
5
Business Enterprise Agility and DevOps Ways of Working Reconciliation
This chapter is related to the DevOps evolution Ways of Working (WoW) workstream and is divided into two main parts – the DevOps and business enterprise agility relation, reconciliation, and agnosticness as the first part and the design of the DevOps organizing principles in an agile context as the second part. We will start by providing a short overview of the relationship between DevOps and Agile, introducing the point that the two concepts can be reconciled agnostically. Then, we will discuss four agile models: basic agile, Scaled Agile Framework (SAFe), Spotify, and value streams, all of which have been adopted by incumbents, while also providing an overview of their organizing structures. Moving on, we will discuss in depth the agile principles of autonomy and self-organization relating to an incumbent’s DevOps context and outline the main reconciliation and agnosticness conceptual dimensions of DevOps and Agile.
In the second part of this chapter, we will outline a tested practice of how to design the organizing principles of DevOps evolution for agile teams while considering the element of relevance through an 11-step framework. We will use the Spotify model as the basis of business enterprise agility. As part of the 11-step framework, an array of guidelines, methods, and lessons learned, as well as points of consideration, will be presented.
In this chapter, we’re going to cover the following main topics:
- The interrelation of Agile and DevOps
- Four examples of incumbents adopting business enterprise agility methods, focusing on basic agile, SAFe, the Spotify model, and value streams/clusters
- The paradox of autonomy and self-organization in Agile DevOps teams
- How DevOps can be agnostically reconciled with business enterprise agility
- A framework for designing DevOps organizing principles in an agnostic agile context
- At relevance elements that need to be taken into consideration
Business enterprise agility and DevOps reconciliation
Agile and DevOps are two concepts that have historically been interrelated in the industry, and this is no coincidence. Following this book’s pattern of discussing real use cases of incumbents, in the first part of this chapter, we will look at four agility models adopted by four different incumbents. We will discover profound similarities in their expected outcomes and principles, and we will reveal their respective reconciliation dimensions and features regarding DevOps.
Why the interrelation of Agile and DevOps is natural and inevitable
To preserve space in this book, and for other obvious reasons, we will refrain from discussing in depth, both academically and theoretically, how Agile and DevOps are interrelated. I imagine this will be quite intuitive and familiar to you. The apparent interrelation and mutual inclusiveness of the two concepts is one of the reasons why it is a common phenomenon in the financial services industry to have them combined under WoW evolutions. It is indeed a universal truth that DevOps adoptions require agility fundamentals to be in place, and in order to achieve the objectives of Agile, DevOps capabilities need to be enabled. It is not only a matter of mutual success dependency but also a business case materialization objective, to increase the return on investment, by getting the most out of the two concepts in a given organization.
It is simple; you will not get the most out of a CI/CD pipeline (DevOps engineering) if your product teams do not plan and deliver their work incrementally (agility). Equally, you will not be able to measure progress based on working software (agility) if you do not have the means for automation and quality assurance (DevOps engineering) to deliver working software. With the same logic, you will not have cross-functional teams (agility) if you do not shift the operations people left in the software development lifecycle, also referred to as the SDLC (DevOps WoW). The examples can go on forever.
Proving a Point Early in This Chapter
Spend some time attempting to reconcile the principles of the Agile manifesto with the principles of DevOps one by one and relate them to real examples from your organization. You will discover that the principles of the two are 100% reconcilable, especially if you read between the lines in a couple of cases. They are also agnostic in the sense that each reconciled principle can be applied in any Agile and DevOps context. It is beautiful, isn’t it?
But enough with the overarching (yet important in setting the scene) theoretical background. Let’s get practical and down to the reality of this reconcilable relationship, starting with discussing the most well-established business enterprise agility models that incumbents adopt.
Four business enterprise agility methodologies
The term business enterprise agility has become very common in the industry and refers to the incumbent’s ability to adapt rapidly to external environment changes, such as customer behavior, competitive rivalry, and new technological advancements, as mentioned in Chapter 1, The Banking Context and DevOps Value Proposition. Responding rapidly to events in the external environment requires agility in the internal business environment. For example, suppose there are French presidential elections taking place this coming Sunday and polls predict the victory of a candidate that global markets do not seem to favor. Therefore, you should be able to predict the volatility of Monday’s markets and perhaps proactively handle the capacity of your trading systems, adjust the thresholds on your services’ monitoring, double-check your auto-healing mechanism, conduct the markets opening operational readiness check earlier, and even execute a risk-hedging trading strategy on the business side. Being able to rapidly respond to either planned (such as elections) or unplanned (such as COVID-19) events through combining business and technological means is the core of business enterprise agility.
In this section, we will discuss four enterprise agility models through the lens of banking, inspired by how incumbents adopted them. Note that it is not in our scope to discuss every single detail of the models or compare them. The objective is to outline them and get a better understanding of the influence they can have on a DevOps evolution, as well as examining how DevOps can be agnostic to the business enterprise agility model.
Basic agility – the greenfield paradigm
This is the most basic Agile WoW setup and yet is a fundamental step in moving toward enterprise business agility in the long run. It is characterized more by isolated agility and not any methodology of scale based on domains, flows, or capabilities, as we will see in the other three models. Its main objective is to establish the fundamentals of agility with a focus on adopting Scrum and its ceremonies (backlog refinement and prioritization, sprint planning, and retrospectives), Kanban, or even Scrumban (combining elements of Scrum and Kanban). It also involves establishing agility-inspired roles, such as the product owners holding the product feature prioritization keys, the Scrum master ensuring that the agile teams have everything they need to deliver for a sprint, and the agile coach ensuring continuous evolution in the teams’ agile WoW. This kind of setup is often observed both in business IT as well as infrastructure and technological utility teams, and we mostly find it in small new entrants to the industry or greenfield banks established by an incumbent parent. Some examples of the agile teams found in such a setup are as follows. Here, we are using a greenfield digital bank as an example:
- Agile feature team: Payments functionality in the mobile banking application’s backend
- Agile product team: Temenos Banking-as-a-Service
- (Agile) platform team: Google Cloud Platform
The dependencies between the agile teams are mostly handled on a need-to-know basis by teams aligning individually or by simple portfolio planning mechanisms. In such setups, we observe relatively high autonomy and self-organization in the agile teams, characterized by a relative variation in WoW, organizing principles, topologies, and skill sets. Standardization and economies of scale are easier to achieve on the technological side due to their low complexity and lack of legacy.
Scaled business enterprise agility
Now, let’s discuss scale by looking into business enterprise agility models that organize structures and principles. With the self-descriptive term organizing structures and principles, we refer to the structures and principles under which an incumbent is organized to adopt the respective model. It is important to clarify two things before we move on. Though most of the use case examples we will cover in this section come from business IT product areas, the models have also been applied to the infrastructure and technological utility areas within those incumbents’ organizations, which is an important element from a DevOps evolution perspective. Another element of commonality across the three is that they use scaled portfolio planning mechanisms to synchronize their organizational structures.
