
This class of system began to develop in the '90s. Under this approach, recommendations are generated based on the interests of other similar users. Such recommendations are the result of the collaboration of many users, hence the name of the method.
The classical implementation of the algorithm is based on the principle of k-nearest neighbors (kNN). For every user, we look for the k most similar to them (in terms of preferences). Then, we supplement the information about the user with known data from their neighbors. So, for example, if it is known that your neighbors are delighted with a movie, and you have not watched it for some reason, this is a great reason to recommend this movie.
The similarity is, in this case, a synonym for a correlation of interests and can be considered in many ways—Pearson's correlation, cosine distance, Jaccard distance, Hamming distance, and other types of distances.
The classical implementation of the algorithm has one distinct disadvantage—it is poorly applicable in practice due to the quadratic complexity of the calculations. As with any nearest neighbor method, it requires the calculation of all pairwise distances between users (and there may be millions of users). It is easy to calculate that the complexity of calculating the distance matrix is 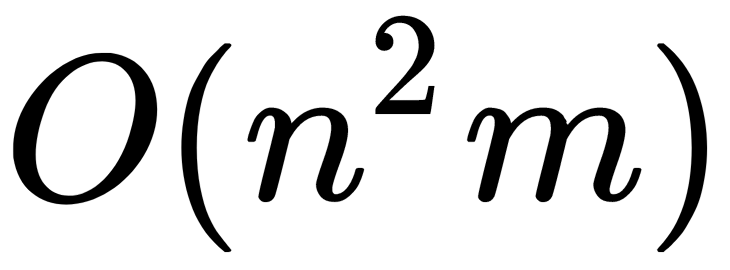 , where
, where 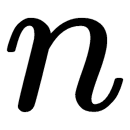 is the number of users, and
is the number of users, and 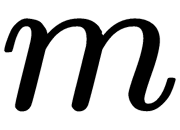 is the number of items (goods).
is the number of items (goods).
This problem can be partly solved by purchasing high-performance hardware. But if you approach it wisely, then it is better to introduce some corrections into the algorithm in the following way:
- Update distances not with every purchase but with batches (for example, once a day).
- Do not recalculate the distance matrix completely, but update it incrementally.
- Choose some iterative and approximate algorithms (for example, Alternating Least Squares (ALS)).
Fulfill the following assumptions to make the algorithm more practical:
- The tastes of people do not change over time (or they do change, but they are the same for everyone).
- If people's tastes are the same, then they are the same in everything.
For example, if two clients prefer the same films, then they also like the same book. This assumption is often the case when the recommended products are homogeneous (for example, films only). If this is not the case, then a couple of clients may well have the same eating habits but their political views might be the opposite; here, the algorithm is less efficient.
The neighborhood of the user in the space of preferences (the user's neighbors), which we analyze to generate new recommendations, can be chosen in different ways. We can work with all users of the system; we can set a certain proximity threshold; we can choose several neighbors at random, or take the k most similar neighbors (this is the most popular approach). If we take too many neighbors, we get a higher chance of random noise—and vice versa. If we take too little, we get more accurate recommendations, but fewer goods can be recommended.
An interesting development in the collaborative approach is trust-based recommendations, which take into account not only the proximity of people according to their interests, but also their social proximity and the degree of trust between them. If, for example, we see that on Facebook, a girl occasionally visits a page that has her friend's audio recordings, then she trusts her musical taste. Therefore, when making recommendations to the girl, you can add new songs from her friend's playlist.