
CHAPTER 5
Stream Ciphers and Block Ciphers
In this chapter, you'll learn the means of support of the entire cryptographic world. You will learn how to encrypt and decrypt messages with a shared secret, which is how the vast majority of today's encryption on the Internet functions. In fact, encryption is used every day using techniques you'll learn in this chapter. This chapter introduces you to the development of stream ciphers, block ciphers, and cryptographically secure pseudorandom number generators. You'll gain an understanding of some of the analyses of the underlying algorithms and the best attacks that exist in the real world. You'll also learn the amount of security you must build in, based on the client you are serving, and how long it needs to stay secure. You'll walk away with being able to randomize every message you send, which will help you build a solid career in cryptography. Through this chapter, you'll gain cryptographic knowledge as you do the following:
- Learn how to convert between hexdigest and plaintext
- Gain an understanding of stream ciphers and CSPRNGs
- Learn about block ciphers
- Explore various modes of encryption and their weaknesses
- Gain an understanding of blocks as streams
Convert between Hexdigest and Plaintext
Before we dive into stream and block ciphers, I will show you some of the harder bits that involve the conversion between hexdigest and plaintext. To perform the conversions in Python, you'll use the binascii library. The binascii module provides several methods to convert between ASCII-ended binary expressions and binary. It comprises low-level functions written in C for superior performance.
In this section, you will learn about hexlify and unhexlify, modules in the binascii library. Hexlify returns the hexadecimal representation; each byte of data converts into a two-digit hex representation. The output results in the returned hexadecimal being twice the length of the data passed into the hexlify function. The following code converts the string “apples are red” to its hexadecimal representation. You will find that the length of the value referenced by passhex is twice the size of the value referenced by the password variable.
import binasciipassword = b"apples are red"print(password)apples are red>>> passhex = binascii.hexlify(password)>>> print(passhex)b'6170706c65732061726520726564'>>> print(len(password))14>>> print(len(passhex))28
You probably noticed that the first two digits of the passhex variable equal 61; you can look up the code, hex, and characters in an ASCII table. To demonstrate how to convert from characters, code, and hex, examine the following Python code:
>>> passhexb'6170706c65732061726520726564'>>> print(ord('a'))97>>> print(hex(97))0x61>>> print(format(ord('a'), 'x'))61
The binascii function unhexlify, which takes a hexadecimal string as a parameter, is the inverse. As you might imagine, the hexadecimal string must contain an even number of hexadecimal digits. Since the output of the hexlify function returns twice the length, unhexlify returns half the length. Here's an example of using unhexlify to convert back to binary from hexadecimal:
>>> unpasshex = binascii.unhexlify(passhex)>>> unpasshexb'apples are red'
Furthermore, Python allows you to use an x escape character to convert from hexadecimal back to plaintext, as shown here:
>>> hx = 'x61'>>> hx'a'
Use Stream Ciphers
Let's now start exploring private-key cryptography by looking at what stream ciphers are and then examine them as a combination of the one-time pad (OTP) and cryptographically secure pseudorandom number generators (CSPRNGs). The concepts of the OTP that make it perfectly secure are what you capitalize on to make a more robust cipher. As you may recall from Chapter 2, the one-time pad takes a message of n bits and a uniformly random secret key of the same length and generates a ciphertext by bitwise XOR. The encryption and decryption methods are identical operations.
When you examine the elegance of the OTP, you will undoubtedly see its weaknesses as well:
- You must arrange a key exchange between the sender and receiver of the message; this is true in all symmetric schemes.
- You can use the key only once.
- The key length is equal to the message length; if you have a way to send the key securely, then perhaps you could have just sent the message.
You could resolve one of the most significant OTP problems if both parties could generate keys on the fly with the other party. Ideally, both parties would use an unpredictable pseudorandom number generator that would start from the same seed and generate a uniformly random stream of noise that acts like the one-time pad key. As you witnessed in the previous chapter, PRNGs can be predictable and therefore can be cracked. Thus, we need to find improved cryptographically secure pseudorandom number generators.
The goal of this section is to guide you through the creation of your first “do it yourself” stream cipher. We will utilize an insecure stream cipher as an experiment to gain an understanding of the underlying mechanics. Once you complete it, you should feel comfortable with the use of XOR, seeds, and the general structure of a stream cipher. This section builds the base in which we add improvements with true security in mind.
In building your first stream cipher, you take the idea of the one-time pad mixed with the convenience of PRGNs to create an encryption scheme. Since we haven't explored any nonbreakable PRNGs yet, we will work with an insecure one, but the mechanics are identical when you have a more secure source of pseudorandom bits. It is important to know that since you want to use the stream cipher to work on real-world data, it is going to have to encrypt ASCII characters, which means you need to think about the use of random bytes more than the use of random bits. It is not much of a change, but it is worth mentioning.
To start, we select the C rand() function as our PRNG since we have code for it from Chapter 4. It generates 31 bits at a time (the numbers are mod 231), and you want 8 bits at a time. For the sake of this example, use the lowest 24 bits of each number that comes out and generate three bytes of randomness for our stream. Using these guidelines, this should allow you to generate a convention that matches the partner with which you are communicating. A rand()-generated number might look like temp = 2158094741372. If you want three bytes of randomness from that, you could follow these steps:
>>> temp = 2158094741372>>> temp % 2**8124>>> (temp>> 8) % 2**8111>>> (temp>> 16) % 2**8120
The code should produce three numbers uniformly chosen between 0 and 255. Now let's write our own simple PRNG function. It should produce four output numbers, [1471611625, 1204518815, 463882823, 963005816]:
def crand(seed):r=[]r.append(seed)for i in range(30):r.append((16807*r[-1]) % 2147483647)if r[-1] < 0:r[-1] += 2147483647for i in range(31, 34):r.append(r[len(r)-31])for i in range(34, 344):r.append((r[len(r)-31] + r[len(r)-3]) % 2**32)while True:next = r[len(r)-31]+r[len(r)-3] % 2**32r.append(next)yield (next>> 1 if next < 2**32 else (next % 2**32)>> 1)mygen = crand(2018)firstfour = [next(mygen) for i in range(4)]print firstfour[1471611625, 1204518815, 463882823, 963005816]
Now that you have your PRNG producing a predictable output, let's take the message “Hello world!” using the secret seed of 2018. We'll take the bytes in largest to smallest order for convenience, as shown here:
import binasciidef crand(seed):r=[]r.append(seed)for i in range(30):r.append((16807*r[-1]) % 2147483647)if r[-1] < 0:r[-1] += 2147483647for i in range(31, 34):r.append(r[len(r)-31])for i in range(34, 344):r.append((r[len(r)-31] + r[len(r)-3]) % 2**32)while True:next = r[len(r)-31]+r[len(r)-3] % 2**32r.append(next)yield (next>> 1 if next < 2**32 else (next % 2**32)>> 1)mygen = crand(2018)rands = [next(mygen) for i in range(4)]plaintext = b"Hello world!"hexplain = binascii.hexlify(plaintext)hexkey = "".join(map(lambda x: format(x, 'x')[-6:], rands))cipher_as_int = int(hexplain, 16) ^ int(hexkey, 16)cipher_as_hex = format(cipher_as_int, 'x')
Armed with what you have learned thus far, can you find the original message to the following?
