
There are two areas in data analysis that look for anomalies: outlier detection and novelty detection.
A new object or novelty is an object that differs in its properties from the objects in the training dataset. Unlike an outlier, the new object is not in the dataset itself, but it can appear at any point after a system has started working. Its task is to detect when it appears. For example, if we were to analyze existing temperature measurements and identify abnormally high or low values, then we would be detecting outliers. On the other hand, if we were to create an algorithm that, for every new measurement, evaluates the temperature's similarity to past values and identifies significantly unusual ones, then we are detecting novelties.
The reasons for outliers appearing include data errors, the presence of noise, misclassified objects, and foreign objects from other datasets or distributions. Let's explain two of the most obscure types of outliers: data errors and data from different distributions. Data errors can broadly refer to inaccuracies in measurements, rounding errors, and incorrect entries. An example of an object belonging to a different distribution is measurements that have come from a broken sensor. This is because these values will belong to a range that may be different from what was expected.
Novelties usually appear as a result of fundamentally new object behavior. For example, if our objects are computer system behavior descriptions, then after a virus has penetrated the computer and deleted some information from these descriptions, they will be rendered as novelties. Another example of a novelty could be a new group of customers that behave differently from others but have some similarities to other customers. The main feature of novelty objects is that they are new, in that it's impossible to have information about all possible virus infections or breakdowns in the training set. Creating such a training dataset is a complicated process and often does not make sense. However, fortunately, we can obtain a large enough dataset by focusing on the ordinary (regular) operations of the system or mechanism.
Often, the task of anomaly detection is similar to the task of classification, but there is an essential difference: class imbalances. For example, equipment failures (anomalies) are significantly rarer than having the equipment functioning normally.
We can observe anomalies in different kinds of data. In the following graph, we can see an example of anomalies in a numeric series:
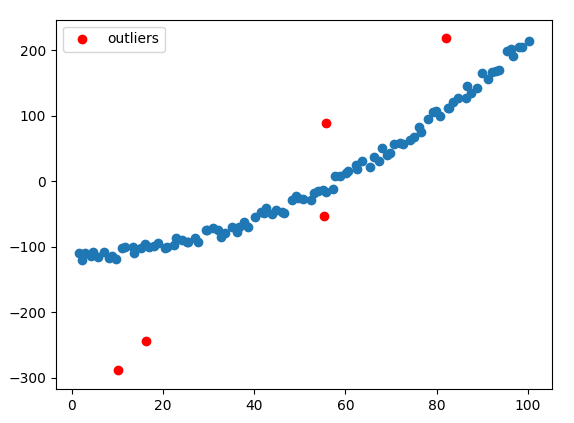
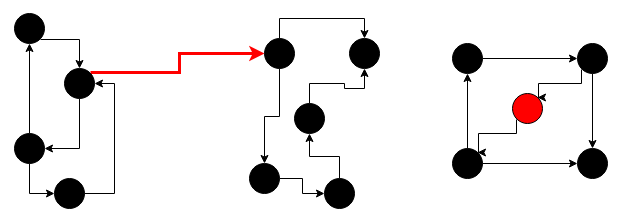
In the following diagram, we can see anomalies in graphs; these anomalies can be as edges as well as vertices (see elements marked with a lighter color):
The following text shows anomalies in a sequence of characters:
AABBCCCAABBCCCAACABBBCCCAABB
The quality or performance of anomaly detection tasks can be estimated, just like classification tasks can, by using, for example, AUC-ROC.
We have discussed what anomalies are, so let's see what approaches there are to detect them.