
It's almost unheard of for a database installation to not require some credentials for access in a production system, and there are other parameters that need to be kept track of across the various object types whose data will be saved in the data store. Since those parameters will be common for all of the different object types in use (for the most part), creating a mechanism that can be used to gather them all up seems like a logical first step. The common parameters that will most likely be needed were noted in the RDBMS exploration earlier, and are as follows:
- host
- port
- database
- user
- password
By the time hms_sys is deployed to a production environment, these will almost certainly be saved in some sort of configuration file, and it doesn't hurt to get that logic in place now, rather than waiting to do so later. All of the data store configuration and connection parameters can be captured in a single object instance—a DatastoreConfig:
class DatastoreConfig:
"""
Represents a set of credentials for connecting to a back-end
database engine that requires host, port, database, user, and
password values.
"""
With the exception of the port property, which only allows int values from 0 through 65535 (the normal range of valid ports in a TCP/IP connection), there's nothing substantially new in the property getter-, setter-, and deleter-methods. The _set_port method's value checking is very straightforward, as follows:
def _set_port(self, value:int) -> None:
if type(value) != int:
raise TypeError(
'%s.port expects an int value from 0 through 65535, '
'inclusive, but was passed "%s" (%s)' %
(self.__class__.__name__, value, type(value).__name__)
)
if value < 0 or value > 65535:
raise ValueError(
'%s.port expects an int value from 0 through 65535, '
'inclusive, but was passed "%s" (%s)' %
(self.__class__.__name__, value, type(value).__name__)
)
self._port = value
The __init__ method is also very straightforward, though it has no required arguments, because not all database engines will need all of the parameters, and the class is intended to be very generic. Connection issues that occur as a result of incomplete or invalid configuration will have to be handled at the relevant object level:
###################################
# Object initialization #
###################################
def __init__(self,
host=None, port=None, database=None, user=None, password=None
):
"""
Object initialization.
self .............. (DatastoreConfig instance, required) The instance
to execute against
host .............. (str, optional, defaults to None) the host-name
(FQDN, machine network-name or IP address) where
the database that the instance will use to persist
state-data resides
port .............. (int [0..65535], optional, defaults to None) the
TCP/IP port on the host that the database
connection will use
database .......... (str, optional, defaults to None) the name of
the database that the instance will use to persist
state-data
user .............. (str, optional, defaults to None) the user-name
used to connect to the database that the instance
will use to persist state-data
password .......... (str, optional, defaults to None) the password
used to connect to the database that the instance
will use to persist state-data
"""
Since there will eventually be a need to read configuration data from a file, a class method (from_config) is defined to facilitate that, as follows:
###################################
# Class methods #
###################################
@classmethod
def from_config(cls, config_file:(str,)):
# - Use an explicit try/except instead of with ... as ...
try:
fp = open(config_file, 'r')
config_data = fp.read()
fp.close()
except (IOError, PermissionError) as error:
raise error.__class__(
'%s could not read the config-file at %s due to '
'an error (%s): %s' %
(
self.__class__.__name__, config_file,
error.__class__.__name__, error
)
)
# - For now, we'll assume that config-data is in JSON, though
# other formats might be better later on (YAML, for instance)
load_successful = False
try:
parameters = json.loads(config_data)
load_successful = True
except Exception as error:
pass
# - YAML can go here
# - .ini-file format here, maybe?
if load_successful:
try:
return cls(**parameters)
except Exception as error:
raise RuntimeError(
'%s could not load configuration-data from %s '
'due to an %s: %s' %
(
cls.__name__, config_file,
error.__class__.__name__, error
)
)
else:
raise RuntimeError(
'%s did not recognize the format of the config-file '
'at %s' % (cls.__name__, config_file)
)
The local MongoDB connections for development can then be created as instances of DatastoreConfig, with the minimum parameters needed to connect to a local database, as follows:
# - The local mongod service may not require user-name and password
local_mongo = DatastoreConfig(
host='localhost', port=27017, database='hms_local'
)
Reading and writing data against a Mongo database, using the pymongo library, requires a few steps, as follows:
-
A connection to the Mongo engine has to be established (using a pymongo.MongoClient object). This is where the actual credentials (the username and password) will apply, if the Mongo engine requires them. The connection (or client) allows the specification of…
-
The database where the data is being stored has to be specified. The database value in the configuration takes care of specifying the name of the database, and the database itself, a pymongo.database.Database object, once returned by the client/connection allows the creation of…
- The collection where the actual documents (records) reside (a pymongo.collection.Collection object), and where all of the data access processes actually occur.
