
Some SQL statements have a reasonably constant execution time. Examples include the CREATE TABLE and GRANT statements. It does not matter under which circumstances such statements are executed; they always need a certain execution time. There is no way to reduce their execution time. However, this is not the case for all statements. The time required to process SELECT, UPDATE, and DELETE statements varies from one statement to the next. One SELECT statement might be processed in 2 seconds, while another could take minutes. The required execution time of this type of statements can indeed be influenced.
Many techniques are available for reducing the execution time of SELECT, UPDATE, and DELETE statements. These techniques range from reformulating statements to purchasing faster computers. In this book, we discuss three of them. In Chapter 19, “Designing Tables,” we looked at adding redundant data, as a result of which the execution time of certain statements can be improved. This chapter describes indexes and how their presence or absence can strongly influence execution times. In Chapter 29, “Optimization of Statements,” we deal with reformulating statements. Improving execution times is also known as optimization.
Note in advance: The first sections that follow do not so much cover SQL statements as provide useful background information on how SQL uses indexes.
In this book, we assume that if we add rows, they are stored in tables. However, a table is a concept that SQL understands but the operating system does not. This section provides some insight into how rows are actually stored on hard disk. This information is important to understand before we concentrate on the workings of an index.
Rows are stored in files. In some SQL products, a file is created separately for each table. In other products, tables can also share a file, and sometimes the rows of one table can be spread over multiple files (and also over multiple hard disks).
Each file is divided into data pages, or pages, for short. Figure 20.1 is a graphical representation of a file that contains the data of the PLAYERS table. The file consists of five pages (the horizontal, gray strips form the boundaries between the pages). In other words, the data of the PLAYERS table is spread over five pages of this file.
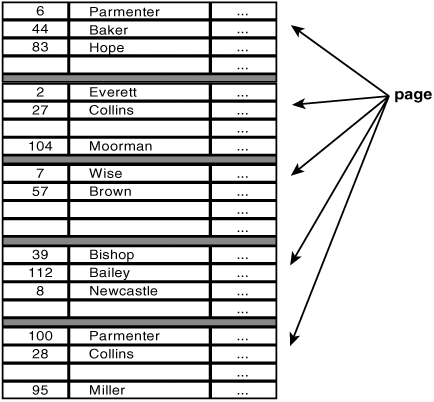
In this example, it is clear that each page has enough space for four rows and that each page is not completely filled. How do these “gaps” arise? When new rows are added, SQL automatically stores these after the last row of the final page. If that page is full, an empty page is added to the file. So, a gap is created not during the process of adding rows, but when rows are deleted. SQL does not fill the gaps automatically. If it did, SQL would have to find an empty space when a row is added, and for large tables, this would take too much time. Imagine that the table contains one million rows and that all pages are full except for the penultimate page. If a new row had to be stored in a gap, first all other rows would have to be accessed to locate a gap. Again, this would delay the process too much; that is why rows are inserted at the end.
In this example, we have also assumed that a page consists of a maximum of four rows. How many rows really fit in a page is determined by two factors: the size of the page and the length of the rows. The size of a page depends on the operating system and the SQL product itself. Sizes such as 2K, 4K, 8K, and 32K are very common. The length of a row from the PLAYERS table is about 90 bytes. This means that approximately 45 rows would fit into a page of size 4K.
It is important to realize that pages always form the unit of I/O. If an operating system retrieves data from a hard disk, this is done page by page. Systems such as UNIX or Windows do not retrieve 2 bytes from disk. Instead, they collect the page in which these 2 bytes are stored. A database server, therefore, can ask an operating system to retrieve one page from the file, but not just one row.
Two steps are required to retrieve a row from a table. First, the page in which the row is recorded is collected from disk. Second, we have to find the row in the page. Some products handle this problem very simply: They just browse through the entire page until they find the relevant row. Because this process takes place entirely within internal memory, it is carried out relatively fast. Other products use a more direct method; each page contains a simple list with numbered entities in which the locations of all rows that occur on that page can be found. This list has a maximum number of entities and can record a certain number of locations; let us assume that this number is 256. In addition, each row has a unique identification. This row identification consists of two parts: a page identification and a number that indicates a row in the list. Now, we can find a row by first selecting the correct page and then retrieving the actual location of the row within the page. We return to this subject in the next section.
SQL has several methods of accessing rows in a table. The two best known are the sequential access method (also called scanning or browsing) and the indexed access method.
The sequential access method is best described as “browsing through a table row by row.” Each row in a table is read. If only one row has to be found in a table with many rows, this method is, of course, very time-consuming and inefficient. It is comparable to going through a telephone book page by page. If you are looking for the number of someone whose name begins with an L, you certainly do not want to start looking under the letter A.
When SQL uses the indexed access method, it reads only the rows that exhibit the required characteristics. To do this, however, an index is necessary. An index is a type of alternative access to a table and can be compared with the index in a book.
An index in SQL is built like a tree consisting of a number of nodes. Figure 20.2 is a pictorial representation of an index. Notice that this is a simplification of what an index tree really looks like. Nevertheless, the example is detailed enough to understand how SQL handles indexes. At the top of the figure (in the light gray area) is the index itself, and at the bottom are two columns of the PLAYERS table: PLAYERNO and NAME. The nodes of the index are represented by the long rectangles. The node at the top forms the starting point of the index and is known as the root. Each node contains up to three values from the PLAYERNO column. Each value in a node points to another node or to a row in the PLAYERS table, and each row in the table is referenced through at least one node. A node that points to a row is called a leaf page. The values in a node have been ordered. For each node, apart from the root, the values in that node are always less than or equal to the value that points to that node. Leaf pages are themselves linked to one another. A leaf page has a pointer to the leaf page with the next set of values. In Figure 20.2, we represent these pointers with open arrows.
