
CHAPTER 12 Dependability Assessment
Learning objectives of this chapter are to understand:
• The concepts and limitations of quantitative assessment.
• The role and limitations of prescriptive standards.
• The use of rigorous arguments in dependability assessment.
• How the dependability of a system can be determined.
• Effective ways to approach the problem of dependability assurance.
12.1 Approaches to Assessment
Throughout this book, we have been concerned with creating dependable computer systems. In Chapter 2, we discussed the need for defining dependability requirements, and in subsequent chapters, we examined various ways in which we might meet the defined requirements for software while remaining aware of what is happening on the hardware side.
Our final task is to determine whether we have met the dependability requirements for a specific software system. Examining this issue is important, because otherwise we might end up with one of two unacceptable circumstances:
• The system that we have built has lower dependability than is required, and so the system might fail more frequently than is considered acceptable.
• The system that we have built has higher dependability than is required. Higher dependability might not seem like a problem, but we are likely to have expended more resources than needed to produce the system and perhaps lost a competitive edge as a result.
Dependability assessment of computer systems has been a subject of study for as long as there have been computers. A great deal of research has been conducted on probabilistic assessment, and the technology that has evolved is both elaborate and sophisticated. The greatest successes have been in assessing the effects of degradation faults. Probabilistic assessment of the effects of design faults, especially software faults, has been far less successful.

FIGURE 12.1 The contract model between the overall system and the components used in the system.
Covering dependability assessment, particularly probabilistic assessment, in depth is beyond the scope of this book. Our emphasis will remain on dependability of the software system. Software engineers need to understand how overall system assessment is done, at least in part, because many of the techniques used in dependability assessment at the overall system level can be applied at the software system level. In this chapter we will discuss three different approaches to dependability assessment that are in more or less common use:
Quantitative Assessment. Quantitative assessment is the estimation of a probability associated with an entity either by direct measurement or by modeling.
Prescriptive Standards. Prescriptive standards base dependability assessment of an entity on the process by which the entity was built.
Rigorous Argument. Rigorous argument is a non-quantified approach to assessment in which an argument is created that the entity is suitable for its intended use.
Throughout this chapter, keep in mind the dependability contract concept that was introduced in Section 2.8.3. The general concept is repeated in Figure 12.1. The dependability requirements for a computer system derive from the design of the system of which the computer system is a component, and meeting those dependability requirements can be thought of as a contract between the systems engineers and the computer and software engineers.
12.2 Quantitative Assessment
Several attributes of dependability are probabilistic, and this suggests that we could use some form of measurement to see whether the requirement has been met. Reliability and availability, for example, are probabilities that we could assess perhaps by measurement. Similarly, performance metrics such as Mean Time Between Failures (MTBF) and Mean Time To Failure (MTTF) are expected values of distributions and so estimating these quantities by sampling should be possible. Such estimates can be obtained by operating the system of interest and noting when failures occur. Routine statistical procedures can be applied to estimate both the expected value of interest and the variance.
As we shall see in Section 12.2.4, quantitative assessment of dependability attributes faces several challenges that limit its applicability. Some attributes are not quantifiable, for some systems there are no reliable models to use, and some desired levels of dependability cannot be estimated in reasonable amounts of time.
12.2.1 The Basic Approach
Estimating probabilities in complex systems is achieved using a variety of sophisticated analysis techniques, including statistical sampling, Markov modeling, approximations, and so on. Fundamentally, however, quantitative estimates of system properties are derived by applying the following two-step process:
(1) Estimate parameters of constituent part by life testing. The quantitative properties of system constituent parts are estimated by observing a sample set of identical parts in operation and measuring their rate of failure.
(2) Estimate system parameters by modeling. Models that predict system parameters based on the parameters of constituent parts are developed. These models are then used with the data obtained in part parameter estimates to estimate the system parameters of interest.
As an example of quantitative assessment, consider the simple computer system shown in Figure 12.2. The computer is composed of six constituent parts: (1) a processor, (2) a memory, (3) a power supply, (4) a parallel data bus linking the processor and memory, (5) a collection of peripherals, and (6) a printed circuit board, often called the mother board, upon which the processor, memory, and ancillary electronics are mounted. Using life testing, the manufacturers of the components have determined that the probabilities of failure per hour for the constituent parts have mean values of 10-6 for the processor, 10-6 for memory, 10-5 for the power supply, 10-8 for the data bus, 10-3 for the peripheral system (meaning loss of at least one from perhaps several), and 10-4 for the mother board. We model the probability of failure of the system using the following assumptions:
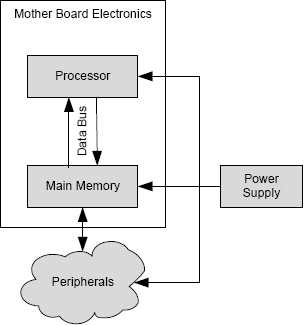
FIGURE 12.2 A simple computer system for which we need a quantitative measure of the probability of failure.
• The six constituent parts fail with statistical independence (see Section 6.4.1).
• When a constituent part fails, the failure is fail stop (see Section 6.5.4).
• Failure of any of the six constituent parts causes the entire computer to fail.
Since we know the probabilities of failure of the individual constituent parts and we are assuming that part failures are independent, the probability of failure of the computer per hour is just the sum of the probabilities of failure of the six parts, i.e., 0.00111201. Clearly, this value is dominated by the probability of failure of the peripheral system.
As a second example of quantitative assessment, consider the dual-redundant architecture discussed in Section 6.3.1 on page 155. Suppose that the rate of failure per unit time of each processor has been determined by life testing to be 10-6. In this case, both processors have to be operational or the comparator will be forced to shut the system down. Assuming that processor failures are independent, the failure rate of the system derived from processor failure is the sum of the two processor failure rates, 10-6 + 10-6. Thus the failure rate is much higher than that of a single processor and the MTTF has been cut by a half. Although that is the cost, recall from Section 6.3.1 that the important benefit gained is error detection.
12.2.2 Life Testing
Life testing is a process in which a set of identical parts is placed into an operational environment, and the performance of the members of the set is monitored. Life testing of personal computers is illustrated in Figure 12.3. The test environment includes a variety of environmental effects. Various part parameters can be estimated by observing the behavior of the parts being tested. In particular, failures can be observed. In Figure 12.3, one of the computers has failed.
The operational environment could be an artificial one in a laboratory or the actual environment in which the parts operate. In the laboratory approach, the operating circumstances can be both controlled and varied. For example, in the case of integrated circuits, the change in MTTF with case temperature, humidity, and vibration can be measured by conducting life testing with the environmental parameters set appropriately. Such measurement also allows assessment of the rate of infant mortality so that volume development and delivery can take account of infant mortality properly.

FIGURE 12.3 Long duration life testing of components using replication. In this case one computer has failed.
Two difficulties that arise with life testing in a laboratory are:
• The cost of the laboratory itself.
• The difficulty in both determining and creating the correct operational environment.
Though often large, the cost issue is predictable and the cost/benefit analysis can be performed reasonably easily. Dealing with the operational environment is more difficult. If the environment used in testing is not that which the parts will experience in operation, the various estimates that are obtained by life testing might be inaccurate.
