
Chapter 2. The Software Engineer in Test
Imagine for a moment the perfect development process. It would begin with test. Before even a single line of code is written, a developer would ponder what it will take to test it. He will write tests for boundary cases, for data values too large and too small, for values that would push loops beyond their limits, and for a myriad of other concerns. Some of these tests will be part of the functions she writes, self-testing code or unit tests. For these types of tests, the person who writes the code and understands it best is the one who is most qualified to test it.
Other tests require knowledge outside the actual codebase and must rely on external infrastructure. For example, a test that retrieves data from a remote data store (a database server or the cloud) either requires that database to exist or requires a simulated version of it be available for testing. Over the years, the industry has used any number of terms to describe such scaffolding including test harnesses, test infrastructure, mocks, and fakes. In a perfect development process, such scaffolding would be available for every interface a developer would ever encounter so that any aspect of any function you would ever want to write could be tested any time you wanted to test it (remember, we are imagining a perfect world!).
This is the first place where a perfect development process requires a tester. There is a different kind of thinking involved in writing feature code and writing test code. It becomes necessary to distinguish between a feature developer and a test developer. For feature code, the mindset is creating and considering users, use cases, and workflow. For test code, the mindset is about breaking and writing code that will draw out cases that disrupt the user and his workflow. Because we are in the fairytale land of the perfect development process, we might as well employ separate developers: one who writes features and one who enables them to be broken.
Our utopian development process requires any number of feature developers and test developers collaborating to build a complicated product. True utopia should even allow for one developer per feature and any number of test developers buzzing around working on a central test infrastructure and assisting feature developers with their specific unit-testing issues that might otherwise distract them from the construction process that requires most of their concentration.
As feature developers write functional code and test developers write test code, a third concern rears its head: that of the user. Clearly in our perfect utopian testing world, this task should fall on a third class of engineer with the feature developers and test developers gainfully occupied elsewhere. Let’s call this newcomer a user developer. User-oriented tasks like use cases, user stories, user scenarios, exploratory testing, and so on are the order of business here. User developers concern themselves with how the features tie together and form an integrated whole. They work on systemwide issues and generally take the view of the user when asking whether the sum of the parts is actually something useful to a real community of end users.
This is our idea of software development utopia, three classes of developers collaborating on usable, reliable perfection—each of them specialized to handle something important and each of them interoperating and collaborating as equals.
Who wouldn’t want to work for a company that implemented software this way? You can certainly sign us up!
Unfortunately, none of us work for that company. Google, like all the other companies before it, has done its best to measure up and perhaps because of our position at the end of the queue of those who tried, we’ve learned from the mistakes of our forebears. Google has also benefitted from being at the inflection point of software moving from massive client-side binaries with multi-year release cycles to cloud-based services that are released every few weeks, days, or hours.1 This confluence of happy circumstances has endowed us with some similarities to the utopian software development process.
Google SWEs are feature developers, responsible for building components that ship to customers. They write feature code and unit test code for those features.
Google SETs are test developers, responsible for assisting SWEs with the unit test portion of their work and also in writing larger test frameworks to assist SWEs in writing small and medium tests to assess broader quality concerns.
Google TEs are user developers, responsible for taking the users’ perspectives in all things that have to do with quality. From a development perspective, they create automation for user scenarios and from a product perspective, they assess the overall coverage and effectiveness of the ensemble of testing activity performed by the other engineering roles. It is not utopia, but it is our best attempt at achieving it in a practical way where real-world concerns have a way of disrupting best intentions in the most unforeseen and unforgiving way.
Note
Google SWEs are feature developers. Google SETs are test developers. Google TEs are user developers.
In this book, we are concerned primarily with the activity of the SET and TE roles and include the activity of the SWE as a subset of both of these roles because the SWE is heavily involved but usually under the direction of an engineer who actually has the word test in his or her title.
The Life of an SET
In the early days of any company, testers generally don’t exist.2 Neither do PMs, planners, release engineers, system administrators, or any other role. Every employee performs all of these roles as one. We often like to imagine Larry and Sergey puzzling over user scenarios and unit tests in those early days! But as Google grew, the SET was the first role that combined the engineering flavor of a developer with the quality-minded role of a tester.3
Development and Test Workflow
Before we dig into the workflow specific to SETs, it is helpful to understand the overall development context in which SETs work. SETs and SWEs form a tight partnership in the development of a new product or service and there is a great deal of overlap in their actual work. This is by design because Google believes it is important that testing is owned by the entire engineering team and not just those with the word test in their job title.
Shipping code is the primary shared artifact between engineers on a team. It is the organization of this code, its development, care, and feeding that becomes the focus of everyday effort. Most code at Google shares a single repository and common tool chain. These tools and repository feed Google’s build and release process. All Google engineers, regardless of their role, become intimately familiar with this environment to the point that performing any tasks associated with checking in new code, submitting and executing tests, launching a build, and so on can be done without conscious thought by anyone on the team (assuming that person’s role demands it).
This single repository makes a great deal of sense as engineers moving from project to project have little to relearn and so called “20 percent contributors”4 can be productive from their first day on a project. It also means that any source code is available to any engineer who needs to see it. Web app developers can see any browser code they need to make their job easier without asking permission. They can view code written by more experienced engineers and see how others performed similar tasks. They can pick up code for reuse at the module or even the control structure or data structure level of detail. Google is one company and has one easily searchable (of course!) source repository.
This openness of the codebase, the harmony of the engineering toolset, and companywide sharing of resources has enabled the development of a rich set of shared code libraries and services. This shared code works reliably on Google’s production infrastructure, speeding projects to completion and ensuring few failures due to underlying shared libraries.
Code associated with the shared infrastructure has a special type of treatment by engineers, and those working on it follow a set of unwritten but common practices that speak to the importance of the code and the care that engineers take when modifying it.
• All engineers must reuse existing libraries, unless they have very good reason not to based on a project-specific need.
• All shared code is written first and foremost to be easily located and readable. It must be stored in the shared portion of the repository so it can be easily located. Because it is shared among various engineers, it must be easy to understand. All code is treated as though others will need to read or modify it in the future.
• Shared code must be as reusable and as self-contained as possible. Engineers get a lot of credit for writing a service that is picked up by multiple teams. Reuse is rewarded far more than complexity or cleverness.
• Dependencies must be surfaced and impossible to overlook. If a project depends on shared code, it should be difficult or impossible to modify that shared code without engineers on dependent projects being made aware of the changes.
• If an engineer comes up with a better way of doing something, he is tasked with refactoring all existing libraries and assisting dependent projects to migrate to the new libraries. Again, such benevolent community work is the subject of any number of available reward mechanisms.5
• Google takes code reviews seriously, and, especially with common code, developers must have all their code reviewed by someone with a “readability” in the relevant programming language. A committee grants readabilities after a developer establishes a good track record for writing clean code which adheres to style guidelines. Readabilities exist for C++, Java, Python, and JavaScript: Google’s four primary languages.
• Code in the shared repository has a higher bar for testing (we discuss this more later).
Platform dependencies are dealt with by minimizing them. Every engineer has a desktop OS as identical as possible to Google’s production system. Linux distributions are carefully managed to keep dependencies at a minimum so that a developer doing local testing on his own machine will likely achieve the same results as if he were testing on the production system. From desktop to data center, the variations between CPU and operating system are minimal.6 If a bug occurs on a tester’s machine, chances are it will reproduce on a developer’s machine and in production.
All code that deals with platform dependencies is pushed into libraries at the lowest level of the stack. The same team that manages the Linux distributions also manages these platform libraries. Finally, for each programming language Google uses, there is exactly one compiler, which is well maintained and constantly tested against the one Linux distribution. None of this is magic, but the work involved in limiting the impact of multiple environments saves a great deal of testing downstream and reduces hard-to-debug environmental issues that distract from the development of new functionality. Keep it simple, keep it safe.
Note
Keeping it simple and uniform is a specific goal of the Google platform: a common Linux distribution for engineering workstations and production deployment machines; a centrally managed set of common, core libraries; a common source, build, and test infrastructure; a single compiler for each core programming language; language independent, common build specification; and a culture that respects and rewards the maintenance of these shared resources.
The single platform, single repository theme continues with a unified build system, which simplifies working within the shared repository. A build specification language that is independent of a project’s specific programming language directs the build system. Whether a team uses C++, Python, or Java, they share the same “build files.”
A build is achieved by specifying a build target (which is either a library, binary, or test set) composed of some number of source files. Here’s the overall flow:
1. Write a class or set of functions for a service in one or more source files and make sure all the code compiles.
2. Identify a library build target for this new service.
3. Write a unit test that imports the library, mocks out its nontrivial dependencies, and executes the most interesting code paths with the most interesting inputs.
4. Create a test build target for the unit test.
5. Build and run the test target, making necessary changes until all the tests pass cleanly.
6. Run all required static analysis tools that check for style guide compliance and a suite of common problems.
7. Send the resulting code out for code review (more details about the code review follow), make appropriate changes, and rerun all the unit tests.
The output of all this effort is a pair of build targets: the library build target representing the new service we wish to ship and a test build target that tests the service. Note that many developers at Google perform test-driven development, which means step 3 precedes steps 1 and 2.
Larger services are constructed by continuing to write code and link together progressively larger library build targets until the entire service is complete. At this point, a binary build target is created from the main source file that links against the service library. Now you have a Google product that consists of a well-tested standalone binary, a readable, reusable service library with a suite of supporting libraries that can be used to create other services, and a suite of unit tests that cover all the interesting aspects of each of these build targets.
A typical Google product is a composition of many services and the goal is to have a 1:1 ratio between a SWE and a service on any given product team. This means that each service can be constructed, built, and tested in parallel and then integrated together in a final build target once they are all ready. To enable dependent services to be built in parallel, the interfaces that each service exposes are agreed on early in the project. That way, developers take dependencies on agreed-upon interfaces rather than the specific libraries that implement them. Fake implementations of these interfaces are created early to unblock developers from writing their service-level tests.
SETs are involved in much of the test target builds and identify places where small tests need to be written. But it is in the integration of multiple build targets into a larger application build target where their work steps up and larger integration tests are necessary. On an individual library build target, mostly small tests (written by the SWE who owns that functionality with support from any SET on the project) are run. SETs get involved and write medium and large tests as the build target gets larger.
As the build target increases in size, small tests written against integrated functionality become part of the regression suite. They are always expected to pass and when they fail, bugs are raised against the tests and are treated no differently than bugs in features. Test is part of the functionality, and buggy tests are functional bugs and must be fixed. This ensures that new functionality does not break existing functionality and that any code modifications do not break any tests.
In all of this activity, the SETs are centrally involved. They assist developers in deciding what unit tests to write. They write many of the mocks and fakes. They write medium and large integration tests. It is this set of tasks the SET performs that we turn to now.
Who Are These SETs Anyway?
SETs are the engineers involved in enabling testing at all levels of the Google development process we just described. SETs are Software Engineers in Test. First and foremost, SETs are software engineers and the role is touted as a 100 percent coding role in our recruiting literature and internal job promotion ladders. It’s an interesting hybrid approach to testing that enables us to get testers involved early in a way that’s not about touchy-feely “quality models” and “test plans” but as active participants in designing and creating the codebase. It creates an equal footing between feature developers and test developers that is productive and lends credibility to all types of testing, including manual and exploratory testing that occurs later in the process and is performed by a different set of engineers.
Note
Test is just another feature of the application, and SETs are the owner of the testing feature.
SETs sit side by side with feature developers (literally, it is the goal to have SWEs and SETs co-located). It is fair to characterize test as just another feature of the application and SETs as the owner of the testing feature. SETs also participate in reviewing code written by SWEs and vice versa.
When SETs are interviewed, the “coding bar” is nearly identical to the SWE role with the added requirement that SETs know how to test the code they create. In other words, both SWEs and SETs answer coding questions. SETs are expected to nail a set of testing questions as well.
