
Chapter 6. Operations
Whenever I see the word Operation, especially Trifling Operation, I at once write off the patient as dead.
George Bernard Shaw
In this chapter, we deal with the issues involved in actually operating your network once you have it installed. We’ll look at how to configure the necessary infrastructure services and network glue such as DNS and firewalls. Finally, we’ll consider some examples of transition and interoperability—how to live peacefully with IPv6 and IPv4 into the foreseeable future.
DNS
DNS is the first service that needs to be configured while you are working with IPv6, since just about every network service of consequence involves converting hostnames to IP addresses and back again. (It’s even more crucial than in IPv4, since the addresses are so much longer to type and harder to remember.)
When you add IPv6 addresses to your existing DNS records, it is worth emphasizing that you are adding them. Your usual IPv4 addresses remain in place and applications that know nothing about IPv6 will continue to use IPv4. Even applications that understand IPv6 but are not yet connected to the IPv6 Internet should work too, since they should “fall back” to the IPv4 addresses once it becomes apparent that IPv6 isn’t connected.
A second important thing to keep in mind is your DNS server doesn’t have to speak IPv6 itself to answer a request for an IPv6 address: any request, irrespective of whether it’s for an IPv4 or IPv6 address, can itself be made over IPv4 or IPv6. In short, this means that you can start adding IPv6 addresses to the DNS without upgrading your nameserver. Answering DNS queries over IPv6 is referred to as using IPv6 transport.
In the following sections we will first look at the relevant record types for including IPv6 addresses in the DNS, and then look at how they fit into the various DNS zone files. Then we’ll look at configuring nameservers to answer requests that arrive over an IPv6 network connection (i.e., IPv6 transport) and finally advertising your nameserver as being available over IPv6.
Once you have some IPv6 DNS records, other IPv6 enabled hosts automatically begin to speak IPv6 to your machines. We look at problems that can arise at this stage.
Record Types
During the design phase of IPv6, there were two competing schemes for how requests for IPv6 addresses would be satisfied: the first scheme was based on a simple generalization of the way that DNS works for IPv4; then later a more complicated scheme was proposed that was designed to allow changes of address prefix more easily, to aid network renumbering. After an epic struggle between the two, the scheme more closely resembling IPv4 has been selected as the standard, though some adjustments have been made to it along the way.
IPv4 DNS lookups
Let’s begin by briefly reviewing how IPv4 DNS requests are conducted. The DNS provides two commonly used services relating to IPv4 addresses: converting hostnames to addresses and converting addresses to hostnames.
Suppose we want to know the IPv4 address for www.example.com. IPv4 addresses
correspond to a DNS record of type “A,” so we send a request to
our local recursive nameserver looking for a
type A record for www.example.com. If this recursive
server does not have the answer cached, then it will send the
request to one of the root servers.
The root server will send a reply that it doesn’t know the A record for www.example.com, but will return NS
records telling us the names of the .com nameservers and possibly A records
for some of these names. These A records are referred to as
glue.
Now our recursive server knows who to ask about .com domains and so picks one of the
nameservers it was told about and asks one of them for the A
records for www.example.com.
The .com nameserver will say it
doesn’t know the A record for www.example.com but, as before, will
return NS records with A record glue so our recursive server knows
who the nameserver for example.com is.
Finally, the recursive server will ask an example.com nameserver for the A record
for www.example.com and will
receive a reply containing the IPv4 address. This response is
forwarded to the client that originally made the request.
The process for converting IPv4 addresses to hostnames is
similar but we look for a PTR record containing a hostname rather
than an A record containing an IPv4 address. There is one
twist—the in-addr.arpa
domain. If we want to know the hostname for 192.0.2.4, it is treated as a lookup for
a PTR record for 4.2.0.192.in-addr.arpa. Where does this
come from? We reverse the order of the 4 parts of the IPv4 address
and then stick in-addr.arpa on
the end. This is because DNS stores the most specific information
at the left hand end of an address, but IP addresses store the
most specific information at the right hand end. Once we have this
name our recursive nameserver asks the nameservers for arpa, in-addr.arpa, ... 4.2.0.192.in-addr.arpa until we find the
PTR record telling us the name for 192.0.2.4.
In summary, IPv4 DNS is built on a mix of A, NS and PTR
records containing IPv4 addresses, nameserver names and hostnames
respectively, where `reverse’ lookups are done in the in-addr.arpa domain.
V6 lookups
The scheme that has been adopted for IPv6 lookups makes the minimum number of changes to the IPv4 method. Instead of A records containing an IPv4 address, a new record type called AAAA (pronounced “quad A”) containing an IPv6 address was created. NS and PTR records remain unchanged and continue to contain hostnames, which are, of course, address-type independent.
Reverse lookup for 2001:0DB8::3210 in this scheme were
originally done by requesting a PTR record for 0.1.2.3.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.int.
So we basically use the “reverse the digits” method from IPv4, but
appending ip6.int rather than
in-addr.arpa. As a matter of
housekeeping this is being moved to looking up 0.1.2.3.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa,
so the ip6.int domain is being
deprecated in favor of ip6.arpa. This format is referred to as
the “reverse nibble” format.
Setting up DNS
Adding an IPv6 address to the DNS is a straight-forward matter. Suppose we have the entries
for example.com as shown in
Example 6-1, and we want
to let people know that www.example.com can be reached at IPv6
address 2001:0DB8::3210, then
all we need to do is add an AAAA record to the zone, as shown in
Example 6-2.
; Zone file for example.com
@ IN SOA ns.example.com. hostmaster.example.com. (
2002101900; Serial
28800 ; Refresh 8 hours
7200 ; Retry 2 hours
604800 ; Expire 7 days
86400 ) ; TTL 1 day
IN NS ns.example.com.
IN NS ns2.example.com.
ns IN A 10.11.12.13
ns2 IN A 192.0.2.6
www IN A 10.11.12.15; Zone file for example.com
@ IN SOA ns.example.com. hostmaster.example.com. (
2002102000; Serial
28800 ; Refresh 8 hours
7200 ; Retry 2 hours
604800 ; Expire 7 days
86400 ) ; TTL 1 day
IN NS ns.example.com.
IN NS ns2.example.com.
ns IN A 10.11.12.13
ns2 IN A 192.0.2.6
www IN A 10.11.12.15
IN AAAA 2001:db8::3210Setting up the reverse entry for this AAAA record is a
little more complicated, as we will need to talk to the provider
of our IPv6 address space to get the appropriate reverse zone
under ip6.arpa delegated to our
nameserver. Delegation is the process of assigning
responsibility for a zone to a particular set of servers, if
you’re not familiar with it you may want to consult DNS
and BIND by Paul Albitz and Cricket Liu (O’Reilly).
The move from ip6.int to
ip6.arpa is, at the time of
writing, proceeding apace, but you may still want the ip6.int domain delegated. Less than one
in five of the reverse queries we see uses the ip6.int domain. Most resolvers check
ip6.arpa only now, but some
resolvers try ip6.int if
lookups in ip6.arpa
fail.
With IPv6 the provider of our address space will usually be
our ISP, or for large organizations, the RIRs. However, if you are
using transitional address space, such an address in the 6to4
2002::/16 block or an address
in the local addressing range, then it may be harder to get the
zone delegated. The system for delegation of 2.0.0.2.ip6.arpa is not yet operational,
but is likely to involve nothing more than visiting a web page
(probably https://6to4.nro.net/) using 6to4. If you
find yourself in the situation where you cannot get the zone
corresponding to your address space delegated, you can run a
nameserver for the zone without delegation. In this case, the
records will only be visible to hosts directly querying your
nameserver, but that may be sufficient for internal needs, such as
preventing programs requesting reverse DNS mappings from timing
out or giving errors.
Once we have the appropriate ip6.arpa zone delegated to our
nameserver, the zones for reverse domains are typically simpler
than those for forward lookups, as shown in Examples Example 6-3 and Example 6-4. The format of the
zone files for ip6.int and
ip6.arpa is identical, so if
you are maintaining both zones, you only need to maintain one
file. Remember to contact the administrators of any DNS servers
that you have listed as nameservers for these zones so that they
can configure their servers to act as DNS secondaries for these
zones.
; Zone file for 11.10.in-addr.arpa
@ IN SOA ns.example.com. hostmaster.example.com. (
2002101900; Serial
28800 ; Refresh 8 hours
7200 ; Retry 2 hours
604800 ; Expire 7 days
86400 ) ; TTL 1 day
IN NS ns.example.com.
IN NS ns2.example.com.
13.12 IN PTR ns.example.com.
15.12 IN PTR www.example.com.; Zone file for 0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.int or
; 0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa
@ IN SOA ns.example.com. hostmaster.example.com. (
2002101900; Serial
28800 ; Refresh 8 hours
7200 ; Retry 2 hours
604800 ; Expire 7 days
86400 ) ; TTL 1 day
IN NS ns.example.com.
IN NS ns2.example.com.
0.1.2.3.0.0.0.0.0.0.0.0.0.0.0.0 IN PTR
www.example.com.Calculating the reverse nibble format for reverse zone
entries can be a bit of a chore, so you may want to use a tool
like Peter Bieringer’s ip6calc,
available from http://www.deepspace6.net/projects/ipv6calc.html.
For example, ipv6calc -in ipv6addr -out revnibbles.arpa ::1 will output 1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.arpa..
Once you have added the forward and reverse DNS entries, you can
check they match up and are visible to the rest of the world using
http://www.maths.tcd.ie/cgi-bin/check_dns.pl.
So, now that we know what the zone files and DNS records look like, how do we actually add them to our DNS configuration? This depends on what DNS server software is being used. We’ll look at the ISC’s BIND package, Dan Bernstein’s djbdns, the Microsoft DNS server and NSD.
- BIND
BIND is the best known DNS server available. BIND 8 has the beginnings of support for IPv6, enough for AAAA records and the new reverse domains.[1] The BIND 8.4 family of releases includes IPv6 transport. BIND 9 has actually offered full IPv6 support for longer than BIND 8 has, but isn’t as fast as BIND 8, so the 8.4 release is to accommodate people with very heavily loaded nameservers who want to offer a service over IPv6.
Most of the Unix-like operating systems we consider ship with BIND, but new versions of BIND can be obtained at http://www.isc.org/products/BIND/ or as extra software packaged by the vendor.
Within BIND, zones are stored as text files, like those shown in Example 6-2 and Example 6-4. Each zone is listed in the file named.conf. To add a record you can just edit the appropriate zone file, but remember to update the serial number in the SOA record. After changing the zone file you have to reload the zone by either restarting the server or by using the ndc reload (BIND 8) or rndc reload (BIND 9) commands.
Example 6-5 shows the part of the named.conf file for
ns.example.com. It shows four zone files for whichns.example.comis the master. The configuration allows192.0.2.6(i.e.,ns2.example.com) to perform zone transfers. The zone files would correspond to those shown in Examples Example 6-2, Example 6-3, and Example 6-4. Note that we use the same zone file for theip6.arpaandip6.intdomains.
zone "example.com" {
type master;
file "example.com.fwd";
allow-transfer { 192.0.2.6; };
};
zone "11.10.in-addr.int" {
type master;
file "example.com.4rev";
allow-transfer { 192.0.2.6; };
};
zone "0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa" {
type master;
file "example.com.6rev";
allow-transfer { 192.0.2.6; };
};
zone "0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa" {
type master;
file "example.com.6rev";
allow-transfer { 192.0.2.6; };
};- djbdns
DJBDNS is Dan Bernstein’s attempt to strip what it means to be a nameserver and a caching resolver down to the bare essentials, and implement only that, with the aim of improving security. In this case, there are two pieces of software you need to think about.
The first is dnscache, which is the caching resolver program. This can successfully retrieve AAAA records. It does not, unless patched, use IPv6 transport.
