
CHAPTER 10. Choosing and Running a Pilot Program
If configuration management is new to your organization, you should establish a pilot program to test the waters. If your organization has tried and failed at configuration management, you should establish a pilot program to help regain lost confidence. As a matter of fact, the only time that a pilot program doesn’t make sense is if you’ve already been successful and have an effective configuration management service today. For the rest of us, choosing and running a good pilot program is a great way to find out how much configuration management can benefit your organization.
So what is a pilot program and why is it so important? First, it is important to understand that by pilot, I do not mean test. A pilot is a full production implementation of configuration management on a smaller scale. All of the people executing the steps should be the people who will have those jobs for the long term. All processes should be the ones you intend to use when you do full-scale configuration management. The tools should be fully installed and verified before you start the pilot. The only thing different between a pilot program and full-scale production is that you will have a narrow focus and very close scrutiny.
The pilot program offers an opportunity to validate your execution capability in a short-term way. It should be treated as a separate project inside the larger project of implementing configuration management. As a separate project, it will have a planning phase, a measurements baseline, an execution, and then an evaluation phase. These short phases are wrapped in all the normal disciplines of project management, as shown in the visual outline of this chapter in Figure 10.1.
Figure 10.1 A pilot is a small-scale project with a full lifecycle.
Reasons to Perform a Pilot
There are many benefits from performing a pilot for any kind of information technology (IT) work. For configuration management, there are very few risks to balance against these benefits. You should always plan to do a pilot, especially if configuration management is a new discipline to your organization. This section gives you the reasons why a pilot is almost always a good idea. Figure 10.2 provides an overview of the key reasons, which include
- Validating the processes work for your organization
- Exercising a new configuration management organization
- Practicing with the Key Process Indicators (KPIs)
- Building momentum for the long deployment ahead
Figure 10.2 The pilot builds overall confidence in configuration management.

One of the best reasons to perform a pilot is to make sure you have the correct processes defined. Tools are fairly easy to test, and many organizations have well-defined procedures for unit test, system test, integration test, and user acceptance test. There are also organized ways to plan the tests, execute the tests, and record defects against tools that are found as a result of tests.
Processes, on the other hand, pose a whole different set of issues. Most organizations are not very good at testing the process work they have done, and those that have tried tend to use their development methodologies and wonder why the testing of processes isn’t very effective. To fully validate that the processes are working well requires several executions of the process in a setting that is as close to reality as possible. Fortunately, a pilot program offers this opportunity.
As I said, a pilot is not the place to conduct testing. You aren’t really testing the process during the pilot. Testing would involve consciously causing every possible process decision box to be executed and every branch of each procedure to be executed in a sequential order. A pilot simply puts the processes into production, which will inevitably lead to the most common branches and flows being executed multiple times. Some less-common scenarios might never be encountered during the pilot phase at all, but that is acceptable as long as the processes work in the real world. Although a pilot isn’t a test of the processes, it is a great way to overcome whatever weaknesses might have occurred during the test phase.
If processes are difficult to test, organization structures are even more so. Unfortunately, experience shows that most IT project fail exactly because the organization isn’t able to execute the process effectively. Thorough testing of the organization would involve verifying that each responsibility is adequately assigned to a role, each person clearly understands the role(s) they’ve been asked to perform, and that each person is fully qualified and trained to execute the roles they’ve been assigned. This kind of thorough testing is seldom completed, usually because of time pressures or because nobody really knows what all the roles and responsibilities are going to be until after the project has started.
So a second great reason to perform a pilot is to validate that the organization is ready to meet the overall needs of your configuration management service. Like the process validation described earlier, this is not a test but a way of overcoming the normal weakness of not having a prior test of the organization. If configuration management is new to your organization, and especially if you’ve created a new team or department responsible for configuration management, it will be important to emphasize that this is not an employment test. If the organization does not work, it isn’t because the people are defective, but because there has been insufficient definition of the roles, insufficient training, or perhaps too many responsibilities for one role to handle.
