a producer (generateProducer method) that should simulate a constant interaction with a source of data, and every 50 milliseconds it is emitting a value between 100 and 150 with 2 decimals.
This is a typical example where the back pressure operators could help out; we really don’t need to update the UI every 50 milliseconds because more than a useful experience, we are going to create a constant refresh that won’t be well received by our users, and it will be very intensive, in particular, on low-end machines. So what can we do to alleviate the pressure on the observer that is going to receive these values?
If in generateProducer method , instead of returning the observable as it is, we could add a back pressure operator like this one:
In this case, the sampleTime operator will emit a value only every 500 milliseconds, ignoring the other values received in the meantime.
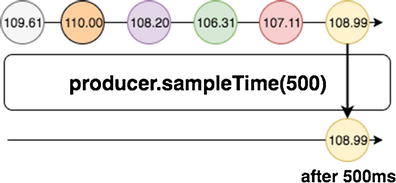
Marble diagram showing sampleTIme operator with half-second debounce
In the component code , we are going to subscribe to the observable received from the producer property and display the value in our UI:
As we can notice inside the componentDidMount method , provided by the React component life cycle, we are subscribing to the producer (the observable created before in the main application) and then we set the stock value in the React state object for displaying it in our paragraph element.
In Rx.JS we can use multiple back pressure operators like debounce or throttle, but there are many others for handling the back pressure properly. It’s important to remember to not create a huge buffer of data when the producer is emitting a large amount of data. So as a rule of thumb, remember that when we don’t need all the data emitted by an observable, we should really filter them for providing a better user experience to our users and improve the performance of our Reactive applications.
Wrap-Up
In this chapter, we explained how to work with a few key reactive concepts; in particular, we introduced the concepts of streams, observables and observers on Rx.JS and streams and listeners in XStream. We also reviewed the most famous libraries implementations and how we can use them in order to manipulate our streams.
We have discovered what and hot and cold observables are and how to handle the back pressure when we receive a large amount of data that we don’t need to share all of inside our stream.
Now we have all the tools we need to see concrete implementation and how different frameworks/libraries introduced reactive programming in the front-end world.
Obviously, the aim of this book is not going in depth on each single operator or a specific library but providing the knowledge to jump from a library to another one without headaches.
There are also other libraries not mentioned in this chapter that could replace Rx.JS and XStream like, for instance, Most.js ( https://github.com/cujojs/most ) or IxJS ( https://github.com/ReactiveX/IxJS ) or Kefir ( https://rpominov.github.io/kefir/ ) or FlyD ( https://github.com/paldepind/flyd ) or again Bacon.js ( https://baconjs.github.io/ ).
All of them have their pros and cons and I strongly suggest taking a look at each single one as well as picking the right library for your projects.
In the next few chapters we are going to see Reactive programming in action. In particular we will explore Cycle.js and how this simple library is able to handle function reactive programming with its innovative architecture called MVI (Model-View-Intent). We then approach MobX, a library very famous in the reactive front-end world that is becoming more popular day by day and is solving the application state management in an easy and reactive way. We will finish this book with SAM Pattern, an architectural pattern that provides a reactive structure that is totally framework agnostic, giving us the possibility to integrate it in any existing or greenfield project.