


IBM DB2 for i
This chapter describes the following enhancements to the DB2 for i functions in IBM i version 7.2:
For more information about the IBM i 7.2 database enhancements, see the IBM i Technology Updates developerWorks wiki:
8.1 Introduction to DB2 for i
DB2 for i is a member of the DB2 family. This database is integrated and delivered with the IBM i operating system. DB2 for i has been enhanced from release to release of IBM i. In addition, DB2 for i is also enhanced by using the DB2 PTF Groups, where PTF Group SF99702 applies to IBM i 7.2 for DB2. This group does not change in V7R2.
IBM i 7.2 brings many DB2 functional, security, performance, and management enhancements. Most of these enhancements are implemented to support agility or what is referred to as a data-centric approach for the platform.
A data-centric paradigm requires business application designers, architects, and developers to focus on the database as a central point of modern applications for better data integrity, security, business agility, and a lower time to market factor. This is in contrast to an application-centric approach, where data manipulation, security, and integrity is, at least partially, governed by the application code. A data-centric concept moves these responsibilities over the underlying database.
A data-centric approach ensures consistent and secure data access and manipulation regardless of the application and the database interface that are used. Implementing security patterns for business critical data, and data access and manipulation procedures within DB2 for i, is now easier than ever, and more importantly, it removes code complexity and a security-related burden from business applications.
This approach is especially crucial for contemporary IT environments where the same data is being manipulated by web, mobile, and legacy applications at the same time. Moving data manipulation logic over the DB2 for i also uses all the current and future performance enhancements, database monitoring capabilities, and performance problem investigation tools and techniques.
The following key IBM i 7.2 database enhancements support this data-centric approach:
•Row and column access control (RCAC)
•Separation of duties
•DB2 for i services
•Global variables
•Named and default parameter support on user-defined functions (UDFs) and user-defined table functions (UDTFs)
•Pipelined table functions
•SQL plan cache management
•Performance enhancements
•Interoperability and portability
•LIMIT x OFFSET y clause
This chapter describes all the major enhancements to DB2 for i in IBM i 7.2.
8.2 Separation of duties concept
Separation of duties is a concept that helps companies to stay compliant with standards and government regulations.
One of these requirements is that users doing administration tasks on operating systems (usually they have *ALLOBJ special authority) should not be able to see and manipulate customer data in DB2 databases.
Before IBM i 7.2, when users had *ALLOBJ special authority, they could manipulate DB2 files on a logical level and see the data in these database files. Also, there was a problem because someone who was able to grant permission to other users to work with data in the database had also authority to see and manipulate the data inside the databases.
To separate out the operating system administration permissions and data manipulation permissions, DB2 for i uses the QIBM_DB_SECADM function. For this function, authorities to see and manipulate of data can be set up for individual users or groups. Also, a default option can be configured. For more information about the QIBM_DB_SECADM function, see 8.2.1, “QIBM_DB_SECADM function usage” on page 323.
Although the QIBM_DB_SECADM function usage can decide who can manipulate DB2 security, there is another concept in DB2 for i 7.2, which helps to define which users or groups can access rows and columns. This function is called Row and Column Access Control (RCAC). For more information about RCAC, see 8.2.2, “Row and Column Access Control support” on page 325.
8.2.1 QIBM_DB_SECADM function usage
IBM i 7.2 now allows management of data security without exposing the data to be read or modified.
Users with *SECADM special authority can grant or revoke privileges to any object even if they do not have these privileges. This can be done by using the Work with Function Usage (WRKFCNUSG) CL command and specifying the authority of *ALLOWED or *DENIED for particular users of the QIBM_DB_SECADM function.
From the Work with Function Usage (WRKFCNUSG) panel (Figure 8-1), enter option 5 (Display usage) next to QIBM_DB_SECADM and press Enter.
|
Work with Function Usage
Type options, press Enter.
2=Change usage 5=Display usage
Opt Function ID Function Name
QIBM_DIRSRV_ADMIN IBM Tivoli Directory Server Administrator
QIBM_ACCESS_ALLOBJ_JOBLOG Access job log of *ALLOBJ job
QIBM_ALLOBJ_TRACE_ANY_USER Trace any user
QIBM_WATCH_ANY_JOB Watch any job
QIBM_DB_DDMDRDA DDM & DRDA Application Server Access
5 QIBM_DB_SECADM Database Security Administrator
QIBM_DB_SQLADM Database Administrator
|
Figure 8-1 Work with Function Usage panel
In the example that is shown in Figure 8-2, in the Display Function Usage panel, you can see that default authority for unspecified user profiles is *DENIED. Also, both the DEVELOPER1 and DEVELOPER2 user profiles are specifically *DENIED.
|
Display Function Usage
Function ID . . . . . . : QIBM_DB_SECADM
Function name . . . . . : Database Security Administrator
Description . . . . . . : Database Security Administrator Functions
Product . . . . . . . . : QIBM_BASE_OPERATING_SYSTEM
Group . . . . . . . . . : QIBM_DB
Default authority . . . . . . . . . . . . : *DENIED
*ALLOBJ special authority . . . . . . . . : *NOTUSED
User Type Usage User Type Usage
DEVELOPER1 User *DENIED
DEVELOPER2 User *DENIED
|
Figure 8-2 Display Function Usage panel
If you return back to the Work with Function Usage panel (Figure 8-1 on page 323) and enter option 2 (Change usage) next to QIBM_DB_SECADM and press Enter, you see the Change Function Usage (CHGFCNUSG) panel, as shown in Figure 8-3. You can use the CHGFCNUSG CL command to change who is authorized to use the QIBM_DB_SECADM function.
|
Change Function Usage (CHGFCNUSG)
Type choices, press Enter.
Function ID . . . . . . . . . . > QIBM_DB_SECADM
User . . . . . . . . . . . . . . Name
Usage . . . . . . . . . . . . . *ALLOWED, *DENIED, *NONE
Default authority . . . . . . . *DENIED *SAME, *ALLOWED, *DENIED
*ALLOBJ special authority . . . *NOTUSED *SAME, *USED, *NOTUSED
|
Figure 8-3 Change Function Usage panel
In the example that is shown in Figure 8-4, the DBADMINS group profile is being authorized for the QIBM_DB_SECADM function.
|
Change Function Usage (CHGFCNUSG)
Type choices, press Enter.
Function ID . . . . . . . . . . > QIBM_DB_SECADM
User . . . . . . . . . . . . . . DBADMINS Name
Usage . . . . . . . . . . . . . *ALLOWED *ALLOWED, *DENIED, *NONE
Default authority . . . . . . . *DENIED *SAME, *ALLOWED, *DENIED
*ALLOBJ special authority . . . *NOTUSED *SAME, *USED, *NOTUSED
|
Figure 8-4 Allow the DBADMINS group profile access to the QIBM _DB_SECADM function
Showing the function usage for the QIBM_DB_SECADM function now shows that all users in the DBADMINS group now can manage DB2 security. See Figure 8-5.
|
Display Function Usage
Function ID . . . . . . : QIBM_DB_SECADM
Function name . . . . . : Database Security Administrator
Description . . . . . . : Database Security Administrator Functions
Product . . . . . . . . : QIBM_BASE_OPERATING_SYSTEM
Group . . . . . . . . . : QIBM_DB
Default authority . . . . . . . . . . . . : *DENIED
*ALLOBJ special authority . . . . . . . . : *NOTUSED
User Type Usage User Type Usage
DBADMINS Group *ALLOWED
DEVELOPER1 User *DENIED
DEVELOPER2 User *DENIED
|
Figure 8-5 Display Function Usage panel showing the authority that is granted to DBADMINS group profile
8.2.2 Row and Column Access Control support
IBM i 7.2 is now distributed with option 47, IBM Advanced Data Security for IBM i. This option must be installed before using Row and Column Access Control (RCAC).
RCAC is based on the DB2 for i ability to define rules for row access control (by using the SQL statement CREATE PERMISSION) and to define rules for column access control and creation of column masks for specific users or groups (by using the SQL statement CREATE MASK).
|
Note: RCAC is described in detail in Row and Column Access Support in IBM DB2 for i, REDP-5110. This section only briefly describes the basic principles of RCAC and provides a short example that shows the ease of implementing the basic separation of duties concept.
|
Special registers that are used for user identifications
To implement RCAC, special registers are needed to check which user is trying to display or use data in a particular table. To be able to identify users for the RCAC, IBM i uses several special registers that are listed in Table 8-1.
Table 8-1 Special registers for identifying users
|
Special register
|
Definition
|
|
USER
or
SESSION_USER
|
The effective user of the thread is returned.
|
|
SYSTEM_USER
|
The authorization ID that initiated the connection is returned.
|
|
CURRENT USER
or
CURRENT_USER
|
The most recently program adopted authorization ID within the thread is returned. When no adopted authority is active, the effective user of the thread Is returned.
|
|
CURRENT_USER: The CURRENT_USER special register is new in DB2 for IBM i 7.2. For more information, see IBM Knowledge Center:
|
VERIFY_GROUP_FOR_USER function
The VERIFY_GROUP_FOR_USER function has two parameters: userid and group.
For RCAC, the userid parameter is usually one of special register values (SESSION_USER, SYSTEM_USER, or CURRENT_USER), as described in “Special registers that are used for user identifications” on page 326.
This function returns a large integer value. If the user is member of group, this function returns a value of 1; otherwise, it returns a value of 0.
RCAC example
This section provides a brief example of implementing RCAC. This example uses an employee database table in a library called HR. This employee database table contains the following fields:
•Last name
•First name
•Date of birth
•Bank account number
•Employee number
•Department number
•Salary
Another database table that is called CHIEF contains, for each employee number, the employee number of their boss or chief.
You must create the following group profiles, as shown in Example 8-1:
•EMPGRP, which contains members of all employees
•HRGRP, which contains members from the HR department
•BOARDGRP, which contains members of all bosses or chiefs in the company
Example 8-1 Create group profiles for the RCAC example
CRTUSRPRF USRPRF(EMPGRP)
PASSWORD(*NONE)
TEXT('Employee group')
CRTUSRPRF USRPRF(HRGRP)
PASSWORD(*NONE)
TEXT('Human resources group')
CRTUSRPRF USRPRF(BOARDGRP)
PASSWORD(*NONE)
TEXT('Chiefs group')
Next, create the user profiles, as shown in the Example 8-2. For simplicity, this example assumes the following items:
•The user profile password is the same as the user profile name.
•For all employees, the user profile name is the same as employee’s last name.
Example 8-2 Create user profiles for the RCAC example
CRTUSRPRF USRPRF(JANAJ)
TEXT('Jana Jameson')
GRPPRF(EMPNO)
SUPGRPRF(HRGRP)
-- Jana Jameson works in the HR department
CRTUSRPRF USRPRF(JONES)
TEXT('George Jones - the company boss')
GRPPRF(EMPGRP)
SUPGRPPRF(BOARDGRP)
-- George James is a boss in the company and is an employee as well.
CRTUSRPRF USRPRF(FERRANONI)
TEXT('Fabrizion Ferranoni')
GRPPRF(EMPGRP)
CRTUSRPRF USRPRF(KADLEC)
TEXT('Ian Kadlec')
GRPPRF(EMPGRP)
CRTUSRPRF USRPRF(NORTON)
TEXT('Laura Norton')
GRPPRF(EMPGRP)
CRTUSRPRF USRPRF(WASHINGTON)
TEXT('Kimberly Washington')
GRPPRF(EMPGRP)
Now, create the DB2 schema (collection) HR and employee table EMPLOYEE. The primary key for the employee table is the employee number. After creating the database table EMPLOYEE, create indexes EMPLOYEE01 and EMPLOYEE02 for faster access. Then, add records to the database by using the SQL insert command. See Example 8-3.
|
Note: When entering SQL commands, you can use either the STRSQL CL command to start an interactive SQL session or use IBM Navigator for i. If you use STRSQL, make sure to remove the semicolon marks at the end of each SQL statement.
|
Example 8-3 Create the schema, database table, and indexes, and populate the table with data
CREATE TABLE HR/EMPLOYEE
(FIRST_NAME FOR COLUMN FNAME CHARACTER (15 ) NOT NULL WITH DEFAULT,
LAST_NAME FOR COLUMN LNAME CHARACTER (15 ) NOT NULL WITH DEFAULT,
DATE_OF_BIRTH FOR COLUMN BIRTHDATE DATE NOT NULL WITH DEFAULT,
BANK_ACCOUNT CHARACTER (9 ) NOT NULL WITH DEFAULT,
EMPLOYEE_NUM FOR COLUMN EMPNO CHARACTER(6) NOT NULL WITH DEFAULT,
DEPARTMENT FOR COLUMN DEPT DECIMAL (4, 0) NOT NULL WITH DEFAULT,
SALARY DECIMAL (9, 0) NOT NULL WITH DEFAULT,
PRIMARY KEY (EMPLOYEE_NUM)) ;
CREATE INDEX HR/EMPLOYEE01 ON HR/EMPLOYEE
(LAST_NAME ASC,
FIRST_NAME ASC) ;
CREATE INDEX HR/EMPLOYEE02 ON HR/EMPLOYEE
(DEPARTMENT ASC,
LAST_NAME ASC,
FIRST_NAME ASC);
-- Now created the table CHIEF and add data
CREATE TABLE HR/CHIEF
(EMPLOYEE_NUM FOR COLUMN EMPNO CHARACTER(6 ) NOT NULL WITH DEFAULT,
CHIEF_NO CHARACTER(6 ) NOT NULL WITH DEFAULT,
PRIMARY KEY (EMPLOYEE_NUM)) ;
INSERT INTO HR/CHIEF VALUES
(
'G76852', 'G00012') ;
INSERT INTO HR/CHIEF VALUES
(
'G12835', 'G00012');
INSERT INTO HR/CHIEF VALUES
(
'G23561', 'G00012');
INSERT INTO HR/CHIEF VALUES
(
'G00012', 'CHIEF ');
INSERT INTO HR/CHIEF VALUES
(
'G32421', 'G00012');
-- Load exapmple data into EMPLOYEE table
INSERT INTO HR/EMPLOYEE
VALUES('Fabrizio', 'Ferranoni',
DATE('05/12/1959') , 345723909, 'G76852','0001', 96000) ;
INSERT INTO HR/EMPLOYEE
VALUES('Ian', 'Kadlec',
DATE('11/23/1967') , 783920125, 'G23561', '0001', 64111) ;
INSERT INTO HR/EMPLOYEE
VALUES('Laura', 'Norton',
DATE('02/20/1972') , 834510932, 'G00012', '0001', 55222) ;
INSERT INTO HR/EMPLOYEE
VALUES('Kimberly', 'Washington',
DATE('10/31/1972') , 157629076, 'G12435', '0005' , 100000);
INSERT INTO HR/EMPLOYEE
VALUES('George', 'Jones',
DATE('10/11/1952') , 673948571, 'G00001', '0000' , 1100000);
INSERT INTO HR/EMPLOYEE
VALUES('Jana ', 'Jameson',
DATE('10/11/1952') , 643247347, 'G32421', '0205' , 30000);
Now comes the most important and most interesting part of this example, which is defining the row and column access rules. First, specify the row permission access rules, as shown in Example 8-4. The following rules are implemented:
•Each employee should see only their own record, except for employees from the human resources department (group HRGRP).
•Chiefs (group BOARDGRP) should have access to all rows.
Example 8-4 Example of row access rule
CREATE PERMISSION ACCESS_TO_ROW ON HR/EMPLOYEE
FOR ROWS WHERE
(VERIFY_GROUP_FOR_USER(SESSION_USER,'BOARDGRP') = 1)
OR
(VERIFY_GROUP_FOR_USER(SESSION_USER,'EMPGRP') = 1
AND UPPER(LAST_NAME) = SESSION_USER)
OR
(VERIFY_GROUP_FOR_USER(SESSION_USER,'HRGRP') = 1)
ENFORCED FOR ALL ACCESS
ENABLE ;
-- Activate row access control
ALTER TABLE HR/EMPLOYEE ACTIVATE ROW ACCESS CONTROL ;
Here is an explanation of Example 8-4 on page 329:
1. This example creates a rule that is called ACCESS_ON_ROW.
2. First, a check is done by using the VERIFY_GROUP_FOR_USER function to see whether the user profile of the person who is querying the employee table (SESSION_USER) is part of the group BOARDGRP. If the user is a member of BOARDGRP, the function returns a value of 1 and they are granted access to the row.
3. If the user is member of the EMPGRP group, a check is done to see whether this user has records in the file (UPPER(LAST_NAME) = SESSION_USER). For example, employee Ian Kadlec cannot see the row (record) of the employee Laura Norton.
4. Another verification is done to see whether the user profile is a member of the group HRGRP. If yes, the user profile has access to all employee records (rows).
5. If none of conditions are true, the user looking at the table data sees no records.
6. Finally, using the SQL command ALTER TABLE....ACTIVATE ROW ACCESS CONTROL, the row permission rules are activated.
Example 8-5 shows an example of using column masks. The SQL CREATE MASK statement is used to hide data in specific columns that contain sensitive personal information, such as a bank account number or salary, and present that data to only authorized people.
Example 8-5 Example of creating column masks
-- Following are masks for columns, BANK_ACCOUNT and SALARY
CREATE MASK BANKACC_MASK ON HR/EMPLOYEE FOR
COLUMN BANK_ACCOUNT RETURN
CASE
WHEN (VERIFY_GROUP_FOR_USER(SESSION_USER, 'BOARDGRP' ) = 1
AND UPPER(LAST_NAME) = SESSION_USER )
THEN BANK_ACCOUNT
WHEN VERIFY_GROUP_FOR_USER(SESSION_USER, 'HRGRP' ) = 1
THEN BANK_ACCOUNT
WHEN UPPER(LAST_NAME) = SESSION_USER
AND
VERIFY_GROUP_FOR_USER(SESSION_USER, 'EMPGRP' ) = 1
THEN BANK_ACCOUNT
ELSE '*********'
END
ENABLE;
CREATE MASK SALARY_MASK ON HR/EMPLOYEE FOR
COLUMN SALARY RETURN
CASE
WHEN UPPER(LAST_NAME) = SESSION_USER
AND VERIFY_GROUP_FOR_USER(SESSION_USER, 'EMPNO') = 1
THEN SALARY
WHEN VERIFY_GROUP_FOR_USER(SESSION_USER, 'BOARDGRP' ) = 1
THEN SALARY
WHEN VERIFY_GROUP_FOR_USER(SESSION_USER, 'HRGRP' ) = 1
THEN SALARY
ELSE 0
END
ENABLE;
-- Activate both column masks
ALTER TABLE HR/EMPLOYEE ACTIVATE COLUMN ACCESS CONTROL ;
Here is an explanation of Example 8-5 on page 330:
1. This example is creating a column mask that is called BANKACC_MASK, which is related to the BANK_ACCOUNT column.
2. If the user accessing the data is a chief (member of the BORADGRP group), then show only their bank account data.
3. If the user accessing the data is an HR department employee (member of the HRGRP group), then show all employee bank account numbers.
4. All other users should not see the bank account number, so the data is masked with ‘*********’.
5. Next, create the column mask that is called SALARY_MASK, which is related to the SALARY column.
6. If the user accessing the data is an employee (member of the EMPGRP group), then show only their salary data.
7. If the user accessing the data is an HR employee (member of the HRGRP group), then show all the salary data.
8. If the user accessing the data is a chief (member of the BOARDGRP group), then show all the salary data.
9. All other users should not see the salary data, so the data is masked with ‘*********’.
10. Finally, using the SQL command ALTER TABLE....ACTIVATE Column ACCESS CONTROL, the column mask rules are activated.
Results
When user JONES logs on (they are a member of the BOARDGRP group), they see the results from the EMPLOYEE table, as shown in Figure 8-6. A chief can see all employees and their salaries, but can see only their own bank account number.
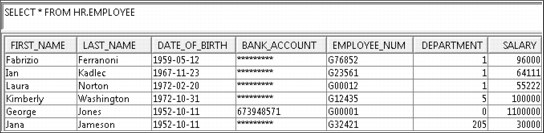
Figure 8-6 EMPLOYEE table as seen by the JONES user profile (Chief)
When any employee (in this example, the KADLEC user profile) logs on, they see the results from the EMPLOYEE table, as shown in Figure 8-7. In this case, each employee sees all data, but only data that is related to their person. This is a result of the ACCESS_TO_ROW row permission rule.

