
Chapter 6
Structure in Perceptual Representations
PERCEPTUAL REPRESENTATION AND PERCEPTUAL EXPERIENCE
For those of us who are normally sighted, the visual world is one of the most compelling facets of psychological experience. Without effort or attention, merely opening our eyes reveals a coherent sense of the outside world. Visual experience provides information about the three-dimensional layout of the world and about the size, shape, color, texture, and motion of objects, and this information is rapidly integrated with information from other perceptual modalities.
Visual perception is the prime example of a central paradox in cognitive science: What is difficult for people to do is easy for computers, but what is easy for people to do is difficult for computers. The apparent ease of visual perception belies the massive amount of processing needed to transform the two-dimensional patterns of light that strike the two retinas into detailed visual experience. The huge processing load of visual perception is obvious from two converging lines of evidence. First, studies of the anatomy and functionality of the brain reveal that a significant amount of the cortex of the human brain is involved in visual processing. Second, computational models of vision have proved difficult to construct. Creating robots that see is not simply a matter of attaching a video camera to a computer and writing a simple program. Substantial research has been devoted to specific problems like extracting edges from scenes and finding corresponding aspects of the visual images received by each eye (e.g., Horn, 1973; Kosslyn, 1994; Marr, 1982).
The complexity of visual processing is important to bear in mind because the representations that people have presented in models of vision and perception may seem inconsistent with visual experience. Conscious visual experience is seamless: Objects have obvious relative sizes and positions in space. It is not obvious, however, how multiple representations are integrated to form such a uniform and compelling view of the world. I do not provide a theory of the unity of perceptual experience or even attempt to summarize the literature on visual perception; that effort would require a book to itself. Instead, I follow up the themes of chapter 5 by discussing structured representations that have been presented in models of visual perception. I begin with a discussion of structured representations in perception and object recognition and extend my discussion to include visual imagery. I end with an examination of the relation between perceptual representation and spatial language.
STRUCTURE IN VISUAL REPRESENTATION
In chapter 5, I introduced structured representations, which involve explicit links that encode relationships among properties of objects. Attributes take the entities they describe as arguments; relations explicitly relate two or more other representational elements (which could be objects, attributes, or even other relations). This structure seems intuitively plausible for many complex concepts. For example, as I discuss in chapter 7, events seem to have a natural structure that involves distinguishing between the various actors in an event and encoding the actions they perform as well as carrying information about causal relations to explain why these actions are carried out.
The intuitive basis for structured representations of visual scenes is less obvious. The unitary perceptual experience of seeing does not seem (at first glance) to be compatible with representations involving relations and connections to the things they relate, but the notion of perception as a veridical “picture” of what is in the world begins to fade as one looks closely at perception. Gestalt psychologists (e.g., Goldmeier, 1972; Wertheimer, 1923/1950) carried out classic work on the ability of the human perceptual system to organize the world. Their work demonstrated that perception is not simply a true readout of the outside world. Instead, the perceptual system imposes a structure on the world.
Figure 6.1A shows two lines, each composed of seven black dots that, in each line, are evenly spaced (Goldmeier, 1972). The two lines differ only in the relative spacing of the dots, which are much closer together in the bottom row than in the top. Perceptual experience of these rows is different, however: The bottom row appears to be organized into a line much more strongly than does the top row, which looks like a group of dots all lined up. Goldmeier (1972) suggested that there is a tension between seeing the material and the form of a percept. In this example, the dots are the material, and the line is the form. Increasing the proximity of the dots increases the likelihood that the perceptual system promotes seeing the line (i.e., the form) rather than just a collection of collinear dots (i.e., the material).
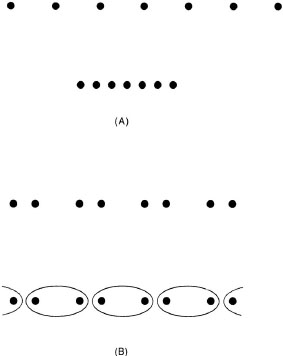
FIG. 6.1. Sample items demonstrating Gestalt principles. A: material and form; B: grouping.
Figure 6.1B shows another way that the perceptual system can organize a stimulus. In the upper row of this figure, the dots seem to be organized into four groups of two, where the groups are defined by their proximity; thus, the perceptual system seems to group elements that are near to each other. In the lower row, however, the same dots have ovals drawn around them so that the ovals enclose dots that are far apart. In this case, the dots in each oval seem grouped together, even though the spacing between the dots is the same as in the upper row of the figure (Palmer, 1992). Thus, the perceptual system uses elements of the stimuli in the world to make guesses about what is in the world, and the percept reflects these guesses. The percept is thus a representation of the stimulus, but not a veridical copy of it.
The Gestalt psychologists formulated several “laws” of perception characterizing the types of elements that were likely to be grouped together, but they did not present detailed descriptions of perceptual representations. Later researchers began to suggest how perceptual representations were structured. In Figure 6.2 there are many possible ways that the top configuration can be broken into component parts; two possible breakdowns are shown at the bottom of the figure. For the present purposes, what is most important is that the middle decomposition seems more natural than the bottom decomposition. This intuition was confirmed by participants in a set of studies by Reed (1974). Participants were shown a figure like the top one in Figure 6.2, and were asked to verify whether the next part shown was contained in the pattern. Participants responded more quickly and accurately to some parts (like the middle one in Figure 6.2) than to others (like the bottom one in the figure), a result suggesting that the figures were being decomposed into parts. Palmer (1977, 1978b) carried out a similar set of studies.
Another proposal about the way the perceptual system imposes structure on the visual world comes from Leyton (1992), who suggested that the perceptual system is specially attuned to symmetries in the world. The door of a new car often is smoothly curved; a dent in this smooth curve is immediately obvious and calls attention to a force that has acted on the object. In contrast, no point on the smooth curve of the door of an unblemished new car calls for attention, because there is no visual evidence of causal forces acting on the door. The perceptual system may interpret visual input in terms of causal forces acting on an item, and asymmetries may be markers of these causal forces. I will return to this proposal later.
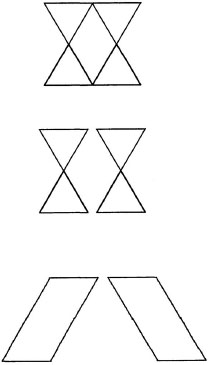
FIG. 6.2. Sample configurations similar to those used by Reed (1972) and subcomponents of the configurations.
The idea that the visual system constructs representations of the world is also suggested by the nature of vision itself. When talking about vision, it is often handy to ignore the fact that visual scenes are processed through a succession of fixations. Nevertheless, the visual system is not like a video camera that takes in all information in some (reasonably wide) angle in the direction in which it is pointed; the eyes constantly move, scan the scene, and focus on particular aspects of the world. This scanning is necessary because the retina of the eye is not uniform. Instead, it has different sensitivity at different points. There is a high degree of concentration of light-sensitive cells in a small area in the center of the retina called the fovea with fewer light-sensitive cells in the periphery. Further, the relative density of color-sensitive cells is greater in the fovea than in the periphery. The net effect of this structure is that the stable perception of the visual world is a product of the integration of many fixations (as well as the suppression of the smeared images that occur as the eyes move). It is possible that the visual information from a pair of successive fixations is matched through a point-by-point matching of successive images, but this method would be computationally intensive and subject to problems from changes in low-level factors like light intensity. The process of finding correspondences between successive fixations is probably augmented with higher level representations of the objects in the world, in addition to information about lower level aspects of scenes.