A very simple, functional example of the connection/database/collection setup for hms_sys development might include the following:
client = pymongo.MongoClient() # Using default host and port database = client['hms_sys'] # Databases can be requested by name objects = database['Objects'] # The collection of Object # documents/records
At this point, the objects object, as a Mongo Collection, provides methods for reading, writing, and deleting documents/records in the Objects collection/table.
The organization of documents in a collection can be very arbitrary. That objects collection could be used to store Artisan, Product, and Order state data documents all in the same collection. There's no functional reason that prevents it. Over a long enough period of time, though, reading data from that collection would slow down more than reads from collections that, for example, grouped those same Artisan, Product, and Order state data documents into separate collections—one collection for each object type. There might be other considerations that will make such a grouping beneficial, as well. Keeping objects of the same type would probably make managing them through a GUI tool easier, and might be similarly beneficial for command-line management tools.
Taking all of the preceding factors together, a fairly optimal integration of data storage and parameters across the objects in the hms_sys data store would include the following:
- One or more client connections to a common MongoDB instance, whose credentials and parameters are all configurable and are eventually controlled by a configuration file
- One database specification that is common to all of the objects in the Central Office code bases, from the same configuration that the client setup uses
- One collection specification per object type, which could be as simple as using the name of the class
Having made all of these decisions, we can create an ABC that central-office application and service objects can derive from in much the same way that Artisan Application data objects derived from JSONFileDataObject, as we saw in Chapter 12, Persisting Object Data to Files,—call it HMSMongoDataObject. Since it will need to be available to both the Artisan Gateway service and the Central Office application, it needs to live in a package that is available to both. Without creating another package project solely for this purpose, the logical place for it to live would be in a new module in hms_core; and, if the naming convention established in the Artisan code base is followed, that module would be named data_storage.py.
Diagrammed, the relationship between HMSMongoDataObject and the final central-office data objects looks much like the Artisan Application's counterparts, although hms_co .. Order is not included, because it may need some special consideration that we haven't explored:
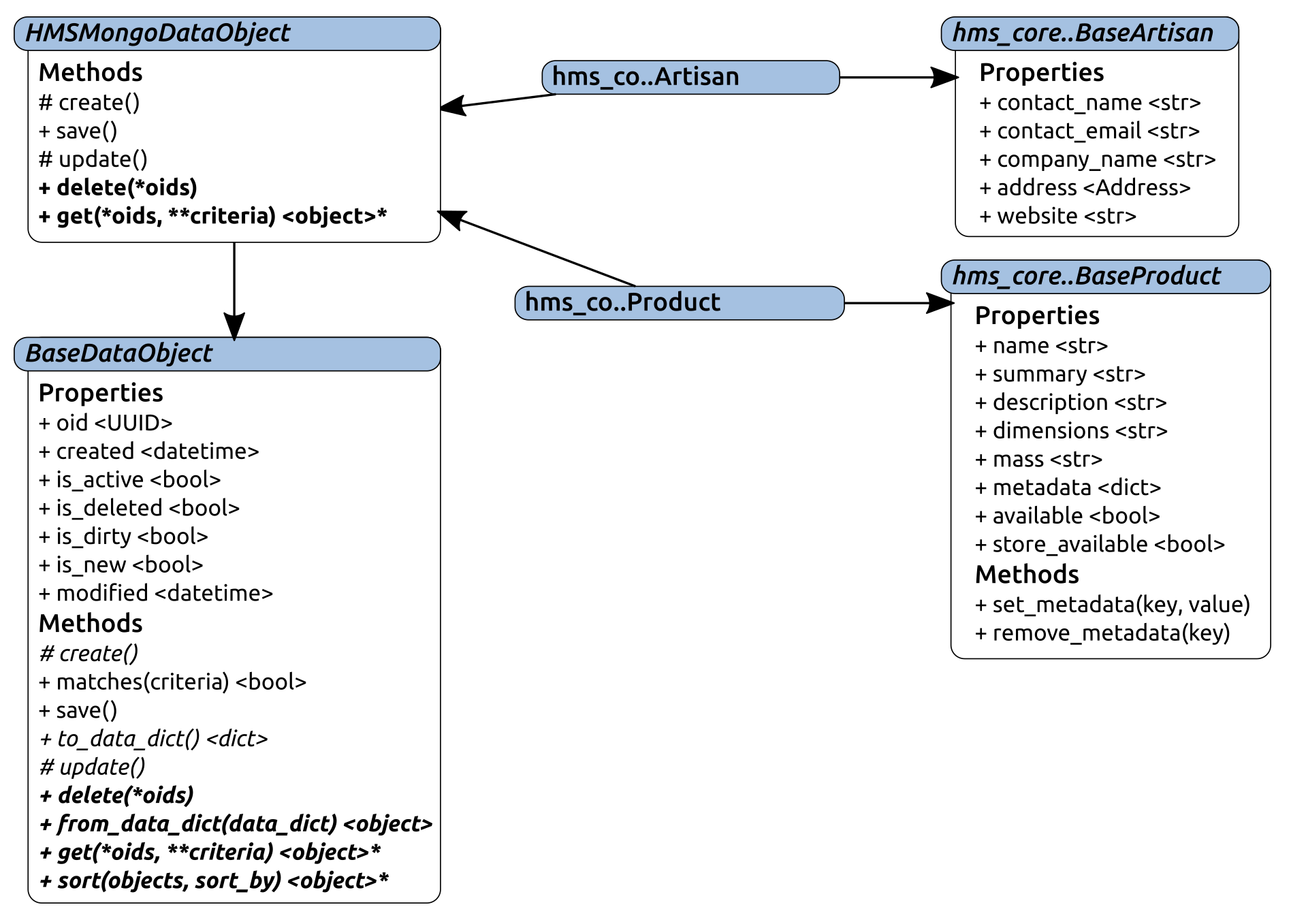
The implementation of HMSMongoDataObject starts by inheriting from BaseDataObject, and then it includes the following:
