
In This Chapter
The success of a network game often hinges on its ability to handle network communications. While strong network support and near-invisible connectivity will not necessarily boost the player’s opinion of a game, bad networking will render the game less playable. And of course, the less playable a game is, the less it will be played—and subsequently, the smaller the market it will have.
Poor network communications stem from a number of causes, nearly all of them revolving around issues that are beyond the control of the developer: line speeds, underperforming network hardware, poor operating system support, and so on. Even so, there are many steps a developer can take to mitigate the worst effects.
Primarily, this chapter deals with the three core networking issues: loss, jitter, and latency, or lag. Innovative solutions are offered, including a discussion of ways to minimize the in-flight data, compress data being transmitted, and predict the state of the universe. All the techniques outlined here contribute in some way to the fluid playing of the game, as well as offering some level of protection against hacking and cheating.
Note

You’ll learn more about protecting against hacking and cheating in Chapter 8, “Removing the Cheating Elements.” This chapter is mainly concerned with helping improve the transit of data from A to B, possibly via C, in a way that is efficient, reliable, secure, and, above all, realistic given the tools at your disposal.
Besides the various problems that stem from unreliable data delivery, there are also issues relating to data that simply never arrives and connections that break completely. Solutions to these two conditions are also dealt with in this chapter—even if, at first glance, there seems to be very little that you can do about them.
A secondary goal of this chapter is to improve security with improvements in the networking layer. As you shall see, the two solutions are often intertwined, which goes some way to helping thwart the inevitable rise of cheating factions with a popular network game.
Network communication issues affect different multi-player game models in different ways, depending on the technology and platform used to deploy the product. Clearly, the more networking (and more clients) there are, the more the various issues will affect the game. But there are also certain physical factors that affect the performance of the networking technology used.
From the most to least affected gaming models, the following is a short run-down of some of the common issues:
Internet multi-player games. Internet multi-player games that are not Web based are clearly the most affected. In short, in this model, everything is out of the control of the developer. Developing for consoles will remove one of the unknowns (the platform), but all the networking unknowns will remain. These include the following:
Distance
Line speeds
Network hops
Reliability of lines
Internal networking issues
Private WAN multi-player. The next most affected games are private WAN multi-player games. In this case, some of the communications will be out of the control of the developer. But this game type is also not generally used, as it is quite expensive to set up a gaming WAN just for one game—although part of the aforementioned Internet multi-player game model may be a private WAN, especially if there are communication conduits between servers. It is best not to separate the servers by the Internet if at all possible.
LAN multi-player. One of the least affected categories is LAN multi-player games; these should run in a more-or-less predictable environment. Of course, there will be issues relating to networking support, but they will not usually be linked to the stability, reliability, or speed of the communication infrastructure. More likely, issues in this category will relate to the setup of the network as a whole.
Single-machine multi-player. Of course, single-machine multi-player games are among the least affected. Although they might use some network game–style technologies (relating to the way in which the various players interact at the game level), these are outside the scope of this book.
In addition to these, network communication can have an effect on the following network game models:
Web-strategy games. These games might be affected, but it is questionable whether this has a direct impact on playability. Web pages are inherently non-real time, and while it might be annoying for a site to be slow on occasion, slow performance is rarely a stopping point for the game. Of course, it will become an issue if the game is never available due to saturation—but this is more about scalability than it is about communications per se.
Play by e-mail. By a similar token, play-by-e-mail games suffer almost zero effect from network-communications issues, even if the Internet goes down for a time.
Whatever else, the developer must remember one thing: Nobody controls the quality of service offered by the Internet, and there are no guarantees that it will actually be fit for use at any given time. So steps must be taken to make sure that, should the worst happen, the game will remain playable right up until the point that it is no longer possible to compensate for the underlying network service.
Lost data and erratic or uneven performance, as well as general network slowness must all be compensated for. This chapter now looks at the two principal culprits of network errors—loss and latency—before seeing how they are caused and how the effects can be mitigated.
Data sent over a network is first broken into multiple packets, which vary in size depending on the protocol used and other key factors. These packets are then reassembled when they arrive at their destination, usually in the right order.
Sometimes, packet loss occurs—that is, a packet is lost during transit, presumably dropped somewhere along the line. In gaming terms, this could have a disastrous effect on the local game environment if the lost data is a piece of status data—although it may just manifest itself as slight jitter, which occurs as the environment adjusts to the missing data.
For now, let’s assume that the loss occurs upon entry to or exit from routers or anywhere that the data has to transition from one interface to another via network hardware. In such cases, the loss is linked to the reaction time of the underlying hardware; if the hardware doesn’t react quickly enough, the packet will be dropped. Regardless of the cause, packet loss is considered to be a reasonably critical event, as data will become corrupted or lost.
The TCP/IP protocol has built-in safeguards to combat data loss. Because it is a guaranteed delivery protocol, its underlying mechanisms try their best to obtain data intact, reassembling packets received in the correct order. When packets go missing, the protocol re-requests them, or else the connection fails in some way. This all happens before the data is delivered to the application and is transparent. Without the guaranteed delivery offered by TCP/IP, Web pages would not load reliably, and many applications simply would not work.
In contrast, UDP includes no such mechanism. Data is delivered to the application exactly as it is received, with no underlying safeguard against out-of-order or missing data packets—which, naturally, has some advantages and disadvantages. Advantages include ease of implementation and speed. The protocol is faster and, because it does not need to trap TCP/IP events such as lost and out-of-order packets, it can be easier to implement. The disadvantages, however, are that if there is any checking that needs to be done, it must be done by custom code. This will complicate the solution if guaranteed delivery is required, as will the relative paucity of flow-control information provided by UDP as compared with TCP.
As a game developer using UDP, you either live with the consequences (and revel in the advantages) of using UDP or build safeguards to protect against real data loss. These might include increasing the data-transmission rate to improve the game-environment sampling rate, incorporating prediction capabilities in the client and/or server, or just mimicking the TCP mechanisms to re-request missing data.
Different categories of data can also be dealt with in different ways. For example, a video stream using UDP can probably put up with lost data by degrading relatively gracefully (missing pixels, jittery display, etc.). But a pure digital stream, in which every piece of data is relevant (e.g., combat moves in a fighting game), cannot be handled in this way, meaning UDP would not be a good option. That’s because with UDP, packet loss is highly likely to take place, whereas if the game uses TCP, then packet loss is likely never to take place. These inherent safeguards, however, slow the network—meaning you must make a decision as to whether you live with this or switch to UDP and handle things like flow control and guaranteed data delivery yourself.
This decision must factor in the importance of the data stream—which, in turn, depends largely on the kind of game you are creating. Some games require guaranteed data delivery—especially RTSes and fight action games, where every piece of information counts. For such games, TCP provides a slower but more robust solution—but UDP can be used if the programmer is willing to take responsibility for ensuring the data flow. On the other hand, if the network portion of the game is just relaying a constant stream of frequently updated data (rather like a video of the unfolding events) without attaching importance to specific data exchanges, then UDP can be used to great effect because the flow control is less important. As long as out-of-sequence packets are dropped, the result will be solid enough to ignore the occasional dropped packet.
As mentioned, packet loss can result in latency—that is, a significant slowdown in network communications—as the network tries to adjust to the missing data. Repeated dropped packets will cause everything to slow down, as the underlying protocol re-requests missing packets. Other potential bottlenecks—which will be explored later on—include the following:
Buffer overrun, causing lost packets
Bottlenecks and hardware speed
Distance and line speeds
In addition to slowing the network, latency can lead to synchronization issues between players’ local views of the game environment and everything in it versus the server’s view of the game environment. Indeed, different players may end up with different views—although this may not matter as long as the outcome of the game is not affected. In other words, as long as the players have a chance to catch up with each other, and the game plays out as normal, the fact that they take marginally different routes to the same conclusion doesn’t matter. Web-based strategy games like Project Rockstar, for example, do not rely on fast network connections; if things are a little slow, there are no real consequences.