Processes and organization are difficult to test before production, and measurements are impossible. Until you actually start executing the process against production data, you cannot really capture any of the metrics associated with configuration management. Two classes of measurements are available:
- Those associated with the entire configuration management service
- Those used to track just the success or failure of the pilot
We’ll talk about this latter group a bit later in this chapter, but for now let’s focus on those measurements that will report the day-to-day and month-to-month health of the configuration management service.
A critical part of the pilot effort should be making sure that all measurements are in place and working from the beginning. How do you know if a measurement is working? You know the measurement is working by comparing the data collected against the soft evidence of perceptions about that part of the service. For example, you might be counting the number of incidents that get resolved more quickly because of configuration management data. The reports after a week of the pilot show that only two incidents were marked as having been solved more quickly; but when you interview a server administrator, she can very quickly recall three or four times when going to the configuration management data really helped her resolve an issue more quickly. Your only conclusion would be that the measure isn’t working—either because it is too difficult to record the data needed, or because somewhere in the process the data is getting confused.
Chapter 14, “Measuring and Improving CMDB Accuracy,” is devoted to helping you create and use good measurements. This is a very important topic, especially if you are implementing configuration management in a series of phases or releases, because getting future funding will depend on showing the value of the service you’re building. Use the pilot to really understand and refine the metrics you gather.
At the end of it all, a pilot is really about increasing confidence. For yourself and the configuration management implementation team, the pilot will help you validate the planning you’ve put into the process, the organization, and the measurements. For your sponsors, the pilot is the first chance to see if their investment in the project will yield returns. For the skeptical people who are sitting on the sidelines wondering if there actually is any value to this whole IT Infrastructure Library (ITIL) journey, the pilot will show that the first steps are positive and the rest of the journey is possible.
In the rest of this chapter, we’ll talk about how to make your pilot successful so that you can build this kind of confidence. And just in case your best laid plans don’t work out, read the last section on what happens when pilots fail.
Choosing the Right Pilot
Now that you know all the reasons why you perform a pilot, it is time to think about what shape that pilot will take. It sounds simple to start up a pilot, but when you think about it more deeply, you’ll find there are many ways to go about it. In this section, we consider how to choose the right shape for your pilot program.
One easy way to select a pilot is by using geography. You might decide that the pilot will perform configuration management within your headquarters building, within a specific site that your organization operates, or perhaps even within a designated country if you are part of a very large organization. The common factor is that it will be relatively easy to establish the boundary of the pilot based on geographic borders.
A geographically based pilot is a great choice for many. You’ll want to review the points about setting span from Chapter 3, “Determining Scope, Span, and Granularity,” because in essence all you’re doing when choosing a pilot is determining the span of the first part of your total effort. The set of configuration items (CIs) and relationships in the pilot will be selected as much for political reasons as it is for technology reasons. You might get extra support from your CIO if you choose a geography that includes corporate headquarters. Or, perhaps you need to solidify your relationship with the research division, so you choose the geography with the largest research site. You’ll certainly want to choose a pilot that gives you the highest possible chance of overall success, and that is not always the one that is technically easiest.
One issue that will quickly arise with a geographical pilot is what to do with those CIs that span multiple geographies. These could be something physical, such as a wide area network line with one end in your chosen geography and the other end in a different geography. The issue will need to be decided for logical entities such as a business application used by people all over the company. Each of these items will need to be dealt with in defining the exact coverage for your pilot.
If your organization is managed very hierarchically, with strong distinctions between business units, divisions, or even departments, it might make sense to choose a pilot based on business organizations. You could do configuration management for just one division, or perhaps even a single department. This is slightly more complex to do than a geographic pilot. You need to make everyone aware that if an incident or change affects the selected organization, then configuration data should be collected, used, and tracked.
For example, suppose you’ve chosen to pilot configuration management with just the research division. You need to notify the service desk, on-site technicians, server administrators, change management review boards, and anyone else who might come in contact with research about the pilot choice. All those groups will need to behave differently if their work is on behalf of research. That can be a complex communication and training challenge, but might be worthwhile if the political advantage of working with research is big enough.
Just like with a geographical pilot, there are seams or cracks in an organization pilot that must be considered. These normally will be in the form of shared infrastructure. Again, consider that pesky wide area network line. Odds are good that it is shared by many different organizations, so you need to decide whether it is in or out of scope for an organization-based pilot program.
