CHAPTER 4
ATTACKING WEB AUTHENTICATION
Authentication plays a critical role in the security of a web application since all subsequent security decisions are typically made based on the identity established by the supplied credentials. This chapter covers threats to common web authentication mechanisms, as well as threats that bypass authentication controls entirely.
WEB AUTHENTICATION THREATS
We’ve organized our discussion in this section loosely around the most common types of authentication prevalent on the Web at the time of this writing:
• Username/password Because of its simplicity, this is the most prevalent form of authentication on the Web.
• Strong(er) authentication Since it’s widely recognized that username/ password authentication has fundamental weaknesses, many web sites are beginning to provide stronger forms of authentication for their users, including token- and certificated-based authentication.
• Authentication services Many web sites outsource their authentication to Internet services such as Windows Live ID (formerly known as Microsoft Passport), which implements a proprietary identity management and authentication protocol, and OpenID, which is an open standard for decentralized authentication service providers. Both services will be briefly covered at a high level in this chapter.
Username/Password Threats
Although there are numerous ways to implement basic username/password authentication, web implementations generally fall prey to the same types of attacks:
• Username enumeration
• Password guessing
• Eavesdropping
In this section, we’ll discuss each of these attack types and which common web authentication protocols are most vulnerable to them.
NOTE
We haven’t provided risk ratings for any of the attacks listed in this chapter because these are really generic attack types and the risk level depends on the specific implementation of the attack.
 Username Enumeration
Username Enumeration
Username enumeration is primarily used to provide greater efficiency to a password-guessing attack. This approach avoids wasting time on failed attempts using passwords for a user who doesn’t exist. For example, if you can determine there is no user named Alice, there’s no point in wasting time trying to guess Alice’s password. The following are some examples of functionality often used in web applications that may allow you to determine the username.
Profiling Results
In Chapter 2, we discussed a few places to identify ambient user information within a web site, such as source code comments. Smart attackers always review their profiling data because it’s often a rich source of such information (textual searches across the profiled information for strings like userid, username, user, usr, name, id, and uid often turn it up).
In Chapter 8, we will also discuss common web site structures that give away usernames—the most obvious offender here is the directory named after a user that service providers commonly employ to host customer web content (e.g., http://www.site.com/~joel).
Error Messages in Login
A simple technique to determine if a username exists is to try to authenticate to a web application using invalid credentials and then examine the resulting error message. For example, try authenticating to the target web application using the username Alice and the password abc123. You are likely to encounter one of three error messages similar to the ones listed here, unless you actually successfully guessed the password:
• You have entered a bad username.
• You have entered a bad password.
• You have entered a bad username/password combination.
If you receive the first error message, the user does not exist on the application and you should not waste any time trying to guess the password for Alice. However, if you received the second error message, you have identified a valid user on the system, and you can proceed to try to guess the password. Lastly, if you received the third message, it will be difficult to determine if Alice is actually a valid username (this should be a hint to application designers to use the third message in their own authentication mechanisms).
A good example of this is the login functionality implemented by the SiteMinder web authentication product from Computer Associates (CA), who acquired the technology with its acquisition of Netegrity in November 2004. With SiteMinder, you can perform username enumeration by evaluating the error page. If an incorrect username is entered, the site attempts to load nouser.html. If a valid username is entered with an incorrect password, the site attempts to load failedlogin.html.
Error Messages in Self-Service Password Reset Features
Similar to the user enumeration vulnerabilities just discussed, self-service password reset (SSPR) functionality is also a common source of user enumeration disclosure vulnerabilities. SSPR is a feature implemented by many web sites that allows users who have either forgotten their password or are otherwise unable to authenticate to fix the problem themselves via “self-service”; the most typical implementation is a “Forgot Password?” or similar link that e-mails a new password to the e-mail address specified by the user. The e-mail address “authenticates” the user via an alternate mechanism, assuming only the user in question can access that e-mail account and retrieve the new password.
Unfortunately, applications that insecurely implement this functionality will often report whether the supplied user account name or e-mail address is valid. An attacker can use the difference in the response between the valid and invalid case to detect whether the account exists.
In addition to user enumeration, applications that randomly generate new passwords in response to SSPR requests are also vulnerable to denial-of-service (DoS) attacks. For example, a particularly malicious attacker might create a script to request new passwords repeatedly for each username that is discovered. If the requests are repeated frequently enough, this will flood the target user accounts with e-mails containing new passwords, never allowing that user enough time to use the new password to authenticate against the application.
Registration
Many web applications allow users to select their own usernames in the registration process. This presents another vector for determining the username. During the registration process, if you select a username of another user who already exists, you are likely to be presented with an error such as “Please choose another username.” As long as the username you have chosen follows the application guidelines and does not contain any invalid characters, this error message is likely an indication that the chosen username is already registered. When given a choice, people often create usernames based on their real names. For example, Joel Scambray may choose usernames such as Joel, JoelS, JScambray, etc. Therefore, attackers can quickly generate a list of common usernames based on real names found in phone books, census data, and other online resources. CAPTCHA technology can be deployed to help mitigate the risk of these attacks. Detailed information on CAPTCHA is available in the “User Registration Attacks” section of this chapter.
Account Lockout
To mitigate the risk of a password-guessing attack, many applications lock out accounts after a certain number of failed login attempts. Depending on the risks inherent to the application, account lockout thresholds may be set to 3, 5, or more than 10 failed authentications. Many high-volume commercial web sites set the lockout threshold much higher (e.g., 100 failed attempts) to defray the support costs related to unlocking user accounts (typically higher for lower lockout thresholds); again, there is a balance between ease-of-use/support and security that varies depending upon the specific risks faced by a given application. Applications also commonly unlock accounts automatically after a period of 30 minutes, 1 hour, or 24 hours. This is also done to reduce the number of calls made to the support desk to reset accounts. This countermeasure effectively slows down a password-guessing attack and, given a good password policy, is considered a good balance of security and usability.
However, account lockout only makes sense for valid usernames. How do you lock out an account that doesn’t exist? These are subtleties that many applications implement incorrectly. For example, if the account lockout is set at 3, will an account be locked out if it doesn’t exist? If not, you may have stumbled upon a way to determine invalid accounts. If you lock out an account, the next time you log in, you should receive an error message. However, most applications don’t track this for invalid accounts. Lastly, the best way to prevent username enumeration from account lockout is to not tell the user he or she was locked out at all. This, however, will almost surely result in a frustrated and angry user.
Sometimes account lockout is implemented using client-side functionality like JavaScript or hidden tags. For example, there may be a variable or field that represents login attempts. It is trivial to bypass client-side account lockout by modifying the client-side JavaScript or by using a proxy to directly POST login actions (the Burp Suite repeater functionality is good for this; Burp Suite is discussed in Chapter 2) and bypass the JavaScript altogether.
Timing Attacks
If all else fails, a timing attack may be the last resort of a frustrated attacker. If you can’t enumerate usernames from error messages, registration, or password changes, try calculating the time it takes for an error message to appear for a bad password versus a bad username. Depending on how the authentication algorithm is implemented and the types of technologies used, there may be a significant difference in the time it takes for each type of response (“bad username” versus “bad password”). Observing differences in response timing can provide clues to legitimate usernames and passwords. However, for this technique to be effective, the difference needs to be large enough to overshadow fluctuations due to network latency and load. Keep in mind that this technique is prone to producing a large number of false positives.
Before moving into the next section on password guessing with known usernames, we should note that allowing attackers to determine the username is a risk that many online businesses have simply accepted, despite the protestation of concerned security professionals.
Password Guessing
Not surprisingly, password guessing is the bane of username/password authentication schemes. Unfortunately, such schemes are common on the Web today and thus fall prey to this most basic attack techniques.
Password-guessing attacks can usually be executed regardless of the actual authentication protocol in place. Manual guessing is always possible, of course, and automated client software exists to perform password guessing against the most commonly used protocols. We’ll discuss some common password-guessing tools and techniques next.
Manual Password Guessing
Password-guessing attacks can be carried out via both manual and automated means. Manual password guessing is tedious, but we find human intuition frequently bests automated tools, especially when customized error pages are used in response to failed forms-based login attempts. When performing password guessing, our favorite choices are shown in Table 4-1.
While the list in Table 4-1 is limited, it serves as a good illustration of the type of weak passwords commonly used in applications. With an automated tool, an entire dictionary of username/password guesses can be thrown at an application much more quickly than human hands can type them. A basic search engine query will reveal that several of these dictionaries are widely available online, including tailored dictionaries that focus on certain types of applications, hardware, or devices.
Automated Password Guessing
There are two basic approaches to automated password guessing: depth first and breadth first. Depth-first algorithms try all the password combinations for a username before trying the next username. This approach is likely to trigger account lockout very quickly because hundreds of authentication attempts will be made against the same account in a short amount of time. Breadth-first algorithms try the combination of different usernames for the same password. Because the authentication attempts are not made consecutively against the same account, the breadth-first method is less likely to trigger an application’s account lockout mechanism. Let’s look at some of the automated web password-guessing tools available today.
CAUTION
Automatic password guessing can perform a denial-of-service attack against the application. There is always an increased load on the server and the risk of locking accounts. If you are an attacker, this may be intentional. If you are a tester, however, you should determine if there is an account lockout and proceed accordingly.

Table 4-1 Common Usernames and Passwords Used in Guessing Attacks (Not Case-sensitive)
TIP
If a password policy is in place and enforced, you can reduce the set of possible passwords to just those permitted by the password policy. For example, if you know that the password policy only allows for alphanumeric characters and requires a combination of capital and lowercase characters, you don’t need to waste time on dictionary words that don’t include numbers. On the other hand, if you are looking at a banking application that uses a four-digit ATM PIN as the password, you know you’ve got a pretty good chance of guessing the PIN/password in around 5,000 guesses.
One of the most common authentication protocols used on the Internet today is HTTP Basic. It was first defined in the HTTP specification itself, and while it is by no means elegant, it does get the job done. Basic authentication has its fair share of security problems, and those problems are well documented (the primary issues are that it sends the username/password in a trivially decodeable fashion and that it eagerly sends these credentials with each request).
