
4 Designing function signatures and types
- Designing good function signatures
- Fine-grained control over the inputs to a function
- Using
Unitas a more flexible alternative tovoid
The principles we’ve covered so far define FP in general, regardless of whether you’re programming in a statically typed language like C# or a dynamically typed language like JavaScript. In this chapter, you’ll learn some functional techniques that are specific to statically typed languages. Having functions and their arguments typed opens up a whole set of interesting considerations..
Functions are the building blocks of a functional program, so getting the function signature right is paramount. And because a function signature is defined in terms of the types of its inputs and outputs, getting those types right is just as important. Type design and function signature design are really two faces of the same coin.
You may think that after years of defining classes and interfaces, you know how to design your types and functions. But it turns out that FP brings a number of interesting concepts to the table that can help you increase the robustness of your programs and the usability of your APIs.
4.1 Designing function signatures
A function’s signature tells you the types of its inputs and outputs; if the function is named, it also includes the function’s name. As you code more functionally, you’ll find yourself looking at function signatures more often. Defining function signatures is an important step in your development process, often the first thing you do as you approach a problem.
I’ll start by introducing a notation for function signatures that’s standard in the FP community. We’ll use it throughout the book.
4.1.1 Writing functions signatures with arrow notation
In FP, function signatures are usually expressed in arrow notation. There’s great benefit to learning it because you’ll find it in books, articles, and blogs on FP: it’s the lingua franca used by functional programmers from different languages.
Let’s say we have a function f from int to string; it takes an int as input and yields a string as output. We’ll notate the signature like this:
In English, you’d read that as f has type of int to string or f takes an int and yields a string. In C#, a function with this signature is assignable to Func<int, string>.
You’ll probably agree that the arrow notation is more readable than the C# type, and that’s why we’ll use it when discussing signatures. When we have no input or no output (void or Unit), we’ll indicate this with ().
Let’s look at some examples. Table 4.1 shows function types expressed in arrow notation side by side with the corresponding C# delegate type and an example implementation of a function that has the given signature in lambda notation.
Table 4.1 Expressing function signatures with arrow notation
The last example in table 4.1 shows multiple input arguments: we just group them with parentheses. (Parentheses indicate tuples, so in fact, we’re notating a binary function as a unary function whose input argument is a binary tuple.)
Now, let’s move on to more complex signatures, namely those of HOFs. Let’s start with the following method (from listing 2.10) that takes a string and a function from IDbConnection to R and returns an R:
How would you notate this signature? The second argument is itself a function, so it can be notated as IDbConnection → R. The HOF’s signature is notated as follows:
And this is the corresponding C# type:
The arrow syntax is slightly more lightweight and is more readable, especially as the complexity of the signature increases.
4.1.2 How informative is a signature?
Some function signatures are more expressive than others, by which I mean that they give us more information about what the function is doing, what inputs are permissible, and what outputs we can expect. The signature () → (), for example, gives us no information at all: it may print some text, increment a counter, launch a spaceship . . . who knows? On the other hand, consider this signature:
Take a minute and see if you can guess what a function with this signature does. Of course, you can’t really know for sure without seeing the actual implementation, but you can make an educated guess. The function returns a list of T’s and takes a list of T’s, as well as a second argument, which is a function from T to bool, a predicate on T.
It’s reasonable to assume that the function uses the predicate on T to filter the elements in the list. In short, it’s a filtering function. Indeed, this is exactly the signature of Enumerable.Where. Let’s look at another example:
Can you guess what the function does? It returns a sequence of C’s and takes a sequence of A’s, a sequence of B’s, and a function that computes a C from an A and a B. It’s reasonable to assume that this function applies the computation to elements from the two input sequences, returning a third sequence with the computed results. This function could be the Enumerable.Zip function, which we discussed in section 3.2.3.
These last two signatures are so expressive that you can make a good guess at the implementation, which is a desirable trait. When you write an API, you want it to be clear, and if the signature goes hand in hand with good naming in expressing the intent of the function, all the better.
Of course, there are limits to how much a function signature can express. For instance, Enumerable.TakeWhile, a function that traverses a given sequence, yielding all elements as long as a given predicate evaluates to true, has the same signature as Enumerable.Where. This makes sense because TakeWhile can also be viewed as a filtering function, but one that works differently than Where.