These examples do not support any particular model of representation in perception. They simply demonstrate that the perceptual system imposes a structure on the input it receives and that these biases are consistent with the assumption that the perceptual system decomposes visual objects into parts. In the next section, I discuss some specific proposals that have been made for structured representations in perception.
Structured Representations of Objects
Objects are a particularly important aspect of visual experience. It seems a trivial observation that our world is segmented into objects, even for very young children (Spelke, 1990). Yet, much work must be done on the pattern of light that reaches the eye to determine which aspects of a scene are coherent objects. Because of the salience of objects in vision and the importance of vision for recognizing objects in the world, many theories of perceptual representation have focused on object representations. Most of these theories are primarily concerned with object recognition.
Marr (1982) suggested the general form of a theory of object representation suitable for object recognition. His proposal focused on a 3D model representation with three central assumptions. First, object recognition takes place with representations defined in object-centered coordinates. Representing something in object-centered coordinates means that the location of each point in an object is defined relative to other parts of the object itself rather than to the person viewing the object. For example, in object-centered coordinates, the head of the schematic human figure in Figure 6.3 is given relative to other parts of the person like the torso and arms.
Marr’s assumption that object representations have object-centered coordinates is interesting because representation in early visual processing is probably viewer centered. A viewer-centered representation is one in which the relative locations of elements are defined with respect to the viewer. For example, from where I am sitting right now, there is a green Gumby figurine at eye level, and just below that is the top edge of my computer monitor. If I move, the viewer-centered locations of these objects move as well. If I stand on my head, the edge of the monitor is above the feet of the Gumby figurine. Early in the visual process, the retina receives only a pattern of light, from which the visual system must extract key information, such as sharp discontinuities in the intensity of the light, that might signal edges of objects. Object-centered representations cannot be created until the visual system determines what patches of light are likely to form coherent objects. According to Marr, extracting information like edges or textures occurs in viewer-centered coordinates, but object recognition involves matching current input to stored representations of objects seen previously. As an observer’s viewpoint changes, the features in the image change as well. Thus, if the representations used for object recognition are cast in viewer-centered coordinates, there have to be many different views of each object in memory to account for the ability to recognize objects from a variety of perspectives. Marr suggested that it is more efficient to store object-centered object representations.
The second main assumption of Marr’s 3D model representation is that it involves generalized cones and the relations among them. A generalized cone need not be cone shaped: The term generalized cone denotes that objects need not be cylinders (which have circles of the same radius at each end). Instead, the cross-section of a generalized cone may get wider or narrower along its main axis (i.e., the longest axis of the cone). A generalized cone abstracts across the details of a solid shape. For example, if a cylinder is used as the representation of a metal garbage can, it may abstract over the fluting that is a common design on these cans. These generalized cones are the primitive elements of the 3D model representations, and Marr selected them because he assumed that determining cones from information available in lower level visual processes was a straightforward process.
More than one generalized cone can be combined into the representation of an object to store more complex shapes. Figure 6.3 shows several objects formed from combinations of cones. Representations containing two or more cones must also have relations that determine the relative positions of the cones, although Marr was not specific about the nature of these relations. He assumed that the relations could be stated in terms of vectors. In particular, each generalized cone was assumed to have a major axis, typically the longest axis of the cone. The point of contact of the major axes of two cones and the angle between them define the relation between pairs of cones in the representation.
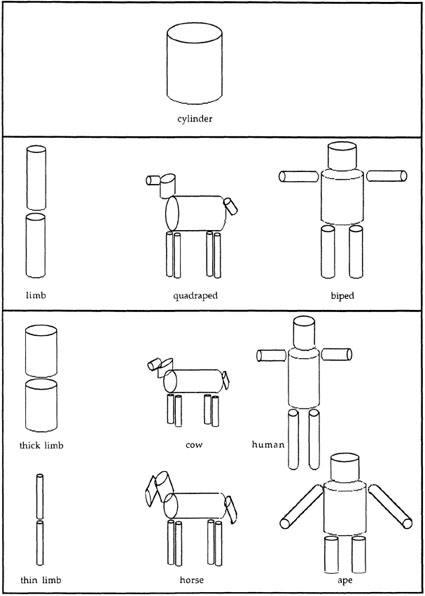
FIG. 6.3. Objects represented by using a three-dimensional model constructed from generalized cones. Drawn after Marr (1982).
The representations in Figure 6.3 are highly abstracted from the details of visual objects. The human figure in the middle of the third row has the basic components (head, torso, arms, legs), but lacks many other aspects (including parts like hands, fingers, and feet as well as color and textural features). On the basis of people’s ability to identify line drawings and stick figures, Marr assumed that many color and textural details are not required for object recognition. Specific aspects of shape probably do need to be represented, and Marr assumed that the 3D model representations were hierarchically structured, with more specific representations of components being nested in more abstract representations. An example of hierarchical structure is shown in Figure 6.4. In this figure of a human, the arm is decomposed into a pair of cones joined at the elbow. The wrist and hand can likewise be nested in this description. On this view, associations between more specific and more general representations of the same aspect of an object can be used during recognition.
Marr assumed that object recognition involves finding homologies between the representation of a new object in the visual field and the representation of stored objects. The new representation is compared to previously stored representations, and correspondences, of both common parts and common relations, are found between them. Although Marr did not spell out this process, it seems similar in spirit to the process of structural alignment described in chapter 5, in which elements in pairs of structured representations are placed in correspondence.
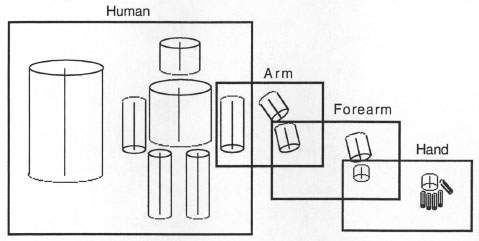
FIG. 6.4. Hierarchical structure of 3D models. Drawn after Marr (1982).
Biederman proposed a related view of representation for object recognition (1987; Hummel & Biederman, 1992). His theory, called recognition-by-components, also focused on the role of primitives and the relations among them in object recognition. A brief description of this theory was presented in chapter 3 when I introduced the notion of primitives. In Marr’s theory, the primitive volume elements were assumed to be generalized cones, but no constraints were placed on what sorts of generalized cones they were. In most of Marr’s work, cylinders stood for the generalized cones. Biederman extended this work by positing a specific set of primitives consisting of 36 generalized cones that he called geons. The geons can be developed by changing properties of a prototypical generalized cone as shown in Figure 6.5. A prototypical geon like a cylinder can vary along a number of dimensions: Instead of round edges, it can have straight edges; instead of a straight axis, it can have a curved axis; instead of parallel sides, it can have sides that expand or sides that expand and then contract like a cigar. Finally, the geon can have complete rotational symmetry like a cylinder, it can have reflectional symmetry like an oval, or it can be asymmetric. Combinations of these properties define the basic set of 36 geons.