When we encounter a page protected by Basic authentication in our consulting work, we generally turn to Hydra to test account-credential strength. Hydra is a simple tool that takes text lists of usernames and passwords (or combinations of both) and uses them as dictionaries to implement Basic authentication password guessing. It keys on “HTTP 302 Object Moved” responses to indicate a successful guess, and it will find all successful guesses in a given username/password file (that is, it won’t stop guessing once it finds the first valid account). The following example shows Hydra being used on Windows (via the Cygwin library) to guess an HTTP Basic password successfully. We’ve used Hydra’s –C option to specify a single username/password file as input and we are attacking the /secure directory (which must be specified following the http-get parameter):
D:Toolbox> hydra -C list.txt victim.com http-get /secure
Hydra v5.0 (c) 2005 by van Hauser / THC - use allowed only for legal purposes.
Hydra (http://www.thc.org) starting at 2005-11-08 21:21:56
[DATA] 6 tasks, 1 servers, 6 login tries, ~1 tries per task
[DATA] attacking service http-get on port 80
[STATUS] attack finished for victim.com (waiting for childs to finish)
[80][www] host: 192.168.224.40 login: user password: guessme
Hydra (http://www.thc.org) finished at 2005-11-08 21:22:01
Hydra supports http-head, http-get, https-head, https-get, and http-proxy for attacking web applications.
WebCracker is an older, Windows-based GUI application that is similar to Hydra but is not as customizable in our experience. It is an excellent tool for a novice, or for performing a quick assessment of account password strength. Figure 4-1 shows WebCracker successfully guessing some accounts on a target URL.
Brutus is a generic password-guessing tool that comes with built-in routines for attacking HTTP Basic and Forms-based authentication, among other protocols like SMTP and POP3. Brutus can perform both dictionary attacks (based on precomputed wordlists like dictionaries) and brute-force attacks, where passwords are randomly generated from
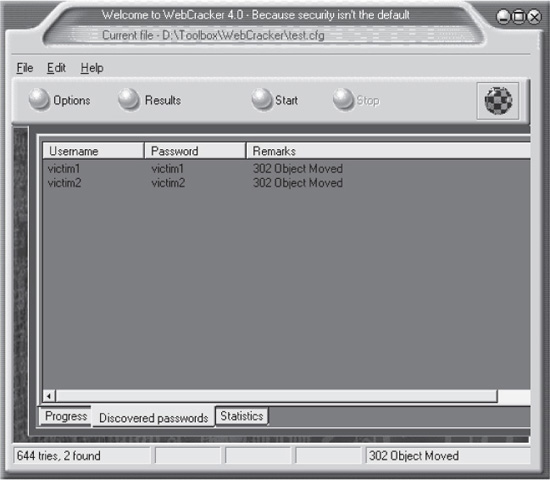
Figure 4-1 WebCracker successfully guesses Basic authentication credentials.
a given character set (say, lowercase alphanumeric characters). Figure 4-2 shows the main Brutus interface after performing a Basic authentication password-guessing attack.
Brutus also performs Forms-based authentication attacks (which we will discuss in an upcoming section). The one thing that annoys us about Brutus is that it does not display guessed passwords when performing Forms-based attacks. We have also occasionally found that it issues false positive results, claiming to have guessed an account password when it actually had not. Overall, however, it’s tough to beat the flexibility of Brutus when it comes to password guessing.
NTLM Authorization Proxy Server
Integrated Windows authentication (formerly known as NTLM authentication and Windows NT challenge/response authentication) uses the
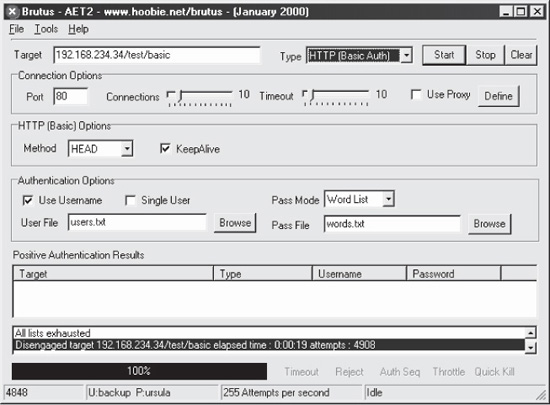
Figure 4-2 The Brutus password-guessing tool guesses 4,908 HTTP Basic authentication passwords in 19 seconds.
proprietary Microsoft NT LAN Manager (NTLM) authentication algorithm over HTTP. It is implemented primarily by Microsoft’s Internet Explorer browser and IIS web servers, but is also available in other popular software like Mozilla’s Firefox browser through its support of the Simple and Protected GSS-API Negotiation Mechanism (SPNEGO) Internet standard (RFC 2478) to negotiate Kerberos, NTLM, or other authentication protocols supported by the operating system (for example, SSPI on Microsoft Windows, GSS-API on Linux, Mac OS X, and other UNIX-like systems implement SPNEGO).
Support for NTLM authentication in security assessment tools has greatly improved over the years, and this support is available in both the Paros and Burp client-side proxies. If your tool of choice does not support NTLM, that support can be obtained through the NTLM Authorization Proxy Server (APS) utility created by Dmitry Rozmanov.
TIP
A detailed description of how to implement APS is available on the Hacking Exposed Web Applications web site at http://www.webhackingexposed.com/ntlm-aps.html.
 Countermeasures for Password Guessing
Countermeasures for Password Guessing
The most effective countermeasure against password guessing is a combination of a strong password policy and a strong account lockout policy. After a small number of unsuccessful login attempts, the application should lock the account to limit the exposure from this type of attack. However, be aware that applications implementing an aggressive account lockout policy may expose themselves to denial-of-service attacks. A malicious attacker targeting such an application may try to lock out all of the accounts on the system through repeated failed authentication attempts. A good compromise that many application developers choose is to temporarily lock the account for a small period of time, say ten minutes. This slows down the rate of password guessing, thereby hindering the effectiveness of password-guessing attacks. With the use of a strong password policy, the likelihood that an attacker will be able to randomly guess a password is greatly diminished. An effectively large key space for passwords, greater than eight alphanumeric characters, in combination with a strong account lockout policy mitigates the exposure against password brute-forcing.
Recently, many high-profile web sites such as eBay have begun tracking IP addresses and associating them with your account. For example, attempting to gain access to your account from an unusual IP or from different IPs within a certain time window may trigger additional authentication or requirements such as CAPTCHA. These techniques are designed to prevent distributed or automated guessing attacks. Some financial sites have implemented even stronger requirements such as sending a text message with a confirmation number to a number listed on the account. This confirmation number must then be supplied to the web application in order to successfully authenticate.
NOTE
Many web authentication schemes have no integrated account lockout feature—you’ll have to implement your own logic here.
Also, as we’ve noted already, one issue that can frustrate script kiddies is to use custom response pages for Forms-based authentication. This prevents attackers from using generic tools to guess passwords.
One variation on this is to use Completely Automated Public Turing Tests to Tell Computers and Humans Apart (CAPTCHA) to fool automated password-guessing routines (we’ll discuss CAPTCHAs in more detail later in this chapter).
Finally, it always pays to know what it looks like when you’ve been attacked. Here is a sample log snippet in an abbreviated W3C format taken from a server that was attacked with a Basic authentication password-guessing tool. As can be seen here, the tool used to perform the brute-force attack, Brutus, is listed as part of the user-agent string:
#Fields: c-ip cs-username cs-method cs-uri-query sc-status cs(User-Agent)
192.168.234.32 admin HEAD /test/basic - 401 Mozilla/3.0+(Compatible);Brutus/AET
192.168.234.32 test HEAD /test/basic - 401 Mozilla/3.0+(Compatible);Brutus/AET
192.168.234.32 root HEAD /test/basic - 401 Mozilla/3.0+(Compatible);Brutus/AET
Authentication failures are written to the Security Event Log, so we recommend regularly monitoring it for signs of potential brute-forcing attacks. For more details on the different types of logging that occurs for authentication failures, please see the additional links at the end of this chapter. Figure 4-3 shows what a typical log event looks like following a Basic password-guessing attack.
Eavesdropping and Replay Attacks
Any authentication protocol that exposes credentials while in transit over the network is potentially vulnerable to eavesdropping attacks, which are also called sniffing attacks after the colloquial term for network protocol analyzers. A replay attack usually is built upon eavesdropping and involves the use of captured credentials by an attacker to spoof the identity of a valid user.
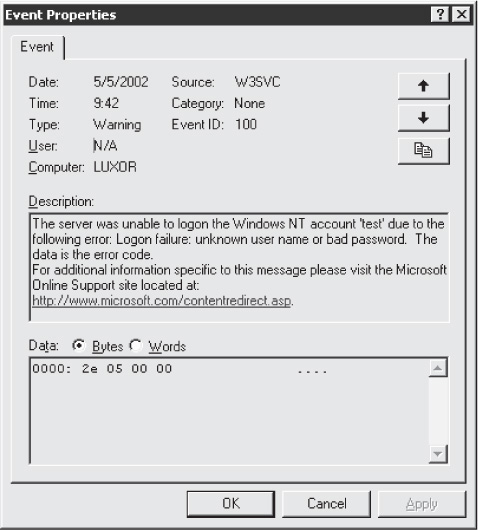
Figure 4-3 Password-guessing attempts against Windows IIS result in these events written to the Security Log.
Unfortunately, some of the most popular web authentication protocols do expose credentials on the wire. We’ll talk about common attacks against popular web authentication protocols in the following sections.
Basic
We’ve already seen how HTTP Basic authentication can be vulnerable to password guessing. Now we’ll talk about another weakness of the protocol. In order to illustrate our points, we’ll first give you a bit of background on how Basic works.
Basic authentication begins when a client submits a request to a web server for a protected resource, without providing any authentication credentials. In response, the server will reply with an access denied message containing a WWW-Authenticate header requesting Basic authentication credentials. Most web browsers contain routines to deal with such requests automatically by prompting the user for a username and a password, as shown in Figure 4-4. Note that this is a separate operating system window instantiated by the browser, not an HTML form.
