
The essence of algorithms based on the graph theory is to represent target objects in graph form. Graph vertices correspond to objects, and the edge weights are equal to the distance between vertices. The advantages of graph clustering algorithms are their excellent visibility, relative ease of implementation, and their ability to make various improvements based on geometrical considerations. The main algorithms based on graph theory are the algorithm for selecting connected components, the algorithm for constructing the minimum spanning tree, and the multilayer clustering algorithm.
The algorithm for selecting connected components is based on the R input parameter, and the algorithm removes all edges in the graph with distances greater than R. Only the closest pairs of objects remain connected. The algorithm's goal is to find the R value at which the graph collapses into several connected components. The resulting components are clusters. For the selection of the R parameter, a histogram of the distribution of pairwise distances is usually constructed. For problems with a well-defined cluster data structure, there will be two peaks in the histogram—one corresponds to in-cluster distances and the second to inter-cluster distances. The R parameter is selected from the minimum zone between these peaks. Managing the number of clusters using the distance threshold can be difficult.
The minimum spanning tree algorithm first builds a minimal spanning tree on the graph, and then successively removes the edges with the highest weight. The following diagram shows the minimum spanning tree obtained for nine objects:
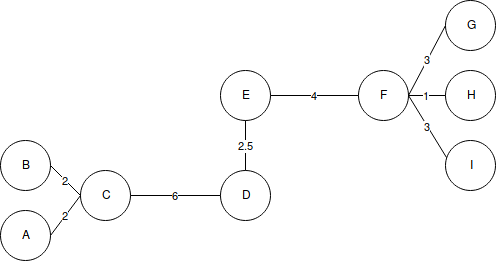
