
Origin stories are often messy. What you are about to read is no exception.
The story of open source software is a maze of twisty streams feeding into each other and into the main channel. They’re part and parcel with the history of the Unix operating system, which itself is famously convoluted. In this chapter, we’ll take a look at open source’s humble beginnings.
In the Beginning
Going even further back, the sharing of human-readable source code was widespread in the early days of computing. A lot of computer development took place at universities and in corporate research departments like AT&T’s Bell Labs. They had long-established traditions of openness and collaboration, with the result that even when code wasn’t formally placed into the public domain, it was widely shared.
Computer companies shipping software with their systems also often included the source code. Users frequently had to modify the software themselves so that it would support new hardware or because they needed to add a new feature. The attitude of many vendors at the time was that software was something you needed to use the hardware, but it wasn’t really a distinct thing to be sold.

IBM 704 at NASA Langely in 1957. Source: Public domain.
The culture of sharing code—at least in some circles—was still strong going into the late 1970s when John Lions of the University of New South Wales in Australia annotated the Sixth Edition source code of the Unix operating system. Copies of this “Lions’ Commentary” circulated widely among university computer science departments and elsewhere. This sort of casual and informal sharing was the norm of the time even when it wasn’t really technically allowed by the code’s owner, in this case AT&T.
Ah, Unix
The idea of modifying software to run on new or different hardware gained momentum around Unix. Unix was rewritten in 1973–1974 (for its V4 release) in C, a programming language newly developed by Dennis Ritchie at Bell Labs. Using what was, by the standards of the time, a high-level programming language for this purpose, while not absolutely unique, was nonetheless an unusual, new, and even controversial approach.
More typical would have been to use the assembly language specific to a given machine’s architecture. Because of the close correspondence between the assembler and an architecture’s machine code instructions (which execute directly on the hardware), the assembler was extremely efficient, if challenging and time-consuming to write well. And efficiency was important at a time when there wasn’t a lot of spare computer performance to be wasted.
However, as rewritten in C, Unix could be modified to work on other machines relatively easily; that is, it was “portable.” This was truly unusual. The norm of the day was to write a new operating system and set of supporting systems and application software for each new hardware platform.
Of course, to make those modifications, you needed the source code.
AT&T was willing to supply this for several reasons. One was especially important. After the Sixth Edition was released in 1975, AT&T began licensing Unix to universities and commercial firms, as well as the United States government. But the licenses did not include any support or bug fixes, because to do so would have been “pursuing software as a business,” which AT&T did not believe that it had the right to do under the terms of the agreement by which it operated as a regulated telephone service monopoly. The source code let licensees make their own fixes and “port” Unix to new systems.
However, in the early 1980s, laid-back attitudes toward sharing software source code started to come to an end throughout the industry.
No More Free Lunches?

AT&T entered into a consent decree in 1982 that allowed it to pursue software as a business. This led to the increasing commercialization of Unix. Source: Public domain.
This would lead, over the course of about the next decade, to the messy “Unix Wars” as AT&T Unix licensees developed and shipped proprietary Unix versions that were all incompatible with each other to greater or lesser degrees. It’s an extremely complicated and multi-threaded history. It’s also not all that relevant to how open source has evolved other than to note that it created vertical silos that weren’t all that different from the minicomputers and mainframes that they replaced. The new boss looked a lot like the old boss.
During the same period, AT&T—in the guise of its new Unix System Laboratories subsidiary—got into a legal fight with the University of California, Berkeley over their derivative (a.k.a. “fork”) of Unix, the Berkeley System Distribution (BSD). Specifically, it was a squabble with the Computer Systems Research Group (CSRG) at Berkeley, but I’ll just refer to the university as a whole here.
Berkeley had been one of AT&T’s educational licensees. Over time, it modified and added features to its licensed version of Unix and, in 1978, began shipping those add-ons as BSD. Over time it added significant features, involving the outright re-architecting and rewriting of many key subsystems, and the addition of many wholly new components. As a result of its extensive changes and improvements, BSD was increasingly seen as an entirely new, even better, strain of Unix; many AT&T licensees would end up incorporating significant amounts of BSD code into their own Unix versions. (Which contributed further to the Unix wars as different companies favored the AT&T strain or the Berkeley strain in their products.)
Berkeley continued developing BSD to incrementally replace most of the standard Unix utilities that were still under AT&T licenses. This eventually culminated in the June 1991 release of Net/2, a nearly complete operating system that was ostensibly freely redistributable. This in turn led to AT&T suing Berkeley for copyright infringement.
Suffice it to say that the commercialization of Unix, which had been the hub around which much source code sharing had taken place, helped lead to a more balkanized and closed Unix environment.
PCs Were a Different Culture
But the sharing ethos was also eroding more broadly.