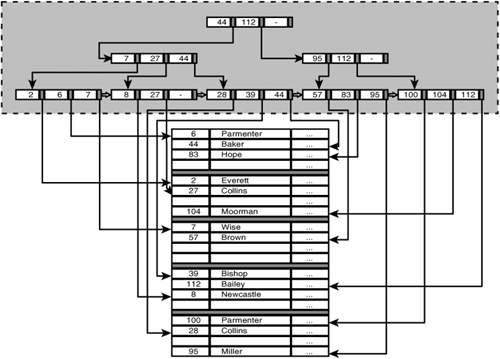
What does a pointer really look like? A pointer is nothing more than a row identification. We introduced this concept in the previous section. Because a row identification consists of two parts, the same also applies to an index pointer: the page in which the row occurs and the entity of the list that indicates the location of the row within the page.
Broadly speaking, SQL supports three algorithms for using indexes. The first algorithm is for searching rows in which a particular value occurs. The second algorithm is for browsing through an entire table or a part of a table via an ordered column. Finally, the third algorithm is used if several values of a column must be retrieved. We illustrate these algorithms with three examples. The first example is of how SQL uses the index to select particular rows.
Example 20.1. Imagine that all rows with player number 44 must be found.
Look for the root of the index. This root becomes the active node.
Is the active node a leaf page? If so, continue with step 4. If not, continue with step 3.
Does the active node contain the value
44? If so, the node to which this value points becomes the active node; go back to step 2. If not, choose the lowest value that is greater than44in the active node. The node to which this value points becomes the active node; go back to step 2.Look for the value
44in the active node. Now this value points to all pages in which rows of thePLAYERStable appear where the value of thePLAYERNOcolumn is44. Retrieve all these pages from the database for further processing.Find for each page the row where the value
PLAYERNOcolumn is equal to44.
Without browsing through all the rows, SQL has found the desired row(s). In most cases, the time spent answering this type of question can be reduced considerably if SQL can use an index.
In the next example, SQL uses the index to retrieve ordered rows from a table.
Example 20.2. Get all players ordered by player number.
Look for the leaf page with the lowest value. This leaf page becomes the active node.
Retrieve all pages to which the values in the active node are pointing for further processing.
If there is a subsequent leaf page, make this the active node and continue with step 2.
The disadvantage of this method is that if players are retrieved from disk, there is a good chance that a page must be fetched several times. For example, the second page in Figure 20.2 must be fetched first to retrieve player 2. Next, the first page is needed for player 6, then the third page for player 7, and finally the fourth page for player 8. So far, there is no problem. However, if player 27 is to be retrieved next, the second page must be retrieved from disk again. Meanwhile, many other pages have been fetched, and because of that, the odds are that the second page is no longer in internal memory and, therefore, cannot be read again. The conclusion is that because the rows were not ordered in the file, many pages must be fetched several times, and that does not exactly improve the processing time.
To speed up this process, most products support clustered indexes. Figure 20.3 contains an example. With a clustered index, the sequence of the rows in the file is determined by the index, and this can improve the execution time for the sorting process considerably. If we now retrieve the players from the file in an ordered way, each page will be fetched only once. SQL understands that when player 6 is retrieved, the correct page is already in the internal memory; the retrieval of player 2 caused this. The same applies to player 7.
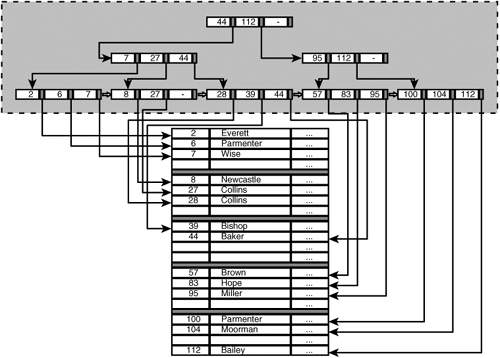
Clustered indexes offer no additional advantages for direct access (the first algorithm) to rows. Working with this index form is recommended when you want to retrieve ordered rows often.
The third algorithm is a combination of the first two.
Example 20.3. Get all players with number 39 up to and including 95.
Look for the root of the index. This root becomes the active node.
Is the active node a leaf page? If so, continue with step 4. If not, continue with step 3.
Does the active node contain the value
39? If so, the node to which this value points becomes the active node; go back to step 2. If not, choose the lowest value that is greater than39in the active node. The node to which this value points becomes the active node; go back to step 2.In the active node, retrieve all rows that belong to the values between
39and95. If95appears in this node, you are ready. Otherwise, continue with the following step.If there is a subsequent leaf page, make this the active node and continue with step 5.
This algorithm can be useful when a SELECT statement contains conditions in which, for example, BETWEEN, a greater than operator, or certain LIKE operators occur.
Here are some remarks concerning indexes:
If values in a table are updated, or if rows are added or deleted, SQL automatically updates the index. So, the index tree is always consistent with the contents of the table.
In the previous table, an index was defined on the
PLAYERNOcolumn of thePLAYERStable. This is the primary key of this table and contains no duplicate values. An index can also be defined on a nonunique column, such as theNAMEcolumn. The result of this is that one value in a leaf page points to multiple rows—one pointer for each row in which the value occurs.It is possible to define many indexes on a table, but because a clustered index affects the way in which rows are stored, each table may contain only one clustered index.