Sometimes, however, it does matter—most notably in online games that rely on speed and skill. For example, latency would be problematic in a first-person shooter (FPS) where a client reports that a bullet has not hit the player (because the player has moved), but everyone else sees that it has because their own view has not been updated with the new status information. (This example, courtesy of Jason Leigh [LEIGH01], is expanded a bit later in this chapter.) If nothing is done to address these types of issues, then playing becomes an awkward, frustrating, and unfulfilling experience.
Unfortunately, there is little you as a game designer can do to address latency, which is not a result of a design flaw in the game but rather is caused by the fragility of the delivery medium. It comes down to the manufacturer of the server, the owner of the Web-site hardware, and the Web-server software. You can, however, estimate the possible impact of latency on your game. To do so, you must first determine the game’s bandwidth requirements, which you do by way of calculation and testing. One approach is to track the number of packets sent and received during test sessions in order to profile network usage. Profiling tools, such as those used for tracking the use of memory and other resources, will help in this respect.
Note
Profiling tools are present in most modern integrated development environments (IDEs)—more specifically, as part of the debugging toolkit for most game-development platforms, both native and console. Failing that, the programmer will have to install profiling code himself or herself in the debug build, which will slow the build a little but also provide an accurate profile of the code as it is executed.
Beyond that, you can perform experiments to determine at what point raw network latency becomes an issue for players. This involves adding network inconsistencies to an otherwise perfect (or near perfect) connection, whilst the game is being played, with the goal to expose imperfections in the environment’s ability to deal with such inconsistencies. So, while it is being played, you could introduce code in the network layer that drops packets, rearranges them, delays them, or introduces random amounts of jitter by combining all of the above. This will allow you to build up a profile of how the game reacts to network issues that relate to the gaming experience being delivered.
With this information in hand, you have two choices:
Improve the robustness of the game so that should the latency spiral, the effect is less noticeable. This might include separating the data streams so that the important data is prioritized.
Note
Some data is clearly more important than other data, and must be treated as such. For example, latency on status updates related to movement in a high-speed driving game (like Burnout Dominator) will have more of an impact on the gaming experience than latency on status requests relating to the number of players in the system at a given moment in time.
Reduce latency in the system as a whole, as well as in the network component. This can only be done if the data transfer and networking have been adequately profiled beforehand.
Note
As noted in the preceding bullet, you must consider general system latency as well as network latency. If the network layer produces a constant latency of 200ms but the database is not scaling properly, this might cause jitter (discussed momentarily). Also, if the database tends to freeze on certain operations, this will introduce additional latency.
For games operating in real time that use the Internet for networking, you will need to make some concessions locally to try to improve the communications and data transfer that you can control—because you can’t control the Internet.
Latency is the principle cause of two irritating artifacts:
One of the most irritating manifestations of network latency is jitter, which occurs when latency is not constant, but fluctuating. In essence, jitter results from some—but not necessarily all—data being delayed. What’s more, the length of time by which the data is delayed will usually vary, meaning it cannot be accurately predicted. Jitter can also stem from packet loss (e.g., video jitter in UDP), which creates holes in the incoming data screen. If this is vital data that has a direct consequence in the game, the result will be more than just an uneven experience. Moreover, the causes of jitter will negatively affect attempts at packet serialization, where packets are given serial numbers in an attempt to thwart hackers (see Chapter 8). This is compounded when packets arrive out of order or if the system throws them out because of the effects of jitter.
Some symptoms of jitter are evident on the players’ side. For one, jitter prevents players from predicting movement accurately. If the movement data relating to other artifacts in the system is inconsistently delivered, the resulting movement will be similarly inconsistent. This will quite likely destroy an FPS, because players simply will not be able to exert the same amount of control over their in-game personae as before. Even if local movement is crisp and responsive, the game environment and other players’ avatars will seem to move in an entirely unpredictable fashion.
All this is to say that jitter poses serious problems for high-speed precision skill games, such as driving-based games (Burnout) and one-on-one fighting games (Street Fighter IV). The fact that both of these games have central network gaming components implies that the issues relating to jitter are not insurmountable. Note, however, that network jitter has next to no discernable effect on the playability of Web strategy games. It can be mildly annoying, however, in text-based MUDs, in that screen updates sometimes fly off the visible area of the screen. On the whole, though, this is not a big issue.
Lag, a term that was coined in the 1990s to describe a general slowdown of the entire game environment, is a symptom of more or less constant (within a given time frame) latency. Because it is constant, it is less annoying for both programmers and players than jitter. It can also be predicted to a certain extent—or at least recognized by the game engine and corrected for.
Although it is less annoying and more predictable than jitter, lag can render a game unplayable if many different players have different levels of lag—meaning something must be done to mitigate it. This book looks at some ways to minimize the impact of lag issue in the upcoming section titled “Solutions to Network Latency Problems,” but it is worth taking a moment here to explain the problem more fully.
What happens is this: The client on machine A updates in such a way that the player appears to be much farther away when his or her avatar starts moving as compared to the view of the same scene from the client on machine B. This is caused by the uneven reaction time. Luckily, in this simple case, the machines themselves can compensate quite easily through the clever use of status messages and minimization of data in transit, the aim of these measures being to enable fast updates when they’re needed. There will, however, be a point at which the system breaks down—specifically, when the machines must adjust to the slowest speed of the system connected.
This issue is the subject of research studies [NETGAMES01], which attempt to gauge the effect on playability when clients update at different times due to lag caused by latency. One such study notes that the point at which a game such as EverQuest2 becomes unplayable is when latency exists in excess of 1250ms. Up to this 1.25-second delay, however, there is quite a lot of room for machines to compensate locally for any network deficiencies. But of course, such maneuvering will involve a compromise between quality of experience versus security (see Chapter 8). That is, the more logic you put on the client side to enable it to make decisions on its own, the more scope there will be for foul play. For example, if a machine is tasked with relaying the result of any local decisions back to the server, the game is put at risk from the interception and subsequent alteration of status messages.
Key causes of general slowness include the usual issues: distance, hardware power, and wider Internet problems (software/hardware configuration, momentary DNS blips, and so on). In addition, dropped packets and other similar occurrences can also cause things to slow down somewhat.
Many of these issues are completely beyond the control of the game developer. Some might even be beyond the control of the service running the game (in the event that it is remotely hosted). Some, however, can be mitigated by running the game on your own hardware. Indeed, this is the solution of choice for most client/server games (like Eve Online, for example). But as you have seen, those games represent only a portion of the entire network-game genre.
What follows is a breakdown of the various steps developers can take to combat latency and jitter, and how doing so affects network game development. Some of the solutions are physical, while others are design based, but all center around the kind of network topography that the game uses to distribute its user base as well as to distribute the responsibility for updating the game environment and various clients.
If you assume for a moment that a finite number of clients want to interconnect within a game environment that is part of a collective consciousness, then it is clear that this game environment can either be stored centrally (i.e., in a client/server network topography) or be distributed over the population (i.e., in a peer-to-peer network topography). Both approaches offer certain advantages and disadvantages with respect to latency and other issues, depending on the type of game you want to design and the type of data that needs to be transferred.
By choosing an appropriate network topography for your game, you can ensure that the system makes the best use of network resources. At the same time, you can make sure you get the right balance with respect to the system’s ability to perform network-connectivity tasks and process data in the game environment.