Once the user types in his or her password, the browser reissues the requests, this time with the authentication credentials. Here is what a typical Basic authentication exchange looks like in raw HTTP (edited for brevity). First, here’s the initial request for a resource secured using Basic authentication:
GET /test/secure HTTP/1.0
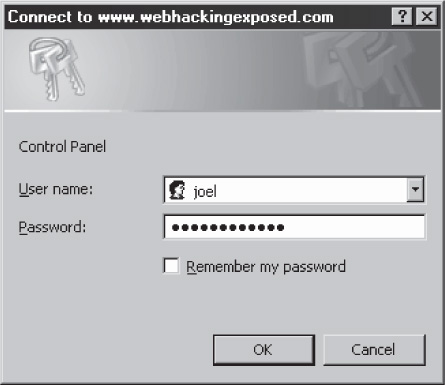
Figure 4-4 A web browser prompts a user for Basic authentication.
The server responds with an HTTP 401 Unauthorized (authentication required) message containing the WWW-Authenticate: Basic header:
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Basic realm="luxor"
This causes a window to pop up in the client browser that resembles Figure 4-4. The user types his or her username and password into this window and clicks OK to send it via HTTP:
GET /test/secure HTTP/1.0
Authorization: Basic dGVzdDp0ZXN0
Note that the client has essentially just re-sent the same request, this time with an Authorization header. The server then responds with another “unauthorized” message if the credentials are incorrect, a redirect to the resource requested, or the resource itself, depending on the server implementation.
Wait a second—where are the username and password? Per the Basic authentication spec, the authentication credentials are sent in the Authorization header in the response from the client and the credentials are encoded using the Base64 algorithm. Those unfamiliar with Base64 may, at first glance, believe it is a type of encryption due to the rather opaque encoded form. However, because Base64 is a type of encoding, it is trivial to decode the encoded values using any number of readily available utilities or scripting languages. A sample Perl script has been provided here to illustrate the ease with which Base64 can be manipulated:
#!/usr/bin/perl
# bd64.pl
# decode from base 64
use MIME::Base64;
print decode_base64($ARGV[0]);
Let’s run this bd64.pl decoder on the value we saw in our previous example of Basic authentication in action:
C:bd64.pl dGVzdDp0ZXN0
test:test
As you can see, Basic authentication is wide open to eavesdropping attacks, despite the inscrutable nature of the value it sends in the Authorization header. This is the protocol’s most severe limitation. When used with HTTPS, the limitation is mitigated. However, client-side risks associated with Basic authentication remain because there is no inactivity timeout or logout without closing the browser.
Digest
Digest authentication, described in RFC 2617, was designed to provide a higher level of security than Basic. Digest authentication is based on a challenge-response authentication model. This technique is commonly used to prove that someone knows a secret, without requiring the person to send the secret across an insecure communications channel where it would be exposed to eavesdropping attacks.
Digest authentication works similarly to Basic authentication. The user makes a request without authentication credentials and the web server replies with a WWW-Authenticate header indicating credentials are required to access the requested resource. But instead of sending the username and password in Base64 encoding as with Basic, the server challenges the client with a random value called a nonce. The browser then uses a one-way cryptographic function to create a message digest of the username, the password, the given nonce value, the HTTP method, and the requested URI. A message digest function, also known as a hashing algorithm, is a cryptographic function that is easily computed in one direction and should be computationally infeasible to reverse. Compare this hashing method with Basic authentication that uses the trivially decodable Base64 encoding. Any hashing algorithm can be specified within the server challenge; RFC 2617 describes the use of the MD5 hash function as the default.
Why the nonce? Why not just hash the user’s password directly? Although nonces have different uses in other cryptographic protocols, the use of a nonce in Digest authentication is similar to the use of salts in other password schemes. It is used to create a larger key space to make it more difficult for someone to perform a database or precomputation attack against common passwords. Consider a large database that can store the MD5 hash of all words in the dictionary and all permutation of characters with less than ten alphanumeric characters. The attacker would just have to compute the MD5 hash once and subsequently make one query on the database to find the password associated with the MD5 hash. The use of the nonce effectively increases the key space and makes the database attack less effective against many users by requiring a much larger database of prehashed passwords.
Digest authentication is a significant improvement over Basic authentication, primarily because cleartext authentication credentials are not passed over the wire. This makes Digest authentication much more resistant to eavesdropping attacks than Basic authentication. However, Digest authentication is still vulnerable to replay attacks because the message digest in the response will grant access to the requested resource even in the absence of the user’s actual password. But, because the original resource request is included in the message digest, a replay attack should only permit access to the specific resource (assuming Digest authentication has been implemented properly).
Other possible attacks against Digest authentication are outlined in RFC 2617.
NOTE
Microsoft’s implementation of Digest authentication requires that the server have access to the cleartext version of the user’s password so digests can be calculated. Thus, implementing Digest authentication on Windows requires that user passwords be stored using reversible encryption, rather than using the standard one-way MD4 algorithm.
For those of you who like to tinker, here’s a short Perl script that uses the Digest::MD5 Perl module from Neil Winton to generate MD5 hashes:
#!/usr/bin/perl
# md5-encode.pl
# encode using MD5
use Digest::MD5 qw(md5_hex);
print md5_hex($ARGV[0]);
This script outputs the MD5 hash in hexadecimal format, but you could output binary or Base64 by substituting qw(md5) or qw(md5_base64) at the appropriate spot in line 4. This script could provide a rudimentary tool for comparing Digest authentication strings to known values (such as cracking), but unless the username, nonce, HTTP method, and the requested URI are known, this endeavor is probably fruitless.
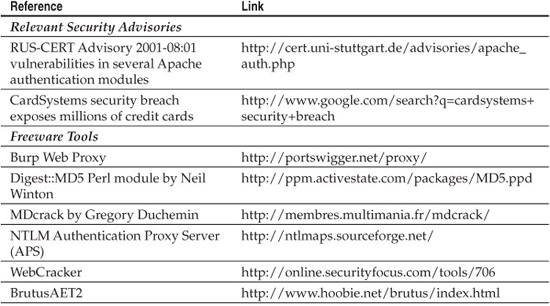
MDcrack, an interesting tool for cracking MD5 hashes, is available from Gregory Duchemin (see the “References & Further Reading” section at the end of this chapter for a link).
Eavesdropping Countermeasures
The use of 128-bit SSL encryption can thwart these attacks and is strongly recommended for all web sites that use Basic and Digest authentication.
To protect against replay attacks, the Digest nonce could be built from information that is difficult to spoof, such as a digest of the client IP address and a timestamp.
Forms-based Authentication Attacks
In contrast to the mechanisms we’ve discussed to this point, Forms-based authentication does not rely on features supported by the basic web protocols like HTTP (such as Basic or Digest authentication). It is a highly customizable authentication mechanism that uses a form, usually composed of HTML with FORM and INPUT tags delineating input fields, for users to enter their username and password. After the user credentials are sent via HTTP or HTTPS, they are then evaluated by some server-side logic and, if valid, some sort of unique token of sufficient length, complexity, and randomness is returned to the client for use in subsequent requests. Because of its highly customizable and flexible nature, Forms-based authentication is probably the most popular authentication technique deployed on the Internet. However, since it doesn’t depend on a standardized HTTP authentication specification, there is no standardized way to perform Forms-based authentication.
A simple example of Forms-based authentication will now be presented to illustrate the basic principles on which it is based. While this example will be based on Microsoft ASP.NET Forms authentication because of its simplicity, we’ll note the key points that are generic to all types of Forms authentication. Here’s the scenario: you have a single directory on a web server with a file, default.aspx, that requires Forms authentication before it can be accessed. In order to implement ASP.NET Forms authentication, two other files are needed: a web.config file in this directory (or at the application root) and a login form to take username/password input (call it login.aspx). The web.config file specifies which resources will be protected by Forms authentication, and it contains a list of usernames and passwords that can be queried to validate credentials entered by users in login.aspx. Of course, any source of username/password information could be used—for example, a SQL database. It is recommended that a salted hash of the password is stored instead of the original password to mitigate the risk of exposing the passwords and make dictionary-based attacks more difficult. Here’s what happens when someone requests default.aspx:
GET /default.aspx HTTP/1.0
Since the web.config file specifies that all resources in this directory require Forms authentication, the server responds with an HTTP 302 redirect to the login page, login.aspx:
HTTP/1.1 302 Found
Location: /login.aspx?ReturnUrl=%2fdefault.aspx
The client is now presented with the login.aspx form, shown in Figure 4-5.
This form contains a hidden field called “state,” and two visible fields called “txtUser” that takes the username input and “txtPassword” that takes the password input. These are all implemented using HTML INPUT tags. The user diligently enters his or her
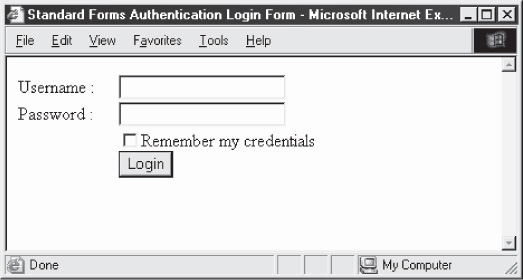
Figure 4-5 A standard login form implemented in ASP.NET
username and password and clicks the Login button, which POSTs the form data (including hidden fields) back to the server:
POST /login.aspx?ReturnUrl=%2fDefault.aspx HTTP/1.0
STATE=gibberish&txtUser=test&txtPassword=test
The POST method should always be used instead of the GET verb for sending the username and password, although both verbs accomplish the same thing. The reason for preferring POST to GET is to prevent the insecure storage of authentication credentials at the client (in the browser history), at caching intermediary devices such as proxies, and at the remote application server since these systems will often cache or log HTTP GET data for statistical or performance reasons. These commonplace mechanisms can lead to the inadvertent exposure of user authentication credentials stored in GET requests to unauthorized users.
Note that unless SSL is implemented, the credentials traverse the wire in cleartext, as shown here. The server receives the credential data and validates them against the username/password list in web.config (again, this could be any custom datastore). If the credentials match, then the server will return a “HTTP 302 Found with a Location” header redirecting the client back to the originally requested resource (default.aspx) with a Set-Cookie header containing the authentication token:
HTTP/1.1 302 Found
Location: /Default.aspx
Set-Cookie: AuthCookie=45F68E1F33159A9158etc.; path=/
htmlheadtitleObject moved/title/headbody
Note that the cookie here is encrypted using 3DES, which is optionally specified in ASP.NET’s web.config file. Now the client re-requests the original resource, default.aspx, with the newly set authentication token (the cookie) automatically appended to the HTTP header:
GET /Default.aspx HTTP/1.0
Cookie: AuthCookie=45F68E1F33159A9158etc.
