
In This Chapter
This chapter is about testing games that have a network component—a task that is not as easy as it might at first seem. Take a minute now to think back over everything that we covered in Chapter 5, “Creating Turn-By-Turn Network Games,” Chapter 6, “Creating Arcade and Massively Multi-Player Online Games (Real-Time),” Chapter 7, “Improving Network Communications,” and Chapter 8, “Removing the Cheating Elements.” Now realize that we have to test every aspect of that—not just the game, but the mechanisms that we have put in place for:
Communication
Multi-player systems
Cheating/hacking avoidance
Improving network performance
Persistent world data storage
Etc.
This makes testing one of the most important parts of the development paradigm. Part of the reason for this is that a game is one of the most unpredictable computing systems one can design. Added to this, a multi-player game is a strongly emergent system in which it is very hard to tell what kinds of internal states the combination of diverse players and complex rules/systems will create. The interplay of all the variables make it very hard to be sure that everything is working as intended under normal circumstances, and adding a network and a multi-player component only compounds this.
Not only do we have to test the game, but also all the supporting systems that make sure that the game delivers in the multi-player networked environment where not every player has the same skill level or is honest.
This chapter is broken down into several areas:
Principles. This outlines the basic principles of the testing process, and how to track and measure it.
Network testing. This encompasses various considerations for the different kinds of network-game models (including Web games), at the network layer.
Logic testing. This ensures that the code that drives the game is tested beyond the usual test cycles required for single-player games.
Code re-use in testing. This novel approach to testing isolates code from the system (game) under test and associates it with data that can drive automated test processes.
It is also important to know what needs to be tested explicitly with scenarios designed by humans, and know what is tested implicitly when those scenarios are executed by play testing. Added to this, it is worthwhile to break down the scenarios into those that must be tested by a human play tester as opposed to those that can be tested in an automated fashion.
There is a balance to be struck between the cost of employing people to test and developing the technology to test in an automated fashion. In the latter case, the game developer is reduced to desk-checking the results, which is far cheaper than employing human play testers. However the testing is to be performed, we must always strive to cover as much of the game as possible, knowing that 100% coverage is often an unrealistic dream.
This is a book on the fundamentals of development, and one chapter on testing will not replace the kind of experience and skill that comes from actually doing it. That said, this chapter will teach you how to approach the subject and what questions to ask when preparing a network-game development project.
One bane of network programmers’ lives is testing. It is difficult to test non-networked single-player games, but when the basis for the game is that geographically diverse players must interact in a virtual environment, it becomes much harder to ensure that the game has been adequately tested.
There are three aspects that need to be given attention:
Process: the various stages and milestones of the testing process
Components: what is going to be tested
Types of testing: how each component is going to be tested, taking account of the process
Once these three points are addressed, you can move on to more specific testing theory and practice, but first we need to be clear on exactly what we mean by the word “testing.”
Broadly speaking, from a real-time software perspective, we can often break down the whole testing paradigm into two principles:
Testing for correctness. This tests to see if the right software has been implemented correctly—i.e., there are no programming errors in the logic. Testing the correctness of the software essentially ensures that the game logic has been correctly implemented on a case-by-case basis. For example, if the game logic dictates that when a player enters a room, the light goes on, and when the player leaves, the light goes out, this can be tested for correctness. If, when the player enters the room, the light fails to go on, then the software has not been correctly implemented. And if when the player leaves, the light stays on, by a similar token, the software has not been correctly implemented.
Testing for robustness. This tests to see if the software will stand up to a barrage of unexpected data and/or logic flows. A robust software application will continue to be correct, even when unexpected data or logic flows might confuse it. For example, if a second player comes into the room and then leaves, and the light turns off, then you could say that this is a case of incorrect implementation because the first player would be left in the dark. But if the players do something unexpected, like try to shoot the light bulb, then the software has to be robust enough to recognize that the light will go out permanently.
This is where it gets more complex for video games, and even more so for networked video games. In any real-time system, there will be issues relating to the response time and ways to make sure that the system responds within a time span that does not cause behavioral issues that have a detrimental effect on the entirety.
However, when a network is involved, lower response times can often be attributed to substandard network programming or unfavorable network conditions. Therefore, it can be hard to figure out what the cause of an issue might actually be—the system, an individual component, or the network in general.
The trick is to make sure that the correctness and robustness principles are both observed, even when simulating network issues, and therefore factoring them out of the equation early on.
Earlier, we noted that programming network games was a case of not bolting it on to an existing (tested) game. This opens up another set of problems: If there is no single-player game, then there is nothing we can test for integral robustness and performance before adding network functionality. So, we might seem to have shot ourselves in the foot by tackling the development process in such a way.
Nonetheless, there are plenty of techniques that can be used to reduce the impact whilst keeping high span of test cases. Some of these involve a little extra work, such as simulating parts of the system that are not available or that we want to react in a predictable manner. (As an aside, when we use the term “predictable,” we do not necessarily mean “correct.” Predictable behavior that would be unexpected or erroneous in normal playing circumstances is a valid form of test data that is required to ensure that the correctness and robustness of the system is adequately exercised.)
Testing in video games is a whole other possible book, and can involve any, or all of, the following:
Play testing
Simulated play testing
AI-versus-AI testing
Test-data replay
No doubt each development team will have its own way of doing things, but these four have been selected because they have special significance/application in network-game testing. The reason for this is because they allow wide coverage for low investment—if the game has been developed correctly.
One prerequisite for the above is that we can hook into the game code in such a way as to be able to measure (or profile) the performance of each component. In addition, we should be able to inject data into the various interface streams—the interfaces in this case being that which exists between the player and the front-end (otherwise known as the “man machine interface,” or MMI), between the client and the server (should this exist), and the between the sever and its component parts. This last will include things like the database, which should be based on third-party components and therefore tested for behavior, at which point it is the data model and any database-side scripting (such as SQL-stored procedures) that are being tested rather than the underlying database system itself.
The first of the above list, play testing, is easy enough to appreciate. The player sits in front of the game (with a real server or simulated behavioral model behind the front-end) and plays through various scenarios. Afterward, the player reports his or her findings. This might seem easy enough, but it is very expensive in terms of people power. If you were to test an entire game from first principles to final shipping copy with 100% coverage, it would likely be prohibitively expensive—hence the need to know how to achieve maximum coverage with a minimum of test cases.
Of course, the next item in the list—simulated play testing—helps to an extent, but it can be tricky to know how far to exercise the system. In other words, a dumb client can be built that will try to achieve 100% coverage, but we don’t really know whether the system has been adequately tested for all combinations of behavior. This is where in-game AI-versus-AI testing and test-data replay come in. In the former, we allow the AI of a system to play the game, based on mapping input stimuli to responses in the game. In doing so, we assume that the in-game drama that unfolds over several runs allows us to fully exercise the system. This can be helped along by adding some randomness to the finite state machines (FSMs) that govern the versus AI’s behavior.
Now, we won’t know if we have done this without some kind of empirical measurement, and test-data replay is supposed to help. The principle is that test-data replay takes a set of known test data representing situations in the playing environment that fall into one of three categories of probability of occurrence:
Can: the usual rule-abiding flow of play
Cannot: things that are against the game rules, or could be spoofed by a hacker
Should not: things that are unlikely, but could happen
The first two are obvious enough, but the last grouping includes things like players intentionally running into walls or trying to go through a window rather than a door.