The problem of determining and creating the correct operational environment is a major difficulty. To see this, consider the problem of conducting life testing on DRAM integrated circuits. As noted above, the effect on the rate of failure of the case temperature, the humidity, and vibration can be measured in or predicted for the anticipated operating environment quite well. However, the rate of failure is also affected by data-access patterns, by physical shock, and by the thermal shock associated with powering the device on and off. These latter three factors are difficult to predict for consumer devices since operating patterns vary so widely.
12.2.3 Compositional Modeling
Life testing is practical for constituent parts that are less expensive and that can be both operated and monitored successfully without a lot of expensive and complicated equipment. Life testing is impractical for devices such as complete computers or even large disk assemblies.
For more complex devices, the approach that is followed is based on compositional models. The probabilistic parameter of interest for the device is estimated using a model of the device. Such models predict what will happen to the device when individual parts fail in some way. The probabilistic performance of the constituent parts from which the device is built are estimated using life testing.
In a large disk drive, for example, the failure distributions of individual electrical and some mechanical parts are assessed by life testing, and then parameters such as the MTTF of the device are estimated from a model of the device. In the case of a disk drive, some types of fault are intermittent because of the way in which disk drives operate. Many times, disk reads and writes succeed after an initial failure if the operation is retried. Disk controllers know that and exploit the effect to avoid failures. Such techniques have to be included in the dependability model for the device.
Models are difficult to build and in many cases are based upon sophisticated mathematics. In some cases, assumptions have to be made that are not completely realistic in order to make the mathematics tractable. To deal with the possibility of inaccuracies in models, system developers frequently observe the population of systems that have been deployed and check that failures are occurring at a rate no worse than the rate predicted by the model.
12.2.4 Difficulties with Quantitative Assessment
Despite the cost and difficulty of determining the operational environment, life testing and modeling work well in many circumstances, and so thinking that they could be applied universally is tempting. There are three issues that arise which preclude their use in a number of circumstances where we need dependability assessment:
Non-Quantifiable Attributes. Obviously, some attributes of dependability cannot be quantified. There is no useful metric for confidentiality, for example. For systems where confidentiality is important, some other mechanism of assessment is needed.
Unavailability of Models. Although the use of models in dependability assessment has proven useful, there are many circumstances in which models are either insufficiently accurate or just not available at all. The most important area in which models do not exist is in dealing with design faults. Compositional models for systems subject to design faults cannot be created by somehow measuring the rate of failure of the constituent parts and then trying to infer failure rates for the system.
This problem is especially serious for software, because the problem means that we cannot estimate dependability attributes of a million line software system from the measured attributes of ten thousand procedures, each one hundred lines long, or any other combination. Without compositional models for design faults, the only alternatives are:
- To develop quantitative estimates of dependability parameters using life testing alone, i.e., to subject the entire system to testing in the operational environment. For software, this means that complete instances of the software system of interest have to be operated and observed. The size and complexity of modern software systems usually preclude such an approach.
- To develop system-level models of dependability parameters based upon system-level characteristics and sometimes performance observations. Examples for software dependability are reliability-growth models such as the Littlewood-Verrall model [90]. In a reliability-growth model, the reliability of the software is estimated by modeling the faults in the software and the repair process. The software is operated and repaired as failures occur, and the circumstances of the operation and the failure are used to calibrate the model. Once the model parameters are set, an estimate of the reliability of the software can be obtained.
Ultra-High Levels of Dependability. Life testing depends upon observing failures of a population under test in order to be able to estimate population statistics. Observing no failures allows a lower bound to be estimated but that bound could be far from the actual value.
If ultra-high levels of dependability are needed, levels such as 10-9 failures per hour, as is typical of critical elements of avionics systems, then the population will experience failures extremely rarely. Producing estimates in cases such as this has been shown to be essentially infeasible because of the time needed to obtain the necessary data [24]. In the case of a system required to demonstrate a failure rate of 10-9 per hour or less, for example, the total test time necessary is hundreds of thousands of years. Even with large numbers of replicates (if that were possible), the total time will still be a large number of years. Testing times of this duration are completely infeasible.
For more modest goals, such as systems that have to demonstrate a failure rate of less than 10-4 failures per demand, as might be the case for a protection system, the test time is still a factor that has to be considered carefully in determining how to assess a dependability metric.
In summary, dependability requirements are often defined in quantitative terms, and that means we have to show that the system, as built, will meet those requirements. For degradation faults, using life testing of constituent parts and modeling of systems, estimation of the required probabilities is feasible and successful in practice. For design faults, including software faults of course, quantitative assessment is problematic. Estimates can be obtained for systems with relatively low dependability requirements, but estimation becomes infeasible at higher levels. Finally, there is always a concern that data about rates of failure obtained by measurement of constituent parts might not reflect that which will be seen in practice, because the operational environment used for data collection might not be the same as the environment that is seen once the system is deployed.
12.3 Prescriptive Standards
Dealing with the challenges posed by quantitative modeling is sufficiently difficult that the preferred approach to building systems frequently has to be pushed to the side. Instead, prescriptive development standards are used. Requiring prescriptive standards is the approach chosen by many government agencies that regulate the use of computing systems.
A prescriptive standard is any standard that dictates development practice in some way. Typically, in order to comply with the standard, a prescriptive standard specifies that during development either:
(a) Certain work products must be produced.
(b) Certain specific development actions must be undertaken.
(c) Certain goals must be met.
(d) A combination of (a), (b), and (c) is required.
Earlier standards tended to focus on prescribed work products or development actions, i.e., (a) and (b) above. In some cases, prescriptive standards document what amounts to standardized development processes that are required for the construction of certain systems or system components. Implied in this approach is that such prescriptive standards essentially define dependability requirements for the systems being regulated.
Prescriptive standards often require the use of engineering techniques that are generally accepted to be useful in terms of achieving dependability. For example, a prescriptive standard for software might require that certain test techniques be used during software development. The use of a specific technique is usually justified, because, when used properly, the technique is known to have a particular benefit in terms of dealing with faults.
Typically, prescriptive standards address major aspects of dependability, and standards are, as a result, frequently lengthy and detailed. Despite their length, in many cases, standards are accompanied by even longer documents that explain how the standard should be interpreted and what is required for compliance.
The use of goal-based standards, i.e., (c) above, is emerging as a more flexible approach. The concept is merely to define the required outcome and to leave the approach to meeting these outcomes to the system developers.
Prescriptive standards have been developed for use at the levels of both the application system and the computer system. Some examples of prescriptive standards are:
| Overall system level: | |
| DoD Mil Std 882B IEEE 1228 IEC 61508 ISO/IEC 15026:1998 |
System Safety Program Requirements. Standard for Software Safety Plans. Functional safety of electrical/electronic/programmable electronic safety-related systems. Information technology — System and software integrity levels. |
| Computer system level: RTCA DO-178B NASA-STD-8739.8 UL 1998 SAE ARP 4754 |
Software Considerations in Airborne Systems and Equipment Certification. Software Assurance Standard. Standard for Software in Programmable Components. Certification Considerations for Highly-Integrated or Complex Aircraft Systems. |
12.3.1 The Goal of Prescriptive Standards
The overall goal of prescriptive standards is to define and require development activities or artifacts that will effect fault avoidance and fault elimination such that the implied dependability requirements will be met. Engineers are then required to follow a development process that complies with the standard. Without such a requirement, regulators would have a difficult job determining whether a system submitted for certification has the necessary dependability properties. Regulators cannot rely exclusively upon quantitative assessment, as we discussed in the previous section. Thus, regulators can only proceed in one of two ways:
• Conduct some form of lengthy and expensive examination of the computer system in question in order to establish to their satisfaction that the necessary dependability requirements will be met. If no rules apply to the development process, then regulators are faced with a starting point for their examination of a system that would be completely arbitrary. This approach is hardly practical.