The server verifies the cookie is valid and then serves up the resource with an HTTP 200 OK message. All of the 301 and 302 redirects occur transparently in the background without notifying the end-user of the activity. End result: user requests resource, is challenged for username/password, and receives resource if he or she enters the correct credentials (or a custom error page if he or she doesn’t). The application may optionally provide a “Sign Out” button that deletes the cookie when the user clicks it. Or the cookie can be set to expire in a certain timeframe when it will no longer be considered valid by the server (such as inactivity or maximum session length timeouts).
Again, this example uses a specific end-to-end technology, ASP.NET FormsAuthentication, to demonstrate the basics of Forms authentication. Any other similar technology or combination of technologies could be employed to achieve the same result.
Like the other authentication technologies discussed thus far, Forms-based authentication is also subject to password-guessing attacks. We like to use Brutus (introduced earlier in this chapter) for attacking Forms-based authentication, primarily because of its Modify Sequence | Learn Form Settings feature. This feature allows the user to simply specify a URL to a login form, and Brutus automatically parses out the fields for username, password, and any other fields supported by the form (including hidden). Figure 4-6 shows the HTML form interpreter.
Brutus also allows you to specify what responses you expect from the login form upon successful authentication. This ability is important because of the highly customizable nature of Forms authentication, as it is common for sites to implement unique response pages for successful and unsuccessful logins. With the Brutus tool, you can customize password guessing to whatever responses the particular target site uses.
Forms-based authentication is also clearly vulnerable to eavesdropping and replay attacks if the authentication channel is not encrypted with HTTPS or other encryption protocols.
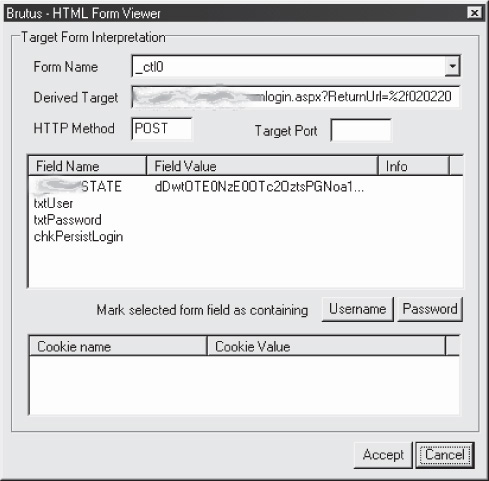
Figure 4-6 Brutus’ HTML form interpreter parses a login form, highlighting fields for subsequent attack.
Forms-based authentication almost always uses session cookies to store an authentication token temporarily so a user accessing a web site does not have to repeatedly supply his or her authentication credentials with each request. A session cookie is stored only in memory, as opposed to a persistent cookie that is stored on the disk and persists across sessions. Cookies can sometimes be manipulated or stolen outright, and may disclose inappropriate information if they are not encrypted (note that ASP.NET was configured to 3DES-encrypt the cookie in our example). See Chapter 5 for more on attacking cookies.
There are two cookie attribute flags, secure and HTTPOnly, that are important when issuing session or persistent cookies containing sensitive information (ideally, sensitive information should never be persisted in a cookie, and if it needs to be, that information should always be encrypted). When a cookie is issued with the secure flag, client browsers that honor the secure attribute will never send that cookie over a nonHTTPS secured channel. The HTTPOnly flag was originally created by Microsoft, and it is a modest attempt to protect users from session hijacking and data exfiltration attacks targeting sensitive data in application cookies. Client browsers that support HTTPOnly will not allow JavaScript to access data in the corresponding cookie even if that access would normally be permitted based on the same origin policy. HTTPOnly is meant as a failsafe to protect the session ID and other sensitive values from being easily exfiltrated as a result of a malicious script injection attack (e.g., XSS). However, once attackers have the ability to execute malicious script in a target application, they will have free reign to perform any action in that application in the security context of the victim user, regardless of whether the attacker can directly access the session cookie or not. Normally, this would be accomplished by creating a series of background asynchronous requests (XmlHttpRequest) to execute sensitive functionality. Although there is some debate in the security community as to the overall usefulness of this protective mechanism, developers are encouraged to use this feature, when possible, as an additional layer of defense in their applications. With that said, the priority of application developers should always be to first rid their applications of the input validation vulnerabilities that lead to malicious script injection attacks. More information regarding the secure and HTTPOnly cookie attribute flags can be found in the “References & Further Reading” section at the end of this chapter.
Some application developers make the mistaken assumption that data hidden from users in the form of “hidden” HTML input fields are not visible to end-users. They may then shuffle sensitive authentication credentials or other data into these fields rather than relying on cookie-based session IDs to authenticate users for certain transactions. While not a very common occurrence, application security assessors should train themselves to pay close attention to the types of data being stored in hidden fields.
Bypassing SQL-backed Login Forms
On web sites that perform Forms-based authentication with a SQL backend, SQL injection can be used to bypass authentication (see Chapter 6 for more specific details on the technique of SQL injection). Many web sites use databases to store passwords and use SQL to query the database to validate authentication credentials. A typical SQL statement will look something like the following (this example has been wrapped across two lines due to page-width constraints):
SELECT * from AUTHENTICATIONTABLE WHERE Username = 'username input' AND
Password = 'password input'
If input validation is not performed properly, injecting
Username' --
in the username field would change the SQL statement to this:
SELECT * from AUTHENTICATIONTABLE WHERE Username = 'Username'
--AND Password = 'password input'
The dashes at the end of the SQL statement specify that the remainder of the SQL statement is a comment and should be ignored. The statement is equivalent to this:
SELECT * from AUTHENTICATIONTABLE WHERE Username = 'Username'
And voilà! The check for passwords is magically removed!
This is a generic attack that does not require much customization based on the web site, as do many of the other attacks for Forms-based authentication. We’ve seen tools in the underground hacker community that automate this attack.
To take the attack one level higher, SQL injection can be performed on the password field as well. Assuming the same SQL statement is used, using a password of
DUMMYPASSWORD' OR 1 = 1 --
would have a SQL statement of the following (this example has been wrapped across two lines due to page-width constraints):
SELECT * from AUTHENTICATIONTABLE WHERE Username = 'Username'
AND Password = 'DUMMYPASSWORD' OR 1 = 1 -- '
The addition of OR 1 = 1 at the end of the SQL statement would always evaluate as true, and authentication can once again be bypassed.
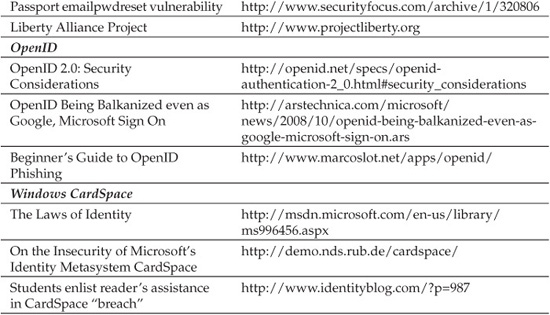
Many web authentication packages were found to be vulnerable to similar issues in mid-2001. The Apache mod_auth_mysql, oracle, pgsql, and pgsql_sys built SQL queries and did not check for single quotes (these vulnerabilities were described in a CERT advisory from the University of Stuttgart, Germany; see the “References & Further Reading” section at the end of this chapter for a link).
Bypassing LDAP-backed Login Forms
Not all applications integrate the authentication component with a backend SQL database server. Many web applications, especially on corporate intranets, use servers based on the Lightweight Directory Access Protocol (LDAP) to provide similar authentication capabilities. If insecurely coded, these applications may expose LDAP injection vulnerabilities that could be exploited to bypass authentication controls. While the exact syntax used to exploit these vulnerabilities is different from that of SQL injection, the underlying concept is identical. More information on LDAP injection attacks is available in Chapter 6 of this book and interested readers are encouraged to refer to that chapter for further information.
Bypassing XML-backed Login Forms
Although far less common than SQL-backed and LDAP-backed authentication components, some applications rely on static XML files to store application user data and login credentials. Just as in the SQL and LDAP case, applications that fail to properly validate user-supplied credentials may expose a vulnerability that allows attackers to bypass normal authentication controls. The classic case of this is an application that uses the username supplied during authentication to construct an XPath query to query the appropriate record from the backend XML document. If the username is not properly validated for characters that have special meaning in XPath queries, then an attacker may be able to modify the query to return arbitrary records, regardless of whether a correct password is supplied. More concrete examples of XML and XPath injection can be found in Chapter 7.
Countermeasures for Forms-based Authentication Attacks
The same countermeasures we discussed previously for password guessing, eavesdropping, and replay attacks are advised for Forms-based authentication as well.
The best way to prevent SQL injection and other injection attacks is to perform input validation (see Chapter 6) and to use parameterized SQL queries or parameterized stored procedures. Input validation should be performed to ensure that usernames do not contain invalid characters. HTML tag characters, whitespace, and special characters such as !, $, %, and so forth, should be prohibited when possible. Care must be taken when using stored procedures to code those procedures securely so they do not simply move the SQL injection vulnerability from the application to the database procedure. As a general rule, developers should refrain from using dynamically constructed SQL queries, especially when those queries contain user-supplied input.
Preventing XML and LDAP injection attacks is achieved through strong input validation that prevents the use of characters with special meaning in these two technologies. When it is not possible to completely prohibit use of these special characters, special care must be taken to properly escape the authentication credentials, using the appropriate APIs, when performing authentication against the backend datastores.
We’ll also throw in the standard admonition here to ensure that all software packages used by your web application are updated with the latest patches and to the latest release. It is one thing to have a Forms bypass attack performed against your own custom code, but something else entirely when your free or commercial authentication package turns up vulnerable to similar issues.
Strong(er) Web Authentication
Clearly, the username/password-based authentication mechanisms that predominate on the Web today have their faults. What alternatives exist? Are there weaknesses with them as well?
Passwords are only single-factor—something the user knows. Passwords are also typically very low-entropy credentials, which makes password guessing feasible. To make matters worse, these passwords are often re-used across several different applications. Thus, the primary mitigation for password-based authentication risks is to move to multifactor authentication, preferably using higher-entropy credentials. We’ll discuss some classic and new approaches making their way into the market currently. These new approaches mark the evolution of authentication on the Web to functionality that is more resistant to the rising risk of online fraud, such as from phishing (see Chapter 9 for more information on phishing).