Hex: e5d8443c6ac32d3ee5c7398ecf7f9e03f619Seed: 54321
If you get stuck, you can find the solution in the ch5_decrypt file on this book's website.
One crucial concept you'll now explore is the use of the nonce, also called the initialization vector (IV). These concepts, which would have been monumental during World War II, are the encryption version of a salt and save us from the inherent risks of a user sending the same message several times. You have explored how to fix one flaw of the one-time pad by generating a key that is the same length as the message; you still cannot use the same key multiple times. Two possible fixes could include the following:
- Do not restart the PRNG: Not restarting the PRNG requires both sides to carefully coordinate with each other so that they stay at the same part of the communication stream on the encryption and decryption side; this could offer challenges if some messages are lost in transit or if there are parallel message-sending channels.
- Use some public randomness to change the secret key effectively: This idea is that you generate, from a true entropy source, a nonce. A nonce is a one-time set of random bytes that mingles with the private key to change the output of the encryption scheme.
The ultimate goal of this is to allow you to send the same message 100 times in a row, with the same private key, and each time it would look entirely random and uncorrelated. From here on out, your goal is to use a nonce/IV so that the same message is never encrypted the same way twice. Most computers have a source of randomized bytes from entropy that we can pull data from to build random bytes. They pool sources of entropy like temperature, user actions, timings, and other unique factors. This information is then used by CSPRNGs to turn that entropy into uniform random bytes. A poorly generated key or initial seed will cripple even the most secure CSPRNG.
In the previous encryption scheme, you created a PRNG function along with a secret seed. Now we begin by generating a nonce so that when you are encrypting a message, you first generate some entropy bytes that pass along with the ciphertext. The nonce should be sent in the clear, so it should look random. To generate six bytes of noise, use the following Python code:
import osnonce = os.urandom(6)print(nonce)
Ideally, you need a convention to translate the nonce and your secret key (54321) into a new seed or key. Other schemes may have their ways of letting the nonce interact with the scheme; in this case, changing the seed is excellent for learning the concepts. The method presented here will be to concatenate the nonce and the secret key (as hex), then to apply the SHA256 hash function to those bytes (not hex), and take the lowest 32 bits as the new seed.
Here is what the Python looks like:
import os, hashlib, binasciinonce = os.urandom(6)hexnonce = binascii.hexlify(nonce)oursecret = 54321concatenated_hex = hexnonce + format(oursecret, 'x')even_length = concatenated_hex.rjust(len(concatenated_hex) + len(concatenated_hex) % 2, '0')hexhash = hashlib.sha256(binascii.unhexlify(even_length)).hexdigest()newseed = (int(hexhash, 16)) % 2**32print(newseed)
To get a consistent key on both the sending and receiving side, we directly pass the nonce. To test this, replace the previous nonce with “cc4304c09aee” and keep the original seed of 54321. The new seed that generates should equate to “3336748862.” Now you need a system for sending the nonce in your ciphertext. If you have the first six bytes as nonce bytes and the remaining bytes as the ciphertext, you can pass everything in the same message. Since the underlying generator is C's rand function, the encryption is still not strong enough to protect any secrets, but it is much stronger than it was.
Knowing the first six bytes are nonce bytes, here is a new challenge for you:
Secret Key: 61983Message: 3e08816f1377f89f1c596fc197dd52946c92577bfd7c25c3
If you get stuck, you can find the solution in the ch5_decrypt2 file on this book's website.
Answer: Seed is 42847799; the message is 'this is a message.'
Ideally, by now, you are gaining an understanding of how stream ciphers work. Stream ciphers are generally not as secure or well-understood as block ciphers (which we study next). In software, you will most likely deal with block ciphers, though there are tools such as Wireguard which will use stream ciphers. Wireguard is a software VPN protocol that uses the ChaCha20 stream cipher; you will learn more about ChaCha20 later in this chapter. So, while some tools may use stream ciphers, stream ciphers play a more significant role in the hardware ecosystem. With space-constrained devices that need encrypted data streams, we need fast hardware implementations that encrypt bit-by-bit. So, as you code these, imagine the hardware version. As outlined in the previous section, the encryption schemes are still not strong enough to protect any classified data. In this part, you examine a full-strength encryption scheme called Trivium. Bart Preneel and Christophe De Cannière created it and submitted it to the eSTREAM competition. eSTREAM is a project that was organized by the EU Ecrypt network to help identify new stream ciphers that may be suitable for widespread adoption. The project began in November 2004 and completed in April 2008. It is designed to provide a reasonably efficient software encryption implementation and is specified as an International Standard under ISO/IEC 29192-3.
In Chapter 4, you first learned about pseudorandomness. A linear-feedback shift register (LFSR) is an algorithm for generating pseudorandom numbers. The sequence of pseudorandom numbers generated by an LFSR can be used as the one-time pad for an encryption algorithm. However, it has a major weakness: the numbers generated are periodic, and an attacker can figure out the key using a known plaintext attack. In the previous section, you used a PRNG to make a stream cipher. The next level of complexity that you can utilize would be something similar to the Trivium stream cipher, which uses a CSPRNG that generates one bit at a time. It tries to make the LFSR idea more secure by having multiple registers that interfere with each other. The intuitive notion is that LFSRs yield to linear algebra, so let's add just enough complexity to be nonlinear. Figure 5.1 represents a schematic of a three-register Trivium implementation.

Figure 5.1: Three-register representation of Trivium
When looking at Figure 5.1, you see it as three separate registers that each produce their own output. The final output bit is the XOR of all three output bits. The output of each register is also used to help form the input of another register.
For the initialization, to kick-start Trivium, it accepts two inputs: an 80-bit key and an 80-bit IV. The 80-bit key is loaded into the leftmost 80 bits of the first register. The 80-bit IV is loaded into the leftmost 80 bits of the second register. Finally, the final 3 bits of the third register are set to 1 (the rightmost bits).
The stream is then run 4 × 288 times with the output discarded; this is now the opening state.
Let's do the first (tossed-out) run using an all 1 key and an all 1 IV, to show the idea. Bits 1−80 are all 1, bits 94−173 are all 80, and bits 286−288 are all 1; everything else is 0. The first output bit is an XOR of three different bits, so let's look at the first register. The output of register 1 is the XOR of bit 66 (1) and bit 93 (0), which is 1. Register 2's output is bit 162 XOR bit 177, which is also 1. Finally, register 3 is the XOR of bit 288 (1) and bit 243 (0), so also a 1. Thus, the first output is 1. Now everything must slide, so let's look at the feedback. The input to register 2 is the XOR of bit 171 (1) and the XOR of that first register's output bit (1) and the product of bits 91 and 92 (0), so 1 + 1 + 0 = 0 is the new input bit to register 2. All the other bits in register 2 slide one to the right. (Register 2 is now 0 in bit 94, 1 in bits 95−174, and 0 everywhere else.) Likewise, you can trace that the new input bit of register 3 is a 1. The new input bit for register 1 is a 0.
Now that we have introduced stream ciphers, you can examine some additional stream ciphers, namely, ARC4, Vernam, Salsa20, and the ChaCha20 ciphers. Both the Salsa20 and the ChaCha20 are similar in nature as they were created by the same author.