We then replay this test data through a simulated entity (with or without AI) and see how the system responds. This is great for multi-player networked games as we can have several sets of test data and replay the game over and over whilst changing (tweaking) other aspects of the system.
As long as we can measure the results, it makes testing more efficient and effective. There are even possibilities, in a multi-player environment, to play several sets of test data and simulated entities against (or alongside) each other, thereby exercising even more of the system. (Clearly some of this code, and even the data-replay models, are going to be re-useable in the game proper if correctly programmed, but we deal with code re-use in the last section of this chapter.)
Taking into account this suggested methodology, the basic testing process then becomes:
Develop the test approach—play testing, simulated play testing, AI-versus-AI testing, or test-data replay.
Develop the test data based on in-game actions/stimuli.
Apply the test data to the game environment (test).
Refine the test data based on results.
Refine the game based on results.
Change as little as possible/practical and run again.
There are a few things from this process that get lost in most game-testing processes. For example, the test analysts have to take the time to refine the test data in an intelligent fashion, and the developers have to be careful to change as little as possible before running the tests again.
There is a temptation to throw everything but the kitchen sink into the test data during the so-called refinements, and programmers might spot things that they believe need changing (often calling for “improvements”) that have nothing to do with the last test run, but that nonetheless have an effect on future test runs. It is easy to get stuck in a loop whereby the test data and code changes are constantly cancelling each other out. But the feedback process is very important, as testing should be a process of continuous refinement—of both the test data and approach as well as the system under test.
On the other hand, nothing beats a devious human when it comes to stretching a system, and there is no substitute for real play testing. These play testers will still need an approach, complete with scripts to follow (the parallel to test data in automated testing), as well as a period of refinement. Again, this refinement should cover what they’re supposed to do and how the system is supposed to react.
So, what are we testing? There are several key components that should be tested in this manner, and we shall look at each in turn.
Briefly, the following are the main components in the system that need to be tested:
Network: the connection/data transfer code
Interaction: what many people would classify as the game proper
Middleware: anything that connects the underlying system (hardware or software) with the custom code that makes up the game
Database: the back end that stores all the player data
Different game models may have other components, such as specific hardware controllers (think of steering wheels or Guitar Hero–/Rock Band–style peripherals) that need to be tested as well, but this list ought to be fairly standard across all game types.
Obviously, in a book about network-game development, much of the emphasis is on the communication between systems. The network component includes the communication, encoding/encrypting, and session-management aspects of the system. Each must be tested for data throughput, correctness, and simulated network problems and recovery. The reason we do this is to make sure that any mechanisms we have put in place to counteract the problems isolated in Chapter 7 are working correctly.
These include the correction of the following:
Latency, lag and jitter
Data corruption
Out-of-order reception
Etc.
In addition, the game logic must be tested in cases where we fail to correctly address any of these issues in the network layer to see at what point (if any) the behavior becomes corrupted by the inability of the network layer to cope. Only then can we decide if the system is correctly implemented. Simulating network errors will likely be a large part of this component, and there are third-party tools that exist to synthesize network problems.
Principally, this component involves testing the MMI. Luckily, it can be tested using people or automated scripted testing tools. There are two sides to the MMI: the actual reaction of the interface to the player and the communication of the player’s intent to the core system.
It is also important that the network indicators and network-level interaction be tested to make sure that even if there are underlying network problems, the experience degrades as gracefully as possible. Part of this should be dealt with in tandem with the network component.
Looking at these aspects may lead to some redesign, redevelopment, and subsequent retesting of the interface and/or underlying network-communications architecture to make sure that, as far as possible, the interaction is not damaged by issues out of the player’s control.
This includes anything (up to and including off-the-shelf components) that facilitates the relationship between the interface and the game environment. The interaction with the middleware must be tested, as well as the way it performs given the information that it is provided with as part of its integration with the game.
Testing is important because the middleware is often the link between two solutions. For example, cell-phone middleware exists to make porting of games from a non–cell phone platform easier. Therefore, it provides facilities that might not exist in the standard development environment. As such, it has to be properly tested.
The temptation is to assume that some functionality will have already been tested. This is most frequently the case if off-the-shelf components have been used (i.e., forum software, CMS, network-layer tools, etc.). However, it would be unwise to assume that any testing that has been conducted was either complete or correct.
Of course, if the middleware is present in a non-critical part of the system, then the emphasis on testing it can be reduced in favor of spending more time testing those aspects that provide core functionality within the gaming system.
The database is usually where the whole game environment is stored. As such, it becomes one of the most important components in the system. In addition, it is also usually on the critical path, as it needs to be in place before most of the game-environment persistence testing can be performed.
As mentioned, it is vital to test the stored procedures created to help manage the back-office systems. These are like little programs running on the database server that execute tasks better done on the database rather than in memory used for the game proper.
In addition, the various interfaces into the database environment must be checked for correctness (ability to process data) and robustness (in case they receive bogus requests). This last could relate to hackers, rogue software, or just bad client-side programming leading to unexpected behavior.
The database middleware ought to have been tested already. That said, the behavior, capacity, and robustness of the database itself has to be tested in this component. One particularly important aspect of these tests is the stress test, and it is one that can be hard to address. To help in this, stress testing the database can draw from many of the previous techniques, especially in creating sets of randomly populated test data that can be applied en masse to the database to see how it reacts.
Finally, all of the above must make use of one or more testing harnesses. A test harness is usually a piece of software that makes use of the functions under test, usually in isolation of the larger system. However, several parts of the system can be grouped and tested using a test harness to manipulate them. Other uses for the test harness are to subject the system to simulated behavior and measure responses. This is a key use for the test harness in network game testing, where testing must be extensive to allow for the added complexity of multiple simultaneous users—and a test harness is often the only way to achieve this. These are designed to manage the parts of the system not under test. One guiding principle is that the testing harness not add substantial load to the system. Otherwise, the results can be skewed, particularly in capacity and stress tests.
There are two ways to look at this: as a performance-analysis safety net or as an unfortunate side effect of placing additional load on the system. Whichever camp you fall into, one thing is clear: Any effect that the test harness has needs to be measured and taken into account in the final analysis.
All of the aforementioned components will require some kind of test harness, so it is not something that can be ignored. The fastest-performing test harness may also turn out to be a harness that simply replays test data sets as it does not have to think. Of course, this comes with an additional set of issues: Dumb test harnesses may not be much use in certain circumstances.
On the other hand, AI-based test harnesses may turn out to be potential bottlenecks. This will undoubtedly be the case if many are asked to run on the same system. Again, it is important that any conclusions drawn from results based on load, stress, or testing under conditions of duress are taken with the knowledge that there may have been other influences at work.
An example of the extrapolation that is required is to take a system designed to offer a gaming environment for 1,000-plus players. There is no way that the test team can hope to simulate the attachment of 1,000-plus clients to the system using 1,000 PCs, so there might be one or two PCs (or at most five to 10) tasked with running up to 100 clients each. One thing we can say for sure is that this is highly unlikely to result in the accurate testing of the client interface, because part of any problems might be due to the fact that we are asking so much of each individual PC. In addition, the game server is unlikely to be stressed by 10 PCs running 100 clients each; their combined performance will be well below any stress thresholds in the system. Again, their reaction times will be very slow due to the fact that they are running so many processes.