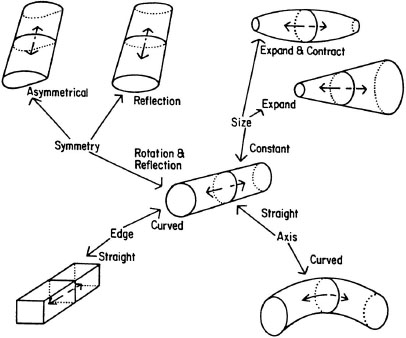
FIG. 6.5. Geons and the properties that derive them. From I. Biederman (1985). Copyright © 1985 by Academic Press. Reprinted with permission.
Geons can be grounded in simple aspects of the visual world; in particular, they can be recognized by attending to nonaccidental properties of images, which are evident in views of objects from a variety of vantage points. For example, if two edges in an object are parallel, they appear to be roughly parallel when viewed from a variety of angles; thus, parallel lines are a nonaccidental property. Other nonaccidental properties are symmetry and the straightness and collinearity of lines. Geons differ from each other in terms of their nonaccidental properties; for example, a cylinder differs from a cone and a cigar by having straight parallel lines along its major axis. Because geons are based on nonaccidental properties, they should be easy to identify across a variety of views of an object. In this way, geons ease the identification of objects from multiple viewpoints. The focus on nonaccidental properties also helps explain why objects can be difficult to identify from certain vantage points. Figure 6.6A shows a line drawing of a bucket, which is fairly recognizable. Viewing the bottom of the bucket when it is turned over, however, is a different matter: One sees two concentric circles (Figure 6.6B). These concentric circles are not a nonaccidental property; they are accidental because they are seen only when looking down at the bucket when it is turned over. Objects can be very difficult to identify in configurations with compelling accidental properties.
Objects are not represented with a single generalized cone but are composed of many geons. When an object is represented by many geons, its representation is structured by having relations that describe the spatial configuration of the object. Different objects can have the same set of geons in their representations related in different ways. With a small set of geons and relations, many objects can be represented in much the same way that a finite vocabulary of words and a syntax for combining these words can be used to construct an infinite set of sentences. Biederman suggested that information about the relationships among geons is contained at the vertices of edges in objects, where geons tend to come together. The top image in Figure 6.7 shows an object with line segments removed only between vertices. The middle object has line segments removed at the vertices. The top figure seems easier to identify than the middle one, consistent with the assumption that information about relations between elements is captured at vertices. Biederman (1987) provided a number of examples demonstrating this phenomenon.
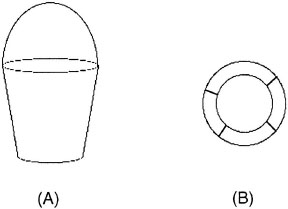
FIG. 6.6. A: Typical view of a bucket with nonaccidental properties. B: Bottom view of a bucket with salient accidental properties.
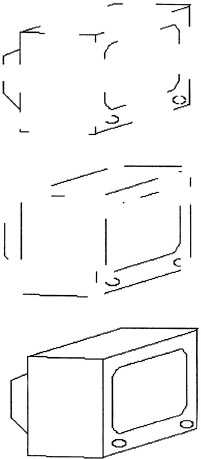
FIG. 6.7. Drawings of a television set; line segments removed from between the vertices (top figure) or at the vertices (middle figure).
The theories of object recognition developed by Marr and Biederman both assume that visual object representations consist of primitive elements and relations between them. These primitive elements are identified by nonaccidental properties of visual images. In this way, the viewer-centered representations of early vision can be translated into object-centered representations that are more suitable for object identification. Comparing the representation of a new object to the representations of objects already in memory involves some process of structural comparison. One possible candidate for this process is the structural alignment process described in chapter 5. Structural representations seem most appropriate for describing objects with easily discernible parts like tables, chairs, or standing animals. Objects that do not have obvious part structures like loaves of bread or bushes may not be well characterized by structural descriptions (Ullman, 1996).
Metric Information in Visual Object Representations
The previous discussion focused on structural descriptions in the recognition of visual objects. These structural descriptions have a nice property of abstracting away from the specific image in the world and allowing the determination of commonalities that can be masked by differences in specific properties of the forms of objects. For example, one can match the legs of two images of birds, even if they differ slightly in length or thickness. Matching these parts requires some abstraction away from the specific forms of the images.
Despite the advantage of abstracting away from image properties, one also needs some information about metric aspects of the visual world. For example, as I write, my coffee cup is next to my computer and in front of my telephone (in viewer-centered coordinates). If I reach to pick up the cup, I do not simply reach next to my computer; unless I reach a certain distance from it, I may knock over the cup or pick up something else. Knowing that there is a handle on the left side of the cup can be useful, but it is also important to know the particular location of the handle. This information is important for grasping the cup and also for helping me to identify the cup as mine rather than as someone else’s. This metric information may be quite difficult to talk about but may still be represented (Schooler & Engstler-Schooler, 1990).
Kosslyn (1994) suggested that relational and metric information are treated separately in the visual system. He posited that the right hemisphere of the brain is specialized to handle metric representations of objects, whereas the left hemisphere system is specialized to handle qualitative relational information. I do not attempt to evaluate this claim here except to note the need for a quantitative representation of space in perceptual representations, and the possibility that distinct brain systems process this information.1
Ullman (1996) stressed this point and suggested that a variety of representational and processing systems must work together to permit objects to be recognized. Although he conceded that structural descriptions of objects are useful in many situations, he thought that some object recognition requires representations that store metric information. This style of representation may be particularly important when objects are defined by changes in contour rather than by a set of parts. For example, the tool in Figure 6.8 does not have any good parts associated with it, but Ullman suggested that stable features of the object can be determined by finding extremes in curvature and centers of enclosed regions (like those shown in Figure 6.8B). These features can be used to compare the object to stored image representations in memory, and the image can be stretched and rotated to make the images match as best as possible. After performing this process, which Ullman calls image alignment, the degree of match between the stored and new images can be determined by summing the distance between each point in the new image and the closest point in the stored image. The object can then be identified as an example of the class depicted by the best-fitting image in memory.
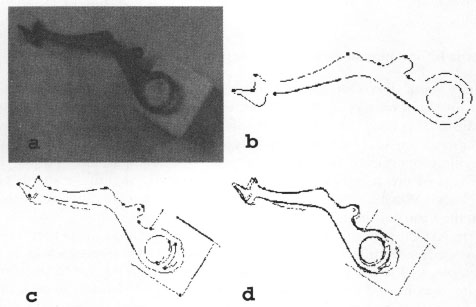
FIG. 6.8. Example of image alignment. From D. P. Huttenlocher and S. Ullman (1990). Copyright © 1990 by Kluwer Academic Publishers. Reprinted with permission.
The structural description methods of representation avoided the problem of viewpoint dependence by creating object-centered representations. The image alignment model of object recognition is viewpoint dependent. To allow objects to be recognized from many different viewpoints, Ullman suggested that many different images of the same object are stored and that the current image is compared to many images of the same object as well as to images of different objects (see also Tarr & Pinker, 1989).
By storing images in visual memory, the visual system can have access to metric information about objects not available from the representations posited by most structural description theories. For example, imagine trying to identify specific models of cars. All of these cars are likely to have the same parts (wheels, body, windows, doors). For most cars, the parts are likely to be related in about the same way (the wheels are under the body of the car; the windows are set into the doors). What differs is metric information about the cars. A Volkswagen Beetle can be distinguished from a Honda Civic because of differences in the curvature of the roof, not because of the presence of specific parts or even qualitative differences in size. Further, as discussed earlier, motor movements require more specific information about the distances in the visual world than is available from a structural description.
