
This chapter provides an overview of the end-to-end Identity Governance process and insights into how best to approach the problem. Later, we will provide an organizational-, project-, and deployment-focused set of recommendations. This chapter is focused on the technology and what to look for when selecting and deploying an enterprise-grade Identity Governance solution.
This chapter lays out the basic steps and major process involved in an Identity Governance (IG) program. It starts with how to establish visibility and context over the current state. It then covers the major elements of an IG process from basic control process to enterprise role management and policy evaluation. We finish this chapter with the advanced process of using AI to create “predictive” governance.
Visibility, Connectivity, and Context
As already discussed in Chapter 4, visibility over who has access at any given point in time is a critical first step in the governance process. To manage user access, you have to enable visibility and context over the current access configuration. The phrase “you can’t manage what you don’t see” has never been more relevant that here. You have to discover everywhere users have access and entitlement via existing accounts and access. In many cases, a given organization may already have a tool that provides some degree of visibility and control over the account management process. You just need to leverage that tool in the initial visibility process.
The critical first part of an overall Identity Governance process is enabling and maintaining visibility over the “current state”. This requires integration with authoritative sources of identity, connectivity to target applications where the accounts and access control resides, and the building of something we call an entitlement catalog.
Connectivity to the target resources is a key part of the Identity Governance process. Although there are many ways to implement connectivity, we have always found that the approach to developing, deploying, and maintaining this connectivity is one of the quintessential elements of a successful enterprise-class IGA deployment. Later we provide a comprehensive look at how to approach connectivity and provide a simple classification system for understanding and evaluating how this is done in the Identity Governance solution.
We use the term context
in the title of this section to represent an understanding of the meaning of access. All too often, user access is managed without a good understanding of what that access actually means.
Access control technology, so the accounts, groups, profiles, attributes, and permissions that implement the control inside the target systems, is very rarely developed with the direct interaction of the business in mind. Things like cryptic naming standards and complex hierarchical implementation models make it nearly impossible for non-IT security professionals to understand the context of what the access actually means. “Bob is in the admin group in Active Directory. Does that mean he can access my personal information?” The ultimate goal of Identity Governance is to help answer that question by connecting (or reconnecting) the access security model with the business meaning of that specific access control. Understanding the relationship between identities, users, access, and data is the context we are talking about; creating a consistent map of this access context is one of their primary goals of this technology
Through the process of Identity Governance, we close the gap between the various entitlement control systems and the business users that ultimately own them. As we gain visibility into the various authoritative sources of identity, and we establish application and entitlement source connectivity, we can start to overlay business policies and create the foundation for ongoing lifecycle management.
Authoritative Sources of Identity
Gaining visibility and establishing user access context requires connectivity to all sources of identity across employees, contractors, and business partners. We use the term “authoritative” to mean that these systems are the true source of user records for a given identity type or persona. Unfortunately, these sources of identity information are rarely, if ever, in the same actual application or system. Employee records are fairly consistently centered on a core HR system like Workday or SAP HCM. This is in reference to the employee number we discussed in Chapter 4. Information about nonemployees (contractors, business partners, and customers) tends to be stored in a mix of enterprise repositories like Microsoft Active Directory and custom database application systems. So, in short, identity source records are spread out across multiple systems.
In most organizations, we see multiple sources of identity, even within a given class of users. Due to mergers and acquisitions, system migrations, and the general history of IT, many organizations even have multiple HR systems. A critical part of the IG process is consolidating these various authoritative sources to create a single view of all identity records. This single repository of user data does not replace the original authoritative sources; it simply creates a virtual consolidated view that we often refer to as a “governance system of record.” This is that critical linkage between identities and all the accounts they have access to. This governance system of record can then be used as a central point of reference around which we can relate all accounts and access and further apply context.
Approach to Connectivity
An Identity Governance solution should be able to connect to every directory, database, application, and all other repositories of access information – literally every place an identity can be instantiated as an account. An enterprise-grade Identity Governance solution must provide a range of connectivity models in order to meet this goal. These connectors tend to fall into four main categories – these are explained in detail later in this chapter:
- Direct API – Using authorized application interface programming calls from a directory source or application, account information can be managed.
- Shared Repository – Using a purpose-built repository to share identity and account information.
- Standards-Based – Using industry standards for protocols, data sources can exchange identity and account information.
- Custom Application – Using custom code or proprietary connectors, identity and account information can be managed.
It should be duly noted that we do not differentiate or classify the connector type by the “cloudy-ness” of the target. Whether the target source is on-premise, in the public/private cloud, or inside the control panel of the Starship Enterprise, it’s how you get to that application or system that matters not where its physically located. Be cautious of any identity and access administration system that divides its functionality based on “where the app runs.” The end user does not care where the application “runs” and nor should you. An authorized connector that is properly secured should work regardless of where it is placed and what it is connecting too.
Regardless of the classification of the connection type, management, and storage of a connection proxy accounts can be a big issue. For an Identity Governance system to make any form of connection to an external application or system, it requires its own authorization. These are the functional and system accounts defined in another chapter. This is a somewhat circular issue; the governance service manages the end-user credentials in the app, yet it also requires its own account or credential to do so. This access often requires highly privileged API tokens and application accounts. These accounts and credentials must themselves be stored, managed, and audited. As a best practice, we highly recommend the vaulting and management of these credentials in a PAM vault or password safe or API key management system that is external to the Identity Governance engine. We cover the topic of integrating Identity Governance and PAM in detail in a later chapter.
A well-architected approach to connectivity must also allow for things we cannot connect to from the management system. This may sound like an oxymoron, a connector for things you can’t connect to, but it turns out to be an important point in the overall approach to visibility and context. To explain, in many systems, it is possible to get “read-only” access to the application entitlement model via a “manual feed.” A great example is a CSV (comma-separated values) file provided by a business partner. You don’t connect to the application, yet you do have visibility as to its configuration at a given point in time. A standards-based connector (see in the following) can easily import that data and create relevant connections in your identity and account model. But how do you manage and change these records? This is where integrating Identity Governance with an IT Service Management (ITSM) solution becomes critical by providing manual change ticket control processes. By using an internal or external source of “change ticket and tracking,” we can still implement a controlled lifecycle for manual administrative changes. This idea of “reading on one channel” (via an export CSV) and “writing on another channel” (via ITSM change ticket) is something we call a dual-channel approach and often proves critical to rapid and extensive deployment in the early stages of a project.
Finally, although an approach to connectivity for IG must be comprehensive, secure, and highly adaptable, it cannot be a burden or an anchor to a rapid and extensive deployment project. Therefore, a successful approach to connectivity must also include out-of-box application on-boarding tools that employ “wizards and workflows” and embedded best practices to accelerate the registration and overall entitlement on-boarding process. Look very carefully at these capabilities when designing your implementation and make sure the vendors you consider can do this for every critical application in your environment. Getting the data into the Identity Governance system can be a major hurdle to project success. All vendors, approaches, and technologies are not equal in this area - in fact, you might find some of them extremely limited.
Direct-API Connectivity
Direct-API connectors provide connectivity between the IGA server and the target application by some form or API or remote read and write mechanism. In general, these connectors are provided by the IG vendor and should provide coverage for all of the major enterprise applications on-premise and in the cloud. These connectors typically use the API libraries supplied by the target application vendor and often make use of a stored credential (see the preceding best practice) for authentication.
Examples of direct-API connectors include systems like SAP, Salesforce, Box, Office 365, and AWS (to name but a few). An enterprise-class Identity Governance solution should provide extensive, stable direct-API connectors and must be wholly and completely responsible for managing their development lifecycle across version changes in the target system. That is, they should be forward and backward compatible to older versions that a vendor may have released and easily adaptable to new APIs that deprecate old ones or change functionality.
Shared-Repository Connectivity and Deferred Access
Shared-repository connectors cover centralized systems like enterprise directories (e.g., Active Directory), Single Sign-On systems (e.g., Okta), and all forms of externalized authorization. They are called out here due to the common potential pitfalls with this implementation. To explain, it has been common practice in enterprise application development to centralize application accounts and key parts of the application access to a shared repository like Active Directory or LDAP. In this model, a group membership is used to control functional access inside the application. The access control is therefore deferred (hence the title) from the application to groups and group membership within the centralized service.
In order to audit and administer this class of application access, we must connect to the shared repository. The challenge then becomes sorting out which group membership (entitlement) belongs to which application. It’s important to understand that to the directory, these are just accounts and groups, and there is nothing to relate them back to the actual applications. The governance solution must then break out this “one connected resource” and allow the business user to understand the context of the “many applications that it is serving.” As an example, let’s revisit Bob. He is John Titor’s friend. Bob is a user with an account in an admin group; when the admin group is the authorization model for MyCustomApp, we must govern at the MyCustomApp level, not just at the “shared-repository” level. Poor implementation of shared-repository connections can be a significant hindrance to business user adoption and overall deployment success. Look carefully at this issue when selecting and architecting a solution for your environment and pay attention to how each vendor handles these models.
Standards-Based Connectivity
Standards-based connectors cover any form of target system connectivity that can employ (or reuse) a standard connection technology model. Good examples of standards-based connectors are for systems like LDAP, JDBC, CSV, REST, and SCIM. Here the target system supports a standards-based connectivity API. The IG server then simply employs that API and allows for the “registration of new instances” of the application, without the need for any new connector code.
In most cases, standards-based connectors are a special case of direct-API and shared-repository connectors and are only listed as a separate category here due to weaknesses and flaws that may exist in their implementation. For example, target instance registration must be simple and easy to use – a simple matter of inputting a few connection parameters and possibly defining a schema for import. This is often not the case in vendor implementations. In any case, the connector code must be maintained by the vendor, and all aspects of the deployment must be lightly streamlined and wizard-based including authentication to the shared resource.
Another example of an important standards-based connector is the System for Cross-domain Identity Management (SCIM RFC-1746). This warrants a special shout-out as a significant standards-based connectivity model. In an ideal world, every application would have full support for SCIM. Later, we will have an expanded discussion of SCIM and its implementation of this important standard.
Custom-Application Connectivity
Custom-application connectors allow for a specific tenant or deployment of the IGA service to develop its own custom connections for target resources not covered elsewhere. Typically, the customer (or its deployment/technology partner) will go through the same process that the Identity Governance vendor did, to deliver its prepacked direct-API connectors or custom protocol connection adapter. For custom-application connectors to be successful in deployment, they should follow important best practices around development and deployment.
In development, custom connectors should be based on a tool kit provided by the vendor. This tool kit should guide the developer through best practices in the development and must provide technology to ensure the testing and integrity of the finished connector. In deployment, no custom connector should be able to change or affect the lifecycle of the core underlying governance server or service. This sounds so obvious that the reader may assume this to be the case for all systems. However, this is often not the case. Some implementations of custom connectors can break the overall deployment by affecting the functioning of the “higher-level” components of the IG process (i.e., lifecycle management, certification, or policy controls). And of course, like all other connectors, connector authentication must be secure and resilient – custom or vendor supplied.
Connector Reconciliation and Native Change Detection
An Identity Governance (IG) system is responsible for the administration and configuration management of access control wherever it resides. The connector tier is responsible for reaching out into the infrastructure, making changes, and thus managing accounts associated with an identity or an owner. However, changes often happen locally to that application or infrastructure. Local admin actions can and do happen, and it’s the job of the IG system to understand those changes and “do the right thing.” This is the process of reconciliation and change detection.