During the 1980s, the personal computer space was increasingly dominated by the IBM PC and its clones running a Microsoft operating system. Nothing that looked much like open source developed there to a significant degree. In part, this probably reflected the fact that the relatively standardized system architecture of the PC made the portability benefits of having source code less important.
Furthermore, most of the tools needed to develop software weren’t included when someone bought a PC and the bill for those could add up quickly. A bare-bones BASIC programming language interpreter was included with Microsoft’s DOS operating system, but that was seen as hopelessly outdated for serious programming, even by the not-so-demanding standards of the time. When Borland’s more modern Turbo Pascal debuted in 1984 for only 50 dollars, it was a radical innovation given that typical programming language packages went for hundreds of dollars. Programming libraries and other resources—including information that was mostly locked up in books, magazine, and other offline dead tree sources—added to the bill. Making a few changes to a piece of software was not for the casual hobbyist.
People did program for the IBM PC, of course, and over time a very healthy community of freeware and shareware software authors came into being.
I was one of them.
Shareware, at least as the term was generally used at the time, meant try-before-you-buy software. Remember, this is a time when boxed software sold at retail could go for hundreds of dollars with no guarantee that it would even work properly on your computer. And good luck returning it.
The main software I wrote was a little DOS file manager, 35KB of assembler, called Directory Freedom, derived from some assembly code listings in PC Magazine and another developer’s work. It never made a huge amount of money, but it had its fan base and I still get emails about it from time to time. I also wrote and uploaded to the local subscription bulletin board system (BBS) various utility programs that I originally wrote for my own use.
But distributing source code was never a particularly big thing.
Breaking Community
Similar commercializing dynamics were playing out in other places. The MIT Artificial Intelligence (AI) Lab, celebrated by Steven Levy in Hackers as a “pure hacker paradise, the Tech Square monastery where one lived to hack, and hacked to live,” was changing. Here, it was Lisp that was commercializing.
The Lisp programming language was the workhorse of artificial intelligence research, but it required so many hardware resources that it didn’t run well on the ordinary computers of the day. As a result, for close to a decade, members of the AI Lab experimented with systems that were optimized to run Lisp. By 1979, that work had progressed to the point where commercialization looked like a valid option.
Eventually two companies, Symbolics and Lisp Machines Inc., would be formed. But it ended up as a messy and acrimonious process that led to much reduced open collaboration and widespread departures from the Lab.
Richard Stallman was one member of the AI Lab who did not head off to greener corporate Lisp pastures but nonetheless felt greatly affected by the splintering of the Lab community. Stallman had previously written the widelyused Emacs editing program. With Emacs, as Glyn Moody writes in Rebel Code, “Stallman established an ‘informal rule that anyone making improvements had to send them back’ to him.”
His experiences with the effects of proprietary code in the Symbolics versus Lisp Machines Inc. war led him to decide to develop a free and portable operating system, given that he had seen a lack of sharing stifling the formation of software communities. In another widely told story about Stallman’s genesis as a free software advocate, he was refused access to the source code for the software of a newly installed laser printer, the Xerox 9700, which kept him from modifying the software to send notifications as he had done with the Lab’s previous laser printer.
Free Software Enters the Fray

Stallman’s Free Software Foundation and GNU project are generally taken as the beginning of free and open source software as a coherent movement. Source: Victor Siame [email protected] under Free Art License.
As justification, he went on to write that “I consider that the golden rule requires that if I like a program I must share it with other people who like it. I cannot in good conscience sign a nondisclosure agreement or a software license agreement. So that I can continue to use computers without violating my principles, I have decided to put together a sufficient body of free software so that I will be able to get along without any software that is not free.”
It was to be based on the Unix model, which is to say that it was to consist of modular components like utilities and the C language compiler that’s needed to build a working system. The project began in 1984. To this day, there is in fact no “GNU operating system” in that the GNU Hurd operating system kernel has never been completed. Without a kernel, there’s no way to run utilities, applications, or other software as they have no way to communicate with the hardware.
However, Stallman did complete many other components of his operating system. These included, critically, the parts needed to build a functioning operating system from source code and to perform fundamental system tasks from the command line. It’s a hallmark of Unix that its design is very modular. As a result, it’s entirely feasible to modify and adapt parts of Unix without wholesale replacing the whole thing at one time. (A fact that would be central to the later development of Linux.)
Establishing the Foundations of Free
However, equally important from the perspective of open source’s origins was the GNU Manifesto that followed in 1985, the Free Software Definition in 1986, and the GNU Public License (GPL) in 1989, which formalized principles for preventing restrictions on the freedoms that define free software.
The GPL requires that if you distribute a program covered by the GPL in binary, that is, machine-readable form, whether in original or modified form, you must also make the human-readable source code available. In this way, you can build on both the original program and the improvements of others but, if you yourself make changes and distribute them, you also have to make those changes available for others to use. It’s what’s known as a “copyleft” or reciprocal license because of this mutual obligation.
