
13
Site Reliability Engineering in the FSI
This chapter introduces us to the world of site reliability engineering (SRE) and is divided into three main parts: academic/conceptual, practical, and real-world use cases. As with every chapter, we will start by outlining its value proposition in the DevOps 360° evolution, after we first define SRE based on Google’s paradigm and publications, also outlining the SRE definition view of our book. We will then move forward by discussing the DevOps versus SRE dilemma that dominates the industry, looking into the similarities and differences between the two concepts. Afterward, we will detail the SRE value proposition by looking into its respective tenets, which is a fundamental aspect of adopting SRE. Continuing, we will introduce an array of proven practices and mechanisms that support SRE adoption at relevance. They will focus on engagement and adoption models, people, as well as reconciliation with concepts such as the IT Infrastructure Library (ITIL). The last part of the chapter will discuss some real-world examples of incumbents that have adopted the concept of SRE. We will discuss the respective operating models, motivating factors, as well as what is positive and what is not so positive.
In this chapter, we’re going to cover the following main topics:
- The value proposition of SRE for the DevOps 360° evolution
- The DevOps versus SRE dilemma
- The fundamental SRE tenets
- Practical and proven practices for adopting SRE
- Different incumbent use cases for adopting various SRE operating models
What is the value proposition of SRE for the DevOps 360° evolution?
We will start this chapter with a small conceptual overview of what SRE is, before looking into its value proposition for the DevOps 360° evolution. SRE is a concept conceived by Google, sometime around 2003, when the first Google SRE team was formed. During the summer of 2016, the first official Google publication, under the title Site Reliability Engineering: How Google Runs Production Systems, officially introduced SRE into the world of DevOps. Since then, several financial services institutions (including ones that I have worked for/with) have started to embrace the concept – some of them by understanding its practical value and finding success with it, with others admiring its “coolness” and creating more LinkedIn posts and job titles than finding any real success.
How does Google define SRE?
According to posts on Google Blogs, SRE is a broad concept and open to various interpretations. Ben Treynor, VP of Engineering at Google and founder of SRE, defines the concept as what happens when a software engineer is tasked with designing an operations team or what happens when you handle operations as a software problem. Another, metaphorical definition that can be found in Google’s publications is SRE is what happens when you change the tires of a racing car while it is going at 100 miles per hour. A third definition describes SRE as prescriptive ways of measuring and achieving reliability through engineering and operations work. I personally prefer to go through its acronym and explain the terms from right to left:
SRE – S: Site, R: Reliability, E: Engineering
The utilization of engineering means ensuring the reliable operations of a site.
To provide a little bit more clarity, means can be any technology, practice, process, people’s skills, and so on that relates to engineering.
Short parenthesis – we will consider “S” to mean “service” from now on
The letter S in SRE stands for the word site in Google’s context, and this makes sense. Think of google.com as being a site. In our book, the S in SRE will stand for the word service. That refers to a business application offering a service to the incumbent’s clients or a DevOps platform offering a service to the incumbent’s Agile DevOps teams.
From the preceding definitions, one can safely derive two main elements of SRE. Firstly, SRE is concerned with embedding software engineering practices in building and operating reliable services. Secondly, SRE lacks a universal definition. Do you remember which other concept in this book lacks a universal definition? You remember correctly – DevOps, of course!
Food for thought
I wonder why those great concepts lack a universal definition. Is it maybe on purpose, as pragmatic DevOps and SRE should be based on what you want to make out of them?
As you can rightly guess, and most probably have already observed within your organizations, the absence of SRE definition consistency reveals two aspects of it that are similar to DevOps. Firstly, it reveals the broadness and versatility of SRE as a concept. Secondly, it reveals how it is a source of misinterpretation in the FSI through misconceptions. The latter is also considered one of the main challenges in how organizations approach its adoption.
To ensure that we speak the same SRE language in this book, we will go with the way I find suitable to explain SRE. Therefore, in the coming sections, when I refer to SRE, you will know that I am referring to the utilization of engineering means to ensure the reliable operations of a service, which are practices we will see later in the chapter.
My favorite definition of SRE
SRE is the purest distillation of DevOps! This is a spot-on definition in my opinion, and I think most of you that have implemented SRE successfully and pragmatically would agree. Nonetheless, it is not a very practical one to use in a corporate context.
What is the concrete and pragmatic value proposition of SRE to the DevOps 360° evolution?
We will take an unconventional approach in this chapter compared to the previous ones in defining the value proposition. Indeed, we will be allocating almost half of this chapter’s content to circulating the SRE value proposition for the DevOps 360° evolution, going through several elements of SRE. And we will start that circulation by providing our view on a dominant dilemma, not only in the financial services industry but broadly across industries.
What is the notorious “DevOps versus SRE” dilemma?
In order to agree, firstly, that SRE has a value proposition to the DevOps 360° evolution, we need to provide clarity on the relationship between the two concepts. The DevOps versus SRE dilemma in the industry is about whether organizations should adopt DevOps or SRE. It is an either/or in simple words, under the belief that the two concepts are conflictual. Going directly to the point, as I do not wish to spend time providing examples of nonsense dilemmas, SRE and DevOps are not conflictual concepts, as many in the financial services industry perceive them, or want them (in order to promote personal agendas) to be. In my book (literally and figuratively), SRE and DevOps are two complementary concepts. In essence and reality, in the way I have used and reconciled both, SRE is an effective way to scale and accelerate a DevOps evolution. I personally see SRE as part of DevOps and not as a concept to be adopted in parallel. There is the Google statement class SRE implements DevOps. That statement, in my opinion, is the most targeted and clear way to state the relationship between the two. In other words, SRE can be interpreted, perceived, and applied as an extension of DevOps principles and practices through greater emphasis on the reliability aspects of a service. And now you will tell me, “But mate, that statement is not really practical. Especially when addressing people who have limited exposure to both DevOps and SRE. There must be a more tangible/practical way to explain the relationship.”
I created the following table years ago in my attempt to explain to people what can be perceived to be the commonalities and specific focus areas between DevOps and SRE. My ambition was to capture the common principles and objectives of the two while emphasizing the reliability and operations focus of the latter. It worked well!
|
DevOps |
SRE |
|
Commonalities | |
|
Embracing change and risk Breaking the organizational silos Automation Technology utilization Visibility and visualization Release velocity and engineering Gradual service changes Fail fast and learn Shift operations and quality left in the SDLC | |
|
Specific Focus | |
|
Production operations are part of it |
Production operations are at the center of it |
|
The focus is on releasing “fast” |
The focus is on releasing “reliably” |
|
Focus on functional requirements |
Focus on non-functional requirements |
Table 13.1 – DevOps and SRE mainstream commonalities and specific focus
Before you shoot me
I deeply acknowledge that the special focus areas in certain cases are not that distinct if the concepts are reconciled correctly. Although, in an average incumbent’s context, as we saw earlier in the book, where DevOps is equalized with speed and CI/CD pipelines while focusing on developers and omitting operations, the preceding special focus distinction is spot on to get SRE discussions going.