There are two primary methods of understanding that something has changed out in the real world. Either the IG system is notified of the change by the target system, or it does a delta change analysis based on its own cached (previous) version of the configuration – this is traditionally referred to as reconciliation or recon in the IG vendor space. It is important that your IG system and processes support both methods. If available, change detection from the managed system itself is preferable. For example, most LDAP servers support a special attribute polling mechanism (in Microsoft Active Directory, this is referred to as “USN-Changed”) that tells the reader that something has changed. This removes the need for the costly processing associated with a delta change assessment by the IG platform.
Historically, reconciliation and change detection have been a significant area of product differentiation. Outside of the processing cost of delta change analysis, some systems do not handle reconciliation well. When the reconciliation process finds delta records, these “badly behaving implementations” have no choice but to treat the local change as an error and automatically change it back to the previous known value. This can cause unforeseen issues with product maintenance, upgrades, and even runtime security. Mature IG systems will allow for change triggers and control processes to be executed upon local change detection. This allows for the execution of business process logic, rather than a blind admin overwrite. Having the ability to “handle the change with a business process” can be a significant factor in initial deployment success when local changes tend to be more prevalent and ongoing change control is less robust.
Correlation and Orphan Accounts
As discussed, the overall goal of an Identity Governance (IG) project is to understand and manage the relationships between people, access, and data. At the core of this goal is the logical connection between an account, token, or credential (the access) and a real human being. The ongoing process of connecting people to accounts and access is called correlation and is shown in Figure 7-1. In the ideal world, every account matches up perfectly with a human (identity), and you have 100% correlation (for the record, that’s something we never see out of the gate). Account access that does not correlate back to a known user is often referred to as an orphan account. Orphan accounts can be a significant security weakness. Post-breach forensic analysis shows that the adversary creates and uses new accounts throughout the cyber killing chain. It is therefore essential for ongoing governance and security to instrument, and, if at all possible, to automate, the detection and rapid resolution of orphan accounts.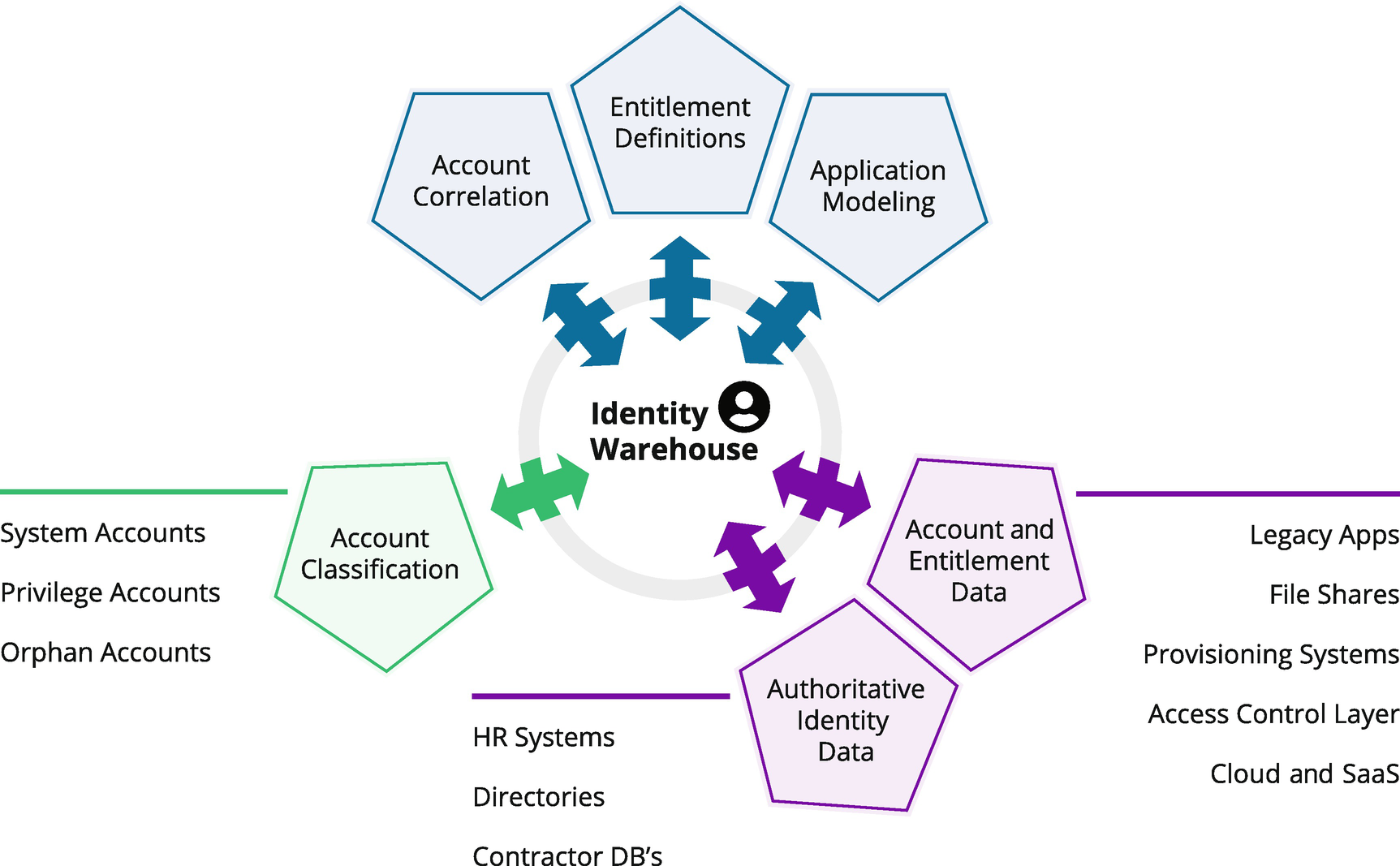
Figure 7-1
A summary of the overall account and privilege correlation. Identities, accounts, and privileges continually flow into the system, and items that don’t connect back to a human are flagged for the attention of application and system administrators
The presence of system, functional, privileged, and application accounts poses a significant challenge to this process. The accounts and privileges used for system-to-system access and the administration of the IT infrastructure are rarely if ever directly correlatable to a known user without a dedicated process. In large ecosystems, there can be hundreds and potentially thousands of accounts that will not correlate without a deliberate and specific process of managed correlation. An enterprise-grade IG solution will provide core product capabilities to help either manually or automatically resolve these issues. Manual correlation using graphical “searching and connecting” will greatly help the admin establish and maintain links between known owners and orphan accounts. Automated matching algorithms can also help suggest relationships and potential connections. This automated discovery technology can also provide important insights around the integration with Privileged Account Management (PAM) solutions. Finding privilege and directing the PAM solution to take control of the account can be a significant win. Chapter 13 provides more details on the best practices around the integration between PAM and IG solutions.
Visibility for Unstructured Data
As highlighted in the introduction of this chapter, it is critically important that an enterprise Identity Governance (IG) process covers the information and intellectual property stored in files and unstructured data repositories like OneDrive, Box, and SharePoint. Visibility over who has access to what must include this information, so it is increasingly important that we connect, aggregate, and correlate from our unstructured repositories too.
Critical in this visibility process is the ability to inventory, classify, and comprehend what is stored where and how it is protected and actually accessed. The file classification process helps inventory and understand where secrets are stored. Traversing and documenting the access control model for file storage devices and services helps us understand the complexities of its access. All of this information must be integrated with the overall governance process and made available from the enterprise entitlement catalog. Only then can the data classification be mapped back to acceptable use by an identity.
Building an Entitlement Catalog
At the center of the Identity Governance (IG) process sits the entitlement catalog. An entitlement is the generic name given to a technical access control facility that we care to catalog and manage. Whereas an entitlement catalog is simply a registry of these capabilities found across all systems, how this catalog is built, maintained, and leveraged across the IG solution is of critical importance.
The catalog itself provides a place to register entitlements and establish metadata and context on their meaning. We use the term entitlement as an abstraction for all things that provide access. It provides a place to normalize access across the many and varied forms of its implementation. It provides consistency and business level context for the complexity and neuance of access. Enterprise-class IG solutions have sophisticated and extensive capabilities in this area. When selecting a commercial IG solution, we recommend looking for an entitlement catalog that delivers best practices around defining ownership, approval process, definitions, and classification capabilities. The entitlement catalog is the center of an IG solution, so look for a highly extensible metadata framework aspart of the solution. This metadata will allow you to define custom attributes that represent your business’s needs and satisfy the business requirements for regulatory compliance.
Later on, we discuss the topic of zero trust and attribute-based access that expands on this metadata concept. A flexible entitlement catalog will greatly help drive the zero trust cause by allowing for the “promotion” of basic identity attributes like “location” or “job code” to be entitlements in the catalog. When identity attributes are used in access control decisions, they become “entitlement giving” and we must manage them as such.
And finally, in advanced systems, look for lifecycle controls over the catalog itself. When access decisions and control processes are based on information stored in the catalog, look for approvals and change controls over the catalog itself. Remember that, in an entitlement-driven control system, metadata is king; so protect your metadata like it is the crown jewel. It literally is the data map for all identity-based entitlements within your entire managed environment.
The Power to Search and Report
In conclusion for the topic of visibility, controls, and connectivity sits the power of search and reporting. Now that we have all this information on people access and data, let’s make it available and visible to the people and processes that can benefit from it. Regardless of how the information is being stored inside the Identity Governance (IG) solution, it is critically important that the data is available to search, query, and report upon. An enterprise-class solution will provide multiple paths to access its data. In developing your IG processes, plan for a simple search and query capability that allows business and IT security staff to find people, view their current and desired state access, and, importantly, understand the meaning of this access at a business and data security level. All structured and unstructured query and reporting capabilities should be able to be run at scheduled intervals and be delivered via email with “click-through” verification to confirm, track, and audit their delivery and acceptance.
Lastly, all IG solutions must ensure that reports, queries, and all data access inside the IG solution are fully respectful of a defined security and privacy model. Specifically, this means establishing and maintaining strong access controls over who can access and retrieve data from the IG system at all times, whether from the user interface or from a data access API. This usually requires the IG solution itself to have a complete Role-Based Access Control (RBAC) model of its own in order to meet these requirements. Information is power and we must ensure that the critical information stored inside the IG system is protected at all times.
Full Lifecycle Management
Lifecycle Management (LCM) is at the center of the Identity Governance (IG) process. It captures, models, and maintains the core states of the “automated assignment lifecycle.” One of the major objectives of an IG system is to provide controls and automation throughout the ever-changing lifecycle of the user and their access to data. A summary of the overall LCM subsystem is shown in Figure 7-2.