Figure 8-7 EMPLOYEE table as seen by the KADLEC user profile
When a human resources employee (in this example, the JANAJ user profile) logs on, they see the results from EMPLOYEE table, as shown in Figure 8-8. A human resources employee sees the bank accounts and salaries of all employees.

Figure 8-8 EMPLOYEE table as seen by the JANAJ user profile (human resources employee)
All other user profiles see an empty database file.
Adding the OR REPLACE clause to masks and permissions
Similar to other Data Definition Language (DDL) statements, the OR REPLACE clause was added to the following SQL commands:
•CREATE MASK
•REPLACE MASK
•CREATE PERMISSION
•REPLACE PERMISSION
The use of the OR REPLACE clause makes it easier to redeploy the RCAC rule text. For more information about the OR REPLACE clause, see IBM Knowledge Center:
8.3 DB2 security enhancements
This section describes the following DB2 security-related enhancements in IBM i 7.2:
8.3.1 QIBM_DB_ZDA and QIBM_DB_DDMDRDA function usage IDs
The QIBM_DB_ZDA and QIBM_DB_DDMDRDA function usage IDs block database server inbound connections. These function usage IDs ship with the default authority of *ALLOWED:
•You can use the QIBM_DB_ZDA function usage ID to restrict ODBC and JDBC Toolbox from the server side, including Run SQL Scripts, System i Navigator, and DB2 specific portions of Systems Director Navigator for i.
•You can use the QIBM_DB_DDMDRDA function usage ID to lock down DDM and IBM DRDA application server access.
These function usage IDs can be managed by the Work with Function Usage (WRKFCNUSG) CL command or by using the Change Function Usage (CHGFCNUSG) CL command. For an example of using the CHGFCNUSG CL command, see Example 8-6.
Example 8-6 Deny user profile user1 the usage of the DDM and DRDA application server access
CHGFCNUSG FCNID(QIBM_DB_DDMDRDA) USER(user1) USAGE(*DENIED)
8.3.2 Authorization list detail added to authorization catalogs
Using an authorization list eases security management and also improves performance because user profiles do not need to contain a list of objects to which they are authorized. They need to contain the authorization list that contains these objects.
Table 8-2 lists the DB2 for i catalogs that were updated to include the AUTHORIZATION_LIST column.
|
Note: Catalogs QSYS2/SYSXSROBJECTAUTH and QSYS2/SYSVARIABLEAUTH were already updated in IBM i 7.1 to have the AUTHORIZATION_LIST column.
|
Table 8-2 Catalogs containing the AUTHORIZATION_LIST column
|
Catalog
|
Catalog description|
|
|
QSYS2/SYSPACKAGEAUTH
|
*SQLPKG - Packages
|
|
QSYS2/SYSUDTAUTH
|
*SQLUDT - User-defined types
|
|
QSYS2/SYSTABAUTH
|
*FILE - Tables
|
|
QSYS2/SYSSEQUENCEAUTH
|
*DTAARA - Sequences
|
|
QSYS2/SYSSCHEMAAUTH
|
*LIB - Schema
|
|
QSYS2/SYSROUTINEAUTH
|
*PGM and *SRVPGM - Procedures and Functions
|
|
QSYS2/SYSCOLAUTH
|
Columns
|
|
QSYS2/SYSXSROBJECTAUTH
|
*XSROBJ - XML Schema Repositories
|
|
QSYS2/SYSVARIABLEAUTH
|
*SRVPGM - Global Variables
|
8.3.3 New user-defined table function: QSYS2.GROUP_USERS()
QSYS2.GROUP_USERS() is a new UDTF that you can use to create queries that can specify a group profile as its parameter and list user profiles in this group as the output.
The QSYS2.GROUP_USERS() function returns user profiles that have the specified group set up as their main or supplemental group. See Figure 8-9.

Figure 8-9 Example of the QSYS2.GROUP_USERS() UDTF
8.3.4 New security view: QSYS2.GROUP_PROFILE_ENTRIES
The new QSYS2.GROUP_PROFILE_ENTRIES security view returns a table with the following three columns:
•GROUP_PROFILE_NAME
•USER_PROFILE_NAME
•USER_TEXT
It accounts for both group and supplemental group profiles.
Figure 8-10 shows an example of using the QSYS2.GROUP_PROFILE_ENTRIES security view.

Figure 8-10 Example of the QSYS2.GROUP_PROFILE_ENTRIES security view
8.3.5 New attribute column in the SYSIBM.AUTHORIZATIONS catalog
The SYSIBM.AUTHORIZATIONS view is a DB2 family compatible catalog that contains a row for every authorization ID.
The SYSIBM.AUTHORIZATIONS catalog is extended to include a new column that is called ALTHORIZATION_ATTR, which differentiates users from groups. See Figure 8-11 on page 335.

Figure 8-11 SYSIBM.AUTHORIZATIONS catalog showing the new ALTHORIZATION_ATTR column
8.3.6 New QSYS2.SQL_CHECK_AUTHORITY() UDF
The QSYS2.SQL_CHECK_AUTHORITY() UDF is used to determine whether the user calling this function has the authority to object that is specified. The object type must be *FILE. The first parameter is the library and the second parameter is the object name. The result type is SMALLINT.
There are two possible result values:
•1: User has authority
•0: User does not have authority
Figure 8-12 shows the user that has authority to the CZZ62690/QTXTSRC object.

Figure 8-12 Example of user of the QSYS2.SQL_CHECK_AUTHORITY UDF
8.3.7 Refined object auditing control on QIBM_DB_OPEN exit program
Previously, an exit program control (*OBJAUD) was added to limit exit program calls. Because of the wide use of *CHANGE object auditing in some environments, the *OBJAUD control did not reduce the calls to the exit program enough in some environments.
The Open Data Base File exit program was enhanced to support two new values for the exit program data: OBJAUD(*ALL) and OBJAUD(*CHANGE).
Example 8-7 shows that three approaches are now possible.
Example 8-7 Object auditing control on the QIBM_DB_OPEN exit program
First example: The exit program is called when using any object auditing.
ADDEXITPGM EXITPNT(QIBM_QDB_OPEN) FORMAT(DBOP0100) PGMNBR(7) PGM(MJATST/OPENEXIT2) THDSAFE(*YES) TEXT('MJA') REPLACE(*NO)PGMDTA(*JOB *CALC '*OBJAUD')
Second example: The exit program is called when using *ALL object auditing.
ADDEXITPGM EXITPNT(QIBM_QDB_OPEN) FORMAT(DBOP0100) PGMNBR(7) PGM(MJATST/OPENEXIT2) THDSAFE(*YES) TEXT('MJA') REPLACE(*NO) PGMDTA(*JOB *CALC 'OBJAUD(*ALL)')
Third example: The exit program is called when using *CHANGE object auditing.
ADDEXITPGM EXITPNT(QIBM_QDB_OPEN) FORMAT(DBOP0100) PGMNBR(7) PGM(MJATST/OPENEXIT2) THDSAFE(*YES) TEXT('MJA') REPLACE(*NO) PGMDTA(*JOB *CALC 'OBJAUD(*CHANGE)')
8.3.8 Simplified DDM/DRDA authentication management by using group profiles
The new function of simplified DDM/DRDA authentication management by using group profiles enhances the authentication process when users connect to a remote database by using DDM or DRDA, for example, by using the SQL command CONNECT TO <database>.
Before this enhancement, any user connecting to a remote database needed to have a server authentication entry (by using the Add Server Authentication Entry (ADDSVRAUTHE) CL command) with a password for their user profile.
|
Note: To use the ADDSRVAUTE CL command, you must have the following special authorities:
•Security administrator (*SECADM) user special authority
•Object management (*OBJMGT) user special authority
|
You can use this enhancement to have a server authentication entry that is based on a group profile instead of individual users. When a user is a member of a group profile, or has a group profile set up as supplemental in their user profile, then only the group profile must have a server authentication entry. See Example 8-8.
Example 8-8 Use a group profile authentication entry to access a remote database
First create a group profile called TESTGROUP:
CRTUSRPRF USRPRF(TESTGROUP) PASSWORD(*NONE)
Then create a user profile TESTUSR and make it a member of TESTGROUP:
CRTUSRPRF USRPRF(TESTUSR) PASSWORD(somepasswd) GRPPRF(TESTTEAM)
Create the server authentication entry:
ADDSVRAUTE USRPRF(TESTGROUP) SERVER(QDDMDRDASERVER or <RDB-name>) USRID(sysbusrid) PASSWORD(sysbpwd)
User TESTUSR then uses the STRSQL command to get to an interactive SQL session and issues the following command, where RDB-name is a remote relational database registered using the command WRKRDBDIRE:
CONNECT TO <RDB-name>
The connection attempt is done to the system with <RDB-name> using <sysbusrid> user profile and <sysbpwd> password.
The following steps define the process of group profile authentication:
1. Search the authentication entries where USRPRF=user profile and SERVER=application server name.
2. Search the authentication entries where USRPRF=user profile and SERVER='QDDMDRDASERVER'.
3. Search the authentication entries where USRPRF=group profile and SERVER=application server name.
4. Search the authentication entries where USRPRF=group profile and SERVER='QDDMDRDASERVER'.
5. Search the authentication entries where USRPRF=supplemental group profile and SERVER= application server name.
6. Search the authentication entries where USRPRF=supplemental group profile and SERVER='QDDMDRDASERVER'.
7. If no entry was found in all the previous steps, a USERID only authentication is attempted.
|
Note: When the default authentication entry search order (explained in the previous steps) is used, the search order ceases at connect time if a match is found for QDDMDRDASERVER.
|
The QIBM_DDMDRDA_SVRNAM_PRIORITY environment variable can be used to specified whether an explicit server name order is used when searching for authentication entries.
Example 8-9 shows an example of creating the QIBM_DDMDRDA_SVRNAM_PRIORITY environment variable.
Example 8-9 Create the QIBM_DDDMDRDA_SVRNAM_PRIORITY environment variable
ADDENVVAR ENVVAR(QIBM_DDMDRDA_SVRNAM_PRIORITY) VALUE(’Y’) LEVEL(*JOB or *SYS)
For more information about how to set up authority for DDM and DRDA, see IBM Knowledge Center:
8.3.9 IBM InfoSphere Guardium V9.0 and IBM Security Guardium V10
IBM Security Guardium® (formerly known as IBM InfoSphere® Guardium) is an enterprise information database audit and protection solution that helps enterprises protect and audit information across a diverse set of relational and non-relational data sources. It allows companies to stay compliant with wide range of standards. Here are some of security areas that are monitored:
•Access to sensitive data (successful or failed SELECTs)
•Schema changes (CREATE, DROP, ALTER TABLES, and so on)
•Security exceptions (failed logins, SQL errors, and so on)
•Accounts, roles, and permissions (GRANT and REVOKE)
The Security Guardium product captures database activity from DB2 for i by using the AIX based IBM S-TAP® software module running in PASE. Both audit information and SQL monitor information is streamed to S-TAP. Audit details that are passed to S-TAP can be filtered for both audit data and also DB2 monitor data for performance reasons.
Figure 8-13 shows how Security Guardium collects data from DB2 monitors and the audit journal.

Figure 8-13 InfoSphere Guardium V9.0 Collection Data flow
With InfoSphere Guardium V9.0, DB2 for IBM i can now be included as a data source, enabling the monitoring of accesses from native interfaces and through SQL. Supported DB2 for i data sources are from IBM i 6.1, 7.1, and 7.2.
The Data Access Monitor feature is enhanced in V9.0 with the following capabilities:
•Failover support for IBM i was added.
•Support for multiple policies (up to nine), with IBM i side configuration.
•Filtering improvements, with IBM i side configuration.
For more information about InfoSphere Guardium V9.0 and DB2 for i support, see the following website:
The successor version of InfoSphere Guardium V9.0 is IBM Security Guardium V10.
Version 10 has the Data Access Monitor feature and has a new Vulnerability Assessment (VA) feature. Vulnerability Assessment with IBM i contains a comprehensive set of more than 130 tests that show weaknesses in your IBM i security setup. It allows reporting for IBM i 6.1, 7.1, and 7.2 partitions.
Version 10 has the Data Access Monitor feature and has a new Vulnerability Assessment (VA) feature. Vulnerability Assessment with IBM i contains a comprehensive set of more than 130 tests that show weaknesses in your IBM i security setup. It allows reporting for IBM i 6.1, 7.1, and 7.2 partitions.
Data Access Monitor Enhancements in IBM Security Guardium V10
The Data Access Monitor feature has the following functions for the IBM i client:
•Failover support for IBM i was added.
•Support for multiple policies (up to nine), with IBM i side configuration.
•Filtering improvements, with IBM i side configuration.
•Support for S-TAP load balancing (non-enterprise).
•Encrypted traffic between S-TAP and collector.
•Closer alignment with other UNIX S-TAP.
Figure 8-14 shows the revised S-TAP architecture and enhanced Guardium topology for
IBM Security Guardium V10.
IBM Security Guardium V10.