Indexes can also be defined on combinations of values. Those are called composite indexes. Each value in a node is then a concatenation of the individual values. The leaf pages point to rows in which that combination of values appears.
Several other important observations can be made about the use of indexes. The two most important are these:
Nodes of an index are just like rows in a table, stored in files. Therefore, an index takes up physical storage space (just like an index in a book).
Updates to tables can lead to updates to indexes. When an index must be updated, SQL tries, where it can, to fill the gaps in the nodes to complete the process as quickly as possible; however, an index can become so “full” that new nodes must be added. This can necessitate a total reorganization of the index which can be very time-consuming.
Several types of indexes exist. In this section, we discussed what is called the B-tree index. The letter B stands for “balanced.” A characteristic feature of a B-tree index is that all the branches of the tree have roughly the same length. Later in this chapter, we describe other types of index.
As we already mentioned, this section presents a very simplified picture of the workings of an index. In practice, for example, a node in an index tree can accommodate not just three, but many values. For a more detailed description of indexes, see [DATE95].
Chapter 5, “SELECT Statement: Common Elements,” described which clauses are executed successively during the processing of a SELECT statement. These clauses form a basic strategy for processing a statement. In a basic strategy, we assume sequential access to the data. This section discusses how the use of an index can change the basic strategy to an optimized strategy.
SQL tries to choose the most efficient strategy for processing each statement. This analysis is performed by a module within SQL, called the optimizer. (The analysis of statements is also referred to as query optimization.) The optimizer defines a number of alternative strategies for each statement. It estimates which strategy is likely to be the most efficient, based upon factors such as the expected execution time, the number of rows, and the presence of indexes. (In the absence of indexes, this can be the basic strategy.) SQL then executes the statement according to its chosen strategy.
Following are some examples to show what optimized processing strategies can look like.
Example 20.4. Get all information about player 44. (We assume that there is an index defined on the PLAYERNO column.)
SELECT * FROM PLAYERS WHERE PLAYERNO = 44
The FROM clause: Usually, all rows would be retrieved from the PLAYERS table. Speeding up the processing by using an index means that only the rows in which the value in the PLAYERNO column is 44 are fetched.
The intermediate result is:
PLAYERNO NAME ...
-------- ----- ---
44 Baker ...
The WHERE clause: In this example, this clause was processed simultaneously with the FROM clause.
The SELECT clause: All columns are presented.
The difference between the basic strategy and this “optimized” strategy can be represented in another way.
The basic strategy is:
RESULT := [];
FOR EACH P IN PLAYERS DO
IF P.PLAYERNO = 44 THEN
RESULT :+ P;
ENDFOR;
The optimized strategy is:
RESULT := []; FOR EACH P IN PLAYERS WHERE PLAYERNO = 44 DO RESULT :+ P; ENDFOR;
With the first strategy, all rows are fetched by the FOR EACH statement. The second strategy works much more selectively. When an index is used, only those rows in which the player number is 44 are retrieved.
Example 20.5. Get the player number and town of each player whose number is less than 10 and who lives in Stratford; order the result by player number.
SELECT PLAYERNO, TOWN FROM PLAYERS WHERE PLAYERNO < 10 AND TOWN = 'Stratford' ORDER BY PLAYERNO
The FROM clause: Fetch all rows where the player number is less than 10. Again, use the index on the PLAYERNO column. Fetch the rows in ascending order, thus accounting for the ORDER BY clause. This is simple because the values in an index are always ordered.
The intermediate result is:
PLAYERNO ... TOWN ...
-------- --- --------- ---
2 ... Stratford ...
6 ... Stratford ...
7 ... Stratford ...
8 ... Inglewood ...
The WHERE clause: The WHERE clause specifies two conditions. Each row in the intermediate result satisfies the first condition, which has already been evaluated in the FROM clause. Now, only the second condition must be evaluated.
PLAYERNO ... TOWN ...
-------- --- --------- ---
2 ... Stratford ...
6 ... Stratford ...
7 ... Stratford ...
The SELECT clause: Two columns are selected.
The intermediate result is:
PLAYERNO TOWN
-------- ---------
2 Stratford
6 Stratford
7 Stratford
The ORDER BY clause: Because of the use of an index during the processing of the FROM clause, no extra sorting needs to be done. The end result, then, is the same as the last intermediate result shown.
Next, we show the basic strategy and the optimized strategy for this example.
The basic strategy is:
RESULT := [];
FOR EACH P IN PLAYERS DO
IF (P.PLAYERNO < 10)
AND (P.TOWN = 'Stratford') THEN
RESULT :+ P;
ENDFOR;
The optimized strategy is:
RESULT := [];
FOR EACH P IN PLAYERS WHERE PLAYERNO < 10 DO
IF P.TOWN = 'Stratford' THEN
RESULT :+ P;
ENDFOR;
Example 20.6. Get the name and initials of each player who lives in the same town as player 44.
SELECT NAME, INITIALS
FROM PLAYERS
WHERE TOWN =
(SELECT TOWN
FROM PLAYERS
WHERE PLAYERNO = 44)
Here are both strategies.
