
OpenCL runtime and concurrency model
Abstract
The OpenCL execution model is key to achieving a high level of performance across a range of architectures without extraordinary programming effort. This chapter discusses the different components of the execution model. The host-side execution model and the device-side execution model are explained. The device-side execution model also includes device-side enqueuing of kernels, which is a powerful new component of OpenCL 2.0.
OpenCL supports a wide range of devices, ranging from discrete graphics processing unit (GPU) cards with thousands of “cores” to small embedded central processing units (CPUs). To achieve such wide support, it is vital that the memory and execution models for OpenCL be defined in such a way that we can achieve a high level of performance across a range of architectures without extraordinary programming effort. In this chapter, we discuss the different components of the execution model.
5.1 Commands and the Queuing Model
OpenCL is based on a task-parallel, host-controlled model, in which each task is data parallel. This is maintained through the use of thread-safe command-queues attached to each device. Kernels, data movement, and other operations are not simply executed by the user calling a runtime function. These operations are enqueued onto a specific queue using an asynchronous enqueue operation, to be executed at some point in the future. The synchronization points occur between commands in host command-queues and between commands in device-side command-queues.
The commands enqueued into OpenCL’s command-queues can be kernel execution commands, memory transfer commands, or synchronization commands. Completion of a command from the point of view of the host program is guaranteed only at a command-queue synchronization point. The following are the primary command synchronization points:
• Waiting for the completion of a specific OpenCL event.
• A clFinish() call that blocks the host’s execution until an entire queue completes execution.
• Execution of a blocking memory operation.
5.1.1 Blocking Memory Operations
Blocking memory operations are perhaps the most commonly used and easiest to implement method of synchronization. Instead of querying an event for completion, and blocking the host’s execution until the memory operation has completed, most memory transfer functions simply provide a parameter that enables synchronous functionality. This option is the blocking_read parameter in clEnqueueReadBuffer(), and has synonymous implementations in the other data transfer application programming interface (API) calls.
Enabling the synchronous functionality of a memory operation is commonly used when transferring data to or from a device. For example, when transferring data from a device to the host, the host should not try to access the data until the transfer is complete as the data will be in an undefined state. Therefore, the blocking_read parameter can be set to CL_TRUE to ensure that the transfer is complete before the call returns. Using this synchronous functionality allows host code that utilizes the data to be placed directly after the call with no additional synchronization steps. Blocking and nonblocking memory operations are discussed in detail in Chapter 6.
5.1.2 Events
Recall from Chapter 3 that events are used to specify dependencies between commands. Each clEnqueue API call can generate an event representing the execution status of the command, and also takes an event list that specifies all of the dependencies that must be completed before execution of the command. Generating events and supplying them as dependencies are the mechanism that allows the OpenCL runtime to implement its execution task graph.
As the command moves into and out of the command-queue and through its stages of execution, its status is constantly updated within its event. The possible states that a command can be in are as follows:
• Queued: The command has been placed into a command-queue.
• Submitted: The command has been removed from the command-queue and submitted for execution on the device.
• Ready: The command is ready for execution on the device.
• Running: Execution of the command has started on the device.
• Ended: Execution of the command has finished on the device.
• Complete: The command and all of its child commands have finished execution.
Owing to the asynchronous nature of the OpenCL API, API calls cannot simply return error conditions or profiling data that relate to the execution of the OpenCL command. The API calls return error conditions relating information known at enqueue time (e.g., validity of parameters) However, OpenCL also provides a mechanism for checking error conditions relating to the execution of the command. The error conditions related to the execution of a command can be queried through the event associated with the command. Indeed, completion can be considered a condition similar to any other. Querying an event’s status is done using the API call clGetEventInfo() and passing the argument CL_EVENT_COMMAND_EXECUTION_STATUS to the parameter param_name.
Successful completion is indicated when the event status associated with a command is set to CL_COMPLETE. Notice that the description of “complete” specifies that the execution of a command and all of its child commands has finished. Child commands are relevant when a kernel enqueues child kernels for execution. This is discussed with device-side enqueuing later in this chapter.
Unsuccessful completion results in abnormal termination of the command, which is indicated by setting the event status to a negative value. In this case, the command-queue associated with the abnormally terminated command and all other command-queues in the same context may no longer be available.
The API call clWaitForEvents() can be used to have the host block execution until all events specified in the wave-list have finished executing.
5.1.3 Command Barriers and Markers
An alternative method of synchronizing without blocking the host is to enqueue a command barrier. A command barrier is conceptually similar to calling clWaitForEvents() from the host, but is managed internally to the runtime. Barriers are enqueued using the clEnqueueBarrierWithWaitList() command, which takes an optional list of events to wait on. If no events are provided, the barrier waits for completion of all preceding commands in the command-queue.
Markers are similar to barriers and are enqueued with the matching clEnqueueMarkerWithWaitList() command. The difference between a barrier and a marker is that the marker does not block the execution of subsequent commands in the queue. The marker therefore allows the programmer to query when the completion of all specified events occurs without inhibiting execution.
By combining these synchronization commands and the use of events, OpenCL provides the ability to produce sophisticated task graphs enabling highly complicated behavior. This ability is important when utilizing out-of-order command-queues, which allows the runtime to optimize command scheduling.
5.1.4 Event Callbacks
OpenCL allows a user to register callbacks that can be utilized by events. The callback functions are invoked when the event reaches a specified state. The clSetEventCallback() function is used to register a callback for an OpenCL event:
The parameter command_exec_callback_type is the parameter used to specify when the callback should be invoked. The possible arguments are limited to CL_SUBMITTED, CL_RUNNING, or CL_COMPLETE.