Free and open source software was still in its infancy in the late 1980s. (Indeed, the “open source” term hadn’t even been coined yet.) Linux was not yet born. BSD Unix would soon be embroiled in a lawsuit with AT&T. The Internet was not yet fully commercialized. But, especially with the benefit of hindsight, we can start to discern patterns that would become important: collaboration, giving back, and frameworks that help people to know the rules and work together appropriately.
But it was the Internet boom of the 1990s that would really put Linux and open source on the map even if this phase of open source would turn out to be just the first act of an ultimately more important story. This is the backdrop against which open source would rise in prominence while the computer hardware and software landscape shifted radically.
Fragmented Hardware and Software
Turn the clock back to 1991. A Finnish university student by the name of Linus Torvalds posted in a Usenet newsgroup that he was starting to work on a free operating system in the Unix mold as a hobby. Many parts of Stallman’s initial GNU Project were complete. In sunny California, Berkeley has shipped the first version of its Unix to be freely distributable.
Free software had clearly arrived. It just wasn’t a very important part of the computing landscape yet.
Vertical Silos Everywhere
It was a very fragmented computing landscape. The Unix market was embroiled in internecine proprietary system warfare. Many other types of proprietary computer companies were also still around—if often past their prime.
The most prominent were the “Route 128” Massachusetts minicomputer companies, so called because many were located on or near the highway by that name, which partially encircled the adjacent cities of Boston and Cambridge on the northeast coast of the United States. However, there were also many other vendors who built and sold systems for both commercial and scientific computing. Most used their own hardware designs from the chips up through disk drives, tape drives, terminals, and more. If you bought a Data General computer, you also bought memory, reel-to-reel tape drives, disk drives, and even cabinets from either the same company or a small number of knock-off add-on suppliers.
Their software was mostly one-off as well. A typical company would write its own operating system (or several different ones) in addition to databases, programming languages, utilities, and office applications. When I worked at Data General during this period, we had about five different non-Unix minicomputer operating systems plus a couple of different versions of Unix.
Many of these companies were themselves increasingly considering a wholesale shift to their own versions of Unix. But it was mostly to yet another customized hardware and Unix operating system variant.
Most computer systems were still large and expensive in those days. “Big Iron” was the common slang term. The analysis and comparison of their complicated and varied architectures filled many an analyst’s report.
Even “small business” or “departmental” servers, as systems that didn’t require the special conditions of the “glass room” datacenter were often called, could run into the tens of thousands of dollars.
Silos Turn On Their Side
However, personal computers were increasingly starting to be stuck under desks and used for less strenuous tasks. Software from Novell called NetWare, which specialized in handling common tasks like printing or storing files, was one common option for such systems. There were also mass-market versions of Unix. The most common came from a company called Santa Cruz Operation that had gotten into the Unix business by buying an AT&T-licensed variant called Xenix from Microsoft. Many years later, Santa Cruz Operation—or more accurately a descendent of them using the name SCO—would instigate a series of multiyear lawsuits related to Linux that would pull in IBM and others.
More broadly, there was a pervasive sea change going on in the computer systems landscape. As recounted by semiconductor maker Intel CEO Andy Grove in Only the Paranoid Survive, a fundamental transformation happened in the computer industry during the 1990s. As we’ve seen, the historical computer industry was organized in vertical stacks. Those vertical stacks were increasingly being rotated into a more horizontal structure.
It wasn’t a pure transformation; there were (and are) still proprietary processors, servers, and operating systems.
But more and more of the market was shifting toward a model in which a system vendor would buy the computer’s central processing unit from Intel, a variety of other largely standardized chips and components from other suppliers, and an operating system and other software from still other companies. They’d then sell these “industry standard” servers through a combination of direct sales, mail order, and retail.
During this period, Advanced Micro Devices (AMD) was also producing compatible x86 architecture processors under license from Intel although the two companies would be embroiled in a variety of contractual disputes over time. AMD would later enjoy a short period of some success against Intel with its Opteron processors but has largely remained in Intel’s shadow.
The PC model was taking over the server space.
Grove described this as the 10X force of the personal computer. The tight integration of the old model might be lacking. But in exchange for a certain amount of do-it-yourself to get everything working together, for a few thousand dollars you got capabilities that increasingly rivaled those of engineering workstations you might have paid tens of thousands to one of the proprietary Unix vendors to obtain.
Which Mass-Market Operating System Would Prevail?
With the increasing dominance of x86 established, there was now just a need to determine which operating system would similarly dominate this horizontal stack. There was also the question of who would dominate important aspects of the horizontal platform more broadly such as the runtimes for applications, databases, and areas that were just starting to become important like web servers. But those were less immediately pressing concerns.
