
Content handlers are one of the ideas that got developers excited about Java in the first place. At the time that HotJava was created, Netscape, NCSA, Spyglass, and a few other combatants were fighting a battle over who would control the standards for web browsing. One of the battlegrounds was the ability of different browsers to handle various kinds of files. The first browsers understood only HTML. The next generation understood HTML and GIF. JPEG support was soon added. The intensity of this battle meant that new versions of browsers were released every couple of weeks. Netscape made the first attempt to break this infinite loop by introducing plug-ins in Navigator 2.0. Plug-ins are platform-dependent browser extenders written in C that add the ability to view new content types such as Adobe PDF and VRML. However, plug-ins have their drawbacks. Each new content type requires the user to download and install a new plug-in, if indeed the right plug-in is even available for the user’s platform. To keep up, users had to use huge amounts of bandwidth just to download new browsers and plug-ins, each of which would fix a few bugs and add a few new features.
The Java team saw a way around this. Their idea was to use Java to
download only the parts of the program that had to be updated rather
than the entire browser. Furthermore, when the user encountered a web
page that used a new content type, the browser could automatically
download the code that was needed to view that content type. The user
wouldn’t have to stop, ftp a plug-in, quit the browser, install
the plug-in, restart the browser, and reload the page. The mechanism
that the Java team envisioned was the content handler. Each new data
type that a web site wanted to serve would be associated with one
content handler written in Java. The content handler would be
responsible for parsing the content and displaying it to the user in
the web browser window. The abstract class that content handlers for
specific data types such as PNG or RTF would extend was
java.net.ContentHandler. James Gosling and Henry
McGilton described this scenario in 1996:
HotJava’s dynamic behavior is also used for understanding different types of objects. For example, most Web browsers can understand a small set of image formats (typically GIF, X11 pixmap, and X11 bitmap). If they see some other type, they have no way to deal with it. HotJava, on the other hand, can dynamically link the code from the host that has the image allowing it to display the new format. So, if someone invents a new compression algorithm, the inventor just has to make sure that a copy of its Java code is installed on the server that contains the images they want to publish; they don’t have to upgrade all the browsers in the world. HotJava essentially upgrades itself on the fly when it sees this new type.[28]
Unfortunately, content handlers never
really made it out of Sun’s white papers into shipping
software. The ContentHandler class still exists in
the standard library, and it has some uses in custom applications.
However, neither HotJava nor any other web browser actually uses it
to display content. When HotJava downloads an HTML page or a
bitmapped image, it handles it with hardcoded routines that process
that particular kind of data. When HotJava encounters an unknown
content type, it simply asks the user to locate a helper application
that can display the file, almost exactly as a traditional web
browser such as Netscape Navigator or Internet Explorer would do.
(Figure 17.1 demonstrates.) The promise of
dynamically extensible web browsers automatically downloading content
handlers for new data types as they encounter them was never
realized. Perhaps the biggest problem was that the
ContentHandler class was too generic, providing
too little information about what kind of object was being downloaded
and how it should be displayed.
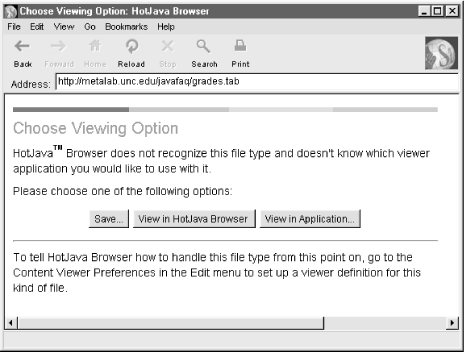
Figure 17-1. HotJava’s reaction to an unexpected content type, even though a content handler for this type is installed
Note
A much more robust and better thought-out content handler mechanism is now available under the name JavaBeans Activation Framework. This is a standard extension to Java 1.1 and later that provides the necessary API for deciding what to do with arbitrary datatypes at runtime. However, JAF has not yet been used inside web browsers or even widely adopted, though certainly that shouldn’t stop you from using it inside your own applications if you find it useful. See http://java.sun.com/beans/glasgow/jaf.html for more details.
A content handler is an instance of a subclass of
java.net.ContentHandler:
public abstract class ContentHandler extends Object
Note
The SAX2 interface for XML parsing defines a completely separate
interface named ContentHandler. This has nothing
to do with the content handlers we’re discussing in this
chapter.
This class knows how to take a URLConnection and a
MIME type and turn the data coming from the
URLConnection into a Java object of an appropriate
type. Thus, a content handler allows an applet to understand new
kinds of data. Since Java lowers the bar for writing code below
what’s needed to write a browser or a Netscape plug-in, the
theory is that many different web sites can write custom handlers,
rather than having to rely on the overworked browser
manufacturers.
Java can already download classes
from the Internet. Thus, there isn’t much magic to getting it
to download a class that can understand a new content type. A content
handler is just a .class file like any other.
The magic is all inside the web browser, which knows when and where
to request a .class file to view a new content
type. Of course, some browsers are more magical than others.
