
OpenCL host-side memory model
In order to be portable across a variety of hardware, OpenCL provides a well-defined abstract memory model. The abstract memory model is general enough to map to a wide range of devices, yet provides strong enough memory ordering guarantees to express classes of parallelism important to developers. Providing an abstract memory model also serves as a clean interface between programmers and hardware. Using the abstract memory model, programmers can write code that follows the rules of the model without being concerned about the memory system of the device that will eventually execute the kernel. Similarly, vendors implementing the runtime can map the abstract memory model to their hardware, and be sure that programmers will interact with it using only specific, predefined operations.
Previous chapters have already touched on some aspects of OpenCL’s memory model. For instance, we have seen the use of memory object types such as buffers and images in the examples in Chapters 3 and 4. We have also been introduced to memory spaces such as global and local memory. This chapter and Chapter 7 will discuss the memory model in more detail. We will present the memory model as two parts, which we refer to as the host-side memory model and the device-side memory model. The host-side memory model is relevant within the host program, and involves allocation and movement of memory objects. The device-side memory model discussed in the next chapter is relevant within kernels (written in OpenCL C), and involves running computations using memory objects and other data.
OpenCL devices such as graphics processing units (GPUs) and other accelerators frequently operate with memory systems separate from the main memory associated with the computer’s primary central processing unit (CPU). By default, OpenCL’s host-side memory model supports a relaxed consistency in which global synchronization of memory is defined only on the completion of events. An important addition to the OpenCL 2.0 specification is optional support of consistency guarantees that closely mirror those of C/C++11 and Java.
To support systems with multiple discrete memories and various consistency models, OpenCL’s memory objects are defined to be in a space separate from the host CPU’s memory. Any movement of data in and out of OpenCL memory objects from a CPU pointer must be performed through application programming interface (API) functions. It is important to note that OpenCL’s memory objects are defined within a context and not on a device. That is, in general, moving data in and out of a buffer need not move data to any specific device. It is the job of the runtime to ensure that data is in the correct place at the correct time.
This chapter begins by describing the types of memory objects defined by OpenCL, followed by a description of their management using the host API.
6.1 Memory Objects
OpenCL defines three types of memory objects—buffers, images, and pipes—that are allocated using the host API. Buffers and images serve as data storage that is accessible from the host and randomly accessible from within a kernel. Unlike buffers and images, pipes serve only as a first in, first out (FIFO) mechanism between kernels. Data from within a pipe cannot be accessed by the host.
Buffer objects are one-dimensional arrays in the traditional CPU sense, and are similar to memory allocated through malloc() in a C program. Buffers can contain any scalar data type, vector data type, or user-defined structure. The data stored in a buffer is sequential, such that the OpenCL kernel can access it using pointers in a random access manner familiar to a C programmer.
Image objects take a different approach. The data layout transformations involved in optimizing image access make it difficult to define pointer access to this data because the relationship of one memory location to another becomes opaque to the developer. As a result, image structures are completely opaque not only to the developer but also to the kernel code, accessible only through specialized access functions. Because GPUs are designed for processing graphics workloads, they are heavily optimized for accessing image data. This has three main advantages:
1. GPU cache hierarchies and data flow structures are designed to optimize access to image-type data.
2. GPU drivers optimize data layouts to support the hardware in providing efficient access to the data, particularly when two-dimensional access patterns are used.
3. Image-access hardware supports sophisticated data conversions that allow data to be stored in a range of compressed formats.
The remainder of this section describes each type of memory object in more detail.
6.1.1 Buffers
Buffer objects are similar to arrays allocated using malloc(), so their creation is relatively simple. At the simplest level, creation requires a context in which to create the buffer, a size, and a set of creation flags. The API call clCreateBuffer() is used to create a buffer object.
The function returns a buffer object, requiring the error code to be returned through a variable passed by reference as the last parameter. The flags parameter allows various combinations of read-only/write-only data access and allocation options. For example, in the following code, we create a read-only buffer that will use the same storage location as host array a, which is of the same size as the buffer. We will discuss allocation options (e.g., CL_MEM_USE_HOST_PTR) in more detail later in this chapter. Any error value will be returned in err, which can be any of a range of error conditions defined in the specification. As we have seen, CL_SUCCESS is returned by OpenCL functions upon successful completion.