In a class (and associated text) entitled “Multiplayer Game Development,” Jason Leigh identifies four kinds of multi-player video-game networking topographies (which he calls “connectivity models”) [LEIGH01]. Paraphrasing his paper, these are as follows:
Shared centralized. This topography is the basic Web-game or server-oriented action game topography. In this model, every client connects to one—and only one—central server, as in Figure 7.1. Here, the server maintains the game environment, acting as a hub to relay data between clients. The key limitation of this topography on real-time action games relates to the number of players a single server can support; any estimations in this area must be based on available processing power and how much processing is farmed out to client systems. The less work the server has to do, the more clients it can support at one time.
Note
Allowing clients to assume some of the processing tasks can help mitigate latency issues, but remember—the more the clients are permitted to do, the more scope there is for foul play (see Chapter 8).
Replicated homogeneous. This model is the exact opposite of the shared centralized model; there is no central server in absolute control. That means every client is responsible for processing the game data according to the game rules. Clients then send updates to each other (i.e., a multicast solution). In this topography, each client must be connected either directly to all the other clients or via a central routing point, as in Figure 7.2. This approach can help reduce the role of the server to a simple routing hub or remove the central point altogether. Although such distributed processing has been used in the past for virtual-reality simulations, it is not widespread; that’s because in this model, all the game logic typically has to be replicated across the participants. In other words, it is highly redundant. Although it is doubtful that a pure replicated homogeneous solution would work in network gaming, it is possible that some aspects of the approach could be used in network gaming to good effect.
Shared distributed (peer-to-peer). This model allows clients to connect to each other via some kind of central point, which also mediates. In comparison to the replicated homogeneous topography, the server in this topography has more of a role to play in making sure that the rules are respected. The topography is almost exactly the same as in Figure 7.2, except that the central point validates in addition to routing. The function of the central server is simply to keep on top of the game environment and maintain any persistent states. Local machines report the results of their own processing, and also include clever algorithms to present a smoother game experience to the player. This model will prove to be effective for some games, particularly where processing time is vital (i.e., most Unreal Tournament–type multi-player FPS games) and where a single-player version of the game already exists, because it ensures that the code base is accurately replicated across participants.
Shared distributed (client/server). This is the topography of choice for most MMORPGs and large persistent-world games. It breaks up an enormous game environment into various server groupings, allowing clients to move between them and sharing the processing loads, making the topography scalable as well as robust. Again, it is the same topography as the one shown Figure 7.2; only the responsibilities are a little different (and, of course, there are many instances of the client/server relationship). As in the shared distributed (peer-to-peer) model, there is ample scope for farming out local tasks. The key difference is that the game-environment processing is performed centrally; it is the game server that relays the results of actions to the clients. This topography provides for more central control, hence its use in MMORPG environments.
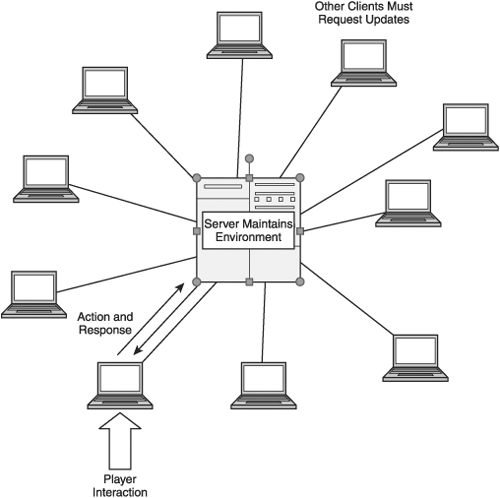
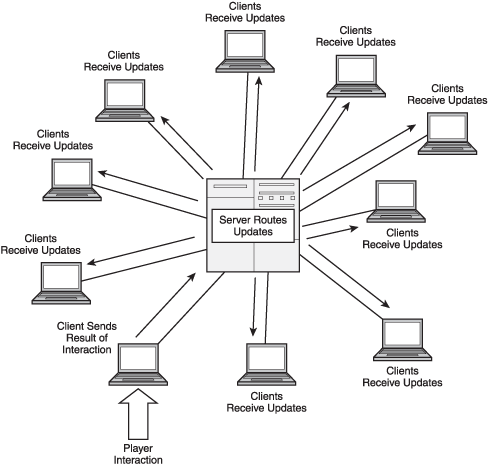
Most large-scale multi-player games are based around a cluster of interconnected servers in order to reduce internal system latency—the theory being that the less work a single server has to do, the more quickly it will be able to respond to the clients connected to it. A vast quantity of that work involves trying to receive data from and send data to clients—meaning that if you can reduce the number of clients, you also reduce the work. In other words, fewer clients over more machines means a more responsive playing experience.
Additional steps can be taken to further distribute processing—and, by extension, spread network traffic—with or without splitting the environment over multiple servers, depending on the amount of work each is supposed to do. For example, reducing the quantity of data (or the frequency of data exchange) will have a similar effect to reducing the number of clients on a server, thereby lessening the need to break up the environment into multiple zones. The problem remains, though, if one particular zone becomes overpopulated; in that case, you have no recourse if a strict zone-based server topography has been used. It would, at this point, be more logical to segment the population either geographically or by load sharing across two servers previously tasked to separate zones. Trying to do this dynamically probably won’t work; moreover, an additional layer of network latency will creep in if the database becomes connected to two different servers at the same time. This database connection will usually take place over a (possibly internal) network connection, thereby introducing another dependency on the weak link: the network layer.
In addition to choosing the best topography to combat effects of network problems, you can also design in some solutions that address the twin issues of network latency and system latency. Given that system latency is a function of the network layer as well as the processing done outside of that bottleneck, you must design the whole system with this in mind. That said, it is the network connectivity that will likely cause most latency issues, as it is the slowest point as well as the least predictable.
This section deals principally with workarounds that are part of the design of the underlying game application software.
Note
Poorly designed solutions waste time in various ways, all of which can increase system latency. Additionally, some of these ways are linked directly to network processing, and can exacerbate issues that emerge due to the natural latency of a network connection.
Many things can be done in the logic layer to make sure that overall system latency is kept to a minimum. In addition, you can make certain tweaks to mitigate the effect of intensive processing and network faults and thereby prevent jitter—although lag can rarely, if ever, be countered effectively. Examples include the following:
Networking loops
Bandwidth reduction and caching
Sharing responsibility
Of course, almost everything you do in this arena is going to involve a balance of security versus networking versus available processing power—both on the side of the client and on the side of the server.
Game designers and developers program in a loop fashion, with the following types:
Input loops (from the physical world)
Logic loops (processing the input with respect to the game environment)
Rendering loops (the drawing and audio)
Each of these loops operates continuously. The input loop does so on an interrupt basis, waiting for feedback from the player via the man machine interface (MMI). The logic loop processes all the game logic, possibly on an interrupt basis, as well as performing a general monitoring function. The rendering loop ensures that those areas that need to be repainted are, and that the sound (spatial sound, background music, sound effects, etc.) is correctly overlaid with respect to the state of the immediate game environment. Normally, these three types of loops (although there may be more) are placed in separate threads, enabling the processor to try to farm out the processing in time slices in order to get everything done more efficiently and thereby improve the experience for the player.
In addition to these, we must also create a network loop—both on the client and server sides—that operates on an interrupt basis for incoming connections and data, but on a regular basis for outgoing data. In addition, this loop is as important—if not more so—than regular player interaction, so this must be worked into the time-slicing algorithm that farms out work to the processor.
Note
There are different algorithms for devoting time to various tasks based on their importance, available time slices, and other dynamic factors. All in all, the scheduling operates to make sure that everything gets done in such a way as to provide a consistent gaming experience.