ARC4
The RC4 stream cipher was created by Ron Rivest in 1987. RC4 was classified as a trade secret by RSA Security but was eventually leaked to a message board in 1994. RC4 was originally trademarked by RSA Security so it is often referred to as ARCFOUR or ARC4 to avoid trademark issues. ARC4 would later become commonly used in a number of encryption protocols and standards such as SSL, TLS, WEP, and WPA. In 2015, it was prohibited for all versions of TLS by RFC 7465. ARC4 has been used in many hardware and software implementations. One of the main advantages of ARC4 is its speed and simplicity, which you will notice in the following code:
"""Implement the ARC4 stream cipher. - Chapter 5"""def arc4crypt(data, key):x = 0box = range(256)for i in range(256):x = (x + box[i] + ord(key[i % len(key)])) % 256# swap range objectsbox = list(box)box[i], box[x] = box[x], box[i]x = 0y = 0out = []for char in data:x = (x + 1) % 256y = (y + box[x]) % 256box[x], box[y] = box[y], box[x]out.append(chr(ord(char) ^ box[(box[x] + box[y]) % 256]))return ''.join(out)key = 'SuperSecretKey!!'origtext = 'Dive Dive Dive'ciphertext = arc4crypt (origtext, key)plaintext = arc4crypt (ciphertext, key)print('The original text is: {}'.format(origtext))print()print('The ciphertext is: {}'.format(ciphertext))print()print('The plaintext is {}'.format(plaintext))print()
The ARC4 example should produce the same output that you see in Figure 5.2.

Figure 5.2: ARC4 stream cipher
Vernam Cipher
The Vernam cipher was developed by Gilbert Vernam in 1917. It is a type of one-time pad for data streams and is considered to be unbreakable. The algorithm is symmetrical, and the plaintext is combined with a random stream of data of the same length using the Boolean XOR function; the Boolean XOR function is also known as the Boolean exclusive OR function. Claude Shannon would later mathematically prove that it is unbreakable. The characteristics of the Vernam cipher include:
- The plaintext is written as a binary sequence of 0s and 1s.
- The secret key is a completely random binary sequence and is the same length as the plaintext.
- The ciphertext is produced by adding the secret key bitwise modulo 2 to the plaintext.
One of the disadvantages of using an OTP is that the keys must be as long as the message it is trying to conceal; therefore, for long messages, you will need a long key:
def VernamEncDec (text, key):result = "";ptr = 0;for char in text:result = result + chr(ord(char) ^ ord(key[ptr]));ptr = ptr + 1;if ptr == len(key):ptr = 0;return resultkey = "thisismykey12345";while True:input_text = input(" Enter Text To Encrypt: ");ciphertext = VernamEncDec(input_text, key);print(" Encrypted Vernam Cipher Text: " + ciphertext);plainttext = VernamEncDec(ciphertext, key);print(" Decrypted Vernam Cipher Text: " + plainttext);
Salsa20 Cipher
The Salsa20 cipher was developed in 2005 by Daniel Bernstein, and submitted to eSTREAM. The Salsa20/20 (Salsa20 with 20 rounds) is built on a pseudorandom function that is based on add-rotate-xor (ARX) operations. ARX algorithms are designed to have their round function support modular addition, fixed rotation, and XOR. These ARX operations are popular because they are relatively fast and cheap in hardware and software, and because they run in constant time, and are therefore immune to timing attacks. The rotational cryptanalysis technique attempts to attack such round functions.
The core function of Salsa20 maps a 128-bit or 256-bit key, a 64-bit nonce/IV, and a 64-bit counter to a 512-bit block of the keystream. Salsa20 provides speeds of around 4–14 cycles per byte on modern x86 processors and is considered acceptable hardware performance. The numeric indicator in the Salsa name specifies the number of encryption rounds. Salsa20 has 8, 12, and 20 variants. One of the biggest benefits of Salsa20 is that Bernstein has written several implementations that have been released to the public domain, and the cipher is not patented.
Salsa20 is composed of sixteen 32-bit words that are arranged in a 4×4 matrix. The initial state is made up of eight words of key, two words of the stream position, two words for the nonce/IV, and four fixed words or constants. The initial state would look like the following:
| Constant | Key | Key | Key |
| Key | Constant | Nonce | Nonce |
| Stream | Stream | Constant | Key |
| Key | Key | Key | Constant |
The Salsa20 core operation is the quarter-round that takes a four-word input and produces a four-word output. The quarter-round is denoted by the following function: QR(a, b, c, d). The odd-numbered rounds apply QR(a, b, c, d) to each of the four columns in the preceding 4×4 matrix; the even-numbered rounds apply the rounding to each of the four rows. Two consecutive rounds (one for a column and one for a row) operate together and are known as a double-round. To help understand how the rounds work, let us first examine a 4×4 matrix with labels from 0 to 15:
| 0 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 |
The first double-round starts with a quarter-round on column 1 and row 1. The first QR round examines column 1, which contains 0, 4, 8, and 12. The second QR round examines row 1, which contains 0, 1, 2, 3. The second double-round picks up starting at the second column and second row position (5, 9, 13, 1). The even round picks up 5, 5, 7, 4. Notice that the starting cell is the same for each double-round:
| DOUBLE-ROUND 1 | DOUBLE-ROUND 3 |
| QR(0, 4, 8, 12) | QR(10, 14, 2, 6) |
| QR(0, 1, 2, 3) | QR(10, 11, 8, 9) |
| DOUBLE-ROUND 2 | DOUBLE-ROUND 4 |
| QR(5, 9, 13, 1) | QR(15, 3, 7, 11) |
| QR(5, 6, 7, 4) | QR(15, 12, 13, 14) |
A couple libraries are available that will help simplify the Salsa20 encryption scheme. You can access the salsa20 library by doing a pip install salsa20.
Once you have the library installed, you can use the XSalsa20_keystream to generate a keystream of the desired length, or you can pass any message (plaintext or ciphertext) to have it XOR'd with the keystream. All values must be binary strings that include str for Python 2 or the byte for Python 3. Here, you will see a Python implementation of the salsa20 library:
from salsa20 import XSalsa20_xorfrom os import urandomIV = urandom(24)KEY = b'*secret**secret**secret**secret*'ciphertext = XSalsa20_xor(b"IT'S A YELLOW SUBMARINE", IV, KEY)print(XSalsa20_xor(ciphertext, IV, KEY).decode())IT'S A YELLOW SUBMARINE
One of the reasons why you should be familiar with Salsa20 is that it is consistently faster than AES. It is recommended to use Salsa20 for encryption in typical cryptographic applications.
ChaCha Cipher
ChaCha is a modification of Salsa20 published by Bernstein in 2008. It uses a new round function that increases diffusion and increases performance on some architectures. The ChaCha cipher is a stream cipher that uses a 256-bit key and a 64-bit nonce/IV. Currently the AES block cipher has a dominant role in secret key encryption; in addition, many systems have started to implement hardware acceleration for AES, thus adding to its growing adoption. With AES owning the market share for secret key encryption, it would cause major issues if AES becomes cryptographically insecure. AES has been shown to be weak around cache-collision attacks; therefore, Google has proposed ChaCha20 as an alternative and actively uses it within TLS connections. Currently ChaCha is three times faster than software-enabled AES and, like Salsa20, is not vulnerable to timing attacks. ChaCha operates by creating a keystream that is then XOR'd with the plaintext and has been standardized with RFC 7539.
