
Cloud Based Agent Framework for the Industrial Automation Sector
Francisco P. Maturana1; Juan L. Asenjo2 1 Common Architecture and Technology, Rockwell Automation, Cleveland, OH, USA
2 Customer Support and Maintenance, Rockwell Automation, Cleveland, OH, USA
Abstract
This chapter presents a novel idea that leverages technologies such as intelligent agent-based control and cloud computing to enhance business and operations intelligence in the industrial automation domain. We present the infrastructure framework for an analytics orchestrator that orchestrates high-level analytics required for proactive control of real-time applications. The programming model that has been used to develop applications using the infrastructure is also described here. The analytics orchestrator is designed to be scalable, flexible, and reusable to enable any user to interface with the analytics framework. We also present a use case where we have used cloud services to develop a remote monitoring application for an energy system.
11.1 Introduction
The industrial automation domain has come a long way from electromechanical centralized control to distributed, modular, and intelligent control-level applications. The automation industry today is using multi-core programmable logic controllers to enhance the performance of real-time control systems. However, the increasing complexity of the applications requires more than just device-level computing power. It needs collaborative frameworks to effectively manage the interconnected systems of devices. Such frameworks are envisioned to manage system-level intelligence, unlimited data accumulation and global data availability, and the creation of knowledge based on observed data. Improvements to the hardware and features are not enough to cope with this increasing complexity.
Applications and information require a different paradigm in which collaboration among distributed agents can be achieved seamlessly (Ribiero and Barata, 2011; Pěchouček and Mařík, 2008; Maturana et al., 2012, 2013; Gutierrez-Garcia and Sim, 2010; Hamza et al., 2012; Talia, 2012). It is believed that agents will provide the foundation for a collaborative approach to enable supervisory control with autonomous capabilities and with access to large amounts of information for supporting the information-based automation enterprise.
Current work in control-based agents has established a specific strategy to leverage agents into the supervisory level to simplify and enhance the automation capabilities of the system for handling complex control scenarios (for example, system reconfiguration, fault tolerance, dynamic resource discovery, late binding, etc.). In this strategy, agents become involved in the decision-making process when an event that requires complex computations occurs in the physical world. Nonetheless, the idea is to also explore the proactive side of the spectrum in which agents can also suggest better ways to control the systems.
Agents have to do with business intelligence rules and a mix of device- and system-level information. Now that data can be stored in the big data storage of the cloud, how to merge agent capabilities with the cloud in a harmonious information processing system is one of the challenges of this work. Agent capabilities are established for interfacing them with high-end computing capabilities of cloud services.
The data collected from machines and applications are growing at fast rates, leading to torrential volumes of data. As data grows, the physical infrastructure and computing capabilities required to maintain the data scales up, which in turn keeps increasing the cost to maintain the data. But the focus needs to be shifted from maintaining data to utilizing the data so as to enhance business and operations intelligence for solving domain-specific problems. Thus, adopting cloud computing technology in the industrial automation domain is the most promising solution to lower the cost, increasing computing capabilities and establishing unlimited runtime memory while reducing the burden to maintain the infrastructure.
A framework that connects intelligent agents with cloud analytics services is described. A remote monitoring service for an energy system application is also presented.
11.2 Application Overview
Having data collected from onsite sensors and real-time industrial applications is growing at a fast pace. To be able to analyze and process this large an amount of data in a timely fashion, the onsite data must be collected, serialized, encrypted, and compressed into a suitable format and ingested into the cloud. Each parameter in the system, also known as a “tag,” is associated with a timestamp in order to form time series sensor data. Microsoft’s Windows Azure (Microsoft Azure, 2014) provides a framework to store and maintain this type of data in well-organized blob storage, Hadoop, or SQL databases.
The cloud is all about the “unlimited” storage and computing resources needed to process “big data” (volume, velocity, and variety). The cloud infrastructure essentially provides a data pipeline between onsite devices and cloud applications. This pipeline has the ability to negotiate storage with the cloud-level applications so as to scale up the storage capacity of the emitting system as needed.