SAFe – Scaled Agile Framework
The first of the scaled agile models we will look at is SAFe, which is widely adopted by several incumbents. To better relate it with the incumbent’s content, we will use a customer account opening example from the digital banking domain.
What are the value streams?
Value streams are defined as the steps that an incumbent’s teams need to follow to deliver an end-to-end solution (from concept to revenue) that continuously flows to the customer, in the form of either a product or a service. Normally, value streams are attributed to a specific business line, such as retail banking or capital markets, depending on the incumbent’s business operating model. The fundamental usage of value streams is in identifying and understanding the sequence of steps that need to be executed and their chronological order, to add customer value, in addition to identifying bottlenecks and gaps in order to improve them. Do you remember the business-critical flow examples from Chapter 4, Enterprise Architecture and the DevOps Center of Excellence? It is the same concept, with the difference that in that chapter, it wasn’t within our scope to cover end-to-end value streams, but only their critical path.
The anatomy of a value stream is based on three main elements:
- Event trigger: An important event that triggers the flow of value; for example, a customer fills in the online form to open a new deposit account
- Steps: The sequential activities that the incumbent needs to follow to successfully open the customer’s new account
- Value: The final value that the customer receives (a new deposit account), upon successfully fulfilling the value stream’s steps
What are the operational and development value streams?
In SAFe, value streams are primarily of two types, but there are also cases where the two are mixed:
- Operational value streams: The sequence of activities conducted and people who perform them, to deliver the final product or service to end clients. This final product is the one built by the development value streams:
- A marketing specialist attracted the client through a targeted email, based on insights from the customer behavior insights analytics team.
- A retail banking accounts officer reviewed the customer’s application.
- A compliance officer conducted the background checks.
- Another retail banking accounts officer opened the deposit account.
- Development value streams: The sequence of activities that need to be conducted and the people who follow them to deliver a business solution by utilizing technological means:
- The customer analytics application that was developed by the analytics IT agile team
- The mobile banking application that was developed by the online banking agile team
- The KYC application that was developed by the compliance IT agile team
The relationship between the two types of value streams is one to many, with several development value streams supporting an operational value stream (see Figure 5.1). The development value streams comprise agile teams, which are cross-functional and should contain all the necessary people and skills to ensure independent value delivery across the SDLC. The philosophy behind this approach is to enable the best possible autonomy level for each development value stream and eliminate dependencies at both the intra-value stream level and the operational value stream level:
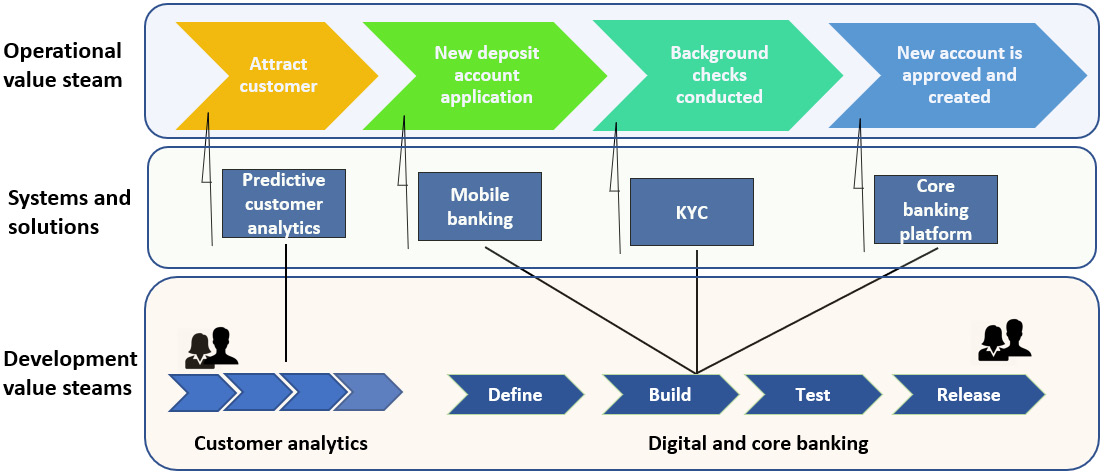
Figure 5.1 – Diagram of new deposits account opening value streams
Agile Release Trains (ARTs)
The concept of Agile Release Trains (ARTs) refers to a long-lasting and self-organized collection of Agile teams, which, along with other stakeholders, form a virtual organization that plans and delivers a particular operational value workstream together, aligned toward the same mission. ARTs also follow the objectives of cross-functionality, autonomy, and independence in delivering value. Depending on the size of the value stream and its products and services, the relationship of ARTs to it can be from one to one to one (value stream) to many (ARTs).
Certain roles and topologies are applied to an ART. Let’s take a look.
The roles are as follows:
- Release train engineer: A leadership role that facilitates the overall execution of the release train, including possible dependencies on other ARTs.
- Product manager: Responsible for the overall product and services roadmap.
- ART architect: Overlooking the entire ART’s architectural matters.
- Business owner: A business stakeholder who holds the ultimate responsibility for the products and services delivered.
- Agile teams: They do the work.
The topologies are as follows:
- Stream-aligned teams: Organized around delivering direct end value to customers
- Complicated subject teams: Organized around subsystems that require deep expertise and specialization
- Platform teams: Organized around shared platform offerings to the agile teams
- Enabling teams: Organized around providing advancement support to the agile teams
Spotify model
The name of this model is borrowed from one of the world’s largest audio streaming subscription service providers, Spotify. The Spotify model was first introduced to the industry in 2012 as a business and team agility model, inspired by how Spotify has organized and scaled its WoW to improve software development and product delivery agility. There are certain industry rumors on whether this is really the case, but they are not our concern. In this section, we will look at the core aspects of the model while using the risk business domain as an example.
What are the Spotify model’s organizational structures?
The Spotify model consists of five main organizational and operational structures:
- Squads
- Tribes
- Chapters
- Guilds
- Centers of excellence (CoEs)
What is a squad?
A squad is an autonomous and self-organizing unit that is responsible for the design, implementation, launch, and operations of specific products and services within a certain business domain. They correspond to the agile team of SAFe. Taking the example of the business domain of risk, the following are possible squads:
- Squad 1: Market risk
- Squad 2: Credit risk
- Squad 3: Counterparty risk
- Squad 4: Liquidity risk
The roles and profiles that we will find in a squad vary per implementation and typically consist of software developers, operations engineers, DevOps engineers, software development engineers in test (SDETs), cloud engineers, and architects. As with all models based on Scrum principles, each squad has a product owner (squad lead), Scrum master, and agile coach (usually shared across squads).
What is a tribe?