OpenCL also supports subbuffer objects that allow us to divide a single buffer into multiple smaller buffers that may overlap and that can be read, written, copied, and used in much the same way as their parent buffer object. Note that overlapping subbuffers and the combination of subbuffers and their parent buffer objects constitutes aliasing, and behavior is undefined in these circumstances.
6.1.2 Images
In OpenCL, images are storage objects that differ from buffers in three ways. Images are
1. opaque types that cannot be viewed directly through pointers in device code;
2. multidimensional structures; and
3. limited to a range of types relevant to graphics data rather than being free to implement arbitrary structures.
Image objects primarily exist in OpenCL to offer access to special function hardware on graphics processors that is designed to support highly efficient access to image data. These special function units do not always support the full range of access modes necessary to enable buffer access, but they may provide additional features such as filtering in hardware in a highly efficient manner. Filtering operations enable efficient transformations of image data based on collections of pixels. These operations would require long instruction sequences with multiple read operations, but can be performed very efficiently in dedicated hardware units.
Image data is accessed through specialized access functions in the kernel code, which are discussed Chapter 7 with the device-side memory model. Access to images from the host is not significantly different from access to buffers, except that all functions are expanded to support addressing in multiple dimensions. Thus, for example, clEnqueueReadImage() is more like clEnqueueReadBufferRect() than clEnqueueReadBuffer().
The major difference between buffers and images from the host is in the formats that images can support. Whereas buffers support the basic OpenCL types and structures made from them, image formats are more subtle. Image formats are a combination of a channel order and a channel type. Channel order defines the number of channels and the order in which they occur—for example, CL_RGB, CL_R, or CL_ARGB. Channel type is selected from a wide range of storage formats from CL_FLOAT to less-storage-hungry formats such as CL_UNORM_SHORT_565, which packs into a single 16-bit word in memory. When they are accessed from kernel code, reading from any of these formats results in upconversion to a standard OpenCL C type. The list of image formats can be queried by the API call clGetSupportedImageFormats().
Image objects are created using the API call clCreateImage(), which has the following signature:
In the creation of an image, the context, flags, and host_ptr parameters are the same as in the creation of a buffer. The image format (image_format) and image descriptor (image_desc) parameters define image dimensions, data format, and data layout. These structures are described in detail in Chapter 4 along with an example initializing them for an image object.
6.1.3 Pipes
OpenCL 2.0 provides a new type of memory object called a pipe. A pipe organizes data in an FIFO structure, which facilitates the passing of processed data from one kernel to another. With the relaxed memory model defined in prior versions of the standard, this operation would not be possible, because there were no guarantees about the state of memory before a kernel was complete. The implication of a pipe is that within a device two kernels must be able to share a region of memory and guarantee protection of some shared state. This identifies an important trend in processors, as any device that can support pipes must at least have the ability to implement atomic operations on data shared between kernels, and must have a memory consistency model that supports acquire and release semantics.
One can imagine that given these device capabilities programmers could implement their own version of a pipe using a buffer. While this is feasible given the OpenCL 2.0 memory model, it would require a large amount of programming effort. Pipes are thus a nice abstraction that enables producer-consumer parallelism, and simplifies programmer effort in other scenarios that were difficult to program in prior versions of OpenCL (such as packing data when each work-item generates a variable number of outputs). The use of a pipe when running the producer and consumer on the same device also allows vendors to potentially map the pipe to specialized memories that may be lower latency than main memory. Pipe objects are not allowed to be read from or written to the host, so accesses to pipe objects are covered when we describe the device-side memory model.
The data in a pipe are organized as packets, where a packet can be any supported OpenCL C or user-defined type. The API to create a pipe is clCreatePipe(), with the following signature:
When a pipe is created, the packet size (pipe_packet_size) and the maximum number of packets (pipe_max_packets) must be supplied. As with other calls to create memory objects, there is a parameter to pass flags related to object allocation. In the case of a pipe, the only valid option related to access capability is CL_MEM_READ_WRITE, which is the default. Further, since a pipe cannot be accessed by the host, CL_MEM_HOST_NO_ACCESS will also be used implicitly, even if this is not specified by the programmer.