The emphasis is slightly different for the client and server implementations (assuming that you are eschewing the capability to allow clients to contact each other directly). For the client, there is communication with only a single entity—the server—in the client/server topography being used. This enables you to incorporate into the network layer design a blocking socket call—which blocks until there is data to be read, and is ignored by the system until data is available—thereby releasing CPU cycles back to the system. (The alternative is to have the thread waste cycles in a busy-waiting loop, awaiting data. Even if the system operates on a time-slicing basis, it would still mean that for the whole time-slice, the network thread would effectively be doing nothing.)
In contrast, this would precipitate a disaster on the server side; the system cannot afford to block a socket when there might be data coming in from another socket. Because clients might be trying to send data to the server, it needs to have a thread that can poll multiple sockets but not block on any of them. This is the fundamental difference (with respect to network communications) between the client and the server.
This, then, is the first rule in improving network communications: Never waste time on a socket that has no incoming data—but do not use blocking sockets where multiple sockets are to be used.
Note
This is also the case for replicated models, where each client has to multicast data to all other points in the game network. In such cases, each client is also a server, as it has to be in a position to both send data to multiple points and receive data from multiple points.
The interplay between the client input, network input and output, and game logic threads is the determining factor in overall system latency, manifested though the perceived reaction time of the game to the player’s input, other players’ actions, and the network component. Other game-development books cover these issues more completely; here, we are concerned only with the latter part—the network component. Experimentation and testing are the only ways that the developer can determine the best way to hook all the processing points together and facilitate communication between them at the game-code level.
Improving network communications begins with choosing the best protocol—TCP or UDP—for the tasks that need to be carried out. As mentioned, different data-exchange requirements can take advantage of the different mechanisms used by TCP and UDP with respect to data delivery. That said, these protocols also share some key similarities—most notably the need to reduce bandwidth usage to the extent that it is possible. After all, both use the same underlying physical technology—a wire—to transfer data. And clearly, the less data you need to push around the network, the better.
Data comes in two flavors:
That which is needed to run the game (communicate between entities)
That which is needed to set up the game (level data and other resources).
One approach is to blend the use of UDP and TCP to make good use of available bandwidth—but care should be taken to ensure that the appropriate data is put in the appropriate protocol. On the one hand, vital data that would introduce latency into the system if it were lacking should be delivered via TCP, but the volume should be reduced. Data that is not so critical can be delivered via UDP—but if it has to be synchronized, then it is better to reduce the volume as much as possible in order to use less bandwidth and reduce processing overhead in correcting the transmission errors.
In addition to reducing bandwidth, it’s a good idea to cache large data repositories such as level files and images. This is rather like a Web browser storing image files for later use; resources that are loaded frequently and do not change often are ideal targets for caching in networked video games. This can be done either as needed or at the start of the game session. In the first instance, the resources are delivered in-line via spare capacity in the data exchange so that they are available when needed. In the second, the user must actively download them (as was the mechanism used in Unreal Tournament) in order to have the correct shapes, sounds, level files, and graphics available at the start of the play session.
Another way to reduce bandwidth is to allow clients to take responsibility for some of the processing. In this way, they relay only the result of that processing, rather than every possible state change, back to the server.
Because state changes result from interactions between the player and the game—as well as other players and artifacts within the game environment—the processing of the game rules is outsourced to the collective clients. Earlier, this chapter covered an extreme example of this in its discussion of the distributed homogeneous topography. That model was deemed too high risk, but if each client is (separately) also calculating cause and effect, then the server could validate the decisions by comparison. This would be far quicker than calculating cause and effect itself, would reduce data transmission, and would offer a more robust solution with respect to possible cheating than the alternative.
One easy example is the aforementioned bullet fired within the game environment, provided by Jason Leigh [LEIGH01]. The message sent to update the clients simply relays the state change of the bullet. It is up to the clients to figure out for themselves who has been hit. In addition, they should play a role in computing how the bullet should fly and then relaying to everyone else the end effect—not the state changes, nor the position at a given time in their local rendering of the game environment, but the end result: hit or miss. In this way, we a) don’t have to relay more data than is necessary, and b) don’t have to wait for the data before showing the action to the player. This avoids the flooding of the network by state messages and also helps mitigate any natural latency or jitter in the system.
You should be aware, however, that this approach opens up possibilities for people to interfere with the game-client processing. For example, they might claim that the bullet hasn’t hit anyone—when in fact it has—by intercepting the message and changing the status information. Feasibly, this could be achieved without other players being aware of it, as their system will simply render the data that has been provided to them. Until the bullet disappears in thin air, nobody will notice that there is something amiss.
All this is just another way of saying that as a game developer, you must find a balance between security and performance.
As you’ve learned, latency is roughly defined as a significant slowdown in network connections—but one that is more or less constant, meaning that unlike network issues like jitter, its effects can be predicted to some degree. Accounting for latency can sometimes simply mean anticipating certain things in the absence of real data.
TCP has higher natural latency than, for example, UDP. That’s because TCP tries to validate the data stream. When a packet is dropped, TCP realizes this and tries to correct for it, waiting for the missing data to be relayed—which increases latency. One way to minimize latency, then, might be to use UDP. With this protocol, data simply disappears if a packet is dropped. Whether this is an appropriate solution, however, depends on the game type and the logic controlling the interactions in the game environment.
Using a game-environment update model that averages positions of in-game artifacts (avatars, NCPs, etc.) can both address packet loss in UDP (at least until a critical threshold is reached) and smooth out the effects of jitter in both TCP- and UDP-based networked games (again, up to a threshold of estimated positions). If this threshold is exceeded, a jarring effect could occur as the positions are re-established based on incoming data. Key to designing a solution that takes this into account is understanding how latency in the networking component of the system builds up in the first place.
To understand how you can avoid latency, you need also to understand that network processing often employs buffers. A buffer is simply a place where data is stored before it is processed (either somewhere over the network or by the gaming client).
Systems generally have input buffers, where data is stored before processing, and output buffers, which need to be filled before the data is sent. The output buffer is also used to queue data in the event that the network beyond becomes saturated. In times of low traffic, the buffer can then be emptied, allowing the system to catch up.
Ideally, the interplay between these two buffers enables the system in the middle (be it a network or a processor) to be balanced such that it is always operating at maximum saturation when there is data to be processed. That means filling and emptying the buffers in an organized fashion, allowing just enough slack to be robust. (The slack is used to stock the buffer in the event the processor or network becomes saturated and has to take a brief time-out.) If an input buffer is not emptied quickly enough (i.e., the client is slow to process), then data will be lost. In essence, because the buffer is full, there is nowhere to put incoming packets, and as a result they will be dropped, causing data loss. If, on the other hand, the output transmission fails for some reason, preventing packets from being sent quickly enough (at the server), then the output buffers will also fill up. In this case, packets will be dropped unless you provide a solution for this on the server (see the section “Rate Adjustment Strategies” later in this chapter)—namely, backing up the system and making sure that no additional data is generated. This will potentially cause the gaming system to visibly pause—one of the worst effects of latency.
A network is also composed of various routers, firewalls, bridges, and so forth that deal with ongoing network transmission—commonly network transmission that you can’t control. Worse still, you have no interfaces at your disposal that would allow you to adapt to the situation. Moreover, these devices also use buffers—and these buffers have the same limitations as described above. Packets are dropped because flow is interrupted by poor performance, either locally or remotely. Quite often, simply being in the middle of the flow is what causes packets to be dropped as buffers fill up.