Later in this chapter, we provide insight into how the LCM “state model” usually works and describe the process flows in a typical implementation. At the center of the LCM process are governance models. We will cover what governance models are and describe the pivotal role they play in the overall LCM process. We’ll also break out one of those models – the enterprise roles – and provide a more detailed view of the “role” they play in the LCM process. We finish this topic area with a discussion on embedded controls and what to expect in the area of controls automation during the LCM process.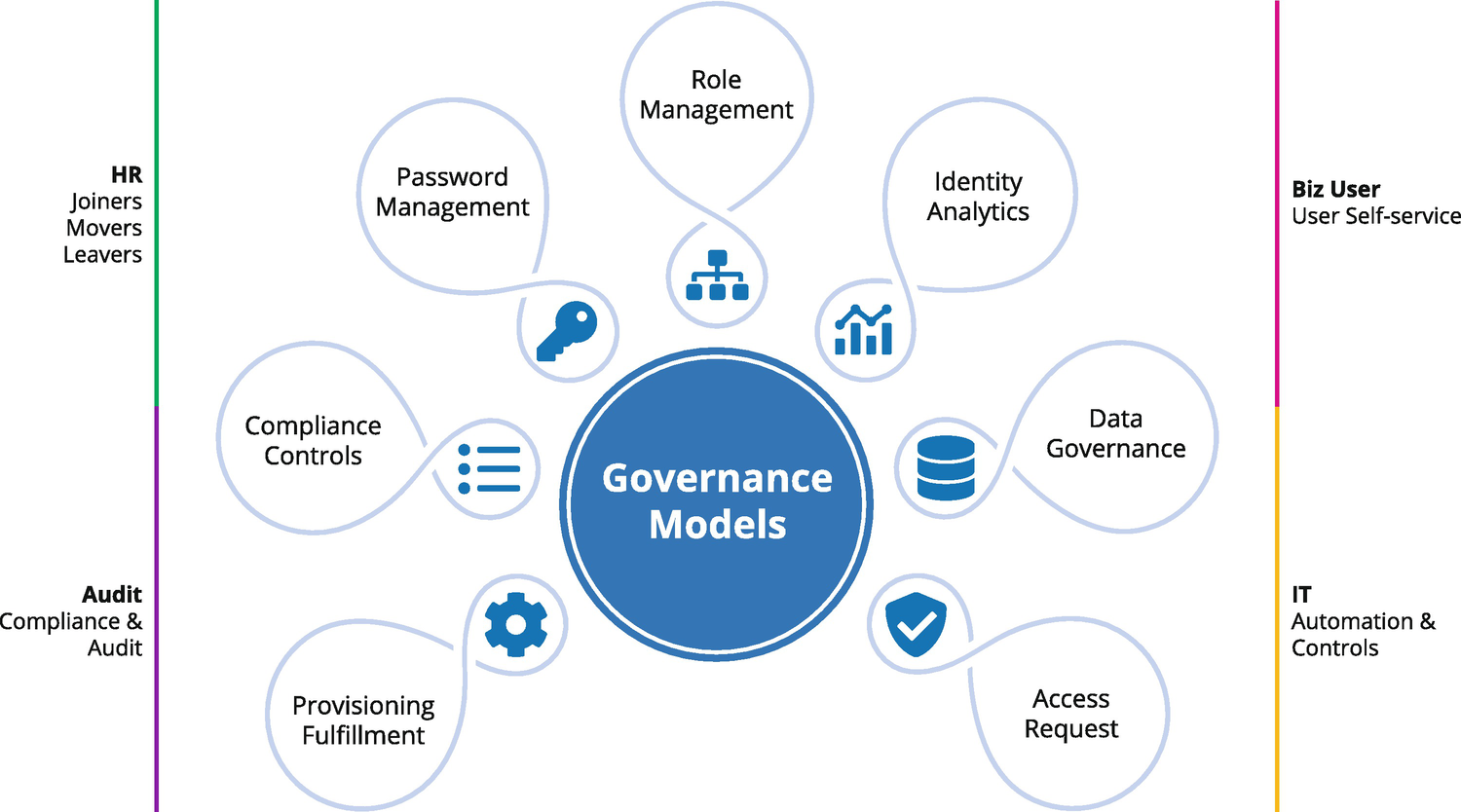
Figure 7-2
The overall LCM processes. At the center are the core governance models that drive the LCM process. Surrounding these models are the major LCM events and actions that drive the system
The LCM State Model and Lifecycle Events
The overall goal of a Lifecycle Management (LCM) system is to provide automation and controls for the complete lifecycle of system and application access. We use the term “LCM state model” for the title of this section because at its core, the LCM process is best driven by known states and the transitions between these states called events. In the simplest example, we might model an employee state as being either “hired or fired.” When someone receives a terminal letter, we record a “leaver event,” and we carry out the actions defined in the governance model for this event – most likely “remove all access.” So, at the highest level, an LCM system drives its automation based on known states, change events, and clearly defined governance models.
LCM States
LCM
states tend to be centered on the people or users of systems that flow into the LCM model from HR and contractor management sources. Most established HR processes come with their own defined state models; examples from a model system are shown in Table 7-1.
Table 7-1
Sample LCM states
Sample LCM States | |
|---|---|
Prehire | In many systems, employee and contractor records flow into the IGA system before the users’ start date. These user records are modeled as “prehire” to enable the IGA system to carry out actions prior to an official start date. |
Hired | When a record moves to the “Hired” LCM state, the system triggers provisioning actions associated with the start of employment or contact. |
Terminated | When a record moves to a “Terminated” LCM state, the system triggers actions associated with the removal of access. |
An enterprise-class Identity Governance (IG) system should come with a defined set of LCM Human Resources (HR) states out of the box, but will also be configurable to capture the new states specific to each deployment scenario.
Joiner, Mover, and Leaver Events
Although most organizations use a formal HR process with their own “employee record states,” it has become common practice in Identity Governance to adopt an abstraction of the main record state and define specific control actions when users join, move, and leave (JML). JML events are often triggered by HR record states, but can also be triggered by the IG system itself. Remember that the primary goal of an IG system is to overlay governance and to provide automation and sustainable controls. Therefore, a JML event could be triggered by an action initiated in the IG system user interface (UI) or may be based on a control threshold being hit like a maximum risk score. In this sense, a JML event is a core governance action rather than a change in HR status, so most automated systems differentiate between the two.
Lifecycle Triggers and Change Detection
Many things can cause trigger actions within an enterprise-class Identity Governance (IG) solution. JML events are a simple abstraction of the broader class of actions often referred to as lifecycle triggers. These events can be triggered based on just about anything inside the IG system or from an external API call. The idea is to “run a process,” usually a predefined workflow or program execution hook, based on some change in the access model, its state, or its context. An enterprise-class IG solution will allow for extensive configuration in this area and in doing so will allow for the support of many varied management use cases.
A frequent use of lifecycle triggers is to execute a defined control. You should expect to see the ability to execute standard governance actions such as access reviews, reapprovals, policy evaluations, and standardized workflows when trigger points are met and lifecycle events are executed. You should also expect the configuration and ongoing maintenance of this area of solution to be fully supported in the UI of the product. It is increasingly important that these types of “business rules” are visible to, and under the control of the business user, and not an IT programmer. Having the configuration of triggers and associated actions buried deep inside deployment code should be considered a bad practice.
Often lifecycle triggers are executed based on value changes in the data observed or cached by the Identity Governance system – this is often referred to as change detection. It’s important to understand the difference between LCM change detection and connector reconciliation. Here we are creating event triggers based on value changes in governance model rather than in the connector change data. For example, we might choose to post a notification when a “security clearance” attribute changes in a managed application, or we might set the system to re-execute an approval process when there are more than a certain number of changes to an individual user’s entitlement assignment state. This “overlaying of controls” is an important part of the value of a governance-based approach to lifecycle management.
Delegation and Manual Events
As depicted in Figure 7-2 on the overall LCM process, an important lifecycle input comes from the UI of the Identity Governance (IG) solution in the form of manual delegation events. A core value proposition of a governance-based approach to identity management is providing a UI for the business to carry out actions and actually take control. This then becomes the interface for day-to-day management actions. Allowing delegated administration over fine-grained access frees the IT security administrator to focus on setting policies rather than executing changes. The ultimate manual delegation is self-service, the delegation of responsibility for a prescribed set of administration actions to the individual end user. This usually includes functions such as access request, password resets (inside or outside of a Single Sign-On solution), account unlocking, and the ability to participate in the ongoing certification and verification of access.
We highlight these manual LCM inputs because they should not happen in isolation. All changes, whether native to the managed application, automated by the IG system, or input from the UI initiated by the end user, must be subject to the same controls and governance; all must be fully documented and logged for governance reporting and threat detection.
Taking a Model-Based Approach
At the center of Figure 7-2 are the core governance models that drive the automation process. As we described in the introduction to Identity Governance (IG), it is critically important to establish core policy models that define the desired state. The term “policy” is considerably overused in IT and specifically in the security and management of IT. For the sake of clarity, we offer the following working definition of a governance policy model:
IGA policy models are used to capture the desired state, known best practice configuration, and an inventory of controls and governance actions. These models are abstract representations of how accounts and privileges should be set, approved, audited, and used to some known state. Examples of IGA policy models include the entitlement catalog, provisioning schemas, approval and ownership records, audit requirements, role models, lifecycle triggers, and Separation of Duty rules.
All of the different model record types that are defined and used in the IG process form a baseline for reconciliation between the current and desired state. An enterprise-class IG solution will, wherever possible, provide easy-to-use graphical UI capabilities to make these models accessible to users from the business side of the house. There’s a phrase often used around successful IG deployments – it goes something like “let the models drive the process.” This simple phrase captures the importance of the models themselves and how they should be employed by the governance platform during the ongoing lifecycle process.
Enterprise Roles as a Governance Policy Model
One of the most often used and most hotly debated governance model is the enterprise role. The “enterprise” prefix is important. There are many types of roles in many different types of systems. Here we are specifically referring to the groups of entitlements and control policies defined and managed in the governance system itself. Enterprise roles (just called roles from here on out) are a critically important model to get right. You don’t have to use them to operate a governance-based lifecycle, but if you do use them and you get them right, you can vastly simplify the whole process.
The basic definition of roles was covered in Chapter 4 and will be expanded upon later. For clarity here, simply understand that a good role model will provide a place to define, verify, and reconcile access, a place to define the correct configuration or entitlement, a place to establish assignment approvals, and a place to track the ongoing state of access across potentially thousands of target applications, hundreds of thousands of users, and millions of entitlements.
Embedded Controls
As discussed earlier in this section, regardless of where change input or request comes from, you should never be able to circumvent the governance policy. This is another one of those conversations like functional accounts – where never means never! The term embedded controls is used to highlight the fact that governance policies (like approvals and separation of duty rules) are embedded in the process. We will cover detective and preventive policies later in this chapter, but for now, we simply need to highlight that, throughout the lifecycle of access – from Joiner through Mover to Leaver – controls like Separation of Duty (SoD) - clear approval processes, and specific audit controls like event-based access reviews should be embedded into the governance process.
Provisioning and Fulfillment
Provisioning is the term long used in identity management to represent the overall process of delivering access to applications and data. It usually involves employing various connectivity means to deliver the right access to the right people at the right time. We suffix provisioning with the term “fulfillment” as a reminder that, in complex enterprise scenarios, there are a multitude of ways that this access can be fulfilled. Provisioning and fulfillment (for brevity, here on referred to as just provisioning) in a governance-based approach represents how the system assures completion of an action, regardless of how it gets delivered across the “last mile.”
