
Chapter 3
Featural Representations
WHAT IS A FEATURE?
In the discussion of spatial representations in chapter 2, I pointed out that spatial representations are continuous. Points can lie arbitrarily close to each other in a representational space, and a distance between points can be calculated. That distance is then used to represent a psychological quantity like similarity or preference. A different approach to representation assumes that the elements in mental representations have discrete components often called features.
Features are a form of symbolic representation. Semiotic theorists (going back to Peirce; Buchler, 1940) have distinguished among iconic, indexical, and symbolic representations. Icons are signs (or representations) that bear a perceptual resemblance to the thing they represent. A painting of George Washington is an iconic representation of him. Indices are items that derive their meanings from direct (generally physical) connections to the object they denote. A plumb bob indexes verticality because it is pulled down by gravity. Clouds index a storm because they are causally related to the storm. Finally, a symbol denotes its referent because of an established convention. Words in language are symbolic because the connection between a pattern of sounds and a concept is determined by the convention of the linguistic community. Features are symbolic because the cognitive system arbitrarily associates a feature with the thing it represents.
To get an intuitive sense of what is meant by features, think of all possible properties of dogs. At a crude level, properties like “four legs,” “barks,” “has fur,” “eats dog food” can be considered features of dogs. These features specify properties of dogs, that are shared to a greater or lesser degree with other objects in the world.
In this chapter, I discuss featural representations in some detail. I begin by discussing independent features and the notions of additive and substitutive dimensions. Then, I examine information that may become associated with features. Next, I address the issue of primitives in featural representations, look at some processes that may act over featural representations, and discuss some uses of featural models in psychology. Along the way, I discuss the strengths and weaknesses of featural representations.
FEATURES
Features are symbols that correspond to particular aspects of the represented world. A feature is an entity or object in the representing world. Analogous to a real object, a feature is a discrete unit that can be manipulated. A feature may also have sharp boundaries like a real object so that there is often a clear dividing line between what is and is not represented by a particular feature. These properties are guidelines; in some instances, features have fuzzy boundaries.
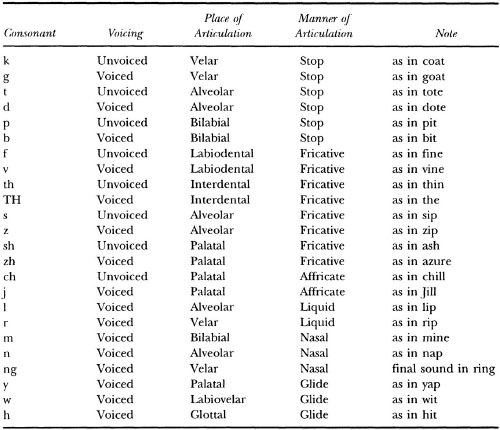
An early use of features in psychology was to represent the set of phonemes in human languages. Phonemes are the speech sounds of language. For example, the /g/ in gate or gone is a phoneme. A phoneme (like /g/) can be described by a set of articulatory features, which are organized into a set of dimensions. Dimensions are qualities along which a speech sound can vary. For example, articulatory features have dimensions including voicing (whether the vocal cords are engaged), place of articulation (where the air in the vocal cavity is blocked), and manner of articulation (how the air in the vocal cavity is blocked). To represent a particular speech sound, each dimension must be given a value. The phoneme /g/ is voiced (the vocal cords are engaged early in the production of this sound). The place of articulation of /g/ is velar because the tongue meets the roof of the mouth at the soft palate (velum). Finally, the manner of articulation of /g/ is a stop consonant; producing the sound /g/ requires stopping the flow of air for some period. The important values of articulatory features can be determined by looking at minimal pairs, which are pairs of words that differ in meaning, but whose phonetic form differs in only a single phonetic feature such as gap (/gæp/) and cap (/kæp/). In this case, the initial phonemes /g/ and /k/ differ only in that the vocal cords are engaged early for the first and late for the second—that is, they differ in voicing. Table 3.1 presents the articulatory features of a number of English phonemes.1
Table 3.1
Some Articulatory Features of English Consonants
Articulatory features are thought to be discrete, with sharp boundaries between phonemes. This claim is supported by evidence of categorical perception of speech sounds. In one classic study of categorical perception, investigators repeatedly played a simple syllable to infants (e.g., /ba/) and measured the rate at which the infants sucked a nipple (Eimas, 1971). After a short time, the infants habituated to the speech sound being played, and their sucking rate decreased. At this point, the speech sound was changed by altering an aspect of its sound. For example, the voice onset time could be varied by changing the amount of time from the onset of the syllable during which a spectrum of energy corresponding to the engagement of the vocal cords was added to the speech signal. Infants dishabituated to the change (as evidenced by a sharp increase in sucking rate) only when the speech sound changed the phoneme from voiced to unvoiced (or vice versa). Thus, when the change in voice onset time changed the syllable from a /ba/ to a /pa/, infants’ sucking rate increased. Changes in a phoneme (e.g., two different versions perceived as /ba/) did not change infants’ sucking rate. This pattern of data suggests that the boundaries of features deciding between phonemes are sharp.2 A further property of discreteness is that a phoneme either possesses a given feature or it does not. For example, in an articulatory representation of English phonemes, a given consonant is either a velar or it is not. It cannot be partially velar.
Because articulatory features are organized into dimensions, groups of features all describe the same aspect of a phoneme. The voicing dimension can take on the values voiced and unvoiced. Likewise, the place of articulation dimension can take on values like velar, alveolar, labial, or dental, which each describe a place where the tongue meets a portion of the mouth. The dimensions of phonetic features are substitutive because having one value along a particular dimension, like voicing or manner, precludes having any other values at the same time (Gati & Tversky, 1982). That is, a consonant cannot be both voiced and unvoiced, both a labial and a velar or both a stop and a fricative. (I come back to the issue of substitutive dimensions later.)
Another important property of articulatory features is that they are primitive. Primitive features are those that cannot be decomposed into more basic units. The articulatory feature theory of speech assumes that no representational elements are more basic than the features that can be combined to form an equivalent representation. (I discuss primitives later.)
Buried in the concept of primitives is the assumption that features can vary in their level of specificity. Psychologists have often assumed that features of objects have a particular grain size reflecting the degree of a feature’s specificity. Specific features can represent only a narrow range of things in the represented world. General features have a broad range of things that they represent. A feature representing a particular shade of red, say brick red, is a highly specific feature, applicable to an object only if the object is brick red. At the other end of the spectrum, evaluative features like good or rugged are very general. Exactly what is meant by a feature like good or rugged varies depending on what is being described by those features. A good boy is not the same as a good horse, which is not the same as a good movie. At heart, though, all of these features imply some type of positive evaluation.