The basic strategy is:
RESULT := [];
FOR EACH P IN PLAYERS DO
HELP := FALSE;
FOR EACH P44 IN PLAYERS DO
IF (P44.TOWN = P.TOWN)
AND (P44.PLAYERNO = 44) THEN
HELP := TRUE;
ENDFOR;
IF HELP = TRUE THEN
RESULT :+ P;
ENDFOR;
The optimized strategy is:
RESULT := []; FIND P44 IN PLAYERS WHERE PLAYERNO = 44; FOR EACH P IN PLAYERS WHERE TOWN = P44.TOWN DO RESULT :+ P; ENDFOR;
These were three relatively simple examples. As the statements become more complex, it also becomes more difficult for SQL to determine the optimal strategy. This, of course, also adds to the processing time. There is a noticeable quality difference among the optimizers of the various SQL products. Some SQL products have reasonably good optimizers, but others seldom find an optimal strategy and choose the basic strategy.
If you want to know more about the optimization of SELECT statements, see [KIM85]. However, you do not actually need this knowledge to understand SQL statements, which is why we have given only a summary of the topic.
The definition of the CREATE INDEX statement is as follows:
<create index statement> ::=
CREATE <index type> INDEX <index name>
ON <table specification>
( <column in index> [ { , <column in index> }..
|
Example 20.7. Create an index on the POSTCODE column of the PLAYERS table.
CREATE INDEX PLAY_PC ON PLAYERS (POSTCODE ASC)
Explanation: In this example, a nonunique index is created (correctly). The inclusion of ASC or DESC indicates whether the index should be built in ascending (ASC) or descending (DESC) order. If neither is specified, SQL takes ASC as its default. If a certain column in a SELECT statement is sorted in descending order, processing is quicker if a descending-order index is defined on that column.
Example 20.8. Create a compound index on the columns WON and LOST of the MATCHES table.
CREATE INDEX MAT_WL ON MATCHES (WON, LOST)
Explanation: Multiple columns may be included in the definition of index, as long as they all belong to the same table.
Example 20.9. Create a unique index on the columns NAME and INITIALS of the PLAYERS table.
CREATE UNIQUE INDEX NAMEINIT ON PLAYERS (NAME, INITIALS)
Explanation: After this statement has been entered, SQL prevents two equal combinations of name and initials from being inserted into the PLAYERS table. The same could have been achieved by defining the column combination as alternate key.
Portability
For some SQL products, a column on which a unique index has been defined can contain one NULL value at the most, whereas a column with a nonunique index can contain multiple NULL values.
Example 20.10. Create a clustered and unique index on the PLAYERNO column of the PLAYERS table:
CREATE UNIQUE CLUSTERED INDEX PLAYERS_CLUSTERED ON PLAYERS (PLAYERNO)
Explanation: After this statement has been entered, the index makes sure that rows are recorded on hard disk in an ordered way; see the explanation of Example 20.1.
It should be noted that MySQL does not support clustered indexes.
Indexes can be created at any time. You do not have to create all the indexes for a table right after the CREATE TABLE statement. You can also create indexes on tables that already have data in them. Obviously, creating a unique index on a table in which the column concerned already contains duplicate values is not possible. SQL notes this and does not create the index. The user has to remove the duplicate values first. The following SELECT statement helps locate the duplicate C values (C is the column on which the index must be defined):
SELECT C FROM T GROUP BY C HAVING COUNT(*) > 1
Indexes can also be entered with an ALTER TABLE statement; see the following definition.
<alter table statement> ::= ALTER TABLE <table specification> <table |
The DROP INDEX statement is used to remove indexes.
<drop index statement> ::= DROP INDEX <index name> |
Example 20.12. Remove the three indexes that have been defined in the previous examples.
DROP INDEX PLAY_PC DROP INDEX MAT_WL DROP INDEX NAMEINIT
Explanation: When you drop an index, the index type is not mentioned. In other words, you cannot specify the words UNIQUE and CLUSTERED.
Many SQL products (including MySQL) create a unique index automatically if a primary or alternate key is included within a CREATE TABLE statement. The name of the index is determined by the SQL product itself.
Example 20.13. Create the T1 table with one primary key and three alternate keys.
CREATE TABLE T1
(COL1 INTEGER NOT NULL,
COL2 DATE NOT NULL UNIQUE,
COL3 INTEGER NOT NULL,
COL4 INTEGER NOT NULL,
PRIMARY KEY (COL1, COL4),
UNIQUE (COL3, COL4),
UNIQUE (COL3, COL1) )
After the table has been created, SQL executes the following CREATE INDEX statements behind the scenes:
CREATE UNIQUE INDEX "PRIMARY" USING BTREE ON T1 (COL1, COL4) CREATE UNIQUE INDEX COL2 USING BTREE ON T1 (COL2) CREATE UNIQUE INDEX COL3 USING BTREE ON T1 (COL3, COL4) CREATE UNIQUE INDEX COL3_2 USING BTREE ON T1 (COL3, COL1)
Be sure that the name PRIMARY is placed between double quotes because it is a reserved word.
In the next sections, as well as in other chapters, we use a special version of the PLAYERS table. This new table contains the same columns as the original PLAYERS table. The difference, however, is that that table might hold thousands of rows and not just 14. That is why the table is called PLAYERS_XXL.
The original PLAYERS table contains normal values, such as Inglewood and Parmenter. The PLAYERS_XXL table contains artificially created data. The POSTCODE column, for example, contains values such as p4 and p25, and the STREET column contains values as street164 and street83. The following sections show how this big table can be created and filled.
Example 20.14. Create the PLAYERS_XXL table.