A tribe is a collection of squads that operate within the same business domain. For instance, the collection of squads that we provided as examples previously would all belong to a tribe called group risk, which is responsible for the incumbent’s enterprise risk calculation and reporting activities. Typically, each tribe has two leadership profiles – a tribe lead, who is a senior director from the respective business line, and an IT lead, who is responsible for the technological aspects of the tribe. Another important role is played by the tribe architect, who overlooks the overall architectural evolution of the tribe and is usually linked closely to the tribe’s representation in the DevOps evolution working groups. Tribes are formed not only around business domains but also around technological utilities, with concentrated DevOps capabilities platform teams being an example.
What is a chapter?
In the Spotify model, chapters are defined as the concertation of specific competencies in terms of people skills, knowledge, and expertise building. The typical chapters that you will find are as follows:
- Software development
- Operations engineering
- DevOps, referring to DevOps technological capabilities such as CI/CD
- Quality assurance engineering
- Cloud engineering
In essence, each squad consists of people from various chapters, and the versatility of their skills depends on the portfolio the squad supports and how it is to evolve in the future. Each chapter is led by a chapter lead, who is responsible for the HR and personal development matters of the chapter’s members.
What is a guild?
Guilds represent informal structures across the chapters and squads of a single tribe or across tribes. The purpose of guilds is to share knowledge and best practices across several disciplines, as well as standardizing and achieving economies of scale. Typical guilds that you can find in industry adoptions are around streamlining and aligning the following:
- Operations, compliance, and quality assurance
- DevOps adoptions from a WoW and technological perspective
- Customer journey digitalization
- Public cloud capabilities and operating models
What are CoEs?
CoEs are staffed with scarce people/resources from various disciplines and domains and act as enablers that support a domain’s advancements in the tribes. DevOps, enterprise architecture, quality assurance, and the cloud are common examples.
The following diagram shows the Spotify model’s organizational structures and roles in terms of group risk and digital banking. In this example, the chapters that we covered previously have been depicted, along with how their members form cross-functional squads consisting of five profiles each. The two tribes are supported by the DevOps CoE in adopting the DevOps model and have formed a guild (joined two squads, one per tribe) to collectively pilot the new SDLC compliance as code framework:

Figure 5.2 – Group risk and digital banking tribes representative example
Agile value streams or clusters
This model is not a formal industry framework or methodology but a construction of collective proven practices, which I have seen being labeled as either Agile value streams or clusters.
What are the organizational structures of Agile value streams or clusters?
The organizational structures of Agile value streams or clusters will remind you a little bit of SAFe in terms of the operational and development value streams approach and the Spotify model in terms of the business domains approach, while you will consider them identical from an autonomous and self-organizing Agile teams perspective.
What is a value stream or a cluster?
This is a collection of the needed capabilities, from a people, process, and technological perspective, to deliver end-to-end value for a particular business line. To explain this, we will use the example from the market’s trade life cycle flow, which we saw in the previous chapter when discussing critical flows. The trade life cycle flow represents the end-to-end value that is created for the capital market clients, after the execution of sequential activities, which comprise various capabilities coming into play.
What is a sub-value stream or cluster?
This is a subset of a value stream or cluster that is independent, autonomous, and dedicated to a specific sub-business line of the value stream or cluster. For example, in the trade life cycle, we can have three major sub-value streams or clusters:
- Trading front office: Responsible for trading sales and execution
- Trading back office: Responsible for post-trade safekeeping and settlement
- Trading middle office: Responsible for trading risk and accounting calculations
What is a cross-sub-value stream or cluster?
These are temporary virtual structures where people across sub-value streams join forces for a certain period to deliver a large-scale program. This is normally either of a regulatory, internal restructuring, or scaled simplification nature. The following are examples from markets:
- FRTB and MiFID II regulatory programs
- Trading legal structure changes
- Consolidation and simplification of global assets trading activities
What are Agile teams?
Agile teams are autonomous and self-organized teams that belong to the sub-value streams or subclusters and are responsible for all the activities to design, build, deploy, and operate IT applications while utilizing cross-functional skills.
What are functional pods or tactical enablers?
These are highly specialized teams that support on-demand people allocation in the Agile teams for a certain period of time in a rotational mode. Rotational indicates movement from supporting one team to another. The pods consist mostly of people with expertise in advanced technologies that are rare across the DevOps technological and infrastructure ecosystem.
What are communities of practice?
Communities are where people across the value streams gather to share knowledge and experience on a particular domain. Examples include the DevOps community of practice (CoP; CI/CD proven practices), the quality assurance CoP (regression test proven practices), and the cloud CoP (application modernization best practices).
What are platform teams?
Platform teams also have an important role in value streams or clusters as they offer fundamental technological and infrastructure capabilities.
The following diagram shows the value stream or cluster organizing structures from the perspective of a representative incumbent, which focuses on the markets and core banking life cycles:

Figure 5.3 – Visual representation of the value streams or clusters organizing structure
What are the main roles of value streams or clusters?
At the value stream/cluster level and the sub-value stream/cluster level (that is, the value stream business lead and sub-value stream business lead), the following roles exist:
- Business lead: This is the business director, who has ultimate accountability for the products and services delivered by the value stream. This would be the global markets COO.
- Tech lead: This is the technology director, who has ultimate accountability for the technological aspects of the value stream. This would be the global markets CIO.
- Agile coach: This person overlooks the value stream’s overall Agile journey.
- Chief architects: This person is responsible for the value stream’s target portfolio architecture evolution, also in alignment with architectural dependencies from other value streams. Each of them is dedicated to a sub-value stream.
Business enterprise agility field guides and playbooks
A common tool that is used by incumbents to support their business enterprise agility evolution and adoption of the new WoW is what are commonly called field guides or playbooks. These are manuals on the steps to follow during the transition. The following are some common elements that you can find in those manuals:
- The value proposition of shifting to the new methodology
- The fundamental big shifts in agile practices between the old and new WoW
- Overview of the structures and ceremonies in the new setup
- Roles and responsibilities of the new organizational structures
- Guidelines on the enterprise portfolio planning mechanism
- Adoption steps and lessons learned from the areas that first piloted the transitions
This is an important artifact that must be reconciled with your DevOps evolution WoW organizing principles. Based on my experience, such agility field guides and playbooks usually lack a strong DevOps embodiment, which eventually results in inadequate designs and adoptions, characterized by concept reconciliation gaps in the long run, and often require the redesign of certain principles. In the next section, we will examine the dimensions that enable the DevOps and business enterprise agility model’s reconciliation agnosticness.
DevOps and business enterprise agility agnosticness
So far, we have outlined and discussed the dominant business enterprise agility models that a representative sample of incumbents have either already adopted or are in the process of doing so.
There were three reasons why we outlined those models:
- To inspire you on potential approaches you can take
- To examine conceptual similarities across them that are related to the DevOps evolution
- To collect data so that you can make a point that DevOps and business enterprise agility models can be reconciled in an agnostic way
I hope you have got some inspiration! Before we look into the other two objectives, I would like to make an aside and discuss a paradox that the enterprise agility models we have discussed have in common that also has a broader influence on the DevOps evolution. This paradox is autonomy and self-organization in an incumbent’s context.