6.2 Memory Management
When OpenCL creates memory objects, they are allocated in the global memory space that is visible to all devices in a context. Although OpenCL provides the abstraction of a single global memory, in reality many heterogeneous systems have multiple devices that may have restrictions about sharing address spaces and may have physically separate memories—as is the case in systems with a CPU and a discrete GPU. In these cases, the runtime may need to create multiple copies of the data for each device over the course of execution. Even in shared-memory systems where data does not need to be replicated between memories, almost all memory accesses by a device replicate data in a cache hierarchy or in hardware buffers. When data is replicated, it is possible that a copy on one device is inconsistent with memory that is visible to another device. Given the potential for replicated, nonconsistent views of a memory object, how do we ensure that we are working with the latest copy of data to obtain the expected results?
Later, we will discuss fine-grained memory ordering and visibility when dealing with shared virtual memory (SVM), but for now we will assume that we are working with memory objects with a default (non-SVM) allocation. When a default memory object is used, OpenCL’s relaxed consistency model does not allow multiple kernels to modify the object at the same time. No modification is guaranteed to be visible until after the kernel completes execution, and since the runtime can create multiple copies of a memory object, two kernels updating different copies of the same object would likely result in the updates from one being completely masked by the other. If we take this a step further, the result of reading from a memory object while another kernel is modifying it is undefined, since there are no guarantees about when the data will become visible before the kernel completes execution. Aside from these responsibilities of the programmer, it is up to the runtime to ensure that data is in the correct place at the correct time. This combination of a relaxed memory model and the runtime’s responsibility of memory management allows efficient execution with high portability and minimal programmer effort.
In addition to portability, the designers of the OpenCL specification also understood that in practice transfers are inefficient, and moving data only on demand would likely lead to poor performance. Therefore, OpenCL provides commands that allow the programmer to suggest how and where data is allocated, and where and when the data should be moved. Depending on the system that is running the OpenCL application, these choices may have a large impact on performance. The following two sections describe allocation and movement of memory objects—without and with memory allocation flags, respectively. The API calls that we discuss are based on buffer types, although in general operations described for buffers have synonymous implementations for images. Pipes are distinct from images and buffers, as the host does not have the ability to access the memory space allocated for a pipe.
6.2.1 Managing Default Memory Objects
Recall that when a memory object is created, the call to create the object (e.g., clCreateBuffer()) takes a parameter called flags, and another called host_ptr. The signature of clCreateBuffer() is listed again below for convenience:
Some options passed to flags tell the runtime how and where the programmer would like the buffer’s space to be allocated, and host_ptr can be used either to initialize the buffer or directly for storage. This section will describe working with memory objects when no allocation-related options are passed to flags, although we will discuss the option for initializing memory objects. The next section will describe the programmer’s options that can affect where memory is physically allocated.
By default, OpenCL does not specify where the physical storage allocated for a memory object must reside—it specifies simply that the data is located in “global memory.” For example, the runtime could decide to allocate space in CPU main memory or in video memory on a discrete GPU. Most likely it will create multiple allocations for the data and migrate the latest copy as needed.
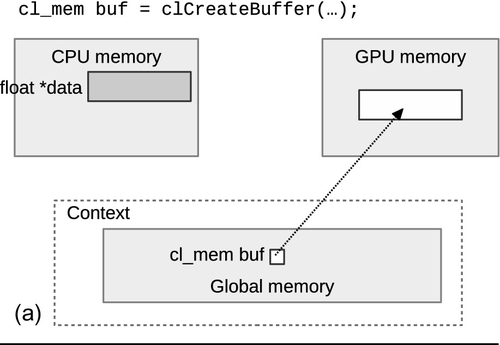
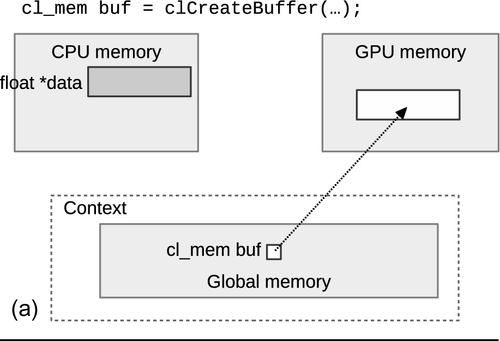
When an object is created, it has the option of being initialized with host data by providing a valid pointer to host_ptr, and specifying the flag CL_MEM_COPY_HOST_PTR to flags. This combination of parameters will create a new allocation for the buffer and copy the data provided by host_ptr. Since the API call to create the buffer does not generate an event, we can assume that a copy of the data in host_ptr is complete when clCreateBuffer() returns. Figure 6.1 shows how the runtime may choose to migrate data if a buffer is initialized during creation, passed as an argument to a kernel, and then read back after the kernel execution.