The guarantees related to the ordering of the callback functions are limited. For example, if different callbacks are registered for CL_SUBMITTED and CL_RUNNING, while the state changes are guaranteed to happen in successive order, the callback functions are not guaranteed to be processed in order. As we will discuss in Chapters 6 and 7, memory state cannot be guaranteed for any state other than CL_COMPLETE.
5.1.5 Profiling Using Events
Determining the execution time of a command is naturally expressed via events, as the transition through each state can be expressed by associating a timer value with each state. To enable the profiling of commands, creation of the command-queue must include providing the flag CL_QUEUE_PROFILING_ENABLE to the properties parameter of clCreateCommandQueueWithProperties().
Any command that generates an event can then be profiled using a call to clGetEventProfilingInfo():
By querying the timer value associated with the transition, the programmer can determine how long the command sat in the queue, when it was submitted to the device, etc. Most commonly, the programmer will want to know the actual duration that the command performed “useful” work (e.g., how long data transfer took, or how long the kernel took to execute). To determine the time that the command actually spent executing, the arguments CL_PROFILING_COMMAND_START and CL_PROFILING_COMMAND_END can be passed as the param_name parameter in subsequent calls to clGetEventProfilingInfo(). When a kernel enqueues child kernels, the total time including all child kernels can be obtained by passing CL_PROFILING_COMMAND_COMPLETE as the argument. OpenCL defines that the timer values returned must be in the nanosecond granularity.
5.1.6 User Events
So far we have seen events that are generated by passing an event pointer argument to various API calls. However, what if the programmer desires that an OpenCL command’s execution wait for a host-based event? For example, the programmer may want his OpenCL data transfer to wait until a file has some new data. To enable this capability, user events were added to the specification in OpenCL 1.2.
Since the state transitions of user events are controlled by the application developer and not by the OpenCL runtime, the number of states possible for user events are limited. User events can be in a submitted state (CL_SUBMITTED), in a completed state (CL_COMPLETE), or in an error state. When a user event has been created, the execution status of the user event object’s state is set to CL_SUBMITTED.
The state of a user event can be changed by clSetUserEventStatus().
The execution_status parameter specifies the new execution status to be set. As this is a user event, the status can be CL_COMPLETE or a negative integer indicating an error. A negative integer value causes all enqueued commands that wait on this user event to be terminated. It should be noted that clSetUserEventStatus() can be called only once to change the execution status of an event.
5.1.7 Out-of-Order Command-Queues
The command-queues in the OpenCL examples in Chapters 3 and 4 were created as default, in-order queues. In-order queues guarantee that commands will be executed in the order in which they have been enqueued to the device by the application. However, it is possible for a queue to execute out-of-order. An out-of-order queue has no default ordering of the operations defined in the queue. If the runtime decides that it has, for example, a direct memory access (DMA) engine that can execute in parallel with compute units, or the device can execute multiple kernels at once, it is at liberty to schedule those operations in parallel, with no guarantee that one command completes execution before another starts.
The command-queue creation API (clCreateCommandQueueWithProperties()) has as properties bit field, which we have not used until now. One of the properties available for this bit field is to enable out-of-order execution of the queue (CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE). Specifying this property will create an out-of-order queue on devices that support out-of-order execution.
The code in Listing 5.1 shows the host portion of a program that uses an out-of-order command queue to write an input buffer, execute two kernels, and read an output buffer back to the host. This series of commands is ordered by specifying event dependencies between successive commands. The task graph created by these event dependencies is what allows an out-of-order queue to determine which commands can be processed. In the example in Listing 5.1, the memory transfer functions are nonblocking and the final synchronization by the host is performed by using clWaitForEvents() on the read event. Performing nonblocking memory transfers is important when using out-of-order queues to expose the potential for overlapping transfers and execution.
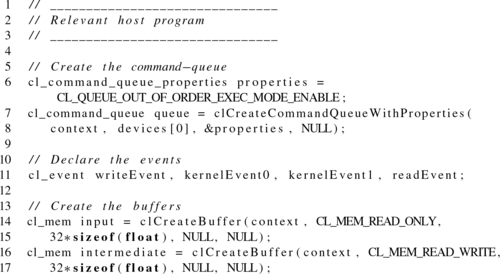

Out-of-order command-queues do not guarantee out-of-order execution. In order to avoid deadlock in a robust application, it is important to enqueue commands while being aware that they could execute serially. We see in the code in Listing 5.1 that even if the commands enqueued were executed in order that they were enqueued, the program will execute correctly. However, if the commands to “enqueue input data” and “enqueue the first kernel” were reversed in the source code, the developer may still expect the queue to execute out-of-order. However, the program would deadlock if the queue behaves as an in-order queue since the kernel execution event would wait for the write data.
5.2 Multiple Command-Queues
If we have multiple devices in a system (e.g., a CPU and a GPU, or multiple GPUs), each device needs its own command-queue. However, OpenCL also allows multiple command-queues from a context to be mapped to the same device. This is potentially useful to overlap execution of independent commands or overlap commands and host-device communication, and is an alternative to out-of-order queues. Understanding the synchronization capabilities and the host and device memory models (Chapters 6 and 7) is necessary for the management of multiple command-queues.