• Require a prescribed set of development artifacts or practices that, taken together, provide a high degree of assurance that fault avoidance, fault elimination, and fault tolerance have been applied properly and comprehensively. The role of the regulator is then to check that the prescribed development practices have been applied as desired. This approach is entirely practical.
Prescriptive standards come in a variety of forms and from a variety of sources. Government agencies that regulate software for use in situations where the public interest has to be protected usually require that software to be submitted for approval be produced using a prescribed standard. Other prescriptive standards have been developed by the International Organization for Standardization (ISO) and the Institute of Electrical and Electronic Engineers (IEEE). Such standards can be followed voluntarily.
12.3.2 Example Prescriptive Standard — RTCA/DO-178B
The Federal Aviation Administration regards compliance with a standard known as RTCA/DO-178B1 [120] as an acceptable means of receiving regulatory approval for software to be used on commercial air transports. The title of the standard is “Software Considerations In Airborne Systems And Equipment Certification.” EURO-CAE is the European Organization for Civil Aviation Equipment, and EUROCAE ED12B is an identical standard to RTCA/DO-178B. DO-178B is not the only method of obtaining regulatory approval, but not following the standard requires showing that the development procedures followed are equivalent to DO-178B. In practice, essentially all avionics software is developed in compliance with DO-178B. DO-178B does not apply to ground software such as that used in air-traffic-control systems.
Note that DO-178B is a software dependability standard, not a safety standard. This distinction is important, because safety has to be addressed separately. DO-178B was published in 1992, and various documents have been released by the FAA since the standard was published either to provide an interpretation of the standard or to offer guidance on compliance. Of special importance in terms of interpretation of DO-178B is RTCA/DO-248 [121].
Software can be found on board commercial air transports in autopilots, flight management systems, flight control systems, navigation systems, communications systems, engines controls, fuel management systems, brakes, and many other systems. For an overview of avionics functionality and development methods, see The Glass Cockpit [77].
The DO-178B standard plays an important role by providing the framework within which all of these computer systems are developed. Comprehensive compliance leads to regulatory approval. Thus such compliance implies for legal purposes that the necessary dependability requirements have been met.
Dependability Requirements
DO-178B defines five software levels for avionics systems designated A through E, with A as the most critical. The five levels and their definitions are shown in Table 12.1.
| Level | Definition |
| A | Software whose anomalous behavior, as shown by the system safety assessment process, would cause or contribute to a failure of system function resulting in a catastrophic failure condition for the aircraft. |
| B | Software whose anomalous behavior, as shown by the system safety assessment process, would cause or contribute to a failure of system function resulting in a hazardous/severe-major failure condition for the aircraft. |
| C | Software whose anomalous behavior, as shown by the system safety assessment process, would cause or contribute to a failure of system function resulting in a major failure condition for the aircraft. |
| D | Software whose anomalous behavior, as shown by the system safety assessment process, would cause or contribute to a failure of system function resulting in a minor failure condition for the aircraft. |
| E | Software whose anomalous behavior, as shown by the system safety assessment process, would cause or contribute to a failure of system function with no effect on aircraft operational capability or pilot workload. Once software has been confirmed as level E by the certification authority, no further guidelines of this document apply. |
TABLE 12.1. RTCA DO-178B criticality levels.
Although not labeled as such, the entries in this table are software dependability requirements. Devices such as flight-control systems and autopilots that have full control of an airplane are criticality level A since their failure could cause an accident. The other levels are progressively less critical. The actual software dependability requirements are implied rather than stated explicitly. At level A, for example, software failure could cause catastrophic consequences if failure of the software led to a failure of a critical aircraft subsystem such as the flight-control system.
Deriving a specific dependability requirement for software from these criticality levels is difficult, because the concern is with the associated system, not the software. The notion, therefore, is to begin at the critical-system level. Informally, the FAA requirement at level A is that system failure should be extremely improbable, and the FAA defines this term to be a probability of 10-9 per hour, i.e., the probability of correct operation for one hour is required to be 1 – 10-9 or greater [46].
The first step in applying DO-178B is to determine which criticality level has to be used for the critical system in question. The level is determined by the system safety assessment process based on the effect that failure of the system of which the software is a part would have on the aircraft. Establishing the criticality level of the system allows the software’s dependability requirements to be defined and the dependability contract between the system and the software established.
Examining a couple of examples is helpful to see the difficulty here. A flight-control system is a computer that links the pilot’s primary controls, the yoke and rudder pedals, to the control surfaces of the aircraft (flaps, rudder, etc.). Total loss of the system would almost certainly lead to an accident. Thus, the probability of failure of the flight-control system per hour has to be less than 10-9. But this is for the entire flight-control system, not just the software. Even with great care, the probability of failure of the computer hardware might well be of this order. So the reliability requirement on the software would have to be even more extreme. The practical manifestation of this requirement is to designate the software level A.
Now consider a critical system whose failure would not necessarily endanger the aircraft immediately, e.g., an autopilot. An autopilot can fly the aircraft automatically under many flight scenarios and is usually determined to be level A. This requirement applies to an autopilot in a somewhat different way from the way the requirement applies to a flight-control system. The difference arises because catastrophic consequences can only occur if (a) the autopilot fails, (b) the failed autopilot flies the aircraft in a dangerous way during certain phases of flight, and (c) the human pilot is unaware of the failure. Again, much of the probability of failure that can be permitted will be taken up by the hardware. In dealing with the software, the dependability requirement that is paramount is error detection and fail-stop failure semantics.
Dependability requirements expressed as levels, such as those shown in Table 12.1, are used in many other standards and are often referred to as software integrity levels. For example, the ISO/IEC 15026 standard is entitled “Information technology — System and software integrity levels” and establishes a framework for the meaning and definition of software integrity levels [70]. Since software is tied to system dependability with the contract structure discussed in Section 2.8.3, software integrity levels are often included in system safety standards. The contract then defaults to the software meeting the required integrity level.
Process Activities
DO-178B consists of 12 sections, an annex, and three appendices. The major sections are:
• Section 2 - System Aspects Relating To Software Development
• Section 3 - Software Life Cycle
• Section 4 - Software Planning Process
• Section 5 - Software Development Processes
• Section 6 - Software Verification Process
• Section 7 - Software Configuration Management Process
• Section 8 - Software Quality Assurance Process
• Section 9 - Certification Liaison Process
• Section 10 - Overview of Aircraft and Engine Certification
• Section 11 - Software Life Cycle Data
• Section 12 - Additional Considerations
• Annex A - Process Objectives and Outputs by Software Level
The majority of the DO-178B standard is a detailed explanation of the expected software development process together with extensive definitions of terms. As an example of the details of the standard, Section 4, “Software Planning Process”, consists of the following six subsections:
• 4.1 Software Planning Process Objectives
• 4.2 Software Planning Process Activities
• 4.3 Software Plans
• 4.4 Software Life Cycle Environment Planning
• 4.4.1 Software Development Environment
• 4.4.2 Language and Compiler Considerations
• 4.4.3 Software Test Environment
• 4.5 Software Development Standards
• 4.6 Review and Assurance of the Software Planning Process
Section 4 does not prescribe a specific approach to process planning that has to be followed. Rather, the section defines detailed, low-level objectives. The introductory paragraph of section 4 states:
“This section discusses the objectives and activities of the software planning process. This process produces the software plans and standards that direct the software development processes and the integral processes. Table A 1 of Annex A is a summary of the objectives and outputs of the software planning process by software level.”