As you might imagine it is a difficult role to fill and it is entirely possible that the relatively low numbers of Google SETs isn’t because Google has created a magic formula for productivity, but more of a result of adapting our engineering practice around the reality that the SET skill set is hard to find. However, one of the nice side effects of the similarity of the SWE and SET roles is that both communities make excellent recruiting grounds for the other and conversions between the roles are something that Google tries its best to facilitate. Imagine a company full of developers who can test and testers who can code. We aren’t there yet and probably never will be, but there is a cross section of these communities, SWE-leaning SETs, and SET-leaning SWEs, who are some of our best engineers and make up some of our most effective product teams.
The Early Phase of a Project
There is no set rule at Google for when SETs engage in a project, as there are no set rules for establishing when projects become “real.” A common scenario for new project creation is that some informal 20 percent effort takes a life of its own as an actual Google-branded product. Gmail and Chrome OS are both projects that started out as ideas that were not formally sanctioned by Google but overtime grew into shipping products with teams of developers and testers working on them. In fact, our friend Alberto Savoia (see his preface to this book) is fond of saying that “quality is not important until the software is important.”
There is a lot of innovation going on within loose-knit teams doing 20 percent work. Some of this work will end up nowhere, some will find its way into a larger project as a feature, and some may grow into an official Google product. None of them get testing resources as some inalienable right of their existence. Stacking a project potentially doomed to failure with a bunch of testers so they can build testing infrastructure is a waste of resources. If a project ends up being cancelled, what did that testing infrastructure accomplish?
Focusing on quality before a product concept is fully baked and determined to be feasible is an exercise in misplaced priorities. Many of the early prototypes that we have seen come from Google 20 percent efforts end up being redesigned to the point that little of the original code even exists by the time a version is ready for dogfood or beta. Clearly testing in this experimental context is a fool’s errand.
Of course, there is risk in the opposite direction too. If a product goes too long without testing involvement, it can be difficult to undo a series of design decisions that reduce testability to the point that automation is too hard and resulting test tools too brittle. There may be some rework that has to be done in the name of higher quality down the road. Such quality “debt” can slow products down for years.
Google doesn’t make specific attempts to get testers involved early in the lifecycle. In fact, SETs involved early are often there with their developer hat on as opposed to their testing hat. This is not an intentional omission, nor is it a statement that early quality involvement is not important. It is more an artifact of Google’s informal and innovation-driven project creation process. Google rarely creates projects as a big bang event where months of planning (which would include quality and test) are followed by a large development effort. Google projects are born much less formally.
Chrome OS serves as a case in point. It was a product all three authors of this book worked on for over a year. But before we joined formally, a few developers built a prototype, and much of it was scripts and fakes that allowed the concept of a browser-only app model to be demonstrated to Google brass for formal project approval. In this early prototyping phase, the concentration was on experimentation and proving that the concept was actually viable. A great deal of time testing or even designing for testability would have been moot given the project was still unofficial and all of the demonstration scripts would eventually be replaced by real C++ code. When the scripts fulfilled the demonstration purpose and the product was approved, the development director sought us out to provide testing resources.
This is a different kind of culture that exists at Google. No project gets testing resources as some right of its existence. The onus is on the development teams to solicit help from testers and convince them that their project is exciting and full of potential. As the Chrome OS development directors explained their project, progress, and ship schedule, we were able to place certain demands concerning SWE involvement in testing, expected unit testing coverage levels, and how the duties of the release process were going to be shared. We may not have been involved at project inception, but once the project became real, we had vast influence over how it was to be executed.
Team Structure
SWEs often get caught up in the code they are writing and generally that code is a single feature or perhaps even smaller in scope than that. SWEs tend to make decisions optimized for this local and narrow view of a product. A good SET must take the exact opposite approach and assume not only a broad view of the entire product and consider all of its features but also understand that over a product’s lifetime, many SWEs will come and go and the product will outlive the people who created it.
A product like Gmail or Chrome is destined to live for many versions and will consume hundreds of developers’ individual work. If a SWE joins a product team working on version 3 and that product is well documented, testable, and has working stable test automation and processes that make it clear how to add new code into this mix, then that is a sign that the early SETs did their job correctly.
With all of the features added, versions launched, patches made, and good intentioned rewrites and renames that happen during the life of a project, it can be hard to identify when or if a project ever truly comes to an end. Every software project has a definite beginning, though. We refine our goals during that early phase. We plan. We try things out. We even attempt to document what we think we are going to do. We try to ensure that the decisions made early on are the right decisions for the long-term viability of the product.
The amount of planning, experimentation, and documentation we produce before we begin to implement a new software project is proportional to the strength of our convictions in the long-term viability and success of that project. We don’t want to begin with little in the way of planning only to find out later that planning would have been worthwhile. We also don’t want to spend weeks in the early phase only to discover at its conclusion that the world around us has either changed or is not what it was originally thought to be. For these reasons, some structure around documentation and process during this early phase is wise. However, it is ultimately up to the engineers who create these projects to decide what and how much is enough.
Google product teams start with a tech lead and one or more founding members of various engineering roles. At Google, tech lead or TL is an informal title granted to the engineer or engineers responsible for setting the technical direction, coordinating activities, and acting as the main engineering representative of the project to other teams. He knows the answer to any question about the project or can point to someone who does. A project’s tech lead is usually a SWE or an engineer of another discipline working in a SWE capacity.
The tech lead and founding members of a project begin their work by drafting the project’s first design doc (described in the next section). As the document matures, it is leveraged as evidence of the need for additional engineers of various specializations. Many tech leads request an SET early on, despite their relative scarcity.
Design Docs
Every project at Google has a primary design doc. It is a living document, which means that it evolves alongside the project it describes. In its earliest form, a design doc describes the project’s objective, background, proposed team members, and proposed designs. During the early phase, the team works together to fill in the remaining relevant sections of the primary design doc. For sufficiently large projects, this might involve creating and linking to smaller design docs that describe the major subsystems. By the end of the early design phase, the project’s collection of design documents should be able to serve as a roadmap of all future work to be done. At this point, design docs might undergo one or more reviews by other tech leads in a project’s domain. Once a project’s design docs have received sufficient review, the early phase of the project draws to a close and the implementation phase officially begins.
As SETs, we are fortunate to join a project during its early phase. There is significant high-impact work to be done here. If we play our cards right, we can simplify the life of everyone on the project while accelerating the work of all those around us. Indeed, SETs have the one major advantage of being the engineer on the team with the broadest view of the product. A good SET can put this breadth of expertise to work for the more laser-focused developers and have impact far beyond the code they write. Generally broad patterns of code reuse and component interaction design are identified by SETs and not SWEs. The remainder of this section focuses on the high-value work an SET can do during the early phase of a project.
A SET’s role in the design phase is to simplify the life of everyone on the project while accelerating the work of all those around him.
There is no substitute for an additional pair of eyes on a body of work. As SWEs fill in the various sections of their design docs, they should be diligent about getting peer feedback prior to sending their document to a wider audience for official review. A good SET is eager to review such documents and proactively volunteers his time to review documents written by the team and adds quality or reliability sections as necessary. Here are several reasons why:
• An SET needs to be familiar with the design of the system she tests (reading all of the design docs is part of this) so being a reviewer accomplishes both SET and SWE needs.
• Suggestions made early on are much more likely to make it into the document and into the codebase, increasing an SET’s overall impact.
• By being the first person to review all design documents (and thus seeing all their iterations), an SET’s knowledge of the project as a whole will rival that of the tech lead’s knowledge.
• It is a great chance to establish a working relationship with each of the engineers whose code and tests the SET will be working with when development begins.
Reviewing design documents should be done with purpose and not just be a general breeze through, as though you are reading a newspaper. A good SET is purposeful during his review. Here are some things we recommend:
• Completeness: Identify parts of the document that are incomplete or that require special knowledge not generally available on the team, particularly to new members of the team. Encourage the document’s author to write more details or link to other documentation that fill in these gaps.
• Correctness: Look for grammar, spelling, and punctuation mistakes; this is sloppy work that does not bode well for the code they will write later. Don’t set a precedent for sloppiness.
• Consistency: Ensure that wording matches diagrams. Ensure that the document does not contradict claims made in other documents.
• Design: Consider the design proposed by the document. Is it achievable given the resources available? What infrastructure does it propose to build upon? (Read the documentation of that infrastructure and learn its pitfalls.) Does the proposed design make use of that infrastructure in a supported way? Is the design too complex? Is it possible to simplify? Is it too simple? What more does the design need to address?
• Interfaces and protocols: Does the document clearly identify the protocols it will use? Does it completely describe the interfaces and protocols that the product will expose? Do these interfaces and protocols accomplish what they are meant to accomplish? Are they standard across other Google products? Can you encourage the developer to go one step further and define his protocol buffers? (We discuss more about protocol buffers later.)
• Testing: How testable is the system or set of systems described by the document? Are new testing hooks required? If so, ensure those get added to the documentation. Can the design of the system be tweaked to make testing easier or use pre-existing test infrastructure? Estimate what must be done to test the system and work with the developer to have this information added to the design document.
Note
Reviewing design documents is purposeful and not like reading a newspaper. There are specific goals to pursue.
When an SET discusses this review with the SWE who created the design document, a serious conversation about the amount of work required to test it and the way in which that work is shared among the roles happens. This is a great time to document the goals of developer unit testing along with the best practices team members will follow when delivering a well tested product. When this discussion happens in a collaborative way, you know you are off to a good start.
Interfaces and Protocols
Documenting interfaces and protocols at Google is easy for developers as it involves writing code! Google’s protocol buffer language7 is a language-neutral, platform-neutral, extensible mechanism for serializing structured data—think XML, but smaller, faster, and easier. A developer defines how data is to be structured after it is in the protocol buffer language, and then uses generated source code to read and write the structured data from and to a variety of data streams in a variety of languages (Java, C++, or Python). Protocol buffer source is often the first code written for a new project. It is not uncommon to have design docs refer to protocol buffers as the specification of how things will work once the full system is implemented.
An SET reviews protocol buffer code thoroughly, because he will soon implement most of the interfaces and protocols described by that protocol buffer code. That’s right, it is an SET who typically implements most of the interfaces and protocols in the system first, because the need for integration testing often arises before it is possible to construct all subsystems on which the entire system depends. To enable integration testing early on, the SET provides mocks and fakes of the necessary dependencies of each component. Such integration tests have to be written eventually, and they’re more valuable when they’re available as the code is still being developed. Further, the mocks and fakes would be required for integration testing at any stage, as it is much easier to inject failures and establish error conditions through mocks than it is to do so within a system’s production dependencies.
Automation Planning
A SET’s time is limited and spread thinly and it is a good idea to create a plan for automating testing of the system as early as possible and to be practical about it. Designs that seek to automate everything end-to-end all in one master test suite are generally a mistake. Certainly no SWE is impressed by such an all-encompassing endeavor and an SET is unlikely to get much assistance. If an SET is going to get help from SWEs, his automation plan must be sensible and impactful. The larger an automation effort is, the harder it is to maintain and the more brittle it becomes as the system evolves. It’s the smaller, more special purpose automation that creates useful infrastructure and that attracts the most SWEs to write tests.
Overinvesting in end-to-end automation often ties you to a product’s specific design and isn’t particularly useful until the entire product is built and in stable form. By then, it’s often too late to make design changes in the product, so whatever you learn in testing at that point is moot. Time that the SET could have invested in improving quality was instead spent on maintaining a brittle end-to-end test suite.
At Google, SETs take the following approach.
We first isolate the interfaces that we think are prone to errors and create mocks and fakes (as described in the previous section) so that we can control the interactions at those interfaces and ensure good test coverage.
The next step is to build a lightweight automation framework that allows the mocked system to be built and executed. That way, any SWE who writes code that uses one of the mocked interfaces can do a private build and run the test automation before they check their code changes into the main codebase, ensuring only well tested code gets into the codebase in the first place. This is one key area where automation excels: keeping bad code out of the ecosystem and ensuring the main codebase stays clean.
In addition to the automation (mocks, fakes, and frameworks) to be delivered by the SET, the plan should include how to surface information about build quality to all concerned parties. Google SETs include such reporting mechanisms and dashboards that collect test results and show progress as part of the test plan. In this way, an SET increases the chances of creating high-quality code by making the whole process easy and transparent.