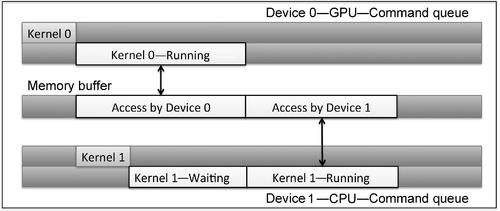
Figure 5.1 shows an OpenCL context with two devices. Separate command-queues are created to access each device. Listing 5.2 shows the corresponding code to create two command-queues, with each command-queue targeting a different device. It is important to note that synchronization using OpenCL events can be done only for commands within the same context. If separate contexts were created for the different devices, then synchronization using events would not be possible, and the only way to share data between devices would be to use the host to explicitly copy data between buffer objects.

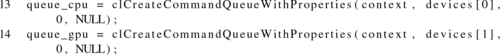
Multiple device programming with OpenCL can be summarized with two execution scenarios usually seen in parallel programming for heterogeneous devices:
• Pipelined execution: Two or more devices work in a pipeline manner such that one device waits on the results of another, shown in Figure 5.2.
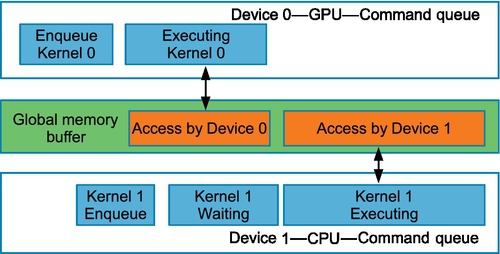
• Independent execution: A scenario in which multiple devices work independently of each other, shown in Figure 5.3.
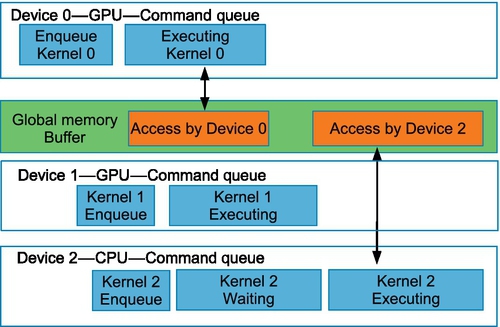
In the code in Listing 5.3, the wait-list orders execution such that the kernel on the GPU queue will complete it’s execution before the CPU queue begins executing the kernel (showing the pipelined execution scenario).

The code in Listing 5.4 shows an execution model in which the kernels are executed on different devices in parallel. The multidevice example in Figure 5.4 shows a case where two GPUs process kernels independently. The command enqueued on the CPU waits for both kernels on the GPU to complete execution.

5.3 The Kernel Execution Domain: Work-Items, Work-Groups, and NDRanges
OpenCL execution is centered on the concept of a kernel. A kernel is a unit of code that represents a single instance of a kernel function executing on a compute device as written in the OpenCL C language. A kernel-instance is at first sight similar to a C function: In the OpenCL C language, a kernel looks like a C function. The OpenCL kernel takes a parameter list, has local variables (similarly to how Pthreads have their own local variables), and standard control flow constructs. What makes the OpenCL kernel different from a C function is its parallel semantics. We described in Chapter 3 how an OpenCL work-item defines just one sliver of a large parallel execution space. In this section, we expand on the previous discussion by providing the motivation for the hierarchical execution model of work-items, work-groups, and NDRanges.
A kernel dispatch is initiated when the runtime processes an entry in a command-queue created by a call to clEnqueueNDRangeKernel(). A kernel dispatch consists of a large number of work-items intended to execute together to carry out the operations specified in the kernel body. The enqueue call creates an NDRange (an n-dimensional range) worth of work-items. An NDRange defines a one-, two-, or three-dimensional grid of work-items, providing a simple and straightforward structure for parallel execution. When mapped to the hardware model of OpenCL, each work-item runs on a unit of hardware abstractly known as a processing element, where a given processing element may process multiple work-items in turn.
Within a kernel dispatch, each work-item is largely independent. In OpenCL, synchronization between work-items is intentionally limited. This relaxed execution model allows OpenCL programs to scale to devices possessing a large number of cores. As scalable devices are usually organized in a hierarchical manner—especially the memory system—OpenCL similarly provides a hierarchical structure of its execution space.
To flexibly support devices with a large number of processing cores, OpenCL divides the global execution space into a large number of equally sized one-, two-, or three-dimensional sets of work-items called work-groups. Within each work-group, some degree of communication is allowed. The OpenCL specification defines that an entire work-group can run concurrently on an element of the device known as a compute unit. This form of concurrent execution is vital to allow synchronization. Work-groups allow local synchronization by guaranteeing concurrent execution, but they also limit communication to improve scalability. An application that involves global communication across its execution space is usually inefficient to parallelize with OpenCL. To enable efficient work-group communication, a compute unit will likely be mapped to a core so that work-items of a work-group can communicate under a shared cache or scratchpad memory.
By defining larger dispatches with more work-groups, OpenCL kernels scale onto larger and more heavily threaded devices on which more work-groups and more work-items can execute at once. OpenCL work-items attempt to express parallelism that could be expressed using Win32 or POSIX threads. The hierarchical execution mode of OpenCL takes that a step further, because the set of work-items within a work-group can be efficiently mapped to a smaller number of hardware thread contexts. This can be viewed as a generalization of single instruction multiple data (SIMD) execution, where vectors execute multiple operations over multiple cycles. However, in the OpenCL case, subvectors (work-items) can maintain their own program counters until synchronization points. The best example of this is on the GPU, where as many as 64 work-items execute in lock step as a single hardware thread on an SIMD unit: on AMD architectures, this is known as a wavefront, and on NVIDIA architectures, it is called a warp. Even though the work-items execute in lockstep, different work-items can execute different instruction sequences of a kernel. This can occur if different work-items evaluate a conditional statement such as an if-else branch to different results. While work-items may proceed in lockstep through both blocks of the if-else branch, the hardware is responsible for squashing the results of the operations that should not have been executed. This phenomenon is commonly known as divergence, and can greatly affect kernel performance since work-items need to execute redundant operations and squash results.
