
The action-value actor-critic algorithm still has high variance. We can reduce the variance by subtracting a baseline function, B(s), from the policy gradient. A good baseline is the state value function,  . With the state value function as the baseline, we can rewrite the result of the policy gradient theorem as the following:
. With the state value function as the baseline, we can rewrite the result of the policy gradient theorem as the following:

We can define the advantage function  to be the following:
to be the following:

When used in the previous policy gradient equation with the baseline, this gives us the advantage of the actor-critic policy gradient:
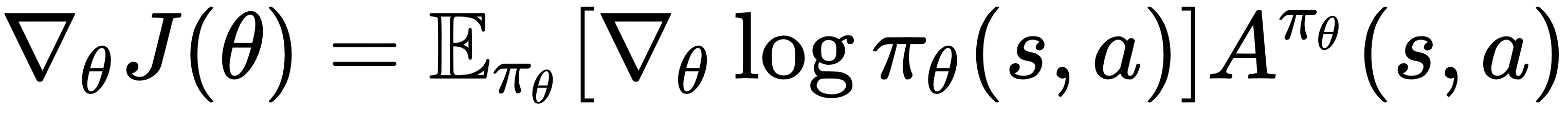
Recall from the previous chapters that the 1-step Temporal Difference (TD) error for value function  is given by the following:
is given by the following:

If we compute the expected value of this TD error, we will end up with an equation that resembles the definition of the action-value function we saw in Chapter 2, Reinforcement Learning and Deep Reinforcement Learning. From that result, we can observe that the TD error is in fact an unbiased estimate of the advantage function, as derived in this equation from left to right:

With this result and the previous set of equations in this chapter so far, we have enough theoretical background to get started with our implementation of our agent! Before we get into the code, let's understand the flow of the algorithm to get a good picture of it in our minds.
The simplest (general/vanilla) form of the advantage actor-critic algorithm involves the following steps:
- Initialize the (stochastic) policy and the value function estimate.
- For a given observation/state
 , perform the action,
, perform the action,  , prescribed by the current policy,
, prescribed by the current policy,  .
. - Calculate the TD error based on the resulting state,
 and the reward
and the reward  obtained using the 1-step TD learning equation:
obtained using the 1-step TD learning equation:

- Update the actor by adjusting the action probabilities for state
 based on the TD error:
based on the TD error:
- If
 > 0, increase the probability of taking action
> 0, increase the probability of taking action  because
because  was a good decision and worked out really well
was a good decision and worked out really well - If
 < 0 , decrease the probability of taking action
< 0 , decrease the probability of taking action  because
because  resulted in a poor performance by the agent
resulted in a poor performance by the agent
- If
- Update the critic by adjusting its estimated value of
 using the TD error:
using the TD error:
 , where
, where  is the critic's learning rate
is the critic's learning rate
- Set the next state
 to be the current state
to be the current state  and repeat step 2.
and repeat step 2.