
The most widespread regularization methods are L2-regularization, dropout, and batch normalization. Let's take a look:
- L2-regularization (weight decay) is performed by penalizing the weights with the highest values. Penalizing is performed by minimizing their
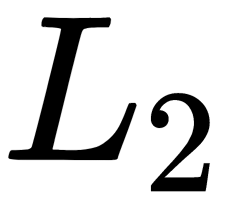 -norm using the
-norm using the  parameter – a regularization coefficient that expresses the preference for minimizing the norm when we need to minimize losses on the training set. That is, for each weigh,
parameter – a regularization coefficient that expresses the preference for minimizing the norm when we need to minimize losses on the training set. That is, for each weigh,  , we add the term,
, we add the term, 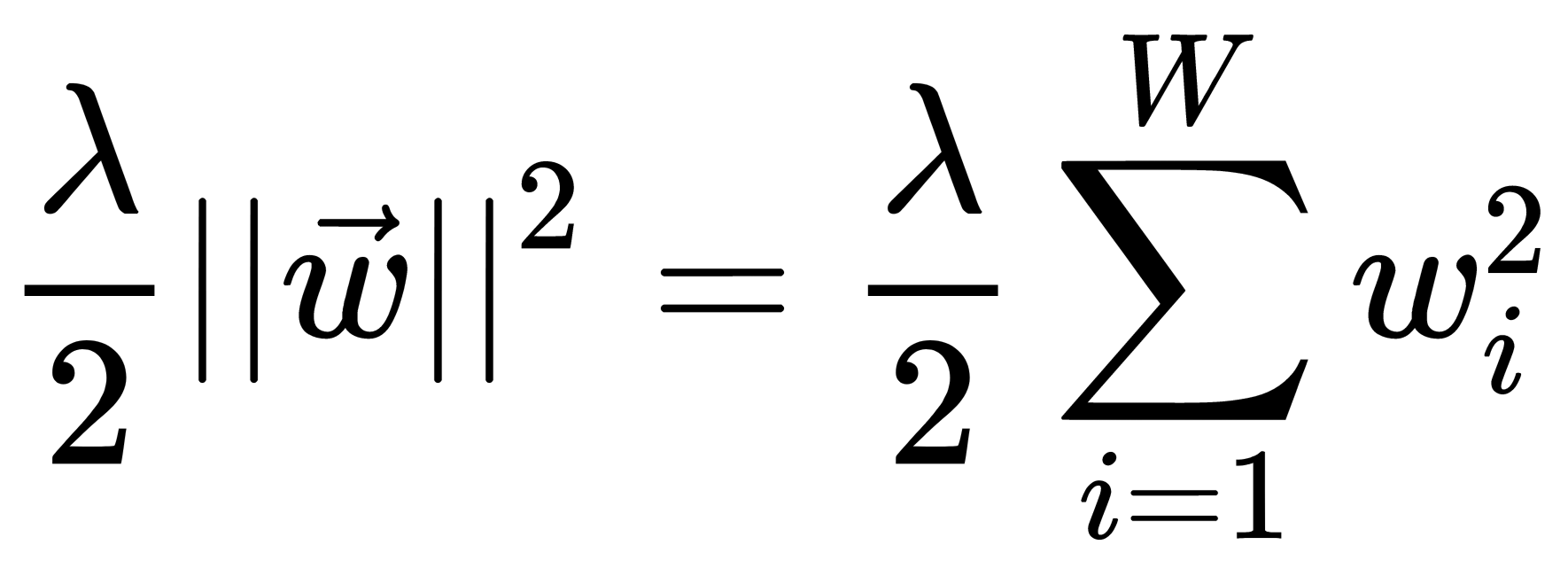 , to the loss function,
, to the loss function, 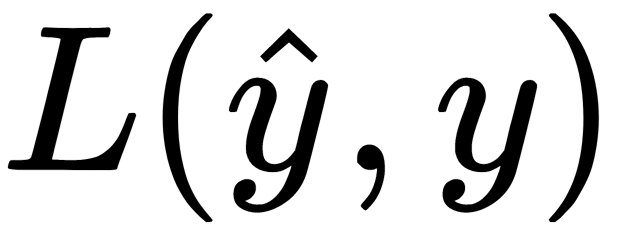 (the
(the 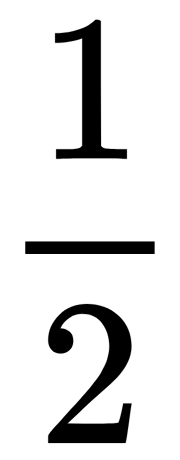 factor is used so that the gradient of this term with respect to the
factor is used so that the gradient of this term with respect to the  parameter is equal to
parameter is equal to 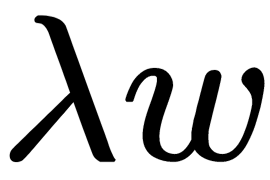 and not
and not 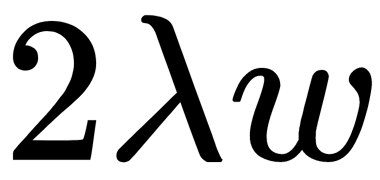 for the convenience of applying the error backpropagation method). We must select
for the convenience of applying the error backpropagation method). We must select  correctly. If the coefficient is too small, then the effect of regularization is negligible. If it is too large, the model can reset all the weights.