Of course, this is unrealistic, and we all know that the only way to test the server for capacity is to load up several machines with low-impact test harnesses and let them generate work for the server. Nonetheless, it is this kind of thinking that needs to go into the careful construction of the test cases.
An important consideration is the type of tests that must be conducted at each stage of the development and testing process.
There are two main types of traditional test methodologies:
White-box testing
Black-box testing
We will look at each in turn in a generalized fashion. (Note that the definitions, while standardized in general test theory, have been bent a little to fit into the network game–development paradigm being presented in this book.)
The first type of testing, white-box testing, is totally transparent with respect to the system under test. We can see what each component is supposed to be doing, and what data it processes during the design of the test cases. The game programmer’s knowledge is used to make sure that all aspects of (and logic paths through) the system are covered.
The drawback is that if any aspect of the system changes, then the test cases will need to change too, because they are intimately related to the actual data and logic that is inherent in the game. So, white-box testing is really only appropriate at the unit-testing level, before the game is put together for the first time with all the components in place.
Black-box testing, on the other hand, derives test cases from the external behavior of the system. As such, it will usually not be able to trap all the control paths, and the test cases are constructed without knowledge of the internal construction of the system. In game terms, this means that the test cases are prepared from the perspective of the interface (be it the MMI or a logical interface). This might include automated testing using third-party software to take the place of the player, play testing with a human, or substituting parts of the system with dumb test harnesses.
The important point is that the tester should not use any knowledge of the internal structure of the system to perform the tests. The reason for this might not be obvious at first, but relates to the possibility that the tester will unconsciously create a test set that avoids possible problem areas given his or her specialized knowledge.
Before starting the testing, it is important to have a high-level strategy that will uncover problems as early in the development process as possible. The following is a best-case strategy, but it will often transpire that not all the various bases can be covered due to budgetary constraints. It is important to understand at what levels which kinds of testing are important, and where testing activities can be trimmed down if required by the realities of the business cycle.
This is white-box testing, hopefully done at the component level so that each one is completely tested before they are combined together as part of the integration phase. Reality dictates that this will rarely be the case, and units may well move into integration before they have been completely tested.
Each tester should know what the behavior of each component will be given a set of inputs, and these inputs should feed forward into future test iterations. This means that it should be possible to trigger certain responses based on inputs to the system on a repeatable basis.
Automated testing is the only way that enough coverage will be achieved that the testers can be confident that each component has been adequately tested. Since white-box test methodologies are being used, it ought to be possible to create test harnesses and replay test data sets that provide nearly 100% test coverage.
There is a drawback: The test harnesses themselves must, of course, be tested. Because of this potential problem area, it is advised to keep the test harnesses as simple as possible, with as little standalone and as much re-used logic as possible. In essence, the more re-use of existing solutions can take place, the less chance there is that the test harness itself will be at fault rather than the system under test.
This stage in the test strategy occurs when the first build is ready to go, and should apply to the complete system or at least a completely interactive system. In other words, all the components should be in place in a broad sense, but they may not have the detail that they will later on. For example, there might be wireframes rather than textured objects, or levels might not be as large as they are intended to be in the final game. Nonetheless, all the logic of the game must be in place, as it is at this point that we will also get a first look at the playability of the game and a chance to correct the balance.
Automated testing should play a large part here. It is made possible by the fact that the system can still be tweaked relatively easily without a big impact on the time scale. Removing and adjusting components is still feasible; making changes in the underlying game design, less so.
This is the first time that the complete system is tested in a black-box style, and probably the first time that a human gets to play the game properly. Of course, different components may find themselves in beta testing at different times. So, the first play through of the client interface may well take place with a simulated server side presented as a set of test-data replayed through a test harness, or as a simple, rule-based, reactive system, designed more to demonstrate the game than to challenge the player.
Again, the play testing probably needs to be mixed in with automated testing, possibly even in the same sessions. This allows one play tester to play in the same system as several simulated players, which helps to make better use of the available person power than having them all play together for extended periods of time.
You must remember that there is a need, at this point, to have strict reporting criteria and key goals. If the play tester is experienced, there may be a temptation to give vague instructions along the lines of “Play the game and see how you get on.” If this is the case, however, then the play tester will likely miss some aspects of the game that ought to be tested more fully at this stage. They will still add some unpredictability to the game, though—if not quite as much as in the public beta stage.
This part of the overall strategy is where the general public is permitted to play the game for the first time. It can be a spooky moment for the development team as they wait to see what the playing public makes of the interface, game balance, difficulty levels, accessibility, and so on.
It is also a very labor-intensive phase, as the testers need to be monitored along with the game itself. This makes it an expensive part of the process, and not one that should be extended or repeated unnecessarily.
At this stage, anything beyond minor upgrades will be prohibitively expensive to repair and will more likely result in reducing the available features rather than trying to fix something that could have an impact elsewhere in the game.
It may well also be the first time that the production game servers are exposed to networks other than the private LAN used by the development team. As such, all manner of things can go wrong, and experience has shown that a phased approach is best. After all, if time is taken before the play testers are put into place to bring the system up and check that everything works as far as possible without them, their time will be far more efficiently used when the testing of the game proper begins.
The network layer includes everything up to and including the client-side networking, but does not include testing the back end or logic. What it does include are the bits and bytes that facilitate the transfer of data from one point to the other, as well as the guarantee that the data arrives correctly, in time, and tamper free.
The idea of testing is to get a handle on what the network capability is, but not to see what kind of capacity the whole system has. There is a necessity to check how stable the network-processing layer is and how it can, if need be, be improved—but not with respect to the rest of the system. This is because it is likely that things like the database are scalable—i.e., if you add more hardware, they get faster—and also because they are generally shared resources. So, it is of little interest, when testing the network layer, to have to take account of other potential bottlenecks.
What we do want to know, however, is what kind of load our networking layer will handle. The only way to do this is to try to break it—both at the physical level, with overwhelming traffic frequency, and at the logical level, with corrupted, hacked, delayed, and otherwise tampered-with data.
Again, there is the need to check for robustness and performance. The system has to be able to cope with both high volumes of traffic (performance) as well as situations in which that traffic is somehow corrupt (robustness). Part of the robustness testing is also to see what happens when the performance threshold is exceeded.
This section deals exclusively with robustness and performance as it relates to the actual transfer of data. To satisfy both these criteria, we also need to make sure that both the network layer and game logic can deal with the following:
These can all be simulated using tools that introduce (simulate) network-connectivity issues between one of more systems. These tools typically exist in either hardware or software, or as a system that sits on the network between the client and the server.
This is at the base of all network issues, and is a vital part of robustness testing as well as in testing the correctness of any software solution to issues surrounding uneven network communication.
In some cases, this can be simulated as part of the game framework. For example, Microsoft’s XNA Game Studio includes a latency and data-loss simulator as standard to help developers test networked games. These are typically used to simulate issues from the client side (i.e., as a bolt-on to the client software), but the server side cannot be ignored. To this end, it is worth understanding how latency can be introduced in a test harness. In fact, it is not a complex matter, and simply requires introducing debug code in the network handling layer. This code must be compiled to allow the following
Delaying packets
Dropping packets
In addition, it should allow for some basic statistics to be recorded, which will allow for post-mortem examination of the debug code. These should include the following
Data throughput rates
Packet loss as a percentage of traffic
In addition, the latency simulator must be capable of being tweaked to allow the following:
Changing data order
Variable delays
Variable packet-drop rates
The key is to make it lightweight (so as not to adversely affect processing) and to place it between the actual interface to the network and the game code itself. An alternative would be to place a piece of hardware that mimics a router but allows the user to introduce the effects noted above on individual connections.