FEATURES AND FEATURE DETECTORS
The featural view of representation has received some support from work in neuroscience on the feline and monkey visual systems (believed to be good models for the human visual system). The pioneering work of Hubel and Wiesel (e.g., Hubel & Wiesel, 1965; Hubel, Wiesel, & LeVay, 1975) produced results consistent with the presence of “feature detectors” in the visual cortex. Hubel and Wiesel found neurons that were sensitive to lines of particular orientations in particular areas of visual space in the visual cortex. When a neuron is sensitive to a line in a particular orientation, it fires more often for lines in this orientation than for lines in other orientations. Cells near each other in the visual cortex are sensitive to lines of similar orientations. Other cells, called hypercomplex cells, seem to fire selectively to more complex environmental features like line segments of a particular length or corners. Although this work is exciting in that it suggests that the brain may actually code some aspects of the perceptual environment as features, researchers must take care in interpreting these data. They do not specify any process that uses the representation: If the selective firing of neurons in the visual cortex does correspond to the encoding of visual features, it is not clear how these features are used to turn the featural information into a perception of the visual world. Thus, before knowing what sort of representation the visual system is constructing, we must know more about how the information is being processed (see also Uttal, 1971).
It is interesting that to the extent that neurons encode visual features, the features are not discrete. When a neuron is said to fire selectively for lines of a particular orientation, it means that the firing rate of the neuron3 is highest for a line of that orientation. Lines with an orientation similar to that of the optimal rate yield somewhat lower firing rates. The overall rate of neural firing is like that depicted in the schematic graph in Figure 3.1. Thus, the features that these detectors are sensitive to have fuzzy rather than discrete boundaries. These fuzzy boundaries confer several advantages on neural systems. First, because there are many cells with similar preferred orientations, the loss of any individual cell is not catastrophic. Second, the activity of neurons with similar preferred orientations can be combined to yield more accurate assessments of the orientation of the line than can be determined from the firing of any single cell. In sum, an analysis of feature detectors in the visual system suggests that there is a high degree of redundancy in feature representation and also that the features themselves have fuzzy boundaries.
TYPES OF FEATURE DIMENSIONS
Featural models have two types feature dimensions: additive and substitutive dimensions (Gati & Tversky, 1982). Additive dimensions are features that can be added to the representation of an object regardless of what other features it has. For example, imagine the head of a novel animal. This head may have ears, but whether it has ears is not dependent on other features that the head is imagined to have.4 In contrast, substitutive dimensions are collections of features for which any given object can have only one value. True psychological dimensions have this substitutive structure. For example, a simple object cannot be both large and small because having the feature large precludes the object from also having the feature small.5 Shape, color, and texture are other examples of substitutive dimensions, as are the articulatory features discussed in the previous section.
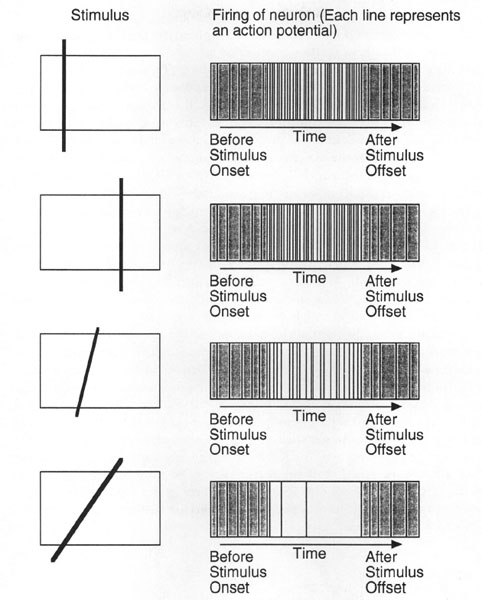
FIG. 3.1. Demonstrations of firing frequencies to lines of particular orientations in a receptive field. The receptive field is tuned to vertical lines. Vertical lines appearing anywhere on the receptive field give rise to a high rate of firing relative to a background. Lines at orientations near vertical give rise to somewhat lower rates of firing. Lines at orientations far from vertical give rise to very low firing rates.
FEATURE INDEPENDENCE
Objects are described by collections of features. To facilitate the creation of processes that act over the features of an object, it is handy to assume that the features are independent of each other. The assumption of feature independence takes a few different forms, and so it is worth discussing in more detail. One possibility is that, across the features of represented objects, there is no correlation between features possessed by objects. On this view of independence, the probability that an object has some feature c1 given that it has some other feature c2 is simply the base-rate probability that any object has feature cl. This view of feature independence is unlikely to be correct. For natural kinds (e.g., animals and plants), there are correlated sets of features in the world. Objects with leaves tend not to have legs and fur, although objects with legs often have fur. Indeed, Rosch and Mervis (1975) suggested that a fundamental aspect of natural kind categories is that they reflect correlations between features that exist in the world (see also Malt, 1995). Likewise, substitutive dimensions consist of features that are decidedly not independent; any object can have at most one value along a substitutive dimension.
A second possibility is that the presence of features may be correlated, but features are treated as being independent by the processes that act over them. For example, A. Tversky’s (1977) contrast model assumed that features representing objects are grouped into sets (in a formal set-theoretic sense). This situation is depicted in Figure 3.2. Each circle stands for a set of features representing an item in the represented world. The advantage to treating objects as sets is that elementary set operations can be used to compare pairs of objects. In Figure 3.2, the overlapping region of the circles is the intersection of the feature sets. The nonoverlapping regions of the circles are the set differences. According to the contrast model, the similarity of two objects a and b represented by feature sets A and B is determined by
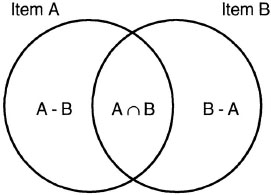
FIG. 3.2. Feature sets that are compared. The overlap of the feature sets is the commonalities of the pair, and the nonoverlapping regions are the differences.
where θ, α, and β are weighting factors. In this model, each feature is treated independently of every other feature. The independence allows the determination of whether any particular feature is a common feature (i.e., a member of the set intersection {A ∩ B}) or a distinctive feature (i.e., a member of either of the set differences {A – B}, or {B – A}) to be done separately for each feature.
In this model, the perceived similarity of a pair increases with the size of the set of commonalities and decreases with the size of the set of differences. The weighting factors (i.e., θ, α, and β) allow the contrast model to account for changes in emphasis on commonalities or differences in different contexts. One reason that these weighting factors can be used is that the set of common features and the sets of distinctive features (called the components of similarity) are independent of each other. Because of this independence, the weighting factors can be set individually. In some circumstances, it may be beneficial to give high weight to the commonalities (if the focus is on what a pair of objects have in common). In this case, the parameter θ can be large and can allow the perceived similarity of a pair to be strongly dependent on the set of common features. Similarly, it may be important to weight one or both sets of distinctive features heavily (i.e., to use large values of α or β). Only when the components of similarity are independent can the value of each parameter be set independently of the values of the other parameters.
Treating features as independent allows models to avoid a variant of the holism problem described in chapter 1. In philosophy, holism has been identified as the problem that the meaning of any particular representational element (in this case, features) may depend on the meaning of every other representational element that an individual knows. If every feature is independent, understanding the meaning of a concept described by a set of features requires only looking at the set of features used to describe that object. Because the processing capacity of any cognitive agent is finite, it is important to have a way to constrain the features that must be considered when processing a representation.