The second is tinydns, the authoritative nameservice program. Here there are two options. Tinydns includes support for arbitrary record types, which can be input using an octal notation. Example 6-6 shows a little Perl script that can output the records.[2] This script is passed a host name and an IPv6 address. For example tinyaaaa www.example.com 2001:db8::3210, will output a line such as:
:www.example.com:28:�40�01�15270�00�00�00�00�00�00�00�00�00�00�62�20
which can be added to the end of the /service/tinydns/root/data file. You then update tinydns’s database by using the supplied makefile from the tinydns data directory: cd /tinydns/root ; make. PTR records can be handled via tinydns’s "^" record type indicator as usual. Thus, the line for
www.example.comin /service/tinydns/root/data would be:^0.1.2.3.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa: www.example.com.:86400
Felix von Leitner provides a patch for djbdns. It provides easy-to-use tools for the creation of AAAA and reverse records, and also includes support for IPv6 transport. The patch can be found at http://www.fefe.de/dns/. Like all unofficial patches, you may have trouble receiving timely support.
#!/usr/bin/perl
# Script specifically for creating quad A record lines for unpatched tinydns.
# Input taken is the dns name and the address in the usual format;
# ifconfig format is fine.
# Uses the expandv6 function given earlier.
require 'expand.pl';
$name = $ARGV[0] || die ("No name");
$addr = $ARGV[1] || die ("No address");
$addr = &expandv6($addr);
$addr =~ s/://ig;
for ($offs=0;$offs<length($addr);$offs=$offs+2) {
$fqv6[$ind]=substr($addr,$offs,2);
$tmp = $fqv6[$ind];
$ind++;
}
printf(":$name:28:");
foreach $component(@fqv6) {
printf("\%03o", hex("$component"));
}
printf("
");- Microsoft DNS
The DNS server service in Windows 2003 Server family supports IPv6 records and even supports IPv6 transport. Management can be performed using the DNS program under Administrative Tools.
You can add static AAAA records to a zone by selecting a zone, going to the Action menu, choosing Other New Records and selecting IPv6 Host (AAAA). You’ll then be prompted for the name of the host and the IPv6 address in the usual format.
Before you can add PTR records you will first need to create the appropriate reverse zone. You can do this by selecting Reverse Lookup Zones and then choosing New Zone from the Action menu. Choose Primary Zone or Secondary Zone, as appropriate. Next enter the “Reverse lookup zone name” directly rather than using the Network ID. Note that when creating an IPv6 reverse zone you need to enter a zone name ending in
ip6.intorip6.arpabefore you can continue.Once the zone exists, a PTR record can then be added by selecting the zone, choosing New Pointer (PTR) from the Action menu. You must enter the PTR (without the part represented by the zone) into the “Host IP number” field and the hostname into the “Host name” field.
Alternatively, if you feel comfortable directly changing zone files more directly you can use the
dnscmd/RecordDeleteanddnscmd/RecordAdd, or edit the zone files in C:WINDOWSsystem32dns.Many people are familiar with the automatic “register-themselves-in-DNS” behavior of Windows hosts. This behavior extends to IPv6 addresses.[3] Enabling dynamic updates is a property of a zone and can be enabled at the time a zone is created, or can tweaked later by choosing Properties from the Action menu and then adjusting Dynamic Updates under the General tab.
- NSD
NSD is an authoritative-only Nameserver developed by NLNetLabs in association with RIPE. It’s designed to be high performance and to be used by very busy nameservers. For example, it is in use serving the root zone and
.nl.NSD’s zone files are listed in the nsd.zones file. The zones themselves are in the same text format as BIND zone files, so you can edit these in the way described for BIND above. After editing, remember to run nsdc rebuild to build the database from the new files.
From version 2.0.0 of NSD, IPv6 has been enabled by default but can be manually disabled using —disable-ipv6. (Earlier versions of NSD required you to enable IPv6 support yourself using either —enable-ipv6 or by adding -DINET6 to FEATURES—and originally IPv6 support was restricted to KAME-based platforms.) Table 6-1 shows the location of BIND configuration files.
IPv6 Transport
We have covered how to add IPv6 addresses into the DNS, which is (initially at least) likely to be running over IPv4. In this section we discuss how to get DNS running over IPv6. The first step here is to make sure that your DNS server can answer queries over IPv6. This may require a configuration option or, in some cases, a patch to the software. Let us quickly run through the details of the necessary changes for each server.
- BIND
Needs version 8.4 or 9 and listen-on-v6 must be given in the options stanza of named.conf. Example 6-7 shows a typical options stanza for a network—we listen for queries on all IPv4 and IPv6 addresses, but restrict the answering of queries to our own IPv4 and IPv6 subnets (in this example the IPv4 network is NATed).
options {
directory "/etc/namedb";
pid-file "run/named.pid";
listen-on { any; };
listen-on-v6 { any; };
query-source address * port *;
query-source-v6 address * port *;
allow-query { 127.0.0.1; 10.0.0.0/8; 2001:db8:1cc1::/48; ::1; };
allow-transfer { 127.0.0.1; 10.0.0.0/8; 2001:db8:1cc1::/48; ::1; };
allow-recursion { 127.0.0.1; 10.0.0.0/8; 2001:db8:1cc1::/48; ::1; };
};One peculiarity of the BIND 9 listen-on-v6 directive is that it currently only accepts any or none as possible addresses. This limitation has been addressed in BIND 9.3.0.
- djbns
Requires a patch from http://www.fefe.de/dns/.
- Microsoft
IPv6 transport can be enabled with dnscmd
/config/EnableIPv61command and then restart your nameserver with dnscmd/restart. You may need to install dnscmd if you are not already using Windows Support Tools.- NSD
Version 1.1 supported IPv6 transport on KAME platforms, version 1.2 and later have wider support.To verify that the server is responding to queries over IPv6, a tool such as nslookup, host or dig can be used.[4] For example, if
ns.example.comhas address2001:0DB8::3211, then we can use the command dig www.example.com @2001:0DB8::3211 to send a test query. If the query is successful, a selection of records relating towww.example.comwill be shown, otherwise we’d expect a timeout message. (For this to work as expected, you need a version of dig from an IPv6 capable version of BIND.)
Once you are sure that the server is answering queries over
IPv6, it should be safe to begin advertising your IPv6 capable DNS
server. To do this, just add AAAA records for the hostnames listed
as NS records for your zone. Example 6-8 shows our example.com zone with an AAAA record for
ns.example.com.
; Zone file for example.com
@ IN SOA ns.example.com. hostmaster.example.com. (
2002102000; Serial
28800 ; Refresh 8 hours
7200 ; Retry 2 hours
604800 ; Expire 7 days
86400 ) ; TTL 1 day
IN NS ns.example.com.
IN NS ns2.example.com.
ns IN A 10.11.12.13
IN AAAA 2001:db8::3211
ns2 IN A 192.0.2.6
www IN A 10.11.12.15
IN AAAA 2001:db8::3210There are a few points to remember when you do this. First,
remember to add an entry to the corresponding reverse zones. Second,
the zone above you may have a glue A record for your nameserver. If
so, you should contact them and ask for a glue AAAA record too. So,
the example.com administrator
would contact their .com
registrar to ask for an AAAA glue record for ns.example.com. You may also want to think
twice before creating an NS record pointing to a host using an
autoconfigured address. See the Section 6.1.4 later in this
chapter for more details.
Recursive DNS Servers
In Section 5.3.4
in Chapter 5 we
spoke about configuring DNS clients, and we’ve just described how to
set up the zones for authoritative DNS servers. The third part of
the DNS infrastructure consists of recursive servers. These take
simple requests from clients (“What is the AAAA record for www.example.com?”) and figure out the
sequence of authoritative servers that must be contacted to answer
the query.
For the foreseeable future, recursive resolvers will need to be dual stacked. Why? There are many domains that don’t have any authoritative servers that speak IPv6. Your recursive resolver will need to contact these to answer queries, so it will need to speak IPv4.
If dual-stacking all your recursive servers is not an option, then it is possible to set up forwarders. These are DNS servers that receive requests from clients and forward them on to a recursive resolver. Forwarders can also cache the responses from the recursive servers, thus spreading the load. For example, Example 6-9 shows how BIND can be configured to forward requests by adding directives to the options section of named.conf. Multiple forwarders can be listed.
options {
forward only;
forwarders {
2001:db8:4c6:111::53;
2001:db8:4c6:222::53;
};
// Rest of named.conf follows.
};As with authoritative nameservers, you may want to consider the implications of configuring a recursive nameserver with an autoconfigured address, particularly if you will be hard-coding that address into any configuration files.
AAAA bug workarounds
Several authoritative DNS servers have exhibited bugs when queried for AAAA records. There are two variants of the bug. In one variant, the bad authoritative server returns an error to say the domain does not exist. This answer can be cached by a recursive server, which then assumes that no A records exist for the domain. The end result of this is that the domains served by that nameserver become unavailable.
The second variant of this problem is that the bad authoritative server just doesn’t bother replying to queries for AAAA records at all. When the requests time out a request for A records successfully made and things proceed as usual. The end effect of this is a long delay when connecting to the domains served by the bad nameserver.
The correct solution to these problems is to contact the administrator of these problem servers and ask them to have the server fixed. The most commonly impacted servers seem to be DNS-based load balancing systems, of the type used by some busy web sites. Usually the administrators of these servers are eager to resolve such problems, but for some there seems to have been some complications in resolving the problem.
There doesn’t seem to be a good workaround for the first variant of the problem but on the whole it doesn’t cause any side effects other than making the site in question difficult to contact. The second variant is more irritating, because several web based ad servers have this problem. It means that other web sites displaying the ads may also have to suffer the long delay while the AAAA requests timeout.
There are workarounds for this second variant of the problem. One solution is to get your recursive nameserver to respond quickly for the domain. The easiest way to do this is to configure it to be authoritative for the domain and to give it an empty zone file. Example 6-10 shows example lines from a recursive resolver’s named.conf that direct two currently problematic domains to the empty zone file shown in Example 6-11.
zone "uk.adserver.example.net" {
type master;
file "blankzone";
};
zone "de.adserver.example.net" {
type master;
file "blankzone";
};; Empty zone file for quick responses.
@ IN SOA ns.example.com. hostmaster.example.com. (
2003062700 ; Serial
3600 ; Refresh
300 ; Retry
3600000 ; Expire
3600 ) ; Minimum
IN NS ns.example.com.Another solution to this problem that will work with BIND 8
or BIND 9 is to mark these servers as bogus
in your named.conf as you
discover them. This will prevent any queries being made to these
machines. Suppose you find that 192.0.2.99 does not respond to queries
for AAAA records (perhaps by running dig
AAAA www.example.com @192.0.2.99) and you also don’t
want to make queries to 10.76.65.54 because it is a private
address being advertised as a nameserver by some organization,
then you could use the directives shown in Example 6-12 to make BIND
ignore these nameservers from then on.
server 192.0.2.99 { bogus yes; };
server 10.76.65.54 { bogus yes; };This second technique[5] has both advantages and disadvantages relative to the first one. The first technique only requires you to identify the domain name that is causing problems. The second technique requires that you track down the problematic nameserver once you know the problem domain. However, the second technique fixes the problem for all domains that nameserver is responsible for.
Gotchas
Some problems may arise once other hosts begin to contact you over IPv6. For example, if there is some service that you only provide over IPv4, an initial attempt to connect to it over IPv6 might fail, producing a warning message before the client falls back to IPv4. Similarly, IPv6 enabled hosts without a connection to the IPv6 Internet may complain about unavailability of routes before falling back to IPv4. These issues don’t usually cause operational problems, but may confuse or raise the curiosity of users.
A more serious sort of problem is with IPv6 aware programs that do not correctly fall back to IPv4 in the event of the IPv6 connection failing. This problem is more serious, as skilled intervention by a human is required to resume normal operation. The correct solution to this problem is, of course, to contact your vendor and ask for IPv4 fallback to be correctly implemented. If that’s not practical, interim measures might involve either backing out the problem AAAA record or creating a special DNS entry that only has an A record for problem applications.