Some of the key differences between ChaCha and Salsa include improved diffusion per round, which offers an enhanced resistance to cryptanalysis. ChaCha, like Salsa20, builds a 4×4 matrix and adds the results to the original matrix to obtain a 16-word or 64-byte output block. Three additional differences should be noted. First, the ChaCha series permutes the order of words in the output block to match the permutation; this is designed to save time on SIMD (single instruction, multiple data) platforms but does not make any difference on speed in other platforms. SIMD is a class of parallel computers that can perform the same operation on multiple data points simultaneously. Most modern-day CPU designs include SIMD instruction to improve the performance of multimedia.
The second difference is that ChaCha builds the initial matrix with all attacker-controlled input words at the bottom:
| Constant | Constant | Constant | Constant |
| Key | Key | Key | Key |
| Key | Key | Key | Key |
| Input | Input | Input | Input |
These constants are the same as in Salsa20. The first round of ChaCha adds keys into the constants. The key words are copied in order; the input words are the block counter followed by the nonce.
The third difference is that ChaCha processes through rows in the same order in every round. The first round modifies first, fourth, third, second, first, fourth, third, second along columns, and the second round modifies first, fourth, third, second, first, fourth, third, second along southeast diagonals:
quarter_round (x0,x4,x8,x12)quarter_round (x1,x5,x9,x13)quarter_round (x2,x6,x10,x14)quarter_round (x3,x7,x11,x15)quarter_round (x0,x5,x10,x15)quarter_round (x1,x6,x11,x12)quarter_round (x2,x7,x8,x13)quarter_round (x3,x4,x9,x14)
The four quarter-round words are always in top-to-bottom order in the matrix. A couple libraries are available that will offer ChaCha as an encryption scheme. You may also elect to use a pure Python implementation. To implement ChaCha using Python, use the following recipe:
"""Implement the ChaCha20 stream cipher."""import structimport sys, os, binasciifrom base64 import b64encodedef yield_chacha20_xor_stream(key, iv, position=0):# Generate the xor stream with the ChaCha20 cipher."""if not isinstance(position, int):raise TypeErrorif position & ~0xffffffff:raise ValueError('Position is not uint32.')if not isinstance(key, bytes):raise TypeErrorif not isinstance(iv, bytes):raise TypeErrorif len(key) != 32:raise ValueErrorif len(iv) != 8:raise ValueErrordef rotate(v, c):return ((v << c) & 0xffffffff) | v>> (32 - c)def quarter_round(x, a, b, c, d):x[a] = (x[a] + x[b]) & 0xffffffffx[d] = rotate(x[d] ^ x[a], 16)x[c] = (x[c] + x[d]) & 0xffffffffx[b] = rotate(x[b] ^ x[c], 12)x[a] = (x[a] + x[b]) & 0xffffffffx[d] = rotate(x[d] ^ x[a], 8)x[c] = (x[c] + x[d]) & 0xffffffffx[b] = rotate(x[b] ^ x[c], 7)ctx = [0] * 16ctx[:4] = (1634760805, 857760878, 2036477234, 1797285236)ctx[4 : 12] = struct.unpack('<8L', key)ctx[12] = ctx[13] = positionctx[14 : 16] = struct.unpack('<LL', iv)while 1:x = list(ctx)for i in range(10):quarter_round(x, 0, 4, 8, 12)quarter_round(x, 1, 5, 9, 13)quarter_round(x, 2, 6, 10, 14)quarter_round(x, 3, 7, 11, 15)quarter_round(x, 0, 5, 10, 15)quarter_round(x, 1, 6, 11, 12)quarter_round(x, 2, 7, 8, 13)quarter_round(x, 3, 4, 9, 14)for c in struct.pack('<16L', *((x[i] + ctx[i]) & 0xffffffff for i in range(16))):yield cctx[12] = (ctx[12] + 1) & 0xffffffffif ctx[12] == 0:ctx[13] = (ctx[13] + 1) & 0xffffffffdef chacha20_encrypt(data, key, iv=None, position=0):# Encrypt (or decrypt) with the ChaCha20 cipher.if not isinstance(data, bytes):raise TypeErrorif iv is None:iv = b'�' * 8if isinstance(key, bytes):if not key:raise ValueError('Key is empty.')if len(key) < 32:key = (key * (32 // len(key) + 1))[:32]if len(key)> 32:raise ValueError('Key too long.')return bytes(a ^ b for a, b inzip(data, yield_chacha20_xor_stream(key, iv, position)))def main():#key = os.urandom(32)key = b'superSecretKey!!'print('The key that will be used is {}'.format(key))print()plaintext = b'We all live in a yellow submarine.'print('The plaintext is {}'.format(plaintext))iv = b'SecretIV'print()enc = chacha20_encrypt(plaintext, key, iv)decode_enc = b64encode(enc).decode('utf-8')print('The encrypted string is {}. '.format(decode_enc))print()dec = chacha20_encrypt(enc,key, iv)print('The decrypted string is {}. '.format(dec))print()if __name__ == "__main__":sys.exit(int(main() or 0))
The preceding code should produce output that looks similar to Figure 5.3.

Figure 5.3: Python implementation of ChaCha20
If you would like to use a prepackaged implementation, you can install the chacha20ploy1305 library; you will need to perform a pip install chacha20poly1350. Once you do, you can implement ChaCha20 using the following code:
import osfrom chacha20poly1305 import ChaCha20Poly1305# generate a random key that has 32 bitskey = os.urandom(32)print('The key that will be used is {}'.format(key))print()plaintext = b'Attack the yellow submarine.'print('The plaintext is {}'.format(plaintext))print()# generate a random IV that has 12 bitsiv = os.urandom(12)cip = ChaCha20Poly1305(key)ciphertext = cip.encrypt(iv, plaintext)print(ciphertext)print()plaintext = cip.decrypt(iv, ciphertext)print(plaintext)print()
The preceding use of the ChaCha20Poly1305 library should produce output similar to Figure 5.4.

Figure 5.4: ChaCha20Poly1305
An alternative library that you may find helpful as well is the Crypto library. You can import ChaCha20 from the Crypt.Cipher library:
import jsonfrom base64 import b64encodefrom Crypto.Cipher import ChaCha20from Crypto.Random import get_random_bytesplaintext = b'Attack at dawn'key = get_random_bytes(32)cipher = ChaCha20.new(key=key)ciphertext = cipher.encrypt(plaintext)nonce = b64encode(cipher.nonce).decode('utf-8')ct = b64encode(ciphertext).decode('utf-8')result = json.dumps({'nonce':nonce, 'ciphertext':ct})print(result){"nonce": "IZScZh28fDo=", "ciphertext": "ZatgU1f30WDHriaN8ts="}
Use Block Ciphers
Stream ciphers work by generating pseudorandom bits and XORing them with your message. Block ciphers take in a fixed-length message, a private key, and they produce a ciphertext that is the same length as the fixed-length plaintext message. Now we will examine the construction of block ciphers.