class HMSMongoDataObject(BaseDataObject, metaclass=abc.ABCMeta):
"""
Provides baseline functionality, interface requirements, and
type-identity for objects that can persist their state-data to
a MongoDB-based back-end data-store.
"""
Since we'll be using a DatastoreConfig object to keep track of a common configuration for all derived classes, that becomes a class attribute (_configuration), as follows:
###################################
# Class attributes/constants #
###################################
# - Keeps track of the global configuration for data-access
_configuration = None
MongoDB documents, when they are created, have an _id value that, if passed to a normal from_data_dict to create an instance of the class, will throw an error. There hasn't been an _id argument in any of our implementations so far, and there's no reason to expect one to surface anywhere down the line, because we're using our own oid property as the unique identifier for object records. In order to prevent that from happening, from_data_dict will need to either explicitly remove that _id value from its object creation process, or keep track of all of the valid arguments that can exist, and filter things accordingly. Of those two options, the latter, while slightly more complicated, also feels more stable. In the (unlikely) event that more fine-grained filtering of data is needed during object creation in from_data_dict, tracking the valid arguments will be easier to maintain than having to modify a long list of key removals:
# - Keeps track of the keys allowed for object-creation from
# retrieved data
_data_dict_keys = None
Since we have decided that all objects of any given type should live in a collection with a meaningful and related name, the approach that needs the least effort is simply using the class name as the name of the MongoDB collection that state data for instances of the class live in. We can't rule out a potential need to change that, though, so another class attribute that allows that default behavior to be overridden feels like a sensible precaution:
# - Allows the default mongo-collection name (the __name__
# of the class) to be overridden. This should not be changed
# lightly, since data saved to the old collection-name will
# no longer be available!
_mongo_collection = None
The properties of HMSMongoDataObject look relatively normal at first glance, but there is a significant difference that may not be obvious at first. Since data access for any given class is focused on instances of that class, and creation of database connections and collections could be computationally expensive, having a single connection for all data object classes is a tempting idea—that implementation would have the instance-level connection and database properties' underlying storage attributes be members of HMSMongoDataObject, not of the derived classes themselves, or instances of those classes.