In summary, some signatures are more expressive than others. As you develop your APIs, make your signatures as expressive as possible—this facilitates the consumption of your APIs and adds robustness to your programs.
4.2 Capturing data with data objects
Functions and data are like the two sides of a coin: functions consume and produce data. A good API needs functions with clear signatures and well-designed data types to represent the inputs and outputs of these functions. In FP (unlike OOP), it’s natural to draw a separation between logic and data:
In this section, we’ll look at some basic ideas for designing data objects. We’ll then move on to the somewhat more abstract concepts of representing the absence of data (section 4.3) or the possible absence of data (chapter 5).
Imagine that you’re in the business of life insurance. You need to write a function that calculates a customer’s risk profile based on their age. The risk profile will be captured with an enum:
You’re pair programming with David, a trainee who comes from a dynamically typed language, and he has a stab at implementing the function. He runs it in the REPL with a few inputs to see that it works as expected:
Risk CalculateRiskProfile(dynamic age) => (age < 60) ? Risk.Low : Risk.Medium; CalculateRiskProfile(30) // => Low CalculateRiskProfile(70) // => Medium
Although the implementation does seem to work when given reasonable inputs, you’re surprised by David’s choice of dynamic as the argument type. You show him that his implementation allows client code to invoke the function with a string, causing a run-time error:
CalculateRiskProfile("Hello") // => runtime error: Operator '<' cannot be applied to operands➥ of type 'string' and 'int'
You explain to David that you can tell the compiler what type of input your function expects, so that invalid inputs can be ruled out. You rewrite the function, taking an int as the type of the input argument:
Risk CalculateRiskProfile(int age) => (age < 60) ? Risk.Low : Risk.Medium; CalculateRiskProfile("Hello") // => compiler error: cannot convert from 'string' to 'int'
Is there still room for improvement?
4.2.1 Primitive types are often not specific enough
As you keep testing your function, you find that the implementation still allows for invalid inputs:
Clearly, these are not valid values for a customer’s age. What’s a valid age, anyway? You have a word with the business to clarify this, and they indicate that a reasonable value for an age must be positive and less than 120. Your first instinct is to add some validation to your function—if the given age is outside of the valid range, throw an exception:
Risk CalculateRiskProfile(int age) { if (age < 0 || 120 <= age) throw new ArgumentException($"{age} is not a valid age"); return (age < 60) ? Risk.Low : Risk.Medium; } CalculateRiskProfile(10000) // => runtime error: 10000 is not a valid age
As you type this, you’re thinking that this is rather annoying:
-
You’ll have to write additional unit tests for the cases in which validation fails.
-
There are other areas of the application where an age is expected, so you’re probably going to need this validation there as well. This may lead to some code duplication.
Duplication is usually a sign that separation of concerns has been broken: the CalculateRiskProfile function, which should only concern itself with the calculation, now also concerns itself with validation. Is there a better way?
4.2.2 Constraining inputs with custom types
In the meantime, your colleague Frida, who comes from a statically typed functional language, joins the session. She looks at your code so far and finds that the problem lies in your use of int to represent age. She comments, “You can tell the compiler what type of input your function expects so that invalid inputs can be ruled out.”
David listens in amazement because those were the very words you patronized him with a few moments earlier. You’re not sure what she means exactly, so she starts to implement Age as a custom type that can only represent a valid value for an age as in the following listing.
Listing 4.1 A custom type that can only be instantiated with a valid value
public struct Age { public int Value { get; } public Age(int value) { if (!IsValid(value)) throw new ArgumentException($"{value} is not a valid age"); Value = value; } private static bool IsValid(int age) => 0 <= age && age < 120; }
This implementation still uses an int as the underlying representation for an age, but the constructor ensures that the Age type can only be instantiated with a valid value.
This is a good example of functional thinking: the Age type is created precisely to represent the domain of the CalculateRiskProfile function. This can now be rewritten as follows:
This new implementation has several advantages:
-
The concern of validating the age value is captured in the constructor of the
Agetype, removing the need for duplicating validation wherever an age is processed.