AES and Triple DES are the most common block ciphers in use today. From the student's point of view, DES is still interesting to study, but due to its small 56-bit key size, it is considered insecure. In 1999, two partners, Electronic Frontier Foundation and distributed.net collaborated to publicly break a DES key in 22 hours and 15 minutes. Here, we will use the PyCrypto library to demonstrate how to use DES to encrypt a message. The following recipe is using the ECB block mode; you will learn about the various modes later in this chapter. To execute the following recipe, perform a pip install PyCrypto:
from Crypto.Cipher import DESkey = b'shhhhhh!'origText = b'The US Navy has submarines in Kingsbay!!'des = DES.new(key, DES.MODE_ECB)ciphertext = des.encrypt(origText)plaintext = des.decrypt(ciphertext)print('The original text is {}'.format(origText))print('The ciphertext is {}'.format(ciphertext))print('The plaintext is {}'.format(plaintext))print()
This should produce the following output:
The original text is b'The US Navy has submarines in Kingsbay!!'The ciphertext is b'xf6x0bbxf9Lx15Ixf9x0fxe2xee_^xdaQXxe1yxe5xeaxd3Zxc8yxeexd3x86Hxf0Nnx83x93 Od@6Hxd4'The plaintext is b'The US Navy has submarines in Kingsbay!!'Press any key to continue . . .
The key was 'shhhhhh!' and the message was 'The US Navy has submarines in Kingsbay!!'. The ciphertext was 40 bytes long; 40 mod 8 = 0, so there is no need to pad this example. If you were to implement a block cipher in reality, you should use a padding function that ensures the block length.
There are a few things you need to be aware of when using block ciphers. First, block ciphers only encrypt a fixed number of bytes at a time. If you played around with the preceding example, you noticed that the message had to have a length in multiples of 8; therefore, the message would need to be 8, 16, 24, 32, and so on. If your message is more than one block length, you would have to handle it; padding the message, or adding extra bytes to the end, is the most common option.
Second, block ciphers are considered a cryptographic primitive, or a basic building block to a more useful cryptographic message system. If you needed to handle larger blocks of arbitrary length, you would use a block cipher mode of operation, which describes how to apply a single-block operation to securely transform data chunks that are larger than blocks. You may have also noted that the example did not provide a nonce. That is another task of the mode you select. The block cipher itself has one job only: straight encryption with a single key and a fixed-length message. It is the cryptographic version of software engineering.
Third, block ciphers are pseudorandom shuffles that can be encrypted and decrypted; every input has one and only one output. In mathematics, this is called a function. An invertible function is one that also has a unique input for every output. Imagine a block cipher with a block length of 512. It takes in a 512-bit binary string and maps it to another 512-bit binary string. Since you can decrypt a 512-bit binary ciphertext, the decryption process is considered invertible to the encryption process. This relationship allows us to conclude that a block cipher is a permutation. The strength of the cipher is the extent to which its shuffling is indistinguishable from random shuffling. If a block cipher does its job well, then specifying a key should be like grabbing a random permutation from the set of all possible permutations. If we can determine that a particular scheme has some pattern in it that we can use to distinguish the cipher from genuinely random permutations, then the block cipher is considered weak. You explore various modes such as the CTR (counter) and OFB (output feedback) in the next chapter as they relate to various modes and which ones are recommended for image encryption. For now, all you need to know is the following:
- CTR style: If the nonce is 6, then get the random stream out of our permutation done in CTR style.
- OFB style: If the IV is 6, then get the random stream out of our permutation in OFB mode.
Note that the length of the permutation cycles has something to do with the strength of OFB as a CSPRNG. CTR is more resistant to this issue as a CSPRNG.
Block Modes of Operations
In the cryptography world, a block cipher mode of operation is an algorithm that uses a block cipher to provide encryption. A block cipher, when used alone, is only appropriate for the encryption or decryption of one fixed-length group of bits called a block. A mode of operation describes how to repeatedly apply a cipher's single-block operation to securely encrypt or decrypt amounts of data that are larger than a block.
A block cipher mode of operation uses an IV to ensure distinct ciphertexts even when the same key and plaintext are used for the encryption. Block ciphers can operate on more than one block size, though the block size is required to be fixed. Therefore, any blocks that may be smaller than the required size will require padding to ensure that the block size is full. (There are, however, modes that do not require padding because they effectively use a block cipher as a stream cipher.)
The earliest modes of operation include the ECB, CBC, OFB, and CFB, which were all specified in FIPS 81 (1981), DES Modes of Operation. The US National Institute of Standards and Technology (NIST) revised the list of approved modes of operation by including AES as a block cipher and adding the CR mode in 2001 as specified in NIST SP800-38A. In January 2010, NIST added XTS. While there are other modes of operations, they have not been approved by NIST.
The block cipher modes ECB, CBC, OFB, CFB, CTR, and XTS provide confidentiality, but they fail to protect against malicious tampering or accidental modification. Tampering or modification can be detected with a digital certificate or using a separate message authentication code such as CBC-MAC. We will cover CBC-MAC in Chapter 7.
ECB Mode
The ECB mode, formally named Electronic Codebook, divides the message into blocks and each block is encrypted separately. In Chapter 6, you will see visual examples of the weakness of encryption using ECB. Hint: you may still be able to determine what the original image is when using ECB mode even with strong encryption. ECB mode is typically used as an example of how to use block ciphers incorrectly. In Figure 5.5, you will see that plaintext enters the ECB block mode cipher encryption mode, which accepts a key and produces the encryption. Each block is encrypted the same, thus decreasing the scheme's effectiveness.

Figure 5.5: ECB mode encryption

Figure 5.6: ECB mode decryption
In Figure 5.6, you will see that ciphertext enters the block cipher decryption mode, which accepts a key and produces the decryption.
CBC Mode
The CBC mode, formally named Cipher Block Chaining, was created in 1976 by Ehrsam, Meyer, Smith, and Tuchman. When using CBC mode, each block of plaintext is XOR'd with the previous ciphertext block. This ensures that each ciphertext block depends on all plaintext blocks processed up to that point. As shown in Figure 5.4, the IV is used on the initial block and then the produced ciphertext is used to encrypt the plaintext of the next block. Figure 5.7 shows the inverse operation.
CBC is the dominant mode of operation. Its major drawback is that encryption must be performed sequentially as opposed to encrypting in parallel. A second drawback is that the message must be padded to a multiple of the cipher block size.