Currently, the only way to make this work in a browser is in
conjunction with an applet that knows how to request the content
handler explicitly. It can also be used—in fact, it can be used
considerably more easily—in a standalone application that
ignores browsers completely.
Specifically, a content handler reads data from a
URLConnection and constructs an object appropriate
for the content type from the data. Each subclass of
ContentHandler handles a specific MIME type and
subtype, such as text/plain or
image/gif. Thus, an image/gif
content handler returns a URLImageSource object (a
class that implements the ImageProducer
interface), while a text/plain content handler
returns a String. A database content handler might
return a java.sql.ResultSet object. An
application/x-macbinhex40 content handler might
return a BinhexDecoder object written by the same
programmer who wrote the application/x-macbinhex40
content handler.
Content handlers are intimately tied to
protocol handlers. In the previous chapter, the getContent( ) method of the URLConnection class
returned an InputStream that fed the data from the
server to the client. This works for simple protocols that return
only ASCII text, such as finger,
whois, and daytime. However,
returning an input stream doesn’t work well for protocols such
as FTP, gopher, and HTTP that can return many different content
types, many of which can’t be understood as a stream of ASCII
text. For protocols like these, getContent( )
needs to check the MIME type, and then use the
createContentHandler( )
method of the
application’s ContentHandlerFactory to
produce a matching content handler. Once a
ContentHandler exists, the
URLConnection’s getContent( ) method calls the
ContentHandler’s getContent( )
method,
which creates the Java object to be returned. Outside of the
getContent( ) method of a
URLConnection, you rarely, if ever, call any
ContentHandler method. Applications should never
call the methods of a ContentHandler directly.
Instead, they should use the getContent( ) method
of URL or URLConnection.
An object that implements the
ContentHandlerFactory
interface is respons- ible for
choosing the right ContentHandler to go with a
MIME type. A ContentHandlerFactory is installed in
a program by the static
URLConnection.setContentHandlerFactory( )
method. Only one
ContentHandlerFactory may be chosen during the
lifetime of an application. When a program starts running, there is
no ContentHandlerFactory; that is, the
ContentHandlerFactory is null.
When there is no factory, Java looks for content handler classes with
the name type.subtype, where
type is the MIME type of the content and
subtype is the MIME subtype. It looks for these
classes first in any packages named by the
java.content.handler.pkgs property, then in the
sun.net.www.content
package. The
java.content.handler.pkgs property should contain
a list of package prefixes separated from each other by a vertical
bar (|). This is similar to how Java finds protocol handlers. For
example, if the java.content.handler.pkgs property
has the value
com.macfaq.net.www.content|org.cafeaulait.content
and your program is looking for a content handler for text/xml files,
then it would first try to instantiate
com.macfaq.net.www.content.text.xml. If that
fails, it would next try to instantiate,
org.cafeaulait.content.text.xml. If that fails, as
a last resort, it would try to instantiate
sun.net.www.content.text.xml. These conventions
are also used to search for a content handler if a
ContentHandlerFactory is installed but the
createContentHandler( ) method returns
null.
To summarize, here’s the sequence of events:
A
URLobject is created that points at some Internet resource.The
URL’sgetContent( )method is called to return an object representing the contents of the resource.The
getContent( )method of theURLcalls thegetContent( )method of its underlyingURLConnection.The
URLConnectiongetContent( )methodcalls the nonpublic methodgetContentHandler( )to find a content handler for the MIME type and subtype.getContentHandler( )checks to see whether it already has a handler for this type in its cache. If it does, that handler is returned togetContent( ). Thus, browsers won’t download content handlers for common types, such as text/html, every time the user goes to a new web page.If there wasn’t an appropriate
ContentHandlerin the cache and theContentHandlerFactoryisn’t null,getContentHandler( )calls theContentHandlerFactory’screateContentHandler( )method to instantiate a newContentHandler. If this is successful, theContentHandlerobject is returned togetContent( ).If the
ContentHandlerFactoryis null orcreateContentHandler( )fails to instantiate a newContentHandler, then Java looks for a content handler class namedtype.subtype, wheretypeis the MIME type of the content andsubtypeis the MIME subtype in one of the packages named in thejava.content.handler.pkgssystem property. If a content handler is found, it is returned. Otherwise . . .Java looks for a content handler class named
sun.net.www.content.type.subtype. If it’s found, it’s returned. Otherwise,createContentHandler( )returns null.If the
ContentHandlerobject is not null, then thisContentHandler’sgetContent( )method is called. This method returns an object appropriate for the content type. If theContentHandleris null, anIOExceptionis thrown.Either the returned object or the exception is passed up the call chain, eventually reaching the method that invoked
getContent( ).
You can affect this chain of events in three ways: first, by
constructing a URL and calling its
getContent( ) method; second, by creating a new
ContentHandler subclass that getContent( ) can use; third, by installing a
ContentHandlerFactory with
URLConnection.setContentHandlerFactory( ),
changing the way the application looks for content handlers.
[28] James Gosling and Henry McGilton, The Java Language Environment, A White Paper, May 1996, http://java.sun.com/docs/white/langenv/HotJava.doc1.html.