That would, in effect, require that all data objects for hms_sys live in the same database and be accessed through the same MongoDB instance at all times. While that's not an unreasonable requirement, it could make moving live system data problematic. The entire system might need to be shut down for such a data move. As a compromise, the connection and database properties of each class will be members of that class, instead – which would, for example, allow Artisan object data to be moved independently of Product data. This may not be a likely consideration in the near future of the system, but it doesn't feel like a bad compromise to make if it has the potential of reducing effort somewhere down the line:
###################################
# Property-getter methods #
###################################
def _get_collection(self) -> pymongo.collection.Collection:
try:
return self.__class__._collection
except AttributeError:
# - If the class specifies a collection-name, then use that
# as the collection...
if self.__class__._mongo_collection:
self.__class__._collection = self.database[
self.__class__._mongo_collection
]
# - Otherwise, use the class-name
else:
self.__class__._collection = self.database[
self.__class__.__name__
]
return self.__class__._collection
def _get_configuration(self) -> DatastoreConfig:
return HMSMongoDataObject._configuration
def _get_connection(self) -> pymongo.MongoClient:
try:
return self.__class__._connection
except AttributeError:
# - Build the connection-parameters we need:
conn_config = []
# - host
if self.configuration.host:
conn_config.append(self.configuration.host)
# - port. Ports don't make any sense without a
# host, though, so host has to be defined first...
if self.configuration.port:
conn_config.append(self.configuration.port)
# - Create the connection
self.__class__._connection = pymongo.MongoClient(*conn_config)
return self.__class__._connection
def _get_database(self) -> pymongo.database.Database:
try:
return self.__class__._database
except AttributeError:
self.__class__._database = self.connection[
self.configuration.database
]
return self.__class__._database
The collection, connection, and database properties are also handled differently, for the purposes of deletion. The actual objects that are retrieved by the getter methods are lazily instantiated (created when they are needed, in order to reduce system load when they aren't going to be used), and, because they don't exist until they are first created (by a reference to them), it's just easier to truly delete them, rather than set them to some default value, such as None:
###################################
# Property-deleter methods #
###################################
def _del_collection(self) -> None:
# - If the collection is deleted, then the database needs
# to be as well:
self._del_database()
try:
del self.__class__._collection
except AttributeError:
# - It may already not exist
pass
def _del_connection(self) -> None:
# - If the connection is deleted, then the collection and
# database need to be as well:
self._del_collection()
self._del_database()
try:
del self.__class__._connection
except AttributeError:
# - It may already not exist
pass
def _del_database(self) -> None:
try:
del self.__class__._database
except AttributeError:
# - It may already not exist
pass
The property definitions are slightly different than what we've used in the past, because those properties can be retrieved or deleted, but not set. This corresponds to the idea that the database and collection can only be retrieved (opened) or closed (deleted). Accordingly, they have no setter methods defined or attached to the properties themselves, and the configuration property takes that a step further – it is read-only:
###################################
# Instance property definitions #
###################################
collection = property(
_get_collection, None, _del_collection,
'Gets or deletes the MongoDB collection that instance '
'state-data is stored in'
)
connection = property(
_get_connection, None, _del_connection,
'Gets or deletes the database-connection that the instance '
'will use to manage its persistent state-data'
)
database = property(
_get_database, None, _del_database,
'Gets or deletes the MongoDB database that instance '
'state-data is stored in'
)
configuration = property(
_get_configuration, None, None,
'Gets, sets or deletes the configuration-data '
'(DatastoreConfig) of the instance, from HMSMongoDataObject'
)
The __init__ method looks very much like the __init__ method of JSONFileDataObject, with the same arguments (and for the same reasons). Since we have no properties that require default values to be set, however, the only thing that it needs to do is call its own parent constructor, as follows:
###################################
# Object initialization #
###################################
def __init__(self,
oid:(UUID,str,None)=None,
created:(datetime,str,float,int,None)=None,
modified:(datetime,str,float,int,None)=None,
is_active:(bool,int,None)=None,
is_deleted:(bool,int,None)=None,
is_dirty:(bool,int,None)=None,
is_new:(bool,int,None)=None,
):
"""
Object initialization.