Digital Certificates
Certificate authentication is stronger than any of the authentication methods we have discussed so far. Certificate authentication uses public key cryptography and a digital certificate to authenticate a user. Certificate authentication can be used in addition to other password-based authenticated schemes to provide stronger security. The use of certificates is considered an implementation of two-factor authentication. In addition to something you know (your password), you must authenticate with something you have (your certificate). Certificates can be stored in hardware (e.g., smart cards) to provide an even higher level of security—possession of a physical token and availability of an appropriate smart card reader would be required to access a site protected in such a manner.
Client certificates provide stronger security, however, at a cost. The difficulty of obtaining certificates, distributing certificates, and managing certificates for the client base makes this authentication method prohibitively expensive for large sites. However, sites that have very sensitive data or a limited user base, as is common with business-to-business (B2B) applications, would benefit greatly from the use of certificates.
There are no current known attacks against certificate-based authentication, given the private certificate remains protected. However, systems that fail to check the validity of certificates based on certificate revocation lists (CRLs) may improperly permit the use of a revoked stolen certificate. Of course, if an attacker is able to compromise the PKI infrastructure itself, then bypassing normal certificate authentication controls may be possible. As you saw in Chapter 1, many web hacking tools such as the Paros and Burp client-side proxies support certificate-based authentication.
SiteKey
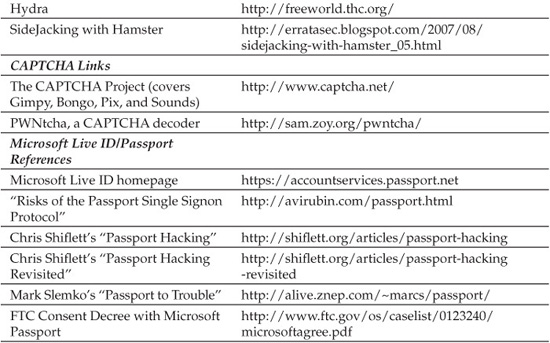
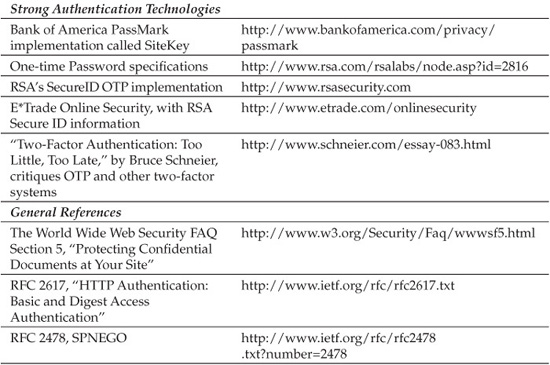
PassMark Security, Inc., was founded in 2004 to focus on strong authentication in the financial services market, and by year-end 2005, they claimed nearly 15 million customers were protected by their PassMark technology. This result is likely due almost entirely to Bank of America’s implementation of PassMark technology in mid-2005 for their (then) 13 million online banking customers. BofA branded their implementation “SiteKey.” PassMark was acquired by RSA Data Security in 2006.
PassMark/SiteKey is based on two-factor, “two-way” authentication. It uses two-factor authentication comprised of a user password and information about the device from which the user is authenticating (multiple devices can be registered). To achieve two-way authentication, the user is provided secret information during the login process so he or she can authenticate the site.
Here’s how this works in practice: at login, the user’s device is authenticated passively using a special device ID created at account registration, providing for server-to-client authentication. The user types in his username and is then challenged to identify an image and associated phrase before he types in his password. The image/phrase is designed to provide simple, visual/textual authentication of the site to mitigate against malicious sites masquerading or spoofing the legitimate one (as is the case with phishing). After entering the correct password, the user is authenticated as normal. See the “References & Further Reading” section at the end of this chapter for links to further demonstrations of PassMark/SiteKey.
PassMark/SiteKey provides for better security than simple username/password-based systems, but how much better? We’ve tested some PassMark-protected applications in our consulting work, and here are some of our findings, integrated with criticisms from the Internet community at large.
One of the early assertions that PassMark is vulnerable to man-in-the-middle (MITM) attacks appears unfounded. PassMark uses secure cookies, which are only sent on SSL connections. Unless the user accepts the failed SSL handshake, the secure cookie isn’t sent across. So PassMark appears no more vulnerable than SSL itself to MITM attacks.
However, when Bank of America’s SiteKey implementation can’t identify the device from which you are authenticating (because it hasn’t been registered), it will ask you to answer a secret question. This is susceptible to an MITM attack since the attacker can just proxy the question/answer between the user/web site.
Additionally, PassMark’s design of presenting a unique image/phrase to valid users creates a username enumeration vulnerability by allowing an attacker to determine easily if an account is valid or not. As noted at the outset of this chapter in the discussion of username enumeration, this is generally not a severe vulnerability because the attacker would still have to guess the password associated with the account.
Some of the broader community’s criticisms of PassMark and SiteKey have included assertions that PassMark is only encumbering existing username/password systems with the addition of a device ID, raising usability issues as users are prompted for numerous secret questions when they inevitably attempt to authenticate from various devices (other computers, kiosks, phones, PDAs, etc.).
Perhaps most seriously, some critics have raised the issue of PassMark creating universal reliance on the ongoing confidentiality of consumer device ID information (which must be stored by the authenticating businesses). If one implementer suffers a security breach of device ID information, all implementers of PassMark potentially lose the benefit of two-factor authentication that it provides. See the “References & Further Reading” section at the end of this chapter for links to more analyses of PassMark and SiteKey.
One-time Passwords
One-time passwords (OTPs) have been around for many years. As you might guess from the name, OTP protocols involve a server and client pre-establishing a collection of secrets (say, a list of passwords) that are used only once per authentication transaction. Continuing with our example of password lists, at the first authentication, the client provides the first password on the list, and both the server and the client then delete that password from the list, making it useless for future authentications. The primary idea behind OTP is to reduce much of the sensitivity of the password itself, so users don’t have to be exposed to the complexities of keeping them secure. Links to more information about OTP can be found in the “References & Further Reading” section at the end of this chapter.
The most popular commercial OTP implementation at the time of this writing is RSA Security’s SecureID system. Rather than shared lists of passwords, SecureID implements a synchronization protocol between the client and server, such that passwords (actually numeric sequences or PIN codes) are only usable within a small window of time (say, 30 seconds). This clever variation on OTP provides for high security since the password is only valuable to the attacker within the 30-second window (for example). After each time window expires, the client generates a new password in synchronization with the server. The client is typically a small hardware device (sometimes called a dongle or fob) that performs the OTP protocol and generates new passwords at each time interval.
OTP systems have historically proven resistant to attack (at least, the well-implemented ones like SecureID) and remain popular for limited scale, higher-security applications such as remote access to corporate networks over a VPN. The main drawback to larger-scale, consumer-oriented deployments remains the cost of the client devices, distribution, and management, which can run as much as $100 per customer per device. Business and consumer attitudes toward these costs have started to change with the recent increased attention to online fraud, and businesses are starting to turn to OTP to address customer concerns in this area.
Early evidence for this was online financial institution E*Trade’s implementation of SecureID for select customers, announced in March 2005 (see the “References & Further Reading” section at the end of this chapter for links). E*Trade calls it the “Complete Security System with optional Digital Security ID” and provides it free of charge to customers maintaining certain minimum balance and transaction volumes in a given period. E*Trade hedges its bets somewhat by noting in its terms of use that a $25 charge may be imposed for each additional or replacement SecureID fob, and that they may impose a fee or may discontinue the service in the future.
Like any security measure, OTP is not perfect. Cryptography expert Bruce Schneier published a paper identifying how phishing can still bypass OTP by setting up a fraudulent site that simply proxies the OTP exchange with the legitimate site, or by installing malicious software on the user’s computer that hijacks a previously authenticated session. And, of course, there is always the potential for replay if the window for password re-use is set too wide. Nevertheless, OTP clearly raises the bar for security, and the attacks proposed by Schneier are generic to any authentication system and will need to be addressed separately to some extent.
Web Authentication Services
Many web site operators simply want to outsource the complexities of security, especially authentication. The market quickly recognized this phenomenon in the late 1990s, as Microsoft acquired Firefly Network and adapted its technologies to become one of the Internet’s first authentication services, Microsoft Passport (now known as Windows Live ID), which could be used by other sites to manage and authenticate customer identities. Originally, Windows Live ID was planned to handle authentication for sites outside of Microsoft and at one point could even boast of heavy hitters such as eBay.com as one of its members. However, the service was never widely adopted outside of Microsoft web properties and is now primarily restricted to web applications managed by Microsoft or closely integrated with Microsoft services. To fill the void left by the retreat of Microsoft, a relatively new set of specifications to define an open, decentralized authentication service emerged in 2005 as the result of work by LiveJournal creator Brad Fitzpatrick. Originally known as Yadis, and now dubbed OpenID, this service has grown in popularity over the years and now boasts of over one billion OpenIDs and nine million web sites consuming those IDs. This section will cover at a high level these two technologies and how they relate to authentication security.
Windows Live ID
Windows Live ID is the latest stage in the evolution of Microsoft’s Passport service and is used to authenticate to Microsoft’s core web applications, including MSN, Hotmail, Messenger, Xbox Live, Channel9, among others. A Windows Live ID is a digital identity consisting of one or more claims that are used to authenticate users to the Windows Live ID authentication service. These claims may be comprised of information such as a user’s e-mail address, the organization(s) that user belongs to, and the roles, relationships, and other authorization-related data associated with the user. Authentication is accomplished through the use of a username/password pair, strong passwords and security PIN combinations, smart cards, or self-issued Windows CardSpace cards. The Windows Live ID service also supports specialized mechanisms such as RADIUS protocol to authenticate nonstandard devices including cell phones and the Xbox 360.