To take advantage of Microsoft Azure PaaS (platform as a service), the main focus is to achieve a high volume, high velocity, and high variety of data transferring in a highly secure fashion. Once the data is made available to Azure, it is consumed using a native Microsoft and open-source technology stack for dashboards, batch/stream processing, and analytics (e.g., Hadoop ecosystem, Cloud ML, Power BI, Excel, SQL reporting system, etc.). These features enable users to monitor data from various locations anytime and anywhere while enabling the remote monitoring of applications. To perform analytics on this data stored in the cloud, a robust data pipeline infrastructure was required to enable users to develop domain-specific analytics to enhance business and operations intelligence. The infrastructure was developed based on the following requirements:
(a) The flexibility to enable any user to build their own domain-specific application using this infrastructure;
(b) An infrastructure that can scale out the analytics vertically across various applications and horizontally across multiple customers;
(c) The ability to support multi-tenancy so that multiple customers can operate in parallel;
(d) The ability to provide a secure operating environment for each customer;
(e) A common interface to interact with onsite agents and cloud providers; and
(f) The ability to ensure a timely response and handle error conditions.
An energy generation application based on the preceding framework has been implemented around remote monitoring capabilities. A turboexpander machine produces fuel and electrical power in a co-generation process. The turboexpander produces around 1000 data points (including temperature, pressure, flow, alarms, etc.) every 250 ms. This single machine generates upward of 70-80 GB of uncompressed data per month. Thus, the goal is to implement a cloud-based infrastructure that incorporates high-performance data collection and analysis, user interaction, distributed data storage, fault tolerance, and global data availability. The architecture and implementation of this application is described in Section 11.3.3.
11.3 Application Details
11.3.1 System Architecture
An analytics orchestrator framework has been designed to integrate on premise-level analytics (primarily represented by agents) with cloud-level analytics and data repositories (big data). Throughout this framework, agents control the execution of analytics and the accessing to big data in local or remote clouds to search for answers to events. This framework encapsulates various functions for connecting plant floor-level controllers (the actual source of data) with the cloud-level data ingestion mechanism, as shown in Figure 11.1.
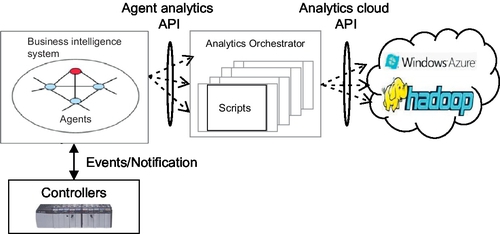
In this framework, there is an application-level system composed of physical hardware, sensors, and networks, etc., all interconnected to perform a process or activity aimed at producing a product or generating a resource such as energy or fuel. The agents and analytics orchestrator were created on different virtual machines and communicated using sockets. The cloud analytics services were invoked during a restful client interface.
11.3.1.1 Controllers
Controllers contain control logic for processing sensor data and to effect control commands into the hardware. The controllers collect the process data in the form of tags in a tag-table image (database). Agent software encapsulates business intelligence rules and they also possess the ability to reason about those rules with other agents in a cooperative decision-making network.
11.3.1.2 Agent modules
Agents are intelligent modules that make decisions that require high computing power within finite time constraints. An agent-based control system is an intelligent control system with control algorithms, high-level reasoning parts, and a data table interface. The control algorithm is dedicated to monitoring the machine status in reactive fashion. The control algorithm is programmed with sufficient logic for emitting event messages to the reasoning level (the agent). The agent evaluates the event to establish a scenario, which can be resolved locally by the agent alone or in collaboration with other agents. Each agent is assigned a set of capabilities that can be used to analyze the scenario. Each capability comprises a set of operations. The capabilities of an agent are registered with the directory services for establishing a network of capabilities that can be leveraged together in the cooperative decision-making process. In essence, the directory services act as the social organizer for the agents.
The core mechanism around the decision-making process is the contract net protocol (Smith, 1980). It is a task-sharing protocol in multi-agent systems consisting of a collection of nodes or agents that form a contracting network. The agents with a particular capability analyze the requests from the controllers and generate a request that is sent to the analytics orchestrator. The request is generated based on a contract that has been predefined between the agents and the analytics orchestrator. In this contract, the agents include all the information required by the analytics orchestrator to route the request to a specific analytics provider. The agents then wait for the response from the analytics provider.
11.3.1.3 The analytics orchestrator
The analytics orchestrator is an intelligent router that routes the requests from the agents to the cloud analytics services. The communication between agents and the analytics orchestrator, and the analytics orchestrator and the cloud, are based on contracts. The agents are generally on the premises and interact with the controllers that control the application. The analytics orchestrator can be on site or in the cloud. The analytics orchestrator communicates with cloud analytics via a restful interface.