Bringing clarity to the autonomy and self-organization paradox
Autonomy and self-organization can become ambiguous terms in your DevOps evolution, as on the one hand, they will be open to various interpretations that, in some cases, will be backed by personal motives of individuals and teams, while on the other hand require specific contextual characteristics that are probably absent from an incumbent’s context. Therefore, it is of absolute importance to DevOps decode the two terms and come to a consensus about what those two principles imply for your DevOps context. Does, for instance, autonomy mean that our agile DevOps team can have their own priorities, bypassing the enterprise planning mechanisms, or does self-organization mean that they can bypass fundamental organizing principles and structure designs and therefore do it their way? To answer those questions, you need to provide convincing answers backed up by solid business justifications. Remember that you come from a hybrid setup of daily organizing principles and people could have developed certain habits that require persuasive and, in some cases, coercive means in order to change.
Decoding autonomy and self-organization in a DevOps context
A common objective in all business enterprise agility models is to enable autonomous and self-organizing agile teams, which should also be an objective for your DevOps WoW organizing principles. Let’s attempt to decode those two terms in our DevOps context.
Understanding autonomy
Autonomy has ancient Greek roots as a term and means self-governed (αὐτόνομος; αὐτο meaning self and νόμος meaning law). Going by this definition, we can interpret that agile DevOps teams should have their own law and be self-governed in the way they operate. Now, self-governance also implies the absence of external interventions. But in a corporate environment of an incumbent, that is rarely the case (if at all). Top management business decisions, regulatory demand, and inevitable dependencies on other DevOps agile teams often jeopardize your ability to be self-governed. One way or another, in one shape or form, eventually, your agile DevOps teams will have to give up their right to autonomy. If you are being told you need to organize into squads; you need to prioritize compliance requirements above your backlog; you cannot have dedicated DevOps engineers in your squads; you cannot go directly to the public cloud, but need to wait for the landing zone to be ready; you cannot release daily because you have not yet been granted your license; and you cannot hire because you are under a hiring freeze; are you really autonomous? In an attempt to be self-governed, you will realize that you need to balance self-governance and central governance. C’est la vie!
Confusing autonomy with self-sufficiency
An anti-pattern that I have observed in several DevOps contexts is the mistaken conflation of autonomy with self-sufficiency. Self-sufficiency refers to an Agile DevOps team requiring little or no support and interaction with others. This mistaken interpretation is one of the main sources of DevOps complexity in organizations, especially in the domain of DevOps engineering, characterized by a proliferation of home-grown solutions, built under protectionism practices, and supporting self-sufficiency/empire-building motives. Under a self-sufficiency modus operandi, every team has its own CI/CD pipeline, observability tools, implementation of IT controls, means to verify access, and security policies – the list can go on. Self-sufficiency-driven implementations damage DevOps evolutions in the long run, bringing complexity, operational risk and cost, lack of compliance, and conflict of internal interests and priorities. Therefore, it is vital to make this distinction between autonomy and self-sufficiency clear to your agile DevOps teams.
Understanding self-organization
Self-organization is the ability of individuals to interact with each other to establish order without the need for external intervention. In our DevOps context, this means the agile DevOps teams establish an internal order to their daily modus operandi without constraints imposed on them by the broader organization. They can agree on how often they can release, how to monitor their services, who will be on call this weekend, and how many of the regression test cases will be automated and run in every build. But isn’t this a paradox? How can we be self-organizing if, for instance, strict segregation of duties and identity and access management requirements are forced on our daily operations? If, for instance, Andrius, who is a developer, is only allowed to code and Paulius, who is an operations person, only does operations, your team is put into groups of self-organization boundaries, right?
The pragmatic conclusion
Please do not misperceive me, as my intention is not to make autonomy and self-organization seem impossible. Quite the opposite – especially for true agile DevOps teams of high maturity, essential elements of autonomy and self-organization elements can be observed. But still, my experience in the financial services industry taught me a lesson, through constant repetition: Be pragmatic and do not fall into “buzzword” fallacies. In a real banking context of a systemically important incumbent, agile DevOps teams cannot be fully autonomous and their ability to self-organize will be frequently compromised.
The most suitable phrase that summarizes this reality is DevOps organizationally aligns autonomy through the ability to self-organize where applicable. I appreciate it sounds paradoxical, but this is the reality. There are mechanisms through which teams can apply for greater autonomy and self-organization and gain the corresponding allowance, as we will see later in this book.
Self-Determination, Sovereignty, and Organized Hypocrisy
These three international relations terms always come to my mind when I hear about teams’ autonomy and self-organization in DevOps. In international relations, self-determination refers to the legal right of people (referring to nations) to define their destiny in the international system through the creation of states. Sovereignty refers to the ability of a state to self-govern, after its self-determination, without any external intervention. Does this sound similar to the autonomy we described previously? We all know, however, that, in many cases, state sovereignty is compromised by other states (humanitarian intervention) or due to belonging to a global governance body (European Union). This fact of sovereignty, which is, in essence, fragile and compromised, is called organized hypocrisy in international relations. This is the paradox of being recognized as self-governed without being self-governed.
What are the reconciliation agnosticness dimensions?
The agnostic nature of business enterprise agility modes and DevOps can be observed across four major dimensions, with countless subdimensions that rise through the conduct of the actual reconciliation activity:
- General principles that underpin the concept, as we saw earlier in this chapter
- The expected outcomes that aim to be achieved by the concept’s adoption
- Common organizing structures and mechanisms that are deployed in each team
- Specific DevOps implementation principles that can be applied in any agile team
Before we look into the outcomes, organizing structures, mechanisms, and implementation principles, let’s define what agnostic means. In our DevOps context, agnostic means being able to reconcile different concepts (agile) and adapt to different contexts (incumbents) without significant alterations. In other words, a DevOps 360° operating model can and must be reconciled with the basic agile model, SAFe, the Spotify model, and the value streams model in different incumbents’ contexts, without major alternations.
Reconcilable and agnostic desired outcomes
The following are outcomes that characterize both business enterprise agility and DevOps:
- Ensure consistency and reusability.
- Improve speed of delivery and time to market.
- Improve productivity and experience.
- Get close with the business partners.
- Improve customer outcomes and value.
- Focus on end-to-end value and flows instead of isolated products and services.
- Improve business performance and agility.
- Optimize delivery performance and operational efficiency, eliminating lead times.
Reconcilable and agnostic organizational structures and mechanisms
Both DevOps and business enterprise agility models recognize the importance of utilizing the following organizational structures and mechanisms:
- Platform teams: On achieving harmonized scale and respective economies, it is a necessity to have solid and reliable DevOps platforms that offer a wide range of DevOps engineering capabilities, products, and services.