The basic process behind Windows Live ID authentication is this: First, the user attempts to authenticate against a site relying on the Windows Live ID authentication service. Assuming the user is not currently authenticated, she will be redirected to the Windows Live ID authentication site with information about the site she is trying to authenticate to (say, Channel9.msdn.com) in the redirect. The user will then be prompted to enter her Windows Live ID authentication credentials, typically a username and password, and if the authentication attempt succeeds, a number of authentication tokens will be returned in a form in the response. The form will point back to the site that the user is attempting to authenticate against (Channel9), and JavaScript in the response will automatically post the form to convey the authentication tokens to Channel9, thereby successfully completing the authentication process. The form method for conveying the authentication tokens is necessary to communicate the authentication tokens from the live.com domain, where the Windows Live ID service exists, to the Channel9.msdn.com domain, where Channel9 currently resides.
When the target application also exists under the live.com domain (as is the case with Hotmail), the authentication tokens are typically directly set in cookies in the response HTTP header. However, form-based token storage is necessary when the target domain (e.g., channel9.mdsn.com) is different than the Windows Live domain (e.g., live.com) due to the browser-enforced same-origin policy that prevents one domain from accessing the cookie values set in another domain.
A common theme across many of these analyses suggests that one of the biggest dangers in using Windows Live ID authentication is replay attacks using authentication cookies stolen from unsuspecting users’ computers. Of course, assuming an attacker could steal authentication tickets would probably defeat most authentication systems out of the gate, as we noted in our earlier discussion of security token replay attacks in this chapter.
Like any other authentication system, Windows Live ID is also potentially vulnerable to password-guessing attacks (the minimum password length is six characters, with no requirements for different case, numbers, or special characters). Although there is no permanent account lockout feature, after a certain number of failed login attempts, an account will be temporarily prevented from logging in (this lasts a “few moments” according to the error message). This is designed to add significant time to online password-guessing attacks.
Windows Live Delegated Authentication
The Windows Delegated Authentication service allows application developers to leverage externally exposed Windows Live authentication web services to interact and retrieve data associated to a specific Windows Live ID and service. For example, a developer could create an application to connect and retrieve Windows Live Contacts data (used by Hotmail, Messenger, and Mobile) for use in his or her own application. In Microsoft’s terminology, the Windows Live Contacts API providing access to the contacts data is known as the resource provider and the application connecting to that is called the application provider. For the access attempt to succeed, a user must permit the operation through the consent user interface. The lifetime and validity of the consent, as well as the scope of the data access permitted, can be adjusted at any time by the end-user.
When a user provides permission through the consent UI for an application provider to access a resource provider, a consent token and delegation token are returned to the application provider for use in subsequent operations. The combination of these two tokens is required for the application provider to authenticate subsequent operations to access data protected by the resource provider. The consent token contains information defining the “offers” and “actions” the user has permitted the application provider to access as well as other important data needed by the application provider. The delegation token is an encrypted block of data contained within the consent token that must be passed to the resource provider when executing operations to retrieve or manipulate authenticated user data. It is important to note that delegation tokens can be used to authenticate to the resource provider even if the corresponding user has logged out of Windows Live. However, the lifetime of the consent and delegation token is defined by the end-user.
While delegated authentication does provide developers with the flexibility they need to create applications integrated with Microsoft resource providers, it does so at some additional security risk to end-users. First, there is always the risk that an application provider is compromised, resulting in both the disclosure of active authentication tokens to unauthorized parties and access to locally cached data originating from the resource provider. This potential disclosure increases the overall attack surface of the data accessible through the resource providers.
Of course, there is always the risk of a malicious user registering a nefarious application provider and luring unsuspecting or gullible users (who are, let’s face it, a dime a dozen) into providing consent to access resource providers. Although this risk deserves consideration, it is not significantly different from a normal phishing attack.
OpenID
OpenID is a user-centric, decentralized authentication system providing services identical to that of Windows Live ID. The key difference is that in OpenID, there is no central authentication provider. Any number of organizations can become providers, allowing for greater choice and flexibility.
The process of authenticating to a site, referred to as a relying party (previously OpenID consumer), is simple. First, a nonauthenticated user visits a web site supporting OpenID—for this example, let’s say slashdot.com—and selects OpenID as his method of authentication. The user is then prompted to provide a URL that specifies his unique identity on the provider he has selected. For example, one popular provider, MyOpenID (www.myopenid.com), creates URLs of the form <username>.myopenid.com, where <username> is the name selected when the MyOpenID account was created. When the user attempting to authenticate to the relying party (Slashdot) supplies this URL, he is redirected to a login page at the provider site (MyOpenID) that prompts for the password selected when the account was created. If the user provides the correct password, he will be redirected back from the OpenID provider to the original site as an authenticated user. From this point, he may be asked to complete profile-related information if this is the first time he has authenticated with the site.
This example uses passwords as the required authentication credentials, although this is not mandated by the OpenID specification. Not mandating the type of credentials to be used allows authentication providers to support any number of credential types such as client-side certificates, biometric devices, or smart cards.
The biggest downside to using OpenID is that a single compromise of the OpenID account credentials will result in the compromise of every OpenID web application used by the victim user until that point. While the attacker may not know what applications those are, it is trivial to enumerate the popular sites until the attacker strikes upon something interesting. This risk can be mitigated through enforcing strong passwords, rotating passwords on a periodic basis, or simply by selecting a stronger authentication method such as client-side certificates and other digital identity systems such as Windows CardSpace.
The risk of credential theft is heightened by the ease with which attackers can dupe users into providing these credentials at malicious OpenID phishing sites. When talking about OpenID security, this issue is often the first raised. For example, it is trivial to create a web site that appears to accept a normal OpenID provider URL yet on the backend redirects the authenticating user to an attacker-controlled web site constructed to resemble the selected provider. Unless users are paying careful attention to the web site they have been redirected to, it is unlikely they will notice the attack until it is too late (if at all). Other security considerations have been enumerated in the OpenID 2.0 authentication specification, a link to which can be found in the “References & Further Reading” section at the end of this chapter.
As part of a phishing-resistant authentication solution for OpenID, in February 2007, Microsoft announced a partnership with JanRain, Sxip, and VeriSign to collaborate on integration of Microsoft Windows CardSpace digital identity platform technology into OpenID implementations. Because CardSpace relies on the use of digital identities backed by cryptographic technologies, attackers will have a hard time impersonating clients without directly compromising the digital identities stored on the client machine. More information regarding Microsoft Windows CardSpace is provided in the next section.
While not security related, another downside to OpenID is that it has yet to be adopted by many of the major players in the online community. While Microsoft, Google, and Yahoo! now serve as OpenID providers, none of these organizations currently consumes these identities for use in their most popular web properties. In other words, users will not be using a Google-based OpenID account to log in to Hotmail anytime soon.
Windows CardSpace
Windows CardSpace is an Identity Selector technology to provide identity and authentication services for application end-users. The analogy that is frequently used to explain this technology is that of a wallet. In our day-to-day lives, we use a variety of cards, including credit, health insurance, driver license, and gym membership cards to authenticate our identities to the appropriate organizations. Some identification cards, such as credit cards, require a high level of security and assurance that the person holding the card is the actual owner. Other cards, such as a gym membership or library card, require less assurance, and the effects of a forged or stolen card are far less serious. Windows CardSpace is a digital wallet application users can employ to manage their digital identities (referred to as information cards) for a variety of services. These identities may be official cards issued and signed by third-party trusted identity providers, or they may be personal information cards that are self-signed by the user. Applications that require a high level of security may require an information card signed by a specific organization, whereas other applications may accept any self-signed identity.
In May 2008, researchers at the University of Bochum in Germany described an attack against the CardSpace technology that could be used to impersonate the identity of victim users against an attacker-specified site for the lifetime of a security authentication token. The attack relies on the malicious modification of client-side DNS entries and the improper trusting of an attacker-supplied server-side certificate in order to succeed. While not outside the realm of possibility, attacks that succeed in both poisoning the client-side DNS and getting a user to trust a malicious server certificate are generally going to succeed regardless of the authentication technology used. Links to both an article describing the attack and legitimate criticisms of the methods used (including a response by Kim Cameron, Chief Identity Architect of Identity at Microsoft) can be found in the “References & Further Reading” section at the end of this chapter.
BYPASSING AUTHENTICATION
Many times you find yourself banging the wall when a door is open around the corner. This idea is similar to attacking web authentication. As we noted in the beginning of the chapter, many applications are aware of the important role that authentication plays in the security of the application, and therefore, they implement very strong protocols. In these situations, directly attacking the protocol itself may not be the easiest method of hacking authentication.
Attacking other components of the application, such as hijacking or spoofing an existing authenticated session, or attacking the identity management subsystem itself, can both be used to bypass authentication altogether. In this section, we’ll discuss some common attacks that bypass authentication entirely.
Token Replay
Security tokens of some sort are commonly issued to users who have successfully authenticated so they do not need to retype credentials while navigating the authenticated sections of an application. An unfortunate side effect of this mechanism is that authentication can be bypassed by simply replaying maliciously captured tokens, a phenomenon sometimes called session hijacking.
Web applications typically track authenticated user sessions through session IDs stored in browser cookies. We’ll discuss common mechanisms for guessing or obtaining cookie-based session IDs briefly in this section. For more information on attacks against authorization and session state, please consult Chapter 5.
Session ID Attacks
Two basic techniques to obtain session IDs are prediction and brute-forcing.
Older web applications often used easily predictable, sometimes even sequential, session identifiers. Nonsequential session IDs generated using insecure algorithms or pseudorandom number generators with insufficient entropy may be predictable using mathematical techniques such as statistical forecasting. While all of the major application servers now attempt to use unpredictable session identifiers, occasionally new attacks are discovered against even widely used and popular technologies. For example, in March 2010, security researcher Andreas Bogk disclosed a vulnerability in the PHP platform session ID–generation functionality that could result in the pool of possible session IDs being reduced to the point that brute-force session ID attacks become feasible. This serves to illustrate the point that, in security, nothing can be taken for granted and that the best approach is always a defense-in-depth strategy and focus on the fundamentals.
Brute-forcing session IDs involves making thousands of requests using all possible session IDs in hopes of guessing one correctly. The number of requests that need to be made depends on the key space of the session ID. Thus, the probability of success for this type of attack can be calculated based on the size and key space of the session ID. Attempted brute-forcing of the session IDs used in popular web application servers such as Java, PHP, ASP.NET, etc., is a rather pointless exercise due to the size of the session IDs these platforms generate. However, this attack may yield useful results against applications generating custom session IDs or other authentication tokens.