To provide evidence for the contrast model of similarity, A. Tversky (1977) asked subjects to list the features of a number of objects and asked a second group of subjects to rate the similarity of several pairs of these objects. Tversky determined the common and distinctive features for each pair in the ratings task by matching the features from the feature listing task. He weighted features by the number of subjects that listed each feature and found a positive correlation between the number of common features and rated similarity and a negative correlation between the number of distinctive features and rated similarity. This study provides clear evidence supporting the contrast model and also demonstrates that assumptions about knowledge representation can affect the way psychological data are collected. The contrast model assumes that objects are represented as collections of features, and so it is reasonable to ask subjects to list features of objects to confirm the predictions of the model. Testing a model of similarity that made other assumptions about knowledge representation would require a different methodology (see Markman & Gentner, 1993a, 1996; chap. 5).
By treating features as independent, featural models can use straight-forward processes like elementary set operations to determine the commonalities and differences of a pair. The components of similarity are also independent, and the weights given to the commonalities and differences can be set independently. Unlike the continuous mental space models discussed in chapter 2, featural models provide an explicit indication of how a pair of objects is similar and how it is different, whereas mental space models gave only a distance between points. Featural models have a set of commonalities whose features can be examined to see what makes a pair similar. This property is important, because the presence of discrete objects in the representing world allows featural models to determine in what way a pair is similar. Likewise, a featural model has sets of differences whose features can be examined to see what makes a pair dissimilar.
USING FEATURES TO REPRESENT CONCEPTS
How can a list of features represent a concept? Researchers have developed several feature-based models of concepts. Early workers on concepts searched for a set of features that were necessary and sufficient for an item in the world to be an instance of that concept. Necessary features are features that an item must have to be an instance of the concept (see Smith & Medin, 1981, for a discussion of this issue). A sufficient set of features is the minimal set of features such that if an item has this set, it is an instance of the concept, but removing any feature from the set keeps the item from being an instance of the concept. A bachelor can be defined as an unmarried male, where the features unmarried and male are necessary and jointly sufficient to specify instances of the concept bachelor. It has proved difficult, however, to specify necessary and sufficient features for most natural concepts (Wittgenstein, 1968), even for a straightforward concept like bachelor. An unmarried 10-year-old boy is not a bachelor. Would extending the set of features to include adult solve the problem? Aside from the ambiguity of a feature like adult (is an 18-year-old an adult?), there are other problems. A 30-year-old priest is an unmarried (adult) male, but he is not a very good instance of a bachelor. It is appropriate to say that a 30-year-old priest is technically a bachelor, but then an explanation is required for why the hedge technically is appropriate for 30-year-old priests, but not for 30-year-old unmarried male lawyers.
A featural model of concepts need not assume that concepts are defined by collections of necessary and sufficient features. Research on category representations in psychology has suggested other possible representations. According to one view, category representations consist of prototypes or average members of a category (Posner & Keele, 1970; Reed, 1972; Rosch, 1975; Rosch & Mervis, 1975). On this view, the category representation contains information about features that are typically associated with the category. The concept of bird may consist of features typically associated with birds, such as wings, feathers, small size, and chirping. Deciding whether a new instance is a bird involves comparing the features of the new instance with those of the prototype. If there is sufficient overlap, the new instance is categorized as a bird. Of course, some mistakes might be made, such as identifying a bat as a bird, but these mistakes often occur, and may require that exceptions to the prototype be stored specially.
Another important property of prototypes is that they can be considered the default values for a concept. Default features are properties of an item that one would guess to be true of the item without other information. If I say that something is a bird and say nothing else about it, then it is possible to make some assumptions about what properties it has. Default features can also be used to guess the values of features unknown about an object. If I say that I saw a small eagle at the zoo, it is known that the eagle is small, because I say so, but it is likely to be further assumed that it has wings and feathers, because they are default properties of birds.6
Another proposal for the nature of category representations is that people store specific exemplars of categories that they have seen (Kruschke, 1992; Medin & Schaffer, 1978; Nosofsky, 1986, 1987; see chap. 8). Exemplar models assume that the features associated with individual category members (or exemplars) are stored in memory. Like prototype models, exemplar models also assume that new instances are categorized with respect to their similarity to the stored category representation, but the stored category representation consists of various stored exemplars. In both exemplar and prototype models, featural representations can be used to categorize items without requiring that the category representation consist of a set of necessary and sufficient features. Instead, these models propose that a measure of featural similarity (i.e., the degree of feature match and mismatch between the new instance and the category representation as in A. Tversky’s, 1977, contrast model) can be used to categorize the objects.
FEATURE PROCESSING AND INFORMATION BUNDLED WITH FEATURES
When objects are represented as points in a multidimensional space (as discussed in chap. 2), the dimensions of the space can be thought of as ordered substitutive dimensions whose particular values correspond to the feature values along them (see Gati & Tversky, 1982, for a similar discussion). In a spatial representation, however, the processing operations consist only of ways of measuring the distance between points by using some metric. In contrast, featural models permit a wider range of processes and by extension allow a broader range of information to be associated with features.
A simple process that can be carried out with featural models is comparison. The central example of a feature comparison model is A. Tversky’s (1977) contrast model described in the previous section. Another simple comparison model can be used to illustrate how featural representations can be extended. In chapter 2, I discussed the model of sentence verification described by Rips et al. (1973). These researchers demonstrated that the time it took for subjects to verify sentences of the form “A robin is a bird” was related to the similarity between the nouns in the sentence, when similarity was defined as the inverse of distance in a multidimensional space.
E. E. Smith, Shoben, and Rips (1974) also presented a featural model of sentence verification. In this model, a key fact to be explained was the presence of fast true and fast false responses in the sentence verification task. Subjects can very quickly verify sentences like “A robin is a bird” and can very quickly determine to be false sentences like “An aardvark is a bird.” In contrast, sentences like “An emu is a bird” require a long time to verify as true, and sentences like “A bat is a bird” require a long time to reject as false. Smith et al. suggested that objects are represented as sets of features and that the features of objects are further subclassified as characteristic or core features of an object. Characteristic features are those typically associated with the object, but that are not necessary for an object to be a member of a class. For the category birds, the feature flies is characteristic, because not all birds fly. Core features are necessary for inclusion in the category. All birds have feathers, and so feathers is a core feature of birds.
With objects represented as sets of core and characteristic features, Smith et al. assumed a two-stage process of sentence verification. The first stage involves a comparison of all features (both core and characteristic) of the nouns in the sentence. If the objects are very similar (i.e., they share many features), people quickly deem the sentence true. If the objects are very dissimilar (i.e., they share few features), they quickly deem the sentence false. Objects that fall in an intermediate range of similarity are passed to a second stage, in which only the core features are considered. At this stage, if the objects share core features, a true response is made (in this case, the response is slow, because two stages must be carried out). In contrast, if the objects do not share core features, a slow false response is made. Subjects can make mistakes when objects in a sentence share many characteristic features but few core features or have few characteristic features but share the core features that make them a member of a category.
This model has two key aspects. First, the use of core and characteristic features demonstrates that features can have other information associated with them in addition to the information they encode about an object. This information can affect subsequent processing of the object that the features describe. Second, this featural model demonstrates that cognitive processes can be based on information that is technically irrelevant to the task but that eases processing. Comparing objects using all their features is easier than segregating features by their status as core or characteristic and then comparing. In most cases, the comparison yields the correct results quickly and thus is used instead of a more thorough but more labor intensive process.