self .............. (HMSMongoDataObject instance, required) The
instance to execute against
"""
# - Call parent initializers if needed
BaseDataObject.__init__(self,
oid, created, modified, is_active, is_deleted,
is_dirty, is_new
)
# - Perform any other initialization needed
Like JSONFileDataObject, the _create and _update methods for HMSMongoDataObject aren't necessary. MongoDB, like the JSON file approach that was used earlier, doesn't distinguish between creating and updating a document. Both processes will simply write all of the object data to the document, creating it if necessary. Since they are required by BaseDataObject but aren't of use in this context, the same implementation, simply raising an error with developer-useful information, will suffice:
###################################
# Instance methods #
###################################
def _create(self) -> None:
"""
Creates a new state-data record for the instance in the back-end
data-store
"""
raise NotImplementedError(
'%s._create is not implemented, because the save '
'method handles all the data-writing needed for '
'the class. Use save() instead.' %
self.__class__.__name__
)
def _update(self) -> None:
"""
Updates an existing state-data record for the instance in the
back-end data-store
"""
raise NotImplementedError(
'%s._update is not implemented, because the save '
'method handles all the data-writing needed for '
'the class. Use save() instead.' %
self.__class__.__name__
)
The implementation of save, supported by the class-level collection and its database and connection ancestors, is very simple. We need to acquire the data_dict for the instance and tell the MongoDB connection to insert that data. The one complicating factor in this process is the standard MongoDB _id value that was mentioned earlier. If we did nothing more than calling insert, there would be no _id value for the MongoDB engine to use to identify that a document that already exists does, in fact, exist. The inevitable result of that would be the creation of new document records for existing items on every update (instead of replacing existing documents), polluting the data with out-of-date instances on every update.
Under normal circumstances, the easiest solution for this would be to either change the oid property to _id during data writing processes and from _id back to oid during data reads, or to simply change the oid properties that have been established thus far to _id in the classes defined thus far. The first option would require only a bit of effort in each to_data_dict and from_data_dict method, including the ones already defined in the Artisan data objects, but it would tend to be more error-prone, as well, and it would require additional testing. It's a viable option, but it may not be the best one. Changing the names of the oid properties to _id across the board would be simpler (little more than a wide-scale search-and-replace operation, really), but it would leave the classes with what would look like a protected property name that would actually be a public property. Functionally, that's not such a big deal, but it flies in the face of Python code standards, and it is not a preferred option.
Another option is to simply assure that the hms_sys oid properties and the _id values that MongoDB generates are identical. While that does mean that individual document record sizes will increase, that change is trivial – on the order of 12 bytes per document record. Since that could be handled by the save method's process, as a simple addition to the data_dict value being saved (and would need to be ignored, or otherwise dealt with, during from_data_dict retrievals, as a part of that process), there would only be two places where it would have to be written or maintained.
That feels like a much cleaner option, even with the additional data being stored. The final implementation of save, then, would be as follows:
def save(self):
if self._is_new or self._is_dirty:
# - Make sure to update the modified time-stamp!
self.modified = datetime.now()
data_dict = self.to_data_dict()
data_dict['_id'] = self.oid
self.collection.insert_one(data_dict)
self._set_is_dirty(False)
self._set_is_new(False)
The corresponding change in from_data_dict uses the _data_dict_keys class attribute that was defined earlier. Since _data_dict_keys may not have been defined, but needs to be, checking that it's been defined and raising a more detailed error message will make debugging those (hopefully rare) occasions easier. Once that's been verified, the incoming data_dict will simply be filtered down to only those keys that match an argument in the __init__ method of the class, and will be passed to __init__ to create the relevant instance:
@classmethod
def from_data_dict(cls, data_dict):
