
Decision trees are a suitable family of elementary algorithms for bagging since they are quite complicated and can ultimately achieve zero errors on any training set. We can use a method that uses random subspaces (such as bagging) to reduce the correlation between trees and avoid overfitting. The elementary algorithms are trained on different subsets of the feature space, which are also randomly selected. An ensemble of decision tree models using the random subspace method can be constructed using the following algorithm.
Where the number of objects for training is N and the number of features is 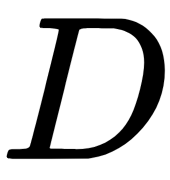 , proceed as follows:
, proceed as follows:
- Select
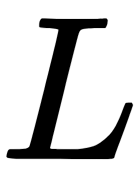 as the number of individual trees in the ensemble.
as the number of individual trees in the ensemble. - For each individual
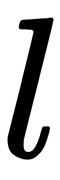 tree, select
tree, select 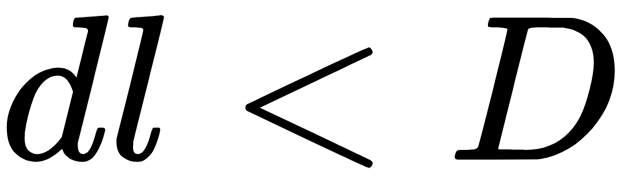 as the number of features for
as the number of features for 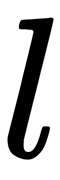 . Typically, only one value is used for all trees.
. Typically, only one value is used for all trees. - For each tree, create an
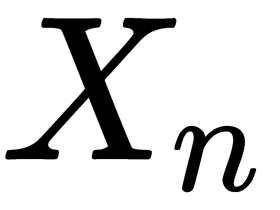 training subset using bootstrap.
training subset using bootstrap.
Now, build decision trees from 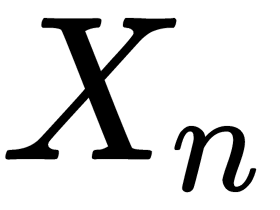 samples, as follows:
samples, as follows:
- Select
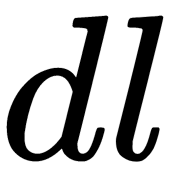 random features from the source, then the optimal division of the training set will limit its search to them.
random features from the source, then the optimal division of the training set will limit its search to them. - According to a given criterion, we choose the best attribute and make a split in the tree according to it.
- The tree is built until no more than
 objects remain in each leaf, or until we reach a certain height of the tree, or until the training set is exhausted.
objects remain in each leaf, or until we reach a certain height of the tree, or until the training set is exhausted.
Now, to apply the ensemble model to a new object, it is necessary to combine the results of individual models by majority voting or by combining a posteriori probabilities. An example of a final classifier is as follows:
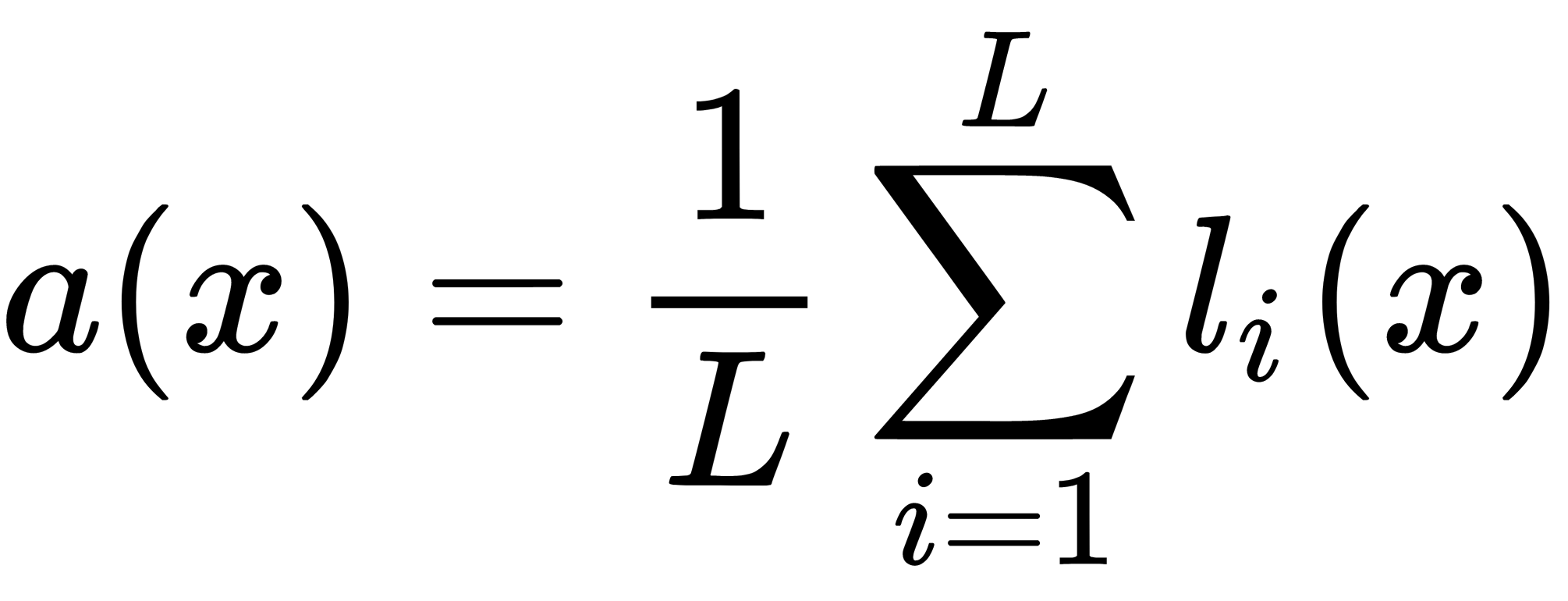