The use of overall similarity as a heuristic is common in many psychological processes (e.g., A. Tversky & Kahneman, 1974). Tversky and Kahne-man described situations in which people who are making a judgment focus on an object’s similarity to (or representativeness of) a general class rather than on other factors that may be more relevant to the judgment at hand. In one situation, the researchers told people that, from descriptions of 100 people, one description had been selected at random. They also told the subjects that 80% of the people in the group were lawyers and 20% were engineers. The description selected at random was designed to be highly similar to the stereotypical engineer (e.g., has good mathematics ability, dresses poorly, likes to read science fiction books for pleasure). People judged that the person described was highly likely to be an engineer, despite the fact that the base-rate probability of the person’s actually being an engineer was only 20%. The judged likelihood that the person was an engineer did not change much if people were told that the description was drawn from a population of 80% engineers and 20% lawyers. Tversky and Kahneman suggested that people in this judgment task attended too much to the similarity of the object to the stereotypical engineer and did not focus enough on relevant statistical information like base rates.
DEGREE OF MEMBERSHIP AND DEGREE OF BELIEF
The core-characteristic distinction used by Smith et al. (1974) is actually an example of a general class of information that has often been associated with featural models encoding the degree of membership (or typicality) of a feature or the degree of belief in a feature along with the feature itself. In these models, features are not classified as exclusively core or exclusively characteristic; rather it is assumed that a dimension specifies to what extent a feature is criterial of a given category (Smith et al., 1974, also acknowledged the possibility that their core-characteristic distinction was graded).
The degree of membership of features in categories has been examined explicitly in prototype models of categorization. As discussed previously, a prototype is an average member of a category, and researchers have proposed them as a way that people structure concepts. The concept bird may be associated with an average bird that is probably more like a robin than a penguin (Posner & Keele, 1970; Reed, 1972; Rosch & Mervis, 1975). Prototypes may store only information about features typically associated with a category. Smith and Medin (1981) and Barsalou (1990) argued that prototypes (or more generally category abstractions) may store features associated with a category along with information about the frequency with which the feature appeared in the category. Table 3.2 shows a simple prototype for the category bird. The numbers at the right of the table are the number of instances of birds with the features at the left. This frequency can be thought of as the degree of membership or degree of typicality of the feature for a concept. Prototypes may contain information about sets of features whose membership is typically correlated. For example, animals with wings and feathers also tend to fly.
Table 3.2
Prototype of the Category Bird
| Feature | Instances |
| Wings | 100 |
| Feathers | 100 |
| Sings | 86 |
| Flies | 89 |
| Small | 62 |
| Medium | 36 |
| Large | 2 |
| Beak | 96 |
| Legs | 100 |
| Brown | 27 |
| Red | 14 |
| Blue | 9 |
| Black | 14 |
| Gray | 18 |
Once the membership of features in concepts is graded rather than all or none, more complex processing assumptions must be made. When the features are discrete, new instances of a category presumably have the features in the abstraction. When the features are graded, the degree of membership of a feature is an estimate of the likelihood that the feature is part of the new instance (or in the case of correlated features, the likelihood that the set of features is part of the instance). Some way of combining the information about degree of feature membership is needed.
Research in artificial intelligence (AI) on belief maintenance offers some insight into how the degree of belief in a feature is processed. One way of thinking about the graded membership of features in concepts is as the degree of belief that the feature describes a member of the category. Often, large AI reasoning systems have databases of knowledge called knowledge bases. The facts in these knowledge bases may not be known with certainty to be true or false. Modelers have handled statements not known to be true or false with certainty factors, which are typically numerical values associated with each fact in the knowledge base and which express the degree of belief in the statement.7 Along with these values come procedures for combining certainty factors from more than one statement to allow reasoning about statements whose truth value is uncertain.
The certainty factor can be a statement of probability. In the prototypes described earlier, in which the number of instances with a given feature is tracked, the numbers can be converted into the proportion of instances of the concept (e.g., birds) with the feature. If the sample that generated the prototype reflects the population of items that one is likely to encounter in the future, the proportions can be thought of as probabilities that a new instance of a category has a given feature of the prototype. The probabilities can be combined to judge the probability that the new instance has conjunctions of features of the prototype by using standard laws of probability (Shafer, 1996). If the presence of two features in a category is independent, the probability that a new instance has both features is simply the product of the probabilities that it has either feature alone.
The certainty factors need not be interpretable as probabilities, however, and the rules of probability combination need not apply. Lenat and Guha (1990) discussed other ways of using certainty factors in knowledge bases. The facts in a knowledge base are the beliefs of an agent. Lenat and Guha argued that the best way to know how strongly a belief is held is to know why it is held (see J. L. Pollack, 1994). A belief can be strongly held because it is connected to many other beliefs that depend on it, or it can be strongly held because there is a strong argument that the fact’s being true (or a strong argument against a fact’s being true [J. L. Pollack, 1994]). When one does not know exactly why a belief is true or false, certainty factors can be used.
These certainty factors can be numbers, such as numbers on a scale from 0 to 100, which, unlike probabilities, need not be interpreted as expected likelihoods. Lenat and Guha (1990) argued against this use of certainty factors, because it establishes a common currency of belief. Imagine that one believes that all birds have wings and holds the belief with certainty 96 (pretty sure, but leaving open the possibility that there is a wingless bird). Imagine one has another belief that bricks are made out of clay, and one holds the belief with certainty 95. These certainty factors may be excellent values for reasoning in the domain of birds or in the domain of bricks. These certainty factors are global numbers, however, and setting them allows one to assume that the belief in birds having wings is stronger than the belief that bricks are made out of clay. Such hairsplitting about beliefs across domains does not seem to be cognitively plausible.8
Lenat and Guha (1990) advocated a system of certainty with five states of belief: absolutely true, true, unknown, false, absolutely false. The true and absolutely true states differ only in that true leaves open the (small) possibility that the belief can turn out to be false, whereas absolutely true does not leave open even a glimmer of doubt. A similar difference holds between false and absolutely false. These five states allow combinations of certainty factors in a modified truth table, as shown in Table 3.3. With two arguments related to a belief, as shown in Table 3.3, if both arguments support the absolute truth of the belief, it is believed with a certainty of absolute truth. Likewise, pairs of arguments for absolute falseness yield beliefs with certainty absolutely false.
When there is a contradiction between true and false beliefs, the system assumes that the certainty of the belief is unknown. This is actually a reasonable course of action. In a situation in which two people give compelling arguments on opposite sides of an argument, if there is no good reason to favor one argument over another, then one may decide that the truth of the fact in contention is unknown pending a resolution to this debate.
The purpose of this section is not to provide a detailed review of work on belief maintenance but to emphasize two main aspects of belief maintenance. First, most information attached to features (or beliefs) is simply a a stand-in for other information not known more specifically. For example, a value of the “degree of core-ness” of a feature is a stand-in for knowledge about why the feature is a core or characteristic feature of a category. Likewise, a certainty factor is a stand-in for more detailed knowledge about why the belief is true or false. Such stand-ins are useful for two reasons. First, one may not always know the reason for holding a belief (or why a feature is a core feature). Second, actions must often be taken quickly, and reasoning from domain knowledge about beliefs (or typicality or core-ness) may take more time than is available; thus storing a shorthand notation for certainty (or typicality or core-ness) may make online processing more efficient.