Figure 8-14 IBM Security Guardium V10 Collection Data flow
For more information about Security Guardium V10 and DB2 for i support, see the following website:
There is also an article in IBM developerWorks covering more details of IBM Security Guardium V10:
8.4 DB2 functional enhancements
This section introduces the functional enhancements of DB2 for i 7.2, which include the following items:
8.4.1 OFFSET and LIMIT clauses
In SQL queries, it is now possible to specify OFFSET and LIMIT clauses:
•The OFFSET clause specifies how many rows to skip before any rows are retrieved as part of a query.
•The LIMIT clause specifies the maximum number of rows to return.
This support is useful when programming a web page containing data from large tables and the user must page up and page down to see additional records. You can use OFFSET to retrieve data only for a specific page, and use LIMIT to see how many records a page has.
The following considerations apply:
•This support is possible only when LIMIT is used as part of the outer full select of a DECLARE CURSOR statement or a prepared SELECT statement.
•The support does not exist within the Start SQL (STRSQL) command.
For more information about the OFFSET and LIMIT clauses, see IBM Knowledge Center:
8.4.2 CREATE OR REPLACE table SQL statement
DB2 for i now allows optional OR REPLACE capability to the CREATE TABLE statement. This improvement gives users the possibility of a much better approach to the modification of tables strategy. Before this support, the only way to modify a table was to use an ALTER TABLE statement and manually remove and re-create dependent objects.
The OR REPLACE capability specifies replacing the definition for the table if one exists at the current server. The existing definition is effectively altered before the new definition is replaced in the catalog.
Definition for the table exists if the following is true:
•FOR SYSTEM NAME is specified and the system-object-identifier matches the system-object-identifier of an existing table.
•FOR SYSTEM NAME is not specified and table-name is a system object name that matches the system-object-identifier of an existing table.
If a definition for the table exists and table-name is not a system object name, table-name can be changed to provide a new name for the table.
This option is ignored if a definition for the table does not exist in the current server.
When the table already exists, the CREATE OR REPLACE TABLE SQL statement can specify behavior that is related to the process of changing the database table by using the ON REPLACE clause.
There are three options:
•PRESERVE ALL ROWS
The current rows of the specified table are preserved. PRESERVE ALL ROWS is not allowed if WITH DATA is specified with result-table-as.
All rows of all partitions in a partitioned table are preserved. If the new table definition is a range partitioned table, the defined ranges must be able to contain all the rows from the existing partitions.
If a column is dropped, the column values are not preserved. If a column is altered, the column values can be modified.
If the table is not a partitioned table or is a hash partitioned table, PRESERVE ALL ROWS and PRESERVE ROWS are equivalent.
•PRESERVE ROWS
The current rows of the specified table are preserved. PRESERVE ROWS is not allowed if WITH DATA is specified with result-table-as.
If a partition of a range partitioned table is dropped, the rows of that partition are deleted without processing any delete triggers. To determine whether a partition of a range partitioned table is dropped, the range definitions and the partition names (if any) of the partitions in the new table definition are compared to the partitions in the existing table definition. If either the specified range or the name of a partition matches, it is preserved. If a partition does not have a partition-name, its boundary-spec must match an existing partition.
If a partition of a hash partition table is dropped, the rows of that partition are preserved.
If a column is dropped, the column values are not preserved. If a column is altered, the column values can be modified.
•DELETE ROWS
The current rows of the specified table are deleted. Any existing DELETE triggers are not fired.
REPLACE rules
When a table is re-created by REPLACE by using PRESERVE ROWS, the new definition of the table is compared to the old definition and logically, for each difference between the two, a corresponding ALTER operation is performed. When the DELETE ROWS option is used, the table is logically dropped and re-created; if objects that depend on the table remain valid, any modification is allowed.
For more information, see Table 8-3. For columns, constraints, and partitions, the comparisons are performed based on their names and attributes.
Table 8-3 Behavior of REPLACE compared to ALTER TABLE functions
|
New definition versus existing definition
|
Equivalent ALTER TABLE function
|
|
Column
|
|
|
The column exists in both and the attributes are the same.
|
No change
|
|
The column exists in both and the attributes are different.
|
ALTER COLUMN
|
|
The column exists only in new table definition.
|
ADD COLUMN
|
|
The column exists only in existing table definition.
|
DROP COLUMN RESTRICT
|
|
Constraint
|
|
|
The constraint exists in both and is the same.
|
No change
|
|
The constraint exists in both and is different.
|
DROP constraint RESTRICT and ADD constraint
|
|
The constraint exists only in the new table definition.
|
ADD constraint
|
|
The constraint exists only in the existing table definition.
|
DROP constraint RESTRICT
|
|
materialized-query-definition
|
|
|
materialized-query-definition exists in both and is the same.
|
No change
|
|
materialized-query-definition exists in both and is different.
|
ALTER MATERIALIZED QUERY
|
|
materialized-query-definition exists only in the new table definition.
|
ADD MATERIALIZED QUERY
|
|
materialized-query-definition exists only in the existing table definition.
|
DROP MATERIALIZED QUERY
|
|
partitioning-clause
|
|
|
partitioning-clause exists in both and is the same.
|
No change
|
|
partitioning-clause exists in both and is different.
|
ADD PARTITION, DROP PARTITION, and ALTER PARTITION
|
|
partitioning-clause exists only in the new table definition.
|
ADD partitioning-clause
|
|
partitioning-clause exists only in the existing table definition.
|
DROP PARTITIONING
|
|
NOT LOGGED INITIALLY
|
|
|
NOT LOGGED INITIALLY exists in both.
|
No change
|
|
NOT LOGGED INITIALLY exists only in the new table definition.
|
NOT LOGGED INITIALLY
|
|
NOT LOGGED INITIALLY exists only in the existing table definition.
|
Logged initially
|
|
VOLATILE
|
|
|
The VOLATILE attribute exists in both and is the same.
|
No change
|
|
The VOLATILE attribute exists only in the new table definition.
|
VOLATILE
|
|
The VOLATILE attribute exists only in the existing table definition.
|
NOT VOLATILE
|
|
media-preference
|
|
|
media-preference exists in both and is the same.
|
No change
|
|
media-preference exists only in the new table definition.
|
ALTER media-preference
|
|
media-preference exists only in the existing table definition.
|
UNIT ANY
|
|
memory-preference
|
|
|
memory-preference exists in both and is the same.
|
No change
|
|
memory-preference exists only in the new table definition.
|
ALTER memory-preference
|
|
memory-preference exists only in the existing table definition.
|
KEEP IN MEMORY NO
|
Any attributes that cannot be specified in the CREATE TABLE statement are preserved:
•Authorized users are maintained. The object owner might change.
•Current journal auditing is preserved. However, unlike other objects, REPLACE of a table generates a ZC (change object) journal audit entry.
•Current data journaling is preserved.
•Comments and labels are preserved.
•Triggers are preserved, if possible. If it is not possible to preserve a trigger, an error is returned.
•Masks and permissions are preserved, if possible. If it is not possible to preserve a mask or permission, an error is returned.
•Any views, materialized query tables, and indexes that depend on the table are preserved or re-created, if possible. If it is not possible to preserve a dependent view, materialized query table, or index, an error is returned.
The CREATE statement (including the REPLACE capability) can be complex. For more information, see IBM Knowledge Center:
8.4.3 DB2 JavaScript Object Notation store
Support for JavaScript Object Notation (JSON) documents was added to DB2 for i. You can store any JSON documents in DB2 as BLOBs. The current implementation for DB2 for i supports the DB2 JSON command-line processor and the DB2 JSON Java API.
The current implementation of DB2 for i matches the subset of support that is available for DB2 for Linux, UNIX, and Windows, and DB2 for z/OS.
The following actions are now supported:
•Use the JDB2 JSON Java API in Java applications to store and retrieve JSON documents as BLOB data from DB2 for i tables.
•Create JSON collections (single BLOB column table).
•Insert JSON documents into a JSON collection.
•Retrieve JSON documents.
•Convert JSON documents from BLOB to character data with the SYSTOOLS.BSON2JSON() UDF.
For details and examples, see the following article in IBM developerWorks:
8.4.4 Remote 3-part name support on ASSOCIATE LOCATOR
Before this enhancement, programmers could not consume result sets that were created on behalf of a remote procedure CALL. With this enhancement, the ASSOCIATE LOCATOR SQL statement can target RETURN TO CALLER style result sets that are created by a procedure that ran on a remote database due to a remote 3-part CALL.
This style of programming is an alternative to the INSERT with remote subselect statement.
Requirements:
•The application requestor (AR) target must be IBM i 7.1 or higher.
•The application server (AS) target must be IBM i 6.1 or higher.
For more information about how to use this enhancement, see IBM Knowledge Center:
8.4.5 Flexible views
Before the flexible views enhancement, programmers could build static views only by using the CREATE VIEW SQL statement, which created a logical file. If a different view or a view with different parameters (WHERE clause) was needed, a new static view had to be created again by using the CREATE VIEW SQL statement.
This enhancement provides a way to build views that are flexible and usable in many more situations just by changing the parameters. The WHERE clause of the flexible view can contain both global built-in variables and the DB2 global variables. These views also can be used for inserting and updating data.
8.4.6 Increased time stamp precision
In IBM i 7.2, up to 12 digits can be set as the time stamp precision. Before IBM i 7.2, only six digits were supported as the time stamp precision. This enhancement applies to DDL and DML. You can specify the time stamp precision in the CREATE TABLE statement. You can also adjust existing tables by using the ALTER TABLE statement.
Example 8-10 Increased time stamp precision
CREATE TABLE corpdb.time_travel(
old_time TIMESTAMP,
new_time TIMESTAMP(12),
no_time TIMESTAMP(0),
Last_Change TIMESTAMP NOT NULL IMPLICITLY HIDDEN FOR EACH ROW ON UPDATE AS
ROW CHANGE TIMESTAMP);
INSERT INTO corpdb.time_travel
VALUES(current timestamp, current timestamp,
current timestamp);
INSERT INTO corpdb.time_travel
VALUES(current timestamp, current timestamp(12),
current timestamp);
SELECT old_time,
new_time,
no_time,
last_change
FROM corpdb.time_travel;
SELECT new_time - last_change as new_minus_last,
new_time - old_time as new_minus_old,
new_time - no_time as new_minus_no
FROM corpdb.time_travel;
Figure 8-15 shows the results of the first SELECT statement in Example 8-10. Notice that the precision of the data of each field varies depending on the precision digits.
Figure 8-15 Results of the first SELECT statement
The second SELECT statement in Example 8-10 calculates the difference of NEW_TIME and each other field. Figure 8-16 shows the results of this SELECT statement. The second record of the result is expressed with the precision as 12 digits because the value that is stored in NEW_TIME has 12 digits as its precision.
Figure 8-16 Results of the second SELECT statement
|
Note: You can adjust the precision of the time stamp columns of existing tables by using an ALTER TABLE statement. However, the existing data in those columns has the remaining initial digits because precision of time stamp data is determined at the time of generation.
|
For more information about timestamp precision, see IBM Knowledge Center:
8.4.7 Named and default parameter support for UDF and UDTFs
Similar to named and default parameters for procedures in IBM i 7.1 TR5, IBM i 7.2 adds this support for SQL and external UDFs. This enhancement provides the usability that is found with CL commands to UDF and UDTFs.
Example 8-11 shows an example of a UDF that specifies a default value to a parameter.
Example 8-11 Named and default parameter support on UDF and UDTFs
CREATE OR REPLACE FUNCTION DEPTNAME(
P_EMPID VARCHAR(6) , P_REQUESTED_IN_LOWER_CASE INTEGER DEFAULT 0)
RETURNS VARCHAR(30)
LANGUAGE SQL
D:BEGIN ATOMIC
DECLARE V_DEPARTMENT_NAME VARCHAR(30);
DECLARE V_ERR VARCHAR(70);
SET V_DEPARTMENT_NAME = (
SELECT CASE
WHEN P_REQUESTED_IN_LOWER_CASE = 0 THEN
D.DEPTNAME
ELSE
LOWER(D.DEPTNAME)
END CASE
FROM DEPARTMENT D, EMPLOYEE E
WHERE E.WORKDEPT = D.DEPTNO AND
E.EMPNO = P_EMPID);
IF V_DEPARTMENT_NAME IS NULL THEN
SET V_ERR = 'Error: employee ' CONCAT P_EMPID CONCAT ' was not found';
SIGNAL SQLSTATE '80000' SET MESSAGE_TEXT = V_ERR;
END IF ;
RETURN V_DEPARTMENT_NAME;
END D;
Example 8-12 shows the VALUES statement that uses the example UDF in Example 8-11 as specifying different values to the P_REQUESTED_IN_LOWER_CASE parameter.
Example 8-12 VALUES statement specifying a different value to the parameter in the UDF
VALUES(DEPTNAME('000110'),
DEPTNAME('000110', 1 ),
DEPTNAME('000110', P_REQUESTED_IN_LOWER_CASE=>1));
Figure 8-17 on page 347 shows the results of Example 8-12.
Figure 8-17 Results of the VALUES statement that uses the UDF
8.4.8 Function resolution by using casting rules
Before IBM i 7.2, function resolution looked for only an exact match with the following perspectives:
•Function name
•Number of parameters
•Data type of parameters
With IBM i 7.2, if DB2 for i does not find an exact match when using function resolution, it looks for the best fit by using casting rules. With these new casting rules, if CAST() is supported for the parameter data type mismatch, the function is found.
For more information about rules, see IBM Knowledge Center:
Example 8-13 describes a sample function and a VALUES statement that uses that function.
Example 8-13 Sample function that casting might have occurred
CREATE OR REPLACE FUNCTION MY_CONCAT(
FIRST_PART VARCHAR(10),
SECOND_PART VARCHAR(50))
RETURNS VARCHAR(60)
LANGUAGE SQL
BEGIN
RETURN(FIRST_PART CONCAT SECOND_PART);
END;
VALUES(MY_CONCAT(123,456789));
Figure 8-18 shows the results of the VALUES statement with an SQLCODE-204 error before IBM i 7.2.

Figure 8-18 Results of the VALUES statement with an SQLCODE-204 error before IBM i 7.2
Figure 8-19 shows the results with IBM i 7.2, in which the function is found with casting rules.

Figure 8-19 Results of the VALUES statement with the FUNCTION found with casting rules
8.4.9 Use of ARRAYs within scalar UDFs
IBM i 7.2 can create a type that is an array and use it in SQL procedures. In addition to this array support, an array can be used in scalar UDFs and in SQL procedures.
Example 8-14 shows an example of creating an array type and using it in a UDF.
Example 8-14 Array support in scalar UDFs
CREATE TABLE EMPPHONE(ID VARCHAR(6) NOT NULL,
PRIORITY INTEGER NOT NULL,
PHONENUMBER VARCHAR(12),
PRIMARY KEY (ID, PRIORITY));
INSERT INTO EMPPHONE VALUES('000001', 1, '03-1234-5678');
INSERT INTO EMPPHONE VALUES('000001', 2, '03-9012-3456');
INSERT INTO EMPPHONE VALUES('000001', 3, '03-7890-1234');
CREATE TYPE PHONELIST AS VARCHAR(12) ARRAY[10];
CREATE OR REPLACE FUNCTION getPhoneNumbers (EmpID CHAR(6)) RETURNS VARCHAR(130)
BEGIN
DECLARE numbers PHONELIST;
DECLARE i INTEGER;
DECLARE resultValue VARCHAR(130);
SELECT ARRAY_AGG(PHONENUMBER ORDER BY PRIORITY) INTO numbers
FROM EMPPHONE
WHERE ID = EmpID;
SET resultValue = '';
SET i = 1;
WHILE i <= CARDINALITY(numbers) DO
SET resultValue = TRIM(resultValue) ||','|| TRIM(numbers[i]);
SET i = i + 1;
END WHILE;
RETURN TRIM(L ',' FROM resultValue);
END;
VALUES(getPhoneNumbers('000001'));
Figure 8-20 shows the results of creating an array type and using it in a UDF.