You’re still throwing an exception in the Age constructor, but we’ll remedy that in section 5.4.3. There’s still some room for improvement, however.
In the preceding implementation, we used Value to extract the underlying value of the age, so we’re still comparing two integers. There are a couple of problems with that:
-
Reading the
Valueproperty not only creates a bit of noise, but it also means that the client code knows about the internal representation ofAge, which you might want to change in the future. -
Because you’re performing integer comparison, you’re also not protected if, say, someone accidentally changes the threshold value of
60to600, which is a validintbut not a validAge.
You can address these issues by modifying the definition of Age, as the following listing shows.
Listing 4.2 Encapsulating the internal representation of the age
public class Age { private int Value { get; } ❶ public static bool operator <(Age l, Age r) ❷ => l.Value < r.Value; public static bool operator >(Age l, Age r) => l.Value > r.Value; public static bool operator <(Age l, int r) ❸ => l < new Age(r); public static bool operator >(Age l, int r) => l > new Age(r); }
❶ Keeps the internal representation private
❷ Logic for comparing an Age with another Age
❸ For ease of use, makes it possible to compare an Age with an int; the int is first converted into an Age.
Now the internal representation of an age is encapsulated, and the logic for comparison is within the Age class. You can rewrite your function as follows:
What happens now is that a new Age is constructed from the value 60 so that the usual validation is applied. (If this throws a run-time error, that’s fine because it indicates a developer error; more about this in chapter 8.) When the input age is then compared, this comparison happens in the Age class, using the comparison operators you’ve defined. Overall, the code is just as readable as before, but more robust.
In summary, primitive types are often used too liberally (this has become known as primitive obsession). If you need to constrain the inputs of your functions, it’s usually better to define a custom type. This follows the idea of making invalid state unrepresentable. In the preceding example, you can’t represent an age outside of the valid bounds.
The new implementation of CalculateRiskProfile is identical to its original implementation, except for the input type, which is now Age, and this ensures the validity of the data and makes the function signature more explicit. A functional programmer might say that now the function is honest. What does that mean?
4.2.3 Writing honest functions
You might hear functional programmers talk about honest or dishonest functions. An honest function is simply one that does what it says on the tin: it honors its signature—always. For instance, consider the function we ended up with in section 4.2.2:
Its signature is Age → Risk, which declares, “Give me an Age, and I will give you back a Risk.” Indeed, there’s no other possible outcome.1 This function behaves as a mathematical function, mapping each element from the domain to an element of the codomain, as figure 4.1 shows.
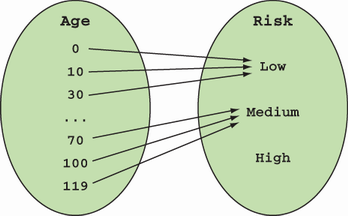
Figure 4.1 An honest function does exactly what the signature says: it maps all possible values of the input type(s) to a valid value of the output type. This makes the behavior of your functions predictable and your program more robust.
Compare this to the previous implementation, which looked like this:
Risk CalculateRiskProfile(int age) { if (age < 0 || 120 <= age) throw new ArgumentException($"{age} is not a valid age"); return (age < 60) ? Risk.Low : Risk.Medium; }
Remember, a signature is a contract. The signature int → Risk says, “Give me an int (any of the 232 possible values for int), and I’ll return a Risk.” But the implementation doesn’t abide by its signature, throwing an ArgumentException for what it considers invalid input (see figure 4.2).

That means this function is dishonest—what it really should say is “Give me an int, and I may return a Risk, or I may throw an exception instead.” Sometimes there are legitimate reasons why a computation can fail, but in this example, constraining the function input so that the function always returns a valid value is a much cleaner solution.
In summary, a function is honest if its behavior can be predicted by its signature:
Note that these requirements are less stringent and less formal than function purity. Notably, a function that performs I/O can still be honest. In this case, its return type should typically convey that the function may fail or take a long time (for example, by returning its result wrapped in an Exceptional or a Task, which I’ll discuss in chapters 8 and 16, respectively.)