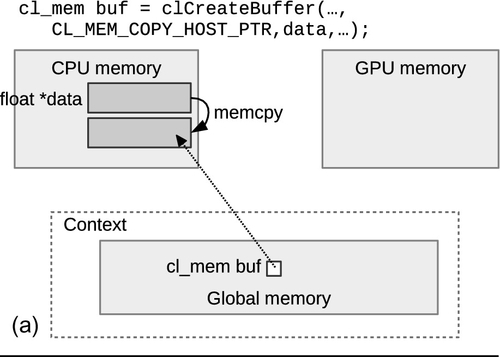
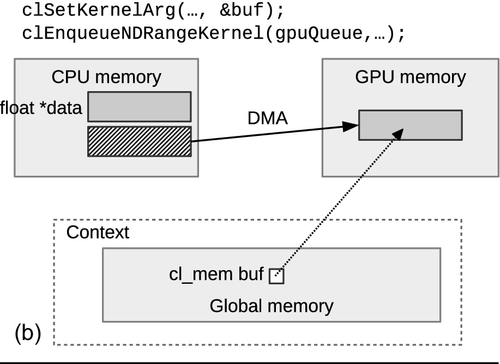
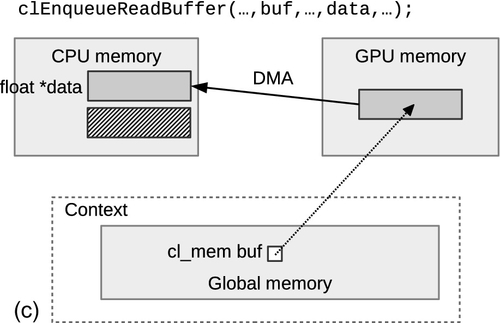
In general, it is inefficient to move data allocated on one device to another device—in Chapter 8, we will describe the relative memory bandwidths in a modern CPU and GPU, and compare the interconnects used when transferring data. To allow programmers to perform data transfers as efficiently as possible, OpenCL provides a number of API calls dedicated to moving data in different ways. Keep in mind that the optimal choice will depend both on the algorithm and on the system characteristics.
The first set of commands that we will discuss are intended to be used to perform an explicit copying of data from the host to a device or vice versa, as shown in Figure 6.2. These commands are clEnqueueWriteBuffer() and clEnqueueReadBuffer(). The signature of clEnqueueWriteBuffer() is as follows:
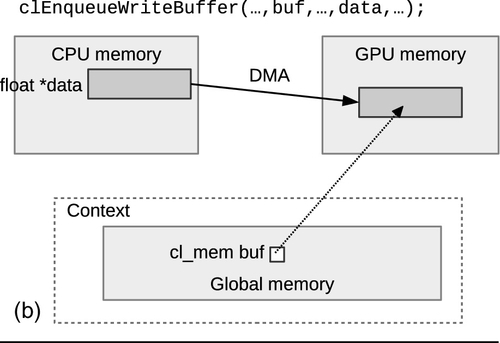
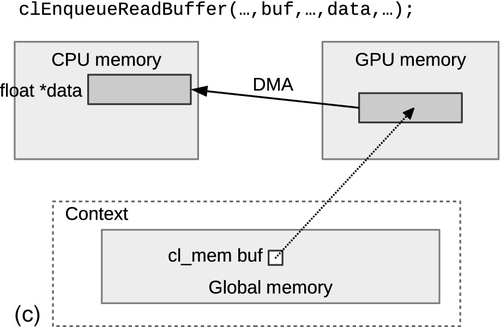
The signature of clEnqueueReadBuffer() is identical to that of clEnqueueWriteBuffer(), except that blocking_write is replaced with blocking_read. In the signature, a transfer will occur between the buffer and the host pointer ptr. The write call specifies a copy from the host to the device (technically just to global memory), and the read call specifies a copy from the device to the host. Notice that the signature includes a command-queue parameter. This is slightly awkward as there is no way to explicitly initialize a memory object after creation without also having to specify a target device. However, for most applications the programmer knows which device the data will target, and specifying a command-queue allows the runtime to target a device directly and avoid an additional copy. This design also allows the runtime to begin to transfer the data much sooner than if it had to wait until it had processed a kernel-execution command that required use of the buffer on a specific device.