Examples of these problems are shown in Example 6-13. The first two show warning messages produced on FreeBSD and the final entry shows a buggy telnet client on AIX 4.3.
v6host% rsh www.example.com echo hello connect to address 2001:db8::3210: Connection refused Trying 10.11.12.15... hello v6noroute% ssh www.example.com ssh: connect to address 2001:db8::3210 port 22: No route to host [email protected]'s password: Last login: Wed Oct 23 16:04:03 2002 from v6host www.example.com% aix% telnet www.example.com Trying... telnet: connect: No route to host aix% telnet 10.11.12.15 Trying... Connected to 10.11.12.15. Escape character is '^]'. FreeBSD/i386 (www.example.com) login:
Note that IPv4 only users should never see any of these problems, as they will ignore IPv6 entries in the DNS.
It is also worth checking that your DNS Secondary servers support any new record types you are using. AAAA records are supported by most nameservers, so this shouldn’t be a problem. Some of the more exotic types, such as A6, might not be supported—this could result in a secondary nameserver becoming “lame.”
One other interesting question is the topic of updating
addresses that you put in the DNS. In the case of static manual
addressing or static DHCPv6 the addresses can be managed in the same
way as IPv4 addresses always have been, because they are presumed
constant enough to advertise.[6] However, if you are using IPv6 autoconfiguration then
address changes may be more frequent—a change of Ethernet card or
motherboard may result in a change of address. It may be
particularly important to consider this when the address will be
written in a configuration file. For example, to fully update an NS
record you may have to contact a local registrar to update glue.
Likewise for recursive DNS servers, where the address may be
manually entered into many resolv.conf files. In fact, it might be
useful to dedicate a whole /64 to
a single authoritative or recursive DNS server. This makes it easy
to move such servers within your routing infrastructure, since a /64
can be advertised much more cleanly than multiple /128’s, and also
facilitates anycast DNS service.
Finally, we would recommend resisting any temptation you might feel to put link-local, site-local or any sort of local addresses in the public DNS; it can only lead to confusion and unpleasant surprises. There are ongoing discussions about how this might be made useful and meaningful, but it is far from clear what the eventual conclusion will be.
IPsec
IPsec is a security system operating at a low level common to both IPv4 and IPv6. It has only recently risen out of relative obscurity with the advent of commonly-available virtual private networks (VPNs), but is deserving of more attention than it gets since it attempts to solve the key security problem of today: application independent encryption and authentication of data. In essence it munges headers and encrypts data packets to provide the following services:
- Authentication
The Authentication Header (AH) provides a way to check that a packet came from a given source and that it has not been modified in transit.
- Confidentiality
The contents of packets may be encrypted, preventing people from determining their contents. This is provided by a protocol called Encapsulating Security Payload (ESP).
Both of these services use shared secret keys. These keys can be manually configured, but automatic configuration is generally more flexible, so IPsec defines a protocol for the management of these keys. This allows the use of certificates for the generation and authentication of these shared secrets. IPsec also defines a compression protocol to get around the problem that encrypted traffic is rarely compressible.
To reiterate a point from Section 3.9, the important aspect of IPsec is that it operates far below the application layer. Combined with the system-wide configurability of IPsec, this means it can be used to provide security services to legacy applications. Its use is also required for aspects of Router Renumbering and Mobility, because of the unpleasant security implications of using them in an unauthenticated setting.
The main body of IPsec is defined in RFC 2401. Other RFCs give specific details of the component protocols.
There is a certain degree of alphabet soup to be understood before one wades into the details:
- SA
A Security Association is a key and an algorithm pair used for encryption or authentication between two hosts. It’s a one-way association—you need two of these for a given bidirectional conversation.
- SAD
The Security Association Database is the list of currently known SAs.
- SPI
The Security Parameter Index is a part of the SA. It is a number that allows multiple SAs to exist concurrently between two hosts. This potentially allows different encryption algorithms or keys/algorithms to be used for independent conversations (say SMTP and HTTP to the same host). It also allows you to periodically change keys without interrupting the flow of data.
- SPD
The Security Policy Database contains rules that say which SAs must be applied to which packets.
Configuration
To try to understand all this, let’s consider an example. Suppose you want to allow people to use telnet, but want to make sure it is encrypted. First, you create an entry in the policy database (SPD) that says that telnet packets that are sent or received must be encrypted.
Now, before telnet packets can be sent you must make sure that the hosts at both ends know the algorithms and keys that will be used for encryption. This can be done by manual configuration or by using a protocol called IKE (Internet Key Exchange). An SPI will also be assigned to identify this key/algorithm pair that has been chosen. The local IP address, SPI, key and algorithm will be stored in the SAD on both hosts.
So, when the telnet command is run, the IP stack sees the policy in the SPD saying the packet must be encrypted and consults the SAD to find the correct SA for this packet. It then encrypts the data with the key and sends it off with the SPI in the header.
At the other end, the host receives an encrypted packet, searches its SAD for an entry with matching destination address and SPI. When it finds one, it unencrypts the packet using the specified algorithm/key and passes the data on. The security policy on the receiving host sees that the packet has been decrypted and lets it through. If someone sent an unencrypted packet, then the security policy would cause it to be discarded at this stage.
So, to run through that quickly: the SPD decides if packets need to have IPsec applied, and the SAD contains the list of algorithm/key pairs in use indexed by an identifier, the SPI.
As a concrete of example of this we’ll show how to configure FreeBSD and Solaris to encrypt telnet.
FreeBSD uses the setkey for manual IPsec configuration. Example 6-14 shows input to the setkey program. The add directives create entries in the SA database, we have chosen to create two with SPI 0x534 and 0x776 respectively. We have specified the DES algorithm (in CBC mode) and have given the keys as hexadecimal numbers. The addspd directives create security policies that say packets to or from TCP port 23 on input or output require encryption.
add 2001:db8:b8::1
2001:db8:bcc1::1
esp 0x534 -E des-cbc 0xd4fd9563eede3b07;
add 2001:db8:bcc1::1
2001:db8:b8::1
esp 0x776 -E des-cbc 0xa70864e7df39ae89;
spdadd ::/0[23] ::/0 tcp -P out ipsec esp/transport//require;
spdadd ::/0[23] ::/0 tcp -P in ipsec esp/transport//require;
spdadd ::/0 ::/0[23] tcp -P out ipsec esp/transport//require;
spdadd ::/0 ::/0[23] tcp -P in ipsec esp/transport//require;On Solaris, two separate commands are used to configure the SAD and SPD. The ipseckey command allows the configuration of keys and algorithms and the ipsecconf command allows the definition of policies. Example 6-15 and Example 6-16 shows the corresponding commands for Solaris.
Note that on both ends of the connection we specify the same key and algorithm for a given source, destination and SPI triple.
add esp
spi 0x534
src6 2001:db8:b8::1
dst6 2001:db8:bcc1::1
encralg des encrkey d4fd9563eede3b07
add esp
spi 0x776
src6 2001:db8:bcc1::1
dst6 2001:db8:b8::1
encralg des encrkey a70864e7df39ae89{ dport 23 } ipsec { encr_algs des }
{ sport 23 } ipsec { encr_algs des }Most of the platforms we have mentioned have basic IPsec support for IPv6, allowing this sort of manual configuration. (Table 6-2 shows IPSec configuration commands.) However on some platforms support is not complete, particularly in the area of IKE. IKE is supposed to save you the trouble of configuring keys manually by automatically authenticating, generating and exchanging keys between hosts that wish to communication via IPsec. It also makes use of digital certificates to authenticate remote hosts. Unfortunately, if you wish to use it in a coherent and controlled manner it is (at the moment) tricky, because although interoperability details are getting better, implementation quality varies, and ease of administration leaves something to be desired, never mind that running a certification authority is something few people are willing to do! No doubt the details will be sorted out, refined and documented eventually, but for now we will move on.
OS | IPsec configuration tools |
Solaris | ipseckey and ipsecconf. |
Linux | IPsec available as an add-on from the FreeS/WAN project at http://www.freeswan.org/, and USAGI includes a patch for IPsec over IPv6. pluto is the configuration daemon. |
AIX | Within smit choose Communications Applications and Services → TCP/IP → Configure IP Security (IPv6). |
WinXP | ipsec6 |
Win2003 | ipsec6 |
FreeBSD | setkey |
Mac OS X | setkey |
Tru64 | sysman and ipsecd |
Routing
In this section we’ll look at some of the aspects of configuring IPv6 routers. We’ll begin with the configuration of routing advertisements sent to end hosts, as this is an important area of IPv6 operation that doesn’t have an analogue in IPv4. After that we’ll move on to the configuration of the inter-router protocols.
Router Advertisements and Renumbering
Router Advertisements, as discussed in Section 3.4.2 in Chapter 3, are a way of providing configuration information to hosts on your network. Usually you will not need to do much more than turn on router advertisements and your router will automatically advertise the IPv6 prefixes on the interfaces they have configured.
In some unusual situations you may want to adjust parameters. For example, if you run a wireless network or a dial-up network, then you may want to adjust the lifetimes of the prefixes to be short so that the nodes in the network deprecate them quickly after the router stops advertising them or the node moves out of wireless range. If you adjust the lifetime of a prefix, you may also want to adjust how often the prefix is advertised—the maximum time between advertisements should be less than the lifetime of the prefix to make sure it does not accidently become deprecated.
IOS
On Cisco’s IOS you have to do very little to enable router advertisements—when you enable ipv6 unicast-routing and configure an IPv6 address on an interface, the router will begin to send advertisements and reply to solicitations. More control of router advertisements is available with the ipv6 nd commands, which control neighbor discovery in general. These commands are applied on a per-interface basis. If you don’t want your router sending router advertisements, then you can use ipv6 nd suppress-ra.
JUNOS
On JUNOS, router advertisements are disabled by default but can be
enabled using set protocols router-discovery interface
ifname;. The set protocols router-discovery hierarchy level also
includes statements for configuring which prefixes are advertised
and associated lifetimes and timeouts, for example set protocols router-discovery interface
ifname lifetime 900 sets the advertised
life time to 15 minutes.
KAME’s rtadvd
rtadvd, as the abbreviation might suggest, is the program responsible for performing the Router Advertisement function on (for example) KAME-equipped FreeBSD routers.[7]
By default, rtadvd does its best to behave sensibly; you must specify a list of interfaces to send advertisements on and, if no specific configuration is found, it will read prefixes for the interfaces from the existing routing table and use those as the basis for its advertisements. This examination of the routing/interface configuration is periodic, and actually extends to deprecating prefixes if they are removed by administrator action (or, indeed, automatically) from the routing table. Of course, its default behavior can be overridden by the administrator by means of rtadvd.conf, which, rather bizarrely, is a configuration file in the style of termcap.
The configuration file does have the rather pleasant property of only over-riding the attributes you specify, so in the example shown in Example 6-17 we are altering the prefix advertised for the xl0 interface. Since this is a static route that we wish to advertise, we will have to invoke rtadvd with the -s parameter. Full details of rtadvd can be found in the man pages for rtadvd and rtadvd.conf.
Other route advertisement daemons
Most of the operating systems we’ve mentioned come with a daemon that can perform route advertisement. Unfortunately, other than the basic ideas, there isn’t much in common between the daemons. Only the KAME rtadvd and the Linux radvd daemon operate on more than one platform. The radvd daemon operates on both Linux and BSD systems and is bundled with most Linux distributions or available directly from http://v6web.litech.org/radvd/. It is maintained by Nathan Lutchansky and Pekka Savola.
Table 6-3 shows the daemon/command for each of our platforms. You should be able to consult vendor documentation for the details of each.
Softly softly
Occasionally it may be useful to prohibit RAs or other “noise” across a network. This is often found at exchange points, where it would be inappropriate for members to pollute the commons with advertisements that other routers or hosts might accidentally start using. Example 6-18 shows a configuration file for doing just this on a Cisco router.
interface Ethernet0/0 description A quiet interface, suitable for peering LAN ip address 192.0.2.1 255.255.255.0 ipv6 address 2001:db8:ace:fad::1 ip access-group 101 in no ip redirects no ip proxy-arp ipv6 enable no ipv6 redirects ipv6 nd suppress-ra !