This has a feedback effect in TCP networks because on the one hand, they try to retransmit to guarantee delivery, and on the other, devices using the TCP protocol will reduce transmission rates to try to reduce congestion. The net effect is that latency increases artificially—in addition to the natural network latency that exists. In contrast, in a situation involving high latency—with buffers filling up and packets dropping everywhere—UDP will not attempt to correct for it. It simply allows the data to drop into the ether, expecting the software application using the protocol to correct for missing data.
Note
In these cases, TCP is almost too smart; such occurrences of packet loss and latency can actually be a good argument for not using it as a network protocol. Indeed, most video-transmission packages use UDP and live with the data loss rather than use TCP and experience high levels of latency.
With large volumes of data, this might be a viable approach—as long as there is (as with some video transmissions) a high level of redundancy. If, however, there is a relatively low level of redundancy, and a high quantity of significant data, then this approach may not work.
Either way, a good solution is to control the rate of sending to try to minimize—or at least learn to live with—the effects of latency and packet loss on the network game infrastructure. This can be done at the client and on the server.
Rate adjustment simply involves changing the rate at which data is sent or received (or even requested). This can be a dynamic operation, with the rate being changed as the network components sense shifts in the state of their communications conduits, or it can be a set-and-forget option at the start of the transmission session. Clearly, the latter approach could lead to issues with latency and buffer overflow during the session, while dynamically changing the transfer rates can help to provide a more even experience.
Note
Rate adjustment is common in many streaming applications; these enjoy the most benefits from rate adjustment because they tend to use the most bandwidth.
Rate adjustment occurs on two fronts:
The incoming packets for all clients. The incoming packet stream must be dealt with in a timely fashion—that is to say, as quickly as possible. Otherwise, congestion will occur at the various endpoints, causing logical latency at the core game logic layer as it races to catch up. If, as the input stream backs up, the processor is tied up doing something else (i.e., in one of the other game loops), the processor will become flooded as soon as it turns to the packet stream to process the data. If this happens consistently, the system must consider requesting that the data-transfer rate be adjusted—either by slowing down the transfer or reducing the data in the stream. There is, of course, a balance here between the time taken to process incoming packets and the time needed to render the game environment. This is why, as noted previously, it is essential to position the network processing loop correctly in the system as a whole.
The send rate across all clients. On the server side, there exists the possibility that a sending rate that is good for one client is not good for the others. Being able to adjust the data rate on the server side to accommodate this is necessary when the clients must remain synchronized with each other (i.e., in an action or fighting game); otherwise, some clients will get ahead of others in a very visible way. After all, clients will naturally relay data as quickly as it is available to them, so the server must throttle the sending rate as it relays the packets. For a collection of clients in relative proximity in the game environment, the server must decide what the relay rate will be for each client, as only the server knows which clients are associated with in-game entities that are logically close to each other. The server then has to adjust the relay rate to match the slowest client so that all clients receive data at roughly the same rate. This data relay rate may be slower than the natural network latency; indeed, it’s a kind of artificial latency that you can control and that is shared by all the clients.
Rate adjustment may also be necessary at the client side in cases where the server-side buffers are filling up too quickly. This can happen because the server has too much to do (too many clients) or because the onward transmission is much slower than the incoming rate of data reception. In such cases, communication between clients and server is vital to synchronize the data-exchange rate as well as to make sure that every client cuts its data-transfer rate as required. The result is a network-wide agreed (or negotiated) data-transfer rate that keeps all parties in sync without exposing the player to latency, lag, or jitter.
As a last resort, you can always send less data, less often. The result is not faster data transfer, as is the case with non–stream based data exchanges like status information, but actually transferring less data. While it means different things to different applications, this approach can lead to holes in the transmission. For example, in a streamed application, a lower data-transmission rate usually means a lower-quality result. This can mean something relatively benign, such as lower-quality sound or video, or something quite profound, such as jittery in-game movement. It really is a last resort, and is to be avoided as much as possible.
That said, because this approach is desirable due to its speed and efficiency, to improve on both, you could try to make sure that each piece of data to be transferred is smaller. One approach is to strip out all the extraneous data and make for a more efficient exchange of information—hopefully without any loss of quality or integrity. That’s what the next section is all about.
This section discusses what I call the “Principle of Minimum Data in Transit,” or how you can use network bandwidth more efficiently. It centers on ensuring that:
You transfer only the data that you need to.
The data is constructed in such a way as to convey maximum meaning.
The first point is easily made. If the game works on the principle of downloadable content with a purely distributed network game topography, then there will be very little reason to exchange data. Some, if not all, of the processing can be done on the client, thereby minimizing the data in flight—but also drastically increasing exposure to hacking.
This last is part of the problem with data in transit. It is not possible to talk about network efficiency without mentioning security and hacking. After all, in proprietary client-based games (refer to Chapter 1, “The Challenge of Game Networking,” and Chapter 2, “Types of Network Games”) , the game’s designer puts the entire game’s content at the mercy of the end user. The whole framework is there—the game software; the resources that make up the graphics, sound files, and level files; the logic that controls it; and the engine that processes it. If the platform is a PC—or even a console with a hard drive—then the whole package is available to the end user. If he or she is even slightly devious, the end-user might just reverse-engineer the code to figure out how the game has been put together—including the exchange of data. From there, it is a short step to figuring out how to use it for his or her own advantage.
All of the following techniques require code on the client side to make them work. They are therefore vulnerable in some way to this kind of attack. The trick (as you shall see in Chapter 8) is to make it so hard to crack that hackers simply won’t bother.
By a similar token, all of the following also apply in some small measure to games where the client is truly dumb—i.e., it displays only the result of passing requests to the server. Typically, dumb clients make no decisions for themselves. They merely query the server, without ever updating the game environment (see Chapter 8). You explored this approach in the first few chapters of the book—for example, while exploring text-based MUD games. Clearly, in this case, there’s not a lot you can do to reduce the data being sent to the terminal.
On the other hand, data-reduction strategies can work for Web strategy games, even if the client is dumb. Theoretically, at least, these games should be less subject to hacking, as there is really nothing to gained by doing so; the game environment logic remains on the server. There might, however, be something to gain by automated playing—especially with online games in which spending hours performing fairly mundane tasks is rewarded—which can cause network congestion. That said, the kind of person who is going to go down that road will probably be a minority. The problem occurs when such people decide to propagate their creations, allowing others to take advantage of the loopholes they have discovered. Data reduction can help combat this in two ways:
By rendering the data less immediately readable
By mitigating the worst effects of network congestion, should the worst happen
Before you can address possible data bloat, however, you must know what the actual consumption is. That means some form of data measurement must be built into the development version of the game in order to estimate actual network usage. After you determine this, you can then concentrate efforts on the areas causing bottlenecks rather than trying to reduce all data to a bare minimum (whilst possibly sacrificing quality of streamed data and ease of development and maintenance in the process).
Of course, the first obvious data-reduction technique is to relay only the data that is absolutely necessary. This sounds obvious—but it is seductively easy to build game logic around the constant presence of data, which, in the network environment, might not be possible. Instead, game logic should be built around the lack of data—or at least the assumption that data will be delayed—rather than the necessity of having data every x cycles. This approach will reduce the refresh rate, which will help keep data in transit to a minimum—but it needs to be backed up by techniques to compensate for the “missing” data.
If you plan to use dead reckoning, you can dispense with many data-exchange cycles, intervening only when the player does something unexpected. Dead reckoning only works, however, in games where in-game artifacts have known trajectories that are not expected to deviate. For example, if a vehicle is traveling at a given velocity in a certain direction, you can more or less gauge where it will be a few update cycles from now. You don’t really need to relay data that tells the clients that the vehicle is still following the same trajectory; instead, you can simply relay a status change message when that trajectory does change. In this way, you can dispense with a lot of intermediate data-refresh cycles. By a similar token, you need not send all the data pertaining to a client every time an update is processed. Rather, you only need to send data that has changed. This is related to the dead-reckoning example. (Note that for client-side updates, you also need some way for a client to request a refresh if something goes amiss.)