Consider the following fundamental parameters of the algorithm and their properties:
- The number of trees: The more trees, the better the quality, but the training time and the algorithm's workload also increase proportionally. Often, with an increasing number of trees, the quality on the training set rises (it can even go up to 100% accuracy), but the quality of the test set is asymptote (so, you can estimate the minimum required number of trees).
- The number of features for the splitting selection: With an increasing number of features, the forest's construction time increases too, and the trees become more uniform than before. Often, in classification problems, the number of attributes is chosen equal to
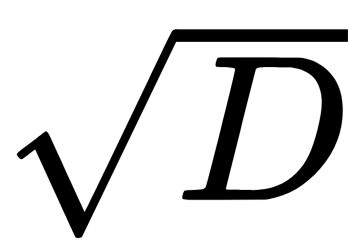 and
and 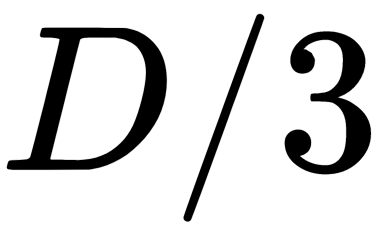 for regression problems.
for regression problems. - Maximum tree depth: The smaller the depth, the faster the algorithm is built and will work. As the depth increases, the quality during training increases dramatically. The quality may also increase on the test set. It is recommended to use the maximum depth (except when there are too many training objects, and we obtain very deep trees, the construction of which takes considerable time). When using shallow trees, changing the parameters associated with limiting the number of objects in the leaf and for splitting does not lead to a significant effect (the leaves are already large). Using shallow trees is recommended in tasks with a large number of noisy objects (outliers).
- The impurity function: This is a criterion for choosing a feature (decision rule) for branching. It is usually MSE/MAE for regression problems. For classification problems, it is the Gini criterion, the entropy, or the classification error. The balance and depth of trees may vary depending on the specific impurity function we choose.
We can consider a random forest as bagging decision trees, and during these trees' training, we use features from a random subset of features for each partition. This approach is a universal algorithm since random forests exist for solving problems of classification, regression, clustering, anomaly search, and feature selection, among other tasks.
In the following section, we will see how to use different C++ libraries for developing machine learning model ensembles.