TABLE 3.3
Truth Table for Certainty Factors
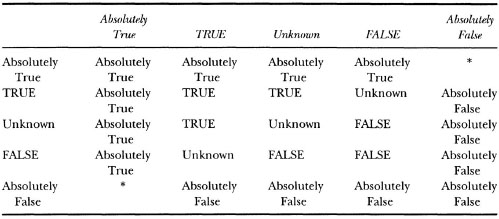
*When absolutely true and absolutely false statements collide, the difference must be resolved through reasoning.
A second important aspect of belief maintenance is that adding new information to features requires the addition of new processing assumptions that use the information. In the case of core and characteristic information, the new processes must filter out the characteristic features when making comparisons as in the second stage of the model of E. E. Smith et al. (1974). In the case of belief, the use of certainty factors requires positing a truth table that can combine these factors. The use of probabilistic information can require more complex combination schemes. Thus, adding complexity to the representation comes at the expense of requiring additional processing assumptions.
PRIMITIVE REPRESENTATIONAL ELEMENTS
What does a feature mean? As previously discussed, it is possible to label features like voiced for phonemes or has wings for birds, but these labels are there for our benefit. They allow us to look at a description of the knowledge possessed by the system and to know what it must mean. A computational system cannot directly interpret a feature label; what would the label be interpreted into? The system must operate the same way, even if features have labels that are uninterpretable by English speakers. For example, the prototype for the bird category shown in Table 3.2 can easily be rewritten with generic symbols. The cognitive model must be able to use these generic symbols, even if an outside observer does not know what they mean. A system must operate even if the feature wings is coded as GXB1, the feature feathers is coded as GQR4, and so on.
As discussed in chapter 1, part of a symbol’s meaning involves grounding. At some point, the represented world for some symbols must be perceptual information coming from the outside world. Presumably, this perceptual information grounds the symbol in physical reality (or at least the part of reality to which sensory systems are attuned). Not all symbols need a represented world that involves perceptual information. Indeed, many proposals for mental representation suggest that symbols with complex meanings can be built up by having represented worlds that are other representational elements in the cognitive system. In such systems, complex symbols are thought to be decomposable into a set of semantic primitives, which are the simplest representational elements. The primitives are typically assumed to be grounded and derive their meaning from a direct relationship to a represented world outside the cognitive system rather than indirectly through decomposition into other symbols.
Perceptual Primitives
One example of decomposition into semantic primitives is the system of articulatory features used to open this chapter. The representation of a phoneme consists of a set of primitive features, each of which corresponds directly to an element of the speech production environment, such as voicing or place of articulation. The assumption that phonemes can be decomposed into primitive features has led to a search for aspects of the speech signal that correspond to primitives (Jakobsen, Fant, & Halle, 1963). These aspects of the speech signal are the connection between symbols and the world, a connection that grounds the primitives. To date, identifying aspects of the auditory speech signal that are markers of phonetic features has proved difficult (Blumstein & Stevens, 1981). If the relation between this possible representing world and the represented world of speech sounds is not discovered, the decomposition of phonemes into primitive features may turn out to be a powerful linguistic tool, but not a reflection of psychological reality.
The use of primitives is common in models of visual perception. The discovery of neurons that fire selectively to lines of particular orientations, to lines that move in particular directions, or to even more complex features like edges (as previously described) suggests that, at some level, visual input may be analyzed into features. Biederman (1987) suggested that the representation of visual objects consists of generalized cones, which he called geons, connected by relations between them (relations between representational elements are discussed in chap. 5). Some sample geons are shown in Figure 3.3A. According to this theory, the object recognition system has a limited number of geons that serve as the basic representational vocabulary; Biederman posited 36 geons as the basis of his theory. Figure 3.3B shows how various objects can be constructed from a set of geons.
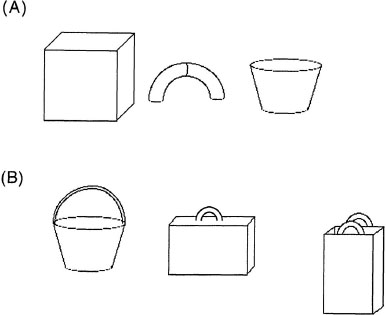
FIG. 3.3. A: A simple set of geon primitives like those proposed by Biederman (1987) in his model of visual object recognition. B: A set of objects that can be created from a set of geons (b).
Geons embody two important parts of representational systems that posit a set of primitive elements. First, the limited vocabulary of 36 geons can be combined by using spatial relations to form about 154 million objects made of 3 or fewer geons.9 This range of objects is certainly sufficient to account for the number that humans can discriminate. Second, geons are posited to be true primitive elements in that they are assumed to represent perceptual properties outside the cognitive system. Geons themselves are recognized via nonaccidental properties of objects, visual aspects of objects that do not change their form substantially through rotations of objects. Examples of nonaccidental properties are parallel lines and collinearity (broken line segments that would form a single line if connected). In the case of parallel lines, for example, many rotations of an object in space still yield an image in which the lines are (nearly) parallel. Geons are only one theory of the primitives underlying object recognition. Other proposals have focused on different aspects of visual objects like defining major axes and radii of objects (Marr, 1982). This issue is taken up again in chapter 6.
There is something quite appealing about perceptual primitives. In particular, because the represented world is outside the organism, it is easy to see that primitives may ground a representation. One need only find a connection (i.e., a set of representing rules) that correlates the primitives to the environment. Perhaps all concepts, even quite abstract ones, can ultimately be decomposed into a set of perceptual primitives. As I discuss in chapter 9, many cognitive linguists have suggested that abstract concepts are understood in terms of perceptual (or emotional) domains (e.g., Gibbs, 1994; Lakoff & Johnson, 1980). Although it is not entirely clear how all abstract concepts can be decomposed into physical or bodily terms (e.g., Murphy, 1996, 1997), it remains an intriguing possibility.
Conceptual Primitives
Proposals of representational primitives are not limited to perceptual systems. Many researchers have focused on developing a set of conceptual primitives (E. V. Clark, 1979; Fillmore, 1978; Miller & Johnson-Laird, 1976; Norman & Rumelhart, 1975; Schank, 1972, 1975). Most systems of conceptual primitives assume structured representations like those I discuss later in the book. To illustrate the notion of primitives, I discuss E. V. Clark’s (1979) semantic feature hypothesis of word meaning. (I return to structural theories of primitives in chap. 7.)
According to the semantic feature hypothesis, word meaning is determined by a set of primitive features associated with a word. These features can be acquired independently. For example, when a child first learns the word dog, he or she may learn the features [+ animate] and [+ four legged]. This set of features underspecifies the concept dog; thus, the child over-extends the word dog to cows, horses, cats, and other four-legged animals. In this notation, features are enclosed by brackets and are listed along with a plus sign that denotes that they are known to be true of a concept (i.e., [+ feature]) or a minus sign that denotes that they are known to be false of a concept (i.e., [– feature]).