There is an apparent, undoubted, and significant conceptual overlap, as well as an overlap of objectives, between the two concepts, as you can see. The main difference, if we go by the traditional and mainstream distinction, is that DevOps focuses more on speed and software development, while SRE focuses on reliability and operations. We do not, however, espouse that traditional and mainstream distinction in this book. Nevertheless, it is unfortunately deeply rooted in the financial services industry’s perspective of SRE, and you might have to use it when explaining the relationship of DevOps and SRE to people. In our book, both DevOps and SRE complement each other in enabling the DevOps equilibrium. How do they do it in reality? There is no one solution and it depends on the reconciliation model you follow.
Closing this section, I am convinced through practical experience and not only academic theory that there is no either-or dilemma in the DevOps to SRE relationship. It is clearly a relationship of co-existence and mutual inclusiveness that very much depends on your business case and operating model in how it will be shaped.
Do you remember the DevOps lexicon?
SRE will bring new concepts and terminology to your evolution. You will need to enrich your DevOps lexicon with those.
Expressing the practical value proposition as “tenets”
In practically explaining the SRE value proposition to DevOps, I would like to introduce the term SRE tenets. Google defines SRE tenets as the basic set of responsibilities that SRE teams adhere to when tasked with supporting a service. At Google, adherence to SRE tenets is mandatory for every single SRE team. You can also perceive the collection of tenets as the SRE part of the DevOps WoW white paper that we referred to in Chapter 5, Business Enterprise Agility and DevOps Ways of Working Reconciliation. The basic SRE tenets that Google defines are the following, always concerning the reliability improvements of a service:
- Availability
- Performance
- Effectiveness
- Emergency response
- Monitoring
The preceding tenets are a core foundation of what an SRE team should be tasked with: monitoring the health of a service, improving its availability, and so on. Nevertheless, SRE as a concept goes much deeper than those five tenets. In addition, in a corporate environment of an incumbent, it is an impossible mission to promote a new concept such as SRE in such a simplistic way. You will hear arguments such as we already monitor our service, we have an emergency response in place, and we call it “on call,” and more. Here comes the point. An inability to make clear to people what’s in it for them and their service with SRE will make it impossible to get buy-in. Considering this parameter, but also four other factors, I deliberately adjusted the tenets the first time I implemented SRE at scale, mixing them with SRE practices. Otherwise, there would have been zero chance of getting buy-in. It actually worked and then that adjustment became my repeated pattern. Before we move on to the details of the adjusted tenets, let us look at the totality of factors that made me take that approach.
The four factors on top of what’s in it for me are the following:
- SRE is what you make of it. Therefore, you shape the tenets to fit your context and ambition.
- You will have to reconcile SRE with ITIL, which you most probably started adopting many years before SRE. Therefore, you have to make SRE relevant to ITIL.
- You will have to reconcile SRE with DevOps, which again, you most probably started implementing earlier. Therefore, you have to make SRE relevant to DevOps.
- Do you remember the policy that is called segregation/separation of duties that we discussed in Chapter 8, 360° Regulatory Compliance as Code? You will have to make sure that it is not violated, to make the SRE duties clear.
At the end of the day, in the first pages of Google’s first SRE book, Site Reliability Engineering: How Google Runs Production Systems, the authors state that their intention for the book is not to tell people how to do it, but to inspire them in how to do it (kind of the motto of this book also). Therefore, a huge thank you (and I honestly mean it) to Google for the inspiration.
The SRE balance – 50%-50%
Before we move on to the tenets, I wish to open an important parenthesis and introduce you to an SRE concept that underpins the tenets – the concept of SRE balance. SRE is a software engineering-oriented concept with a strong operational focus. This equilibrium between software engineering and operations work is materialized through the concept of 50%-50%. 50%-50% aims to ensure that site reliability engineers spend 50% of their time on improving a service’s reliability through engineering work, with the other 50% invested in a service’s operational activity. When it is observed that more than 50% of the time has been spent of service operations, the elimination of the excess amount must be achieved through engineering improvements, with the time being prioritized in the team’s backlog. Ideally, and when your SRE team as well as the service they support is mature enough, you should strive to move the pendulum toward engineering – 20% of time spent on operations and 80% of time spent on engineering must be your target.
What are the fundamental “tenets”?
As I mentioned earlier in the chapter, SRE is what you make of it. Defining the SRE tenets is, in my experience, the first step in defining what you want to get out of SRE in your organization. The logic is simple, right? Defining what the SRE teams will be responsible for also defines what you want to achieve with SRE and, consequently, what the SRE value proposition is for your DevOps 360° operating model and evolution. In this section, we will look into what I propose the bare minimum SRE tenets can be, as I have seen them being implemented and paying off in various SRE adoptions across incumbents.
Important note: SRE is a production-focused function, keeping the “lights on”!
In the following tenets, I will deliberately avoid making special mention of the responsibility of SRE in operating the production environment of a business service or platform. SRE is an operations-oriented function, as we mentioned, and therefore operating production environments are taken for granted as a responsibility. Therefore, in the following tenets, there is no need to make explicit reference to responsibilities such as emergency response, incident management, postmortems, deployments, and continuity management.
SRE tenet 1 – maintain the balance of the DevOps equilibrium
To refresh your memory, the DevOps equilibrium as we have defined it in this book balances time to market – reliability – compliance across the SDLC and toward the final value added through software delivery for end clients. Let me make a clarification before I get misunderstood. It is not only a site reliability engineer’s job to maintain that equilibrium. It is the responsibility of the entire cross-functional agile DevOps team and its product owner. However, there must be someone accountable and someone responsible for the equilibrium’s maintenance. I’m sure you know from personal experience that where everyone is accountable and responsible, no one really is. To my mind, the accountability for maintaining the DevOps equilibrium should be with the product owner of the agile DevOps team, while the responsibility should be with the ones that gatekeep that production environment. That will be the SRE team (where one exists). As we will see later in the chapter, you must not – and technically you will not – adopt SRE across your portfolio.
There are several mechanisms that you can deploy in maintaining this equilibrium. The master mechanism, however, is the production readiness review (PRR) that we first introduced in Chapter 9, The DevOps Portfolio Classification and Governance, of the book. In pragmatic and sustainable SRE adoption, it is the SRE team that is responsible for the PRR mechanism. Obviously, the SRE team does not have ownership of all the items included in the PRR but is responsible for conducting it. That responsibility, as you might expect, comes with relative authority. As in, an SRE team, upon evidence that a product or a service is not production-ready (breaches parts of the PRR), upon agreement with the product owner, can stop the release or launch.
But that never happens in reality, Spyridon
It depends. If you have a healthy relationship with the development teams and you have gained the blind trust of your business partners through results, you can exercise your right to block product launches and releases.
Another fundamental SRE mechanism that is used to balance the time to market and reliability equilibrium and is normally included in the PRR is what in Google terms is called the error budget. The error budget’s core objective is to address a structural DevOps conflict between operations, concerned with service stability and development as well as time to market. The core objective is to balance the concepts of release velocity and service-level objective (SLO). To explain that balance, I like the car metaphor SRE definition that we mentioned earlier. Suppose that service A is a car. The SLO of the car is that its speed should be constant at 100 miles/hour. The release velocity of the car represents the objective of changing the tires of the car, on demand, without impacting its speed. If in the attempt to change the tires the speed is reduced to 80 miles/hour, then its SLO is breached. If, on the other hand, the risk of changing tires (release velocity) is not considered as breaching its SLO, then its release velocity is jeopardized. Therefore, one of the core objectives of SRE is to maximize both the SLO and the release velocity, while maintaining the equilibrium between them.