Testability
SWEs and SETs work closely on product development. SWEs write the production code and tests for that code. SETs support this work by writing test frameworks that enable SWEs to write tests. SETs also take a share of maintenance work. Quality is a shared responsibility between these roles.
A SET’s first job is testability. They act as consultants recommending program structure and coding style that lends itself to better unit testing and in writing frameworks to enable developers to test for themselves. We discuss frameworks later; first, let’s talk about the coding process at Google.
To make SETs true partners in the ownership of the source code, Google centers its development process around code reviews. There is far more fanfare about reviewing code than there is about writing it.
Reviewing code is a fundamental aspect of being a developer and it is an activity that has full tool support and an encompassing culture around it that has borrowed somewhat from the open source community’s concept of “committer” where only people who have proven to be reliable developers can actually commit code to the source tree.
At Google everyone is a committer, but we use a concept called readability to distinguish between proven committers and new developers. Here’s how the whole process works:
Code is written and packaged as a unit that we call a change list, or CL for short. A CL is written and then submitted for review in a tool known internally as Mondrian (named after the Dutch painter whose work inspired abstract art). Mondrian then routes the code to qualified SWEs or SETs for review and eventual signoff.8
CLs can be blocks of new code, changes to existing code, bug fixes, and so on. They range from a few lines to a few hundred lines with larger CLs almost always broken into smaller CLs at the behest of reviewers. SWEs and SETs who are new to Google will eventually be awarded with a readability designation by their peers for writing consistently good CLs. Readabilities are language specific and given for C++, Java, Python, and JavaScript, the primary languages Google uses. They are credentials that designate an experienced, trustworthy developer and help ensure the entire codebase has the look and feel of having been written by a single developer.9
There are a number of automated checks that occur before a CL is routed to a reviewer. These pre-submit rules cover simple things such as adherence to the Google coding style guide and more involved things such as ensuring that every existing test associated with the CL has been executed (the rule is that all tests must pass). The tests for a CL are almost always included in the CL itself—test code lives side by side with the functional code. After these checks are made, Mondrian notifies the reviewer via email with links to the appropriate CLs. The reviewer then completes the review and makes recommendations that are then handled by the SWE. The process is repeated until both the reviewers are happy and the pre-submit automation runs clean.
A submit queue’s primary goal in life is to keep the build “green,” meaning all tests pass. It is the last line of defense between a project’s continuous build system and the version control system. By building code and running tests in a clean environment, the submit queue catches environmental failures that might not be caught by a developer running tests on an individual workstation, but that might ultimately break the continuous build or, worse, make its way into the version control system in a broken state.
A submit queue also enables members of large teams to collaborate on the main branch of the source tree. This further eliminates the need to have scheduled code freezes while branch integrations and test passes take place. In this way, a submit queue enables developers on large teams to work as efficiently and independently as developers on small teams. The only real downside is that it makes the SET’s job harder because it increases the rate at which developers can write and submit code!
SET Workflow: An Example
Now let’s put all this together in an example. Warning: this section is going to get technical and go into a bunch of low-level details. If you are interested only in the big picture, feel free to skip to the next section.
Imagine a simple web application that allows users to submit URLs to Google that would then be added to Google’s index. The HTML form accepts two fields: url and comment, and it generates an HTTP GET request to Google’s servers resembling the following:
GET /addurl?url=http://www.foo.com&comment=Foo+comment HTTP/1.1
The server-side of this example web application is broken into at least two parts: the AddUrlFrontend (which accepts the raw HTTP request, parses it, and validates it) and the AddUrlService backend. This backend service accepts requests from the AddUrlFrontend, checks them for errors, and further interacts with persistent storage backends such as Google’s Bigtable10 or the Google File System.11
The SWE writing this service begins by creating a directory for this project:
$ mkdir depot/addurl/
He or she then defines the protocol of the AddUrlService using the Google Protocol Buffer12 description language as follows:
File: depot/addurl/addurl.proto
message AddUrlRequest {
required string url = 1; // The URL entered by the user.
optional string comment = 2; // Comments made by the user.
}
message AddUrlReply {
// Error code, if an error occurred.
optional int32 error_code = 1;
// Error message, if an error occurred.
optional string error_details = 2;
}
service AddUrlService {
// Accepts a URL for submission to the index.
rpc AddUrl(AddUrlRequest) returns (AddUrlReply) {
option deadline = 10.0;
}
}
The addurl.proto file defines three important items: the AddUrlRequest and AddUrlReply messages and the AddUrlService Remote Procedure Call (RPC) service.
We can tell by inspecting the definition of the AddUrlRequest message that a url field must be supplied by the caller and that a comment field can be optionally supplied.
We can similarly see by inspecting the definition of the AddUrlReply message that both the error_code and error_details fields can optionally be supplied by the service in its replies. We can safely assume that these fields are left empty in the common case where a URL is accepted successfully, minimizing the amount of data transferred. This is the convention at Google: Make the common case fast.
Inspection of the AddUrlService reveals that there is a single service method, AddUrl, that accepts an AddUrlRequest and returns an AddUrlReply. By default, calls to the AddUrl method time out after an elapsed time of 10 seconds, if the client did not receive a response in that time. Implementations of the AddUrlService interface might involve any number of persistent storage backends, but that is of no concern to clients of this interface, so those details are not present in the addurl.proto file.
The ‘= 1’ notation on message fields has no bearing on the values of those fields. The notation exists to allow the protocol to evolve over time. For example, in the future, someone might want to add a uri field to the AddUrlRequest message in addition to the fields that were already there. To do this, they can make the following change:
message AddUrlRequest {
required string url = 1; // The URL entered by the user.
optional string comment = 2; // Comments made by the user.
optional string uri = 3; // The URI entered by the user.
}
But that would be silly. Someone is more likely to want to rename the url field to uri. If they keep the number and type the same, then they maintain compatibility between the old and new versions:
message AddUrlRequest {
required string uri = 1; // The URI entered by the user.
optional string comment = 2; // Comments made by the user.
}
Having written addurl.proto, our developer proceeds to create a proto_library build rule, which generates C++ source files that define the items from addurl.proto and that compile into a static addurl C++ library. (With additional options, source for Java and Python language bindings are also possible.)
File: depot/addurl/BUILD
proto_library(name="addurl",
srcs=["addurl.proto"])
The developer invokes the build system and fixes any issues uncovered by the build system in addurl.proto and in its build definitions in the BUILD file. The build system invokes the Protocol Buffer compiler, generating source code files addurl.pb.h and addurl.pb.cc, as well as generating a static addurl library that can be linked against.
The AddUrlFrontend can now be written by creating a class declaration of AddUrlFrontend in a new file, addurl_frontend.h. This code is largely boilerplate.
File: depot/addurl/addurl_frontend.h
#ifndef ADDURL_ADDURL_FRONTEND_H_
#define ADDURL_ADDURL_FRONTEND_H_
// Forward-declaration of dependencies.
class AddUrlService;
class HTTPRequest;
class HTTPReply;
// Frontend for the AddUrl system.
// Accepts HTTP requests from web clients,
// and forwards well-formed requests to the backend.
class AddUrlFrontend {
public:
// Constructor which enables injection of an
// AddUrlService dependency.
explicit AddUrlFrontend(AddUrlService* add_url_service);
~AddUrlFrontend();
// Method invoked by our HTTP server when a request arrives
// for the /addurl resource.
void HandleAddUrlFrontendRequest(const HTTPRequest* http_request,
HTTPReply* http_reply);
private:
AddUrlService* add_url_service_;
// Declare copy constructor and operator= private to prohibit
// unintentional copying of instances of this class.
AddUrlFrontend(const AddUrlFrontend&);
AddUrlFrontend& operator=(const AddUrlFrontend& rhs);
};
#endif // ADDURL_ADDURL_FRONTEND_H_
Continuing on to the definitions of the AddUrlFrontend class, the developer now creates addurl_frontend.cc. This is where the logic of the AddUrlFrontend class is coded. For the sake of brevity, portions of this file have been omitted.
File: depot/addurl/addurl_frontend.cc
#include "addurl/addurl_frontend.h"
#include "addurl/addurl.pb.h"
#include "path/to/httpqueryparams.h"
// Functions used by HandleAddUrlFrontendRequest() below, but
// whose definitions are omitted for brevity.
void ExtractHttpQueryParams(const HTTPRequest* http_request,
HTTPQueryParams* query_params);
void WriteHttp200Reply(HTTPReply* reply);
void WriteHttpReplyWithErrorDetails(
HTTPReply* http_reply, const AddUrlReply& add_url_reply);
// AddUrlFrontend constructor that injects the AddUrlService
// dependency.
AddUrlFrontend::AddUrlFrontend(AddUrlService* add_url_service)
: add_url_service_(add_url_service) {
}
// AddUrlFrontend destructor - there's nothing to do here.
AddUrlFrontend::~AddUrlFrontend() {
}
// HandleAddUrlFrontendRequest:
// Handles requests to /addurl by parsing the request,
// dispatching a backend request to an AddUrlService backend,
// and transforming the backend reply into an appropriate
// HTTP reply.
//
// Args:
// http_request - The raw HTTP request received by the server.
// http_reply - The raw HTTP reply to send in response.
void AddUrlFrontend::HandleAddUrlFrontendRequest(
const HTTPRequest* http_request, HTTPReply* http_reply) {
// Extract the query parameters from the raw HTTP request.
HTTPQueryParams query_params;
ExtractHttpQueryParams(http_request, &query_params);
// Get the 'url' and 'comment' query components.
// Default each to an empty string if they were not present
// in http_request.
string url =
query_params.GetQueryComponentDefault("url", "");
string comment =
query_params.GetQueryComponentDefault("comment", "");
// Prepare the request to the AddUrlService backend.
AddUrlRequest add_url_request;
AddUrlReply add_url_reply;
add_url_request.set_url(url);
if (!comment.empty()) {
add_url_request.set_comment(comment);
}
// Issue the request to the AddUrlService backend.
RPC rpc;
add_url_service_->AddUrl(
&rpc, &add_url_request, &add_url_reply);
// Block until the reply is received from the
// AddUrlService backend.
rpc.Wait();
// Handle errors, if any:
if (add_url_reply.has_error_code()) {
WriteHttpReplyWithErrorDetails(http_reply, add_url_reply);
} else {
// No errors. Send HTTP 200 OK response to client.
WriteHttp200Reply(http_reply);
}
}
HandleAddUrlFrontendRequest is a busy member function. This is the nature of many web handlers. The developer can choose to simplify this function by extracting some of its functionality into helper functions. However, such refactoring before the build is stable, unit tests are in place, and unit tests are passing is unusual.
At this point, the developer modifies the existing build specification for the addurl project, adding an entry for the addurl_frontend library. This creates a static C++ library for AddUrlFrontend when built.
File: /depot/addurl/BUILD
# From before:
proto_library(name="addurl",
srcs=["addurl.proto"])
# New:
cc_library(name="addurl_frontend",
srcs=["addurl_frontend.cc"],
deps=[
"path/to/httpqueryparams",
"other_http_server_stuff",
":addurl", # Link against the addurl library above.
])
The developer starts his build tools again, fixing compiler and linker errors in addurl_frontend.h and addurl_frontend.cc until everything builds and links cleanly without warnings or errors. At this point, it’s time to write unit tests for AddUrlFrontend. These are written in a new file, addurl_frontend_test.cc. This test defines a fake of the AddUrlService backend and leverages the AddUrlFrontend constructor to inject this fake at test time. In this way, the developer is able to inject expectations and errors into the workflow of AddUrlFrontend without modification of the AddUrlFrontend code itself.