Ullman proposed that both object-centered representations (like structural descriptions) and viewer-centered representations are used by the visual system to mediate object recognition. On this view, a combination of the image alignment process and a structural description process may provide a robust mechanism for visual object recognition. A combination of approaches to representation may be more powerful than any single representation-process pair. In general, multiple complementary mechanisms may work to solve difficult cognitive problems. This proposal for redundancy is not a cop-out on the part of researchers who cannot find the “right” answer; as I discuss in chapter 10, this redundancy is fundamental to thinking about hard cognitive problems. Different kinds of representations have different strengths and weaknesses, and a combination of representational approaches is the only way to assure that a system provides a robust solution to the problems it is designed to answer.
Causal Information in Visual Object Representations
The previous two sections focused primarily on visual representations used for object recognition. These representations make an assumption that is easy to miss: that the point of visual representation is to store information about what the world outside looks like. There must be explicit representations of properties like edges, boundaries, or relations between parts of objects. This assumption seems plausible enough, although it is not necessary. Gibson (1950, 1986) argued that enduring representations of the properties of images in the visual world are not needed. Instead, he argued that people perceive aspects of the world in terms of their affordances. On his view, the goal of perception is to provide functional information about objects in the world such as whether things can be grasped, picked up, or walked around. (I discuss Gibson’s views about perception further in chap. 10.)
Visual representations may involve determining properties beyond the sizes and shapes of objects or their parts. One interesting theory of this type was developed by Leyton (1992), who argued that the purpose of vision is to extract causal information from the environment. He argued that symmetry in the world is a sign of the absence of causality and that asymmetries in the world reflect past causal forces. A simple example of this causal view is shown in Figure 6.9. At the right is a square. A square is symmetric in a variety of ways: All the sides are the same length, and all the angles are equal. A rectangle, like the one just to the left of the square, has two sides that are longer than the other two. Leyton suggested that the visual system interprets the longer sides as having been expanded by some force. Similarly, a parallelogram has angles that are not equal. Leyton argued that these can be interpreted as coming from a rectangle that has been sheared. Finally, the tilted parallelogram at the far left in Figure 6.9 has angles that diverge from the vertical and horizontal planes that help define the visual field. Leyton argued that this tilted parallelogram is interpreted as having been rotated by a force. On this view of vision, visual representation is not meant for representing perceptual properties of the visual world but rather for representing causal forces in the world.
Leyton presented a detailed grammar of the forces likely to have acted on objects to create shapes. For example, a protrusion in a circle, like that shown in Figure 6.10A, can be detected as a set of changes in the curvature of the object. This protrusion can be interpreted as an inner force that has pushed outward. In contrast, an indentation in a perimeter can be interpreted as a resistance from the outside. In Figure 6.10B, the indentation in the center is viewed as the product of a resisting force pushing inward. The protrusions on either side of the indentation show evidence of forces pushing outward on either side of the resistance. For example, if one sees a dented car, then, just as in Figure 6.10B, one may view it as the product of a force pushing inward. Attention is drawn to this asymmetry because it is the locus of causal information in the environment.
The detection of axes of symmetry in objects occurs broadly in vision but can also take place in object recognition. Leyton suggested that the determination of axes of symmetry in complex objects in combination with smoothing of small local perturbations on the surface of objects can lead to a representation that contains generalized cones like those suggested by Marr and Biederman. On Leyton’s view, these generalized cones are used because they are easily derived from the detection of axes of symmetry and not because of the presence of nonaccidental properties or because cylinders are useful approximations of object shapes that make good primitives. Finally, the detection and explanation of asymmetries can occur for objects without good “parts,” objects that Ullman (1996) suggested may not be amenable to representation by structured visual representations.
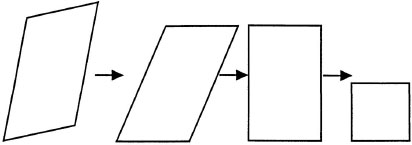
FIG. 6.9. Causal transformations of a rotated parallelogram derived from asymmetries like those discussed by Leyton (1992).
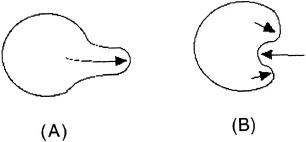
FIG. 6.10. A: Circle with a protrusion; B: Circle with an indentation.
An interesting aspect of Leyton’s theory is the recognition that visual perception itself requires the detection of asymmetries in the environment, although in this case the asymmetries are in the environment of light. If a steady uniform beam of light is shined at the eye, there is nothing to see. Only when light bouncing off surfaces causes asymmetries in the pattern of light that hits the eye is there anything to detect. Color involves the asymmetric absorption of some wavelengths of light rather than others. Rotation of an object in space leads to the compression of an image selectively along the dimension of rotation. Uniform fields that recede into space lead to increases in the density of points. In all these ways, the visual system uses asymmetries in the environment as cues to important aspects of the visual world. According to this view, asymmetries in visual representation are marked as elements to be explained in the process of comprehending a visual scene.
It is probably going to far too assume that the only important thing in visual representation is information about causal forces in the world. One important aspect of vision is that it provides information about the world in the absence of a specific goal for how the information is used. People may want to navigate in the world or to identify objects or to ponder the aesthetic value of a pattern. The visual system provides information suitable for all these tasks. In contrast, any functional approach, whether based on affordances or on the extraction of causal information, assumes a set of goals that the organism may have relative to the information. Any information not relevant to these goals is unavailable. Although it is probably helpful to get causal information about forces in the world, it cannot be the only information yielded by the perceptual system.
STRUCTURE IN MENTAL IMAGERY AND MENTAL MODELS
One of the fiercest battles about representation in cognitive science was fought over mental imagery. Just to ground the phenomenon of interest, answer the following three questions.
![]()
![]()
![]()
All three questions seem answerable, but Question 1 is qualitatively different from the other two. Answering “Abraham Lincoln” requires accessing a stored fact that one was likely to have been told (perhaps many times). In contrast, answering Questions 2 and 3 probably does not involve accessing stored answers. One may never have pondered these questions before. Many who answer these questions report using mental imagery. For Question 2, they may form a mental image of the house they lived in at the age of 10 and then count the windows in the image, or they may take a mental tour of the house and count the windows in each room. For Question 3, people often imagine a collie and a horse standing side by side and compare the height of the top of the dog’s head to the height of the bottom of the horse’s tail.
This self-report of the utility of mental imagery has spurred numerous investigations of people’s ability to use and manipulate mental images. As discussed in chapter 2, early researchers of imagery examined whether people can carry out the same transformations on mental images as they can on real images, such as rotating or stretching them. Shepard, Metzler, and Cooper (Cooper, 1975; Metzler & Shepard, 1974; Shepard & Cooper, 1982) presented subjects with pairs of two- and three-dimensional objects and asked them to make same-different judgments. On some same trials, identical objects were rotated slightly either in the plane of the image or in depth. The time to respond to these items was linearly related to the difference in orientation. Regression lines fitted to these data yielded a slope of about 2 milliseconds per degree of rotation. The data suggested that people carry out these same-different judgments by mentally rotating the objects to a common orientation before comparing them.