CREATE TABLE PLAYERS_XXL
(PLAYERNO INTEGER NOT NULL PRIMARY KEY,
NAME CHAR(15) NOT NULL,
INITIALS CHAR(3) NOT NULL,
BIRTH_DATE DATE,
SEX CHAR(1) NOT NULL,
JOINED SMALLINT NOT NULL,
STREET VARCHAR(30) NOT NULL,
HOUSENO CHAR(4),
POSTCODE CHAR(6),
TOWN VARCHAR(30) NOT NULL,
PHONENO CHAR(13),
LEAGUENO CHAR(4))
Example 20.15. Create the stored procedure FILL_PLAYERS_XXL next.
CREATE PROCEDURE FILL_PLAYERS_XXL
(IN NUMBER_PLAYERS INTEGER)
BEGIN
DECLARE COUNTER INTEGER;
TRUNCATE TABLE PLAYERS_XXL;
COMMIT WORK;
SET COUNTER = 1;
WHILE COUNTER <= NUMBER_PLAYERS DO
INSERT INTO PLAYERS_XXL VALUES(
COUNTER,
CONCAT('name',CAST(COUNTER AS CHAR(10))),
CASE MOD(COUNTER,2) WHEN 0 THEN 'vl1' ELSE 'vl2' END,
DATE('1960-01-01') + INTERVAL (MOD(COUNTER,300)) MONTH,
CASE MOD(COUNTER,20) WHEN 0 THEN 'F' ELSE 'M' END,
1980 + MOD(COUNTER,20),
CONCAT('street',CAST(COUNTER /10 AS UNSIGNED INTEGER)),
CAST(CAST(COUNTER /10 AS UNSIGNED INTEGER)+1 AS CHAR(4)),
CONCAT('p',MOD(COUNTER,50)),
CONCAT('town',MOD(COUNTER,10)),
'070-6868689',
CASE MOD(COUNTER,3) WHEN 0 THEN '0' ELSE COUNTER END);
IF MOD(COUNTER,1000) = 0 THEN
COMMIT WORK;
END IF;
SET COUNTER = COUNTER + 1;
END WHILE;
COMMIT WORK;
UPDATE PLAYERS_XXL SET LEAGUENO = NULL WHERE LEAGUENO = '0';
COMMIT WORK;
END
Explanation. After this stored procedure has been created, the table is not yet filled.
Explanation: With this statement, the PLAYERS_XXL table is filled with 100,000 rows. The stored procedure begins with emptying the table completely. After that, as many rows as specified in the CALL statement will be added.
To be absolutely sure that inefficient processing of SELECT statements is not due to the absence of an index, you could create an index on every column and combination of columns. If you intend to enter only SELECT statements against the data, this could well be a good approach. However, such a solution raises a number of problems; not least is the cost of index storage space. Another important disadvantage is that each update (INSERT, UPDATE, or DELETE statement) requires a corresponding index update and reduces the processing speed. So, a choice has to be made. We discuss some guidelines next.
In CREATE TABLE statements, we can specify primary and alternate keys. The result is that the relevant column(s) will never contain duplicate values. It is recommended that an index be defined on each candidate key so that the uniqueness of new values can be checked quickly. In fact, as mentioned in Section 20.7, SQL automatically creates a unique index for each candidate key.
Joins can take a long time to execute if there are no indexes defined on the join columns. For a large percentage of joins, the join columns are also keys of the tables concerned. They can be primary and alternate keys, but they may also be foreign keys. According to the first rule of thumb, you should define an index on the primary and alternate key columns. What remains now are indexes on foreign keys.
In some cases, SELECT, UPDATE, and DELETE statements can be executed faster if an index has been defined on the columns named in the WHERE clause.
Example:
SELECT * FROM PLAYERS WHERE TOWN = 'Stratford'
Rows are selected on the basis of the value in the TOWN column, and processing this statement could be more efficient if there were an index on this column. This was discussed extensively in the earlier sections of this chapter.
An index is worthwhile not just when the = operator is used, but also for <, <=, >, and >=. (Note that the <> operator does not appear in this list.) However, this gains time only when the number of rows selected is a small percentage of the number of rows in the table.
This section started with “In some cases.” So, when is it necessary to define an index, and when is it not? This depends on several factors, of which the most important are the number of rows in the table (or the cardinality of the table), the number of different values in the column concerned (or the cardinality of the column), and the distribution of values within the column. We explain these rules and illustrate them with some figures resulting from a test performed with SQL.
This test uses the PLAYERS_XXL table; see the previous section. The results of the tests are represented in three diagrams; see Figure 20.4. Diagrams (a), (b), and (c) contain the processing times of the following SELECT statements, respectively:
SELECT COUNT(*) FROM PLAYERS_XXL WHERE INITIALS = 'in1' SELECT COUNT(*) FROM PLAYERS_XXL WHERE POSTCODE = 'p25' SELECT COUNT(*) FROM PLAYERS_XXL WHERE STREET = 'street164'
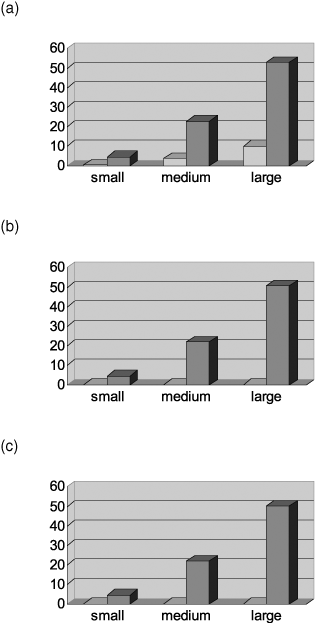
Each SELECT statement has been executed on the PLAYERS_XXL table with three different sizes: small (100,000 rows), medium (500,000 rows), and large (1,000,000 rows). Each statement has also been executed with (light gray bars) and without (dark gray bars) an index. Each of the three statements was run in six different environments. To give reliable figures, each statement was run several times in each environment, and the average processing speed is shown in seconds in the diagrams.