# - Assure that we have the collection of keys that are
# allowed for the class!
if cls._data_dict_keys == None:
raise AttributeError(
'%s.from_data_dict cannot be used because the %s '
'class has not specified what data-store keys are '
'allowed to be used to create new instances from '
'retrieved data. Set %s._data_dict_keys to a list '
'or tuple of argument-names present in %s.__init__' %
(cls.__name__, cls.__name__, cls.__name__, cls.__name__)
)
# - Remove any keys that aren't listed in the class'
# initialization arguments:
data_dict = dict(
[
(key, data_dict[key]) for key in data_dict.keys()
if key in cls._data_dict_keys
]
)
# - Then create and return an instance of the class
return cls(**data_dict)
In order to allow all HMSMongoDataObject-derived classes to be configured at once, we need to provide a class method to that end. The one caveat to the implementation of this method is that all of the derived classes will also have the method available, but the method changes the _configuration attribute of the HMSMongoDataObject class, even if it's called from a derived class. It can be reasonably expected that calling, say, Artisan.configure, would configure data access for only Artisan objects – but that is not what should happen, so we'll raise an error to make sure that it doesn't go unnoticed if it's attempted:
###################################
# Class methods #
###################################
@classmethod
def configure(cls, configuration:(DatastoreConfig)):
"""
Sets configuration values across all classes derived from
HMSMongoDataObject.
"""
if cls != HMSMongoDataObject:
raise RuntimeError(
'%s.configure will alter *all* MongoDB configuration, '
'not just the configuration for %s. Please use '
'HMSMongoDataObject.configure instead.' %
(cls.__name__, cls.__name__)
)
if not isinstance(configuration, DatastoreConfig):
raise TypeError(
'%s.configure expects an instance of '
'DatastoreConfig, but was passed "%s" (%s)' %
(
cls.__name__, configuration,
type(configuration).__name__
)
)
HMSMongoDataObject._configuration = configuration
Since all of the class methods that interact with the data store will need the relevant connection, and it may not have been created by an instance before the call was made, having a helper class method to acquire the connection will be useful. It is also possible to force the acquisition of all of the relevant data store objects by creating an instance, but that feels cumbersome and counter-intuitive:
@classmethod
def get_mongo_collection(cls) -> pymongo.collection.Collection:
"""
Helper class-method that retrieves the relevant MongoDB collection for
data-access to state-data records for the class.
"""
# - If the collection has already been created, then
# return it, otherwise create it then return it
try:
return cls._collection
except AttributeError:
pass
if not cls._configuration:
raise RuntimeError(
'%s must be configured before the '
'use of %s.get will work. Call HMSMongoDataObject.'
'configure with a DatastoreConfig object to resolve '
'this issue' % (cls.__name__, cls.__name__)
)
# - With configuration established, we can create the
# connection, database and collection objects we need
# in order to execute the request:
# - Build the connection-parameters we need:
conn_config = []
# - host
if cls._configuration.host:
conn_config.append(cls.configuration.host)
# - port. Ports don't make any sense without a
# host, though, so host has to be defined first...
if cls._configuration.port:
conn_config.append(cls.configuration.port)
# - Create the connection
cls._connection = pymongo.MongoClient(*conn_config)
# - Create the database
cls._database = cls._connection[cls._configuration.database]
# - and the collection
if cls._mongo_collection:
cls._collection = cls._database[cls._mongo_collection]
# - Otherwise, use the class-name
else:
cls._collection = cls._database[cls.__name__]
return cls._collection
The implementation of the delete class method is very simple; it boils down to iterating over the provided oids, and deleting each one in the iteration. Since delete is interacting with the data store, and it's a class method, it calls the get_mongo_collection class method that we defined first:
@classmethod
def delete(cls, *oids):
"""
Performs an ACTUAL record deletion from the back-end data-store
of all records whose unique identifiers have been provided
"""
# - First, we need the collection that we're working with:
collection = cls.get_mongo_collection()
if oids:
for oid in oids:
collection.remove({'oid':str(oid)})
@classmethod
def from_data_dict(cls, data_dict):