In another classic set of studies, Kosslyn, Ball, and Reiser (1978) had people learn a map of a fictitious island. After learning this map, the investigators asked people to imagine the map and to travel from one landmark to another. Scanning times for this mental map were longer for objects far apart on the map than for objects near together, a result suggesting that mental scanning involves traversing the region between landmarks. Zooming in on the map so that its mental image was large yielded longer scanning times than did zooming out on the map so that its mental image was small. These data suggest that mental images are like real images in many ways.
The debate that raged in cognitive science involved determining in what way a mental image resembled a real image. On one side, there was ample evidence that mental images could be transformed like real images and that they contained some amount of metric information (that is, information about the distances between points in the image). On the other side was the problem that if a mental image was simply a copy of a real image, there would need to be some process that could “see” the mental image and process it. Otherwise, there is a danger of an infinite regress of images: There would have to be a homunculus looking at the internal image, and the homunculus would have an image in his or her head, and there would be a homunculus to read that image, and so on. Furthermore, not all tasks that can be done with real images can also be done with mental images. For example, it is not possible to count the stripes on a mental image of a tiger, even though the stripes on a real image can be counted (Pylyshyn, 1981).
Proposals for the representations used in mental imagery have begun to resemble proposals for the representations of visual objects (Hinton, 1979; Kosslyn, 1994; Tye, 1991). Indeed, Kosslyn (1994) suggested that the visual system used mental images to assist in object recognition. For example, an activated mental image can help fill in obscured details from the visual world. On this view, it should be no surprise that mental images use the same kinds of representations as do visual object representations. Kosslyn further pointed out that one reason why people may not be able to carry out all the same operations on mental images that they can on visual images is that some operations on real images require multiple fixations. Multiple fixations are not possible on mental images, because the mental image is processed in visual buffers that are used to facilitate the integration of visual information from different fixations. Counting the stripes on a tiger requires scanning across the tiger, making a number of successive eye fixations, and counting the stripes along the way. The mental image cannot be similarly scanned, because the image is processed in areas of cortex far down the line from the retina.
In addition to arguments that mental images can play a role in object recognition, there are also demonstrations of imagery phenomena compatible with the presence of structure in mental imagery. Hinton (1979) produced a compelling example: He asked people to hold a finger about 1 foot off the surface of a table and then to imagine a cube with one corner touching the finger and the diagonally opposite corner touching the table at the point of the table directly below the finger in the air. The imagined cube should appear to be standing on its corner. Then Hinton asked people to point to the other corners of the cube. Whoever is unfamiliar with this example should try to accomplish it.
It is quite difficult to do this task correctly. A picture of a wire-frame cube standing on its edge is shown in Figure 6.11A. Many people point to only four corners in the air, even though there are six more corners of the cube (in addition to the ones touching the table and the finger). People often put these four corners on the same plane arranged in a square. As shown in Figure 6.11A, the remaining six corners are not in the same plane, but are arranged in a shape like a crown. Hinton suggested that people have difficulty with this task because of the way their representations of the cube are structured. The default structure is as a pair of squares separated by edges. Hinton repeated the cube task by asking people to imagine a cube on a table in front of them with one face pointing at them. Then they were to imagine tilting the cube away from them so that it rested on its back edge, with the diagonal edge vertically above it (as in Figure 6.11B). When asked to point to the corners of the cube in this task, people had no difficulty. This finding is compatible with the default structure. A second possible representation that people can generate is as two tripods extending from opposite corners, where each tripod is rotated by 60 degrees, and the alternating legs of the two tripods are connected to form the remaining edges of the cube. This structure requires keeping track of more edges than does the double square representation and hence is more difficult to process. Of central importance for this discussion is simply that mental images do appear to have structure and that different ways of structuring an image can change the relative ease of processing the image.
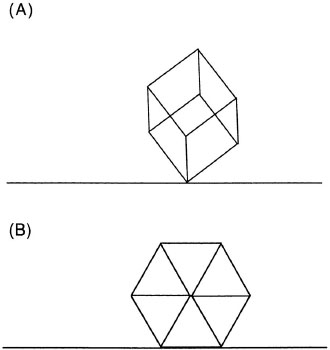
FIG. 6.11. A: Cube resting on one point with the diagonal point directly above it; B: Cube resting on one edge.
As previously discussed, researchers have suggested that visual object representations contain information about relations among parts as well as metric data that encode specific information about distance and geometric properties. Likewise, there is some evidence that mental images have information about both structural and metric properties. If mental images had information only about parts and relations among parts, it would be very difficult to form a mental image and then find emergent properties of the image. In contrast to this prediction, Finke, Pinker, and Farah (1989) gave people simple descriptions such as this:

With descriptions of this type, on nearly 50% of trials on which they were able to do the correct transformation, people interpreted this item as a tree. These identifications required a different segmentation of the object into parts than was given in the initial description. Thus, people’s ability to interpret these mental images as pictures suggests that some amount of metric information was also incorporated into the images.
It is unclear how visual representations and mental images preserve metric information. One possibility is that images involve some kind of array representation, in which the image is stored as a two-dimensional array of pixels with filled points distinguished from empty points (see the discussion of Knapp & Anderson’s, 1984, model in chap. 2). Ullman’s (1984, 1996) image alignment mechanism involves this kind of array representation. Kosslyn (1994), who also suggested that metric spatial relations are important to visual processing, was vague about the way metric information is represented.
The potential problem with array representations of metric information is that processes operating over them must be defined. An array does preserve geometric relations like angles between lines and contains more precise information about the relative location of elements in an image than is contained in general categorical relations like beside or near. Some process must actually calculate the angle between the lines or determine the relative distances between elements for an array representation to be useful.
Defining processes that operate successfully on arrays has proved difficult. One reason for this difficulty is that arrays are limited in their spatial resolution, and transformations of objects in arrays tend to lose information. The processes that transform images in an array have to reason about the behavior of each element (pixel) independently, rather than use a higher level description of the object being transformed. Figure 6.12 illustrates the problems with local transformations. In this figure, I rotated a square in a computer drawing package through 180 degrees in 12 unequal steps. The 90- and 180-degree rotations are marked on the figure. Each of these rotations is no longer a clear square; the lines become progressively more diffuse with successive rotations. To get a computer drawing package to make smooth rotations of figures requires a mathematical description of the object as a square rather than a pixel representation of it. Because of this difficulty in transforming images, it has been difficult to provide accounts of phenomena like mental rotation by using array representations.
One issue that I have ignored in this discussion is the status of the mental image itself. When many people have performed tasks that involve mental imagery, they have reported having a conscious experience similar to the experience of looking at objects in the world (although perhaps not as rich). Some have argued that the conscious experience of the mental image is crucial to the use of imagery; others have argued that the experience occurs as a byproduct of the processing done while performing imagery tasks. Although this debate is interesting (and is captured in many references cited in this section), it is not relevant to the representational issues at hand. Mental images have representations, and these representations are quite similar to those required by the visual system for other tasks. This observation provides no way of resolving the importance of the conscious experience of mental images.
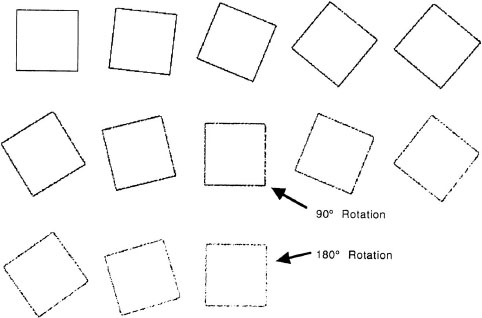
FIG. 6.12. Successive rotations of an array representation of a square. The 90° and 180° rotations of the square marked on the figure are no longer clear squares like the original.