Multiple Routers
Interesting things start to happen if you have more than one router making announcements on the same segment. If they are configured with addresses on the same subnet, then the EUI-64 algorithm will ensure that your host is assigned the same address by each router—but it will have multiple default routes. The behavior that results depends a little on the host’s operating system; however, neighbor unreachability discovery should allow a host to fail over to a second default route if it detects that the first router has gone away. Unfortunately there is no way to control which router will be preferred if there are multiple routers available. In drafts of the router discovery RFC, a field was included to allow routers to advertise themselves as high, medium or low priority. This mechanism is supported by some routers and operating systems, but the preference field was not included in RFC 2461 so you cannot depend on it being present. Work is underway to complete the standardization of advertising more detailed routing information to end hosts, including routes to specific prefixes and if those hosts should have a high, medium or low preference for those routes.
If you have multiple routers in different subnets on the same segment, your host will receive a different address from each router (although the last 64 bits will probably be the same—that’s EUI-64 again). This is fine, technically, but there are other factors you must keep in mind. When making outward connections your host’s IPv6 stack will go through an address selection process, outlined in Section 3.5 in Chapter 3. So be aware that the address you think you’re using might not be the address you’re actually using if multiple prefixes are being advertised on a link.
Routing Protocols
The operation of BGP, OSPF and other routing protocols in an IPv6 environment is startlingly (and mercifully) similar to their IPv4 equivalents. The advantages are obvious—the learning curve is smaller, your existing routing policies will probably migrate, and you can give the illusion of working very hard by staying in late one night and photocopying the IPv4 routing configuration.
Of course, there are gotchas. Some routing protocol implementations don’t cope well if your IPv4 topology is different to your IPv6 layout—that is, if some of your routers aren’t dual stacked. A workaround might be to use a different routing protocol for IPv6 (for example, if your existing network uses OSPF already, you might use IS-IS for IPv6) but that is not to be taken lightly. Aside from the extra administration overhead for your NOC staff, troubleshooting may become needlessly complex when the two different routing protocols make different decisions on the best route to a customer’s site. Though this can also be viewed as a feature: failures of one routing protocol are likely to be independent of the other, providing redundancy when you need it most.
In addition to IOS and JUNOS, we’ll also discuss Quagga, and its ancestor Zebra in this section. Zebra is an implementation of various routing protocols for the Linux and BSD operating systems. Although it is useful it seems to have become somewhat unmaintained; Quagga is a project to further extend Zebra, and appears to be kept more up-to-date. Both include support for IPv6 BGP in its bgpd and for OSPF IPv6 in ospf6d. Zebra does not support IS-IS, but Quagga does.
RIP
RIP is one of the simpler routing protocols to implement, and so IPv6 support for RIP appeared in IOS before it was ready for either IS-IS or OSPF. It’s also very easy to configure.
Example 6-19 shows
how to configure RIP on Cisco IOS. To add ::/0, the default route, to your
announcements on a particular interface use the default-information originate option. If
you only want to send the default route using
RIP, you may substitute default-information only.
! ! Configure RIPv6 with process name "backbone" ! ipv6 router rip backbone ! ! Now configure it on every interface we want to run RIPv6 on ! interface FastEthernet0/0 ipv6 router rip backbone ! ! Send the default route ::/0 to the router on Serial0 ! interface Serial0 ipv6 router rip backbone ipv6 rip backbone default-information originate
On JUNOS, RIP can be configured using the protocols ripng group, which acts just like the IPv4 equivalent protocols rip group.
OSPF
Traditionally, OSPF has been one of the most popular internal routing protocols on the Internet, favoured by service providers and enterprises that have outgrown RIP. That said, the protocol changes to support IPv6 were more fundamental than were required by IS-IS and RIP, so it has come a little late to the IPv6 scene. However, it’s been ratified and implemented by the major vendors, and is ready for deployment. The good news—on the surface, it’s not changed much.
How has OSPF configuration changed on IOS? To run an OSPF command you might be familiar with in IPv4, you probably just want to substitute “ipv6” everywhere you would have typed “ip”—for example, show ipv6 ospf neighbor will list the IPv6 adjacencies that have been formed by the router.
This substitution persists into the configuration. Whereas IS-IS and BGP have been modified to handle IPv4 and IPv6 data together (using address-family subsections of the IS-IS and BGP configurations to separate IPv4 and IPv6) the IPv6 version of OSPF runs as a completely separate process. Where we would configure an IPv4 OSPF process using router ospf 1, we may then configure an IPv6 OSPF process, entirely independently, using ipv6 router ospf 100.
Like most routing protocols, OSPF selects a 32-bit router ID. Usually this will be the IPv4 address of one of the loopback interfaces, but it’s a good idea to configure this explicitly with the router-id command. If you don’t have an IPv4 address on your router, OSPF won’t work until you set this. Any 32-bit number will do as long as it’s unique within your network (which is why an IPv4 address is a reasonable choice, if the router has one).
Perhaps the biggest change between IPv4 and IPv6 OSPF configuration on IOS is entirely cosmetic, but removes a dreadful inconsistency. In BGP, the network statement specifies which subnets you wish to advertise. In OSPF for IPv4, the network statement also specifies a list of subnets, but they are not directly advertised; OSPF is simply enabled on any interfaces that have addresses within those subnets. Then, the prefixes associated with those interfaces (not the original subnets you specified) are inserted into the routing table. It’s enough to make a CCNA weep and a Juniper salesperson jump for joy.
So for IPv6 the network statement has been mercifully removed, and one configures OSPF on a per-interface basis a little like RIP. While configuring an interface, issue ipv6 ospf 100 area 0 to enable OSPF (use the same process number you specified with ipv6 router ospf) and put the interface in area 0.
One artifact of this is that you should explicitly enable OSPF on your loopback interface, if you have one, in order to make sure that its address enters the routing table.
Example 6-20 shows a basic example of how to configure OSPF on a Cisco, and Example 6-21 shows an equivalent configuration under JUNOS.
! ! Configure OSPFv6 with process number 100 ! ipv6 router ospf 100 ! ! Give this process an explicit router-id - must be unique in our OSPF network ! router-id 192.168.0.101 ! ! Log whenever our neighbours appear or disappear ! log-adjacency-changes ! ! Turn on OSPF on our loopback and ethernet interfaces ! interface Loopback0 ipv6 address 2001:DB8:101::/64 ipv6 enable ipv6 ospf 100 area 0 ! interface FastEthernet0/0 ipv6 address 2001:DB8:1::1/64 ipv6 enable ipv6 ospf 100 area 0 !
Integrated IS-IS
IS-IS is of the OSI breed, and has the notable distinction of not running over IP. This is why you must to assign a unique NET id for each router; where other routing protocols might borrow IDs from your IPv4 address pool,[8] IS-IS is truly protocol independent.
Like OSPF, each IS-IS router must be configured with an area
name. Also, an IS-IS router needs a NET, or Network Entity Title.
This is a large number, in a particular format, but most of the
number can pulled from thin air as long as each NET address is
unique within your network. Most sites use the IPv4 loopback
address of the router and pad it out with zeroes so as to appear
in correct format—for example, 192.168.2.1 becomes net 49.0001.1921.6800.2001.00—but you might
choose any convenient system you like that ensures that the number
remains unique. An example configuration is shown in Example 6-22; this enables
IS-IS on the router and turns it on the Fast Ethernet interface,
which will have the effect of adding the interface’s address range
to the IS-IS routing table. It will also start speaking IS-IS to
any other routers on that network that are similarly
configured.
! ! Configure IS-IS in area "backbone" ! router isis backbone ! address-family ipv6 redistribute static ! Optionally, redistribute routes into IS-IS exit-address-family ! ! NET here based on second and third segments of our IPv6 address ! but any other convention may be used. Leading 49.0001 and ! trailing 0000.00 should remain intact. ! net 49.0001.0db8.0008.0000.00 ! ! Now configure it on every interface we want to run IS-IS on ! interface FastEthernet0/0 ipv6 router isis backbone
An equivalent, though slightly more elaborate, configuration for Juniper routers is shown in Example 6-23. Here the ISO address, needed for IS-IS, is specified on the loopback interface, alongside the IPv4 and IPv6 loopbacks. family iso is also specified on the interfaces we want to run IS-IS on, and some tweaking of the IS-IS options takes place under the protocols section of the configuration.
interfaces {
fe-1/0/0 {
description "IPv6 ethernet with IS-IS";
unit 0 {
family iso;
family inet6 {
address 2001:0770:0800:0003::1/64;
}
}
}
lo0 {
description "Loopback interface with ISO address";
unit 0 {
family inet {
filter {
input inbound;
}
address 127.0.0.1/32;
address 193.1.195.17/32;
}
family iso {
address 49.0001.0770.0800.0000.00;
}
family inet6 {
address 2001:0770:0800:0000::/128;
}
}
}
}
protocols{
isis {
no-ipv4-routing;
interface all {
level 1 disable;
}
interface fxp0.0 {
disable;
}
}
}One thing to note is that if you want to use IS-IS to route both your IPv4 and IPv6 traffic, then your IPv4 and IPv6 topology must be the same. However, Juniper and Cisco are offering IS-IS multi-topology extensions to allow separate IS-IS topologies to operate simultaneously.
BGP
Perhaps the routing protocol that has survived the trip from IPv4 to IPv6 most unscathed is BGP. This is somewhat ironic (or perhaps iconic,) since one of the great unsolved problems in IPv6 is how to reign in the inevitable increase in size of the global routing table.
For a basic BGP-4+ configuration, you need the following information:
Your Autonomous System (AS) number,
The prefixes (i.e., addresses) you wish to advertise,
The AS numbers and addresses of your peers’ routers.
If you’ve done BGP in IPv4 land, none of this will be
terribly shocking. If you’ve not configured BGP before, there is
one truism: the routing protocol itself is reasonably simple, but
the odd behaviors that arise from connecting many thousand
networks together can be complex. In particular, if you attempt to
advertise any route other than a /35 or /32, you may encounter difficulty; many
sites filter announcements of networks smaller than these, (and a
few misguided souls even filter networks that are bigger) and so
some parts of the Internet may not be able to reach you.
If you already have an AS number from your IPv4 network, you may re-use this on the IPv6 Internet. Typically BGP is spoken by medium and large ISPs who will have an AS number anyway. Most end sites speaking IPv6 won’t usually need to speak BGP and will not require an AS number.[9] If these sites need to swap IPv6 routing information then they can use one of the other protocols that we have discussed.
One thing that may surprise you, if you are familiar with implementing BGP on Cisco, is what IPv6 does to your existing configuration. The BGP section of the running-config is split into sections by protocol: IPv4 unicast, IPv6 unicast, IPv4 multicast and so on. If you’ve used multi-protocol BGP before, say for MPLS VPNs, then IPv6 will be easy for you since it’s just a new address family. The config for each BGP session is split in two—up top go configuration elements that are protocol-independent, such as the remote router’s AS number. Further down are protocol-specific configurations such as the routes you wish to filter. This is elegant in many ways, as it allows you to maintain separate route-maps and filter lists for your IPv4 and IPv6 data in each peer. At first glance you may find it disconcerting to do a sh run only to find your lovingly crafted IPv4 route maps missing; don’t worry, they’re still there, just keep scrolling.
The address-family split is quite intuitive once you’re used to it, but one consequence is that you have to explicitly activate your peers under the address-family ipv6 section. If you see the error “% Activate the neighbor for the address family first” on a Cisco, you’re either trying a line that needs to go under address-family ipv6, or you need to activate that peer.
As with IPv4, there are differences between internal and external BGP. For example, while you only need to maintain one BGP session with your external peers (typically from the router that connects directly to them), you must still maintain a BGP session with every other router in your own AS, even those routers that aren’t directly connected. This is known as the BGP full mesh. Just as with IPv4, Route Reflectors and BGP Confederations may be used to work around this for larger networks.