The answer wasn’t immediately obvious. Microsoft’s popular MS-DOS and initial versions of Windows were designed for single-user PCs. They couldn’t support multiple users like Unix could and therefore weren’t suitable for business users who needed systems that would let them easily share data and other resources. Novell NetWare was one multiuser alternative that was very good at what it did—sharing files and printers—but it wasn’t a general purpose operating system. And, while there were Unix options for small systems, they weren’t really mass market.
Microsoft Swings for the Fences
Microsoft decided to build on its desktop PC domination to similarly dominate servers.
Microsoft’s initial foray into a next-generation operating system ended poorly. IBM and Microsoft signed a “Joint Development Agreement” in August 1985 to develop what would later become OS/2. However, especially after Windows 3.0 become a success on desktop PCs in 1990, the two companies increasingly couldn’t square their technical and cultural differences. For example, IBM was primarily focused on selling OS/2 to run on its own systems—naming its high-profile PC lineup PS/2 may have been a clue—whereas Microsoft wanted OS/2 to run on a wide range of hardware from many vendors.
As a result, Microsoft had started to work in parallel on a re-architected version of Windows. CEO Bill Gates hired Dave Cutler in 1988. Cutler had led the team that created the VMS operating system for Digital’s VAX computer line among other Digital operating systems. Cutler’s push to develop this new operating system is well-chronicled in G. Pascal Zachary’s Show Stopper!: The Breakneck Race to Create Windows NT and the Next Generation at Microsoft (Free Press, 1994) in which the author describes him as a brilliant and, at times, brutally aggressive chief architect.
Cutler had a low opinion of OS/2. He also had a low opinion of Unix. In Show Stopper! a team member is quoted as saying “He thinks Unix is a junk operating system designed by a committee of Ph.D.s. There’s never been one mind behind the whole thing, and it shows, so he’s always been out to get Unix. But this is the first time he’s had the chance.”
As a result, Cutler undertook the design of a new operating system that would be named Windows NT upon its release in 1993.
IBM continued to work on OS/2 by itself, but it failed to attract application developers, was never a success, and was eventually discontinued. This Microsoft success at the expense of IBM was an early-on example of the growing importance of developers and developer mindshare, a trend that Bill Gates and Microsoft had long recognized and played to considerable advantage. And it would later become a critical factor in the success of open source communities.
Windows NT Poised to Take It All
Windows NT on Intel was a breakout product. Indeed, Microsoft and Intel became so successful and dominant that the “Wintel” term was increasingly used to refer to the most dominant type of system in the entire industry. By the mid-1990s, Unix was in decline, as were other operating systems such as NetWare.
Windows NT was mostly capturing share from Unix on smaller servers, but many thought they saw a future in which Wintel was everywhere. Unix systems vendors, with the notable exception of Sun Microsystems under combative CEO Scott McNealy, started to place side bets on Windows NT. There was a sense of inevitability in many circles.
The irony was that, absent Windows NT, Unix would likely have conquered all. Jeff Atwood wrote that “The world has devolved into Unix and NT camps exclusively. Without NT, I think we’d all be running Unix at this point, for better or worse. It certainly happened to Apple; their next-generation Copland OS never even got off the ground. And now they’re using OS X which is based on Unix.”
Unix might still have remained the operating system of choice for large systems with many processors; Windows NT was initially optimized for smaller systems. But it was easy to see that Windows NT was fully capable of scaling up and had been architected by Cutler to be able to serve as a Unix replacement. Once it got there, it was going to be very difficult not to rally around something that had become an industry standard just as Intel’s x86 processor line had. Products selling in large volume have lower unit costs and find it far easier to establish partnerships and integrations up and down the new stack with its horizontal layers.
The Internet Enters the Mainstream
But wait. It wasn’t quite “Game over man.” A couple other things were happening by now. The Internet was taking off and the first versions of Linux had been released.
By 1990, the Internet had been in existence, in some form, for a couple of decades. It originated with work commissioned by the US Defense Advanced Research Projects Agency (DARPA) in the 1960s to build fault-tolerant communication with computer networks. However, you probably hadn’t heard of it unless you were a researcher at one of the handful of institutions connected to the early network. The Internet emerged from this obscurity in the 1990s for a variety of reasons, not least of which was the invention of the World Wide Web—which for many people today is synonymous with the Internet—by English scientist Tim Berners-Lee while working at CERN.
From Scale-Up to Scale-Out
The great Internet build-out of the late 1990s lifted many boats, including the vendors of high-end expensive hardware and software. The quartet of Sun, networking specialist Cisco, storage disk array vendor EMC, and database giant Oracle was nicknamed the “four horsemen of the Internet.” It seemed as if every venture capital-backed startup needed to write a big check to those four.