To summarize, mental images are not simply pictures in the head; they use the same kinds of representations that were proposed in discussions of visual objects. Mental imagery seems to rely on structural representations in which parts are bound together by relations. The particular structure used to represent an item determines what mental transforms are easy and difficult to do on the image. Despite the centrality of structured representations in imagery, some information about geometric properties, which allow the creative use of imagery to find emergent perceptual properties, must also be preserved.
VISUAL REPRESENTATION AND LANGUAGE
There is often a tension between perception and language. The common adage “A picture is worth a thousand words” attests to the difficulty of giving precise descriptions that capture the essential aspects of visual information in language. Nonetheless, there is an important relationship between visual representation and language. People can talk about space, and indeed notions of space seem to pervade language use. Language may direct attention to aspects of visual scenes that are likely to be important. In this section, I examine two places in which visual information and spatial language interact. First, I discuss the use of spatial language in general and then explore the use of spatial models to interpret discourse about scenes with a spatial extent.
Spatial Language
Although there are many ways to talk about space, an intriguing aspect of language is the system of spatial prepositions. Prepositions are a class of words that specify relations among elements in sentences. Most languages have only a small number of prepositions (particularly relative to the number of nouns and verbs), and so they are easy to study exhaustively. For this reason, authorities have intensively studied preposition systems of a variety of languages, and other work has contrasted the prepositions used across languages. In this section, I begin with a cursory overview of linguistic work on prepositions to motivate the discussion of spatial representation and then examine the relation between this work and proposals for visual representation.
An Overview of Prepositions. Many prepositions in language have a primary meaning that is spatial. The English prepositions on, in, over, above, behind, and near are primarily spatial terms, although they can be used in a variety of other circumstances as well (Lakoff, 1987; Lakoff & Johnson, 1980). Prepositions exist in all known human languages, and all languages have many prepositions that deal with space. Despite this similarity, prepositions in different languages treat space and objects in space differently. In this section, I examine a few general characteristics of spatial prepositions and their relation to perceptual representations.
Many researchers have pointed out that prepositions take an abstract functional view of space (Bowerman, 1989; Cienki, 1989; Herskovits, 1986; Landau & Jackendoff, 1993; Regier, 1996; Talmy, 1983; Vandeloise, 1991). First, spatial language involves spatial relations between elements. These elements are often objects (The airplane is above the house), well-defined parts of objects (He has a good head on his shoulders), or locations (Chicago is near Lake Michigan). Second, prepositions typically distinguish between their arguments. One, which I call the landmark, is typically more fixed in location or prominent than the other (which I call the trajector).’2 Third, only some aspects of objects and of space seem to matter for prepositions. Talmy (1983) pointed out that prepositions may provide information about the relative width of the dimensions of objects but not the specific shapes. For example, one can say:
![]()
or
![]()
despite the fact that tennis courts are typically rectangular but lakes are not as regularly shaped. These sentences are better used, however, as descriptions of statements for situations like those in Figure 6.13A, in which the trajectory of motion traverses the shorter dimension of the landmark than for situations like the one in Figure 6.13B, in which the trajectory of motion traverses the longer dimension of the landmark. These cases are better described using prepositions like up or down as in:
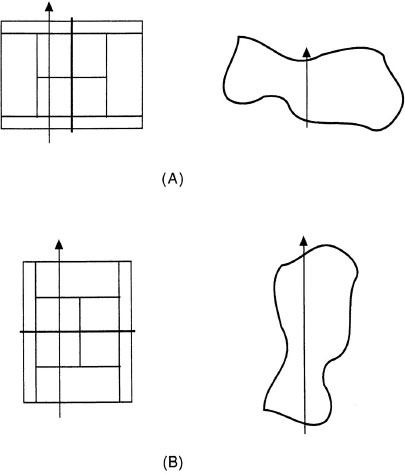
FIG. 6.13. (A) Good and (B) bad examples of movement across a surface.
![]()
The shape of objects can be eliminated altogether for prepositions that treat one of the elements as a point. Herskovits (1986) suggested that the preposition at treats the landmark as a point. Large locations must be far away for this preposition to be used properly. While standing on a lake shore looking at a boat, one cannot say:
![]()
but one can use this sentence if he or she is in Manhattan and the boat is on a lake in upstate New York. In the latter case, the lake is far enough away to be treated as a point.
The preposition at has a number of other related uses as well (Herskovits, 1986). Not only does it suggest nearness to some point; it also often carries the assumption that the landmark is used for its intended function. Thus, the sentence:
![]()
implies that Betsy is working at her desk. The sentence:
![]()
carries with it more of a sense that Ed is shopping than does the related:
![]()
These examples demonstrate that prepositions carry with them information about both spatial relations associated with objects and the way that actors interact with objects.
Two other aspects of prepositions are important for this discussion. First, as the discussions of across and at should make clear, prepositions can refer either to trajectories or to static relations between elements. Second, there are many ways of conceptualizing spatial relations, and existing languages use different ways. A number of linguists have pointed out that a speaker of English located at the point of the observer in Figure 6.14 would say:
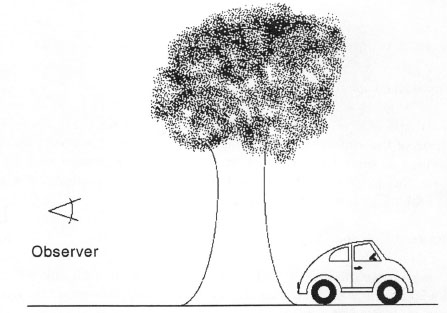
FIG. 6.14. Demonstration of the deictic use of the English preposition behind.
whereas a speaker of the African language Hausa would use the equivalent preposition for “in front of” (Vandeloise, 1991). English and Hausa differ in what is considered to be the front of an object in relation to a deictic center (where a deictic center is a location, like the current position of the speaker, which must be fixed before the rest of the relation can be interpreted).3 In English, the front of an object is the one facing the deictic center, whereas in Hausa, the front of an object is the face oriented in the same direction as the object at the deictic center. Some of these aspects of preposition use are likely to reflect the representations underlying prepositions; others may reflect convention in a particular language (Herskovits, 1986; Regier, 1996).
Representation of Spatial Information in Spatial Language. There are two varieties of proposals for the representations of prepositions: logic based and perception based. Logic-based repare exemplified by the work of Miller and Johnson-Laird (1976). In their analysis of the relation between language and perception, they provided predicate calculus representations like those discussed in chapter 5. These authors stated that the preposition at can be represented by the general schema:
![]()
That is, the preposition at should be used if the object bound to the variable x is included in some region defined by the variable y. This representation does seem to capture the general structure of statements about space for which at is used. The use of logic as a representation for prepositions has the property of providing a rigorous definition for each preposition.
The particular definition of at presented by Miller and Johnson-Laird has some flaws. For example, it does not help to distinguish why the sentence:
![]()
does not sound grammatical, but if it is stipulated that Lucas is watching a basketball game at Madison Square Garden, then the sentence:
is perfectly appropriate. As discussed previously, Herskovits (1986) suggested that at treats the landmark as a point, although the landmark is typically a region. A simple predicate calculus description does not capture this geometry fully and does not account for the observation that at implies that an object is being used for its intended purpose as in Example 6.9.