New features are added to words to account for differences in meaning between words. A key pragmatic component of Clark’s theory of lexical development is the principle of contrast. The assumption behind this principle is that children learning a lexicon assume that no two words have exactly the same meaning (i.e., that no two words are associated with exactly the same features). For example, if a child has associated the features [+ animate] and [+ four legged] with the word dog and the child then hears the word cow, this word can also apply to animate things with four legs. By the principle of contrast, however, either the word cow or the word dog (or both) is given features that allow the meanings to be differentiated. The child may associate the features [+ animate, + four legged, + moo] with cow and the features [+ animate, + four legged, + bark] with dog. Once this specification occurs, a child does not overgeneralize words as often as he or she did before.
E. V. Clark (1979) applied this featural analysis to concepts that can be specified by count nouns (i.e., nouns that refer to countable objects like dog and cow), but she also applied it to other concepts like those that can be specified by prepositions. For example, she suggested that children first learn that the preposition before applies to time, so that it is given the feature [+ time]. Later, the child realizes that this preposition relates events that do not occur at the same time and so extends the representation of before to [+ time, – simultaneous]. Finally, as the child contrasts before with other temporal prepositions like after, he or she reaches a representation consisting of [+ time, – simultaneous, + prior].
Another interesting aspect of the semantic feature hypothesis is that the features can be about aspects of the represented world (e.g., [+ animate] or [+ time]) but also about more abstract aspects of language usage. For example, the English words brag and boast may seem to be a counterexample to the principle of contrast. For most people, these words mean basically the same thing. Clark, however, suggested that these words differ in register; that is, in the audience for which they are appropriate. It seems more suitable to say:
![]()
than to say:
![]()
because boasted is a more formal term than bragged. Clark suggested that semantic features can contain information about aspects of language like register, aspects that allow the meaning of one word to be distinguished from the meaning of another. Similarly, features may represent differences in dialect, so that the word soda can be recognized as appropriate for use on the East Coast of the United States to refer to carbonated soft drinks, whereas the word pop can be recognized as appropriate for use in the Midwest of the United States for the same concept.
Semantic features are assumed to be primitives because they are used across a variety of concepts. All word meaning is thought to be composed of the meanings of a set of primitive features. Furthermore, no two words are permitted to have the same featural representation. If two words are given the same feature set, the language system searches for a way to extend at least one of the representations to make the sets nonidentical. Clark acknowledged that a limitation of her theory is that a complete set of semantic features for any language cannot currently be specified. Thus, although the semantic feature hypothesis posits that concepts are composed of primitives, it does not give a full account of what the primitives are.
Earlier, I noted that an important function of primitives is to provide grounding for more complex concepts, but it is not entirely clear how semantic features serve that function. One possibility is that there are correspondences between these primitives and perceptual information (perhaps even other perceptual representations). Another (rather implausible) possibility is that these conceptual primitives actually represent specific perceptual instances. With features like [+ time], which refers to the abstract property of time, this solution seems unlikely to work. Ultimately, the success of any system of primitives rests on an ability to ground symbols, and thus, the difficulty grounding a set of primitives can be seen as an important limitation of a theory of conceptual primitives.
General Issues About Primitives
Even if it was possible to specify a set of primitives for a language, there still must be a set of reasoning processes that carry out the implications of sentences. For example, in the sentence:
![]()
the representation must make clear that the act of giving involves a change of possession of an object (in this case, a necklace). The representation must also make clear that in this case, the physical location of the necklace is also likely to change location. It is tempting to add a feature like [+ change-location] to the representation of the word give, but other instances of giving do not involve the same change in location, as in:
![]()
in which there is a change of possession without a change in location. If a system of representation is truly to capture the subtleties of the implications that people draw during text comprehension, these issues must be dealt with. This problem is not trivial: The general issue of determining what changes given an action has been called the frame problem in AI, and is often thought to be one of the most difficult problems that cognitive science has to solve. (I return to the frame problem in chap. 9; see also Ford & Hayes, 1991; Ford & Pylyshyn, 1996.)
A second important issue involves the level of abstraction most suitable for representing things during normal processing. Discussions of conceptual primitives have never been entirely clear as to whether it is best to decompose information automatically into primitives or to represent things at a higher level of abstraction and decompose only when necessary. By representing things at a higher level of abstraction, I mean having representational elements that correspond to semantically complex concepts like give or trade. The advantage to representing these complex concepts directly is that their primitive representation requires a lot of representational information. Storing only primitives may place too large a memory load on the cognitive system. Thus, it may be advantageous to represent things at a higher level of abstraction some of the time. Always representing things in terms of a small set of primitives implies that it is easy to see similarities between distant domains, but although people sometimes see analogies between domains, they often do not notice similarities between distant domains.
J. D. Fodor, J. A. Fodor, and Garrett (1975) formulated a related argument: They suggested that if concepts were always decomposed into their primitives, it should be more difficult to process concepts requiring more primitives than to process those requiring fewer. For example, it should be harder to process the sentence:
![]()
than to process the sentence:
![]()
because many linguistic analyses have suggested that chasing something involves the intention to catch it, and thus the concept of catching is subsumed in the concept of chasing. Intuitively, however, these sentences seem about equally easy to process. On the basis of evidence like this, J. D. Fodor et al. concluded that there is unlikely to be a fixed set of properties into which all concepts are decomposed.
The alternative to decomposing concepts automatically into primitives is to represent some information without decomposing it. This solution also has its price. Imagine representing the concept dog with a symbol DOG and the concept cow with a symbol COW. These symbols are distinct (they have different names) and not at all similar. Only when these elements are broken down into their more primitive elements does the similarity between them become evident (i.e., when they are both seen as involving features like [+ animate] and [+ four legged]). Thus, operating over abstract representations risks missing similarities between concepts. Any decision about how to represent a concept has implications for what is easy and hard to do with it. The right way to approach this problem depends in large part on the domain in which a model is being developed.
GENETIC ALGORITHMS
So far, I have discussed only very simple processes associated with featural representations. For example, I have described how sets of features representing two objects can be compared by using elementary set operations. As a demonstration of a more complex process, I examine a set of computational procedures called genetic algorithms (Holland, 1992; Mitchell, 1996; Whitley, 1993), which require an assumption of feature independence to work. Genetic algorithms are inspired by transformations observed in genetic processes just as the earlier described connectionist models were inspired by patterns of connection and activity in networks of neurons. Genetic algorithms are useful for finding combinations of features that are beneficial to have in a complex environment. For example, someone looking to invest money can use a genetic algorithm to search for a combination of features that are predictive of growth in a company.
Genetic algorithms are loosely based on real genetic processes. In particular, genetics assumes that the units of heredity (the genes) are located in arbitrary positions along chromosomes. Any gene can take on multiple values, called alleles. Organisms reproduce by passing their genes to a new generation. In the case of asexual reproduction, the offspring gets all the genes of the previous generation, but some genes may change because of a mutation. Organisms best fitted to their environment are most likely to reproduce, and new generations of organisms should have an over-representation of the fittest organisms relative to less fit organisms. Finally, when an organism reproduces sexually, there may be mixing of the genetic material of two organisms. A number of possible mixing strategies can be used to combine genes. Animals like humans have two complete sets of genetic material in the form of pairs of chromosomes, and sections of chromosomes can be swapped in a process called crossover.