correctly. If the coefficient is too small, then the effect of regularization is negligible. If it is too large, the model can reset all the weights. - Dropout regularization consists of changing the structure of the network. Each neuron can be excluded from a network structure with some probability,
 . The exclusion of a neuron means that with any input data or parameters, it returns 0.
. The exclusion of a neuron means that with any input data or parameters, it returns 0.
Excluded neurons do not contribute to the learning process at any stage of the backpropagation algorithm. Therefore, the exclusion of at least one of the neurons is equal to learning a new neural network. This "thinning" network is used to train the remaining weights. A gradient step is taken, after which all ejected neurons are returned to the neural network. Thus, at each step of training, we set up one of the possible 2N network architectures. By architecture, we mean the structure of connections between neurons, and by N, we're denoting the total number of neurons. When we are evaluating a neural network, neurons are no longer thrown out. Each neuron output is multiplied by (1 - p). This means that in the neuron's output, we receive its response expectation for all 2N architectures. Thus, a neural network trained using dropout regularization can be considered a result of averaging responses from an ensemble of 2N networks. - Batch normalization makes sure that the effective learning process of neural networks isn't impeded. It is possible that the input signal to be significantly distorted by the mean and variance as the signal propagates through the inner layers of a network, even if we initially normalized the signal at the network input. This phenomenon is called the internal covariance shift and is fraught with severe discrepancies between the gradients at different levels or layers. Therefore, we have to use stronger regularizers, which slows down the pace of learning.