File: depot/addurl/addurl_frontend_test.cc
#include "addurl/addurl.pb.h"
#include "addurl/addurl_frontend.h"
// See http://code.google.com/p/googletest/
#include "path/to/googletest.h"
// Defines a fake AddUrlService, which will be injected by
// the AddUrlFrontendTest test fixture into AddUrlFrontend
// instances under test.
class FakeAddUrlService : public AddUrlService {
public:
FakeAddUrlService()
: has_request_expectations_(false),
error_code_(0) {
}
// Allows tests to set expectations on requests.
void set_expected_url(const string& url) {
expected_url_ = url;
has_request_expectations_ = true;
}
void set_expected_comment(const string& comment) {
expected_comment_ = comment;
has_request_expectations_ = true;
}
// Allows for injection of errors by tests.
void set_error_code(int error_code) {
error_code_ = error_code;
}
void set_error_details(const string& error_details) {
error_details_ = error_details;
}
// Overrides of the AddUrlService::AddUrl method generated from
// service definition in addurl.proto by the Protocol Buffer
// compiler.
virtual void AddUrl(RPC* rpc,
const AddUrlRequest* request,
AddUrlReply* reply) {
// Enforce expectations on request (if present).
if (has_request_expectations_) {
EXPECT_EQ(expected_url_, request->url());
EXPECT_EQ(expected_comment_, request->comment());
}
// Inject errors specified in the set_* methods above if present.
if (error_code_ != 0 || !error_details_.empty()) {
reply->set_error_code(error_code_);
reply->set_error_details(error_details_);
}
}
private:
// Expected request information.
// Clients set using set_expected_* methods.
string expected_url_;
string expected_comment_;
bool has_request_expectations_;
// Injected error information.
// Clients set using set_* methods above.
int error_code_;
string error_details_;
};
// The test fixture for AddUrlFrontend. It is code shared by the
// TEST_F test definitions below. For every test using this
// fixture, the fixture will create a FakeAddUrlService, an
// AddUrlFrontend, and inject the FakeAddUrlService into that
// AddUrlFrontend. Tests will have access to both of these
// objects at runtime.
class AddurlFrontendTest : public ::testing::Test {
protected:
// Runs before every test method is executed.
virtual void SetUp() {
// Create a FakeAddUrlService for injection.
fake_add_url_service_.reset(new FakeAddUrlService);
// Create an AddUrlFrontend and inject our FakeAddUrlService
// into it.
add_url_frontend_.reset(
new AddUrlFrontend(fake_add_url_service_.get()));
}
scoped_ptr<FakeAddUrlService> fake_add_url_service_;
scoped_ptr<AddUrlFrontend> add_url_frontend_;
};
// Test that AddurlFrontendTest::SetUp works.
TEST_F(AddurlFrontendTest, FixtureTest) {
// AddurlFrontendTest::SetUp was invoked by this point.
}
// Test that AddUrlFrontend parses URLs correctly from its
// query parameters.
TEST_F(AddurlFrontendTest, ParsesUrlCorrectly) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource and
// to contain a 'url' query parameter.
http_request.set_text(
"GET /addurl?url=http://www.foo.com HTTP/1.1
");
// Tell the FakeAddUrlService to expect to receive a URL
// of 'http://www.foo.com'.
fake_add_url_service_->set_expected_url("http://www.foo.com");
// Send the request to AddUrlFrontend, which should dispatch
// a request to the FakeAddUrlService.
add_url_frontend_->HandleAddUrlFrontendRequest(
&http_request, &http_reply);
// Validate the response.
EXPECT_STREQ("200 OK", http_reply.text());
}
// Test that AddUrlFrontend parses comments correctly from its
// query parameters.
TEST_F(AddurlFrontendTest, ParsesCommentCorrectly) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource and
// to contain a 'url' query parameter and to also contain
// a 'comment' query parameter that contains the
// url-encoded query string 'Test comment'.
http_request.set_text("GET /addurl?url=http://www.foo.com"
"&comment=Test+comment HTTP/1.1
");
// Tell the FakeAddUrlService to expect to receive a URL
// of 'http://www.foo.com' again.
fake_add_url_service_->set_expected_url("http://www.foo.com");
// Tell the FakeAddUrlService to also expect to receive a
// comment of 'Test comment' this time.
fake_add_url_service_->set_expected_comment("Test comment");
// Send the request to AddUrlFrontend, which should dispatch
// a request to the FakeAddUrlService.
add_url_frontend_->HandleAddUrlFrontendRequest(
&http_request, &http_reply);
// Validate that the response received is a '200 OK' response.
EXPECT_STREQ("200 OK", http_reply.text());
}
// Test that AddUrlFrontend sends proper error information when
// the AddUrlService encounters a client error.
TEST_F(AddurlFrontendTest, HandlesBackendClientErrors) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource.
http_request.set_text("GET /addurl HTTP/1.1
");
// Configure the FakeAddUrlService to inject a client error with
// error_code 400 and error_details of 'Client Error'.
fake_add_url_service_->set_error_code(400);
fake_add_url_service_->set_error_details("Client Error");
// Send the request to AddUrlFrontend, which should dispatch
// a request to the FakeAddUrlService.
add_url_frontend_->HandleAddUrlFrontendRequest(
&http_request, &http_reply);
// Validate that the response contained a 400 client error.
EXPECT_STREQ("400
Error Details: Client Error",
http_reply.text());
}
The developer would likely write many more tests than this, but this is enough to demonstrate the common patterns of defining a fake, injecting that fake into a system under test, and using that fake in tests to inject errors and validation logic into the workflow of a system under test. One notable test missing here is one that would mimic a network timeout between the AddUrlFrontend and the FakeAddUrlService backend. Such a test would reveal that our developer forgot to check for and handle the condition where a timeout occurred.
Agile testing veterans will point out that everything done by FakeAddUrlService was simple enough that a mock could have been used instead. These veterans would be correct. We implement these features via a fake purely for illustrative purposes.
Anyhow, our developer now wants to run these tests. To do so, he must first update his build definitions to include a new test rule that defines the addurl_frontend_test test binary.
File: depot/addurl/BUILD
# From before:
proto_library(name="addurl",
srcs=["addurl.proto"])
# Also from before:
cc_library(name="addurl_frontend",
srcs=["addurl_frontend.cc"],
deps=[
"path/to/httpqueryparams",
"other_http_server_stuff",
":addurl", # Depends on the proto_library above.
])
# New:
cc_test(name="addurl_frontend_test",
size="small", # See section on Test Sizes.
srcs=["addurl_frontend_test.cc"],
deps=[
":addurl_frontend", # Depends on library above.
"path/to/googletest_main"])
Once again, the developer uses his build tools to compile and run the addurl_frontend_test binary, fixing any compiler and linker errors uncovered by the build tools and this time also fixing the tests, test fixtures, fakes, and/or AddUrlFrontend itself based on any test failures that occur. This process starts immediately after defining the previous FixtureTest, and is repeated as the remaining test cases are added one at a time. When all of the tests are in place and passing, the developer creates a CL that contains all of these files, fixes any small issues caught by presubmit checks, sends that CL out for review, and then moves on to the next task (likely writing a real AddUrlService backend) while waiting for review feedback.
$ create_cl BUILD
addurl.proto
addurl_frontend.h
addurl_frontend.cc
addurl_frontend_test.cc
$ mail_cl -m [email protected]
When review feedback arrives, the developer makes the appropriate changes (or works with the reviewer to agree on an alternative), potentially undergoes additional review, and then submits the CL to the version control system. From this point on, whenever someone makes changes to any of the code in these files, Google’s test automation systems know to run the addurl_frontend_test to verify that those changes did not break the existing tests. Additionally, anyone seeking to modify addurl_frontend.cc has addurl_frontend_test as a safety net to run while making their modifications.
Test Execution
Test automation goes beyond writing individual test programs. If we consider what it takes to be useful, we have to include compiling test programs, executing them, and analyzing, storing, and reporting the results of each execution as part of the automated testing challenge. Test automation is in effect an entire software development effort in its own right.
Having to worry about all these issues distracts engineers from concentrating on writing the right automation and making it useful for their projects. Test code is only useful in the context of being executable in a way that accelerates development and doesn’t slow it down. Thus, it has to be integrated into the actual development process in a way that makes it part of development and not separate from it. Functional code never exists in a vacuum. Neither should test code.
Thus, a common infrastructure that performs the compilation, execution, analysis, storage, and reporting of tests has evolved, reducing the problem back to where we want it to be: Google engineers writing individual test programs and submitting them to this common infrastructure to handle the execution details and ensuring that the test code gets the same treatment as functional code.
After an SET writes a new test program, he creates a build specification of that test for the Google build infrastructure. A test build specification includes the name of the test, the source files from which it is built, its dependencies on any libraries or data, and finally a test size. Every test must specify its size as either small, medium, large, or enormous. After the code and build specifications for a test are in place, Google’s build tools and test execution infrastructure take care of the rest. From that moment forward, a single command initiates a build, runs the automation, and provides views for the results of that test.
Google’s test execution infrastructure places constraints on how tests are written. These constraints and how we manage them are described in the following section.
Test Size Definitions
As Google grew and new employees were hired, a confusing nomenclature of types of tests persisted: Unit tests, code-based tests, white box tests, integration tests, system tests, and end-to-end tests all add different levels of granularity, as shown in Figure 2.1. Early on, it was decided enough is enough, so we created a standard set of names.

Figure 2.1 Google employs many different types of test execution.
Small tests verify the behavior of a single unit of code generally isolated from its environment. Examples include a single class or a small group of related functions. Small tests should have no external dependencies. Outside of Google, small tests are commonly known as “unit tests.”
Small tests have the narrowest scope of any of the test categories and focus on a function operating in isolation, as depicted in Figure 2.2. This limited scope enables small tests to provide comprehensive coverage of low-level code in a way that larger tests cannot.
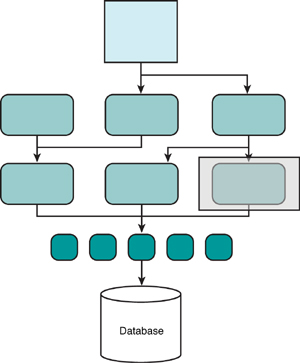
Figure 2.2 Illustration of the scope of a small test where often only a single function is involved.
Within small tests, external services such as file systems, networks, and databases must be mocked or faked. Where appropriate, mocking of internal services within the same module as the class under test is also encouraged to further reduce any external dependencies.
Isolated scope and absence of external dependencies mean that small tests can be run quickly; therefore, they are executed frequently, leading to quicker discovery of bugs. The general idea is that as developers execute these tests and as they modify functional code, they also maintain the small tests for that code. Isolation can also enable shorter build and execution times for tests.
Medium tests validate the interaction of one or more application modules, as depicted in Figure 2.3. Larger scopes and longer running times differentiate medium tests from small tests. Whereas small tests might attempt to exercise all of a single function’s code, medium tests are aimed at testing interaction across a limited subset of modules. Outside of Google, medium tests are often called “integration tests.”

Figure 2.3 Medium tests include multiple modules and can include external data sources.
The longer running times of medium tests require test execution infrastructure to manage them and they often do not execute as frequently as smaller tests. Medium tests are generally organized and executed by SETs.
Note
Small tests verify the behavior of a single unit of code. Medium tests validate the interaction of one or more units of code. Large tests verify that the system works as a whole.
Mocking external services for medium tests is encouraged but not required, unless performance considerations mandate mocking. Lightweight fakes, such as in-memory databases, can be used to improve performance where true mocking might not be immediately practical.
Large and enormous tests are commonly referred to as “system tests” or “end-to-end tests” outside of Google. Large tests operate on a high level and verify that the application as a whole works. These tests are expected to exercise any or all application subsystems from the UI down to backend data storage, as shown in Figure 2.4, and might make use of external resources such as databases, file systems, and network services.
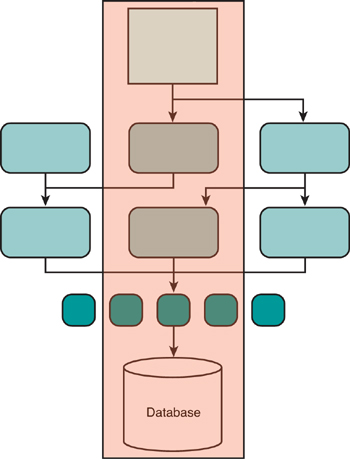
Figure 2.4 Large and enormous tests include modules that encompass end-to-end execution.
Use of Test Sizes in Shared Infrastructure
Automation of test execution can be a difficult service to provide in a universal way. For a large engineering organization to share common test execution infrastructure, that infrastructure must support execution of a variety of testing jobs.