If the programmer only wants to copy certain bytes to or from the buffer, the parameters offset and size can be used to specify the offset in the buffer to begin the copying and the number of bytes to copy, respectively. Notice that ptr is the starting location on the host for reading and writing data. The offset parameter only refers to the offset within the buffer object. It is up to the programmer to have ptr point to the desired starting location.
These data transfer functions are intended, like the rest of the OpenCL API, to be used asynchronously. That is, if we call clEnqueueReadBuffer(), we cannot expect to be able to read the data from the host array until we know that the read has completed—through the event mechanism, a clFinish() call, or by passing CL_TRUE to clEnqueueReadBuffer() to make it a blocking call. Thus, for example, the following host code sequence does not guarantee that the two printf() calls A and B will generate different values even if outputBuffer’s content would suggest that it should. The printf() of C is the only point in the code where the printed value is guaranteed to be that copied from outputBuffer.
This is a vital point about OpenCL’s memory model. Changes to memory are not guaranteed to be visible, and hence memory is not guaranteed to be consistent, until an event reports that the command’s execution has finished (we will discuss the differences with SVM later). This works both ways: in a transfer between a host pointer and a device buffer, you cannot reuse the data pointed to by the host pointer until you know that the event associated with the asynchronous copying of data into the device buffer has finished. Indeed, a careful reading of the OpenCL specification suggests that this is because buffers are associated with the context and not with a device. A clEnqueueWriteBuffer() enqueue, even on completion, does not guarantee that data have been moved to the device, and guarantees only that it has been moved out of the host pointer.
Unlike other API calls in OpenCL, data transfer calls generally allow us to specify synchronous execution. Had we replaced the previous call with
execution of the host thread would stall at the call to clEnqueueReadBuffer() until the copying finishes and all data is visible to the host.
In addition to transferring data between the host and the device, OpenCL provides a command, clEnqueueMigrateMemObjects(), to migrate data from its current location (wherever that may be) to a specified device. For example, if a buffer is created and initialized by passing CL_MEM_COPY_HOST_PTR to clCreateBuffer(), clEnqueueMigrateMemObjects() can be used to explicitly transfer the data to the device. It can also be used to transfer data between devices if an application is utilizing more than one device for computation. Notice that neither of these goals could be accomplished efficiently with clEnqueueReadBuffer() and clEnqueueWriteBuffer(), since both require the transfer to begin or end at the host. The signature of clEnqueueMigrateMemObjects() is as follows:
Unlike previous data transfer commands, clEnqueueMigrateMemObjects() takes an array of memory objects, allowing multiple objects to be migrated with a single command. As with all clEnqueue calls, the event produced should either be passed as a dependency to any dependent commands, or be queried directly for completion. When the event’s status has been set to CL_COMPLETE, the memory objects will be located on the device associated with the command-queue that was passed as the argument to the command_queue parameter.
Aside from explicitly telling the runtime where memory objects should be migrated, this command has another subtle performance implication. If the programmer is able to enqueue this command such that it is processed during an unrelated operation (such as a kernel execution that does not include any of the specified memory objects), migration can potentially overlap the former operation and hide the transfer latency. Note that hiding the transfer latency can also occur in a similar manner with calls to clEnqueueWriteBuffer() and clEnqueueReadBuffer().
For migrating memory objects, the specification also provides a flag, CL_MIGRATE_MEM_OBJECT_HOST, that tells the runtime that the data should be migrated to the host. If CL_MIGRATE_MEM_OBJECT_HOST is supplied, the command-queue passed to the function will be ignored.
6.2.2 Managing Memory Objects with Allocation Options
The API calls described in the previous section were used to tell the OpenCL runtime to copy data between the host and a device, or to migrate data to a certain device. Alternatively, this section describes how the host and the device can directly access data that is physically located in the other’s memory.
OpenCL provides two mechanisms for the programmer to specify that a memory object should be physically allocated in a place that allows the data to be mapped into the host’s address space. Providing the option CL_MEM_ALLOC_HOST_PTR to flags in clCreateBuffer() tells the runtime to allocate new space for the object in “host-accessible” memory, and CL_MEM_USE_HOST_PTR tells the runtime to use the space pointed to by host_ptr directly. Since they represent two different allocation options, these flags are mutually exclusive and cannot be used together for the same memory object. Note that “host-accessible memory” is intentionally vague, and could include main memory connected to the host processor or a region of device memory that can be mapped into the host’s address space.