This execution model where all work-items appear to have an independent program counter is a simpler development model than explicit use of SIMD instructions as developers are used to when using Streaming SIMD Extensions (SSE) intrinsics on x86 processors. Because of this SIMD execution, it is often noted that for a given device, an OpenCL work-group’s size should be an even multiple of that device’s SIMD width. This value can be queried from the runtime as the parameter CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE to the clGetKernelWorkGroupInfo() function.
OpenCL defines built-in functions callable from within a kernel to obtain the position of a given work-item in the execution range. Some of these functions take a dimension value, listed here as uint dimension. This refers to the zeroth, first, or second dimension in the iteration space as provided in the multidimensional NDRange parameters when enqueueing the kernel:
• uint get_work_dim(): Returns the number of dimensions in use in the dispatch.
• size_t get_global_size(uint dimension): Returns the global number of work-items in the requested dimension.
• size_t get_global_id(uint dimension): Returns the index of the current work-item in the global space in the requested dimension.
• size_t get_local_size(uint dimension): Returns the size of work-groups in this dispatch in the requested dimension. If the kernel is executed with a nonuniform work-group size, remainder work-groups (discussed later in this chapter) may return different values for uniform work-groups.
• size_t get_enqueued_local_size(uint dimension): Returns the number of work-items in the uniform region of the NDRange in the requested dimension.
• size_t get_local_id(uint dimension): Returns the index of the current work-item as an offset from the beginning of the current work-group.
• size_t get_num_groups(uint dimension): Returns the number of work-groups in the specified dimension of the dispatch. This is get_global_size() divided by get_enqueued_local_size().
• size_t get_group_id(uint dimension): Returns the index of the current work-group. That is, the global index of the first work-item in the work-group, divided by the work-group size.
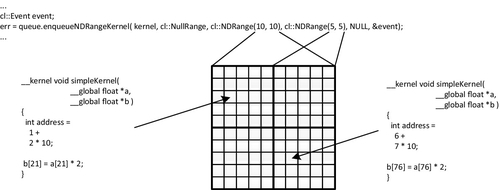
As an example of execution of a simple kernel, take the trivial kernel in Listing 5.5 that executes over a two-dimensional execution space, multiplies an input array by two, and then assigns it to the output array. Figure 5.4 shows how this executes in practice. The call to get_global_id() returns different values for each work-item referring to different points in the iteration space. In this trivial example, we use the position in the space to directly map to a two-dimensional data structure. In real examples, more complicated mappings are possible, depending on the input and output structures and the way an algorithm will process the data.

In previous versions of OpenCL, it was required that all dimensions of an NDRange were multiples of the corresponding work-group dimensions. For example, an NDRange of size 800 × 600 could not have work-groups sized 16 × 16, because ![]() . As work-groups should be sized to complement execution and memory hardware, this often required programmers to create NDRanges that were larger than the problem set. If we wanted work-groups to be sized 16 × 16, we would need to increase the NDRange size to 800 × 608. The difficulty with this approach is that work-items are created that do not map to the data set, and must be handled appropriately (e.g., checking the index and immediately returning for any out-of-range work-items). However, this technique creates headaches when one is performing operations such as barrier synchronizations that require all work-items in the group to perform the operation. To alleviate this problem, OpenCL 2.0 has removed the requirement that NDRange dimensions should be multiples of work-group dimensions. Instead, OpenCL 2.0 defines remainder work-groups as the boundaries of the NDRange, and the last work-group need not have the same dimensions as defined by the programmer. In the case of the 800 × 600 NDRange and 16 × 16 work-groups, the last row of work-groups will be sized 16 × 8. The functions get_local_size() and get_enqueued_local_size() can be used to get the size of the actual work-group (possibly with remainder dimensions), and the size of the uniform work-groups, respectively.
. As work-groups should be sized to complement execution and memory hardware, this often required programmers to create NDRanges that were larger than the problem set. If we wanted work-groups to be sized 16 × 16, we would need to increase the NDRange size to 800 × 608. The difficulty with this approach is that work-items are created that do not map to the data set, and must be handled appropriately (e.g., checking the index and immediately returning for any out-of-range work-items). However, this technique creates headaches when one is performing operations such as barrier synchronizations that require all work-items in the group to perform the operation. To alleviate this problem, OpenCL 2.0 has removed the requirement that NDRange dimensions should be multiples of work-group dimensions. Instead, OpenCL 2.0 defines remainder work-groups as the boundaries of the NDRange, and the last work-group need not have the same dimensions as defined by the programmer. In the case of the 800 × 600 NDRange and 16 × 16 work-groups, the last row of work-groups will be sized 16 × 8. The functions get_local_size() and get_enqueued_local_size() can be used to get the size of the actual work-group (possibly with remainder dimensions), and the size of the uniform work-groups, respectively.
OpenCL 2.0 has also introduced built-in functions for linear indexing that simplifies a common calculation that programmers had to code by hand in prior versions of the specification. Linear indexing provides a well-defined, unique index for a work-item, regardless of the number of dimensions in the NDRange or work-group. These functions are get_global_linear_id() and get_local_linear_id(), which provide a global linear index within the NDRange, and a local linear index within the work-group, respectively:
• size_t get_global_linear_id(): Returns a one-dimensional global ID for the work-item.
• size_t get_local_linear_id(): Returns a one-dimensional local ID for the work-item.