The latency simulator is at the base of the network error–simulation package. From it, many other situations can be simulated, including jitter and lag.
Jitter is sophisticated latency caused by random dropped or delayed packets that results in the data being delivered in an inconsistent fashion. In essence, it can be simulated by changing the rate of data delivery in such a way that the latency varies over time, across a normal distribution curve, in a random fashion.
This last is important, as it requires that the jitter simulation be able to pick a data packet (or data group) at random and subject it to a random amount of latency such that only a small percentage is affected. The data that is affected should be affected in such a way that is unpredictable and where the extent varies.
The effect can be bolstered by randomly changing the order of packets and intermittently dropping packets. Note that these last two are discrete events, whereas the latency part of the jitter simulation is scalar: It has an extent, rather than just a decision as to whether to change the data.
An extended period of jitter eventually becomes lag.
This is a simpler form of latency, where the latency simulator is set to delay (drop or swap) packets for an extended period at a constant rate. This is very useful for testing logical workarounds in the code to deal with extended periods of data latency, which are the main cause of the lag effect.
Naturally, introducing such a device will also have an effect on the database-side, and possibly server-side, as well as client-side performance. In other words, network issues can affect the LAN as well as the WAN connections, and it is vital not to ignore the possibility of local problems that will affect the system as a whole.
The key to the testing process is the ability to introduce these facets into the system and then see how it reacts. This should be done in both in an automated way as well as with real humans on the client side. Automation enables us to test a large number of occurrences, whilst the human testing enables us to get an idea of how it feels to play the game when the errors are introduced.
Therefore, we need way to measure the effects on the client interface and the end user (player), as well as the end effects on the system. This will require quantitative analysis as well as qualitative analysis of the results, with statistics being measured in game by the test harness, as well as question-and-answer sessions yielding information from the players themselves.
Once we have performed the analyses, we can draw conclusions as to the appropriateness of the network programming and logic behind the network handling. Explicitly, we will know if the safeguards that have been written into the system to handle network errors are sufficient.
There several things we can do to simulate network errors:
Drop packets (especially if using UDP)
Corrupt packet data
Delay packets
Change order of packets
Etc.
Each of these aspects will attempt to test the network and game logic in a different way, and improvements to the network handling in the game are likely to be made as a result. Because of this refinement process, it is important not to throw too much at the system at once; otherwise, it might become difficult to trace back the origins of a specific handling defect.
On the other hand, if the game is using layers of network protocols for communication, then it can become very important to quickly perform as many corrupted-data and data-delay tests as possible. For example, if UDP is being used, with logic implemented to help counteract the issues that can arise when a non–stream oriented protocol is used, then this has to be tested first.
If the game uses TCP/IP, which is stream oriented and has the benefit of almost guaranteed delivery, then the testing irregularities that are introduced will be different. The logic used to handle the packet synchronization, for example, may be vastly different, and reliant on the inherent stream-handling capabilities of the protocol.
Despite the special nature of the test equipment, testing the network layer in this way follows the same principles as laid out in the beginning of the chapter, so all the same processes and testing types are equally applicable.
Apart from introducing errors and behavioral artifacts into the stream, it is also important to spend time making sure that the network is resilient to high loads.
Load Testing the network layer (and system behind it) requires the following:
This means that we need to be able to make some important measurements:
Requests made (per timeframe)
Requests treated (per timeframe)
Response time (per request/response)
While carrying out this testing, there should be limited game functionality behind the network components. In other words, only that game logic required to process the request should be present—i.e., no database connectivity code, and stubs for everything else that uses a server-side shared resource that might be external to the system under test.
The reason for this is simple: We need to be able to measure the network performance in isolation so that when we measure the system’s performance as a whole, as part of determining the scalability, we want to be able to factor out things over which we have less control. The network interface tends to be such a thing.
The test team needs to measure and track everything in a spreadsheet. This is useful for creating predictions as to the point at which the network component will fail in the absence of enough test hardware to force the issue. In addition, you must remember also that any encryption and compression needs to be taken into consideration at the server side, as it will affect performance. The client side will be less critical if a strict client/server relationship exists, with all communication passing through the server.
This emphasis will change, however, if the server re-routes data to clients without processing, or where each client may receive direct messages (i.e., for in-game communication between players). In these cases, although rare, it will be necessary to also test the client software under similar conditions and gauge the network performance for them in tandem. The added complication is that a client may need to prioritize server communication over personal communication if and when the network becomes saturated.
We start, however, with the assumption that traffic is almost entirely one way.
Depending on the gaming model being used, it is possible that the vast majority of traffic in the network game will be one way:
Server → clients
Clients → server
Client → client (rare)
Generally speaking, the relationship will be either one to many or many to one, as shown in Figure 9.1.
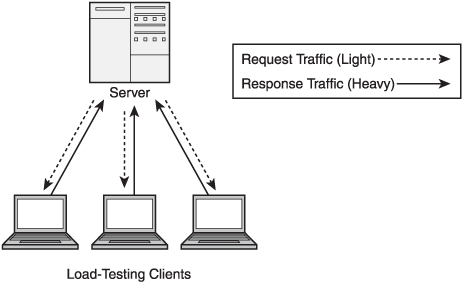
From the point of view of the server in Figure 9.1, it has a one-to-many relationship with the clients. Conversely, there are many clients, all communicating with a single server.
Pushing data from the server to the clients can be simulated by simply not putting any “real” systems on the other side. If there is no response to be created (or if there is just a token one), then this can be handled by a single machine pretending to be multiple clients. This can be a simple harness with no logic behind it beyond what is necessary to make sure that the data arrives and can be processed. The idea is to do as much work as possible and make sure that the network can keep up with the data at the physical, logical, and interface levels.
This harness can double as a system for capturing the data, measuring response times, and analyzing network behavior. Of course, the more complex it becomes and the more overhead it requires, then the more distorted the results will become and the fewer clients can be simulated.
This testing model can also be used for e-mail updates in turn-by-turn games, for example; here, it doesn’t matter if there is no reply, and we need to test the volume of e-mails that can be reliably sent within a given timeframe.
Load testing the other way round (from client to server) presents more of a problem. Even if an extremely light-weight, trimmed-down client is used, a single machine is less likely to be able to put enough stress on the server. Hence, multiple machines, or a spare server, will be needed to perform the testing correctly.
It is important to put pressure on the network layer, but also to remain realistic. If the game is quite niche (i.e., a specialist game with a low expected following), it is unlikely that it will get 1,000,000 subscribers in a short term. Given this, it is useless to use that as a target figure. Maybe a couple of thousand simulated simultaneous connections, of even a few hundred, will be enough.
Client-to-client testing follows similar rules, but each machine will be required to simultaneously emulate multiple clients. This means that the testing overhead will be even greater, especially since more logic will be needed to effectively simulate the dialog between the two machines.
It is up to the test team to find a balance that is realistic and yet provides test coverage that makes it worthwhile to carry out the tests in the first place.
Duplex-load testing involves traffic in both directions, at the same time. We assume that this goes beyond the simple request/response dialog where the flux of data is predominately in one direction—from client to server, or server to client. Figure 9.2 shows the bi-directional nature of the traffic.