Batch normalization offers a straightforward solution to this problem: normalize the input data in such a way as to obtain zero mean and unit variance. Normalization is performed before entering each layer. During the training process, we normalize the batch samples, and during use, we normalize the statistics obtained based on the entire training set since we cannot see the test data in advance. We calculate the mean and variance for a specific batch, 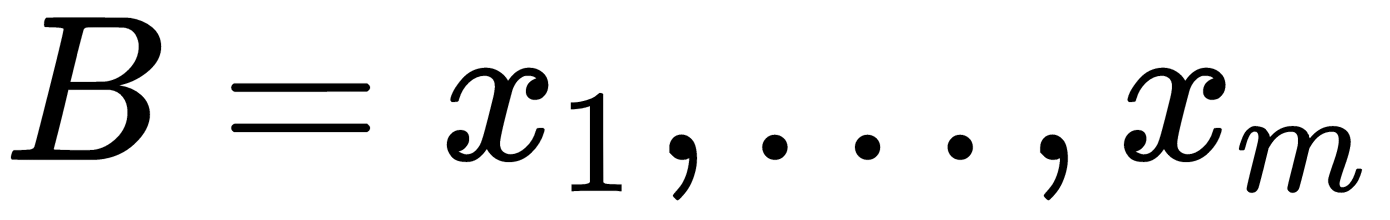 , as follows:
, as follows:
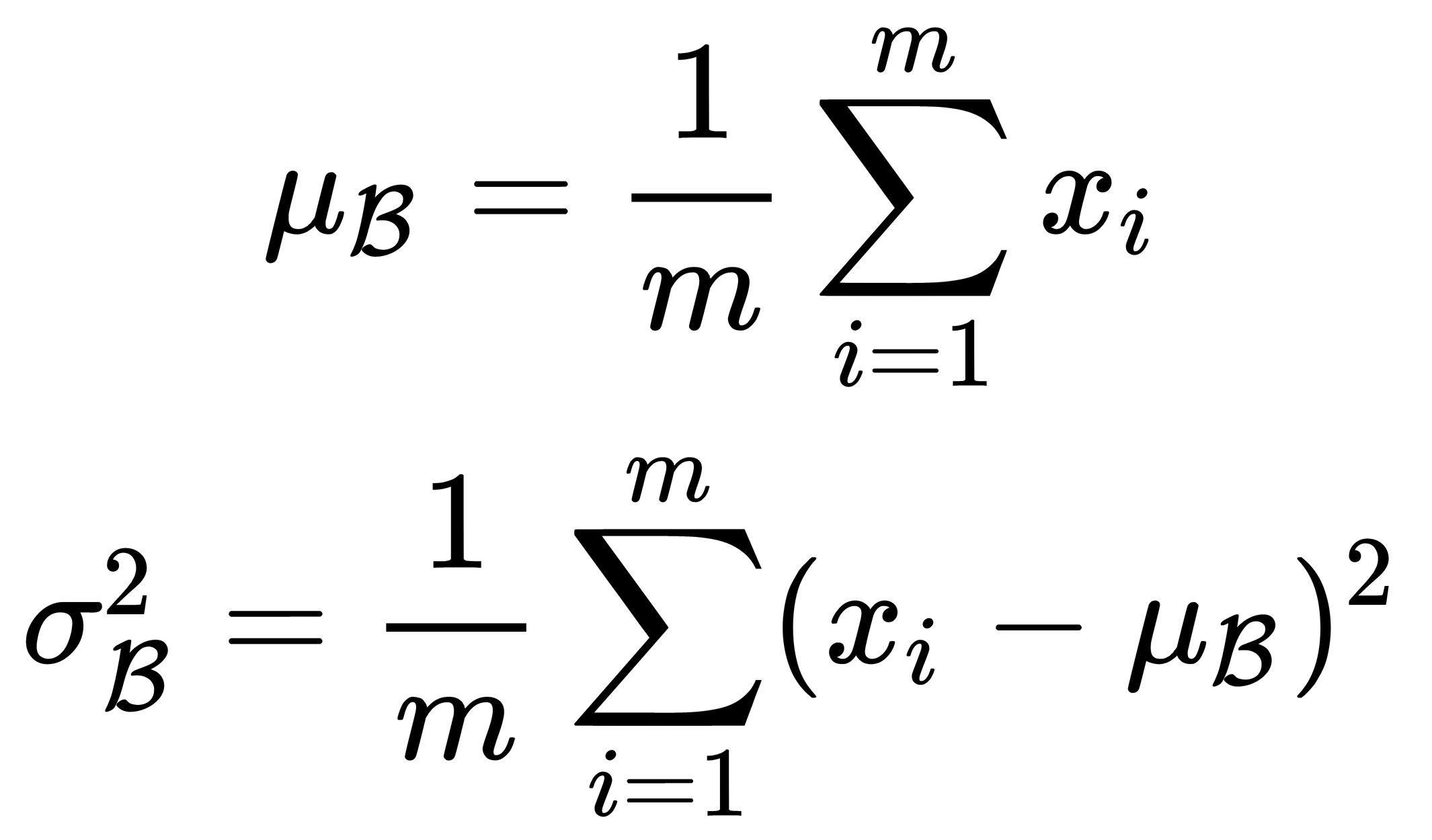
Using these statistical characteristics, we transform the activation function in such a way that it has zero mean and unit variance throughout the whole batch:
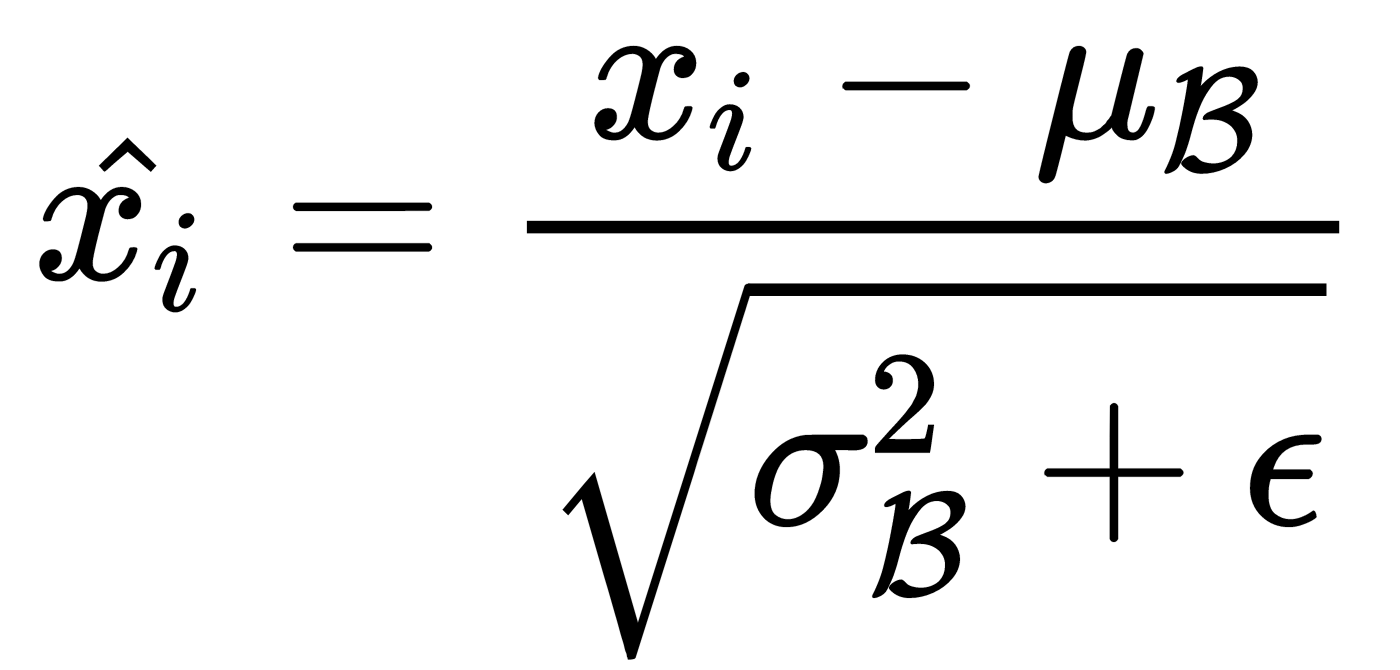
Here,  is a parameter that protects us from dividing by 0 in cases where the standard deviation of the batch is very small or even equal to zero. Finally, to get the final activation function,
is a parameter that protects us from dividing by 0 in cases where the standard deviation of the batch is very small or even equal to zero. Finally, to get the final activation function, 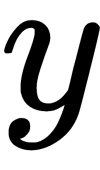 , we need to make sure that, during normalization, we don't lose the ability to generalize. Since we applied scaling and shifting operations to the original data, we can allow arbitrary scaling and shifting of normalized values, thereby obtaining the final activation function:
, we need to make sure that, during normalization, we don't lose the ability to generalize. Since we applied scaling and shifting operations to the original data, we can allow arbitrary scaling and shifting of normalized values, thereby obtaining the final activation function:
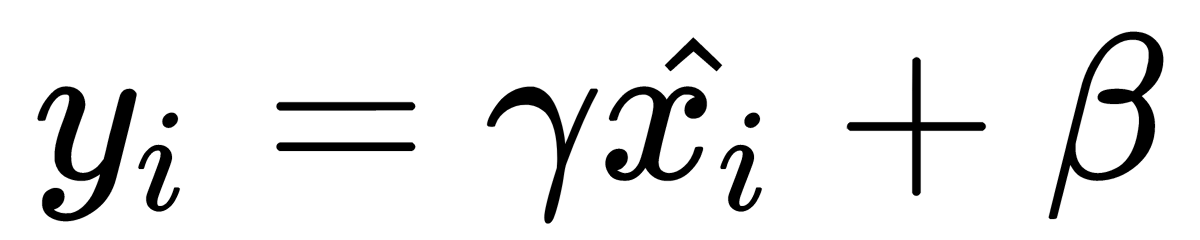
Here, 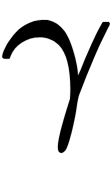 and
and 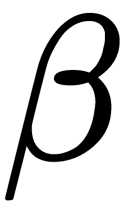 are the parameters of batch normalization that the system can be trained with (they can be optimized by the gradient descent method on the training data). This generalization also means that batch normalization can be useful when applying the input of a neural network directly.
are the parameters of batch normalization that the system can be trained with (they can be optimized by the gradient descent method on the training data). This generalization also means that batch normalization can be useful when applying the input of a neural network directly.
This method, when applied to multilayer networks, almost always successfully reaches its goal – it accelerates learning. Moreover, it's an excellent regularizer, allowing us to choose the learning rate, the power of the 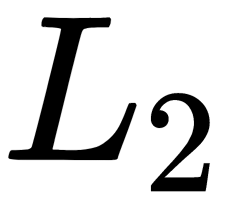 -regularizer, and the dropout. The regularization here is a consequence of the fact that the result of the network for a specific sample is no longer deterministic (it depends on the whole batch that this result was obtained from), which simplifies the generalization process.
-regularizer, and the dropout. The regularization here is a consequence of the fact that the result of the network for a specific sample is no longer deterministic (it depends on the whole batch that this result was obtained from), which simplifies the generalization process.
The next important topic we'll look at is neural network initialization. This affects the convergence of the training process, training speed, and overall network performance.