Provisioning Gateways and Legacy Provisioning Processes
As discussed earlier relating to the best practices for connectivity, in governance we must allow for a myriad of ways to connect to the applications and systems that need to be managed. In complex enterprise scenarios, the provisioning server or process may not have routed Internet Protocol (IP) access to the target applications. For example, when applications sit behind corporate firewalls, or are deployed behind Network Address Translation (NAT) subnets, the governance solution may need to provide a gateway
process that can provide a single secure inbound connection channel, to marshal the provisioning for multiple target applications running behind that NAT or firewall. In some scenarios, a gateway might be a “dumb router of requests” and may only be used to circumvent network topology restrictions and IP routing limitations. In other scenarios, a gateway might be a sophisticated software appliance that offers guaranteed delivery, enhanced security, and increased performance. In either case, the Identity Governance process uses the gateway as a pass-through fulfillment engine. This provides a basic tiered architecture model where the gateway is the only resource managing the connection between the governance server and the managed resources and assets.
In deployment, it is also commonplace to encounter legacy provisioning systems and processes, either commercial off-the-shelf solutions (COTS) or homegrown custom-engineered processes. In either case, these legacy capabilities will often remain in place for an extended period. It then becomes the job of the new governance-based provisioning platform to deliver a connector to, and for, that legacy system. More advanced Identity Governance platforms will abstract this provisioning integration pattern and create a standardized modular approach that can help drive simpler integration code and promote lower maintenance costs over time.
Provisioning Broker, Retry, and Rollback
An enterprise-class provisioning engine is a sophisticated piece of software. It is responsible for initiating, managing, and monitoring all changes to downstream systems. When a governance platform supports the encapsulation of entitlements into groups and roles, the provisioning engine has to understand the potentially overlapping obligations this can create during the ongoing assignment and de-assignment lifecycle. It is commonplace to find the same entitlement being used in different groups and roles. Therefore, the provisioning logic has to understand a complex matrix of responsibilities and obligations and only add or take away the right attributes and entitlements. This process of “brokering” change across a complex state model and a complex connector model is depicted in Figure 7-3.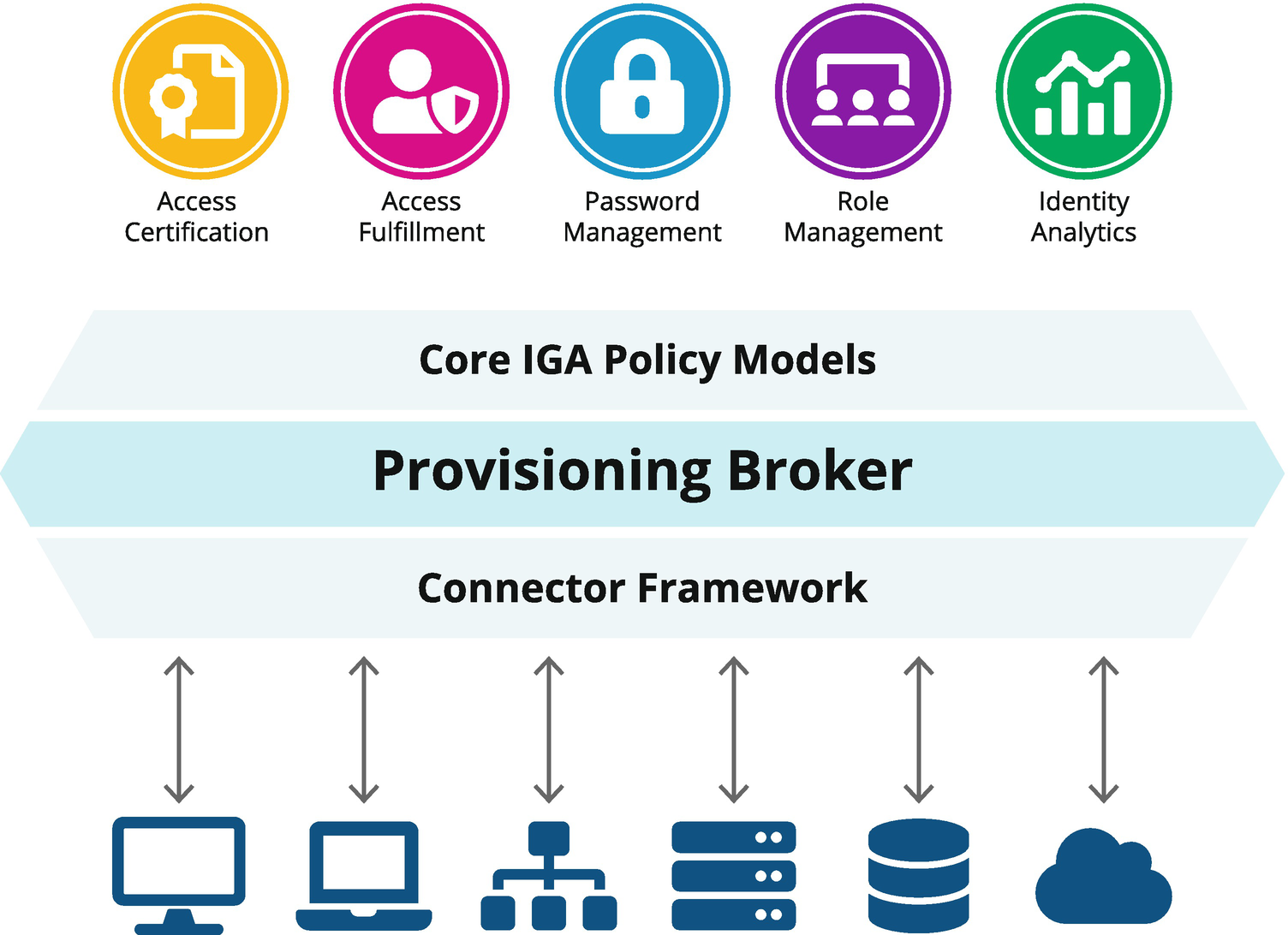
Figure 7-3
The provisioning “broker” challenge – manage state across competing requests and various connection means
It is also worth examining how a given provisioning engine executes in fail-over, disaster recovery, and retry scenarios. Target systems will always at some point be “unavailable,” and read and write transactions will subsequently fail from time to time. It is therefore critically important that the engine itself is resilient to a host of error conditions. For example, when provisioning an enterprise role that contains four entitlements from four separate systems, if the last of the four provisioning actions fails, should the rest of the entitlements be “rolled back” and removed? Or when a failure does occur, how many times should a failing transaction be retried before the engine just gives up and moves into rollback mode? Answering these questions ends up being both target system specific and use case dependent. It is therefore essential that the provisioning engine should be flexible enough and configurable enough to handle all such scenarios.
An essential part of dealing with the complexity of the enterprise provisioning process comes from its internal management and monitoring capabilities. There are “a lot” of competing things going on in the provisioning tier, so it is essential that the core engine should provide metrics on all aspects of its execution and process flow. If these items get out synchronization due a network outage, natural disaster, or other condition that causes resource unavailability, reconciling multiple changes can be a monumental task. Unless the Identity Governance solution has comprehensive, built-in tracking, monitoring, and root-cause analysis capabilities, managing the provisioning processes themselves can be burdensome.
Entitlement Granularity and Account-Level Provisioning
In some simple implementations of a provisioning process, fulfillment stops at the account level. When the provisioning engine does not understand or profess to manage “entitlement granularity,” it is said to support “account-level provisioning” only. These implementations do not understand entitlement granularity and do not manage the account attributes that define the actual access control model. In these scenarios, a separate, often manual process is used to add the actual entitlements to the account out of band.
Our experience shows that, without full scope of control over entitlement granularity in the provisioning process, control gaps soon emerge. Account-level provisioning is a short pour from the enterprise provisioning cup and in our opinion should be avoided wherever possible.
Governance Policy Enforcement
A key part of adopting a governance-based approach to identity is the ongoing development and enforcement of governance policies. Identity Governance (IG) policies form a backbone for operational efficiency, enhanced security, and sustainable compliance. There are many different types of policies and several ways they can be implemented. In this section, we provide an overview of the business rules that drive access compliance and discuss how Identity Governance policies can help. Here we provide an overview of the three main policy types typically seen in an enterprise deployment, and we introduce the differences between detective and preventive policies when used as part of an overall governance-based approach.
Business Rules for Access Compliance
In Chapter 8, we’ll discuss meeting compliance mandates. Working with internal and external audit, each business will define its own set of business rules to drive sustainable compliance over user access. The business rules that drive sustainable compliance are just that – business rules – and therefore should ultimately be owned by the business users. For this reason, it is a common best practice for business rules captured in a governance platform to have strong delegated administration capabilities. This allows actual business users to view, edit, understand, or, at the very least, “sign off” on policy definition lifecycles. This delegated administration is how the governance system should be designed to work on a daily basis. Identity Governance should not be the responsibility of just one team “in compliance.” Identity Governance business policies span multiple groups and should include multiple participants. Good governance policies should have strong metadata to document ownership responsibly and where possible should also capture remediation advice that is meaningful to the business users dealing with the policy violations it uncovers.
There are many different types of business rules out there. The most commonly deployed policy types we see in deployment are Separation of Duty policies, account policies, and entitlement policies, each of which are described in more detail in the following sections.
Separation of Duty (SoD) Policies
Separation of Duty (or SoD)
policies are a common audit requirement in regulated industries. The goal is to identify users that have conflicting access inside the same application (inter-application) or between related applications (intra-application). Based on job roles and responsibilities or relative to inappropriately overlapping personas, SoD rules provide a framework for understanding what should and shouldn’t be allowed. In general terms, these policies look to identify any individual that is responsible for completing a sensitive transaction without verification and oversight. The textbook example often used is “invoice creation” and “invoice payment” within the same vendor payment system – sometimes shortened to the “maker-checker problem.”
From a security perspective, SoD can be a significant factor in the prevention and detection of infrastructure security issues too. It is common practice to mandate a separation between the development, testing, and deployment of security measures. This can help reduce the risk of unauthorized activity and common configuration mistakes.
Due to the potential complexities involved in defining and implementing SoD rules, it is highly desirable to have an automated system that can help test and simulate SoD rules before they are executed in live situations or placed into live production scenarios. Being able to pre-run and evaluate the violation output before any violation events and processes are kicked-off will optimize time for rule development and can help ensure rules are fit for purpose.
Account Policies
It is also commonplace to encounter business policies that affect basic account provisioning. Policies are often required to manage accounts that have not been used for a specific period of time (usually referred to as dormant or stale accounts). Dormant accounts are a known common identity attack vector
and are of specific concern to IT security. They also represent wasted resources. With an enterprise Salesforce account costing as much as $3,000 per user per year, it is easy to see how the management of unused accounts could also be a significant cost-savings too. Dormant accounts should not be confused with rogue or phantom accounts which are created to meet objectives outside of accepted business policies.
Account policies can also help manage the overall access risk profile for an organization by tracking people with multiple accounts in the same application or infrastructure. The more access people have, the more damage they can do if their identity becomes compromised. In this sense, tracking accounts-by-identity can provide insight into areas of most exposure and risk and can help ensure that the account correlation and ownership process is adhered to at all times.
Entitlement Policies
As described earlier, a critical part of the governance process is understanding and cataloging your entitlements. This “entitlement context” allows you to build policies that enforce specific assertions about who should and who shouldn’t have access to the systems and data we are responsible for. For example, an entitlement policy might look for non-managers with access to manager-specific applications. During organizational changes such as individual promotions and wholesale department reorganizations, people’s roles and responsibilities often change, and their actual systems access often does not. Entitlement policies are a useful construct for embedding checks and balances into the change process and making sure that access restrictions are enforced when user responsibilities and organizational alignments change.