4.2.4 Composing values into complex data objects
You might require more data to fine-tune the implementation of your calculation of health risk. For instance, women statistically live longer than men, so you may want to account for this:
enum Gender { Female, Male } Risk CalculateRiskProfile(Age age, Gender gender) { var threshold = (gender == Gender.Female) ? 62 : 60; return (age < threshold) ? Risk.Low : Risk.Medium; }
The signature of the function thus defined is as follows:
How many possible input values are there? Well, there are 2 possible values for Gender in this admittedly simplistic model and 120 values for Age, so in total, there are 2 × 120 = 240 possible inputs. Notice that if you define a tuple of Age and Gender, 240 tuples are possible. The same is true if you define a type to hold that same data like this:
Whether you call a binary function that accepts an Age and a Gender, or a unary function that takes a HealthData, 240 distinct inputs are possible. They’re just packaged up a bit differently.
Earlier I said that types represent sets, so the Age type represents a set of 120 elements, and Gender, a set of 2 elements. What about more complex types such as HealthData, which is defined in terms of the former two?
Essentially, creating an instance of HealthData is equivalent to taking all the possible combinations of the two sets, Age and Gender (a Cartesian product), and picking one element. More generally, every time you add a field to a type (or a tuple), you’re creating a Cartesian product and adding a dimension to the space of possible values of the object, as figure 4.3 illustrates.

For this reason, in type theory, types that are defined by aggregating other types (whether in a tuple, a record, a struct or a class) are called product types. In contrast, you have sum types. For instance, if types A and B are the two only concrete implementations of C, then
The number of possible C’s is the sum of all possible A’s and all possible B’s. (Sum types are also known as union types, discriminated unions, and a number of other names.)
This concludes our brief foray into data object design. The main takeaway is that you should model your data objects in a way that gives you fine control over the range of inputs that your functions will need to handle. Counting the number of possible instances can bring clarity. Once you have control over these simple types, it’s easy to aggregate them into more complex data objects. Now, let’s move on to the simplest type of all: the empty tuple or Unit.
4.3 Modeling the absence of data with Unit
We’ve discussed how to represent data; what about when there is no data to represent? Many functions are called for their side effects and return void. But void doesn’t play well with many functional techniques, so in this section, I’ll introduce Unit, a type that we can use to represent the absence of data without the problems of void.
4.3.1 Why void isn’t ideal
Let me start by illustrating why void is less than ideal. In section 2.1.2, we covered the all-purpose Func and Action delegate families. If they’re so all-purpose, why do we need two of them? Why can’t we use Func<Void> to represent a function that returns nothing just like we use Func<string> to represent a function that returns a string? The problem is that although the framework has the System.Void type and the void keyword to represent no return value, Void receives special treatment by the compiler and can’t therefore be used as a return type. (In fact, it can’t be used at all from C# code.)
Let’s see why this can be a problem in practice. Say you need to gain some insight as to how long certain operations take, and to do so, you write a HOF that starts a stopwatch, runs the given function, and stops the stopwatch, printing out some diagnostic information. This is a typical example of the setup/teardown scenario I demonstrated in section 2.3. Here’s the implementation:
public static class Instrumentation { public static T Time<T>(string op, Func<T> f) { var sw = new Stopwatch(); sw.Start(); T t = f(); sw.Stop(); Console.WriteLine($"{op} took {sw.ElapsedMilliseconds}ms"); return t; } }
If you wanted to read the contents of a file and log how long the operation takes, you could use this function:
It would be quite natural to want to use this with a void-returning function. For example, you might want to time how long it takes to write to a file, so you’d like to write this:
Instrumentation.Time("writing to file.txt" , () => File.AppendAllText("file.txt", "New content", Encoding.UTF8));
The problem is that AppendAllText returns void, so it can’t be represented as a Func. To make the preceding code work, you need to add an overload of Instrumentation.Time that takes an Action:
public static void Time(string op, Action act) { var sw = new Stopwatch(); sw.Start(); act(); sw.Stop(); Console.WriteLine($"{op} took {sw.ElapsedMilliseconds}ms"); }
This is terrible! You have to duplicate the entire implementation just because of the incompatibility between the Func and Action delegates. (A similar dichotomy exists in the world of asynchronous operations between Task and Task<T>.) How can you avoid this?