By removing the link between C and D, with a length of 6 units (the edge with the maximum distance), we obtain two clusters: {A, B, C} and {D, E, F, G, H, I}. We can divide the second cluster into two more clusters by removing the edge EF, which has a length of 4 units.
The multilayer clustering algorithm is based on identifying connected components of a graph at some level of distance between objects (vertices). The threshold C defines the distance level—for example, if the distance between objects is 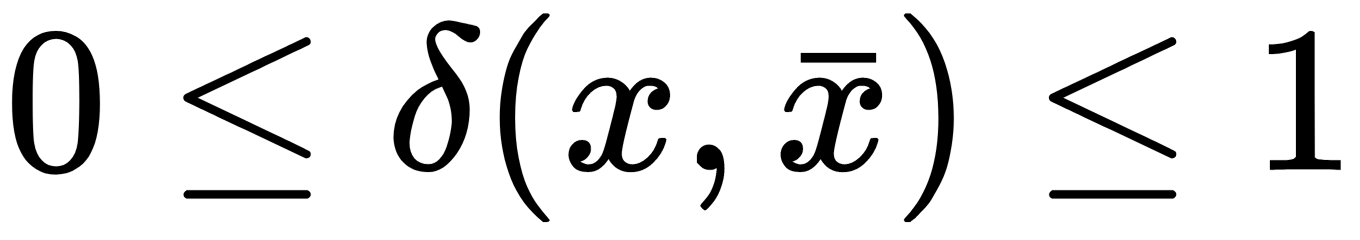 , then
, then  .
.
The layer clustering algorithm generates a sequence of sub-graphs of the graph G that reflect the hierarchical relationships between clusters 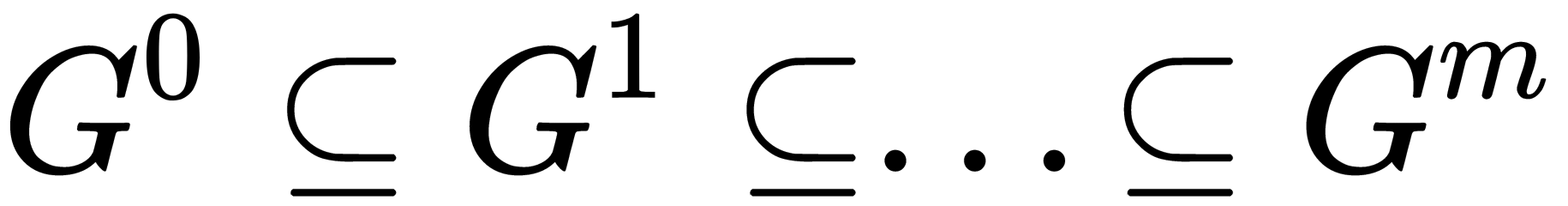 , where the following applies:
, where the following applies:
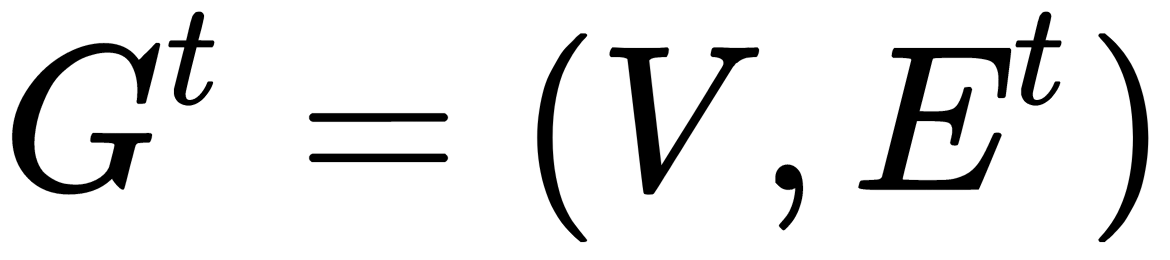 : A sub-graph on the
: A sub-graph on the 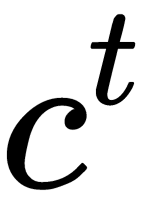 level
level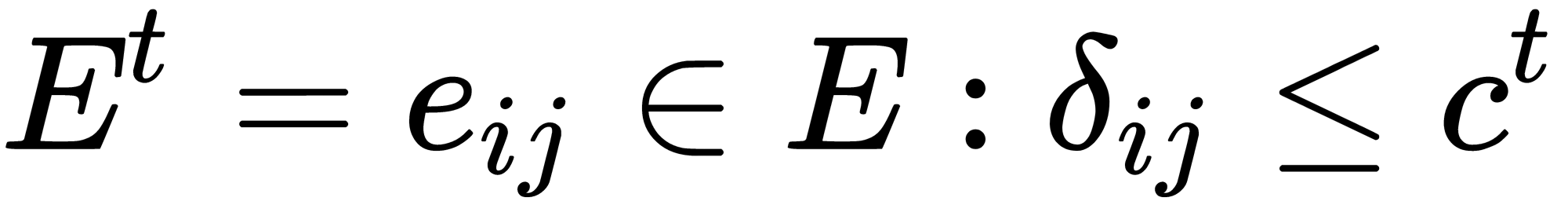
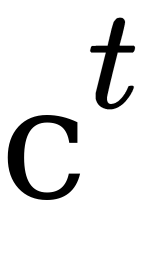 : The tth threshold of distance
: The tth threshold of distance : The number of hierarchy levels
: The number of hierarchy levels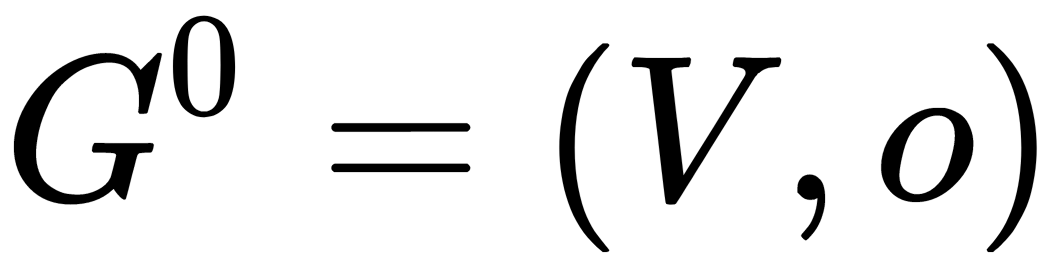 , o: An empty set of graph edges, when
, o: An empty set of graph edges, when 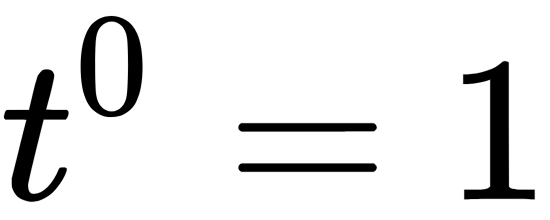
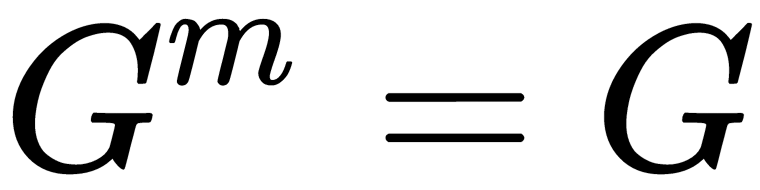 : A graph of objects without thresholds on distance, when
: A graph of objects without thresholds on distance, when 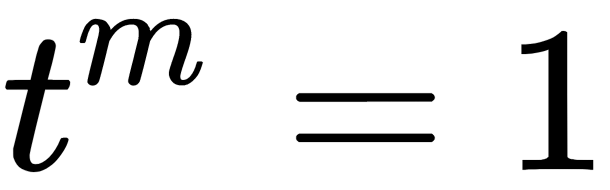
By changing the  distance thresholds, where
distance thresholds, where  , it is possible to control the hierarchy depth of the resulting clusters. Thus, a multilayer clustering algorithm can create both flat and hierarchical data partitioning.
, it is possible to control the hierarchy depth of the resulting clusters. Thus, a multilayer clustering algorithm can create both flat and hierarchical data partitioning.