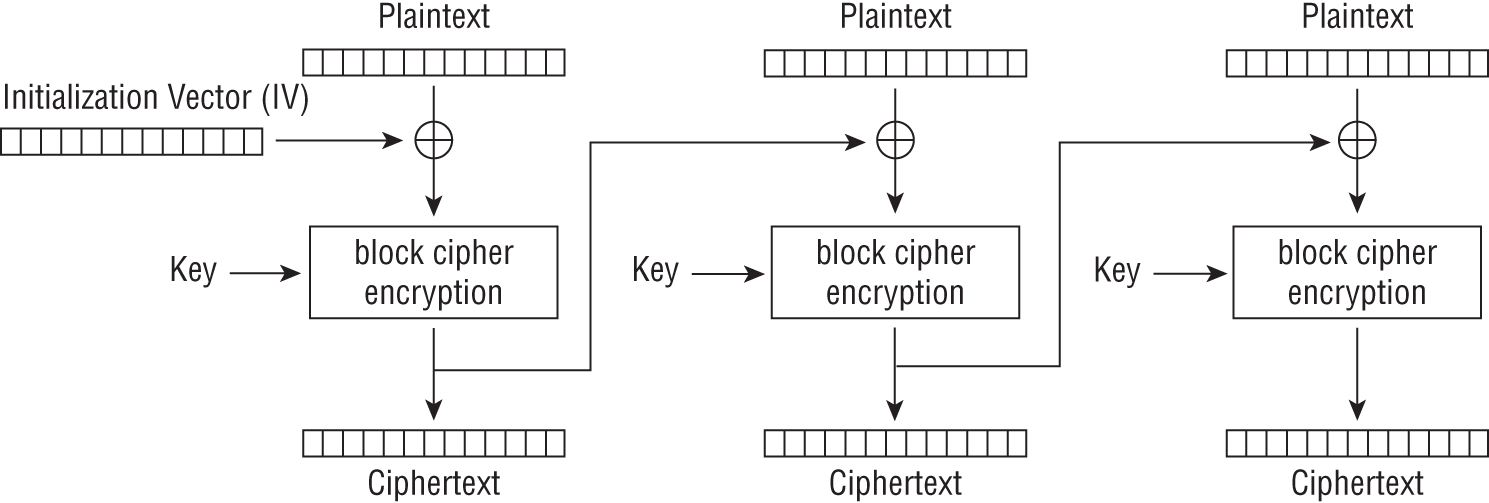
Figure 5.7: Cipher Block Chaining (CBC) mode encryption
Decrypting using the CBC mode with an incorrect IV causes the first block of generated plaintext to be corrupt, but subsequent plaintext blocks will be corrected. Examine Figure 5.8. Do you see why this is true? You may have noticed that each block is XOR'd with the ciphertext of the previous block and not the resulting plaintext. Therefore, a plaintext block can be recovered from two contiguous blocks of ciphertext. Consequently, decrypting with CBC mode can be performed in parallel. This also means that a one-bit change to the ciphertext in that particular block causes corruption of the corresponding blocks of plaintext and inverts the corresponding bit in the subsequent block of plaintext, but the remaining blocks should remain intact. This may make the CBC mode vulnerable to different padding oracle attacks such as POODLE.

Figure 5.8: Cipher Block Chaining (CBC) mode decryption
CFB Mode
We now explore a close relative to the CBC. The CFB, more formally known as the Cipher Feedback mode, makes a block cipher into a self-synchronizing stream cipher. While the CFB encryption and decryption modes are very similar, some small differences exist. As you examine Figure 5.9, you will notice that an initialization vector (IV) is only used to encrypt the first block. After the first block, the encrypted blocks are used in place of the IV; this continues until the end of the process.

Figure 5.9: Cipher Feedback (CFB) mode encryption
Self-synchronizing protects the cipher if part of the ciphertext is lost; this helps recover data due to transmission errors. If an error occurs, the receiver will only lose part of the original message and should still be able to continue decrypting correctly. CFB also allows for operations that do not include a self-synchronizing process, in which synchronizing will only occur if an entire block of ciphertext is lost. If only a single bit or byte is lost, the decryption will be corrupt. If you need to make a self-synchronizing stream cipher that will work for any multiple of x bits, you will need to initialize a shift register of the size of the block with the IV; this process will provide an encrypted block cipher with the x bits of the results XOR'd with x bits of the plaintext to produce x bits of the ciphertext.
Similar to the CBC mode, any changes that propagate from the plaintext will affect the ciphertext, and encryption cannot be performed in parallel. You can, however, parallelize the decryption procedure, which is shown in Figure 5.10.

Figure 5.10: CFB mode decryption
CFB offers two advantages over CBC mode with the stream cipher modes OFB and CTR: first, the block cipher is only used in the encryption process, and second, the message does not need to be padded to a multiple of the cipher block size.
OFB Mode
The OFB mode, formally named Output Feedback, makes a block cipher into a synchronous stream cipher. OFB mode generates keystream blocks that are XOR'd with plaintext blocks to get the ciphertext. See Figure 5.11 for a visual representation. As with other stream ciphers, modifying a bit in the ciphertext will result in a flipped bit in the produced plaintext at the same location. This characteristic allows many error-correcting codes to function normally. The encryption and decryption methods are the same.
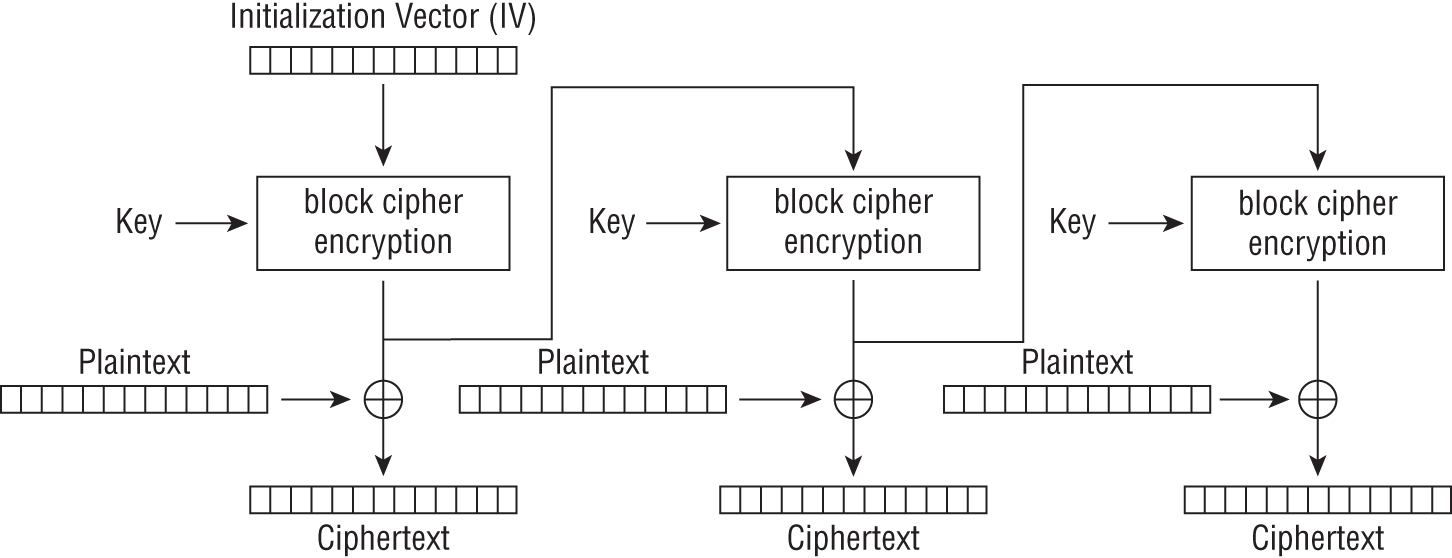
Figure 5.11: Output Feedback (OFB) mode encryption
As with the CBC mode, the OFB cipher operation depends on the previous blocks and therefore cannot be performed in parallel. One notable difference is that because the ciphertext and plaintext are only used for the final XOR, the block cipher operations may be performed in advance. This property will allow the final step to be performed in parallel once the cipher or plaintext is available. See Figure 5.12 for a review of OFB mode decryption.