A third dimension you can use in choosing a pilot is technology. Perhaps you want configuration management for only servers, only workstations, or even just the mainframe equipment as a pilot program. A technology-driven pilot is the easiest to understand and contain because it fits nicely with the structure you’ve already named for the scope of your overall effort. Simply pick some of the categories from your scope documentation, and manage those while disregarding others.
The three dimensions of geography, organization, and technology can be combined in interesting ways to identify the scope that is best for your organization. You might choose servers in the Dayton data center, or all equipment supporting marketing in Singapore. The set of three axes and an example of choosing the right scope among them is shown in Figure 10.3.
Figure 10.3 Choosing a good pilot involves navigating in three dimensions.

Be sure to carefully document the pilot scope. Nothing is worse than having mistaken expectations at the beginning of the pilot, because it is almost impossible to recover if you are planning to build one thing and others expect you to build something else. The scope document should be very concrete and give examples of what will be included and what will be excluded. This document should be carefully reviewed and widely published after it is approved by your sponsor.
Measuring Your Pilot Project
As soon as a suitable scope is chosen, you should begin thinking about the definition of success for your pilot. Because your goal is to build confidence, you will want to be able to demonstrate success in the most quantitative terms possible. Although positive feelings and happy IT people will definitely help, it is solid, uncontestable numbers that will really convince your team and your sponsors that your configuration management effort has gotten off to a good start with the pilot.
Note that the pilot does not need to have the same set of measurements as the overall configuration management service. The pilot has a shorter term and thus must be measured in weeks rather than months. Data accuracy, for example, is a long-term measure that normally takes months to establish. While accuracy should never be neglected, it isn’t normally the kind of measure that will demonstrate success of a pilot.
Focus instead on the benefits your organization is hoping to get from configuration management. If you’re hoping to see less failed changes, create a measurement related to how the availability of configuration data affects your success rate. If the goal is to improve your compliance posture, choose your pilot accordingly and create a measure around how configuration data helps improve compliance. The measurements you choose should be able to be measured at least a couple of times during your pilot and should demonstrate conclusively that your pilot is trending toward the promised benefits. You shouldn’t expect that the pilot will completely overcome the startup costs of an immature organization, but you should run the pilot program at least long enough to see a trend toward improvement.
Don’t get overly ambitious with measurements. Three or four solid numbers can be enough to demonstrate the success of a pilot, whereas 30 or 40 different measurements will only confuse everyone about what the real goals are. And while strong numbers will prove your case, don’t forget to gather the “soft” benefits as well. Specifically solicit comments from people who have benefited from the pilot, and use those “sound bites” to decorate your measurements presentation. Although they aren’t as powerful as the numbers, if the comments you get are positive, they will build confidence more quickly.
Ultimately, your measurements should be used as acceptance criteria for the pilot. Suppose you establish a measurement for reduced incident resolution time based on having configuration data. You could say that pilot is successfully concluded when you see more than 80 percent of the in-scope incidents being resolved at least two minutes faster. These kinds of very specific and measurable criteria are what will take the controversy out of the success (or failure) of the pilot.
While you probably won’t be publishing all of the measures for the full configuration management program during the pilot, this is a good time to at least establish baselines for the critical measures going into the future. Going back to accuracy, just because you can’t measure it several times and see a trend during pilot doesn’t mean you shouldn’t at least measure it to establish a baseline for the future. This is a part of validating the overall measurements—a key reason why you are performing the pilot in the first place.
Running an Effective Pilot
A key thing to remember while actually executing your pilot is that you will be under a microscope. Every success and failure will reflect on not only the pilot, but will indicate to your sponsors and the wider organization what they can expect from the entire configuration management service. If this seems like a lot of pressure to put on a single project, you have the right impression. Success of the pilot is a critical component for going forward and can lay the foundation for the entire future effort.
In order to manage this level of visibility, you should start your pilot project slowly and publicly. Celebrate small victories, such as capturing your first configuration item, helping to resolve your first incident with configuration information, or getting past the first execution of any of your processes. These small successes will communicate to everyone that the effort is valuable and that you will achieve the larger goals of the pilot.