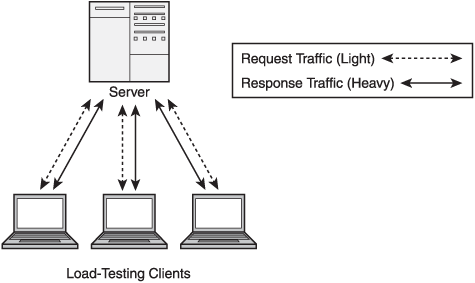
Most of the games in the action genre will fall into the network model shown in Figure 9.2. It is especially important for games where the client needs to send data to the server whilst it is also expecting to receive updates and other data from the server. This goes beyond a simple request/response architecture.
Again, the rendering of the results of the dialog between the two parties is not tested as part of the network load testing. However, there are two points to make. The first is that the data used for testing should not be too artificial, and the data should be processed and a meaningful update posted. It might be randomly generated, but it should follow the profile of data that might occur in the game. Second, it is important to make sure that the client can keep up with the server and vice versa, so any overhead has to be more or less equivalent on both platforms. You should bear in mind that, after all, we are only trying to establish that the network layer is robust enough to process under heavy loads.
This is less important for other gaming models (where a little lag is not an issue) but critical for action games. Consequently, the network, even more than before, is only half of the story; attention must also be paid to the performance of the logic layer, discussed in section “Testing the Logic Layer.”
The previous sections have assumed that we will be testing peak load. We must also be sure, however, that the network layer is robust under sustained load as well. Note that the volumes of data will likely be lower than during peak-load testing due to the impracticality of being able to generate enough data and the lower likelihood of a sustained load in the production system.
We can tentatively define “sustained load” as a given number of network events (transactions) at a reasonable load (say 60% of total capacity) for an extended period of time (on the order of half to a full day). This is designed to simulate unusually high traffic during a specific in-game campaign, concerted player movement, special event, or just vacation/weekend processing.
The end goal is to ensure that if every anticipated user was active at the same time, the system would be able to cope. The data profile in this case is likely to be a spike (peak-load test) followed by abnormally high activity, but spread in a more typical way, over time (sustained-load testing).
Again, perhaps this is slightly more relevant for action games and games, where the conversation between the client and server is duplex in nature, than in other game forms. However, even a Web game can suffer the ignominy of a false restart when everyone tries to log back in at once after an outage, so this testing is valid for any online game.
This type of testing is especially important for subscription-based services, because there is a relationship between the hardware available and the income generated by players. The cost of increased hardware requirements brought about by an increase in subscribers (users, players) will be offset by the additional income.
If we can’t measure the existing capacity, then we cannot estimate the new requirements based on additional players, and therefore have no way of knowing whether the system is cost scalable. By “cost scalable,” we mean that the cost of supporting new players has to be balanced out by their subscription payment. That is, obtaining the first new users must not tip the capacity such that extra hardware, which has not been budgeted for, is required. Only after there are sufficient additional users to pay for new hardware can that hardware be implemented.
If the budget assumed that the existing hardware will support 1,000 users (sustained-load test), and the cost of maintaining that has been spread over 1,000 subscriptions, then the 1,001st player to come online will increase the hardware cost disproportionately. In other words, that player’s subscription payment will not balance out the cost of supporting him or her—especially if a duplicate system has to be put in place.
Therefore, anticipating how much extra capacity can be gained, whether it will be enough, and how much it will cost compared to the subscription fee should all figure into the measurements being taken during the sustained-load testing.
If the variables are correctly taken into account, a system should be budgeted for whereby the capacity of the server is overcompensated by the income that it generates. Then, when the tipping point occurs and new hardware must be acquired, at least it is already partially paid for. (Of course, at this point, the logic behind the synchronization of the two systems has to be revisited, and a whole new set of testing problems present themselves as the game environment becomes spread over multiple machines.)
For Web games, however, this cost might not be relevant or useful to estimate, since the cost base is usually much lower than for a dedicated gaming server. In essence, Web games can be implemented more cheaply because they do not place high loads on the server, especially if they are turn based with daily activity limits. Incidentally, it might seem as if this only applies to Internet games, but the same exercise should also be done for LAN games, as it will be important to know how much hardware must be taken to the next LAN party.
The peak-traffic tests stress the system to a given point, simulating the simultaneous actions of a collection of players. This could also be called a “bulk sign on,” as experienced by Eve Online, which holds the record for the number of simultaneously connected players. During the Futuris Powerplay gaming show held in Brussels, Belgium, one of the Eve Online servers seemed to fall over, and the team on the desk held its collective breath as we witnessed the re-logging-in of thousands of players. Testing for this kind of event is vital to maintain the image of the game. (Eve Online managed to cope with the sudden influx of players re-connecting, and, indeed, the only reason that anyone knew there had been such an event was by the fact that the players went offline and then came back.)
After such an event, the system is usually given time to recover—either naturally or by enforcing play limits—as the system caches are emptied and the databases re-aligned. While peak activity takes place, there are likely to be some tasks that are suspended until time can be found to service them, and it is important that they are not put of indefinitely.
Peak-traffic testing should also test these safety systems. Likewise, for systems that cache requests and process them internally at a different rate than that at which the requests arrive, peak-traffic testing will be important.
Depending on social and geographic trends in the target audience, there will likely be different usage peaks during the playing day. This will mean that there will be occasions where there are many players online at once and the system has to be robust enough to cope—or fail gracefully if a certain threshold is reached.
We have looked mainly at emulating multiple clients with a single machine, but for WAN gaming, it is also important to look at some other situations. For example, players might be connecting over thousands of kilometers of fiber-optic cable, or dialing in using a plain old telephone line.
Getting geographically diverse clients might be an issue, and the cost of doing so has to be weighed against the expected performance bottleneck that it creates. It is likely that the bottleneck is elsewhere than at the network level, given the performance of networks today. If, however, the server is located in a place that is not well connected to the Internet, then this may well be a problem—especially if the majority of the expected clients are located in places that have ultra-fast network connections.
In addition, many of the same tests have to be conducted with diverse client systems such as hand-held or cell-phone devices, which cannot be easily simulated. The question here is, How can we be sure that the clients can cope with the data being thrown at them? The answer, of course, is that we cannot—unless we test. So, load, sustained, and peak testing will also apply to clients in these circumstances, and it all goes hand in hand with making sure that the logic layer, as well as the network layer, is up to the job.
Having tested the network layer and everything that manages the transfer of data in safety and with a modicum of guaranteed delivery, we must now turn our attention to testing the logic that is behind the game itself. This follows the usual testing practices for single-player, non-networked games, and these aspects are covered in more detail in other books on the subject of game development.
There are, however, a few things that are worth mentioning in the context of network games. First, we shall assume that the logic layer in this case comprises:
The front end (Web browser, plug-in, proprietary front end, etc.)
The game server middleware logic (everything that is not network related)
The back-end database
Supporting third-party components
It is important to note that this list leaves out the network communication, compression, security, and encryption layers. We will only mention those aspects where they touch the above components—for example:
In scope: peak login requests, player logs in, session tested against database, session updated in database, password decoded and verified, etc.
Out of scope: peak network requests for static encrypted data
An obvious part of being able to test this is being able to simulate player interaction with the game environment.
Player interaction can happen at several levels within the game, from the front-end to the logical interaction of the players’ in-game representations with each other and the game system. This section looks at the interaction with the game environment, not necessarily via the front-end interface. Actual testing of this component is covered later in this chapter, in the section “Testing the Client Software.”