Figure 8-20 Results of a scalar UDF that uses an array
8.4.10 Built-in global variables
New built-in global variables are supported in IBM i 7.2, as shown in Table 8-4. These variables are referenced-purpose-only variables and maintained by DB2 for i automatically. These variables can be referenced anywhere a column name can be used. Global variables fit nicely into view definitions and RCAC masks and permissions.
Table 8-4 DB2 built-in global variables that are introduced in IBM i 7.2
|
Variable name
|
Schema
|
Data type
|
Size
|
|
CLIENT_IPADDR
|
SYSIBM
|
VARCHAR
|
128
|
|
CLIENT_HOST
|
SYSIBM
|
VARCHAR
|
255
|
|
CLIENT_PORT
|
SYSIBM
|
INTEGER
|
-
|
|
PACKAGE_NAME
|
SYSIBM
|
VARCHAR
|
128
|
|
PACKAGE_SCHEMA
|
SYSIBM
|
VARCHAR
|
128
|
|
PACKAGE_VERSION
|
SYSIBM
|
VARCHAR
|
64
|
|
ROUTINE_SCHEMA
|
SYSIBM
|
VARCHAR
|
128
|
|
ROUTINE_SPECIFIC_NAME
|
SYSIBM
|
VARCHAR
|
128
|
|
ROUTINE_TYPE
|
SYSIBM
|
CHAR
|
1
|
|
JOB_NAME
|
QSYS2
|
VARCHAR
|
28
|
|
SERVER_MODE_JOB_NAME
|
QSYS2
|
VARCHAR
|
28
|
Example 8-15 shows an example of a SELECT statement querying some client information.
Example 8-15 Example of a SELECT statement to get client information from global variables
SELECT SYSIBM.client_host AS CLIENT_HOST,
SYSIBM.client_ipaddr AS CLIENT_IP,
SYSIBM.client_port AS CLIENT_PORT
FROM SYSIBM.SYSDUMMY1
As for getting client information, TCP/IP services in QSYS2, which were introduced in
IBM i 7.1, can be also used, as shown in Example 8-16.
IBM i 7.1, can be also used, as shown in Example 8-16.
Example 8-16 Get client information from TCP/IP services in QSYS2
SELECT * FROM QSYS2.TCPIP_INFO
For more information about DB2 built-in global variables, see IBM Knowledge Center:
8.4.11 Expressions in PREPARE and EXECUTE IMMEDIATE statements
In IBM i 7.2, expressions can be used in the PREPARE and EXECUTE IMMEDIATE statements in addition to variables.
Example 8-17 and Example 8-18 are the statements for getting the information about advised indexes from QSYS2 and putting them into a table in QTEMP. Example 8-17 is an example for before IBM i 7.2 and Example 8-18 is the example for IBM i 7.2. With this enhancement, many SET statements can be eliminated from the generation of the WHERE clause.
Example 8-17 Example of EXECUTE IMMEDIATE with concatenating strings before IBM i 7.2
SET INSERT_STMT = 'INSERT INTO QTEMP.TMPIDXADV SELECT * FROM
QSYS2.CONDENSEDINDEXADVICE WHERE ';
IF (P_LIBRARY IS NOT NULL) THEN
SET WHERE_CLAUSE = 'TABLE_SCHEMA = ''' CONCAT
RTRIM(P_LIBRARY) CONCAT ''' AND ';
ELSE
SET WHERE_CLAUSE = '';
END IF;
IF (P_FILE IS NOT NULL) THEN
SET WHERE_CLAUSE = WHERE_CLAUSE CONCAT ' SYSTEM_TABLE_NAME = ''' CONCAT
RTRIM(P_FILE) CONCAT ''' AND ';
END IF;
IF (P_TIMES_ADVISED IS NOT NULL) THEN
SET WHERE_CLAUSE = WHERE_CLAUSE CONCAT ' TIMES_ADVISED >= ' CONCAT
P_TIMES_ADVISED CONCAT ' AND ';
END IF;
IF (P_MTI_USED IS NOT NULL) THEN
SET WHERE_CLAUSE = WHERE_CLAUSE CONCAT 'MTI_USED >= ' CONCAT
P_MTI_USED CONCAT ' AND ';
END IF;
IF (P_AVERAGE_QUERY_ESTIMATE IS NOT NULL) THEN
SET WHERE_CLAUSE = WHERE_CLAUSE CONCAT ' AVERAGE_QUERY_ESTIMATE >= ' CONCAT
P_AVERAGE_QUERY_ESTIMATE CONCAT ' AND ';
END IF;
SET WHERE_CLAUSE = WHERE_CLAUSE CONCAT ' NLSS_TABLE_NAME = ''*HEX'' ';
SET INSERT_STMT = INSERT_STMT CONCAT WHERE_CLAUSE;
EXECUTE IMMEDIATE INSERT_STMT;
Example 8-18 Example of EXECUTE IMMEDIATE with concatenating strings for IBM i 7.2
EXECUTE IMMEDIATE 'INSERT INTO QTEMP.TMPIDXADV SELECT * FROM
QSYS2.CONDENSEDINDEXADVICE WHERE ' CONCAT
CASE WHEN P_LIBRARY IS NOT NULL THEN
' TABLE_SCHEMA = ''' CONCAT RTRIM(P_LIBRARY) CONCAT ''' AND '
ELSE '' END CONCAT
CASE WHEN P_FILE IS NOT NULL THEN
' SYSTEM_TABLE_NAME = ''' CONCAT RTRIM(P_FILE) CONCAT ''' AND '
ELSE '' END CONCAT
CASE WHEN P_TIMES_ADVISED IS NOT NULL THEN
' TIMES_ADVISED >= ' CONCAT P_TIMES_ADVISED CONCAT ' AND '
ELSE '' END CONCAT
CASE WHEN P_MTI_USED IS NOT NULL THEN
' MTI_USED >= ' CONCAT P_MTI_USED CONCAT ' AND '
ELSE '' END CONCAT
CASE WHEN P_AVERAGE_QUERY_ESTIMATE IS NOT NULL THEN
' AVERAGE_QUERY_ESTIMATE >= ' CONCAT P_AVERAGE_QUERY_ESTIMATE CONCAT ' AND '
ELSE '' END CONCAT
' NLSS_TABLE_NAME = ''*HEX'' ';
8.4.12 Autonomous procedures
In IBM i 7.2, an autonomous procedure was introduced. An autonomous procedure is run in a unit of work that is independent from the calling application. A new AUTONOMOUS option is supported in the CREATE PROCEDURE and ALTER PROCEDURE statements.
By specifying a procedure as autonomous, any process in that procedure can be performed regardless of the result of the invoking transaction.
Example 8-19 shows an example of creating an autonomous procedure that is intended to write an application log to a table. In this example, procedure WriteLog is specified as AUTONOMOUS.
Example 8-19 Autonomous procedure
CREATE TABLE TRACKING_TABLE (LOGMSG VARCHAR(1000),
LOGTIME TIMESTAMP(12));
COMMIT;
CREATE OR REPLACE PROCEDURE WriteLog(loginfo VARCHAR(1000))
AUTONOMOUS
BEGIN
INSERT INTO TRACKING_TABLE VALUES(loginfo, current TIMESTAMP(12));
END;
CALL WriteLog('*****INSERTION 1 START*****');
INSERT INTO EMPPHONE VALUES('000002', 1, '03-9876-5432');
CALL WriteLog('*****INSERTION 1 END*****');
CALL WriteLog('*****INSERTION 2 START*****');
INSERT INTO EMPPHONE VALUES('000002', 2, '03-8765-4321');
CALL WriteLog('*****INSERTION 2 END*****');
/**roll back insertions**/
ROLLBACK;
SELECT * FROM EMPPHONE WHERE ID = '000002';
SELECT * FROM TRACKING_TABLE;
Figure 8-21 show the results of creating an array type and using it in a UDF.

Figure 8-21 Results of an AUTONOMOUS procedure
For more information about AUTONOMOUS, see the IBM Knowledge Center:
8.4.13 New SQL TRUNCATE statement
A new SQL TRUNCATE statement deletes all rows from a table. This statement can be used in an application program and also interactively.
The TRUNCATE statement has the following additional functions:
•DROP or REUSE storage
•IGNORE or RESTRICT when delete triggers are present
•CONTINUE or RESTART identity values
•IMMEDIATE, which performs the operation without commit, even if it is running under commitment control
Figure 8-22 shows the syntax of the TRUNCATE statement.

Figure 8-22 Syntax of the TRUNCATE statement
For more information about the TRUNCATE statement, see IBM Knowledge Center:
8.4.14 New LPAD() and RPAD() built-in functions
Two new built-in functions, LPAD() and RPAD(), are introduced in IBM i 7.2. These functions return a string that is composed of strings that is padded on the left or right.
Example 8-20 shows an example of the LPAD() built-in function. This example assumes that the CUSTOMER table, which has a NAME column with VARCHAR(15), contains the values of Chris, Meg, and John.
Example 8-20 LPAD() built-in function
CREATE TABLE CUSTOMER(CUSTNO CHAR(6), NAME VARCHAR(15));
INSERT INTO CUSTOMER VALUES('000001', 'Chris');
INSERT INTO CUSTOMER VALUES('000002', 'Meg');
INSERT INTO CUSTOMER VALUES('000003', 'John');
SELECT LPAD(NAME, 15, '.') AS NAME FROM CUSTOMER;
Figure 8-23 show the results of the SELECT statement, which pads out a value on the left with periods.

Figure 8-23 Results of the SELECT statement with LPAD()
Example 8-21 shows the example of RPAD() built-in function.
Example 8-21 SELECT statement with RPAD()
SELECT RPAD(NAME, 10, '.') AS NAME FROM CUSTOMER;
Opposite to LPAD(), the results of the SELECT statement, which is shown in Figure 8-24, pads out a value on the right with periods. Note that 10 is specified as the length parameter in RPAD() so that the result is returned as a 10-digit value.

Figure 8-24 Results of the SELECT statement with RPAD()
Both LPAD() and RPAD() can be used on single-byte character set (SBCS) data and double-byte character set (DBCS) data, such as Japan Mix CCSID 5035. DBCS characters can also be specified as a pad string, as can SBCS characters.
Figure 8-25 shows an example of LPAD() for DBCS data within a column that is defined as VARCHAR(15) CCSID 5035 and aligned each row at the right end. A double-byte space (x’4040’ in CCSID 5035) is used as a pad string in this example. As shown in Figure 8-25, specifying DBCS data as a pad string is required for aligning DBCS data at the right or left end.

Figure 8-25 Results of an example of LPAD() for DBCS data
For more information about LPAD() and RPAD(), including considerations when using Unicode, DBCS, or SBCS/DBCS mixed data, see IBM Knowledge Center:
•LPAD()
•RPAD()
8.4.15 Pipelined table functions
Pipelined table functions provide the flexibility to create programmatically virtual tables that are greater than what the SELECT or CREATE VIEW statements can provide.
Pipelined table functions can pass the result of an SQL statement or process and return the result of UDTFs. Before IBM i 7.2 TR1, creating an external UDTF is required for obtaining the same result as the pipelined table function.
Example 8-22 shows an example of creating a pipeline SQL UDTF that returns a table of CURRENT_VALUE from QSYS2.SYSLIMITS.
Example 8-22 Example of pipeline SQL UDTF
CREATE FUNCTION producer()
RETURNS TABLE (largest_table_sizes INTEGER)
LANGUAGE SQL
BEGIN
FOR LimitCursor CURSOR FOR
SELECT CURRENT_VALUE
FROM QSYS2.SYSLIMITS
WHERE SIZING_NAME = 'MAXIMUM NUMBER OF ALL ROWS'
ORDER BY CURRENT_VALUE DESC
DO
PIPE (CURRENT_VALUE);
END FOR;
RETURN;
END;
Example 8-23 shows an example of creating an external UDTF that returns the same result of a pipeline SQL UDTF, as shown in Example 8-22. These examples show that pipelined functions allow the flexibility to code more complex UDTFs purely in SQL without having to build and manage a compiled program or service program.
Example 8-23 Example of external UDTF
CRTSQLCI OBJ(applib/producer) SRCFILE(appsrc/c80) COMMIT(*NONE) OUTPUT(*PRINT) OPTION(*NOGEN)
CRTCMOD MODULE(applib/producer) SRCFILE(qtemp/qsqltemp) TERASPACE(*YES) STGMDL(*INHERIT)
CRTSRVPGM SRVPGM(applib/udfs) MODULE(applib/producer) EXPORT(*ALL) ACTGRP(*CALLER)
CREATE FUNCTION producer() RETURNS TABLE (int1 INTEGER) EXTERNAL NAME applib.udfs(producer) LANGUAGE C PARAMETER STYLE SQL
Pipelined table functions can be used in the following cases:
•UDTF input parameters
•Ability to handle errors and warnings
•Application logging
•References to multiple databases in a single query
•Customized join behavior
These table functions are preferred in the case where only a subset of the result table is consumed in big data, analytic, and performance scenarios, rather than building a temporary table. Using pipelined table functions provides memory savings and better performance instead of creating a temporary table.
For more information about pipelined table functions, see the following website:
8.4.16 Regular expressions
A regular expression in an SQL statement is supported by IBM i 7.2. A regular expression is one of the ways of expressing a collection of strings as a single string and is used for specifying a pattern for a complex search.
Table 8-5 shows the built-in functions and predicates for regular expressions in DB2 for i.
Table 8-5 Function or predicate for regular expressions
|
Function or predicate
|
Description
|
|
REGEXP_LIKE predicate
|
Searches for a regular expression pattern in a string and returns True or False.
|
|
REGEXP_COUNT
REGEXP_MATCH_COUNT
|
Returns a count of the number of times that a pattern is matched in a string.
|
|
REGEXP_INSTR
|
Returns the starting or ending position of the matched substring.
|
|
REGEXP_SUBSTR
REGEXP_EXTRACT
|
Returns one occurrence of a substring of a string that matches the pattern.
|
|
REGEXP_REPLACE
|
Returns a modified version of the source string where occurrences of the pattern found in the source string are replaced with the specified replacement string.
|
Example 8-24 shows an example of a regular expression in a pipelined table function that searches and returns URL candidates from a given string.
Example 8-24 Example of a regular expression in a pipelined table function
CREATE OR REPLACE FUNCTION FindHits(v_search_string CLOB(1M), v_pattern varchar(32000) DEFAULT '(w+.)+((org)|(com)|(gov)|(edu))')
RETURNS TABLE (website_reference varchar(512))
LANGUAGE SQL
BEGIN
DECLARE V_Count INTEGER;
DECLARE LOOPVAR INTEGER DEFAULT 0;
SET V_Count = REGEXP_COUNT(v_search_string, v_pattern,1,'i');
WHILE LOOPVAR < V_Count DO
SET LOOPVAR = LOOPVAR + 1;
PIPE(values(REGEXP_SUBSTR(v_search_string,v_pattern, 1, LOOPVAR, 'i')));
END WHILE;
RETURN;
END;
SELECT * FROM TABLE(FindHits('Are you interested in any of these colleges: abcd.EDU or www.efgh.Edu. We could even visit WWW.ijkl.edu if we have time.')) A;
For more information about regular expressions, see the following website:
8.4.17 JOB_NAME and SERVER_MODE_JOB_NAME built-in global variables
New built-in global variables JOB_NAME and SERVER_MODE_JOB_NAME are supported by IBM i 7.2. JOB_NAME contains the name of the current job and SERVER_MODE_JOB_NAME contains the name of the job that established the SQL server mode connection.
Each of these global variables has the following characteristics:
•Read-only, with values maintained by the system.
•Type is VARCHAR(28).
•Schema is QSYS2.
•Scope of this global variable is session.
If there is no server mode connection, the value of SERVER_MODE_JOB_NAME is NULL. This means that SERVE_MODE_JOB_NAME is valid for only QSQSRVR and if it referenced outside of a QSQSRVR job, the NULL value is returned.
For more information about these global variables, see the following links:
•IBM i Technology Updates:
•IBM Knowledge Center:
8.4.18 RUNSQL control of output listing
The parameters that are shown in Figure 8-26 are now available in the Run SQL (RUNSQL) CL command. The RUNSQL CL command can be used to run a single SQL statement. These new parameters work the same as described in the RUNSQLSTM CL command.
|
Run SQL (RUNSQL)
Type choices, press Enter.
Source listing options . . . . . OPTION *NOLIST
Print file . . . . . . . . . . . PRTFILE QSYSPRT
Library . . . . . . . . . . . *LIBL
Second level text . . . . . . . SECLVLTXT *NO
|
Figure 8-26 New parameters on the RUNSQL CL command
For more information about the RUNSQL CL command, see the following website:
8.4.19 LOCK TABLE ability to target non-*FIRST members
The LOCK TABLE SQL statement is enhanced to allow applications to target specific members within a multiple-member physical file. An application can use the Override Database File (OVRDBF) or the CREATE ALIAS SQL statements to identify the non-*FIRST member.
For more information about LOCK TABLE SQL statement, see IBM Knowledge Center:
8.4.20 QUSRJOBI() retrieval of DB2 built-in global variables
The QUSRJOBI() API JOBI0900 format is extended to allow for direct access to the following DB2 for i built-in global variable values that are mentioned in 8.4.10, “Built-in global variables” on page 351:
•CLIENT_IPADDR
•CLIENT_HOST
•CLIENT_PORT
•ROUTINE_TYPE
•ROUTINE_SCHEMA
•ROUTINE_NAME
For more information about this enhancement, including the position of each value in JOBI0900, see the following website:
8.4.21 SQL functions (user-defined functions and user-defined table functions) parameter limit
The maximum number of parameters for user-defined functions and user-defined table functions was increased from 90 to 1024. Also, the maximum number of returned columns was increased from (125 minus the number of parameters) to (1025 minus the number of parameters).
8.4.22 New binary scalar functions
New built-in scalar functions were introduced in IBM i 7.2 to support interaction with Universal Unique Identifiers (UUIDs) across distribute systems:
•VARBINARY_FORMAT scalar function: This scalar function converts character data and returns a binary string.
•VARCHAR_FORMAT_BINARY scalar function: This scalar function converts binary data and returns a character string.
Both scalar functions can specify a format-string that is used to interpret a given expression and then convert from or into the UUIDs standard format.
For more information, see IBM Knowledge Center:
8.4.23 Adding and dropping partitions spanning DDS logical files
In previous IBM i versions, if you wanted to add a partition or drop a partition of a DDS logical file, you had to delete the logical file or all members in that logical file had to be removed before running the ALTER TABLE statement.
In IBM i 7.2, the ALTER TABLE ADD PARTITION and DROP PARTITION statements allow spanning of DDS logical files. If the DDS logical file was created over all existing partitions, DB2 for i manages the automatic re-creation of the logical file to compensate for removed partitions and to include new partitions.
Figure 8-27 shows the ALTER TABLE ADD PARTITON support for spanning DDS logical files.