The error budget in its simplest format is calculated as 100% availability minus the target SLO of a service. So, for example, if the defined SLO of a service is 99% availability, the error budget is 1%.
The error budget technically represents the amount of time that a service can fail, without contractual implications, and is complemented by corresponding policies that serve as protocols for balancing the equilibrium.
Typically, an error budget has a tolerance zone, and this is because it might be breached only slightly, or a breach might be caused by factors external to the specific business application. So, in our example, if we exceed 1% only by 0.5% (the tolerance percentage), there will be no real contractual consequences in an incumbent’s context. But if we exceed the 0.5% tolerance zone, reliability enhancements will need to be prioritized compared to new features, till the error budget gets back within the target numbers.
SRE tenet 2 – service observability
The second very important SRE tenet is the one of service observability. In this context with service observability, we define a set of practices that support the collection, processing, and visualization of production data that represents the health status of a business application, a service, or a platform. Under service observability, we include both service monitoring and also logging.
Did you notice?
We called this tenet service observability and not purely observability. You will understand why when we reach the release engineering tenet later in the chapter.
The usage of such a set of practices is for several, critical to the SRE function, purposes:
- Production environment visibility
- Proactive incident management
- Problem management
- Error budget tracking
- Capacity management
- Input for the PRR
- Regulatory evidence
SRE uses some specific measurements that are embedded in service observability frameworks. These are the following:
- Service-level agreements (SLAs): These are contractual agreements made between product owners and SRE teams on the desired availability uptime of a service.
- Service-level objectives (SLOs): The measure that the SRE team uses for fulfilling SLA targets.
- Service-level indicators (SLIs): Specific and directly measurable indicators of a service’s health, such as CPU usage on production machines, connection to stock exchange latency on price feeds, or Kafka topics’ data completeness.
Other metrics that are often used in an SRE context are the following:
- Mean time to detect (MTTD): Indicating the acceptable, according to the SLA, lead time till a production incident, for instance, is discovered
- Mean time to react (MTTR): Indicating the acceptable, according to the SLA, lead time till a site reliability engineer or the system itself (autonomous operations) reacts to initiate its restoration
- Mean time to recover (MTTR): Indicating the acceptable, according to the SLA, lead time till the service is recovered
Of course, as well as the preceding metrics, we also need to include the error budget mechanism that we discussed earlier, in the previous section.
Service observability alone is “epidermic” reliability
A common anti-pattern that I have seen in the context of incumbents is to perceive the implementation of automated and real-time monitoring by itself as a proactive reliability improvement mechanism. The fact that you caught an alert fast and managed to prevent an incident is a preventive reliability approach. Finding the actual root cause and fixing it using engineering practices is a proactive approach.
SRE tenet 3 – elimination of “toil”
Delivering and running software inevitably requires manual interventions across the SDLC. Those manual interventions, especially if they are repeatable and automatable, in SRE terms are called toil. The elimination of toil through engineering means across the SDLC is a core tenet of SRE. There are three sayings in Google that I find very applicable in defining the SRE’s relationship with toil: invent more and toil less, automate this year’s jobs away, and automate ourselves out of a job. Toil comes in various shapes and forms, and despite the fact that SRE is an operations-oriented function, toil elimination must be targeted across the SDLC. The following are some examples where, typically, toil is observed across the SDLC:
- A lack of event-driven CI orchestration
- A lack of auto-failover capabilities built into the business application or platform by design
- A lack of automated generation of PRR evidence
- A lack of automated raising and closure of incidents and change requests
- A lack of autoscaling
- A lack of automated SLIs
- A lack of test automation
- A lack of automated change request impact analysis
The benefits of automating toil are massive, from increasing DevOps productivity to faster restoration of services, and overall SDLC operational efficiencies to minimizing the cost of operating a production environment.
The QA framework SRE – an SRE shift-left paradigm
In one of the banks I worked at, we had a QA framework site reliability engineer only taking care of advancing our test automation framework as well as the solutions of developer disposal test environments and data.
Addressing toil tactically is vital to also maintaining the DevOps equilibrium and the SRE balance. The more manual interventions across the SDLC, the more likelihood there is of defects and incidents, which can lead to reliability jeopardization and release velocity slowdowns. That, consequently, can make site reliability engineers spend more than 50% of their time on operations-related tasks, which will violate the 50%-50% SRE balance. Even more so, the accumulation of toil, adds to the long-term technical debt of a business application or DevOps platform, which can result in constant production firefighting.
Your ambition in addressing toil must be to shift left as much as possible across the SDLC while going as close as possible toward a sufficient degree of autonomous production operations and level 0 (self-service) request fulfillment for your clients.
The fallacy of NoOps in SRE
NoOps is a buzzword (in my opinion) that has made an appearance in the industry in recent years and has been associated with DevOps and SRE. Pretty self-descriptive by its acronym, NoOps stands for no operations, indicating that the level of autonomy of services through automation, engineering, and intelligence has to reach 100% – a pure fallacy looking at the context of an incumbent bank, even in state-of-the-art cloud-native applications. It is a sufficient level of autonomous operations you should strive for, not NoOps.
Important considerations for toil
Automating everything or automating without a tactical plan does not make sense (in certain cases, it is not practically and technically possible, actually) from various perspectives:
- Scaled automation can cause a domino effect in cases of scaled incidents.
- Some tasks need to remain manual because either they are needed for the incubation of new people, the automation ROI is not worth it, or your business partners or regulator require you to conduct them manually.
- You need to align on the mathematical formula of measuring the toil impact and ROI.
- Fix toil by using proper shift-left engineering practices and not simple scripts that restart servers when they are down.
- When toil cases are discovered during incidents, firstly conduct the root cause analysis, and afterward, consider your toil elimination options.
- Do not directly link toil elimination to reducing the number of people in your organization.
Automate everything! (Please don’t)
Automate everything is yet another famous buzzword in the corridors of incumbents. Do you remember the 1,000,000 hours of lead time saved KPT from Chapter 11, Benefit Measurement and Realization? The same thinking is behind the ambition/fallacy of automating everything. Automate “tactically” and “smart” is the right ambition.
SRE tenet 4 – release engineering
With the term release engineering, we define the SRE tenet that is concerned with the design and implementation of efficiencies and improvements across the SDLC, releasing high-quality software in a fast and reliable manner. In my book (literally and figuratively), and based on my experience with SRE in the FSI, release engineering must cover the following aspects across the SDLC from ideation to first launch, living production, and eventually sun setting:
- Built-in by design reliability engineering practices for how a service is designed, built, deployed, and operated
- Entire SDLC observability in terms of lead times and velocities
- Engineering implementation of DevOps controls across the SDLC, fulfilling the DevOps equilibrium
- Deployment strategies (technical release, canary, blue/green, and so on)
- Business application and platform modernization
- Automation of PRRs
- Optimization toward autonomous operations
- Shift left and by design non-functional/quality aspects of the SDLC
- Technological interoperability
As you can observe, the release engineering tenet covers several aspects of the rest of the SRE tenets and, in my opinion, must be the backbone of your SRE tenets.