Preventive and Detective Policy Enforcement
Preventive policy controls represent an attempt to deter or prevent some undesirable state or event from occurring. We say preventive because they are proactive and stand “in-line” for a given change and prevent it from going the wrong way. You can think of this as being a real-time policy evaluation. Some good examples of preventive controls are separation of duty rules implemented at the time of new access provisioning or self-service access request. Quite simply, don’t let bad configurations get setup in the first place.
Detective controls are simply a periodic process to find these same undesirable states once they have already occurred. You can think of this as being a batch-oriented policy evaluation. Good examples here are access reviews, reporting and analysis, and inventory variance assessment. SoD analysis is also relevant here as we still need to check that a “toxic combination” has not occurred in the underlying system without our knowledge or participation.
One of the most common questions that arises from the discussion of preventive and detective control is the statement that “if an organization has full preventive controls, do they still need detective policy evaluation”? The simple answer is you need both. In the perfectly organized world of administration utopia, all changes happen in sequence and according to policy. In the real world of IT and business, things trend heavily toward entropy and errors, and omissions should be expected. The right approach is to strike a balance between preventive and detective policies and ensure that critical checks and balances are done in-line and executed periodically as a safety net.
Violation Management
If you have important policies, you have important violations to those policies. With governance rules touching security, operational efficiency, and compliance, it’s increasingly critical to carefully manage policy exceptions and violations. This often requires specific tooling within the Identity Governance platform for managing violations, one that has its own dedicated lifecycle management. This typically includes a registry of violations and a dedicated means of auditing remediation steps and actions that take place as a result of the violation
Certification and Access Reviews
Certification and access reviews are an important part of the Identity Governance process. They enable managers or other responsible delegates to review and verify user access privileges in a consistent and highly auditable way. Building on the policy, role, and risk models established during the governance process, access reviews provide a controlled review point for the current state of user entitlement.
Purpose and Process
An access review is a recurring verification process designed to allow managers (or their delegates) to carry out a “manual” check to ensure that users have the right access to the right systems and data. Born out of corporate and financial audit requirements such as PCI and SOX, the process strives to force the business and IT security to come together to ensure least privilege and appropriate user access.
The Identity Governance server collects fine-grained access or entitlement data from all of its connected systems and formats the information into structured “reports” that can be sent to the appropriate reviewers for verification. Typically, a certification is a collection of access reviews. For example, a Department-level Manager Certification process would include individual access reviews for each manager, and each manager would have a separate review for their staff. This process of review and attestation forms a baseline from which we can assess the current state and manage its change over time.
There are many different types of certification and access review – the most common are shown in Table 7-2.
Table 7-2
Different types of certification and access review
Certification Type | Description/Purpose |
|---|---|
Manager | Shows a manager the access granted to direct reports to confirm that they have the entitlements they need to do their job but no more than they need |
Application owner | Lists all identities and their entitlements related to a specific application so the owner of that application can confirm that all entitlements to the application are appropriate |
Entitlement owner | Most useful for managed entitlements owned by an individual; lists accounts with a specific entitlement for the entitlement owner to certify |
Advanced | Allows for creation of custom certifications based on groups or populations of users |
Role membership | Lists identities connected to specified role(s) |
Role composition | Shows assignments or entitlements that are encapsulated within roles (role set reported can be filtered) |
Group membership | Lists identities assigned to one or more groups |
Group permissions | List the permissions that are granted to a group for selected application(s) |
In general, certifications proceed through several phases from initial generation to completion. Figure 7-4 shows the various phases through which a certification will flow.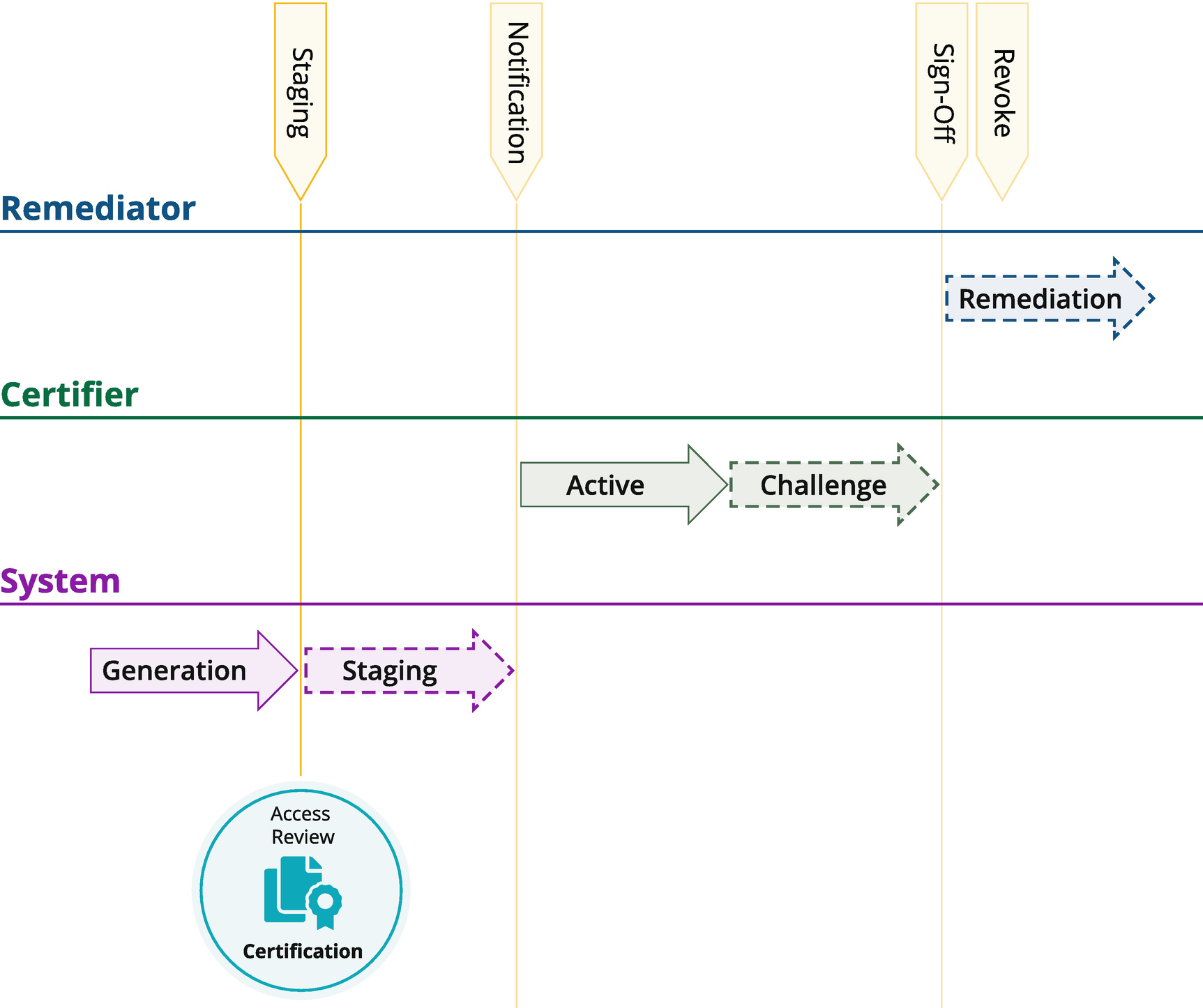
Figure 7-4
A typical certification process flow
The first step in the certification lifecycle is the Generation Phase. This involves specifying the dataset to be included in the review cycle and defining its schedule. This creates one or more access reviews for the attention of the appropriate certifier(s). The parameters specified for the certification constrain the data to be included in each review and dictate which phases will be applied to the ongoing process.
Enterprise-class solutions will usually provide a Staging Phase. Staging allows the system to generate candidate access reviews and “stage” them such that they can be checked before becoming visible to the certifiers. In large-scale certification campaigns, this checkpoint can be a critical operational step in preventing errors and ensuring the best possible business user experience.
Once the access reviews are generated, the next step is the Notification Phase. Simply this is letting everyone involved in the process know that they have work to do. Although this may seem obvious and trivial, a certification campaign is often a highly regulated business process, and so ensuring the right people are engaged throughout the process requires various notification means and involves escalations and process changes in real time to ensuring the timely completion of a given campaign.
During the Active Phase of a certification, the lines of business are actively reviewing and verifying access. In some cases, it is desirable to have actions and remediations executed in real time with the review. For example, finding that a “terminated employee” still has access to business-sensitive data may require immediate revocation action. In other circumstances, all changes may be collected together into a batch and executed post sign-off of the overall campaign.
Some Identity Governance systems will also implement a Challenge Phase in the certification process. Here, identities are notified before a revocation affecting their entitlements is executed; this allows them the opportunity to dispute the decision and offer an argument for why they should retain the access.
The Sign-Off Phase is when all of the required decisions have been made for a given access review and the certifier is asked to formally close the review process. Typically, the sign-off action puts the access review into a read-only status that prevents any further changes to the review decisions.
Finally, in the Revocation Phase, entitlements are changed in the source applications. Depending on the complexity of the provisioning process and the nature of the connectivity to the target application, the revocation process can be highly manual, fully automated, or a mix of both. For example, if there is no automated provisioning write channel available for a given application, remediation of access in that application may only be practically achieved by sending emails to the admin or opening an IT change ticket.
Certification Pitfalls
The most commonly talked about pitfall in the certification process is the dreaded “rubber stamp syndrome.” This is when an approver bulk-approves all access rights by “selecting all” and clicking “approve.” Specifically this is done without an understanding of the access, and so no true value-based decision is ever made. This usually happens when campaigns are poorly designed and the appropriate context for the access (business-friendly names, descriptions, metadata, etc.) is not provided to the reviewer.
Certification fatigue can also be a factor in highly regulated environments. When business users feel presented with endless lists of entitlements and with overlapping certification timelines, the reviewers quite rightly get despondent and lose faith in the process. This can all be easily avoided by the proper planning of certification campaigns and by the use of more policy and exception-based approaches to the process. If possible, move to a role-based and delta change–based certification model in an effort to reduce the number of things that need to be reviewed. Most importantly, make sure that the business interface for managing the reviewer process is business-friendly and easy to use.
Another major pitfall for certification is incorrect and incomplete data. The old phrase “garbage in equals garbage out” is very germane here. The access data under review should be as current as possible and the scope of the systems covered as broad as possible. There is little point executing a detective control mechanism like an access review, if the data is wildly out of date or only covers part of the access landscape.