Figure 8-27 Spanning DDS logical files
8.4.24 Direct control of system names for global variables
The optional clause FOR SYSTEM NAME was added to the CREATE VARIABLE SQL statement. The FOR SYSTEM NAME clause directly defines the name for these objects.
In Example 8-25, LOC is the system-object-identifier, which is assigned as a system object name instead of an operating system-generated one. However, selecting this system-object-identifier has some considerations:
•The system name must not be the same as any global variable already existing on the same system.
•The system name must be unqualified.
Example 8-25 Example of a CREATE VARIABLE SQL statement using the FOR SYSTEM NAME clause
CREATE VARIABLE MYSCHEMA.MY_LOCATION FOR SYSTEM NAME LOC CHAR(20) DEFAULT (select LOCATION from MYSCHEMA.locations where USER_PROFILE_NAME = USER);
For more information about this topic, see the IBM Knowledge Center:
8.4.25 LOCK TABLE ability to target non-FIRST members
The LOCK TABLE SQL statement is enhanced to allow applications to target specific members within a multiple-member physical file. The application can use the Override Database File (OVRDBF) command or the CREATE ALIAS SQL statement to identify the non-*FIRST member.
8.5 DB2 for i services and catalogs
DB2 for i now allows programmers to use SQL as a query language and a traditional programming language. Over time, the SQL language has gained new language elements that allow traditional programming patterns. Using UDFs, stored procedures, triggers, and referential integrity support, it is now easy to keep part of the programming logic encapsulated within the database itself, reducing the complexity of programming in third-generation programming languages, such as ILE RPG, ILE C/C++, ILE COBOL, and Java.
Moreover, DB2 for i provides a service that allows programmers and system administrators to access system information by using the standard SQL interface. This allows programming and system management to be managed in an easier way.
The following topics are covered in this section:
8.5.1 DB2 for i catalogs
DB2 for i catalogs contain information about DB2 related objects, such as tables, indexes, schemas, columns, fields, labels, and views.
There are three classes of catalog views:
•DB2 for i catalog tables and views (QSYS2)
The catalog tables and view contain information about all tables, parameters, procedures, functions, distinct types, packages, XSR objects, views, indexes, aliases, sequences, variables, triggers, and constraints in the entire relational database.
•ODBC and JDBC catalog views (SYSIBM)
The ODBC and JDBC catalog views are designed to satisfy ODBC and JDBC metadata API requests.
•ANS and ISO catalog views (QSYS2)
The ANS and ISO catalog views are designed to comply with the ANS and ISO SQL standard. These views will be modified as the ANS and ISO standard is enhanced or modified.
|
Note: IBM i catalogs contain tables or views that are related only to the IBM i operating system.
|
DB2 for i catalogs can be grouped by related objects, as shown in the following tables.
Table 8-6 lists the catalogs.
Table 8-6 Catalogs
|
Name
|
Catalog type
|
Description
|
|
SYSCATALOGS
|
DB2
|
Information about relational database
|
|
INFORMATION_SCHEMA_CATALOG_NAME
|
ANS/ISO
|
Information about relational database
|
Table 8-7 lists the schemas.
Table 8-7 Schemas
|
Name
|
Catalog type
|
Description
|
|
SYSSCHEMAS
|
DB2
|
Information about schemas
|
|
SQLSCHEMAS
|
ODBC/JDBC
|
Information about schemas
|
|
SCHEMATA
|
ANS/ISO
|
Statistical information about schemas
|
Table 8-8 lists the database support.
Table 8-8 Database support
|
Name
|
Catalog type
|
Description
|
|
SQL_FEATURES
|
ANS/ISO
|
Information about the feature that is supported by the database manager
|
|
SQL_LANGUAGES
|
ANS/ISO
|
Information about the supported languages
|
|
SQL_SIZING
|
ANS/ISO
|
Information about the limits that are supported by the database manager
|
|
CHARACTER_SETS
|
ANS/ISO
|
Information about supported CCSIDs
|
Table 8-9 lists the tables, views, and indexes.
Table 8-9 Tables, views, and indexes
|
Name
|
Catalog type
|
Description
|
|
SYSCOLUMS
|
DB2
|
Information about column attributes
|
|
SYSCOLUMS2
|
DB2
|
Information about column attributes
|
|
SYSFIELDS
|
DB2
|
Information about field procedures
|
|
SYSINDEXES
|
DB2
|
Information about indexes
|
|
SYSKEYS
|
DB2
|
Information about indexes keys
|
|
SYSTABLEDEP
|
DB2
|
Information about materialized query table dependencies
|
|
SYSTABLES
|
DB2
|
Information about tables and views
|
|
SYSVIEWDEP
|
DB2
|
Information about view dependencies on tables
|
|
SYSVIEWS
|
DB2
|
Information about definition of a view
|
|
SQLCOLUMNS
|
ODBC/JDBC
|
Information about column attributes
|
|
SQLSPECIALCOLUMNS
|
ODBC/JDBC
|
Information about the columns of a table that can be used to uniquely identify a row
|
|
SQLTABLES
|
ODBC/JDBC
|
Information about tables
|
|
COLUMNS
|
ANS/ISO
|
Information about columns
|
|
TABLES
|
ANS/ISO
|
Information about tables
|
|
VIEWS
|
ANS/ISO
|
Information about views
|
Table 8-10 lists the constraints.
Table 8-10 Constraints
|
Name
|
Catalog type
|
Description
|
|
SYSCHKCST
|
DB2
|
Information about check constraints
|
|
SYSCST
|
DB2
|
Information about all constraints
|
|
SYSCSTCOL
|
DB2
|
Information about columns referenced in a constraint
|
|
SYSCSTDEP
|
DB2
|
Information about constraint dependencies on tables
|
|
SYSKEYCST
|
DB2
|
Information about unique, primary, and foreign keys
|
|
SYSREFCST
|
DB2
|
Information about referential constraints
|
|
SQLFOREIGNKEYS
|
ODBC/JDBC
|
Information about foreign keys
|
|
SQLPRIMARYKEYS
|
ODBC/JDBC
|
Information about primary keys
|
|
CHECK_CONSTRAINTS
|
ANS/ISO
|
Information about check constraints
|
|
REFERENTIAL_CONSTRAINTS
|
ANS/ISO
|
Information about referential constraints
|
|
TABLE_CONSTRAINTS
|
ANS/ISO
|
Information about constraints
|
Table 8-11 lists the privileges.
Table 8-11 Privileges
|
Name
|
Catalog type
|
Description
|
|
SYSCOLAUTH
|
DB2
|
Information about column privilege
|
|
SYSCONTROLS
|
DB2
|
Information about row permissions and column masks
|
|
SYSCONTROLSDEP
|
DB2
|
Information about row permissions and column masks dependencies
|
|
SYSPACKAGEAUTH
|
DB2
|
Information about package privilege
|
|
SYSROUTINEAUTH
|
DB2
|
Information about routine privilege
|
|
SYSSCHEMAAUTH
|
DB2
|
Information about schema privilege
|
|
SYSSEQUENCEAUTH
|
DB2
|
Information about sequence privilege
|
|
SYSTABAUTH
|
DB2
|
Information about table privilege
|
|
SYSUDTAUTH
|
DB2
|
Information about type privilege
|
|
SYSVARIABLEAUTH
|
DB2
|
Information about global variable privilege
|
|
SYSXSROBJECTAUTH
|
DB2
|
Information about XML schema privilege
|
|
SQLCOLPRIVILEGES
|
ODBC/JDBC
|
Information about privileges granted on columns
|
|
SQLTABLEPRIVILEGES
|
ODBC/JDBC
|
Information about privileges granted on tables
|
|
AUTHORIZATIONS
|
ANS/ISO
|
Information about authorization IDs
|
|
ROUTINE_PRIVILEGES
|
ANS/ISO
|
Information about routine privilege
|
|
UDT_PRIVILEGES
|
ANS/ISO
|
Information about type privilege
|
|
USAGE_PRIVILEGES
|
ANS/ISO
|
Information about sequence and XML schema privilege
|
|
VARIABLE_PRIVILEGES
|
ANS/ISO
|
Information about global variable privilege
|
Table 8-12 lists the triggers.
Table 8-12 Triggers
|
Name
|
Catalog type
|
Description
|
|
SYSTRIGCOL
|
DB2
|
Information about columns used in a trigger
|
|
SYSTRIGDEP
|
DB2
|
Information about objects used in a trigger
|
|
SYSTRIGGERS
|
DB2
|
Information about trigger
|
|
SYSTRIGUPD
|
DB2
|
Information about columns in the WHEN clause of a trigger
|
Table 8-13 lists the routines.
Table 8-13 Routines
|
Name
|
Catalog type
|
Description
|
|
SYSFUNCS
|
DB2
|
Information about user-defined functions
|
|
SYSJARCONTENTS
|
DB2
|
Information about JAR files for Java routines
|
|
SYSJAROBJECTS
|
DB2
|
Information about JAR files for Java routines
|
|
SYSPARMS
|
DB2
|
Information about routine parameters
|
|
SYSPROCS
|
DB2
|
Information about procedures
|
|
SYSROUTINEDEP
|
DB2
|
Information about function and procedure dependencies
|
|
SYSROUTINES
|
DB2
|
Information about functions and procedures
|
|
SQLFUNCTIONSCOLS
|
ODBC/JDBC
|
Information about function parameters
|
|
SQLFUNCTIONS
|
ODBC/JDBC
|
Information about functions
|
|
SQLPROCEDURECOLS
|
ODBC/JDBC
|
Information about procedure parameters
|
|
SQLPROCEDURES
|
ODBC/JDBC
|
Information about procedures
|
|
PARAMETERS
|
ANS/ISO
|
Information about procedure parameters
|
|
ROUTINES
|
ANS/ISO
|
Information about routines
|
Table 8-14 lists the XML schemas.
Table 8-14 XML schemas
|
Name
|
Catalog type
|
Description
|
|
XSRANNOTATIONINFO
|
DB2
|
Information about annotations
|
|
XSROBJECTCOMPONENTS2
|
DB2
|
Information about components in an XML schema
|
|
XSROBJECTHIERARCHIES
|
DB2
|
Information about XML schema document hierarchy relationships
|
|
XSROBJECTS
|
DB2
|
Information about XML schemas
|
Table 8-15 lists the statistics.
Table 8-15 Statistics
|
Name
|
Catalog type
|
Description
|
|
SYSCOLUMSTAT
|
DB2
|
Information about column statistics
|
|
SYSINDEXSTAT
|
DB2
|
Information about index statistics
|
|
SYSMQTSTAT
|
DB2
|
Information about materialized query table statistics
|
|
SYSPACKAGESTAT
|
DB2
|
Information about package statistics
|
|
SYSPACKAGESTMTSTAT
|
DB2
|
Information about the SQL statement in packages
|
|
SYSPARTITIONDISK
|
DB2
|
Information about partition disk usage
|
|
SYSPARTITIONINDEXES
|
DB2
|
Information about partition indexes
|
|
SYSPARTITIONINDEXDISK
|
DB2
|
Information about index disk usage
|
|
SYSPARTITIONINDEXSTAT
|
DB2
|
Information about partition index statistics
|
|
SYSPARTITIONMQTS
|
DB2
|
Information about partition materialized query tables
|
|
SYSPARTITIONSTAT
|
DB2
|
Information about partition statistics
|
|
SYSPROGRAMSTAT
|
DB2
|
Information about programs, service programs, and modules that contain SQL statements
|
|
SYSPROGRAMSTMTSTAT
|
DB2
|
Information about SQL statements embedded in programs, service programs, and modules
|
|
SYSTABLEINDEXSTAT
|
DB2
|
Information about table index statistics
|
|
SYSTABLESTAT
|
DB2
|
Information about table statistics
|
|
SQLSTATISTICS
|
ODBC/JDBC
|
Statistical information about tables
|
Table 8-16 lists the miscellaneous objects.
Table 8-16 Miscellaneous objects
|
Name
|
Catalog type
|
Description
|
|
SYSPACKAGE
|
DB2
|
Information about packages
|
|
SYSSEQUENCES
|
DB2
|
Information about sequences
|
|
SYSTYPES
|
DB2
|
Information about built-in data types and distinct types
|
|
SYSVARIABLEDEP
|
DB2
|
Information about objects that are used in global variables
|
|
SYSVARIABLES
|
DB2
|
Information about global variables
|
|
SQLTYPEINFO
|
ODBC/JDBC
|
Information about types of tables
|
|
SQLUDTS
|
ODBC/JDBC
|
Information about built-in data types and distinct types
|
|
USER_DEFINED_TYPES
|
ANS/ISO
|
Information about types
|
|
SEQUENCES
|
ANS/ISO
|
Information about sequences
|
For more information, see IBM Knowledge Center:
8.5.2 DB2 for i Services
DB2 for i Services is a consistent set of procedures, UDFs, UDTFs, tables, and views that make programming in SQL easier.
DB2 for i Services is grouped by the following related areas:
DB2 for i Services health center procedures
You can use DB2 for i Services health center procedures to capture and view information about the database.
Table 8-17 lists the DB2 for i Services health center procedures.
Table 8-17 DB2 for i Services health center procedures
|
Service name
|
Type
|
Descriptions
|
|
QSYS2.HEALTH_ACTIVITY
|
Procedure
|
Returns summary counts of database and SQL operations over a set of objects within one or more schemas.
|
|
QSYS2.HEALTH_DATABASE_OVERVIEW
|
Procedure
|
Returns counts of all the different types of DB2 for i objects within the target schemas.
|
|
QSYS2.HEALTH_DESIGN_LIMITS
|
Procedure
|
Returns detailed counts of design limits over a set of objects within one or more schemas.
|
|
QSYS2.HEATH_ENVIRONMENTAL_LIMITS
|
Procedure
|
Returns detail on the top 10 jobs on the system for different SQL or application limits.
|
|
QSYS2.HEALTH_SIZE_LIMITS
|
Procedure
|
Returns detailed size information for database objects within one or more schemas.
|
|
QSYS2.RESET_ENVIRONMENTAL_LIMITS
|
Procedure
|
Clears out the environment limit cache for the database.
|
Fro more information, see IBM Knowledge Center:
DB2 for i Services utility procedures
DB2 for i Services utility procedures provide interfaces to monitor and work with SQL in jobs on the current system or to compare constraint and routine information across the system.
Table 8-18 lists the DB2 for i Services utility procedures.
Table 8-18 DB2 for i Services utility procedures
|
Service name
|
Type
|
Descriptions
|
|
QSYS2.CANCEL_SQL
|
Procedure
|
Requests cancellation of an SQL statement for the specified job.
|
|
QSYS2.DUMP_SQL_CURSORS
|
Procedure
|
Lists the open cursors for a job.
|
|
QSYS2.FIND_AND_CANCEL_QSQSRVR_SQL
|
Procedure
|
Finds a set of jobs with SQL activity and safely cancels them.
|
|
QSYS2.FIND_SQSRVR_JOBS
|
Procedure
|
Returns information about a QSQSRVR job.
|
|
QSYS2.GENERATE_SQL
|
Procedure
|
Generates the SQL data definition language statements that are required to re-create a database object.
|
|
QSYS2.RESTART_IDENTITY
|
Procedure
|
Examines the source-table and determines the identity column and its next value.
|
|
SYSTOOLS.CHECK_SYSCST
|
Procedure
|
Compares entries in the QSYS2.SYSCONSTRAINTS table between two systems.
|
|
SYSTOOLS.CHECK_SYSROUTINE
|
Procedure
|
Compare entries in the QSYS2.SYSROUTINES table between two systems.
|
For more information, see IBM Knowledge Center:
DB2 for i Services plan cache procedures
DB2 for i provides procedures for programmatic access to the plan cache and can be used for scheduling plan cache captures or pre-starting an event monitor.
Table 8-19 lists the DB2 for i Services plan cache procedures.
Table 8-19 DB2 for i Services plan cache procedures
|
Service name
|
Type
|
Descriptions
|
|
QSYS2.CHANGE_PLAN_CACHE_SIZE
|
Procedure
|
Changes the size of the plan cache.
|
|
QSYS2.DUMP_PLAN_CACHE
|
Procedure
|
Creates a snapshot (database monitor file) of the contents of the cache.
|
|
QSYS2.DUMP_PLAN_CACHE_PROPERTIES
|
Procedure
|
Creates a file containing the properties of the cache.
|
|
QSYS2.DUMP_PLAN_CACHE_topN
|
Procedure
|
Creates a snapshot file from the active plan cache containing only those queries with the largest accumulated elapsed time.
|
|
QSYS2.DUMP_SNAP_SHOT_PROPERTIES
|
Procedure
|
Creates a file containing the properties of the snapshot.
|
|
QSYS2.END_ALL_PLAN_CACHE_EVENT_MONITOR
|
Procedure
|
Ends all active plan cache event monitors started either through the GUI or uses the start_plan_cache_event_monitor procedures.
|
|
QSYS2.END_PLAN_CACHE_EVENT_MONITOR
|
Procedure
|
Ends the specific event monitor that is identified by the given monitor ID value.
|
|
QSYS2.START_PLAN_CACHE_EVENT_MONITOR (2)
|
Procedure
|
Starts an event monitor to intercept or capture plans as they are removed from the cache and generates performance information into the specified database monitor file.
|
|
QSYS2.CLEAR_PLAN_CACHE
|
Procedure
|
Clears plan cache (alternative to performing a system IPL).
|
|
QSYS2.EXTRACT_STATEMENTS
|
Procedure
|
Returns details from a plan cache snapshot in the form of an SQL table or a result set.
|
For more information, see IBM Knowledge Center:
DB2 for i performance services
DB2 for i performance services provide interfaces to work with indexes and a view to see information about database monitors.
Table 8-20 lists the DB2 for i performance services.
Table 8-20 DB2 for i performance services
|
Service name
|
Type
|
Descriptions
|
|
SYSTOOLS.ACT_ON_INDEX_ADVICE
|
Procedure
|
Creates new indexes for a table based on indexes that are advised for the table.
|
|
SYSTOOLS.HARVEST_INDEX_ADVICE
|
Procedure
|
Generates one or more CREATE INDEX statements in source file members for a specified table based on indexes that are advised for the table.
|
|
QSYS2.OVERRIDE_QAQQINI
|
Procedure
|
Establishes a temporary version of the QAQQINI file.
|
|
QSYS2.RESET_TABLE_INDEX_STATISTICS
|
Procedure
|
Clears usage statistics for indexes that are defined over a table or tables.
|
|
QSYS2.SYSIXADV
|
Table
|
Indexed advised system table.
|
|
SYSTOOLS.REMOVE_INDEXES
|
Procedure
|
Drops any indexes meeting the specified criteria.
|
|
QSYS2.DATABASE_MONITOR_INFO
|
View
|
Returns information about database monitors and plan cache event monitors on the server.
|
For more information, see IBM Knowledge Center:
DB2 for i application services
DB2 for i application services provide interfaces that are useful for application development.
Table 8-21 lists the DB2 for i application services.
Table 8-21 DB2 for i application services
|
Service name
|
Type
|
Descriptions
|
|
QSYS2.OVERRIDE_TABLE
|
Procedure
|
Sets the blocking size for a table.
|
|
QSYS2.DELIMIT_NAME
|
UDF
|
Returns a name with delimiters if the delimiters are needed for use in an SQL statement.
|
|
SYSPROC.WLM_SET_CLIENT_INFO
|
Procedure
|
Sets values for the SQL client special registers.
|
For more information, see IBM Knowledge Center:
8.5.3 IBM i Services
IBM i Services are part of the IBM DB2 for i Services. They represent procedures, tables, UDFs, UDTFs, and views that the SQL programmer or user can use to get information about operating system objects such as PTFs, Group PTFs, user profiles, TCP/IP information, and system values. This provides benefits such as a standard interface to work on a cross-platform environment, an easy way to get system information without a coding to call system APIs, and reduce time to market for programming.
|
Note: IBM i Services provide information that is related only to the IBM i operating system.
|
To give an example about what information the IBM i Services can provide, some services are described in this section.
GROUP_PTF_CURRENCY
An SQL view GROUP_PTF_CURRENCY can be used to do a comparison of the PTF groups that are installed on the partition against the server level lists on the IBM Preventive Service Planning (PSP) website. The information of this view provides the status of the PTF group on the partition, current level of PTF groups, and the latest level of PTF groups available from IBM. This provides an easy way for a system administrator to manage the currency of PTF groups on the system with a latest information provided.
|
Note: Connection to the PSP website is required for a correct result of this query.
|
Example 8-26 show example SQL statement to find available updates for PTF groups.
Example 8-26 SQL statement to find available updates for PTF groups
SELECT PTF_GROUP_ID,PTF_GROUP_TITLE,PTF_GROUP_LEVEL_INSTALLED,PTF_GROUP_LEVEL_AVAILABLE
FROM SYSTOOLS.GROUP_PTF_CURRENCY
WHERE PTF_GROUP_CURRENCY = ‘UPDATE AVAILABLE’;
Figure 8-28 shows the result of using GROUP_PTF_CURRENCY to find available updates for PTF groups.