However, a lot of Internet infrastructure (think web servers)—as well as high-performance scientific computing clusters—ran on large numbers of smaller systems instead. Unix vendors, most notably Sun, were happy to sell their own smaller boxes for these purposes. but those typically carried a lot higher price tag than was the norm for “industry standard” hardware and software.
The use of more and smaller servers was part of a broader industry shift in focus from “scale-up” computing to “scale-out.” Distributed computing was driven by the maturation of the client/server and network/distributed computing styles that first emerged and gained popularity in the 1980s. This seemed like something that played to the Microsoft wheelhouse.
Internet Servers Needed an Operating System
Yet, Windows NT wasn’t really ideal for these applications either. Yes, it was rapidly taking share from Unix in markets like small business and replicated sites in larger businesses—to the point where a vendor like Santa Cruz selling primarily into those markets was facing big losses. However, network infrastructure and scientific computing roles had mostly favored Unix historically for both reasons of custom and technology. For example, the modular mix-and-match nature of Unix had long made it popular with tinkerers and do-it-yourselfers. Transitioning to Windows NT was therefore neither natural nor easy.
BSD Unix was one obvious alternative. It did make inroads but only limited ones. The reasons are complicated and not totally clear even with the benefit of hindsight. Lingering effects of the litigation with AT&T. Licensing that didn’t compel contributing back like the GPL does. A more centralized community that was less welcoming to outside contributions. I’ll return to some of these later, but, in any case, BSD didn’t end up having a big effect on the software landscape.
Enter Linux
Into this gap stepped Linux paired with other open source software such as GNU, the Apache web server, and many other types of software over time.
Recall our Finnish university student Linus Torvalds. Working on and inspired by MINIX, a version of Unix initially created by Andrew Tanenbaum for educational purposes, Torvalds began writing an operating system kernel.
The kernel is the core of a computer's operating system. Indeed, some purists argue that a kernel is the operating system with everything else part of a broader operating environment. In any case, it is usually one of the first programs loaded when a computer starts up. A kernel connects application software to the hardware of a computer and generally abstracts the business of managing the system hardware from “userspace” things that someone trying to use the computer to do something cares about.
A New *nix
Linux is a member of the Unix-like (or sometimes “*nix”) family of operating systems. The distinction between Unix and Unix-like is complicated, unclear, and, frankly, not very interesting. Originally, the term “Unix” meant a particular product developed by AT&T. Later it extended to AT&T licensees. Today, The Open Group owns the Unix trademark, but the term has arguably become generic with no meaningful distinction between operating systems that are indisputably a true Unix and those that are better described as Unix-like for reasons of trademark or technical features.
Torvalds announced his then-hobby project in 1991 to the broader world in a Usenet posting to the newsgroup comp.os.minix. He soon released version 0.01, which was mostly just the kernel.
By the next year, Torvalds had relicensed Linux under the GPL. Others had created the first Linux distributions to simplify installing it and to start packaging together the many components needed to use an operating system. By 1993, over 100 developers were working on the Linux kernel; among other things they adapted it to the GNU environment. The year 1994 saw version 1.0 of Linux, the addition of a graphical user interface from the XFree86 project, and commercial Linux distributions from Red Hat and SUSE.
Linux Grows in Popularity
Initially, Linux was popular especially in university and computing research organizations, much as Unix itself had been starting in the mid-1970s, and Solaris from the mid-1980s. Linux also started finding its way into many network infrastructure roles for file and print sharing, Web and FTP serving, and similar tasks.
You could download it for free or buy it on a disk for cheap. It’s worth being explicit about what “cheap” meant in this context. The early to mid-1990s were still the era of the retail software stores like Egghead Software and hefty publications like Computer Shopper, a large format magazine filled with ads for computer gear and software, that hit over 800 pages at its peak. Consumers were accustomed to buying boxed software, including the aforementioned Windows NT, at prices that easily ran into the hundreds of dollars. For a company accustomed to buying business applications from the likes of Oracle, this might have seemed like a bargain. But not many university students or even young professionals saw it that way. One of my current colleagues remembers being blown away by the fact that he could buy Red Hat Linux on a CD from a discount retailer for about six dollars. That’s cheap.
Eclipsing Unix
Linux was also compatible with Unix programs and skills. A wide range of software development tools were available for it. (Again, for free or cheap.) It had all the applications needed to run it as either part of a big cluster or in a server closet somewhere. The low costs involved also meant that Linux could be and frequently was brought in the back door of companies without IT management even having to know and approve.
By the close of the 1990s, Linux and open source more generally were not yet the dominant force and influence that they are today. But the market share of Linux was already eclipsing Unix on x86 servers. It was running some of the largest supercomputers in the world on the TOP500 list. It was the basis for many of the infrastructure products like “server appliances” sold during the dot-com boom.