Each subsection of section 4 is a detailed set of definitions and objectives. Subsection 4.1 of section 4, for example, is shown in Figure 12.4. Although stated as objectives, the details are so precise that they define many of the activities that must be present in the process.
The heart of the compliance mechanism for the standard is meeting all of objectives. As an aid, ten tables are listed in Annex A. The tables are essentially summaries of the objectives for various process requirements showing to which criticality level the objective applies, whether compliance has to be established independently, and so on. Each table targets a major process area. Table A-1 entitled “Software Planning Process”, is shown in Figure 12.5. This table is the summary for some parts of section 4.

FIGURE 12.4 Subsection 4.1 of DO-178B.
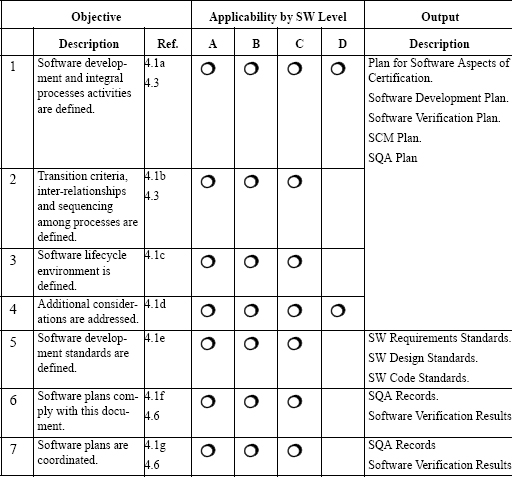
FIGURE 12.5 Part of Table A-1 from Annex A of DO-178B.
As can be seen in Figure 12.5, the objectives stated in the left column of the table are all in the form of “yes/no” questions. Mere existence of an artifact is not sufficient. The artifact must meet the intent of the standard as interpreted by the inspector checking compliance.
12.3.3 The Advantages of Prescriptive Standards
Prescriptive standards have three significant advantages:
Targeted fault avoidance and fault elimination. Techniques can be included in the standard that are designed to avoid or eliminate certain classes of faults in a very specific way. For example, certain programming languages or test techniques might be required. The use of targeted techniques in standards is a special case of the concepts on managing software fault avoidance and elimination discussed in Section 7.10 on page 212.
Process guidance and coverage. Process structures can be included in the standard that are designed to ensure that crucial process steps are carried out in the right order and with the correct form. For example, rigorous and documented configuration management might be required so as to ensure that software versions are properly managed.
Enhanced engineering communication. The fact that engineers are following a prescriptive standard means that they have a comprehensive basis for communication. All the engineers involved in development know what has to be done, and what has to be done is largely defined in a small set of documents. The artifacts to be produced for submission to the regulating agency are well defined, and so the targets of engineering activities are fairly clear.
12.3.4 The Disadvantages of Prescriptive Standards
Despite their advantages, prescriptive standards suffer from two significant disadvantages:
Prescriptive standards are inflexible. By their very nature, prescriptive standards dictate details of the development process. Some standards dictate less detail than others and focus more on specific development objectives. Some standards also permit deviation from the prescribed approach provided the deviation is carefully documented and fully justified.
The challenge, however, lies in the spectrum of systems that are covered by a single standard. RTCA DO-178B/EUROCAE ED12B, discussed in Section 12.3.2, for example, has to cover all digital systems that fall within the definitions of level A through level D. A specific system might benefit from a different development technology, but such deviations are difficult to effect in practice. Despite efforts to make standards less constraining, the effect of a standard in the certification process makes engineers reluctant to deviate from the prescribed standard at all. To do so risks certification failure for the system they are developing.
Prescriptive standards rely upon an unjustified assumption. The use of a prescriptive standard includes the assumption that by following the complete standard, an overall dependability requirement for the developed system will be met. That requirement might be quantitative, but by following the standard, there is no obligation to measure or model probabilities.
More specifically, in the context of dependability, prescribed processes rely upon the following assumption:
If a specific prescriptive standard is followed to develop a particular artifact, then that artifact will possess a certain dependability property as a result of having been developed according to the standard.
Unfortunately, there is no basis for the assumption that significant dependability properties will be met by following a documented set of development procedures. Even if somehow this were possible, there would be no guarantee that the developers followed the standard precisely as intended. Thus, relying on a prescribed standard is far from an assured way of meeting dependability goals about any system. In particular, there is no basis for assuming that quantitative dependability goals will be met by following a prescribed development standard. Despite this disadvantage, the use of standards in a number of industries has proven quite successful. Although there is no basis for the fundamental assumption, experience has shown that large numbers of systems have provided service over a substantial period of time with an acceptably low failure rate. Thus, in a sense, the basis for the assumption has become the record of use.
Except for some situations in Europe, virtually all systems that have to achieve high levels of dependability and which are the subject of regulation rely upon prescriptive standards. In the United States, for example, the Federal Aviation Administration, the Food and Drug Administration, and many parts of the Department of Defense use prescriptive standards.
12.4 Rigorous Arguments
In order to deal with the difficulties of quantitative assessment and prescriptive standards, a new approach to dependability assessment has been developed that is based upon the use of rigorous argument. The concept is (a) to develop a system, and (b) to develop an argument to justify a claim about the system. Specifically, developers:
• Construct the system using a process and technology that they choose. Techniques can be chosen based upon the needs of the system being built, including elements of existing prescriptive standards if desired.
• Construct an argument that documents their rationale for believing that the system has certain important properties, usually those associated with dependability.
The argument makes the developers’ rationale explicit, and this notion is what makes this technique unique. Developers of systems that have high dependability requirements always have a rationale for their choices of technology. Similarly, there is a rationale for the detailed content of any prescriptive standard, but the rationale is never written down in a systematic and comprehensive way.
12.4.1 The Concept of Argument
Much of the work on the use of rigorous argument in dependability is based on the work of Toulmin [139]. The idea of an argument is both familiar and unfamiliar to computer and software engineers. Everybody knows (or thinks they know) what an argument is. But few people are familiar with the idea of documenting an argument and even less familiar with the idea of a rigorous argument.
In essence, the argument contains the developers’ thinking behind their choices of development processes, tools, and techniques. The argument says:
We, the developers, believe that the system we have built
meets the dependability requirements because…
The argument has to be a good one, because the argument is the primary means by which a decision is made about whether a system should be used. This decision about system use should not be based on anything but a strong argument combined with the associated evidence.
Informally, a rigorous argument about the dependability of a system is part of an overall dependability case that consists of the following five main parts:
• An overall, high-level dependability claim (the top-level goal) that has been established for the system.
• A definition of the context within which the top-level goal is expected to hold. Context includes everything that might be needed to constrain the applicability of the dependability argument to a given set of circumstances.
• An explicit argument that shows how the overall dependability claim can be reasonably inferred from the underlying evidence. In practice, multiple different argument strategies are sometimes used in conjunction to argue dependability in a given case.
• A collection of supporting evidence in the form of assessments of either system properties or properties about how the system was developed. These assessments come from techniques such as measurements, analyses, testing, modeling, and simulation.