Figure 8-28 Query result of GROUP_PTF_CURRENCY IBM i Services
ACTIVE_JOB_INFO and GET_JOB_INFO
ACTIVE_JOB_INFO and GET_JOB_INFO services can be used together to get the information of the job, such as CPU consumption, SQL statement text, and temporary storage. The system administrator can use this information for monitoring purposes or a programmer can use this information to find for a long-running SQL statement.
Example 8-27 shows an example SQL statement to find a long-running SQL statement.
Example 8-27 SQL statement to find a long-running SQL statement
WITH ACTIVE_USER_JOBS(Q_JOB_NAME) AS (
SELECT JOB_NAME FROM TABLE
(ACTIVE_JOB_INFO('NO','','','')) X WHERE JOB_TYPE <> 'SYS')
SELECT Q_JOB_NAME, V_SQL_STATEMENT_TEXT,
CURRENT TIMESTAMP-V_SQL_STMT_START_TIMESTAMP AS SQL_STMT_DURATION, V_CLIENT_USERID,
B.* FROM ACTIVE_USER_JOBS,
TABLE(QSYS2.GET_JOB_INFO(Q_JOB_NAME)) B
WHERE V_SQL_STMT_STATUS = 'ACTIVE'
ORDER BY SQL_STMT_DURATION DESC;
Figure 8-29 shows the result of using ACTIVE_JOB_INFO and GET_JOB_INFO to find a long-running SQL statement.

Figure 8-29 Query result of ACTIVE_JOB_INFO and GET_JOB_INFO IBM i Services
IBM i Services is grouped by the following related areas:
IBM i Application services
This procedure provides an interface that can be used in applications. Table 8-22 lists the IBM i Application services.
Table 8-22 IBM i Application services
|
Services name
|
Type
|
Description
|
|
QSYS2.QCMDEXC
|
Procedure
|
Runs a CL command.
|
IBM i Java services
This view and procedure provides Java information and JVM management options. Table 8-23 on page 373 lists the IBM i Java services.
Table 8-23 IBM i Java services
|
Service name
|
Type
|
Description
|
|
QSYS2.JVM_INFO
|
View
|
Returns information about active Java Virtual Machine (JVM) jobs.
|
|
QSYS2.SET_JVM
|
Procedure
|
Manages specific JVM jobs by specific actions.
|
IBM i Journal services
This function and view provides journal information. Table 8-24 lists the IBM i Journal services.
Table 8-24 IBM i Journal services
|
Service name
|
Type
|
Description
|
|
QSYS2.DISPLAY_JOURNAL
|
UDTF
|
Returns information about journal entries.
|
|
QSYS2.JOURNAL_INFO
|
View
|
Contains information about journals, including remote journals.
|
IBM i Librarian services
This service provides object and library lists information. Table 8-25 lists the IBM i Librarian services.
Table 8-25 IBM i Librarian services
|
Service name
|
Type
|
Description
|
|
QSYS2.LIBRARY_LIST_INFO
|
View
|
Contains information about a current job’s library list.
|
|
QSYS2.OBJECT_STATISTIC
|
UDTF
|
Returns information about objects in a library.
|
IBM i Message handling services
This function and view provides system message information. Table 8-26 lists the IBM i Message handling services.
Table 8-26 IBM i Message handling services
|
Service name
|
Type
|
Description
|
|
QSYS2.JOBLOG_INFO
|
UDTF
|
Returns one row for each message in a job log.
|
|
QSYS2.REPLY_LIST_INFO
|
View
|
Contains information about a current job’s reply list.
|
IBM i Product services
This view provides information about IBM i licensed products. Table 8-27 lists the IBM i Product services.
Table 8-27 IBM i Product services
|
Service name
|
Type
|
Description
|
|
QSYS2.LICENSE_INFO
|
View
|
Contains information about all products or features that contain license information.
|
IBM i PTF services
This view provides information about PTFs on IBM i. Table 8-28 lists the IBM i PTF services.
Table 8-28 IBM i PTF services
|
Service name
|
Type
|
Description
|
|
SYSTOOLS.GROUP_PTF_CURRENCY
|
View
|
Contains a query that implements a live comparison of the PTF Groups that are installed on the partition against the service levels that are listed on the IBM Preventive Service Planning website.
|
|
SYSTOOLS.GROUP_PTF_DETAILS
|
View
|
Contains a query that implements a live comparison of the PTFs within PTF Groups that are installed on the partition against the service levels that are listed on the IBM Preventive Service Planning website.
|
|
QSYS2.GROUP_PTF_INFO
|
View
|
Contains information about the group PTFs for the server.
|
|
QSYS2.PTF_INFO
|
View
|
Contains information about PTFs for the server.
|
IBM i Security services
This view, procedure, and function provide security information and the ability to managed security attributes. Table 8-29 lists the IBM i Security services.
Table 8-29 IBM i Security services
|
Service name
|
Type
|
Description
|
|
QSYS2.DRDA_AUTHENTICATION_ENTRY_INFO
|
View
|
Contains user server authentication entry information.
|
|
QSYS2.FUNCTION_INFO
|
View
|
Contains details about function usage identifiers.
|
|
QSYS2.FUNCTION_USAGE
|
View
|
Contains details about function usage configuration.
|
|
QSYS2.GROUP_PROFILE_ENTRIES
|
View
|
Contains one row for each user profile that is a part of group profile.
|
|
SYSPROC.SET_COLUMN_ATTRIBUTE
|
Procedure
|
Sets the SECURE attribute for a column so the variable value that is used for the column cannot be seen in the database monitor or plan.
|
|
QSYS2.SQL_CHECK_AUTHORITY
|
UDF
|
Returns an indication of whether the user is authorized to query the specified *FILE object.
|
|
QSYS2.USER_INFO
|
View
|
Contains information about user profiles.
|
IBM i Spool services
This view and function provides information about spool files. Table 8-30 lists the IBM i Spool services.
Table 8-30 IBM i Spool services
|
Service name
|
Type
|
Description
|
|
QSYS2.OUTPUT_QUEUE_ENTRIES
|
UDTF
|
Returns one row for each spooled file in an output queue.
|
|
QSYS2.OUTPUT_QUEUE_ENTRIES
|
View
|
Returns one row for each spooled file in every output queue.
|
IBM i Storage services
This view provides information about storage and storage device. Table 8-31 lists the IBM i Storage services.
Table 8-31 IBM i Storage services
|
Service name
|
Type
|
Description
|
|
QSYS2.MEDIA_LIBRARY_INFO
|
View
|
Returns information the same as the WRKMLBSTS command.
|
|
QSYS2.SYSDISKSTAT
|
View
|
Contains information about disks.
|
|
QSYS2.SYSTMPSTG
|
View
|
Contains one row for each temporary storage bucket that is tracking some amount of temporary storage across the system.
|
|
QSYS2.USER_STORAGE
|
View
|
Contains information about storage by user profile.
|
IBM i System health services
This table, view, and global variable are combined to provide information about limits on your system. Table 8-32 lists the IBM i System health services.
Table 8-32 IBM i System health services
|
Service name
|
Type
|
Description
|
|
QSYS2.SYSLIMTBL
|
Table
|
Contains information about limits that are being approached.
|
|
QSYS2.SYSLIMITS
|
View
|
Contains information about limits. This view builds upon the SYSLIMTBL table with others.
|
|
QIBM_SYSTEM_LIMITS_PRUNE_BY_ASP
QIBM_SYSTEM_LIMITS_PRUNE_BY_JOB
QIBM_SYSTEM_LIMITS_PRUNE_BY_OBJECT
QIBM_SYSTEM_LIMITS_PRUNE_BY_SYSTEM
QIBM_SYSTEM_LIMITS_SAVE_HIGH_POINTS_BY_ASP
QIBM_SYSTEM_LIMITS_SAVE_HIGH_POINTS_BY_JOB
QIBM_SYSTEM_LIMITS_SAVE_HIGH_POINTS_BY_OBJECT
QIBM_SYSTEM_LIMITS_SAVE_HIGH_POINTS_BY_SYSTEM
|
Global variables
|
Used to guide the pruning action perform by DB2 to prevent excess storage consumption within the SYSLIMTBL table. All the global variables are in the SYSIBMADM schema.
|
IBM i TCP/IP services
This view and procedure provides information about TCP/IP. Table 8-33 lists the IBM i TCP/IP services.
Table 8-33 IBM i TCP/IP services
|
Service name
|
Type
|
Description
|
|
SYSIBMADM.ENV_SYS_INFO
|
View
|
Contains information about the current server.
|
|
QSYS2.NETSTAT_INFO
|
View
|
Returns information about IPv4 and IPv6 network connections.
|
|
QSYS2.NETSTAT_INTERFACE_INFO
|
View
|
Returns information about IPv4 and IPv6 interfaces.
|
|
QSYS2.NETSTAT_JOB_INFO
|
View
|
Returns information about jobs that use IPv4 and IPv6 network connections.
|
|
QSYS2.NETSTAT_ROUTE_INFO
|
View
|
Returns information about IPv4 and IPv6 routes.
|
|
QSYS2.SET_SERVER_SBS_ROUTING
|
Procedure
|
Allows a user to configure some servers to use alternative subsystems based on the user profile that is establishing the connection.
|
|
QSYS2.SERVER_SBS_ROUTING
|
View
|
Returns information about the users who have alternate subsystem configurations for some IBM i servers.
|
|
QSYS2.TCPIP_INFO
|
View
|
Contains TCP/IP information for the current host connection.
|
IBM i Work management services
This view and function provides system value and job information. Table 8-34 lists the IBM i Work management services.
Table 8-34 IBM i Work management services
|
Service name
|
Type
|
Description
|
|
QSYS2.ACTIVE_JOB_INFO
|
UDTF
|
Returns one row for each active job.
|
|
QSYS2.GET_JOB_INFO
|
UDTF
|
Returns one row containing the information about a specific job.
|
|
QSYS2.MEMORY_POOL
|
UDTF
|
Returns one row for every storage pool.
|
|
QSYS2.MEMORY_POOL_INFO
|
View
|
Returns one row for every active storage pool.
|
|
QSYS2.OBJECT_LOCK_INFO
|
View
|
Returns one row for every lock that is held for every object on the partition.
|
|
QSYS2.RECORD_LOCK_INFO
|
View
|
Returns one row for every record lock for the partition.
|
|
QSYS2.SCHEDULED_JOB_INFO
|
View
|
Returns information the same as the WRKJOBSCDE command.
|
|
QSYS2.SYSTEM.STATUS
|
UDTF
|
Returns a single row, contains information about the current partition.
|
|
QSYS2.SYSTEM_STATUS_INFO
|
View
|
Return a single row, contains information about the current partition.
|
|
QSYS2.SYSTEM_VALUE_INFO
|
View
|
Contains information about system values.
|
For more information, see IBM Knowledge Center:
8.6 DB2 performance
In the IBM i 7.2 release of DB2 for i, a considerable effort was undertaken to enhance the runtime performance of the database, either by extending existing functions or by introducing new mechanisms.
Runtime performance is affected by many issues, such as the database design (the entity-relationship model, which is a conceptual schema or semantic data model of a relational database), the redundancy between functional environments in a composite application environment, the level of normalization, and the size and volumes processed. All of these items influence the run time, throughput, or response time, which is supported by the IT components and is defined by the needs of the business. Performance optimization for database access must address all the components that are used in obtained, acceptable, and sustainable results, covering the functional aspects and the technical components that support them.
This section describes the DB2 for i performance-related enhancements in IBM i 7.2. To benefit from them, application or system configuration changes are not needed in most cases.
The following topics are covered in this section:
8.6.1 SQE I/O cost model
SQL Query Engine (SQE) uses a structure that is called access plan for every database query to retrieve the data in an optimized manner.
An access plan is a control structure that describes the actions that are necessary to satisfy each query request. It contains information about the data and how to extract it. For any query, whenever optimization occurs, the query optimizer develops an optimized plan of how to access the requested data.
Preparing an optimized access plan is a complex task and requires the optimizer to rely on many sources of information. One of these sources of information is the I/O cost for accessing a database object (table scan, index probe, and so on). I/O cost can be described as the amount of time that is needed for all I/O operations that are required to access the object.
Before IBM i 7.2, the I/O cost model was based on the assumption that any I/O operation time was 25 milliseconds, regardless of the configuration of the system and attached storage solution. In response to significant hardware changes, including storage solutions for modern IBM i systems, and the big data paradigm that is often reflected in I/O-intensive database operations, the I/O cost model in IBM i 7.2 has changed.
Table 8-35 compares disk read times for various IBM i storage types with the original SQE I/O cost model.
Table 8-35 Disk read times for storage technologies compared to original SQE cost model
|
Storage technology
|
Typical read time in milliseconds1
|
|
Internal disks
|
4 -10
|
|
External disks/SAN
|
1 - 6
|
|
Solid-state drives (SSDs)
|
Less than 1
|
|
Original SQE model
|
25
|
1 Disk read times depend on many factors and can differ between environments.
The SQE optimizer now relies on sample actual access times instead of a fixed value. The optimizer is provided with more accurate disk read times, which results in more accurate I/O cost calculation. More accurate I/O cost prediction means better access plan preparation for faster query execution. Sample access times are measured during every IPL and at independent ASP vary- on time by recording disk read times for sample pages. These sample times are evaluated and updated at appropriate intervals during system operation. This ensures that the optimizer always has a current view of disk performance. This data allows the optimizer to distinguish unique I/O performance characteristics for internal, external, and solid-state drives.
As a result, for modern systems, I/O cost is now often lower (compared to the original SQE cost model based on 25-millisecond read operation, as shown in Table 8-35). The SQE processes I/O in a more intensive manner (more aggressively). In many cases, this results in a moderate performance improvement for I/O-intensive queries compared to IBM i 7.1 running on the same hardware.
8.6.2 SQE support for native file opens, Query/400, and OPNQRYF
Release to release, SQE has been enhanced to support a broader scope of database operations, SQL statements, and IBM i interfaces. The purpose of these efforts has not changed since the introduction of SQE in V5R2. SQE can process database access and run queries faster than the classic query engine (CQE). It also provides more detailed information, kept in the plan cache, about query implementation and statistics. This data can be used by the database application developers and DB2 engineers to optimize query performance. Investigation of DB2 for i performance problems is easier when SQE processes the query instead of CQE.
Accessing data through following DB2 for i interfaces is now supported by SQE, without any application or user change:
•File open and read operations in programs that are written in high-level languages (such as COBOL, RPG, and C++) for tables with RCAC enabled only
•Open Data Base File (OPNDBF) CL command for native SQL views and partitioned tables opens
•Open Query File (OPNQRYF) CL command
•IBM Query for i (formerly Query/400) licensed program 5770QU1
A new option that is called SQE_NATIVE_ACCESS is now available in the QAQQINI file that you can use to change the default behavior of IBM i 7.2 and force CQE to process native opens in HLL programs, OPNDBF, OPNQRYF, or IBM Query for i queries.
Table 8-36 SQE_NATIVE_ACCESS parameter values in the QAQQINI file
|
Value
|
Description
|
|
*NO
|
V7R1 native open unless SQE is required.1
|
|
*YES
|
SQE attempts to implement a native open of an SQL view or native query.
|
|
*DEFAULT
|
The same as *YES.
|
1 SQE is required for RCAC-enabled tables, sequence objects, global variables, OLAP, CUBE, and ROLLUP.
Using IBM System i Navigator, you can search the SQL plan cache for statements by using native opens, if the statement was processed by the SQE. Figure 8-30 shows the SQL Plan Cache Statements view for OPNQRYF statements and the Visual Explain view for the selected statement. The highlighted Query Engine Used value is SQE.
|
Tip: Use the OPNDBF string for searching for OPNDBF native open statements and QUERY/400 string for searching for IBM Query for i native open statements.
|

Figure 8-30 SQL Plan Cache Statements and Visual Explain view for OPNQRYF
You can see the same statements by using the IBM Navigator for i web interface. Under the Database section, expand Databases and right-click the database of your choice in the Databases tab. Click SQL Plan Cache → Show Statements. You can use the filters view to filter statements by using the same criteria as for IBM System i Navigator. Visual Explain functions are not available from the web interface at the time of writing. Figure 8-31 shows an example of a filtered view.