The configuration example we’re about to consider assumes that you want to send only IPv6 information over an IPv6 BGP session, and IPv4 information over an IPv4 session. While the syntax allows you to do otherwise, it’s common practice to separate the peerings, even if they run on the same physical link. This keeps next-hops consistent and ensures that transmission problems affecting one protocol[10] don’t affect the other.
Example 6-24 shows a typical BGP-4+ configuration on a Cisco router.
router bgp 65001 ! ! If your router is IPv6 only, you need to specify a router-id ! bgp router-id 192.168.1.2 bgp log-neighbor-changes ! ! Configure an external peer ! neighbor 2001:DB8:FF:AC1::1 remote-as 65002 neighbor 2001:DB8:FF:AC1::1 description Our upstream ISP ! ! Configure a peer within our own AS, originating from our loopback addr ! neighbor 2001:770:8:: remote-as 65001 neighbor 2001:770:8:: description Our other PoP neighbor 2001:770:8:: update-source Loopback0 ! ! IPv4-specific configuration - we must make sure not to send ! any IPv4 routing information over our IPv6 BGP sessions ! address-family ipv4 no neighbor 2001:DB8:FF:AC1::1 activate no neighbor 2001:770:8:: activate exit-address-family ! ! IPv6-specific configuration ! address-family ipv6 ! ! start sending (only) our IPv6 routes to this peer, using filter list 41 ! neighbor 2001:DB8:FF:AC1::1 activate neighbor 2001:DB8:FF:AC1::1 filter-list 41 out ! ! send IPv6 routes to our internal peer, no filtering ! but set the next-hop to our own address instead of the remote router ! neighbor 2001:770:8:: activate neighbor 2001:770:8:: next-hop-self ! ! The prefixes that are local to our network ! network 2001:770::/32 ! exit-address-family ! ! AS-path access-list 41 permits our AS (^$) and our customer, AS 65003 ! ip as-path access-list 41 permit ^$ ip as-path access-list 41 permit _65003$
In line with the list above, the details are:
Our Autonomous System (AS) number: 65001.
The prefixes we wish to advertise:
2001:770::/32.The AS numbers and addresses of our IPv6 peers’ routers: AS65002 is directly connected on
2001:DB8:FF:AC1::1, and the other router in AS1 is at2001:770:8::.
In addition to our own prefix, we have also chosen to advertise routes we have learned from AS65003, so our AS-path access list is configured to permit that announcement.
There is one other thing that might surprise those of us familiar with IPv4 BGP, and it’s not a pleasant surprise either. On a Cisco, if your router is IPv6-only, you will need to explicitly configure a router id for BGP. This is normally selected from the IPv4 addresses configured on the router, but where none are available BGP simply won’t work until a valid router ID is configured. We have reliable reports that this is almost as maddening as forgetting to configure ipv6 unicast-routing.
Finally, don’t forget that most of the BGP commands on IOS have changed from variations on show ip bgp to show bgp ipv6.
On Juniper, the configuration syntax is unbearably similar to that for BGP with IPv4. An example config is shown in Example 6-25.
protocols {
bgp {
export heanet-networks;
group ibgp-v6 {
type internal;
local-address 2001:770:0800::;
family inet6 {
any;
}
neighbor 2001:770:8:: {
description Salinger;
}
neighbor 2001:770:8:B::1 {
description Miranda;
}
neighbor 2001:770:88:8:: {
description Charon;
}
}
group extpeer-v6 {
type external;
family inet6 {
unicast;
}
peer-as 65002;
neighbor 2001:DB8:FF:AC1::1;
}
}
}
policy-options {
prefix-list heanet-v6 {
2001:770::/32;
}
policy-statement heanet-networks {
term Heanet-v6 {
from {
family inet6;
prefix-list heanet-v6;
}
then accept;
}
term ELSE {
then reject;
}
}
}Example 6-26 shows a simple bgpd.conf for Zebra 0.93b. Beware, the syntax for advertising IPv6 prefixes depends somewhat on the version of Zebra/Quagga, so you will want to check the documentation with your version. Fortunately, the bgpd documentation includes a configuration for IPv6 at the end of its info page, which can serve as a handy template.
router bgp 65295 bgp router-id 10.0.0.10 neighbor 2001:db8:a000::c5 remote-as 65481 address-family ipv6 network 2001:db8:8000:1::/32 neighbor 2001:db8a0000:c5 activate exit-address-family
Of course, just because you’re advertising addresses using
BGP doesn’t mean your peers—or indeed, their peers—will accept
them. The rules for this aren’t quite as locked down as they are
in the more mature IPv4 Internet, so you may get away with some
configurations that are frowned upon in certain parts of the
network. In particular, if you attempt to advertise a /48, /64 or any prefix longer than a /35, you are likely to find your
announcements filtered by at least parts of the IPv6
Internet.
Incidentally, as one grows more familiar with BGP, one might begin to see what all the fuss is about regarding tunnels and their impact on performance. One of the metrics that BGP uses to determine the distance between networks is the AS path length (that is, how many autonomous systems there are between you and the destination.) Without some sort of local configuration, an IPv6-in-IPv4 tunnel appears to be no better or worse than a super-fast dedicated fibre optic link. In reality, that tunnel might transit many different IPv4 networks with varying performance. Stories abound of traffic from Dublin to Vienna being routed via California and Japan thanks to unwise tunnelling.[11]
Recommended filter lists are to be found, however, and as a matter of best practice should be followed, especially if you provide transit to network other than your own. Gert Doring maintains such a Best Current Practice list at http://www.space.net/~gert/RIPE/ipv6-filters.html and groups such as Cymru provide “bogon” lists at http://www.cymru.com/Documents/bogonv6-list.html.
Multicast Routing
Beyond link-local multicast, the deployment of IPv6 multicast is still at a relatively early stage. IPv6 multicast routing involves additional daemons, but most implementations lack full support at the time of writing. KAME provide PIM implementations pim6dd and pim6sd so deploying multicast routers based on the KAME platform has become popular.
For now, if you are interested in multicast routing in IPv6, we suggest you join M6Bone, the experimental IPv6 multicast network at http://www.m6bone.net/.
Firewalls
In this section we’ll look at IPv6 and firewalling, or in particular, packet filtering. Packet filtering, in general, is the process of examining packets as they enter and exit a network and making a decision about allowing them through or dropping them. Usually packet filters allow you to make decisions on factors such as:
Protocol (e.g., TCP, UDP, or ICMP)
Source and destination port number/ICMP type (e.g., 80 is HTTP; 25 is SMTP)
Source and destination IP address
Incoming and outgoing interface
TCP flags, sequence numbers and window values
IP fragmentation offset and size
The rules used to filter packets can either be statically configured or rules may be updated dynamically by the traffic itself. For example, TCP data traffic may only be passed if the normal 3-way handshake has been completed. These sorts of dynamic rules are referred to as stateful packet filtering.
Many existing packet filters offer additional features, such as packet normalization (where unusual looking IP streams are normalized before being allowed through the firewall), sequence number rewriting (where TCP initial sequence numbers are made more random), transparent proxying (where HTTP connections are redirected to a proxy server without the client’s knowledge) or NAT (where several machines are made to appear as a single IP address).
Most of what is known about IPv4 packet filtering applies directly to the IPv6 situation, as layer 3 (TCP and UDP) and above are largely the same in both IPv4 and IPv6. There are a few differences at the lower layers, though.
Note that the examples in this section are given in a Cisco IOS ACL-like format. These are intended as the sort of rules that you may want to include in a packet filter rule set. They will need to be translated so that they have the correct syntax for your platform.
Filtering on IPv6 Addresses
The obvious difference is that we must now filter on IPv6 addresses. Less obvious is the fact that most devices will now have multiple IPv6 addresses, and so you may need to have several rules where one was sufficient in the IPv4 case.
Furthermore, different types of IPv6 address are also common, so you may have to consider the filtering of link-local and anycast addresses.
However, filtering of link-local addresses is not usually necessary, as link-local traffic should not be forwarded between networks. Still, if you happen to have filtering (layer 2) switches that filter within a single logical network, you may have to consider what needs to be done with link-local traffic.
Regardless of their future, site-local addresses will almost certainly require filtering, to prevent the leak of site-local traffic to and from your site. Naturally, this requires deciding where the boundary of your site is and then configuring the packet-filters on the boundary routers to keep site-local traffic completely internal. One of the factors that was held against the original site-local addressing scheme was confusion when a router was a member of more than one site. If you are not using site-local addresses, then it should be safe to block their use at all firewalls within your network.
The use of link-local multicast addresses is central to the correct operation of IPv6, and so you should think very carefully about applying filtering to these addresses. Most of the important link-local multicast traffic is ICMP traffic used for neighbor discovery (see the Section 3.4 section in Chapter 3).
There are also other special addresses to be considered within
IPv6. The loopback address ::1
needs to treated in the same way as 127.0.0.1. The IPv4 address space is also
embedded in the IPv6 address space as mapped addresses ::ffff:0.0.0.0/96, compatible addresses
::0.0.0.0/96 and 6to4 addresses
2002::/16.
Filtering ICMPv6
With IPv4, protocols such as ARP are used to provide low-level IP to MAC translations (see the Section 1.4 section in Chapter 1). ARP is a non-IP protocol, and so has never been an important factor when designing rules for IP packet filters.
In IPv6 these functions are provided by Neighbor Discovery, which is at the ICMP level, so we must now consider this when designing rules. Similarly, as autoconfiguration can now be driven by routers as well as DHCP servers, we must also account for this. So, any packet filtering put in place must allow Router Discovery to happen. We also have to remember that both Neighbor Discovery and Router Discovery use multicast.
One approach to this is to allow ICMP traffic to and from
link-local addresses. We also need to allow traffic from the
unspecified address :: and to the
link-scope multicast addresses to accommodate Duplicate Address
Detection. Here’s an example of the sort of rules necessary:
! DAD (unspec -> link-local multicast) permit ipv6-icmp from :: to ff02::/16 ! RS, RA, NS, NA (link-local unicast -> link-local unicast or multicast) permit ipv6-icmp from fe80::/10 to fe80::/10 permit ipv6-icmp from fe80::/10 to ff02::/16
As a safety net against foot-shooting, recent versions of Cisco’s IOS supplement the usual implicit `deny all’ with additional implicit rules permit icmp any any nd-na and permit icmp any any nd-ns. This shows the alternative approach of explicitly allowing the ICMP messages you want, rather than allowing traffic with addresses in the right range.
It is also important to remember that IPv6 is more sensitive to the filtering of ICMP error messages relating to path MTU discovery, so it is not possible to filter out all ICMP messages, as some networks have chosen to do for IPv4.
Ingress and Egress Filtering
Ingress and egress filtering usually refer to checking that packets have appropriate source and destination addresses before they enter or leave your site. This sort of filtering is considered important in preventing IP spoofing, and in particular anonymous attacks on hosts.
As packets enter our site we need to check that the source address of the packet does not claim to be within our site. We could check that a packet’s destination is one of the following:
The filtering router’s link-local or global address
An appropriate multicast address
An appropriate site-local address (if site-local addresses are in use)
A global address within the site
The decision to allow or deny traffic with site-local addresses will depend on where the filter is in a site and if that site exchanges site-local traffic with other sites. If site-local addresses are not in use, then it should be safe to block all site-local traffic on border routers.
Naturally you may want to filter incoming traffic to certain addresses and ports, as you would with IPv4. Less important is the screening of packets on ingress for destination addresses not in your site. Such packets are unusual, as odd-ball destination addresses should not be routed toward your site in the first place.
To prevent nodes within our site impersonating nodes in the networks of others we need to check that the source address is within our site or is the router itself. The router itself might include a link-local address and the unspecified address if you are not applying the rules discussed in the previous section, Section 6.4.2, although allowing link-local traffic of a non-ICMP type can also be useful. You may also want to check that the destination address is not without your site, to prevent misrouted traffic from looping.
Example 6-27 shows a simple implementation of these rules. In the example, variables are set to represent the network on the inside of the packet filter host and the address of the packet filter itself.