Some of these problems can be circumvented by additional work on the representations. For example, additional senses of at can make it clear that, as discussed earlier, at often refers to objects used for their intended purpose. Further, Miller and Johnson-Laird’s representations for prepositions were developed primarily through an analysis of English prepositions. Extensive analysis of prepositions cross-linguistically has suggested some commonalities in the distinctions made by prepositions across languages, and the primitive relations used to describe prepositions should probably be designed to account for both commonalities and differences in prepositions across languages (Cienki, 1989; Regier, 1996; Vandeloise, 1991).
An alternative to predicate calculus representations like those developed by Miller and Johnson-Laird has focused on the relationship between spatial language and perceptual representations. Landau and Jackendoff (1993; Jackendoff, 1987) stated that there are similarities in the abstractions made by prepositions and the visual representations proposed by Marr (1982). As already discussed, the 3D model representation proposed by Marr assumes that object representations are hierarchically organized structures in which the fine details of object shapes are abstracted to generalized cylinders with relations between cylinders. Jackendoff (1987) observed that, just like Marr’s 3D models, prepositions highlight important intrinsic axes of objects. Linguists have pointed out that crabs are said to walk “sideways,” because their main axis of symmetry defines their front and back and their direction of motion is perpendicular to this axis of symmetry. Thus, a crab would not walk into an object placed in front of it.
Further, Landau and Jackendoff (1993) noted that prepositions abstract across objects in a manner similar to that proposed in models of visual representation. Just as proposals like those of Marr and Biederman assumed that generalized cones can describe real objects despite fine variations in their surface detail, so too do prepositions abstract away from the fine detail of objects. For example, one can say:
![]()
even though the road near the cliffs along the Hudson River is straight and the cliffs are not. The preposition can be used because the border between the Palisades and the Hudson River can be conceptualized as a straight axis that abstracts across the local surface variations. Indeed, as discussed in the previous section, beyond some information about the relative width of objects (which helps determine its axes), very little shape information is incorporated into prepositions at all. Landau and Jackendoff suggested that this similarity between observations about spatial prepositions and proposals for visual representations is not accidental. Visual representations constrain the information supplied to prepositions. This use of visual representation helps ground the meanings of the prepositions.
The notion that visual representation can constrain the acquisition of prepositions was examined in a computational model that Regier (1996) developed. This model uses a technique called constrained connectionism, in which the input is developed by making assumptions consistent with what is known about visual representations. This input is then fed to a standard connectionist network (like those described in chap. 2), and a set of prepositions is learned. The model was explicitly designed to learn prepositions from a number of different languages, to see whether the assumptions about visual representation could provide constraints on the kinds of prepositions that do and do not appear in different languages.
The architecture of the model is shown in Figure 6.15. As shown in the diagram, the input to the model consists of simplified movies of motions between objects. The movies each have two objects in them, which are labeled trajector (TR) and landmark (LM). The model then performs a perceptual analysis of the movie to provide an assessment of the properties of the current movie (labeled Current in the figure). This current state is further analyzed to find both the Source and the Path of the motion. This information is used as input to a set of trainable connection weights that learn how the perceptual analysis is related to the prepositions in the language being learned.
The model assumes that all information needed to learn the spatial prepositions of a language can be determined from a perceptual analysis of the scenes of the movie. This analysis finds the outer boundaries of the trajector and landmark and then determines the angle between them. In addition, for each frame of the movie, the model determines whether any part of the object is inside the landmark (and if so, how much). The output of this visual processor consists of information about the relative center of mass of the trajector and landmarks, the relative position of trajector and landmark in the final scene, the extent of the trajector’s and landmark’s overlap (if any), and information about whether the trajector passes through the area of the landmark at any point during the movie.4
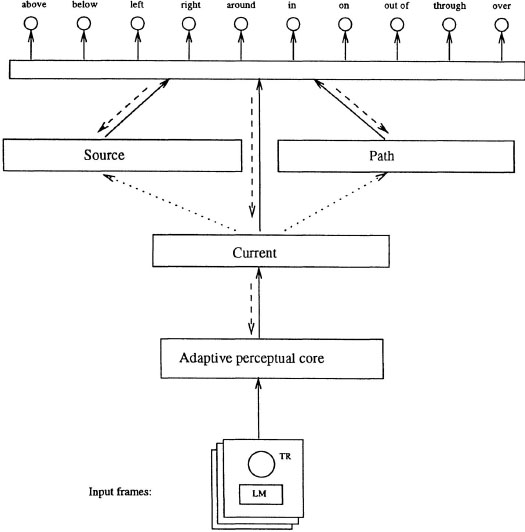
FIG. 6.15. Architecture of Regier’s constrained connectionist model of preposition learning. From T. Regier (1997). Copyright © 1997 by Academic Press. Reprinted with permission.
The data, which constitute the basis of the spatial representation of prepositions, are then fed to a set of trainable connection weights that learn to map these features of the movie onto the prepositions of the language that the model is being taught. Different runs of the model have been taught prepositions from English, Russian, German, Japanese, and Mixtec, each of whose prepositions break the world up in different ways. The model is capable of learning the distinctions made by these languages.
Regier’s model assumes that a few key elements of spatial information are critical for understanding most prepositions. The relative center of mass of the objects is particularly important: It provides information about the static location of pairs of objects. The use of center of mass reflects the fact that prepositions are only very generally influenced by object shape. In particular, the center of mass of an object is in the center if the object is symmetric, but asymmetries in the object pull the center of mass toward an edge of the object and provide rudimentary information about its shape. The model also uses a category representation of whether the objects come in contact or overlap. This information too is important, because a preposition like above can apply only to objects that are not touching. In addition, categorical information about whether one object is wholly contained by another is important. For example, the preposition inside requires that one object be completely in the other. Interestingly, the preposition in does not have the same requirement: One can say:
![]()
even if it is the topmost apple in a large pile that is supported by a bowl. In this case, the enclosing surface of the bowl is treated as if it rises up to include the whole pile. In sum, of the large amount of information that could have been used as the basis of preposition representations, Regier’s model assumes that only a small subset of it is actually incorporated into the visual basis of prepositions.
An interesting aspect of Regier’s model is the way it deals with the absence of negative evidence in language learning. Many theorists have pointed out that language learning is particularly difficult, because children receive only positive instances of sentences and rarely get negative feedback (see Pinker, 1991, for an extended discussion of this issue). Regier, having taken a cue from researchers who suggested that children treat words as mutually exclusive, assumed that a positive instance of one preposition is implicit negative evidence for all other prepositions (E. V. Clark, 1987; E. M. Markman & Wachtel, 1988). Words are not truly mutually exclusive, however. For instance, the prepositions above and over can be used interchangeably in some circumstances. Thus, the negative evidence provided by the use of another preposition to describe a scene is weaker than is the positive evidence provided by the use of the preposition to describe it. This assumption allows the network to learn a variety of prepositions without receiving any negative instances (i.e., without seeing an instance labeled as “not over”). In this way, the model provides an implementation of E. V. Clark’s (1979) principle of contrast described in chapter 3.