• A list of the assumptions that have been made in the argument. Some aspects of the development and assessment process have to rely on assumptions that cannot easily be justified by available forms of evidence.
The fact that the argument is explicit, i.e., actually documented, brings several immediate advantages:
Argument review by developers. The developers of the target system have to construct the argument, and, in doing so, they have to think about the argument’s contents. Thus, the argument is reviewed as it is built, and the argument can affect technology choices made by developers.
Argument review by other engineers. Engineers not involved in development of the system or the argument can examine the argument and determine whether they think the argument is convincing. This examination is a form of inspection and is an effective way of assessing arguments.
Argument review by regulators. Explicit arguments provide regulators with precisely the view that they need when they are trying to assess whether the dependability goals of a system have been met with sufficient fidelity to protect the public interest.
Argument permanence. The argument is always available, because it is written down. Thus, the rationale is never lost as it would be if the rationale were only discussed verbally.
Argument quality. The fact that the argument is rigorous means that the argument is more likely to be convincing, and, in some sense, “correct”.
As with other topics in this book, we cannot cover rigorous arguments in depth. Our discussion begins in the next section with a review of the present major use of rigorous arguments, safety cases. In Section 12.4.3, we present some of the basic aspects of safety case and argument structure. The remaining sections present (a) an example of a safety argument and how the argument might be developed, (b) a popular notation, the Goal Structuring Notation, that has been developed for documenting arguments, and (c) the concept of using patterns in argumentation.
12.4.2 Safety Cases
The use of rigorous argument was pioneered in the field of system safety primarily in the United Kingdom (U.K.). Over a period of several decades, various significant accidents occurred in the U.K., including a fire at the Windscale nuclear reactor in 1957, an explosion at the Flixborough chemical plant in 1974, an explosion on the Piper Alpha oil platform in 1988, and a collision of passenger trains at Clapham in 1988. These accidents and other accidents and incidents over the past 50 years led to the development of a detailed safety culture that includes safety cases.
The concise definition of a safety case is:
“A safety case should communicate a clear, comprehensive and defensible argument that a system is acceptably safe to operate in a particular context.” [75]
There are three important phrases to note about this definition:
“clear, comprehensive and defensible”. The argument has to be clear so as to be accessible. The argument has to be comprehensive, because all aspects of safety have to be addressed. And the argument has to be defensible, because the argument must be convincing to all the stakeholders and not subject to a successful rebuttal.
“acceptably safe”. Since systems cannot be shown to be completely safe, the argument has to show what is practical. Thus the level of risk that the stakeholders of the system will tolerate must be part of the goal that the argument addresses.
“particular context”. A system is designed to operate in a specific context, and, if the system is operated in a different context, then the system could be unsafe. Thus, the operating context must be stated and considered in the use and evaluation of the argument.
Creating a safety case that meets the definition is an elaborate process. There are four major tasks that have to be undertaken:
Determine what level of safety will be acceptable. This determination is a process of negotiation driven primarily by those charged with protecting the public interest. For a medical device, for example, the prospect of patient injury is obviously the focus, but different patient injuries have different implications.
Determine what the operating context will be. The operating context involves a wide range of factors, each of which might have many attributes. For a medical device, for example, determining the operating context requires that those developing the context ascertain everything about where, when, by whom, for what purpose, and how the device will be used.
Determine all the relevant system details. Many different engineering disciplines are involved in the development of any modern engineered system. Medical devices, for example, are motivated by medical professionals, but the creation of the device is likely to involve mechanical engineers, materials scientists, electrical engineers, computer engineers, software engineers, and probably others.
Create an argument that is clear, comprehensive and defensible. In practice, documented arguments tend to be large. They depend on many other documents that provide the context, the evidence, and so on. The totality of the materials that constitute the safety case will often be hundreds of pages. An argument can seem reasonable to one engineer but not to another. An argument can be malformed in subtle ways that are hard to see but which make the argument insufficient.
12.4.3 Regulation Based on Safety Cases
Safety cases are used extensively in the United Kingdom (U.K.) as the primary means of documenting safety and demonstrating compliance with associated regulation. The following U.K. agencies require safety cases in some areas of their jurisdiction:
• The Health and Safety Executive for various elements of the nuclear industry and for offshore installations such as oil platforms.
• The Office of Rail Regulation for rail signaling and management.
• The Ministry of Defence for all safety-critical defense systems.
• The Civil Aviation Authority for air-traffic services safety requirements.
An important example of regulation based on safety cases is U.K. Ministry of Defence, Defence Standard 00-56 [140]. This standard is goal-based and different from the standards mentioned earlier in this chapter. The standard is only 18 pages long yet it covers a wide range of systems. The standard states:
The purpose of this Standard is to set requirements that enable the acquisition of systems that are compliant with both safety legislation and MOD safety policy.
In other words, the standard is considered all that is needed to protect the interests of the various stakeholders for U.K. defence systems. The heart of the standard is the requirement that a safety case be supplied for any compliant system. The standard states:
The Contractor shall produce a Safety Case for the system on behalf of the Duty Holder. The Safety Case shall consist of a structured argument, supported by a body of evidence, that provides a compelling, comprehensible and valid case that a system is safe for a given application in a given environment.
A second important example of regulation based on safety cases is the U.K. Civil Aviation Authority’s CAP 670 Air Traffic Services Safety Requirements [141]. This is also a goal-based standard. The standard states:
Whilst the contents of the document may be of interest to other parties, this document is addressed to ATS providers who are expected to demonstrate compliance with applicable requirements either directly or through the provision of safety assurance documentation which may be in the form known as a safety case.
At the time of writing, no regulating agency in the United States requires the use of safety cases as discussed here. The Food and Drug Administration (FDA) does not currently require them but has issued guidance for particular devices that permits their use [48].
12.4.4 Building a Safety Case
The Structure of a Safety Case
A complete safety case is the composition of the safety argument, all the information used by the argument such as the evidence and the context definitions, and any ancillary materials such as informal descriptions that might be considered useful. The argument provides the reader with the rationale, and the other materials provide the details to which the argument refers.
The high-level structure of a safety case is illustrated in Fig. 12.6. At the top right is the safety claim (a requirement that has to be met) that is expressed as a goal. At the bottom right is the body of supporting evidence that will be used as the basis of the safety argument. Linking the supporting evidence to the top-level goal is the safety argument. This argument should show how the top-level goal follows from the supporting evidence.
To the left in the figure are the details of the operating context, a set of explicit assumptions that are being made and which will be used as part of the basis for the argument, and a set of justifications that explain why certain strategies were used in the argument and why they should be accepted.
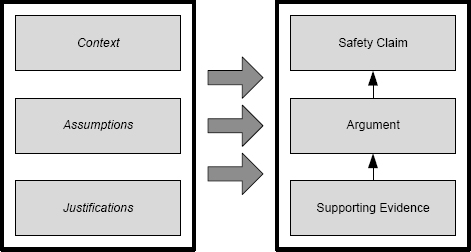
FIGURE 12.6 The overall content and basic structure of a safety case.
The Structure of a Safety Argument
The structure of a safety argument is a hierarchy of goals. A higher-level goal is decomposed into a set of lower-level goals that, if satisfied, can be combined according to a strategy to argue that the higher-level goal is satisfied. Decomposition is applied to all goals until low-level goals can be reasonably inferred from available evidence.