# - Assure that we have the collection of keys that are
# allowed for the class!
if cls._data_dict_keys == None:
from inspect import getfullargspec
argspec = getfullargspec(cls.__init__)
init_args = argspec.args
try:
init_args.remove('self')
except:
pass
try:
init_args.remove('cls')
except:
pass
print(argspec)
if argspec.varargs:
init_args.append(argspec.varargs)
if argspec.varkw:
init_args.append(argspec.varkw)
raise AttributeError(
'%s.from_data_dict cannot be used because the %s '
'class has not specified what data-store keys are '
'allowed to be used to create new instances from '
'retrieved data. Set %s._data_dict_keys to a list '
'or tuple of argument-names present in %s.__init__ '
'(%s)' %
(
cls.__name__, cls.__name__, cls.__name__,
cls.__name__, "'" + "', '".join(init_args) + "'"
)
)
# - Remove any keys that aren't listed in the class'
# initialization arguments:
data_dict = dict(
[
(key, data_dict[key]) for key in data_dict.keys()
if key in cls._data_dict_keys
]
)
# - Then create and return an instance of the class
return cls(**data_dict)
The get method of HMSMongoDataObject also starts by assuring that the relevant collection is available. Structurally, it looks a lot like its counterpart in JSONFileDataObject, which should come as no great surprise, since it's performing the same sort of actions, and uses the same method signature that was defined in BaseDataObject. Because MongoDB has more capabilities available than the file system, there are some noteworthy differences:
@classmethod
def get(cls, *oids, **criteria) -> list:
# - First, we need the collection that we're working with:
collection = cls.get_mongo_collection()
# - The first pass of the process retrieves documents based
# on oids or criteria.
Rather than try to work out a (probably complex) mechanism for dynamically generating arguments for the find functionality of pymongo that include both oids and criteria, we'll handle requests based on the combination of oids and criteria that are present. Each branch in the code will result in a list of data_dict items that can be converted to a list of object instances later on.
If oids are provided, then the initial request will only concern itself with those. At present, the expectation is that get calls with oids will usually have only a few oids involved (usually just one, in fact), so using very basic functionality to get each document that corresponds to a single oid in the list should suffice, at least for now:
# - We also need to keep track of whether or not to do a
# matches call on the results after the initial data-
# retrieval:
post_filter = False
if oids:
# - oid-based requests should usually be a fairly short
# list, so finding individual items and appending them
# should be OK, performance-wise.
data_dicts = [
collection.find_one({'oid':oid})
for oid in oids
]
If, somewhere down the line, there is a need to handle longer collections of oids, pymongo supports that, as well; so, we'll leave a comment about that in place, just in case we need it later:
# - If this becomes an issue later, consider changing
# it to a variant of
# collection.find({'oid':{'$in':oids}})
# (the oids argument-list may need pre-processing first)
If oids and criteria are both provided, the eventual list of objects will need to be filtered with the matches method, so the presence of criteria will have to be monitored and tracked. If oids and criteria are both supplied, then we'll need to know that later, in order to filter the initial results:
if criteria:
post_filter = True
If only criteria is passed, then the entire set of data_dicts can be retrieved with a single call, using a list comprehension to gather the found items from the cursor that find returns:
elif criteria:
# - criteria-based items can do a find based on all criteria
# straight away
data_dicts = [
item for item in collection.find(criteria)
]
If neither oids nor criteria is passed, then we will want to return everything available, as follows:
else:
# - If there are no oids specified, and no criteria,
# the implication is that we want *all* object-records
# to be returned...
data_dicts = [
item for item in collection.find()
]
Once the initial data_dict has been generated, it will be used to create the initial list of object instances, as follows:
# - At this point, we have data_dict values that should be
# able to create instances, so create them.
results = [
cls.from_data_dict(data_dict)
for data_dict in data_dicts
if data_dict # <-- This could be None: check it!
]
And, if we still need to filter those results down even more (if we set post_filter to True earlier), then the same filter process that was used in JSONFileDataObject can be used now, calling the matches method of each object in the initial results and only adding it to the final results list if it returns True, as follows:
# - If post_filter has been set to True, then the request
# was for items by oid *and* that have certain criteria
if post_filter:
results = [
obj for obj in results if obj.matches(**criteria)
]
return results
All of the basic CRUD operations that are needed for Artisan Gateway and Central Office data objects should be easy to implement at this point, by simply deriving them from the corresponding Base class in hms_core and HMSMongoDataObject:
- Create and update operations still happen simply by calling the save method of any instance.
- Read operations are handled by the get class method, which also allows for a fair bit of functionality for finding objects, though there might be the need for additional functionality that supports more complex capabilities later on.
- Delete operations are handled by the delete class method; again, there may be the need for deletion capabilities that aren't based on the oid, but for now, this will suffice.