It is important to know that the INITIALS column contains only two different values, in1 and in2; the POSTCODE column contains 50 different values; and, finally, in the STREET column, every value occurs ten times at the most. All this means that the first SELECT statement contains a condition on a column with a low cardinality, the third statement has a condition on a column with a high cardinality, and the second statement has a condition on a column with an average cardinality.
The following rules can be derived from the results. First, all three diagrams show that the larger the table is, the bigger the impact of the index is. Of course, we can define an index on a table consisting of 20 rows, but the effect will be minimal. Whether a table is large enough for it to be worth defining an index depends entirely on the system on which the application runs. You have to try for yourself.
Second, the diagrams show that the effect of an index on a column with a low cardinality (so few different values) is minimal; see diagram (a) in Figure 20.4. As the table becomes larger, the processing speed starts to improve somewhat, but it remains minimal. For the third statement with a condition on the STREET column, the opposite applies. Here, the presence of an index has a major impact on the processing speed. Moreover, as the database gets larger, that difference becomes more apparent. Diagram (b) in Figure 20.4 confirms the results for a table with an average cardinality.
The third factor that is significant in deciding whether you will define an index is the distribution of the values within a column. In the previous statements, each column concerned had an equal distribution of values. Each value occurred just as many times within the column. What if that is not the case? Figure 20.5 shows the results of the following two statements:
SELECT COUNT(*) FROM PLAYERS_XXL WHERE SEX = 'M' SELECT COUNT(*) FROM PLAYERS_XXL WHERE SEX = 'F'
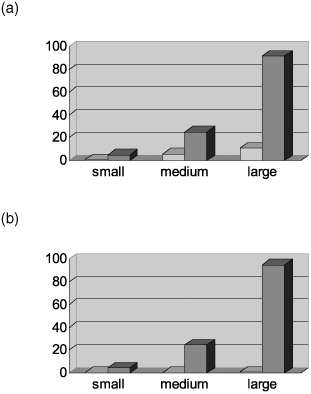
For these tests, the division of the values in the SEX column were as follows: The M value was present in 95% of the rows, and the F value in 5%. This is an extreme example of a nonequal distribution and indicates the difference clearly. In diagram (a) in Figure 20.5, we can see that the impact of the index is minimal, while the impact in diagram (b) in that figure is large. If an index is defined, counting all women in the large PLAYERS table is carried out approximately 180 times faster.
If a WHERE clause contains an AND operator, an index is usually defined on the combination of columns to ensure a more efficient processing.
Example:
SELECT * FROM PLAYERS WHERE NAME = 'Collins' AND INITIALS = 'DD'
CREATE INDEX NAMEINIT ON PLAYERS (NAME, INITIALS)
In some cases, when you are executing such a SELECT statement, it can suffice to have an index on only one of the columns. Imagine that duplicate names seldom occur in the NAME column and that this is the only column with an index. Usually, SQL will find all the rows that satisfy the condition NAME = 'Collins' by using this index. Only infrequently will it retrieve a few too many rows. In this case, an index on the combination of columns will take up more storage space than necessary and will not significantly improve the processing of the SELECT statement.
Indexes defined on combinations of columns are also used for selections in which only the first column (or columns) of the index are specified. Therefore, SQL uses the previous NAMEINIT index to process the condition NAME = 'Collins' but not for INITIALS = 'DD' because the INITIALS column is not the first one in the NAMEINIT index.
If SQL needs to sort the result of a SELECT statement by a column that has no index, a separate (time-consuming) sort process must be performed. This extra sorting can be avoided if you define a clustered index on the relevant column. When the rows are fetched from the database (with the FROM clause), this index can be used. The intermediate result from the FROM clause is already ordered by the correct column. After that, no extra sorting is necessary. This rule is valid only if the column concerned does not contain many NULL values (because NULL values are not stored in an index), and if the SELECT statement does not have a WHERE clause with a condition that can be optimized.
When exactly does SQL perform a sort? If you add an ORDER BY clause to a SELECT statement, there is a good chance that SQL performs a sort. In addition, when columns are to be grouped (with the GROUP BY clause), all the rows must be sorted first. SQL can process a GROUP BY clause more quickly when the rows are already ordered. If you use DISTINCT in the SELECT clause, all rows must be ordered (behind the scenes) to determine whether they are equal. Therefore, the order rule is again applicable: SQL can process DISTINCT more quickly when the rows are already ordered.
Finally, note that it naturally makes little sense to define two indexes on the same column or combination of columns. Therefore, consult the COLUMNS_IN_INDEX table to check whether an index has already been defined on a column or on a combination of columns.
For a long time, SQL products supported only the B-tree index form, as described in previous sections. Other index forms have now been added, mainly because of the increasing popularity of data warehousing (see Section 1.8, in Chapter 1, “Introduction to SQL”). In this section, we discuss five types: the multitable index, the virtual column index, the selective index, the hash index, and the bitmap index.