- Shared services: Their importance in supporting operational efficiency and improving DevOps productivity is recognized.
- DevOps CoEs, CoPs, and enablement teams: The value of CoEs, CoPs, and enablement teams to support and facilitate the adoption in the DevOps agile teams is a commonality.
- Value flows: Mechanisms of end-to-end value delivery as well as end-to-end feedback loops have a special position in both concepts.
- Organizational applicability: Both concepts recognize the importance of being equally adopted across the organization both by business IT teams and also infrastructure and technological functions, as well as utility functions.
- Software development methodology: Scrum is at the heart of both concepts.
- Enterprise portfolio planning: This is a synchronization and alignment mechanism that is set up through the business enterprise agility models and is utilized by the DevOps evolution as part of DevOps enablement and adoption.
DevOps Lessons Learned on Organizing Structures
Once upon a time, there was an incumbent bank adopting the Spotify model with the ambition to have all the newly established tribes moving from shadow IT CI/CD pipelines to the central one. For this purpose, they decided to omit DevOps (also known as CI/CD engineering) chapters, under the belief that in the absence of dedicated CI/CD engineers, the squads would be forced to migrate to the central offering. I leave it to your imagination to guess how effective this approach was and what its impact was on the overall DevOps transformation.
Reconcilable and agnostic DevOps implementation principles in agile teams
Regardless of the business enterprise agility model that you go with, and even if you do not have just one, the deployment of DevOps principles in DevOps agile teams should and can be agnostic. This will help you avoid DevOps disruptions, in case your business enterprise agility model changes in the future, enabling a DevOps lift-and-shift approach if need be. Certain DevOps implementation principles can be adopted in any agile DevOps team, despite the enterprise agility model under which it operates:
- Shift operations left, operationally and organizationally.
- Embed DevOps engineers in the agile DevOps teams.
- Automate and optimize across the SDLC.
- Utilize technological common platforms and CoEs.
- Be measured upon commonly agreed DevOps performance measurements.
- Organize under segregation/separation of tasks and not duties.
- Build compliance and security by design across your portfolio.
- Adopt DevOps capabilities at relevance across your portfolio.
- Cater for multi-speeds across your portfolio.
- Offload any operational overhead to shared services.
- Enable DevOps skills cross-functionality across the SDLC.
- Continuously identify and implement DevOps improvements.
I am certain that the preceding dimensions provide clarity on the concepts that enable concept reconciliation while keeping a context-agnostic character. While it might sound simple, needless to say it requires effort, experience, creativity, and organization, along with a little bit of reading between the concept’s lines, to achieve a practical high degree of reconciliation and agnosticness between Agile and DevOps.
Agile DevOps teams – organizing principles design
In the second part of this chapter, starting with this section, we will look at an approach to define the core of your DevOps 360 model WoW by examining organizing and, consequently, operating principles. This exercise is fundamental as it lays the foundation of how you will organize from a DevOps context perspective, which will sequentially be reconciled with your business enterprise agility model, comprising your complete Agile DevOps WoW model. In the upcoming sections, we will outline a proven approach to conduct this exercise in the form of steps. We will take a representative real-world example and use the Spotify model as the business enterprise agility model.
Tip
This exercise should be carried out behind closed doors to ensure minimal organizational disturbance, resistance, and uncertainty. Due to its influence on upcoming responsibility distribution, it can turn into a diplomatic and political matter, so it is advisable that, among the governing bodies of your evolution, you build an early coalition on the precise expected outcome and steer the exercise accordingly. You get my point, right? Before involving people within the governing bodies, you already know the potential outcomes of the exercise.
In the upcoming sections, we will outline and describe the steps to be followed, which, when conducting the exercise in real life, should be executed iteratively.
Step 1 – defining the core capabilities and actors
We propose four main groups to be part of this exercise:
- DevOps 360° vision authority: To resolve any potential disputes and make the ultimate decisions, as well as granting intermediate approvals
- The DevOps 360° design and advocacy group and the DevOps CoE: To orchestrate the primary and secondary actors and be the counterpart for the vision authority
- The DevOps WoW workstream (recall the workstreams we defined in Chapter 3, The DevOps 360° Operating Model Pillars and Governance Model), which will be subdivided into two main groups:
- Primary actors: The people directly involved with building and running software. They are part of the business tribes – that is, Agile DevOps teams. This also includes software developers and application operations specialists, some of which should already be part of your DevOps 360° design and advocacy group.
- Secondary actors: A selection of stakeholders from the broader DevOps ecosystem to whom the primary actors have a first-level dependency from a DevOps perspective. CI/CD tooling and core infrastructure teams, shared services, and CoEs can be on this list, which can grow to the extent you please. Some of those should also already be in the DevOps 360° design and advocacy group, as well as in the squad or satellite members of other workstreams.
Each actor should represent a DevOps capability, and it is proposed that you start outlining the capabilities before you appoint anyone. As a technology director told me once, “Don’t tell me who you need, but what you need them for.” Needless to say, the appointed people must have deep and well-rounded DevOps experience, meaning that they can see the big picture while having the ability to deep dive into the details.
Tip
In choosing the actors, try to be as broad as possible in terms of state-of-the-art DevOps operating models, business lines, and technological foundation. Remember that your outcome will be enterprise applicable and that you must capture the best possible extent of contextual variations.
Step 2 – capturing the detailed business enterprise agility model
Ensure that you have captured and communicated both the big picture and the details of the chosen business enterprise agility model to those involved. Simply put, get them to read and understand the agile field guide/playbook. As we discussed earlier in this chapter, the business enterprise agility model has probably been developed in advance, so you need to tap into that and even propose amendments to it after completing the exercise.
Step 3 – capturing the detailed regulatory/compliance context
It is an absolute necessity that you do your regulatory homework and have a fair idea of which organizing principles model you wish to end up with, with those that were initially validated across the respective compliance and audit functions. The primary area of interest is identity and access management to production, including infrastructure, data, and business logic, as well as people roles from a separation/segregation of duties perspective. Also, any specific requirements on organizational structure, such as people having operations responsibilities, people being unable to report to a squad product owner, or that people accessing very restricted and confidential data should report to a product owner, need to be captured. In addition, get clarity on whether you are subject to hardcore separation/segregation of duties policies or whether flexible just-in-time access mechanisms on accessing production data, given valid business justifications, are considered adequate. The inability to conduct the compliance background check well in advance may lead to the outcome of the organizing principles exercise either not complying at all or only partially complying, with significant engineering efforts required. I warned you!
Reminder
If we ever meet, remind me to tell you the story of the 10 gaps that we identified in an incumbent’s capabilities during the organizing principles adoption feasibility study.
Step 4 – capturing the current Agile DevOps teams’ topologies
There are mainly two ways to evolve from the old WoW to the new one:
- Start with the current state of the art and evolve it to the future, gradually.
- Define the future desired state and work backward, again gradually.