There is one other attack against session IDs that has largely fallen along the wayside as improvements in session ID security have been made over the years. That attack is known as session fixation. Session fixation is a type of attack where an attacker is able to set, in advance, the session ID that an application server will use in a subsequent user authentication. Because the attacker is setting the value, a user who authenticates using this preset session ID will immediately be exposed to a session hijacking attack. While this vulnerability is far less common than it used to be many years ago, application assessors need to be aware of this vulnerability and need to know how to identify it in web applications. Please refer to the “Session Fixation” section in Chapter 5 and “References & Further Reading” for more information regarding this attack technique.
TIP
David Endler of iDefense.com has written a detailed exposé of many of the weaknesses in session ID implementations. Find a link to it in the “References & Further Reading” section at the end of this chapter.
Hacking Cookies
Cookies commonly contain sensitive data associated with authentication. If the cookie contains passwords or session identifiers, stealing the cookie can be a very successful attack against a web site. There are several common techniques used to steal cookies, with the most popular being script injection and eavesdropping. We’ll discuss script injection techniques (also referred to as cross-site scripting) in Chapter 6.
Reverse engineering the cookie offline can also prove to be a very lucrative attack. The best approach is to gather a sample of cookies using different input to see how the cookie changes. You can do this by using different accounts to authenticate at different times. The idea is to see how the cookie changes based on time, username, access privileges, and so on. Bit-flipping attacks adopt the brute-force approach, methodically modifying bits to see if the cookie is still valid and whether different access is gained. We’ll go into more detail on cookie attacks in Chapter 5. Before embarking on attacks against cookie values, care should be taken to first understand any encoding used and whether the cookie needs to be decoded for the attack to be successful. One common mistake made by application developers is to use an encoding format, such as Base64, when encryption is required. This mistake is sometimes seen in applications caching role information in the cookie for performance reasons. Because Base64 is trivially decoded, an attacker can decode, modify, and re-encode the cookie value to potentially change his or her assigned role and gain unauthorized access to the application. Tools such as the Burp web proxy have great support for manipulating cookies and encoding, decoding, and hashing values using common algorithms.
Countermeasures to Token Replay Attacks
Eavesdropping is the easiest way to steal security tokens like cookies. SSL or other appropriate session confidentiality technologies should be used to protect against eavesdropping attacks.
In addition to on-the wire eavesdropping, be aware that there are a slew of security issues with commonly used web clients that may also expose your security tokens to malicious client-side malware or cross-site scripting manipulation (see Chapter 9 for more on this).
In general, the best approach is to use a session identifier provided by the application server. However, if you need to build your own, you should also design a token that can’t be predicted and can’t be practically attacked using brute-force methods. For example, use a random number generator of sufficient entropy to generate session identifiers. In addition, to prevent brute-force attacks, use a session identifier with a large enough key space (roughly 128 bits with current technology) that it can’t be attacked using brute-force. Keep in mind there are subtleties with pseudorandom number generators that you must consider when using them. For example, concatenating four randomly generated 32-bit integers to create a single 128-bit session identifier is not as secure as randomly generating a single 128-bit value using a cryptographically secure PRNG. By providing four samples to prevent brute-force attacks, you actually make session ID prediction easier.
You should also implement integrity checks across security tokens like cookies and session IDs to protect against tampering at the client or during transit. Tampering can be prevented by using hashed message authentication codes (HMACs) or by simply encrypting the entire cookie value.
In general, storing sensitive data in a client-side security token is not recommended, even if you implement strong confidentiality and integrity-protection mechanisms.
Cross-site Request Forgery
Cross-site request forgery (often abbreviated as XSRF or CSRF) is a web application attack that leverages the existing trust relationship between web applications and authenticated users to force those users to commit arbitrary sensitive transactions on the behalf of an attacker. In security literature, this attack is often classified as one manifestation of a confused deputy attack. The deputy in this case is the web application client browser and confused simply refers to the inability of the browser to properly distinguish between a legitimate and unauthorized request.
Despite the extremely dangerous nature of XSRF attacks, these attacks have received less attention than the more easily understood web application vulnerabilities such as XSS. As recently as 2006, XSRF attacks were referred to as a “sleeping giant,” and listing in the OWASP Top 10 project was not achieved until the year 2007. Even at the time of this writing, XSRF vulnerabilities are being actively reported against popular application web sites.
The reader might be wondering then, if XSRF vulnerabilities present such a significant risk, why, until now, have they received such little attention? While opinions certainly vary on this question, part of the reason undoubtedly has to do with how inherent this vulnerability is to the stateless nature of the HTTP specification that requires an authentication token (usually a combination of a session ID cookie and additional authorization tokens) be sent with every request. Common sense dictates that security vulnerabilities are generally caused by mistakes application developers make during design and development or administrators make in deployment. Contrary to this, XSRF vulnerabilities occur when developers simply omit an XSRF prevention mechanism from their application. In other words, if developers have not actively defended against this issue and their application supports sensitive authenticated transactions, then the application is usually vulnerable, by default, with a few exceptions.
So what constitutes an XSRF attack? The classic example is that of a banking application that permits users to transfer funds from one account to another using a simple HTTP GET request. Assume the transfer account action takes the following form:
http://xsrf.vulnerablebank.com/transferFunds.aspx?
toaccount=12345&funds=1000.00¤cy=dollars
Continuing with the above example, assume an attacker creates a malicious HTML page on a system under her control containing the following JavaScript code:
<script type="text/javascript">
var i = document.createElement("image");
i.src = "http://xsrf.vulnerablebank.com/transferFunds.aspx?
toaccount=EVIL_ATTACKER_ACCNT_NUMBER&funds=1000.00¤cy=dollars";
</script>
The effect of this JavaScript code is to create a dynamic HTML image tag (<img ...>), and set the source to that of the funds transfer action on the vulnerable banking application. Client browsers of users authenticated with the banking web site that are lured into visiting the malicious page will execute the attacker’s JavaScript to create a background HTTP GET request for the source of the dynamic image, which, in this case, is the funds transfer action, and that action will be executed just as if the user had willingly performed it. The key to remember here is that whenever a browser makes a request to a resource on another domain, any cookies associated with that domain, port, and path will automatically be attached to the HTTP header and sent along with the request. This includes, of course, session cookies used to identify the authenticated user to the application. The result is that the attacker has successfully forced a banking user to transfer funds from the user’s account to the attacker’s account.
While this example is somewhat contrived and serves to merely illustrate the fundamental issue, similar vulnerabilities have been reported against live systems that could result in heavy financial loss for the vulnerable organization. For example, in 2006, it was reported on the security mailing list Full Disclosure that Netflix was vulnerable to cross-site request forgery issues that, according to David Ferguson who originally disclosed the vulnerability, could result in the following:
• Adding movies to his rental queue
• Adding a movie to the top of his rental queue
• Changing the name and address on the account
• Enabling/disabling extra movie information
• Changing the e-mail address and password on the account
• Cancelling the account (unconfirmed/conjectured)
Fortunately, the Netflix vulnerability was disclosed before any real damage was inflicted. However, as can be seen from the list of actions this vulnerability made possible, the potential damage, both in terms of real financial loss and damage to Netflix’s brand, of a successful attack against the Netflix userbase simply cannot be understated.
It should be noted that while the example used to illustrate this issue was an HTTP GET request, HTTP POST requests are also vulnerable. Some developers appear to be under the misapprehension that simply changing vulnerable GET requests to POST will be sufficient to remediate XSRF vulnerabilities. However, this only makes life for attackers slightly more difficult as now they have to construct JavaScript to construct and POST the form automatically. In order to prevent the browser from automatically redirecting the victim user to the vulnerable application when the POST is submitted, the JavaScript can be embedded in a hidden iframe tag in the malicious page. As a general application design rule, any action with consequence should be constructed using a HTTP POST request.
Countermeasures to Cross-site Request Forgery Attacks
There are primarily three common methods for preventing XSRF attacks:
• Double-posted cookie In the double-posted cookie mitigation technique, each form used to commit a sensitive transaction is generated with a hidden input field containing the value of the current user’s session ID or other securely generated random value stored in a client-side cookie. When the form is posted, the application server will check if the cookie value in the form matches the value received in the HTTP request header. If the values do not match, the request will be rejected as invalid and an audit log will be generated to record the potential attack. This method relies on the attacker not knowing the client session cookie value. If that value is disclosed through another channel, this strategy will not be successful (and session hijacking attacks will also become a concern).
• Unique form nonce The unique form nonce remediation strategy is perhaps the most common method for preventing XSRF attacks. In this method, each form is constructed per request with a single hidden input field containing a securely generated random nonce. The nonce has to be generated using a cryptographically secure pseudorandom number generator, or it could be vulnerable to attack. When the application server receives the form parameter values as part of an HTTP POST request, it will compare the value of the nonce with the value stored in memory and reject the request as invalid should the values differ or should the nonce have timed out. This method can be tricky to implement if the application requires generating and associating nonce and nonce timeout values for each request containing a sensitive transaction form. Some development frameworks implement routines that provide similar functionality out-of-the-box, for example, Microsoft’s ASP.NET ViewState feature that persists changes to the state of a form across postbacks.
• Require authentication credentials This remediation method requires authenticated users to reenter the password corresponding to their authenticated session whenever performing a sensitive transaction. This strategy is common in web applications that have a few sensitive rare transactions. Common areas of an application secured in this fashion are user profile data update forms. Care should be taken to include audit and lockout functionality on these pages to prevent XSRF authentication brute-forcing attacks that attempt to update profile data by repeatedly forcing requests with randomly guessed passwords.
To illustrate how the banking transfer funds action would be remediated using the unique form nonce solution described, consider the following form action:
<form id="fundsTransfer" method="POST" action="transferFunds.aspx">
<input type="textbox" name="funds" value="0.00">
<input type="textbox" name="toaccount" value"="">
<!-- other input fields as needed -->
<input type="hidden" name="xsrfToken" value="eozMKoWO6g3cIUa13y5wLw==">
</form>
Notice how an additional hidden parameter, xsrfToken, has been added to the form. A new xsrfToken value is randomly generated using a cryptographically secure pseudorandom number generator each time a request for the corresponding page is made. Because the attacker does not have knowledge of this value, he or she will be unable to create a malicious form to forge transfer funds transactions.