Given that the network layer has already been tested and the capacity of the network is known, this aspect can be left out. This, in turn, means that multiple clients on the local system can be simulated over a much faster, higher-capacity network connection. This is very important because we want to get as much testing of the logic done in as short a time, and in as automated a way, as possible so as to reduce the cost of testing and make the whole process more efficient.
To make sure that we are exercising the logic in a way that touches as much of the game design as possible, scenarios have to be created that consist of sequences of actions:
Valid action chains
Non-valid action chains
Mixed action chains
These should feel vaguely familiar, as they are very similar to the approach we used in testing the network layer. Here, again, the system is therefore being tested for things like
Robustness. It doesn’t fall down when multiple bad requests are made.
Scalability. It can process multiple good requests in sequence.
Interoperability. It correctly detects close-proximity player actions.
The last point is primarily important for massively multi-player games (action or turn based) where the action sequences can change based on other actions taken by players in close proximity to each other. This does not mean close physical proximity, but logical proximity within the game space. If you are finding this hard to grasp, then try to imagine two players approaching each other in game space, and the list of actions that could be carried out. If one of the players chooses to talk rather than fight, the context-sensitive logic has to be able to deal with the fact that there are two possible action sequences that can be offered and that they are not mutually exclusive. In other words, just because one player chooses not to fight doesn’t preclude the other from taking a more violent stance.
The first item, robustness, means creating situations that are unexpected. Clearly, only the game designer can decide what those might be, and the best way to actually do it is to generate huge amounts of test data and throw it at the system (see the section “Re-Using Prediction Code in Testing” later in this chapter). Robustness testing is, of course, important for any game, but it is essential in testing network (and particularly online) games, which are much more unpredictable. As we have pointed out in the course of the book, multi-player games are by their very nature strongly emergent systems; as such, only extensive testing will ensure that they are working correctly at every level.
Scalability simply means trying to make sure that the system can cope at various levels. This should not be confused with the playability of a game designed for thousands of users that only gets tens and is hence rendered unplayable. That is a design problem, and as such is important, but not part of this book, which is about turning a design into reality. Scalability in this case simply means making sure that the in-game logic can handle various levels of player interaction.
A final point worth making: What happens when there is a usage mismatch and the network can’t cope with the peak processing, or vice versa? This aspect also needs to be tested. By stripping out the network layer when testing the logic part, we can be sure that the logic layer is at least as capable as the network layer. This ought to suffice.
Bearing the above in mind, you ought to be able to devise some devious plans for testing the logic. However, we cannot neglect two important stress-testing parts: the middleware and the database, which we shall look at now.
It is important to make sure the server can keep up with the expected number of clients—a task that is largely dealt with at the network layer in the network tests. This is only the front-end bottleneck, however, as there is also bound to be a lot of facilitating software, which I choose to place under the general umbrella term “middleware.”
Thus, the middleware, in this case, includes the operating system as well as any file-sharing mechanisms, backup software, and other programming items that support the game whilst not actually being a part of it, per se. Naturally this also includes third-party components and in-line tools. An example of a third-party component might be a graphics-rendering subsystem (either online or off—i.e., Torque), and in-line tools might refer to data-generation systems that create bits of the game environment procedurally as the players explore new areas.
These all have to be subjected to stress testing, even if you believe that they have been tested adequately for the services they bring. One of the key advantages of using middleware is that it speeds the development process, and a big part of this is being able to rely on the fact that the components are tested. That said, you never know to what level they perform until you try—hence the necessity to stress test them at every level. The same goes for subsystems, such as databases.
As with other third-party components, it is important to check that the database can keep up with the rest of the system. If caching has been implemented (where updates are posted during quieter times), then this also needs to be exercised to check that it is working correctly and that in-between caching the system still operates as expected.
Again, like network testing, stress testing can be thought of in terms of sustained traffic and peak traffic. This enables us to check that the database is durable, scalable, and robust:
The same kinds of questions need to be asked about the scalability and organization of the data-storage component as of the server layer as a whole. This is especially true in terms of pricing the system. In other words, we need to know how much it would cost to add another user, another 100 users, or another 1,000. Stress testing lets us know at what point the database will begin to fail to support the operations that we throw at it.
At some point, we have to make the decision to split the game environment over several databases. Besides the logical separation, and the change in game logic that supports this, we also need to know who will bear the additional cost. Stress-testing the database, as before with the network layer, lets us find the cost of this tipping point—but it does take rather a lot of data, using white-box testing, to get accurate results.
Lots of database testing can be automated, both by throwing data at it through a proprietary front-end as raw database access statements or through automated manipulation of the client system. The first approach is faster and easier to deploy; the second is a step closer to reality. Different stress-testing tasks will require different levels of automation. Clearly, it is useless to spend time on unrealistic test cases, so a balance must be found.
The data itself need not always be meaningful, except in the context of the game environment, design of the database, and possible values of the various data types. As long as the database scheme is adhered to, the data can be generated more or less at random.
For example, in test terms:
| is just as valid as |
| or even |
| but not |
| (interpretation = numerical) |
Some of the test data will also need to contain specific items designed to break the schema, and this falls into the general white-box testing of the system as a whole. Again, it is useful to have a concept of valid, invalid, and unlikely (borderline) test cases to draw from, designed by those involved in creating the database infrastructure.
Part of the logic and stress testing is to check how the logic layer responds to database errors. There are many ways in which errors at the database level can be dealt with—from simply reporting the error and standing down the system to gracefully recovering and trying not to affect the flow of the game at all. Different systems and different designs will have different solutions, but it remains important to check that, even if the most benign solution (system halt) has been chosen, the required operations take place if errors are encountered. Again, this requires a high level of test data.
Vast amounts of test data can, and therefore will, need to be generated. This technique is especially useful when testing non-interactive, multi-player network games, as we shall now examine.
One might think it would be easier to get non-interactive network games right, but this is not necessarily the case. Part of the problem is that they tend to take longer to play out, and therefore it takes time to achieve the same level of coverage. This means they can be expensive to test manually, so the emphasis ought to be on automated testing (see the last section of this chapter, “Prediction Is AI in Practice”). This reduces the need to involve humans to play the game at the regular speed, which is not usually cost effective. So, testing non-interactive games requires some ingenuity to make sure that they are correctly exercised.
In addition, with Web games in particular, there is an additional aspect to test—the presentation layer. This is something that the game developer only has limited control over since different browsers may render the results differently.
There are a number of techniques that must be used to test the Web interface of a game, and we have to attack the problem at several levels:
Visual keys: i.e., reading data returned by the system
Interaction with the simulated user: i.e., clicks and key presses
In order to link the simulated user actions to the result, it is necessary to scrape the HTML that is returned for information (status), and then interact using something like AutoHotKey (AHK) or WinRunner (or other Mercury tools) to simulate mouse and keyboard action.
To help the scraping process, it is sometimes a good idea to put comments in the generated HTML, using the following syntax:
<!-- comments -->
Advanced interaction can be done via JavaScript (pseudo AJAX), again through AHK, or by direct manipulation of the browser through an externally scripted interface. This interface must be capable of sending key presses to the main window to emulate the user behavior.