5.3.1 Synchronization
“Synchronization” refers to mechanisms that constrain the order of execution between two or more execution units. In general, OpenCL intentionally limits synchronization between execution units. This is influenced by the desire for scalability, but also by the wide variety of devices that are targeted by OpenCL. For example, OpenCL runs on devices in which threading is managed by hardware, such as GPUs, in addition to operating-system-managed threading devices such as mainstream x86 CPUs. This can cause issues in enabling performance and correctness of concurrent programs. With an x86 thread, it is possible to attempt to lower a semaphore and block the thread If the semaphore is unavailable, the operating system will remove the thread from execution and is free to schedule anything in its place with little in the way of resource constraints. On a GPU, applying the same trick in the GPU equivalent of a thread (the wavefront on AMD hardware) is problematic because the resources occupied are fixed. For example, removing one wavefront from execution does not free its resources, so it is possible to reach a situation in which a wavefront that is not yet able to fit on the device is required to free the semaphore before one that is already on the device is able to continue. Because the wavefronts on the device are waiting for that semaphore, they never get to execute, and so the system deadlocks.
To circumvent this eventuality, OpenCL defines blocking synchronization (i.e., a barrier) only for work-items within the same work-group. In Chapter 7, we will see that OpenCL 2.0 now also provides lock-free memory ordering constraints using atomics and fences. However, their goal is to enable broader classes of algorithms based on memory visibility guarantees, and not to provide synchronization of execution order. The following sections deal with synchronization within a work-group using barriers, and synchronization of commands, respectively.
5.3.2 Work-Group Barriers
A call to provide a barrier by a work-item within a work-group dictates that the work-item cannot continue past the barrier until all work-items in the group have also reached the barrier. This is a program-counter-level restriction, which means that each barrier in the code is treated as a different execution barrier. As a result, when a work-group barrier is placed within control flow in the kernel, all work-items within the group must encounter that barrier. The net effect of this is that behavior of barriers within control flow that diverges between different work-items in the group is undefined: on many devices, this leads to deadlock as work-items wait for others that will never reach the barrier.
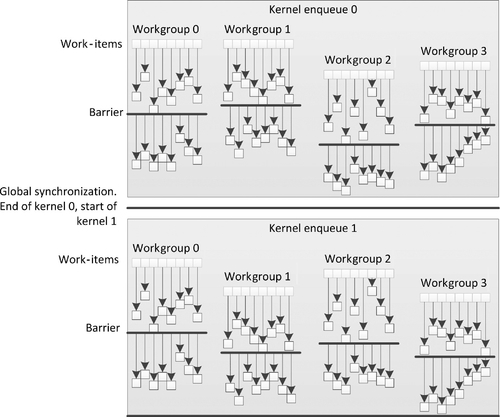
A simple example of OpenCL synchronization is shown in Figure 5.5. In this diagram, we see an initial kernel enqueue with four work-groups of eight work-items each. Under the loosest interpretation of the OpenCL specification (i.e., disregarding hardware implementations), the work-items in each work-group proceed at differing rates. When the work_group_barrier() function is called, the most advanced work-item waits for all others to catch up, continuing only after all have reached that point. Different work-groups and work-items in other work-groups proceed with a schedule independent of the schedules of the other work-groups until the end of the kernel.
The signatures of the built-in functions to provide a work-group barrier are as follows:
In Chapter 7, we will discuss the details regarding the scope parameter (as well as go into more detail regarding the flags parameter). However, for now it is sufficient to understand that the flags provided to the function determine which memory operations need to be visible to the other work-items in the group when the barrier operation completes.
The options for flags include the following:
• CLK_LOCAL_MEM_FENCE: Requires that all accesses to local memory become visible.
• CLK_GLOBAL_MEM_FENCE: Requires that all accesses to global memory become visible.
• CLK_IMAGE_MEM_FENCE: Requires that all accesses to images become visible.
In the following example, we will see work-items caching data into local memory, where each work-item reads a value from a buffer and requires that it become visible to all other work-items in the group. To do this, we will call work_group_barrier() and pass it the flag CLK_LOCAL_MEM_FENCE.
Between kernel dispatches, all work is guaranteed to be complete and all memory is guaranteed to be consistent. Then the next kernel launches with the same semantics. If we assume that the kernels enqueued as 0 and 1 in Figure 5.5 are produced from the same kernel object, the kernel code and API calls in Listing 5.6 could be expected to produce the behavior shown in Figure 5.5.


In this case, the behavior we see from the work-items is a simple wrapping neighborwise addition of elements in local memory, where availability of the data must be guaranteed before neighbors can read.
5.3.3 Built-In Work-Group Functions
The OpenCL C programming language implements built-in functions that operate on a work-group basis. As with the barrier operation, these built-in functions must be encountered by all work-items in a work-group executing the kernel. Thus, if the work-group function is within a conditional block, all the work-items in the work-group should have the same result of the conditional evaluation.
The work-group evaluation functions have been defined for all OpenCL C built-in data types, such as half, int, uint, long, ulong, float, and double. We have followed the terminology in the OpenCL specification, where gentype refers to the generic data types defined in the OpenCL C programming language. There are three types of built-in evaluation functions, categorized on the basis of their functionality:
1. predicate evaluation functions;
2. broadcast functions; and
3. parallel primitive functions (reduce and scan).
5.3.4 Predicate Evaluation Functions
The predicate evaluation functions evaluate a predicate for all work-items in the work-group and return a nonzero value if the associated condition is satisfied. The signatures of the predicate evaluation functions are as follows:
The function work_group_any() returns a nonzero value if any of the evaluations within the work-group result in a nonzero value. The function work_group_all() returns a nonzero value if all of the evaluations within the work-group result in nonzero values. An example of using the work_group_all() function is shown in Listing 5.7.