Some common jobs that share Google test execution infrastructure are
• A developer compiles and runs a small test and would like to get the results immediately.
• A developer would like to run all the small tests for a project and get the results quickly.
• A developer would like to compile and run only the tests in a project that are impacted by a pending change and get the results immediately.
• An engineer would like to collect code coverage for a project and view the results.
• A team would like to run all small tests for a project for every CL submitted and distribute the results for review within the team.
• A team would like to run all tests for a project after a CL is committed to the version control system.
• A team would like to collect code coverage results weekly and track progress over time.
There might be times when all of the previous jobs are submitted to Google’s test execution system simultaneously. Some of these tests might hog resources, bogging down shared machines for hours at a time. Others might take only milliseconds to run and could be run in parallel with hundreds of other tests on a single shared machine. When each test is labeled as small, medium, or large, it makes it easier to schedule the jobs because the scheduler has an idea of how long a job will take to run, thus it can optimize the job queue to good effect.
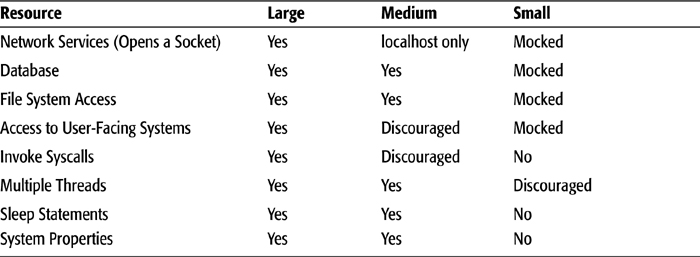
Google’s test execution system uses test sizes to distinguish fast jobs from slower ones. Test sizes guarantee an upper bound on each test’s execution time, as described in Table 2.1. Test sizes also imply the potential resource needs of a test, as described in Table 2.2. Google’s test execution system cancels execution and reports a failure for any test that exceeds the time or resource requirements associated with its test size. This forces engineers to provide appropriate test size labels. Accurate test sizing enables Google’s test execution system to make smart scheduling decisions.
Table 2.1 Goals and Limits of Test Execution Time by Test Size

Table 2.2 Resource Usage by Test Size
Benefits of Test Sizes
Each test size offers its own set of benefits. Figure 2.5 summarizes these benefits. The benefits and weaknesses of each test size are listed for comparison.
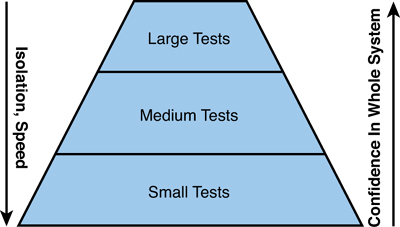
Figure 2.5 Limitations of various test sizes.
Large Tests
The benefits and weaknesses of large tests include the following:
• Test what is ultimately most important: how the application works. Account for the behavior of external subsystems.
• They can be nondeterministic because of dependencies on external systems.
• Broad scope means that when tests fail, the cause might be difficult to find.
• The data setup for testing scenarios can be time-consuming.
• A high level of operation often makes it impractical to exercise specific corner cases. That’s what small tests are for.
Medium Tests
The benefits and weaknesses of medium tests include the following:
• With looser mocking requirements and runtime limitations, provide development groups a stepping stone they can use to move from large tests toward small tests.
• They run relatively fast, so developers can run them frequently.
• They run in a standard developer environment, so developers can run them easily.
• Account for the behavior of external subsystems.
• They can be nondeterministic because of dependencies on external systems.
• They are not as fast as small tests.
Small Tests
The benefits and weaknesses of small tests include the following:
• Lead to cleaner code because methods must be relatively small and tightly focused to be easily tested; mocking requirements lead to well-defined interfaces between subsystems.
• Because they run quickly, they can catch bugs early and provide immediate feedback when code changes are made.
• They run reliably in all environments.
• They have a tighter scope, which allows for easier testing of edge cases and error conditions, such as null pointers.
• They have focused scope, which makes isolation of errors very easy.
• Don’t exercise integration between modules. That’s what the other test categories do.
• Mocking subsystems can sometimes be challenging.
• Mock or fake environments can get out of sync with reality.
Small tests lead to code quality, good exception handling, and good error reporting, whereas larger tests lead to overall product quality and data validation. No single test size in isolation can solve all of a project’s testing needs. For this reason, projects at Google are encouraged to maintain a healthy mixture of test sizes among their various test suites. It is considered just as wrong to perform all automation through a large end-to-end testing framework as it is to provide only small unit tests for a project.
Note
Small tests lead to code quality. Medium and large tests lead to product quality.
Code coverage is a great tool for measuring whether a project’s tests have a healthy mixture of small, medium, and large tests. A project can create a coverage report running only its small tests and another report running only its medium and large tests. Each report should show an acceptable amount of coverage for the project in isolation. If medium and large tests produce only 20 percent code coverage in isolation, while small tests provide nearly 100 percent coverage, the project is likely lacking in evidence that the system works end-to-end. If the numbers were reversed, it would likely be hard to maintain or extend the project without spending a lot of time debugging. Google engineers are able to create and view these coverage reports on-the-fly using the same tools they use to build and run their tests by specifying an additional command-line flag. Coverage reports are stored in the cloud and can be viewed internally in any web browser by any engineer.
Google spans many types of projects, many with very different testing needs so the exact ratios of small-to-medium-to-large tests are left up to the teams—this is not prescribed. The general rule of thumb is to start with a rule of 70/20/10: 70 percent of tests should be small, 20 percent medium, and 10 percent large. If projects are user-facing, have a high degree of integration, or complex user interfaces, they should have more medium and large tests. Infrastructure or data-focused projects such as indexing or crawling have a very large number of small tests and far fewer medium or large tests.
Another internal tool we use for monitoring test coverage is Harvester. Harvester is a visualization tool that tracks all of a project’s CLs and graphs things such as the ratio of test code to new code in individual CLs; the sizes of changes; frequency of changes over time and by date; changes by developer, and others. Its purpose is to give a general sense of how a project’stesting changes over time.
Test Runtime Requirements
Whatever a test’s size, Google’s test execution system requires the following behavior. It is, after all, a shared environment:
• Each test must be independent from other tests so that tests can be executed in any order.
• Tests must not have any persistent side effects. They must leave their environment exactly in the state when it started.
These requirements are simple enough to understand, but they can be tricky to abide by. Even if the test itself does its best to comply, the software under test might offend through the saving of data files or setting environment and configuration information. Fortunately, Google’s test execution environment provides a number of features to make compliance straightforward.
For the independence requirement, engineers can specify a flag when they execute their tests to randomize the order of test execution. This feature eventually catches order-related dependencies. However, “any order” means that concurrency is also a possibility. The test execution system might choose to execute two tests on the same machine. If those two tests each require exclusive access to system resources, one of them might fail. For example:
• Two tests want to bind to the same port number to exclusively receive network traffic.
• Two tests want to create a directory at the same path.
• One test wants to create and populate a database table while another test wants to drop that same table.
These sorts of collisions can cause failures not only for the offending test, but also for other tests running on the test execution system, even if those other tests play by the rules. The system has a way of catching these tests and notifying the owners of the test. By setting a flag, a test can be marked to run exclusively on a specific machine. However, exclusivity is only a temporary fix. Most often, tests or the software being tested must be rewritten to drop dependencies on singular resources. The following remedies solve these problems:
• Have each test request an unused port number from the test execution system, and have the software under test dynamically bind to that port number.
• Have each test create all directories and files under a temporary unique directory that is created for and assigned to it by the test execution system just prior to test execution and injected into the process’s environment.
• Have each test start its own database instance in a private, isolated environment based on directories and ports assigned to them by the test execution system.
The maintainers of Google’s test execution system went so far as to document their test execution environment fairly exhaustively. Their document is known as Google’s “Test Encyclopedia” and is the final answer on what resources are available to tests at runtime. The “Test Encyclopedia” reads like an IEEE RFC, using well-defined meanings of “must” and “shall.” It explains in detail the roles and responsibilities of tests, test executors, host systems, libc runtimes, file systems, and so on.
Most Google engineers have likely not found the need to read the “Test Encyclopedia” and instead learn from others or by trial and error as their tests fail to run properly, or through feedback during code reviews. Unbeknownst to them, it is the details expressed in that document that allowed a single shared test execution environment to serve the test execution needs of every Google project. Nor are those engineers aware that the “Test Encyclopedia” is the main reason that the behaviors of tests running in the shared execution environment exactly match the behaviors of tests running on their personal workstations. The gory details of great platforms are invisible to those who use them. Everything just works!
1. Get the latest copy of the code.
2. Run all tests.
3. Report results.
4. Repeat 1–3.
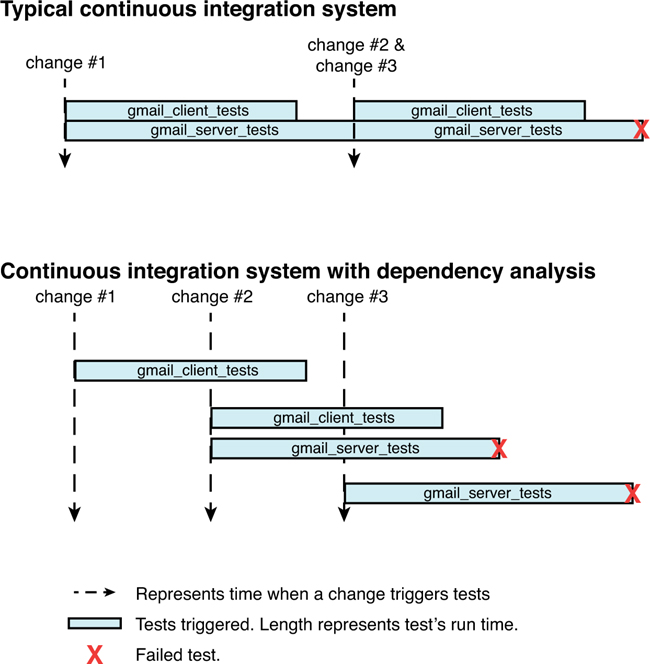
Figure 2.6 A typical continuous integration system.
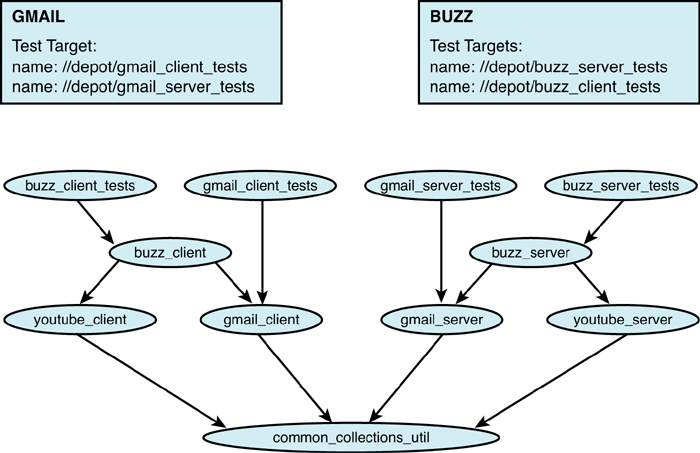
Figure 2.7 Example of build dependencies.
Case 1: Change in Common Library
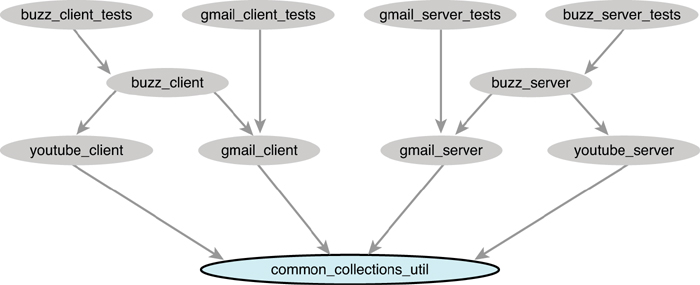
Figure 2.8 Change in common_collections_util.h.
