
Let's consider the most common method that's used to train a feedforward neural network: the error backpropagation method. It is related to supervised methods. Therefore, it requires target values in the training examples.
The idea of the algorithm is based on the use of the output error of a neural network. At each iteration of the algorithm, there are two network passes – forward and backward. On a forward pass, an input vector is propagated from the network inputs to its outputs and forms a specific output vector corresponding to the current (actual) state of the weights. Then, the neural network error is calculated. On the backward pass, this error propagates from the network output to its inputs, and the neuron weights are corrected.
The function that's used to calculate the network error is called the loss function. An example of such a function is the square of the difference between the actual and target values:
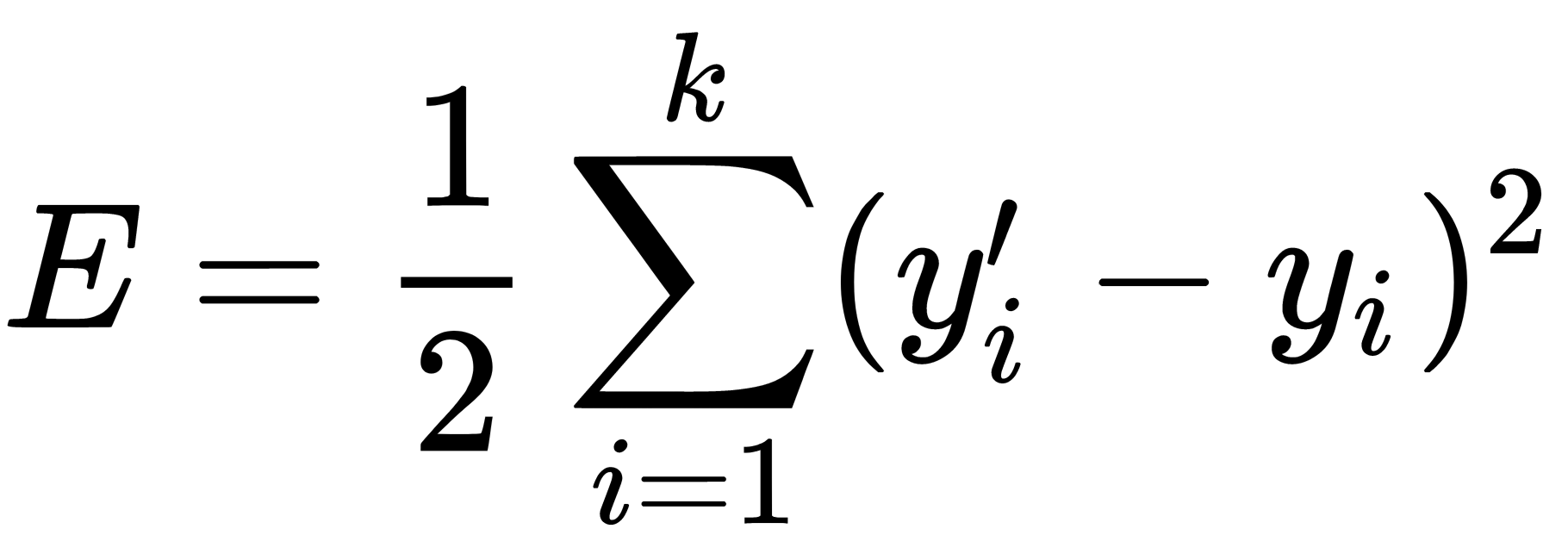
Here, k is the number of output neurons in the network, y' is the target value, and y is the actual output value. The algorithm is iterative and uses the principle of step-by-step training; the weights of the neurons of the network are adjusted after one training example is submitted to its input. On the backward pass, this error propagates from the network output to its inputs, and the following rule corrects the neuron's weights:
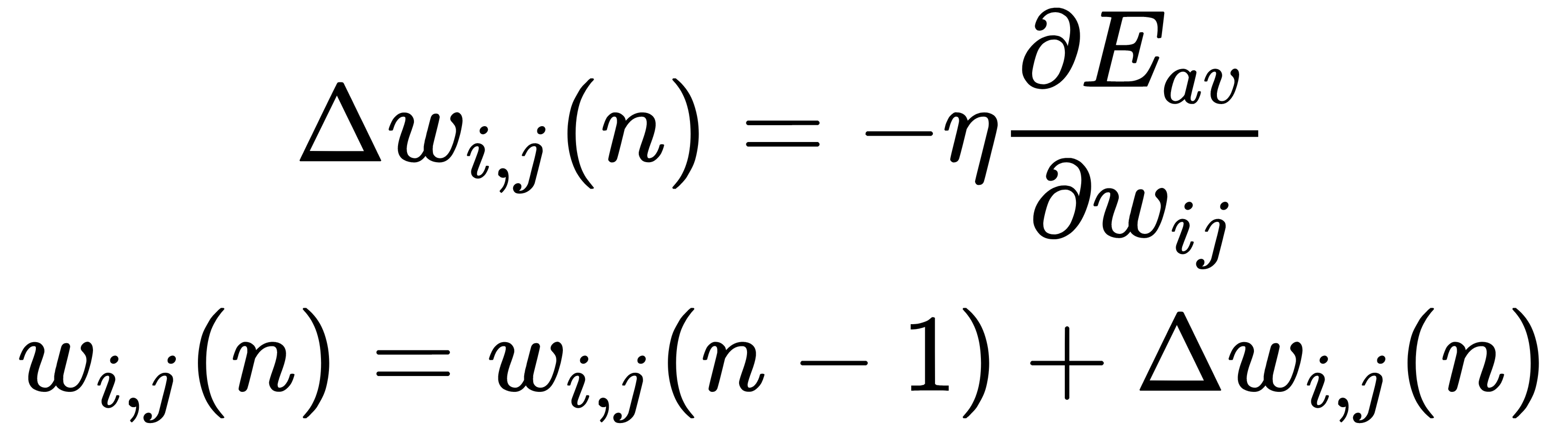
Here, 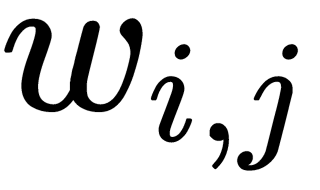 is the weight of the
is the weight of the  connection of the
connection of the 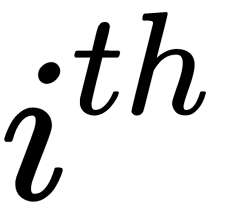 neuron and
neuron and 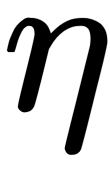 is the learning rate parameter that allows us to control the value of the correction step,
is the learning rate parameter that allows us to control the value of the correction step, 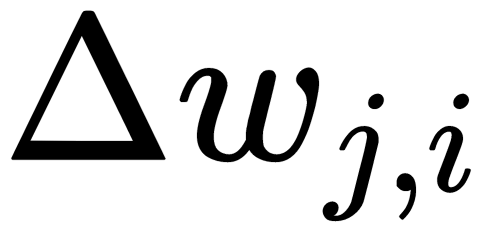 . To accurately adjust to a minimum of errors, this is selected experimentally in the learning process (it varies in the range from 0 to 1).
. To accurately adjust to a minimum of errors, this is selected experimentally in the learning process (it varies in the range from 0 to 1). 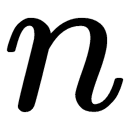 is the number of the hierarchy of the algorithm (that is, the step number). Let's say that the output sum of the ith neuron is as follows:
is the number of the hierarchy of the algorithm (that is, the step number). Let's say that the output sum of the ith neuron is as follows:
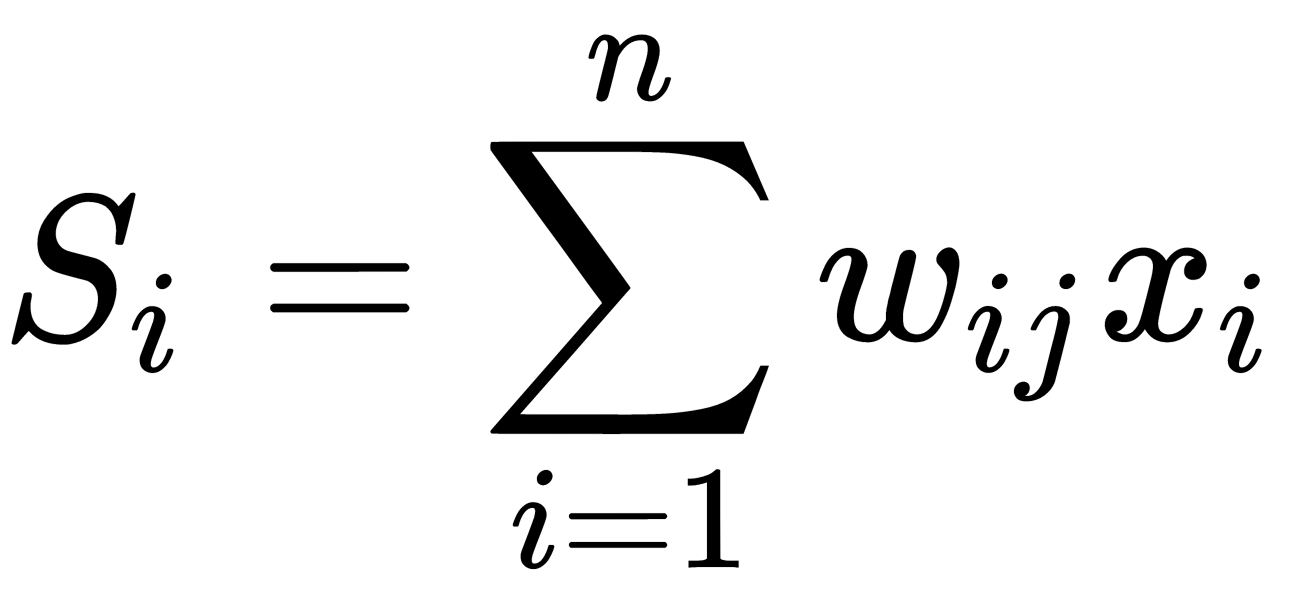
From this, we can show the following:
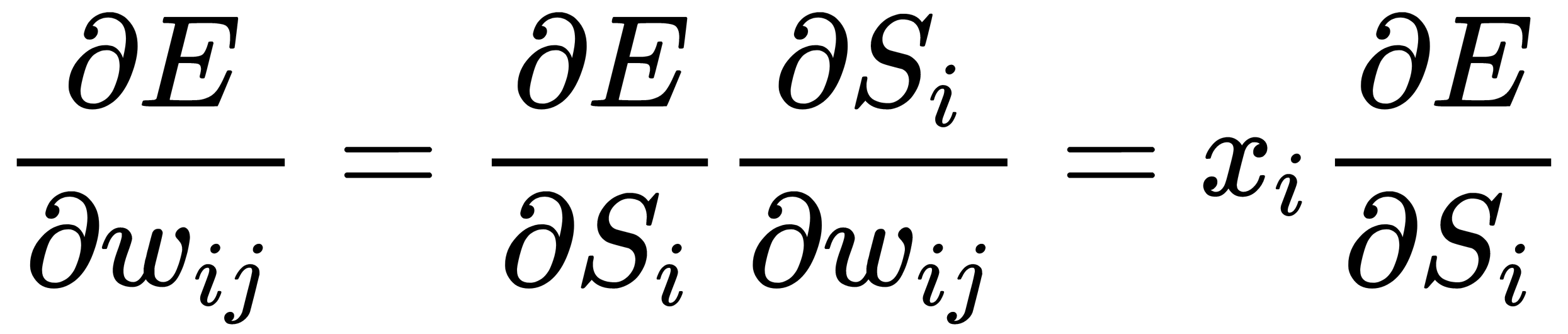
Here, we can see that the differential, 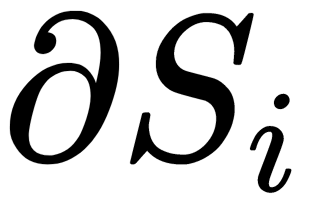 , of the activation function of the neurons of the network, f (s), must exist and not be equal to zero at any point; that is, the activation function must be differentiable on the entire numerical axis. Therefore, to apply the backpropagation method, sigmoidal activation functions, such as logistic or hyperbolic tangents, are often used.
, of the activation function of the neurons of the network, f (s), must exist and not be equal to zero at any point; that is, the activation function must be differentiable on the entire numerical axis. Therefore, to apply the backpropagation method, sigmoidal activation functions, such as logistic or hyperbolic tangents, are often used.
In practice, training is continued not until the network is precisely tuned to the minimum of the error function, but until a sufficiently accurate approximation is achieved. This process allows us to reduce the number of learning iterations and prevent the network from overfitting.
Currently, many modifications of the backpropagation algorithm have been developed. Let's look at some of them.