5.3.5 Broadcast Functions
The broadcast functions transmit data from one work-item within the work-group to all other work-items within the work-group. The function signature is overloaded on the basis of the number of work-group dimensions:
Looking at the signatures, we see the value x is the variable to be broadcast by the work-item identified by the work-item indices specified as local_id_*. The function return value will return the broadcast value to each work-item.
5.3.6 Parallel Primitive Functions
OpenCL supports two built-in parallel primitive functions: reduce and scan. These functions are common in many parallel applications, and requiring them to be implemented per device by the vendor will likely result in much higher performing code than if they were implemented by a programmer using a general algorithm. The signatures for the reduce and scan functions are as follows:
In these functions, the <op> suffix can be replaced with add, min, or max. Therefore, to find the maximum value of a local array, the following OpenCL C code could be used:
Most parallel programmers will be familiar with the prefix-sum operation, which can be implemented using work_group_scan_inclusive_add() or work_group_scan_exclusive_add(). The inclusive and exclusive versions of the scan operations specify whether or not the current element should be included in the computation. An inclusive scan of an array generates a new array where each element i is the sum of the elements up to and including i. Alternatively, an exclusive scan excludes the current element i. Each work-item provides and is returned the value corresponding to its linear index within the work-group.
The order of floating-point operations is not guaranteed for the parallel primitive functions, which can be a concern as floating-point operations are not associative.
5.4 Native and Built-In Kernels
OpenCL defines two additional types of mechanisms to enqueue execution on a compute device besides OpenCL cl_kernel objects. They are known as native kernels and built-in kernels. Native and built-in kernels both have orthogonal usage scenarios. Native kernels provide a mechanism to enqueue standard C functions for execution on a compute device. Built-in kernels are kernels that are specific to a particular device and provide a mechanism to allow an application developer to leverage special hardware that may be present on the device.
5.4.1 Native Kernels
Native kernels are an alternative to callbacks that are more cleanly integrated into the OpenCL execution model. Native kernels allow standard C functions compiled with a traditional compiler (rather than OpenCL kernels) to be executed within the OpenCL task graph, be triggered by events, and trigger further events. Native kernels can be queued for execution on a device and share memory objects with OpenCL kernels.
The difference between enqueuing a native kernel versus enqueuing an OpenCL kernel is that rather than taking a cl_kernel object as an argument, the native kernel enqueue function (clEnqueueNativeKernel()) takes a function pointer to a standard C function. The argument list is provided separately along with its size.
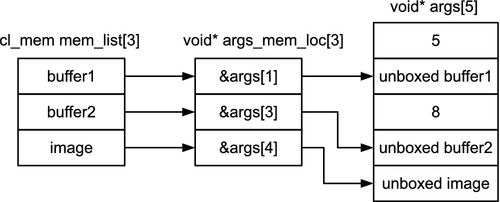
Regular OpenCL kernels use buffer and image objects passed as kernel arguments, and it would be useful to pass these to native kernels as well. Passing arguments to native kernels in OpenCL is done by a process called unboxing. Arguments are passed to native kernels by passing in a list of memory objects, in the argument mem_list, and a list of pointers, args_mem_loc, storing memory objects at addresses where the unboxed memory pointers will be placed.
To illustrate the point, consider Listing 5.8, in which a native function foo() expects an argument list containing five values, where the indices 0 and 2 are set to integers 5 and 8, respectively, and the indices 1, 3, and 4 are two buffer objects and an image object. This is shown in Figure 5.6.
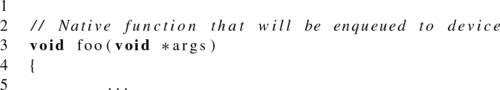
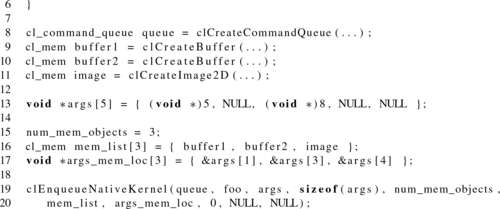
5.4.2 Built-in Kernels
Built-in kernels are tied to a particular device and are not built at runtime from source code in a program object. The common use of built-in kernels is to expose fixed-function hardware acceleration capabilities or embedded firmware associated with a particular OpenCL device or custom device. The semantics of a built-in kernel may be defined outside OpenCL, and hence are implementation defined.
An example of built-in kernel infrastructure is the motion estimation extension for OpenCL released by Intel. This extension depends on the OpenCL built-in kernel infrastructure to provide an abstraction for harnessing the domain-specific acceleration (for motion estimation in this case) in Intel devices that support OpenCL.
5.5 Device-Side Queuing
In prior versions of OpenCL, commands could be enqueued to a command-queue only from the host. OpenCL 2.0 has lifted this restriction by defining device-side command-queues, which allow a child kernel to be enqueued directly from a kernel executing on a device (referred to as the parent kernel).
The main benefit of a device-side command-queue is that it enables nested parallelism—a parallel programming paradigm where a thread executing a parallel task can spawn additional threads to execute additional tasks [1]. Nested parallelism is commonly seen in applications where the number of threads needed to execute an algorithm to completion may not be known when the threads are spawned. Nested parallelism can be contrasted with a single level of fork-join parallelism, where threads are spawned, complete their task, and then exit. The main difference between single-level fork-join parallelism and nested parallelism is shown in Figure 5.7. In single-level fork-join parallelism (Figure 5.7), the parallel threads created for execution simply finish their task and then terminate. In the nested parallelism case shown in Figure 5.7, two threads create additional threads for execution.