Genetic algorithms are designed by analogy to the simplified genetic model just described (see Holland, 1992, for an extensive description of this analogy). In a genetic algorithm, an object in a domain is represented by a set of features, which consist of a set of characters in a string. Figure 3.4A shows an example of a string, which is analogous to a chromosome of an organism. Each position along a string (analogous to a gene) can have a value (analogous to an allele). In the terminology used earlier in this chapter, the string represents a set of dimensions of variation and feature values for these dimensions.10 In many systems, each element in a string is a different feature dimension, although in some complex systems, combinations of a few values are jointly interpreted as features.
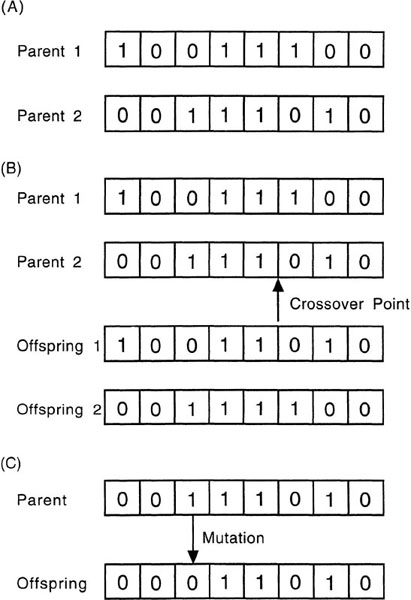
FIG. 3.4. A: Two parent strings in a genetic algorithm. B: Two parent strings producing two child strings with a crossover after the fifth element. C: A parent string producing a child string with a mutation.
As an example of how a genetic algorithm can be used, suppose there is a large database of information about corporations whose stock is publicly traded. The information may include profits, outstanding loans, and the length of time the corporation has been publicly held. To predict how the value of the stock for such a company will change in the next year, one can find combinations of attributes that are predictive of increasing stock prices, select arbitrary combinations of features, and then evaluate these combinations by checking the database for stocks with these combinations to determine whether the average stock price of such companies rose or fell. If there are many potentially relevant attributes of companies, searching the entire set of combinations would take too long, and so it would be nice to have an intelligent process for deciding which combination of features is best. This search can be done with a genetic algorithm.
The search starts with some number of strings (the population) whose values are chosen randomly. Thus, each string has an arbitrary combination of features. The goodness of each string (its fitness) is determined by calculating the mean price change of stocks with this collection of features. Then, a new generation of strings is created by first ordering the initial set of strings by their fitness score. Pairs of strings are randomly selected to be parents of new offspring (with replacement) with a probability that reflects the fitness ratings (the more fit the string, the more likely it is chosen). These two strings are added to the next generation of strings. With some probability, the two parent strings are crossed as shown in Figure 3.4B. When a pair of strings is crossed, all the values after some point (also randomly determined) are switched between strings. This operation is analogous to the process of crossover described earlier. Finally, as shown in Figure 3.4C, each individual string entry can be mutated (e.g., changed to its opposite value) with some second probability. This operation is analogous to genetic mutations that have also been observed in nature.
In this way, a new population of strings is created, and the process repeats. The strings are again evaluated, and again a new generation of strings is created. Because the fittest strings are over-represented in each new population, the average fitness of the strings increases. Different strings with good fitness probably derive their fitness from having good values on different features. Thus, the crossover operation, which recombines strings, sometimes stumbles on a good combination and thereby generates a string with a higher fitness level than its parent strings. This new string is likely to become over-represented in subsequent generations because of its high fitness. Finally, the random “mutation” of features may also introduce beneficial values that increase the fitness of a string. In this way, genetic algorithms provide an effective way to search a large space of possibilities efficiently. As discussed by Mitchell (1996), genetic algorithms have been used for both engineering applications (such as predicting the stock market) and scientific applications (like simulations of real populations).
Here, I have just described a simple genetic algorithm. There are many ways that this type of system can be extended. The representation need not involve binary units; the units can each take on many values. The mapping of the representing world of units in the string to the represented world can be complex. The algorithm used to select new members of the next generation can also be made complex and can be designed to selectively favor the best strings from an old generation. Finally, there are a host of additional “genetic” operations that can be applied to strings in addition to the crossover and mutation operations described here. Many of these additional operations are also inspired by transformations that actual genes may undergo, but this is not a requirement of genetic algorithms. These changes can allow a genetic algorithm to search in complex domains, and they add new transformations that help a genetic algorithm find better combinations of feature values.
Genetic Algorithms and Cognitive Models
Genetic algorithms have been applied to cognitive tasks. One classic example is the prisoner’s dilemma game, which involves choices by pairs of people. Participants are asked to assume that they and a partner have just committed a crime and that both have been caught. Each one is held in a separate cell and is asked to testify against the partner in exchange for a reduced sentence. Each is told that the partner is being offered the same deal. The structure of the game is shown in Figure 3.5. If one agrees to testify and the partner refuses, he or she is given probation, and the partner receives a stiff sentence (say 5 years). If one agrees to testify and the partner does as well, both get moderately high sentences (say 4 years). If one refuses to testify and the partner testifies against him or her (in the reverse of the first scenario), he or she gets a stiff sentence (5 years), and the partner goes free. Finally, if both refuse to testify, they can be convicted only of a lesser charge, and both receive a light sentence (say 2 years). Researchers have used this game extensively in studies of game theory to examine aspects of cooperation. Clearly, it is in the best interests of the pair to cooperate with each other and refuse to testify; this tactic minimizes the number of years that the pair must serve. For any individual, however, if he or she is guaranteed that the partner does not testify, the optimal strategy is to defect against the partner, testify, and thereby receive probation, while the partner goes to prison for a stiff sentence.
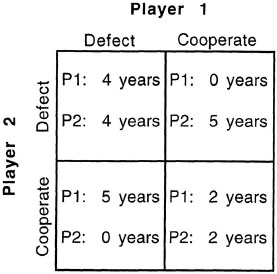
FIG. 3.5. Structure of the prisoner’s dilemma game. Each player has been accused of a crime, and each has the option to testify against his or her partner (defect) or refuse to testify (cooperate). The payoffs for the game are shown in the matrix.
In the most interesting version of the prisoner’s dilemma game, multiple “rounds” are played sequentially to allow players to use information about the partner’s previous behavior to decide what to do in the next round. A simple strategy of tit for tat is more effective than almost any other when playing a sequence of games. When using this strategy, players cooperate with their partner in the first round, and on each subsequent round they just do what their partner did on the previous round. This strategy punishes defections by partners immediately and also rewards cooperation.
Axelrod (1987) studied whether a genetic algorithm would develop some version of the tit-for-tat strategy. The strings in this system consisted of information about the previous three games played in a sequence. Each of the 64 positions in the string represented a different set of outcomes of the previous three games.11 For example, the first position represented a situation in which both players cooperated with each other in all three games. If the value in a given position was a C, then the system was recommending that the player cooperate again in the next round, and if the value was a D, then the system was recommending that the player testify (or in the language of the prisoner’s dilemma, defect). The initial strings were randomly generated. Strings were evaluated by having these “strategies” played against eight strategies that people often use when playing the prisoner’s dilemma. In 40 different runs of the program, Axelrod found that the program often developed a strategy in which it would reciprocate, as the tit-for-tat strategy would recommend. Because the algorithm found some ways to exploit the particular set of rules it was tested against, its strategy was not completely tit-for-tat.