Evolution and Future State
Like everything in the IT space, the process of certification and access reviews has changes as the technology to manage governance has matured. Most enterprises, and most Identity Governance vendors, have been through an evolution in how the certification process is defined and executed. This evolution is depicted in Figure 7-5.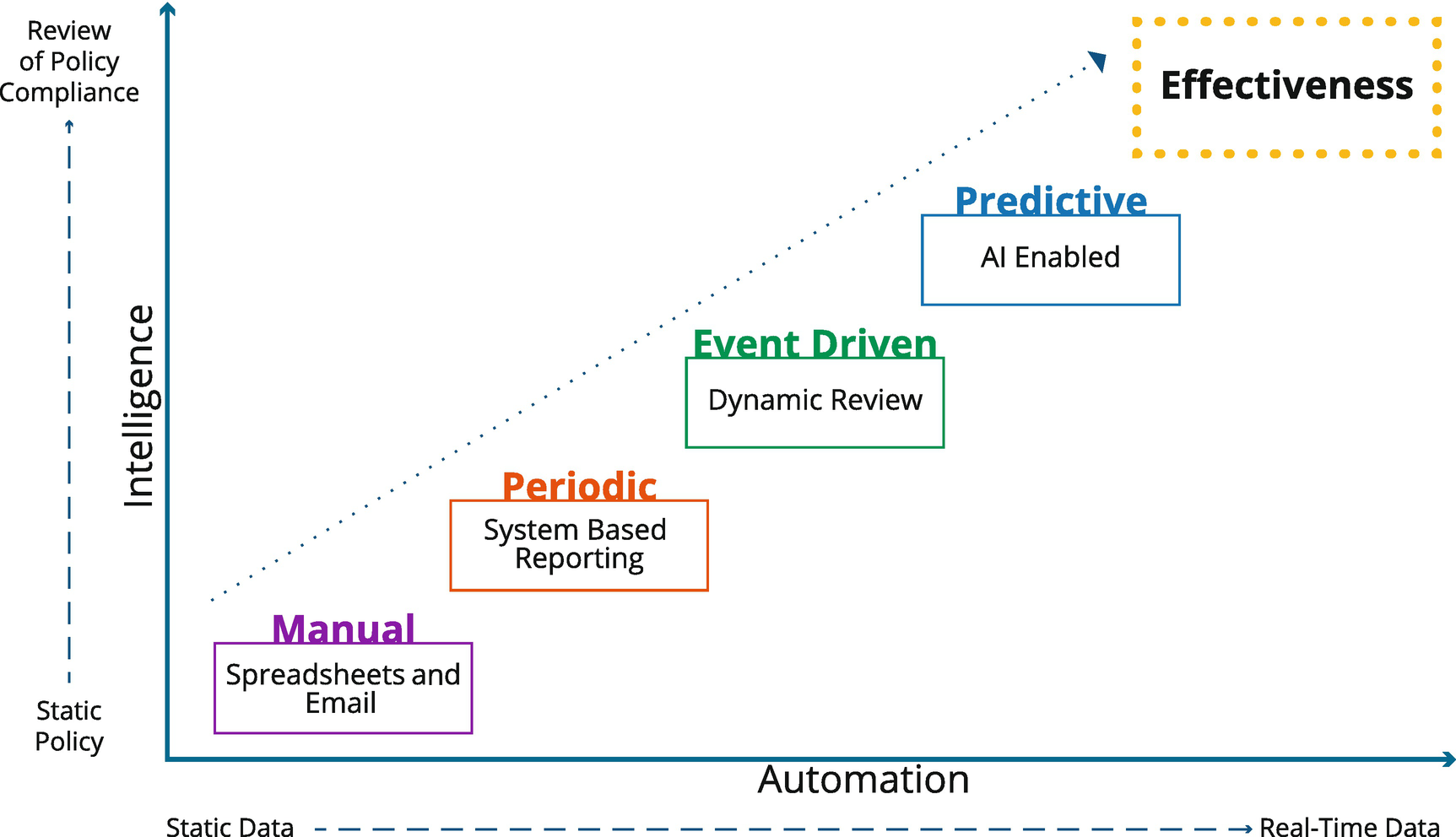
Figure 7-5
The evolution of certification in which access reviews move from being manual to the future state of an AI-enabled predicative governance process
In its earliest phases of deployment, the certification process was a Manual activity completed with the use of spreadsheets over email. Some organizations still carry out their certifications this way today. If the scale is small enough or the regulatory control mandate “light” enough, this approach may be sufficient. Most organizations, however, quickly outgrow a manual approach; or maybe worse, gaps in the security and integrity of a manual approach make it impossible to meet required levels of compliance.
Many organizations today still approach certification as a Periodic control. They run bulk certifications on a regular rolling cadence, and everyone does the “quarterly access review dance.” A periodic approach, delivered through a decent user interface that includes current data and informed entitlement context, is more than enough compliance for many organizations. Many Identity Governance vendors also stop here in their product offerings, and this can be a serious limitation for many enterprise environments.
Fortunately, many organizations today are moving rapidly toward an event-driven approach to certifications. With large volumes of entitlement certifications to contend with, and a significant volume of data changes in the infrastructure, it’s often beneficial to allow lifecycle events and governance policies to trigger dynamic access reviews only when they are needed. For example, you might elect to review all administration rights for a group of admins on a quarterly basis, but then based on unusual admin activity, you might automatically rereview a specific admin. Connecting the ongoing access review cycle to key security “stimulus” can make an access review the very control that stops a breach or exploitation. This then makes an access review one of the basic tools for protecting against identity attack vectors
.
The future of certification, however, lies in a Predictive approach. Later, we will fully address the topic of Artificial Intelligence and Machine Learning. This technology is enabling next-generation Identity Governance platforms to take the notions of event-driven certification to the next level. Here we see the governance platform making value- and data-based decisions (based on behavioral baseline and peer-group analysis) to create a more dynamic and real-time approach to the process. Imagine your manager being asked to confirm your account groups for a mission-critical application, because you just logged in from an odd location – that’s a responsive and highly predictive approach to a detective governance control and is rapidly becoming one of the key future drivers for leading technology providers in this space.
Enterprise Role Management
The topic of enterprise role management could be a book of its own. We only covered a brief definition of it in Chapter 4. In this section, we can still only hope to scratch the surface of this complex and sometimes overwhelming topic. Over the past several decades, roles and Role-Based Access Controls (RBACs)
have swung in and out of favor like a giant regulatory pendulum. Throughout this time, there has however always been a thread of inevitable need and vital functional capability that enterprise roles have provided.
Generally speaking, RBAC is an approach to access security that relies on a person’s role within an organization to determine what access they should have. A role is a collection of entitlements each user receives when they are assigned to that role. One of the main goals of a role-based system is to grant employees only the access they need to do their jobs and to prevent them from having access that is not appropriate to their persona or responsibilities. A well-designed RBAC system also simplifies and streamlines the administration of access, by grouping sets of access in a logical and intuitive way. Based on things like department, job function, title, persona or region, roles are assigned to users, and their access rights are then automatically aligned with those roles out in the infrastructure. This provides a secure and efficient way of managing access and helps keep things simple for administrators, certifiers, and the users requesting access.
In this section, we will try to focus on the core value propositions for roles and highlight some of the known best practices for their use and overall management. We provide an overview of the current engineering, discovery, and peer-group analysis process and highlight some of the best approaches to the “role definition” process. We then provide an introduction to the topic of managing the lifecycle of these role definitions – so how best to manage the role models you create as the business needs change. We then finish this section with a summary on where we see roles as part of the overall Identity Governance process looking forward.
Why Roles?
When done right, enterprise roles offer a significant increase in operational efficiency for IT audit and for the business user. Today, the business is tasked with owning and operating much of the data access process, and enterprise roles (from here on out just referred to as roles) offer a mechanism for simplifying that process. Roles also allow an organization to meaningfully move toward a “manage by exception” paradigm by defining known groups of access aligned with business activities and functions and highlighting where the current state differs from the model view.
Quite simply, roles make certification and access reviews simpler, faster, and more business-friendly. During the business certification process, roles allow the user to focus on the assignment of groups of entitlements rather than getting lost in individual entitlement configuration. This is often referred to a role assignment certification. A separate process can then focus on the composition of a given role – so what’s in the role ready to be assigned to an individual – this is often referred to as a role composition certification.
Roles enable a structured control model for the lifecycle of entitlement changes. Imagine needing to add a new application access profile for all “basic users.” Roles help prevent having to manage these changes at an individual user or account level. Instead, changes to the access assignment model can be made at the role level and pushed out to each user by the provisioning process in an automated fashion.
Roles also greatly enhance the security audit and controls process. Auditors and security professionals can validate access and access management processes at the role level, rather than working with individual entitlements and individual assignments. This vastly simplifies the administration and oversight burden and allows specialists to focus on defining and validating governance policies instead.
Finally, roles provide an important “model construct.” A role (and its supporting metadata and control processes) provides a concrete model construct around which the business and IT can come together to define, capture, and enforce “the desired state,” hence helping to ensure that the right people have the right access to the right data.
Role Model Basics
There are many varied approaches to how role models are defined. One of the more commonly employed approaches is to adopt a basic two-tier model to facilitate matching a user’s business responsibilities (persona and actual job) to their function access. This is depicted in Figure 7-6.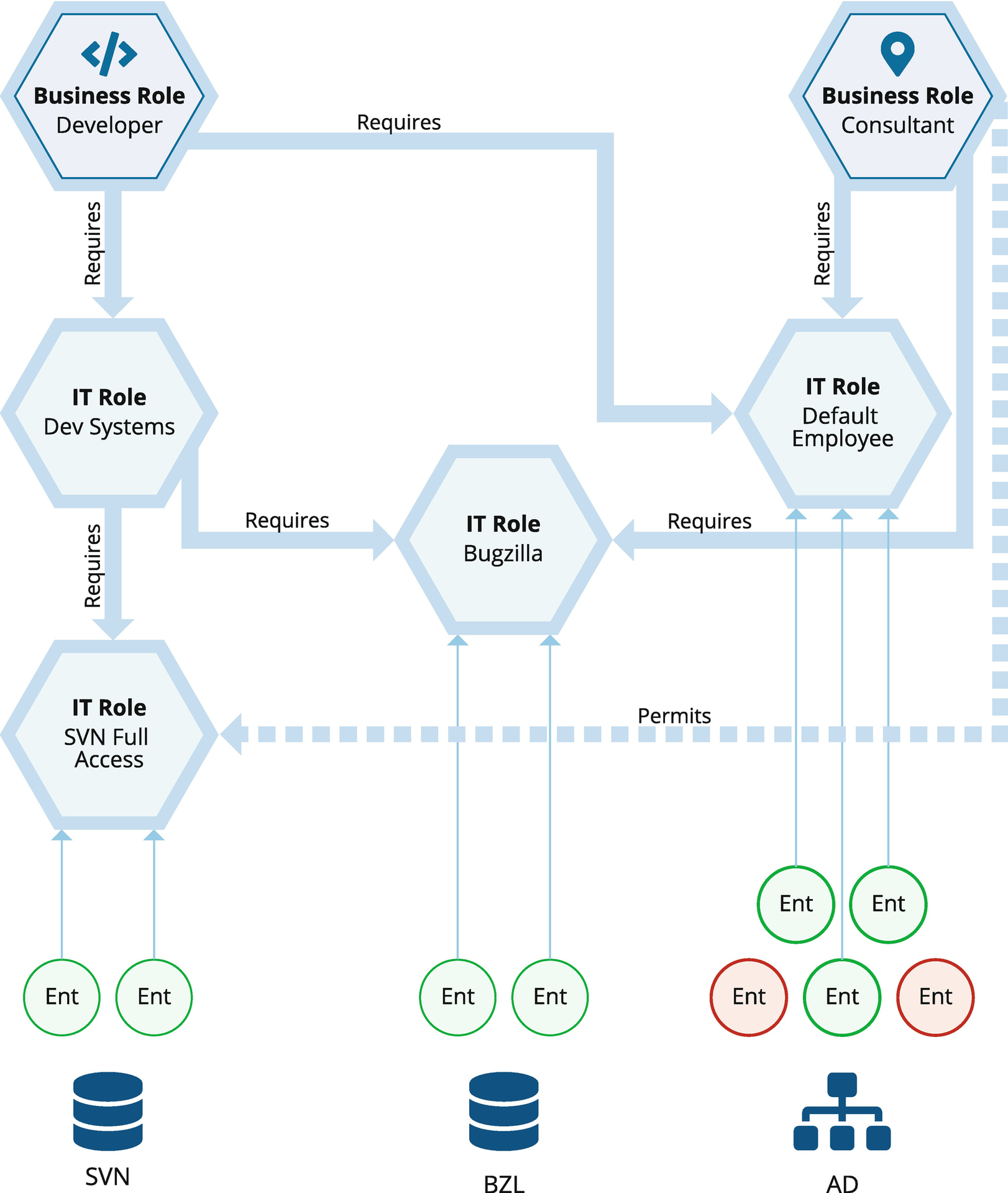
Figure 7-6
Depiction of a classic two-tier role model with role optional and mandatory assignment relationships
Business Roles
Generally, a business role represents job functions, titles, persona, or responsibilities. They are usually tied to the organizational structure and are assigned to users based on their functions in the business – such as “treasury analyst” or “accounts payable clerk.” Business roles are abstract, logical grouping of people that should share similar access entitlements. They are directly assigned to users automatically via identity attribute matching rules on the role definition – so using an identity attribute like job title or department to collect groups of identities together based on who they are and what they do.