As with default memory objects, the flag CL_MEM_COPY_HOST_PTR can be used with CL_MEM_ALLOC_HOST_PTR to allocate host-accessible memory and initialize it immediately. However, CL_MEM_COPY_HOST_PTR and CL_MEM_USE_HOST_PTR cannot be used together, as the argument passed to host_ptr will represent a pre-existing allocation, and it does not make sense to initialize it with itself.
It would be reasonable to assume that by specifying an option to allocate data in host-accessible memory that the data would be allocated in CPU main memory, and the compute device would access the data directly from there. In fact, when either of these flags is provided, this is what will occur on some systems. In a system with a CPU and a discrete GPU, this scenario would send GPU accesses to the memory object across the PCI Express bus. When a device accesses data directly from the host’s memory in this way, the data is often referred to as zero-copy data.
Although using CL_MEM_USE_HOST_PTR or CL_MEM_ALLOC_HOST_PTR may result in the creation of zero-copy data on the host, it is not explicitly required by the specification. It is completely valid for the runtime to create storage in CPU memory and then copy it to device memory for a kernel execution. In this scenario, a discrete GPU would be able to access the buffer directly from its own video memory. In fact, if CL_MEM_ALLOC_HOST_PTR is used, it is also completely valid for the runtime to allocate storage solely in device memory as long as it can be mapped into the host’s address space. Remember that the specification says that passing CL_MEM_ALLOC_HOST_PTR creates space in host-accessible memory, and not necessarily in host memory itself.
In shared-memory systems, or when a CPU is being used as the device, CL_MEM_USE_HOST_PTR may prevent unnecessary copies of data from being created and lead to better performance. For example, imagine that the device selected to execute a kernel is the same CPU as the host: if the option CL_MEM_USE_HOST_PTR is not specified, then the application will incur the overhead of allocating additional space for the buffer and making a copy of the data. One could imagine a similar situation for heterogeneous shared-memory processors, such as accelerated processing units (APUs). If the CPU and GPU share the same memory, does it make sense to use CL_MEM_USE_HOST_PTR for APUs as well? As with many optimization-related considerations, the answer depends on a number of factors.
In the case of APUs, the OpenCL runtime or device driver may optimize memory accesses for a certain device by allocating data with system-specific flags (e.g., cached vs. uncached) or may have other performance considerations, such as nonuniform memory accesses (NUMA). For example, when running on some APUs, CL_MEM_USE_HOST_PTR may lead to the buffer being treated as cacheable and fully coherent. This can cause inefficient accesses by the GPU, which must now probe the CPU cache hierarchy prior to accesses. Especially when using APUs, the programmer should understand the device-specific performance implications of creating memory objects with the CL_MEM_USE_HOST_PTR and CL_MEM_ALLOC_HOST_PTR flags.
Since CL_MEM_USE_HOST_PTR and CL_MEM_ALLOC_HOST_PTR specify that data should be created in host-accessible memory, the OpenCL specification provides a mechanism for the host to access the data without going through the explicit read and write API calls. In order for the host to access the data storage of a memory object, it must first map the memory object into its address space. Note that mapping does not necessarily imply creating a copy, unlike a call to clEnqueueReadBuffer() which would always result in a copy of the data. In systems where zero-copy memory objects are supported, a call to map the data into host memory would simply require that all in-flight updates to the data have finished and are visible to the host.
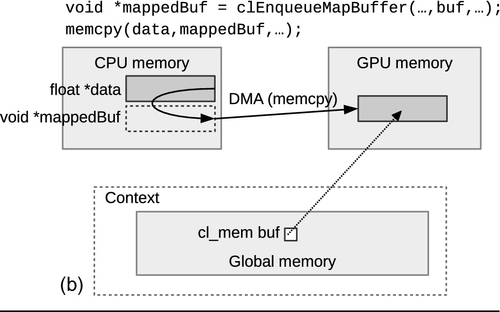
The call to map memory objects is type specific. For a buffer, the call is clEnqueueMapBuffer(), with the following signature:
When clEnqueueMapBuffer() is called, it returns a pointer that is valid on the host. When the event returned by clEnqueueMapBuffer() is set to CL_COMPLETE, it is safe for the host to access the data, which is mapped to the pointer returned by the call. As with clEnqueueWriteBuffer() and clEnqueueReadBuffer(), this call has a blocking parameter, blocking_map, which when passed CL_TRUE will turn the call into a blocking call. If blocking_map is set, then the host is able to access the returned pointer as soon as the call completes.