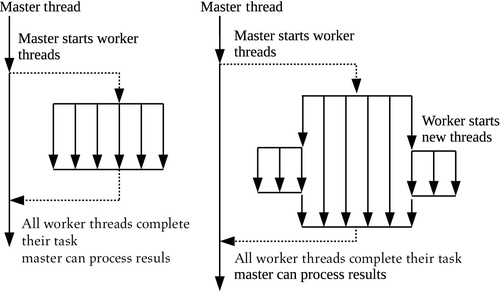
Nested parallelism benefits applications with an irregular or data-driven loop structure. A common data-driven algorithm is the breadth-first search (BFS) graph algorithm. The BFS algorithm begins at a root node of a graph and inspects all the neighboring nodes. Then for each of the neighboring nodes, it inspects their unvisited neighboring nodes, and so on, until all nodes have been visited. While BFS is being parallelized, the number of new vertices that are discovered by each vertex is not known when the application is started. Device-side enqueuing allows application developers to implement OpenCL kernels with nested parallelism in a more natural manner without additional host-device communication.
To summarize, the main benefits of device-side queues are as follows:
• Kernels can be enqueued directly from the device. This removes the requirement of synchronization or communication with the host, and potentially eliminates expensive data transfers.
• Expressing algorithms naturally. Previously, algorithms containing recursion, irregular loop structures, or other constructs that do not fit a uniform single level of parallelism had to be redesigned for OpenCL.
• By their expressing algorithms naturally, finer granularities of parallelism may be exposed to schedulers and load balancers dynamically. This allows devices to efficiently adapt in response to data-driven decisions or workloads.
In order to enqueue a child kernel for execution, a kernel may make a call to the OpenCL C built-in function enqueue_kernel(). It is very important to note that enqueue_kernel() will enqueue a kernel for each work-item that executes the function. The following is one of four variations of the function signature:
From the signature, we can see that as with host-side commands, a device-side enqueue also requires a command-queue. The flags parameter is used to specify when the child kernel should begin execution. There are three possible options with the following semantics:
• CLK_ENQUEUE_FLAGS_NO_WAIT: The child kernel can begin executing immediately.
• CLK_ENQUEUE_FLAGS_WAIT_KERNEL: The child kernel must wait for the parent kernel to reach the ENDED before executing. In this case, the parent kernel has finished executing. However, other child kernels could still be executing on the device.
• CLK_ENQUEUE_FLAGS_WAIT_WORK_GROUP: The child kernel must wait for the enqueuing work-group to complete its execution before starting.
It is also important to note that the parent kernel cannot wait for the child kernel to complete execution. A parent kernel’s execution status is considered to be “complete” when the parent kernel itself and all its child kernels have completed execution. The execution status of a parent kernel will be CL_COMPLETE if this kernel and all its child kernels complete execution successfully. The execution status of the kernel will be an error code (given by a negative integer value) if it or any of its child kernels encounter an error, or are abnormally terminated.
Similarly to clEnqueueNDRangeKernel(), enqueue_kernel() also requires a parameter that defines the dimensions of the NDRange (specified by parameter ndrange). As with the host-side call, providing a global offset and work-group size is optional. Creating a variable of type ndrange_t to describe the execution unit configuration is done using permutations of the following built-in functions:
where <N> is 1, 2, or 3. For example, creating a two-dimensional NDRange with dimensions 800 × 600 could be performed using
Finally, the last parameter of enqueue_kernel(), block, is the kernel that will be enqueued. The format for specifying the kernel is defined using Clang blocks. The following two sections describe in detail how device-side command-queues are utilized, and how a nested kernel is specified using the block syntax.
As with host API calls, enqueue_kernel() returns an integer status that indicates whether or not the enqueue succeeded. The function returns CLK_SUCCESS on success and CLK_ENQUEUE_FAILURE on failure. If the programmer desires a more specific error message regarding a failing enqueue, passing the option “-g” to clBuildProgram() or clCompileProgram() will enable finer-granularity error reporting, with values such as CLK_INVALID_NDRANGE or CLK_DEVIce:QUEUE_FULL.
5.5.1 Creating a Device-Side Queue
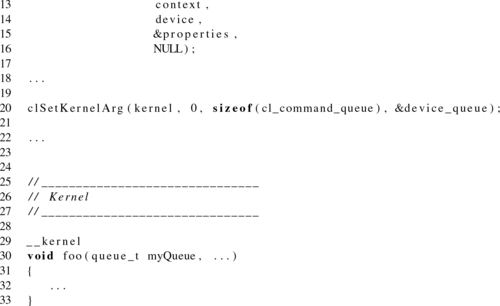
A device-side command-queue needs to be created on the host using the same API call as for host-side queues: clCreateCommandQueueWithProperties(). To specify that a queue should be created as a device-side queue, the properties parameter should be passed the parameter CL_QUEUE_ON_DEVICE. Additionally, when a device queue is being created, the specification requires that the argument CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE is also passed (using the OR-bitwise operator), since a device queue is treated as an out-of-order queue in OpenCL 2.0. The command-queue object can then be passed to the kernel as an argument, which will be specified as type queue_t in the kernel signature. An example showing a kernel with a command-queue parameter is provided in Listing 5.9.

Optionally, an additional argument, CL_QUEUE_ON_DEVIce:DEFAULT, can be supplied to clCreateCommandQueueWithProperties(), which will make the command-queue the “default” device-side command-queue for the device. This provides a simplification for the programmer, as the default queue can be accessed within a kernel using a built-in function, saving the developer the effort of passing the queue as a kernel argument.
