
In the previous chapter we saw how to use the Kinect sensor skeleton tracker for providing inputs to our application. In this chapter we will explicate how to use the Kinect sensor's speech recognition capability as an additional natural interface modality in our applications. Speech recognition is a powerful interface that increases the adoption of software solutions by users with disabilities. Speech recognition can be used in working environments where the user can perform his/her job or task away from a traditional workstation.
In this chapter we will cover the following topics:
- The Kinect sensor audio stream data
- Grammars defined by XML files and programmatically
- How to manage the Kinect sensor beam and its angle
The Microsoft Kinect SDK setup process includes the installation of the speech recognition components.
The Kinect sensor is equipped with one array of four microphone devices.
The array of microphones can be handled using the code libraries released by Microsoft since Windows Vista. These libraries include Voice Capture DirectX Media Object (DMO) and the Speech Recognition API (SAPI).
In managed code, Kinect SDK v1.6 provides a wrapper extending the Voice Capture DMO. Thanks to the Voice Capture DMO, Kinect provides capabilities such as:
- Acoustic echo cancellation (AEC)
- Automatic gain control (AGC)
- Noise suppression
The Speech Recognition API is the development library that allows us to use the built-in speech recognition capabilities of the operating system while developing our custom application. These APIs can be used with or without the Kinect sensor and its SDK.
Let's understand what a speech recognition process is and how it works.
The goal of the speech recognition process is to convert vocal commands spoken by the user into actions performed by the application. The speech recognition process is executed by a speech recognizer engine that analyzes the speech input against predefined grammar.
The scope of the speech recognizer engine is to verify that the received speech input is a valid command. A valid command is one that satisfies the syntactic and semantic rules defined by grammar. A valid command recognized by the speech recognizer engine is then converted into actions that the application can execute.
Grammar defines all the rules and the logical speech statements we want to apply in our specific situations. In order to accept and process more natural speaking styles and improve the user experience, we should aim to define flexible grammars.
The grammar we use is based on the standard defined by the W3C Speech Recognition Grammar Specification Version 1.0 (SRGS). This grammar is defined using XML files. The detailed specifications of the grammar and the XML schema are published at http://www.w3.org/TR/speech-grammar.
Let's introduce a simple grammar structured as a list of rules that declares the words and/or phrases used by the speech recognition engine to analyze the speech input.
Our goal is to define a set of commands that the user can enunciate. We list all the commands as words and/or phrases in the grammar file. The speech engine is going to analyze the Kinect sensor audio stream data and map them against the commands list. Once a given command is recognized with sufficient confidence, we then execute the action associated to the command.
The following XML file defines the rules of our simple grammar. The grammar is implemented using two distinct semantic categories: UP and DOWN. Within any single category we can define one or more as synonymous using the <item> node (for example, up, move up, and tilt up are all synonymous and the speech engine treats them in the same way):
<grammar version="1.0" xml:lang="en-US" root="rootRule" tag-format="semantics/1.0-literals" xmlns="http://www.w3.org/2001/06/grammar">
<rule id="rootRule">
<one-of>
<item>
<tag>UP</tag>
<one-of>
<item> up </item>
<item> move up </item>
<item> tilt up </item>
</one-of>
</item>
<item>
<tag>DOWN</tag>
<one-of>
<item> down </item>
<item> move down </item>
<item> tilt down </item>
</one-o>
</item>
</one-of>
</rule>
</grammar>Note
Instead of using an XML file, we could create grammar programmatically as demonstrated in the following code snippet:
var commands = new Choices();
commands.Add(new SemanticResultValue("up", "UP"));
commands.Add(new SemanticResultValue("move up", "UP"));
commands.Add(new SemanticResultValue("tilt up", "UP"));
commands.Add(new SemanticResultValue("down", "DOWN"));
// etc.
var gb = new GrammarBuilder { Culture = ri.Culture };
gb.Append(commands);
var g = new Grammar(gb);The grammar can be amended programmatically too. We may decide to change the grammar while our application is running.
There are scenarios where we could use rules and semantic definitions to organize grammar's content into logical groupings. This approach is very useful for decreasing the amount of information to be processed. For instance, we could imagine a video game where we need to add or remove words and/or phases per each specific stage or level of the video game.