! Ingress filtering applied to incoming packets on external interface. deny ipv6 from $inside_network to any ! Egress filtering applied to outgoing packets on external interface. deny ipv6 from any to $inside_network permit ipv6 from fe80::/10 to any permit ipv6 from $filter_ip_address to any out permit ipv6 from $inside_network to any
Suspicious Addresses
In IPv4 there are certain addresses that, if seen on the wire, are considered suspicious. Packets with these addresses are often filtered to prevent any confusion they might cause. The sort of addresses considered suspicious are the loopback address, private addresses, and subnet broadcast addresses.
Example 6-28 shows the sort of rules that you might consider. It includes filtering out all mapped addresses, compatible addresses (or a subset of them that are based on special use IPv4 addresses) and 6to4 addresses that are based on special IPv4 addresses. We also filter well-known site-local multicast traffic, which would normally have no reason to cross a border router.
! Disallow mapped addresses, as they shouldn't be on the wire. deny ipv6 from ::ffff:0.0.0.0/96 to any deny ipv6 from any to ::ffff:0.0.0.0/96 ! Denying automatically tunnelled traffic using compatible addresses deny ipv6 from ::0.0.0.0/96 to any deny ipv6 from any to ::0.0.0.0/96 ! If some compatible addresses are allowed, ! then these should probably be filtered. deny ipv6 from ::224.0.0.0/100 to any deny ipv6 from any to ::224.0.0.0/100 deny ipv6 from ::127.0.0.0/104 to any deny ipv6 from any to ::127.0.0.0/104 deny ipv6 from ::0.0.0.0/104 to any deny ipv6 from any to ::0.0.0.0/104 deny ipv6 from ::255.0.0.0/104 to any deny ipv6 from any to ::255.0.0.0/104 ! Disallow packets to malicious 6to4 prefix. deny ipv6 from 2002:e000::/20 to any deny ipv6 from any to 2002:e000::/20 deny ipv6 from 2002:7f00::/24 to any deny ipv6 from any to 2002:7f00::/24 deny ipv6 from 2002:0000::/24 to any deny ipv6 from any to 2002:0000::/24 deny ipv6 from 2002:ff00::/24 to any deny ipv6 from any to 2002:ff00::/24 deny ipv6 from 2002:0a00::/24 to any deny ipv6 from any to 2002:0a00::/24 deny ipv6 from 2002:ac10::/28 to any deny ipv6 from any to 2002:ac10::/28 deny ipv6 from 2002:c0a8::/32 to any deny ipv6 from any to 2002:c0a8::/32 ! Filter site-local multicast. deny ipv6 from ff05::/16 to any deny ipv6 from any to ff05::/16
Packages Available for IPv6 Firewalling
There is a great deal of variability in the packet filtering software available on various platforms, so we will not go into details of each package. All software should be able to support the basic rules described in the preceeding sections, so it is only a matter of consulting vendor documentation to determine the correct syntax. However, we will take a moment to mention some of the packages available.
Linux supports IPv6 packet filtering using the ip6tables command, the basic setup of which are covered in Peter Bieringer IPv6 HOWTO at http://www.bieringer.de/linux/IPv6/IPv6-HOWTO/IPv6-HOWTO.html.
FreeBSD and Mac OS Panther also support IPv6 packet filtering using the ip6fw. Documentation is available in the man page and the basic rule sets are listed in /etc/rc.firewall6. On Panther rules can also be adjusted using the network control panel. The ip6fw command does not have as comprehensive set of features as provided for IPv4 by the ipfw command.
Recent versions of FreeBSD also ship with an IPv6 capable version of Darren Reed’s IPFilter. IPFilter also supports other platforms such as Solaris and BSD/OS. Further documentation is available at http://coombs.anu.edu.au/~avalon/. Recent 5.X releases of FreeBSD also ship with the pf packet filter from OpenBSD, which has full IPv6 support.
Cisco support for IPv6 access lists is quite complete and the Cisco document Implementing Security for IPv6 provides details and examples of how these can be configured. Cisco’s firewall products are just beginning to include IPv6 support and should be should be mainstream in the near future.
At the time of writing, Checkpoint have been offering IPv6 for some time and Netscreen have announced comprehensive IPv6 support in their ScreenOS integrated firewall and VPN product.
Windows XP Service Pack 2 (or the Advanced Networking Pack for earlier versions of Windows XP) includes a personal firewall called the IPv6 Internet Connection Firewall. It provides basic stateful firewalling for IPv6 for a single host. It is actually a regular Windows Service, so once installed it can be enabled and disabled using the Services Administrative Tool. Fine control over the firewall is available using netsh firewall, including per-port and per-interface controls.
Impact of IPv6 Deployment on IPv4 Filtering
If your IPv6 connectivity is via an IPv6-in-IPv4 tunnel of some sort (e.g., either a configured tunnel or 6to4), then you may have to allow this traffic through your IPv4 packet-filter. As we’ve mentioned several times, this traffic operates on IPv4 protocol 41.
IPv4 filtering can also be indirectly affected by IPv6 deployment because packets may be sent to dual-stacked hosts via IPv6. This means a service blocked by the IPv4 firewall may be accessible over IPv6, unless the IPv6 firewall is appropriately configured.
While not directly an IPv6 issue, the increased availability of IPsec in the IPv6 world brings up some thorny issues for the network administrator. When ESP is used to encrypt the payload of an IPv6 packet, it is not possible to examine any of the encrypted fields in the packet, which may make it impossible to tell if the packet is a UDP or TCP packet, what the port numbers are and what any TCP sequence numbers might be. Some limited control could be exerted over encrypted traffic by limiting access to IKE, the system used to dynamically establishes keys for IPsec. It runs on UDP port 500, and could be filtered normally. However, if static keys are used, or dynamic keys are established using some other protocol then all bets are off.
Port Scanning
Particular forms of port scanning are rendered ineffective by IPv6’s large address space. In particular, if someone chooses an IPv4 address at random then the chances are reasonably good that they will hit a live machine. In the IPv6 world, the chance of them hitting a live machine is hugely reduced. This makes randomly targeting machines for port scanning, virus infection or other malicious traffic a much less practical strategy. Hopefully this means that we will never see anything like the SQL Slammer in the IPv6 Internet.
While not actually a packet filtering issue, it is an issue that is linked with firewalling in many people’s minds. In particular, some people have used NAT to try and reduce their statistical exposure to random port scanning, by reducing the number of public addresses they use. It is interesting to see that IPv6 handles this problem by going to the other extreme!
Gotchas
Dealing with autoconfiguration and privacy addressing is something that can make IPv6 packet filtering a little tricky. Remember that if you use autoconfiguration (rather than DHCPv6 or manual configuration of addresses) then a change of network card can result in a change of IPv6 address. So, if your firewall rules mention any autoconfigured IPv6 addresses then the rules need to be kept up to date. One way to get around this is to explicitly assign addresses to hosts that are mentioned in your firewall rules, rather than assigning them automatically.
A variation of this idea is to assign addresses to specific services you offer, rather than to hosts. In this scheme, you might have a host that offers an SMTP and a HTTP service, but you give the host multiple addresses and advertise one address for SMTP and one address for HTTP. The firewall rules can reflect this by only allowing SMTP to the SMTP address and only allowing HTTP to the HTTP address, thus reducing the chance of unexpected interactions between services and firewall rules.
Another way to tackle the problem of autoconfigured hosts
changing address is to put the hosts with different firewall
requirements in different networks and use router advertisements to
assign different prefixes. This allows your firewall to match on
prefix rather than worrying about Interface IDs. Remember that you
have a lot of subnets to play with in a /48.
Privacy addressing is the technique where a host generates a
new, effectively random, address for itself periodically (see the
Section 3.4.2 in Chapter 3 for more details). Again, if
a host is using these addresses it may complicate packet filtering.
However, the prefix of these addresses will all be the same, so if
the firewall requirements of all addresses with one prefix are the
same, then you don’t need to worry about this. The equivalent of
statically configuring addresses here is to disable privacy
addressing. This can be achieved on Windows (where it is on by
default) using the command nets
h interface ipv6 set privacy state=disabled. On most other platforms
privacy addressing is off by default, but can be turned on if
desired: for example, sysctl
-w net.inet6.ip6.use_tempaddr=1 on
KAME.
When designing firewall rules, remember that you need to let enough ICMPv6 messages through to allow local neighbor discovery and Path MTU discovery to work. In particular, blocking ICMPv6 errors will cause problems because Packet Too Big messages will be lost. The obvious symptom of this broken path MTU discovery is that TCP connections hang when they have to transfer large amounts of data.
In an effort to allow Packet Too Big messages, one of the authors had carefully configured a FreeBSD firewall to pass ICMP messages with the command allow icmp from any to any, not realizing that the correct command was allow ipv6-icmp from any to any. The incorrect command was actually legal allowing (meaningless) ICMPv4 datagrams in IPv6 packets. The moral? Read your packet filter’s documentation carefully to find differences between the IPv4 and IPv6 syntax.
Management
Any moderate-size network will have mechanisms for the automatic configuration and monitoring of the network. We’ve already talked about IPv6 autoconfiguration, but we’ll mention DHCPv6 in this section again. We’ll also take a look at the state of SNMP for IPv6.
Running DHCPv6
At the time of writing, the 800-pound gorilla of DHCP implementations, ISC DHCPd, does not support IPv6. More importantly, most of the operating systems we have mentioned do not yet support configuration via DHCPv6.
If you cannot wait, there are a variety of implementations out there. For example, HP provide a dhcpv6d for HP-UX, and also include a client. KAME has a minimal DHCPv6 implementation, which isn’t really designed for managing addresses, but can provide simple additional configuration information. In particular, it can be used to distribute the address of the local DNS server. The setup of their small server and client programs is described at http://www.kame.net/newsletter/20030411/. The only additional advice we can add is to explicitly specify the location of the client and server configuration files using the -c option to dhcp6c and dhcp6s.
There is a port of the KAME DHCPd to Linux available from http://sourceforge.net/projects/dhcpv6. It actually includes more complete address assignment features.
With respect to integrating the DHCP and DHCPv6 services, at the moment, the closest you can get is running the two in parallel from the same information and have both servers hand out static addresses to given MAC addresses. DHCPv6 is not currently capable of carrying IPv4 specific information and vice versa.
SNMP
SNMP has two parts that need to support IPv6. The protocol itself, which as the name suggests is extremely simple, doesn’t require much modification to run over IPv6. The information that SNMP manages, or MIBs as they are known, requires significantly more work because new MIBS are needed that can contain IPv6 addresses or concepts specific to IPv6. The basic changes for SNMP and IPv6 are in RFC 3291 and there are a new set of IPv6 related MIBs to follow.
Promiscuous IPsec in IPv6 has the potential to fix a lot of the arguments that took place over the security of SNMP—arguments that resulted in the vast majority of management systems exchanging important information over plain-text, essentially unauthenticated UDP packets.
The split between IPv6 support for the protocol and IPv6 for the information is very like the split in DNS between IPv6 transport and IPv6 records. It is possible to have equipment that can transport IPv6 MIBs over IPv4 and vice versa. This means that dual-stacked SNMP devices can be managed from IPv4-only management stations.
If you aim to operate an IPv6-only network, you will want to check with vendors of your switches, routers, management stations and other devices to ensure that they support IPv6 transport. At least JUNOS and recent releases of NET-SNMP[12] are known to. We’ll comment on the support in NET-SNMP as it is used on a wide range of platforms and its syntax is a little unusual.
IPv6 support for NET-SNMP is integrated into the 5.0.X family of releases. You can enable support for IPv6 MIBs and IPv6 transport independently at compile time by giving the configure program the option —with-mib-modules="mibII/ipv6" or —with-transports="UDPIPv6" respectively.
NET-SNMP’s SNMP agent is called snmpd and when given no options listens on all IPv4 addresses. You can give a list of alternative transports to use on the command line, for example snmpd udpv6::: udp:0.0.0.0 tells it to listen on the IPv6 unspecified address and the IPv4 unspecified address, resulting in an agent listening on all IPv4 and IPv6 addresses.