This key-press approach is easier than trying to manipulate the mouse unless it is known exactly where each of the elements will appear on the screen, because different browsers may well put them in different places. Where the only interface is mouse based, without keyboard handling at all, a human has to be used to check the interface across different platforms. However, since all browsers respond to the Tab key for moving between fields/links/controls, and the space bar for activation (as well as the Backspace key for navigation), it can save time to take this approach for game logic testing.
A simple example is in testing a sign-up form. If we assume that there are two fields—player name and e-mail address, both mandatory—we can test various data-entry possibilities and scrape the results page to check whether the constraints have been correctly applied. Again, we can use generated data for this to expand the test data set beyond what would be feasible if real people were expected to sit in front of the machine and type.
The mechanics include sending Tab-key-presses followed by normal key presses, and making sure that the form is submitted. An alternative is to retrieve the document object model (DOM) using JavaScript and XML, and set the fields explicitly.
The final step is to trigger the form submission This is marginally more complex, but also linked explicitly to Web gaming using clients that support JavaScript and an HTML, XML, or XHTML front end.
Part of the testing solution will also need to measure the critical performance indicators. However, it is unlikely that you will be able to test for a large quantity of simultaneous clients unless a large number of machines is available; that will likely have to be left for the public beta.
On the other hand, multiple, faster-than-human requests can be made using the browser over a local network (the end product will likely be delivered over a WAN/the Internet) by using the above mechanisms. This enables us to measure
Server reaction time
Client rendering time
Mean time to failure
From the above, we can estimate the capacity as well as whether the game logic works at all. A similar approach can be taken for e-mail games, where the data transfer is purely on the basis of an exchange of plain-text e-mails; obviously, here we can simulate many, many clients on a single PC platform.
One of the great aspects of play-by-e-mail games is that they allow the ultimate flexibility in terms of platform. In fact, any platform with e-mail can play. But the drawback is that there is the widest scope for misinterpretation or erroneous submissions. This means that the server has to be robust enough to accept everything from valid requests to spam without falling over. Ideally, everything in between should be be tested, just to make sure that the parsing logic is robust enough to deal with variable levels of player competence in presenting their action requests. Cellphone text-message games have an advantage in that there is less possibility to spam the server with erroneous requests.
It is easy to test the logic locally, too, by supplying text files that can be parsed by the server and the relevant changes effected on the back end. This enables the developer to create vast sets of test data and measure the responses of the game server.
At the same time, because of the batch nature of the game, performance is also less of an issue—after all, for a daily-update game (likely to be the most frequent of update cycles), the server has several hours to perform various tasks. Each of these has to be tested, and will include the following:
Processing incoming e-mail
Deciding the consequences of players’ actions
Generating the new game environment
Forwarding status e-mails to players
It is the last three items in this list that are likely to be the most time consuming and error prone, provided that a pre-processing software solution is used to remove any e-mails that are clearly garbage from the queue.
To avoid denial of service (DOS) attacks, the mechanism that separates the three categories of e-mail must also be extensively tested. These categories are as follows:
Valid requests: actionable
Possibly valid requests: return to sender
Junk (a.k.a spam): drop
This last is vital—you don’t want to spend time processing spam. Again, you should see echoes of the test data sets from previous sections—valid, invalid, borderline—which point to the correct strategy and processes to use.
One point to note is that the possibly valid requests should be rejected in real time to allow the player a chance to resubmit. Each player might also be required to send in several e-mails to secure his or her move (action) quota, depending on the game model implemented. This approach is midway between online and offline gaming.
One genre of multi-player network games provides a real headache for testing: what I call “online/offline games.” These include games like Perplex City, for example, where there is a very tangible link between the real and virtual worlds. It becomes impossible, at this point, to test every aspect, because it is an extremely complex gaming model to apply.
These games also unfold at a leisurely pace such that it is unlikely that an error at a given time will substantially affect the outcome of the game. The game can even be in a state of perpetual development as the end goal is reached, as long as the whole thing is planned correctly from the outset—including provision testing.
The thing with test data is that each piece would just be one isolated incident in a socially advanced game model. Thus, the notion of test data changes slightly. The socially advanced aspect is important. More than other kinds of games, the model benefits from a slow unfolding of events. Each piece of interaction between players (at all levels in the real and virtual world) helps to spread the clues. These clues are destined to eventually provide the solution to the game, as well as opportunities for espionage, false leads, and other devious “trust nobody,” conspiracy-style gameplays by the system and players alike. (As noted in Chapter 8, this is not classified as cheating unless the game’s creators have taken explicit steps to prevent/punish such behavior.)
Testing such a complex interplay of various beings in the virtual and real worlds is, sadly, impossible in quantitative terms. In qualitative terms, however, we can plan for various test cases that comprise detailed “what-if” scenarios. But this approach is naturally more about blue-sky thinking and discussion than it is about empirical results. Nonetheless, all the stress, load, and interface testing still holds. After all, the game might become very popular, and the players still need a way to communicate, be it through online forums, live Web chat, or a virtual world such as Google’s Lively or Second Life.
In a nutshell, we test the client to make sure that it can cope with the demands placed on it. If the network game under development is based on a single-player action game, then it will, of course, have been tested as part of the normal development cycle.
In addition, multi-platform online games that use the Web browser to access the system will have different capabilities than those used in development. These cases need to be tested as well.
We shall make a distinction between testing a Web-browser (virtual) interface and a client package that is completely under the control of the software developer. The latter has the advantage that it should, from a software point of view, be completely understood, making white-box testing that much easier.
The proprietary client is the piece of software that is used to interact with the game environment. In a sense, it is the portal through which the game environment can be manipulated by the player, and the tool that the player uses to interact with other entities in that game environment.
The capability of the client software has to be tested on several levels:
As a gaming interface
As a conduit for player actions
As a relay for the state of the game environment
This last item includes other players. It is important that the client software is capable of reacting to changes very quickly. In reality, it must react at least as quickly as human players can perceive that those changes will have an effect on their progress through the game and/or their immediate situation.
Clearly this means that the test harness must be the ultimate player, able to respond quickly and evaluate the situation almost immediately. All the other principles of performance and measuring that performance also apply, which places additional burdens on the developer of the test harness to make a robust test platform. In addition, testing across multiple platforms might be important to maximize reach. Of course, if it is a single-platform release, this will be less important.
Despite fact that HTML, XHTML, XML, CSS, and JavaScript (the most likely development languages for Web games) are all well-documented standards, different platforms do react slightly differently.
There are many browsers, and some of these are platform dependent:
Windows: IE, Firefox (Opera)
Mac: Safari
Mobile: Opera
Linux: Firefox, Opera
Etc.
Often, the best solution is to pick something that is closed binary platform independent like Macromedia Flash, or up-and-coming cross-platform solutions like Adobe AIR, Yahoo! Widgets, or Opera plug-ins. With the exception of the last, these have the advantage of being non-browser dependent, and of rendering results in a similar way across all supported platforms.
In addition, there are the various open standards like the Facebook API, which allow games to be deployed under slightly more interoperable standards. These are linked, of course, to the platform (Facebook, MySpace, etc.).
All target platforms need to be tested using the same scenario and the same set of supposed player actions, and must be verified by a human. It is currently very difficult to test Web interfaces of this nature automatically. This makes the testing process very resource intensive—more so, in fact, than with a proprietary software application that accesses the system via the network component, where the actual code can be linked into and vast data sets used to test the system. The final outcome is that Web-usability testing often has to be performed by a human, and that makes it expensive.