And even just by the year 2000, it had attracted thousands of developers from all over the world. The open source development model was working.
Open Source Accelerates
Open source software was born in the 20th century but its great impact has been as a 21st-century phenomenon.
In part, this is because computing changed in a way that was beneficial to open source software such as Linux. Open source has also surely acted as something of a feedback loop to amplify many of those trends.
As we’ve seen, many of the major early open source projects had an affinity for networked, scale-out computing. Initially, this seemed at odds with the way many enterprise IT departments approached their infrastructure and applications, which tended toward the scale-up and monolithic. Need more capacity? Upgrade your server. Big check, please.
A New Enterprise IT Model
However, by the early 2000s, many organizations were revising how they thought about enterprise IT. As my then-analyst colleague Jonathan Eunice would write in a 2001 research note: “. . . we must understand that what constitutes enterprise computing today is in fact evolving quite rapidly. Every day it moves a little more toward, and morphs a little further into, the realm of network computing. Enterprise IT is increasingly implemented with standardized infrastructure, as well as increasingly is delivered over an Internet Protocol network connection. IT departments increasingly structure themselves, their missions, and their datacenters as do services providers.”
In the world of the Big Iron Unix vendors, an enormous amount of work went into vertical scalability, failover clustering, resource management, and other features to maximize the performance and reliability of single servers. Linux (and Windows) plugged away at features related to these requirements over time. But the world increasingly placed a lower priority on those needs and shifted its attention to the more distributed and network-centric workloads that were closer to the initial open source sweet spot. In fact, there’s an argument to be made that at least some of the Linux development work funded by companies like IBM in the early 2000s focused far too obsessively on making Linux a better scale-up Unix.
Born on the Web
The demand for open source software in the new millennium has also been accelerated by a new class of businesses, which it is no exaggeration to say would not have been possible in the absence of open source. Just one cloud service provider, Amazon Web Services, is reported to have over one million servers. At that scale, presumably Amazon could have licensed the source code for an operating system or other software and then adapted them to their needs. However, like Google, Facebook, and essentially all Internet companies of any size, they primarily run open source software.
In part, this is simply a matter of cost. Especially for those companies offering services that they monetize only indirectly through advertising or other means (think free consumer Gmail from Google), it’s unclear that the economics would work if they needed to pay for software in the traditional historical manner.
That’s not to say that everything these companies use is free. It often makes sense for even technologically sophisticated organizations to establish commercial relationships with some of their suppliers. These companies also require many of the same kinds of specialized financial and other categories of software and software services all large businesses need. It rarely makes sense to do everything in-house.
Nonetheless, these companies are in a sense almost a new category of system vendor, producing and building much of the software (and even optimized hardware) for their internal use.
Build or Buy ?
Still, every company needs to make decisions about where it focuses internal research and development. This was the central thesis of Nick Carr’s 2003 article in Harvard Business Review entitled “Does IT Matter?” The incredible permeation of software into almost every aspect of business makes some of Carr’s specific arguments seem perhaps overstated. (Many felt this was the case at the time as well.) As software plays into competitive differentiation at many levels, it’s increasingly rare for companies to treat it as a pure commodity that can all be easily outsourced. However, his broader point that firms should focus on those areas where they can truly differentiate and capture value nonetheless applies.
Open source software makes it easier to trade off build and buy decisions because it’s no longer a binary choice. Historically, software tended to be a take-it-or-leave-it proposition. If it didn’t work quite like you wanted it to, you could put in a feature request to a vendor who might do something about it in a release or two. At least if you were an important enough customer. There was often the option of paying for something custom from your supplier, but that still put a lot of process in the way of getting the changes made.
With open source, companies can choose where to use available open source code unchanged—perhaps with the full support of a vendor. Or they can tweak and augment for their particular needs without the need to build the whole thing from scratch.
Disrupting the Status Quo
But, really, these arguments about economics, especially in the context of individual companies, skirt around the most important reasons why open source has accelerated so quickly. These reasons involve moving beyond a narrow view of open source as being just about code. It requires thinking about open source as both a very good development model and the means for individuals and companies to work together in ways that just wasn’t possible previously.