SRE tenet 5 – reliability engineering framework
The last of the SRE tenets (as we define them in this book) is the reliability engineering framework. One core aspect and guiding principle of adopting SRE that I have not yet mentioned is the one of being prescriptive. Indeed, there is another definition of SRE, which states SRE is prescriptive engineered ways of ensuring the reliability of a service. Prescriptive, in our context, simply implies that the practices site reliability engineers use in fulfilling the tenets must be shaped in the form of prescriptive frameworks and enforced across SRE teams. But what are the benefits of being prescriptive?
- Faster scaling by creating reusable and scalable solution recipes.
- The cost of adopting SRE practices is reduced.
- Standardization and simplification are achieved in the portfolio that SRE is engaged with.
- Technical debt can be reduced.
- The mobility of site reliability engineers across SRE teams becomes more effective.
- The structural conflict between SRE, DevOps, and ITIL is addressed in harmony.
- The incubation of junior SREs.
- Evidence for regulatory compliance purposes.
The mechanism that I prefer using in achieving this SRE guiding principle of being prescriptive is the reliability engineering framework. It is an inner source framework that is built and maintained by SRE teams and simply comprises a set of prescriptive ways of applying SRE practices across business applications and platforms. The following are some practices that I have seen defined in a reliability engineering framework:
|
Reliability engineering framework elements |
|
Automated monitoring of error budgets |
|
Backup and restoration procedures |
|
Reliability assessment on system design |
|
Chaos engineering recipes |
|
Microservice observability framework |
|
IT service management automation |
|
Deployment plans and strategies |
|
Technological solutions’ interoperability |
|
Automated failover and restoration procedures |
|
Event-triggered evidence generation |
|
Launch coordination engineering practices |
Table 13.2 – Example of elements in a reliability engineering framework
One of the areas around the reliability engineering framework that SRE puts a focus on is the simplification and standardization of the technological means that enable the framework’s practices. It is in the SRE philosophy that the greater the scale to achieve, the greater the need for technology standardization.
A comprehensive and complete reliability framework should be perceived as a complete SRE adoption guide for the teams that wish to embark on an SRE journey. I have personally found them, in my career, to be excellent tools to promote and accelerate SRE adoption. Although, I have to admit that they are demanding frameworks to design, implement, adopt, and maintain.
Wrapping the tenets up
The following figure provides a summary of the potential responsibilities of an SRE team based on our SRE tenet definitions. As stated in the figure, the more your SRE setup matures over time, the more the SRE balance should be positively influenced, with more time available for engineering innovation rather than operations tasks:

Figure 13.1 – Sample of the SRE tenets balance
I strongly recommend that you place absolute top priority when starting your SRE journey on clearly identifying the SRE tenets as one of your foundational steps. An inability to do so will generate several challenges on your way, from defining the white paper of responsibilities and demarcating them with other teams to securing funding, and planning the SRE incubation of people to achieving SRE recognition and acceptance within your organization.
Did you notice?
We did not mention any business inquiry support tasks as part of the tenets. That was intentional and you will discover why in the third part of the chapter.
Concluding this section, the SRE value proposition for the DevOps 360° evolution and operating model is that SRE adoption can provide the necessary governance and procedural, capability, and organizational means for embedding reliability engineering practices and ways of working across your DevOps 360° SDLC and at relevance. Whether SRE is relevant to every part of your business applications and platforms portfolio and what the relevance eligibility mechanism can be will be examined in the next section.
What are the foundational elements of SRE adoption “at relevance”?
In this section, we will investigate some of the fundamental aspects of how to design an SRE relevance mechanism that can support you in being tactical and pragmatic in your approach.
SRE eligibility
One of the most well-known SRE mottos of Google is not all areas require SRE involvement. That is an absolute truth, which makes us conclude that you should adopt SRE at relevance in a multi-speed banking concept, as with DevOps. But what are the criteria of relevance that you should consider? As you might guess, they do not differ much from the relevance criteria that define DevOps speed, which I cite here to refresh your memory:

Figure 13.2 – The DevOps speed formula
In the SRE context, the application of the speed formula is a little bit more focused/complex compared to broader DevOps adoption. This is due to two key determinants in our DevOps speed equation, as well as one enabler and one parameter, which are the most crucial in adopting SRE-specific practices, compared to other DevOps practices. The two key determinants are the ones of reliability and technology:
- Reliability in the sense that SRE is primarily concerned with service reliability aspects with this becoming the dominant equation determinant. The tougher the reliability requirements, the more need there is for site reliability engineers. Talking from experience, only the absolutely ultra-critical parts of an incumbent’s portfolio really require SRE engagement. Those are either flagship applications, widely shared enterprise DevOps platforms, or core infrastructure components.
- Technology in the sense of how appealing and adaptable to SRE practices the technological stack of a business application or platform is. Appealing in terms of attracting people to work with these technologies and adaptable in terms of providing the ability to implement modern SRE practices (see a mainframe compared to a cloud-native setup).
And now, we come to our enabler, which is the people. There is an expression in the industry that goes SRE does not scale. That expression refers to the challenge of finding on the market the necessary SRE people and skills in terms of quality and quantity. In simple words, it is more likely not to find people that have SRE know-how, the mentality, and the desire to focus on reliability engineering practices compared, for instance, to people with experience in and desire to work with the software development of CI/CD pipelines. And you will also face challenges convincing internal people to move from software development roles to reliability engineering roles. Some find operations a downgrade of their CV, while others are scared of the idea that they will be tasked with the reliability engineering of your portfolio flagships. Last but not least, a key parameter to consider when deciding on your SRE eligibility is scale. In my experience with SRE, the greater the scale of a business application or platform, the greater the SRE need is and the greater the ROI. Scale, in our case, can be the variety and size of infrastructure assets, the number of developers, the number of dependencies on other business applications, the number of deployments per day, and so on. That is why I always advise taking the ecosystem and value stream approach in an SRE adoption.
In summary, reliability targets and technological aspects of a business application or platform, as well as the availability of people skills and the setup’s scale, are the key determinants in my opinion in defining where SRE is pragmatically eligible and where not.
A true story about the importance of technology
I am certain any ex-site reliability engineers of mine that read this book will vividly remember this one. In one of the SRE teams we worked in, we had only cloud-native technologies in our portfolio of responsibility. Due to an internal reorganization, I inherited some legacy applications. We had to make sure they operated smoothly till they were decommissioned, at some point in the future. When we took them over, we realized that their technical debt was massive. Literally, none of the cloud-native site responsibility engineers wanted to work with those legacy applications. Several warned me that if we did not get rid of the legacy applications, they would leave the team. The team’s climate was damaged, but we eventually worked around it with contractors. Lesson learned: if your technological stack is not SRE-appealing or is not in the modernization process to become SRE-appealing, it is not SRE-eligible.