Figure 8-31 SQL Plan Cache Statements view for OPNQRYF within IBM Navigator for i
For more information about CQE, SQE, query dispatcher, and SQL plan cache, see IBM Knowledge Center:
For more information about the QAQQINI file and its options, see IBM Knowledge Center:
8.6.3 PDI for DB2
Performance Data Investigator (PDI) was enhanced to allow database engineers (DBE) and database administrators (DBA) to access quickly database performance-related information.
PDI is part of IBM Navigator for i and is accessible through the Investigate Data link under the Performance section. PDI is a common interface that is used for various performance data that is collected on an IBM i system.
The database content page of the PDI requires the IBM Performance Tools for i (5770-PT1) Option 1 - Manager Feature licensed program to be installed on your system.
Figure 8-32 shows the perspectives that are available for the Database part of the PDI in
IBM i 7.2.
IBM i 7.2.

Figure 8-32 New database-related perspectives for PDI
Starting from the top-level system-wide overview, the DBE or DBA can open more detailed sections of the performance data that is related to a particular job or thread or SQL plan cache.
Figure 8-33 shows the PDI view of SQL CPU utilization for jobs and tasks. The following drill-down options are available from within this interface:
•CPU Utilization for Jobs or Tasks
•CPU Utilization Overview

Figure 8-33 SQL CPU utilization by job and task PDI view
PDI data can be presented in graphs or tables. You can choose performance data files (either current or previous), zoom in and out of a range of intervals of interest, or even modify an SQL statement to retrieve other than the default set of data.
The Plan Cache Searches view is shown on Figure 8-34.

Figure 8-34 Plan Cache Searches PDI view
For more information about PDI, see IBM Knowledge Center:
8.6.4 Queries with a long IN predicate list
In IBM i 7.2, SQE recognizes when many values are specified on an IN list and automatically converts the IN list to a more efficient INNER JOIN.
8.6.5 Index advice and OR predicates
In IBM i 7.2, the Index Advisor is extended to include queries that OR together local selection (WHERE clause) columns over a single table. OR advice requires two or more indexes to be created as a dependent set. If any of the OR’d indexes are missing, the optimizer cannot choose these dependent indexes for implementation of the OR-based query.
This relationship between OR-based indexes in the SYSIXADV index advice table is through a new DEPENDENT_ADVICE_COUNT column.
For more information about Index Advisor, see IBM Knowledge Center:
For more information about index advice and OR predicates, see IBM Knowledge Center:
8.6.6 KEEP IN MEMORY for tables and indexes
Before IBM i 7.1, the only way to preinstall an object into a main storage pool was by using the Set Object Access (SETOBJACC) CL command. Loading database files or programs in to a main storage pool reduces data access time and results in performance gains. However, the effect of the SETOBJACC CL command is temporary and does not persist over an IPL. To remove the object from the main storage, run the SETOBJACC CL command with the *PURGE option.
In IBM i 7.1, the CHGPF and CHGLF CL commands were extended with the Keep in memory parameter (KEEPINMEM) to allow the operating system to bring automatically a table or index into a main storage pool when the table or index is used in a query. For queries running within SQE, this enhancement results in performance gains. The operating system also automatically purges the objects with the memory-preference from the main store when they are no longer used by the query.
IBM i 7.2 is enhanced with the comprehensive support for the keep-in-memory function. The following SQL statements are extended with the KEEP IN MEMORY keyword:
•CREATE TABLE
•CREATE INDEX
•ALTER TABLE
•DECLARE GLOBAL TEMPORARY TABLE
A new option that is called MEMORY_POOL_PREFERENCE is now available in the QAQQINI file, which you can use to direct the database engine to attempt to load objects to a specified storage pool. This option does not ensure that a specified storage pool is used.
Table 8-37 MEMORY_POOL_PREFERENCE parameter values
|
Value
|
Description
|
|
*JOB
|
Attempt to use the storage pool of the job
|
|
*BASE
|
Attempt to use the Base storage pool
|
|
nn
|
Attempt to use the Storage pool nn
|
|
*DEFAULT
|
The same as *JOB
|
The Display File Description (DSPFD) CL command output is extended with the new Keep in memory field, under the Data Base File Attributes section, as shown in Example 8-28.
Example 8-28 DSPDF partial output with Keep in memory field
Access path . . . . . . . . . . . . . . . . : Arrival
Maximum record length . . . . . . . . . . . : 26
Volatile . . . . . . . . . . . . . . . . . : No
Keep in memory . . . . . . . . . . . . . . : KEEPINMEM *YES
File is currently journaled . . . . . . . . : Yes
Current or last journal . . . . . . . . . . : QSQJRN
Library . . . . . . . . . . . . . . . . . : CORPDB
This enhancement, also known as memory-preference, is comprehensive and affects all available BD2 management interfaces, including the following interfaces:
•CLI commands
•IBM System i Navigator
•IBM Navigator for i
Figure 8-35 shows the memory-preference information of a table definition that is available from IBM System i Navigator.

Figure 8-35 Memory-preference information for a table definition in IBM System i Navigator
Figure 8-36 shows the memory-preference information of a table description that is available from IBM System i Navigator.

Figure 8-36 Memory-preference information for a table description in IBM System i Navigator
Figure 8-37 shows the memory-preference information of an index definition that is available from IBM System i Navigator.

Figure 8-37 Memory-preference information for an index definition in IBM System i Navigator
Figure 8-38 shows the memory-preference information of an index description that is available from IBM System i Navigator. The same information is available from IBM Navigator for i.

Figure 8-38 Memory-preference information for an index description in IBM System i Navigator
Figure 8-39 shows the memory-preference information of a table definition that is available from IBM Navigator for i.

Figure 8-39 Memory-preference information for a table definition in IBM Navigator for i
Figure 8-40 shows the memory-preference information of a table description that is available from IBM Navigator for i.

Figure 8-40 Memory-preference information for a table description in IBM Navigator for i
Figure 8-41 shows the memory-preference information of an index definition that is available from IBM Navigator for i.

Figure 8-41 Memory-preference information for an index definition in IBM Navigator for i
Figure 8-42 shows the memory-preference information of an index description that is available from IBM Navigator for i.

Figure 8-42 Memory-preference information for an index description in IBM Navigator for i
For more information about the memory-preference enhancement, see the IBM i Technology Updates website:
For more information about DB2 for i SQL statements, see IBM Knowledge Center:
For more information about the QAQQINI file and its options, see IBM Knowledge Center:
8.6.7 Collection Services enhancements
Collection Services now collects SQL statistics on a job and system level. Here is a list of performance data files that are extended with SQL information:
•QAPMJOBOS: Data that is specific to system jobs
•QAPMSYSTEM: System-wide performance data
A new file that is called QAPMSQLPC is available. It contains the performance data about the SQL Plan Cache that is collected by the *SQL collection category.
For more information about Collection Services files descriptions, see IBM Knowledge Center:
8.6.8 Enhanced index build logic for highly concurrent environments
DB2 for i index build processing is enhanced to gauge its aggressiveness for index key processing based upon the run priority of the index build job. The priority is set up for the application job.
Table 8-38 compares the behavior of the index build job when changing the priority.
Table 8-38 Index build behavior based on the run priority
|
Job priority
|
Index keys that are processed before looking for held users
|
Wait time
|
|
1 - 19
|
Process many keys at a time.
|
Wait less time before trying to get a seize.
|
|
20 - 80
|
Process a few keys at a time (same as before this enhancement).
|
Wait the same amount of time as before the enhancement.
|
|
81 - 99
|
Process two keys at a time.
|
Wait a longer time than before the enhancement.
|
8.6.9 Accepting a priority change for a parallel index build
DB2 for i now allows you to change the priority of index build jobs when using IBM i operating system option 26 - DB2 Symmetric Multiprocessing. Option 26 is a chargeable feature.
The index builds run as part of jobs QDBSRVxx, where xx is in range from 1 to the number of CPU cores that the logical partition has assigned.
Before this enhancement, these jobs ran with priority 52. Now, you can change the run priorities of individual QDBSRVxx jobs.
Changing the run priority of the index build job changes the priority of the SMP tasks.
The Change System Job (CHGSYSJOB) command is enhanced to allow priority changes to DB server jobs.
Table 8-39 shows a comparison of behavior of the index build job when changing the priority.
Table 8-39 Index build behavior based on the run priority
|
Job priority
|
Index keys that are processed before looking for held users
|
Wait time
|
|
1-19
|
Process many keys at a time.
|
Wait less time before trying to get a seize.
|
|
20-80
|
Process a few keys at a time (same as before this enhancement).
|
Wait the same amount of time as before the enhancement.
|
|
81-99
|
Process two keys at a time.
|
Wait a longer time than before the enhancement.
|
8.6.10 SQE index merge ordering
SQE is enhanced to select and use indexes for both selection and ordering queries where the selected row is not an equal predicate on one set of columns and ordering is on another set of columns. The previous version of SQE could select only one index for selection or ordering but not both. This can help reduce CPU and I/O resource consumption compared to the previous method.
The most likely situations that get performance benefits from this enhancement are the following ones:
•The query is being optimized for first I/O, which is used when a user is waiting for the first set of I/O.
•The result set is large.
•An Index Merge Ordering (IMO) eligible index exists.
For more information, see Index Merge Ordering at:
8.6.11 QSYS2.DATABASE_MONITOR_INFO view
The DATABASE_MONITOR_INFO view is a new DB2 for i Services function that is introduced in IBM i 7.2. This view returns information about database monitors and plan cache event monitors on the server.
Example 8-29 show an SQL statement to select an active database monitor with a data size greater than 200,000 bytes.
Example 8-29 SQL statement to select an active database monitor with a data size greater than 200,000 bytes
SELECT MONITOR_ID,MONITOR_TYPE,MONITOR_STATUS,MONITOR_LIBRARY,DATA_SIZE
FROM QSYS2.DATABASE_MONITOR_INFO
WHERE MONITOR_STATUS = ‘ACTIVE’ AND DATA_SIZE > 200000;
Figure 8-43 shows the query result of DATABASE_MONITOR_INFO DB2 for i Services.

Figure 8-43 Query result of DATABASE_MONITOR_INFO
For more information, see IBM Knowledge Center:
8.6.12 QAQQINI memory preference by pool name
In IBM i 7.2, the QAQQINI (Query Options) MEMORY_POOL_PERFERENCE is enhanced to support memory pool preference by using a share memory pool name or private memory pool identifiers to direct a database to perform paging into the memory pool when supported for database operation.
Previously, a user could specify a system pool ID for a preferred memory pool. But, using a system pool ID made it difficult where a user needed the database to page the query data into a share pool or private memory pool. The user needed to know the system pool ID associated with that named memory pool, and if there was a change on the system pool ID, the user had to update the new system pool ID in QAQQINI unless the database fell back to use the *BASE memory pool.
With this enhancement, users can specify the shared pool name or the private pool name along with its subsystem and library. DB2 then tracks these changes and makes certain that the preferred memory pool for database operation is really what the user intends.
Example 8-30 shows an SQL statement for updating the QAQQINI MEMORY_POOL_PERFERENCE by shared pool name and private pool name.
Example 8-30 Example SQL statement to update QAQQINI MEMORY_POOL_PREFERENCE
---------- Shared pool name ----------
UPDATE MYLIB.QAQQINI
SET QQVAL = ‘*NAME *SHRPOOL1’
WHERE QQPARM = ‘MEMORY_POOL_PERFERENCE
or
---------- *INTERACT pool ----------
UPDATE MYLIB.QAQQINI
SET QQVAL = ‘*NAME *INTERACT’
WHERE QQPARM = ‘MEMORY_POOL_PERFERENCE’
or
---------- Private pool name --------
UPDATE MYLIB.QAQQINI
SET QQVAL = ‘*PRIVATE MYLIB/MYSBS 1’
WHERE QQPARM =’MEMORY_POOL_PERFERENCE’
For more information, see QAQQINI memory preference by pool name at:
8.6.13 Index statistical catalogs enhancement
In IBM i 7.2, the following index statistical related catalogs are enhanced:
•QSYS2.SYSINDEXSTAT
•QSYS2.SYSPARTITIONINDEXES
•QSYS2.SYSPARTITIONINDEXSTAT
They are enhanced to include the following information:
•LAST_BUILD_TYPE:
An indication of whether the last index build is related to a complete build or delayed maintenance build.
•LAST_INVALIDATION_TIMESTAMP
An indication of when an index was last invalidated.
Figure 8-44 shows the query result of the SYSINDEXSTAT catalog with the LAST_BUILD_TYPE and LAST_INVALIDATION_TIMESTAMP columns.

Figure 8-44 Query result of the SYSINDEXSTAT catalog
For more information, see IBM Knowledge Center:
8.6.14 QSYS2.CLEAR_PLAN_CACHE() procedure
The CLEAR_PLAN_CACHE() procedure is a part of DB2 for i Services that is introduced in IBM i 7.2. This procedure provides an alternative way to clear a plan cache instead of performing a system IPL. This procedure can be used by performance analysts to create a consistent environment to evaluate potential database performance changes in a performance test environment or QA environment.
For more information, see IBM Knowledge Center:
8.6.15 Encoded vector indexes only access
Encoded vector indexes were improved so they can be used for projections of columns by an SQE query optimizer. Encoded vector indexes were originally focused on selection keys in the WHERE clause and aggregation. After this Encoded vector indexes only access (EOA) enhancement, they also can be used for column projection in SELECT list.
Also, Index Advisor recommendations to use Encoded Vector Indexes can be seen with REASON_TYPE set to I8.
8.6.16 STRDBMON command filtering improvement
In IBM i 7.2, a filter operation equal to (*EQ) and not equal to (*NE) was added to the Start Database Monitor (STRDBMON) command for the JOB, FTRFILE, and FTRUSER parameters. These allow for more filtering options on the database monitor.
Figure 8-45 on page 397 and Figure 8-46 on page 397 show the filter operations for JOB parameter in the STRDBMON command.
|
Start Database Monitor (STRDBMON)
Type choices, press Enter.
File to receive output . . . . . Name
Library . . . . . . . . . . . *LIBL Name, *LIBL, *CURLIB
Output member options:
Member to receive output . . . *FIRST Name, *FIRST
Replace or add records . . . . *REPLACE *REPLACE, *ADD
Job name:
Name . . . . . . . . . . . . . * Name, generic*, *, *ALL
User . . . . . . . . . . . . Name, generic*, *ALL
Number . . . . . . . . . . . 000000-999999, *ALL
Filter Operator . . . . . . . *EQ *EQ, *NE
Type of records . . . . . . . . *DETAIL *DETAIL, *BASIC, *SUMMARY
Force record write . . . . . . . *CALC 0-32767, *CALC
Initial number of records . . . *NONE 0-2147483646, *NONE
Run time threshold . . . . . . . *NONE 0-2147483647, *NONE
Storage threshold . . . . . . . *NONE 0-2147483647, *NONE
Include system SQL . . . . . . . *NO *NO, *YES, *INI
More...
F3=Exit F4=Prompt F5=Refresh F12=Cancel F13=How to use this display
F24=More keys
|
Figure 8-45 Filter operator for STRDBMON command
|
Start Database Monitor (STRDBMON)
Type choices, press Enter.
Filter by database file:
File . . . . . . . . . . . . . *NONE
Library . . . . . . . . . . Name, generic*
Filter Operator . . . . . . . *EQ *EQ, *NE
+ for more values
Filter by user profile:
User . . . . . . . . . . . . . *NONE Name, generic*, *NONE...
Filter Operator . . . . . . . *EQ *EQ, *NE
+ for more values
Filter by internet address . . . *NONE
More...
F3=Exit F4=Prompt F5=Refresh F12=Cancel F13=How to use this display
F24=More keys
|
Figure 8-46 Filter operator for STRDBMON command
For more information, see Start Database Monitor (STRDBMON) command filtering improvements at:
8.7 Database engineering
A data-centric approach requires performing various tasks by database engineers (DBE) daily. Examples of these tasks include the following ones:
•Database security management
•Database architecture management for particular business applications and goals
•Database performance analysis and tuning
•Database problem identification and resolution
•Database backup and recovery management
The following sections describe the new DB2 for i features and enhancements for DBEs in IBM i 7.2:
8.7.1 IBM System i Navigator DB2 related functions
Although IBM Navigator for i is enhanced with many new features and functions to support database engineers (see 8.7.2, “IBM Navigator for i: DB2 related functions” on page 403), IBM System i Navigator remains a tool of choice for many users.
IBM System i Navigator is the only tool that supports the Visual Explain and Run SQL Scripts functions. It continues to be enhanced twice a year by service pack updates. Many of the
IBM i 7.2 database enhancements are reflected in the current IBM System i Navigator updates.
IBM i 7.2 database enhancements are reflected in the current IBM System i Navigator updates.
|
Note: To use all the available enhancements of the IBM System i Navigator, you must install the current IBM i Access for Windows service pack for Version 7.1. The Version 7.1 client software contains all the IBM System i Navigator enhancements for IBM i 7.2. Also, you must install the current DB2 PTF Group on the managed system.
|
The following DB2 related functions were added to IBM System i Navigator:
For more information about IBM System i Navigator, see IBM Knowledge Center:
Index creation date
For better manageability, a new Date Created column was added to the Indexes view of a particular schema, as shown in Figure 8-47.