The analytics orchestrator listens for incoming requests from the agents. When a request is received, it determines whether it is a new request or if a process already exists for it. The request is discarded if there is a process with the same ID already handling it. If it is a new request, a thread is created to handle it. The request is parsed to extract routing information into the data analytics, which is required for the current calculation requested by the agents. The analytics orchestrator supports a mix of scripts that can be written in high-level languages such as Pig, JavaScript, Hive, etc. The scripts are maintained in a script bank, as shown in Figure 11.2.
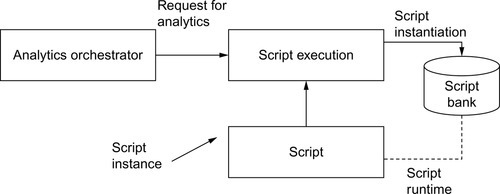
Each script inherits from the ScriptExecution, which manages script class instantiation throughout its class inheritance chain. Once instantiated, the script further parses the original request to extract analytics-specific parameters. The user specifies what analytics should be performed with the data, as well as the other coefficients and threshold data required to process the request. The caveat in this script structure is that the only modifiable part when adding more application-specific functions is at the script-level. This step requires writing a new script and adding it to the bank.
A request is then generated to the requested cloud analytics provider, which is specified by the user. The request is created based on a contract between the analytics orchestrator and the cloud provider. The request is sent to the web service client interface that invokes the requested cloud analytics service.
11.3.1.4 Web service interface
The cloud analytics scripts are deployed as web services and can be invoked by the client web service interface. The web services are based on REST architecture (Rodriguez, 2008). In the REST architectural style, data and functionality are considered as resources and are accessed as uniform resource identifiers (URIs). REST is designed to use a stateless communication protocol such as HTTP. So the client web service interface connects to the requested web service by invoking the URI to the web service specified by the user. The communication is synchronously blocked, which means that the requesting thread is blocked until it receives a response from the cloud analytics web service or the waiting time expires.
11.3.1.5 The cloud analytics provider
Due to the high-end computing capabilities required for performing such a large amount of analytics, the cloud’s analytics capabilities are leveraged in this architecture. Cloud providers use technologies such as NoSQL databases, Hadoop, and MapReduce to perform analytics on big data.
The cloud web service supports multi-tenancy (i.e., it allows multiple customers to access multiple instances of single software). There are service level agreements (SLAs) that define the rules and regulations of the communication between the cloud provider and an external user. Thus, the cloud provider ensures data security and sovereignty in each customer environment. Once the cloud provider receives a request, it analyzes it and invokes the analytics script that will execute analytics and retrieve the requested information. The response is then packed into a predefined response format and sent back to the analytics script that raised the request. Error conditions are also specified as part of the response.
The majority of the functionalities of each of the subsystems have been described. The next section describes the programming model to build an application using this infrastructure.
11.3.2 Programming Model
The programming model consists of three phases: (1) design and programming, (2) runtime, and (3) offline processing.
11.3.2.1 The design and programming phase
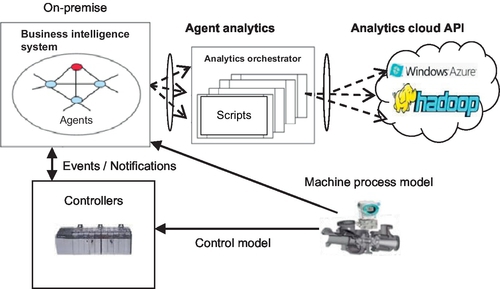
In this phase, the user designs and develops models and scripts that will be executed during the runtime phase. The application-level control logic is modeled in the controllers and the business-intelligence logic is modeled in the agents, as shown in Figure 11.3. The user develops domain-specific analytics to be executed. For example, the user develops analytics scripts either to generate reports and trends or to develop any smart application on top of the analytics orchestrator infrastructure. The user also defines the contracts for communication between agents and the analytics orchestrator and the analytics orchestrator and cloud providers.
11.3.2.2 The runtime phase
During runtime, the application is running on the premises and generates event notifications to the agents. The agents generate requests to the analytics orchestrator, which then executes the specified analytics script that was designed by the user and generates requests to the cloud analytics provider. The cloud analytics providers perform the required analytics and respond back to the analytics orchestrator with the response. The analytics orchestrator analyzes the response to further filter the response data into a format that is understood by the agents. The complete final response is then sent back to the agent that originally triggered the request. The agents make decisions based on the responses and convey the decision to the controller via data table writing and to the users by sending notifications. This sequence of events is shown in Figure 11.4.