There are many things that we can do to help produce a good test platform, but all of them rely on some measure of programming. Code re-use at the testing level—i.e., taking code that has been tested in unit testing and redeploying it for use in alpha and beta testing—is not a new idea. It is, however, one that is not always appreciated, and so it is worth taking a few moments to outline how code that is used for prediction in a game can be turned around and used to test the logic of the game.
When the network game is created, in order to help mitigate some of the effects of network disconnection and/or slowdown, it is possible to use local processing power to try to predict what will happen in various situations. Games such as Street Fighter IV use this technique to level the playing field between players of differing network experience.
For example, a player positioned at a certain place in the 3D space that represents the physical (virtual) game environment might have limited movement options. It ought to be possible to predict, given the player’s position and trajectory, where he or she will be in the next time slice—provided the player does nothing to change it.
Lots of things cannot be predicted, but enough can that we can make up for network stutter and provide a smooth experience. The reliability of inter-network connections (between networks that make up the Internet, for example) does not allow us to be sure that packets of data will always arrive in a timely—or even regular—fashion. This means that, depending on the choices made regarding the sampling frequency for the data to be relayed (by the client, usually), there may be a gap that needs to be filled in by the AI until such a time as the next bit of information is relayed. Prediction helps us to fill that gap.
Any game with non-player characters (NPCs) has to have AI in it to manage them. This AI code can be re-used in the testing process, which means that we are redeploying some (tested) core game code for higher-level testing functions. The game is, in a way, playing against itself. In-game entities that are not controlled by the players will, after all, need to react, but also preempt, based on what the player is likely to do next. They are, in a sense, also players.
The only advance knowledge that is required is that of the system and the capability to synthesize behavior that is known to exercise that system. This is an abstraction that can be coupled with the AI that makes up the prediction/reaction of the system. The result ought to be a robust test bed that can be used to exercise a large proportion of the system. The temptation might be to also test the initial AI in this way, but clearly that approach will work only if we also admit that the AI will be in a state of flux as we uncover issues with its behavioral modeling. This also makes the testing process that much more complex and should be avoided.
The exact proportion of automated testing against human testing is linked to the stage at which we are doing the testing. The aim is to present a mechanism by which we can approach the testing at various stages in the most cost-efficient manner. For example, early-stage testing should be automated, as we expect more basic errors (and more total errors) to be present in early development of the game.
What is important is to concentrate on testing at the anticipated level of player involvement. This measurement of involvement is what sets network-game testing apart from other testing projects. Potentially, there are more players, more systems, and more situations in which the system can be placed. Therefore, we need more data and more active entities to be able to test the system fully than in a single-player non-networked game. This is why we look to a combination of AI, simulation, and data-set generation to provide extensive test coverage at a lower cost point than we might otherwise anticipate.
In an ideal world, alpha testing occurs when the previously tested modules of the game are brought together for the first time and the emergence takes hold. It might also be the first time that some of the unit-tested modules are brought together.
At this stage, we might anticipate that the players will not be able to fully explore the game system. This might be because not everything is fully functional or because of constraints brought about by the game being variously halted during testing activities, by system errors, or by other issues identified by the testing process itself.
So, we might be able to establish limits such as the following mix:
10% player
90% simulated
This means that we anticipate that 90% of the system should be tested in an automated fashion—in other words, by applying test data to in-game entities controlled by the test system at high speed. It should, logically, catch most of the more basic errors that could be present in the system. Only 10% of the time spent testing will be done by real players, who should explore the higher-level functions of the game system under test. This 10% should begin only after the system is 90% stable following the automated testing.
The beta phase may well introduce the game to external players (i.e., a public beta) for the first time. It is also likely the first time that a more or less complete gaming environment is deployed for testing. Due to this, the game environment as a whole should therefore be populated in the following fashion:
20%–30% player
70%–80% simulated
This implies that the game environment, as it is being played, consists of a number of simulated players playing either with or against the human players, and the aim is to completely exercise the gaming mechanisms.
Whereas before we broke the testing process down into two separate processes, player and simulated, in the beta phase, because all the basic errors should have been removed by unit and alpha testing, we are now suggesting that the actual in-game AI entities play side by side with real players.
Whether or not the game developer chooses to actually imbue the virtual players with any kind of AI beyond being able to just play the game, one thing must be certain: that the testing is appropriately exercising the logic of the system such that every possible avenue of play is explored.
The topics we have covered relate to all aspects of testing—from the client to the server. If the advice here is followed, it should yield a stable, robust, yet high-performance gaming platform.
The cost of the testing process should be realistic if the code that is deployed has been fully tested and if appropriate bits have been re-used to reduce the chance of untested code making its way into the chain. For example, testing Web games can often be reduced to automated interface clicking and validation of interface artifacts. In this way, the game can be very rapidly tested, and the rough edges smoothed over before human play testing begins. If a human has to play test a Web game from first principles, it is often a very tiresome and frustrating process—much more so than for testing other platforms—because of the nature of the Web interface.
Client/server action games have a slightly different spin: the interface software (the game proper) has to be tested apart from the server-side software. However, here we have the advantage that the client side can be simulated, even before it is ready, by software that essentially becomes the test platform. We stated that the network component should not feel as if it has been bolted on as an afterthought. In the testing paradigm that we describe here, the old argument that the client side has to be ready before testing can begin becomes obsolete. We do not even foresee the possibility of a single-player game that might need to be complete before testing can begin, so that would make that particular argument redundant. The game has to be tested as it is being developed, and developed starting with the logic and network component, with the visible part of the game tested last.
All the disadvantages that this might appear to represent—specifically in terms of the lack of visible progress as the server side is developed without the client side—are outweighed by the amount of re-use for testing and development of code.
In essence, the server side is tested in isolation, while the client side is tested against an abstraction of the server that uses the same test code as the simulated client that was used to test the server. This circular testing methodology helps to make sure that everything is tested to the same standard, using the same scenarios, but reversed.
A MUD-style, turn-by-turn game lies somewhere in between a Web game and an action game. Communication jitter and lag are often more important and less able to be glossed over than in an action game. Every word counts, and so the emphasis has to be on testing the weak link in the chain: the network layer. We can afford to do this level of network testing and streamlining in a turn-by-turn game because the remainder of the system is, by comparison, less complex than other kinds of networked multi-player games.
Testing can, in general, be handled by throwing technology or people at it. Both come with costs, however. The pertinent question becomes: Does the cost of the technology (probably created by people) compare favorably to both the results achieved by that investment and the equivalent cost of doing it manually? Clearly, re-use at the testing, automation, and even coding levels will increase the likelihood of being able to say that the automated testing has achieved a higher efficiency and therefore lower total cost than using armies of play testers.
Developers and testers understand this, but designers need to be aware that the system they want must be able to be tested in an efficient manner. The risk, if testing is not designed in, is that there will not be enough resources left for testing, and an unfinished product will be shipped and almost immediately patched.
Automated test technology ought also to be reusable across projects if it is to satisfy the above criteria. Although it is also likely that testers could be re-used on future projects, it is often less of a concrete investment—not to mention the tax benefits of being able to write off the cost of actually creating something as opposed to just hiring people on a short-term basis.
So, testing is not just about letting a few college students play games for hours on end. It’s part of the design, part development, and part business strategy that powers any game, and is even more important in networked multi-player games than in almost any other kind of computer software system.