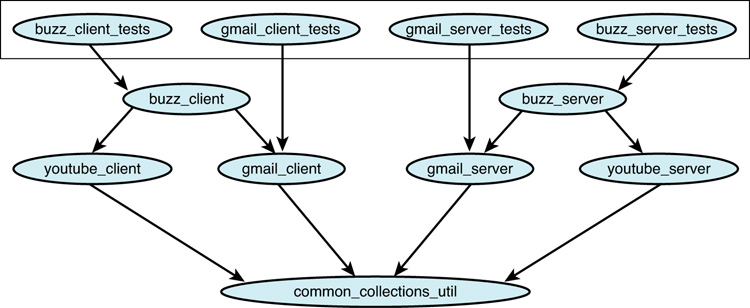
Figure 2.9 Tests affected by change.
Case 2: Change in a Dependent Project
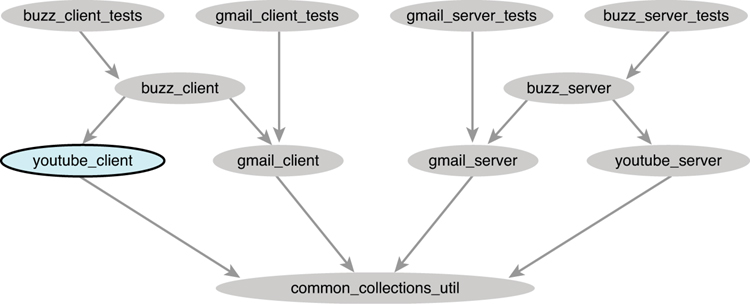
Figure 2.10 Change in youtube_client.
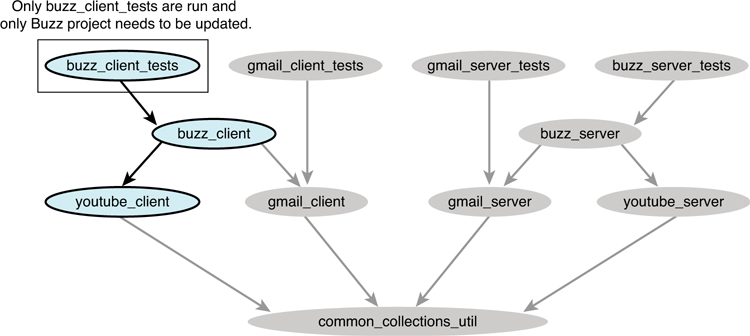
Figure 2.11 Buzz needs updating.
Test Certified
Patrick Copeland’s preface to this book underscores the difficulty in getting developers to participate in testing. Hiring highly technical testers was only step one. We still needed to get developers involved. One of the key ways we did this was by a program called Test Certified. In retrospect, the program was instrumental in getting the developer-testing culture ingrained at Google.
Test Certified started out as a contest. Can we get developers to take testing seriously if we make it a prestigious matter? If developers follow certain practices and achieve specific results, can we say they are “certified” and create a badge system (see Figure 2.12) that provides some bragging rights?

Figure 2.12 Test Certified badges appear on project wiki pages.
Well, that’s Test Certified: a system of testing challenges that if a team completes earns the team a “certified” designation. Level 0 is the starting level for all teams. After a team shows a mastery of basic code hygiene practices, it reaches level 1 and then progresses through the levels, which end at 5 to match some external models such as capability maturity model.13
The program was piloted slowly with a few teams of testing-minded developers who were keen to improve their practices. After the kinks were worked out of the program, a big contest to get certified was held as a companywide push and adoption was brisk.
It wasn’t as hard a sell as one might think. The benefit to development teams was substantial:
• They got lots of attention from good testers who signed up to be Test Certified Mentors. In a culture where testing resources were scarce, signing up for this program got a product team far more testers than it ordinarily would have merited.
• They received guidance from experts and learned how to write better small tests.
• They understood which teams were doing a better job of testing and thus who to learn from.
• They were able to brag to the other teams that they were higher on the Test Certified scale!
After the companywide push, most teams were climbing the ladder and they were all aware of it. Development Directors with teams moving up the ladder were given good review feedback from Engineering Productivity leads and teams who scoffed at it did so at their own peril. Again, in a company where testing resources are hard to come by, what team would want to alienate Engineering Productivity? Still it wasn’t all flowers and puppies. But we’ll let the people who ran the program tell the whole story.
An Interview with the Founders of the Test Certified Program
The authors sat down with four Googlers who were instrumental in starting the Test Certified program. Mark Striebeck is a development manager for Gmail. Neal Norwitz is an SWE working on tools for developer velocity, Tracy Bialik and Russ Rufer are SETs who as nonmanagers are among the highest-leveled SETs in the company; both are staff-level engineers.
HGTS: What are the origins of the Test Certified program? What problems did the original TC team try to solve? Are those the same problems that the program tries to solve today?
Tracy: We wanted to change Google’s developer culture to include testing as part of every feature developer’s responsibility. They shared their positive experiences with testing and encouraged teams to write tests. Some teams were interested, but didn’t know how to start. Others would put “improve testing” on their team objectives and key results (OKRs),14 which isn’t always actionable. It was like putting “lose weight” on your New Year’s resolutions. That’s a fine, lofty goal, but if that’s all you say, don’t be surprised if it never happens.
Test Certified provided small, clear, actionable steps that teams could take. The first level is getting the basics in place: setting up automation for running tests and gathering test coverage, noting any nondeterministic tests, and making a smoke test suite (if the full test suite was long-running). Each level becomes more difficult, requiring more test maturity. Level 2 targets policies and getting started on improving incremental coverage. Level 3 focuses on testing newly written code. Level 4 focuses on testing of legacy code, which typically requires at least some refactoring for testability. Level 5 demands better overall coverage, writing tests for all bug fixes and using available static and dynamic analysis tools.
Now, all Googlers know that testing is a feature developer’s responsibility. So that problem has been solved. But we still have the problem of teams needing to take action to improve their testing maturity and capability, so Test Certified continues to serve that need.
HGTS: What was the early feedback the Test Certified team received from the SWEs?
Neal: That it’s too hard. They thought our goals were too lofty and many teams were struggling with the basics. We needed to make the levels correspond to work that could be accomplished in their spare time. Also there were issues around Google’s tools at the time and some of the things we were asking for were just too advanced. It was really hard for folks to get started, so we had to think about providing them with some softballs to start the process and convince them they were making progress.
Mark: Yes, we had to make several iterations downward. We tried to meet them halfway by being more realistic and making the runway toward eventual takeoff a lot longer. We didn’t mind increasing the runway but we still wanted escape velocity at some point. That’s how we ended up with the first step being “set up a continuous build, have some green builds, know your coverage.” It was a freebie, but it established some discipline and helped them get from 0 to 1 and put them in a position to want more.
HGTS: Who was eager to adopt?
Neal: It started with most of the people in the Testing Grouplet. This grouplet was meeting regularly and was comprised of the people who were the most enthusiastic about testing. We then branched out to other folks we knew. I think there were a ton of eager folks and that was a nice surprise. We generated more enthusiasm with ToTT15 and other activities that made testing look more fun or sexy: fixits,16 VP mass emails, posters, talks at TGIF, and so on.
Mark: As soon as we reached out to other teams (and we had a bunch of teams who were interested), they realized that this will a) require some serious work, and b) that they don’t have the expertise. That made the beginning really frustrating.
HGTS: Who was reluctant to adopt?
Neal: Most projects. As I mentioned, it was perceived as too hard. We needed to scale back our initial ambitions. There were pretty much two sets of projects: those with no tests and those with really crappy tests. We needed to make it seem so simple that they could do many of the required testing tasks in an afternoon (and they really could with our help).
Mark: Also, this was still the time when the value of testing and test automation wasn’t fully appreciated at Google. Not like it is today, not by a long shot. By far, most teams had the attitude that these are cute ideas, but that they had more important things to do (a.k.a. writing production code).
HGTS: What hurdles did the team have to overcome to get its initial set of adopters?
Neal: Inertia. Bad tests. No tests. Time. Testing was seen as someone else’s problem, be it another developer or a testing team. Who’s got time to test when you are writing all that code?
Mark: Finding teams that were: a) interested enough, b) didn’t have too much of a legacy codebase problem, and c) had someone on the team who would be the testing champion (and who knew enough about testing). These were the three hurdles and we jumped them one at a time, team by team.
HGTS: What pushed the Test Certified program into the mainstream? Was growth viral or linear?
Russ: First there was a pilot that included teams that were especially friendly to testing and teams that the initial Test Certified instigators had close contacts with. We chose our early adopters well, basically the ones who had the best chance of succeeding.
At the point when we announced the “global launch” of Test Certified in mid-2007, there were 15 pilot teams at various rungs of the ladder. Just before the launch, we plastered the walls of every building in Mountain View, New York, and a few other offices with “TC Mystery” posters. Each poster had images representing several of the pilot teams, based on internal project names like Rubix, Bounty, Mondrian, and Red Tape. The only text on the posters said, “The future is now” and “This is big, don’t be left behind” with a link. We got a ton of hits on the link from puzzle-loving Googlers who wanted to see what the mystery was or simply to confirm their guesses. We also leveraged ToTT to advertise the new program and direct those readers to places they could get more information. It was a blitz of information.
That information included why Test Certified was important for teams and what kind of help they could get. It stressed that teams got a Test Certified Mentor and an “in” to a larger community of test expertise. We also offered teams two gifts for participation. First, a glowing build-status orb to show the team when tests on their (often new) continuous build passed (green) or failed (red). The second gift was a nifty Star Wars Potato Head kit. The so-called Darth Tater kit included three progressively larger units, and we awarded these to teams as they climbed higher on the Test Certified ladder. Teams displaying their orbs and potato heads helped build more curiosity and word of mouth about the program.
Testing Grouplet members were the early mentors and spokesmen for the project. As more teams joined, they often had enthusiastic engineers who helped create a buzz around Test Certified and acted as mentors for other teams.
As we each tried to convince more teams to join the program, we shared the best arguments with one another. Some teams joined because you could convince them the ladder steps and mentor availability would help their team improve this important area. Some teams felt they could improve either way, but were convinced the “official” levels would help them get credit for the work they were doing. Other teams were already very mature in their testing approach, but could be convinced to join as a signal to the rest of the company that they felt proper testing was important.
Several months in, with somewhere around 50 teams, a few enterprising members of our Test Engineering organization signed up to be Test Certified Mentors, which was the beginning of a stronger partnership between engineers from product teams and engineers from Engineering Productivity.
It was all very viral, very grass roots with a lot of one-on-one conversations. We went specifically to sell some teams. Other teams came to us.
About a year in, with over 100 Test Certified teams, it felt like new adoption was slowing. Bella Kazwell, who led this volunteer effort at the time, masterminded the Test Certified Challenge. A point system was developed that included activities like writing new tests, signing new teams into Test Certified, and teams improving testing practices or gaining TC levels. There were individual awards, and sites across the globe were also pitted against one another to earn the highest score. Volunteers were energized, and in turn this energized more teams across the company, re-accelerating adoption and attracting more volunteer mentors.
Teams in Test Certified had always used the ladder rungs and criteria as crisp, measurable team goals. By late 2008, there were areas in which some managers began to use these to evaluate teams under their purview, and where Engineering Productivity used a team’s progress against the TC ladder to gauge how serious they were about improving testing, and so how valuable it would be to invest time from the limited pool of test experts with a given team. In certain limited areas, it became a management expectation or launch criteria for teams to reach a level on the ladder.
Today, in 2011, new volunteer mentors continue to join, and new teams continue to sign up, and TC has presence across the company.
HGTS: What changes did the Test Certified program undergo in its first couple of years? Did ladder requirements change? Did the mentoring system change? What adjustments were successful in improving the experience for participants?
Tracy: The biggest change was the number of levels and some of the ladder requirements. We originally had four levels. Going from level 0 to level 1 was deliberately easy. Many teams were finding it difficult to move from level 1 to level 2, especially teams with legacy code that wasn’t testable. These teams became discouraged and were inclined to give up on Test Certified. We added a new level between 1 and 2 that was an easier step to take. We debated calling the new level 1.5, but decided to insert the new level as 2 and renumber the higher levels.