The data that does have to be sent should be combined in one set of data rather than sent in several spurts. This will put it all in one packet, rather than spreading it over several packets. It is worth stalling an update until a full packet can be sent—unless the data is time critical. Again, this is a design issue, not a development one. The decision must be made at the time of the game’s design how the status data (for example) is to be organized:
One shot, all data. In this case, each status update contains all the data—although it may overflow into additional packets unless care is taken to reduce the data that has to be conveyed (for example, by using special encoding rather than plain-text instructions).
Artifact-by-artifact updates. This approach splits updates by in-game artifact role. Therefore, each entity in the game environment has its own update cycle. This can be detrimental to network performance, however, producing multiple data-transfer cycles, which can slow down processing and lead to synchronization problems.
Continuous stream. This is the least efficient way to transfer data (in principle), but cannot be avoided for things like videos, which need to start playing before they can be downloaded in their entirety. This will involve the use of a buffer, as previously explained.
Which of these three possibilities (or something in between) you choose will depend on the game design and the number of individual in-game objects that the environment needs to support.
Although these three approaches have their differences, what is shared among them is that, as far as possible, only state data should be relayed, not individual interactions. This state data is either:
A state change (from one state to another)
A state value (score, resources, etc.)
The client should work out the effect of the interaction on the game state and relay that as a state or state change rather than the details of the interaction.
Note
In cases where the topography is one in which all the logic is contained on the server, this approach may not be appropriate, as the clients will not process enough logic to be able to come to a conclusion. In such situations, it may not be possible to send absolute game environment state data—but it should still be possible to send state changes from the point of view of the client system. This will be the case for many games that are played in the browser, using AJAX technology to manipulate the client view and receive updates from the server.
The data should be encoded so as to be as small as possible (which also helps with obfuscation, as you will see in Chapter 8). That is, rather than transferring something readable, like the following:
money=100;stamina=10;energy=90
you should opt for a data-reduced version:
11 00 FF 20 10 FF 30 90
Not only is the second smaller, it is also easier to process on the client side—and difficult to glean meaning from it by casual means. It is, however, hard to debug, and relies on all members of the team having access to a suitable look-up chart. Generally speaking, the extra effort is worth it.
If you’ve implemented each of these basic approaches to data reduction but are still experiencing data-transmission issues, then perhaps some more advanced techniques are required, such as compression.
All data-reduction techniques that require post processing of data that is received, such as compression, will increase processor load as the data is reconstituted. It is preferable if this can be avoided. That said, if you’ve exhausted the basic data-reduction options, then this can be a good option.
Compression is designed to replace expansive data with data that is encoded in such a way that the redundancies that most data contains are removed. For example, if you know that a rectangle is white and located at x, y on the screen, you do not need to send the location and color of every pixel in the square. Instead, you can just send the top-left corner, the width and height, the fact that it is a rectangle, and the color. This will take up much less space. And you can send the same amount of information to describe even the biggest square that the display can handle, making the compression scalable.
Note
You’ll note that there is a limit going the other way. If the square is smaller than, say, a few pixels in dimension, it is probably more efficient to just send the pixel information rather than the complex data structure that represents the square. Finding the balance between data reduction and the smallest units of non-compressible data is outside the scope of this book, but interesting food for thought nonetheless.
In addition to making data smaller, compression also ensures that casual observation will not yield any directly usable clues as to what the data packet might contain. Put another way, the benefits of using compression are twofold:
Efficiency. Simply put, with compression, less data is transmitted. On the other hand, compression does result in a performance hit on the client and server as the compression/decompression algorithm is applied to the data to be transmitted. (Clearly, you must take care to ensure that any efforts you make to reduce data do not increase latency due to increased load on the processor. Only by measuring this will you be able to determine whether you are helping rather than hindering.)
Obscurity. Obscuring the data ought to make it a little bit harder for hackers to figure out what the data contained in the packet is really for. As long as a relatively incoherent data representation is also employed (as discussed in the preceding section), the data should be relatively meaningless even if someone manages to decompress it.
Note
You should be aware that hackers have access to the code that is doing the decompressing—especially in a distributed model—making reverse engineering a real possibility. The more paranoid you, as a developer, are about this, the better (up to a point).
Be aware that applying compression to multiple packets with UDP (for example) will yield some very odd results if data goes missing. The end result might even be that the data cannot be reconstituted, or that the effort required to patch the hole transcends any benefit from the data-reduction exercise. In this case, simple run-length encoding (RLE) might be a weak but efficient solution. It also might just be all that is necessary. Most compression algorithms work more effectively with sample data; if you restrict compression to small samples, RLE might offer the best compromise of efficiency over speed. Yet again, testing—or at least simulation—is going to be the key to ascertaining the best solution.
One way to mitigate or smooth out effects of short periods of lag and especially of jitter—intermittent pauses in the game data stream caused by natural latency—is to use game environment prediction. This can be applied to three key areas to try to ensure that the effect of jitter is not felt by the player:
The player. This approach involves trying to guess what the player will do next, and whether that varies substantially from what he or she is currently doing. It’s a server-to-client technology, as the local client will know perfectly well what the player is currently doing. For this reason, player prediction is more about how you update remote clients (and the server) with respect to the way that the client is viewed in the game universe. You can afford to have the prediction lag behind slightly as long as it is not noticeable by the player at the remote client on the other side of the server. (After all, at some point, you will correct the prediction.)
Non-player in-game artifacts. These are slightly easier to predict, as they typically follow in-game logic that has been fairly well tested. For example, a bullet, once fired, becomes such an artifact, and is unlikely to deviate from its initial path.
The game environment. This is easy enough to predict, and would apply to things like planets in a space game or the track in a racing game. Much of the reaction of the game environment can be rendered locally; indeed, it barely ever needs to be relayed.
Prediction is particularly great for countering the network stutter that causes jitter, the theory being that updates are spaced with reference to actual events. If, for example, a car is moving in the game at a given velocity and direction, you don’t need updates so regularly because you know where it is going; as such, the data sampling rate can be lower. This is fine as long as you don’t mind a few differences between the clients’ rendering of the gameplay.
But what happens if data is permanently lost? In that case, prediction becomes much more difficult—which is where AI could, in theory, take over. A word of warning, though: In this scenario, you are essentially substituting a real player with an AI equivalent. This has several ramifications, the first being that the player will be playing locally (or frozen out) whilst his or her alter ego, now controlled by the server or a remote client, continues to play on his or her behalf. If it fares poorly, then the player will be (rightly) irritated; if it fares better than the player would have, then the other players will be (also rightly) irritated. The use of AI prediction and player emulation comes into its own, however, when the player disconnects (permanently or temporarily)—something we will look at later in this chapter.
AI prediction is used in fast-paced fighting games such as Street Fighter IV, where small glitches in network connectivity cannot be tolerated. As long as the gaps are small enough, the system can emulate either player, realigning them once the data stream is re-established.
Fighting games in particular rely on a more or less constant stream of data updates. It’s no good trying to post only when something happens; things are happening all the time, and in discrete units. Sooner or later, an update will be missed, and it’s up to the system to predict what happens next—and correct itself when it turns out to be wrong.
As useful as prediction is, it does pose certain problems, such as, What happens if the player does something unexpected? If, for example, the player is moving in a given direction but suddenly stops moving and starts hacking away with a sword at another in-game entity, you need to make sure that this new behavioral trajectory is correctly relayed.