IT Roles
IT roles encapsulate sets of system entitlements. They are tied to actual permissions (which may contain privileged access) within an application or target system. They represent the actual state of the user’s access, such as an account, an entitlement, or set of permissions required to execute a given function. A user’s IT roles can be “detected” by the governance platform based on the observation of the entitlements that the user actually has during account discovery and aggregation. A good example of a detected role would be a “sales engineer” that has access that looks like a “developer” – he or she appears to have the same entitlements as the “basic developer access” IT role, but they have never been assigned that actual role. This “matching” ability can be very useful in the complex world of enterprise entitlement.
IT roles are typically connected back to the identity via role relationships and provisioned to a group of users via its association with an established business role. Here our “basic developer access” IT role contains all the access required for code development, test, and check-in, and it is “assigned” to the “OT Developers” business role members via either a required or optional role relationship.
Required or Mandatory Role Relationships
Required relationships refer to the set of access that someone with a given role must have. Someone with an accounts payable business role, for example, will always need to have read and write access to the accounting system. The required relationship is defined by the relationship type that links together the business role and the IT role that contains the entitlement definitions.
Optional or Permitted Role Relationships
Permitted relationships refer to the set of access that is discretionary. These are groups of permissions or entitlements that a user may be allowed to have, but isn’t required to have. When optional relationships are used to connect an IT role to a business role, the entitlements defined in that IT role are essentially “prescreened” – we know that a user with this business role is allowed to have the permitted access. For example, perhaps all employees are allowed to have VPN access, but aren’t automatically given this access unless they or their manager requests it. This type of discretionary access can really help prevent the over-assignment of entitlements. It creates what can be thought of as “model-based least privilege” and can really help business and IT teams work together to better understand the lifecycle of access.
Engineering, Discovery, and Analysis
The term “engineering” is used around role discovery and definition for a good reason. When used appropriately, roles form a critical part of the overall governance process. Defining and validating a role really is an engineering exercise and an ongoing process, one that takes skilled practitioners, smart tools, and reliable infrastructure. An effective governance platform will provide a range of tools to help with the discovery and analysis process, but will always be dependent on a skilled staff and solid understanding of the applications, network, and infrastructure environment in question. The tools required include but are not limited to
- Entitlement Analysis and Search – A frequently employed starting point for a role engineering project is entitlement analysis and search. With access to an entitlement catalog (showing entitlement context and meaning), and a holistic picture of the current state (via aggregation and the creation of the identity warehouse), the role engineer can carry out ad hoc searches and queries. Simply being able to “see” the data and share that with the engaged business participants can be a big help to the overall role engineering process.
- Automated Role Mining – Role mining analyzes data discovered and collected together in the Identity Governance system. It uses pattern-matching algorithms and peer-group analysis techniques to look for collections of, similar, access and outliers. You can use the results of role mining to help determine what new roles to create. In a two-tier role system, the Identity Governance platform should support automated role mining to create both Business and IT roles. Business roles typically model how users are grouped by business function, including functional hierarchies, project teams, or geographic location. IT roles typically model how application entitlements (or permissions) are logically grouped for streamlined access.Business role mining facilitates the creation of organizational groupings based on identity attributes, for example, department, cost center, or job title. Business role mining should support multiple configuration options to assist users in generating new roles. After the mining process is completed, the new roles are added to the system for lifecycle management.
- Peer-Groups and Identity Graphs – Peer-group analysis is an enhanced derivative of the classic discovery methodologies that is focused on building peer-group data graphs and leveraging a broader dataset that often includes actual usage data. Later, we will discuss more on the topic of peer-groups and data graphs for role lifecycle.
- Manual Role Creation – Many businesses still like to use manual methods in the creation of roles. This classic “pen and paper” exercise involves business analysis techniques to help map out commonalities in the access model. It is therefore important that the Identity Governance systems provide an easy-to-use graphical way for roles to be input into the system “by hand” or in a batch based on some form of role import facility.
Role Lifecycle Management
If you are using enterprise roles, you must manage their lifecycle and control their integrity. If the role defines the access, then you must manage that definition over time and across domains. Role definitions need to be carefully maintained and revalidated on a known control cycle. A sage security practitioner once said, “Control the security configuration or be controlled by the adversary.” Here, this means regular role composition recertification, tight change control, and version management for business and IT role definitions.
Good management over enterprise roles starts with an understanding of authority. Understanding role authority means having a clear definition of ownership. In practice, this simply means having things like “role owner” metadata in the model – but it also expands to more complex things like restricting role import and “sharing.” We often see cases of an Identity Governance system being responsible for “full assignment lifecycle and governance” when the full “role model definition” is delegated to an external unrelated system. If you don’t own the model, you don’t own the integrity. Therefore, make sure your model is governed by your IG system and not something else. Yes, it is that simple, but yet that important.
Enterprise Role Tips and Tricks
Successfully deploying roles as part of an Identity Governance project can be tough. It’s easy to play role quarterback from the comfort of an author’s armchair.1 In reality, however, roles are an area of Identity Governance that warrants seeking help and consultation from an experienced practitioner. That said, here are some best practices that can help any skilled IT or business professional design and implement a successful enterprise role solution:
- Take a Pragmatic Approach – Think of enterprise role engineering as an ongoing program, not a project. Don’t expect to achieve 100% coverage right out of the gate. A comprehensive role solution could take months, or even years, to complete. It is realistic and acceptable to implement roles in incremental steps or phases starting with areas of the business that see high staff turnover and simple user access requirement. Start here and gain experience along the way.
- Know What You’re Trying to Accomplish – Are you trying to make certifications easier? If so, your primary focus will be on evaluating and modeling current access. Is your goal to make access requests easier? In that case, you may want to focus on using roles to help users more easily find and select the roles they want to request. Define clearly what you are trying to accomplish and why.
- Look for Groupings of Role Types – Use automated Business and IT role mining and entitlement analysis techniques to identify patterns and groupings of access that can easily be captured and modeled as roles.
- Enforce Least Privilege – Define roles so that you don’t give people access they don’t need. Setting up roles with support for least privilege is a best practice for reducing security risk, both from malicious intent and from user errors. This will form the basis for preventing against privileged attack vectors .
- Expect Exceptions – In most enterprises, it is difficult or impossible to entirely avoid individual entitlement assignments, especially in areas of highly specialized access needs, such as an IT department. Don’t assume you have to force all entitlements and all access models into the role paradigm.
- Make Roles Reusable – If only one person in the whole organization is assigned a particular role, maybe that access shouldn’t be managed via a role at all. Make sure the roles you define are applicable to groups of people. Avoiding “role explosion” requires setting carefully engineering limits to the coverage and assignment of roles. Having a small, well-controlled, and extensively used role model is far better than a behemoth that no one understands or uses.
- Involve the Business Experts – People within your organization who know the business are often the best resource to engage in both the business role and IT role discovery process. They are often the people that understand access patterns are and how your role model should be used.
- Test and Verify Your Roles – Roles need as much testing and verification as any mission-critical application – maybe more. If you define roles suboptimally at the outset and put them into production, you can end up with a lot of users who lack the access they need or who have more access than they should. This can cause a big cleanup effort if you roll out a role structure that has not been set up and tested properly.
- Develop Processes for Role Maintenance – Roles evolve, and you need to keep them up-to-date. Plan for periodic review and certification of your roles to make sure they’re still current and accurate. Regular certification of role composition and role membership should be part of your ongoing program strategy. This should include a plan for how to retire roles when they are no longer needed. It is important to keep your role definitions accurate and up-to-date, or you can set yourself up to be the victim of the very identity attack vectors discussed in this book.
The Future of Roles
As systems and data access continues to proliferate and decentralize, we find ourselves increasingly dependent on understanding the similarities between people and looking for outliers. A traditional role model is an expression of “expected access,” across a known group of users (peers or even personas). The outliers are the entitlements and the people that fall outside of that group. Traditionally, the focus of roles has been the “norms” rather than the outliers. This traditional, somewhat static view of the world is therefore greatly enhanced by an understanding of usage information and a more dynamic runtime connected dataset.
We see the future of enterprise roles enhanced by the construction of “identity graphs” that represent relationships across identity, access, and usage information calculated as vectors. Using peer-group analysis and a range of graph algorithms, we can model scoped populations and carry out a far more granular and dynamic outlier analysis process. This process then results in essential new input into the role modeling process and forms the basis for a more predictive overall approach to the governance process. This significantly enhances the future of role engineering and lifecycle management and is the focus of leading vendors in the enterprise role space.
Governing Unstructured Data
An area of growing importance in the Identity Governance space is gaining control over unstructured data. Of course, everyone understands what data is, but what exactly do we mean by unstructured data? The term “unstructured” refers to the fact that this data has no predictable form or structure – for example, a PDF file, containing personally identifiable information (PII), sitting on a file system or out on a Dropbox share. This data often resides under the corporate governance radar and has an access control model that is usually not synchronized with application-level governance controls and oversight.
Changing Problem Scope
The sheer volume of file-based unstructured data is staggering. Within a given organization, there might be hundreds of thousands, if not millions, of unstructured data items. Is this data sufficiently categorized, monitored, and controlled? Are the effective access models often used for unstructured data understood by security administration staff, and can they be managed in unison with the rest of the access we give to our user populations? Probably not.
The truth is most organizations lack the infrastructure and best practices to properly deal with unstructured data. Many lack the tools to create visibility – to locate, classify, and catalog unstructured data. Most lack the controls to define stakeholder ownership and manage its lifecycle. Few have the tools to define and maintain compliance, and unfortunately, most lack the ability to carry out remediation when security issues are identified. This is a problem an enterprise-class Identity Governance solution can help address.