You also need to set up access controls for IPv4 and IPv6
addresses in snmpd.conf. Three
directives are provided for doing this: rocommunity6, rwcommunity6 and com2sec6. These are like their IPv4
counterparts but accept IPv6 hostnames, addresses and CIDR blocks.
For example rwcommunity6 private ::1 allows read-write access from the IPv6
localhost address, and rocommunity6 public 2001:db8:68::/48 allows read-only access
from that /48. The snmpd.conf manual page explains these
directives in more detail.
NET-SNMP is also used as a SNMP client, and can be told to
make IPv6 transport SNMP requests using a similar syntax to that
used for snmpd. The command
snmpwalk -v 1 -c
public udp6:router.example.com would attempt to
use IPv6 to contact router.example.com to display a subtree of
the available SNMP information (using SNMP Version 1).
Possibly the best news for IPv6 SNMP users is that MRTG, the popular tool for plotting statistics based on SNMP, supports IPv6 from the 2.10 family of releases.
Scripting Network Monitoring
In addition to the sort of network monitoring performed using SNMP, many people have built monitoring systems of their own by scripting common commands to check that networks are reachable, routes are sensible and web servers are responding.
These systems are usually built around ping, traceroute and other simple commands. Naturally, any such scripts will need to be either duplicated or modified so that they can monitor both IPv4 and IPv6 network services. Probably the only thing of significant note here is to remember that many commands automatically fall back to IPv4 if an IPv6 connection fails. If this is the case for any commands you are using, you’ll want to specify that IPv6 must be used on the command line (either by using an IPv6 only command like ping6 or by using flags like -6 or -f inet6).
Remember that you have some additional facilities, such as multicast and node information queries, when you are designing an IPv6 monitoring system.
Intrusion Detection
Intrusion Detection Systems (IDS) have become popular in some networking circles in the last few years. Unfortunately, vendors of intrusion detection products seem to have been relatively slow to provide IPv6 support. There is even a reported case of break-ins where IPv6 has been configured on systems after they are compromised, because the crackers know that IPv6 is less likely to be analyzed fully by IDSs.
Help is at hand though. Snort 2 has experimental support for IPv6 (available from http://www.snort.org/) and Lance Spitzner has been talking about IPv6 and honeypots, which is likely to increase the level of interest and support in this area.
Providing Transition Mechanisms
In this section we’ll look at how you might provide infrastructure for two of the transition mechanisms that we discussed in Section 4.1. First we look at 6to4 Relay Routers. These might useful be deployed either by an ISP or at the border of a large organization that has a number of 6to4 users internally.
Second we’ll look at the configuration of the KAME faith system. This is an implementation of TRT, and so we also cover a DNS server, totd, that can convert DNS A records into AAAA records.
We’ll also look at how VLANs and other similar mechanisms can be used to provide IPv6 without disturbing existing IPv4 infrastructure.
We’d like to be able to describe good software to allow an ISP manage tunnels to their customers. Unfortunately, at the time of writing, we are not aware of any generally available software for doing this. It is possible that operation of such software is too ISP specific, probably requiring integration with billing systems and customer databases. One quick solution to this problem would be to become a POP for some tunnel broker service such as http://www.sixxs.net/.
We’ll talk about the more service-oriented transition mechanisms, application proxies and port forwarding in particular, in Chapter 7.
6to4 Relay Routers
Setting up a 6to4 relay router is actually quite a good way for an ISP to begin offering IPv6 services. Currently if an ISP’s customers use 6to4 as a way to experiment with IPv6, their traffic may travel around the world before reaching the IPv6 Internet. Provision of a relay router allows an ISP to route this traffic, destined for the IPv6 Internet, via a transit carrier that supports native or tunnelled IPv6 traffic. This should offer more direct routes for customer traffic.
Why offer a relay router and not some other form of IPv6 connectivity? A relay router requires only one router to be configured for IPv6. It offers the ISP a chance to get some IPv6 experience without a huge outlay of time or money. The router itself should be low maintenance once set up (similar to normal router maintenance). The service offered to customers requires no per-customer setup or support services at the ISP’s end. Even if the router does fail, the use of anycast means that the traffic should automatically fail-over to the next closest relay router.
To deploy a 6to4 relay router you’ll need:
A machine capable of IPv6 forwarding that supports 6to4 pseudo-interfaces
A connection to the IPv4 network where you can advertise a route to
192.88.99.0/24at least locallyA connection to the IPv6 Internet (either natively or via a tunnel) where you may want to advertise
2002::/16
The requirements for a 6to4 relay router are covered in RFC 3068. This RFC is only eight pages long and should be read by anyone deploying a relay router. It covers the configuration of a relay router, advertising it into local and global routing tables, monitoring and fault tracking.
One issue with 6to4 relay routers is that they can be used as a packet laundering service by unscrupulous network users. For this reason you may wish to restrict who has access to your relay routers at appropriate ingress points.
Example 6-29 shows
the configuration of a 6to4 relay router under IOS. The router’s
loopback address is 192.0.2.4 and
we also configure a corresponding 6to4 address 2002:c000:0204::1. The IPv4 anycast
address for 6to4, 192.88.99.1, is
also configured on the lookback interface. We then configure a 6to4
tunnelling interface. We finally configure OSPF to advertise the
anycast address into out IGP. This will result in 6to4 traffic being
drawn toward this router. Note that we do not show the configuration
of the interface providing IPv4 or IPv6 connectivity.
There is one unusual aspect of this configuration, and that is
the “anycast” argument used in the configuration of the 2002:C058:6301:: address on this tunnel
interface. This marks the address as an IPv6 anycast address, which
for a time was only supported in beta versions of IOS, but became
mainstream in 12.2(25)S and 12.3(4)T. Some operators report that
Windows XP 6to4 clients work better when the anycast flag is not set
on the relay.
interface Loopback0 description 6to4 Relay anycast address & Equivalent IPv4 unicast address ip address 192.88.99.1 255.255.255.0 secondary ip address 192.0.2.4 255.255.255.255 ipv6 address 2002:c000:0204::1/128 ipv6 mtu 1480 no ipv6 mfib fast ! interface Tunnel2002 description anycast 6to4 Relay no ip address no ip redirects ipv6 address 2002:C058:6301::/128 anycast ipv6 unnumbered Loopback0 no ipv6 mfib fast tunnel source Loopback0 tunnel mode ipv6ip 6to4 tunnel path-mtu-discovery ! router ospf 1 log-adjacency-changes auto-cost reference-bandwidth 10000 network 192.88.99.0 0.0.0.255 area 0 !
One thing to note is that you may want to manually configure your router’s BGP/OSPF ID manually if you are using any IPv4 anycast addresses. Otherwise you may risk your router choosing the IPv4 anycast address as its router ID, and this may lead to confusion because router IDs are supposed to be unique.
Faith
Faith is a special case proxy; it does IPv6 to IPv4 translation, but using TCP only. As you might imagine, it’s used on dual-stack machines to connect an IPv6-only network to some portion of an IPv4 network. The interesting thing about faithd is that it determines the endpoint of the IPv4 connection by looking at the last 32 bits of the IPv6 destination. It can be useful for general port proxying to NAT friendly services, but also has special support for FTP and rlogin, that are not so NAT friendly. Perhaps the most useful feature of faithd is that it allows you to do TRT for all of the IPv4 address space without configuring 232 addresses on a machine.
Faith is available on KAME-based platforms, and example
configurations are included in the man page. We’ll show an example of how to
allow IPv6 hosts to make telnet connections to IPv4 only hosts.
We’ll consider four hosts: an IPv6 only client, the dual-stacked
host running faithd, the DNS
translator and the regular recursive DNS server. We also need a
block of addresses to use with faith and a block of addresses for
the IPv6 only hosts, we’ll use 2001:db8:68:fa17::/64 and 2001:db8:68:1ff::/64 respectively.
On the IPv6 only client, we set the nameserver to be the address of the DNS translator either by editing resolv.conf or by using DHCPv6.
On the DNS translator we install Feico Dillema’s
totd, a translating DNS server,
available from http://www.vermicelli.pasta.cs.uit.no/ipv6/software.html.
This daemon works like a forwarding DNS server, but we configure it
so that if it sees a request for a host having no IPv6 DNS record
then it takes its IPv4 address a.b.c.d and makes up a IPv6 DNS record
2001:db8:68:fa17::a.b.c.d, making
the host appear to be in our block of addresses used for
faith.
Example 6-30 shows the configuration file for totd used to achieve this translation. Totd is only a forwarding nameserver, so we first point it at the usual resolving nameserver for the network. Second, we configure the prefix that the IPv4 addresses are to be mapped in to.
; Set the address of the real nameserver. forwarder 2001:db8:68:1ff:202:b3ff:fe65:604b port 53 ; Prefix to map IPv4 addresses into. prefix 2001:db8:68:fa17::
Next, we need to configure your network so that packets for
2001:db8:68:fa17::/64 are routed
to the host running faithd. If
the router for your IPv6-only subnet happens to be the host running
faithd, there will be no
configuration needed. Otherwise you will need to adjust the static
or dynamic routing to forward these packets to the faithd host.
Finally, we need to configure faithd itself. Example 6-31 shows a sequence of commands to configure faithd. First we enable the use of faith and enable the special faith interface. We then route packets to the faith prefix via that interface.[13] Then we create the faithd.conf file, allowing access from clients in our IPv6 only subnet to any IPv4 address. The final step is to start faithd, asking it to proxy the telnet service. If we also wanted it to proxy other services, we could run additional instances of faithd.
sysctl net.inet6.ip6.keepfaith=1 ifconfig faith0 up route add -inet6 2001:db8:68:fa17:: -prefixlen 64 ::1 route change -inet6 2001:db8:68:fa17:: -prefixlen 64 -ifp faith0 echo "2001:db8:68:1ff::/64 permit 0.0.0.0/0" > /etc/faithd.conf faithd telnet
The setup is now complete. If a user on the IPv6 only network
tries to telnet to v4only.example.com that happens to have
IPv4 address 192.0.2.15, then the
DNS translator will fabricate the address 2001:db8:68:fa17::c000:020f. The IPv6 only
host will make a connection to this address, that will be routed to
the faithd host. Faithd will make
an IPv4 connection to 192.0.2.15
and relay the data back and forth.
Faithd will work well with NAT friendly protocols that don’t embed addresses. It also knows how to do the necessary protocol magic to make FTP work, and can be extended to support other protocols.
Hacking Native Connectivity Around Incompatible Equipment
We all want native IPv6, but some of us have hardware that doesn’t support it yet. An across-the-board upgrade is likely to be an expensive proposition, but all is not lost; there are ways one can work around incompatible hardware instead of replacing it or relying indefinitely on the IETF-defined transition mechanisms already discussed.
When your gateway router doesn’t support IPv6
For example, the IPv4 router on a LAN doesn’t necessarily need to be the same device as your IPv6 router. If you have a dedicated IPv4 router on your LAN, this might already be obvious. You can add a second router to act as your IPv6 gateway, as shown in Figure 6-1.

However, a common option these days is to use an intelligent layer 3 switch, rather than a router, to provide switching and IP routing in the same device. If this switch does not support IPv6 yet, what options do you have? Well, the decoupling still applies.
The way Cisco (at least) configure routing on a layer 3 switch[14] is to create a virtual interface on the VLAN of your choice. This virtual interface can then be assigned an IPv4 address, and that IPv4 address will typically be used as the gateway address when configuring your hosts. Such a configuration is shown in Example 6-32.
interface Vlan1 description IPv4 gateway for office LAN ip address 192.0.1.1 255.255.255.0 ! interface Vlan2 description IPv4 gateway for server LAN ip address 192.0.2.1 255.255.255.0 ! interface Vlan3 description IPv4 gateway for DMZ ip adderss 192.0.3.1 255.255.255.0 ! interface FastEthernet0/0 description Trunked uplink to IPv6 gateway switchmode trunk encapsulation dot1q switchport mode trunk !