Figure 8-47 New Date Created column in the Indexes list window
For more information about the index creation date within the IBM System i Navigator window and system catalogs, see the following website:
New SQL Performance Monitor parameters
The SQL Performance Monitor Wizard now supports up to 10 user names or group names and generic names in the “Current user or group profile” field.
Also, a new Host variable values field can control how values of the host variables are captured when the monitor is active. The following values are available:
•The *BASE value has the same behavior as on IBM 7.1 or earlier
•The *CONDENSED value allows for less impact to the database
•The *SECURE value prevents host variable values from being visible in the collected data
See Figure 8-48.

Figure 8-48 SQL Performance Monitor Wizard enhancements
For more information about the Host variables values parameter for SQL Performance Monitors, see the following website:
New fields in the Table Definition window
Table and partition definition information is extended with “Preferred storage media is solid-state drive” and “Keep in memory” fields, as shown on Figure 8-49 on page 401.
Also, the Show SQL function is enhanced to support these changes.
Figure 8-49 New fields in the Table Definition window
Program statements for user-defined table function in Visual Explain
You can use Visual Explain to see detailed program statements for UDTFs. See Figure 8-50.

Figure 8-50 Specific program statements for user-defined table functions in Visual Explain
For more information about specific program statements for UDTF in Visual Explain, see the following website:
Automating SQL plan cache operations
New system procedures are added to automate SQL plan cache snapshots and event monitors importation and removal. Before this change, you had to perform these operations manually from the IBM System i Navigator. Here are the new procedures:
•QSYS2/IMPORT_PLAN_CACHE()
•QSYS2/REMOVE_PLAN_CACHE()
•QSYS2/IMPORT_EVENT_MONITOR()
•QSYS2/REMOVE_EVENT_MONITOR()
For more information about automating SQL plan cache operations, see the following website:
Adding multiple view entries support to the journal viewer
Within a journaled environment, you can now select multiple rows, as shown in Figure 8-51. You can then right-click and select View Data. This makes it easier to compare the before and after situation.

Figure 8-51 Journal viewer: select multiple entries
When the data is displayed, you also can control whether you want to see the text or hex formatted data for comparison purposes, as shown in Figure 8-52 on page 403.

Figure 8-52 Journal entry data viewer
8.7.2 IBM Navigator for i: DB2 related functions
IBM Navigator for i has become a robust tool for IBM i management that an administrator can use to control all areas of the system. IBM Navigator for i is intended to replace IBM System i Navigator tool in the future. Many of the IBM Navigator for i enhancements are not available in other tools. The DB2 engineering functions of the tool are not an exception to this rule. Enhancements that are introduced to IBM System i Navigator are also available for IBM Navigator for i except for Visual Explain UDTF statements.
Many improvements were made to the Database functions, resulting in enhanced usability and performance of the web tool. Key changes include the following changes:
•Redesigned window for better usability and performance in a web browser:
– Select Schemas
– SQL Details for Jobs
– Show Status (Table Reorganizations, Table Alters, Index Builds, and OmniFind text index builds)
– Grid Column Chooser
•Performance changes to improve list retrieval, filtering, and data compression
•Usability changes to display lists resulting from database actions in a separate tab for easier navigation between lists
•Usability changes to display selected dialogs as Dojo pop-up menus
•Quick path access to several database windows
The On Demand Performance Center groups menu options and perspectives that are related to database performance, such as SQL plan cache or Index Advisor. The following changes were made to the On Demand Performance Center:
•A menu option was added to SQL Plan Cache snapshots and SQL database performance monitors to view overview charts in PDI.
Figure 8-53 shows the new Investigate Performance Data menu option in the SQL Plan Cache Snapshots window. You can use this option to navigate directly to PDI for snapshot analysis.

Figure 8-53 Investigate Performance Data menu option
•A menu option was added to a selected statement in the SQL Plan Cache to see the job history for that statement.
Figure 8-54 shows a new Show Job History menu option for a selected statement in the SQL Plan Cache Statements window. You can view the jobs that run the selected statement.

Figure 8-54 New Show Job History menu option in the SQL Plan Cache Statements window
•Additional filters are now used when you select to show the statements for a row from the Index Advisor and condensed index advice lists. These filters provide a better match of statements that generated the advice in the SQL Plan Cache.
•The Index Advisor list now includes a column with the times that the index was advised when it depended on other index advice.
Figure 8-55 shows the new Times Advised Dependent on Other Advice column in the Index Advisor view.

Figure 8-55 New Times Advised Dependent on Other Advice column in the Index Advisor window
•A filter was added to the Show Statements window filters, which specifies whether the other filters all need to match.
Figure 8-56 shows a new filter option on the Show Statements window filters, which specifies whether the other filters all need to match.

Figure 8-56 New filter option on the Show Statements Filters window
Database management is extended with the following features:
•Support for new database features:
– Row permissions and column masks and the ability to activate these row- and column-level security capabilities on tables.
– Define multiple event triggers.
– Define named parameters and default values for parameters in SQL stored procedures and functions.
For more information, see 8.2.1, “QIBM_DB_SECADM function usage” on page 323.
•Generate SQL now supports several new options:
– Obfuscate an SQL trigger, function, or procedure.
– Specify whether to schema qualify objects.
– Add the OR REPLACE clause.
– Add KEEP IN MEMORY clause.
Figure 8-57 shows the new options that are available in the Generate SQL window.

Figure 8-57 New options that are available in the Generate SQL window
•Support was added to view the contents of a table. Figure 8-58 shows the new View Contents menu option in the Tables window, which you can use to browse and filter data within the specified table.

Figure 8-58 New View Contents menu option in the Tables window
•Support for the memory-preference for tables and indexes. For more information, see 8.6.6, “KEEP IN MEMORY for tables and indexes” on page 385.
•Table Reorganization status is extended with the following information (see Figure 8-59):
– Record the number where the reorganization started.
– Amount of storage that is returned because of deleted records.
– Number of deleted rows during reorganization.

Figure 8-59 New information in the Table Reorganization status window
For more information about general enhancements of IBM Navigator for i, see 2.1, “IBM Navigator for i” on page 14.
For more information about PDI database-related changes, see 8.6.3, “PDI for DB2” on page 381.
For more information about DB2 for i, see IBM Knowledge Center:
8.7.3 Queued exclusive locks
A new option that is called PREVENT_ADDITIONAL_CONFLICTING_LOCKS is now available in the QAQQINI file. This new option allows the database engine to give preference to the operation that requires an exclusive lock over the operations to lock the object for reading. This option can be useful in situations where application activity on a database is high and cannot be quiesced. Therefore, obtaining an exclusive non-read lock is hard or even impossible.
Table 8-40 describes that values that are available for the PREVENT_ADDITIONAL_CONFLICTING_LOCKS option.
Table 8-40 PREVENT_ADDITIONAL_CONFLICTING_LOCKS parameter values
|
Value
|
Description
|
|
*NO
|
When a job requests an exclusive lock on an object, do not prevent concurrent jobs from acquiring additional exclusive locks on the object.
|
|
*YES
|
New requests for read locks are queued behind the exclusive lock request and wait until the exclusive lock completes or times out.
|
|
*DEFAULT
|
The same as *NO.
|
The following SQL operations are affected by this new option as exclusive lock requests:
•ALTER TABLE (add, alter, or drop a column)
•CREATE TRIGGER
•LOCK TABLE
•RENAME TABLE
For more information about DB2 for i SQL statements, see IBM Knowledge Center:
For more information about the QAQQINI file and its options, see IBM Knowledge Center:
8.7.4 CREATE TABLE AS SELECT from a remote database
It is now possible to create, on a local system, a table that references one or more tables on a remote server. Along with the SELECT statement, you can specify copy options to get attributes, such as the default values or identity column information, which is copied for the new table.
The WITH DATA or WITH NO DATA clause must be specified to indicate whether to populate the table from the remote system. The remote server connection must be defined as a relational database entry (by running WRKRDBDIRE).
Example 8-31 shows how to create a table whose definition reflects a table on a remote server and populates it with the data from the remote server.
Example 8-31 Create a table that reflects a definition on a remote server with data
CREATE TABLE EMPLOYEE4 AS
(SELECT PROJNO, PROJNAME, DEPTNO
FROM REMOTESYS.TESTSCHEMA.EMPLOYEE
WHERE DEPTNO = 'D11') WITH DATA
For more information about creating tables that reference a remote database, see
IBM Knowledge Center:
IBM Knowledge Center:
8.7.5 Live movement of tables and indexes to SSD
Media preference of SQL tables, SQL views, and SQL indexes (the Preferred storage unit parameter of the CHGPF and CHGLF CL commands) can now be changed without obtaining an exclusive lock on the file.
This change can be made when shared read (*SHRRD) or update (*UPDATE) locks exist on the file being changed.
After the *SSD is specified as a preferred storage media, data asynchronously moves to the SSD drives.
8.7.6 Range partitioned tables
Ranged partitioned tables can now be created with partitions out of order, as shown in Example 8-32.
Example 8-32 Create a range partitioned table with partitions out of order
CREATE TABLE CORPDB.SALES_TABLE FOR SYSTEM NAME SALES00002 (
TRANS_DATE TIMESTAMP DEFAULT NULL)
PARTITION BY RANGE (TRANS_DATE NULLS LAST) (
PARTITION PART000001
STARTING ( '2014-01-01-00.00.00.000000' ) INCLUSIVE
ENDING ( '2014-01-31-23.59.59.999999' ) INCLUSIVE,
STARTING ( '2014-08-01-00.00.00.000000' ) INCLUSIVE
ENDING ( '2014-08-31-23.59.59.999999' ) INCLUSIVE,
STARTING ( '2014-05-01-00.00.00.000000' ) INCLUSIVE
ENDING ( '2014-05-31-23.59.59.999999' ) INCLUSIVE )
As a result, the SALES_TABLE range partitioned table was successfully created.
For range partitioned tables, DB2 for i now recognizes whether an update operation is made to the column that was used for range partitioning. If the update affects partition assignment of the row, the row is automatically moved to the correct partition (database file member).
For more information about partitioned tables, see IBM Knowledge Center:
For more information about DB2 for i SQL statements, see IBM Knowledge Center:
8.8 DB2 Web Query for i
DB2 Web Query for i V2.1.0, which provides core analytics and Business Intelligence (BI) platform capabilities, including queries, reporting, OLAP, and dashboards, is now supported.
DB2 Web Query for i is available as either a Standard Edition or Express Edition in IBM i 7.2:
•DB2 Web Query for i Express Edition provides an entry-level software bundle that includes report authoring tools, a Query/400 import function, and analytic reporting options for a small number of users.
With Express Edition, you can generate high-quality reports and OLAP reports for analysts that are interested in understanding trends or finding exceptions in the data to uncover what is driving results.
Also, you can use the spreadsheet pivot table support and integrate ad hoc reporting directly in to Microsoft Excel spreadsheets. DB2 Web Query for i provides an array of mobile capabilities. For example, for those users with mobile devices who must analyze data while on the road, Active Technologies provide analytics for the users disconnected from the server.
•DB2 Web Query Standard Edition combines all of the functions that are included in Express Edition plus more, providing a robust offering that can support up to thousands of users running reports. With Standard Edition, user licenses are included to support a typical rollout of developers and administrators, report authors, and a virtually unlimited number of runtime users and report consumers.
With Standard Edition, you can build more sophisticated dashboards for executives monitoring key performance indicators (KPIs). You can use Standard Edition to create an enterprise report distribution model with the abilities to schedule report execution and distribution through email or save the reports for later viewing. Optionally, use the data adapter for Microsoft SQL Server that is included in Standard Edition to build reports that include data from any of those databases in your network.
Each edition of DB2 Web Query for i has its own unique ordering Product ID. Express Edition is 5733-WQE, and Standard Edition is 5733-WQS. However, the Product ID that is installed on the system is 5733-WQX. Control of whether you can use Express or Standard Edition is done by enabling the appropriate feature through IBM i License Management.
In addition to the data adapter for Microsoft SQL Server, the JD Edwards adapter is available as a separate option of Standard Edition. You can use this adapter to connect to your
JD Edwards environment and view the information that is stored in JD Edwards as a data source for a DB2 Web Query for i environment.
JD Edwards environment and view the information that is stored in JD Edwards as a data source for a DB2 Web Query for i environment.
For more information about DB2 Web Query for i, see IBM DB2 Web Query for i Version 2.1 Implementation Guide, SG24-8063.
DB2 Web Query for i is an independent product from DB2 for i. Enhancements and updates of DB2 Web Query for i are provided as a separate PTF Group from the DB2 for i PTF Group. In DB2 Web Query for i terminology, the PTF Group is also called a test fix. In recent test fixes, the following enhancements were delivered:
•Using workload group controls
•DB2 for IBM z/OS support
•DB2 for Linux, UNIX, and Windows support
•Single sign-on capability with Kerberos
•RESTful web services
•Runtime environment change from Lightweight Infrastructure (LWI) to IBM WebSphere Liberty Profile
For information about the current DB2 Web Query for i PTF Group, see the following website:
8.9 OmniFind Text Search Server for DB2 for i
The OmniFind Text Search Server for DB2 for i (5733-OMF V1R3M0) is available for IBM i 7.2 at no charge. This product is used as a text search engine for documents that are stored in DB2 for i, and it also provides extensions that enable searches for IBM i objects, such as spool files in an output queue or stream files in the Integrated File System (IFS).
A text search collection describes one or more sets of system objects that have their associated text data indexed and searched. For example, a collection might contain an object set of all spool files in output queue QUSRSYS/QEZJOBLOG, or an object set for all stream files in the /home/alice/text_data directory.
The text search collection that is referred to in this document should not be confused with a DB2 schema (sometimes also referred to as a collection) or a Lucene collection (part of the internal structure of a DB2 text search index).
When a text search collection is created, several DB2 objects are created on the system in an SQL schema. The following objects are created in the schema:
•Catalogs for tracking the collection’s configuration
•Catalogs for tracking the objects that are indexed
•SQL stored procedures to administer and search the collection
•A DB2 text search index for indexing the associated text
The administration of the collection is provided with stored procedures, most of which are created in the schema.
In OmniFind Text Search Server for DB2 for i V1R3M0, the following enhancements are included:
•Extensions to index and search non DB2 data:
– Adding an object set for a multiple-member source physical file
– Adding an object set for stream file data
– Altering a text search collection
– Removing object set by attribute:
• Removing object set for spool file data
• Removing object set for stream file data
• Removing an object set for a multiple-member source physical file
•Searching for special characters
•Removing orphaned indexes
•Shutting down a server
•Checking the status and return code for each row in a warning or error state
•RCAC support:
– Creating a secured text search index
– Altering a text search index to secured index
For more information about the enhancements in OmniFind Text Search Server for DB2 for i V1R3M0, see the following resources:
•IBM i 7.2 IBM Knowledge Center:
•And see also the developerWorks OmniFind for IBM i website:
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.