The process of building a safety argument begins with defining the top-level goal of the argument. This goal is the fundamental claim that is being made about the system. Essentially, the form of the goal is a statement of the safety requirement for the system. This goal is decomposed into lower-level goals, and this process continues until the entire hierarchy is complete.
The basic building blocks of a safety argument are:
Goals. A set of goals in which a top-level goal documents the safety claim and other subgoals help to structure and elaborate the argument. Goal statements have the form of a proposition in order that they may be evaluated as true or false.
Contexts. Context is needed to establish the expected operating environment for the system itself and also for the environments in which some of the evidence was obtained.
Strategies. A strategy shows how a higher-level goal will be inferred from lower-level goals.
Solutions. Solutions are the composition of all forms of evidence. Solutions might include data from tests, details of a process step, and so on.
Assumptions. As the name implies, assumptions document the assumptions being made in the argument.
Justifications. Justifications basically provide the reasoning behind the use of a particular strategy.
12.4.5 A Simple Example
To illustrate the basic elements of a safety argument, consider the simple problem of arguing that using a match in an office to light a candle is safe. The top-level safety goal used might be:
Goal: Lighting a candle using a match in my office is adequately safe.
In order to make this goal meaningful, we need to state the context and the meaning that we want for “adequately safe”. This could be done in the following way:
Operating Context: The lighting of the candle will take place in an office that is identified by building number and office number. The details of the office location, dimensions, content, accessibility, and construction materials are provided in certified documents at a specified location.
Adequately safe: Adequately safe means that burning or setting fire unintentionally to anything other than the subject candle is reduced As Low As is Reasonably Practicable (ALARP).
The definition of adequately safe uses the ALARP principle, because that principle provides the form of the claim that is most useful. ALARP in this case means:
• There is no known means of burning or setting fire to an object in the room other than the subject candle that has not been properly identified and made inoperative. Thus, fire can only result from an ignition process that has not been identified, and the expense of seeking other highly unlikely (hopefully non-existent) ignition processes is grossly disproportionate to the expected reduction in risk.
• The cost of installing additional risk-reduction technologies such as a building sprinkler system is grossly disproportionate to the expected reduction in risk.
The only significant hazard that we need to address is a state in which something other than the candle could be set on fire or burned. So the definition of adequately safe is basically that this hazard is as unlikely to occur as we can reasonably make it.
Notice the amount of detail that this goal and the context statement contain, and how the planned notion of “safe” is defined. Also note that this is just the top-level goal statement, not the whole safety argument.
In order to complete the safety argument for this example, the remainder of the argument needs to be developed and the associated evidence generated. The strategy that we will use is to argue that the top-level safety goal follows if the following subgoals holds:
• No children are present in the room when the candle is ignited.
• The room cannot be accessed in an unplanned manner by children.
• There are no combustible materials within a three-meter radius of the location at which matches will be used.
• There is a non-combustible mat below the candle and the space in which the lighted match will be present.
• The contact information for the fire department is accurate and prominently visible.
• The fire department is available at all times that a candle might be ignited.
• The office communications equipment provides highly reliable facilities to contact the fire department.
• There are no combustible gases present.
• The match does not explode or burn out of control.
• No burning matches are present once the candle is alight.
• The candle does not explode or burn out of control.
• The operator is competent to use a match in the required manner.
• The candle cannot be moved out of the office once ignited.
The development process that has to be followed for refinement of any goal is to determine the argument strategy to be used, define the set of subgoals, and review this elaboration of the top-level goal so as to remain convinced that this refinement is valid. Where assumptions have to be made or where additional context has to be added, these need to be documented as part of the refinement also.
The evidence that will be used in this argument includes (but is not limited to):
• All personnel in the room have been checked and found to be adults.
• Materials in the office within three meters of the location at which matches will be used have been shown to be non-combustible by an independent laboratory.
• The office has been checked for explosive gases by an independent laboratory within a short period of time so that explosive gases could not have built up since the test was conducted.
• The candle brand has been tested for burn characteristics by an independent laboratory and found to be adequate.
• The match brand has been checked for burn characteristics by an independent laboratory and found to be adequate.
• The equipment available to extinguish a burning match and to dispose of a hot match has been thoroughly tested by expert fire-prevention engineers.
• The operator has been given training in (a) lighting a candle with a match and (b) determining where within the office space the use of a match would be at least three meters from combustible materials.
Even though this example is simple and is incomplete, note the length of the argument so far, the amount of evidence needed, and the rigor yet relative informality of the approach.
Completing this example, a simple one, requires that we expand all of the sub-goals. One might conclude from the evidence listed above that the subgoals are all valid. But there is at least one flaw in that argument. The flaw is the assumption that if all personnel in the room are adults, then there are no children present. Since people come and go all the time, we need at least two lower-level goals to be able to justify the claim that no children are present. To argue that the operating context is limited to adults, there needs to be a strong argument that children cannot reach the environment. Thus, we need two subgoals:
• All personnel in the room are adults.
• Children cannot gain access to the room.
This second subgoal seems simple since the area in question is an office, and apparently a secretary guards the office in question. In practice, the simplicity of this example is deceptive, and that deception is precisely where the need for a comprehensive argument is greatest. If an error is made so that a child can obtain access to matches, the consequences could be serious. Consider that the argument so far says nothing about what happens if the secretary is not at her desk, whether the office is locked during non-business hours, whether the secretary was trained not to admit children, and so on.
We can (and, of course, should) modify the system and the argument to take care of these omissions. That is simple to do once we have the initial form of the argument. The argument that we obtain will be fairly comprehensive, because we will deal with locking the office, secretary training, and so on. That evidence now includes (hypothetical) documents about company procedures that define secretary training and scheduling.
But the power of rigorous argument is well illustrated at this point, because, when we review the argument, we detect several weaknesses:
• Demanding that the secretary be trained to deny children access to the office does not mean that the secretary either fully understood the training or that he or she would properly enforce the rule of denying children access.
• Requiring that the secretary lock the door whenever he or she is absent does not mean that the secretary will always remember to lock the door.
• There is no indication that the secretary would prohibit the introduction of explosive gases or combustible materials into the office. Even though our top-level goal is argued, in part, by the checks on explosive gases and combustible materials, there is no provision in the system as described to maintain that state.
The fact that the safety of the system depends on significant but subtle details is not necessarily revealed by a rigorous safety argument, but the chances are high that the argument will reveal subtle errors if we build the argument carefully and inspect the argument systematically.
12.4.6 The Goal Structuring Notation
In practice, arguments are large, complex artifacts that have to be read and understood by a variety of people. If they were documented in an ad hoc manner, the chances are high that the reader of an argument would be unfamiliar with whatever notation was used. Having a single, well-designed notation for documenting arguments is important.
The example of lighting a candle given in the previous section demonstrates why rigor and precise notations are needed. The example is for illustration of basic ideas only, and documenting the complete safety case is not necessary. Were the complete safety case needed, informal and unstructured English text would not be satisfactory. Various notations have been developed for documenting arguments, but we will concentrate on just one, the Goal Structuring Notation (GSN).

FIGURE 12.7 The graphic elements of the Goal Structuring Notation (GSN).
The Goal Structuring Notation is a graphic notation that has been developed to provide a complete and unified approach to documenting safety arguments [75]. Tools have been developed to facilitate the editing and analysis of safety cases documented in GSN including ASCE [5], ISCaDE [119], and the University of York add-on for Microsoft Visio [142].