While the pilot is executing, be sure to actively look for ways to improve. A quick adjustment to a process or a fast change to the Configuration Management Database (CMDB) schema when done in pilot might be able to save thousands of dollars or hundreds of hours in the future. Although you shouldn’t just change for the sake of making changes, the pilot is a time for some degree of experimentation and adaptation. Take advantage of the lessons you’re learning while learning them.
To make a change during the pilot, you should have an abbreviated control mechanism. This change control should include a communication mechanism to ensure everyone knows about the change, some evaluation criteria to allow rapid assessment of the change, and a tracking mechanism so you can measure the results of the change. You don’t need fancy tools to track changes in this informal way—email for communication and a spreadsheet for tracking are suitable.
During the pilot, just like during the full production configuration management service, you should be looking constantly for ways to check the accuracy of data. If there is any hint of incorrect or incomplete data, be aggressive in getting it corrected or completed. If the data in the fledgling CMDB is perceived as less than completely useful, your sponsors will get the impression that this is just another failed IT project that had good intentions but ultimately doesn’t deliver on its promises. Nothing will kill the spirit and momentum you’re trying to build in the pilot phase faster than the perception that your data has quality issues.
But how do you avoid quality issues in the data? During pilot, you should have the luxury of double checking nearly everything. Because the set of data you’re managing is intentionally small, you should be able to add extra steps to validate it frequently. Make that extra effort to ensure the success of the pilot and a solid foundation for your CMDB.
In one pilot, our customer was insistent that it was impossible to keep data accurate. In order to prove them wrong, we intentionally set a scope of only about three hundred configuration items with fifty or so relationships. With a data set this small, we did a physical inventory of each CI every three days of the pilot. With this kind of fanatical attention to data accuracy, we achieved one hundred percent accuracy over a seven-week pilot. While this isn’t necessarily the recommended way to keep data accurate, it does show one way to overcome perceptions that the data will always be incorrect.
Finally, during the pilot phase you need to have a strong issue-tracking and resolution process. Keeping track of all issues, regardless of how trivial they might seem, is the best way to increase the satisfaction of your stakeholders. You should announce how issues can be reported, and work with anyone reporting an issue to assign the correct severity to it. Work on the issues of the highest severity first, but be sure to report status on all of the issues. Be attentive to details because, again, the smallest change in the pilot might save you money and time in the longer term.
Some issues might be too big to correct during the original pilot time frame. If the issue is very critical or describes something that simply can’t go on in further production, you will have no choice but to extend your pilot or even postpone it until the issue is resolved. If the issue is small enough, however, don’t be afraid to let its resolution wait until after the completion of pilot.
Evaluating the Pilot
After the pilot has completed, take stock before rushing on to production. You should evaluate the pilot not just for success or failure, but for lessons that can be learned and improvements that should be made. The evaluation step should help not just to improve your configuration management service, but to help other IT projects in their pilot efforts in the future. Figure 10.4 depicts the components of a complete assessment, which are discussed in the following paragraphs.
Figure 10.4 There are several key components in a good pilot assessment.

The evaluation begins with an analysis of the measurements you decided to track. The measurements should show what is working well and what is not working as well as expected. Use all measurements taken during the entire pilot to compile an overall assessment, including strengths and weaknesses, action plans, and recommendations to proceed or wait. This assessment should be reviewed by the team first, and then provided to your sponsors as a summary of the pilot project.
Your assessment should also contain some comments on unexpected benefits from the pilot program. In most projects, you can find benefits that weren’t expected, but which are real nonetheless. You might discover during pilot, for example, that you’ve actually shortened the review time needed for change records. Although you didn’t plan to improve the change management process, this can certainly be claimed as a benefit of the configuration management pilot work. Thus, you would expect all other change reviews to be shorter once you’ve completely rolled out your configuration management service. Spend some time in your evaluation thinking about benefits to the other operational processes that have occurred because of implementing configuration management.