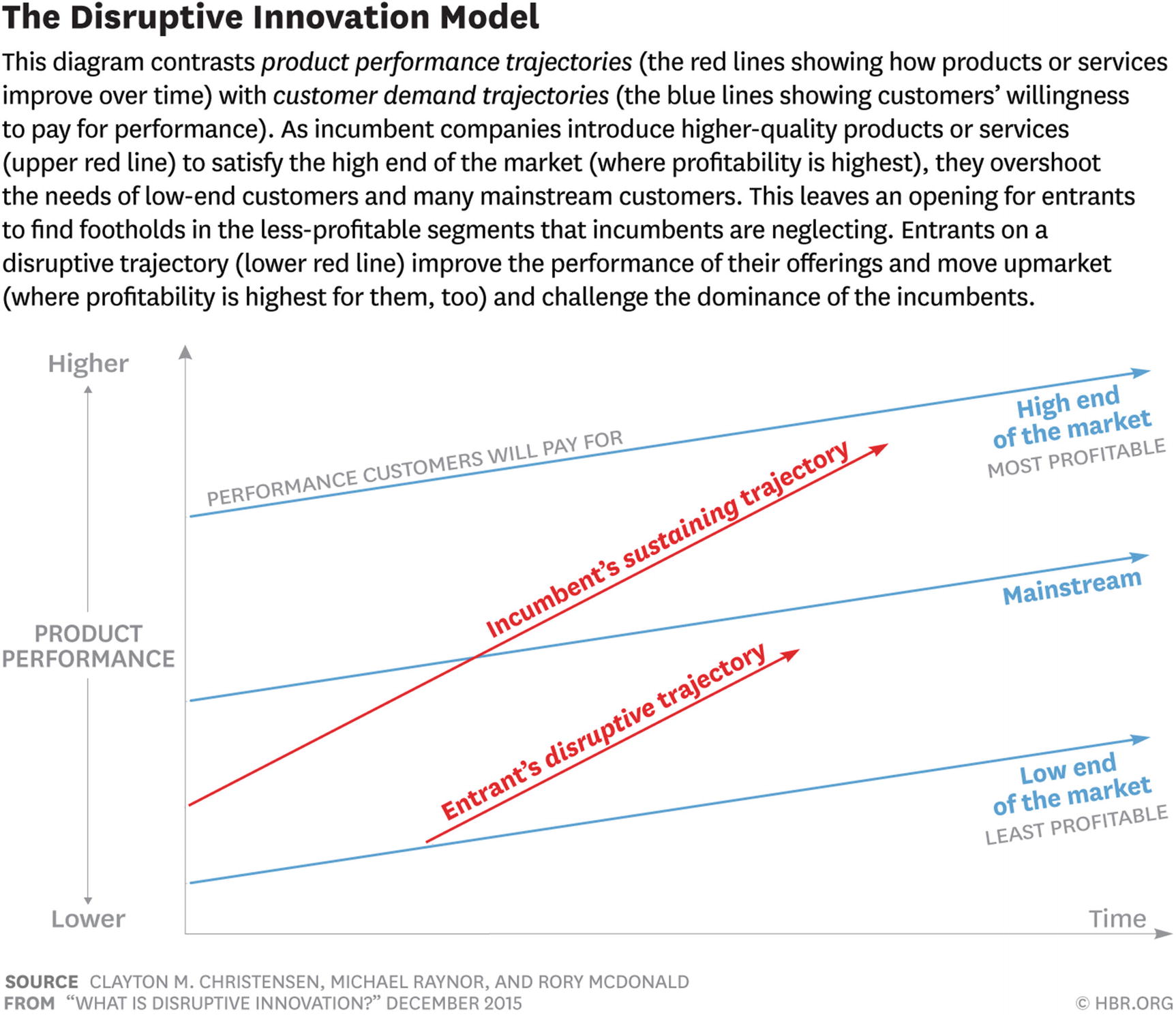
The Disruptive Innovation model. Source: Clayton M. Christensen, Michael Raynor, and Rory McDonald, Copyright HBR.ORG.
Disruptive Innovation is the term coined by Harvard Business School Professor Clayton Christensen to “describe a process by which a product or service takes root initially in simple applications at the bottom of a market and then relentlessly moves up market, eventually displacing established competitors.”
We’ve already seen an example in this book. The personal computer and the servers that evolved from them disrupted the traditional Unix vendors. The Unix vendors themselves often disrupted earlier forms of proprietary systems such as minicomputers.
Christensen also writes that “An innovation that is disruptive allows a whole new population of consumers at the bottom of a market access to a product or service that was historically only accessible to consumers with a lot of money or a lot of skill.” Relative to Unix, Linux fits this definition (as does Windows). And, indeed, a great deal of existing Unix business has shifted to Linux over time. This benefited large and technically sophisticated users who simply wanted to spend less money.
But it also allowed new categories of users and businesses that might well not have been able to afford proprietary Unix. Linux has arguably also been a disrupter to Windows by largely keeping it out of network infrastructure and scientific commuting markets that it might have eventually captured by default in the absence of an alternative like Linux.
We could apply similar arguments to many other categories of open source software. Databases, application servers and other enterprise middleware, programming tools, virtualization . . . For many examples, the major virtue in their early years was that you could download them off the Internet and try them out for free. They weren’t actually better in other respects than the proprietary alternatives.