We also found that some of the requirements were too prescriptive, suggesting a ratio of small to medium to large tests that didn’t apply to all teams. When we added the new level, we also updated the criteria to include some “incremental coverage” numbers and remove the test size ratios.
The mentoring system is still in place, but we now have many teams who “self-mentor.” Because the culture of testing is more pervasive now, we have many teams who don’t need much advice; they just want to track their progress. For those teams, we don’t assign a mentor, but do provide a mailing list for answering their questions and for another pair of eyes to validate their level transitions.
Russ: It’s also worth noting that from the beginning, we knew the Test Certified criteria had to be reasonably applied. Testing isn’t a cookie cutter activity and, occasionally, teams don’t fit the mold we had in mind when selecting the criteria, or a typical tool for tracking test coverage or some other metric won’t work properly for a team. Each criterion had a rationale behind it, and we’ve been open at various points to customizing the criteria for teams that meet the spirit of that prescribed rationale.
HGTS: What does a team stand to gain from participating in the Test Certified program today? What are the costs associated with participating?
Tracy: Bragging rights. Clear steps. Outside help. A cool glowing orb. But the real gain for teams is improved testing.
The costs are minimal, beyond the team focusing on improving their testing maturity. We have a custom tool that allows mentors to track the team’s progress, checking off as each step is achieved. The data is displayed on a page that includes all teams by level, with the ability to click through and see details about a specific team.
HGTS: Are there any steps on the ladder that seem to give teams more trouble than others?
Tracy: The most difficult step is “require tests for all nontrivial changes.” For a greenfield project written in a testable way, this is easy. For a legacy project that wasn’t originally written with testing in mind, this can be tough. This might require writing a big end-to-end test and trying to force the system through particular code paths to exercise the behavior and then figuring out how to witness the result in an automated way. The better, but sometimes longer-term approach is refactoring the code to be more testable. Some teams with code that wasn’t written with testability in mind also find it challenging to provide enough of their test coverage, specifically from small, narrowly focused unit tests versus larger tests covering clusters of classes, or end-to-end tests.
HGTS: Efforts at Google tend to last weeks or quarters, but Test Certified has been around for nearly five years and shows no signs of stopping soon. What contributed to Test Certified passing the test of time? What challenges does Test Certified face going forward?
Russ: It has staying power because it’s not just an activity some individuals took part in; it’s a cultural change at the company. Together with the Testing Grouplet, ToTT, supporting mailing lists, tech talks, and contributions to job ladders and coding style documents, regular testing has become an expectation of all engineers across the company. Whether a team participates in Test Certified or not, it is expected to have a well considered automated testing strategy, either on its own or in partnership with a smaller population of engineers who act as testing experts.
It continues because it’s proven to work. We have very few areas left with even a small fraction of testing done manually, or thrown over the wall. To that end, Test Certified has done its job and this is likely to be its legacy even if the “official” grass-roots program was to end some day.
HGTS: What tips would you give to engineers at other companies who are considering starting similar efforts in their organizations?
Tracy: Start with teams that are already friendly to testing. Grow a kernel of teams that gain value from your program. Don’t be shy about evangelizing and asking others to do so as well. The mentoring aspect was a big part of Test Certified’s success. When you ask a team to try something new or to improve, it’s going to be a lot smoother if they have a contact point into the larger community to ask for help. An engineer or a team might be embarrassed to ask what might be a stupid question on a mailing list, but they’ll feel a lot more comfortable asking that question of a single, trusted TC mentor.
Also find ways to make it fun. Come up with a better name that doesn’t include “certified,” as that can evoke pointy-haired bureaucrats. Or, do what we did, go with a pointy-haired name like “certified” and use it as a foil to constantly remind your larger community that it’s a bad name because you’re not “that kind of program.” Define steps small enough that teams can see and show their progress. Don’t get bogged down trying to create the perfect system with a perfect set of measurements. Nothing will ever be perfect for everyone. Agreeing on something reasonable and moving forward is important when the alternative is being paralyzed. Be flexible where it makes sense to be, but hold the line where you shouldn’t bend.
This concludes the chapter on the life of an SET. The remainder of the material is optional reading about how Google interviews SETs and an interview with Googler Ted Mao who talks about some of the tools Google SETs use.
Interviewing SETs
Successful SETs are good at everything: strong enough programmers to write feature code, strong enough testers to test about anything, and able to manage their own work and tools. Good SETs see both the forest and the trees—they can look at a small function prototype or API and imagine all the ways the underlying code can be used and how it can be broken.
All code at Google is in a single source tree, which means that any code can be used by anyone at anytime—so it better be solid. SETs not only find the bugs that the feature developers missed, but they also look to make sure it is obvious to other engineers how to leverage that code or component, and worry about future-proofing the functionality. Google moves fast, so the code must be clean, consistent, and work long after the original developer has stopped thinking about it.
How do we interview for this skill set and mentality? It’s not easy, but we’ve found hundreds of engineers who fit the bill. We look for a hybrid: a developer with a strong interest and aptitude in testing. A common and effective way to spot great SETs is to give them the same programming questions as we do for all developers and look for how they approach quality and testing. SETs have twice the opportunity to give a wrong answer in an interview!
Simple questions often identify the best SETs. Too much time wasted on tricky coding problems or insisting on functional correctness takes away from time you should use to understand how the candidate thinks about coding and quality. There will be a SWE or SET on an interview loop who poses algorithm problems; the better SET interviewers focus on how the candidate thinks about the solution, not so much the elegance of the solution itself.
Note
SET interviewers focus on how the candidate thinks about the solution, not so much the elegance of the solution itself.
Here’s an example. Pretend it is your first day on the job and you are asked to implement the function acount(void* s); that returns a count of the number of As in a string.
A candidate who dives directly into writing the code is sending a strong message: There is only one thing to do and I am doing it. That one thing is code. The life of an SET does not follow such a serialized view of the world. We want to hear questions.
What is this function used for? Why are we building it? Does the function prototype even look correct? We look for signs the candidate is worried about correctness and how to validate the right behaviors. A problem deserves to be treated with more respect! Candidates who mindlessly jump into coding problems will do the same with testing problems. If we pose a problem to add test variations to modules, we don’t want them to start listing tests until we tell them to stop; we want the best tests first.
An SET’s time is limited. We want candidates to take a step back and find the most efficient way to solve the problem, and the previous function definition can use some improvement. A good SET looks at a poorly defined API and turns it into something beautiful while testing it.
Decent candidates spend a few minutes understanding the specification by asking questions and making statements such as:
• What is the encoding of the incoming string: ASCII, UTF-8, or another?
• The function name is weak, should it be CamelCased, more descriptive, or are there other standard naming practices to be followed here?
• What is the return type? (Maybe the interviewer forgot, so I’ll add an int to the front of the function prototype.)
• That void* is dangerous. We should give it an appropriate type, such as char*, so we can benefit from compile-time type checking.
• What counts as an A? Should it count lowercase As, too?
• Doesn’t this function already exist in a standard library? (For the purpose of the interview, pretend you are the first one implementing this functionality.)
Better candidates will do even more:
• Think about scale: Maybe the return type should be a 64-bit integer because Google often deals with large amounts of data.
• Think about re-use: Why does this function count only As? It is probably a good idea to parameterize this so that an arbitrary character can be counted instead of having a different function defined for each one.
• Think about safety: Are these pointers coming from trusted sources?
The best candidates will:
• Think about scale:
• Is this function to be run as part of a MapReduce17 on sharded18 data? Maybe that’s the most useful form of calling this function. Are there issues to worry about in this scenario? Consider the performance and correctness implications of running this function on every document on the entire Internet.
• If this subroutine is called for every Google query and would be called only with safe pointers because the wrapper does this validation already; maybe avoiding a null check will save hundreds of millions of CPU cycles a day and reduce user-visible latency by some small amount. At least understand the possible implications of full textbook parameter validation.
• Think about optimizations based on invariants:
• Can we assume the data coming in is already sorted? If so, we might be able to exit quickly after we find the first B.
• What is the texture of the input data? Is it most often all As, is it most often a mix of all characters, or is it only As and spaces? If so, there may be optimizations in our comparison operations. When dealing with large data, even small, sublinear changes can be significant for actual compute latencies when the code executes.
• Think about safety:
• On many systems, and if this is a security-sensitive section of code, consider testing for more than just nonnull pointers; 1 is an invalid pointer value on some systems.
• Add a length parameter to help ensure the code doesn’t walk off the end of the string. Check the length parameter’s value for sanity. Null-terminated character strings are a hacker’s best friend.
• If there is a possibility the buffer can be modified by some other thread while this function executes, there may be thread safety issues.
• Should we be doing this check in a try/catch? Or, if the calling code isn’t expecting exceptions, we should probably return error codes to the caller. If there are error codes, are those codes well defined and documented? This shows thinking about the context of the larger code-base and runtime, and this kind of thinking can avoid errors of confusion or omission down the road.
Ultimately, the best candidates come up with a new angle for these questions. All angles are interesting to consider, if they are considered intelligently.
Note
A good SET candidate should not have to be told to test the code she writes. It should be an automatic part of her thinking.
The key in all this questioning of the spec and the inputs is that any engineer who has passed an introductory programming course can produce basic functional code for this question. These questions and thinking from the candidates differentiate the best candidates from the decent ones. We do make sure that the candidate feels comfortable enough socially and culturally to ask questions, and if not, we prod them a bit to ask, making sure their straight-to-the-code behavior isn’t just because they are in an interview situation. Googlers should question most everything without being annoying and by still getting the problem solved.
It would be boring to walk through the myriad of possible correct implementations and all the common mistakes as this isn’t a programming or interviewing book. But, let’s show a simple and obvious implementation for discussion’s sake. Note: Candidates can usually use the language they are most comfortable with such as Java or Python, though that usually elicits some questions to ensure they understand things such as garbage collection, type–safety, compilation, and runtime concerns.
int64 Acount(const char* s) {
if (!s) return 0;
int64 count = 0;
while (*s++) {
if (*s == 'a') count++;
}
return count;
}
Candidates should be able to walk through their code, showing the evolution of pointer and counter values as the code executes with test inputs.
In general, decent SET candidates will do the following:
• Have little trouble with the basics of coding this solution. When doing so, they do not have trouble rewriting or fumbling over basic syntax issues or mixing up syntax or keywords from different languages.
• Show no sign of misunderstanding pointers or allocating anything unnecessarily.
• Perform some input validation upfront to avoid pesky crashes from dereferencing null pointers and such, or have a good explanation of why they are not doing such parameter validation when asked.
• Understand the runtime or Big O19 of their code. Anything other than linear here shows some creativity, but can be concerning.
• If there are minor issues in the code, they can correct them when pointed out.
• Produce code that is clear and easily readable by others. If they are using bitwise operators or put everything on one line, this is not a good sign, even if the code functionally works.
• Walk through their code with a single test input of A or null.
Better candidates will do even more.
• Consider int64 for counters and return type for future compatibility and avoiding overflow when someone inevitably uses this function to count As in an insanely long string.
• Write code to shard/distribute the counting computation. Some candidates unfamiliar with MapReduce can come up with some simple variants on their own to decrease latency with parallel computation for large strings.
• Write in assumptions and invariants in notes or comments in the code.
• Walk through their code with many different inputs and fix every bug that they find. SET candidates who don’t spot and fix bugs are a warning sign.
• Test their function before being asked. Testing should be something they don’t have to be told to do.
• Continue trying to optimize the solution until asked to stop. No one can be sure that their code is perfect after just a few minutes of coding and applying a few test inputs. Some tenacity over correctness should be evident.
Now, we want to see if the candidate can test his own code. Convoluted or tricky test code is likely the worst test code in the world and definitely worse than no code. When tests fail at Google, it needs to be clear what the test is doing. If not, engineers might disable, mark as flaky, or ignore the failures—it happens, and it’s the fault of the SETs and SWEs who wrote and reviewed the code for letting this bad test code into the tree.