Tactical versus organic SRE adoption
As we mentioned, not all areas are SRE-eligible and the demand for site reliability engineers is always higher than the supply. The latter is one of the reasons why many in the industry claim that SRE does not scale. The concept can scale perfectly in reality. It is the people that support its scaling that there will never be enough of in your organization. Let me explain by using the distinction between the tactical and organic approaches that we discussed in Chapter 10, Tactical and Organic Enterprise Portfolio Planning and Adoption, while adjusting them a little bit to a pragmatic SRE context. Therefore, in an SRE context, we have the following:
- Tactical SRE adoption will not be characterized by only an all-hands-on-deck approach (as we described in Chapter 10, Tactical and Organic Enterprise Portfolio Planning and Adoption), but also by the number of pairs of hands available, which will indicate the presence of site reliability engineers that are permanently placed and are dedicated to those areas, as well as exclusive site reliability engineer hiring rights for tactical adoption areas. Due to the scarcity of site reliability engineers, tactical adoption areas should be shaped in ecosystems or value streams, which will allow teams to share site reliability engineers (rotations or scaled operations), enabling an environment for SRE economies of scale.
- SRE organic adoption refers to any other area that will not have dedicated site reliability engineers, will probably struggle to incubate its available people, and also is not SRE-eligible. Nonetheless, those areas can, to the best possible and relevant extent, adopt parts of the reliability engineering framework where viable and applicable.
Storytelling – the tactical SRE eligibility assessment
In one bank I worked at, we built (our CIO was aware) a very solid SRE setup behind the scenes, both technologically and organizationally. It simply worked great. Once we started opening up about our practices and successes, many more teams wanted to follow our path and get help from us. They started pinging us to ask for support, inviting us to give presentations, buying and reading the Google SRE publications, and creating their own SRE visions and job descriptions while requesting a budget to hire site reliability engineers. And there was the real problem. We neither had the available budget to hire site reliability engineers for all teams, nor were we able to find them in the market, or we would have followed that “anarchical approach.” We clearly needed a tactic for how to scale SRE. Our CIO came to me and asked me to create a mechanism that people could use to assess their portfolio and discover whether they had a real business case and were eligible for SRE support. The idea was to have them assessed, collect the results, and see what the actual need was so we could create a tactical scaling plan. It is important to mention that the top-10 ultra-critical services of the bank (plus our setup in capital markets) were by default in scope. It was the rest of the business applications and platforms portfolio we had to assess in an aligned and transparent way. I went ahead and created that eligibility criteria assessment based on the lessons we learned doing SRE for 2 years in my area. It was a self-assessment based on questions across a service’s SDLC and its questions had different reliability importance weight points. The accumulated points of all the questions flagged your area as SRE-eligible or not. Not to our surprise, not many areas passed the eligibility zone. And again, not to our surprise, we could already – before seeing the results – predict which areas passed. There are two messages that I wish to pass through this story. One, you need a structured way to assess SRE eligibility, and two, the areas within your organization that are SRE-eligible are easy to spot.
The engagement model mechanism
The eligibility classification results, as well as the broader SRE operating model that your organization wishes to deploy, define another very important aspect of deploying SRE – what, in Google’s terms, is called the engagement model. Being self-descriptive, the SRE engagement model defines the business case of site reliability engineers being engaged with a particular service. The engagement model is equally applicable in centralized, hybrid, and decentralized SRE operating models, which we will discuss in the last part of this chapter. What is the value of an engagement model?
- It ensures that engagements are value driven through clarity in the scope and outcomes.
- It enables effective tactical scaling.
- It defines the depth level of the engagement with a particular service in terms of tenets.
- It defines the required skills that a site reliability engineer should possess.
Site reliability engineers and the Π-shaped profiles
Do you remember the Π-shaped DevOps professionals of the previous chapter? I also advise you to enable Π-shaped site reliability engineers.
With my SRE experience, I have slightly amended Google’s engagement model, the same as I have done with the tenets, so I can fit it into the different contexts of various incumbents. The three different engagement models I use are the following. I need to clarify, as is visible in the following table, that SRE engagements can combine both hands-on implementations as well as advisory:
|
Early engagement |
Late engagement |
Full engagement |
Advisory | |
|
SDLC phase of the service |
Ideation or early design |
Either first “go live” or already in production |
Ideation or early design to sunsetting |
Any SDLC phase |
|
Objective |
Establish the fundamental practices of reliability engineering from day 0 |
Assess production readiness Support with the gradual deployment of the service in production Address severe instability Operate the service in production |
Ensure service reliability across its life cycle |
Provide consultation on adopting the reliability engineering framework |
|
Ownership level |
Limited: Set up the fundamentals and move on to another service |
Limited: Release or resolve the reliability issues and move on to another service |
Full ownership of the service across its life cycle |
No ownership |
Table 13.3 – SRE engagement model parameters
Adapting and visualizing the SRE engagement models in our DevOps 360° SDLC, we get the following figure:

Figure 13.3 – SRE engagement models visualized in the DevOps 360° SDLC
Another important element of the engagement model framework, in addition to who across the portfolio will get SRE support, is also to define the extent and duration of the support. It is needless to mention that despite the engagement level, the SRE practices deployed must be based on the reliability engineering framework.
Reconciling SRE and ITIL
The second major SRE debate/dilemma (after the one between SRE and DevOps) is the one concerning the relationship between SRE and the ITIL. The conceptual interrelation of the two is quite significant, with Google claiming that SRE is their flavor of implementing IT service management. A big challenge that incumbents traditionally face is how to reconcile SRE and ITIL in a pragmatic way. For reasons derived from misconceptions, and a lack of practical experience with SRE, arguments such as we are not Google, and protectionism over ITIL implementations, incumbents seem to struggle with both the theoretical and practical reconciliation of the two concepts.
The ITIL obsession of incumbents
For the vast majority of incumbents, their ITIL implementation is considered to be their IT gem that needs to be protected against external invaders such as DevOps and SRE. I have not come across a single incumbent that is not obsessed with ITIL, even though several do not admit it. “We are not an ITIL house,” I was told once by an incumbent I was advising. Though when I got access to their IT operations model, it was ITIL v3, pure copy-paste. Back to the point. This obsession with ITIL, in my opinion, is derived from three sources. Firstly, it is easy to label an organization ITIL done, while with DevOps and SRE, you can never be done. Secondly, adopting ITIL requires less mental capital (two available brain cells, an old colleague of mine used to say), compared to DevOps and SRE. Thirdly and lastly, the core ITIL processes are the backbone of regulatory inspections of the IT operations procedures of incumbents.
I will not provide further information on ITIL as it is not in the scope of the section. What I wish to focus on is giving you a taste of how you can approach the reconciliation of the two concepts. The recipe I invented over the years, which has worked with a 100% success rate, is based on the following distinction/argument:
- ITIL offers process definition, design, and governance around IT service management, such as change management.
- SRE offers the means of engineering those IT service management processes across the SDLC phases and embedding left, such as raising CI/CD event-driven change requests.