We can load the grammar invoking the constructor of the Microsoft.Speech.Recognition.Grammar class.
It is possible to load (or unload) simultaneously more than one grammar set in a given speech recognition engine. (Using the SpeechRecognitionEngine.UnloadAllGrammar() method we can unload all the grammar sets currently associated to our speech recognition engine).
Even though we could find various similarities between the System.Speech library and the Microsoft.Speech one, we need to use the latter one as it is optimized for the Kinect sensor. Having said that, it is worth noticing that the Microsoft.Speech library's recognition engine doesn't support DictationGrammar (dictation model), which is instead supported in System.Speech.
Once we have defined the grammar, we can load the same in our speech recognizer engine. Then we need to handle the
SpeechRecognized event (raised when the speech input has been recognized against one of the semantic categories defined in the grammar) and the SpeechRecognizedRejected event (raised when the speech input cannot be recognized against any of the semantic categories).
The following code snippet demonstrates how we initialize the speech recognizer engine. The speech recognizer engine needs to be initialized after streaming data from the Kinect sensor has been started.
For simplicity, we do not report here all the code for starting the Kinect sensor, as it is the same discussed in the previous chapters. Having said that, the source code attached to this chapter includes all the full functioning initialization code.
Let's review the standard approach published by Microsoft at http://msdn.microsoft.com/en-us/library/jj131035.aspx for managing speech recognition.
The instance of the SpeechRecognitionEngine class is obtained thanks to the RecognizerInfo class. The RecognizerInfo class provides information about a SpeechRecognizer or SpeechRecognitionEngine instance. In order to retrieve all the information associated to the Kinect sensor recognizer, we create the
RecognizerInfo class instance calling the GetKinectRecognizer method (detailed in the second code snippet):
RecognizerInfo ri = GetKinectRecognizer();
if (null != ri){
this.speechEngine = new SpeechRecognitionEngine(ri.Id);
using (var memoryStream =
new MemoryStream(
Encoding.ASCII.GetBytes(Properties.Resources.SpeechGrammar)))
{
var g = new Grammar(memoryStream);
speechEngine.LoadGrammar(g);
}
speechEngine.SpeechRecognized += SpeechRecognized;
speechEngine.SpeechRecognitionRejected += SpeechRejected;
speechEngine.SetInputToAudioStream(
sensor.AudioSource.Start(),
new SpeechAudioFormatInfo
(EncodingFormat.Pcm, 16000, 16, 1, 32000, 2, null));
speechEngine.RecognizeAsync(RecognizeMode.Multiple);
}
else
{
//TO DO WHEN NO SPEECH RECOGNIZED
}
}The GetKinectRecognizer method
retrieves the speech recognizer engine parameters that better suit the Kinect sensor audio stream data. The optimal speech recognition engine for the Kinect sensor is obtained from the SpeechRecognitionEngine.InstalledRecognizers() collection of speech recognizer engines available on our machine:
private static RecognizerInfo GetKinectRecognizer()
{
foreach (RecognizerInfo recognizer in SpeechRecognitionEngine.InstalledRecognizers())
{
string value;
recognizer.AdditionalInfo.TryGetValue("Kinect", out value);
if ("True".Equals(value, StringComparison.OrdinalIgnoreCase) && "en-US".Equals(recognizer.Culture.Name, StringComparison.OrdinalIgnoreCase))
{
return recognizer;
}
}
return null;
}The SpeechRecognitionEngine.SetInputToAudioStream method contained in the Microsoft.Speech.Recognition namespace assigns the Kinect Sensor audio stream using sensor.AudioSource.Start() as the input for the current speech recognizer engine instance.
The parameters' values used in our example for setting SpeechAudioFormatInfo are as follows:
The speech recognition can be performed both synchronously and asynchronously. The RecognizeAysnc method is for async recognition, where you need an application to be responsive while the speech recognition engine is performing its job. The Recognize method is for sync operations and can be used when the responsiveness of the application is not a concern.