I propose you start with the future desired state and work backward. It is always more refreshing, provides people with a new perspective, and makes them forget existing constraints and boundaries, allowing them to unleash their creativity on what an ideal future fit would look like. Then, once you have the ideal defined, you work backward through the steps required until you reach the current context. But to work backward, you need to have a fair idea of how your current topologies are shaped.
Having said this, you need to document in some way the current state for various reasons, including the principle of do not attempt to change something if you do not know it well. Capturing the context of your current organizing principles will serve various objectives, including the following:
- Ensure that your target organizing principles are not too challenging to be adopted.
- Your teams will be able to identify themselves and plan a gradual evolution.
- You can define options for your evolution journeys and transition playbooks, as not all teams will have the same destination. Remember that we evolve DevOps at relevance and in a multi-speed incumbent.
- Provides visibility on the enterprise effort ahead to complete the transition.
Let us have a look at the most frequent scenarios that can be seen in the context of an incumbent bank:

Figure 5.4 – The common models of the primary actors that you can find coexisting in an incumbent
Naturally, you can challenge me here and say, “Spyridon, you have been saying from the beginning of this book that DevOps should be adopted at relevance. What is wrong with the five different models, if all five are relevant?” The answer is that there is nothing wrong, so long as there is a strong business value proposition on why teams have chosen model one and not two. For instance, there is transparency and clarity on the decision’s business line justification, but also the necessary means to prove its regulatory compliance, as well as ensuring the elimination of any doubt of operating model overcomplications due to “just because” arguments. Moreover, due to the impact of your enterprise agility model organizing structures, you will be forced to streamline, so in many cases, it is simply a matter of choosing between options A and B. Later in this section, we will prove that only two models, with small modifications, can fit any context, business justification, and value proposition.
The Organized Anarchy Paradox
In international relations, this term refers to the absence of a supreme authority to govern the international system of states. As mentioned in the example of the Leviathan (Chapter 3, The DevOps 360° Operating Model Pillars and Governance Model), the lack of a central government equals anarchy in some theories of international relations. But looking at our international system, states managed to get organized despite the absence of a universal government. This is called organized anarchy. Looking at the variation of DevOps organizing principles in the preceding diagram, the situation looks anarchical, though it is paradoxically organized to some extent.
Talking about grasping the current topologies and organizing principles, I can assume with high confidence that you do not have insights into how every single Agile team across your firm is currently organized and, at the same time, you do not have the percentage allocation for each of the various organizing principle models. I also assume that the five models presented previously are the dominant models in your organization, and you will certainly discover a sixth one along the way. I used to call this sixth model the God knows what they do one. On grasping the most accurate situation that currently characterizes your organization, I propose you use the representatives of the DevOps design and advocacy group, as well as your primary and secondary actors of the exercise, and then take the parts of the organization they represent as samples, having the outcome validated by the vision authority group.
Across the possible topologies and organizing principle models mentioned previously, we can usually identify some specific and rather typical characteristics:
- Fragmentation of organization structures, planning, and delivery mechanisms.
- A hybrid “waterfall and agile” working methodology.
- Ambiguity on separation/segregation of duties policies.
- Application operations and infrastructure teams are not an integral part of the SDLC.
- Development teams own a wide range of home-grown shadow IT solutions.
- Lack of clarity on SDLC processes and policy adherence requirements.
- Ambiguous utilization of common platforms, shared services, and functions.
Step 5 – getting the notation and templates defined
Provide the exercise’s actors with some common templates and notation so that, on the one hand, you get to standardize the output, but also so that they use the same language. You can use any notation you feel comfortable with, which may be one that you have traditionally developed within your organization. In our example, I will use the notation I’ve been using for years as I do not wish to direct you toward any specific methodology and also because I have seen it working with my own eyes. When defining the notation, you should primarily focus on the following aspects:

Figure 5.5 – Spyridon’s topologies and organizing principles notation
Note that if you cannot fit all your exercise’s actors into your notation, this means that you need to enrich either the notation or the list of people you appointed.
Step 6 – setting the approach and principles of the design
You need to clearly define the approach to conducting the exercise and set the guiding principles, especially to be able to steer the result if need be.
Approach 1 – starting to design the core Agile DevOps teams and then expanding
It is proposed that you start with the primary actor’s organizing principles and gradually expand toward the broader DevOps ecosystem:
- View 1 – Agile DevOps squad zoom-in: Start with the organizing principles of the Agile DevOps teams.
- View 2 – fundamental DevOps utilities and keeping the lights on: Expand from the Agile DevOps teams to the most fundamental secondary actors to DevOps.
- View 3 – expanded ecosystem: Start broadening to the extent you please.
Approach 2 – taking the future technological landscape perspective first
Even though you need to cater to a hybrid technological landscape of business IT applications, spanning mainframe and public cloud platforms, it is advised that you start with the most modern part of your portfolio, in this case using the shift right principle of portfolio classification, as we will see in Chapter 9, The DevOps Portfolio Classification and Governance.
Approach 3 – splitting the actors based on the hybrid context and expertise
Ideally, set up a minimum of two groups working in isolation with a hybrid mix of DevOps backgrounds and experiences. Allocate people equally from the design and advocacy authority and the DevOps CoE between each group so that they can steer and coordinate, if need be, but also proactively inform the vision authority about any rising concerns.
Approach 4 – designing principles, guidelines, and considerations
Each group should come up with two models: a proposed one and an alternative one. In doing so, they should consider the following principles, guidelines, and considerations:
- Ignore historical organizational dynamics/structures that led to the current setup.
- Be forward-looking in terms of the capabilities of the DevOps evolution.
- Shift as many capabilities as you can to the left of the SDLC.
- Balance self-sufficiency with economies of scale and operational efficiency.
- Consider the full utilization of platforms, shared services, and functions.
- Cater to a hybrid technological portfolio in each squad.
- Consider access management and separation/segregation of duties principles.
- Business line context, proximity, and relevance are important.
- Make it flexible to evolve in the future and business enterprise agility agnostic.
Step 7 – conducting the actual design
This step is about doing the actual work. In our representative example, our groups were quite aligned and came up with identical proposed and alternative models. Let’s see how they evolved with some interesting at-relevance elements arising.
View 1 – Agile DevOps squad zoom-in
The purpose of this view is to focus specifically on the Agile DevOps teams, which constitute the core of the exercise.
The proposed – dynamic/rotational model
The people that build and run software are perceived to be the same person, under the role of the software developer, in a you build it, you run it modus operandi, and are part of the same squad. Using the squad names from the Spotify model section of this chapter, according to this model, the market risk squad consists of developers that also conduct operations in a rotational mode. For instance, if the squad comprises five developers, one out of the five is responsible for performing operations every week with this person rotating. When not much is required from an operational perspective, the person contributes to operational improvements, which are part of the backlog. The value proposition for this model is that small- to medium-sized platforms and applications that are not exposed to external clients have low to moderate production support needs and do not contain personally identifiable information (PII), so a dynamic separation of tasks model provides more flexibility, autonomy, and operational efficiencies.