From Disruption to Where Innovation Happens
However, during the past decade or so, things started to shift. Early cloud computing projects aimed at those who wanted to build their own clouds were probably the first big inflection point. Big data was another. Today, it’s cloud-native, containers, artificial intelligence, the many projects related to them, and more. The common thread is that the manner in which open source allows innovations from multiple sources to be recombined and remixed in powerful ways has created a situation in which a huge number of the interesting innovations are now happening first in open source.
This is, in part, perhaps because otherwise independent open source communities can integrate and combine in powerful ways.
The Rise of Ecosystems
For example, “big data” platforms increasingly combine a wide range of technologies from Hadoop MapReduce to Apache Spark to distributed storage projects such as Gluster and Ceph. Ceph is also the typical storage backend for the cloud infrastructure project OpenStack—having first been integrated to provide unified object and block storage.
OpenStack networking is also an interesting case because it brings together a number of different communities including Open Daylight (a collaborative software-defined networking project under the Linux Foundation), Open vSwitch (which can be used as a node for Open Daylight), and network function virtualization projects that can then sit on top of Open Daylight—to create software-based firewalls, for example.
The cloud-native space is even more dynamic. It started out being mostly about containers themselves, which are an efficient, lightweight way to isolate applications and application components within an operating system. But it’s expanded with projects like Kubernetes, Prometheus, and hundreds more that encompass container orchestration, monitoring, logging, tracing, testing and building, service discovery, and just about anything else you can imagine might be useful to develop, secure, deploy, and manage distributed applications at scale. We also see the continuing intersection between cloud-native and other areas. For example, both software-defined storage and software-defined networking functionality are being containerized in various ways.
Breaking Up Monoliths
Open source broadly has also evolved in step with a computing landscape that has grown far more distributed and flexible. More integrated too but in a mostly ad hoc and loosely coupled way.
Software both molds the computing environment it runs in and reflects it. A great deal of proprietary software development historically focused on big programs with big license fees that would be (expensively) installed and customized and then left to run for years. Connections between programs and between programs and data required more expensive, complex software going by acronyms like EDI (Electronic Data Interchange ). This fit with proprietary business models.
Complexity was actually a good thing (at least from the vendor’s perspective). It tied customers to a single vendor, generated consulting fees, and created lots of upsell opportunities with all the options needed to make everything work together. Complexity also meant that there was no real way to determine upfront if software was going to work as advertised. In practice, I’ve seen more than one high-end computer systems management program end up as a very expensive bookend sitting on a shelf because it never really quite did the job it was purchased to do.
Even once the Web came onto the scene, initial efforts to have less rigid integrations still reflected traditional ways of doing things. For example, Service-oriented architecture (SOA), at least in its initial form. Many of the core ideas behind SOA, such as separating functions into distinct units that communicate with each other by passing data in a well-defined, shared format, are part of modern architectural patterns such as microservices. However, as implemented at first, SOA was often mired down by heavyweight web services standards and protocols.
By contrast, today’s distributed systems world is more commonly characterized by lightweight protocols like REST; open source software components that can be mixed, matched, and adapted; and a philosophy that tends to favor coding reference implementations rather than going through heavyweight standards-setting processes. Open source has brought Unix-flavored approaches like highly modular design to both platform software and applications more broadly.
Linux and Open Source Had Arrived
In 2003, IBM aired a TV commercial titled “Prodigy.” It featured a young boy sitting and absorbing pearls of wisdom. Hollywood director Penny Marshall: “Everything’s about timing, kid.” Harvard professor Henry Louis Gates: “Sharing data is the first step toward community.” Muhammad Ali: “Speak your mind. Don’t back down.” The commercial ends with someone asking who the kid is. “His name is Linux.”
The ad, created by Ogilvy & Mather, was a don’t-change-the-channel ad with arresting imagery. Then head of IBM’s worldwide advertising, Lisa Baird, said it was targeted at “CEOs, CFOs, and prime ministers.” The investment in this ad reflected how forward-looking individuals and organizations were starting to view open source.
Irving Wladawsky-Berger, who recognized the potential of Linux early on and ran Linux strategy for IBM at the critical turn-of-the-century juncture, noted in a 2011 LinuxCon keynote that “We did not look at Linux as just another operating system any more than we looked at the Internet as just another network.” He went on to say that we viewed it as “a platform for innovation into the future, just like we viewed the Internet.”
Equally notable were the smaller companies like Red Hat, SUSE, and others who were starting to build businesses that not only used but were explicitly based on open source.
It may not have been clear to many in 2000 that Linux was anything more than a Unix-like operating system with an unusual license. Or that open source more broadly was a significant part of the software or business equation. However, here in 2018, it’s clear that Linux and open source broadly are playing a major role in pushing software innovation forward. And that really means pushing business capabilities forward given how inextricably linked they are to software.