This model provides an interesting first step toward understanding how people learn spatial prepositions, although several issues still remain to be explored. For example, the model currently is told which object is the landmark and which is the trajector, but the use of spatial language may highlight the spatial relations between objects, and people may come to view objects as trajectors and landmarks because of the way they use them in language. This model cannot capture other aspects of prepositions like the use of at to refer to objects being used for their intended function. These problems should be viewed as an incompleteness in this approach rather than as a flaw, because this model is still in the process of being developed. For example, the meaning of at that implies intended function may be achieved by giving this model inputs from other sources.
Summary. Prepositions describe spatial relations between objects in the world and in this way bear a resemblance to structured representations of visual objects, which also contain information about spatial relations. Furthermore, like visual representations, prepositions seem to be sensitive to major axes of the objects involved in the preposition, but insensitive to local variations in the contour and texture of objects. These parallels have led some investigators to speculate that the structure of prepositions in language is guided by the structure of visual representations. The link between spatial prepositions and visual representations seems reasonable, although it is clear that other information about objects is also included in prepositions, like their functions and relative salience in the world.
If visual representations form the basis of spatial language and prepositions, this possibility may have an important impact on people’s ability to use language to talk about abstract properties as well. Researchers like Lakoff and Gibbs and their colleagues have proposed that the representation of many abstract concepts, such as emotion and valence, is structured by perceptual experiences (Gibbs, 1994; Lakoff, 1987; Lakoff & Johnson, 1980). Lakoff and Johnson (1980) provided many examples of how the goodness of things in the world is mapped to their spatial position with the general metaphor GOOD is UP such as:
![]()
or
![]()
To the extent that spatial language is rooted in perceptual representations, this phenomenon may suggest how representations of abstract concepts are grounded in perceptual experience. (I discuss the use of concrete domains as metaphors for abstract concepts again in chap. 8.)
Representations of Spatial Configurations
Prepositions are not the only way that language describes space: People also give and receive descriptions of spatial configurations. Although some workers have explored how people coordinate their descriptions of space (e.g., Schober, 1993, 1995), in this section I focus on proposals for the representation of spatial configurations that have been described.
One proposal for the way that people understand descriptions of spatial situations is through the construction of spatial mental models (Mani & Johnson-Laird, 1982).5 For example, if I describe a configuration of tableware on a table, I may say:
The fork is to the left of the plate.
The dessert spoon is behind the plate.
The glass is behind the dessert spoon.
(6.20)
A person reading this description might create a mental model of the configuration with this structure:

where F is the fork, P is the plate, D is the dessert spoon, and G is the glass. Having such a mental model allows the inference of properties that were not stated directly in the description, such as: The glass is behind the plate.
A spatial mental model is an abstract spatial description of a set of objects. The objects themselves are only given placeholders. The plate is not assumed to be round or breakable; it is simply an object that occupies a point in space. Space is assumed to be represented in an array that preserves simple spatial relations between objects. Each model that is constructed places the objects at some position in space, but more than one model may be consistent with a given description. For example, with the description:
The fork is to the left of the plate.
The dessert spoon is behind the plate.
The glass is behind the plate.
(6.22)
the model in Example 6.21 can be constructed, but so can the following model:

Without further disambiguating information, one cannot know which model is most appropriate.
These spatial models may be important for remembering simple configurations for short periods. For example, a person remembering where the car is parked when going to a shopping mall may create a simple mental model with a few landmarks and the spatial relations between them. These spatial models can also be helpful for understanding complex discourse involving spatial relations (Glenberg & Kruley, 1992; Glenberg, Kruley, & Langston, 1994). For example, in a story, if an actor puts down an object and moves to a new location, one can infer that the actor is no longer near the object. In practice, these mental models require effort to construct. There is some evidence that people reading text build models only when they are necessary for understanding a passage (McKoon & Ratcliff, 1992), but they can use information about spatial relationships to understand discourse.
Research on the relationship between spatial models and language has also focused on complex scenes and maps (Franklin, Tversky, & Coon, 1992; Taylor & Tversky, 1992, 1996). In one study, Taylor and Tversky (1992, 1996) asked people to describe areas depicted in maps. They found that people used both survey and route descriptions of the scenes. Objects were discussed in survey descriptions with spatial relations between objects and between an extrinsic source of reference (e.g., using direction terms like north, south, east, west). In contrast, route descriptions referred to spatial locations of objects relative to a moving frame of reference, which was generally assumed to be the speaker. Route descriptions were most common when maps had a single route and landmarks in the map were approximately the same size. Survey descriptions were most common when maps had multiple paths and there were landmarks of varying sizes. Survey descriptions were more common when describing maps than when describing areas that people had learned about by navigating through them.
The studies of spatial descriptions highlighted two interesting facets of spatial representation. First, the locations of objects are almost always referred to relationally. In a survey description, the relations are relative to some external frame of reference (like the cardinal directions) or to particular other objects in the scene. For example, one says:
![]()
Here the church serves as the frame of reference. In route descriptions, relations also dominate, but they are given in terms of the individual following the route, as in:
In 6.24, the basis of the relation is the speaker, who is serving as a deictic center. Thus, like prepositions, descriptions of spatial scenes seem to abstract away from particular metric aspects of spatial scenes.
Perceptual relations are important for two reasons. First, relations are likely to hold between a pair of objects for a wide range of views, whereas metric information changes as soon as any object being described moves. Second, the determination of precise metric information is difficult: Calculating the distance between two objects being observed requires knowing the precise distance from the observer to them as well as the precise distance between them in the image. Thus, spatial relations provide important information about a pair of objects without requiring extensive calculations of metric information.
As a second facet of spatial representation, people give descriptions of visual scenes relative to their own visual experience in acquiring the scenes. Thus, as Taylor and Tversky (1996) found, survey descriptions were more common with maps, and route descriptions were more common with areas that the describer had learned by navigation. People’s visual experience has an important impact on the way they structure their descriptions of spatial scenes. Being presented with an overview of a spatial layout promotes a conceptualization in terms of an external frame of reference, whereas experiencing the spatial layout by traversing through it promotes a conceptualization in terms of routes. This pattern is consistent with observations that people often learn routes between landmarks in new areas they must navigate before learning a global spatial layout.
SUMMARY
This survey suggests that relations are important in perceptual representations and spatial language. There is evidence that people use object-centered representations containing spatial relations among parts. The same structured representations that are important for vision also seem to be important for visual imagery, a finding that may explain some limitations of imagery ability. Finally, relations are also important for spatial language. Spatial prepositions, perhaps the most basic form of spatial language, involve relations between generalized objects and focus on relations between objects or between objects and paths. Complex spatial language also makes use of structured representations. People can represent the relative spatial locations of objects described in discourse. This ability may involve the construction of spatial mental models of scenes. The construction of these mental models may also be informed by people’s specific visual experiences.
1The idea that representations contain both metric information and more structured information was also a part of early dual-coding theories of memory (Kieras, 1978; Posner, Boies, Eichelman, & Taylor, 1969).
2There are many possible ways to refer to these roles.
3The linguistic notion of deixis involves pointing with words (E. V. Clark, 1979). For example, the deictic term there specifies a point in space relative to the speaker. The deictic center is the location from which the pointing takes place. This point is typically the location of the speaker.
4The connections in the modules that perform this perceptual analysis are all trainable, so that the model can optimize its focus on perceptual properties for the language it is learning.
5I thank Philip Johnson-Laird for providing me a copy of his computer program space-4, which constructs spatial mental models from text descriptions.