Conceptually (and to a large extent, practically), this is it. Honestly, each and every ITIL process can be engineered using SRE practices. Of course, this requires in-depth knowledge of both concepts and the respective experience in implementing them. Now, how can you prove the successful reconciliation of the two? Mainly in three ways:
- The first one is to design the two concepts’ reconciliation mechanism. The following figure provides a solid example of how SRE and ITIL concepts are fully reconciled. I acknowledge its oversimplification, but it is important to keep it simple:
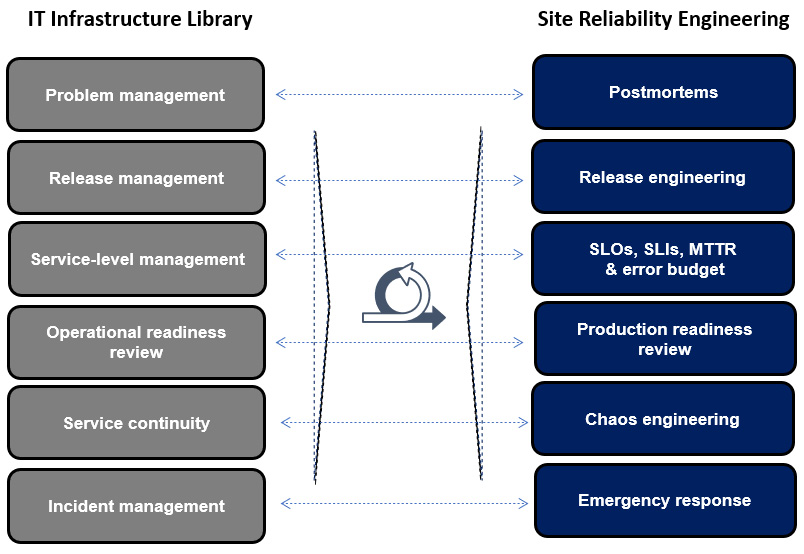
Figure 13.4 – Example of SRE and ITIL reconciliation
- The second is to visually and practically shift the reconciled outcome left in the DevOps 360° SDLC, so your people can also see its reconciliation with your broader DevOps capabilities.
- The third is to prove it practically through your SRE adoption, by collecting evidence on how you have been ITIL compliant in an engineered and efficient way. Automated raising and closure of incidents and change requests, automated service failover, automated service monitoring, automated IT asset reflection in the CMDB, and postmortem reports will be sufficient.
Not to be misperceived
ITIL is a good framework to set ITSM process governance for large incumbents (I doubt any neobank is using it). But it must not be a showstopper in your DevOps and SRE adoption. With good intentions, knowledge, experience, and creativity, DevOps, SRE, and ITIL can be reconciled under one DevOps 360° SDLC beautifully.
The most dominant SRE professions
As the SRE concept has been gaining momentum in the financial services industry, more and more professions and job titles around it have been created by different incumbents. Four are the most dominant and in this section, we will present them. Before looking into those, it is necessary to refer to the core mechanism behind defining these professions. It is your SRE operating model (as we will also see in the next section) that should be the foundation of what SRE professions and respective skills you require. Now, let us look at them:
- Service reliability engineer: This profile will primarily be associated with Agile DevOps teams who develop and operate business applications, either used by internal business units or external clients.
- Client reliability engineer (CRE): Client reliability engineering, according to Google, is a discipline in which the main objective is to create trust in the reliability of services between Google and its clients, combining engineering and advisory acumen. The customer reliability engineer is a profile that, in an incumbent’s context, can be found as follows:
- Fully embedded with an agile DevOps product team dedicated to the non-functional/quality requirements of the product
- As a member of an SRE CoE, supporting service reliability engineers and developers of tactical adoption areas
- In a DevOps platform team, working on eliciting the agile DevOps teams’ requirements and supporting their onboarding to the platform
- Platform reliability engineer: This profile is primarily associated with core platforms that are part of the DevOps 360° technological ecosystem, tasked with their daily operations and reliability improvement matters. Depending on the platform, you will find platoform reliability engineers have corresponding designations – AWS reliability engineer, Azure DevOps reliability engineer, or ServiceNow reliability engineer.
- Platform recovery engineer: This profile will primarily be associated with the core foundation infrastructure and be tasked with minimizing the MTTD, MTT Respond, and MTT Recover in the case of major, disastrous events in the firm’s data centers. In most cases, you will find those reliability engineers sitting in enterprise command centers and control rooms, surrounded by health check monitors.

Figure 13.5 – Overview of the SRE roles on the technological stack
The tenets among the four profiles are the same and when operations in their respective areas do not require attention, they might join forces on broader reliability improvement initiatives, engineering transformations, or maintaining the reliability engineering framework. But how do organizations deploy the various reliability engineering professions, based on their SRE operating model, while also utilizing the engagement model mechanism? We will look into how various incumbents approach SRE in the coming section.
Did you know?
The most common method that incumbents use to incubate their people to become SREs is what I call either a baptism or knighthood ceremony. I have seen it in the context of every single incumbent, literally. People who build monitoring solutions instead of performing manual morning checks or people who write scripts to automate manual processes instead of performing them manually are just repurposed from operations or IT analysts to site reliability engineers. The site reliability engineer title, in my opinion, needs to be earned with decisive reliability engineering work that has shifted left in the SDLC. And while I appreciate that SRE is what you make of it, there are still patterns and anti-patterns in the making.
What are the dominant SRE operating models in the financial services industry?
Throughout my DevOps career, I’ve had the real pleasure of either directly working with various SRE operating models and setups or indirectly being exposed to them through consultation. I have to admit that incumbents and, in general, the financial services industry have been extremely creative in how to approach the SRE operating model. In certain cases, with success, creating strong financial services industry SRE patterns, and in some other cases, not so successfully creating strong financial services industry SRE anti-patterns.
There are, of course, several ways that an SRE operating model can be deployed in the context of a given incumbent. In this section, we will discuss some of the most dominant SRE operating models that I have discovered in the financial services industry, outlining their context and motivating factors, as well as their pros and cons.
Clarifying the term “SRE operating model”
I am certain that, throughout the book, you will become familiar with what I mean when I use the term operating model. I nevertheless want to make sure. With an SRE operating model, we define the WoWs and organizing principles that the various teams subject to the SRE adoption operate upon and interact with.
Use case 1 – the SRE task force model
In this model, the SRE team was a central one and was acting as a task force to support business applications or platforms that had severe reliability issues. The following table summarizes its characteristics.
|
SRE operating model ownership |
SRE task force |
|
Engagement model |
Late – solve reliability issues and move on Rotational |
|
SRE service ownership |
None |
|
Level of centralization |
Highly centralized |
Table 13.4 – The SRE task force operating model parameters overview
Modus operandi: In this model, the site reliability engineers centrally belonged to a team called the SRE task force. They were deployed either as squads or individually in certain agile DevOps business teams (tribes and squads in that context) or common DevOps platforms that were experiencing significant reliability issues. The guiding principles of the setup were join – stabilize – handover – move on. The reliability engineering framework was owned by the SRE task force organization and was mandatory for engagements.
Here are the motivating factors:
- The organization wanted to avoid a massive and uncontrolled “SRE baptism.” Only people belonging to the task force who had proven their skills and went through special interviews could carry the “SRE title.”
- The skills’ scarcity in the market could not allow for massive hirings of site reliability engineers and the organization wanted to tactically use the available ones by centrally and tactically controlling their embodiment to certain client engagements.
- The incumbent wanted to promote SRE primarily as a philosophy and a way of working and secondarily as an engineering practice. Having SREs only in a central team, in timeboxed rotational engagements, passed the message that SRE is a culture that should be embraced and adopted organically in the organization.