The graphic elements that are used in the representation of an argument in GSN are shown in Figure 12.7 and are just the argument building blocks. Each element has an identifying symbol in the top left of the element. The character used indicates the type of element, e.g., “G” for goal, and the integer identifies the specific element. The primary purpose of the identifying symbol is to allow reference to the element in all the associated documentation.
An example of a simple top-level goal and the associated context description for a hypothetical unmanned aircraft system (UAS) is shown in Fig. 12.8. The arrow from the goal element to the context element indicates the dependence of the goal on the context. Note that the contexts in the GSN diagram refer to associated documents, the Safety Manual and the Concept of Operations for the aircraft. These documents will be included in the complete safety case. Note also that the context will include the definition of exactly what the word “safe” is to mean in this case.
With a top-level goal of the form shown in Fig. 12.8 properly stated and the context fully documented, the next step in the development of a safety argument would be to determine the strategy that will be used to argue that the top-level goal is met and the subgoals that will be employed in that strategy. This process of refinement continues until the leaf nodes in the argument are solutions or assumptions.
An example of part of a hypothetical argument documented in GSN for the top-level goal and contexts in Figure 12.8 is shown in Figure 12.9. In this example, the top-level goal is argued using a strategy based on the idea that the risks associated with all credible hazards should be reduced to an acceptable level.
12.4.7 Software and Arguments
The example in Figure 12.9 does not mention software. This is not an omission. Software is not mentioned, because the safety argument is for an application system. The argument decomposition shown has not reached the level where software enters the picture.
Refinement of the argument for goal G8 is shown in Figure 12.10. In this sub-argument, the focus is on a hypothetical ground-based surveillance radar. The radar generates raw data that is processed by a complex computerized analysis system. The analysis system tracks the subject aircraft and determines whether the aircraft is in danger of exiting the airspace within which it is authorized to operate. The radar also looks for intruder aircraft that might enter the operating airspace for the UAS by mistake.

FIGURE 12.8 Top-level goal and context example.

FIGURE 12.9 A small fragment of a safety argument documented in GSN.
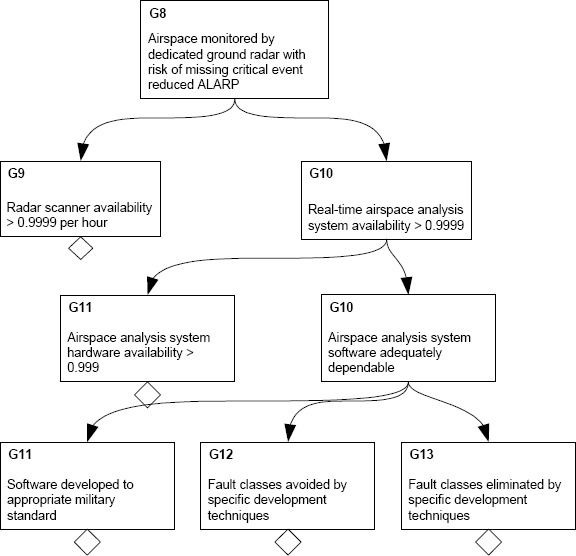
FIGURE 12.10 Refinement of UAS argument down to software level.
In order to have confidence that the analysis system will operate correctly, an argument is needed about the computer system that implements the analysis system. The argument proceeds by splitting the problem into hardware and software claims. The hardware claim includes a statement about the availability of the hardware. Assuming that the only concern with the hardware is degradation faults, this claim is quite reasonable.
Unfortunately, a similar claim cannot be made in this case for the software. The use of fault avoidance and fault elimination techniques can provide assurance that whole classes of faults are missing, but for the remainder of the software faults the argument has to appeal to the process by which the software was constructed. Thus, the argument in the end will rest, in part, upon the assumption that the software has the necessary dependability properties as a result of the development process used. This situation is common and leads us to a discussion about the different types of evidence that can arise.
12.4.8 Types of Evidence
The evidence used in safety arguments can take various forms, and the different forms provide different levels of support for the claims to which they contribute. The fundamental difference is between direct and indirect evidence:
Direct evidence: Direct evidence is evidence about the product itself.
Indirect evidence: Indirect evidence is evidence about how the product was produced.
Direct evidence is preferred, because such evidence derives from and is evidence about the product itself. Indirect evidence has the disadvantage of requiring the basic assumption that a product property can be inferred from the indirect evidence. This problem is the same as the problem we noted with the use of prescribed standards (see Section 12.3.4).
Evidence can be broken down into subtypes that characterize the evidence further. The breakdowns differ between different sources, and so here we will use the characterizations from the U.K. Ministry of Defence in Defence Standard 00-56 [140].
Defence Standard 00-56 distinguishes five types of evidence:
Direct evidence from analysis. During development, various types of analysis are performed on systems and system components, including software. The result of an analysis is typically the establishment of a property of the artifact. Static analysis of software, for example, can establish that certain faults are absent from the software (see Section 7.9.1, page 208). Analytic evidence provides strong support for any claim, although a convincing argument about a general software claim will require a lot of evidence.
Direct evidence from demonstration. Demonstration evidence includes the results of testing, simulation, modeling, and possibly operational use. Testing is, of course, common for many different components of a system, especially software. Simulation and modeling are special mechanisms that correspond roughly to the idea of “testing” algorithms.
Clearly, evidence from operational use is not an option except under special circumstances. Any operational use that is to be included as evidence must have come from some version of the system that is different from the system that is the subject of the safety case. If that were not the situation, the system would have been operating without the planned safety case and presumably with some form of restricted or preliminary authority to operate.
Situations in which operational evidence arises and can be used include operation in an environment different from that for which the safety case is being developed. For example, an unmanned aircraft might be operated for substantial periods of time over an uninhabited desert area and substantial operational experience gained without harm. That evidence about the aircraft system in general and the avionics, navigation, engine-control, and communications software in particular might be used in a safety case for the operation of the aircraft over a populated area.
Direct evidence from the review process. Review evidence is the evidence obtained from rigorous inspection. As discussed in Chapter 10, inspections are highly effective and can be applied to virtually any artifact.
Indirect evidence from a process. As we discussed in Section 12.3.3, there are advantages to the use of prescriptive standards, and citing the use of such standards is of value despite the fact that the evidence is indirect. Care must be taken, however, with any prescriptive standard to seek ways in which the standard might be missing something. Typically, software standards require some form of testing and rely upon that testing for verification. Such testing does not necessarily test the subject artifact in such a way as to reveal application-specific faults. Software testing that relies on branch coverage, for example, will not necessarily reveal faults that cause real-time deadlines to be missed.
Indirect qualitative evidence. Qualitative evidence includes assessment that an artifact has certain properties that are not related quantitatively to the artifact but tend to correlate with a “better” artifact. For software, there are many useful metrics about software design that tend to correlate well with software that is more dependable. Also for software, expert judgment is a valuable form of evidence. Experts with substantial experience can judge various attributes of a software system, including items such as likely completeness of documentation, appropriate types of data structures, appropriate coding techniques, and so on. Such judgment is useful evidence.

FIGURE 12.11 A commonly occurring high-level safety argument.
12.4.9 Safety Case Patterns
Arguments relate evidence to claims and are rarely unique. In fact, commonly used arguments exist, including high-level argument fragments that are distinct from evidence and special arguments that are specific to particular domains. Arguments can be reused by starting with what is usually called a template. Safety case templates are called patterns.