Portability
Not all SQL products support these new index forms. MySQL, for example, does not; therefore, it is not possible to try them with this product. The products that do support them have all implemented different syntaxes. That is why we use an imaginary syntax in the examples.
In the previous sections, an index could be defined only on columns of the same table. For multitable indexes (also called join indexes), this restriction does not apply. This type of index enables you to define an index on columns of two or more tables.
Example 20.18. Create a multitable index on the PLAYERNO columns of the PLAYERS and MATCHES table.
CREATE INDEX PLAY_MAT ON PLAYERS(PLAYERNO), MATCHES(PLAYERNO)
The advantage of this multitable index is that if the two tables are linked with a join to PLAYERNO, this join can be processed very quickly. This is the main reason why this type of index has been added. Try to imagine that the pointers point from a player number (in the index) to multiple rows in different tables.
The index tree that is built for a multitable index is still a B-tree. The only difference is what is stored in the leaf pages.
The second type that we discuss here is the virtual column index. This type of index defines an index not on an entire column, but on an expression.
Example 20.19. Create a virtual column index on the result of the expression (WON – LOST)/2 in the MATCHES table.
CREATE INDEX MAT_HALFBALANCE ON MATCHES((WON – LOST)/2)
Explanation. Instead of storing the values of the columns in the index tree, first the expression is calculated for each row of the table, and the results are recorded in the index tree. The values in the index tree point to the rows in which the result of the expression is equal to that value. Certain restrictions apply to the expression that may be used in the index definition. For example, aggregation functions and subqueries are not permitted.
The main advantage of this index is the improvement of the processing speed of statements in which the relevant expression in the WHERE clause is used. The index MAT_HALFBALANCE increases the performance of this SELECT statement.
SELECT * FROM MATCHES WHERE (WON – LOST)/2 > 1
The index tree of a virtual column index also has the structure of a B-tree. The main difference is that none of the values stored in the index tree is a value that occurs in the table itself.
For a selective index, only some of the rows are indexed, in contrast to a “normal” B-tree index. Imagine that the MATCHES table contains one million rows and that most users are mainly interested in the data of the last two years, which makes up only 200,000 rows. All their questions contain the condition in which the date is not older than two years. However, other users need the other 800,000 rows. For indexes, the more rows there are, the larger the index tree becomes and the slower it is. So, for a large group of users, the index is unnecessarily large and slow. Selective indexes can be used to prevent this.
Example 20.20. Create a selective index on the PAYMENT_DATE column of the PENALTIES table.
CREATE INDEX PEN_PAYMENT_DATE ON PENALTIES WHERE PAYMENT_DATE > '1996-12-31'
Explanation. A WHERE clause is used to indicate which rows in the PENALTIES table need to be indexed. In this case, the optimizer must be smart enough not only to use the index for statements in which information is requested concerning penalties that were paid after 1996; it also has to access the table directly for those rows that have not been indexed.
The last three types of indexes discussed are all variations on the B-tree index. The hash index, however, has a completely different structure. This index is not based on the B-tree. However, the hash index has something in common with the B-tree index: the possibility of accessing the rows in a table directly. The main difference is that no index tree is created. Nevertheless, the term hash index is used often in the literature, and we also use this term in this book.
How does the hash index work? An important difference between the previous types of index and the hash index is that the latter must be created before the table is filled. Therefore, the table must exist but may not contain any rows. When a hash index is created, a certain amount of disk space is reserved automatically. Initially, this hash space is completely empty and will be used to store rows. The size of it is deduced from the size of the hash and is specified when the hash index is created.
Example 20.21. Create a direct-access mechanism for the PLAYERNO column in the PLAYERS table through hashing.
CREATE HASH INDEX PLAYERNO_HASH ON PLAYERS (PLAYERNO) WITH PAGES=100
Explanation: This statement puts aside a hash space of 100 pages for the PLAYERS table. In addition, it indicates that direct access to these rows will go through the PLAYERNO column.
However, the most important aspect is that, when a hash index is created, this leads to the development of a hash function. This hash function converts a player number to an address in the hash space. Here, the address is just the page number. In the previous example, the hash function converts a player number to a page number between 1 and 100. SQL does not show how this function exactly works. For most products, the core of the function is formed by a modulo function (with the number of pages as basis). This would mean that player 27 ends up in page 27, and player 12 and 112 both end up in page 12.
But how and when is this hash function used? In the first place, the function can be used to add new rows. If we add a new row with an INSERT statement, the address is calculated behind the scenes, and the row is stored in the relevant page, although we do not see or notice anything. The process becomes more interesting when we want to fetch rows. If we want to retrieve a player with a SELECT statement, the hash function will also be used. With this, the location of the appropriate row is determined (in which page). SQL immediately jumps to that page and looks for the row in the page. If the row is not present in that page, it does not occur at all in the table. This shows the power of the hash index. A hash index can be even faster than a B-tree index. A B-tree index browses through the entire index tree before the actual rows are found. The hash index allows us to jump to the row almost directly.
Although the hash index provides the fastest access for retrieving several rows from a table, it also has some disadvantages:
If the values in the hash column are distributed equally, the pages in the hash space are also filled equally. For the
PLAYERNOcolumn, we could assume that the number of a new player is always equal to that of the player who was entered last plus 1, in which case the rows are distributed equally. But what if that is not the case? Imagine that player numbers 30 to 50 are absent. Then, certain pages remain much emptier than others, and that shows a disadvantage of the hash index: If the hash function cannot distribute the rows equally over the hash space, certain pages will be very empty and others will be overcrowded. As a result, the execution time of the statements will differ considerably.The second disadvantage is, in fact, another aspect of the first one. If the pages have not been distributed equally, certain pages will not be filled correctly, which means that we are wasting storage space.