Figure 5.6 – The dynamic/rotational model – separation/segregation of tasks
The exercise’s actor found a good number of platforms and applications potentially falling into that category, and some have already been operating under those organizing principles successfully.
The Story of an Angry Aurimas
While discussing the percentage split between development and operations, during the exercise, Tomasz, driven by proven practices, proposed a target of 80% capacity allocation to software development and 20% to operations. Aurimas reacted with “Why should we allocate fixed boundaries to certain activities? This is micromanagement!” He continued, “Just tell me what the performance indicators are that I need to meet and let me organize my team myself!” Both made strong points. Tomasz was setting the right ambition. Shifting operations left in the SDLC would enable us to spend a maximum of 20% of our agile team’s capacity on operations. Aurimas was also right in avoiding the definition of capacity boundaries on how the allocation of people should be managed. Set the performance indicators and let the team self-organize to meet them.
The alternative – fixed model
A separation/segregation of duties is proposed between the people doing software development and those doing software operations. However, both roles are proposed to be part of the same squad, with the operations people shifted left in the SDLC. It is also proposed that you have the operations people’s skills uplifted from an engineering perspective so that they can contribute to the actual product and service innovation backlog by approximately 50% initially. The goal is for this percentage to further increase through operational stability and improved efficiency:

Figure 5.7 – Fixed roles model – separation/segregation of duties
The arguments, as with the proposed solution, were pointing again to the same elements of relevance, such as the platforms and the size of the teams, exposure of the platforms to external clients, large internal business segments, data confidentiality, and the critical need to have people dedicated to production inquires, with speed and proximity being crucial factors of customer satisfaction. There’s also the fact that large platforms turn out to be more business-critical and have a higher focus from a regulatory perspective.
Defining the roles further to the core software development and operations
Once you’re done with the core roles of this view, it is the right moment to drill down to the roles and profiles that a squad will need to be cross-functional. This will have an impact on the chapters that you will have to define. For instance, in both models of our representative example, people asked for DevOps, cloud, and test engineers to be embedded in each squad to facilitate the DevOps evolution from an engineering perspective. This request creates demand for the business enterprise agility model to cater to DevOps, cloud, and QA chapters, if they’re not already in the plan.
Tip
Please do not make the mistake of thinking that in your Agile DevOps teams, you do not need dedicated DevOps engineering profiles, believing that developers will be enough to advance your DevOps engineering adoption. Especially in large setups, such as core banking, you need dedicated DevOps engineering people focusing on DevOps engineering solutions that developers can use. The absence of those profiles is one of the top reasons for DevOps evolutions slowing down.
View 2 – fundamental utilities and keeping the lights on
Having organized the Agile DevOps team, it is time to start including the teams that provide fundamental DevOps utilities and keep the lights on.
The proposed – dynamic/rotational model
An evolution toward View 2 in the dominant model is shown in the following diagram:

Figure 5.8 – View 2 of the dynamic model
As you can see, the technological utilities of common CI/CD pipelines and the Azure cloud have been added, where the squad is to consume the corresponding technologies and embed them into its SDLC. We have also added two shared services – the enterprise service desk (used for business support inquiries) and the enterprise command center (used for first-level technological support inquiries). Since we have smaller and more compact teams in this model, it has been decided that the squads in this model do not utilize those two shared services and have become self-sufficient both from a business and technical support perspective. This means that the market risk squad in our example will handle the full cycle support of the market risk portfolio from a business inquiry perspective as well as a first-line-of-operations perspective. However, it was proposed to leave the option open and let the team decide whether to utilize the shared services, upon agreement with the respective shared services teams.
The alternative – fixed roles
The approach that has been proposed for the alternative model looks slightly different, and this is where context, speed, and relevance again become important. For the teams falling under the alternative, it was proposed to utilize the common technological utilities as well as the shared services utilities. The latter has two consequences on the organizing principles – the core banking squad in our example will not be responsible for business support inquiries as this responsibility will move to the enterprise service desk. It will also not be the one performing first-level operations support, as this will move to the enterprise command center. However, both shared services, on top of ensuring the handover of responsibilities, will have to establish a feedback loop process toward the squad so that L1 business and technological inquiries can be fed back to the Agile DevOps squad for backlog improvement items. L2 support remains with the Agile DevOps squad.
What were the reasons behind those decisions? Let’s take a look:
- Due to the scale of the core banking platform and its scale on the business nature of facing external and internal client, the business inquiries are of high load and have strict SLAs, which require business line knowledge specialization. Having a dedicated core banking business officers squad sitting at the enterprise service desk is more effective.
- The core banking platform backlog requires full undistracted capacity due to its richness but also the business line’s aggressive time-to-market targets. Minimization of production support disturbance will increase DevOps productivity.
- As the operations people have shifted left in the SDLC, the ambition is to minimize the operations noise toward them so that they can focus on improving the platform through engineering work.
- The incumbent bank’s internal data has proven that handing over L1 to the global enterprise center has minimized the requests that reach the development and operations team by 50% and supported the increase in the mean time to detect and recover.

Figure 5.9 – View 2 of the fixed-roles model
A special situation: The markets trading floor flavor on dedicated support services
In both the rotational and fixed models, there is a subflavor when it comes to the utilization of shared services such as service desks and command centers, which is very much related to the nature and proximity of the business line, complemented by zero tolerance for latency and mean time to detect and recover. For example, across capital market areas on incumbents, I have seen a dedicated-to-market service desk, with people sitting next to the traders (literally), and dedicated reliability engineers also sitting next to the traders (literally), resolving inquiries such as trade_ids missing books, the trader blotter not loading, and trade amendment confirmation being processed. It happens I had both roles once upon a time supporting global rates interbank trading, and it was a super insightful experience.
The Story of an Angry Dan
It was a Friday and in the DevOps vision authority group, the outcome of our organizing principle’s work was being presented. Do you remember in Chapter 3, The DevOps 360° Operating Model Pillars and Governance Model how I advised you to check these group members’ temperatures individually? I did not before that meeting. When presenting the alternative model’s part of offloading technical L1 to the enterprise command center, Dan got furious. “This is not agile, it is not DevOps, and it violates self-organization.” He continued, “Who came up with this idea?” I responded, “Jan and Amit from your team did, arguing that it will help increase the team’s productivity and minimize the MTTR.” This topic dominated the meeting on that day, but I will get to the point. For particular areas of your organization, it makes sense to offload L1 support to shared services, even though it does not sound agile. It may sound like something from old-school ITIL v1 books and against DevOps principles, but when it comes to autonomy, it’s worth compromising for operational efficiency and productivity gains.