- There were certain areas with severe reliability issues and closely supervised by the incumbent’s regulator. For budgeting and “political” reasons though, those areas were not allowed to hire. The “SRE Task Force” was a convenient alternative both to support those areas and also to prove the concept.

Figure 13.6 – The SRE task force topology
The following table shows you the SRE task force operating model pros and cons:
|
Pros |
Cons |
|
“Baptism” was avoided. The organization knew that those who were called site reliability engineers had the necessary qualifications. |
The SRE task force, after a certain number of engagements, could not scale anymore. |
|
The SRE people were not misused and were placed tactically in certain areas, delivering decisive work. |
Exiting certain engagements became challenging due to the absence of people to hand knowledge over. |
|
The rotations across various areas provided extensive organizational awareness to the SRE task force team. |
The rest of the organization, due to the absence of hands-on support, struggled to implement more than the basics of the reliability framework. |
|
There was a single area owning the “reliability framework,” which was enriched through task force engagements. |
The engagement rotations had a mixed effect on the site reliability engineers. Switching context and needing to constantly be onboarded to new setups create frustration. |
|
Internal career mobility for the site reliability engineers was promoted through the rotations. |
In certain engagements, site reliability engineers ended up performing more than 50% of the operations work, which resulted in frustration, especially in periods of significant “on-call” involvement due to constant firefighting. |
|
A certain level of standardization of reliability practices was achieved in the task force engagements. |
In several cases, it was challenging for the SRE team to influence the agile DevOps team’s backlog on prioritizing reliability matters over new functionality. |
|
Onboarding of the site reliability engineers in terms of domains and technological stack knowledge as well as access rights management prolonged the start of the engagements. | |
|
A lack of certain technical skills of the site reliability engineers did not make them a good fit for certain engagements. | |
|
With all SREs in engagements, it was challenging to focus on keeping the reliability model updated. | |
|
Several disagreements over the responsibility “white paper” arose, for instance, who was performing the deployments or who was responsible for L1 (emergency response). |
Table 13.5 – SRE task force operating model pros and cons
If you want to know what happened to the SRE task force, “rotation fatigue” kicked in and resulted in the site reliability engineers being absorbed by the areas they were supporting.
Use case 2 – the “triangular” SRE CoE and tactical hiring
In this model, the SRE CoE team is a central one but is acting in a triangular operating model, as the following diagram displays:

Figure 13.7 – The three parts of the triangular SRE CoE
The following table summarizes its characteristics:
|
SRE operating model ownership |
SRE CoE and tactical SRE areas |
|
Engagement model |
Early, late, and full rotational and fixed |
|
Service ownership |
Full ownership of certain parts |
|
Level of centralization |
Hybrid |
Table 13.6 – The “triangular” SRE CoEoperating model and tactical hiring parameters
Modus operandi: The modus operandi of this is simple despite its complexity. The SRE CoE consisted of three major teams, with several sub-teams:
- The platform SRE teams: This part of the SRE CoE owned several SRE technologies and tools that were used by SRE teams. These included observability tools, part of the CI/CD pipelines, and several cloud-native technologies.
- The business applications SRE team: This part of the SRE CoE was responsible for the reliability aspects of business applications that were part of the tactical adoption eligibility, having full ownership of them, with its members embedded in the agile DevOps teams. Those applications were not chosen by coincidence and were part of an “SRE ecosystem” that supported dedicated business value streams.
- The CRE team: This sub-team was acting as a combination of advisors and a task force, supporting different areas with reliability engineering aspects.
The three teams together were responsible for maintaining the “reliability engineering framework.”
Now, in parallel, the agile DevOps teams that were not part of the business applications that the SRE team (the second SRE CoE team) was engaged with had the budget and approval to hire site reliability engineers. They were still part of the “tactical adoption eligibility.”
Here are the motivating factors:
- The ambition was to create a complete SRE ecosystem that would include both platforms and business applications, with the ambition to fully implement SRE in a prescriptive way across them.
- To ensure that the complete set of tactical adoption areas could either be supported directly by the SRE CoE or indirectly also through the ability to hire their own site reliability engineers.
- To create a fully cross-functional SRE CoE where a potential site reliability engineer could be incubated but also existing site reliability engineers could have different career paths.
- To enable a sufficient level of technological self-sufficiency for the teams engaged with the SRE CoE so they could move at top speed. Also, to have the site reliability engineers support the modernization strategy of those areas to eliminate dependency on legacy applications and platforms.
You can see the topologies in the following figure:

Figure 13.8 – The triangular SRE CoE and tactical topology
To get an overview of what worked well and what didn’t work so well in this case, see the following table:
|
Pros |
Cons |
|
The SRE CoE through dedicated focus delivered decisive work. |
Due to its portfolio versatility and hybrid setup, leading the CoE was perceived as “empire building” by certain parts of the organization. That generated cooperation resistance in certain areas. |
|
The visibility across various areas provided extensive organizational awareness to the SRE CoE team. |
Running the daily operations of the CoE and aligning the three teams over priorities and communication was quite a complex task. |
|
There was a single area owning the “reliability framework,” which was kept updated. Scaled reliability engineering recipes were also added. |
At a certain point, the CoE struggled with capacity due to parallel runs (old and modernized setups). |
|
Internal career mobility for the SREs was promoted through the rotations across the three teams. |
Only a few of the CoE people had a software development background and it was challenging to improve reliability through business logic changes. |
|
There was a very high level of standardization of reliability engineering across business applications and platforms. |
In several cases, it was challenging for the SRE team to influence the agile DevOps team’s backlog on prioritizing reliability matters over new functionality. |
|
Due to the magnitude of decisive deliveries, a “high desirability” SRE momentum was created. |
In time, there were conflicts of interest between the platform SRE and business application SRE teams on the platform’s priorities and deliveries. |
|
The platform modernization of the SRE CoE-engaged areas moved fast, eliminating dependencies on legacy platforms and applications. |
Operational confusion rose among the business application site reliability engineers as, functionality-wise, they were referring to the agile product team PO and, HR-wise, to the SRE CoE team leads. |
|
The SRE-owned platforms and tools were ultra-reliable; they were piloted in flagship business applications and direct feedback was captured. |
It took time to assemble and make effective the CoE team as it was a combination of external hiring, internal incubation, and moves. |
|
The tactical areas that did not have direct SRE involvement could advance through their own hiring and the CRE interaction. |
Table 13.7 – Triangular SRE CoE operating model pros and cons
Do you wonder what happened to the SRE CoE? It is still there but with some changes. Due to budget constraints, it has stopped hiring and therefore did not scale much further. It has lost some people to the tactical agile DevOps teams, who actually became software developers there. Due to enterprise technology standardization and consolidation initiatives, the platform SRE team moved out.
How should SREs approach business support inquiry work?
In my experience, your site reliability engineers should not be conducting business production support work. As in, they should not be contacted by the end users of a business application in order to resolve questions of a purely business nature. There are three main three reasons for that. Firstly, SREs are by nature “technical people” and thus enjoy purely technical work. Secondly, you will struggle to find SREs with domain-specific business knowledge or you will find it difficult to get them interested. Thirdly, you need to distract them (the same as with developers) as little as possible from their engineering work. In domains where you adopt SRE, offload the business support work to a service desk, exactly as we proposed in Chapter 7, The DevOps 360° Technological Ecosystem as a Service, when discussing platform team service models.