File Access Governance Capabilities
Some enterprise-class identity management solutions now provide a full suite of management capabilities for applying governance to files containing sensitive information. Table 7-3 highlights some of the governance capabilities required by most organizations.
Table 7-3
Governance capabilities required by organizations
Capability | Use/Benefit |
|---|---|
Data discovery and classification | Discover sensitive data based on keywords, wildcards, regular expressions, and metadata and how files are accessed by users. |
Permission analysis | Evaluate user access to data and how it was granted. Analysis shows access models and ineffective or overexposed. permissions |
Behavioral analysis | Classify folders based on the groups or departments accessing the data. |
Data ownership elections | Employ workflow and business process flow technology to accurately identify and elect proper data owners by enlisting input from users of the data. |
Compliance policies | Predefined policies are designed to accelerate readiness with PII-/PHI-related compliance requirements such as GDPR and HIPAA. |
Data access request | Enable data owners to more intelligently respond to data access requests with enriched identity context. |
Data access certification | Effectively and accurately respond to audits with automated access reviews and certifications. |
Real-time activity monitoring | Track user activity for greater security insight. Monitor access policy violations in real time with automated alerts and responses. |
These capabilities are now becoming foundational requirements for most Identity Governance programs. They should be delivered as simple extensions to the broader Identity and Access Governance platform and deployment. The right approach is to bring together the worlds of structured and unstructured access, to create a single holistic approach. This enables the delivery of a single lifecycle control process for both structured and unstructured data. This will enable you to better meet compliance objectives and ensure an identity attack vector
does not affect potentially sensitive information from your organization.
Self-Service and Delegation
Self-service and delegation are a major part of the overall business value for an Identity Governance program. Intelligent self-service provides big benefits for business cost management, security process improvement, and end-user satisfaction. For the end user, the smartphone has quite literally rewired how people think about getting services. Everyone now expects to find a catalog of enterprise self-service items and a “push-button” delivery model. From a pure cost management perspective, self-service generally means lower overall Total Cost of Ownership (TCO), so it’s a recognized business best practice to lead with a self-service approach in a modern IT environment.
Under the Identity Management governance umbrella, there are now a set of clearly recognized lifecycle management functions that are oriented toward self-service first. In this section, we address where and how Identity Governance self-service fits in the more general IT self-service delivery strategy. Setting a clear direction for the integration between Identity Governance and Information Technology Service Management (ITSM) is an important part of program success. Here, we explain the major options for this integration and make some best practice recommendations. We then finish this section with a deeper dive into the major Identity Governance self-service items of access request, password management, and account controls.
Integrating ITSM and IGA Self-Service
It helps to start this discussion with a formal definition of self-service. The market-leading ITSM provider ServiceNow defines self-service as follows:
Self-service is the ability of a service consumer to resolve their issues and needs without having to call support. Self-service solutions can include everything from using simple FAQ pages, knowledge base articles, and the Service Catalog to complex human-like chat sessions.2
That’s a pretty big self-service picture, so the important question is, where does little-ol’ logical access request and service provisioning fit? Are all of the IAM self-service items just more stuff in a single global ITSM catalog, or is logical access something that should stand-alone? Sadly, there is no simple single answer to this question. Individual business drivers, different product capabilities, and the long tail of legacy IT history result in each organization drawing the line between Identity Governance and ITSM at a different point in the stack – these options are outlined here:
- Launch-in-Context Integration – In the early days of integrating Identity Governance and ITSM, there was a trend toward a basic launch-in-context approach. This meant putting a single service item (the formal Information Technology Information Library (ITIL) term for something exposed as a self-service thing) into the ITSM catalog for “logical access.” Vendor-provided integration then launched the self-service requestor into the user interface of the Identity Governance platform (in a frame or a window). Hopefully this integration also provided the context of a Single Sign-On (SSO) session and deep linking into the service catalog of the Identity Governance product.The benefits here are simplicity and the ability for both products to progress on their own lifecycle. It’s accurate to call this integration model “loosely coupled,” but it’s far from reasonable to call it “highly cohesive.” Challenges invariably come from a lack of visibility between the two platforms. Even with the best efforts of cooperating vendors, the user paradigm shift and lack of true integration ultimately lead to gaps in visibility and functionality.
- Pass-Through Fulfillment – We have also seen a number of successful Identity Governance and ITSM integrations based on a complete pass-through model. Here, a core set of high-value access provisioning services are made “first-class” service items in the ITSM platform, and the governance service is literally plumbed in as an unquestioning and ever-faithful fulfillment execution engine. A pass-through model usually means all the approval action and all the controls lie in the ITSM product scope, and it’s usual to see the Identity Governance provisioning fulfillment happen without workflow or any form of interactive approval in that system.The benefits here lie largely on the ITSM side as it retains full approval visibility. This integration model works well for exposing a small number of very well-defined services – often password reset and a small handful of new access provisioning actions. The challenges here come from a lack of scope (a small number of service items) and the uncomfortable fact that having pass-through provisioning sort of violates the very purpose of having a single control point in Identity Governance in the first place.
- Dynamic Catalog Integration – As API and integration capabilities have advanced, a more detailed and comprehensive integration model now exists between some vendors in this space. Here a dynamic exchange of catalog items, approval processes, and fulfillment progress happens in real time. The Identity Governance team builds “requestable units” and marks them for publication in the ITSM catalog. A “requestable unit” has a carefully managed composition and set of fulfillment steps, defined ownership, known approval steps, and a complete set of tracking metadata that drives the fulfillment process both sides of the integration. Synchronization technology then makes the requestable units available as individual service items in the ITSM system, and both sides are able to track the progress of requests as they move from approvals through to fulfillment.Obviously, this is a fully featured integration paradigm. It benefits from operational integrity and a more dynamic and comprehensive integration model. Unfortunately, this level of integration is only provided by a small number of collaborating vendors and usually does not come cheap.
Self-Service Access Request
Self-service and delegated access request is a basic requirement for most Identity Governance programs. When the business user needs access to a new application or service, they go to their identity and access service portal and search for the access they need. Items are usually added to some form of shopping cart user interface, and after appropriate approvals and controls are completed, the service access is automatically provisioned. There are important nuances to this simple sounding process; these are discussed as follows:
- Managing Requestable Units – Inside a large corporate ecosystem, there can be hundreds of thousands of requestable services or units. We define a requestable unit as a service item with a well-known set of access entitlements and fulfillment requirements. Sometimes, these requestable units are large buckets of access encapsulated in an enterprise role definition. Other times, a requestable service might be an individual entitlement like membership of a specific Active Directory group or access to a single data permission on a managed file share. Each “requestable unit” is carefully cataloged in the Identity Governance system and has established fulfillment obligations, defined approval processes, and established preventive control definitions and (maybe most importantly) has been assigned the correct business metadata such that it is meaningful to the requesting population.It is the specific responsibility of the Identity Governance platform to publish and maintain these requestable units over the lifecycle of the system. Someone has to manage their composition and fulfillment structure and ensure that the defined controls (ownership approval, policy checks, and tracking metadata) are correct and up-to-date.
- Searching and Peer-Group Recommendations – Finding the right thing to request can be a challenge. An enterprise-class governance platform will provide extensive filtering and searching capabilities to help. Allowing the end user (or their delegate) to find services by searching on application, entitlement, and data metadata (so data about the data) is expected functionality.Providing peer-group searching and automated recommendations is becoming a key Identity Governance requirement. By leveraging artificial intelligence and machine learning algorithms, a next-generation governance platform can provide real-time awareness to the access request process. Allowing the people asking for things to “see” what others already have, or are asking for, provides key user insight and enables enhanced controls. Understanding “outlier” requests or suggesting likely peer-group entitlement recommendations vastly simplifies the request experience and allows for more dynamic preventive controls to be defined and implemented.
- Delegation, Capabilities, and Scope – It is also wise to pay special attention to scope and delegation capabilities for access request. An important part of the operational efficiency gains for an Identity Governance program comes from allowing delegates (i.e., business people, managers, HR operatives, project owners, and the help desk) to make requests for a defined group of people.In order to support a secure and auditable approach to access request, the governance platform must provide extensive delegation and scoping capabilities. Requestable units should be scoped such that only defined groups of delegates (or individuals) can see and request them. The overall request catalog model must be flexible enough to allow for complex delegation hierarchies to be defined that only give the right request capabilities to the right people. This is how you allow a project owner in the line of business to be responsible for assigning sensitive fine-grained privileges, in a controlled and auditable manner.
- Overlaying Data-Driven Controls and Governance – Approval workflows are the currency of governance. It’s critical that the access request catalog is supported by dynamic and data-driven approval processes. This means approval workflows should be driven by metadata on the requestable units and the applications and embedded in the delegation model, and not hard-coded in the approval workflow code. This sounds like a technical nuance, but experience shows that getting this right can be the single most impactful factor affecting the long-term cost and maintenance of the Identity Governance system as a whole.As discussed earlier, preventive policy enforcement is a core tenet of access request. Enforcing Separation of Duty controls at the time of access request should be considered a base requirement. As identity-centric artificial intelligence solutions develop to support the access request process, these tools can also provide dynamic peer-group analysis to help overlay more real-time controls that are based on behavioral norms and access request baselines.
- Request Tracking and Management – Finally, as is often the case in systems management, visibility is key. The overall access request process must be rich with monitoring and tracking and must deliver meaningful metrics. The system has to provide embedded instrumentation such that everyone concerned can, where appropriate, get full visibility into what’s being requested by whom and where these requests sit in the overall fulfillment process. This tracking and management data can be used for detailed reporting on service usage and also provides essential input into the ongoing tuning of service definitions (requestable units) over time. Improper reporting or access awarded to the wrong individual is considered another identity attack vector and potential cause of insider threat and risk.
Password Management and Account Self-Service
Anyone with an online account understands the value of password management and account self-service. Who hasn’t forgotten their password or been locked out of their account at some point? Being able to securely reset your own password or unlock your account is a critical enhancement to the end-user experience. A successful password management solution improves business agility and radically reduces operational cost. Industry analysts still estimate that 40% of all IT service desks requests are still tied to password change requests. And, if something as simple as your mailbox is compromised by a threat actor without using multifactor authentication (MFA), a simple “forgot password” request could allow one account to take over your entire identity simply by clicking “forgot password.” This can be a significant identity attack vector
. Providing secure, reliable password recovery capabilities can mitigate this risk by overlaying controls, governance, and oversight for the process.
To that end, the first generation of password management solutions incorrectly focused on the technical aspects of synchronizing passwords across different systems, rather than the strategic needs of the business user. A modern password management approach provides fully automated password recovery and reset capabilities that leverage extensive out-of-box password policy best practices and extensive multifactor authentication capabilities.
As more business applications and systems move to the cloud, organizations need to extend their existing processes and technology to maintain compliance and security over all systems and applications. An enterprise-class password management service empowers all users – including employees, partners, contractors, and vendors – with a secure self-service platform for unlocking accounts and resetting passwords in cloud, SaaS, and on-premise applications and systems. Obviously, this must be done in a highly secure fashion and must not rely on the simple techniques of selecting “forgot password” and sending an email or text message. Both have been proven to be highly susceptible to spoofing and other attack vectors.
Footnotes
1
We had a lot of fun collaborating on this book, as we are both quarterbacks for our respective disciplines.