View 3 – expanded ecosystem
From this point on, you should start expanding and stop when you believe that you have sufficiently covered the broader DevOps ecosystem of stakeholders. In our representative example, there was consensus that both models are to utilize the outcome of the DevOps and Enterprise Architecture CoE’s work in terms of the DevOps 360° operating model and reference architectures, as well as following the policies and procedures of the enterprise service governance and IT risk controls functions. The following diagram shows the representation of the fixed roles model:

Figure 5.10 – Model expanded with CoE and function team examples
Final remarks on this step
Of course, this was just a representative yet pragmatic and practical example. Naturally, there are also other variations and subvariations of models that your context and ambitions might lead you to examine and adopt, while every model will inevitably have its advantages and disadvantages. However, some fundamental DevOps design principles and at-relevance elements, such as shifting operations left, considering business proximity, assessing the usage of managed services and CoEs, and considering compliance and client impact are common and agnostic. Also, it is important to make clear that even though in our example we focused on business Agile DevOps teams being the primary actor, the same exercise needs to be conducted on the technological utilities of your organization.
Step 8 – evaluating based on predefined criteria
Once you have the proposals, you need to evaluate them across some common parameters, which can take the form of a questionnaire. Those parameters should have already been defined as part of the exercise’s homework. I advise you to ask the following questions:
- Do you see compliance gaps that can put your license to operate at risk?
- Do you see issues of adaptability if the business enterprise agility model changes?
- Do you foresee any severe constraints during the adoption by the tribes?
- Can you spot hardcoded elements that will be difficult to adjust?
- Do you foresee any conflict with other models adopted in the organization?
- Does it require shared utility capabilities that are currently not enabled?
- Does it require adjustments in the business enterprise agility model?
Step 9 – feasibility study and compliance foundation
This is the point when you need to open up consciously to the actors of the exercise and carefully and ask them to break the model, while also asking them to point out whether they see design gaps from the perspective of the part of the organization they represent. Ideally, you should also bring people from areas that currently operate under those models so that they can share their experience and provide solid arguments for potential concerns raised.
Mind the compliance part in the early days
Incumbents, especially systemically important ones, are under strict regulatory supervision. Two of the main areas of regulatory concern are as follows:
- Separation/segregation of duties: Referring to which role is responsible for what within the organization.
- Identity and access management: Based on the separation/segregation of duties policy, this specifies what access each role requires, focusing on read, write, and execute.
A typical and traditional hardcoded separation/segregation of duties and identity and access management example is as follows:
Table 5.1 – Family hierarchy and basic access principles
The primary concern relating to the separation/segregation of duties and identity and access management is the following parameters. As part of the Agile DevOps team organizing principles, you need to come up with the respective requirements on roles and access while highlighting the differences between the proposed and alternative models:
- Production IT assets: Servers, databases, messaging queues, and logs
- Production data: Any data stored and used in the production of IT assets
- Business logic repos: Functional code repositories
- Operational logic repos: Non-functional code repositories
- Development and operational tools (also known as DevOps): CI/CD, ITSM, and observability
- Test environments
We will come back to this topic in Chapter 8, 360° Regulatory Compliance as Code where we will focus on compliance as code.
Step 10 – defining the basis for a job description
As you design the organizing principles and define the required roles, you need to start drafting the basis for the job descriptions, primarily for three reasons:
- Input for the incubation plan in terms of competencies, as we will see in Chapter 13, Site Reliability Engineering in the FSI
- Input for the DevOps WoW white paper on responsibilities
- The DevOps capability responsibility demarcation and direction based on the organizing principles need to be defined:
- DevOps engineers are utilizing the common CI/CD pipelines to onboard the applications of the squad they support, through the migration of home-grown solutions where applicable.
- DevOps engineers build their own CI/CD solutions according to the squads’ internal discretion, using the common CI/CD pipelines where applicable.
Step 11 – defining the DevOps WoW white paper
It might sound like an old-school practice, but it is not from a practical perspective: legalize your DevOps evolution operating constitution to specify who is accountable and responsible for what in terms of your daily modus operandi. Remember that you are coming from a proliferation of hybrid operating models situation in a condition of organized anarchy, where there might even be extreme variations of who is currently responsible for what. For instance, in your market domains, the development teams and not the operations teams might be responsible for deployments, while in transaction banking, the operations team is responsible for deployments, while in domains where responsibilities are gray zones, neither the development teams nor the operations team is responsible, and certain activities are conducted based on convenience.
When conducting the white paper exercise, please consider the following:
- It will eventually become a diplomatic game as some will have to give up autonomy, responsibility, and authority.
- Avoid any (at least) obvious favoritism toward particular teams.
- The purpose is not to put boundaries on the team’s self-organization but to create clarity.
- It might trigger or be triggered by organizational changes.
- Nonproliferation agreements on duplicated solutions must be included.
- The broader DevOps ecosystem capability owners and providers should be included.
- It should be a binding agreement and part of your firm’s broader operating model.
- Cater for flexibility and allow deviations from it on non-core responsibilities.
- It needs to be reconciled with your enterprise business agile field guide/playbook.
A Band Analogy for Responsibility Realignment
When conducting responsibilities realignment, make sure that people have the necessary skills and means to fulfill them. If not, create a skills uplift/incubation plan. Do not just reassign responsibilities in the form of baptism. Think of a band. Giving the drummer’s responsibility to the vocalist and the guitarist’s responsibility to the drummer just to refresh the band wouldn’t be a good idea.
Summary
In this chapter, we discussed the foundation of the DevOps evolution’s WoW, combining business enterprise agility and DevOps organizing principles in a way that proves the ability to reconcile the two concepts agnostically. We went through four examples of Agile adoptions by incumbents (basic Agile, SAFe, the Spotify model, and value streams/clusters), relating them to banking context adoption examples. By doing so, we discovered similarities in their organizational structures in terms of principles and objectives. We also discovered several similarities across four dimensions from a DevOps evolution perspective and explained how those similarities enable the concepts to be agnostically reconciled. We also mentioned the principles of autonomy and self-organization and provided arguments on why they cannot be perfectly achieved in an incumbent’s DevOps context. Continuing, we provided an 11-step guide, based on a proven practice, on how to design the organizing principles of the Agile DevOps teams’ evolution; we used the Spotify model as the business enterprise agility model. We also examined the core aspects of the exercise, such as actor and capability identification, the importance of the state of the art in organizing principles and compliance background work, the relevant elements that influence the designs, as well as what questions to ask during the model evaluation. We concluded that the outcome should be documented in a white paper and outlined considerations to make once the actual artifact has been defined.
In the next chapter, we officially enter the second part of this book on the DevOps capabilities evolution and enablement. In particular, we will look into what I call the DevOps backbone and discuss the importance of evolving, interoperating, and engineering your DevOps SDLC.
|
Role |
Access |
|
Developer |
Non-production data |
|
DevOps engineer | |
|
Test engineer | |
|
Operations |
Production data |
|
Application specialist | |
|
Reliability engineer |