Note
The RecognizeMode enum value can be set to either Single or Multiple. The value Single ensures the speech recognizer engine performs only a single operation; whereas setting the value to Multiple will have the recognition to continue to recognize and will not terminate after completion of one speech recognition. In our example, the language and culture used is English en-US. The Kinect sensor supports additional acoustic allowing speech recognition in several locales such as en-GB, en-IE, en-AU, en-NZ, en-CA, French fr-FR, fr-CA, Germany de-DE, and Italian it-IT. The complete list and all the related components—packaged individually—are available at http://www.microsoft.com/en-us/download/details.aspx?id=34809.
For utilizing a different language we need to change the en-US value in the GetKinectRecognizer method and the grammar file. Please note that this setting is detached from the globalization setting defined at operating system level.
The SpeechRecognized event handler handles the result of the speech input analysis and its level of confidence. The SpeechRecognizedEventArgs event argument provides the outcome of the speech recognition through the RecognictionResult Result property.
By testing the SpeechRecognizedEventArgs.Result.Semantics.Value value and assessing SpeechRecognizedEventArgs.Result.Confidence, we can perform the appropriate actions and execute the commands specified in the grammar.
We have to notice that the value of the SpeechRecognizedEventArgs.Result.Confidence property provides the level of confidence the speech bestows on the computed result. The case of Confidence = 1 (100 percent) indicates that the engine is completely confident of what was spoken. On the other end, the case of Confidence = 0 (0 percent), the engine completely lacks confidence.
While performing our example we were in an environment where we could assume a low level of accuracy. For this reason we defined a threshold of 30 percent (0.3). In case we obtain a confidence value lower than the threshold, we reject the result.
It is clear that the threshold is critical to define the level of confidence required to accept the speech recognition process' result. Identifying the right threshold value is a mindful decision we need to take, trading-off elements such as the type of application (its criticality), as well as the environment where the Kinect sensor is operating.
private void SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
// Speech utterance confidence below which we treat speech as if it hadn't been heard
const double ConfidenceThreshold = 0.3;
if (e.Result.Confidence >= ConfidenceThreshold)
{
switch (e.Result.Semantics.Value.ToString())
{
case "UP":
tbRecognizer.Text = "Recognized 'UP' @ " + e.Result.Confidence;
//we increase the kinect elevation angle of 2 degree
this.sensor.ElevationAngle = (int)(Math.Atan(previousAccelerometerData.Z / previousAccelerometerData.Y) * (180 / Math.PI) + 2);
break;
case "DOWN":
tbRecognizer.Text = "Recognized 'DOWN' @ " + e.Result.Confidence;
//we decrease the kinect elevation angle of 2 degree
this.sensor.ElevationAngle = (int)(Math.Atan(previousAccelerometerData.Z / previousAccelerometerData.Y) * (180 / Math.PI) - 2);;
break;
} }}The previous code snippet details our SpeechRecognized event handler implementation. We perform the commands related to the matched grammar semantic if and only if the confidence provided by the speech recognizer engine is above the 0.3 threshold value.
We will notice that we do not need to test all the grammar entries, but instead focus on the semantic categories only. The entire related synonyms are handled by the speech recognition engine itself as a whole:
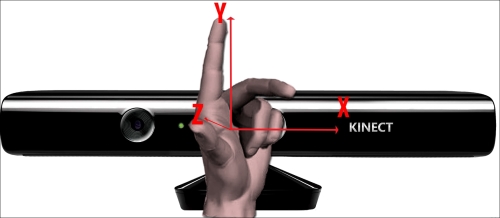
The orientation axis of the Kinect sensor's accelerometer
In our example we attach to the UP and DOWN commands to actions we want to perform against the Kinect sensor
accelerometer. The Kinect for Windows Sensor is equipped with a 3-axis accelerometer configured for a 2g range, where g is the acceleration due to gravity. The axis' orientation is highlighted in the previous image. The accelerometer enables the sensor to report its current orientation computed with respect to gravity.