This genetic algorithm is clearly capable of searching efficiently through a large set of possible strategies to find one that is effective. The assumption of feature independence used by genetic algorithms, however, does seem to limit their psychological plausibility. In this example, the strings consist of the 64 possible outcomes of three consecutive prisoner’s dilemma games. The choice of whether to cooperate or testify in the following round is made independently for each of the 64 outcomes. The strategies that people develop do not have this independence. The tit-for-tat strategy reduces the amount of information that needs to be remembered to determining what the partner did on the previous game and doing that. These strategies tend to group similar cases together rather than treating them all independently.
The assumption of feature independence is crucial to the effective performance of genetic algorithms. These algorithms acquire their power through genetically inspired operations like crossover and mutation. Such operations require that it be possible to arbitrarily switch parts of two strings or to arbitrarily change the value of one element in a string via mutation. If the value on one element in a string was actually determined by an element in another string or if there were structural relations among elements (as in the representations I discuss in later chapters), these operations cannot be carried out. Thus, genetic algorithms work because of the assumption of feature independence (see Lenat & Brown, 1984, for a similar discussion).
This use of independent features is also the source of weaknesses in genetic algorithms. With problems in which the solution requires finding and maintaining building blocks of solutions, genetic algorithms can have great difficulty (see Forrest & Mitchell, 1993; Mitchell, 1996, for a discussion of these “royal road” problems). The algorithms have no way of isolating particular parts of the string as being important for the perceived fitness of the string. As a result, they cannot ensure that these aspects of the string are not disrupted by subsequent operations. Nor can the algorithms focus attention on other areas that may be profitably changed to increase the fitness of the string. For search problems involving specific building blocks, representations with more explicit structure may be useful.
SUMMARY
Features are a simple form of representation using discrete symbols. Discrete symbols typically have sharp boundaries, but in some cases the boundaries are fuzzy. When features have fuzzy boundaries, there are often several whose boundaries overlap as in the feature detectors in the visual system described earlier. Because the features are symbols, they can be accessed and used by the processes that operate on them. One example of feature use was in comparison, in which the comparison process can determine both that a pair was similar (because it shared a certain number of features) and also how it was similar (by virtue of the particular features it shared).
There is only a limited structure to featural representations. In particular, features can be organized into dimensions. When a dimension is substitutive, the presence of one feature along a dimension blocks the presence of any other feature along that dimension. This structure was also evident in genetic algorithms, in which each “gene” can have many different “alleles.”
The virtue of this limited structure is that processes acting over features can treat each feature in a representation as independent of all the other features in the representation. That is, the process does not have to worry about what other features are present or how features are related to each other during processing. For example, A. Tversky’s (1977) contrast model used elementary set operations to determine the commonalities and differences of a pair. Even genetic algorithms, which use processes more complex than those of elementary set operations, still treat each feature independently. This independence allows genetic algorithms to search through a potentially large set of feature combinations efficiently. The cost of this feature independence is that genetic algorithms often fail on problems that require clusters of important features to be kept together.
The discussion of symbols led naturally to an examination of how symbols can be grounded to give them meaning. In this vein, I discussed decompositional models in which complex features can be decomposed into more primitive features until eventually the most primitive features are reached. It is assumed that primitive features can be grounded in some way, perhaps by referring to perceptual information. Thus, the meaning of any feature can be determined either because it is grounded or because it can be decomposed into more primitive features that are grounded. The notion of primitives is important to consider for all symbolic models of representation, even those that make more complex representational assumptions than the ones made by featural representations.
1English phonemes can also be described by a set of phonetic features, which are a set of mutually exclusive features that are also discrete and binary.
2Of course, as in every other aspect of psychology, the picture is substantially more complex than this. Although there are clear demonstrations of categorical perception in adults and children (and even in chinchillas), there are also situations in which people integrate speech information and visual information. The classic phenomenon of this type is the McGurk effect (McGurk & MacDonald, 1976) in which the subject hears the phoneme /ba/, sees a face mouthing the phoneme /ga/, and actually reports hearing the phoneme /da/. These effects do not argue against the use of features as a representation of phonemes, but they do argue that the connection between speech sounds and the perception of phonemes is not direct.
3For those who are unfamiliar with neuroscience, here is a brief and terribly oversimplified description of the neuron. A neuron collects electrical charge in its cell body (soma) until a threshold is reached, at which time an action potential is sent down its axon to the end of the neuron. This action potential causes chemicals called neurotransmitters to be released, and these can then affect the firing of other cells. Because neurons fire in an all or none fashion (via action potentials), it is assumed that the firing rate of the neurons carries information. Thus, the action potential itself is always the same strength, but the number of action potentials per unit time can vary.
4This is not to say, of course, that people do not have theories about organisms suggesting what features they should and should not have. Rather, having ears does not preclude the object from having a range of other features as well.
5One can object to this statement by suggesting that sentences like “Even a large mouse is small, and even a small elephant is large” are interpretable, but it is necessary to distinguish between what can be stated in a sentence and what a representation permits. Presumably, a feature dimension like size represents values on some absolute scale in mental representations. According to this view, a sentence like “That is a small elephant” uses knowledge of elephants to give it a size representation that is still large, but perhaps not as large as a large elephant. There are, of course, other ways to represent size, for example, in a relative way. On this view, representing an elephant as small would actually mean “small relative to other elephants.” Although this view of representation is appealing, it requires the ability to represent relations between objects. (I discuss representational systems capable of representing relations in chaps. 5 to 7.)
6The idea that something can have features by default goes beyond what can be done with some kinds of representations. For example, in chapter 5, I discuss first order predicate calculus (FOPC). In FOPC, a property is known to be true of an object only if it is explicitly stated about the object (or can be proven to be true of the object by the rules of logic). In this instance, there is no notion that some property can be true by default (with no other justification).
7Few AI models use certainty factors any more. Instead, they use other techniques for reasoning about strength of belief like Bayesian statistical methods (Shafer, 1996). The basic idea behind certainty factors is intuitively appealing, however, and it is worth knowing about them and the potential pitfalls of using them.
8When researchers ask people to give numerical probability estimates that particular facts are true, they give them, but there is reason to believe that these estimates are not readouts of internal certainty factors. For example, people tend to round their certainty factors to the nearest number ending in zero or perhaps five, a result suggesting that they think of the probability range in terms of a set of categories (see also Budescu & Wallsten, 1995).
9I discuss the importance of relations in perceptual representations at length in chapter 6
10In some genetic algorithms, the impact of values occurs only indirectly, a finding analogous to the phenotype in genetics. In genetics, two organisms may have the same genotype (as in identical twins), but manifest different surface characteristics on the basis of other factors like environmental richness.
11Actually, the strings had 70 places, but the other 6 were used to determine what to do in the first two games.