11.3.2.3 The offline processing phase
During runtime, anomalies may occur that were not anticipated in the programming phase and therefore cannot be handled by agents or the orchestrator. These anomalies generally are the preamble to process-level alarms that can be detected by the reactive level in the PLC. But the intent in bringing supervisory intelligence to the control system is to be able to learn such alarm-generation conditions and convert them to rules that will help the agents foresee the conditions before they can harm the system—thus, behaving in a more proactive fashion.
In the offline processing phase, the user can analyze these anomalies by extracting parameters and other attributes to understand the phenomena. Historical data accumulated in big data can then be leveraged into place to further understand the phenomena timewise. This type of analysis can be supported by cloud computing techniques such as MapReduce. Once the reason for the anomaly is understood, new business intelligence rules can be added to the system as analytics scripts. With these new rules, the agents would proactively detect the pattern and future occurrences of the events under observation. A self-learning system can be established from this phase, which is designed to continuously adopt new rules without touching the baseline infrastructure.
11.3.2.4 Common API specifications
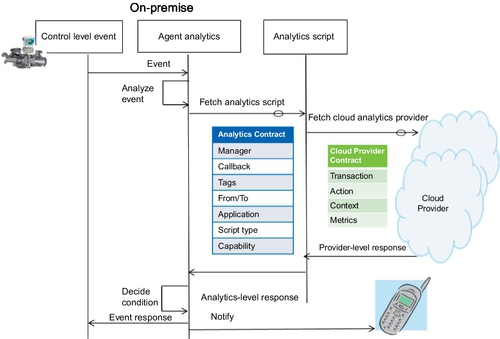
The interface between agents and the analytics orchestrator, and the analytics orchestrator and the cloud provider, is done with contracts. The contract specifies the information that should be conveyed by each party when generating a request or response, as shown in Figure 11.5. The elements in the contract between agents and the analytics orchestrator are described next.
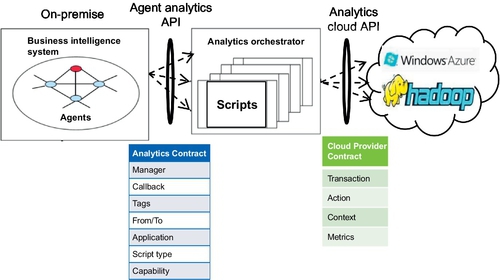
• The manager identifies the tenant.
• Callback specifies the method to be invoked when the response is received.
• Tags specify the parameters on which the analytics are to be performed.
• FromTo indicates the time interval during which the data is to be extracted from the big data storage.
• The application specifies the particular application from which the event occurred.
• Script-type specifies the analytics script group to be contacted. There will be one analytics script group per cloud analytics provider. The analytics script group will prepare the requests to the cloud analytics provider according to the specifications of the particular cloud provider.
• The capability represents the analytics to be performed—for example, to calculate enthalpy.
The elements in the contract between the analytics orchestrator and the cloud analytics provider are as follows:
• The transaction represents the timestamp of the transaction, which is used in analytics to uniquely identify a transaction.
• The action specifies the analytics to be performed by the cloud analytics provider.
• The context specifies the information of the tenant, which is used to locate the data of the tenant in the big data storage.
• The metrics specify the tag values, time intervals, and coefficients and thresholds information required for executing the analytics.
This is one example of a contract that can be defined. The user can modify the details and parameters that need to be included in the contract without affecting the basic infrastructure. Thus, the framework for developing cloud-based analytics applications has been outlines. A use case based on this framework is described in the next section.
11.3.3 Use Case Description
A cloud-based remote monitoring application was developed for a turboexpander machine typically used in the oil and gas industry. The turboexpander generates a torrential amount of data that is moved to the cloud. A worker role is developed that extracts data from the big data storage for a specific time interval, processes the data, performs the required computations, and displays the requested information through dashboards. The data to be extracted, the time interval information, and the output to be displayed are user-specified on a system manifest.
11.3.3.1 Data ingestion into the cloud
Data ingestion from the premises to the cloud infrastructure is facilitated by an on-premise cloud agent. Figure 11.6 shows the on-premise architecture. The time series data or tags from the machine are collected by FTHistorian software (Rockwell Automation, 2013) and stored into a local cache. The cloud agent periodically connects to the FTHistorian and transmits the data to the cloud.