Testing the accelerometer data can help us to detect when the sensor is in an unusual orientation. We may be able to use the angle between the sensor and the floor plane and adjust the 3D projection's data in augmented reality scenarios. The accelerometer has a lower limit of 1 degree accuracy. In addition, the accuracy is slightly temperature-sensitive, with up to 3 degrees of drift over the normal operating temperature range. This drift can be positive or negative, but a given sensor will always exhibit the same drift behavior. It is possible to compensate for this drift by comparing the accelerometer's vertical data (the y axis in the accelerometer's coordinate system) and the detected floor plane depth data, if required.
We can control programmatically the Kinect sensor's field of view using the tilt motor in the sensor. The motor can vary the orientation of the Kinect sensor with an angle of +/-27 degrees. The tilt is relative to gravity rather than relative to the sensor base. An elevation angle of zero indicates that the Kinect is pointing perpendicular to gravity.
In our example we combine three different Kinect sensor capabilities to simulate a complex scenario:
- Speech recognition enables us to issue commands to the Kinect sensor using voice as natural interface—this is demonstrated by the semantics
UPandDOWNin ourSpeechRecognizedevent handler implementation. - The Kinect sensor's accelerator provides the current value for the elevation angle of the tilt monitor. The following formula computes the current elevation angle:
Math.Atan(previousAccelerometerData.Z / previousAccelerometerData.Y) * (180 / Math.PI)Where:
- We adjust the Kinect sensor's orientation using the
KinectSensor.ElevationAngleproperty.
Note
At the time of writing this book, the KinectSensor.ElevationAngle getter had a bug, and it would raise a system exception every time we tried to access it. Hence, to increase (decrease) the Kinect sensor's elevation angle, it is not possible to use the the simple statement KinectSensor.ElevationAngle += value.
In addition to the SpeechRecognized event handler implementation, we recommend to implement the SpeechRejected event handler too, and provide the relevant feedback that the recognition has been rejected:
/// <summary>
/// Handler for rejected speech events.
/// </summary>
/// <param name="sender">object sending the event.</param>
/// <param name="e">event arguments.</param>
private void SpeechRejected(object sender, SpeechRecognitionRejectedEventArgs e)
{
//Provide a feedback of recognition rejected
}In order to increase the reliability and overall quality of our examples, we suggest to detach the SpeechRecognized and
SpeechRejected event handlers and to stop the recognition activities once we close or unload the current window. The following code snippet provides a clean closure of the recognition process we may want to attach to the Window.Closing or Window.Unload event:
if (this.sensor != null)
{
this.sensor.AudioSource.Stop();
this.sensor.Stop();
this.sensor = null;
}
if (null != this.speechEngine)
{
this.speechEngine.SpeechRecognized -= SpeechRecognized;
this.speechEngine.SpeechRecognitionRejected -= SpeechRejected;
this.speechEngine.RecognizeAsyncStop();
}We can certainly combine the Kinect sensor's speech recognition capabilities with the other strengths provided by the Kinect sensor itself.
For instance, we could enhance the example developed during the previous chapter and make a more fluid and natural way to select the image section.
The following grammar defined as an XML file represents the starting point to change the user experience of the example developed in Chapter 3, Skeletal Tracking.
<grammar version="1.0" xml:lang="en-US" root="rootRule" tag-format="semantics/1.0-literals" xmlns="http://www.w3.org/2001/06/grammar">
<rule id="rootRule">
<one-of>
<item>
<tag>SelectLEFT</tag>
<one-of>
<item> select left </item>
<item> track left </item>
</one-of>
</item>
<item>
<tag>SelectRIGHT</tag>
<one-of>
<item> select right </item>
</one-of>
</item>
<item>
<tag>Deselect</tag>
<one-of>
<item> deselect </item>
</one-of>
</item>
</one-of>
</rule>
</grammar> The following code snippet is the alternative or integration to the Chapter 3 example's gesture commands:
private void SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{ const double ConfidenceThreshold = 0.3;
if (e.Result.Confidence >= ConfidenceThreshold)
{
switch (e.Result.Semantics.Value.ToString())
{
case "SelectLEFT":
if (!selected)
{
currentHand = JointType.HandLeft;
selected = true;
}
break;
case "SelectRIGHT":
if (!selected)
{
currentHand = JointType.HandRight;
selected = true;
}
break;
case "Deselect":
selected = false;
frameSelected = false;
startDrag = false;
break;
} }}