If your switch software does not support IPv6 yet, then you cannot assign an IPv6 address to this virtual interface. However, you can place an IPv6 capable router on a port on your switch, configure that port in the desired VLAN and give that device an IPv6 address. The new router will then announce its presence on the VLAN and your hosts will autoconfigure themselves. Your IPv4 traffic will continue to be routed by the layer 3 switch as before. Meanwhile, your IPv6 hosts will direct IPv6 traffic to the new router instead. The switch is none the wiser.
You can repeat this trick for every VLAN in your network—the layout looks like Figure 6-2. Three separate IPv6 routers are shown serving three different VLANs each with a different IPv6 prefix.

Best of all, if your IPv6 router supports VLAN trunking,[15] you may (logically) place this IPv6 device in every VLAN, thus providing an IPv6 router on all attached networks. The result looks like Figure 6-3.

To configure your IPv6 router to do this you create a virtual interface in each VLAN and then configure IPv6 on that virtual interface. The config one might use to configure 802.1q VLANs on a Cisco router can be seen in Example 6-33. To do the same on Linux you might use commands like those in Example 6-34.
interface FastEthernet0/0 description Trunked ethernet interface, gateway for many VLANs no ip address ! interface FastEthernet0/0.1 description IPv6 uplink for office LAN encapsulation dot1q 1 ipv6 address 2001:db8:100:1::1/64 ! interface FastEthernet0/0.2 description IPv6 uplink for server LAN encapsulation dot1q 2 ipv6 address 2001:db8:100:2::1/64 ! interface FastEthernet0/0.3 description IPv6 uplink for DMZ encapsulation dot1q 3 ipv6 address 2001:db8:100:3::1/64 !
# Load the 8021q module modprobe 8021q # Add three VLANs to this ethernet interface vconfig add eth0 1 vconfig add eth0 2 vconfig add eth0 3 # Add IP addresses to the new VLAN interfaces ifconfig eth0.1 up add 2001:db8:100:1::1/64 ifconfig eth0.2 up add 2001:db8:100:2::1/64 ifconfig eth0.3 up add 2001:db8:100:3::1/64
If you have IPv4 access lists or firewalling on your IPv4 gateway, you will want to satisfy yourself with equivalent measures on your IPv6 gateway in order to have the same confidence in your firewalling. If your existing security policy involves using NAT or proxies to hide your IPv4 hosts, you might need to draw up a new policy for IPv6, wherein all your clients are given global addresses.[16]
Ethernet in the WAN
One ISP we know has a number of customers that connect over Fast or Gigabit Ethernet. The staff there are strict routing purists but they invested in a layer 3 switch to deliver this service, since it gave a high port density and was surprisingly good at acting like a “real” router.
This ISP was rather disappointed when its own IPv6 deployment plans overtook those of the vendor who sold them the switch. They did however see this coming, and had a trick up their sleeve.
Normally, the ISP would reserve a Gigabit Ethernet interface on their switch for the customer’s connection, and assign a link IP address directly to that interface, as per a router port. This is shown in Example 6-35. Unfortunately, this does not allow the ISP to provide native IPv6.
interface GigabitEthernet1/1 description Customer Metro Ethernet connection ip address 192.0.2.1 255.255.255.252 speed nonegotiate
For the workaround, they configured the interface on the IPv4-only device as a switchport, and put it in a VLAN on its own. Then they configured a virtual interface on the same device in the same VLAN and assigned the link IPv4 address to that. This is shown in Example 6-36. On a Cisco 7600 (which is essentially a Catalyst 6500 with a special supervisor card) one can safely do this without impacting performance.
interface GigabitEthernet1/1 description Customer Metro Ethernet connection no ip address speed nonegotiate switchport switchport access vlan 101 switchport mode access interface VLAN101 description Customer IPv4 interface for metro ethernet on Gig1/1 ip address 192.0.2.1 255.255.255.252
This is no doubt offending the routing sensibilities of many WAN networkers out there, but it’s important to note that this is just an internal configuration change. The device at the remote end of the link doesn’t need to be VLAN aware. Furthermore, no other device needs an IP address on that VLAN.
Well. No other device needs an IPv4 address. The advantage of configuring the interface as a switchport is that you can then create a separate IPv6 router and connect it to the same Ethernet VLAN, just as described above. You can do this either by connecting the IPv6 router to a switchport in the appropriate VLAN on the IPv4-only device or by connecting the devices using VLAN trunking (as per Example 6-33.)
Figure 6-4 shows all this in action. If an IPv4 packet is sent by the customer, the Ethernet frame will have as its destination the MAC address of the layer 3 switch, and the layer 3 switch will handle it. If an IPv6 packet is sent, the destination MAC address will be the IPV6 router; it will be switched directly to that device and handled appropriately.
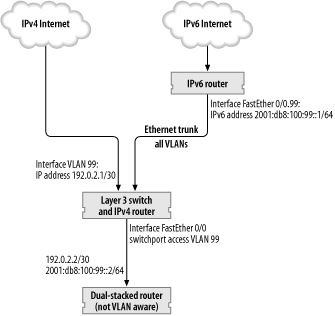
Troublesome ATM devices
There’s a similar hack that one can use with ATM links. ATM is commonly used to link networks at speeds higher than 2Mbps (where leased lines run out of steam) but lower than about STM-1 level (where SONET and SDH start to make more sense). ATM offers a lot of flexibility in configuring circuits, and we may use some of this to our advantage.
An ATM circuit typically has two numbers associated with it—a Virtual Path Identifier (VPI) and a Virtual Circuit Identifier (VCI). These are expressed as a pair, and a unique VPI/VCI pair describes a single ATM circuit. When one orders an ATM link from a telco, they typically provision a virtual path, specifying a particular VPI. The customer may then define as many private virtual circuits (PVCs) over that path as they wish, by choosing a unique VCI for each one.
Normally when used for IP we would configure a single PVC and set its bandwidth to be the same as the bandwidth provided by the telco for the entire virtual path. If the termination points for this PVC are both dual-stacked routers, then we can simply run both IPv4 and IPv6 over the same PVC.
Suppose, however, that one of the routers is IPv4-only. If your circuits land on an ATM switch, rather than directly onto the IPv4-only router, then we can configure a second PVC. The ATM switch can deliver this second PVC to an IPv6-capable router and can be used to provide an IPv6 service without disturbing the original IPv4 connectivity. This is shown in Figure 6-5.

Unlike the VLAN workarounds described above, you must set aside some bandwidth to be dedicated to your IPv6 PVC. If you do not, then you risk oversubscribing your link, and your telco will start dropping cells. (Dropping cells is much worse than dropping packets: you tend to lose bits of packets instead of whole ones, and the impact of congestion is made much, much worse.
MPLS and 6PE
MPLS, or by its full name Multi Protocol Label Switching, is a mechanism to deploy circuit-switched paths around an IP network. Translated for us mortals, the notion is this: there are lots of destination addresses, but often only a small number of paths through a network that are all that frequently used. On a straight IP-only network, every single router does a lookup in its routing table every time it forwards a packet.
With MPLS, all the (relevant) paths in the IP network are set up in advance (usually automatically.) Then the very first MPLS router that encounters a packet will perform the destination lookup, choose the path that will get it to that destination, and will label it. Each subsequent router checks the label (which is a much less onerous task than looking up the destination address,) changes the label if necessary, and then forwards the labelled packet to the next MPLS router. This repeats until the labelled packet reaches its destination in the MPLS network, at which point the label is removed and ordinary routing resumes.
Now, contemporary MPLS networks are usually based on an IPv4 infrastructure. However, a close look reveals that while IPv4 is used in these networks for the setup of labels and paths, it is not used at any point in the transmission of packets. So the packet that gets labelled and passed around doesn’t have to be an IPv4 packet at all.
Cisco’s implementations of AToM (Any Transport over MPLS) and EoMPLS (Ethernet over MPLS) take advantage of this to allow the operator to set up layer 2 circuits over their MPLS network. One can of course run IPv6 over Ethernet or ATM (the transmission protocol used for AToM). If your equipment has this capability, then this may be an easy way to get high performance IPv6 transmission in your core.
One can also remove the middle-man of an extra Layer 2 protocol and label-and-forward IPv6 packets directly. In this instance, the routers at the edge of the MPLS network (typically called “PE” or Provider Edge routers) must be dual-stacked. This is because they obviously need to be able to transmit IPv6 packets, but they must also run IPv4 BGP and take part in the IPv4 setup underlying the MPLS network.
Cisco’s implementation of this is called 6PE. To make this happen, it takes advantage of the flexibility found in multiprotocol BGP. Each PE router sets up BGP sessions, over IPv4, with the other PE routers in the network. (We’re assuming, of course, that the core that connects them doesn’t have IPv6 capability, hence the need to run these sessions over IPv4). The PE routers are then configured to advertise their IPv6 prefixes over their IPv4 BGP sessions—along with the labels needed to reach them. Without the labels, this would be madness; your precious IPv6 routes would be sent to other routers with a next-hop in IPv4-land. In this configuration, however, the packets are labelled and sent through the MPLS network to the remote router with the complicity of the IPv4-only core.
Accounting for hacks
While the methods described above are workarounds rather than permanent deployment strategies, some do have one distinct advantage in common—you have a router interface which is guaranteed to contain only IPv6 traffic. This makes measuring IPv6 traffic with MRTG and other SNMP tools a doddle; many vendors still don’t have separate IPv6 counters for true dual-stacked interfaces.
If your equipment doesn’t support per-protocol byte and packet counters and you would prefer not to use the sub-interface methods we have described, then it may still be possible to count traffic using firewall or ACL rules. When considering such an option, remember that enabling ACLs on some platforms carries a performance penalty.
Summary
In this chapter we’ve covered quite a lot of technical detail on the operating of infrastructure services that keep a network running. The core of this is really the operation of DNS, which everyone running a network will interact with at some time. We’ve also looked at routing, firewalling and network management, all of which are likely to be issues in moderate sized networks. The other thing that we looked at was 6to4 Relay Routers and Faith as examples of the sort of infrastructure that may be useful for IPv4 and IPv6 interoperation. We’ve also looked how you can provide IPv6 at layer 2 without upsetting your IPv4 infrastructure.
[1] Technically, no extra support is necessary for the
“reverse nibble” format now used in ip6.int and ip6.arpa, because they only
use PTR records.
[2] Recent versions of ip6calc can also do this.
[3] We haven’t seen it ourselves, but we’ve heard reports.
[4] If these commands are not available as a base part of your operating system, they are included as part of the BIND package, which can be downloaded from http://www.isc.org/.
[5] Suggested to us by Roland Bless and Mark Doll.
[6] Dynamic DNS, used particularly to reflect changes in addressing of a large set of clients, is not covered here.
[7] Strictly speaking, you are forbidden from sending router advertisements if you are just a host. There are certain cases where it might be useful to do otherwise, but we will not cover them here.
[8] A hairy practice that can go wrong very quickly if one uses IPv4 anycast on your network. If one of the addresses on your loopback interfaces isn’t unique, Murphy’s Law (no relation, honest) suggests that the likelihood of it being chosen as a router ID is immeasurably increased.
[9] Private AS numbers are another option here, if you wish to run BGP for a different reason.
[10] “Oops, did I just type no ip address?"
[11] In case you think this is an urban legend, it has been documented: http://www.ripe.net/ripe/meetings/ripe-45/presentations/ripe45-tt-ipv6/page12.htm.
[12] On Linux, Solaris, and FreeBSD, at least.
[13] Here the syntax is slightly strange, but follows the recommendations of the faithd documentation!
[14] Such as the Catalyst 4000 or 6500 with the appropriate supervisor card.
[15] Note that Linux and FreeBSD both support VLAN trunking if equipped with a modern FastEthernet card, and Cisco routers support it in certain versions of IOS such as the “Enterprise” trains. Our experience is that it doesn’t work on Ciscos with plain 10 megabit Ethernet interfaces—check with your support people.
[16] Of course, that doesn’t mean they’ll be allowed to use them.