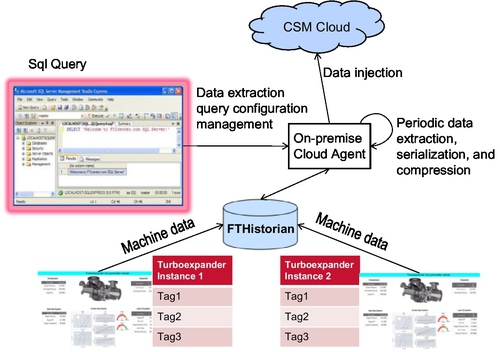
The cloud agent verifies the connectivity between the on-premise site and the cloud before sending the data. If a disruption is detected in the connectivity to the cloud, the cloud agent switches to a local-cache mode (store and forward mode). The cloud agent then forwards the cached data once the connection is restored.
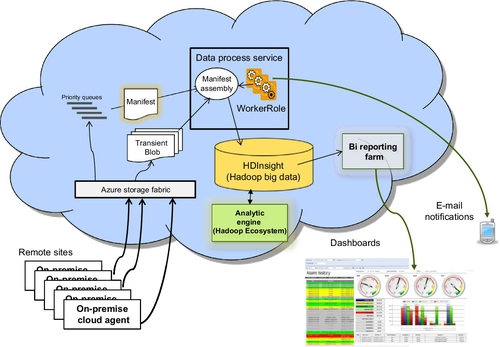
The Microsoft Windows Azure cloud service was utilized for storing the data into the cloud and developing analytics to be performed on the data. When data reach the cloud, the data are put into blob storage and an acknowledgment is sent to the cloud agent verifying reception of the data. The cloud agent then sends a notification to the worker through one of the event priority queues to inform the worker role about the new data that waits in the blob to be processed.
11.3.3.2 The worker role
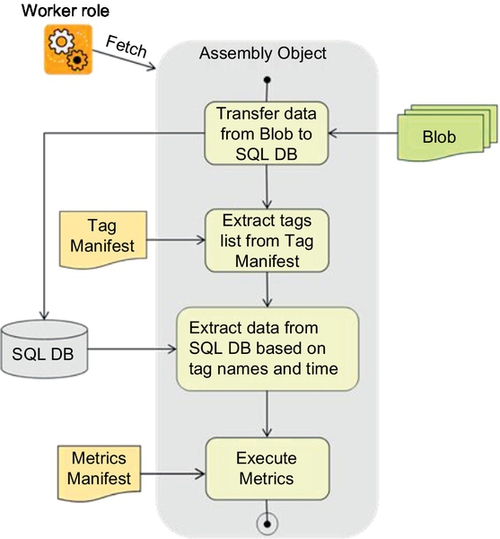
The worker role processes the event notifications/requests from the on-premise cloud agent according to their priority. It identifies the system-level manifest from the event header information. The system-level manifest specifies the tenant information (the unique ID) and the analytics to be performed on the data. The system-level manifest also contains a reference to tag any metrics manifests. The tag manifest contains a list of tags on which the analytics is to be performed. The metrics manifest specifies the coefficients, thresholds, and other constants required for executing the calculations or other activities.
When the worker role receives notifications about the new data, it fetches a manifest identified assembly object to process the data. A minimal action of this assembly is to extract the data from the blob into permanent storage (SQL, Hadoop, Tables). The worker role system depends on assemblies to complete its job. The owner of the data specifies the analytics and therefore he/she characterizes the behavior of the assembly. This worker role architecture is shown in Figure 11.7.
11.3.3.3 Runtime execution
In runtime, the worker role manages the data transition and assembly-level analytics. Once the data is in the cloud, the user can trigger specific analytics via dashboard services. For example, turboexpander analytics calculates net power, cycle efficiency, and the power guarantee. These calculations are offered as analytics options to the user on the dashboard. Each option requires the identification of tags and a time span to perform the calculations. The tags tell the analytics-level assembly what specific data are to be extracted from the tenant’s historical data. The time span parameter tells the analytics-level assembly how much data to extract and if it will be required to interpolate missing data points for the selected interval.
The runtime analytics is a combination of actions and data that depends on descriptive manifests and historical data, as shown in Figure 11.8. The result of the calculations is displayed back on the dashboard on tabular or graphical forms.