Of course your assessment should also document any issues that remain out of the pilot program. Document the issue clearly, and indicate any steps being taken to resolve the issue. At the end of the pilot program you should close out your issue management by either resolving all remaining issues or documenting in your assessment how they will be handled after the pilot.
In its summary and recommendations, your assessment should provide concrete information about how your project achieved its acceptance criteria. Each criterion you defined before the pilot started should be revisited to assess whether the pilot missed the mark, partially met the goal, or completely satisfied the standard. The recommendation you make should be based on this objective assessment of the acceptance criteria, and if it is, there should be no doubt about whether your recommendation will be accepted.
What Happens When Pilots Fail
Hopefully you will never have to read this section. Maybe your pilot will meet and exceed its goals, and you can sail on smoothly in your implementation. Just in case that doesn’t happen, however, this section will describe how to understand and recover from a failed pilot.
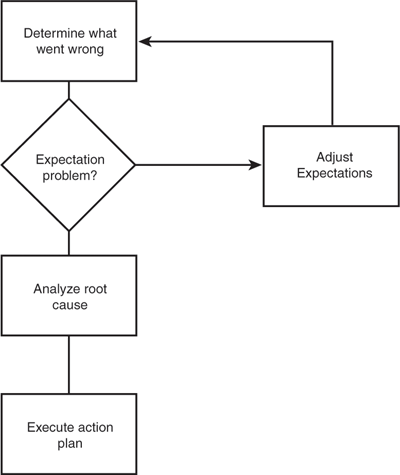
The first thing you need to do with a failed pilot is find out what happened. Was this a real failure of the configuration management service, or a case of failing to meet undocumented expectations? In many cases, you’ll find that the pilot is declared a failure because you failed to do something you never intended to do in the first place. Someone read your scope document, or perhaps your acceptance criteria, and thought you meant something different than you actually intended. This can be a difficult situation to get out of, because it is difficult to have a retrospective discussion of motives. In many cases, this type of dispute will need to be worked through the issue management process, and if the dispute is significant enough, a new pilot may need to be run with a different scope or acceptance set defined.
If the cause of the pilot failure is not found to be mistaken expectations, you should proceed to do a root cause analysis. Dig beneath the symptoms of failure to find the underlying causes. You might find processes that were inadequately or incorrectly defined, team members who didn’t receive adequate training, tools that failed to provide needed functions, or even requirements that were poorly specified. Whatever you find should be documented and worked until you are fairly satisfied that the root cause is well understood.
The integrity of the root cause process can often be enhanced by inviting people outside the project team to participate. If your organization has an independent IT quality group, they would be ideal members of the root cause team. If no such group is available, ask a peer manager or one of your stakeholders from outside the project team to help you really understand the causes of the failure without prejudices associated with having been on the team.
After the root causes have been clearly stated, you can formulate the action plans to address them. Document the actions, including the person taking the action, and definite completion dates. Track this mini-project plan to completion in order to get your configuration management effort back on track. If the actions are going to take a long time to complete, you may need to address some other things before coming back to configuration management. For example, your pilot might have failed because of lack of process discipline among those who resolve incidents. Some incidents could be resolved with configuration data, but others didn’t even have enough basic data to enable the technician to find the right CI.
If you are faced with long-term action items, you need to announce to the organization that although configuration management is a great thing to do, your organization is not yet mature enough to accomplish it. Then go work on the long-term action items and come back to configuration management after those issues are taken care of.
And when your action items are all complete, whether in the short term or after some time, you should run another pilot. It is important to have a successful pilot before moving on to a wider scale roll out of your configuration management service. This is especially true after you’ve had a failed pilot because the confidence in the team and of the team will both need to be bolstered. The full recovery cycle is documented in Figure 10.5.
Figure 10.5 Recovery from a failed pilot is possible.
After the successful pilot (even if you’ve had to try more than once), you’ll be armed with real-world experience that will help you tackle a much wider scope. If you’re staging in your configuration management effort, your next round might be a lot like the pilot—another small, contained effort. If you are in a fairly small organization, you might be able to move from pilot directly to a complete roll out. Either way, the next chapter will help you move from pilot to production as smoothly as possible by describing ways to extend from a pilot program to your full implementation.