SETs should be able to approach testing in a black box manner, operating under the assumption that someone else implemented the function, or in a white box manner, knowing which test cases might be irrelevant given the specifics of their implementation.
In general, decent candidates will do the following:
• Are methodical and systematic. Supplying test data according to some identifiable characteristic (such as string size) and not just random strings.
• Focus on generating interesting test data. Consider how to run large tests and where to get real-world test data.
• Better candidates:
• Want to spin up concurrent threads executing this function to look for cross talk, deadlock, and memory leaks.
• Build long running tests, such as spin up tests in a while(true) loop, and ensure they continue to work over the long haul.
• Remain interested in coming up with test cases and interesting approaches to test data generation, validation, and execution.
Another thing we interview for is “Googliness,” or culture fit. Is the SET candidate technically curious during the interview? When presented with some new ideas, can the candidate incorporate these into her solution? How does she handle ambiguity? Is she familiar with academic approaches to quality such as theorem proving? Does she understand measures of quality or automation in other fields such as civil or aerospace engineering? Is she defensive about bugs you might find in her implementation? Does she think big? Candidates don’t have to be all of these things, but the more, the merrier! And, finally, would we like to work with this person on a daily basis?
It is important to note that if someone interviewing for an SET position isn’t that strong of a coder, it does not mean that she will not be a successful TE. Some of the best TEs we’ve ever hired originally interviewed for the SET position.
An interesting note about SET hiring at Google is that we often lose great candidates because they run into a nontesting SWE or an overly focused TE on their interview loop. We want this diversity in the folks interviewing SET candidates, because they will work together on the job, and SETs are really hybrids, but this can sometimes result in unfavorable interview scores. We want to make sure the bad scores come from interviewers who truly appreciate all aspects of what it takes to be a great SET.
As Pat Copeland says in his forward, there has been and still is a lot of diversity of opinion on SET hiring. Should an SET just be doing feature work if he is good at coding? SWEs are also hard to hire. Should they just be focusing on pure testing problems if they are that good at testing? The truth, as it often is, lies somewhere in the middle.
Getting good SET hires is a lot of trouble but it’s worth it. A single rock star SET can make a huge impact on a team.
An Interview with Tool Developer Ted Mao
Ted Mao is a developer at Google but he’s a developer who has been exclusively focused on building test tools. Specifically, he’s building test tools for web applications that scale to handle everything Google builds internally. As such, he’s a well-known person in SET circles because an SET without good tools will find it hard to be effective. Ted is probably more familiar with the common web test infrastructure at Google than anyone in the company.
HGTS: When did you start at Google, and what excited you about working here?
Ted: I joined Google in June 2004. Back then, I only had experience working at large companies like IBM and Microsoft, and Google was the hot startup to work for and they were attracting a lot of talented engineers. Google was attempting to solve many interesting, challenging problems, and I wanted to work on these problems alongside some of the best engineers in the world.
HGTS: You are the inventor of Buganizer,20 Google’s bug database. What were the core things you were trying to accomplish with Buganizer versus the older BugDB?
Ted: BugsDB was impeding our development process rather than supporting it. To be honest, it was wasting a lot of valuable engineering time and this was a tax paid by every team that used it. The issues manifested themselves in many ways, including UI latency, awkward workflows, and the practice of using “special” strings in unstructured text fields. In the process of designing Buganizer, we made sure that our data model and UI reflected our users’ actual development processes and that the system would be amenable to future extension both in the core product and through integrations.
HGTS: Well you nailed Buganizer. It’s truly the best bug database any of us have ever used. How did you start working on web-testing automation, did you see the need or were you asked to solve a problem with test execution?
Ted: While working on Buganizer, AdWords, and other products at Google, I consistently found that the web-testing infrastructure we had available was insufficient for my needs. It was never quite as fast, scalable, robust, or useful as I needed it to be. When the tools team announced that they were looking for someone to lead an effort in this area, I jumped on the opportunity to solve this problem. This effort became known as the Matrix project and I was the tech lead for it.
HGTS: How many test executions and teams does Matrix support today?
Ted: It really depends on how you measure test executions and teams. For example, one metric we use is what we call a “browser session”—every new browser session for a particular browser is guaranteed to start in the same state, and thus, a test running in the browser will behave deterministically insomuch as the test, browser, and operating system are deterministic. Matrix is used by practically every web frontend team at Google and provisions more than a million new browser sessions per day.
HGTS: How many people worked on these two projects: Buganizer and Matrix?
Ted: During their peak development periods, Buganizer had about five engineers and Matrix had four engineers. It’s always somewhat sad for me to think of what we might have been able to accomplish with a larger, more sustained development team, but I think we did a great job given what we had to work with.
HGTS: What were the toughest technical challenges you faced while building these tools?
Ted: I think that the toughest and often the most interesting challenges for me have always come at design time—understanding a problem space, weighing different solutions and their tradeoffs, and then making good decisions. Implementation is usually straightforward from that point. These types of decisions have to be made throughout the life of a project, and together with implementation, they can make or break the product.
HGTS: What general advice would you give to other software engineers in the world who are working on testing tools?
Ted: Focus on your users, understand their needs, and solve their problems. Don’t forget about “invisible” features like usability and speed. Engineers are uniquely capable of solving their own problems—enable them to leverage your tools in ways you didn’t foresee.
HGTS: What do you see as the next big or interesting problem to be solved in the test tools and infrastructure space?
Ted: One problem I’ve been thinking about lately is how our tools are getting more complex and powerful, but consequently, harder to understand and use. For example, with our current web-testing infrastructure at Google, an engineer can execute one command to run thousands of web tests, in parallel, against multiple browsers. On one hand, it’s great that we’re abstracting away the details of how it all works—where those tests are actually running, where the browsers are coming from, how the test environment is configured, and so on. However, if the test fails and the engineer has to debug it, those details can be essential. We already have a few initiatives in this area, but there’s a lot more we could and should be doing.
An Interview with Web Driver Creator Simon Stewart
Simon Stewart is the creator of WebDriver and browser automation guru at Google. WebDriver is an open source web application testing tool popular inside and outside of Google and historically one of the hottest topics at GTAC, the Google Test Automation Conference. The authors sat down with him recently and got his thoughts on web app test automation and the future of WebDriver.
HGTS: I don’t think many people understand the distinction between Selenium and WebDriver, can you clear it up?
Simon: Selenium was a project started by Jason Huggins while he was at ThoughtWorks. Jason was writing a web application and was targeting IE which at the time was 90+ percent of the market. But he kept getting bug reports from users who had adopted FireFox and he had this problem where he would fix a bug for FF and break the app for IE. For him, Selenium was developed as a way to rev his app and then test to make sure it worked on both browsers.
I was building what became WebDriver a year or so later, but before Selenium was really stable, and was focused on more general web app testing. Not surprisingly, the two of us took different approaches to our implementations. Selenium was built on JavaScript running inside the browser, WebDriver was integrated into the browser itself using automation APIs. Each approach had its advantages and disadvantages. For example, Selenium supported new browsers, like Chrome, almost instantly, but couldn’t do file uploads or handle user interaction very well because it was JavaScript and limited to what was possible in the JS sandbox. Since WebDriver was built into the browser, it could sidestep these limitations, but adding new browsers was very painful. Once both of us started working for Google, we decided to integrate the two.
HGTS: But I still hear people talking about both. Are they still two separate projects?
Simon: Selenium is the name we use for the umbrella project for all browser automation tools. WebDriver happens to be one of those tools. The official name is “Selenium WebDriver.”
HGTS: So how did Google get involved?
Simon: Google hired some former ThoughtWorkers when Google opened the London office a few years back and those guys invited me to come give a tech talk on WebDriver. That talk didn’t inspire a lot of confidence on my part, some guy in the front row fell sound asleep and I had to compete with his snores for the audience. As luck would have it, the recording of the talk failed and there was enough interest that I was invited back to give a snore-free presentation at GTAC. I joined Google shortly thereafter. Now I know where the bodies are buried!
HGTS: Yes, indeed, skeletons in every closet. Seriously though we’ve seen you talk before, it is hard to imagine anyone falling asleep on you. Was this anyone we know?
Simon: No. He’s long gone from Google. Let’s just assume he had a late night beforehand!
HGTS: Let that be a lesson to readers. Falling asleep on Simon Stewart is bad for your career! Now once you joined Google was WebDriver your full time job?
Simon: No, it was my 20 percent project. My day job was working as a product SET but I still managed to move WebDriver forward and at this time some outside contributors were really doing good work. In the early stage of an open source project people pick it up because they need it and there are no other alternatives. It’s built-in incentive to contribute. Now many of the WebDriver users are told by others to use it and they approach it more as a consumer than as a contributor. But in the early days the grass roots WebDriver community really moved the tool forward.
HGTS: Well we all know how the story turns out. WebDriver is very popular within Google. How did it start? Was there one project that piloted it? Any false starts?
Simon: It began with Wave, a social networking product built in our Sydney office that has since gone away. The Wave engineers tried to use Selenium for their test infrastructure but it couldn’t cope. Wave was too complicated. The engineers were diligent enough to track WebDriver down and they started asking a lot of questions, good questions, and it became more than my 20 percent could handle. They reached out to my manager and we negotiated a month-long loan deal and I went down to Sydney to help them build out their test infrastructure.
HGTS: I take it you were successful.
Simon: Yes, the team was good about pitching in to help and we made it work. It drove a bunch of new requirements for WebDriver and it also served as an example to other Google teams that WebDriver was a tool that could handle cutting edge web applications. From that point on, WebDriver never lacked for customers and it made sense for me to work on it full time.
HGTS: The first customer is always the hardest. How did you handle both developing WebDriver and making it work for Wave?
Simon: I used a process called DDD, defect-driven development. I would declare WebDriver flawless and when a customer found a bug I would fix it and once again declare it flawless. That way I fixed only the bugs that people actually cared about. It’s a process that is good for refining an existing product and making sure you are fixing the most important bugs and not spinning on bugs people don’t care about.
HGTS: And are you still the only engineer on WebDriver?
Simon: No, we have a team and are an official project internally at Google and very active in open source. With the ever increasing numbers of browsers, browser versions, and platforms, I tell people that we must be crazy, but we do the impossible every day. It’s something I think most sane engineers shy away from!
HGTS: So post-Wave you had a lot of momentum. Is that where WebDriver pulled away from the older Selenium infrastructure in terms of users?
Simon: I think so. A lot of the original Selenium engineers had moved onto other things and I had all this puppy energy for WebDriver coming off the Wave success. People I never met like Michael Tam from Germany had already started doing really significant work on WebDriver as well and I was careful to nurture those relationships. Michael was the first person I’d not met in person who got permission to submit code to the project’s source repository.
But I didn’t really track the spread of WebDriver all that closely. What was clear was that the closer teams were to me physically, the more likely they were to adopt WebDriver. I think Picasa Web Albums was actually the first team before Wave, and then afterwards Ads picked it up. There is still a silo effect of web automation used at Google. Chrome uses PyAuto, Search uses Puppet (which has an open source versions called Web Puppeteer), and Ads uses WebDriver, etc.
HGTS: What about the future of WebDriver? What’s the direction your team is taking?
Simon: Well the landscape is really getting crowded. Even a few years ago we were looking at a market with one dominate browser. Not anymore. Internet Explorer, FireFox, Chrome, Safari, Opera to name only a few and that’s only the desktop. The proliferation of random WebKit browsers for mobile devices is insane. And the commercial tools ignore them all but IE, which isn’t a sensible strategy post 2008! The next logical step for WebDriver is to standardize it so we can guarantee different web app implementations across browsers. Of course it will help to have the browser makers involved so we can ensure compliance with the WebDriver API.
HGTS: Sounds like a standards committee issue. Any progress there?
Simon: Yes. Unfortunately it means I have to write English instead of code but there is a spec in front of W3C now and that’s a place that all browser vendors get involved.
HGTS: So what is your wish for the future? How will browser automation tools work in the future?
Simon: My hope is that they disappear into the background. That automation APIs are an expectation for every browser and that people stop worrying about the infrastructure and they just use it. I want people thinking about new features in their web apps, not how to automate them. WebDriver will be successful when people forget it is even there.