There are two sides to this. One, the player has stopped moving. Two, the entity at which the player is hacking away probably also stopped moving. If the other system reacts too slowly, then the observed player may no longer be in the correct place at the correct time to effect the new actions.
So how does the system (as a whole) catch up with this sequence of events? Obviously, the first thing is to make sure that the game environment views never diverge too much from each other. That means reeling in the freedom that clients have to maintain their own world view a little bit. This, however, has serious implications with respect to security. For example, if you give too much decision-making power to distributed clients, that decision making might become susceptible to tampering.
For Web games, this not a problem, as no decisions are made in browser. Rather, all decisions are made on the server; the client simply renders them. So even if you need to smooth out the data flow in some way with local (JavaScript) logic to combat lag or jitter, you can’t affect the outcome of the game. The same goes for other client/server games based on dumb clients (i.e., MUDs). That means the only thing you need to worry about here is reflex based. That is, there is the possibility that an automated player could be made to play faster than a human. (We’ll deal with in Chapter 8.) If, however, a smart client is introduced, where some of the logic is implemented on the local system (for example, a shrink-wrapped MMORPG like Everquest), then you start to encounter serious problems. In resolving issues relating to jitter (and/or lag), you run the risk of introducing a security loophole that makes it possible for players to circumvent game rules.
The scenario runs something like this: In trying to ensure that jitter is almost undetectable by players, you let the gameplay out on several clients simultaneously. That means local clients take input from their human player and pass the status and consequences of that input back to the main server. (This was the approach taken in many multi-player strategy games, such as Age of Empires.) Any unexpected in-game moves can be priority-posted along with the consequences, and each copy of the game environment can be checkpointed using a variety of methods (explored in a moment) to make sure that they stay in sync. But what happens if a rogue player intervenes to relay false or augmented information to the main server? Examples might include a sword doing 10 times more damage than it ought to or a strategy game posting inflated resource figures after a certain period of time has elapsed. Once the inflated resources have been passed to the other game clients, the player will be able to do things that he or she ought not to be able to do—things that will allow him or her to overtake the other players in an unfair manner. This makes proper synchronization with respect to the server and other game clients an absolute necessity.
Synchronization involves checkpointing game-environment representations in order to keep all copies of the game environment in sync, even as updates based on decisions made in a distributed fashion are being posted. The checkpointing approach is designed simply to make sure that, at a discrete moment in time, all clients have the same snapshot of the game environment. This allows the clients to be sure that their predictions are true or at least that they can be corrected with real data so that they do not stray too far from reality.
Of course, one thing you need to be sure of is that no one has interfered with the data—which is very tricky. You can avoid packet insertion by following the guidelines in Chapter 8 in general. But what happens when you’ve just lost the plot and want to update?
Let’s look at these in turn. Packet insertion occurs when a client has been modified—or augmented with additional software—to introduce data that should not be there. That data is then forwarded to all clients, thereby changing the way they perceive the game environment and the status of the sending client. Once replicated through the system, it becomes the “truth.”
Checkpointing helps to stymie this cheat attempt. Its power is limited on its own, but when combined with other techniques on the server, all can help minimize the impact of packet insertion by offering a kind of centralized analysis of all client data and a decision as to who is correct (the majority carries the vote). That means if there is a client that has lost the plot and needs a quick refresh, rather than going to potentially corrupted clients, they now have the option of going to the server.
There’s another reason for this too—especially for those who choose UDP for data transmission. Protocols like UDP have no mechanism for ordering data reception. That means each packet must be synchronized using a number that indicates the age of the packet so that older ones can be thrown away if they arrive out of sequence.
So, if you’re trying to correct prediction on the fly, and the packets arrive in the wrong sequence, it will likely make a bad situation worse, unless these steps are taken to rearrange the data as it is received.
You should also implement synchronization detection by the server and other clients. This is as much to enable them to get back into sync as it is to make sure that the data stream still has integrity. It is the server that bears the ultimate responsibility, as it is the only entity that has overall control—not to mention the fact that it is the only part of the system that is more or less guaranteed not to have been tampered with.
Queuing events—a technique frequently used by MMORPGs (such as Everquest)—can help solve a few issues relating to efficiency (and jitter), security, and prediction (although it is, of course, not appropriate for all kinds of games). The phrase “queuing events” doesn’t mean holding up events before relaying them to the client, but rather refers to players being able to queue up events that take a certain length of time to play out. These events are queued on the server, probably one by one, and then passed, as a queue, to the client software. If you assume that the efficiency by which packets are to be transferred does not depend on their size, this approach makes sense, in that it sends as much data as possible at once. With respect to resolving issues relating to prediction, queuing events helps because the discrete wishes of the players can be relayed to the clients ahead of time—like a kind of action buffer that removes the necessity to try to keep up with fast-paced action. The result is that each client can play out the actions in its own time, as long as these buffers are kept fresh—and since they likely contain much less data than a complete environment update or sequence of discrete actions, this shouldn’t be a problem.
This mechanism can be taken to another level by enabling the game system to also queue up events—as long as there is a way to take them out if the AI controlling the queuing changes its mind. This might even be used as a mechanism to return some of the logic processing to the server by allowing it some breathing space as the clients execute the queues of events attached to system-controlled in-game entities.
Of course, the client must make sure that the queue is invisible to the opposing player; otherwise, he or she might be able to cheat by knowing what is coming next. Also, if the data in the queue is delayed for any reason, the other clients will run into problems.
So far, this chapter has dealt with cases in which data is delayed for some reason or the integrity of the data is threatened. In addition to these possible problems, there is the risk that data can go missing, or that the player’s connection could be dropped.
In the worst-case scenario—in which the data doesn’t arrive at all, which sometimes happens when the UDP protocol is used—you have very little in the way of recourse to deal with this. Even so, you must try to combat data loss; otherwise, it may become impossible to play the game. First, however, you must have some way of knowing that data loss has occurred. Unless the underlying protocol reports a loss, it may not immediately be obvious.
With TCP/IP, if one packet is dropped, the whole connection tends to time-out—which is why, on occasion, a Web page will fail to load initially but, when refreshed, loads correctly. This same refresh mechanism can be used to re-establish connections and data streams in a networked video game using TCP/IP. In that case, however, the data will be lost forever because, unlike a Web page, the game environment is in a constant state of flux. UDP, on the other hand, is connectionless—in other words, each collection of packets is sent in isolation, and there is no need to even keep the connection alive between the sending of data. Furthermore, there is no guarantee for data delivery; therefore, the application itself is responsible for detecting dropped packets, which then become a fact of life.
Out-of-sequence packets are the first indicator of data loss. This is not to say that the packets arrive out of order (which, too, might also be an indication); it’s more that there is a visible gap in the packets that arrive. This will be noted, however, only if the detection mechanism is built in to the network-processing logic of the game. Other indicators of data loss can be built into the protocol, such as detection of smaller-than-anticipated packets—for example, where the data header says that there should be 128 bytes, but only 64 are received.
Using some kind of serialization or numbering scheme to validate the stream of incoming data packets is a necessary precaution for UDP, but technically not required for TCP (at least as far as data reception is concerned). That said, serializing the packet streams for TCP is one way to make sure that the data stream maintains integrity, guaranteeing that the data is received as the sending client intended. By extension, you can therefore detect whether there is any data missing in the stream over and above any of the support for this that is built into the protocol. This is important because the client might send the data out in good faith, only for it to be tampered with by the network portion of the system (either inadvertently or maliciously). The underlying protocol might not be able to tell the difference, but the game should be able to detect this and take action.