Developers should also familiarize themselves with platform-specific built-in XSRF prevention technologies when deciding how to approach this issue, as the availability of such a solution can greatly reduce the amount of work they have to do to secure their applications. In general, however, platform-specific technologies will use one of the strategies mentioned previously (most likely, the unique form nonce). More detailed information regarding XSRF mitigation techniques can be found in the pages listed in the “References & Further Reading” section at the end of this chapter.
Identifying Cross-site Request Forgery Vulnerabilities
Given knowledge of the remediation strategies listed in the previous section, identifying XSRF vulnerabilities in web applications is a trivial activity. If the application form under consideration contains a unique nonce, difficult-to-guess cookie value, or parameter requiring an authentication credential, then the form is not vulnerable to XSRF. However, if the form contains no values that cannot be easily guessed by the attacker, then the attacker can reconstruct the form on a third-party site and execute XSRF attacks.
Identity Management
A functional authentication system needs to have some way of managing identities—registration, account management (such as password reset), and so on. These activities also need to be performed securely because errors can impact very sensitive information like credentials. Unfortunately, identity management can be a complex task, and many web applications don’t perform it very well, leaving their authentication system exposed to abuse and bypass.
In this section, we’ll talk about common attacks against identity management.
NOTE
Some web sites seek to avoid the headache of identity management entirely by outsourcing it to a third party. Microsoft’s Windows Live ID is an example of such a service for the Web—see our previous discussion of Live ID for more information.
User Registration Attacks
Sometimes, the easiest way to access a web application is to simply create a valid account using the registration system. This method essentially bypasses attacks against the authentication interface by focusing on the registration process. Of course, filtering account registrations for malicious intent is a challenging proposition, but web applications have developed a number of mechanisms to mitigate against such activity, including Completely Automated Public Turing Tests to Tell Computers and Humans Apart (CAPTCHA). CAPTCHAs are often used in web-based applications when the application owner wants to prevent a program, bot, or script from performing a certain action. Some examples of CAPTCHA include these:
• Free e-mail services Many free e-mail services use CAPTCHA to prevent programs from creating fake accounts, generally to minimize spam.
• Password-guessing attack prevention CAPTCHA has been used in login pages to prevent tools and programs from executing automated password-guessing attacks.
• Search engine bot prevention CAPTCHAs are sometimes used to prevent search engine bots from indexing pages.
• Online polls CAPTCHA can be an effective way to prevent people from skewing results of online polls by ensuring that a program is not responding to the polls.
CAPTCHA is a type of Human Interactive Proof (HIP) technology that is used to determine if the entity on the other side is a human or a computer. This is formally referred to as a Reverse Turing Test (RTT). The difference with CAPTCHA is that it is “completely automated,” which makes it suitable for use in web applications.
Common types of CAPTCHA are often based on text recognition or image recognition. The following images illustrate common implementations of CAPTCHAs.
The following shows the Gimpy-r CAPTCHA, which is considered ineffective since automated routines can beat it regularly:

Next shown is a CAPTCHA used to challenge Hotmail.com registrations. Note the audio CAPTCHA option button in the upper right:
Next is a graphical CAPTCHA from CAPTCHA.net:

Recent advances and research in computer vision and image recognition have provided the groundwork for breaking CAPTCHA. Simple CAPTCHAs like the EZGimpy technology using text recognition has been broken by Greg Mori and Jitendra Malik, researchers at the University of California at Berkeley. Gabriel Moy, Nathan Jones, Curt Harkless, and Randy Potter of Areté Associates have created a program that has broken the more complex Gimpy-r algorithm 78 percent of the time.
As of this writing, the PWNtcha is the most successful of the CAPTCHA decoders. It has over an 80 percent success rate at breaking well-known CAPTCHAs used by popular web sites such as PayPal and Slashdot. Although the code is not released, you can upload a CAPTCHA to the web site for decoding. Figure 4-7 shows an example of using PWNtcha.
Although most researchers have not released programs that break CAPTCHA, the hackers are not far behind the researchers. The authors have worked with several companies that have been victims of hackers creating bots that automatically register accounts. Their response was to use a CAPTCHA. However, within a week, the hackers were able break the CAPTCHA, probably adapting a program they already had in their arsenal. The advances in computer vision and processing power has required more complex CAPTCHAs to be developed to be effective. In some instances, criminal organizations have avoided the complexity of using automation and have simply begun employing the use of humans to break CAPTCHAs.
Credential Management Attacks
Another way to bypass authentication is to attack credential management subsystems. For example, most web sites implement common mechanisms for password recovery, such as self-help applications that e-mail new passwords to a fixed e-mail address, or if a “secret question” can be answered (for example, “What is your favorite pet’s name?” or “What high school did you attend?”).
Figure 4-7 PWNtcha successfully identifying the type of CAPTCHA and the text in the image
We’ve found in our consulting that many of these so-called secret questions are easily guessable and often not considered a “secret.” For example, we once stumbled on a secret question designed to elicit the user’s customer ID and ZIP code in order to recover a password, where the customer ID was sequential and the ZIP code was easily guessed using a dictionary of common ZIP codes or via brute-force mechanisms.
Another classic attack against password reset mechanisms is getting self-help password reset applications to e-mail password reset information to inappropriate e-mail addresses. Even the big guys fall to this one, as an incident in May 2003 with Microsoft’s Passport Internet authentication services showed (as noted earlier, Passport is now called “Windows Live ID,” but we will refer to it by its prior name in the context of earlier attacks against the service as it was called at the time). Passport’s self-help password reset application involved a multistep process to e-mail the user a URL that permitted the user to change his or her password. The URL in the e-mail looked something like the following (manual line breaks have been added due to page-width constraints):
https://register.passport.net/[email protected]&
[email protected]&rst=1
Although the query string variables here are a bit cryptic, the emailpwdreset application in this example will send a password reset URL for the “victim@hotmail. com” account to the e-mail address “[email protected].” Subsequently, “attacker” will be able to reset the password for “victim,” thus compromising the account.
Client-side Piggybacking
We’ve spent most of our effort in this chapter describing ways to steal or otherwise guess user credentials for the attacker to use. What if the attacker simply lets the user do all of the heavy lifting by piggybacking on a legitimately authenticated session? This technique is perhaps the easiest way to bypass nearly all of the authentication mechanisms we’ve described so far, and it takes surprisingly little effort. Earlier in this chapter, we cited an essay by Bruce Schneier on this very point, in which he notes that man-in-the-middle attacks and malicious software installed on end-user machines can effectively bypass almost any form of remote network authentication (you can find a link to his essay in the “References & Further Reading” section in this chapter). We’ll describe some of these methods in detail in Chapter 9, but we thought it important to make this point before we closed out this chapter.
SOME FINAL THOUGHTS: IDENTITY THEFT
<RANT> Identity theft via Internet fraud tactics such as phishing continues to make the media rounds as we write these pages. Like many issues surrounding security, this high profile creates the expectation that technology will magically save the day at some point. New authentication technologies in particular are held out as the silver bullet for the problems of identity theft.
Perhaps someone will invent the perfectly secure and easy-to-use authentication protocol someday, but in the interim, we wanted to decry what we believe to be a much more easily addressed factor in identity theft: the widespread use of personally identifiable information (PII) in web authentication and identity management. Most of us have experienced the use of facts about our personal lives to authenticate us to online businesses: government identification (such as Social Security Number, SSN), home addresses, secret questions (“What high school did you attend?” and so on), birthdates, and on and on.
As Internet search engines like Google and incidents like the 2005 CardSystems security breach are now making plainly obvious, many of these personal factoids are not really that secret anymore. Combined with the prevalence of social networking, these factors make so-called personal information into the least secret aspects of our lives (are you listening, Paris Hilton?) and, therefore, a terrible authenticator. So we’d like to make a simple demand of all of those businesses out there who may be listening: quit collecting our PII and don’t even think about using it to authenticate us! </RANT>
SUMMARY
Authentication plays a critical role in the security of any web site with sensitive or confidential information. Table 4-2 summarizes the authentication methods we have discussed in this chapter.
Web sites have different requirements, and no one method is best for authentication. However, using these basic security design principles can thwart many of the attacks described in this chapter:
• A strong password policy and account lockout policy will render most attacks based on password guessing useless.
• Ensure that all sections of the application requiring authentication are actually covered by the authentication component and that authentication cannot be bypassed by brute-forcing to the resource.
• Do not use personally identifiable information for credentials! They aren’t really secret, and they expose your business to liability if you store them.
• HTTPS should be used to protect authentication transactions from the risk of eavesdropping and replay attacks.
• Input validation goes a long way in preventing hacking on a web site. SQL injection, script injection, and command execution can all be prevented if input validation is properly performed.
• Ensure that authentication security tokens like session identifiers aren’t easily predictable and that they are generated using a sufficiently large key space that cannot easily be guessed.
• Do not allow users to preset session IDs prior to authentication (the server should always generate these values), and always issue a new session ID upon successful authentication.
• Do not forget to harden identity management systems like account registration and credential reset, as weaknesses in these systems can bypass authentication controls altogether.
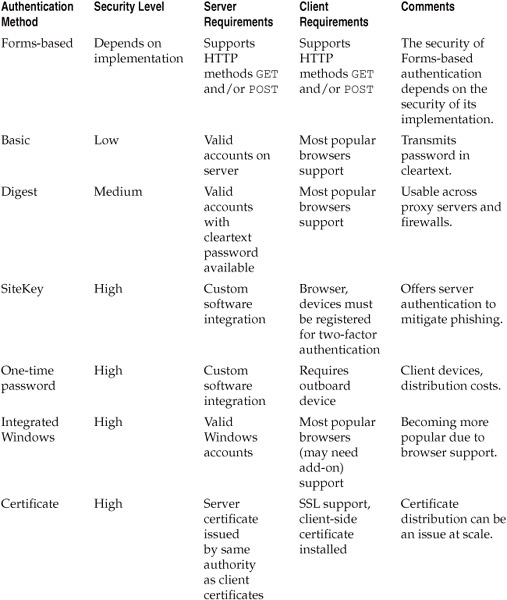
Table 4-2 A Summary of the Web Authentication Mechanisms Discussed So Far
REFERENCES & FURTHER READING