When clEnqueueMapBuffer() is called, there are three different flags that can be passed to the map_flags parameter: CL_MAP_READ, CL_MAP_WRITE, and CL_MAP_WRITE_INVALIDATE_REGION. The flag CL_MAP_READ tells the runtime that the host will be reading the data, and CL_MAP_WRITE and CL_MAP_WRITE_INVALIDATE_ REGION tell the runtime that the host will be modifying the data. CL_MAP_WRITE_INVALIDATE_REGION is an optimization that specifies that the entire region will be modified or disregarded, and so the runtime does not need to map the latest values before it can be modified. By there not being a requirement that the data is in a consistent state, the runtime can potentially allow access to the region much sooner with CL_MAP_WRITE_INVALIDATE_REGION than with CL_MAP_WRITE.
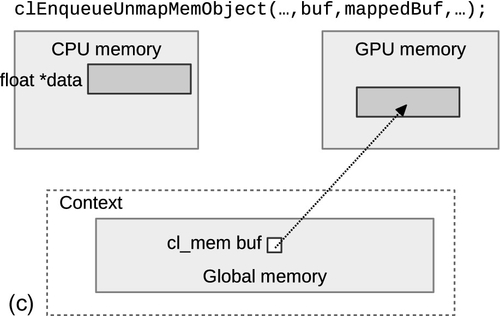
When the host has finished modifying the mapped data, it needs to tell the runtime that it has finished using the complementary unmap call. While the command to map a memory object is type specific, the command to unmap is the same for all memory objects: clEnqueueUnmapMemObject().
Unmapping a memory object requires passing the memory object itself, along with the host pointer (mapped_ptr) that was returned by the call that mapped the data. As with all previous data management commands, when the event returned by clEnqueueUnmapMemObject() is set to CL_COMPLETE, updates to the data are considered complete. Unlike most other calls, there is no parameter that turns clEnqueueUnmapMemObject() into a blocking call. Figure 6.3 shows the process of mapping and unmapping a memory object. Undefined behavior occurs if an object that is currently mapped for reading by the host is written to by a device. Similarly, undefined behavior occurs if an object that is currently mapped for writing by the host is read by a device.
As we have mentioned a number of times throughout this section, the actual behavior associated with these flags is implementation defined, and in practice is highly device specific. To give programmers an idea of how data would be allocated in practice, we will briefly describe the AMD-specific treatment of flags. For default memory objects (no flags supplied) data will likely be allocated in device memory directly. When CL_MEM_USE_HOST_PTR or CL_MEM_ALLOC_HOST_PTR is supplied, if devices in the context support virtual memory, data will be created as pinned (nonpageable) host memory and will be accessed by the device as zero-copy data. If virtual memory is not supported, data will be allocated in device memory as with default memory objects. If the programmer desires data allocation on the device and direct access to data in device memory by the host, AMD provides a vendor-specific extension called CL_MEM_USE_PERSISTENT_MEM_AMD. When this flag is supplied, accesses to a memory object that is mapped into the host’s address space will occur directly from device memory.
6.3 Shared Virtual Memory
One of the most significant updates to OpenCL in the 2.0 standard is the support of SVM. SVM extends global memory into the host’s memory region, allowing virtual addresses to be shared between the host and all devices in a context. An obvious benefit of SVM is the ability to pass pointer-based data structures as arguments to OpenCL kernels. For example, prior to support of SVM, there was no way to have a kernel operate on a linked-list that was created on the host, since each node of the list points to the next node, and the pointers were valid only in the host’s address space. Further, how would one even go about copying a linked list onto the device? Small objects spread across memory were not suited for OpenCL’s memory model, and would have to be marshaled to be suitable for processing by a kernel. SVM removes these limitations and more.
There are three types of SVM in OpenCL:
2. Fine-grained buffer SVM.
3. Fine-grained system SVM.
The reader can refer to Table 6.1 for a summary of the characteristics as we discuss each type of SVM.