Note
Dealing with data loss goes hand in hand with detecting data injection, as the two are sides of the same coin. Data injection is at the core of many of the examples of cheating that you will read about in Chapter 8.
If you think back to the example of the car traveling in a straight line, you’ll remember that everything works right up until the player does something unexpected. This action (or the result of it) is first shown on their screen, after which it is supposed to be relayed to the server. If, for some reason, it is not relayed to the server, the result is that other players do not see the cause—just the effect. The data loss makes the action invisible, because the systems have synchronized to prevent the game-environment views from deviating from each other. The end result is that it just looks bad—in the worst case, as if the other player is cheating—which does not reflect well on the game.
Let’s assume, for example, that the car is racing along, but takes a small diversion to pick up a power-up present on the road (like the power-ups in Mario Cart or WipeOut). From his own point of view, the local player jigs to one side and picks up the power-up. If this is not relayed to the server because of data loss, however, then a strange phenomenon will occur, the effect being that on the player’s system, the object is no longer there, but for the other systems, it is. It is as if the player hasn’t taken the object. This may result in one of the following (as viewed by remote player’s systems):
At some point in time, the object “disappears” with no explanation.
Another player dives in to grab the object, resulting in two players having the same object.
The server or other systems get confused.
Unfortunately, having chosen an update model that farms out the logic to the remote systems, the game designer can do nothing to prevent the object from disappearing or being duplicated. All he or she can do is make sure that the third outcome never happens, as it represents the worst-case scenario. Systems should never need to be reset because they are unable to sync themselves.
Note
Of course, the worst hit will be action games. That’s because in action games, maintaining the flow of action is usually crucial. This is also critical in strategy games that use data in the same way as an action game would.
In the most basic case, missing data can be treated as infinitely delayed data—that is, you can simply hope that the problem will resolve itself. This approach will work for non-action games—but at what point does the game decide that the data is really lost, and that the game has to take action? Some turn-based games, for example, use a counter to count down the rest of the players’ moves based on the first to move (this is the Civilization approach). They also need an internal counter to make sure the connection is still alive, and that the connections can be polled to ensure that every client is still alive.
This polling approach helps in two ways: First, it helps prevent data loss. Second, it makes sure that the players are all still connected, even when they fall silent and no longer actively post actions. This might, at first glance, seem to violate the principles of keeping the data in transit as light as possible and avoiding noisy network communications layers. But it is actually vital in games where there may be substantial gaps in the natural communication between clients and the server. It is also vital for managing games that need to combat dropped connections.
A dropped connection occurs when the network hardware or operating system encounters a glitch, either in the software (driver) or in the hardware. The connection becomes unusable in the short term, with the network layer possibly returning a “time out” error. The result is that the player will (temporarily, we hope) disappear from the game environment at the physical level (that is, the actual network infrastructure level). Of course, the player will still exist in the game environment—and you must decide what to do about that at the logical level.
There are some similarities between network jitter, data loss, and dropped connections, in that the server will not receive data required to update the game environment. Some of the symptoms are also very similar. The difference is that, if the server is correctly monitoring connections, it will know that the connection has been dropped—meaning that it can compensate more easily for the error than if it were just a question of some dropped data. Dropped data tends to be more silent than a dropped connection.
There are two kinds of dropped connections:
Unintentional
Intentional
While it may not be possible to tell difference between the two, they are very different phenomena.
An unintentional dropped connection occurs when, through no fault of the user, the connection becomes temporarily unusable. Once a connection is lost—hopefully unintentionally—the server has several choices, depending on the authorization architecture. The general idea is to re-establish the connection as transparently as possible, depending on the level at which the connection was dropped.
Note
Clearly, if a hardware failure that could lead to security issues caused the dropped connection, then re-establishing the connection is not going to be possible.
Some games store authorization data and can automatically re–log on the player. Indeed, the player might not even notice that the connection was dropped. This is probably the best form of auto-recovery after a dropped connection; the end result might appear similar to, for example, a jittery connection. (Note that this solution would usually be used with console games, but not for PC games, where the machine might be used by multiple people.)
If auto-recovery is not possible and the player needs to re–log on manually, then the server must remove the player from the game environment in a timely fashion. That’s because there is no guarantee that the player will return right away (if at all); he or she might be faced with a long-term or permanent network-connection loss. This action will naturally have a profound effect on the game session in progress.
The following actions, which vary by game type, are likely to be the most appropriate from the point of view of the players:
Action games: automatic re-logon preferred
Strategy games: automatic/semi-manual re-logon
Web-based games, turn-by-turn games: not critical
If the connection is lost but can be re-established, the game developer might indicate this in-game by briefly shimmering the graphical representation of the player to let other players know what has happened. This is purely an aesthetic nicety, but it does serve to inform players about the general network environment. Text-based MUD games from the early 1990s had a similar solution:
[character name] shimmers briefly as <he/she/it> reconnects.
In the game, of course, some form of prediction will be needed at the server or distributed client level. In principle, prediction should make sure that both the local player and the other, remote players notice as little deviation in the gameplay as possible. This is the same as the approach we took for data loss and jitter caused by irregular network latency. It is, in fact, more solid, because you know the reason for the lack of data—i.e., the connection has gone down—which means you can more accurately compensate for the problem.
In cases where the connection cannot be re-established, of course, the player’s in-game representation must be replaced by an AI-controlled one (if the game requires that a certain number of players be present) or removed completely. The decision as to when to remove the player—and what to do with the in-game state—is left up to the game designer. At one extreme, the player can simply be returned to a known safe point in the system, and pick up from where he or she left off at some point in the future. At the other, the player loses everything that he or she had built up in the play session immediately prior to the connection failure.
Unintentional dropped connections should be dealt with sympathetically, without penalizing the player. Some players, however, might choose to manually disconnect—either physically or logically—in order to save their place in the game during an exchange that might lead to their in-game position being compromised. (We’ll deal with this more concretely in Chapter 8.) That, as you probably know, requires a less sympathetic approach.
An intentional dropped connection occurs in its simplest form when the player unplugs the network cable to fake a network connection issue. This can be seen as akin to cheating, as you shall discover in the next chapter; in fact, it is hard to see it any other way.
The only reason that a player would disconnect his or her network cable would be to forcibly remove himself or herself from the game. It’s not something that could happen by accident. Consequently, it ought to be possible to detect it at the physical and logical levels. On the physical side (assuming you categorize data synchronization as physical), you ought to be able to tell whether the client has disconnected manually by intervening at the operating system level (for example). If the connection is closed above the hardware level, you could reasonably infer that the disconnection was intentional and address the issue accordingly. (This relies, however, on that information being available to the server.)
If the cable was just pulled out, there would likely be no warning, so you can assume that it was either intentional or unintentional. You can then perform a few logic operations to try to ascertain the likelihood of the disconnection being intentional. These operations take place on the server, but could also infer the intervention of the client at the start of the next play session—kind of like a post-mortem of the connection failure. The server and client could then come to a decision together as to whether the connection was dropped intentionally.
A scoring system should be established to rapidly grade the disconnect in order to assess the chances of the disconnection being intentional. The aim is to use in-game and network-layer information to determine the likelihood of cheating. Although this is not a guaranteed method of weeding out those who seek to cheat by forcing their machine to disconnect from the server, it is as close as we are likely to come. (Scoring is covered in more detail in Chapter 8.)
This leads to the game developer’s decision as to whether the player should be punished or whether to just let it go—that is, to live with the consequences of intentional disconnection, or try to continue playing using AI techniques so as not to disrupt the game from the point of view of the other players.
Most importantly, the trick is not to confuse the two—intentional and unintentional—forms of network disconnection, as this will alienate and confuse players.