Use case 3 – business applications and platform SRE
In this model, the site reliability engineers were embedded in the business application areas and the core common DevOps and infrastructure teams. There was no central SRE team and, as you can imagine, no commonly agreed upon SRE operating model and reliability engineering framework. The following table provides a summary of the parameters:
|
SRE operating model ownership |
Non-existent |
|
Engagement model |
Each team could specify its own |
|
Service ownership |
Full for either the business application or platform |
|
Level of centralization |
Hybrid |
Table: 13.8 – The business applications and platform SRE operating model parameters
Modus operandi: In this model, two approaches were balanced. The first approach was around SREs embedded in the business application areas. That embodiment was not planned tactically, and it was more based on the desire and ability of certain business applications’ agile DevOps teams. The second approach was more coordinated and tactical, where platform reliability engineers were tactically embedded in the core platform and infrastructure teams.
Here are the motivating factors:
- The organization was simply facing more reliability issues in its core platforms and infrastructure. That was revealed by production incidents and problematic management of data. Therefore, the reliability focus and budget were invested in that area.
- There was an objection to having a central SRE team as the intention was that the various agile DevOps teams should take full responsibility for their reliability aspects. Also, under the motto “SRE cannot scale,” there was a strong internal belief that a central team would become a bottleneck.
- Management wanted to avoid any sense of discrimination in the business application areas in case they were left out of tactical SRE hiring.
- The SRE adoption did not have an enterprise focus and therefore there was no funding allocated to SRE hiring and incubation for the business applications. The platform teams nevertheless had funding allocated under the “infrastructure and platform stabilization” program.
The following figure displays the organizational topologies of use case 3:
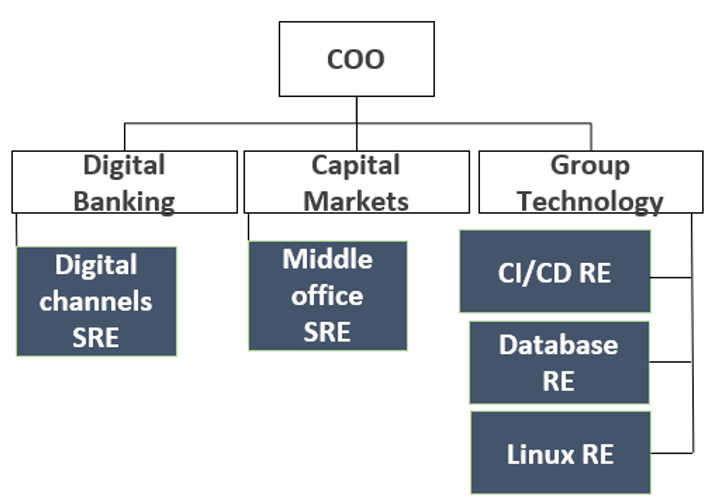
Figure 13.9 – Business application and platform SRE topology
This operating model’s positive and negative results can be found in the following table:
|
Pros |
Cons |
|
The platform reliability engineering teams on the platforms made decisive reliability improvements that hugely benefited the broader organization. |
Due to a lack of funding and coordination, the site reliability engineers hired in the business applications teams could not do decisive reliability work. Incubation through “baptism” was also observed. |
|
Mobility, sharing of reliability engineering practices, and standardization were performed in the platform teams. |
There was a significant variation in the SRE operating model and practices among the business application’s site reliability engineers but also among the platform ones. |
|
The cloud-first central capabilities’ delivery was accelerated. |
A lack of a single source of reliability engineering practices for business applications. |
|
The platform onboarding and service support procedures were improved dramatically and the agile DevOps teams were brought closer to influencing the platform’s backlogs. | |
|
It was the first time that the platform teams conducted an enterprise capacity planning exercise. |
Table 13.9 – Business application and platform SRE operating model pros and cons
Are you wondering what happened? The platform team site reliability engineers are still there currently focusing on advancing the public cloud journey of the organization and DevOps platform portfolio interoperability. Some of the business’ agile DevOps teams have replicated some of the platform reliability solutions in their areas with success.
Use case 4 – “baptized” and/or “random” SRE enablement
I am certain you were expecting this one to come up as I have mentioned the terms in various sections of the chapter already. This model was not coordinated by any central change management activity and was planned and executed on an individual area level, either on business applications or platforms. You can find the parameters of this unorthodox use case in the following table:
|
SRE operating model ownership |
Non-existent |
|
Engagement model |
Each team could specify its own |
|
Service ownership |
Hybrid in either the business applications or platform areas |
|
Level of centralization |
Decentralized |
Table 13.10 – The “baptized” and “random” SRE parameters
Modus operandi overview:
- Baptism: The new SRE modus operandi was almost exactly the same for “traditional L1 support” ITIL-based IT operations conducted by people with either absent or limited engineering skills. The major difference was that the title of those people changed and they attended some sort of training as part of an “incubation plan.” In most cases, the development teams kept full authority across all aspects of the SDLC, including backlog prioritization, deployments, L2 support, and so on. The newly branded site reliability engineers were primarily doing business inquiry support, restarting servers, working on monitoring solutions, and automating manual tasks where they had the skills, being pushed by the development teams on the extreme “right” of the SDLC involvement.
- Random: This simply characterizes organizations where literally every team is free to adopt SRE in its own way, without any alignment.
Motivating factors: Misconceptions, no belief in the real value of the concept, a lack of funding and transformation means, and a desire to rapidly make posts on “SRE successes” on LinkedIn. Doing it for real takes time and effort, you see.
Such SRE adoptions end up being more of a fallacy rather than a real investment and making a positive impact. In my experience, they do not last for long, as they do not deliver on their promises.
Important note
Especially in large and global presence incumbents, several of the processing SRE operating models can be found within the context of a single incumbent. There is literally nothing wrong with that approach (except for use case 4), as long as they are reconciled with the enterprise DevOps operating model and do not come into direct daily operational conflict.
Summary
In this chapter, we technically finished the walk-through of the main elements of our DevOps 360° operating model. Our focus has been on SRE, the value proposition of which we examined both from the lenses of its relationship with DevOps and also through its fundamental tenets. For the former, we concluded with the argument that it is a relationship of mutual inclusiveness and not conflict. For the latter, we discussed the importance of concepts such as the “SRE balance,” “error budgets,” “reliability engineering frameworks,” as well as “reliability engineering,” on the one hand with regard to accelerating the DevOps 360° evolution, as well as defining the responsibilities of your SRE teams. Later in the chapter, we did a deep-dive into some very important proven practices on how to adopt SRE at relevance. Our focus was on adoption and engagement models, eligibility criteria, reconciliation with concepts such as ITIL, as well as the potential SRE roles you can shape and deploy. The last part of the chapter was focused on discussing real use cases from approaches that various incumbents have taken when adopting SRE. We covered the respective motivating factors behind each use case and the core aspects of the various operating models, and we also examined the positive and negative results that those incumbents observed.
The next chapter is the last one in this book. In it, we will have a recap of the most important points of all the book’s chapters and will also provide some final advice for consideration.