11.4 Benefits and Assessment
By utilizing the infrastructure and services offered by cloud computing technology, the cost to store and maintain data on site can be lowered to a great extent. Cloud computing offers on-demand delivery of IT services with pay-as-you-go pricing. This reduces the time and money required to invest in data centers and other IT infrastructures on site. Also, cloud computing can easily provide resources as needed. Any number of servers can be procured, delivered, and be running within no time, thus making it easy to scale up when required (elastic computing).
The industrial automation domain can leverage these cloud computing capabilities so as to manage the huge amounts of data generated by the sensors. Users can remotely monitor the data from various locations whenever and wherever they wish. The data can be used to develop smart applications that can proactively control the system or to generate business- and operation-level intelligence.
The infrastructure described here meets the essential requirements of flexibility, scalability, and reusability and can thus be adopted and interfaced with existing systems with ease. Thus, the merging of industrial control technology with cloud computing technology comes with the benefits of lower costs, higher computing capacities, and unlimited storage facilities, which is the need of the hour in the industrial automation domain.
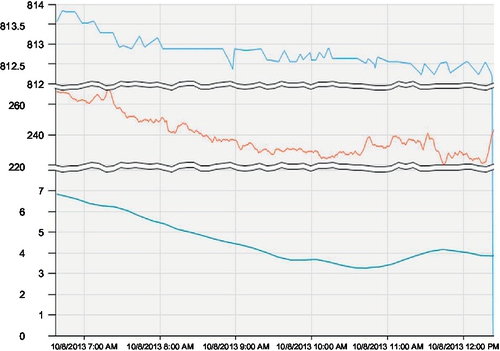
The result of the analytics is displayed to the user through the dashboard, as shown in Figure 11.9. The figure shows the trends of parameters over a period of time defined by the user. This remote monitoring service can enable business decision makers to observe energy trends and possible anomalies, thus providing them with information to design smarter energy monitoring systems.
11.5 Discussion
A lot of research has been conducted in agent-based cloud computing applications (Wang et al., 2011; Patel et al., 2009). A self-organized agent-based service composition framework was discussed, which uses agent-based problem-solving techniques such as acquaintance networks and contract net protocol. This method can be used in scenarios involving incomplete information about cloud participants. The solution described in this paper also leverages the contract net protocol to solve multi-agent event handling tasks throughout contracts.
A multi-agent model for social media services based on intelligence virtualization rules is discussed in Kim et al. (2013). Intelligence multi-agent for resource virtualization (IMAV) manages cloud computing resources in real time and adjusts the resources according to users’ behavior. This aspect of the implementation can be reflected in the script execution model.
A new cloud computing architecture for discovery and selection of web services with higher precision is presented in Gutierrez-Garcia and Sim (2010). It is based on the concept of OCCF (Open Cloud Computing Federation), which incorporates several CCSPs (Cloud Computing Service Providers) to provide a uniform resource interface for the clients. This offers the advantages of unlimited scalability, the availability of resources, the democratization of the cloud computing market, and a reduced cost to clients.
Cloud computing technology offers a plethora of services that are categorized as infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). How to leverage the software services offered by cloud vendors to solve industrial automation-specific problems was a challenge discussed in this work. Some of the major software services that the cloud offers are maintaining and storing vast amounts of data, and performing analytics on data on the order of terabytes, petabytes, and more.
Multi-tenancy and data security and sovereignty are topics to be observed because the globalization of the information is a very important requirement of new distributed systems. These features are crucial to a successful implementation of agent technology in cloud industrial automation.
11.6 Conclusions
Industrial domain applications are increasing in complexity and size, thus calling for the need to scale out the analytics capabilities of industrial control services. The data being collected from machines on site are becoming more cumbersome and expensive to maintain. Thus, services offered by cloud computing technology to store and maintain data are leveraged to meet the ever-increasing demand for storage and computing capabilities.
To meet the growing complexity needs of industrial domain applications, an infrastructure that merges agent technology with cloud computing has been presented. The architecture for enabling proactive control of real-time applications using agents and cloud computing technology has been described. The analytics orchestrator uses a scalable, generic, and flexible API to ease the programming of the domain-level rules. A specific use case in the remote monitoring of turboexpanders was also described.
The solution presented here taps into a strategic partnership between the industrial control expertise with cloud computing and the domain user expertise to solve some critical problems existing today in the industrial automation domain.