One thing to note is that you can obtain an OFB mode keystream by using CBC mode with a constant string of zeros as input. This property can be useful as it allows the usage of fast hardware implementations of CBC mode for OFB mode encryption.
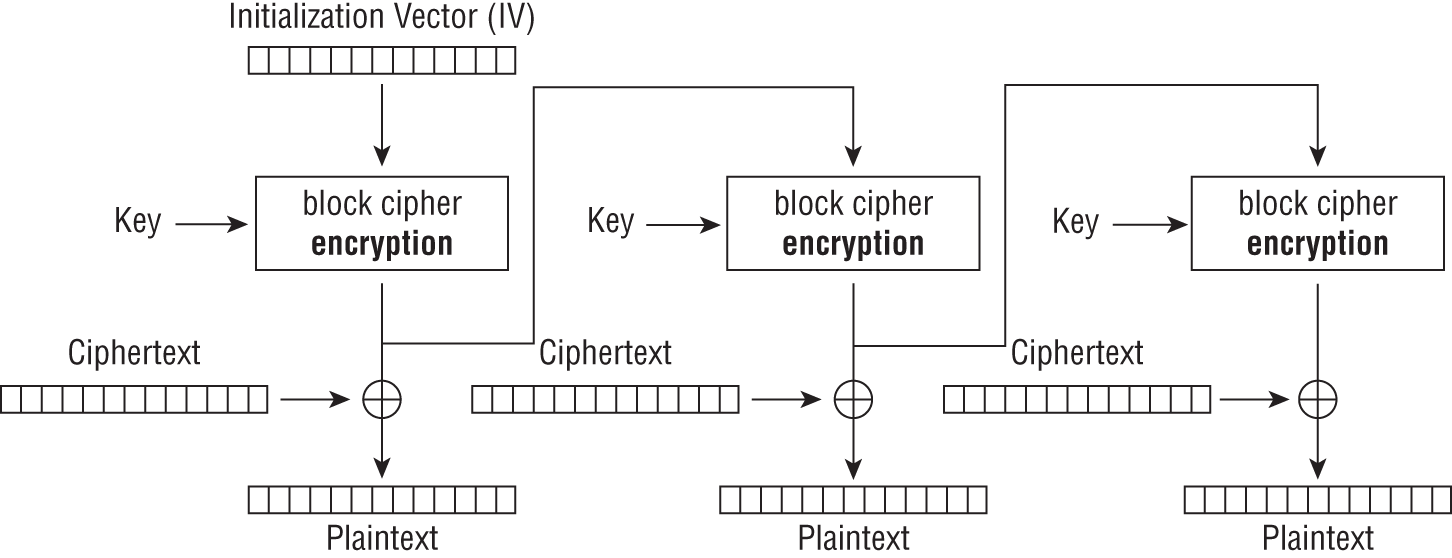
Figure 5.12: Output Feedback (OFB) mode decryption
CTR Mode
CTR mode, also known as Integer Counter mode or Segmented Integer Counter mode, turns a block cipher into a stream cipher. CTR mode was introduced in 1979 by Whitfield Diffie and Martin Hellman. These are two names we will explore in the following chapters. You will see in Figure 5.13 that the CTR generates the keystream block by encrypting successive values of a counter that can be any function that generates a sequence that is guaranteed not to repeat; typically, the simplest counter is to increment by one, although some critics believe using the counter is considered a risk. However, CTR mode is widely accepted and is recommended along with CBC by Niels Ferguson and Bruce Schneier.

Figure 5.13: Counter (CTR) mode encryption
CTR mode allows a random-access property during the decryption process. CTR mode is considered well-suited to operate on a multiprocessor computer where blocks can be encrypted in parallel. If you generate a random IV, it can be combined with the counter using any invertible operation (XOR, addition, or concatenation) to produce a unique counter block for encryption. If the IV is not random, such as a packet counter, the IV and counter should be concatenated. Figure 5.14 illustrates how the counter block is incremented during the decryption process.

Figure 5.14: Counter (CTR) mode decryption
Take caution with how you implement the counter; adding or XORing the IV and counter into a single value could break the security under a chosen-plaintext attack; this is due to the attacker being able to manipulate the entire IV–counter pair to cause a collision. Once an attacker controls the IV–counter pair and plaintext, XOR of the ciphertext with the known plaintext would yield a value that, when XOR'd with the ciphertext of the other block sharing the same IV–counter pair, would decrypt that block. An example using the CTR mode would look similar to the following:
from Crypto.Util import CounterCounter.new(128, initial_value = int(binascii.hexlify('Not very random.'), 16))
Tricks with Stream Modes
Notice that both the CTR and OFB modes act like stream ciphers (the “infinite one-time pad” concept). That is, the block cipher is used to generate a sequence of pseudorandom blocks that are XOR'd with the message. This ensures that the message does not impact the random blocks.
These modes have some strengths and some weaknesses:
Strengths:
- The random stream can be precomputed on the encryption side
- We never have to decrypt a block cipher (so any one-way function can do the job)
- Encryption is decryption (just pass in the IV)
- We don't have to pad the message, just use the bits we need (saves bandwidth on small messages)
- CTR can be efficiently parallelized both for encryption and decryption
- Weaknesses:
- OFB might have short permutation cycles (more in a minute on that)
- Using the same IV twice is deadly (not great in CBC but worse here)
- Tampering with the ciphertext can lead to tampered plaintext (and not just noise)
DIY Block Cipher Using Feistel Networks
In this next section, I want to show you a slick method to use one-way function, like hashes, to create block ciphers using the Feistel network. A Feistel cipher/Feistel network implements a series of iterative ciphers on a block of data and is generally designed for block ciphers that encrypt large quantities of data. A Feistel network works by splitting the data block into two equal pieces and applying encryption in multiple rounds.
The input block is split in the middle to create equal-sized sub-blocks. Examine Figure 5.15; let's call the initial left-hand side sub-block L0, and the initial right-hand side sub-block R0. Let the function Fki be the round function that uses the ith round key, ki. These round keys are generated by the key schedule, which is unspecified. If we have r rounds, then for 1 ≤ i < r.
Li = Ri−1
Ri = Li−1 ⊕ Fki(Ri−1)
and for i = r
Lr = Rr−1 ⊕ Fkr(Lr−1)
Rr = Lr−1
The idea is to split your message into two halves, with one half to make something that looks like noise. Then XOR the other half with the noise. Finally, pass the XOR'd result and the unmodified half. This gives you everything you need to know to go backward, which is the same exact process. In Figure 5.16 you will see an illustration of how the Feistel network decryption works.
Next, convince yourself that reversing one step of the Feistel network is doable by hashing the part that passed in the clear, XORing with the other half, and reversing their spots. Now we want to have our output have the same bit length as our input, which was not true for a hash function.
Use the super-hash as the one-way function in a Feistel network. Our output is a 256-bit hexadecimal number. The input should be 512 bits. Eight bits is enough to encode one ASCII character. The secrets should be 64 characters long.