A third disadvantage is related to how the pages are filled. A page always takes maximum space, and, because of this, it can be full. What happens when the hash function returns this (full) page for another new row? Then, so-called chained pages have to be created with a pointer from the first page. The chained page can be compared to the trailer of a truck: The more chained pages there are, the slower it becomes. If we ask for a certain row, the system goes to the first page to see whether the row occurs there; if not, it looks at the chained page and maybe another chained page. If we take the comparison with the truck further, this would mean that if we were looking for a parcel, we would always look into the truck first, then in the first trailer, then the second, and so on.
What happens when the hash space is full? In that case, a new hash space must be created, and for this, all products have specific SQL statements or special programs that are easy to use. However, although these programs are easy for the user, for SQL, the enlargement of the hash space involves a lot of work; all rows must be fetched from the table, a new space must be made ready, a new hash function must be created (because there are more pages), and, finally, all rows must be placed in the hash space again. If a table contains only ten rows, this process can be performed quickly, but if there are thousands of rows, you can imagine how much time this will take. Thus, the fourth disadvantage of the hash index is that it makes the environment rather static because reorganizing the hash space is something we prefer not to do.
All the types of indexes that we have discussed so far lead to an improvement of the processing speed if the number of different values of the indexed column is not too small. The more duplicate values a column contains, the less advantages an index has. An index on the SEX column of the sample database would not add much to the processing speed of SELECT statements. For many products, the rule of thumb holds that if we are looking for 15% or more of all rows in a table, a serial browsing of the table is faster than direct access through an index. For example, if we are looking for all male players, we are looking for more than 50% of all players. In such a case, an index on the SEX column is pointless. However, browsing through an entire table could take a very long time. Therefore, several vendors have added the bitmap index to their SQL product to improve the performance.
Creating a bitmap index is very much like creating one of the previous indexes.
Example 20.22. Create a bitmap index on the SEX column of the PLAYERS table.
CREATE BITMAP INDEX PLAYERS_SEX ON PLAYERS(SEX)
The internal structure of a bitmap index cannot be compared with that of a B-tree or hash index. It falls outside the context of this book to explain this in detail. However, it is important to remember that these indexes can improve considerably the speed of SELECT statements with conditions on columns containing duplicate values. The more duplicate values a column contains, the slower the B-tree index gets and the faster the bitmap index is. A bitmap index is no use when you are looking for a few rows (or using direct access).
The bitmap index has the same disadvantages as the B-tree index: It slows the updating of data and it takes up storage space. Because the first disadvantage is the more important, bitmap indexes are seldom or never used in a transaction environment, although they are in data warehouses.
Just as with tables and columns, indexes are recorded in catalog tables. These are the INDEXES table and the COLUMNS_IN_INDEX table. The descriptions of the columns of the first table are given in Table 20.1. The columns INDEX_CREATOR and INDEX_NAME are the primary key of the INDEXES table.
Table 20.1. Columns of the INDEXES Catalog Table
DATA TYPE | DESCRIPTION | |
|---|---|---|
|
| Name of the user who created the index (in MySQL, this is the name of the data-base in which the index is created) |
|
| Name of the index |
|
| Date and time when the index is created |
|
| Owner of the table on which the index is defined |
|
| Name of the table on which the index is defined |
|
| Whether the index is unique ( |
|
| Form of the index: |
The columns on which an index is defined are recorded in a separate table, the COLUMNS_IN_INDEX table. The primary key of this table is formed by the columns INDEX_CREATOR, INDEX_NAME, and COLUMN_NAME, described in Table 20.2.
Table 20.2. Columns of the COLUMNS_IN_INDEX Catalog Table
COLUMN NAME | DATA TYPE | DESCRIPTION |
|---|---|---|
|
| Name of the user who created the index (in MySQL, this is the name of the data-base in which the index is created) |
|
| Name of the index |
|
| Owner of the table on which the index is defined |
|
| Name of the table on which the index is defined |
|
| Name of the column on which the index is defined |
|
| Sequence number of the column in the index |
|
| Has the value |
The sample indexes from this section are recorded in the INDEXES and the COLUMNS_IN_INDEX tables, as follows (we assume that all the tables and indexes are created in the TENNIS database):
INDEX_CREATOR INDEX_NAME TABLE_NAME UNIQUE_ID INDEX_TYPE ------------- ---------- ---------- --------- ---------- TENNIS PLAY_PC PLAYERS NO BTREE TENNIS MAT_WL MATCHES NO BTREE TENNIS NAMEINIT PLAYERS YES BTREE INDEX_NAME TABLE_NAME COLUMN_NAME COLUMN_SEQ ORDERING ---------- ---------- ----------- ---------- -------- PLAY_PC PLAYERS POSTCODE 1 ASC MAT_WL MATCHES WON 1 ASC MAT_WL MATCHES LOST 2 ASC NAMEINIT PLAYERS NAME 1 ASC NAMEINIT PLAYERS INITIALS 2 ASC
Example 20.23. Which base table has more than one index?
SELECT TABLE_CREATOR, TABLE_NAME, COUNT(*) FROM INDEXES GROUP BY TABLE_CREATOR, TABLE_NAME HAVING COUNT(*) > 1
Explanation: If a particular index appears more than once in the INDEXES table, it is based upon more than one base table.