4.3.2 Bridging the gap between Action and Func
If you’re going to use functional programming, it’s useful to have a different representation for no return value. Instead of using void, which is a special language construct, we’ll use a special value, the empty tuple (also called Unit). The empty tuple has no members, so it can only have one possible value. Because it contains no information whatsoever, that’s as good as no value.
The empty tuple is available in the System namespace. Uninspiringly, it’s called ValueTuple, but I’ll follow the FP convention of calling it Unit:2
Technically, void and Unit differ in that
-
voidis a type that represents an empty set; as such, it’s not possible to create an instance of it. -
Unitrepresents a set with a single value; as such, any instance ofUnitis equivalent to any other and, therefore, carries no information.
If you have a HOF that takes a Func but you want to use it with an Action, how can you go about this? In chapter 2, I introduced the idea that you can write adapter functions to modify existing functions to suit your needs. In this case, you want a way to easily convert an Action into a Func<Unit>. The next listing provides the definition of the ToFunc function, which does just that. It is included in my functional library, LaYumba .Functional, which I developed to support the teaching in this book.
Listing 4.3 Converting Action into Func<Unit>
using Unit = System.ValueTuple; ❶ namespace LaYumba.Functional; ❷ public static class ActionExt { public static Func<Unit> ToFunc ❸ (this Action action) => () => { action(); return default; }; public static Func<T, Unit> ToFunc<T> ❸ (this Action<T> action) => (t) => { action(t); return default; }; // more overloads for Action's with more arguments... }
❶ Aliases the empty tuple as Unit
❷ This file-scoped namespace includes all of the following code.
❸ Adapter functions that convert an Action into a Unit-returning Func
When you call ToFunc with a given Action, you get back a Func<Unit>. This is a function that when invoked runs the Action and returns Unit.
TIP This listing includes a file-scoped namespace, a feature introduced in C# 10 to reduce indentation. The declared namespace applies to the contents of the file.
With this in place, you can expand the Instrumentation class with a method that accepts an Action, converts it into a Func<Unit>, and calls the existing overload that works with any Func<T>. The following listing shows this approach.
Listing 4.4 HOFs that take a Func or an Action without duplication
using LaYumba.Functional; using Unit = System.ValueTuple; public static class Instrumentation { public static void Time(string op, Action act) ❶ => Time<Unit>(op, act.ToFunc()); ❷ public static T Time<T>(string op, Func<T> f) => // same as before... }
❶ Includes an overload that takes an Action
❷ Converts the Action to a Func<Unit> and passes it to the overload taking a Func<T>
As you can see, this enables you to avoid duplicating any logic in the implementation of Time. You must still expose the overload taking an Action. But given the constraints of the language, this is the best compromise for handling both Action and Func.
While you may not be fully sold on Unit based on this example alone, you’ll see more examples in this book where Unit and ToFunc are needed to take advantage of functional techniques. In summary,
-
Use
voidto indicate the absence of data, meaning that your function is only called for side effects and returns no information. -
Use
Unitas an alternative, more flexible representation when there’s a need for consistency in the handling ofFuncandAction.
NOTE C# 7 introduced tuple notation, allowing you to write, say, (1, "hello") to represent a binary tuple, so logically you’d expect to be able to write (1) for a unary tuple, and () for the nullary tuple. Unfortunately, because of how parentheses work in C# syntax, this is not possible: only tuples with two or more elements can be written using parentheses. We’ll therefore stick with Unit in our C# code and () when using arrow notation. For example, I’ll notate a Func<int, Unit> as int → ().
Summary
-
Make your function signatures as specific as possible. This makes them easier to consume and less error-prone.
-
Make your functions honest. An honest function always does what its signature says, and given an input of the expected type, it yields an output of the expected type—no
Exceptions, nonulls. -
Use custom types rather than ad hoc validation code to constrain the input values of a function.
-
Use
Unitas an alternative tovoidwhen you need a more flexible representation for functions that return no data.
1 There is, however, the possibility of hardware failure, of the program running out of memory, and so on, but these are not intrinsic to the function implementation.
2 Until recently, functional libraries have tended to define their own Unit type as a struct with no members. The obvious downside is that these custom implementations aren’t compatible, so I would call for library developers to adopt the nullary ValueTuple as the standard representation for Unit.