Figure 5.15: Feistel Network encryption
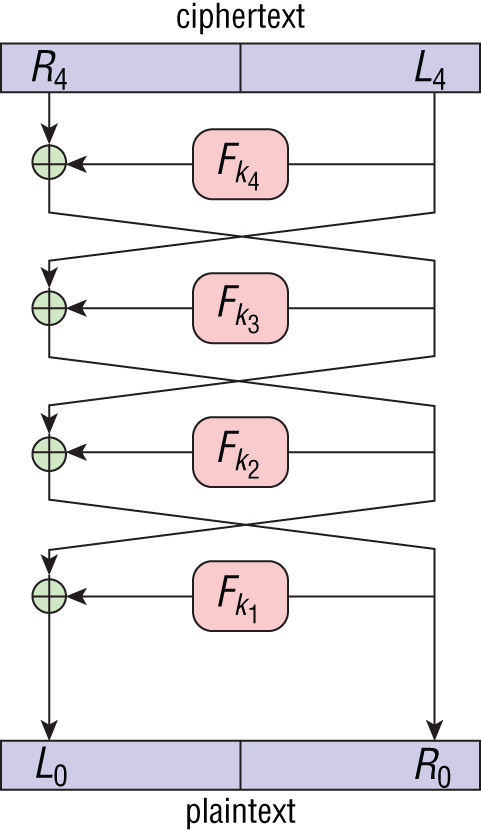
Figure 5.16: Feistel Network decryption
To build the encryption scheme, write a function that consumes a length 64 string and a salt that now acts like a key. Have your scheme do four rounds of a Feistel network and return a hex string of the 512-bit output. For now, you can use 5,000 iterations per super-hash.
Advanced Encryption Standard (AES)
AES stands for Advanced Encryption Standard, and it is the only public encryption scheme that the NSA approves for confidential information. We focus on its use as our main block cipher from now on. AES is the current de facto block cipher, and it works on 16 bytes at a time. It has three possible key lengths: 16-byte, 24-byte, or 32-byte. We know that a block cipher is effectively a deterministic permutation on binary strings, like a fixed-length reversible hash. Given a proper-length key and a 16-byte input we should always get the same 16-byte output. Note that there are typically three ways to work with bytes: plain ASCII, hex digest, and base64 (we haven't played with this yet but we will). A good chunk of your bugs come from transferring between hex and raw. You explore AES in the next chapter as you manipulate images.
Using AES with Python
Earlier in this chapter, you were introduced to PyCrypto as a Python module that enables block ciphers using DES; it also has methods for encrypting AES. The PyCrypto module is similar to the Java Cryptography Extension (JCE) that is used in Java.
The first step we will take in our AES encryption is to generate a strong key. As you know, the stronger the key, the stronger the encryption. The key we use for our encryption is oftentimes the weakest link in our encryption chain. The key we select should not be guessable and should provide sufficient entropy, which simply means that the key should lack order or predictability. The following Python code will create a random key that is 16 bytes:
import osimport binasciikey = binascii.hexlify(os.urandom(16))print ('key', [x for x in key] )key [97, 53, 99, 97, 102, 99, 102, 102, 50, 101, 98, 57, 97, 51, 50, 50, 51, 52, 102, 49, 101, 51, 102, 52, 100, 49, 48, 51, 51, 49, 56, 51]
Now that you have generated a key, you will need an initialization vector. The IV should be generated for each message to ensure a different encrypted text each time the message is encrypted. The IV adds significant protection in case the message is intercepted; it should mitigate the use of cryptanalysis to infer message or key data. The IV is required to be transmitted to the message receiver to ensure proper decryption, but unlike the message key, the IV does not need to be kept secret. You can add the IV to process the encrypted text. The message receiver will need to know where the IV is located inside the message. You can create a random IV by using the following snippet; note the use of random.randint. This method of generating random numbers is less effective and it has a lower entropy, but in this case we are using it to create the IV that will be used in the encryption process so there is less concern with the use of randint here:
iv = ''.join([chr(random.randint(0, 0xFF)) for i in range(16)]) )]) The next step in the process is to create the ciphertext. In this example, we will use the CBC mode; this links the current block to the previous block in the stream. See the previous section to review the various AES block modes.
Remember that for this implementation of AES using PyCrypto, you will need to ensure that you pad the block to guarantee you have enough data in the block:
aes = AES.new(key, AES.MODE_CBC, iv)data = 'Playing with AES' # <- 16 bytesencd = aes.encrypt(data)
To decrypt the ciphertext, you will need the key that was used for the encryption. Transporting the key, inside itself, can be a challenge. You will learn about key exchange in a later chapter. In addition to the key, you will also need the IV. The IV can be transmitted over any line of communication as there are no requirements to encrypt it. You can safely send the IV along with the encrypted file and embed it in plaintext, as shown here:
from base64 import b64encodefrom Crypto.Cipher import AESfrom Crypto.Util.Padding import padimport binascii, osimport randomdata = b"secret"key = binascii.hexlify(os.urandom(16))iv = ''.join(chr(random.randint(0, 0xFF)) for i in range(16))#print ('key: ', [x for x in key] )#print()cipher = AES.new(key, AES.MODE_CBC)ct_bytes = cipher.encrypt(pad(data, AES.block_size))ct = b64encode(ct_bytes).decode('utf-8')print('iv: {}'.format(iv))print()print('ciphertext: {}'.format(ct))print()iv: öhLÒô™Ï2q]>°mâciphertext: BDE+z8ME6r0QgkraNXLuuQ==
File Encryption Using AES
Next, you can encrypt a file using AES by implementing the following Python recipe. The primary difference is opening the file and passing the packs into blocks:
aes = AES.new(key, AES.MODE_CBC, iv)filesize = os.path.getsize(infile)with open (encrypted, ‘w’) as fout:fout.write(struct.pack(‘<Q’, filesize))fout.write(iv)
File Decryption Using AES
To decrypt the previous example, use the following code to reverse the process:
with open(verfile, 'w') as fout:while True:data = fin.read(sz)n = len(data)if n == 0:breakdecd = aes.decrypt(data)n = len(decd)if fsz> n:fout.write(decd)else:fout.write(decd[:fsz]) # <- remove padding on last blockfsz -= n
Summary
After completing this chapter, you should feel comfortable converting between hexdigest and plaintext using the binascii library. The binascii module provides several methods to convert between ASCII-ended binary expressions and binary. We then took a survey of how both stream ciphers and block ciphers work. You should understand that a stream cipher is a symmetric key cipher where plaintext digits are combined with a pseudorandom cipher digit stream. In a stream cipher, each plaintext digit is encrypted one at a time with the corresponding digit of the keystream, to give a digit of the ciphertext stream.
While most stream ciphers are used at the hardware layer, you now understand how to both create and use the Salsa20, ChaCha20, and Vernam ciphers. We then turned our focus on block ciphers and the various modes of operations. We concluded the block cipher exploration by examining which modes allow block ciphers to operate like stream ciphers. We also explored how to create a DIY cipher using a Feistel Network. We finished with an introduction to the Advanced Encryption Standard (AES) cryptosystem. You will explore more about block mode operations and AES in the next chapter as you learn to encrypt images.