
n-step returns are a simple but very useful concept known to yield better performance for several reinforcement learning algorithms, not just with the advantage actor-critic-based algorithm. For example, the best performing algorithm to date on the Atari suite of 57 games, which significantly outperforms the second best algorithm, uses n-step returns. We will actually discuss that agent algorithm, called Rainbow, in Chapter 10, Exploring the learning environment landscape: Roboschool, Gym-Retro, StarCraft-II, DMLab.
Let's first get an intuitive understanding of the n-step return process. Let's use the following diagram to illustrate one step in the environment. Assume that the agent is in state  at time t=1 and decides to take action
at time t=1 and decides to take action  , which results in the environment being transitioned to state
, which results in the environment being transitioned to state  at time t=t+1= 1+1 = 2 with the agent receiving a reward of
at time t=t+1= 1+1 = 2 with the agent receiving a reward of  :
:

We can calculate the 1-step TD return using the following formula:

Here,  is the value estimate of state
is the value estimate of state  according to the value function (critic). In essence, the agent takes a step and uses the received return and the discounted value of the agent's estimate of the value of the next/resulting state to calculate the return.
according to the value function (critic). In essence, the agent takes a step and uses the received return and the discounted value of the agent's estimate of the value of the next/resulting state to calculate the return.
If we let the agent continue interacting with the environment for a few more steps, the trajectory of the agent can be simplistically represented using the following diagram:

This diagram shows a 5-step interaction between the agent and the environment. Following a similar approach to the 1-step return calculation in the previous paragraph, we can calculate the 5-step return using the following formula:

We can then use this as the TD target in step 3 of the advantage actor-critic algorithm to improve the performance of the agent.
For example, you can run
(rl_gym_book) praveen@ubuntu:~/HOIAWOG/ch8$python a2c_agent.py --env Pendulum-v0 with learning_step_thresh=1, monitor its performance using Tensorboard using the command
(rl_gym_book) praveen@ubuntu:~/HOIAWOG/ch8/logs$tensorboard --logdir=., and then after a million or so steps you can compare the performance of the agent trained with learning_step_thresh=10. Note that the trained agent model will be saved at ~/HOIAWOG/ch8/trained_models/A2_Pendulum-v0.ptm . You can rename it or move it to a different directory before you start the second run to start the training from scratch!
To make the concept more explicit, let's discuss how we will use this in step 3 and in the advantage actor-critic algorithm. We will first use the n-step return as the TD target and calculate the TD error using the following formula (step 3 of the algorithm):

We will then follow step 4 in the algorithm discussed in the previous subsection and update the critic. Then, in step 5, we will update the critic using the following update rule:

We will then move on to step 6 of the algorithm to continue with the next state, 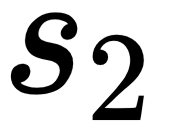 , using 5-step transitions from
, using 5-step transitions from  until
until  and calculating the 5-step return, then repeat the procedure for updating
and calculating the 5-step return, then repeat the procedure for updating  .
.