Table 6.1
Summary of Options for SVM
| Coarse-Grained Buffer SVM | Fine-Grained Buffer SVM | Fine-Grained System SVM | |
| OpenCL object | Buffer | Buffer | None (host memory) |
| Sharing granularity | Buffer | Bytes | Bytes |
| Allocation | clSVMAlloc | clSVMAlloc | malloc (or similar) |
| Consistency | Sync points | Sync points and optional atomics | Sync points and optional atomics |
| Explicit updates between host and device? | Map/unmap commands | No | No |

Coarse-grained buffer SVM allows virtual address sharing to occur at the granularity of OpenCL buffer memory objects. The difference between a coarse-grained SVM buffer and a non-SVM buffer is simply that the host and device share virtual memory pointers. Buffer objects that are allocated to use coarse-grained SVM should be mapped into and unmapped from the host’s address space to guarantee that the latest updates made by a device are visible. To do this, the host thread can call clEnqueueMapBuffer() specify a blocking command to map the buffer region. Recall that by specifying a blocking command, the function will wait for an event to signal the kernel’s completion before returning. When clEnqueueMapBuffer() returns, any memory operations performed by the kernel in that buffer region will be visible to the host.
While non-SVM buffers are created using the API call clCreateBuffer(), the command to create an SVM buffer is clSVMAlloc(), with the following signature:
As with non-SVM buffers, the flags parameter takes read-only, write-only, and read-write options (we will describe the remaining options shortly). The alignment parameter is the minimum byte alignment for this object required by the system. Passing an alignment of zero uses the default alignment, which will be the size of the largest data type supported by the OpenCL runtime. Notice that instead of a cl_mem object, a call to clSVMAlloc() returns a void pointer. As with a call to malloc() from a regular C program, clSVMAlloc() will return a non-NULL value on a successful allocation, or NULL on a failure.
Freeing an SVM buffer allocated with clSVMAlloc() is done using a call to clSVMFree(), which simply takes the context and SVM pointer as parameters.
A call to clSVMFree() is instantaneous, and does not wait for currently enqueued or executing commands to finish. Calling clSVMFree() and then accessing a buffer can therefore result in a segmentation fault as can happen in a normal C program. To allow SVM buffers to be freed after completion of enqueued commands, the specification supplies a command to enqueue a free operation: clEnqueueSVMFree().
Unlike coarse-grained buffer SVM, fine-grained buffer SVM supports sharing at a byte-level granularity within an OpenCL buffer memory object. If (optional) SVM atomic operations are supported, fine-grained buffer SVM can be used by the host and the device to concurrently read and update the same region of the buffer. Fine-grained buffer SVM also enables kernels running on the same or different devices to concurrently access the same region of a buffer as well. Among their other benefits, SVM atomics provide synchronization points to ensure that data is updated according to OpenCL’s memory consistency model. If SVM atomics are not supported, reads from the host and the device can still occur from the same region of the buffer, and updates can occur to nonoverlapping regions.
In order to create a buffer with a fine-grained SVM, the flag CL_MEM_SVM_FINE_ GRAIN_BUFFER needs to be passed to the flags parameter of clSVMAlloc(). Using atomic operations on an SVM buffer requires additionally passing CL_MEM_SVM_ATOMICS to the flags parameter. Note that CL_MEM_SVM_ATOMICS is valid only if CL_MEM_SVM_FINE_GRAIN_BUFFER is also specified.
Fine-grained system SVM extends fine-grained buffer SVM to the host’s entire address space—this includes regions of memory outside the OpenCL context that were allocated using the regular system malloc(). If fine-grained system SVM is supported, buffer objects are no longer necessary for OpenCL programs, and kernels can simply be passed pointers that were allocated on the host.
Determining the type of SVM supported by a device is done by passing the flag CL_DEVIce:SVM_CAPABILITIES to clGetDeviceInfo(). At minimum, OpenCL requires that coarse-grained buffer SVM must be supported by all devices.
6.4 Summary
This chapter presented OpenCL’s memory model from the point of view of the host. The host’s role in the memory model is largely related to the allocation and management of memory objects (buffers, images, and pipes) in global memory. We described in detail the allocation flags that allow the programmer to guide how and where data is allocated, and the management flags that can be used to guide where and when to move data. The chapter concluded with an introduction to the support of SVM, which will be continued in the next chapter that discusses the device-side memory model.