Patterns capture successful argument approaches so that they may easily be reused. They document “best practice” arguments, such as specialized domain expertise, successful certification approaches, and “tools of the trade”.
Various safety case pattern catalogs are available (for example in [76] and [146]), and they should be consulted any time that a safety case is being built. If a suitable pattern is found, that pattern can be instantiated for a specific use, although instantiation must be done carefully to ensure that the argument limitations or restrictions that apply have been properly respected. GSN includes symbols for pattern support.
A commonly occurring high-level safety argument is shown in Figure 12.11. This pattern was the basis of the example in Figure 12.9. The strategies in this pattern can be elaborated with the help of other patterns that address the strategies specifically.
12.5 Applicability of Argumentation
As noted in Section 2.8.1, there is no such thing as safe software or secure software. Software by itself cannot do any harm to people, equipment, the environment, or information. These notions apply to application systems.
Arguments have been applied to all of the dependability attributes that are meaningful at the application system level. When speaking of a dependability attribute other than safety, the term that is sometimes used is an assurance case.
The notion of safety arguments is well established. In practice, outside of equipment safety, assurance cases are being applied primarily in the fields of security and location safety. Security arguments have been the subject of preliminary research and evaluation. An argument that a system is secure in some sense is a valuable complement to the qualitative assessment that has been attempted in the security field in the form of security audits. In the field of location safety, assurance cases have been applied to the assurance of various properties of nuclear fuel handling and to the Yucca mountain nuclear waste repository.
Also as we noted in Section 2.8.3, computer systems in general and software in particular have dependability requirements that are derived from the needs of the overall system within which the computer system will operate. These derived dependability requirements constitute a contract between the computer system and the overall system within which the computer system will operate.
The use of arguments for software is restricted to the meaningful dependability properties of software. Rather than develop separate technologies for arguments about software reliability, software availability, and so on, the more common practice is to create an assurance argument. Such an argument is used to provide assurance that the software meets the dependability requirements derived from the application system.
Why Rigorous Arguments Rather Than Quantitative Assessment?
How does the use of argument mitigate the difficulties with quantitative assessment? As we saw in Section 12.2.4, the three areas of difficulty with quantitative assessment are (1) non-quantifiable attributes, (2) unavailability of models, and (3) ultrahigh levels of dependability. Rigorous arguments provide an approach to dealing with all three areas of difficulty:
Non-quantifiable attributes. Non-quantifiable attributes are usually dealt with by either fault avoidance or fault elimination. Provided the techniques used are comprehensive, the required attribute is present in theory. The major problem that arises is a lack of assurance that the various techniques have been applied properly. By using a rigorous argument, (a) the details of the techniques and their application can be documented and (b) the rationale for believing that the techniques provide the necessary attribute and that the techniques have been applied properly can be properly stated and examined.
Unavailability of models. Without models, the applicability of quantitative assessment is severely restricted. By using a rigorous argument, developers can show that all possible or at least all reasonable measures have been taken in the development of the subject software. This approach does not provide a quantitative assessment, but the approach does provide a strong basis for believing that the ALARP principle has been applied systematically and thoroughly.
Ultra-high levels of dependability. Ultra-high levels of dependability cannot be determined by quantitative means, as we noted in Section 12.2.4. Again, by using a rigorous argument, developers can show that all possible or at least all reasonable measures have been taken in the development of the subject software.
Why Rigorous Arguments Rather Than Prescriptive Standards?
How does the use of argument mitigate the difficulties with prescriptive standards? As we saw in Section 12.3.4, the disadvantages of prescriptive standards are their inflexibility and their dependence on an unjustified assumption. As noted in Section 12.4, there is always an implicit argument associated with any prescriptive standard. This idea is easy to see if one asks the following question for any prescriptive standard:
Why does the standard require what it does?
For each entity that a prescriptive standard requires, there must have been a rationale, and that rationale must have been in the mind of the developers of the standard when the standard was written. Properly composed, structured, and documented, the rationales for the entities could constitute a complete and comprehensive overall argument addressing a suitable top-level claim. Unfortunately for existing standards, this preparation has not been done.
Turning this situation around, we can document our rationale for some aspect of a system’s or software’s dependability attribute and associate that rationale with the process steps that we take to achieve it. Thus, the inflexibility of prescriptive standards is eliminated, because we can tailor the standard to a specific process and justify our process steps with the dependability argument.
Key points in this chapter:
♦ There are three general approaches to dependability assessment: quantitative assessment, prescriptive standards, and rigorous argument.
♦ In most cases, quantitative assessment cannot be applied effectively to software dependability assessment.
♦ Prescriptive standards are applied regularly to software development.
♦ Prescriptive standards are generally of only limited flexibility and so cannot accommodate well the idiosyncracies of systems.
♦ There is no generally applicable relationship between the details of a prescriptive standard and the ensuing dependability of software built using the standard.
♦ Rigorous argument is used to document the rationale that developers have for believing in the dependability attributes of a target artifact.
♦ A rigorous argument is embedded within a comprehensive safety case to provide documentation of the rationale for believing a system is safe.
♦ Safety cases can be scrutinized by independent entities such as certification agencies to allow assessment of the safety of a given system.
Exercises
1. DoD Mil Std 882D is a standard that is available for download [35]. Examine the standard and identify several prescriptive processes and several prescriptive artifact elements that the standard requires.
2. Review Mil Std 882D and determine how the standard requires that hazard identification be conducted.
3. Download a copy of MoD Defence Standard 00-56 [140]. The standard requires that a system developer deliver a safety case to the regulators and that the safety case be “compelling”. The standard does not define compelling for an argument. Develop an argument of your own for the term “compelling”.
4. Sketch out an argument in GSN for the candle example discussed in Section 12.4.5.
5. Software is neither safe nor unsafe (see Section 2.8.1), but rigorous argument can be applied successfully to software. In that case, the argument is referred to as a software assurance argument. Top-level claims in such arguments are the dependability requirements for the software. Develop a GSN pattern that might be used as a starting point in developing an assurance argument for software.
6. In a software assurance argument, determine whether each of the following items of evidence is direct or indirect: (a) report of the inspection of the specification, (b) results of the static analysis of the source program, (c) report of the successful completion of the exit criteria for software testing, and (d) report of test coverage analysis.
7. Concisely explain what is meant by a safety case for a safety-critical system.
8. How is safety defined for a safety case?
9. Critics have claimed that fault trees and safety arguments in the GSN are basically the same thing. If this is the case, explain why. If not, explain why not.
10. Consider an expression in a piece of software that contains 24 inputs (variables or functions that are either true or false). How much time would it take to execute all of the tests required for multiple condition coverage (exhaustive testing) if you could run 200 tests per second?
11. Briefly explain the meaning and significance of the Butler and Finelli result [24].
12. A safety case documented in GSN is a directed, acyclic graph (DAG).
(a) What would be found at the root of the DAG and what would it say?
(b) What major types of nodes are typically found within the DAG?
(c) Would details of a system’s fault tree analysis be included in a typical safety case? If so, how and, if not, why not?
1. DO-178B is copyright by RTCA, Inc. Excerpts are used with permission. Complete copies of DO-178B and other RTCA documents can be purchased from RTCA Inc., 1150 18th Street NW, Suite 910, Washington, DC 20036. (202) 833-9339.