5.5.2 Enqueuing Device-Side Kernels
When enqueuing kernel execution commands using the host API (clEnqueueNDRangeKernel()), we must first set the kernel arguments with clSetKernelArg() before enqueuing the kernel onto a command-queue. When we enqueue kernels into a device-side command-queue with enqueue_kernel(), there is no equivalent mechanism to set arguments. A mechanism is required that can pass kernels and their arguments through the same signature. To perform this operation, OpenCL has chosen to represent kernels and kernel state using Clang block syntax.
Clang blocks have been introduced to the OpenCL specification as a method to encapsulate OpenCL kernels and their arguments in order to enqueue them onto device queues. Blocks are a way to pass code and scope as data. They are known in other languages as closures and anonymous functions. The block type is defined using a result value type and a list of parameter types. With this syntax, the declaration of a block ends up looking very similar to the declaration of a function type. The ∧ operator is used to declare a block variable (where the block references a defined kernel) or to indicate the beginning of a block literal (where the body of the kernel is coded directly in the declaration).
A simple example showing both declaration variations is provided in Listing 5.10.

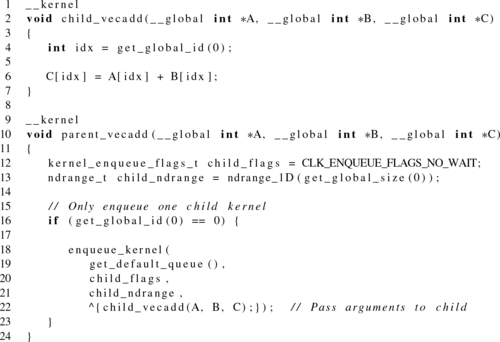
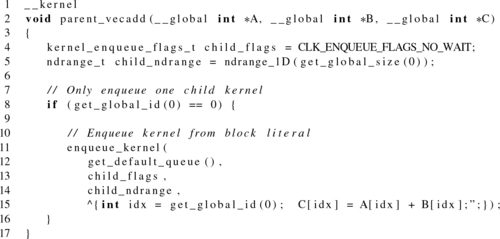
Listing 5.10 shows three syntax options for enqueuing a kernel onto a device queue. However, none of the kernels we have shown required arguments to be passed from parent to child. With the block syntax, arguments are provided when the block is defined. Recall the kernel for a simple vector addition program we saw in Chapter 3:
As a toy example to illustrate argument passing, we can modify the vector addition so that the parent enqueues a child kernel to execute the work. Listing 5.11 shows argument passing when we are creating a block variable, and Listing 5.12 shows argument passing when we are using a block literal. Notice that in Listing 5.11 arguments are provided similarly to standard function calls. However, when we are using a literal in Listing 5.12, no arguments are passed explicitly. Instead, the compiler establishes a new lexical scope within the parent for the literal. While global variables are bound in the expected manner, private and local data must be copied. Note that pointers to local or private address spaces are invalid, as they do not have scope outside their work-group or work-item, respectively. However, creation of local memory regions for child kernels is supported and is discussed next. Because the return type of a kernel is always void, it never needs to be explicitly defined when declaring a block.
Dynamic local memory
When setting arguments using the host API, we can dynamically allocate local memory for a kernel by providing a NULL pointer to clSetKernelArg(). Since we do not have a similar mechanism for setting child-kernel arguments, the enqueue_kernel() function has been overloaded:
To create local memory pointers, the specification defines the block argument to be a variadic function (a function that receives a variable number of arguments). Each argument must be of type local void *. Notice that in the declaration that this argument list replaces the existing void type. The enqueue_kernel() function is also variadic, ending with a variable number of parameters that represent the size of each local array. Listing 5.13 modifies the toy vector addition example to use local memory in order to illustrate the use of dynamic local memory allocation with block syntax.

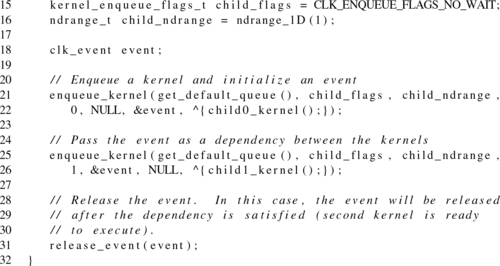
Enforcing dependencies using events
When introducing device-side command-queues, we mentioned that the queues always operate as out-of-order queues. This implies that there must be some mechanism provided to enforce dependency requirements. As on the host, events are used to satisfy this requirement when kernels are enqueued directly from a device. Once again, the enqueue_kernel() function is overloaded to provide this additional functionality:
The reader should notice that the three additional parameters, num_events_in_ wait_list, event_wait_list, and event_ret, mirror event-related parameters from the host API functions.
The final signature of enqueue_kernel() provides support for events and local memory to be utilized together:

5.6 Summary
In this chapter, we discussed a number of topics related to the runtime and execution model. The task-based execution that the runtime provides is based on a queuing model and a dependency mechanism provided by events. Events are also used for profiling OpenCL commands and executing user-defined callbacks associated with a command. The kernel execution domain comprises a hierarchical grouping of work-items into work-groups and NDRanges. A new feature of OpenCL 2.0 is the ability for devices to enqueue work into device-side queues. We introduced the method of generating kernel-instances from within a device using block syntax. While execution ordering and basic synchronization were discussed in this chapter, the following chapters describing the host-side and device-side memory models dive deeper into execution unit communication and synchronization.